Load-Sharing Model under Lindley Distribution and Its Parameter Estimation Using the Expectation-Maximization Algorithm




Abstract
1. Introduction
2. Likelihood Construction
2.1. Working Likelihood for the Load-Sharing Model
2.2. Likelihood Construction with the Lindley Distribution
3. The Proposed EM Algorithm
3.1. An EM Algorithm with the Load-Sharing Model
- E-step:
- M-step:
3.2. The EM-Type Maximum Likelihood Estimates with the Lindley Distribution
- E-step:
- M-step:We differentiate with respect to and obtainFinally, we set the above equation to be zero in order to solve for and obtain the -st EM sequences, denoted by , such that
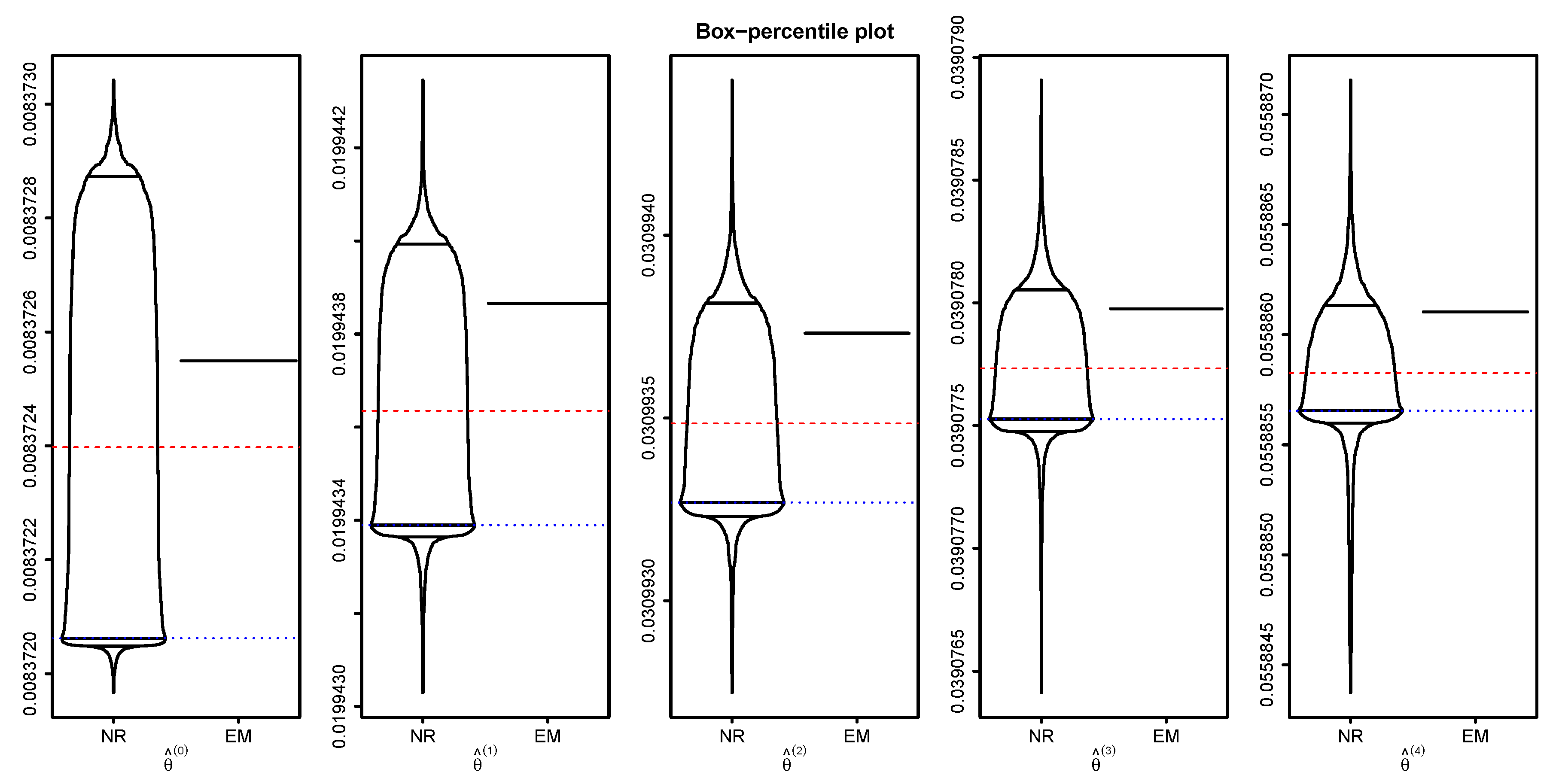
4. Numerical Study
4.1. Real Data Analysis
4.2. Sensitivity of Parameter Estimation Due to Starting Values
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. R Programs for the Proposed EM Algorithm
| # Lindley.LS.EM function |
| Lindley.LS.EM <- function(Y, start = 1, maxits = 1000 L, eps = 1.0E-15) { |
| J = ncol(Y) |
| converged = logical(J) |
| para = numeric(J) |
| THETA = start |
| iter = numeric(J) |
| if( length(start) < J ) THETA = rep_len(start,J) |
| for ( j in 0L:(J-1L) ) { |
| thetaj = THETA[j+1L] |
| V = (J-j-1L) / (J-j) |
| y = Y[,j+1L] |
| while ( (iter[j+1L]<maxits)&&(!converged[j+1L]) ) { |
| w = mean(y+V*(thetaj+thetaj*y+2)/thetaj/(thetaj+thetaj*y+1)) |
| newtheta = (1-w+sqrt( (w-1)^2+8*w ))/(2*w) |
| converged[j+1L] = abs(newtheta-thetaj) < eps |
| iter[j+1L] = iter[j+1L] + 1L |
| thetaj = newtheta |
| } |
| para[j+1L] = newtheta |
| } |
| list(para=para, iter=iter, conv=converged) |
| } |
| # Data |
| > Y0=c(21.02, 24.25, 6.55, 15.35, 39.08, 16.20, 34.59, 19.10, 28.22, |
| 32.00, 11.25, 17.39, 28.47, 23.42, 42.06, 28.51, 34.56, 40.33, |
| 27.56, 9.54, 27.09, 40.36, 41.44, 32.23, 7.53, 28.34, 26.32, 30.47) |
| > Y1=c(30.22, 45.54, 19.47, 16.37, 30.32, 4.16, 46.44, 38.40, 37.43, |
| 45.52, 19.09, 25.43, 31.15, 31.28, 23.21, 33.59, 32.53, 15.35, |
| 46.21, 36.21, 11.11, 33.21, 36.28, 8.17, 37.31, 35.58, 28.02, 40.4) |
| > Y2=c(43.43, 17.19, 23.28, 25.40, 43.53, 39.52, 16.33, 20.17, 25.41, |
| 39.11, 11.59, 22.51, 2.41, 40.03, 45.36, 16.20, 40.44, 28.33, |
| 28.05, 28.12, 23.33, 17.04, 19.13, 41.27, 13.43, 41.48, 29.33, 42.13) |
| Y = cbind(Y0, Y1, Y2) |
| # Use of Lindley.LS.EM() function |
| > Lindley.LS.EM(Y) |
| $para |
| [1] 0.03624714 0.04104211~0.06915810 |
| $iter |
| [1] 58 37~2 |
| $conv |
| [1] TRUE TRUE TRUE |
Appendix B. Generating Lindley-Distributed Random Numbers

References
- Daniels, H.E. The Statistical Theory of the Strength of Bundles of Threads I. Proc. R. Soc. Lond. Ser. A 1945, 83, 405–435. [Google Scholar]
