
Quantifiers in Natural Language: Efficient Communication and Degrees of Semantic Universals


Abstract
1. Introduction
2. Background
2.1. Quantifier Semantics
2.2. Semantic Universals for Quantifiers
2.2.1. Monotonicity
- (1)
- a. Many scientists program in Python.b. Many scientists program.
- (2)
- Q is upward monotone if and only if whenever and ; then, .
- (3)
- a. Few scientists program in Python.b. Few scientists program.
- (4)
- Q is downward monotone if and only if whenever and ; then, .
2.2.2. Conservativity
- (5)
- a. Every student passed.b. Every student is a student who passed.
- (6)
- a. Most Amsterdammers ride a bicycle to work.b. Most Amsterdammers are Amsterdammers who ride a bicycle to work.
- (7)
- Q is conservative if and only if if and only if .
- (8)
- a. Equi students are at the park.b. The number of students is the same as the number of people at the park.
2.3. The Learnability hypothesis
2.4. The Efficient Communication Hypothesis
3. Methods
3.1. Measuring Simplicity and Informativeness
3.2. Measuring Optimality
4. Experiment 1: Degree of Naturalness
4.1. Sampling Languages
- Generalized existential: depending only on .For example: .
- Generalized intersective: depending only on .For example: .
- Proportional: comparing and .For example: .
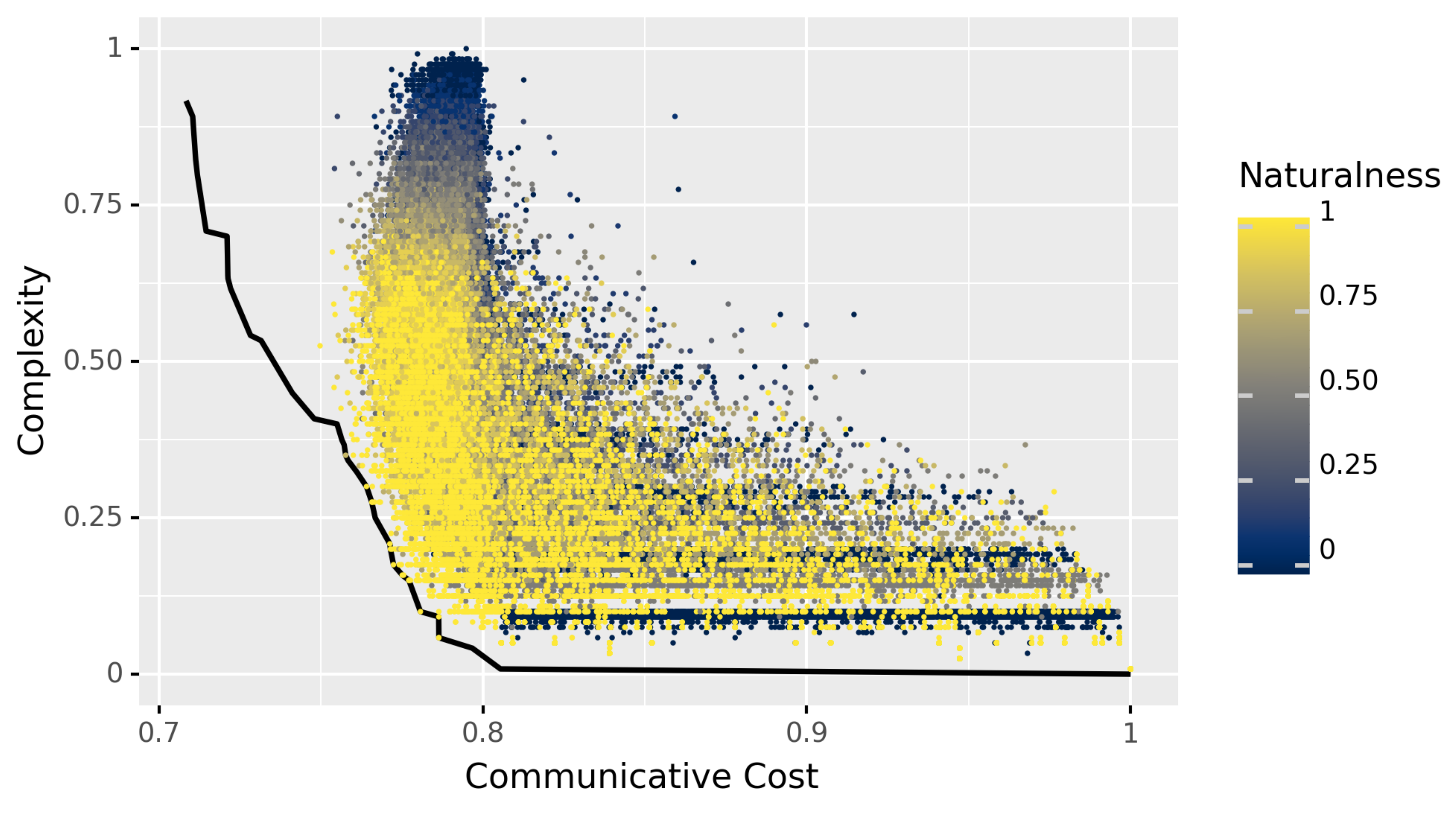
4.2. Results
4.3. Discussion
5. Experiment 2: Degrees of Semantic Universals
5.1. Measuring Degrees of Universals
5.1.1. Monotonicity
5.1.2. Conservativity
5.2. Sampling Procedure
5.3. Results
5.4. Discussion
6. General Discussion
6.1. Status of Semantic Universals
6.2. Relationship to Linguistic Laws
6.3. Future Work
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
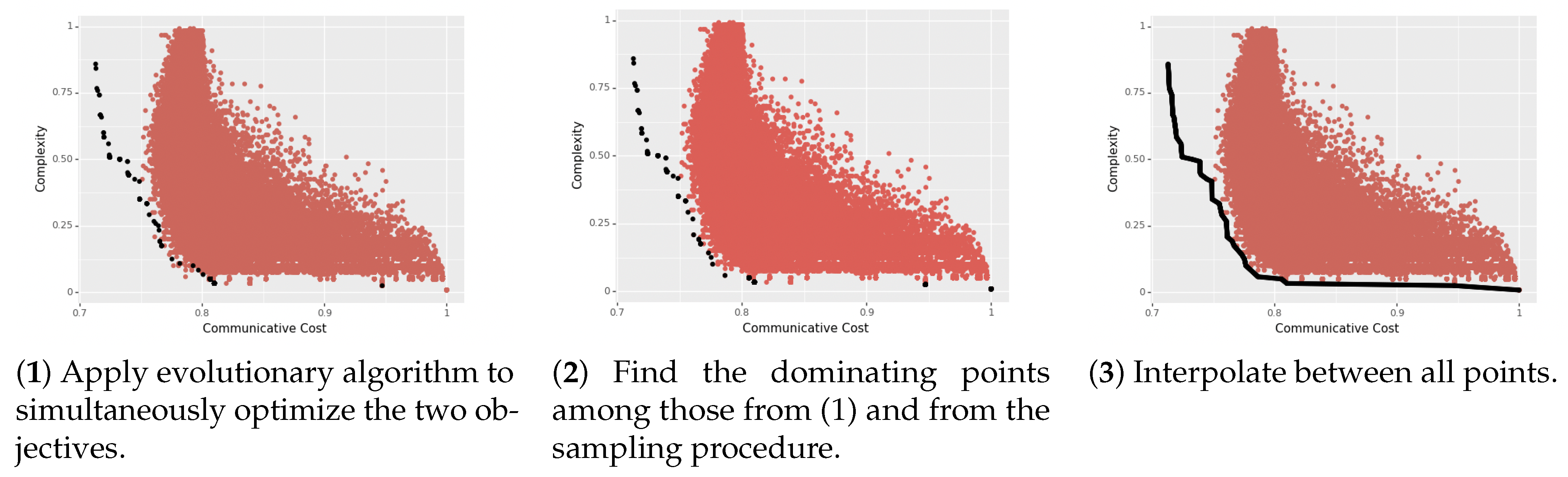
Appendix A. Estimating the Pareto Frontier
| Algorithm A1 Estimating the Pareto Frontier |
| Parameters:num_generations, num_langs |
| Inputs: set of languages L, Pareto dominance method find_dominant, interpolate method |
| function genetic_estimate(num_generations, num_langs) |
| for do |
| end for |
| return languages |
| end function |
| function sample_mutated(languages, amount) |
| for language ∈ languages do |
| for do |
| Add to |
| end for |
| end for |
| for do |
| Add to |
| end for |
