1. Introduction
“With four parameters I can fit an elephant, and with five I can make him wiggle his trunk” is a well-known saying attributed by Enrico Fermi to John Von Neumann [
1]. Indeed, that quote is a good allegory to the core aim of feature selection, which is to select elements from a set
S of features for classifier design during supervised learning, in a trade off between the consideration of as many features as possible and the avoidance of classification error due to the lack of samples. As in the quote, to achieve such trade off, it is necessary to select features that are very informative about the relationship between observations and labels (as the four parameters that “fit an elephant”) at the same time discarding the ones that bring fewer information (as the parameter that makes him “wiggle his trunk”). To evaluate whether a subset
has only very informative features, a possibility is the usage of an information theory-based criteria such as the ones based on conditional entropy.
The conditional Shannon entropy (or simply conditional entropy)
is a measure of the probability mass concentration of a random variable
given the occurrence of the random variable
realization
. If we average the values of
H for all possible realizations of
, then we have the application of a mean conditional entropy (MCE) criterion. During a feature selection procedure,
and
are random variables associated with, respectively, the subset
and the set of labels
in the supervised learning problem. Hence, if
is the cardinality of
X, then we can say that
is
-variate, with the domain of each of its features context-dependent (e.g., discrete or real-valued), whereas
is univariate and draws from
L. Therefore, during the evaluation of a subset
X using a MCE criterion, one must estimate
from data. However, the number of available samples might not be sufficient for good estimates. One way to circumvent the lack of samples is to penalize an underrepresented pair
that is jointly draw from
and
(e.g., a pair that was observed only once); that approach was successfully tested in the designing of morphological operators using MCE as criterion [
2]. Another possibility is the application of hypotheses about the relationship among features. For instance, the Correlation-Based Feature Selection (CFS) is a cost function which works under the assumption that good features are highly correlated with the class, yet uncorrelated with each other [
3]. Thus, CFS is capable to deal with moderate levels of dependence among features [
3]. There are other methods that rely on similar hypotheses, such as the minimum redundancy, maximum relevancy criterion [
4]. However, those criteria fail to handle features with greater levels of interactions among them; two examples of the latter are the parity problem and the inference of intrinsically multivariate predictive genes [
5,
6].
Regardless of the considered criterion, a feature selection algorithm is required to evaluate the collection
of all subsets of
S, using a cost function
whose mapping is a feature selection criterion. Therefore, the goal is to find a subset
that minimizes
c. This latter problem, also known as the
feature selection problem, is NP-hard [
7], which means that it belongs to the class of problems for which the existence of polynomial-time algorithms to solve them is unknown. Once exhaustive search for an optimum
X may be unfeasible even for moderate sizes of
S [
8], there is (in the literature) a number of proposed feature selection algorithms, both optimal and suboptimal ones [
8,
9]. Among the many families of those algorithms, there are the sequential selection, genetic algorithms, and search algorithms that organize the search space as a graph. Sequential selection algorithms are suboptimal, greedy approaches where, given a subset
and for each
, it evaluates
and updates
X with the element
s that minimizes
. Although sequential selection approaches were proposed as early as in the 60’s [
10], the most popular algorithm of that type, the Sequential Forward Floating Selection (SFFS), was introduced in 1994 by Pudil and colleagues [
11]. Opposite to the Sequential Forward Search (SFS) [
12], SFFS allows removal of elements, thus avoiding to get stuck in local minima [
11]. Another important family of algorithms for feature selection is composed of evolutionary methods, among them the Genetic Algorithms (GAs) [
13]. A very efficient GA algorithm is the “Cross generational elitist selection, Heterogeneous recombination, and Cataclysmic mutation GA” (CHCGA), whose complicated name describes its main properties [
14]. Finally, a feature selection procedure that organizes the search space as a graph consider as a vertex each subset
and as an edge a pair of subsets
such that
and
. Therefore, one can apply one of the many graph-search algorithms that are available in the literature; a widely used one for feature selection is the Best-First Search (BFS) [
15].
The aforementioned graph representation of a search space in a feature selection procedure is isomorphic to a Boolean lattice
, where any maximal chain is in the form
, where
. Moreover, due to the phenomenon known as “curse of dimensionality” (i.e., the increase of selected subset
X size without a corresponding increase in the number of samples), the associated costs of any chain in
, that is
, describe an U-shaped curve [
16]. That important observation led to the development of a feature selection procedure based on the minimization of a cost function whose chains in
describe an U-shaped curve; such minimization problem is also known as
the U-curve problem [
16]. Following the introduction of the U-curve problem approach for feature selection, novel algorithms were proposed to tackle that problem; for instance, the improved U-curve Branch and Bound (iUBB) is a branch-and-bound algorithm for solving the U-curve problem that is very robust to noise; however, it has an explicit representation of the whole search space, which constrains the feasibility of this algorithm to small sizes of
S [
17]. More recently, a study proposed the U-Curve Search (UCS) algorithm, which is an improvement on the very first algorithm introduced to tackle the U-curve problem: while the latter was a suboptimal algorithm, UCS always returns an optimal solution [
18]. UCS manages the search space as a Boolean lattice and controls the pruned elements of
through collections of intervals in the form of either
or
, where
. Search space exploration is done through a Depth-First Search (DFS) procedure that tests necessary and sufficient conditions to prune intervals without the risk of losing elements of minimum cost. However, although UCS is indeed an optimal algorithm for the U-curve problem, computational experiments with that algorithm showed that the required computational time to achieve an optimal solution was exponential on the number of considered features [
18], which raised doubts about the nature of that issue: it could be due to algorithm design, to the intrinsic problem structure, or both.
In this work, we demonstrate that the scalability issue verified in the UCS algorithm actually arises from the fact that the U-curve problem is NP-hard. To mitigate this problem, we introduce a new optimal feature selection algorithm, the Parallel U-Curve Search (PUCS). PUCS includes a parallelization scheme that allows an improvement on the required computational time that is proportional to the available resources (CPU cores or threads). Results from computational experiments, either with artificial data or in MCE-based feature selection procedures, confirmed that PUCS can speedup the search for optimal solutions of the U-curve problem. The remainder of this article is organized as follows: in the Results section (
Section 2), we formally introduce the U-curve problem and prove that it is NP-hard (
Section 2.1), present the PUCS algorithm (
Section 2.2) and also results from computational experiments with that new algorithm (
Section 2.3). In the Discussion section (
Section 3), we analyze the results from
Section 2 and discuss possible directions in this research line. Finally, in Materials and Methods (
Section 4), we detail the computational environment and the software used to carry out the experiments shown throughout this paper.
