Approximate Learning of High Dimensional Bayesian Network Structures via Pruning of Candidate Parent Sets


Abstract
1. Introduction
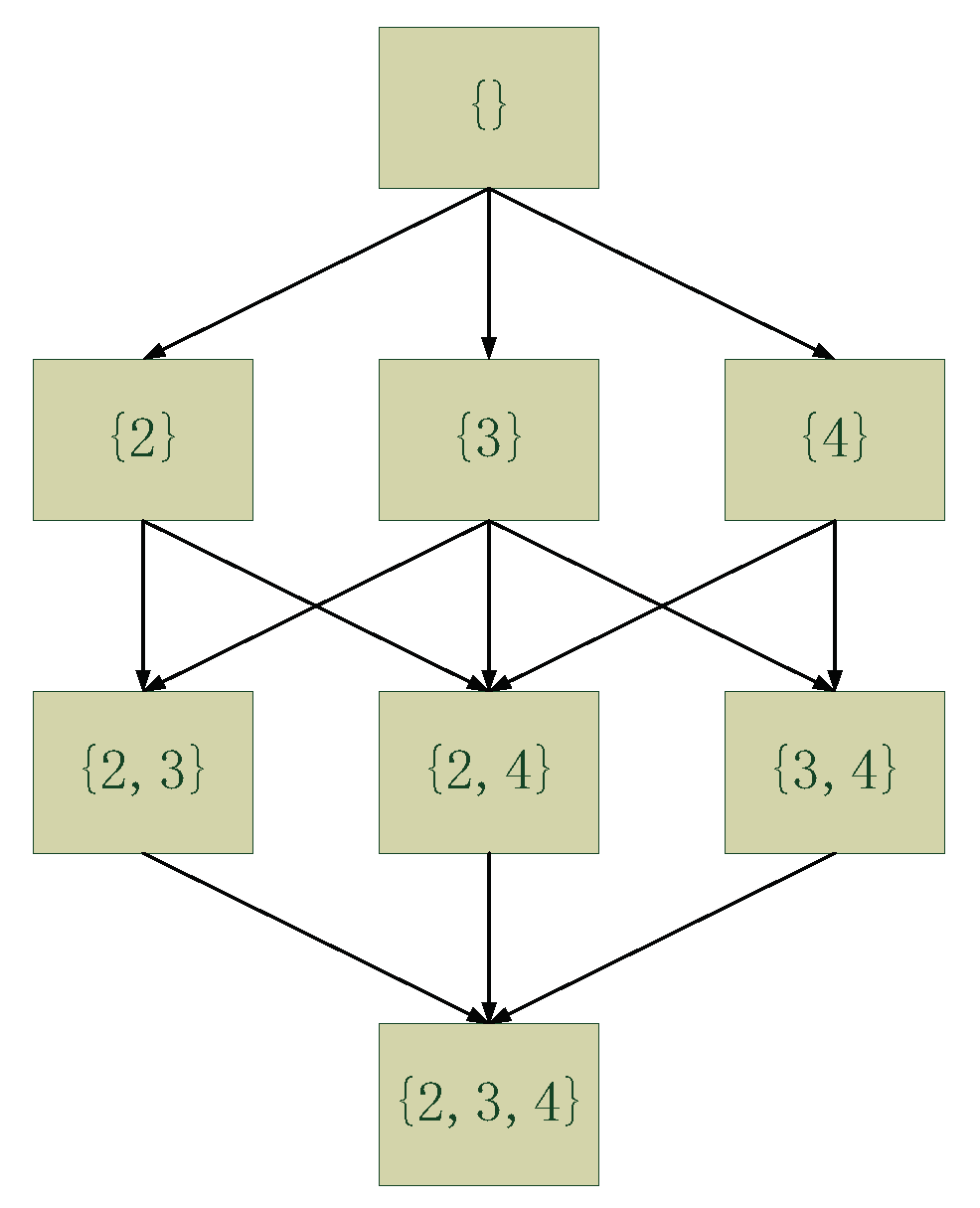
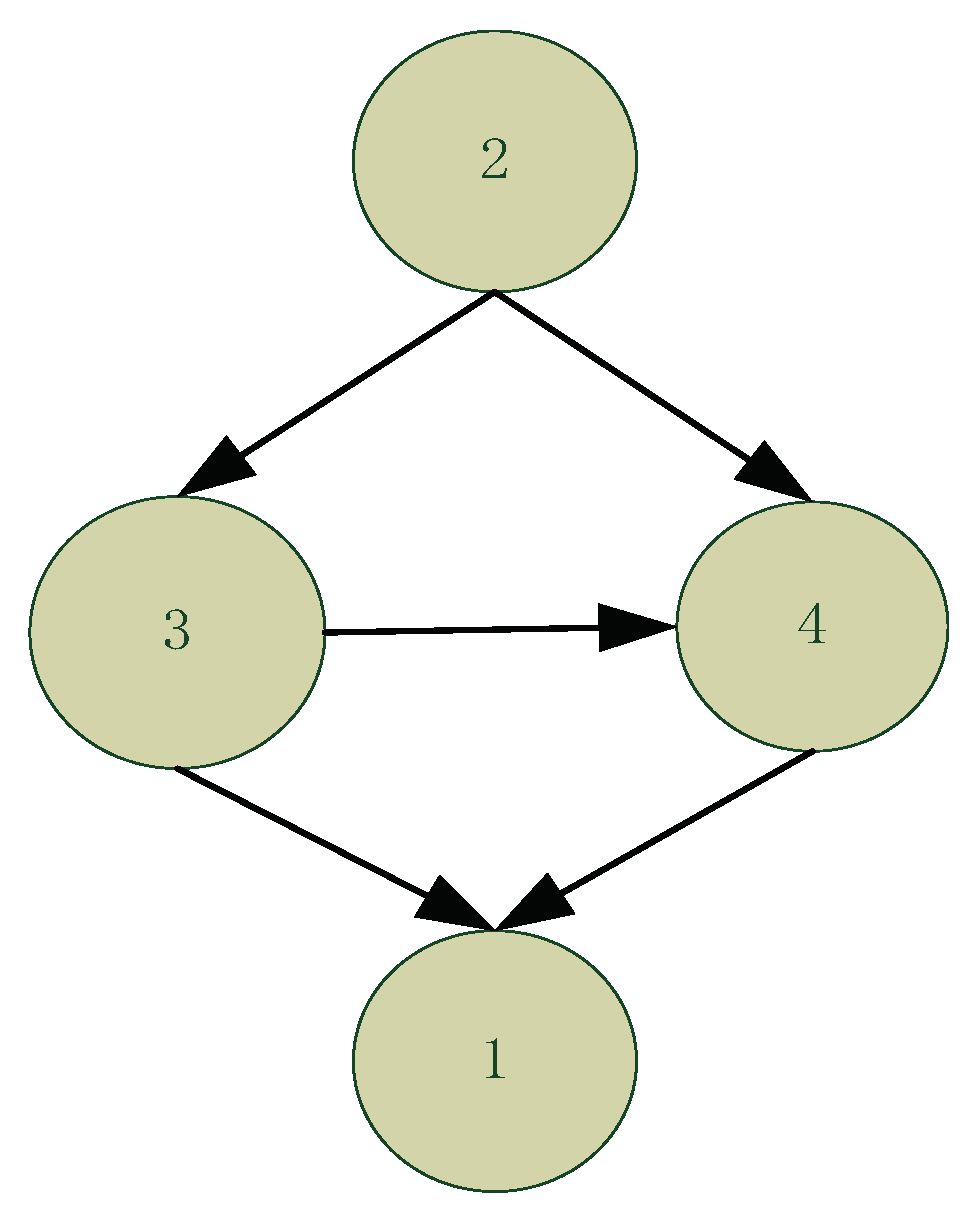
2. Problem Statement and Methodology
- (a)
- Moderate complexity, which assumes less than 1 million legal CPSs per network;
- (b)
- High complexity, which assumes more than 1 million and less than 10 million legal CPSs per network;
- (c)
- Very high complexity, which assumes more than 10 million legal CPSs per network.
