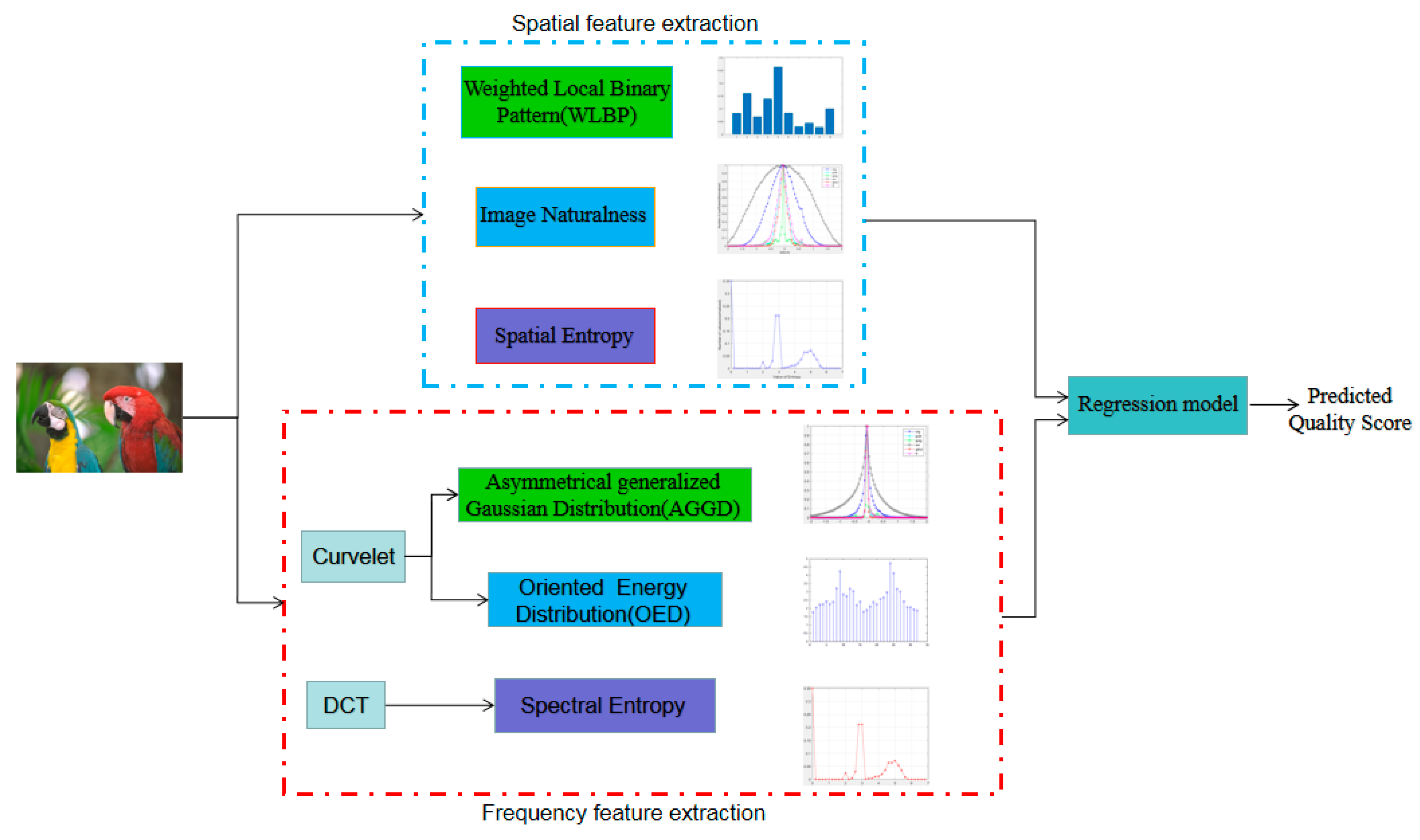
Figure 1.
Overview of the proposed DFF-IQA framework.
Figure 1.
Overview of the proposed DFF-IQA framework.
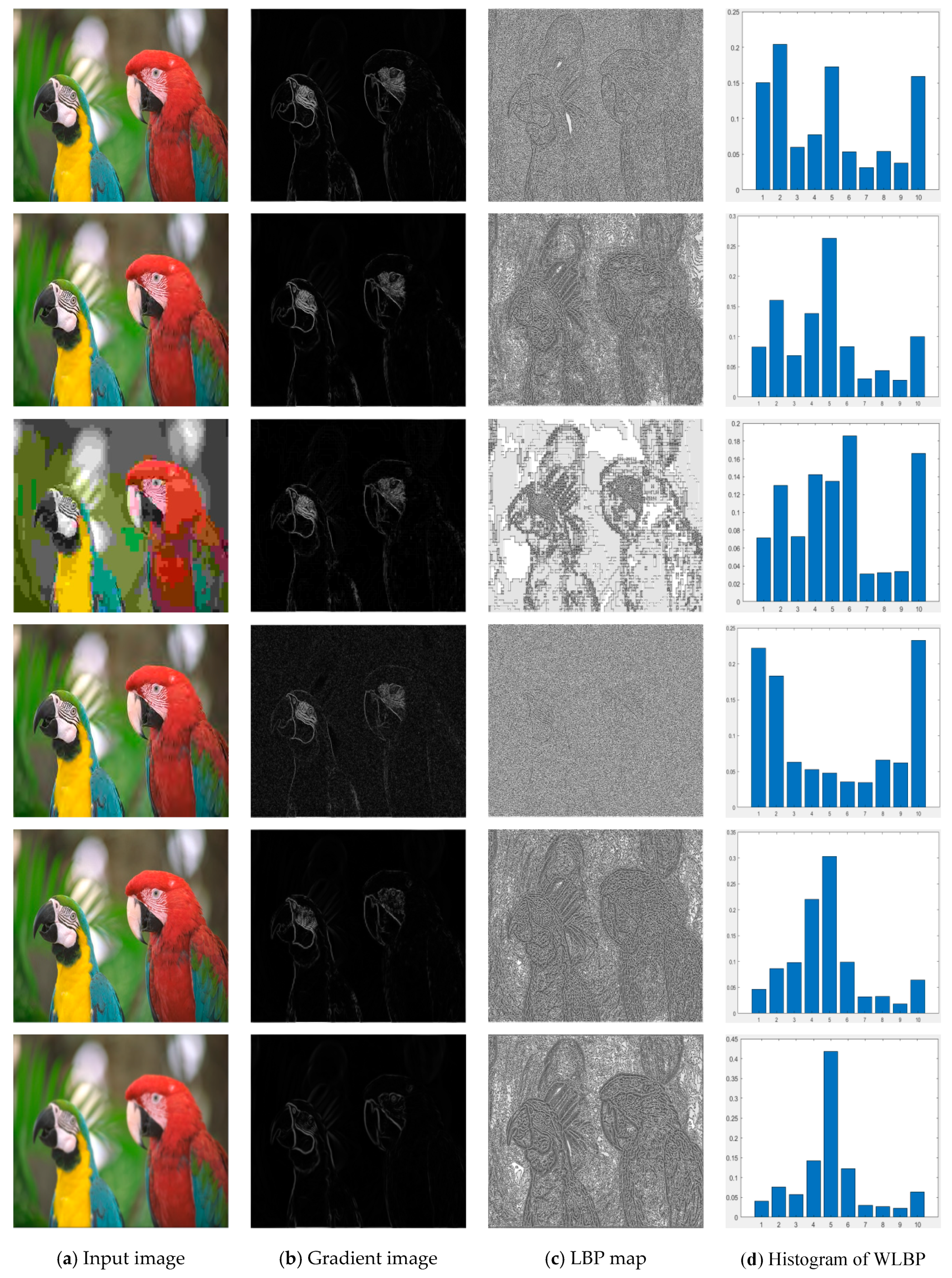
Figure 2.
