
Conditional Deep Gaussian Processes: Multi-Fidelity Kernel Learning


Abstract
:1. Introduction
2. Related Work
3. Background
3.1. Gaussian Process and Deep Gaussian Process
3.2. Multi-Fidelity Deep Gaussian Process
3.3. Covariance in Marginal Prior of DGP
4. Conditional DGP and Multi-Fidelity Kernel Learning
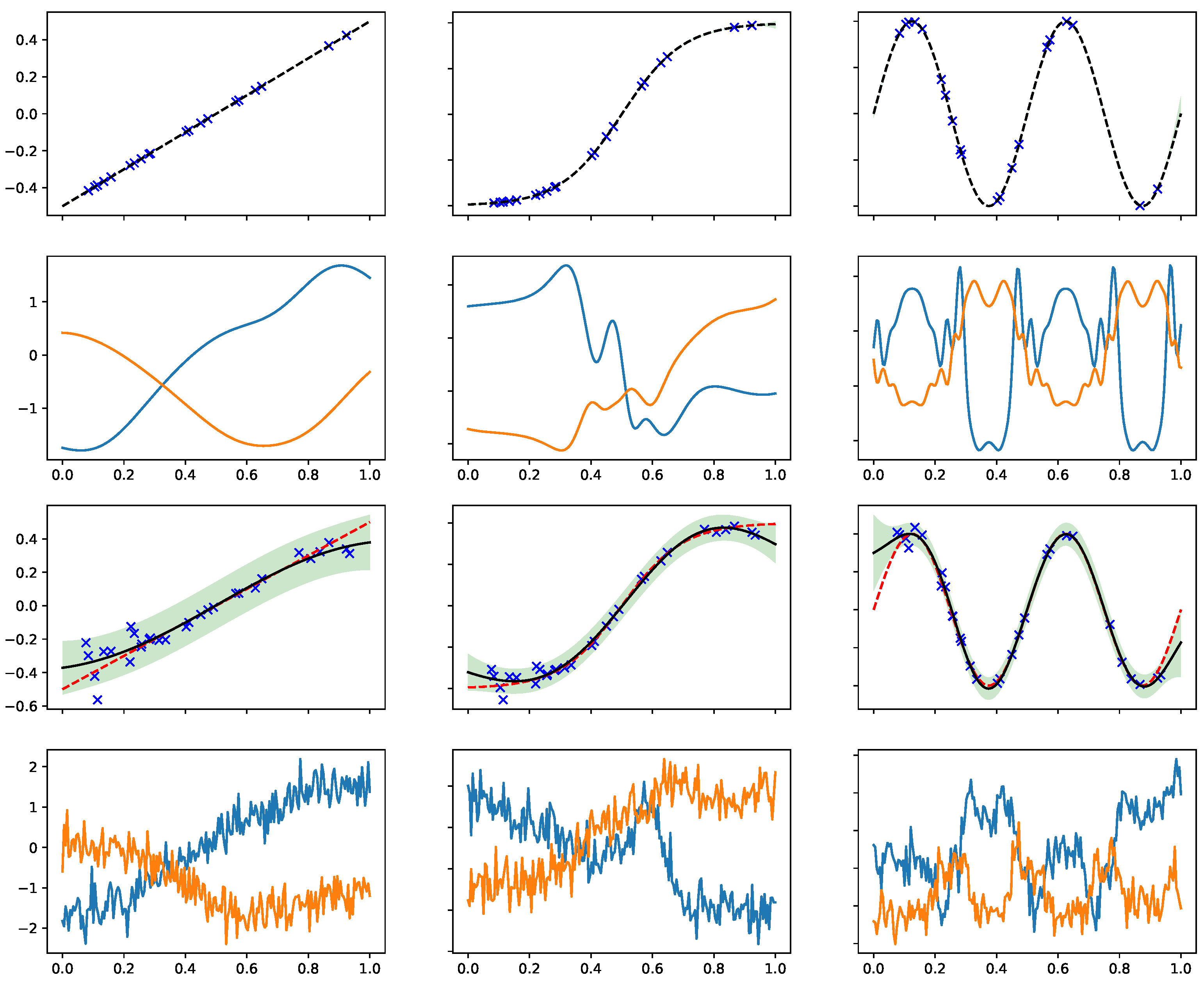
4.1. Analytic Effective Kernels
4.2. Samples from the Marginal Prior
5. Method
| Algorithm 1 A learning algorithm for conditional DGP multi-fidelity regression |
| Input: two sources of data, low-fidelity data () and high-fidelity data (X, y), kernel k1 for function f1, and the test input x*. |
| 1. k1 = Kernel (var = , lengthscale = {Initialize the kernel for inferring g} |
| 2. model1 = Regression(kernel = k1, data = and ) {Initialize regression model for f1} |
| 3. model1.optimize() |
| 4. m, C = model1.predict(input = X, x*, full-cov = true) {Output pred. mean and post cov. of f1} |
| 5. keff = Effective Kernel(var = , lengthscale = , m, C) {Initialize the effective kernel in Equation (12) for SE[ ] and Equation (14) for SC[ ].} |
| 6. model2 = Regression(kernel = keff, data = X, y) {Initialize regression model for f} |
| 7. model2.optimize() |
| 8. , = model2.predict(input = x*) |
| Output: Optimal hyper-parameters {, } and predictive mean and variance at x*. |