3. Results
3.1. Pruning Legal CPSs of Moderate Complexity
3.2. Pruning Legal CPSs of High Complexity
3.3. Pruning Legal CPSs of Very High Complexity
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann: Burlington, MA, USA, 1988. [Google Scholar]
- Constantinou, A.; Fenton, N. Things to Know about Bayesian Networks. Significance 2018, 15, 19–23. [Google Scholar] [CrossRef]
- Spirtes, P.; Glymour, C.; Scheines, R.; Heckerman, D. Causation, Prediction, and Search; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Amirkhani, H.; Rahmati, M.; Lucas, P.; Hommersom, A. Exploiting Experts’ Knowledge for Structure Learning of Bayesian Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2154–2170. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Gao, X.; Ren, H.; Yang, Y.; Di, R.; Chen, D. Learning Bayesian Network Parameters from Small Data Sets: A Further Constrained Qualitatively Maximum a Posteriori Method. Int. J. Approx. Reason. 2017, 91, 22–35. [Google Scholar] [CrossRef]
- Guo, Z.; Gao, X.; Di, R. Learning Bayesian Network Parameters with Domain Knowledge and Insufficient Data. In Proceedings of the 3rd Workshop on Advanced Methodologies for Bayesian Networks, Kyoto, Japan, 20–22 September 2017; pp. 93–104. [Google Scholar]
- Yang, Y.; Gao, X.; Guo, Z.; Chen, D. Learning Bayesian Networks using the Constrained Maximum a Posteriori Probability Method. Pattern Recognit. 2019, 91, 123–134. [Google Scholar] [CrossRef]
- Robinson, R. Counting labeled acyclic digraphs. In New Directions in the Theory of Graphs; Academic Press: New York, NY, USA, 1973; pp. 239–273. [Google Scholar]
- Buntine, W. Theory Refinement on Bayesian Networks. In Proceedings of the 7th Conference on Uncertainty in Artificial Intelligence, Los Angeles, CA, USA, 13–15 July 1991; pp. 52–60. [Google Scholar]
- Heckerman, D.; Geiger, D.; Chickering, D. Learning Bayesian Networks: The Combination of Knowledge and Statistical Data. Mach. Learn. 1995, 20, 197–243. [Google Scholar] [CrossRef]
- Scutari, M. An Empirical-Bayes Score for Discrete Bayesian Networks. Available online: www.jmlr.org/proceedings/papers/v52/scutari16.pdf (accessed on 31 May 2020).
- Akaike, H. Information Theory and an Extension of the Maximum Likelihood Principle. In Proceedings of the 2nd International Symposium on Information Theory, Tsahkadsor, Armenia, 2–8 September 1971; pp. 267–281. [Google Scholar]
- Suzuki, J. A Construction of Bayesian Networks from Databases based on an MDL Principle. In Proceedings of the 9th Conference on Uncertainty in Artificial Intelligence, Washington, DC, USA, 9–11 July 1993; pp. 266–273. [Google Scholar]
- de Campos, L. A Scoring Function for Learning Bayesian Networks based on Mutual Information and Conditional Independence Tests. J. Mach. Learn. Res. 2006, 7, 2149–2187. [Google Scholar]
- Silander, T.; Roos, T.; Kontkanen, P.; Myllymäki, P. Factorized Normalized Maximum Likelihood Criterion for Learning Bayesian Network Structures. In Proceedings of the 4th European Workshop on Probabilistic Graphical Models, Hirtshals, Denmark, 17–19 September 2008; pp. 257–264. [Google Scholar]
- Silander, T.; Leppa-aho, J.; Jaasaari, E.; Roos, T. Quotient Normalized Maximum Likelihood Criterion for Learning Bayesian Network Structures. In Proceedings of the 21st International Conference on Artificial Intelligence and Statistics, Canary Islands, Spain, 9–11 April 2018; pp. 948–957. [Google Scholar]
- Jaakkola, T.; Sontag, D.; Globerson, A.; Meila, M. Learning Bayesian Network Structure using LP Relaxations. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 358–365. [Google Scholar]