| return mutated_languages |
| end function |
| function mutate (language) |
| mutated_language ← language |
| for do |
| end for |
| return mutated_language |
| end function |
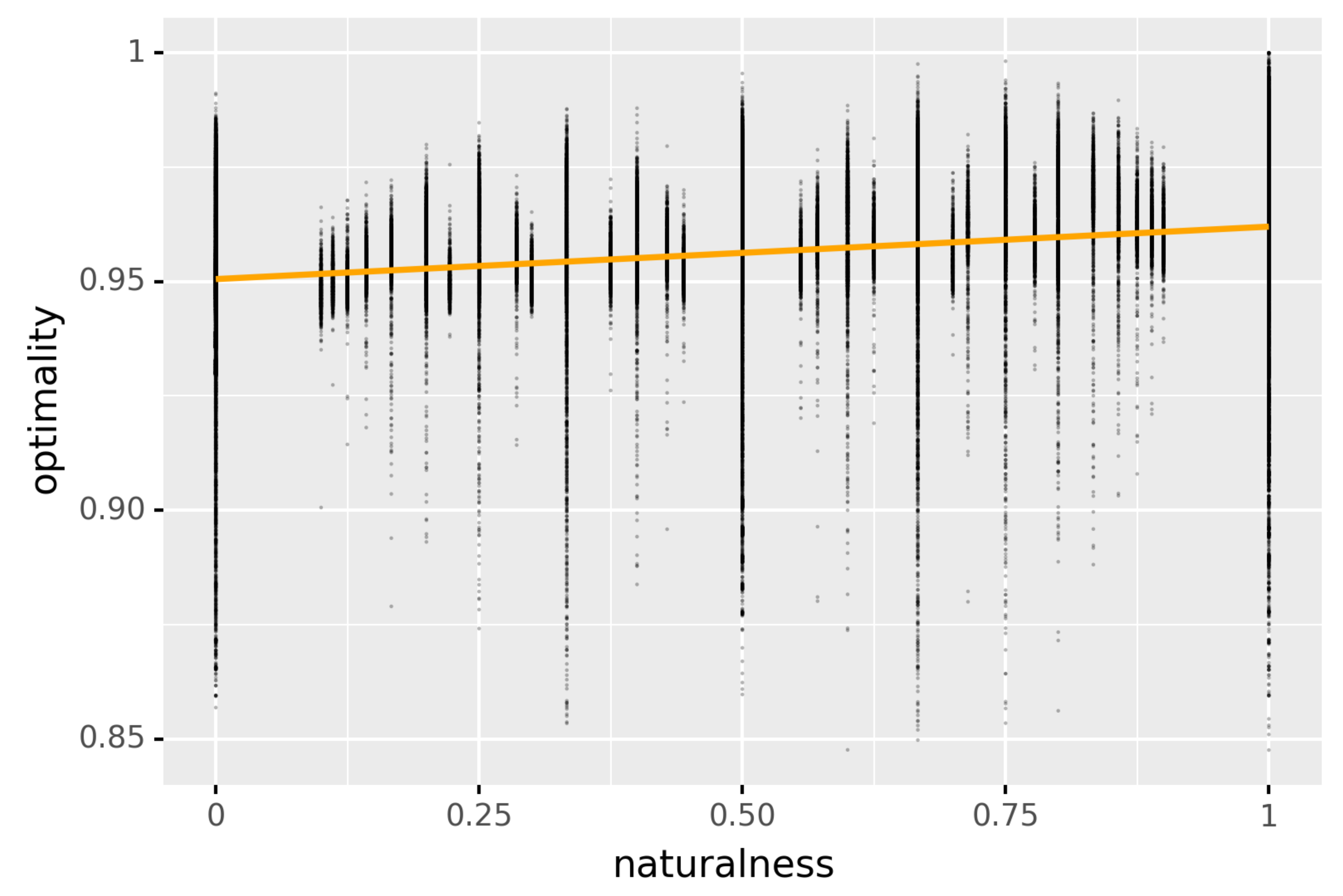
Appendix B. Optimality versus Naturalness

References
- Croft, W. Typology and Universals; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Hyman, L.M. Universals in phonology. Linguist. Rev. 2008, 25, 83–137. [Google Scholar] [CrossRef]
- Von Fintel, K.; Matthewson, L. Universals in semantics. Linguist. Rev. 2008, 25, 139–201. [Google Scholar] [CrossRef]
- Newmeyer, F.J. Universals in syntax. Linguist. Rev. 2008, 25, 35–82. [Google Scholar] [CrossRef]
- Ferrer-i Cancho, R. Euclidean distance between syntactically linked words. Phys. Rev. E 2004, 70, 056135. [Google Scholar] [CrossRef]
- Futrell, R.; Mahowald, K.; Gibson, E. Large-scale evidence of dependency length minimization in 37 languages. Proc. Natl. Acad. Sci. USA 2015, 112, 10336–10341. [Google Scholar] [CrossRef]
- Hahn, M.; Jurafsky, D.; Futrell, R. Universals of word order reflect optimization of grammars for efficient communication. Proc. Natl. Acad. Sci. USA 2020, 117, 2347–2353. [Google Scholar] [CrossRef]
- Zipf, G.K. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology; Addison-Wesley Press: Boston, MA, USA, 1949. [Google Scholar]
- Ferrer-i Cancho, R.; Sole, R.V. Least effort and the origins of scaling in human language. Proc. Natl. Acad. Sci. USA 2003, 100, 788–791. [Google Scholar] [CrossRef]
- Piantadosi, S.T. Zipf’s word frequency law in natural language: A critical review and future directions. Psychon. Bull. Rev. 2014, 21, 1112–1130. [Google Scholar] [CrossRef]
- Altmann, E.G.; Gerlach, M. Statistical Laws in Linguistics. In Creativity and Universality in Language; Esposti, M.D., Altmann, E.G., Pachet, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 7–26. [Google Scholar] [CrossRef]
- Torre, I.G.; Luque, B.; Lacasa, L.; Luque, J.; Hernández-Fernández, A. Emergence of linguistic laws in human voice. Sci. Rep. 2017, 7, 43862. [Google Scholar] [CrossRef]
- Torre, I.G.; Luque, B.; Lacasa, L.; Kello, C.T.; Hernández-Fernández, A. On the physical origin of linguistic laws and lognormality in speech. R. Soc. Open Sci. 2019, 6, 191023. [Google Scholar] [CrossRef]