- Durham, S.D.; Lynch, J.D.; Padgett, W.J. A Theoretical Justification for an Increasing Average Failure Rate Strength Distribution in Fibrous Composites. Nav. Res. Logist. 1989, 36, 655–661. [Google Scholar] [CrossRef]
- Durham, S.D.; Lynch, J.D.; Padgett, W.J.; Horan, T.J.; Owen, W.J.; Surles, J. Localized Load-Sharing Rules and Markov-Weibull Fibers: A Comparision of Microcomposite Failure Data with Monte Carlo Simulations. J. Compos. Mater. 1997, 31, 1856–1882. [Google Scholar] [CrossRef]
- Durham, S.D.; Lynch, J.D. A Threshold Representation for the Strength Distribution of a Complex Load Sharing System. J. Stat. Plan. Inference 2000, 83, 25–46. [Google Scholar] [CrossRef]
- Kim, H.; Kvam, P.H. Reliability Estimation Based on System Data with an Unknown Load Share Rule. Lifetime Data Anal. 2004, 10, 83–94. [Google Scholar] [CrossRef]
- Kvam, P.H.; Peña, E.A. Estimating Load-Sharing Properties in a Dynamic Reliability System. J. Am. Stat. Assoc. 2005, 100, 262–272. [Google Scholar] [CrossRef]
- Singh, B.; Sharma, K.K.; Kumar, A. A classical and Bayesian estimation of a k-components load-sharing parallel system. Comput. Stat. Data Anal. 2008, 52, 5175–5185. [Google Scholar] [CrossRef]
- Wang, D.; Jiang, C.; Park, C. Reliability analysis of load-sharing systems with memory. Lifetime Data Anal. 2019, 25, 341–360. [Google Scholar] [CrossRef]
- Park, C. Parameter Estimation for Reliability of Load Sharing Systems. IIE Trans. 2010, 42, 753–765. [Google Scholar] [CrossRef]
- Park, C. Parameter Estimation from Load-Sharing System Data Using the Expectation-Maximization Algorithm. IIE Trans. 2013, 45, 147–163. [Google Scholar] [CrossRef]
- Deshpandé, J.V.; Dewan, I.; Naik-Nimbalkar, U.V. A family of distributions to model load sharing systems. J. Stat. Plan. Inference 2010, 140, 1441–1451. [Google Scholar] [CrossRef]
- Singh, B.; Gupta, P.K. Load-sharing system model and its application to the real data set. Math. Comput. Simul. 2012, 82, 1615–1629. [Google Scholar] [CrossRef]
- Singh, B.; Gupta, P.K. Bayesian reliability estimation of a 1-out-of-k load-sharing system model. Int. J. Syst. Assur. Eng. Manag. 2014, 5, 562–576. [Google Scholar] [CrossRef]
- Singh, B.; Rathi, S.; Kumar, S. Inferential statistics on the dynamic system model with time dependent failure-rate. J. Stat. Comput. Simul. 2013, 83, 1–24. [Google Scholar] [CrossRef]
- Xu, J.; Hu, Q.; Yu, D.; Xie, M. Reliability demonstration test for load-sharing systems with exponential and Weibull components. PLoS ONE 2017, 12, e0189863. [Google Scholar] [CrossRef]