2. Results
In this section, we present the main contributions of this paper. We start by presenting a formal description of the U-curve problem, followed by a proof that it is actually NP-hard (
Section 2.1). Since the solvability of NP-hard problems in polynomial time is an open problem, such proof means that the U-curve problem can be solved optimally only for small instances (what is “small” in this context is discussed in
Section 2.3). In the sequence, we introduce the Parallel U-Curve Search (PUCS) algorithm, including its theoretical principles, a pseudocode and also an exemplary simulation on a Boolean lattice of degree five (
Section 2.2). Finally, we provide results from computational assays, in which PUCS performance is assessed against other algorithms; to this end, we executed experiments on synthetic data and also in the feature selection step of classifier design (
Section 2.3).
2.1. The U-Curve Problem and Its Computational Complexity
Let S be a non-empty set, and be the collection of all subsets of S, also known as the power set of S. A chain is a collection of pairwise distinct elements in such that . A cost functionc is a function that takes values from the power set of S to the non-negative real numbers, that is, . Let X be an element in . X is of minimum cost (or simply minimum) if there is no element Y in such that and . Those concepts allow us to define a decomposable in U-shaped curves cost function.
Definition 1. Let c be a cost function and S be a non-empty set. c is decomposable in U-shaped curves if for any chain , it holds that if , , then .
A decomposable in U-shaped curves cost function is an extension of the class of set operators that are decomposable as the intersection of a decreasing and an increasing operators [
19]. We can now state the problem that is addressed in this work.
Problem 1. (U-curve) Let S be a non-empty set and c a decomposable in U-shaped curves cost function. Find a subset such that X is minimum.
As it was stated in the previous section, Problem 1 can be used as an approximation for the more general feature selection problem. However, as we will demonstrate in the following, it is unlikely that that Problem 1 can be solved efficiently (i.e., in a polynomial time).
Theorem 1. The U-curve problem is NP-hard.
Proof. We start defining a decision problem version of the U-curve problem by choosing an integer
k and asking whether there is a subset
such that
. We will show that this decision problem is at least as hard as the subset sum problem, a well-known NP-hard problem [
20] (pp. 1013). In the subset sum problem, one has a finite set
W of non-negative integers and a non-negative integer
t, and wants to know if there is a subset
such that the sum of the elements in
Y is exactly
t. Given an instance
of the subset sum problem, we will construct an instance
of the U-curve decision problem, in a time bounded by a polynomial in
. This instance is such that there is a subset
whose sum is equal to
t if and only if there is a subset
whose cost is less or equal to
k. The set
S is defined as a copy of
W, the value of
k is defined as zero, and the cost function
c is:
where
is the absolute value function. Now we will prove that
c is indeed a cost function decomposable in U-shaped curves, that is, for each chain
, for any
,
implies that
. Let us consider two cases. In the first case, let
be an element of
such that
. Thus, for any
we have:
The second case, where
is an element of
such that
, is symmetrical to the first one. Thus, once either
implies that
or
implies that
, it holds that
implies that
. Therefore, we conclude that the cost function
c is decomposable in U-shaped curves.
Finally, we need to show that there is a subset whose sum is equal to t if and only if there is a subset whose cost is less or equal to k:
⇒: If there is a subset whose sum is equal to t, then there is a subset such that and, by the definition of c, the value of is .
⇐: If there is a subset such that , then there is a subset such that and, by the definition of c, implies that the sum of elements in Y is equal to t. □
2.2. The Parallel U-Curve Search (PUCS) Algorithm
We demonstrated that the scalability problem of the UCS algorithm is due to the fact that the U-curve problem (Problem 1) is NP-hard (Theorem 1). To circumvent that issue, we developed the Parallel U-Curve Search (PUCS) algorithm. PUCS solves the U-curve problem through a partitioning of the search space, which enables each part to be solved in an independent, parallelized way. Once each part is also a Boolean lattice, the algorithm can be called recursively on such smaller lattices. As the recursion base case, one might use the UCS algorithm itself or any other procedure, either an optimal or a suboptimal one. In the following, we will present some theoretical principles of the PUCS algorithm, as well as an example of the algorithm dynamics.
