1. Introduction
Random number generators (RNGs) are extensively applied in the field of cryptography and security communications that require fast and trusted random numbers [
1]. So far, there are two types of RNGs—deterministic random number generators (DRNGs) and non-deterministic random number generators (NRNGs). The output sequence of a DRNG is generated with a deterministic algorithm and a provided seed. Despite its good statistical characteristic, the DRNG is not suitable for information security applications, because the deterministic pattern of the DRNG may be identified by adversaries, which incurs malicious attacks and causes the destruction of security system, as in [
2,
3,
4,
5]. On the contrary, a NRNG produces the random sequence by using physical entropy sources, such as electrical noise [
6,
7,
8], quantum fluctuations [
9,
10,
11,
12] and chaotic semiconductor lasers [
13,
14,
15]. In particular, an ultra-fast NRNG using white chaos was proposed and demonstrated in [
16,
17], which has significant potential for improving the information security and securing the communications. However, any NRNG should not be assumed to be fully trusted or secure by default in the real world, because the presence of environmental noise or the unideal characteristics of the physical devices that construct the entropy sources may compromise the integrity of NRNGs [
15,
18]. Therefore, we deem security evaluation for random numbers necessary.
The security analysis of RNGs is an important issue, since the security of cryptographic systems depends on the randomness and unpredictability qualities of RNGs. In most studies, the randomness of random numbers is evaluated by using standard statistical test suites, such as NIST Special Publication 800-22 [
19], AIS 31 [
20], Diehard [
21], and TestU01 [
22], which can detect whether there are obvious statistical defects among random numbers. However, limited by the ability of pattern recognition and data analysis, the standard statistical tests have shown the insufficiency in the security evaluation of RNGs. For instance, some DRNGs with good randomness can pass most statistical tests successfully, although there are weak but inherent correlations among them [
23]. It is necessary to further investigate the security analysis methods and tools for RNGs.
Recently, deep learning (DL) has attracted great attention because of its powerful capability in recognizing patterns and discovering intricate structures in large data sets [
24]. Considering its strength in learning nonlinear manifolds of data [
25], researchers have explored several security analysis methods of random numbers by DL. In [
26,
27], the authors implemented feedforward neural network (FNN) structures for detecting hidden patterns among pseudo-random numbers from DRNGs. Wen et al. [
28] constructed a long short-term memory (LSTM)-based DL to evaluate the randomness of a new DRNG that consists of both regular DRNGs and a physical unclonable function (PUF). However, the above works did not study and prove the performance of DL models in detecting inherent correlations among data. Yang et al. [
29] proposed a novel min-entropy estimation method based on DL models composed of a FNN and a recurrent neural network (RNN) to estimate min-entropy of entropy sources of RNGs. Unfortunately, the estimator is easily given to overestimation for data with subtle correlations. In addition, Zhu et al. [
30] improved the min-entropy estimation on time-varying data by applying a change detection method to a FNN-based estimator. Truong et al. [
18] developed a recurrent convolutional neural network (RCNN)-based predictive model, which detected prominent inherent correlations of deterministic noise sources in a quantum random number generator. Although DL has promising applications in evaluating the quality of random sequences, there are few studies on the security analysis for NRNGs based on white chaos by deep learning.
In this paper, a DL-based predictive analysis is proposed to analyze the security of RNGs. In particular, the temporal pattern attention (TPA)-based DL model is employed to detect hidden correlations that may exist among the long random sequence from RNGs, and then predict the next random number, based on observed random numbers in an input sequence. Next, we investigate the learning capability of the DL model in detecting deterministic correlations, which is applied to the liner congruential DRNG with different periods. In addition, compared with the existing related works, the performance of the model is further evaluated on the prediction accuracy and the length of the training data. Finally, we implement a white chaos-based NRNG, and analyze the security of the NRNG by DL. In particular, the predictive model is used to analyze the security of the data extracted from both stages of the NRNG: the output of a chaotic external-cavity semiconductor laser (ECL) and the final output of the NRNG. Additionally, we investigate the reasons behind the advantage provided by DL.
