Abstract
The main challenge of classification systems is the processing of undesirable data. Filter-based feature selection is an effective solution to improve the performance of classification systems by selecting the significant features and discarding the undesirable ones. The success of this solution depends on the extracted information from data characteristics. For this reason, many research theories have been introduced to extract different feature relations. Unfortunately, traditional feature selection methods estimate the feature significance based on either individually or dependency discriminative ability. This paper introduces a new ensemble feature selection, called fuzzy feature selection based on relevancy, redundancy, and dependency (FFS-RRD). The proposed method considers both individually and dependency discriminative ability to extract all possible feature relations. To evaluate the proposed method, experimental comparisons are conducted with eight state-of-the-art and conventional feature selection methods. Based on 13 benchmark datasets, the experimental results over four well-known classifiers show the outperformance of our proposed method in terms of classification performance and stability.
1. Introduction
Nowadays, classification systems have a lot of contributions in different domains such as bioinformatics, medical analysis, text categorization, pattern recognition, and intrusion detection [1]. The main challenge of these systems is to deal with high dimensionality data, which may include redundant or irrelevant features [2]. These features have a negative effect on classification systems which can lead to (1) reducing the classification accuracy, (2) reducing the classification speed, (3) increasing the classification complexity. To overcome these limitations, features selection introduces an effective solution to reduce the dimensionality of data by selecting the significant features and discarding the undesirable ones [3].
Feature selection methods are divided into three categories: filter [4], embedded [5], and wrapper [6]. These methods can be also classified into two groups according to the role of classifiers in the feature selection process: classification-independent (filter method), and classification dependent group (embedded, and wrapper method) [3]. The former depends only on the data characteristics without considering classifiers in the selection process, while the latter depends on classifiers to assess the significance of features in the selection process. Although the classification-dependent group can return the best feature selection subset, it requires more computational cost as a result of the classification process. Moreover, the selected features related only to the used classifier in the feature selection process. For this reason, classification-independent is more practical for high dimensionality data [7]. In this study, filter feature selection is our interest rather than embedded and wrapper due to its benefits such as simplicity, practicality, scalability, efficiency, and generality [8].
The success of filter methods depends on the amount of extracted information from data characteristics [9]. Motivated by this hypothesis, many theories have been introduced to find the best filter feature selection method such as information theory [10], and rough set theory [11]. Information theory measures can rank the features not only according to their relevancy to class but also with respect to the redundancy of features [12]. Moreover, These measures outperform other measures as correlation due to its ability to deal with linear and non-linear relations [3]. Rough set theory can select a subset of features according to their dependency to class [13]. The main advantages of rough set measures are simplicity, and no user-defined parameter is required. However, the traditional measures of these theories share common limitation, they can not deal directly with continuous features. To overcome this limitation, many research studies have been extended by integrating the previous theories with fuzzy set theory [14,15,16]. Feature selection based fuzzy sets is not only suitable for any kind of data but also extracts more information from classes compared with the traditional feature selection methods [14]. In addition to its ability to deal with noise data [17].
Traditional methods based on previous theories estimate the feature significance based on either individually or dependency discriminative ability. Consequently, there is no general feature selection method, which returns the best feature subset with all datasets [18]. The traditional solution is to understand the data characteristics before the feature selection process. This solution is not efficient because of the high computational cost of expert analysis. To overcome this limitation, a new research direction, called an ensemble feature selection, is introduced, which combines more than one feature selection to cover all situations [2].
In this study, we propose a new ensemble feature selection method (fuzzy feature selection based on relevancy, redundancy, and dependency (FFS-RRD)) to utilize the previous theories. Firstly, we proposed a new method, called fuzzy weighted relevancy-based FS (FWRFS) to estimate the individually discriminative ability. Then, we combined it with fuzzy lower approximation-based FS (L-FRFS) to estimate the dependency discriminative ability [16]. The former method extracts two relations: relevancy and redundancy, while the latter extracts the dependency relation. The aim is to investigate these relations and produce a unique and effective feature selection method to improve classification methods.
The paper is organized as follows: Section 2 presents the main criteria of feature selection: relevancy, redundancy, and dependency. Then, the related work is presented in Section 3. Section 4 introduces the proposed method: fuzzy feature selection based on relevancy, redundancy, and dependency (FFS-RRD). After that, the experiment setup is showed in Section 5. Section 6 analyzes the experimental results. Finally, the conclusion is reported in Section 7.
2. Relevancy, Redundancy, and Dependency Measures
Filter-based FS methods try to find the best feature subset based on data characteristics without depending on classification models [4]. For this reason, they depend on the characteristics of data to find the most significant features. Consequently, filter-based feature selection methods study different data relations such as the relation between features and class, and the relation among features. There are three well-known feature relations: relevancy, redundancy, and dependency.
Firstly, relevancy relation measures the amount of shared information between features and the class [15]. However, some features may have the same relevancy relation and do not add new information to discriminate the classes. These features are considered redundant and no need to be selected. Redundancy relation measures the amount of shared information among features [15]. Another important feature relation is dependency [16]. Dependency relation measures the membership degree of feature subset to class. In the following, we present the definitions of these relations based on the fuzzy set theory [15,16].
