
Bird Species Identification Using Spectrogram Based on Multi-Channel Fusion of DCNNs


Abstract
:1. Introduction
- (1)
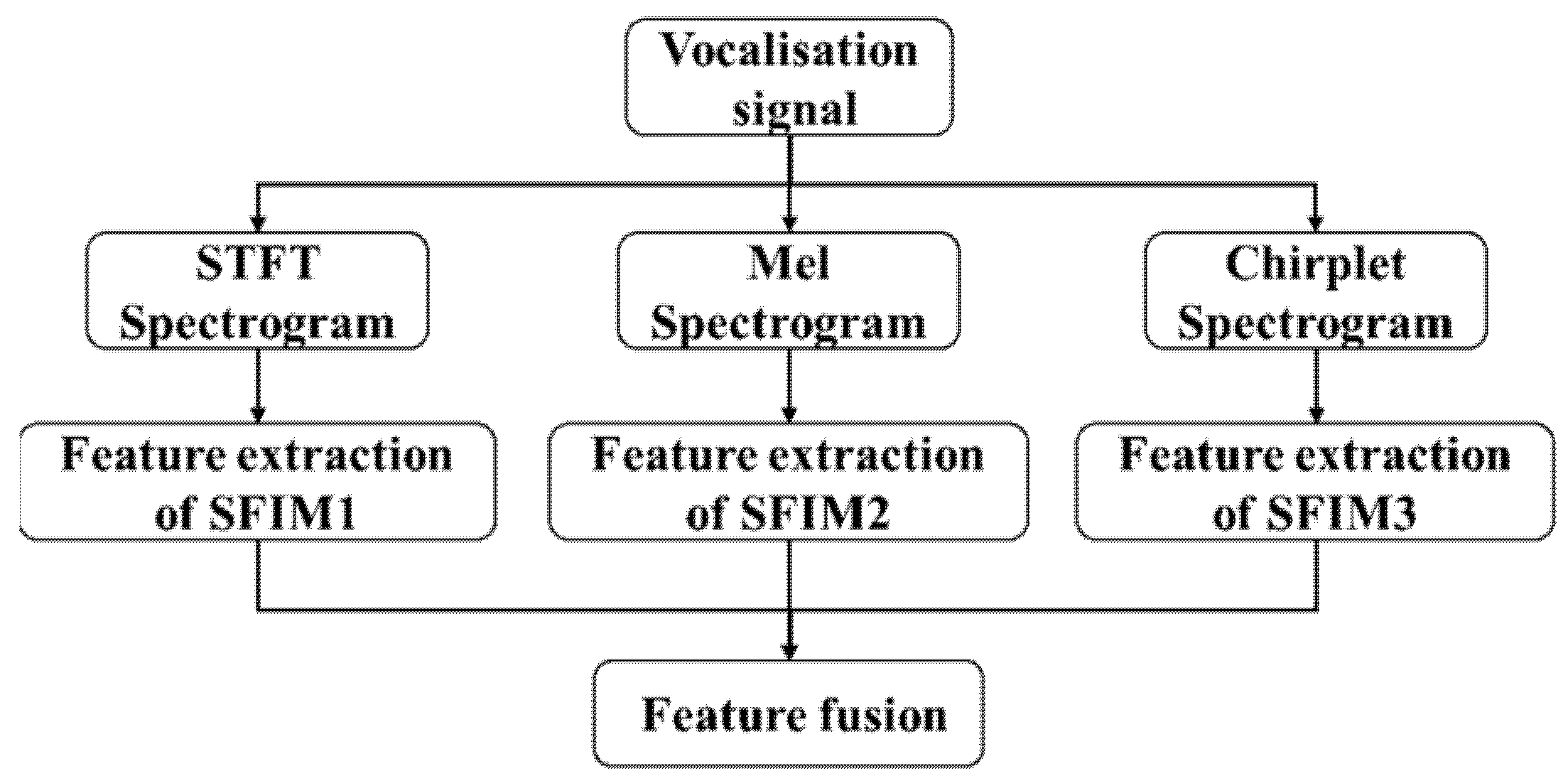
- Considering the imbalance of the bird vocalization dataset, a single feature identification model (SFIM) was built with residual blocks and modified, weighted, cross-entropy function. Three SFIMs were trained with three kinds of spectrograms calculated by short-time Fourier transform, mel-frequency cepstrum transform and chirplet transform, respectively.