Pristine natural image and five distorted versions of it from the LIVE IQA database (“parrots” in LIVE database); from left column to right column are the input image, gradient image, LBP map, and histogram of WLBP. From top to bottom of the first column are pristine image with DMOS = 0, JPEG2000 compressed image with DMOS = 45.8920, JPEG compressed image with DMOS = 46.8606, white noise image with DMOS = 47.0386, fast-fading distorted image with DMOS = 44.0640, and Gaussian blur image with DMOS = 49.1911.
Figure 2.
Pristine natural image and five distorted versions of it from the LIVE IQA database (“parrots” in LIVE database); from left column to right column are the input image, gradient image, LBP map, and histogram of WLBP. From top to bottom of the first column are pristine image with DMOS = 0, JPEG2000 compressed image with DMOS = 45.8920, JPEG compressed image with DMOS = 46.8606, white noise image with DMOS = 47.0386, fast-fading distorted image with DMOS = 44.0640, and Gaussian blur image with DMOS = 49.1911.
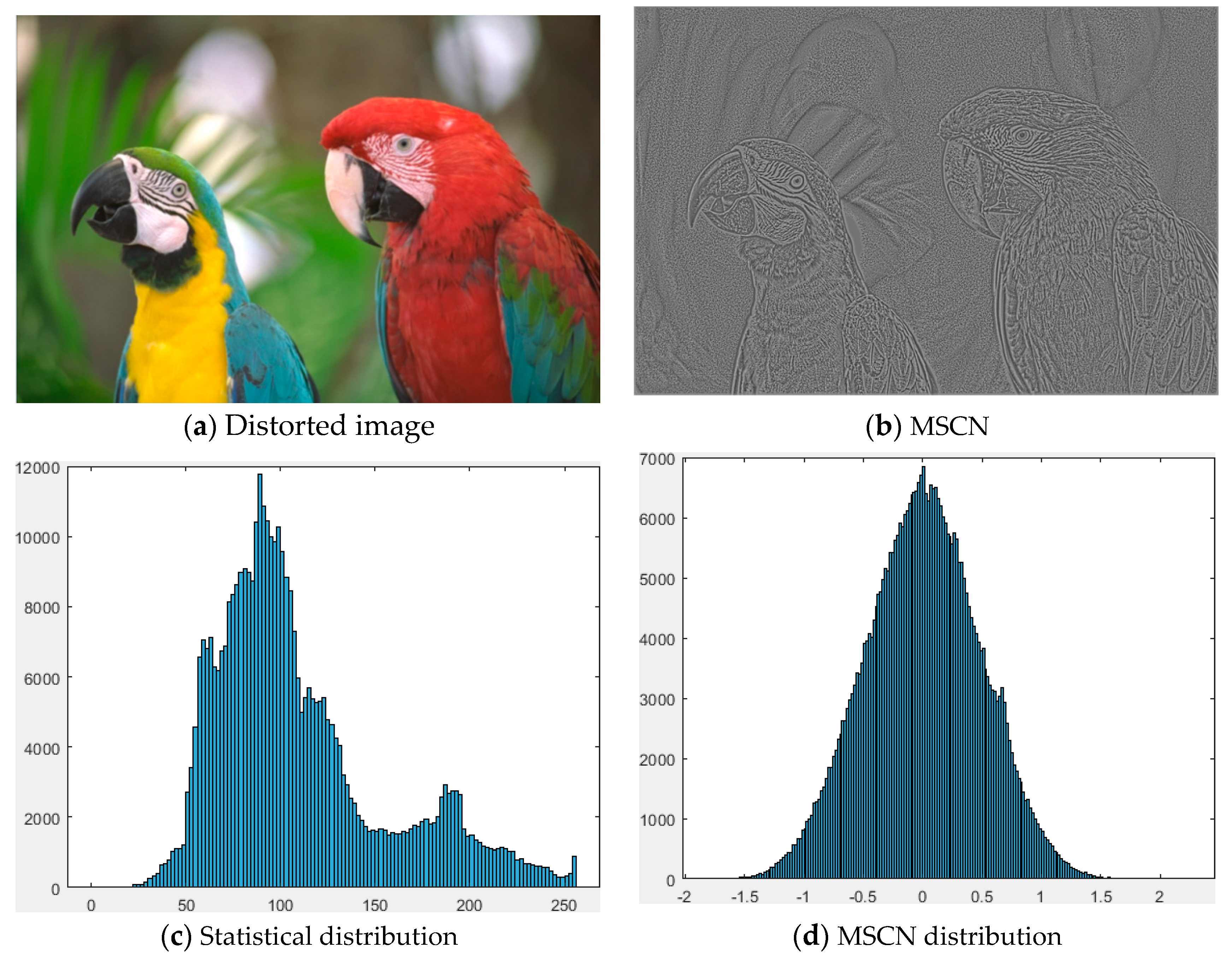
Figure 3.
