1. Introduction
A very large volume of high-spatial resolution imaging datasets is available these days in various domains, calling for a wide range of exploration methods based on image processing. One such dataset has become recently available in the field of neuroscience, thanks to the Allen Institute for Brain Science. This dataset contains
in situ hybridization (ISH) images of mammalian brains, in unprecedented amounts, which has motivated new research efforts [
1,
2,
3]. ISH is a powerful technique for localizing specific nucleic acid targets within fixed tissues and cells; it provides an effective approach for obtaining temporal and spatial information about gene expression [
4]. Images now reveal highly complex patterns of gene expression varying on multiple scales.
Developing analytical tools for discovering gene interactions from such data remains an open challenge due to various reasons, including difficulties in extracting canonical representations of gene activities from images, and inferring statistically meaningful networks from such representations. The challenge in analyzing these images is both in extracting the patterns that are most relevant functionally, and in providing a meaningful representation that would allow neuroscientists to interpret the extracted patterns.
One of the aims at finding a meaningful representation for such images is to carry out classification to
gene ontology (GO) categories. GO is a major bioinformatics initiative to unify the representation of gene and gene product attributes across all species [
5]. More specifically, it aims at maintaining and developing a controlled vocabulary of gene and gene product attributes and at annotating them. This task is far from done; in fact, several gene and gene product functions of many organisms have yet to be discovered and annotated [
6]. Gene function annotations, which are associations between a gene and a term of controlled vocabulary describing gene functional features, are of paramount importance in modern biology. They are used to design novel biological experiments and interpret their results. Since gene validation through in vitro biomolecular experiments is costly and tedious, deriving new computational methods and software for predicting and prioritizing new biomolecular annotations would make an important contribution to the field [
7]. In other words, deriving an effective computational procedure that predicts reliably likely annotations, and thus speeds up the discovery of new gene annotations, would be very useful [
8].
Past methods for analyzing brain images need to reference a brain atlas, and are based on smooth nonlinear transformations [
9,
10]. These types of analyses may be insensitive to fine local patterns, like those found in the layered structure of the cerebellum (The cerebellum is a region of the brain. It plays an important role in motor control, and has some effect on cognitive functions [
11].), or to a spatial distribution. In addition, most machine vision approaches address the challenge of providing human interpretable analysis. Conversely, in bioimaging, usually the goal is to reveal features and structures that are hardly seen even by human experts. For example, one of the new functions that follow this approach is presented in [
12], using a histogram of local
scale-invariant feature transform (SIFT) [
13] descriptors on several scales.
Recently, several machine learning algorithms have been designed and implemented to predict GO annotations [
14,
15,
16,
17,
18]. Following our preliminary work [
19], we pursue in this paper an
artificial neural network (ANN) with many layers (also known as
deep learning), in order to achieve functional representations of neural ISH images.
Indeed, to obtain a compact feature representation of these ISH images, we further explore here
autoencoders (AE) and
convolutional neural networks (CNN). Specifically, we demonstrate that the
convolutional autoencoder (CAE) is most appropriate for the task at hand. (This is similar to the work of Krizhevsky and Hinton [
20], who used deep autoencoders to create short binary codes for content-based images.) Subsequently, we use this representation to learn features of functional GO categories for every image, invoking a simple
-regularized logistic regression classifier, as in [
12]. As a result, each image is represented as a lower-dimensional vector whose components correspond to meaningful functional annotations. As pointed out in [
12], the resulting representations define similarities between ISH images which could be explained, hopefully, by such functional categories.
Our experimental results further demonstrate that the representation obtained using the novel architecture of a so-called
convolutional denoising autoencoder (CDAE) outperforms the previous state-of-the-art classification rate [
12]; specifically, it improves the average AUC from 0.92 to 0.997, achieving 96% reduction in error. The method operates on input images that are downsampled significantly with respect to the original ones to make it computationally feasible.