- (2)
- To achieve better performance, two multi-channel fusion models using three different SFIMs were studied. Furthermore, transfer learning was introduced to decrease the number of trainable parameters of fusion models. The resulting fusion mode model outperforms the feature fusion mode model and SFIMs, the best mean average precision (MAP) reaches 0.914.
- (3)
- Through the comparative experiments with different durations of spectrograms, the results revealed that the duration is suggested to be determined based on the duration distribution of bird syllables.
2. Materials and Methods
2.1. Datasets
2.1.1. Vocalization Signals
2.1.2. Signal Pre-Processing
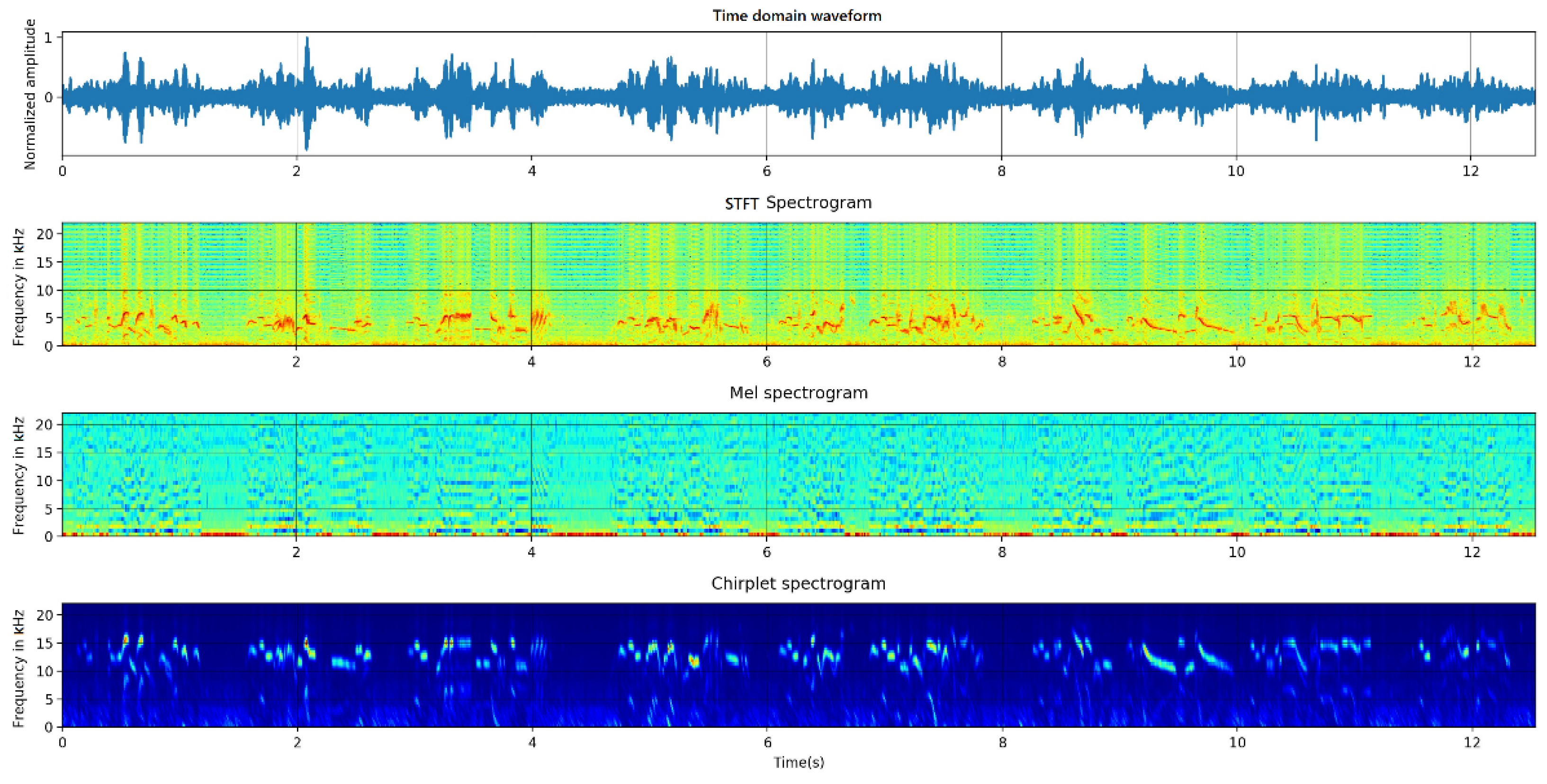
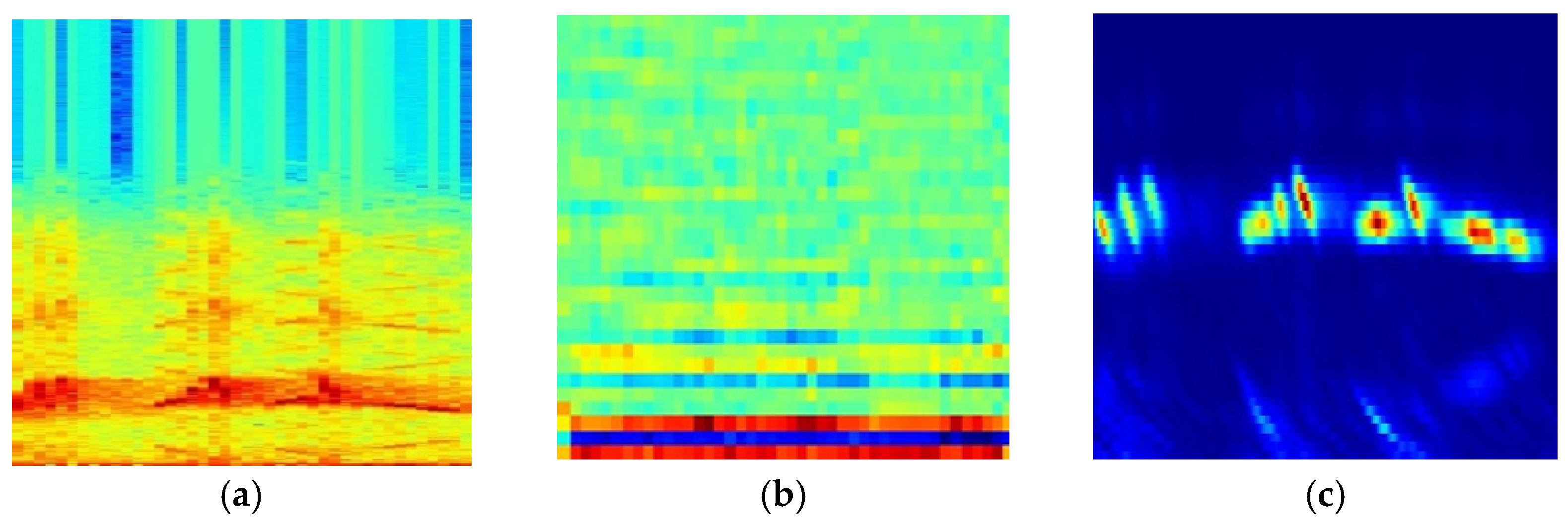
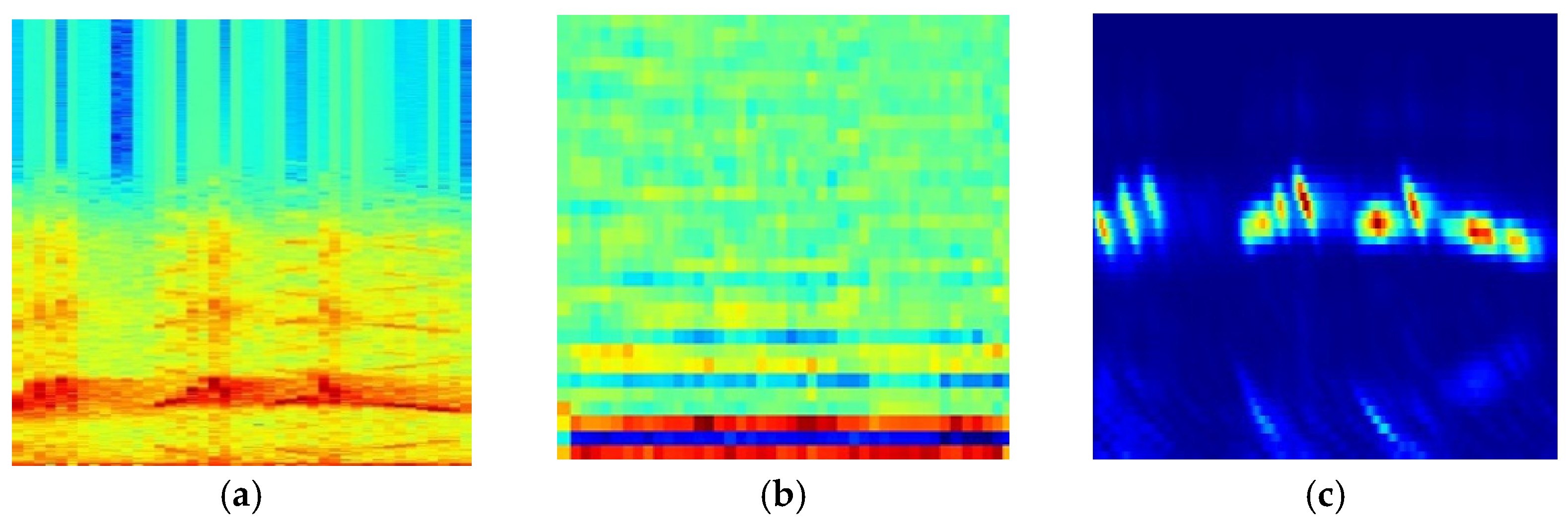
2.1.3. Spectrogram Calculation
2.1.4. Create Sample Sets
2.2. Identification Models
2.2.1. Single Feature Identification Model (SFIM) Based on DCNN
2.2.2. Multi-Channel Identification Models
3. Results and Discussion
3.1. Experimental Setup
3.2. Different Models with the Same Duration of Spectrogram
3.3. Different Models with Different Durations of Spectrogram
3.4. Performance with BirdCLEF2019 Dataset
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Priyadarshani, N.; Marsland, S.; Castro, I. Automated birdsong recognition in complex acoustic environments: A review. J. Avian Biol. 2018, 49, 1–52. [Google Scholar] [CrossRef] [Green Version]
