
Ricci Curvature-Based Semi-Supervised Learning on an Attributed Network


Abstract
1. Introduction
2. Background
2.1. Sectional Curvature and Ricci Curvature
2.2. Coarse Ricci Curvature
3. Methods
3.1. Problem Setting
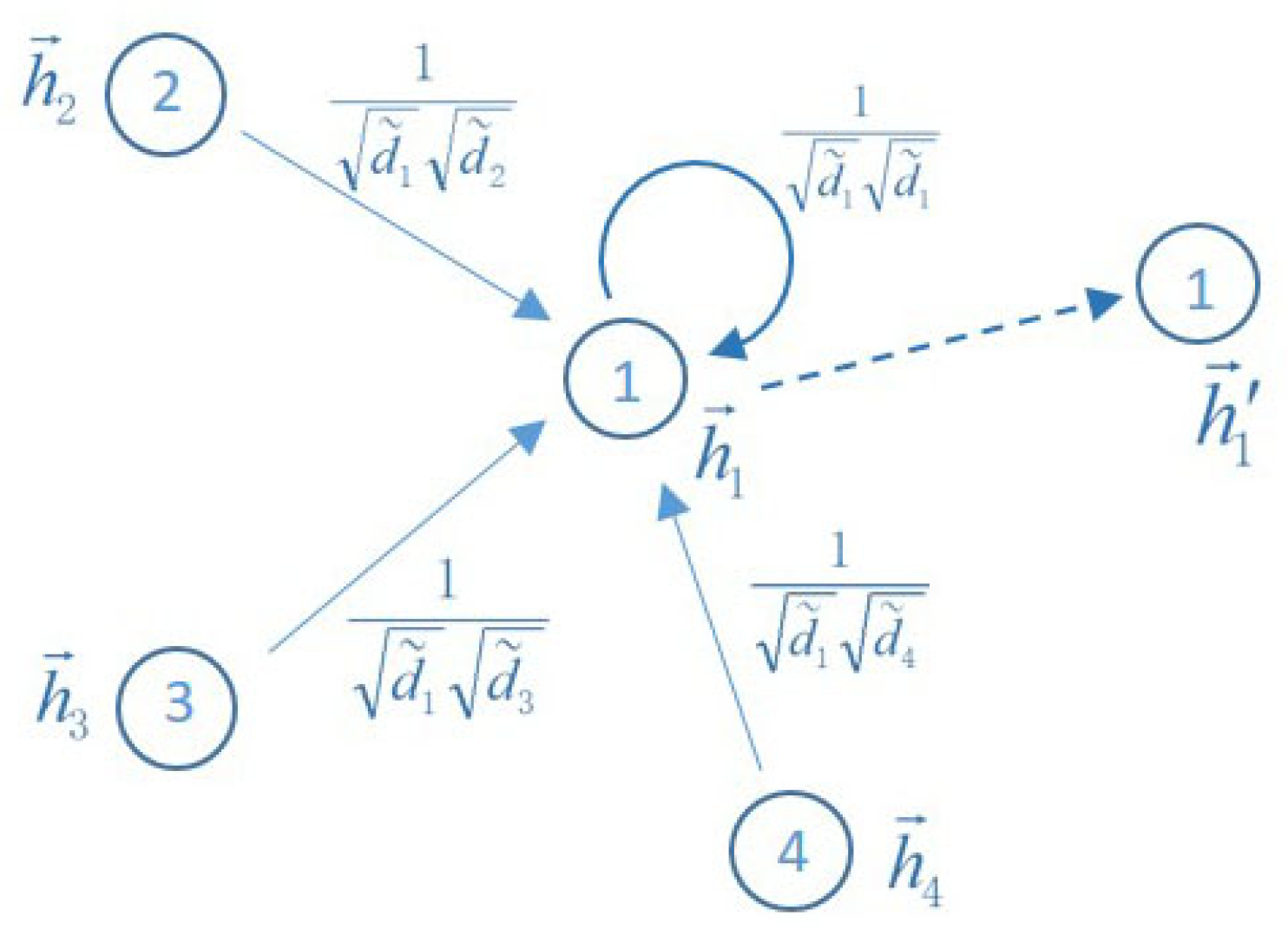
3.2. Neighborhood Aggregation on the Manifold by RCGCN
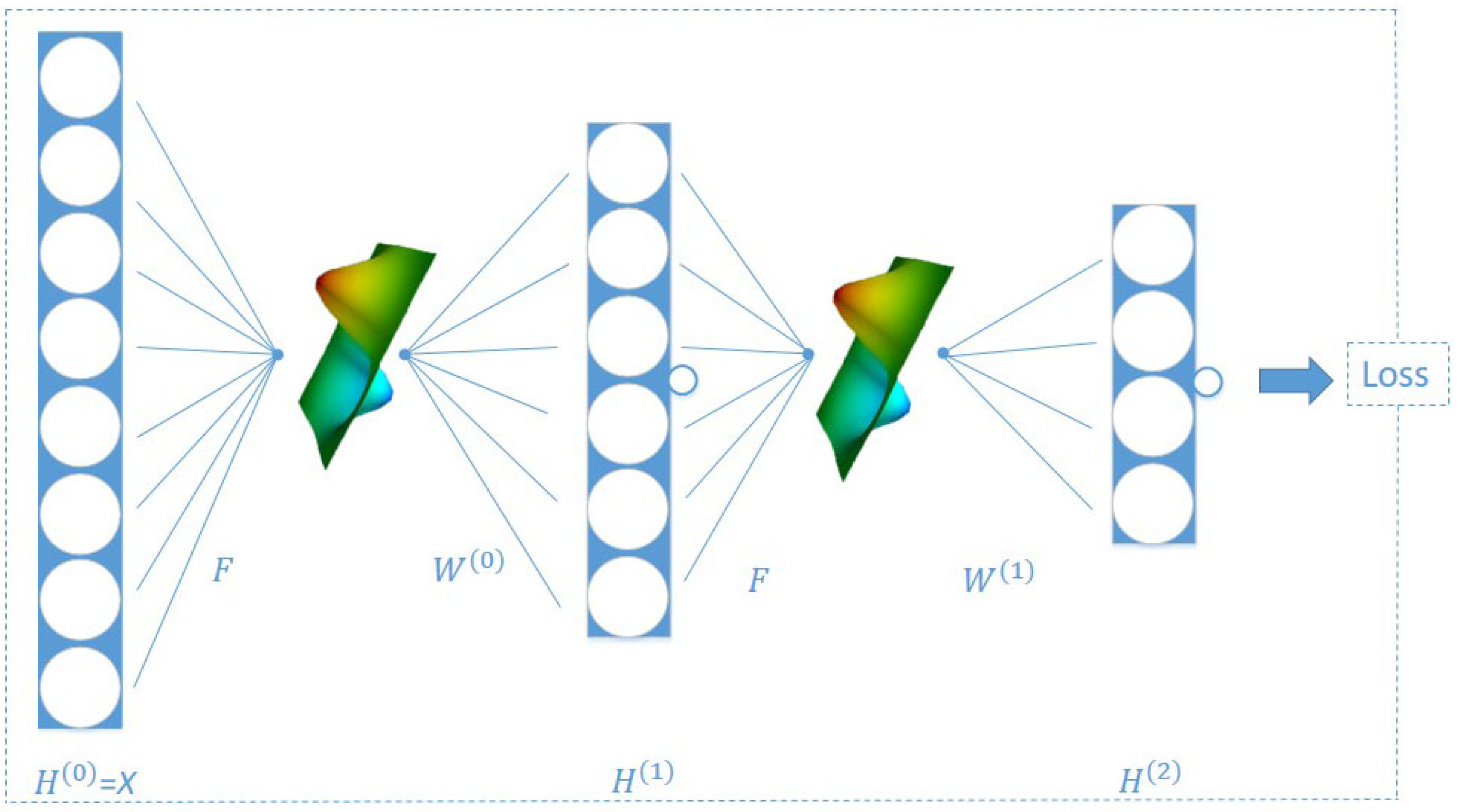
3.3. RCGCN Architecture
4. Experiment
4.1. Datasets
4.2. Setup of Baseline Methods
4.3. Semi-Supervised Node Classification
4.4. Training Time Comparison
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tang, J.; Aggarwal, C.; Liu, H. Node classification in signed social networks. In Proceedings of the 2016 SIAM International Conference on Data Mining, Miami, FL, USA, 5–7 May 2016; SIAM: Philadelphia, PA, USA, 2016; pp. 54–62. [Google Scholar] [CrossRef]
- Gao, S.; Denoyer, L.; Gallinari, P. Temporal link prediction by integrating content and structure information. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management; ACM: New York, NY, USA, 2011; pp. 1169–1174. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 701–710. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 855–864. [Google Scholar] [CrossRef]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1067–1077. [Google Scholar] [CrossRef]
- Shen, E.; Cao, Z.; Zou, C.; Wang, J. Flexible Attributed Network Embedding. arXiv 2018, arXiv:1811.10789. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Grarep: Learning graph representations with global structural information. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; ACM: New York, NY, USA, 2015; pp. 891–900. [Google Scholar] [CrossRef]