Given a dataset , where is a finite set of m instances, is a finite set of n features, and is a finite set of l classes. Let , where is the feature value on U. Every feature can be represented by fuzzy equivalence relation on U and defined by the following fuzzy relation matrix .
where is the fuzzy equivalence relation that defines the similarity degree between and , where .
Fuzzy equivalence class of is defined by the following fuzzy set on U:
Fuzzy entropy of feature f based on is defined as
where, the cardinal value of is defined as .
Indiscernibility relation defines a set of objects that have the same equivalence class, where . The fuzzy partition of U on is defined by , where , and .
The fuzzy lower approximation of a single fuzzy equivalence class X is defined as
where , and is the fuzzy Łukasiewicz implicator.
The fuzzy positive region determines all the objects on U that discriminate the classes of based on a set of features . The fuzzy positive region is defined as
2.1. Relevancy
Let and are two fuzzy relations of feature f and class C on U, respectively. Then, the fuzzy mutual information between f and C is defined as
2.2. Redundancy
Let and be two fuzzy relations of features and on U, respectively. Then, the fuzzy mutual information between and is defined as
2.3. Dependency
Let is a set of features, the dependency degree of is defined as
2.4. Example
To illustrate the computations of previous relations, a small example is presented in Table 1. Firstly, we estimate the relation matrix of each feature based on the following similarity equation [15]:
As C contains discrete values, we estimate the relation matrix according to the crisp way [19].

Table 1.
An example of a small dataset, contains two features (), and class C.
The relation matrix of is:
The relation matrix of is:
The relation matrix of C is:
The fuzzy entropy of is:
The fuzzy entropy of C is:
The relevancy between and C is:
The redundancy between and is:
For the first object of , the fuzzy lower approximation of a single fuzzy equivalence class is:
For the first object of , The fuzzy lower approximation of a single fuzzy equivalence class is:
Similarly, for the remaining objects of :
The fuzzy positive region for the first object is:
For the remaining objects, the fuzzy positive region are:
The dependency degree of is:
3. Related Works
Filter approach evaluates the feature significant based on the characteristics of data only with full independence of classification models [1]. Although the filter approach has many benefits over embedded and wrapper approaches, it may fail to find the best feature subset [20]. For this reason, a great research effort has been introduced to study the feature characteristics with the aim to find the significant features that improve classification models.
Among a variety of evaluation measures, mutual information (MI) has a popularity solution in feature selection based information theory due to its ability to define different relation of features such as relevancy, and redundancy. The main advantages of MI are [3]: (1) ability to deal with deal linear and non-linear relations among features; (2) ability to deal with both categorical and numerical features. In the past decades, MI has been used in many feature selection methods. Mutual information maximization (MIM) [21] defines the significance of features based on the relevancy relation. It suffers from the redundant features. After that, mutual information based feature selection (MIFS) [22] has been introduced and improved in MIFS-U [23] to define the significance of features based on both relevancy and redundancy relation. However, both methods require a predefined parameter to balance between the relevancy and redundancy relations. In [24], minimum redundancy maximum relevance (mRMR) proposes automatic value to estimate the predefined parameter of MIFS, and MIFS-U. In the literature, several feature selection methods have been proposed to find the best estimation of the relevancy and redundancy relations such as joint mutual information (JMI) [25], conditional mutual information maximization (CMIM) [26], joint mutual information maximization (JMIM) [27], and max-relevance and max-independence (MRI) [28]. However, previous studies of feature selection based mutual information do not consider the balance of selected/candidate feature relevancy relation. To avoid this limitation, Zhang et al. [29] has introduced a new method to keep the balance between the feature relevancy relations, called feature selection based on weighted relevancy (WRFS).
Another important solution in the filter approach is rough set which used to measure the dependency relation of features. Feature selection based rough set tries to find the minimal feature subset that maximizes the informative structure of all features (termed a reduct) [30]. The main advantages of the rough set are (1) analyzing only the hidden facts in data, (2) extracting the hidden knowledge of data without additional user-defined information, and (3) returning a minimal knowledge structure of data [19]. Many studies on feature selection based on rough set have been done. Rough Set Attribute Reduction (RSAR) defines the significance of a subset of features based on the dependency relation [31]. However, there is no guarantee to return the minimum feature subset. Han et al. [32] proposes an alternative dependency relation to reduce the computational cost of the feature selection process. Zhong et al. [33] defines the significance of the feature subset based on the discernibility matrix. However, it is impractical for high dimensionality data. In Entropy Based Reduction (EBR) [34], the significance of the feature subset is defined based on entropy which returns the maximum amount of information. In the literature of rough sets, further feature selection methods have been introduced such as Variable precision rough sets (VPRS) [35], and parameterized average support heuristic (PASH) [36].