2. Background
2.1. Biological Background
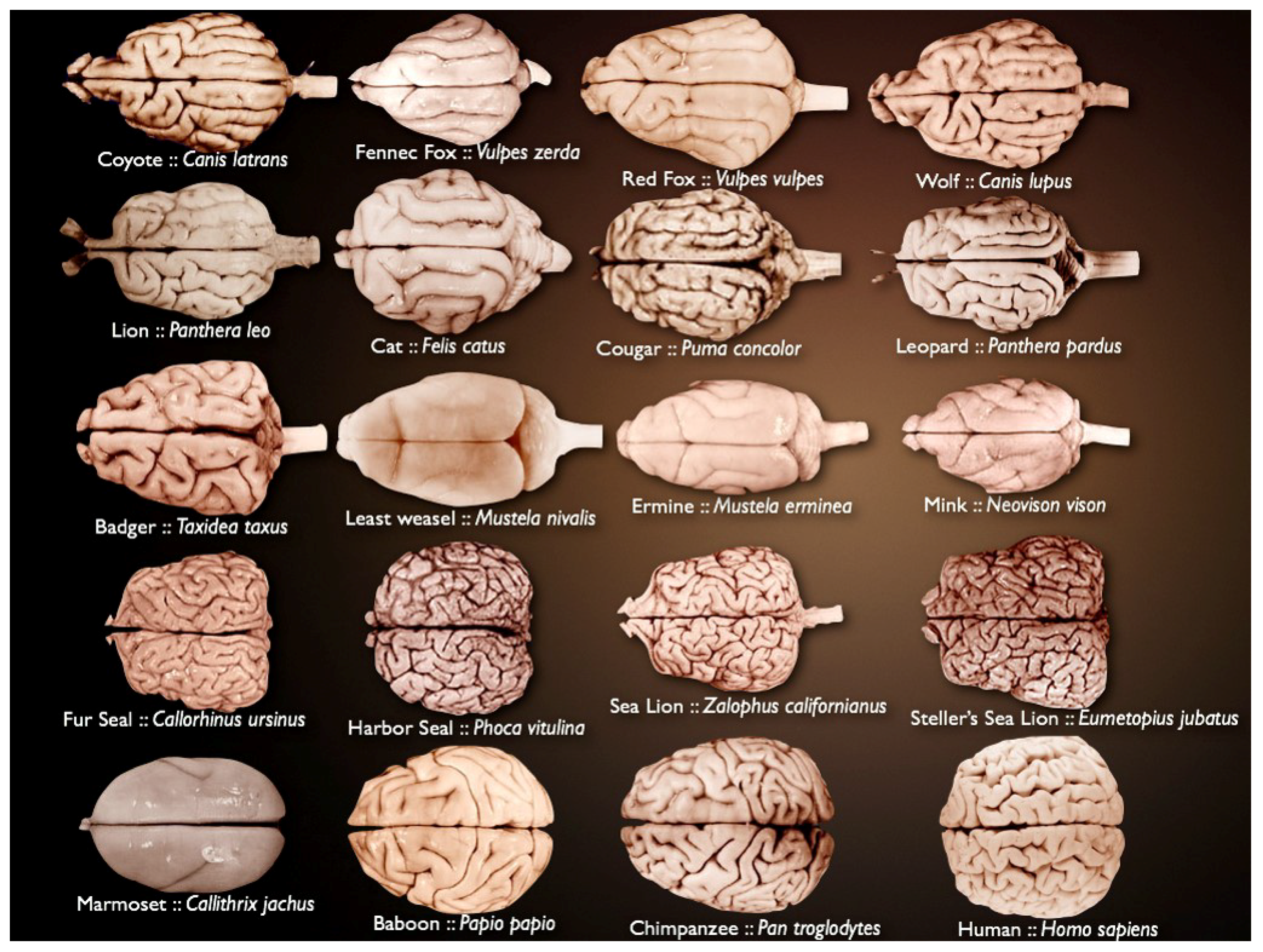
Mammalian brains vary in size and complexity (
Figure 1) and are composed of billions of neurons and glia. The brain is organized in highly complex anatomical structures. This is why it has remained a fascinating challenge for many years.