- Ou, M.; Cui, P.; Pei, J.; Zhang, Z.; Zhu, W. Asymmetric transitivity preserving graph embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 1105–1114. [Google Scholar] [CrossRef]
- Yang, C.; Liu, Z.; Zhao, D.; Sun, M.; Chang, E.Y. Network representation learning with rich text information. IJCAI 2015, 2015, 2111–2117. [Google Scholar]
- Tu, C.; Zhang, W.; Liu, Z.; Sun, M. Max-margin deepwalk: Discriminative learning of network representation. IJCAI 2016, 2016, 3889–3895. [Google Scholar]
- Zhang, D.; Yin, J.; Zhu, X.; Zhang, C. Homophily, structure, and content augmented network representation learning. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 609–618. [Google Scholar] [CrossRef]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 1225–1234. [Google Scholar] [CrossRef]
- Liao, L.; He, X.; Zhang, H.; Chua, T.S. Attributed social network embedding. IEEE Trans. Knowl. Data Eng. 2018, 30, 2257–2270. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Petersen, P.; Axler, S.; Ribet, K. Riemannian Geometry; Springer: Berlin/Heidelberger, Germany, 2006; Volume 171. [Google Scholar]
- von Renesse, M.K.; Sturm, K.T. Transport inequalities, gradient estimates, entropy and Ricci curvature. Commun. Pure Appl. Math. 2005, 58, 923–940. [Google Scholar] [CrossRef]
- Ollivier, Y. Ricci curvature of Markov chains on metric spaces. J. Funct. Anal. 2009, 256, 810–864. [Google Scholar] [CrossRef]
- Cho, H.J.; Paeng, S.H. Ollivier’s Ricci curvature and the coloring of graphs. Eur. J. Comb. 2013, 34, 916–922. [Google Scholar] [CrossRef]
- Bauer, F.; Jost, J.; Liu, S. Ollivier-Ricci curvature and the spectrum of the normalized graph Laplace operator. arXiv 2011, arXiv:1105.3803. [Google Scholar] [CrossRef]