However, both MI and rough set share common limitations when dealing with features of continuous values [19,37]. There are two traditional solutions have been proposed to overcome this limitation: parzen window [38], and discretization process [39]. The former has some limitations: firstly it requires a predefined parameter to compute the window function [40]. Secondly, it does not work efficiently with high dimensional data of spare samples [15]. The latter may lead to loss of feature information [41]. To overcome these limitations, FS based information theory and FS based rough set have been extended by fuzzy set theory to deal with continuous features directly [14,19]. However, most of FS methods based information theory focus on relevancy and redundancy relation, while FS methods based on rough set focus on dependency relation. The former depends on individually discriminative ability, while the latter depends on dependency discriminative ability. As a result, the traditional methods do not take the benefits of all types of discriminative ability.
4. Fuzzy Feature Selection Based on Relevancy, Redundancy, and Dependency (FFS-RRD)
In this section, we present our proposed method, called FFS-RRD, as a filter feature selection method. The effectiveness of filter methods depends on the amount of extracted information from the data characteristics. To promote our proposed method, we used both individually and dependency discriminative ability based on three criteria: relevancy, redundancy, and dependency. FFS-RRD aims to maximize both relevancy and dependency relations and minimize the redundancy ones. To design our proposed method, firstly, we modified WRFS to overcome their limitations: (1) it can not deal with continuous features without the discretization process which may lead to loss of feature information. (2) WRFS does not consider dependency relation in the feature selection process. To overcome these limitations, we estimated WRFS based on the fuzzy concept instead of the probability concept. The extended method, called FWRFS, can deal with any numerical data without the discretization process. Then, we combined FWRFS with fuzzy-rough lower approximations (L-FRFS) [16] to extract the dependency relation. Consequently, we proposed a unique FS method, called FFSRRD, which maximizes both relevancy and dependency, and minimizes the redundancy relation. The three relations can extract more information from the dataset to promote the discriminate ability of feature selection. Figure 1 shows the process of the proposed method FFS-RRD. Both FWRFS and L-FRFS are applied on the same dataset. FWRFS selects the most relevant features and removes the redundancy ones, while L-FRFS selects the most dependency feature subset. The results of each method are combined to return the final feature selection subset. In our study, we used one of the popular combination methods called MIN [2]. MIN method assigns the minimum position of each feature among different results of feature selection methods to be ranked position in the final result.
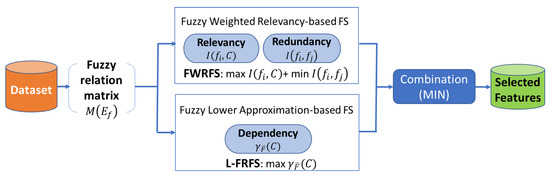
Figure 1.
The process of our proposed method fuzzy feature selection based relevancy, redundancy, and dependency (FFS-RRD): firstly, the fuzzy relation matrix is generated for each feature in the dataset. Then, fuzzy mutual information maximizes the relevancy and minimizes the redundancy, while fuzzy rough set maximizes the dependency. Finally, the results are combined to find the selected features.
The algorithm of the proposed method is presented in Algorithm 1. FFS-RRD depends on a combination of two methods: For the first method, FWRFS is used to return the ranked feature set that maximizes the relevancy and minimizes the redundancy. In the first step (Lines 1–3), The main parameters are initialized: ranked feature set (), candidate feature (), and the current selected feature set (). Then, the feature of maximum relevancy with class is selected to be the first ranked feature in , and removed from the feature set F (Lines 4–8). After that, the feature of maximum relevancy with class and minimum redundancy with selected features is added to , and removed from F. This process is repeated until all features of F are ranked in (Lines 9–14). For the second method, L-FRFS is used to return the subset of features that maximizes the dependency relation. In the first step (Lines 15–17), the main parameters are initialized: selected feature subset (), temporary feature (T), maximum dependency degree (), and the last maximum dependency degree (). Then, the feature of maximum dependency is added to . This process is repeated until the maximum possible dependency degree of features be produced (Lines 18–25). Finally, the result of both methods is combined by to select the final feature subset (Line 26–27).
| Algorithm 1: FFS-RRD: fuzzy feature selection based relevancy, redundancy, and dependency. |
 |
5. Experiment Setup
The main goal of the feature selection process is to improve the classification performance with the minimum feature selection subset. To validate our proposed method, we used four classifiers to compare the proposed method with eight feature selection methods based on benchmark datasets. Figure 2 shows the framework of our experiment. In the following, we present more details about the experiment setup.
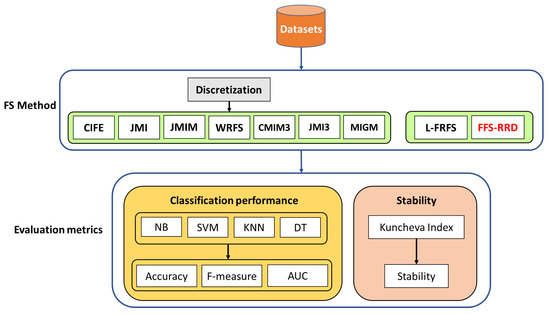
Figure 2.