- Heesen, R.; Hobaiter, C.; Ferrer-i Cancho, R.; Semple, S. Linguistic laws in chimpanzee gestural communication. Proc. R. Soc. B Biol. Sci. 2019, 286, 20182900. [Google Scholar] [CrossRef]
- Berlin, B.; Kay, P. Basic Color Terms: Their Universality and Evolution; University of California Press: Berkeley, CA, USA, 1969. [Google Scholar]
- Gärdenfors, P. The Geometry of Meaning; The MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Jäger, G. Natural Color Categories Are Convex Sets. In Logic, Language, and Meaning: Amsterdam Colloquium 2009; Aloni, M., Bastiaanse, H., de Jager, T., Schulz, K., Eds.; Springer: Berlin, Germany, 2010; pp. 11–20. [Google Scholar] [CrossRef]
- Kemp, C.; Regier, T. Kinship categories across languages reflect general communicative principles. Science 2012, 336, 1049–1054. [Google Scholar] [CrossRef]
- Kemp, C.; Xu, Y.; Regier, T. Semantic typology and efficient communication. Annu. Rev. Linguist. 2018, 4, 109–128. [Google Scholar] [CrossRef]
- Zaslavsky, N.; Kemp, C.; Regier, T.; Tishby, N. Efficient compression in color naming and its evolution. Proc. Natl. Acad. Sci. USA 2018, 115, 7937–7942. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar] [CrossRef]
- Barwise, J.; Cooper, R. Generalized Quantifiers and Natural Language. Linguist. Philos. 1981, 4, 159–219. [Google Scholar] [CrossRef]
- Peters, S.; Westerståhl, D. Quantifiers in Language and Logic; Clarendon Press: Oxford, UK, 2006. [Google Scholar]
- Steinert-Threlkeld, S.; Szymanik, J. Learnability and Semantic Universals. Semant. Pragmat. 2019, 12, 4. [Google Scholar] [CrossRef]
- Steinert-Threlkeld, S.; Szymanik, J. Ease of Learning Explains Semantic Universals. Cognition 2020, 195, 104076. [Google Scholar] [CrossRef] [PubMed]
- Steinert-Threlkeld, S. Quantifiers in natural language optimize the simplicity/informativeness trade-off. In Proceedings of the 22nd Amsterdam Colloquium, Amsterdam, The Netherlands, 18–20 December 2019; Schlöder, J.J., McHugh, D., Roelofsen, F., Eds.; ILLC: Amsterdam, The Netherlands, 2020; pp. 513–522. [Google Scholar]