- Singh, B.; Goel, R. MCMC estimation of multi-component load-sharing system model and its application. Iran J. Sci. Technol. Trans. Sci. 2019, 43, 567–577. [Google Scholar] [CrossRef]
- Xu, J.; Liu, B.; Zhao, X. Parameter estimation for load-sharing system subject to Wiener degradation process using the expectation-maximization algorithm. Qual. Reliab. Eng. Int. 2019, 35, 1010–1024. [Google Scholar] [CrossRef]
- Lindley, D.V. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. B 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Albert, J.R.G.; Baxter, L.A. Applications of the EM algorithm to the Analysis of life length data. Appl. Stat. 1995, 44, 323–341. [Google Scholar]
- Park, C. Parameter Estimation of Incomplete Data in Competing Risks Using the EM algorithm. IEEE Trans. Reliab. 2005, 54, 282–290. [Google Scholar] [CrossRef]
- Amari, S.V.; Mohan, K.; Cline, B.; Xing, L. Expectation-Maximization Algorithm for Failure Analysis Using Incomplete Warranty Data. Int. J. Perform. Eng. 2009, 5, 403–417. [Google Scholar]
- Park, C. A Quantile Variant of the Expectation-Maximization Algorithm and its Application to Parameter Estimation with Interval Data. J. Algorithms Comput. Technol. 2018, 12, 253–272. [Google Scholar] [CrossRef]
- Ouyang, L.; Zheng, W.; Zhu, Y.; Zhou, X. An interval probability-based FMEA model for risk assessment: A real-world case. Qual. Reliab. Eng. Int. 2020, 36, 125–143. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. B 1977, 39, 1–22. [Google Scholar]
- Robert, C.P.; Casella, G. Monte Carlo Statistical Methods, 2nd ed.; Springer: New York, NY, USA, 2005. [Google Scholar]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2002. [Google Scholar]
- Heitjan, D.F.; Rubin, D.B. Inference from coarse data via multiple imputation with application to age heaping. J. Am. Stat. Assoc. 1990, 85, 304–314. [Google Scholar] [CrossRef]
- Heitjan, D.F.; Rubin, D.B. Ignorability and coarse data. AOS 1991, 19, 2244–2253. [Google Scholar] [CrossRef]
- Crowder, M.J. Classical Competing Risks; Chapman & Hall: London, UK, 2001. [Google Scholar]
- Miyakawa, M. Analysis of Incomplete Data in Competing Risks Model. IEEE Trans. Reliab. 1984, 33, 293–296. [Google Scholar] [CrossRef]
- Park, C.; Padgett, W.J. Analysis of Strength Distributions of Multi-Modal Failures Using the EM Algorithm. J. Stat. Comput. Simul. 2006, 76, 619–636. [Google Scholar] [CrossRef]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data; John Wiley & Sons: New York, NY, USA, 2002. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: http://www.r-project.org (accessed on 7 June 2020).