2.2.1. Theoretical Principles of the PUCS Algorithm
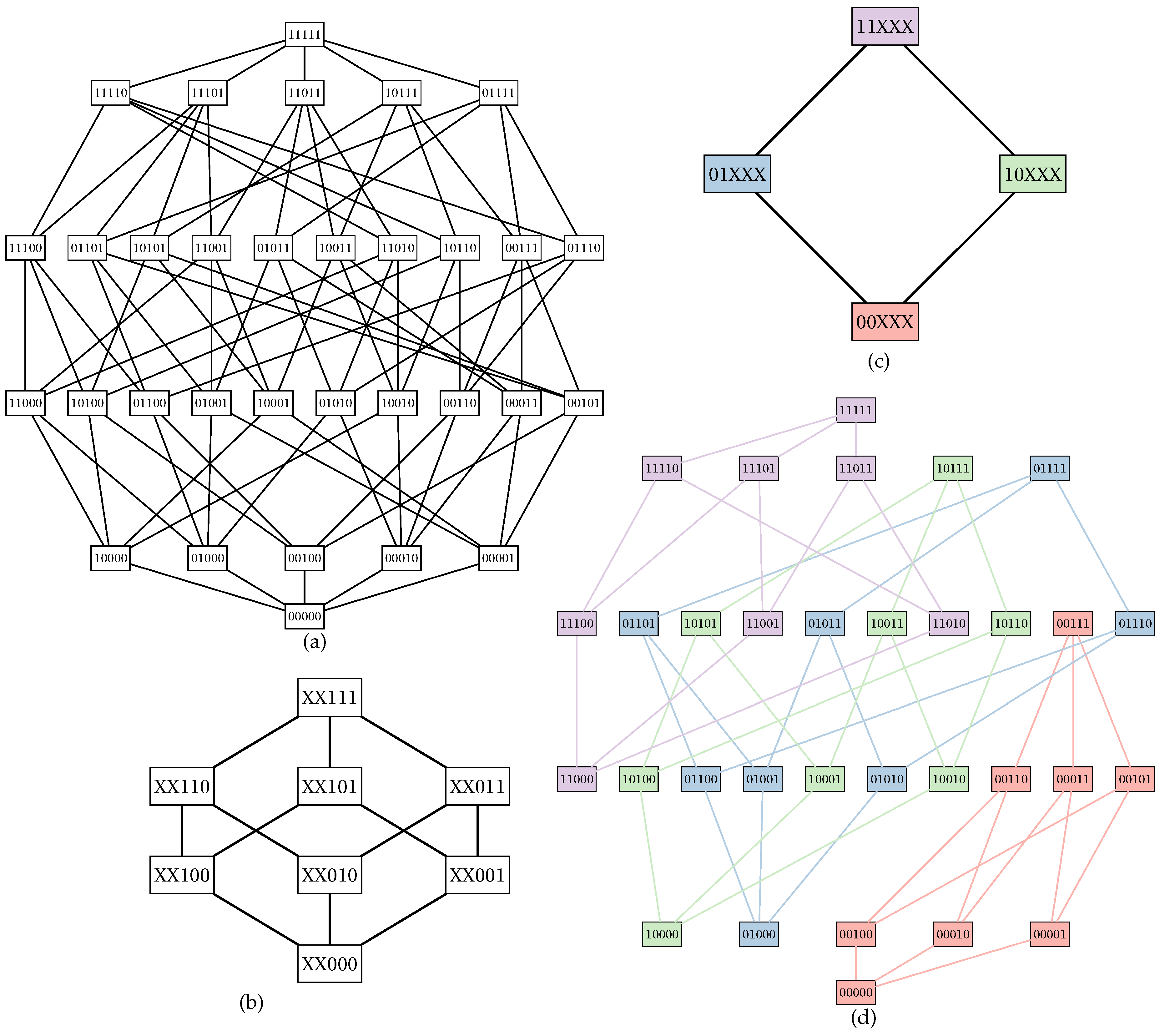
For the sake of simplicity, from now on, we will denote a subset X of S through a binary string, where digit positions correspond to element positions in a lexicographical sorting, and the digit values 0 or 1 represent, respectively, absence or presence of a given element. For example, consider a set : the lexicographical order of S is , and the subset can be represented with the string 01001.
Let
S be a non-empty set, and
c be a decomposable in U-shaped curves cost function. Let us define a subset
named
fixed set; elements in
are called
fixed points. The remaining elements in
S compose a set
named
free set; elements in
are called
free points. A Boolean lattice
can be partitioned into
smaller Boolean lattices of degree
each. For each element
, we define a small Boolean lattice isomorphic to
; such lattice associated with
X is also known as
inner Boolean lattice. The set
of fixed points can also be used to build a Boolean lattice
called
outer Boolean lattice (
Figure 1).
Let
X be an element of
(i.e., an element of the outer Boolean lattice). We can compute the cost of any element
Y in the inner Boolean lattice
associated with
X through a wrapper on the original cost function:
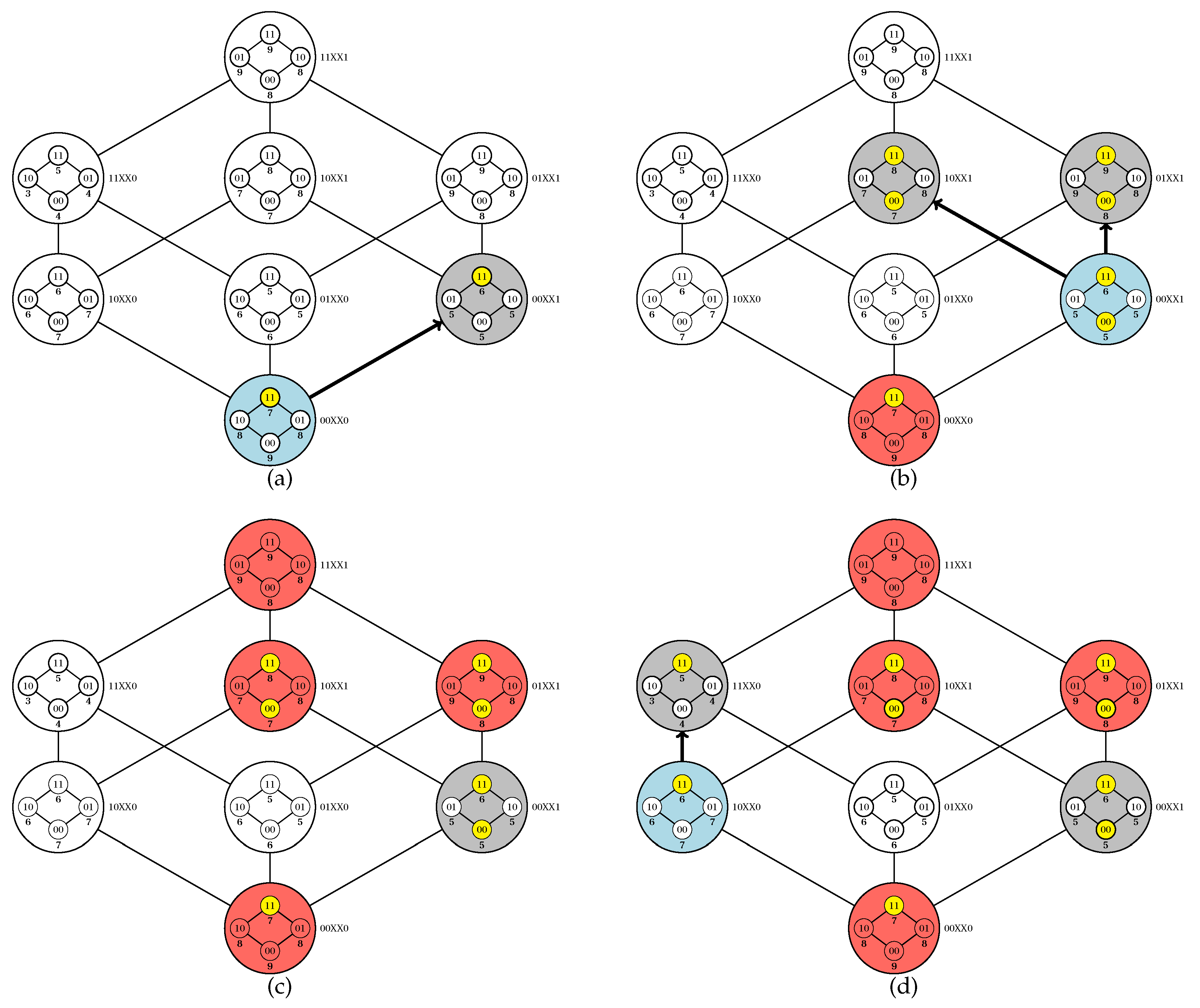
In
Figure 2, we show an example of computation of
for a partition of a Boolean lattice of degree five.