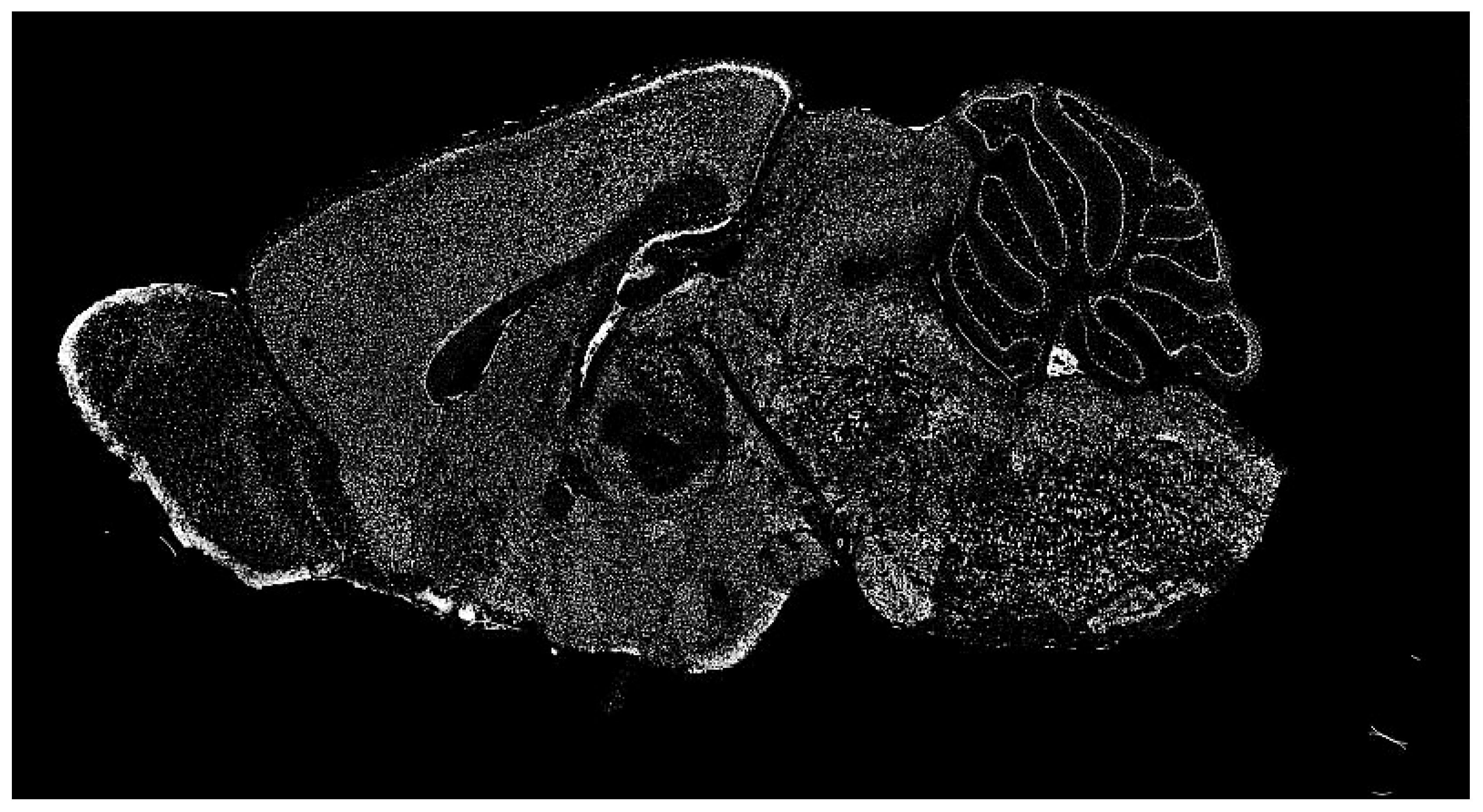
The dataset of the Allen Institute for Brain Science contains a significant repository of ISH images of mammalian brains for many research fields. ISH is a powerful technique for localizing specific nucleic acid targets within fixed tissues and cells. It provides an effective approach for obtaining temporal and spatial information about gene expression [
4]. ISH images reveal highly complex patterns of gene expression varying on multiple scales, as shown in
Figure 2. This information calls for a wide range of exploration methods based on image processing.