- Kvam, P.H.; Peña, E.A. Estimating Load-Sharing Properties in a Dynamic Reliability System; Technical Report; Department of Statistics, University of South Carolina: Columbia, SC, USA, 2003; Available online: https://people.stat.sc.edu/pena/TechReports/KvamPena2003.pdf (accessed on 11 November 2020).
- Ghitanya, M.E.; Atieha, B.; Nadarajah, S. Lindleydistribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Esty, W.; Banfield, J. The Box-Percentile Plot. J. Stat. Softw. Artic. 2003, 8, 1–14. [Google Scholar] [CrossRef][Green Version]
- Lambert, J.H. Observations variae in Mathesin Puram. Acta Helvitica Phys. Math. Anat. Bot. Medica 1758, 3, 128–168. [Google Scholar]
- Pólya, G.; Szegö. Aufgaben und Lehrsätze der Analysis; Springer: Berlin, Germany, 1925. [Google Scholar]
- Adler, A. LamW: Lambert-W Function, R Package Version 1.3.3. 2015. Available online: https://CRAN.R-project.org/package=lamW (accessed on 11 November 2020).


{kind=link}
{kind=link}
| 83.10 | 74.91 | 164.79 | 60.12 | 81.91 | 132.68 | 16.36 | 54.71 | 130.95 | 39.10 | |
| 59.25 | 53.01 | 60.31 | 46.38 | 20.69 | 25.53 | 56.11 | 28.99 | 23.04 | 32.21 | |
| 30.13 | 12.06 | 32.91 | 47.96 | 21.64 | 4.80 | 19.79 | 17.11 | 49.43 | 66.28 | |
| 47.29 | 10.45 | 6.43 | 17.80 | 67.01 | 37.41 | 41.89 | 20.17 | 21.62 | 41.60 | |
| 46.24 | 39.60 | 17.67 | 18.72 | 50.69 | 29.66 | 14.16 | 52.53 | 10.02 | 69.11 |
| Starting Values | Parameter Estimates | Log-Likelihood | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.004 | 1.25 | 2.98 | 3.89 | 4.24 | 0.00822 | 0.02001 | 0.03104 | 0.03876 | 0.05576 | |
| 0.028 | 1.31 | 2.04 | 3.18 | 4.18 | 0.01059 | 0.01959 | 0.03047 | 0.03764 | 0.05875 | |
| 0.021 | 1.18 | 2.69 | 3.38 | 4.77 | 0.01208 | 0.02297 | 0.02731 | 0.03693 | 0.05474 | |
| 0.028 | 1.97 | 2.66 | 3.67 | 4.21 | 0.04123 | 0.02421 | 0.06983 | 0.02912 | 0.05308 | |
| 0.026 | 1.72 | 2.91 | 3.95 | 4.07 | 0.04452 | 0.01781 | 0.03617 | 0.02440 | 0.07059 | |
| 0.002 | 1.90 | 2.75 | 3.24 | 4.12 | 0.05032 | 0.01995 | 0.03164 | 0.04057 | 0.05700 | |
| 0.024 | 1.80 | 2.83 | 3.11 | 4.96 | 0.05417 | 0.01920 | 0.03364 | 0.04358 | 0.05386 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.; Wang, M.; Alotaibi, R.M.; Rezk, H. Load-Sharing Model under Lindley Distribution and Its Parameter Estimation Using the Expectation-Maximization Algorithm. Entropy 2020, 22, 1329. https://doi.org/10.3390/e22111329
Park C, Wang M, Alotaibi RM, Rezk H. Load-Sharing Model under Lindley Distribution and Its Parameter Estimation Using the Expectation-Maximization Algorithm. Entropy. 2020; 22(11):1329. https://doi.org/10.3390/e22111329
Chicago/Turabian StylePark, Chanseok, Min Wang, Refah Mohammed Alotaibi, and Hoda Rezk. 2020. "Load-Sharing Model under Lindley Distribution and Its Parameter Estimation Using the Expectation-Maximization Algorithm" Entropy 22, no. 11: 1329. https://doi.org/10.3390/e22111329
APA StylePark, C., Wang, M., Alotaibi, R. M., & Rezk, H. (2020). Load-Sharing Model under Lindley Distribution and Its Parameter Estimation Using the Expectation-Maximization Algorithm. Entropy, 22(11), 1329. https://doi.org/10.3390/e22111329