- Bartlett, M.; Cussens, J. Integer Linear Programming for the Bayesian Netowork Structure Learning Problem. Artif. Intell. 2015, 244, 258–271. [Google Scholar] [CrossRef]
- Koivisto, M.; Sood, K. Exact Bayesian Structure Discovery in Bayesian Networks. J. Mach. Learn. Res. 2004, 5, 549–573. [Google Scholar]
- Silander, T.; Myllymäki, P. A Simple Approach for Finding the Globally Optimal Bayesian Network Structure. In Proceedings of the 22nd Conference on Uncertainty in Artificial Intelligence, Cambridge, MA, USA, 13–16 July 2006; pp. 445–452. [Google Scholar]
- Yuan, C.; Malone, B. Learning Optimal Bayesian Networks: A Shortest Path Perspective. J. Artif. Intell. Res. 2013, 48, 23–65. [Google Scholar] [CrossRef]
- de Campos, C.; Ji, Q. Efficient Structure Learning of Bayesian Networks using Constraints. J. Mach. Learn. Res. 2011, 12, 663–689. [Google Scholar]
- van Beek, P.; Hoffmann, H.F. Machine Learning of Bayesian Networks using Constraint Programming. In Proceedings of the 21st International Conference on Principles and Practice of Constraint Programming, Cork, Ireland, 31 August–4 September 2015; pp. 429–445. [Google Scholar]
- Teyssier, M.; Koller, D. Ordering-Based Search: A Simple and Effective Algorithm for Learning Bayesian Networks. In Proceedings of the 21st Conference on Uncertainty in Artificial Intelligence, Edinburgh, UK, 26–29 July 2005; pp. 584–590. [Google Scholar]
- Scanagatta, M.; de Campos, C.; Corani, G.; Zaffalon, M. Learning Bayesian Networks with Thousands of Variables. In Proceedings of the 29th Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1864–1872. [Google Scholar]
- Scanagatta, M.; Corani, G.; de Campos, C.; Zaffalon, M. Approximate Structure Learning for Large Bayesian Networks. Mach. Learn. 2018, 107, 1209–1227. [Google Scholar] [CrossRef]
- Lee, C.; van Beek, P. Metaheuristics for Score-and-Search Bayesian Network Structure Learning. In Proceedings of the 30th Canadian Conference on Artificial Intelligence, Edmonton, AB, Canada, 16–19 May 2017; pp. 129–141. [Google Scholar]
- Jensen, F.; Nielsen, T. Bayesian Networks and Decision Graphs; Springer: Berlin, Germany, 2007. [Google Scholar]
- de Campos, C.; Ji, Q. Properties of Bayesian Dirichlet Scores to Learn Bayesian Network Structures. In Proceedings of the 24th AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; pp. 431–436. [Google Scholar]
- Cussens, J. An Upper Bound for BDeu Local Scores. Available online: https://miat.inrae.fr/site/images/6/69/CussensAIGM12_final.pdf (accessed on 31 May 2020).
- Suzuki, J. An Efficient Bayesian Network Structure Learning Strategy. New Gener. Comput. 2017, 35, 105–124. [Google Scholar] [CrossRef]
- Correia, A.; Cussens, J.; de Campos, C.P. On Pruning for Score-Based Bayesian Network Structure Learning. arXiv 2019, arXiv:1905.09943. [Google Scholar]
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Constantinou, A.; Liu, Y.; Chobtham, K.; Guo, Z.; Kitson, N. Large-scale Empirical Validation of Bayesian Network Structure Learning Algorithms with Noisy Data. arXiv 2020, arXiv:2005.09020. [Google Scholar]
- Constantinou, A. Bayesian Artificial Intelligence for Decision Making under Uncertainty. Available online: https://www.researchgate.net/profile/Anthony_Constantinou/publication/325848089_Bayesian_Artificial_Intelligence_for_Decision_Making_under_Uncertainty/links/5b28e595aca27209f314c4a8/Bayesian-Artificial-Intelligence-for-Decision-Making-under-Uncertainty.pdf (accessed on 31 May 2020).



