
Deep Coupling Recurrent Auto-Encoder with Multi-Modal EEG and EOG for Vigilance Estimation


Abstract
:1. Introduction
- The DCRA uses multi-layer gated recurrent units (GRUs) to extract deep features and uses the joint objective loss function to fuse them together.
- The joint loss function uses Euclidean distance similarity metrics in a single mode, and the multi-modal loss is measured by a Mahalanobis distance of metric learning [22,23], which can effectively reflect the distance between different modal data so that the distance between different modes can be described more accurately in the new feature space based on the metric matrix, and the losses of the two modes are summed according to weights.
- Compared to the latest fusion method and the single-modal method, the method proposed in this paper has a lower root mean square error (RMSE) and a higher Pearson correlation coefficient (PCC).
2. Materials and Methods
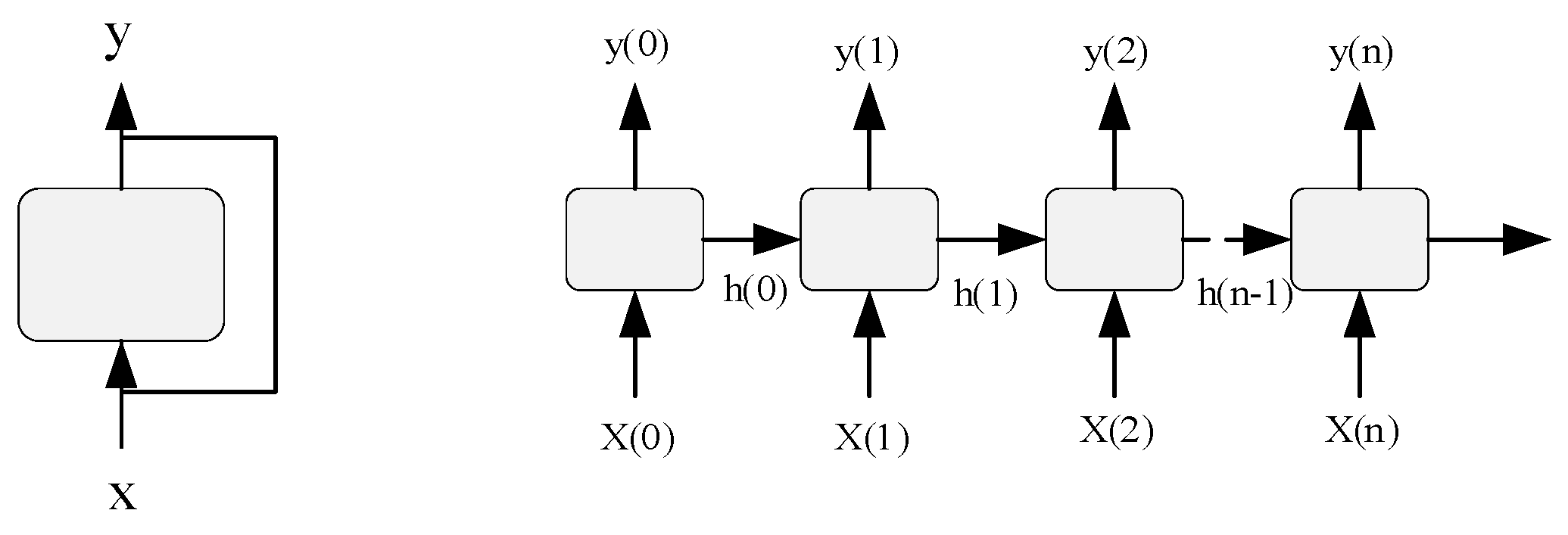
2.1. Auto-Encoder
2.2. Metric Learning
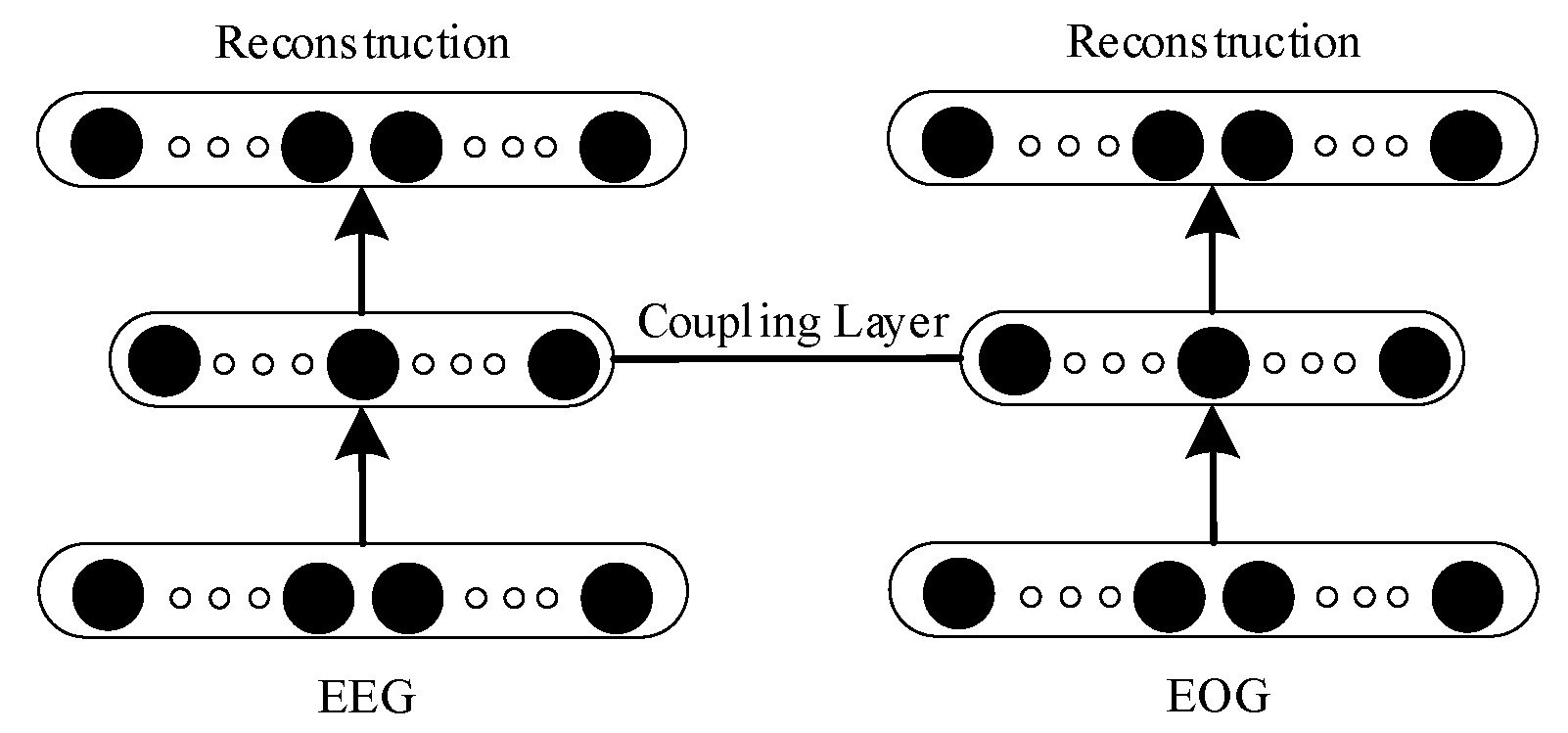
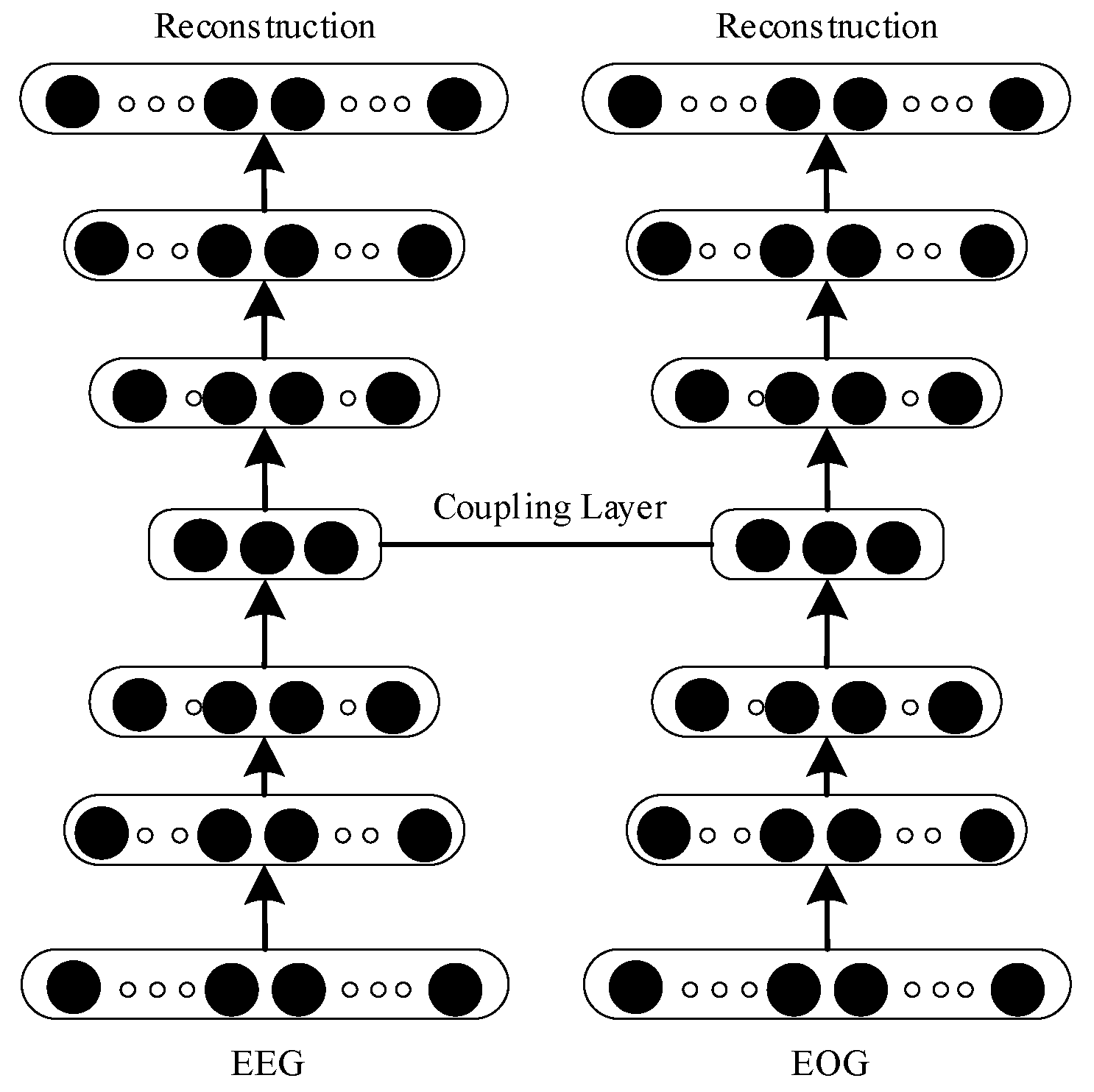
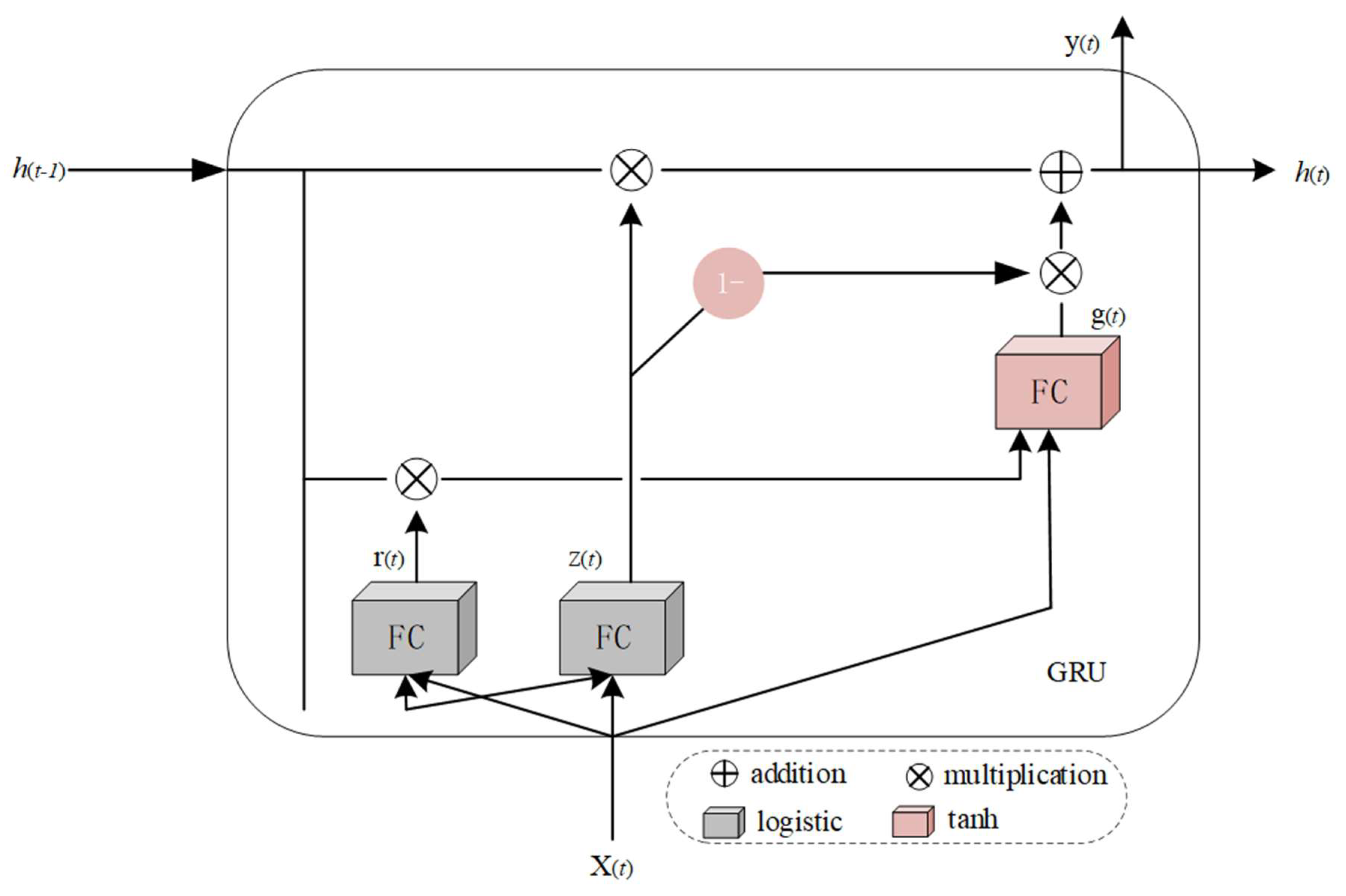
2.3. Deep Coupling Recurrent Auto-Encoder (DCRA)
2.3.1. Coupling Auto-Encoder