An experimental framework of the proposed method fuzzy feature selection based relevancy, redundancy, and dependency (FFS-RRD): firstly, a discretization process is applied before probability-based methods. Then, the compared methods are evaluated in terms of classification performance, and stability.
5.1. Dataset
Our experiment was conducted based on 13 benchmark datasets from machine learning repository (UCI) [42]. The datasets support different classification problems of binary and multi-class data. Table 2 presents a brief description of the experimental datasets.
Table 2.
Description of datasets used in the experiments.
5.2. Compared Feature Selection Methods
Table 3 shows the compared FS methods and their discriminative ability. The compared methods can be divided into two groups: probability-based, and fuzzy-based. Firstly, probability-based group uses the probability concept to estimate information measures. The probability-based group consists of CIFE [43], JMI [25], JMIM [27], WRFS [29], CMIM3 [44], JMI3 [44], and MIGM [45]. This group depends on the discretization process before implementation of feature selection methods. In our experiment, the discretization process transforms the continuous features into discrete features with ten equal intervals [46].
Table 3.
The extracted feature relations of compared feature selection methods.
Unlike a probability-based group which requires discretization preprocess, fuzzy-based group uses the fuzzy concept to estimate information measures. The fuzzy-based group includes L-FRFS [16], and the proposed method FFS-RRD. This group depends on similarity relation which transforms each feature into a fuzzy equivalence relation. In our experiment, we used the following similarity relation [15].
5.3. Evaluation Metrics
The main factors characterize the quality of feature selection methods are its classification performance and stability [47]. The evaluation of our experiment is divided into two parts: classification performance and stability evaluation. Classification performance requires classification models to evaluate the effect of feature selection methods on improving the classification performance, while stability measures the robustness of feature selection methods.
5.3.1. Classification Performance
To evaluate the classification performance, we used three metrics: classification accuracy, F-measure (), AUC. The experiment depends on four classifiers: Naive bayes (NB), support vector machine (SVM), K-nearest neighbors (KNN, K = 3), and decision tree (DT). To find reliable results, we used 10-fold cross-validation where the dataset is divided into ten equal parts, nine for the training phase and one for the test phase [48]. This process is repeated ten times. Then, we calculate the average results to compute the score of accuracy, F-measure, and AUC.
In this experiment, we used a threshold to cut the ranked features and return a subset of selected features. The threshold is the median position of the ranked features (or the nearest integer position if the number of ranked features is even). For L-FRFS, we used the same threshold if the size of the returned subset is more than the median of all features.
5.3.2. Stability Evaluation
The confidence of feature selection method is not only about the improvement of classification performance but also related to the robustness of the method [49]. The robustness of feature selection method against any small change of data, as a noise, is called feature selection stability [50]. In the stability experiment, we injected the data by 10% of noise which is generated based on standard deviation and the gaussian distribution of each feature [51]. Then, we run the feature selection method to return the sequence of features. This process is repeated for ten times with a new returned sequence each time. After that, we measure the stability for each feature selection method based on Kuncheva stability measure which is defined as [52]:
where p is the number of feature selection sequences, and is the Kuncheva stability index between two feature selection sequences , and which is defined as:
where , , and n is the total number of features.
6. Results Analysis
6.1. Classification Performance
6.1.1. Accuracy
Based on NB classifier, it is obvious that FFS-RRD achieved the maximum average accuracy with score 83.4%, as shown in Table 4. The proposed method was more accurate than compared methods by the range from 0.4% to 1.8%. The order of methods ranked after FFS-RRD was JMIM, followed by JMI, both CMIM3 and JMI3, MIGM, WRFS, L-FRFS, and CIFE.
Table 4.
Average classification accuracy on Naive bayes (NB) classifier: our proposed method achieved the best result.
According to SVM classifier, FFS-RRD achieved the maximum average accuracy of all datasets by 86.4%, while L-FRFS achieved the minimum average accuracy by 84.1%, as shown in Table 5. The proposed method outperformed other methods in the range from 0.5% to 2.3%. The second-best feature selection method was JMI, followed by CMIM3, both JMIM and JMI3, WRFS, MIGM, and CIFE.
Table 5.
Average classification accuracy on support vector machine (SVM) classifier: our proposed method achieved the best result.
In the case of KNN classifier, FFS-RRD also was the best feature selection method in the term of average accuracy by 85.4%, while L-FRFS was the worst method by 82.5%, as shown in Table 6. After that, MIGM achieved the second-best method, followed by both JMI and JMIM, JMI3, WRFS, CMIM3, CIFE. The proposed method achieved better accuracy in the range from 0.5% to 2.9%.
Table 6.
Average classification accuracy on K-nearest neighbors (KNN) classifier: our proposed method achieved the best result.
Similarly, FFS-RRD kept the best average accuracy of DT classifier by 84.5%, as shown in Table 7. The proposed method outperformed other methods in the range from 0.4% to 1.4%. In contrast, both CIFE and L-FRFS achieved the worst results by 83.1%. The second-best feature selection method was JMI, followed by JMIM, both WRFS and JMI3, MIGM, and CMIM3.
Table 7.