{kind=link}
{kind=link}
| Child Node | Local BDeu Score | CPS Size | CPS |
|---|---|---|---|
| 0 | −5149.19 | 3 | {9, 85, 95} |
| 0 | −5150.47 | 3 | {9, 94, 95} |
| 0 | −5174.53 | 3 | {85,94, 95} |
| 0 | −5207.08 | 3 | {80,85, 95} |
| 0 | −5208.28 | 3 | {9, 80, 95} |
| … | … | … | … |
| 0 | −6886.30 | 2 | {48,67} |
| 0 | −6886.74 | 1 | {67} |
| 0 | −5174.53 | 1 | {81} |
| 0 | −5174.53 | 1 | {75} |
| 0 | −6889.11 | 0 | {} |
| Node | ID = 0 | ID = 1 | ID = 1 | ID = 1 | ID = 2 | ID = 2 | ID = 2 | ID = 3 |
|---|---|---|---|---|---|---|---|---|
| 1 | ||||||||
| −2288.7 | −2274.6 | −2196.2 | −2240.7 | −2252.8 | −2256.1 | −2171.3 | −2173.5 | |
| 2 | ||||||||
| −2003.7 | −1989.6 | −1900.7 | −1915.1 | −1903.8 | −1918.3 | −1849.2 | −1851.4 | |
| 3 | ||||||||
| −2891.5 | −2799.0 | −2788.5 | −2811.3 | −2714.5 | −2741.9 | −2745.5 | −2692.6 | |
| 4 | ||||||||
| −1951.6 | −1903.6 | −1862.9 | −1871.4 | −1829.5 | −1846.5 | −1819.9 | −1807.6 |
| Maximum In-Degree | Number of All Possible CPSs | Sample Size | ||||
|---|---|---|---|---|---|---|
| 3000 | 6000 | 9000 | 12,000 | 15,000 | ||
| 1 | 10,000 | 8398 | 8926 | 9163 | 9320 | 9394 |
| 84.0% | 89.3% | 91.6% | 93.2% | 93.9% | ||
| 2 | 495,100 | 228,197 | 306,263 | 349,587 | 374,007 | 388,621 |
| 46.1% | 61.9% | 70.6% | 75.5% | 78.5% | ||
| 3 | 16,180,000 | 1,200,429 | 3,260,399 | 5,130,502 | 6,405,394 | 7,343,077 |
| 7.42% | 20.2% | 31.7% | 39.6% | 45.4% | ||
| Sample Size | Asia (8∣2) | Insurance (27∣3) | Water (32∣5) | Alarm (37∣4) | Hailfinder (56∣4) | Carpo (61∣5) | |
|---|---|---|---|---|---|---|---|
| CPSs (graph) | 100 | 41 | 279 | 482 | 907 | 244 | 5068 |
| 1000 | 107 | 774 | 573 | 1928 | 761 | 3827 | |
| 10,000 | 161 | 3652 | 961 | 6473 | 3768 | 16,391 | |
| CPSs (per node) | 100 | 5.13 | 10.33 | 15.06 | 24.51 | 4.36 | 84.47 |
| 1000 | 13.38 | 28.67 | 17.91 | 52.11 | 13.59 | 63.78 | |
| 10,000 | 20.12 | 135.26 | 30.03 | 174.95 | 67.29 | 273.18 |
| Pruning | Asia (100) | Asia (1000) | Asia (10,000) | Insurance (100) | Insurance (1000) | Insurance (10,000) | Water (100) | Water (1000) | Water (10,000) |
|---|---|---|---|---|---|---|---|---|---|
| 90% | −6.70‰ | −1.26‰ | −1.33‰ | −30.74‰ | −62.92‰ | −35.26‰ | −11.84‰ | −28.11‰ | −15.50‰ |
| 80% | −6.70‰ | −1.26‰ | −1.06‰ | −30.74‰ | −37.77‰ | −7.99‰ | −11.15‰ | −19.37‰ | −8.12‰ |
| 70% | −6.70‰ | −1.26‰ | −1.06‰ | −10.50‰ | −13.80‰ | −7.13‰ | −8.21‰ | −2.99‰ | −0.68‰ |