2.2.2. Dynamics of the PUCS Algorithm
Let
X,
Y and
S be non-empty sets such that
. An
interval is a collection of elements in
defined as
. The dynamics of the PUCS algorithm consists of walks along the outer Boolean lattice, pruning intervals from the latter whenever it is allowed, that is, when it does not incur risking losing a global minimum. To this end, we make use of two properties of a Boolean lattice-based search space whose cost function is decomposable in U-shaped curves; those properties were already used previously for the designing of optimal algorithms for the U-curve problem [
18].
Proposition 1. Let be an instance of the U-curve problem, and be a fixed set. Let X and Y be subsets of such that and . If then it holds that for any .
Proof. Suppose that there is a such that . Once , it would hold that , that is, , a contradiction according to the definition of a decomposable in U-shaped curves cost function. □
By the principle of duality, Proposition 1 implies the following result.
Corollary 1. Let be an instance of the U-curve problem, and be a fixed set. Let X and Y be subsets of such that and . If then it holds that for any .
Both Proposition 1 and Corollary 1 establish conditions for pruning of intervals of the Boolean lattice during a walk through the outer Boolean lattice. Therefore, during the execution of PUCS, we test both properties for a given pair of elements in such that :
If , then by Proposition 1 we can remove from the search space elements in ;
If , then by Corollary 1 we can remove from the search space elements in .
In Algorithm 1, we present a pseudocode for the PUCS algorithm. In that pseudocode, a walk throughout the outer Boolean lattice is carried out in a for all loop between lines 8–25. During an iteration of that loop, we evaluate an element X that was recently removed from the current search space (i.e., a collection of outer Boolean lattice elements that were neither explored nor pruned); X is then included into a collection of explored elements. For each element Y from adjacent to X (i.e., an element Y from such that and or and ), the two aforementioned conditions are tested, and pruning procedures are carried out accordingly, thus updating and ; those procedures may result in the replacement of X by one of its adjacent elements, therefore changing the evaluated X in the for all loop and advancing the walk. Eventually, the current search space is fully explored (i.e., ), and we need to look for minima at each inner Boolean lattice associated with elements in , which is accomplished in line 29. This can be done by either calling the PUCS algorithm itself on the Boolean lattice associated with X (i.e., on the instance ) or using another “base algorithm” (e.g., SFFS or UCS).
Code parallelization is feasible in two procedures: the initiation and execution of a walk (an iteration of the
while loop between lines 5 and 27) and the exploration of the inner Boolean lattices (line 29). It is noteworthy that the adopted criteria for choosing an element for walk initiation (line 6) or for adjacency exploration (line 8) impact on the algorithm dynamics; for our computational experiments, we adopted a random choice in both cases. In
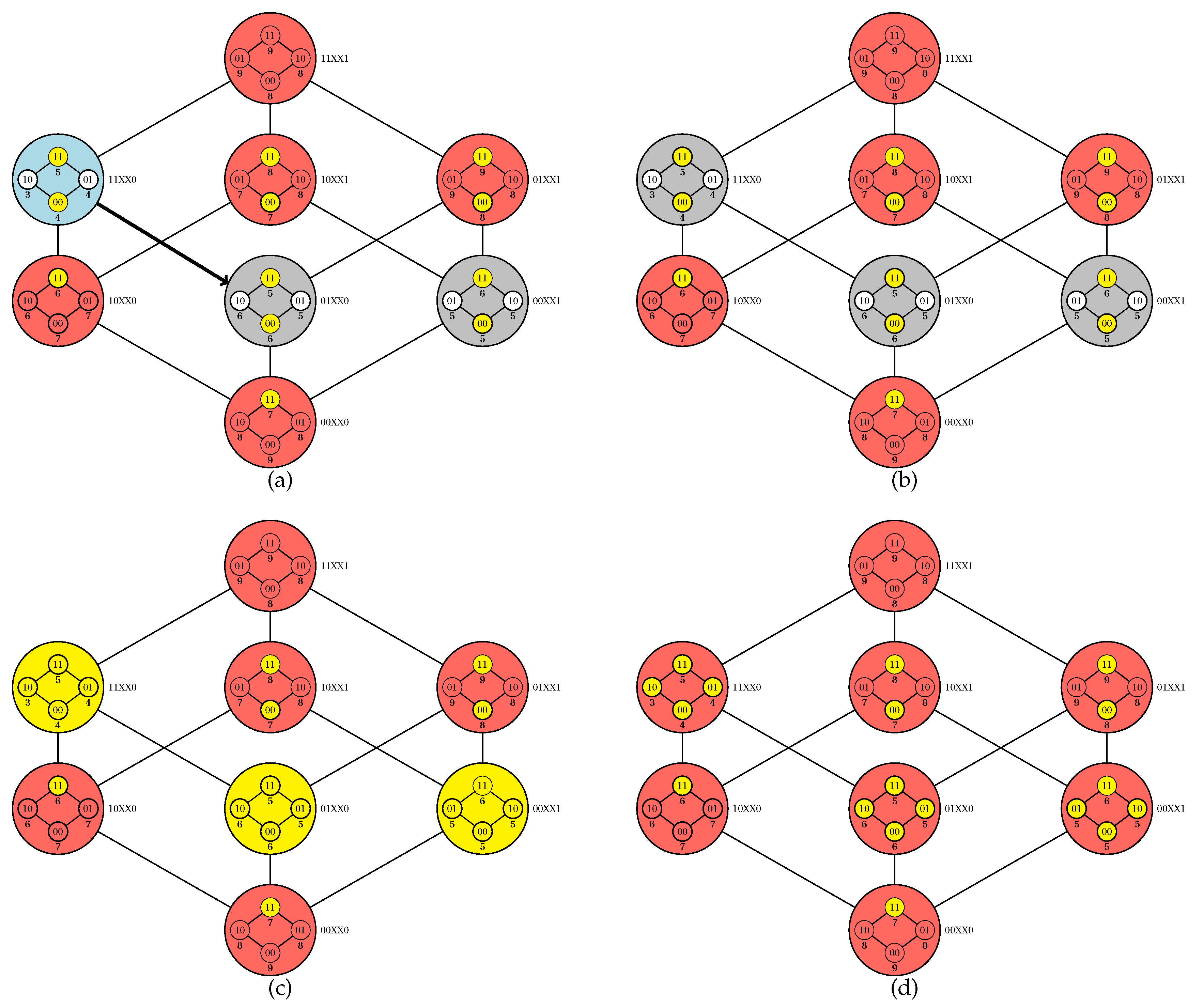
Figure 3 and
Figure 4, we provide a simulation of the PUCS algorithm on the instance of the U-curve problem presented in
Figure 2a, whose outer Boolean lattice is defined as in
Figure 2b.