Average classification accuracy on decision tree (DT) classifier: our proposed method achieved the best result.
6.1.2. F-Measure
Figure 3 shows the F-measure of the compared methods based on the four used classifiers. In NB classifier, FSS-RRD achieved the maximum average F-measure by 88.5%, while MIGM achieved the minimum score by 82.4%. The proposed method outperformed other methods in the range from 1.5% to 6.1%. Similarly, FSS-RRD achieved the maximum average F-measure using SVM by 88.9%, while MIGM achieved the minimum score by 83.5%. The proposed method outperformed other methods in the range from 0.5% to 5.4%. According to KNN classifier, WRFS achieved the maximum average F-measure by 87.7%, while CMIM3 achieved the minimum score by 81.6%. The proposed method achieved the fourth-best position in this case. In DT classifier, FSS-RRD achieved the maximum average F-measure by 87.5%, while MIGM achieved the minimum score by 82.3%. The proposed method outperformed other methods in the range from 0.7% to 5.2%.
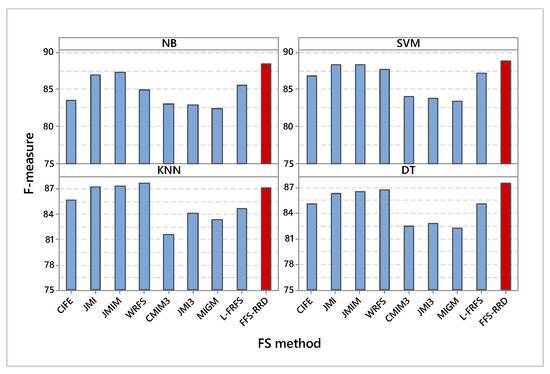
Figure 3.
Average F-measure on the four used classifiers. Our proposed method (FFS-RRD) achieved the best result in all cases except KNN.
6.1.3. AUC
It is obvious that the proposed method achieved the highest AUC compared with other methods using all classifiers (Figure 4). According to NB, FSS-RDD achieved the maximum AUC by 87.8%, while CIFE achieved the minimum AUC by 86.2%. The proposed method outperformed other methods in the range from 0.2% to 1.6%. In SVM classifier, FSS-RDD also achieved the maximum AUC by 81.1%, while L-FRFS achieved the minimum score by 78.2%. The proposed method outperformed other methods in the range from 0.9% to 2.9%. Similarly, FSS-RDD also achieved the maximum AUC using KNN by 85.1%, while L-FRFS achieved the minimum score by 83.3%. The proposed method outperformed other methods in the range from 0.4% to 1.8%. Using DT classifier, FSS-RDD kept the best method by 82.2%, L-FRFS kept the worst method by 79.9%. The proposed method outperformed other methods in the range from 0.4% to 2.3%.
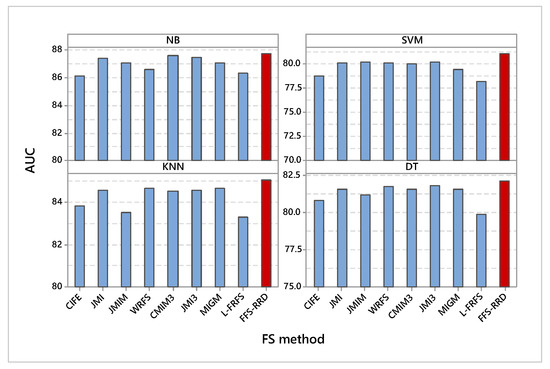
Figure 4.
Average AUC on the four used classifiers. Our proposed method (FFS-RRD) achieved the best result in all cases.
Figure 5 shows the average score of the four classifiers in terms of accuracy, F-measure, and AUC. For accuracy term, FFS-RRD achieved the highest accuracy for all classifiers by 84.9%, followed by JMI, JMIM, JMI3, CMIM3, MIGM, WRFS, CIFE, and L-FRFS by 84.4%, 84.3%, 84.2%, 84.1%, 83.9%, 83.8%, 83.3%, and 82.8%, respectively. The proposed method outperformed other methods in the range from 0.5% to 2.1%. Similarly, FFS-RRD achieved the highest average of F-measure by 87.6%. Then, JMIM achieved the second-best method, followed by JMI, WRFS, L-FRFS, CIFE, JMI3, MIGM, CMIM3 with score 87.4%, 87.3%, 86.8%, 85.7%, 85.7%, 85.3%, 83.4%, 83.9%, 82.8%, respectively. The proposed method outperformed other methods in the range from 0.2% to 4.7%. According to AUC, FFS-RRD achieved the highest AUC with a score 84.0%. JMI3 achieved the second-best method, followed by JMI, CMIM3, WRFS, MIGM, JMIM, CIFE, and L-FRFS by 83.6%, 83.5%, 83.4%, 83.3%, 83.2%, 83.0%, 82.4%, and 81.9%, respectively. The proposed method outperformed other methods in the range from 0.4% to 2.1%.