(a) Distorted image (“parrots” in LIVE database, type of JP2K compressed image with DMOS = 45.8920); (b) Corresponding MSCN coefficients image of (a); (c) Statistical distribution of the distorted image; (d) MSCN histogram distribution of MSCN coefficients.
Figure 3.
(a) Distorted image (“parrots” in LIVE database, type of JP2K compressed image with DMOS = 45.8920); (b) Corresponding MSCN coefficients image of (a); (c) Statistical distribution of the distorted image; (d) MSCN histogram distribution of MSCN coefficients.
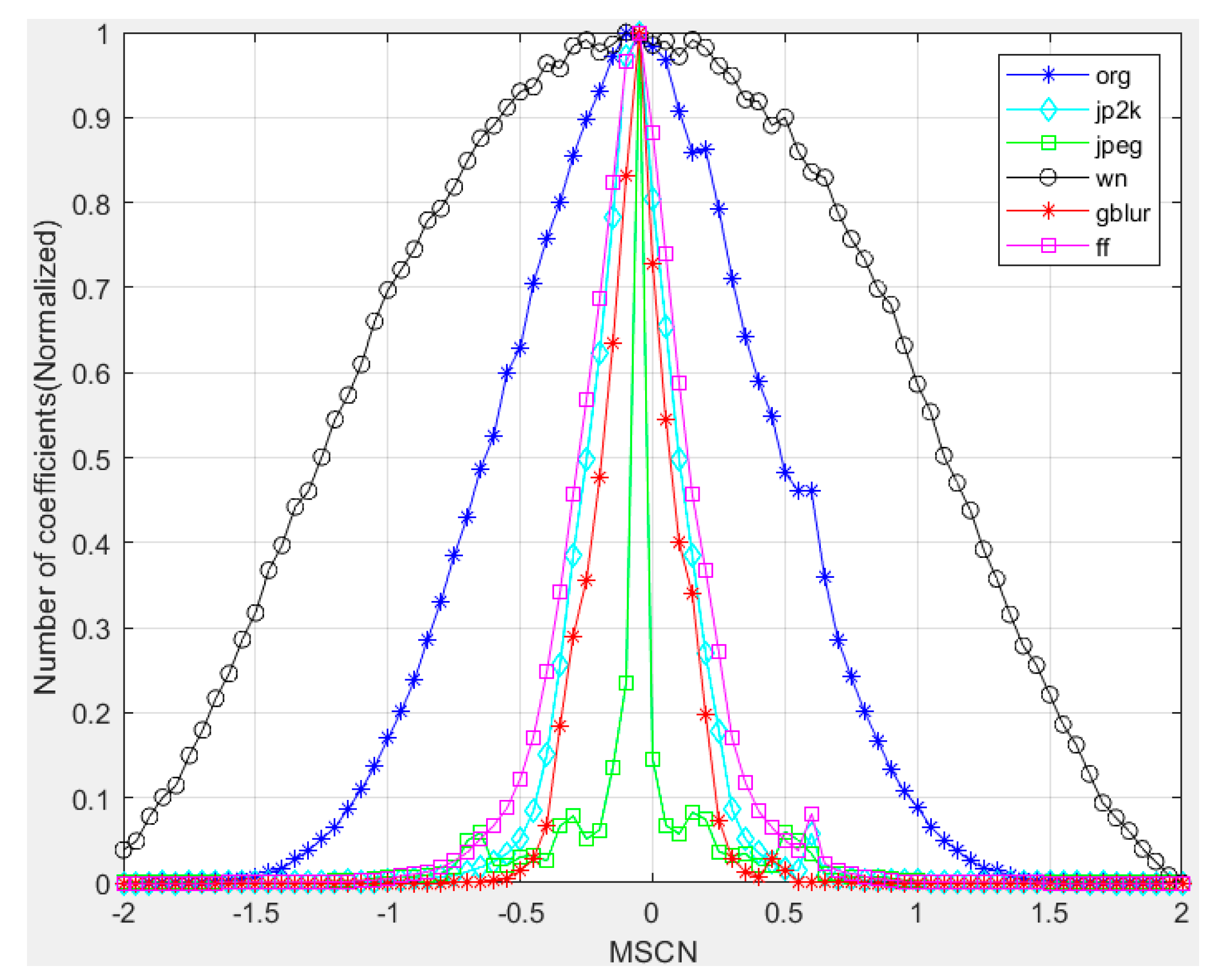
Figure 4.
Histogram of MSCN coefficients for a reference image and its various distorted versions. Distortions from the LIVE IQA database. org: original image (i.e., Pristine natural image). jp2k: JPEG2000. jpeg: JPEG compression. wn: additive white Gaussian noise. blur: Gaussian blur. ff: Rayleigh fast-fading channel simulation.
Figure 4.
Histogram of MSCN coefficients for a reference image and its various distorted versions. Distortions from the LIVE IQA database. org: original image (i.e., Pristine natural image). jp2k: JPEG2000. jpeg: JPEG compression. wn: additive white Gaussian noise. blur: Gaussian blur. ff: Rayleigh fast-fading channel simulation.