2.3.2. Deep Coupling Recurrent Auto-Encoder (DCRA)
| Algorithm 1: DCRA. |
| Input: training data EEG, EOG, Mahalanobis distance M |
| Output: DCRA model parameters |
| 1 Training layer 1 GRU; |
| 2 Training layer 2 GRU; |
| 3 Training layer 3 GRU; |
| 4 Update DCRA parameters using Formula (5) using gradient descent; |
| 5 Repeat steps 1–4 until the model converges. |
3. Data Description and Evaluation Measures
3.1. Dataset
3.2. Evaluation Methods
3.3. Comparison Method
3.4. Learning Mahalanobis Distance
4. Results and Discussion
4.1. Performance Analysis
4.2. Analysis of α
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ji, Q.; Zhu, Z.; Lan, P. Real-Time Nonintrusive Monitoring and Prediction of Driver Fatigue. IEEE Trans. Veh. Technol. 2004, 53, 1052–1068. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.-L.; Lu, B.-L. A Multimodal Approach to Estimating Vigilance Using EEG and Forehead EOG. J. Neural Eng. 2017, 14, 026017. [Google Scholar] [CrossRef] [PubMed]
- Du, L.-H.; Liu, W.; Zheng, W.-L.; Lu, B.-L. Detecting driving fatigue with multimodal deep learning. In Proceedings of the 2017 8th International IEEE/EMBS Conference on Neural Engineering (NER), Shanghai, China, 25–28 May 2017. [Google Scholar]