Finding meaningful representations for such images is one of the main goals which could be used for classification of
gene ontology (GO) categories. GO has the aim of unifying the representation of gene and gene product (A gene product is the biochemical material, either RNA or protein, resulting from expression of a gene.) attributes across all species [
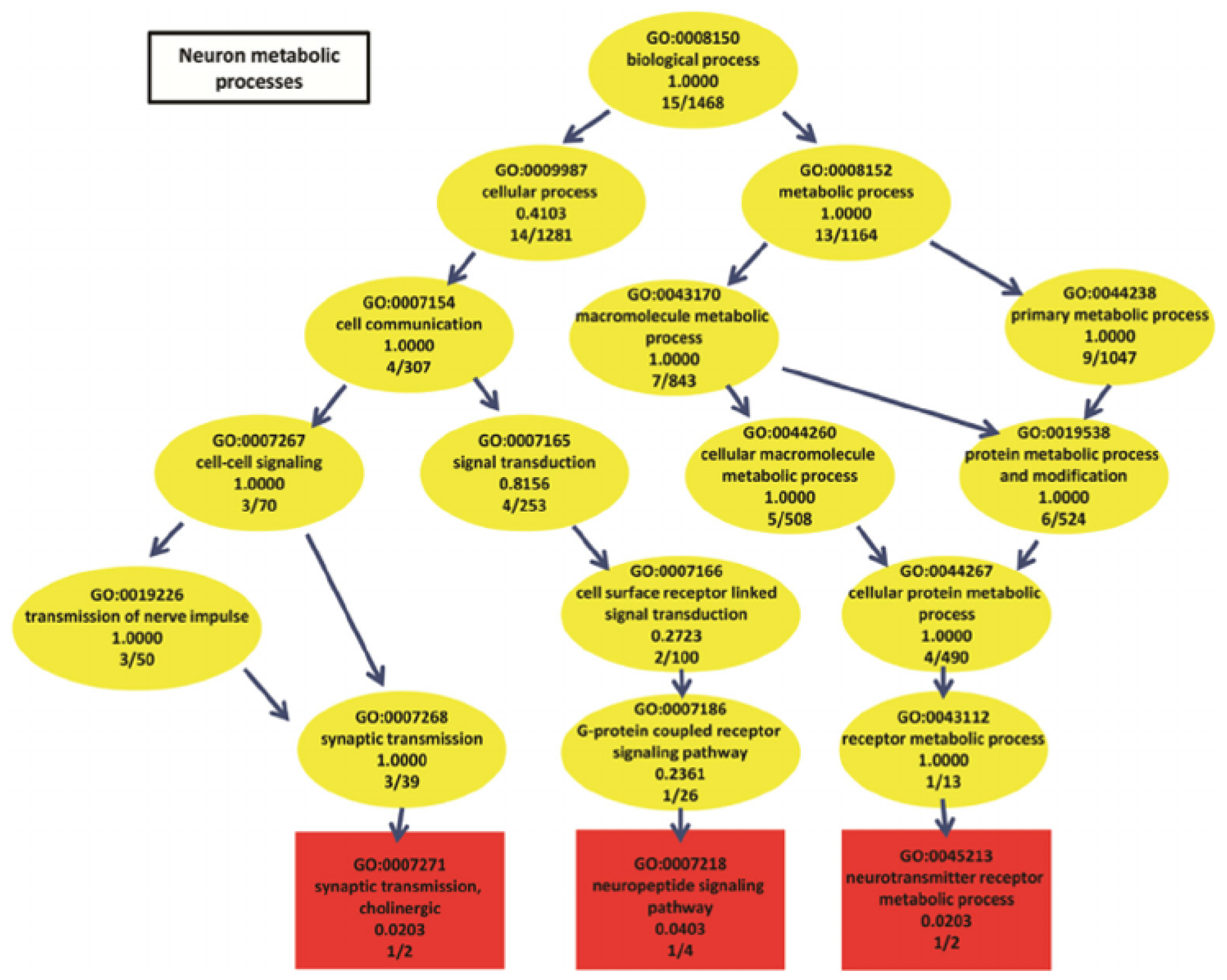
5]. GO categories are shaped in the form of a
directed acyclic graph (DAG), in which each category has relevant subcategories, and vice versa. An example can be seen in
Figure 3.
Thousands of GO categories exist, and the task is far from done; in fact, several gene and gene product functions of many organisms have yet to be discovered and annotated [
6]. Gene function annotations, which are associations between a gene and a term of controlled vocabulary describing gene functional features, are of paramount importance in modern biology. They are used to design novel biological experiments and interpret their results. With that said, gene validation through in vitro biomolecular experiments is costly and lengthy. It is a multi-stage process, which starts by revealing the gene product and then searching for it in known databases. If it appears in the database, progress is possible; otherwise, a series of laboratory studies are needed to reconstruct the gene. Sometimes, it is a short process, but it could also be extremely tedious. For this reason, deriving new computational methods and software for predicting and prioritizing new biomolecular annotations would make an important contribution to the field [
7]. In other words, as previously noted, deriving an effective computational procedure that predicts reliably likely annotations, and thus speeding up the discovery of new gene annotations, would be very useful [
8].