2. Experimental Scheme
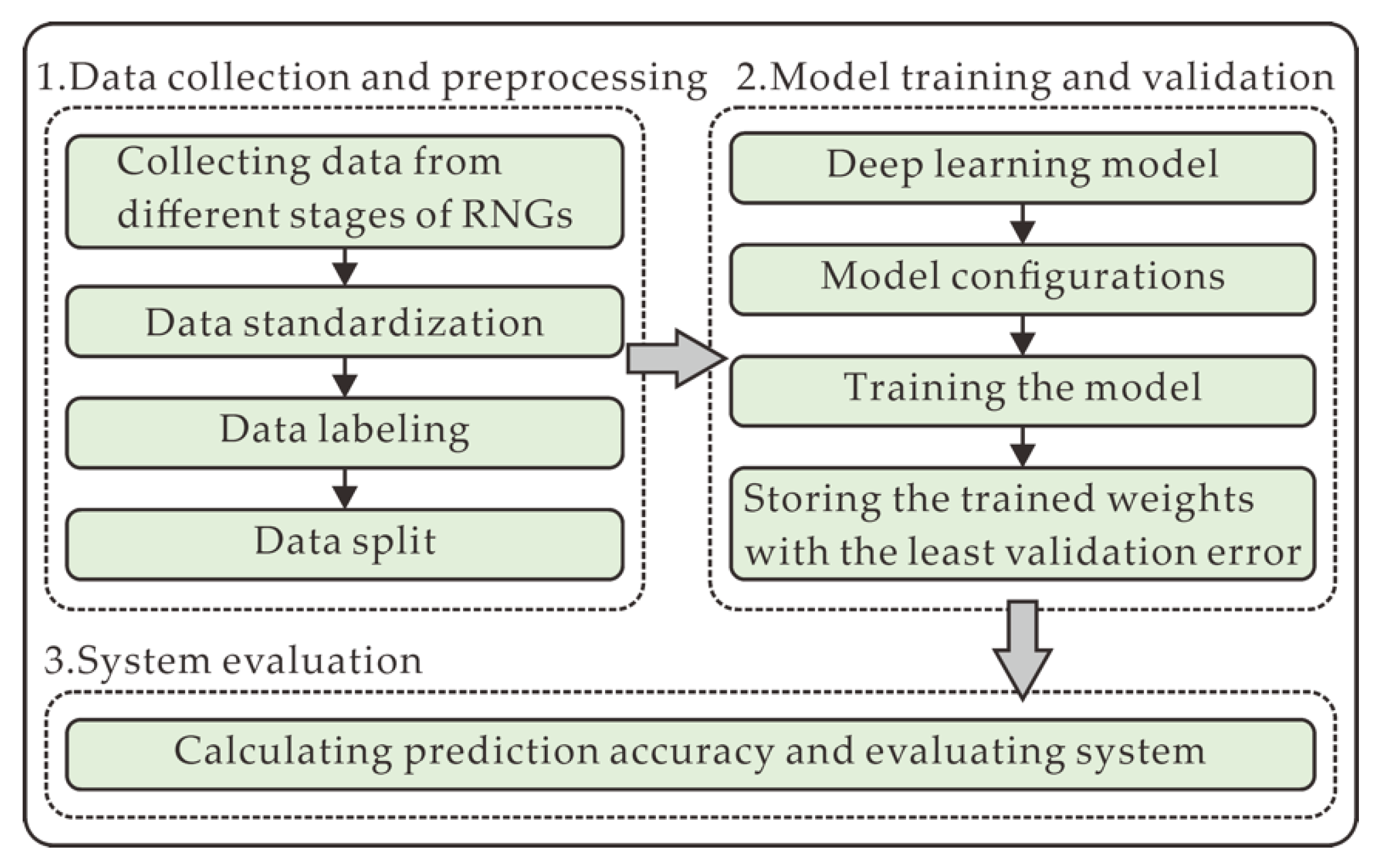
In this section, the overall experimental scheme is illustrated in
Figure 1, mainly comprising data collection and preprocessing (
Section 2.3), model training and validation (
Section 2.5), and system evaluation (
Section 2.6). In the data collection and preprocessing, the datasets are firstly collected from different stages of RNGs that are described in
Section 2.1 and
Section 2.2. Then, the raw data is standardized in the form of
N-bit integers, labeled in the supervised learning approach, and split into three sets including training set, validation set, and test set. In the model training and validation, the predictive DL model is provided and depicted in
Section 2.4. After its parameters are configured, the model is trained and validated in this process. In system evaluation, the performance of the model, and the security of the data are evaluated by the prediction accuracy.
2.1. White Chaos-Based NRNG Setup
The structure of a white chaos-based NRNG consists of an entropy source and entropy extractor, as illustrated in
Figure 2 and described in detail in [
16]. The generation of white chaos [
17], a physical process, can be taken as an entropy source for the NRNG. Two ECLs are introduced into the entropy source, each of which contains a distributed feedback semiconductor laser (DFB) with optical feedback. It is noted that the optical feedback is implemented by a feedback external cavity composed of the laser facet and a fiber mirror. In the feedback cavity, a polarization controller is inserted behind each laser to adjust the polarization of the feedback light, and a variable attenuator is placed in front of the corresponding mirror to tune up the intensity of the feedback light. After optical isolators, the outputs of both lasers are coupled by a 3-dB fiber coupler, and then two optical signals are injected into a balanced photo-detector, in which both identical photodetectors and an electronic circuit are integrated to detect the heterodyne signal. For the entropy extractor, the heterodyne signal is quantized by an 8-bit analog-to-digital converter (ADC), and then the random numbers are generated by selecting
N consecutive least significant bits (LSBs) at each sampled value.
Experimentally, the lasers DFB1 and DFB2, respectively operating at bias currents of 15.6 mA and 15.3 mA, have threshold currents of 10.9 mA and 11.1 mA, respectively. The center wavelengths of DFB1 and DFB2 are 1549.73 nm and 1549.62 nm, respectively. The feedback strength is set to −8.1 dB for ECL1 and −7.9 dB for ECL2. In addition, the feedback delays of both ECLs are 91.7 ns and 91.9 ns, respectively. With these parameters of the entropy source, the white chaos is generated by optical heterodyning. After quantization with the 8-bit ADC, a 320 Gb/s white chaos-based NRNG is realized by selecting 4 LSBs at 80-GHz sampling rate.
For security analysis of the NRNG, we investigate the quality of data collected from the output of the ECL1 and the final output of the NRNG. These are done by applying a novel DL model to data extracted at both stages of the NRNG. Note that the security of ECL1 is only evaluated due to the similarity of ECLs.