2.3. Experimental Evaluation
We will now present results from computational experiments with the PUCS algorithm. We start this subsection discussing the algorithm parametrization, including its main parameters and how they were set up according to the instance type (
Section 2.3.1). In the sequence, we show results with “hard” synthetic data, which were generated taking advantage of the polynomial reduction presented in Equation (
1) (
Section 2.3.2). We also present results in which we assess the PUCS algorithm robustness when it is dealing with real-world instances, in the context of image filter designing (
Section 2.3.3). Finally, we provide results from supervised learning of support-vector machines to classify datasets from the UCI Machine Learning Repository [
21] (
Section 2.3.4).
To perform the experimental evaluation of the proposed algorithm, we used
featsel, a framework coded in C++ especially designed for benchmarking of feature selection algorithms and cost functions [
22]. Thus, we implemented PUCS in featsel, using the OpenMP library for code parallelization [
23]. Full details about the framework setting up and the adopted parallelization scheme are provided in Materials and Methods (
Section 4).
| Algorithm 1 Parallel U-Curve Search (PUCS). |
Require: a non-empty set S of features and a decomposable in U-shaped curves cost function c
Ensure: the elements in of minimum cost
- 1:
▹ stores elements whose costs were computed - 2:
define a set of fixed points (hence is the set of free points) - 3:
▹ contains unexplored/unpruned elements from the outer Boolean lattice - 4:
▹ contains explored elements from the outer Boolean lattice - 5:
whiledo - 6:
remove an element X from - 7:
- 8:
for all such that Y is adjacent to X do - 9:
if and then ▹ Testing Corollary 1 - 10:
remove elements in the interval from and - 11:
- 12:
- 13:
else if and then ▹ Testing Proposition 1 - 14:
remove elements in the interval from and - 15:
else if andthen ▹ Testing Proposition 1 - 16:
remove elements in the interval from and - 17:
- 18:
- 19:
else if and then ▹ Testing Corollary 1 - 20:
remove elements in the interval from and - 21:
else - 22:
- 23:
- 24:
end if - 25:
end for - 26:
∪ { elements in whose costs were computed during this while iteration } - 27:
end while - 28:
for alldo - 29:
∪ { elements of minimum cost in the inner Boolean lattice associated with X } - 30:
end for - 31:
return
|
2.3.1. Algorithm Parametrization
In our PUCS implementation, we considered three main parameters:
The maximum recursion depth/level l that is allowed when PUCS is recursively called to solve an inner Boolean lattice (line 29 in Algorithm 1). The l parameter is an integer ;
The proportion p of features in S that will be fixed points. In our implementation, the fixed set size is given by the smallest integer equal or larger than . The p parameter is in the interval ;
The base algorithm
b that is called to solve an inner Boolean lattice when the recursion level is equal to
l. For optimal-search experiments, the
b parameter was set as U-Curve Branch and Bound (UBB) [
17]; in the case of suboptimal-search experiments,
b was set either as BFS, CHCGA, SFFS or SFS.
The performance of the PUCS algorithm relies heavily on the adopted parametrization; therefore, we will now discuss how to set PUCS parameters according to the instance size. We will consider two types of instances, the small and big ones. Small instances are those that can be solved optimally in a reasonable computational time. Although those instances usually have at most 25 features, naive algorithms such as exhaustive search might already be impractical for solving the problem optimally. On the other hand, big instances are those with more than 25 features, and generally cannot be solved by any optimal algorithm.
Small Instances
For small instances, we can set the base algorithm as an optimal solver, more specifically, U-Curve-Branch-and-Bound (UBB), which is a simple, optimal algorithm to solve the U-curve problem [
17]. For the other two parameters,
p and
l, one should choose them aiming to yield moderate granularity of the partition. A fine-grained partition can create too many parts (up to the point in which every part has only one subset); on the other hand, a coarse-grained partition may not divide the problem enough to allow use of all available computational resources. Therefore, after some assays to assess such trade-off, we decided to set up those parameters as
and
.