- Denić, M.; Steinert-Threlkeld, S.; Szymanik, J. Complexity/informativeness trade-off in the domain of indefinite pronouns. In Proceedings of the Semantics and Linguistic Theory (SALT 30), Virtual Conference, 17–20 August 2020; Volume 30, pp. 166–184. [Google Scholar] [CrossRef]
- Uegaki, W. The informativeness/complexity trade-off in the domain of Boolean connectives. Linguist. Inq. 2021. forthcoming. [Google Scholar]
- Enguehard, É.; Spector, B. Explaining gaps in the logical lexicon of natural languages: A decision-theoretic perspective on the square of Aristotle. Semant. Pragmat. 2021, 14, 5. [Google Scholar] [CrossRef]
- Zaslavsky, N.; Maldonado, M.; Culbertson, J. Let’s talk (efficiently) about us: Person systems achieve near-optimal compression. In Proceedings of the 43rd Annual Meeting of the Cognitive Science Society, Virtual Conference, 26–29 July 2021. [Google Scholar]
- Hackl, M. On the grammar and processing of proportional quantifiers: Most. Versus more Half. Nat. Lang. Semant. 2009, 17, 63–98. [Google Scholar] [CrossRef]
- Kotek, H.; Howard, E.; Sudo, Y.; Hackl, M. Three Readings of Most; Semantics and Linguistic Theory (SALT, 21); Ashton, N., Chereches, A., Lutz, D., Eds.; Linguistics Society of America: Washington, DC, USA, 2011; pp. 353–372. [Google Scholar] [CrossRef]
- Kotek, H.; Sudo, Y.; Howard, E.; Hackl, M. Most Meanings are Superlative. In Experiments at the Interfaces; Syntax and Semantics; Emerald Group Publishing: Bingley, UK, 2011; Volume 37, pp. 101–145. [Google Scholar] [CrossRef]
- Solt, S. On measurement and quantification: The case of Most. more Half. Language 2016, 92, 65–100. [Google Scholar] [CrossRef]
- Keenan, E.L.; Stavi, J. A Semantic Characterization of Natural Language Determiners. Linguist. Philos. 1986, 9, 253–326. [Google Scholar] [CrossRef]
- Steinert-Threlkeld, S. An Explanation of the Veridical Uniformity Universal. J. Semant. 2020, 37, 129–144. [Google Scholar] [CrossRef]
- Hunter, T.; Lidz, J. Conservativity and learnability of determiners. J. Semant. 2013, 30, 315–334. [Google Scholar] [CrossRef]
- Spenader, J.; Villiers, J.D. Are conservative quantifiers easier to learn? Evidence from novel quantifier experiments. In Proceedings of the 22nd Amsterdam Colloquium, Amsterdam, The Netherlands, 18–20 December 2019; Schlöder, J.J., McHugh, D., Roelofsen, F., Eds.; ILLC: Amsterdam, The Netherlands, 2020; pp. 504–512. [Google Scholar]