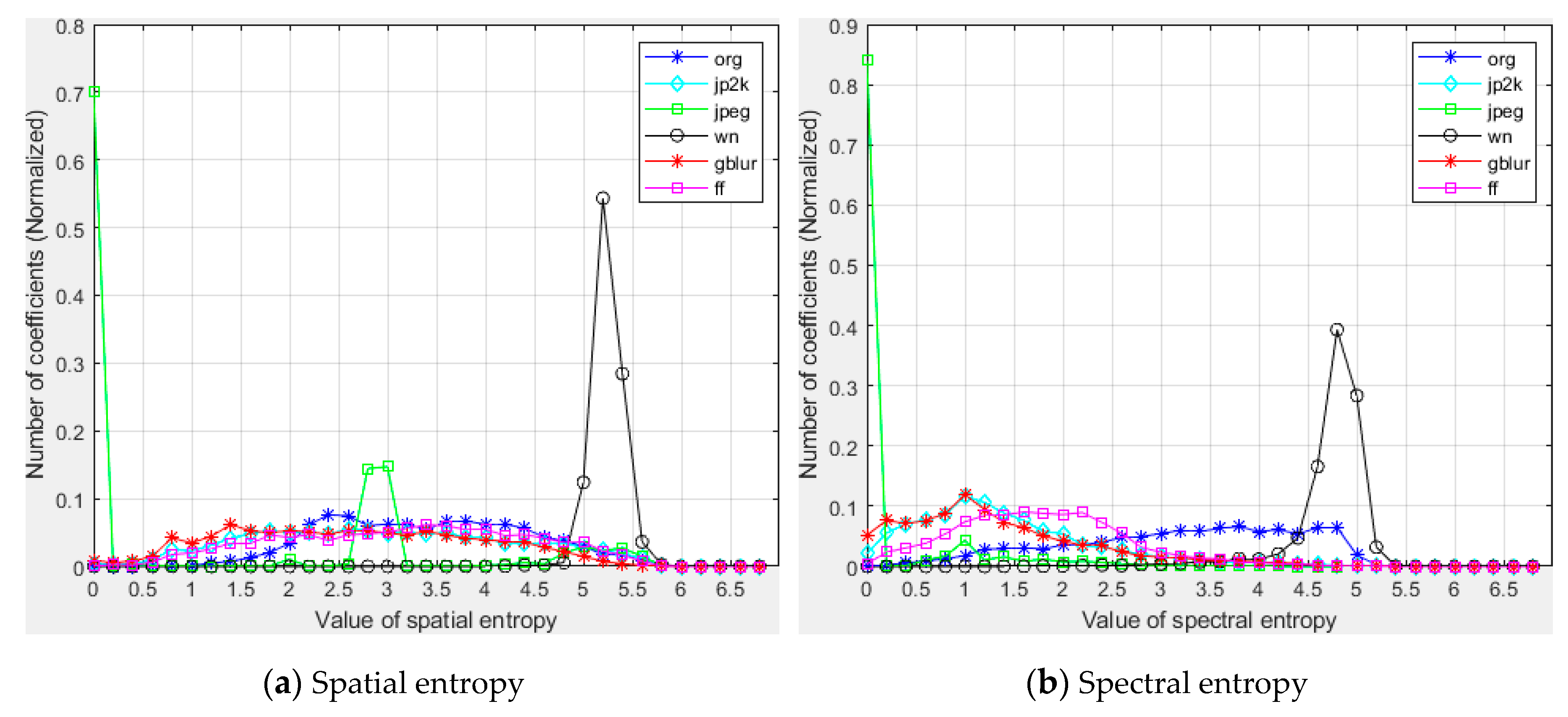
Figure 5.
Histograms of spatial and spectral entropy values for different types of distortion. The ordinate represents the coefficient normalized between 0 and 1.
Figure 5.
Histograms of spatial and spectral entropy values for different types of distortion. The ordinate represents the coefficient normalized between 0 and 1.
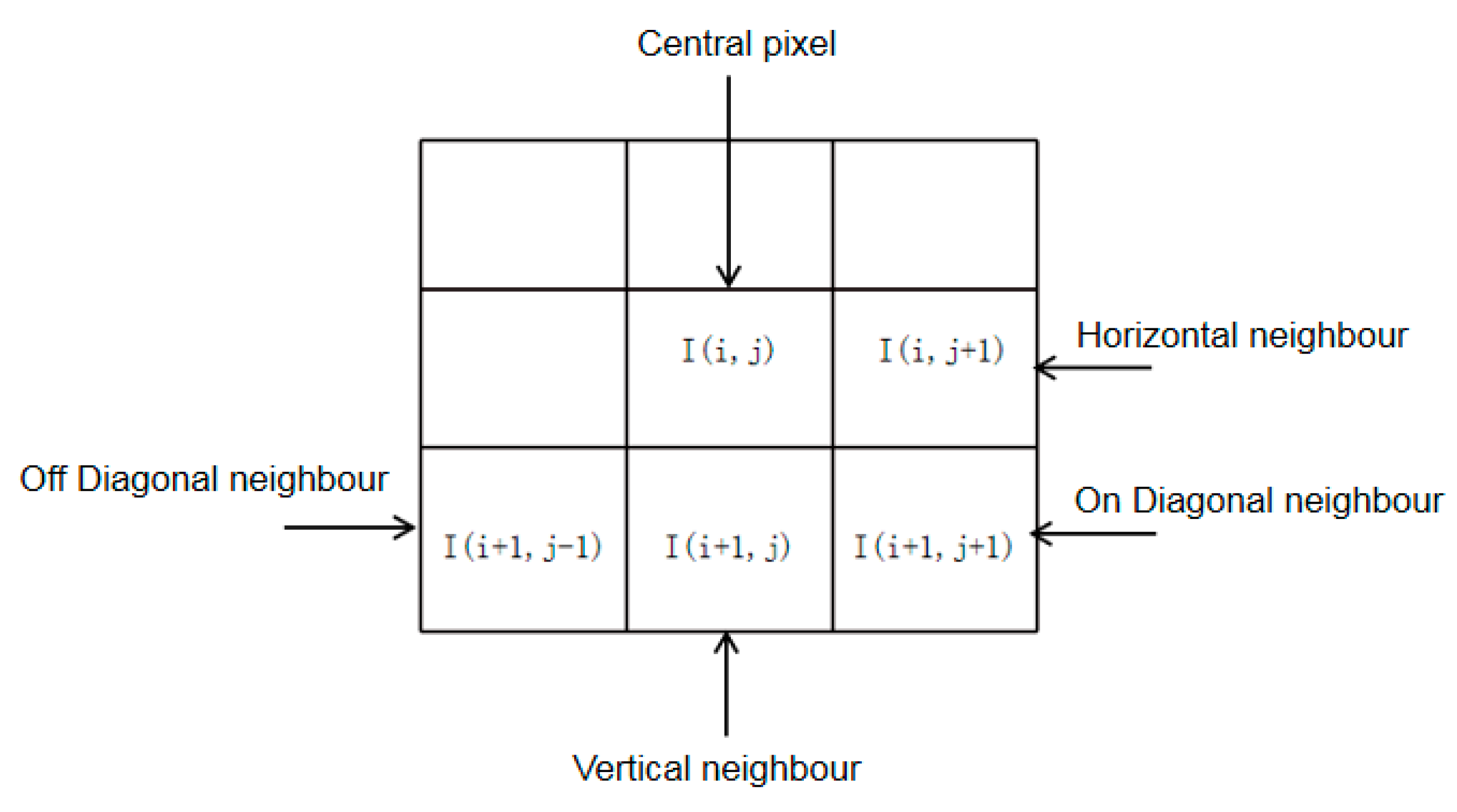
Figure 6.