2.2. DRNG Setup
To demonstrate the robustness of provided DL model, a linear congruential random number generator (LC-RNG) [
31], a typical deterministic mechanism used in many software platforms, is introduced in our experiments. Because a benefit of the LC-RNG is that with appropriate choice of parameters, the period is known and long. The algorithm of LC-RNG is described by recurrence relation:
where
X represents the sequence of random numbers, and
M,
a, and
c are integer constants, which represent the modulus, multiplier, and increment of the generator, respectively. With correctly chosen parameters, the period of the random values is equal to
M for any seed. The generation of pseudo-random numbers will occur if: (1)
M and
c are relatively prime, (2)
a − 1 is divisible by all prime factors of
M, and (3)
a − 1 is divisible by 4 if
M is divisible by 4. In our experiments, we collected the pseudo-random sequences generated by LC-RNG with
a = 25214903917,
c = 1 and
M ∈ (2
24, 2
26, 2
28, 2
30). It is necessary to study the predictive capability of the DL model in discovering inherent and intricate dependencies.
2.3. Data Collection and Preprocessing
In the data acquisition stage, we collect several datasets extracted at different stages of the introduced NRNG, and LC-RNG. At each stage or period of RNGs, 200 million raw random numbers are gathered and standardized in the form of N-bit integers. Out of these, 40%, 10%, and 50% are used for training, validating, and testing the provided DL model, respectively. To assess the consistency of the learning performance of the model, the test dataset is divided into five sub-test datasets, and each of them comprises twenty million random numbers.
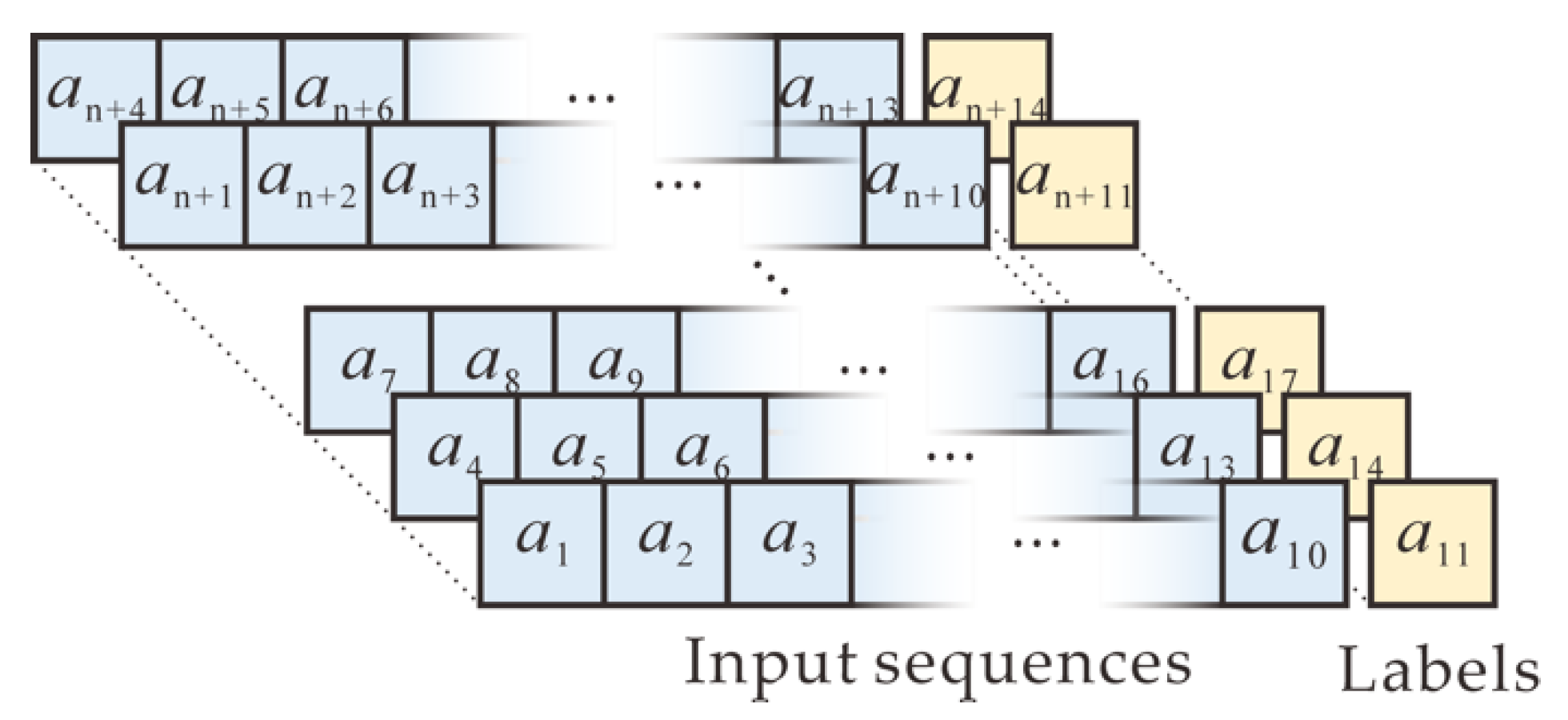
Our task is to learn hidden correlations among the random numbers of RNGs and predict the next number, based on observed random numbers in an input sequence. Therefore, supervised learning with a neural network is performed in data preprocessing. The sequence of collected random numbers is arranged in a conventional approach, as shown in
Figure 3. Specifically, ten consecutive adjacent numbers within the random sequence are used as one input sequence, whereas the next number after the input sequence is used as the output (label). Next, the sequence is shifted by three positions and is updated as another input. Similarly, the next number after the new input sequence also is used as the new output. The shifting process continues until all input sequences and corresponding outputs are generated. In addition, the neural network is trained and tested in the processed datasets in the format of pairs.