Big Instances
For big instances, we set the base algorithm with a suboptimal approach, either BFS, CHCGA, SFFS or SFS. When the PUCS base algorithm is optimal, then parameters
l and
p can only determine the execution time of the algorithm; however, when the base algorithm is a suboptimal one,
l and
p can also interfere on the solution quality, that is, they can determine how close the found solution will be to the global minimum. If the partitioning is fine grained, then more subsets will be visited, producing a solution that tends to be closer to the global minimum. Nevertheless, one cannot increase
l and
p arbitrarily, since this would also increase the execution time. In
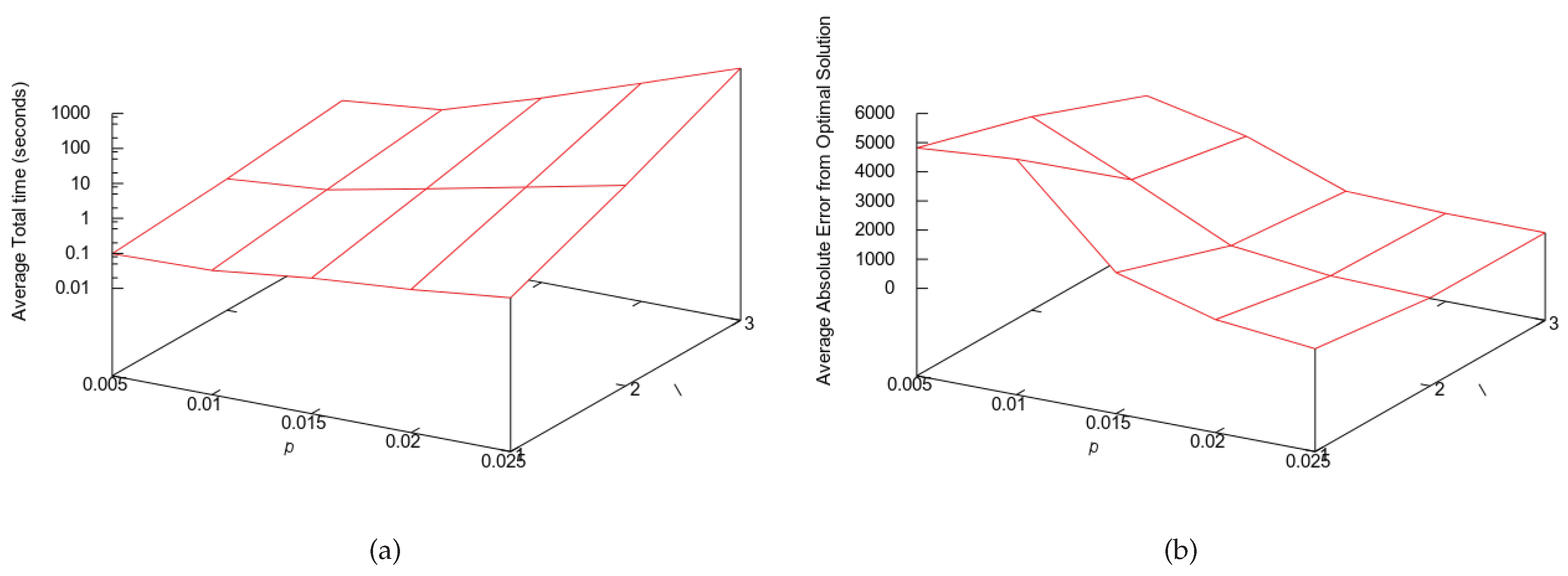
Figure 5, we show the trade-off assessment assay for big instances, where we show how the execution time and solution quality change as we increase the values of
l and
p. Based on those results, we decided to set the PUCS parameters for big instances as
and
, where
n is number of features of the instance.
2.3.2. Experiments with Synthetic Data
As aforementioned, once Equation (
1) is a polynomial reduction from instances of the subset sum problem to instances of the U-curve problem, we used that equation to generate “hard” synthetic instances with
n features: to this end, one just needs to generate
random integers and use subsets of them to compute Equation (
1). We divided our experiments into optimal ones, with instances with up to 18 features, and suboptimal ones, with instances with 30 or more features.
Optimal Experiment
In this experiment, we compared the performance of PUCS against UCS, the optimal algorithm for the U-curve problem that was proposed recently [
18]. We summarize the yielded results in
Table 1. From that table, we remark that even though PUCS needed more calls of the cost function, PUCS outperformed UCS in execution time.
Suboptimal Experiment
In this experiment, the instances had a larger size, ranging from 30 to 100 features; hence, they usually could not be solved by optimal algorithms. For this assay, we set SFS as the PUCS base algorithm and benchmarked this latter with the BFS, CHCGA and SFFS algorithms. Those three latter algorithms were chosen as baselines because each one belongs to a different family of feature selection algorithms, each family with a particular search strategy. In
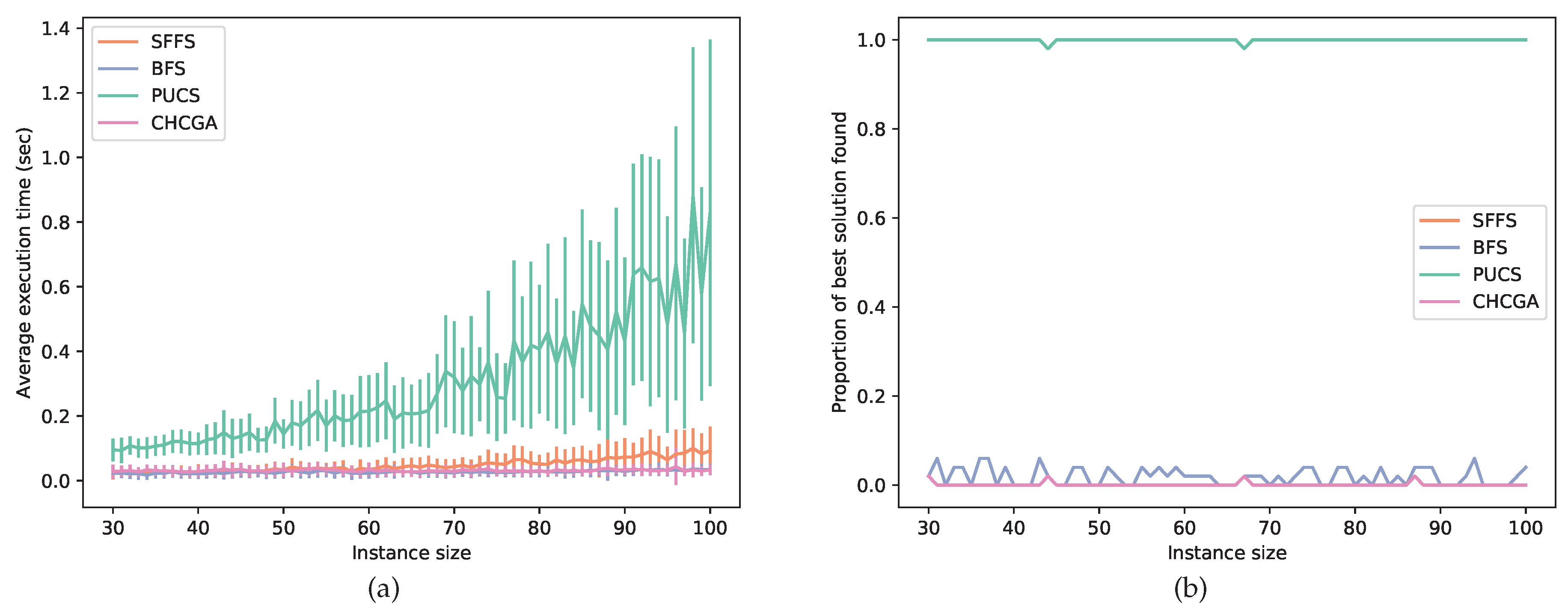
Figure 6, we show a performance comparison between those suboptimal procedures. Observe that PUCS had the worst performance from the computational time point of view. However, for each instance size, PUCS almost always found the best solution among all algorithms.