Various paired products computed in order to quantify neighboring statistical relationships. Pairwise products are computed along four orientations—horizontal, vertical, main-diagonal, and secondary-diagonal at a distance of 1 pixel.
Figure 6.
Various paired products computed in order to quantify neighboring statistical relationships. Pairwise products are computed along four orientations—horizontal, vertical, main-diagonal, and secondary-diagonal at a distance of 1 pixel.
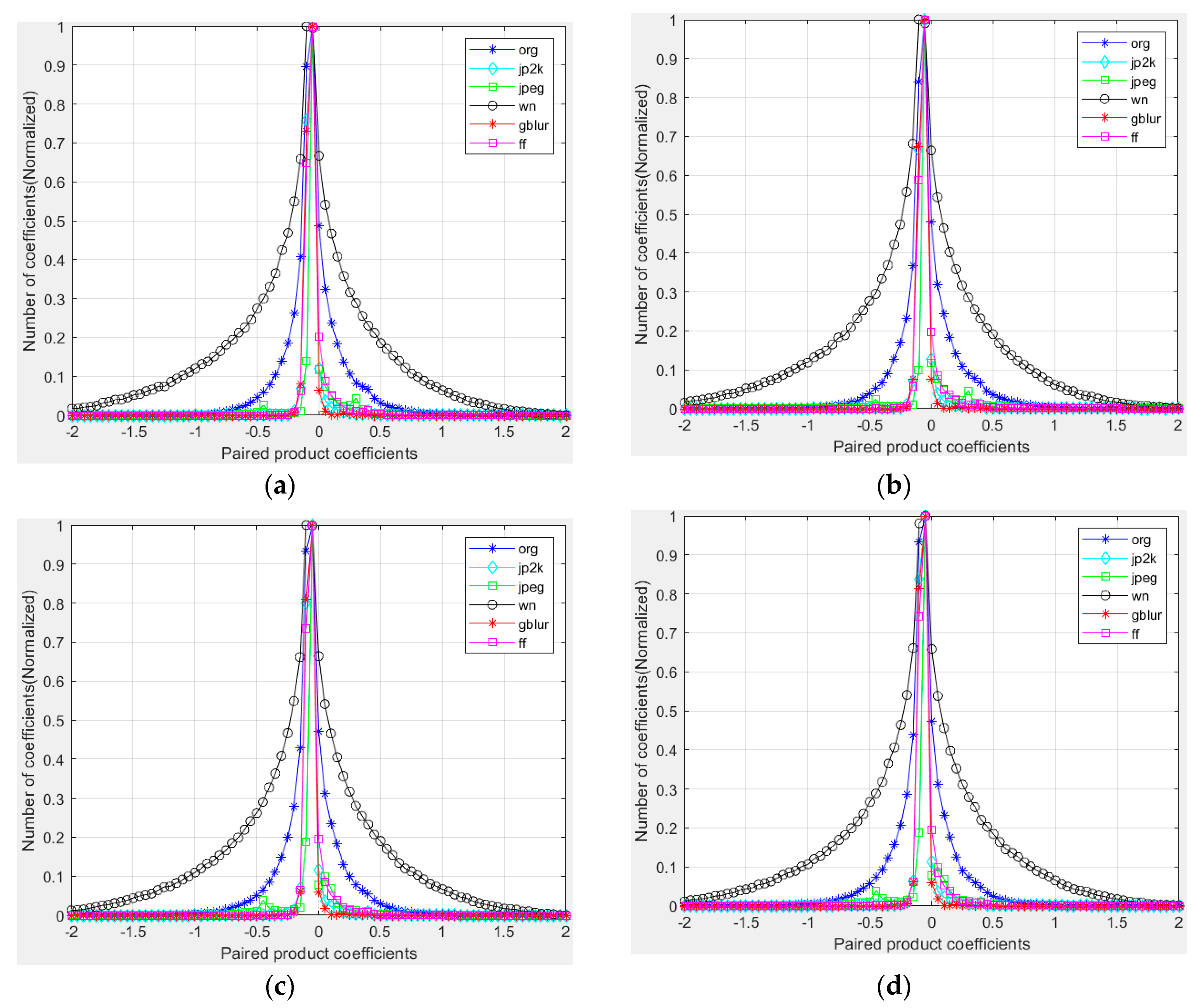
Figure 7.
Histograms of paired products of MSCN coefficients of a natural undistorted image and various distorted versions of it. (a) Horizontal; (b) Vertical; (c) Main-diagonal; (d) Secondary-diagonal. Distortions from the LIVE IQA database. jp2k: JPEG2000. jpeg: JPEG compression. wn: additive white Gaussian noise. gblur: Gaussian blur. ff: Rayleigh fast-fading channel simulation.
Figure 7.
Histograms of paired products of MSCN coefficients of a natural undistorted image and various distorted versions of it. (a) Horizontal; (b) Vertical; (c) Main-diagonal; (d) Secondary-diagonal. Distortions from the LIVE IQA database. jp2k: JPEG2000. jpeg: JPEG compression. wn: additive white Gaussian noise. gblur: Gaussian blur. ff: Rayleigh fast-fading channel simulation.
Figure 8.
Some examples of reference scenes in the LIVE database. (a–i) shows some examples of reference scenes in the LIVE database, including “bikes scene”, “buildings scene”, “caps scene”, “lighthouse2 scene”, “monarch scene”, “ocean scene”, “parrots scene”, “plane scene” and “rapids scene” (not listed one by one due to layout reasons).
Figure 8.
Some examples of reference scenes in the LIVE database. (a–i) shows some examples of reference scenes in the LIVE database, including “bikes scene”, “buildings scene”, “caps scene”, “lighthouse2 scene”, “monarch scene”, “ocean scene”, “parrots scene”, “plane scene” and “rapids scene” (not listed one by one due to layout reasons).