- Green, S.; Marler, P. The Analysis of Animal Communication. J. Theor. Biol. 1961, 1, 295–317. [Google Scholar]
- Graciarena, M.; Delplanch, M.; Shriberg, E.; Stolcke, A. Bird species recognition combining acoustic and sequence modeling. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech, 22–27 May 2011; pp. 1–4. [Google Scholar]
- Kalan, A.K.; Mundry, R.; Wagner, O.J.J.; Heinicke, S.; Boesch, C.; Kühl, H.S. Towards the automated detection and occupancy estimation of primates using passive acoustic monitoring. Ecol. Indic. 2015, 54, 217–226. [Google Scholar] [CrossRef]
- Perez-Granados, C.B.G.; Giralt, D.; Barrero, A.; Julia, G.C.; Bustillo, D.L.A.R.; Traba, J. Vocal activity rate index: A useful method to infer terrestrial bird abundance with acoustic monitoring. Ibis 2019, 161, 901–907. [Google Scholar] [CrossRef]
- Dan, X.; Huang, S.; Xin, Z. Spatial-aware global contrast representation for saliency detection. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 2412–2429. [Google Scholar]
- Koops, H.V.; Van Balen, J.; Wiering, F.; Multimedia, S. A Deep Neural Network Approach to the LifeCLEF 2014 bird task. LifeClef Work. Notes 2014, 1180, 634–642. [Google Scholar]