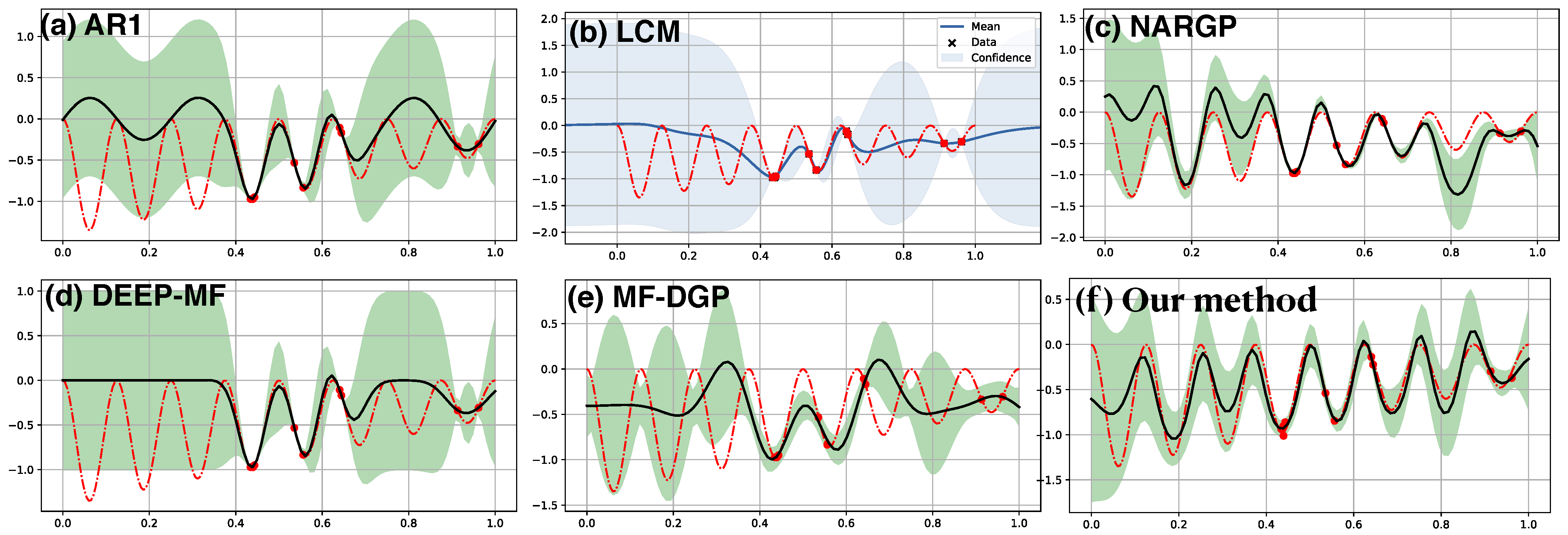
6. Results
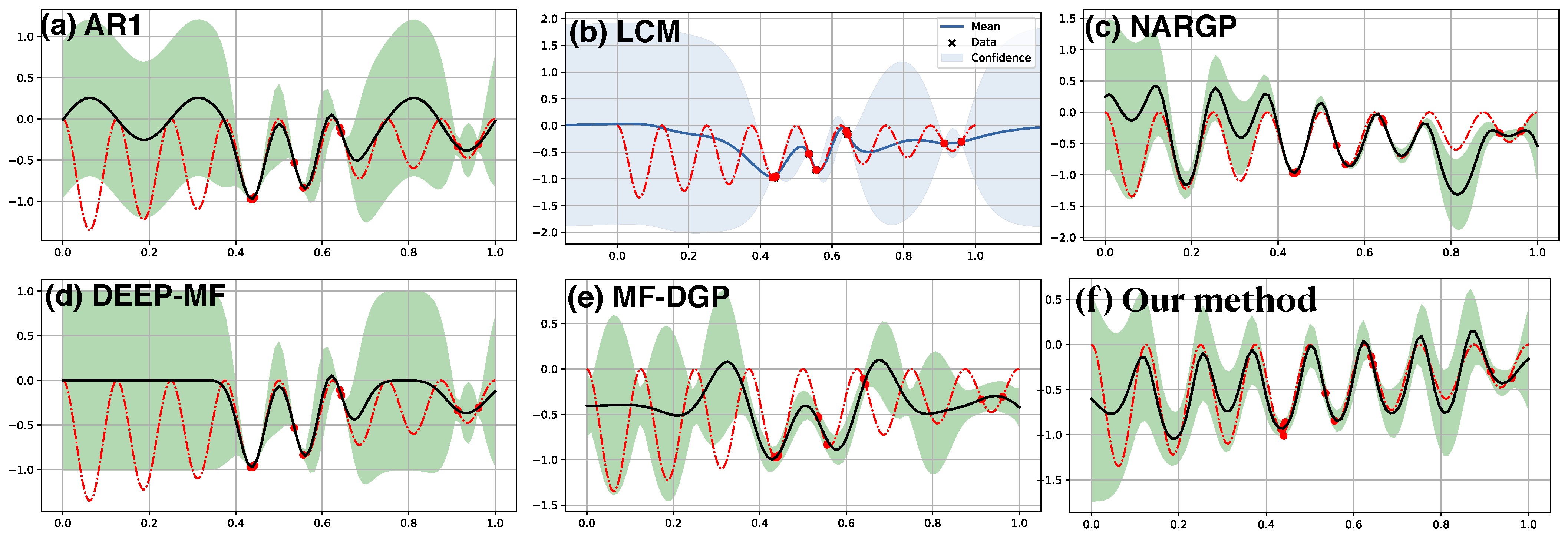
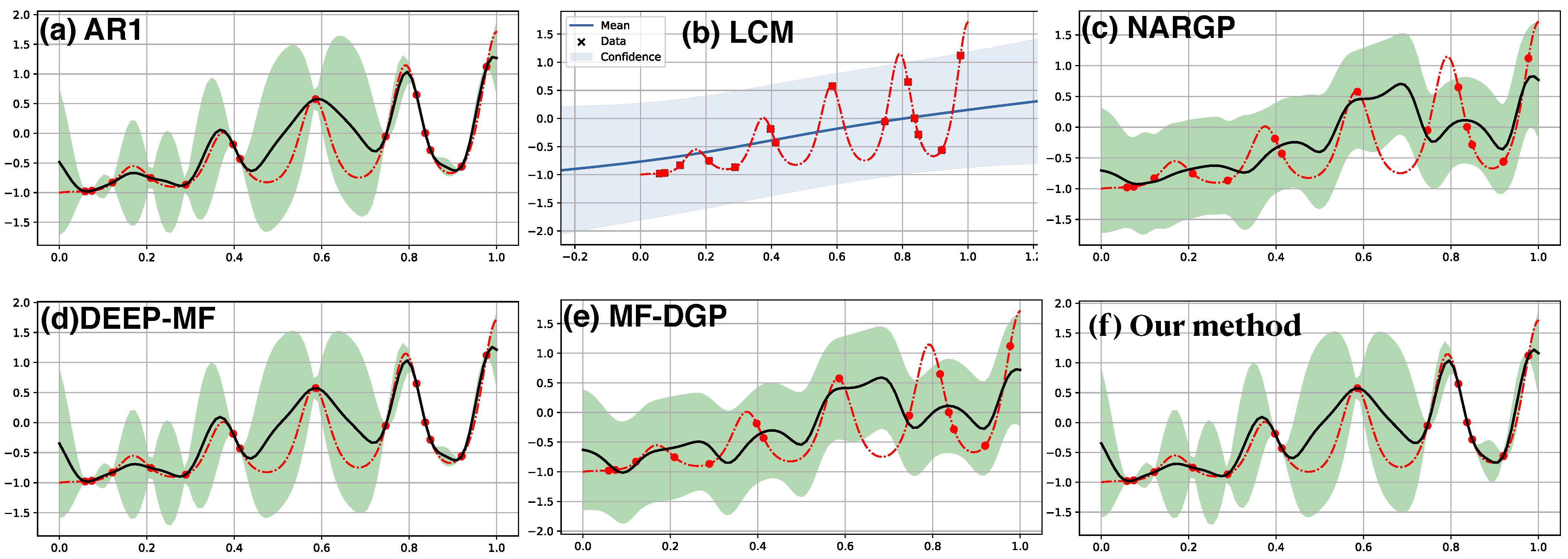
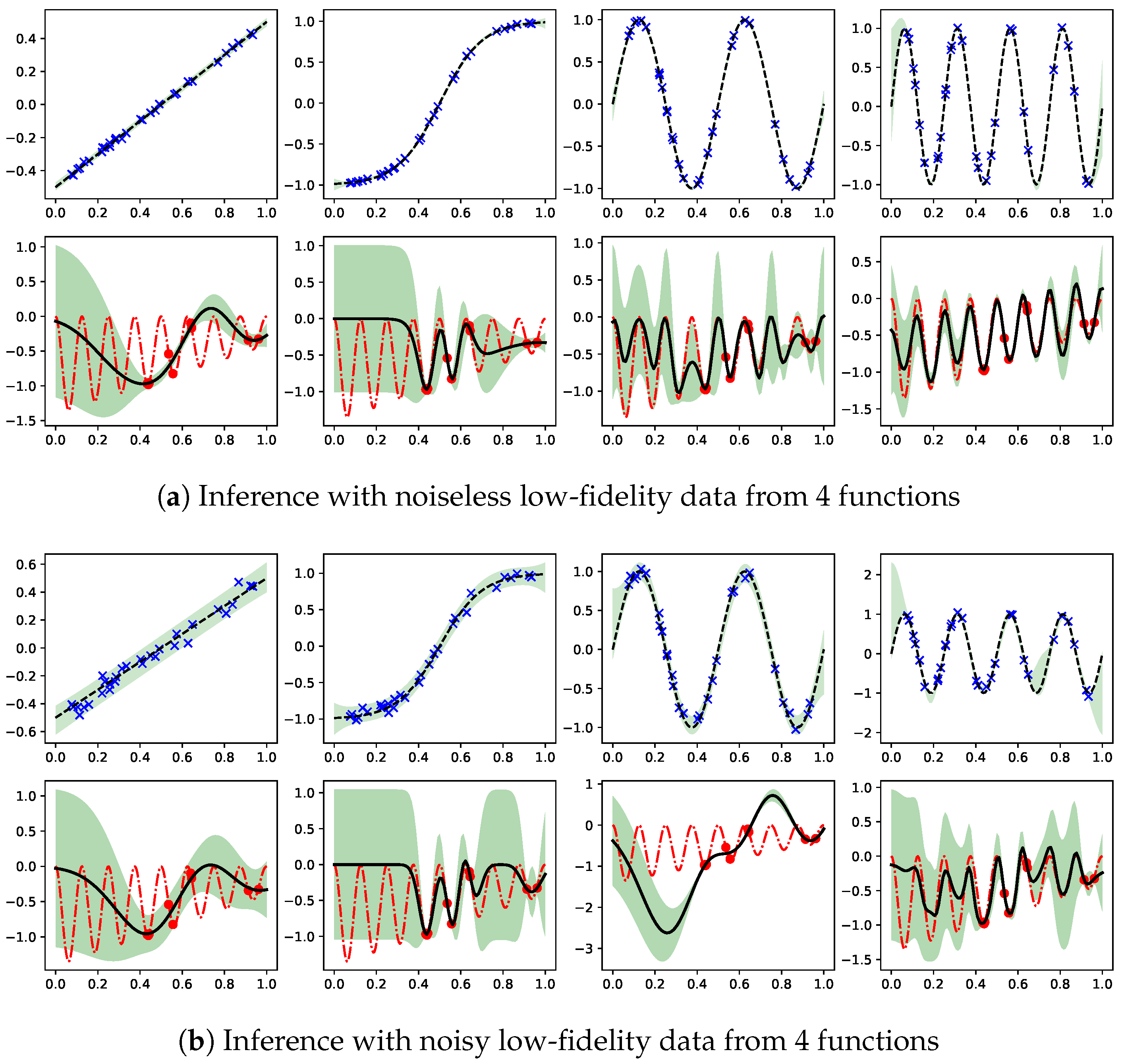
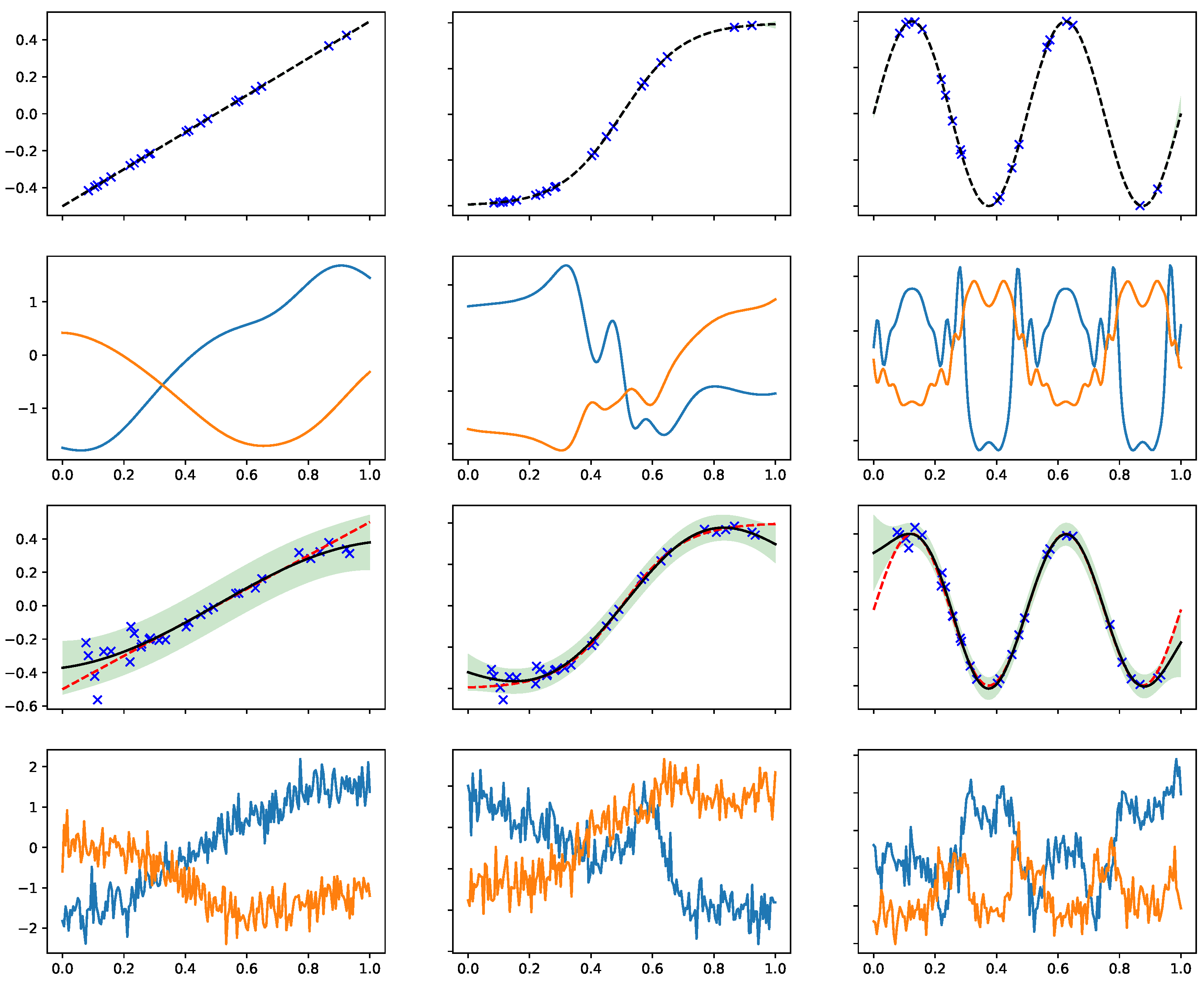
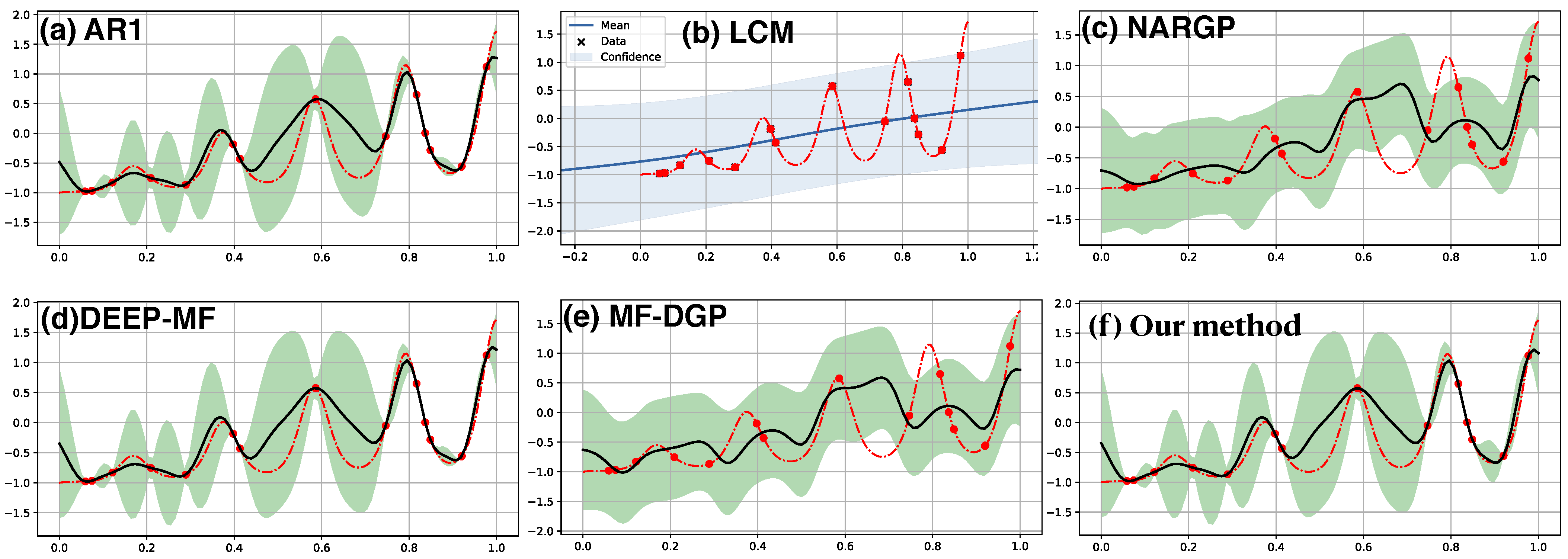
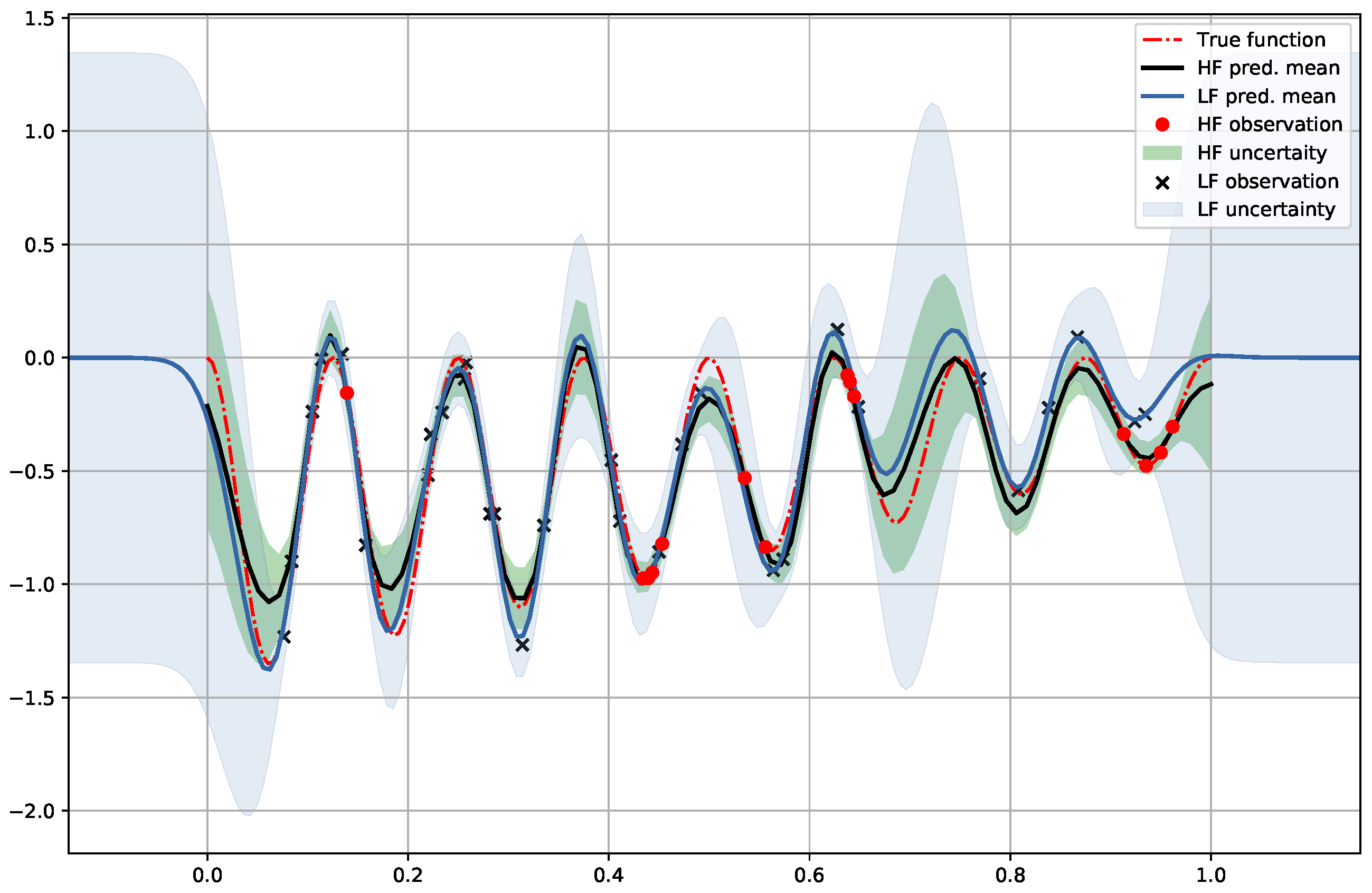
6.1. Synthetic Two-Fidelity Function Regression
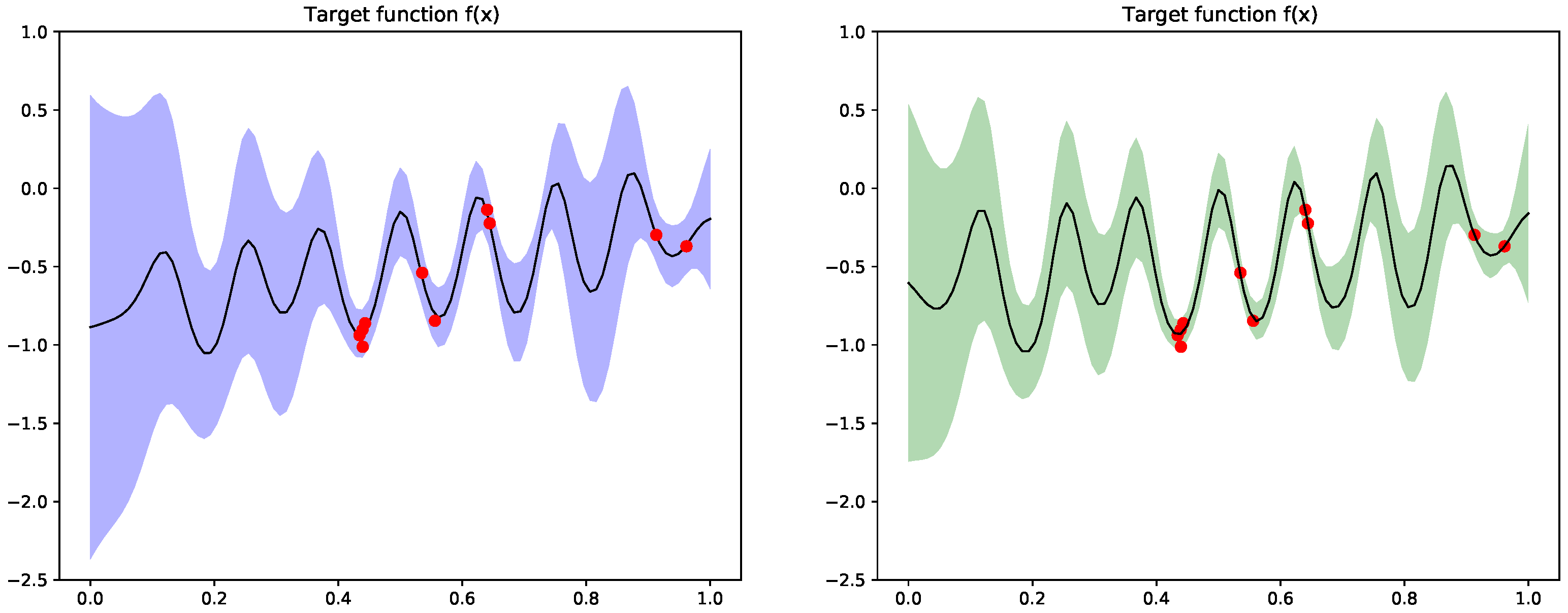
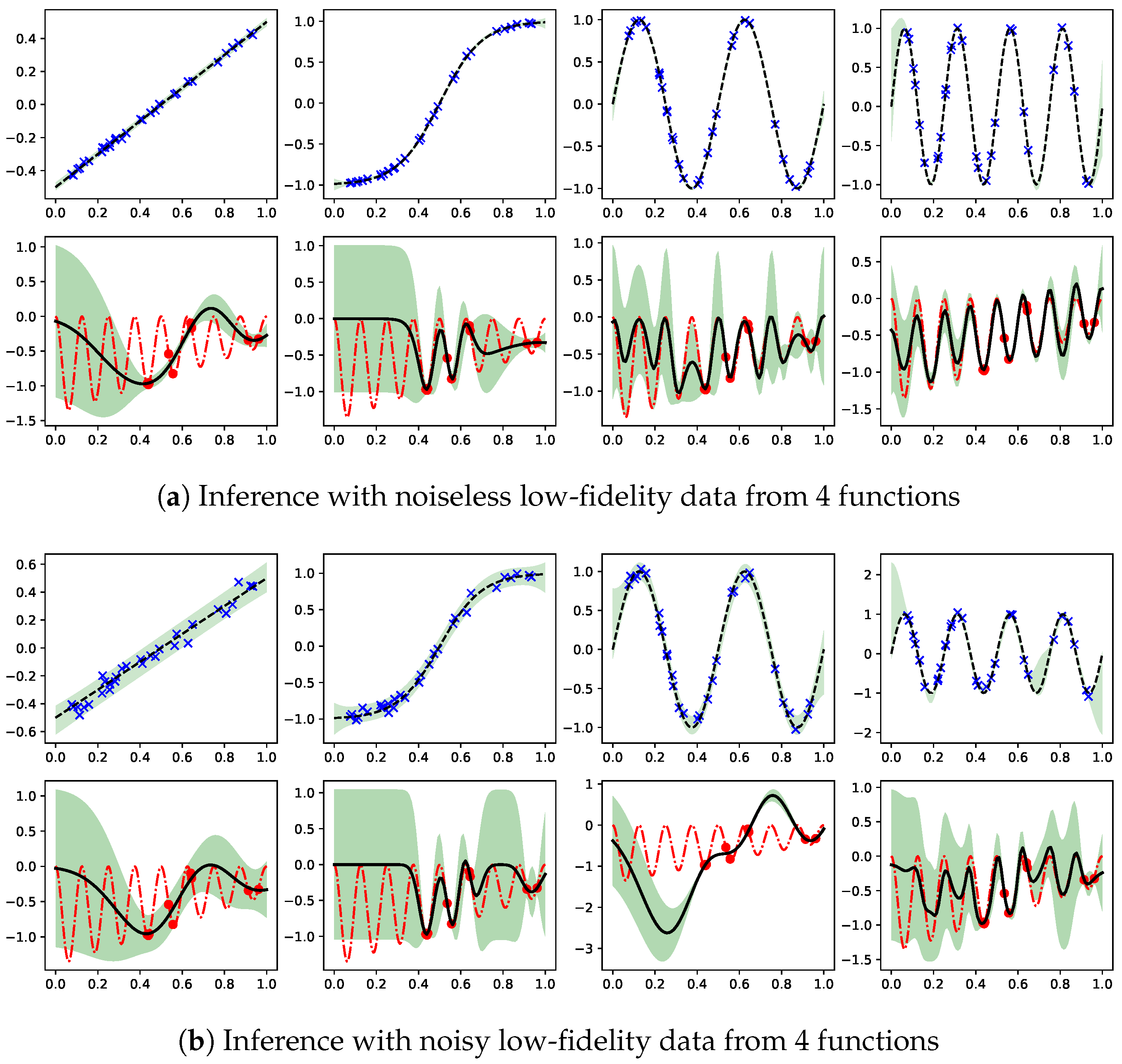
6.2. Compositional Freedom and Varying Low-Fidelity Data
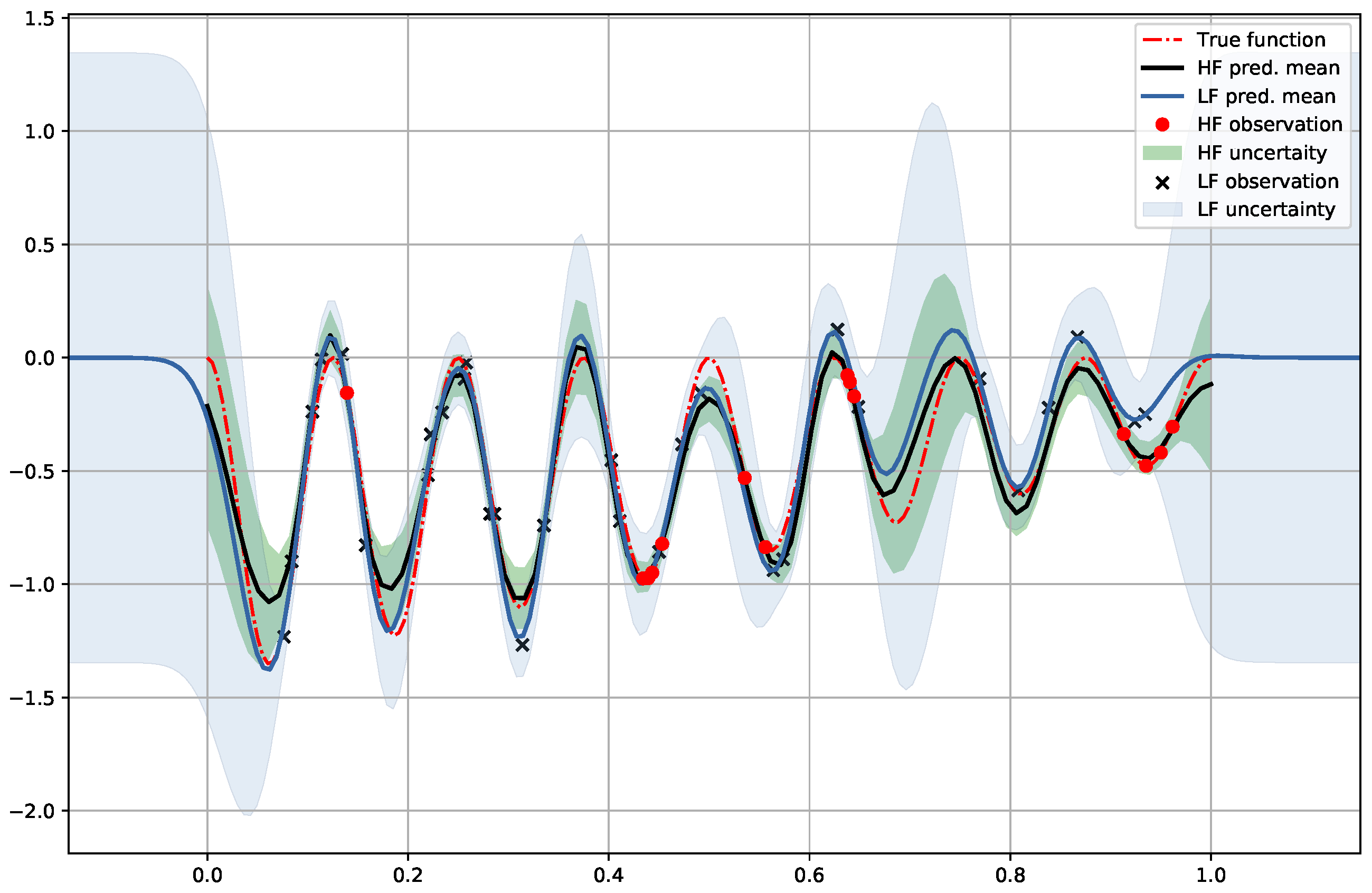
6.3. Denoising Regression
6.4. Multi-Fidelity Data with High Dimensional Input
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DGP | Deep Gaussian Process |
| SE | Squared Exponential |
| SC | Squared Cosine |
Appendix A
References
- Kennedy, M.C.; O’Hagan, A. Predicting the output from a complex computer code when fast approximations are available. Biometrika 2000, 87, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Xing, W.; Kirby, R.; Zhe, S. Multi-Fidelity High-Order Gaussian Processes for Physical Simulation. In Proceedings of the International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 13 April 2021; pp. 847–855. [Google Scholar]
- Cutajar, K.; Pullin, M.; Damianou, A.; Lawrence, N.; González, J. Deep Gaussian processes for multi-fidelity modeling. arXiv 2019, arXiv:1903.07320. [Google Scholar]