- Chemla, E.; Buccola, B.; Dautriche, I. Connecting Content and Logical Words. J. Semant. 2019, 36, 531–547. [Google Scholar] [CrossRef]
- Chemla, E.; Dautriche, I.; Buccola, B.; Fagot, J. Constraints on the lexicons of human languages have cognitive roots present in baboons (Papio Papio). Proc. Natl. Acad. Sci. USA 2019, 116, 14926–14930. [Google Scholar] [CrossRef]
- Maldonado, M.; Culbertson, J. Something about us: Learning first person pronoun systems. In Proceedings of the 41st Annual Meeting of the Cognitive Science Society (CogSci 2019), Montreal, QC, Canada, 24–27 July 2019. [Google Scholar]
- Saratsli, D.; Bartell, S.; Papafragou, A. Cross-linguistic frequency and the learnability of semantics: Artificial language learning studies of evidentiality. Cognition 2020, 197, 104194. [Google Scholar] [CrossRef]
- Gibson, E.; Futrell, R.; Piantadosi, S.T.; Dautriche, I.; Mahowald, K.; Bergen, L.; Levy, R. How Efficiency Shapes Human Language. Trends Cogn. Sci. 2019, 23, 389–407. [Google Scholar] [CrossRef]
- Gibson, E.; Futrell, R.; Jara-Ettinger, J.; Mahowald, K.; Bergen, L.; Ratnasingam, S.; Gibson, M.; Piantadosi, S.T.; Conway, B.R. Color naming across languages reflects color use. Proc. Natl. Acad. Sci. USA 2017, 114, 10785–10790. [Google Scholar] [CrossRef]
- Xu, Y.; Regier, T.; Malt, B.C. Historical Semantic Chaining and Efficient Communication: The Case of Container Names. Cogn. Sci. 2016, 40, 2081–2094. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, E.; Regier, T. Numeral systems across languages support efficient communication: From approximate numerosity to recursion. Open Mind 2020, 4, 57–70. [Google Scholar] [CrossRef] [PubMed]
- Feldman, J. Minimization of Boolean Complexity in Human Concept Learning. Nature 2000, 407, 630–633. [Google Scholar] [CrossRef] [PubMed]
- Goodman, N.D.; Tenenbaum, J.B.; Feldman, J.; Griffiths, T.L. A rational analysis of rule-based concept learning. Cogn. Sci. 2008, 32, 108–154. [Google Scholar] [CrossRef] [PubMed]
- Piantadosi, S.T.; Tenenbaum, J.B.; Goodman, N.D. The logical primitives of thought: Empirical foundations for compositional cognitive models. Psychol. Rev. 2016, 123, 392–424. [Google Scholar] [CrossRef] [PubMed]