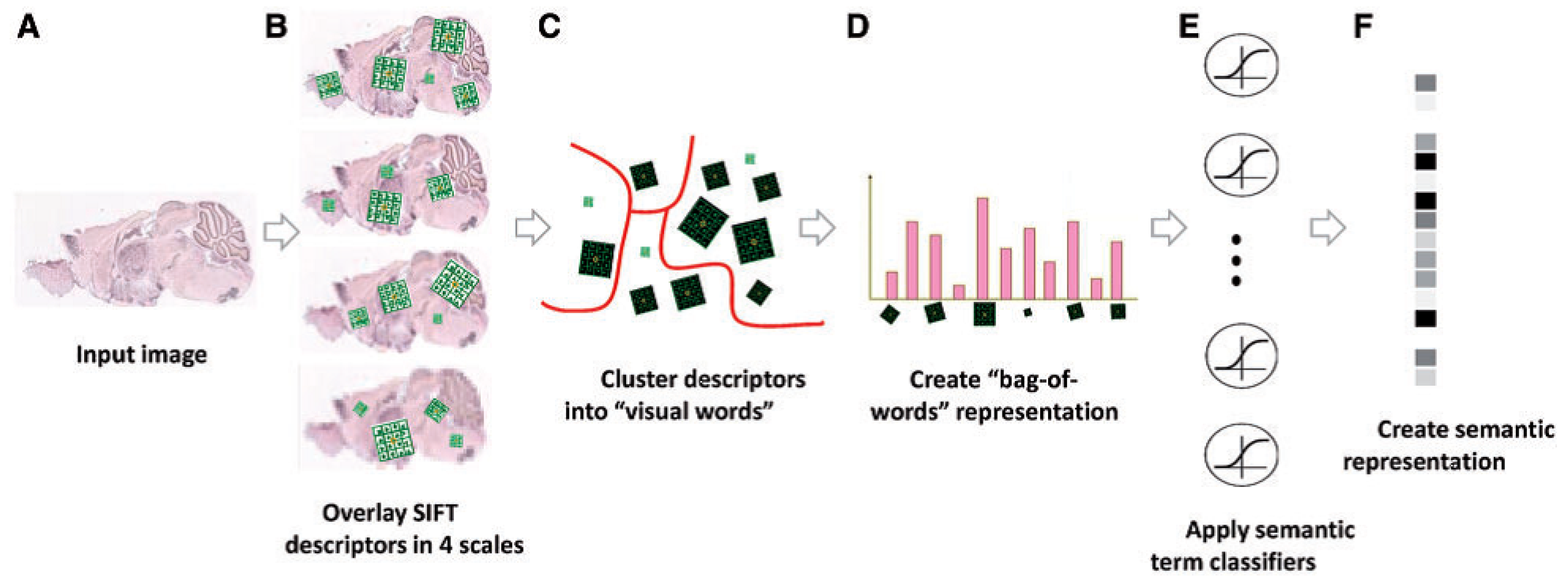
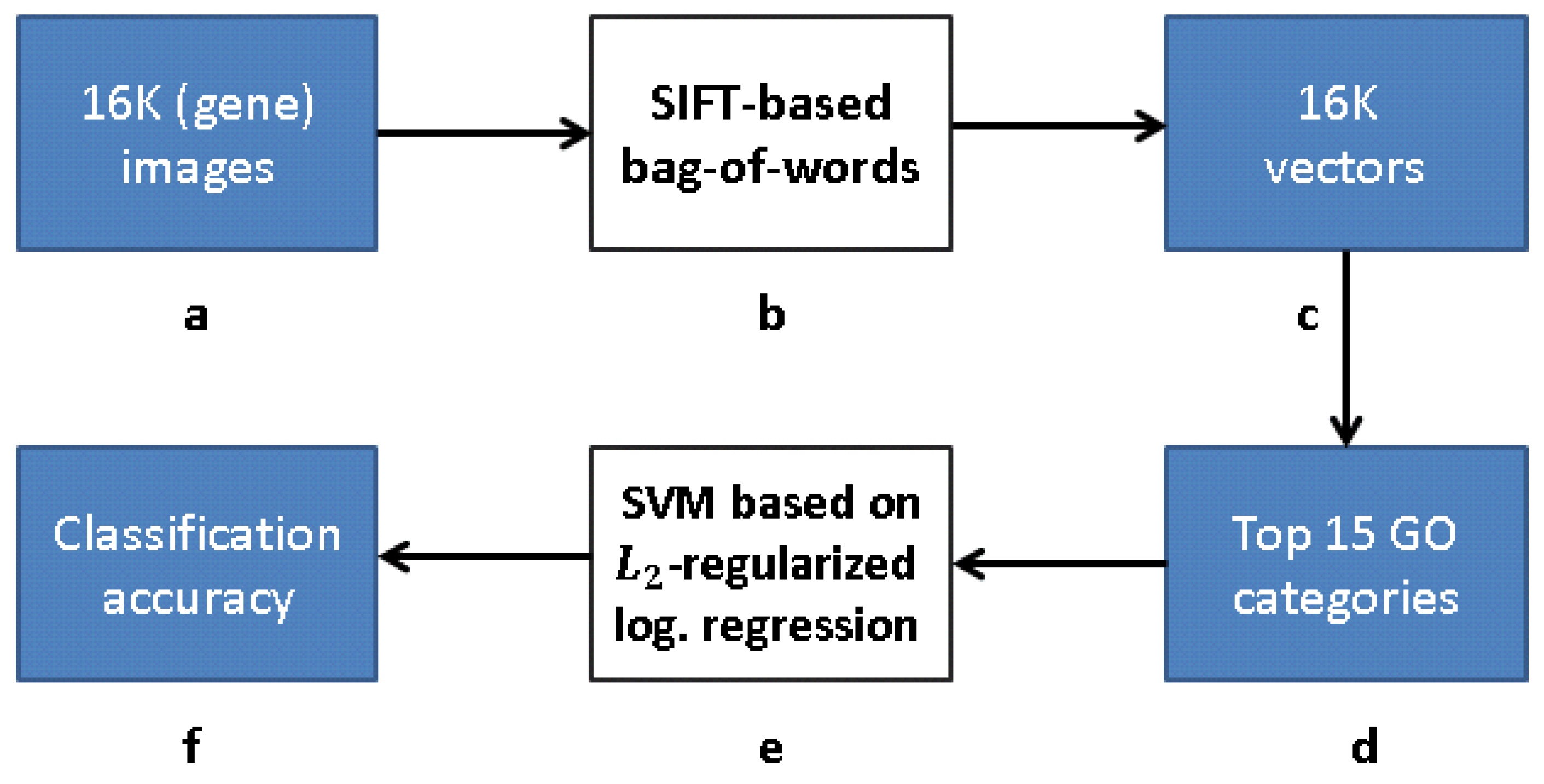
2.2. FuncISH: Learning Functional Representations
ISH images of mammalian brains reveal highly complex patterns of gene expression varying on multiple scales. In [
12], the authors present
FuncISH, a learning method of functional representations of ISH images, using a histogram of local descriptors on several scales. They first represent each image as a collection of local descriptors of SIFT features [
13,
22]. Next, they construct a standard
bag-of-words description of each image, giving a 2004-dimensional representation vector for each gene. Finally, given a set of predefined GO annotations of each gene, they train a separate classifier for each known biological category, using the SIFT bag-of-words representation as an input vector. Specifically, they construct a set of 2081
-
regularized logistic regression classifiers. The GO categories considered are those for which the number of annotations range between 15 to 500. The lower limit is picked to provide enough positive examples for testing, while the higher limit is chosen to preclude the resulting semantic explanations from being too general. A scheme taken from [
12] representing the work flow is presented in
Figure 4 and Figure 9.
Applying [