2.4. Deep Learning Model
Since the output of RNGs is a typical time series, we prefer to focus on recurrent neural networks (RNNs) [
32], which are typical deep neural networks designed for sequence modeling. Nevertheless, simple RNNs are subject to the problem of vanishing gradients during training, and have difficulty discovering deterministic correlations [
33]. In recent years, long short-term memory (LSTM) and gated recurrent unit (GRU), two popular variants of RNNs, have overcome the limited shortcoming of discovering long-term dependencies to some extent, and have achieved success in various applications [
34,
35,
36]. To further solve time series prediction problems, some researchers have introduced attention mechanisms into deep neural networks [
37,
38,
39]. Inspired by [
40], a temporal pattern attention (TPA)-based LSTM is applied to the DL model to capture inherent correlations among random numbers in this paper. Compared with the typical attention mechanism, the provided TPA mechanism can learn the hidden correlations in the intricate time series data with advantage.
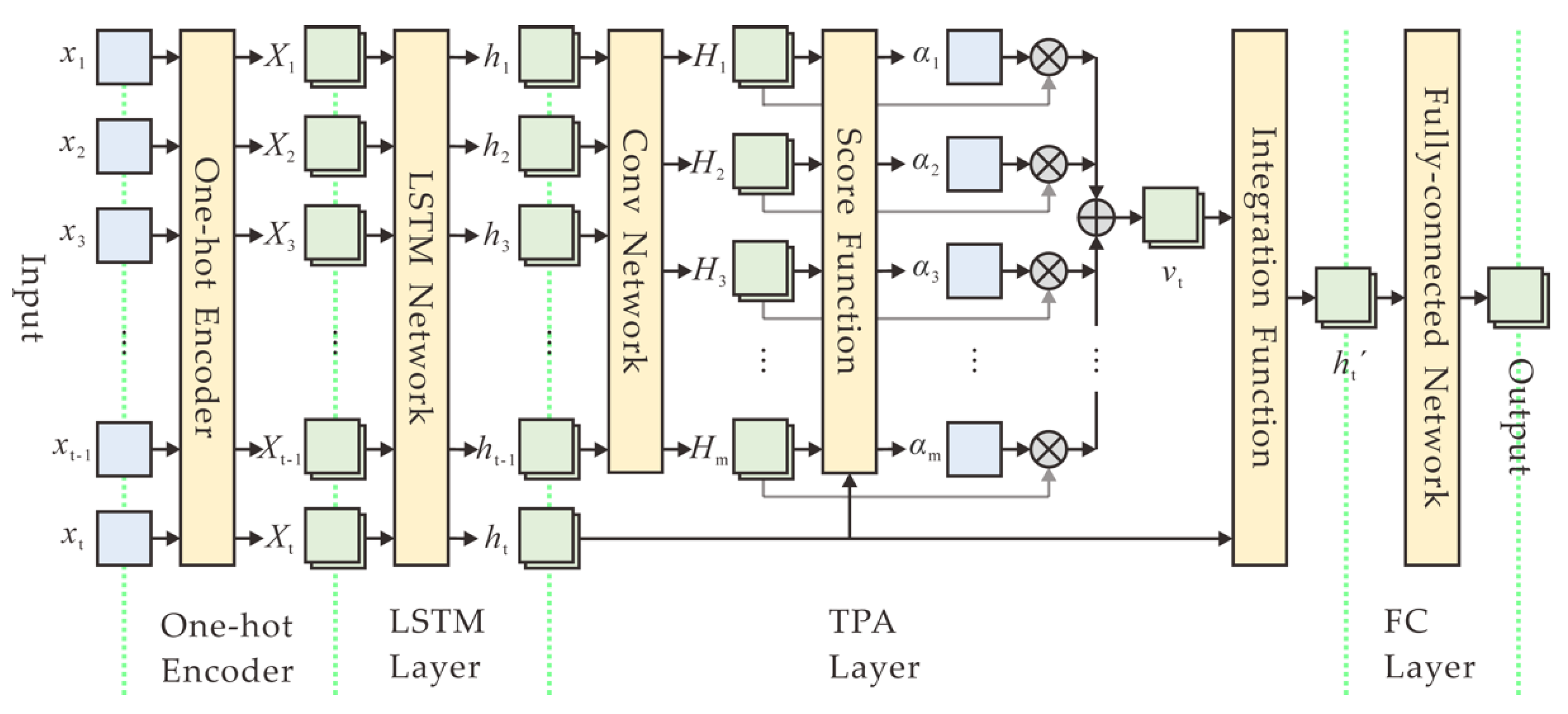
The structure of a TPA-based DL model mainly consists of a one-hot encoder, a LSTM layer, a TPA layer, and a fully connected (FC) layer, as depicted in
Figure 4. Specifically, after data collection and preprocessing, ten
N-bit numbers are firstly encoded into one-hot vectors, each of which is a binary vector that has all zeros values except a significant value used to distinguish different numbers. Then the encoded vectors are sequentially fed to a LSTM layer with 256 output size, which can output the hidden states corresponding to each time step in an input sequence. Afterwards, the output of the LSTM layer is connected to the TPA layer. The attention layer analyzes the information across all previous time steps and selects relevant information to help generate the output. Finally, the attention output configured to size 256 goes to a fully connected (FC) layer, with a softmax activation function because of the multi-classification problem. The output size of the FC layer is configured to 2
N, which is the number of all possible
N-bit numbers in predicting the next value.