- Skyrms, B. Signals: Evolution, Learning, and Information; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Jäger, G. The evolution of convex categories. Linguist. Philos. 2007, 30, 551–564. [Google Scholar] [CrossRef]
- O’Connor, C. The Evolution of Vagueness. Erkenntnis 2014, 79, 707–727. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Lamont, G.B.; van Veldhuizen, D.A. Evolutionary Algorithms for Solving Multi-Objective Problems; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar] [CrossRef]
- Keenan, E.L.; Paperno, D. Handbook of Quantifiers in Natural Language; Studies in Linguistics and Philosophy; Springer: Dordrecht, The Netherland, 2012; Volume 90. [Google Scholar] [CrossRef]
- Paperno, D.; Keenan, E.L. (Eds.) Handbook of Quantifiers in Natural Language: Volume II; Studies in Linguistics and Philosophy; Springer: Dordrecht, The Netherland, 2017; Volume 97. [Google Scholar] [CrossRef]
- Efron, B.; Ribshirani, R.J. An Introduction to the Bootstrap; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Carcassi, F.; Steinert-Threlkeld, S.; Szymanik, J. The emergence of monotone quantifiers via iterated learning. In Proceedings of the 41st Annual Meeting of the Cognitive Science Society (CogSci 2019), Montreal, QC, Canada, 24–27 July 2019; pp. 190–196. [Google Scholar]
- Carcassi, F.; Steinert-Threlkeld, S.; Szymanik, J. Monotone Quantifiers Emerge via Iterated Learning. Cogn. Sci. 2021, 45, e13027. [Google Scholar] [CrossRef]
- Theil, H. On the Estimation of Relationships Involving Qualitative Variables. Am. J. Sociol. 1970, 76, 103–154. [Google Scholar] [CrossRef]
- Zuber, R.; Keenan, E.L. A Note on Conservativity. J. Semant. 2019, 36, 573–582. [Google Scholar] [CrossRef]
- Kirby, S.; Griffiths, T.; Smith, K. Iterated learning and the evolution of language. Curr. Opin. Neurobiol. 2014, 28, 108–114. [Google Scholar] [CrossRef]
- Kirby, S.; Tamariz, M.; Cornish, H.; Smith, K. Compression and communication in the cultural evolution of linguistic structure. Cognition 2015, 141, 87–102. [Google Scholar] [CrossRef] [PubMed]
- Debowski, L. Information Theory Meets Power Laws; Wiley: Hoboken, NJ, USA, 2020. [Google Scholar] [CrossRef]