- Piczak, K. Recognizing Bird Species in Audio Recordings Using Deep Convolutional Neural Networks. CEUR Workshop Proc. 2016, 1609, 1–10. [Google Scholar]
- Toth, B.P.; Czeba, B. Convolutional Neural Networks for Large-Scale Bird Song Classification in Noisy Environment. In Proceedings of theConference and Labs of the Evaluation Forum, Évora, Portugal, 5–8 September 2016; pp. 1–9. [Google Scholar]
- Sprengel, E.; Jaggi, M.; Kilcher, Y.; Hofmann, T. Audio Based Bird Species Identification using Deep Learning Techniques. In Proceedings of the CEUR Workshop, Evora, Portugal, 5–8 September 2016; pp. 547–559. [Google Scholar]
- Cakir, E.; Adavanne, S.; Parascandolo, G.; Drossos, K.; Virtanen, T. Convolutional recurrent neural networks for bird audio detection. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greek Island, 28 August–2 September 2017; pp. 1794–1798. [Google Scholar]
- Agnes, I.; Henrietta-Bernadett, J.; Zoltan, S.; Attila, F.; Csaba, S. Bird sound recognition using a convolutional neural network. In Proceedings of the 2018 IEEE 16th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 13–15 September 2018; pp. 000295–000300. [Google Scholar]
- Xie, J.; Li, W.; Zhang, J.; Ding, C. Bird species recognition method based on Chirplet spectrogram feature and deep learning. J. Beijing For. Univ. 2018, 40, 122–127. [Google Scholar]