In the temporal pattern attention mechanism [
40], given the previous LSTM hidden states
H = (
h1,
h2, …,
ht-1) ∈ ℝ
m×(t-1), a convolutional neural network (CNN) is used to improve the predictive performance of the model by employing CNN filters on the row vectors of
H. The CNN has
k filters, each of which has length of
T. In addition, the CNN with a rectified linear unit activation function yield
HC ∈ ℝ
m×k, where
Hi denotes the convolutional value of the
i-th row vector of
H. Then, the context vector is calculated as a weighted sum of row vectors of
HC. The score function ƒ is defined to evaluate relevance between
Hi and
ht:
where
ht is the present state of the LSTM output, and
Wa ∈ ℝ
k×m. The attention weight
αi is realized by introducing a sigmoid activation function:
To obtain the context vector
vt ∈ ℝ
k, the row vectors of
HC is weighted by
αi:
Finally, we integrate
vt and
ht to yield the output of the attention layer,
where
Wh ∈ ℝ
m×m,
Wv ∈ ℝ
m×k.
In our experimental model, we set the time steps of an input sequence t = 10, the output size of the LSTM m = 256, the number of filters k = 256, and the length of a filter T = 10.
2.5. Model Training and Validation
In addition to the appropriate DL model as a solution for maximizing the probability of predicting the next value successfully, the DL model needs to be configured with several key parameters. The predictive model is regarded as a solution to a multi-classification problem, so the cross-entropy is used as an objective function, which can calculate the bias between the labels and the predicted values. In addition, an Adam optimizer [
41] with a manually set 0.0005 learning rate is introduced to minimize the objective function during training phase. A batch of examples of size 256 is fed into the model during both of the training and the testing. The maximum number of epochs is set to 200, and the training is discontinued once the validation error stops decreasing after 5 successive epochs. The validation error and corresponding trained weights are recorded in the training phase, and the trained weights with the least validation error are used as the final trained weights for evaluating the corresponding test set.
2.6. System Evaluation
Not only the learning capability of the predictive model, but also the security of the data is evaluated by comparing the probability of correct prediction,
Ppred, against the baseline probability,
Pb, which is the highest probability of guessing a variable in the data. For a DL model,
Ppred is the probability of predicting the eleventh number correctly in the test set, according to the preceding ten consecutive numbers. That is,
Ppred is a percentage of all the correct predictions out of the total number of test predictions,
where
NT is the number of correct classifications, and
NF is the number of incorrect classifications. The baseline probability
Pb is related to the minimum entropy of the distribution from which a random value is generated. In NIST Special Publication 800-90B [
42], the min-entropy of an independent discrete variable
X that takes values from a set
A = (
x1,
x2, …,
xk) with probability
Pr(
X =
xi) =
pi, for
i = 1, …,
k is described as:
If a random variable has min-entropy
H, the probability of observing any specific value for
X is no greater than
Pb, which is why it is considered to be the baseline probability. For instance, an
N-bit random number from datasets extracted at a certain stage of the NRNG or LC-RNG has a uniform probability distribution, which means that the highest probability of guessing the output of RNGs is 1/2
N. If the DL-based predictive model could give a higher prediction probability compared to the baseline probability, there exist hidden correlations in the data from the corresponding stage of RNGs. Contrarily, little is learned by the model, and the random numbers have strong resistance against the predictive DL model. On the other hand, compared with the statistical property tests, the performance of the predictive model is studied by learning deviations in the data with different level of complexity.
3. Experimental Results
In this paper, the DL model is implemented based on Keras and the backend of TensorFlow with Python language. In addition, all experiments are performed on a Windows 10 system with an Intel i9 10900X CPU and two NVIDIA RTX 2080Ti GPUs.
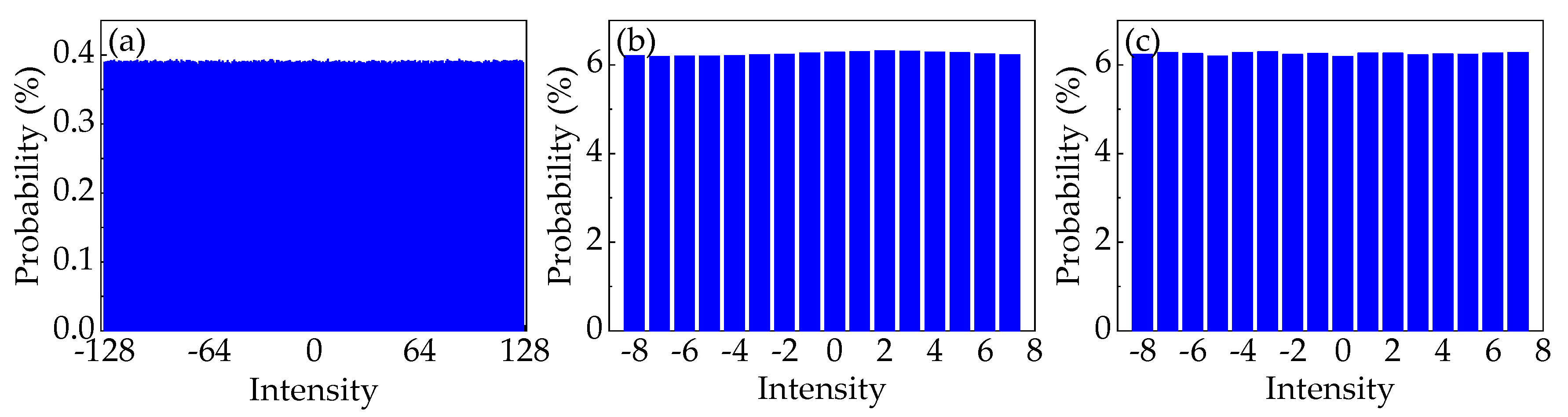
For the first scenario, we investigate the learning capability of the predictive model, which is applied to random numbers collected from the LC-RNG with different periods. Before that, the probability distribution of the 8-bit random numbers at different periods is measured to calculate the corresponding baseline probability. Specifically, the raw values of the intensity of the temporal waveforms are standardized in the form of 8-bit integers between −128 and 127 to generate the corresponding histogram. From these histograms, the 8-bit standardized numbers at different stages are basically subject to the same uniform probability distribution. That is, the baseline probability is 0.39%. In particular, the probability distribution of random integers from LC-RNG with the period of 2
24 is shown in
Figure 5a.