- Li, H.; Zheng, W.-L.; Lu, B.-L. Multimodal vigilance estimation with adversarial domain adaptation networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Varsehi, H.; Firoozabadi, S.M.P. An EEG channel selection method for motor imagery based brain–computer interface and neurofeedback using Granger causality. Neural Netw. 2021, 133, 193–206. [Google Scholar] [CrossRef] [PubMed]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.-P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [Green Version]
- Atrey, P.K.; Hossain, M.A.; El Saddik, A.; Kankanhalli, M.S. Multimodal Fusion for Multimedia Analysis: A survey. Multimed. Syst. 2010, 16, b345–b379. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, Z.; He, X.; Deng, L. Multimodal intelligence: Representation learning, information fusion, and applications. IEEE J. Sel. Top. Signal Process. 2020, 14, 478–493. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Li, W. Multisensor feature fusion for bearing fault diagnosis using sparse autoencoder and deep belief network. IEEE Trans. Instrum. Meas. 2017, 66, 1693–1702. [Google Scholar] [CrossRef]
- Ma, M.; Sun, C.; Chen, X. Deep coupling autoencoder for fault diagnosis with multimodal sensory data. IEEE Trans. Ind. Inform. 2018, 14, 1137–1145. [Google Scholar] [CrossRef]
- Feng, F.; Wang, X.; Li, R. Cross-modal retrieval with correspondence autoencoder. In Proceedings of the 22nd ACM International Conference on Multimedia, Nice, France, 21–25 October 2014. [Google Scholar]
- Wu, Y.; Wang, S.; Huang, Q. Multi-modal semantic autoencoder for cross-modal retrieval. Neurocomputing 2019, 331, 165–175. [Google Scholar] [CrossRef]
- Guo, W.; Wang, J.; Wang, S. Deep multimodal representation learning: A survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Zhang, G.; Etemad, A. Capsule attention for multimodal eeg and eog spatiotemporal representation learning with application to driver vigilance estimation. arXiv 2019, arXiv:1912.07812. [Google Scholar]
- Huo, X.-Q.; Zheng, W.-L.; Lu, B.-L. Driving fatigue detection with fusion of EEG and forehead EOG. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar]
- Zhang, N.; Zheng, W.-L.; Liu, W.; Lu, B.-L. Continuous vigilance estimation using LSTM neural networks. In Proceedings of the International Conference on Neural Information Processing, Kyoto, Japan, 16–21 October 2016. [Google Scholar]