- Salakhutdinov, R.; Tenenbaum, J.; Torralba, A. One-shot learning with a hierarchical nonparametric bayesian model. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2012; pp. 195–206. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6 August 2017; pp. 1126–1135. [Google Scholar]
- Titsias, M.K.; Schwarz, J.; Matthews, A.G.d.G.; Pascanu, R.; Teh, Y.W. Functional Regularisation for Continual Learning with Gaussian Processes. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Process for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Duvenaud, D.; Lloyd, J.; Grosse, R.; Tenenbaum, J.; Zoubin, G. Structure discovery in nonparametric regression through compositional kernel search. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; pp. 1166–1174. [Google Scholar]
- Sun, S.; Zhang, G.; Wang, C.; Zeng, W.; Li, J.; Grosse, R. Differentiable compositional kernel learning for Gaussian processes. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4828–4837. [Google Scholar]
- Damianou, A.; Lawrence, N. Deep Gaussian processes. In Proceedings of the Artificial Intelligence and Statistics, Scottsdale, AZ, USA, 29 April–1 May 2013; pp. 207–215. [Google Scholar]
- Snelson, E.; Ghahramani, Z.; Rasmussen, C.E. Warped Gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 13–18 December 2004; pp. 337–344. [Google Scholar]
- Lázaro-Gredilla, M. Bayesian warped Gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1619–1627. [Google Scholar]
- Salimbeni, H.; Deisenroth, M. Doubly stochastic variational inference for deep Gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Salimbeni, H.; Dutordoir, V.; Hensman, J.; Deisenroth, M.P. Deep Gaussian Processes with Importance-Weighted Variational Inference. arXiv 2019, arXiv:1905.05435. [Google Scholar]
- Yu, H.; Chen, Y.; Low, B.K.H.; Jaillet, P.; Dai, Z. Implicit Posterior Variational Inference for Deep Gaussian Processes. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 14502–14513. [Google Scholar]
- Lu, C.K.; Yang, S.C.H.; Hao, X.; Shafto, P. Interpretable deep Gaussian processes with moments. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 26–28 August 2020; pp. 613–623. [Google Scholar]
- Havasi, M.; Hernández-Lobato, J.M.; Murillo-Fuentes, J.J. Inference in deep Gaussian processes using stochastic gradient Hamiltonian Monte Carlo. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 7506–7516. [Google Scholar]
- Ustyuzhaninov, I.; Kazlauskaite, I.; Kaiser, M.; Bodin, E.; Campbell, N.; Ek, C.H. Compositional uncertainty in deep Gaussian processes. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Toronto, ON, Canada, 3 August 2020; pp. 480–489. [Google Scholar]