| 60% | −6.70‰ | −1.26‰ | −0.72‰ | −8.32‰ | −6.73‰ | −5.32‰ | −6.70‰ | −2.81‰ | −0.44‰ |
| 50% | −6.68‰ | −1.26‰ | −0.72‰ | −7.94‰ | −4.14‰ | −2.83‰ | −1.24‰ | −1.02‰ | −0.27‰ |
| 40% | −0.04‰ | −1.26‰ | −0.72‰ | −2.33‰ | −1.28‰ | −2.07‰ | −0.64‰ | 0‰ | −0.18‰ |
| 30% | 0‰ | −0.9‰ | −0.25‰ | −2.23‰ | 0‰ | −1.22‰ | −0.32‰ | 0‰ | −0.02‰ |
| 20% | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | −0.25‰ | −0.32‰ | 0‰ | 0‰ |
| 10% | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ |
| 0% | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ |
| Pruning | Alarm (100) | Alarm (1000) | Alarm (10,000) | Hailfinder (100) | Hailfinder (1000) | Hailfinder (10,000) | Carpo (100) | Carpo (1000) | Carpo (10,000) |
|---|---|---|---|---|---|---|---|---|---|
| 90% | −78.39‰ | −46.86‰ | −23.13‰ | −34.15‰ | −8.21‰ | −8.82‰ | −7.88‰ | −3.84‰ | −2.90‰ |
| 80% | −30.04‰ | −38.71‰ | −14.44‰ | −25.02‰ | −4.17‰ | −6.05‰ | −5.29‰ | −3.13‰ | −1.99‰ |
| 70% | −18.87‰ | −22.93‰ | −3.88‰ | −10.03‰ | −4.17‰ | −4.23‰ | −4.33‰ | −2.02‰ | −1.94‰ |
| 60% | −13.55‰ | −14.33‰ | −1.99‰ | −2.23‰ | −2.16‰ | −1.38‰ | −4.33‰ | −1.78‰ | −1.85‰ |
| 50% | −4.27‰ | −5.23‰ | −1.79‰ | −1.57‰ | −1.60‰ | −0.57‰ | −3.97‰ | −1.73‰ | −1.10‰ |
| 40% | −3.69‰ | −1.82‰ | −0.20‰ | −1.57‰ | −1.03‰ | −0.57‰ | −2.33‰ | −1.54‰ | −1.06‰ |
| 30% | −1.06‰ | −0.30‰ | 0‰ | −1.27‰ | −0.20‰ | −0.06‰ | −1.51‰ | −1.17‰ | −0.93‰ |
| 20% | −1.06‰ | −0.30‰ | 0‰ | −0.07‰ | −0.19‰ | −0.06‰ | −1.01‰ | −0.25‰ | −0.35‰ |
| 10% | 0‰ | −0.15‰ | 0‰ | 0‰ | −0.19‰ | −0.06‰ | −1.01‰ | −0.18‰ | −0.02‰ |
| 0% | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ | 0‰ |
| Audio-Train | Kosarek-Test | |||||||
|---|---|---|---|---|---|---|---|---|
| Pruning | CPSs | Time (secs) | CPSs | Time (secs) | ||||
| Graph | per Node | Graph | per Node | |||||
| 99% | 73,535 | 735 | −4.352‰ | 1473 | 58,249 | 307 | −7.468‰ | 4260 |
| 95% | 367,258 | 3673 | −0.669‰ | 682 | 287,641 | 1514 | −0.271‰ | 3265 |
| 90% | 734,414 | 7344 | −0.002‰ | 1035 | 575,096 | 3027 | 0‰ | 1803 |
| 80% | 1,468,717 | 14,687 | 0‰ | 2952 | 1,149,980 | 6053 | 0‰ | 16,378 |
| 70% | 2,203,033 | 22,030 | 0‰ | 3908 | 1,724,881 | 9078 | 0‰ | 16,010 |
| 60% | 2,937,329 | 29,373 | 0‰ | 5344 | 2,299,767 | 12,104 | 0‰ | 20,637 |
| 50% | 3,671,663 | 36,717 | 0‰ | 4334 | 2,874,708 | 15,130 | 0‰ | 9033 |
