
The Downside of Heterogeneity: How Established Relations Counteract Systemic Adaptivity in Tasks Assignments


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Agent-Based Model of Task Redistribution
- Agent fitness
- Agent failure
- Task increase and decrease
- Task redistribution
- Full dynamics
- Network of reassignments
3. Results of Agent-Based Simulations
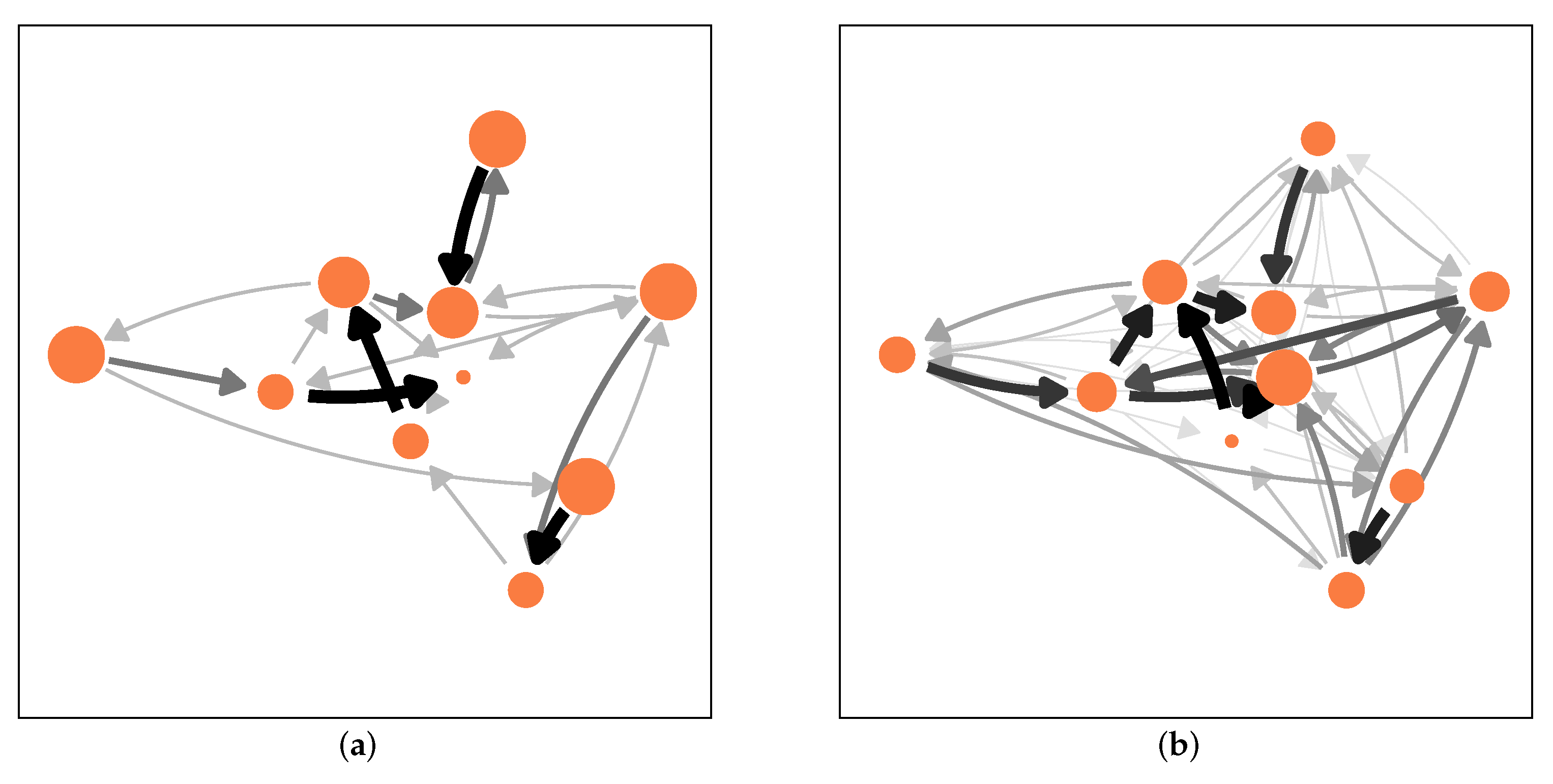
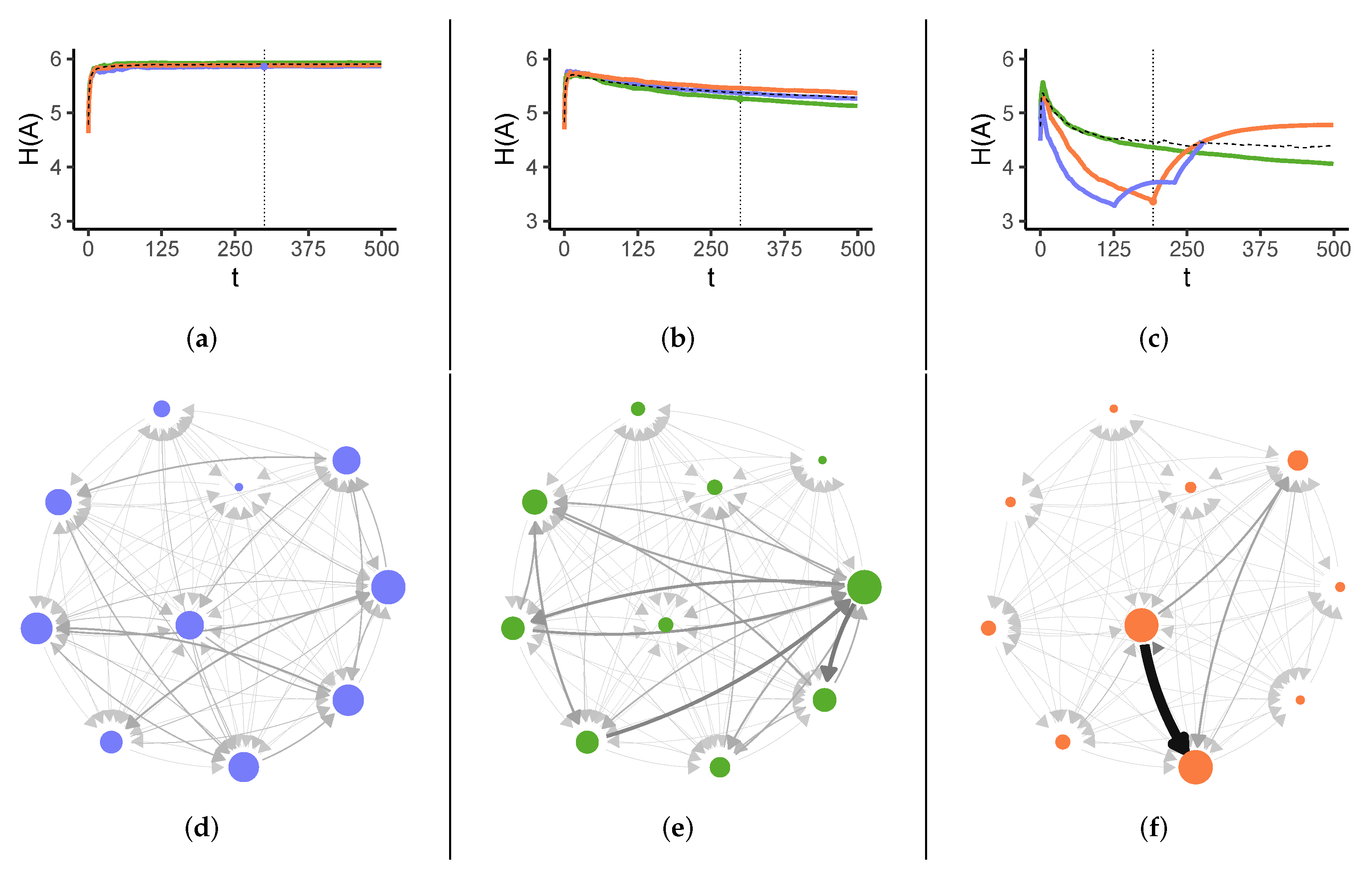
3.1. Evolution of Task Reassignments
3.2. Impact of Heterogeneity
4. Discussion