- Le Gratiet, L.; Garnier, J. Recursive co-kriging model for design of computer experiments with multiple levels of fidelity. Int. J. Uncertain. Quantif. 2014, 4, 365–386. [Google Scholar] [CrossRef]
- Raissi, M.; Karniadakis, G. Deep multi-fidelity Gaussian processes. arXiv 2016, arXiv:1604.07484. [Google Scholar]
- Perdikaris, P.; Raissi, M.; Damianou, A.; Lawrence, N.; Karniadakis, G.E. Nonlinear information fusion algorithms for data-efficient multi-fidelity modelling. Proc. R. Soc. Math. Phys. Eng. Sci. 2017, 473, 20160751. [Google Scholar] [CrossRef] [PubMed]
- Requeima, J.; Tebbutt, W.; Bruinsma, W.; Turner, R.E. The Gaussian process autoregressive regression model (gpar). In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Okinawa, Japan, 16–18 April 2019; pp. 1860–1869. [Google Scholar]
- Alvarez, M.A.; Rosasco, L.; Lawrence, N.D. Kernels for vector-valued functions: A review. arXiv 2011, arXiv:1106.6251. [Google Scholar]
- Parra, G.; Tobar, F. Spectral mixture kernels for multi-output Gaussian processes. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6684–6693. [Google Scholar]