- Xie, J.; Yang, J.; Ding, C.; Li, W. High accuracy individual identification model of crested ibis (Nipponia Nippon) based on autoencoder with self-attention. IEEE Access 2020, 8, 41062–41070. [Google Scholar] [CrossRef]
- Kahl, S.; Wood, C.M.; Eibl, M.; Klinck, H. BirdNET: A deep learning solution for avian diversity monitoring. Ecol. Inform. 2021, 61, 101236. [Google Scholar] [CrossRef]
- Turker, T.; Erhan, A.; Sengul, D. Multileveled ternary pattern and iterative ReliefF based bird sound classification. Appl. Acoust. 2021, 176, 107866. [Google Scholar]
- Zhuang, F.; Ping, L.; Qing, H.; Shi, Z. Survey on transfer learning research. J. Softw. 2015, 26, 26–39. [Google Scholar]
- Zebhi, S.; Almodarresi, S.M.T.; Vahid, A. Human activity recognition by using MHIs of frame sequences. Turk. J. Electr. Eng. Comput. Sci. 2020, 28, 1716–1730. [Google Scholar] [CrossRef]
- Antoine, S.; Herve, G. Audio Bird Classification with Inception-v4 extended with Time and Time-Frequency Attention Mechanisms. LifeClef Work. Notes 2017, 1866, 1–8. [Google Scholar]
- Potamitis, I.; Ntalampiras, S.; Jahn, O.; Riede, K. Automatic bird sound detection in long real-field recordings: Applications and tools. Appl. Acoust. 2014, 80, 1–9. [Google Scholar] [CrossRef]