2.3.3. Assessment of the PUCS Robustness with Real-World Data
During the experiments with synthetic data, the used cost function (Equation (
1)) yielded U-shaped curves without violation of the U-curve property (Definition 1). However, when we use real-world data, the chains of the Boolean lattice
that represents the search space might have such violations, that is, for a given chain
,
, we might have an element
such that
. In that case, if it also holds that
and
, then we say that such violation is an
oscillation.
Therefore, to evaluate the PUCS algorithm robustness when facing chain oscillations of real-world instances, we executed feature selection procedures using samples for classifier designing in the context of image processing. A classifier can be used to perform an image filtering (transformation). One important family of image filters is defined by W-operators, morphological operators that are locally defined in windows (i.e., sets of points in a plane) and translation-invariant [
24]. To design W-operators, one can firstly select the most relevant features (i.e., a window subset) according to a given criterion; for instance, we can use a penalized mean condition entropy (MCE) cost function that was introduced previously [
2], whose formulation is the following: Let
S be the non-empty set of features,
X be an element in
and
be a random variable that draws values from
, the power set of
X. Moreover, let
Y be a discrete random variable representing the class of a given realization
and
P a probability distribution function. The conditional entropy of
Y given
is:
Thus, the mean conditional entropy of
Y given
is:
Once lack of samples might result in underrepresentation of observed pairs
, we penalize pairs that have a unique observation: This is accomplished by considering them as following a uniform distribution, thus yielding the highest entropy in Equation (
4). Thus, the estimation of the penalized mean conditional entropy is:
where
N is the frequency that
has a single sample occurrence and
t is the number of samples.
To accomplish conditional entropy-based feature selection in the W-operator filter designing, we used the same training set of a previous study [
18]. In that study, it was produced ten pairs
of binary images. Each
image was produced by covering its respective
image with 30 % of uniformly distributed, salt-and-pepper noise. For each pair of binary images and for each window size ranging from 7 to 17, a window was screened throughout the image pair, thus producing the samples for the feature selection procedures. Those produced instances can be retrieved from an online repository [
25].
The obtained results are summarized in
Table 2 and
Table 3. In despite of the number of oscillations increased with the increase of the instance size, the PUCS algorithm almost always could find an optimal solution (
Table 2). There was an exception for a single instance of size 17, for which PUCS could not find the global optimum; however, when we replaced UBB for UCS as the base algorithm, PUCS could also find the global minimum for all ten instances of size 17. On the other hand, the suboptimal algorithms (BFS, CHCGA and SFFS) had a decrease in finding the global minimum as a function of instance size, a phenomenon that was already expected in that type of assay.
From the computational point of view, PUCS required much less computational time than UCS; for example, for instances of size 17, PUCS required on average only 3.19% and 1.45% of computational required by exhaustive search (ES) and UCS, respectively (
Table 3). On the other hand, although the number of cost function calls made by PUCS was only 42.09% of the one required by ES, it was 40.63% higher than the one required by UCS. However, when we replaced UBB for UCS as the base algorithm, the PUCS average number of calls of cost function for instances of size 17 was 44913.3 ± 5015.9, which is only 13.57 % higher than the one of UCS.
2.3.4. Experiments with Machine Learning Datasets
Whereas in the previous section we evaluated the robustness of the PUCS algorithm in mean conditional entropy-based feature selection searches, now we assess the performance of PUCS and other algorithms (BFS, CHCGA, SFFS and UCS) in the feature selection step for the designing of Support-Vector Machines (SVMs). SVMs are classifiers that create a decision boundary in the feature space to separate data into two different classes; the boundaries are chosen in a way that they tend to have a maximum distance to the nearest points of both classes [
26].
The experiment started with feature selection procedures on discrete Machine Learning datasets, using the penalized mean conditional entropy (Equation (
6)) as the cost function. After feature selection, we then used the LIBSVM open-source library to train SVM models and perform cross-validation [
27]. For instances where there are more than two classes, the library creates a binary classifier for each pair of classes and use a consensus scheme to classify new data. We used linear SVMs with regularization parameter (i.e., a parameter that changes boundary margin sizes) set as 100. We used 10-fold cross validation (CV) for datasets with less than 100 samples, and leave-one-out for other datasets.
The used datasets were downloaded from the University of California Irvine (UCI) Machine Learning Repository [
21]. A total of five datasets were retrieved, with different number of features, classes and samples (
Table 4). All datasets were converted to the featsel framework format and some of them had their features discretized for feature selection and classification. In
Table 5, we show, for each algorithm and for each dataset, the number of selected features and also the cross-validation (CV) error of the trained SVM classifier. In that experiment, the SVM trained using features selected with PUCS yielded a smallest CV error in the two largest datasets (“Lung cancer” and “Hill Valley”). Moreover, a PUCS feature selection procedure with a given base algorithm yielded a classifier with a CV error equal or smaller to the one of the same base algorithm executed alone in 10 out of 15 procedures (66.67 %). Similarly, the former procedure selected a feature subset of size equal or smaller to the one of the latter also in 10 out of 15 procedures.