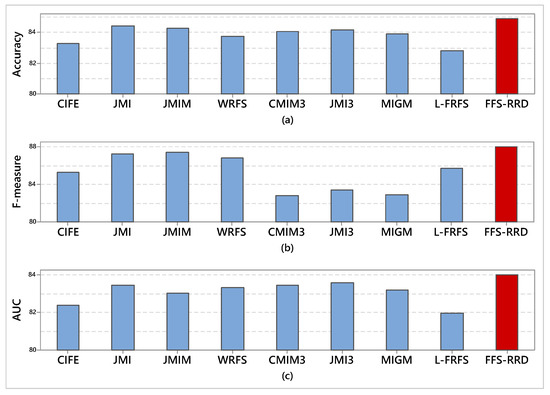
Figure 5.
Average score of all classifiers in terms of accuracy, F-measure, and AUC. Our proposed method (FFS-RRD) achieved the best result.
6.2. Stability
Figure 6 shows the average stability across the first half thresholds on all datasets. FFS-RRS achieved the maximum average of stability by 84.3%, while MIGM achieved the minimum score by 67.9%. After that, L-FRFS achieved the second-best method by 78.6%, followed by JMI3, CIFE, JMI, WRFS, CMIM3, and JMIM with an average score 76.0%. 75.8%, 73.5%, 73.0%, 72.3%, and 71.9%, respectively. The proposed method outperformed other methods in the range from 5.7% to 16.4%. Figure 7 shows a box-plot of average stability for all compared methods on the median threshold. In box-plot, the black circle represents the stability median, while the box represents both lower and upper quartiles. As shown in the box-plot, the stability result of the proposed method is better and more consistent than compared methods.
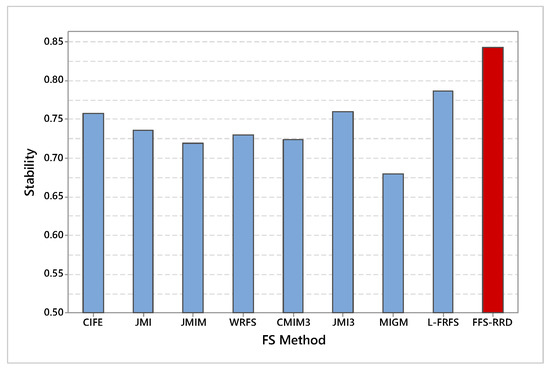
Figure 6.
Average stability across the first half thresholds on all datasets. Our proposed method (FFS-RRD) achieved the best result.
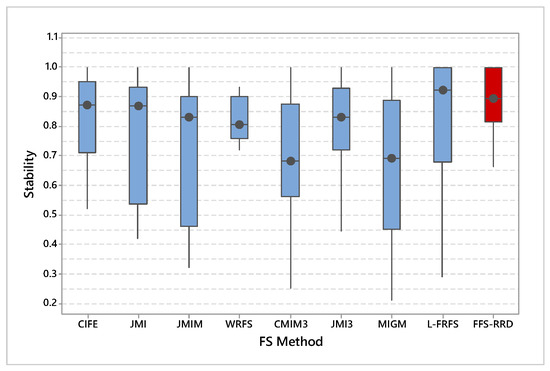
Figure 7.
Average stability for all compared methods on the median threshold. Our proposed method (FFS-RRD) achieved the best result.
By considering the previous results, it is obvious that FFS-RRD achieved the best experimental results in the term of classification performance and feature stability. This is expected where the proposed method considers the individually and dependency discriminative ability of features. On the other hand, it is obvious that fuzzy-based methods are more stable than probability-based methods. The reason returns to using fuzzy sets to estimate the feature significance without information loss. Consequently, it helps fuzzy-based methods to be more stable against the noise.
7. Conclusions
In this paper, we have proposed an ensemble feature selection method, fuzzy feature selection based on relevancy, redundancy, and dependency criteria (FFS-RRD). Unlike the traditional methods, FFS-RRD depends on both individually and dependency discriminative ability. FFS-RRD aims to extract the significant relations from data characteristics to find the best feature subset that improves the performance of classification models. The proposed method consist of combination of two methods: FWRFS, and L-FRFS. FWRFS maximizes the relevancy and minimizes the redundancy relation, while L-FRFS maximizes the dependency relation.
Compared with eight state-of-the-art and conventional FS methods, experiments on 13 benchmark datasets indicate the outperformance of the proposed method in classification performance and stability. Classification performance includes three measures accuracy, F-measure, and AUC. The proposed method FFS-RRD achieved the highest average score of accuracy, and AUC on all datasets, while it achieved the highest average of F-measure on most of the classifiers except KNN classifier. On the other hand, the proposed method achieved the highest average of stability compared with other feature selection methods. In future work, we will extend the proposed method to explore their effect on multi-label classification models.
Author Contributions
Methodology, O.A.M.S., F.L., and Y.-P.P.C.; software, O.A.M.S.; investigation, F.L., X.C., and Y.-P.P.C.; writing—original draft preparation, O.A.M.S., and F.L.; writing—review and editing, F.L., O.A.M.S., X.C., and Y.-P.P.C.; supervision, F.L., and X.C.; funding acquisition, F.L. All authors read and approved the final version of the manuscript.