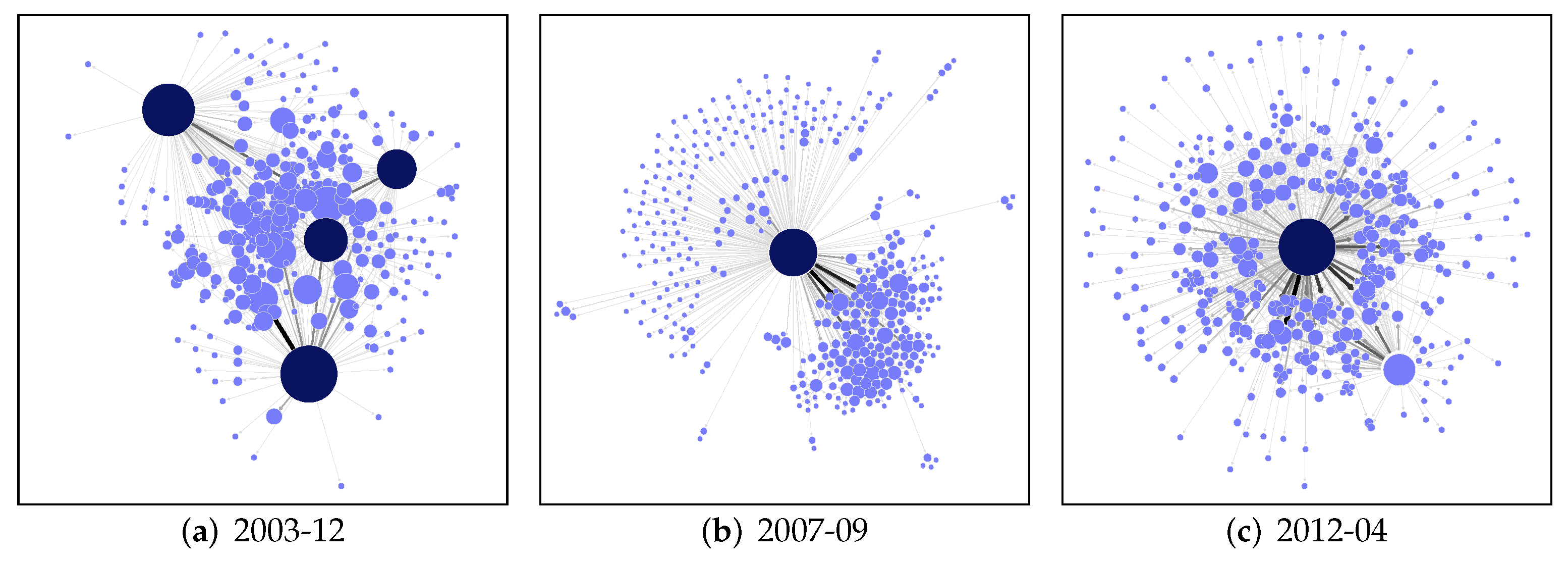
4.1. A Realistic Example
4.2. Systemic Risk
- In our case, agents continuously redistribute tasks, not only if they fail.
- In our model, agents do not equally redistribute their tasks. Instead, the number of tasks redistributed at each time step follows a probability distribution that combines agent features, i.e.,all their fitness values and the history of previous reassignments.
- Our model considers directed and weighted links, where the weight dynamically adjusts according to the history of assignments. i.e.,instead of a static network topology, our model uses an adaptive network [24] which reflects the learning process of agents.
- As our model simulations illustrate, the failure of some agents not necessarily worsens the situation but sometimes leads to a better redistribution of tasks, i.e.,to an improved system state. This is not reflected in most redistribution models, with the fibre bundle model [25,26] as a paragon, because only failing agents redistribute their load, negatively impacting the stability of the system.