- Bultan, A. A four-parameter atomic decomposition of chirplets. IEEE Trans. Signal Process. 2002, 47, 731–745. [Google Scholar] [CrossRef]
- Glotin, H.; Ricard, J.; Balestriero, R. Fast Chirplet Transform to Enhance CNN Machine Listening—Validation on Animal calls and Speech. arXiv 2016, arXiv:1611.08749. [Google Scholar]
- Rizvi, M.; Deb, K.; Khan, M.; Kowsar, M.; Khanam, T. A comparative study on handwritten Bangla character recognition. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 3195–3207. [Google Scholar] [CrossRef]
- Akram, A.; Debnath, R. An automated eye disease recognition system from visual content of facial images using machine learning techniques. Turk. J. Electr. Eng. Comput. Sci. 2020, 28, 917–932. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tekeli, U.; Bastanlar, Y. Elimination of useless images from raw camera-trap data. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 2395–2411. [Google Scholar] [CrossRef]
- Xie, J.; Li, A.; Zhang, J.; Cheng, Z. An Integrated Wildlife Recognition Model Based on Multi-Branch Aggregation and Squeeze-And-Excitation Network. Appl. Sci. 2019, 9, 2794. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Tian, G.; Xu, Y. A novel scene classification model combining ResNet based transfer learning and data augmentation with a filter. Neurocomputing 2019, 338, 191–206. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 354–370. [Google Scholar]