Acknowledgments
This research has been supported by the National Natural Science Foundation (61572368).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Macedo, F.; Oliveira, M.R.; Pacheco, A.; Valadas, R. Theoretical foundations of forward feature selection methods based on mutual information. Neurocomputing 2019, 325, 67–89. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for feature selection: A review and future trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Lee, S.; Park, Y.T.; d’Auriol, B.J. A novel feature selection method based on normalized mutual information. Appl. Intell. 2012, 37, 100–120. [Google Scholar]
- Lazar, C.; Taminau, J.; Meganck, S.; Steenhoff, D.; Coletta, A.; Molter, C.; de Schaetzen, V.; Duque, R.; Bersini, H.; Nowe, A. A survey on filter techniques for feature selection in gene expression microarray analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2012, 9, 1106–1119. [Google Scholar] [CrossRef]
- Imani, M.B.; Keyvanpour, M.R.; Azmi, R. A novel embedded feature selection method: A comparative study in the application of text categorization. Appl. Artif. Intell. 2013, 27, 408–427. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Hu, L.; Gao, W.; Zhao, K.; Zhang, P.; Wang, F. Feature selection considering two types of feature relevancy and feature interdependency. Expert Syst. Appl. 2018, 93, 423–434. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef]
- Oreski, D.; Oreski, S.; Klicek, B. Effects of dataset characteristics on the performance of feature selection techniques. Appl. Soft Comput. 2017, 52, 109–119. [Google Scholar] [CrossRef]
- Bonev, B. Feature Selection Based on Information Theory; Universidad de Alicante: Alicante, Spain, 2010. [Google Scholar]
- Caballero, Y.; Alvarez, D.; Bello, R.; Garcia, M.M. Feature selection algorithms using rough set theory. In Proceedings of the IEEE Seventh International Conference on Intelligent Systems Design and Applications (ISDA 2007), Rio de Janeiro, Brazilm, 20–24 October 2007; pp. 407–411. [Google Scholar]
- Che, J.; Yang, Y.; Li, L.; Bai, X.; Zhang, S.; Deng, C. Maximum relevance minimum common redundancy feature selection for nonlinear data. Inf. Sci. 2017, 409, 68–86. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning about Data; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1991. [Google Scholar]
- Hu, Q.; Yu, D.; Xie, Z. Information-preserving hybrid data reduction based on fuzzy-rough techniques. Pattern Recognit. Lett. 2006, 27, 414–423. [Google Scholar] [CrossRef]
- Yu, D.; An, S.; Hu, Q. Fuzzy mutual information based min-redundancy and max-relevance heterogeneous feature selection. Int. J. Comput. Intell. Syst. 2011, 4, 619–633. [Google Scholar] [CrossRef]
- Jensen, R.; Shen, Q. New approaches to fuzzy-rough feature selection. IEEE Trans. Fuzzy Syst. 2008, 17, 824–838. [Google Scholar] [CrossRef]
- Hüllermeier, E. Fuzzy sets in machine learning and data mining. Appl. Soft Comput. 2011, 11, 1493–1505. [Google Scholar] [CrossRef]
- Freeman, C.; Kulić, D.; Basir, O. An evaluation of classifier-specific filter measure performance for feature selection. Pattern Recognit. 2015, 48, 1812–1826. [Google Scholar] [CrossRef]
- Jensen, R.; Shen, Q. Fuzzy-rough sets for descriptive dimensionality reduction. In Proceedings of the 2002 IEEE World Congress on Computational Intelligence. 2002 IEEE International Conference on Fuzzy Systems, FUZZ-IEEE’02, Honolulu, HI, USA, 12–17 May 2002; Proceedings (Cat. No. 02CH37291). Volume 1, pp. 29–34. [Google Scholar]
- Vergara, J.R.; Estévez, P.A. A review of feature selection methods based on mutual information. Neural Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Lewis, D.D. Feature selection and feature extraction for text categorization. In Proceedings of the Workshop on Speech and Natural Language; Association for Computational Linguistics: Stroudsburg, PA, USA, 1992; pp. 212–217. [Google Scholar]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef]
- Kwak, N.; Choi, C.H. Input feature selection for classification problems. IEEE Trans. Neural Netw. 2002, 13, 143–159. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Onpattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Yang, H.; Moody, J. Feature selection based on joint mutual information. In Proceedings of the International ICSC Symposium on Advances in Intelligent Data Analysis, Genova, Italy, 1–4 June 1999; pp. 22–25. [Google Scholar]
- Fleuret, F. Fast binary feature selection with conditional mutual information. J. Mach. Learn. Res. 2004, 5, 1531–1555. [Google Scholar]
- Bennasar, M.; Hicks, Y.; Setchi, R. Feature selection using joint mutual information maximisation. Expert Syst. Appl. 2015, 42, 8520–8532. [Google Scholar] [CrossRef]