4.3. Conditions for Resilience
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Zanetti, M.S.; Scholtes, I.; Tessone, C.J.; Schweitzer, F. The rise and fall of a central contributor: Dynamics of social organization and performance in the Gentoo community. In Proceedings of the CHASE/ICSE ’13 6th International Workshop on Cooperative and Human Aspects of Software Engineering, San Francisco, CA, USA, 25 May 2013; pp. 49–56. [Google Scholar] [CrossRef] [Green Version]
- Antosz, P.; Rembiasz, T.; Verhagen, H. Employee shirking and overworking: Modelling the unintended consequences of work organisation. Ergonomics 2020, 63, 997–1009. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Malarz, K.; Kowalska-Styczeń, A.; Kułakowski, K. The working group performance modeled by a bi-layer cellular automaton. Simulation 2016, 92, 179–193. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Lorenz, J.; Battiston, S.; Schweitzer, F. Systemic risk in a unifying framework for cascading processes on networks. Eur. Phys. J. B 2009, 71, 441–460. [Google Scholar] [CrossRef]
- Burkholz, R.; Schweitzer, F. A framework for cascade size calculations on random networks. Phys. Rev. E 2018, 97, 042312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schweitzer, F. The law of proportionate growth and its siblings: Applications in agent-based modeling of socio-economic systems. In Complexity, Heterogeneity, and the Methods of Statistical Physics in Economics; Aoyama, H., Aruka, Y., Yoshikawa, H., Eds.; Springer: Tokyo, Japan, 2020; pp. 145–176. [Google Scholar]
- Mahmoud, H. Pólya urn Models; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Collevecchio, A.; Cotar, C.; LiCalzi, M. On a preferential attachment and generalized Pólya’s urn model. Ann. Appl. Probab. 2013, 23, 1219–1253. [Google Scholar] [CrossRef] [Green Version]
- Zingg, C.; Casiraghi, G.; Vaccario, G.; Schweitzer, F. What Is the Entropy of a Social Organization? Entropy 2019, 21, 901. [Google Scholar] [CrossRef] [Green Version]
- Lamersdorf, A.; Munch, J.; Rombach, D. A Survey on the State of the Practice in Distributed Software Development: Criteria for Task Allocation. In Proceedings of the 2009 Fourth IEEE International Conference on Global Software Engineering, Limerick, Ireland, 13–16 July 2009; pp. 41–50. [Google Scholar] [CrossRef] [Green Version]
- Scacchi, W. Understanding the requirements for developing open source software systems. IEE Proc. Softw. 2002, 149, 24–39. [Google Scholar] [CrossRef] [Green Version]
- Bolici, F.; Howison, J.; Crowston, K. Stigmergic coordination in FLOSS development teams: Integrating explicit and implicit mechanisms. Cogn. Syst. Res. 2016, 38, 14–22. [Google Scholar] [CrossRef] [Green Version]
- Ehrlich, K.; Cataldo, M. All-for-One and One-for-All? A Multi-Level Analysis of Communication Patterns and Individual Performance in Geographically Distributed Software Development. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, Seattle, WA, USA, 11–15 February 2012; ACM: New York, NY, USA, 2012; pp. 945–954. [Google Scholar] [CrossRef]
- Goeminne, M.; Mens, T. Evidence for the Pareto principle in open source software activity. In Proceedings of the CEUR Workshop Proceedings, Delft, The Netherlands, 31 October 2011; Volume 708, pp. 74–82. [Google Scholar]
- Zanetti, M.S.; Sarigol, E.; Scholtes, I.; Tessone, C.J.; Schweitzer, F. A quantitative study of social organisation in open source software communities. In Proceedings of the 2012 Imperial College Computing Student Workshop, Schloss Dagstuhl, London, UK, 27–28 September 2012; Volume 28, pp. 116–122. [Google Scholar] [CrossRef]
- Coelho, J.; Valente, M.T. Why Modern Open Source Projects Fail. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Paderborn, Germany, 4–8 September 2017; ACM: New York, NY, USA, 2017; pp. 186–196. [Google Scholar] [CrossRef] [Green Version]
- Gleeson, J.P.; Cahalane, D.J. Seed size strongly affects cascades on random networks. Phys. Rev. E 2007, 75, 056103. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Payne, J.L.; Dodds, P.S.; Eppstein, M.J. Information cascades on degree-correlated random networks. Phys. Rev. E 2009, 80, 026125. [Google Scholar] [CrossRef] [Green Version]