- Kahl, S.; Stoter, F.R.; Goeau, H.; Glotin, H.; Planque, R.; Vellinga, W.P.; Joly, A. Overview of BirdCLEF 2019: Large-Scale Bird Recognition in Soundscapes. Technical Report for 2019BirdCLEF Challenge. Available online: https://hal.umontpellier.fr/hal-02345644/document (accessed on 4 November 2019).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Order | Family | Species | Time (s) |
|---|---|---|---|
| Galliformes | Phasianidae | Phasianus colchicus | 12 |
| Cuculiformes | Cuculidae | C. micropterus | 13 |
| C. saturatus | 52 | ||
| Cuculus sparverioides | 34 | ||
| Passeriformes | Corvidae | Corvus macrorhynchos | 27 |
| Urocissa erythroryncha | 96 | ||
| Turdidae | Phoenicurus auroreus | 37 | |
| Muscicapidae | Ficedula zanthopygia | 61 | |
| F. narcissina | 82 | ||
| F. elisae | 49 | ||
| Paridae | P. major | 54 | |
| Parus palustris | 33 | ||
| P. montanus | 38 | ||
| P. venustulus | 26 | ||
| Sittidae | S. villosa | 29 | |
| Sitta europaea | 36 | ||
| Emberizidae | Emberiza godlewskii | 23 | |
| E. elegans | 71 |
| Output | Identification Model |
|---|---|
| 224 × 224 × 32 | conv, 3 × 3, 32, stride 1 |
| 224 × 224 × 32 | |
| 112 × 112 × 64 | |
| 112 × 112 × 64 | |
| 56 × 56 × 128 | |
| 56 × 56 × 128 | |
| 28 × 28 × 256 | |