- Wang, J.; Wei, J.M.; Yang, Z.; Wang, S.Q. Feature selection by maximizing independent classification information. IEEE Trans. Knowl. Data Eng. 2017, 29, 828–841. [Google Scholar] [CrossRef]
- Zhang, P.; Gao, W.; Liu, G. Feature selection considering weighted relevancy. Appl. Intell. 2018, 48, 4615–4625. [Google Scholar] [CrossRef]
- Hassanien, A.E.; Suraj, Z.; Slezak, D.; Lingras, P. Rough Computing: Theories, Technologies and Applications; IGI Global Hershey: Hershey, PA, USA, 2008. [Google Scholar]
- Chouchoulas, A.; Shen, Q. Rough set-aided keyword reduction for text categorization. Appl. Artif. Intell. 2001, 15, 843–873. [Google Scholar] [CrossRef]
- Han, J.; Hu, X.; Lin, T.Y. Feature subset selection based on relative dependency between attributes. In International Conference on Rough Sets and Current Trends in Computing; Springer: Berlin, Germany, 2004; pp. 176–185. [Google Scholar]
- Zhong, N.; Dong, J.; Ohsuga, S. Using rough sets with heuristics for feature selection. J. Intell. Inf. Syst. 2001, 16, 199–214. [Google Scholar] [CrossRef]
- Jensen, R.; Shen, Q. Fuzzy–rough attribute reduction with application to web categorization. Fuzzy Sets Syst. 2004, 141, 469–485. [Google Scholar] [CrossRef]
- Ziarko, W. Variable precision rough set model. J. Comput. Syst. Sci. 1993, 46, 39–59. [Google Scholar] [CrossRef]
- Zhang, M.; Yao, J. A rough sets based approach to feature selection. In Proceedings of the IEEE Annual Meeting of the Fuzzy Information, Banff, AB, Canada, 27–30 June 2004; Processing NAFIPS’04. Volume 1, pp. 434–439. [Google Scholar]
- Ching, J.Y.; Wong, A.K.; Chan, K.C.C. Class-dependent discretization for inductive learning from continuous and mixed-mode data. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 641–651. [Google Scholar] [CrossRef]
- Kwak, N.; Choi, C.H. Input feature selection by mutual information based on Parzen window. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1667–1671. [Google Scholar] [CrossRef]
- Garcia, S.; Luengo, J.; Sáez, J.A.; Lopez, V.; Herrera, F. A survey of discretization techniques: Taxonomy and empirical analysis in supervised learning. IEEE Trans. Knowl. Data Eng. 2012, 25, 734–750. [Google Scholar] [CrossRef]
- Herman, G.; Zhang, B.; Wang, Y.; Ye, G.; Chen, F. Mutual information-based method for selecting informative feature sets. Pattern Recognit. 2013, 46, 3315–3327. [Google Scholar] [CrossRef]
- Shen, Q.; Jensen, R. Selecting informative features with fuzzy-rough sets and its application for complex systems monitoring. Pattern Recognit. 2004, 37, 1351–1363. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2017. [Google Scholar]
- Lin, D.; Tang, X. Conditional infomax learning: An integrated framework for feature extraction and fusion. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 68–82. [Google Scholar]
- Sechidis, K.; Azzimonti, L.; Pocock, A.; Corani, G.; Weatherall, J.; Brown, G. Efficient feature selection using shrinkage estimators. Mach. Learn. 2019, 108, 1261–1286. [Google Scholar] [CrossRef]
- Wang, X.; Guo, B.; Shen, Y.; Zhou, C.; Duan, X. Input Feature Selection Method Based on Feature Set Equivalence and Mutual Information Gain Maximization. IEEE Access 2019, 7, 151525–151538. [Google Scholar] [CrossRef]
- Dougherty, J.; Kohavi, R.; Sahami, M. Supervised and unsupervised discretization of continuous features. In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 194–202. [Google Scholar]
- Li, Y.; Si, J.; Zhou, G.; Huang, S.; Chen, S. FREL: A stable feature selection algorithm. IEEE Trans. Neural Networks Learn. Syst. 2014, 26, 1388–1402. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Ijcai 1995, 14, 1137–1145. [Google Scholar]
- Pes, B.; Dessì, N.; Angioni, M. Exploiting the ensemble paradigm for stable feature selection: A case study on high-dimensional genomic data. Inf. Fusion 2017, 35, 132–147. [Google Scholar] [CrossRef]
- Nogueira, S.; Brown, G. Measuring the stability of feature selection. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2016; pp. 442–457. [Google Scholar]
- Tsai, Y.S.; Yang, U.C.; Chung, I.F.; Huang, C.D. A comparison of mutual and fuzzy-mutual information-based feature selection strategies. In Proceedings of the 2013 IEEE International Conference on Fuzzy Systems (FUZZ), Hyderabad, India, 7–10 July 2013; pp. 1–6. [Google Scholar]
- Kuncheva, L.I. A stability index for feature selection. In Proceedings of the 25th IASTED International Multi-Conference Artificial Intelligence and Applications, Innsbruck, Austria, 12–14 February 2007; pp. 421–427. [Google Scholar]







© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).