12] to the genomic set of neural mouse ISH images (available from the Allen Brain Atlas) reveals that “most neural biological processes could be inferred from spatial expression patterns with high accuracy”. Despite ignoring important global location information, ∼700 functional annotations were successfully inferred, and then used to detect gene–gene similarities not captured by previous, global correlation-based methods. According to [
12], combining local and global patterns of expression is an important topic for further research, e.g., the use of more sophisticated nonlinear classifiers.
Pursuing further the above classification problem poses a number of challenges. First, defining a certain set of rules that an ISH image has to conform to in order to classify it to the correct GO category. Conventional computer vision techniques, although capable of identifying shapes and objects in an image, seem unlikely to provide effective solutions to the problem of interest. Thus, following the work in [
12], we use deep learning to achieve more accurate results, due to the more effective functional feature representation of the ISH images learned by our neural network.
2.3. Convolutional Neural Networks (CNNs)
CNNs are variations of
multilayer perceptrons, designed to process data that come in the form of multiple arrays, e.g., [
23,
24,
25]. 1D, 2D, and 3D CNNs are used typically for processing signals/sequences, images/spectrograms, and video/volumetric images, respectively. There are four main components associated with CNNs, all of which exploit the properties of natural signals; these are local connections, shared weights, pooling, and the use of many layers.