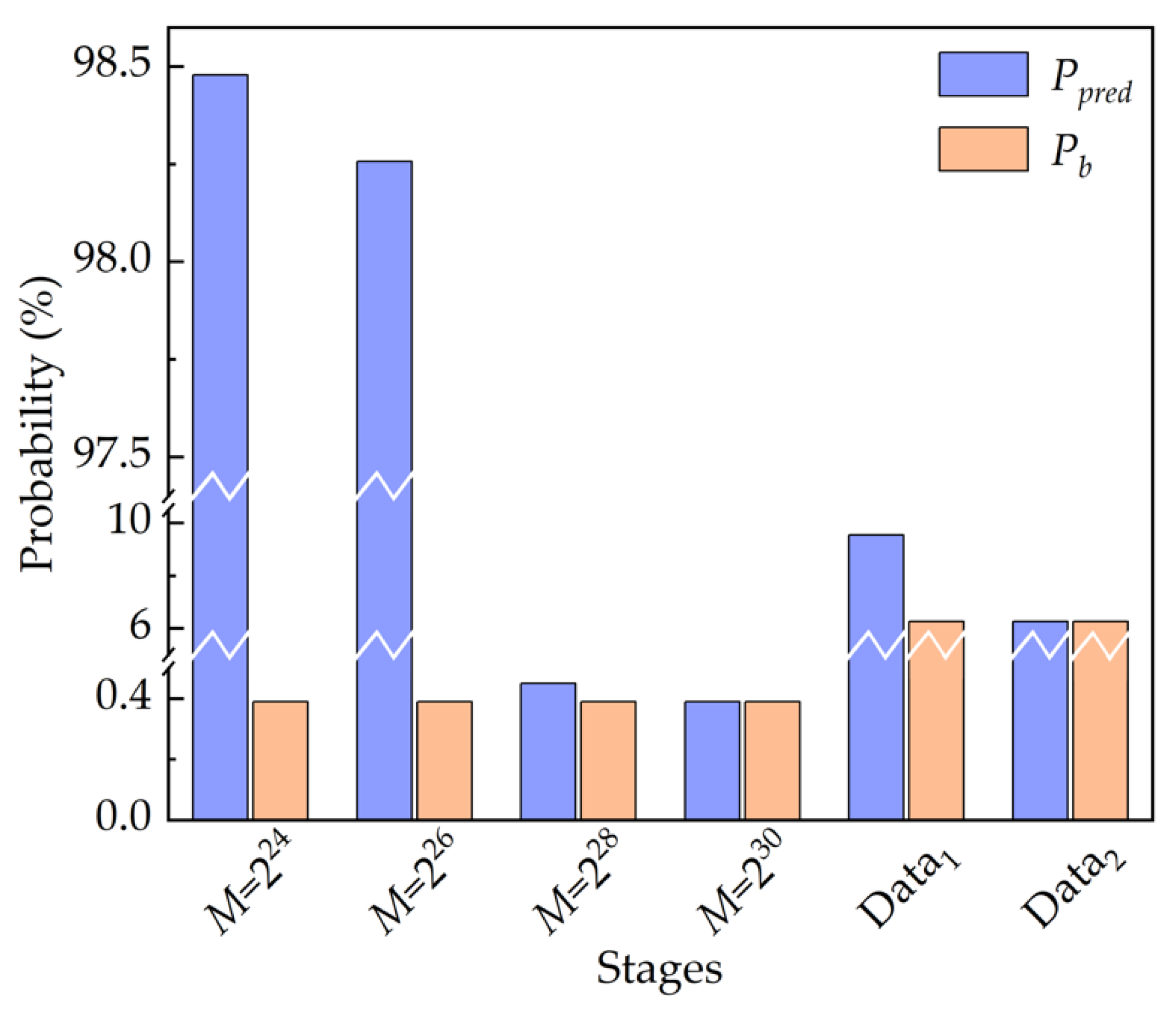
Then, the model shows the predictive capability in learning the inherent and long-term correlations among pseudo-random numbers, as manifested in
Figure 6. The model achieves 98.478 ± 0.07%, 98.256 ± 0.06%, 0.45 ± 0.01%, 0.39 ± 0.01% accuracy in predicting the next random number given precedent consecutive 10 numbers when the period of the LC-RNG,
M, is 2
24, 2
26, 2
28, 2
30, respectively. Please note that the seed for generating pseudo-random numbers in a training set is different from that in the corresponding test set. Evidently, the probability of correct prediction by the model,
Ppred, surpasses the baseline probability,
Pb, when the length of the training set exceeds the period of LC-RNG, i.e.,
M is less than 2
28. In addition, the provided model still has
Ppred better than
Pb by more than 6 standard deviations, even if
M is 2
28, which is much larger than the length of the training set. Meanwhile,
Ppred decreases when
M increases given the same size of training set. When
M is 2
30 or larger,
Ppred is approximately equal to
Pb. It could be that the datasets with higher level of complexity make the model more difficult to detect the correlations among random numbers.