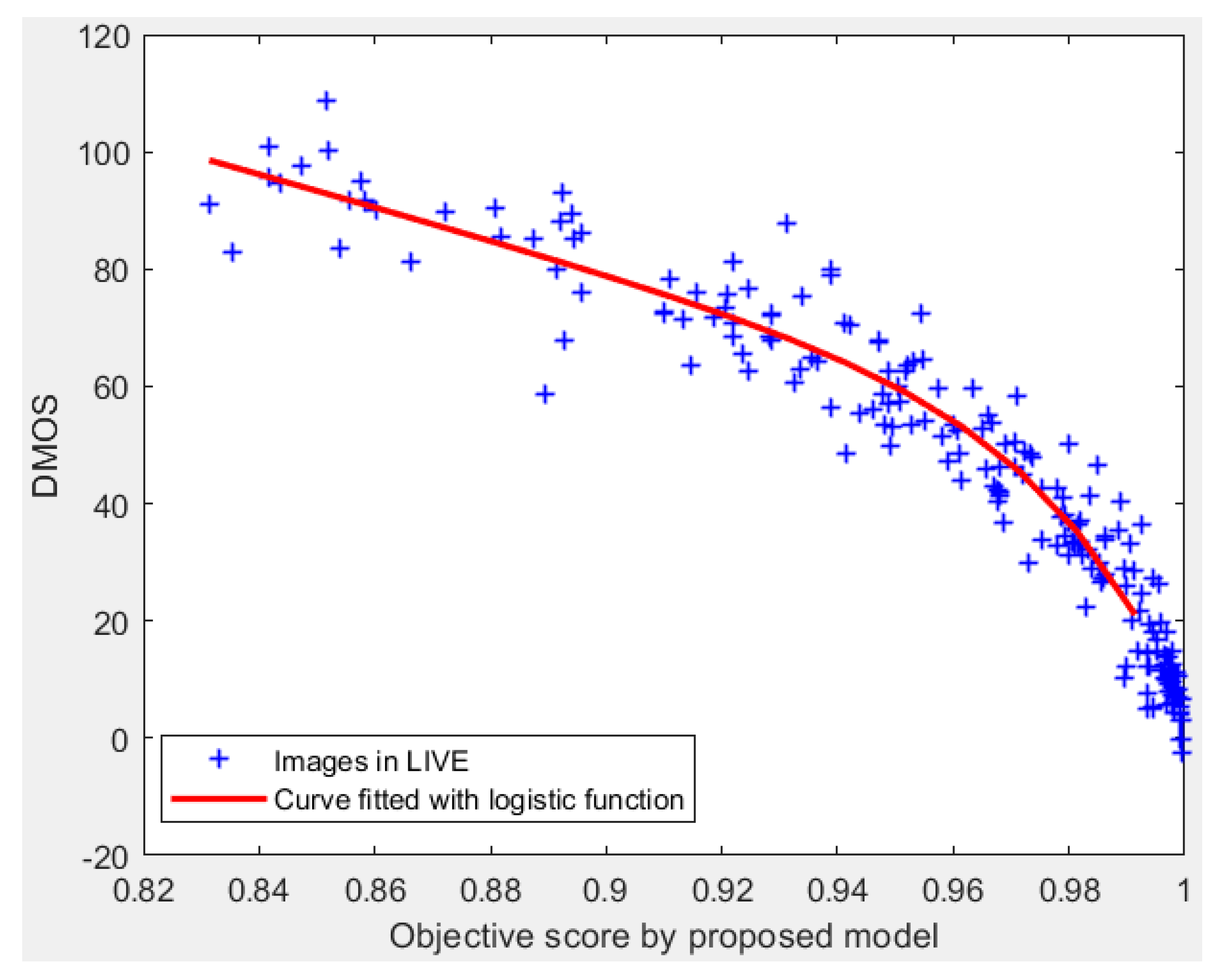
Figure 9.
Scatter plot of the proposed model on LIVE database. Each point (‘+’) represents one test image. The red curve shown in
Figure 9 is obtained by a logistic function.
Figure 9.
Scatter plot of the proposed model on LIVE database. Each point (‘+’) represents one test image. The red curve shown in
Figure 9 is obtained by a logistic function.
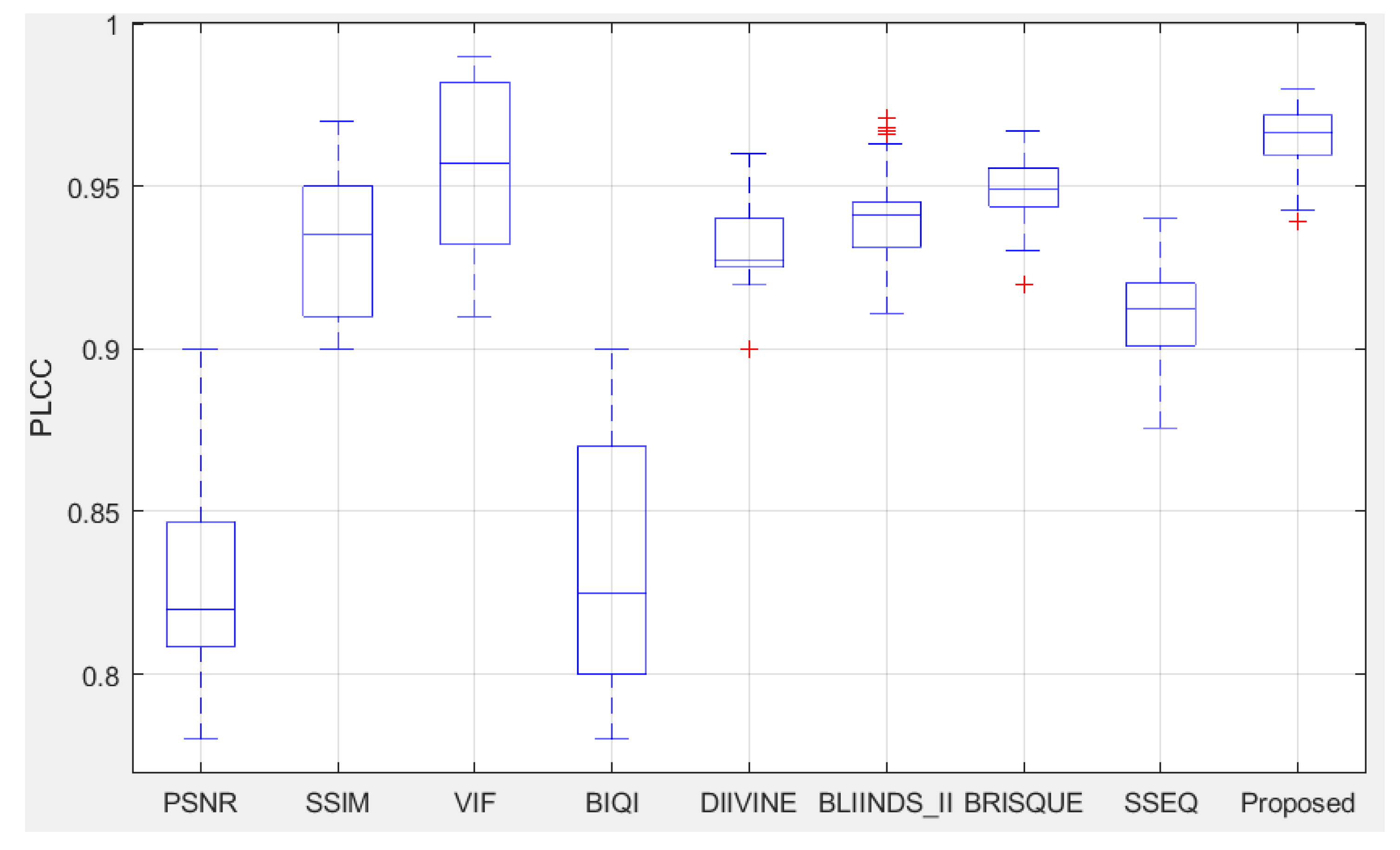
Figure 10.
Box plot of PLCC distributions of the compared IQA methods over 1000 trials on the LIVE database.
Figure 10.
Box plot of PLCC distributions of the compared IQA methods over 1000 trials on the LIVE database.
Table 1.
Features used for Proposed IQA method.
Table 1.
Features used for Proposed IQA method.
| Feature Vector | Feature Description |
|---|
| fNaturalness | GGD fitting parameter describing the image naturalness |
| fOED | Mean kurtosis, anisotropy and scalar energy distribution |
| fEntropy | Means of spatial-spectral entropy and skews values for 3 scales |
| fWLBP | Histogram statistics of gradient weighted local binary patterns |
| fAGGD | AGGD parameter fitting in curvelet domain |
Table 2.
Performance comparison of different features (LIVE database).
Table 2.
Performance comparison of different features (LIVE database).
| Type | Metric | fNaturalness | fOED | fEntropy | fWLBP | fAGGD | fOverall |
|---|
| JP2K | PLCC | 0.9007 | 0.9415 | 0.7970 | 0.9463 | 0.9211 | 0.9563 |
| SROCC | 0.8830 | 0.9270 | 0.7427 | 0.9240 | 0.9030 | 0.9564 |
| RMSE | 10.6202 | 8.2273 | 14.3495 | 7.8592 | 8.6202 | 7.0194 |
| JPEG | PLCC | 0.9183 | 0.9399 | 0.8895 | 0.9400 | 0.9311 | 0.9492 |
| SROCC | 0.8898 | 0.9232 | 0.8671 | 0.9165 | 0.9098 | 0.9604 |
| RMSE | 9.5544 | 8.1526 | 10.8706 | 8.2742 | 7.8544 | 7.5815 |