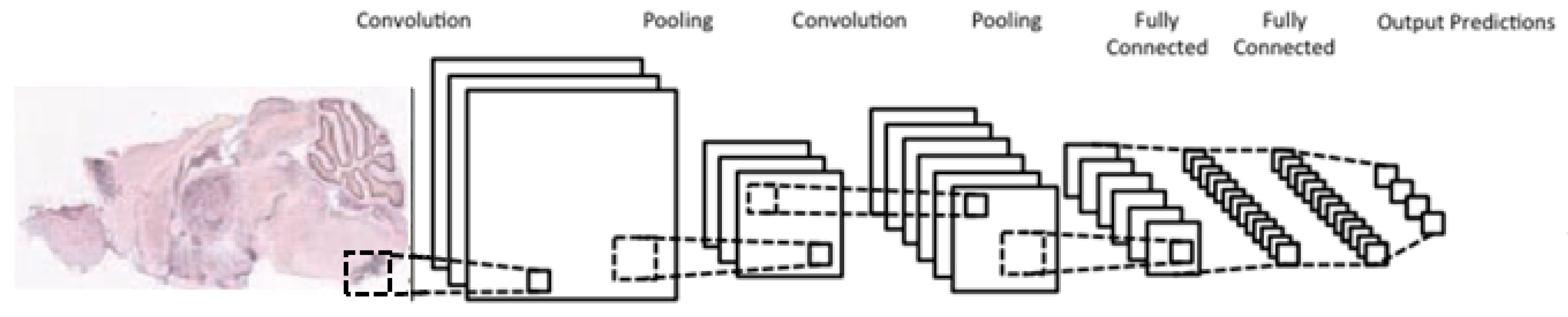
A typical CNN architecture (
Figure 5) is structured as a series of components from two types, convolutional layers and pooling layers. Overall, units in a convolutional layer are organized in feature maps, where each unit is connected to a local region of units in the feature maps of the previous layer, through a set of weights called a filter. This local weighted sum is then passed through an
activation function, such as
or
, which allows such networks to solve nontrivial problems. All units in a feature map share the same filter weights, while different feature maps in a layer use a different filter. The mathematical advantage is that the number of weights to be learned is not dependent on the number of units, but on the number of feature maps and the size of the filter. This is reasonable because in spatial data such as images, often local values are highly correlated, due to the fact that image statistics are invariant to location. In other words, if a pattern appears in one part of the image, it could appear anywhere in the image.
While the role of a convolutional layer is to detect locally connected features from the previous layer, the role of a pooling layer is to merge semantically similar features into one. Pooling layers subsample the data, thus reducing the representation size. For example, a typical pooling method, called max-pooling, selects only the maximum value of a local region of units in one (or more) feature maps (e.g., selects only the maximum value for each 2 × 2 region, thus decreasing the size by a factor of 4). Usually, two or three stages of convolution (using nonlinear functions) and pooling layers are stacked, followed by some fully-connected layers and a final classification layer. Designing a CNN to cope with the relative large size of our input images might be the answer, although it does not provide a solution to our second issue, namely the small number of training samples for each category.
2.4. Auto-Encoders (AEs)
CNNs are effective in a supervised framework [
20,
24,
25,
26,
27], provided a large training set is available. If only a small number of training samples is available, unsupervised pre-training methods, such as
restricted Boltzmann machines (RBM) [
28] or autoencoders [
29], have proven highly effective.
An AE is a neural network which sets the target values (of the output layer) to be equal to the input values, using hidden layers of smaller and smaller size, which comprise a bottleneck. Thus, an AE can be trained in an unsupervised manner, forcing the network to learn a higher-level representation of the input. One or more hidden layers of neurons are used between the input and output layers, where each layer is usually set to have fewer neurons than those in the input and output layers, thus creating a bottleneck structure. In this form, each input is first mapped to a hidden layer (smaller than the input layer), with the objective of reconstructing the original input at the output layer. Note that for a single hidden layer, the set of weights
w between the input layer and the hidden layer, called the “encoder layer”, and the set of weights
between the hidden layer and the output layer, called the “decoder layer”, can be tied (by setting
). Similarly, an AE with more than one hidden layer can maintain tied weights (A typical equation for a feedforward neural network is
, while for autoencoders with tied weights, the equation used is
. Setting
eliminates many degrees of freedom, which has its important advantages.) between the corresponding encoder and decoder layers. In any case, AEs are typically trained using backpropagation with stochastic gradient descent to reduce the reconstruction error [
30].