- Wu, W.; Wu, Q.J.; Sun, W.; Yang, Y.; Yuan, X.; Zheng, W.-L.; Lu, B.-L. A regression method with subnetwork neurons for vigilance estimation using EOG and EEG. IEEE Trans. Cogn. Dev. Syst. 2018, 13, 209–222. [Google Scholar] [CrossRef] [Green Version]
- Połap, D.; Srivastava, G. Neural image reconstruction using a heuristic validation mechanism. Neural Comput. Appl. 2021, 33, 10787–10797. [Google Scholar] [CrossRef]
- Zheng, W.-L.; Liu, W.; Lu, Y.; Lu, B.-L.; Cichocki, A. Emotionmeter: A multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 2018, 49, 1110–1122. [Google Scholar] [CrossRef]
- Zheng, W.-L.; Gao, K.; Li, G.; Liu, W.; Liu, C.; Liu, J.-Q.; Wang, G.; Lu, B.-L. Vigilance estimation using a wearable EOG device in real driving environment. IEEE Trans. Intell. Transp. Syst. 2019, 21, 170–184. [Google Scholar] [CrossRef]
- Lan, Y.-T.; Liu, W.; Lu, B.-L. Multimodal emotion recognition using deep generalized canonical correlation analysis with an attention mechanism. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Wu, W.; Tao, D.; Li, H.; Yang, Z.; Cheng, J. Deep features for person re-identification on metric learning. Pattern Recognit. 2021, 110, 107424. [Google Scholar] [CrossRef]