- Bruinsma, W.; Perim, E.; Tebbutt, W.; Hosking, S.; Solin, A.; Turner, R. Scalable Exact Inference in Multi-Output Gaussian Processes. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1190–1201. [Google Scholar]
- Kaiser, M.; Otte, C.; Runkler, T.; Ek, C.H. Bayesian alignments of warped multi-output Gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Canada, 3–8 December 2018; pp. 6995–7004. [Google Scholar]
- Kazlauskaite, I.; Ek, C.H.; Campbell, N. Gaussian Process Latent Variable Alignment Learning. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Okinawa, Japan, 16–18 April 2019; pp. 748–757. [Google Scholar]
- Williams, C.K. Computing with infinite networks. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–4 December1997; pp. 295–301. [Google Scholar]
- Cho, Y.; Saul, L.K. Kernel methods for deep learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–8 December 2009; pp. 342–350. [Google Scholar]
- Duvenaud, D.; Rippel, O.; Adams, R.; Ghahramani, Z. Avoiding pathologies in very deep networks. In Proceedings of the Artificial Intelligence and Statistics, Reykjavik, Iceland, 22–25 April 2014; pp. 202–210. [Google Scholar]
- Dunlop, M.M.; Girolami, M.A.; Stuart, A.M.; Teckentrup, A.L. How deep are deep Gaussian processes? J. Mach. Learn. Res. 2018, 19, 2100–2145. [Google Scholar]