- Hurd, T.R.; Gleeson, J.P. On Watts’ cascade model with random link weights. J. Complex Netw. 2013, 1, 25–43. [Google Scholar] [CrossRef] [Green Version]
- Gleeson, J.P. Cascades on correlated and modular random networks. Phys. Rev. E 2008, 77, 046117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Watts, D.J. A simple model of global cascades on random networks. Proc. Natl. Acad. Sci. USA 2002, 99, 5766–5771. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Burkholz, R.; Herrmann, H.J.; Schweitzer, F. Explicit size distributions of failure cascades redefine systemic risk on finite networks. Sci. Rep. 2018, 8, 6878. [Google Scholar] [CrossRef] [Green Version]
- Gross, T.; Sayama, H. Adaptive Networks; Springer: Berlin, Germany, 2009. [Google Scholar]
- Pradhan, S.; Hansen, A.; Chakrabarti, B.K. Failure processes in elastic fiber bundles. Rev. Mod. Phys. 2010, 82, 499. [Google Scholar] [CrossRef] [Green Version]
- Daniels, H.E. The statistical theory of the strength of bundles of threads. I. Proc. R. Soc. Lond. Ser. Math. Phys. Sci. 1945, 183, 405–435. [Google Scholar]
- Holling, C.S. Resilience and Stability of Ecological Systems. Annu. Rev. Ecol. Syst. 1973, 4, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Sterbenz, J.P.G.; Hutchison, D.; Çetinkaya, E.K.; Jabbar, A.; Rohrer, J.P.; Schöller, M.; Smith, P. Resilience and survivability in communication networks: Strategies, principles, and survey of disciplines. Comput. Netw. 2010, 54, 1245–1265. [Google Scholar] [CrossRef]
- Hollnagel, E.; Woods, D.D.; Leveson, N. Resilience Engineering: Concepts and Precepts; Ashgate Publishing, Ltd.: Farnham, UK, 2007. [Google Scholar]
- Schweitzer, F.; Casiraghi, G.; Tomasello, M.V.; Garcia, D. Fragile, Yet Resilient: Adaptive Decline in a Collaboration Network of Firms. Front. Appl. Math. Stat. 2021, 7, 6. [Google Scholar] [CrossRef]
- Walker, B.; Holling, C.S.; Carpenter, S.R.; Kinzig, A. Resilience, Adaptability and Transformability in Social-ecological Systems. Ecol. Soc. 2004, 9, 2. [Google Scholar] [CrossRef]
- Scheffer, M.; Carpenter, S.R.; Lenton, T.M.; Bascompte, J.; Brock, W.; Dakos, V.; Van de Koppel, J.; Van de Leemput, I.A.; Levin, S.A.; Van Nes, E.H.; et al. Anticipating critical transitions. Science 2012, 338, 344–348. [Google Scholar] [CrossRef] [Green Version]
- Kitano, H. Biological robustness. Nat. Rev. Genet. 2004, 5, 826–837. [Google Scholar] [CrossRef] [PubMed]
- Sutcliffe, K.M.; Vogus, T.J. Organizing for resilience. Posit. Organ. Sch. Found. New Discip. 2003, 94, 110. [Google Scholar]
- Lengnick-Hall, C.A.; Beck, T.E.; Lengnick-Hall, M.L. Developing a capacity for organizational resilience through strategic human resource management. Hum. Resour. Manag. Rev. 2011, 21, 243–255. [Google Scholar] [CrossRef]
- Casiraghi, G.; Schweitzer, F. Improving the Robustness of Online Social Networks: A Simulation Approach of Network Interventions. Front. Robot. AI 2020, 7, 57. [Google Scholar] [CrossRef] [PubMed]
- Schweitzer, F.; Zhang, Y.; Casiraghi, G. Intervention Scenarios to Enhance Knowledge Transfer in a Network of Firms. Front. Phys. 2020, 8, 382. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casiraghi, G.; Zingg, C.; Schweitzer, F. The Downside of Heterogeneity: How Established Relations Counteract Systemic Adaptivity in Tasks Assignments. Entropy 2021, 23, 1677. https://doi.org/10.3390/e23121677
Casiraghi G, Zingg C, Schweitzer F. The Downside of Heterogeneity: How Established Relations Counteract Systemic Adaptivity in Tasks Assignments. Entropy. 2021; 23(12):1677. https://doi.org/10.3390/e23121677
Chicago/Turabian StyleCasiraghi, Giona, Christian Zingg, and Frank Schweitzer. 2021. "The Downside of Heterogeneity: How Established Relations Counteract Systemic Adaptivity in Tasks Assignments" Entropy 23, no. 12: 1677. https://doi.org/10.3390/e23121677
APA StyleCasiraghi, G., Zingg, C., & Schweitzer, F. (2021). The Downside of Heterogeneity: How Established Relations Counteract Systemic Adaptivity in Tasks Assignments. Entropy, 23(12), 1677. https://doi.org/10.3390/e23121677