- Hinton, G.E.; Zemel, R.S. Autoencoders, minimum description length, and Helmholtz free energy. Adv. Neural Inf. Process. Syst. 1994, 6, 3–10. [Google Scholar]
- Mei, J.; Liu, M.; Wang, Y.-F.; Gao, H. Learning a mahalanobis distance-based dynamic time warping measure for multivariate time series classification. IEEE Trans. Cybern. 2015, 46, 1363–1374. [Google Scholar] [CrossRef]
- Xing, E.; Jordan, M.; Russell, S.J.; Ng, A. Distance metric learning with application to clustering with side-information. Adv. Neural Inf. Process. Syst. 2002, 15, 521–528. [Google Scholar]
- Yang, L.; Jin, R. Distance Metric Learning: A Comprehensive Survey; Michigan State Universiy: East Langing, MI, USA, 2006; pp. 2, 4. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Wang, S.; Jin, R. An information geometry approach for distance metric learning. Artificial Intelligence and Statistics. PMLR. 2009. Available online: http://proceedings.mlr.press/v5/wang09c.html (accessed on 10 September 2021).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Dinges, D.F.; Grace, R. PERCLOS: A Valid Psychophysiological Measure of Alertness as Assessed by Psychomotor Vigilance; Publication Number FHWA-MCRT-98-006; US Department of Transportation, Federal Highway Administration: Washington, DC, USA, 1998.