| 28 × 28 × 256 | |
| 1 × N | global average pool, full connect (fc), softmax |
| Items | Value or Method |
|---|---|
| Batch size | 50 |
| Parameter initialization | Random initialization |
| Optimization algorithm | Adam [29] |
| Learning rate | 0.001 |
| Epochs | 100 |
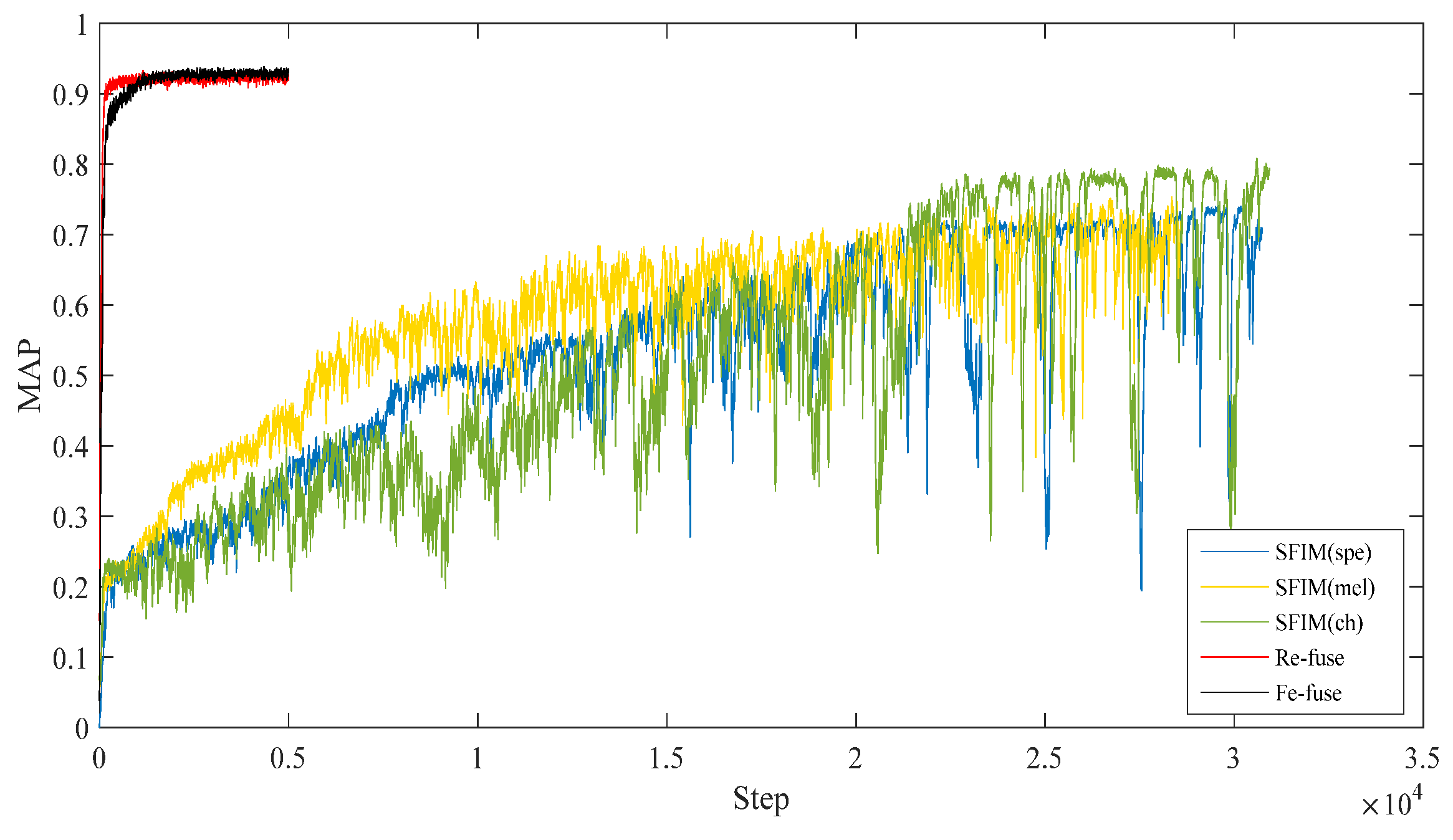
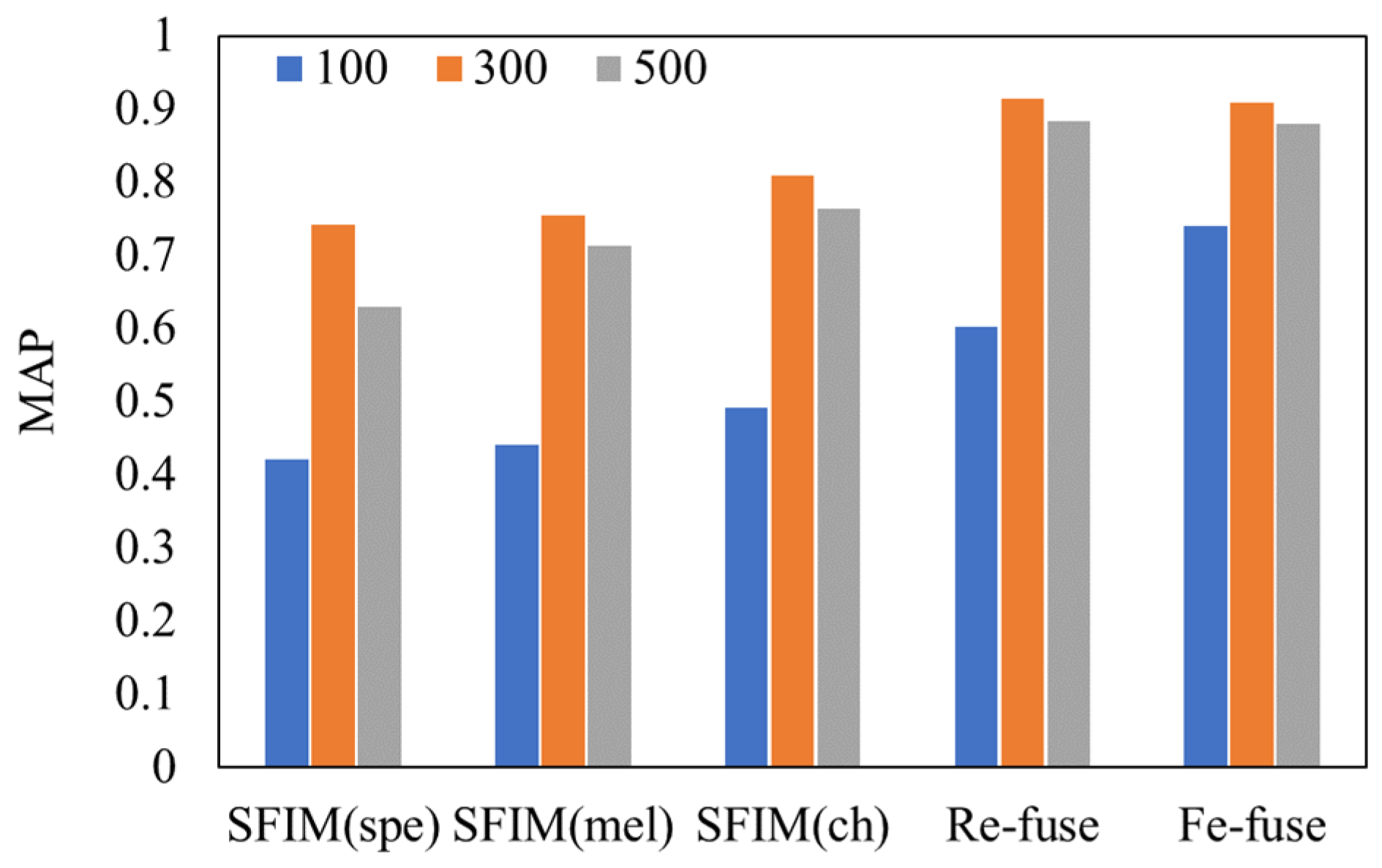
| Model | MAP |
|---|---|
| SFIM (Spe) | 0.742 |
| SFIM (Mel) | 0.754 |
| SFIM (Ch) | 0.808 |
| Re-fuse | 0.914 |
| Fe-fuse | 0.908 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Zhang, L.; Chen, H.; Xie, J. Bird Species Identification Using Spectrogram Based on Multi-Channel Fusion of DCNNs. Entropy 2021, 23, 1507. https://doi.org/10.3390/e23111507
Zhang F, Zhang L, Chen H, Xie J. Bird Species Identification Using Spectrogram Based on Multi-Channel Fusion of DCNNs. Entropy. 2021; 23(11):1507. https://doi.org/10.3390/e23111507
Chicago/Turabian StyleZhang, Feiyu, Luyang Zhang, Hongxiang Chen, and Jiangjian Xie. 2021. "Bird Species Identification Using Spectrogram Based on Multi-Channel Fusion of DCNNs" Entropy 23, no. 11: 1507. https://doi.org/10.3390/e23111507
APA StyleZhang, F., Zhang, L., Chen, H., & Xie, J. (2021). Bird Species Identification Using Spectrogram Based on Multi-Channel Fusion of DCNNs. Entropy, 23(11), 1507. https://doi.org/10.3390/e23111507