| 40% | 4,405,948 | 44,059 | 0‰ | 4587 | 3,449,544 | 18,155 | 0‰ | 14,903 |
| 30% | 5,140,257 | 51,403 | 0‰ | 10,028 | 4,024,450 | 21,181 | 0‰ | 9288 |
| 20% | 5,874,560 | 58,746 | 0‰ | 10,442 | 4,599,334 | 24,207 | 0‰ | 29,603 |
| 10% | 6,608,876 | 66,089 | 0‰ | 11,385 | 5,174,238 | 27,233 | 0‰ | 42,493 |
| 0% | 7,343,077 | 73,431 | 0‰ | 21,643 | 5,748,931 | 30,258 | 0‰ | 82,758 |
| EachMovie-Train | Reuters-52-Train | |||||||
|---|---|---|---|---|---|---|---|---|
| Pruning | CPSs | Time (secs) | CPSs | Time (secs) | ||||
| Graph | per Node | Graph | per Node | |||||
| 99% | 220,378 | 441 | −0.671‰ | 1711 | 375,700 | 423 | −1.269‰ | 3368 |
| 95% | 1,099,782 | 2200 | −0.158‰ | 6471 | 1,874,897 | 2109 | −0.051‰ | 6430 |
| 90% | 2,199,065 | 4398 | 0‰ | 9049 | 3,748,921 | 4217 | 0‰ | 10,002 |
| 80% | 4,397,558 | 8795 | 0‰ | 15,273 | 7,496,843 | 8433 | 0‰ | 34,537 |
| 70% | 6,596,133 | 13,192 | 0‰ | 23,133 | 11,244,877 | 12,649 | 0‰ | 41,554 |
| 60% | 8,795,121 | 17,589 | 0‰ | 9195 | 14,992,798 | 16,865 | 0‰ | 12,925 |
| 50% | 10,993,281 | 21,943 | 0‰ | 15,812 | 18,741,002 | 21,081 | 0‰ | 27,914 |
| 40% | 13,191,681 | 26,383 | 0‰ | 37,244 | 22,488,769 | 25,297 | 0‰ | 17,276 |
| 30% | 15,390,238 | 30,780 | 0‰ | 74,312 | 26,236,772 | 29,513 | 0‰ | 72,208 |
| 20% | 17,588,746 | 35,107 | 0‰ | 24,576 | 29,984,724 | 33,729 | 0‰ | 16,969 |
| 10% | 19,787,306 | 39,575 | 0‰ | 35,952 | 33,732,728 | 37,945 | 0‰ | 69,315 |
| 0% | 21,985,307 | 43,971 | 0‰ | 82,758 | 37,479,789 | 42,159 | 0‰ | 48,704 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Z.; Constantinou, A.C. Approximate Learning of High Dimensional Bayesian Network Structures via Pruning of Candidate Parent Sets. Entropy 2020, 22, 1142. https://doi.org/10.3390/e22101142
Guo Z, Constantinou AC. Approximate Learning of High Dimensional Bayesian Network Structures via Pruning of Candidate Parent Sets. Entropy. 2020; 22(10):1142. https://doi.org/10.3390/e22101142
Chicago/Turabian StyleGuo, Zhigao, and Anthony C. Constantinou. 2020. "Approximate Learning of High Dimensional Bayesian Network Structures via Pruning of Candidate Parent Sets" Entropy 22, no. 10: 1142. https://doi.org/10.3390/e22101142
APA StyleGuo, Z., & Constantinou, A. C. (2020). Approximate Learning of High Dimensional Bayesian Network Structures via Pruning of Candidate Parent Sets. Entropy, 22(10), 1142. https://doi.org/10.3390/e22101142