- Nicolaou, M.A.; Gunes, H.; Pantic, M. Continuous prediction of spontaneous affect from multiple cues and modalities in valence-arousal space. IEEE Trans. Affect. Comput. 2011, 2, 92–105. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International conference on machine learning, Lille, France, 7–9 July 2015. [Google Scholar]
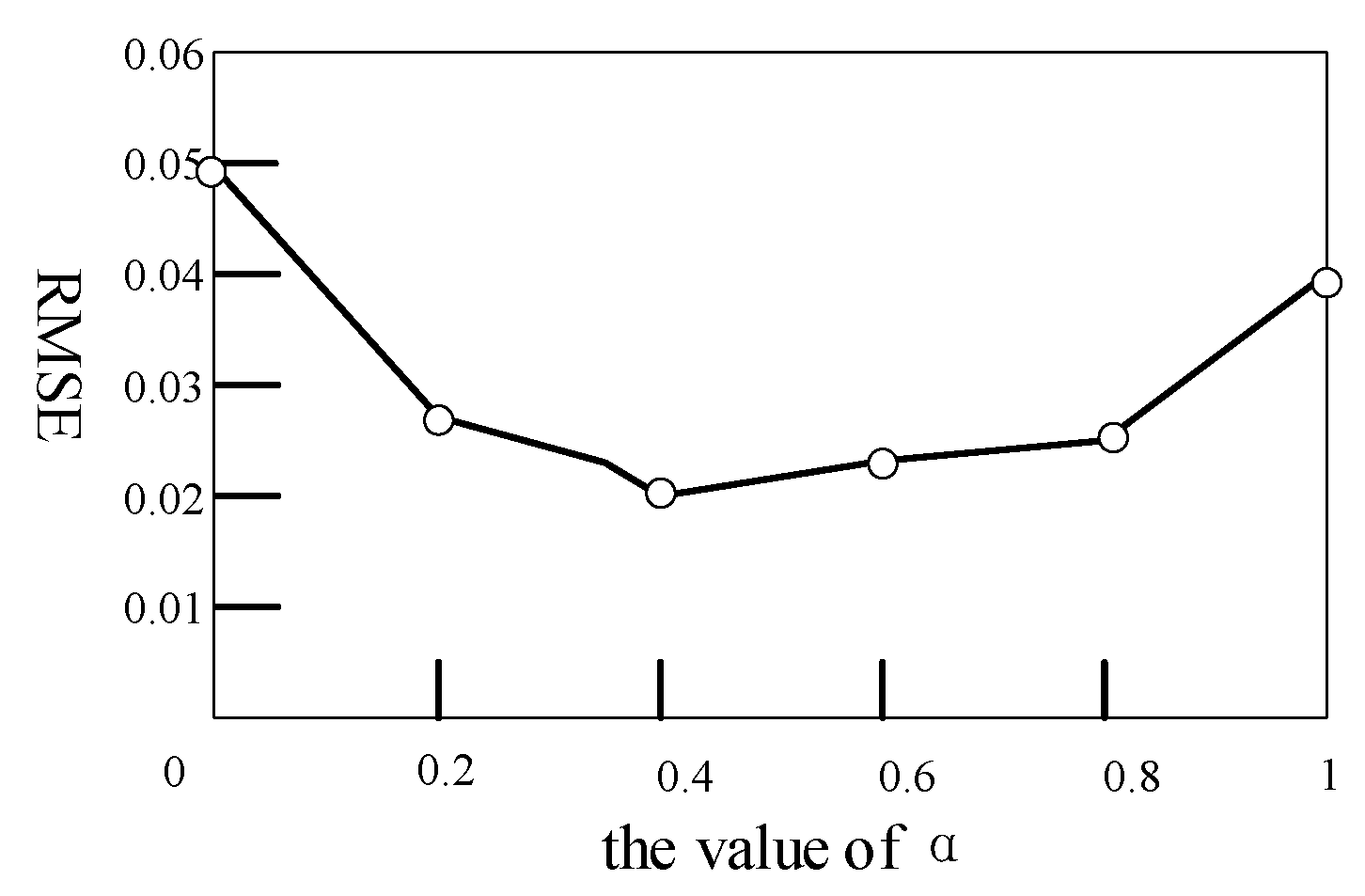

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Name | Units (EEG/EOG) | Activation |
|---|---|---|---|
| 1 | GRU | 36/25 | Relu |
| 2 | GRU | 20/20 | Relu |
| 3 | GRU | 16/16 | Relu |
| 4 | Coupling layer | 10 | |
| 5 | GRU | 16/16 | Relu |
| 6 | GRU | 20/20 | Relu |
| 7 | GRU | 36/25 | Sigmoid |
| NO. | Methods | RMSE | PCC |
|---|---|---|---|
| 1 | SVR | 0.100 | 0.830 |
| 2 | CCRF | 0.100 | 0.840 |
| 3 | CCNF | 0.095 | 0.845 |
| 4 | DAE | 0.094 | 0.852 |
| 5 | GELM | 0.071 | 0.808 |
| 6 | LSTM | 0.080 | 0.830 |
| 7 | DNNSN | 0.080 | 0.860 |
| 8 | LSTM-CapsAtt | 0.029 | 0.989 |
| 9 | DCRA_E | 0.035 | 0.980 |
| 10 | DCRA_M | 0.023 | 0.985 |
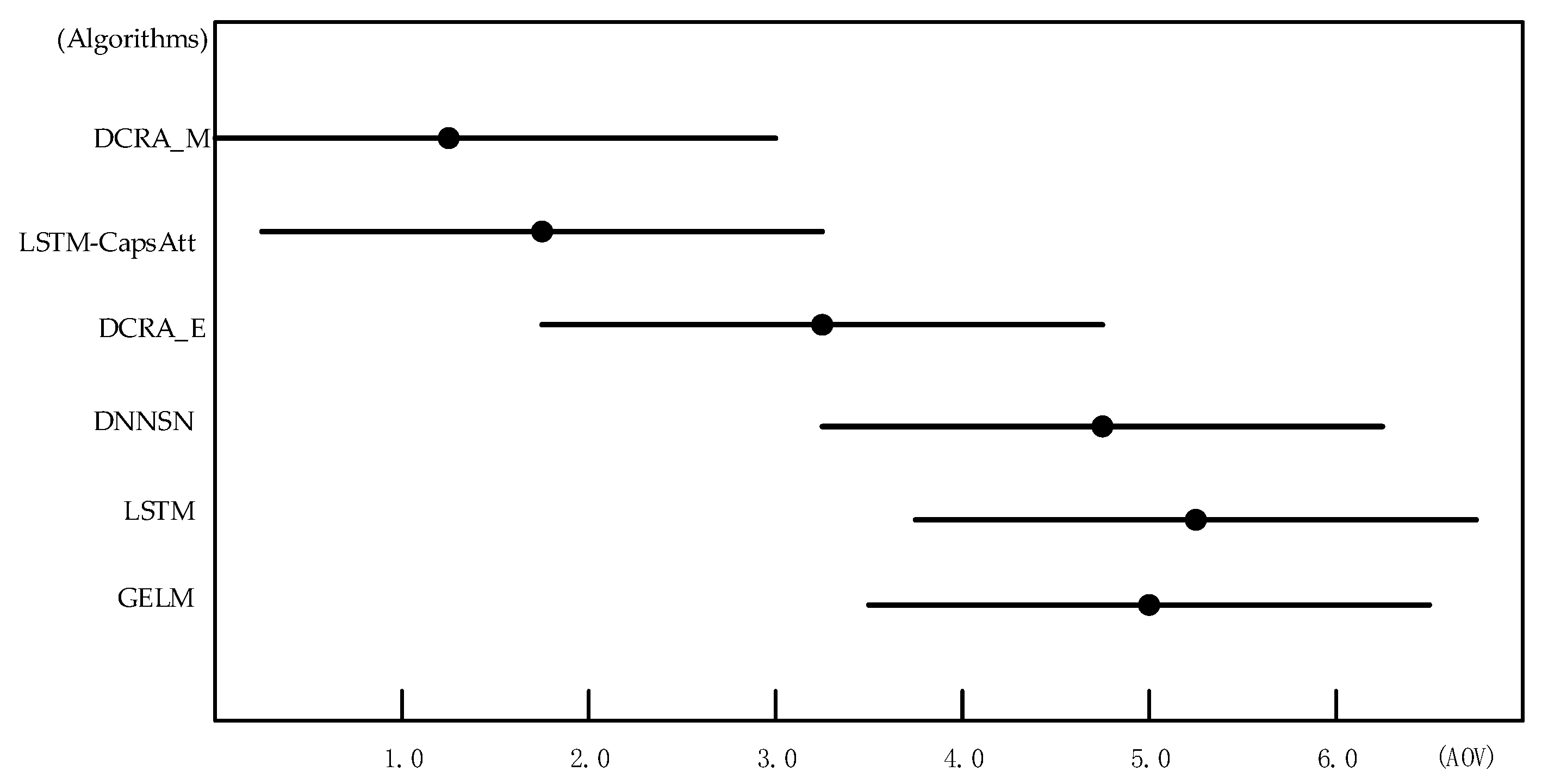
| Dataset | DRCA_M | LSTM-CapsAtt | DRCA_E | DNNSN | LSTM | GELM |
|---|---|---|---|---|---|---|