| Noise | PLCC | 0.9332 | 0.9807 | 0.9550 | 0.9694 | 0.9511 | 0.9938 |
| SROCC | 0.9509 | 0.9805 | 0.9533 | 0.9689 | 0.9798 | 0.9895 |
| RMSE | 7.5913 | 4.3086 | 6.4898 | 2.6210 | 5.5844 | 2.4098 |
| Blur | PLCC | 0.9515 | 0.9498 | 0.7235 | 0.9570 | 0.9520 | 0.9659 |
| SROCC | 0.9518 | 0.9511 | 0.6786 | 0.9355 | 0.9519 | 0.9574 |
| RMSE | 6.3231 | 6.6898 | 14.9504 | 6.2661 | 6.2230 | 5.6003 |
| FF | PLCC | 0.8424 | 0.8757 | 0.6537 | 0.9181 | 0.8920 | 0.9214 |
| SROCC | 0.8185 | 0.8509 | 0.5613 | 0.8878 | 0.8519 | 0.9080 |
| RMSE | 11.8343 | 10.4614 | 14.3495 | 8.8186 | 9.2230 | 8.4213 |
Table 3.
Median SROCC across 1000 train-test trials on the LIVE IQA database. From the indices, we can see that the proposed approach shows the best performance in the individual distortion types (JP2K, JPEG and Noise) and in all distorted types.
Table 3.
Median SROCC across 1000 train-test trials on the LIVE IQA database. From the indices, we can see that the proposed approach shows the best performance in the individual distortion types (JP2K, JPEG and Noise) and in all distorted types.
| Model | JP2K | JPEG | Noise | Blur | FF | All |
|---|
| PSNR | 0.8991 | 0.8483 | 0.9834 | 0.8078 | 0.8985 | 0.8294 |
| SSIM | 0.9512 | 0.9174 | 0.9696 | 0.9514 | 0.9553 | 0.8995 |
| VIF | 0.9514 | 0.9105 | 0.9845 | 0.9723 | 0.9632 | 0.9522 |
| BIQI | 0.8552 | 0.7766 | 0.9765 | 0.9257 | 0.7696 | 0.7598 |
| DIIVINE | 0.9353 | 0.8922 | 0.9827 | 0.9552 | 0.9097 | 0.9175 |
| BLIINDS-II | 0.9463 | 0.9351 | 0.9635 | 0.9335 | 0.8993 | 0.9332 |
| BRISQUE | 0.9458 | 0.9252 | 0.9893 | 0.9512 | 0.9027 | 0.9297 |
| SSEQ | 0.9422 | 0.9512 | 0.9785 | 0.9484 | 0.9036 | 0.8753 |
| Proposed | 0.9564 | 0.9604 | 0.9895 | 0.9574 | 0.9080 | 0.9576 |
Table 4.