- Lin, Y.; Lu, L.; Yau, S.T. Ricci curvature of graphs. Tohoku Math. J. 2011, 63, 605–627. [Google Scholar] [CrossRef]
- Jost, J.; Liu, S. Ollivier’s Ricci curvature, local clustering and curvature-dimension inequalities on graphs. Discret. Comput. Geom. 2014, 51, 300–322. [Google Scholar] [CrossRef]
- Pouryahya, M.; Mathews, J.; Tannenbaum, A. Comparing three notions of discrete ricci curvature on biological networks. arXiv 2017, arXiv:1712.02943. [Google Scholar]
- Yang, Z.; Cohen, W.; Salakhudinov, R. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; PMLR: New York, NY, USA, 2016; pp. 40–48. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Nodes | Edges | Classes | Features |
|---|---|---|---|---|---|
| Cora | Citation network | 2708 | 5429 | 7 | 1433 |
| Citeseer | Citation network | 3327 | 4732 | 6 | 3703 |
| Cornell | WebKB | 183 | 295 | 5 | 1703 |
| Texas | WebKB | 183 | 309 | 5 | 1703 |
| Wisconsin | WebKB | 251 | 499 | 5 | 1703 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Hu, G.; Yu, F. Ricci Curvature-Based Semi-Supervised Learning on an Attributed Network. Entropy 2021, 23, 292. https://doi.org/10.3390/e23030292
Wu W, Hu G, Yu F. Ricci Curvature-Based Semi-Supervised Learning on an Attributed Network. Entropy. 2021; 23(3):292. https://doi.org/10.3390/e23030292
Chicago/Turabian StyleWu, Wei, Guangmin Hu, and Fucai Yu. 2021. "Ricci Curvature-Based Semi-Supervised Learning on an Attributed Network" Entropy 23, no. 3: 292. https://doi.org/10.3390/e23030292
APA StyleWu, W., Hu, G., & Yu, F. (2021). Ricci Curvature-Based Semi-Supervised Learning on an Attributed Network. Entropy, 23(3), 292. https://doi.org/10.3390/e23030292