- White, A.S.; Stengel-Eskin, E.; Vashishtha, S.; Govindarajan, V.; Reisinger, D.A.; Vieira, T.; Sakaguchi, K.; Zhang, S.; Ferraro, F.; Rudinger, R.; et al. The universal decompositional semantics dataset and decomp toolkit. In Proceedings of the LREC 2020—12th International Conference on Language Resources and Evaluation, Conference Proceedings, Marseille, France, 11–16 May 2020; pp. 5698–5707. [Google Scholar]
- Ferrer-i Cancho, R. Optimization Models of Natural Communication. J. Quant. Linguist. 2018, 25, 207–237. [Google Scholar] [CrossRef]
- Van de Pol, I.; Lodder, P.; van Maanen, L.; Steinert-Threlkeld, S.; Szymanik, J. Quantifiers satisfying semantic universals are simpler. In Proceedings of the Annual Meeting of the Cognitive Science Society, Vurtual Conference, 26–29 July 2021. [Google Scholar]
- Bach, E.; Jelinek, E.; Kratzer, A.; Partee, B.H. Quantification in Natural Languages; Studies in Linguistics and Philosophy; Springer: Berlin/Heidelberg, Germany, 1995; Volume 54. [Google Scholar] [CrossRef]
- Srinivas, N.; Deb, K. Muiltiobjective Optimization Using Nondominated Sorting in Genetic Algorithms. Evol. Comput. 1994, 2, 221–248. [Google Scholar] [CrossRef]
- Biscani, F.; Izzo, D. A parallel global multiobjective framework for optimization: Pagmo. J. Open Source Softw. 2020, 5, 2338. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Boolean | Set-Theoretic | Numeric |
|---|---|---|
| ∧, ∨, ¬ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Steinert-Threlkeld, S. Quantifiers in Natural Language: Efficient Communication and Degrees of Semantic Universals. Entropy 2021, 23, 1335. https://doi.org/10.3390/e23101335
Steinert-Threlkeld S. Quantifiers in Natural Language: Efficient Communication and Degrees of Semantic Universals. Entropy. 2021; 23(10):1335. https://doi.org/10.3390/e23101335
Chicago/Turabian StyleSteinert-Threlkeld, Shane. 2021. "Quantifiers in Natural Language: Efficient Communication and Degrees of Semantic Universals" Entropy 23, no. 10: 1335. https://doi.org/10.3390/e23101335
APA StyleSteinert-Threlkeld, S. (2021). Quantifiers in Natural Language: Efficient Communication and Degrees of Semantic Universals. Entropy, 23(10), 1335. https://doi.org/10.3390/e23101335