- Shen, Z.; Heinonen, M.; Kaski, S. Learning spectrograms with convolutional spectral kernels. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 26–28 August 2020; pp. 3826–3836. [Google Scholar]
- Wilson, A.G.; Hu, Z.; Salakhutdinov, R.; Xing, E.P. Deep kernel learning. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 370–378. [Google Scholar]
- Daniely, A.; Frostig, R.; Singer, Y. Toward Deeper Understanding of Neural Networks: The Power of Initialization and a Dual View on Expressivity. In Proceedings of the NIPS: Centre Convencions Internacional Barcelona, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Mairal, J.; Koniusz, P.; Harchaoui, Z.; Schmid, C. Convolutional kernel networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 2627–2635. [Google Scholar]
- Van der Wilk, M.; Rasmussen, C.E.; Hensman, J. Convolutional Gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2849–2858. [Google Scholar]
- GPy. GPy: A Gaussian Process Framework in Python. 2012. Available online: http://github.com/SheffieldML/GPy (accessed on 1 October 2021).
- Wilson, A.; Adams, R. Gaussian process kernels for pattern discovery and extrapolation. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1067–1075. [Google Scholar]
- Lu, C.K.; Shafto, P. Conditional Deep Gaussian Processes: Empirical Bayes Hyperdata Learning. Entropy 2021, 23, 1387. [Google Scholar] [CrossRef]