| D1 | 1 | 2 | 3 | 5 | 4 | 6 |
| D2 | 1 | 2 | 3 | 4 | 6 | 5 |
| D3 | 1 | 2 | 3 | 4 | 5 | 6 |
| D4 | 2 | 1 | 4 | 3 | 6 | 5 |
| D5 | 1 | 2 | 3 | 6 | 5 | 4 |
| AOV | 1.20 | 1.80 | 3.20 | 4.4 | 5.20 | 5.10 |
| Method | RMSE | PCC |
|---|---|---|
| DCRA_M with EEG and EOG | 0.023 | 0.985 |
| DCRA_E with EEG and EOG | 0.035 | 0.980 |
| DRA with EEG | 0.085 | 0.854 |
| DRA with EOG | 0.095 | 0.805 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, K.; Zhou, L.; Wang, H. Deep Coupling Recurrent Auto-Encoder with Multi-Modal EEG and EOG for Vigilance Estimation. Entropy 2021, 23, 1316. https://doi.org/10.3390/e23101316
Song K, Zhou L, Wang H. Deep Coupling Recurrent Auto-Encoder with Multi-Modal EEG and EOG for Vigilance Estimation. Entropy. 2021; 23(10):1316. https://doi.org/10.3390/e23101316
Chicago/Turabian StyleSong, Kuiyong, Lianke Zhou, and Hongbin Wang. 2021. "Deep Coupling Recurrent Auto-Encoder with Multi-Modal EEG and EOG for Vigilance Estimation" Entropy 23, no. 10: 1316. https://doi.org/10.3390/e23101316
APA StyleSong, K., Zhou, L., & Wang, H. (2021). Deep Coupling Recurrent Auto-Encoder with Multi-Modal EEG and EOG for Vigilance Estimation. Entropy, 23(10), 1316. https://doi.org/10.3390/e23101316