Median PLCC across 1000 train-test trials on the LIVE IQA database. From the results, we can find that the VIF model indicates best performance in the individual distortion types of JP2K, Blur and FF. However, the proposed method shows the best index in the whole LIVE database.
Table 4.
Median PLCC across 1000 train-test trials on the LIVE IQA database. From the results, we can find that the VIF model indicates best performance in the individual distortion types of JP2K, Blur and FF. However, the proposed method shows the best index in the whole LIVE database.
| Model | JP2K | JPEG | Noise | Blur | FF | All |
|---|
| PSNR | 0.8836 | 0.8514 | 0.9816 | 0.8007 | 0.8938 | 0.8082 |
| SSIM | 0.9602 | 0.9486 | 0.9862 | 0.9538 | 0.9618 | 0.9102 |
| VIF | 0.9665 | 0.9479 | 0.9925 | 0.9775 | 0.9697 | 0.9522 |
| BIQI | 0.8415 | 0.7605 | 0.9733 | 0.9117 | 0.7343 | 0.7423 |
| DIIVINE | 0.9410 | 0.9098 | 0.9745 | 0.9394 | 0.9127 | 0.9117 |
| BLIINDS-II | 0.9494 | 0.9506 | 0.9615 | 0.9374 | 0.9080 | 0.9242 |
| BRISQUE | 0.9473 | 0.9331 | 0.9884 | 0.9465 | 0.9143 | 0.9494 |
| SSEQ | 0.9465 | 0.9703 | 0.9807 | 0.9608 | 0.9199 | 0.9126 |
| Proposed | 0.9563 | 0.9492 | 0.9938 | 0.9659 | 0.9214 | 0.9671 |
Table 5.
Median RMSE across 1000 train-test trials on the LIVE IQA database. From the experimental data, we can deduce the proposed method shows second performance in the whole database. The best IQA model is the VIF.
Table 5.
Median RMSE across 1000 train-test trials on the LIVE IQA database. From the experimental data, we can deduce the proposed method shows second performance in the whole database. The best IQA model is the VIF.
| Model | JP2K | JPEG | Noise | Blur | FF | All |
|---|
| PSNR | 7.5642 | 8.3268 | 3.0743 | 9.4292 | 7.3991 | 9.4974 |
| SSIM | 4.5392 | 5.0772 | 2.6585 | 4.6825 | 4.4856 | 6.6356 |
| VIF | 4.1945 | 5.0855 | 1.9606 | 3.3313 | 3.9622 | 4.9182 |
| BIQI | 13.7872 | 17.0135 | 5.3805 | 9.6563 | 15.5516 | 15.9546 |
| DIIVINE | 8.5705 | 10.6071 | 5.2138 | 8.0665 | 9.6522 | 9.9346 |
| BLIINDS-II | 8.1732 | 7.7657 | 6.5012 | 8.0698 | 9.7143 | 9.0475 |
| BRISQUE | 8.3627 | 9.3784 | 3.5295 | 7.5637 | 9.4362 | 7.2741 |
| SSEQ | 7.8286 | 5.8468 | 4.3213 | 6.0029 | 8.5420 | 9.3971 |
| Proposed | 7.0194 | 7.5815 | 2.4098 | 5.6003 | 8.4213 | 5.8249 |
Table 6.
Standard deviation of SROCC, PLCC and RMSE across 1000 train-test trials on the LIVE database. From the results, we can find the proposed method shows best performance in PLCC STD, second in SROCC STD, and third in RMSE STD.
Table 6.
Standard deviation of SROCC, PLCC and RMSE across 1000 train-test trials on the LIVE database. From the results, we can find the proposed method shows best performance in PLCC STD, second in SROCC STD, and third in RMSE STD.
| Model | PLCC STD | SROCC STD | RMSE STD |
|---|
| PSNR | 0.0250 | 0.0567 | 2.5851 |
| SSIM | 0.0097 | 0.0145 | 0.4736 |
| VIF | 0.0068 | 0.0073 | 0.4324 |
| BIQI | 0.0655 | 0.0664 | 1.5995 |
| DIIVINE | 0.0274 | 0.0287 | 1.2706 |
| BLIINDS-II | 0.0236 | 0.0248 | 1.1654 |
| BRISQUE | 0.0118 | 0.0141 | 0.9456 |
| SSEQ | 0.0174 | 0.0198 | 1.1651 |
| Proposed | 0.0067 | 0.0078 | 0.5733 |
Table 7.
Statistical significance tests of different IQA models in terms of PLCC. A value of ‘1’ (highlighted in green) indicates that the model in the row is significantly better than the model in the column, while a value of ‘0’ (highlighted in purple) indicates that the model in the row is not significantly better than the model in the column. The symbol “--” (highlighted in blue) indicates that the models in the rows and columns are statistically indistinguishable.
Table 7.
Statistical significance tests of different IQA models in terms of PLCC. A value of ‘1’ (highlighted in green) indicates that the model in the row is significantly better than the model in the column, while a value of ‘0’ (highlighted in purple) indicates that the model in the row is not significantly better than the model in the column. The symbol “--” (highlighted in blue) indicates that the models in the rows and columns are statistically indistinguishable.
| Model | PSNR | SSIM | VIF | BIQI | DIIVINE | BLIINDS-II | BRISQUE | SSEQ | Proposed |
|---|
| PSNR | -- | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| SSIM | 1 | -- | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| VIF | 1 | 1 | -- | 1 | 1 | 1 | 1 | 1 | 0 |
| BIQI | 0 | 0 | 0 | -- | 0 | 0 | 0 | 0 | 0 |
| DIIVINE | 1 | 1 | 0 | 1 | -- | 0 | 0 | 0 | 0 |
| BLIINDS-II | 1 | 1 | 0 | 1 | 1 | -- | 0 | 0 | 0 |
| BRISQUE | 0 | 0 | 1 | 0 | 0 | 0 | -- | 0 | 0 |
| SSEQ | 1 | 1 | 0 | 1 | 1 | 1 | 1 | -- | 0 |
| Proposed | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | -- |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}