- Paleyes, A.; Pullin, M.; Mahsereci, M.; Lawrence, N.; González, J. Emulation of physical processes with Emukit. In Proceedings of the Second Workshop on Machine Learning and the Physical Sciences, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Shah, A.; Wilson, A.; Ghahramani, Z. Student-t processes as alternatives to Gaussian processes. In Proceedings of the Artificial Intelligence and Statistics, Reykjavic, Iceland, 22–25 April 2014; pp. 877–885. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MFDGP | SE[ ] | SC[ ] | GP + | |
|---|---|---|---|---|
| Borehole | −1.87 | 0.56 | ||
| Branin | −2.7 | −2.52 | 5180 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, C.-K.; Shafto, P. Conditional Deep Gaussian Processes: Multi-Fidelity Kernel Learning. Entropy 2021, 23, 1545. https://doi.org/10.3390/e23111545
Lu C-K, Shafto P. Conditional Deep Gaussian Processes: Multi-Fidelity Kernel Learning. Entropy. 2021; 23(11):1545. https://doi.org/10.3390/e23111545
Chicago/Turabian StyleLu, Chi-Ken, and Patrick Shafto. 2021. "Conditional Deep Gaussian Processes: Multi-Fidelity Kernel Learning" Entropy 23, no. 11: 1545. https://doi.org/10.3390/e23111545
APA StyleLu, C.-K., & Shafto, P. (2021). Conditional Deep Gaussian Processes: Multi-Fidelity Kernel Learning. Entropy, 23(11), 1545. https://doi.org/10.3390/e23111545