To substantiate the performance of the attention-based DL model, the NIST Special Publication 800-22 test suite [
19] is employed for evaluating random numbers extracted from the LC-RNG. The test suite is a standard statistical package composed of 15 tests to evaluate the security of random values generated by any RNG. These tests reporting
P-values within the range of 0.01–1.00 are considered to accept the hypothesis that the tested random numbers exhibit no characteristics of order or structure. The test results of random numbers with different periods are shown in
Table 1. The number of passing tests increases as
M increases. The test suite can detect deviations among the data when
M is 2
24, 2
26, respectively. However, the random numbers can pass 15 tests of the test suite when
M is 2
28, 2
30, respectively. Compared with the corresponding results from
Figure 6, the DL model still achieves a higher prediction probability than the baseline probability, when random numbers with the period of 2
28 can pass the NIST test suite successfully. Briefly, the DL-based predictive model has the advantage in detecting correlations among random numbers to some extent, compared to the results of the NIST test suite.
Furthermore, the learning performance of the TPA-based model is further evaluated on the prediction accuracy and the length of the sequence used for training, compared with the existing typical DL methods of evaluating the security of RNGs, including RNN-based model [
29], FNN-based model [
26,
27,
29], RCNN-based model [
18]. These models are trained and tested using the same experimental strategy (see
Section 2.3,
Section 2.4,
Section 2.5 and
Section 2.6). The configuration of the models we compared is shown in
Table 2 and described in detail in [
18,
26,
27,
29]. It is noted that the hyperparameters of the models are modified and optimized to fit the provided strategy, and improve the prediction accuracy. To evaluate the performance, the average prediction accuracy in the five test subsets is taken as the evaluation criterion.
On the prediction accuracy, these models are applied to twenty million datasets from LC-RNG with
M ∈ (2
20, 2
22, 2
24, 2
26). The prediction results of these deep learning models on the LC-RNG with different periods are shown in
Table 3. The baseline probability,
Pb, is still 0.39%, since 8-bit random numbers extracted from different periods follow the same uniform probability distribution. In
Table 3, the simple RNN-based model has no advantage in detecting the intricate correlations among random numbers when
M ≥ 2
22. We speculate that the RNN-based model is subject to the problem of gradient disappearance during the training process, and has difficulty in discovering deterministic correlations. The FNN-based model and RCNN-based model can detect correlations in the data when
M ≤ 2
26, and give higher prediction accuracy than
Pb. However, the TPA-based model consistently achieves a prediction accuracy of more than 95% when
M ≤ 2
24, which is significantly better than the performance of other models. The model still detects the correlations, even though the length of the training set is less than
M.
To compare the effectiveness of these models, we also investigate how the prediction accuracy depends on the length of the training data,
L. We draw the prediction results of these models on the LC-RNG with the period of 2
24, which are shown in
Table 4. The RNN-based model with simple configuration still shows the weak learning capability when
L increases. The performance of FNN-based model and RCNN-based model becomes better as
L increases. These results show that the longer the length of the training set is, the higher the prediction accuracy. In addition, the FNN-based model performs better than others when
L = 3.2 × 10
6, because it consumes most computational resources (trainable parameters) among these models. The TPA-based model gives an obvious advantage in learning the correlations when
L increases, compared with the performance of others. Specifically, given the same length of the training data, the model achieves higher prediction accuracy than other models when
L ≥ 6.4 × 10
6. As shown above, the performance of the predictive model is investigated and demonstrated in this scenario.
For the second scenario, we investigate the security of datasets extracted at different stages of the NRNG based on white chaos from the perspective of DL. Because of the retention of four LSBs in quantization of white chaos, the security of 4-bit data is evaluated in this scenario. Prior to this, the probability distribution of 4-bit datasets extracted at different stages of the NRNG is verified, as shown in
Figure 5b,c. Obviously, the 4-bit integers at different stages are basically subject to the same uniform probability distribution. That is, the baseline probability is 6.25%. Then, the same procedure is used to learn the hidden correlations in the datasets, which are gathered from the output of the ECL
1 (denoted as Data
1) and the final output of the NRNG (denoted as Data
2). The results of the prediction are also shown in
Figure 6. For the ECL
1 stage, the predictive DL model achieves 9.54 ± 0.05% accuracy, which obviously surpasses
Pb in guessing the next random value. For the final output of the NRNG,
Ppred is extremely close to
Pb, i.e., the provided model learns no patterns in the training dataset. For both stages of the NRNG, the results given the DL model are consistent with these of the NIST test suite in
Table 1. In other words, the predictive model does as well as the NIST test suite in this scenario.