For the smaller datasets, namely Breast Cancer, Wine and Zoo, we verified the number of oscillations present in their respective search spaces, which are 94, 1,832 and 226,941, respectively. Hence, we also performed feature selection on those datasets with an exhaustive search (ES). Those procedures yielded SVM classifiers with CV errors for Breast Cancer, Wine and Zoo of 4.1 %, 2.8 % and 6.9 %, respectively. The number of selected features were, respectively, five, four and six. Importantly, when we applied PUCS on those same three datasets with an optimal base algorithm (UBB), the selected subsets were the same of ES, thus yielding the same CV errors and number of selected features of this latter optimal procedure.
3. Discussion
Solving a feature selection problem through an approximation to the U-curve problem is an effective strategy that was demonstrated previously in a wide range of applications such as dataset classification and designing of morphological operators [
16,
17,
18]. However, in all those instances, the computational performance of the U-curve-based algorithm was exponential on the number of features, thus hindering the scalability of the algorithms proposed in those works. Here, we demonstrated that such issue was not due to poorly designed algorithms, since we proved that in fact the U-curve problem is NP-hard (Theorem 1).
Once solving an instance of the U-curve problem probably is not feasible in polynomial time, we presented in this work the Parallel U-Curve Search (PUCS), a new algorithm for that problem that was designed with properties that mitigate the aforementioned scalability issues. PUCS allows us to take advantage of the highly symmetrical structure of the Boolean lattice representation of the search space to produce a partition of the latter (
Figure 1); each part, known as “inner Boolean lattice”, can be solved independently in a parallelized fashion. Moreover, the organization of those parts in a partial order results in a lattice that we called “outer Boolean lattice”: such structure can be explored through walks, in which pruning conditions can be evaluated; if the removal of a search space interval is applicable (according to Proposition 1 or Corollary 1), then one or more parts can be discarded unsolved, thus enhancing the computational performance of the algorithm.
To experimentally validate the new algorithm, we coded PUCS in featsel, a C++ framework for benchmarking of feature selection algorithms and cost functions [
22]. We carried out computational assays with synthetic data, where we evaluated the computational time requirement of PUCS in comparison with UCS, which is the latest proposed algorithm for the U-curve problem [
18]. The optimal experiment showed us that PUCS required just a small fraction of the time spent by UCS: For example, for instances of size 18, on average PUCS required less than 0.1% of the UCS time (
Table 1). However, PUCS computed more times the cost function than UCS: for instances of size 18, PUCS calculated it around four times more often; this could be due to the choice of base algorithm (UBB), which is is known to compute more often the cost function than UCS [
32]. In the suboptimal experiment, we compared PUCS against UCS and other three golden standard algorithms, namely BFS, CHCGA and SFFS. In that assay, the solution found by other algorithms were usually worse than the solution found by PUCS (
Figure 6); the superior PUCS performance might come from the partition scheme, which provides a better coverage of different regions of the search space.
Once in experiments with synthetic data all instances do not violate the U-curve property (Definition 1), we evaluated the PUCS algorithm robustness and optimality when it is dealing with real-world data, since those latter might have violations of that property. Indeed, during the feature selection step of W-operator image filter designing, the number of oscillations per element in the search space increases as a function of instance size (
Table 2): for example, for instances of size 7 (i.e., search space with
elements) the average number of oscillations per element is 0.03, whereas for instances of size 17 (i.e., search space with
elements) that number is 1.03. Nevertheless, the tested optimal algorithms for the U-curve problem have a robustness in respect to those oscillations, returning the global minimum for almost all evaluated instances: the only exception was one instance with 17 features, for which PUCS using UBB as base algorithm could not find the global minimum; once that situation was circumvented when we used UCS instead of UBB as the base algorithm for PUCS, UCS probably is a more robust optimal base algorithm for PUCS than UBB. In those assays in the context of W-operator designing, we also confirmed that the code parallelization of PUCS provides, from the computational point of view, a more efficient feature selection procedure than both exhaustive search and UCS (
Table 3).
We also executed computational assays with Machine Learning datasets, where we evaluated the PUCS algorithm in the feature selection step of Support-Vector Machine (SVM) designing for classification of a number of datasets (
Table 4). In those experiments, we employed the PUCS algorithm with three different parametrizations, each one using one of the benchmarked feature selection algorithms (BFS, CHCGA and SFFS). The idea of that experiment was to show whether the usage of PUCS, combined with one of those renowned suboptimal algorithms, could improve their performance in the feature selection step of classifier designing. Indeed, in two-thirds of those experiments, PUCS combined with one of the mentioned suboptimal algorithm yielded a CV error that was equal to or smaller than the one yielded by the standalone run of the respective suboptimal algorithm (
Table 5); the same proportion was verified when we analyzed the selected number of features, which is related to a reduction of the model complexity (
Table 5). The improvement provided by PUCS might come from the aforementioned property, whose usage allows a more structured exploration of the search space. Besides, the walk through the outer Boolean lattice that represents the search space also allows pruning proceedings, thus preventing the base algorithm from exploring unnecessary regions of the search space and also from computing the cost of a same element twice or more times. Finally, for the smaller datasets (Breast Cancer, Wine and Zoo), we verified that, despite the presence of oscillations in their respective search spaces, the PUCS algorithm, when using an optimal solver for the U-curve problem (UBB) as the base algorithm, could always find the subset that minimizes the penalized mean conditional entropy. The slightly higher CV errors yielded by those optimum subsets in comparison to the smallest CV errors depicted in
Table 5 could be attributed to the constraints on the hypothesis space of SVM models, which is regulated by the learning algorithm parametrization; for example, changes in the regularization parameter and/or in the used kernel (e.g., from linear to polynomial) induce significant changes on the model validation results.
The effectiveness of the proposed algorithm to tackle feature selection in instances with greater levels of interactions among features (e.g., the prediction of intrinsically multivariate genes) is a subject that we intend to investigate in this research line. Another possibility would be the application of PUCS on very large datasets; for instance, on the CASIA Chinese handwriting database, which contains about 3.9 million samples and 7,356 classes [
33]. In particular, it would be interesting to compare the performance of PUCS against minimum redundancy, maximum relevance (MRMR) methods that are often used to solve large problems [
4], which include approaches such as the extended MRMR and the SpecCMI algorithm [
34,
35].

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}