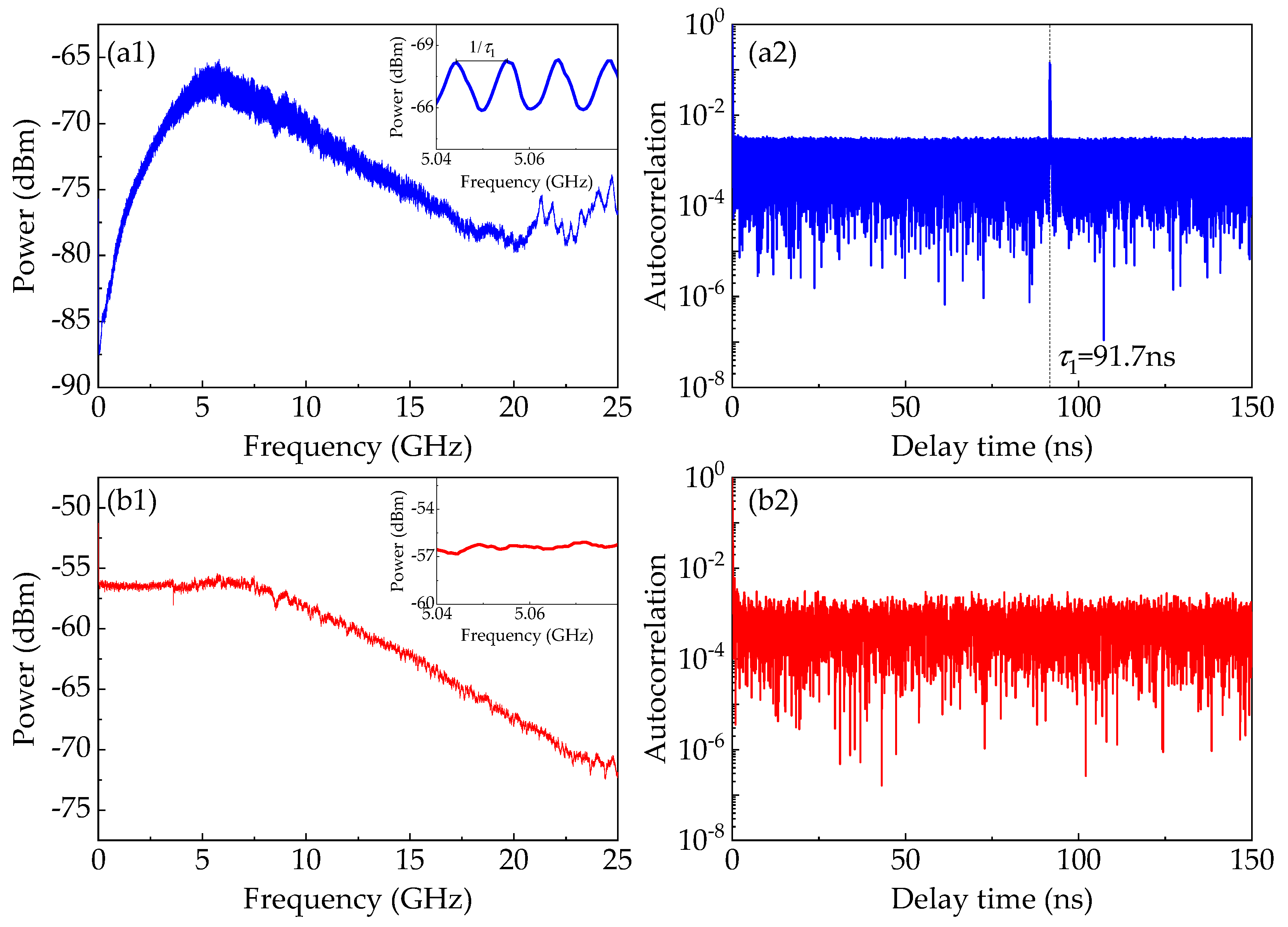
To further investigate the reasons behind the advantage provided by the DL model, temporal properties of the white chaos of the NRNG as well as the chaos of the ECL
1 are depicted in
Figure 7, including the radio-frequency (RF) spectrum, and the autocorrelation function. The RF spectra of the chaos of the ECL
1 and the white chaos are depicted in
Figure 7a1,b1, respectively. For the spectrum map of the chaotic ECL
1, a dominant peak approximately at the relaxation frequency can be clearly observed, which is detrimental to the bandwidth and flatness of chaos of ECL
1 [
17]. Furthermore, we can observe an obvious pattern of periodic modulation from the insert of
Figure 7a1. Please note that the period equals the reciprocal of the feedback delay time. The periodic modulation is actually the time-delay signature (TDS) that destroys the unpredictability and randomness of entropy source. However, in
Figure 7b1, the spectrum of the white chaos is flat and broadband, which is not subject to the dominant peak and the periodic modulation pattern. That is, the white chaos generated by optical heterodyning has the great potential in extracting high-speed and trusted random numbers.
To examine the existence of TDS, we plot the autocorrelation traces of the chaos of the ECL
1 and the white chaos, as depicted in
Figure 7a2,b2, respectively. The autocorrelation trace of the chaotic ECL
1 shows an apparent correlation peak at the feedback delay in
Figure 7a2. We speculate that the retention of four LSBs still preserves the TDS in raw data, which precludes its use as a random number generator. By comparison, after optical heterodyning, the correlation trace of the heterodyne signal has no correlation peak in
Figure 7b2, which indicates the elimination of such time-delay signature by heterodyning of two chaotic ECLs. In addition, other methods [
43,
44,
45] of eliminating the TDS also significantly improve the randomness of RNGs.
In the predictive model, the CNN is introduced into the TPA mechanism. As demonstrated in [
46], the CNN filters play a role of bases in the discrete Fourier transform (DFT), which is used to reveal significant temporal characteristics in the intricate time series. Originally, the frequency domain in DFT serves as a powerful representation for CNN to use in training and modeling [
40]. The frequency-domain representation from CNN filters can reveal the signature of the time delay of the data from the chaotic ECL
1 stage. Thus, we believe that TDS of the chaotic ECL
1 causes the correlations among the data, and then gives the predictive model more chances to learn any temporal information among the data. For the white chaos, TDS is eliminated by heterodyning of two chaotic ECLs, and no characteristics are shown in the frequency domain. Evidently, the model cannot learn any temporal pattern in the training dataset collected from the final output of the NRNG, i.e.,
Ppred ≈
Pb. Therefore, the NRNG has the strong resistance against our predictive DL.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}