An improved approach, which outperforms basic autoencoders in many tasks, is due to
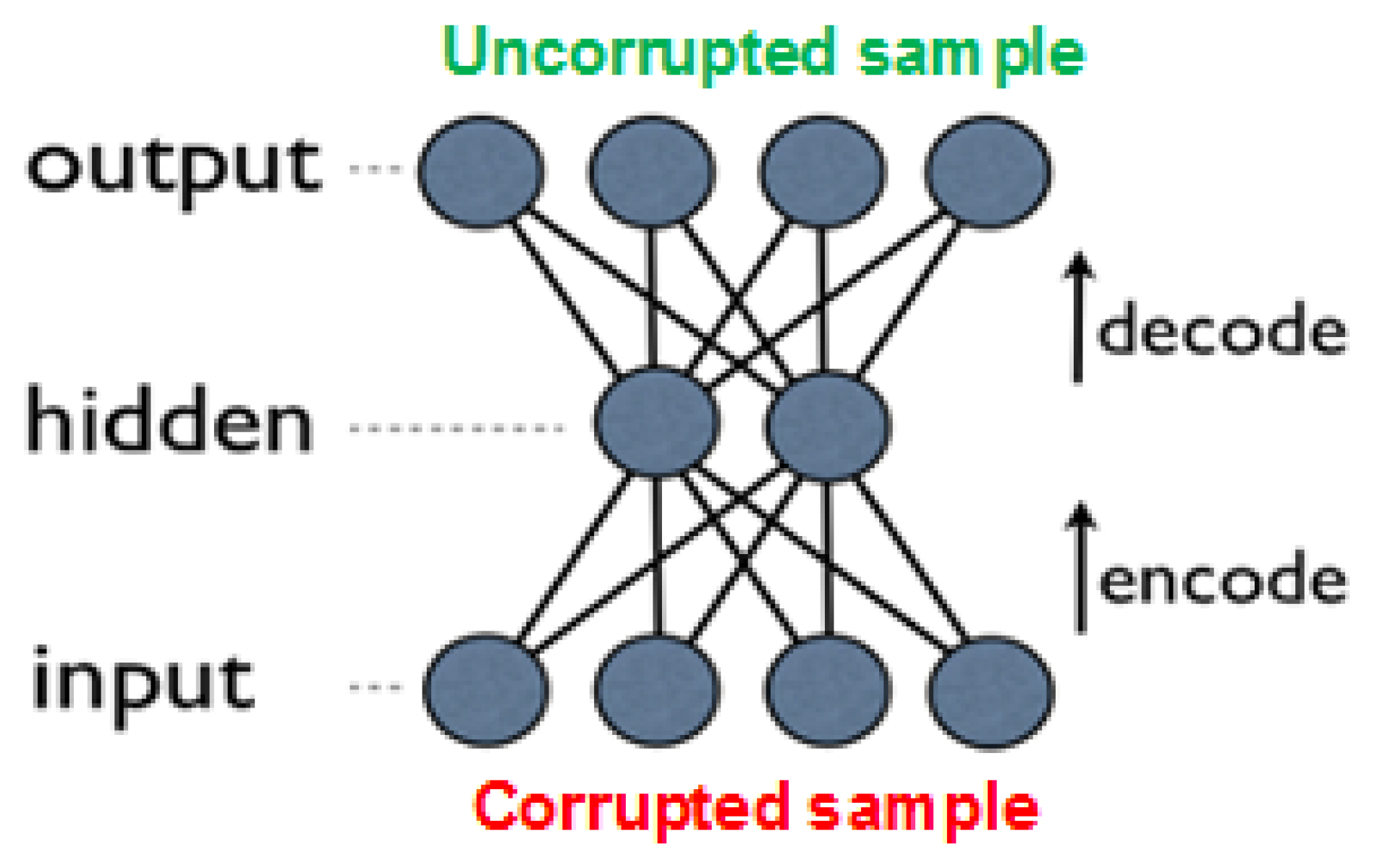
denoising autoencoders (DAEs) [
29,
31]. These are built as regular AEs, where each input is corrupted by added noise, or by setting to zero some portion of the values. Although the input sample is corrupted, the network’s objective is to produce the original (uncorrupted) values in the output layer (see
Figure 6). Forcing the network to recreate the uncorrupted values results in reduced network overfitting (also due to the fact that the network rarely receives the same input twice), and in extraction of more high-level features. Note that the noise is added only during training, while in prediction time the network is given the uncorrupted input.
For any autoencoder-based approach, once training is complete, the decoder layer(s) are removed, such that a given input is transferred through the network and yields a high-level representation of the data. In most implementations (such as ours), these representations can then be used for supervised classification.
In the next section, we present our convolutional autoencoder approach, which operates solely on raw pixel data. This supports our main goal, i.e., learning representations of given brain images to extract useful information more easily, when building classifiers or other predictors. The representations obtained are vectors, which can be used to solve a variety of problems, e.g., that of GO classification. We will consider a representation as promising, if it proves helpful for building accurate supervised classifiers for the biological categories in question.
2.5. Convolutional Autoencoders (CAEs)
CNNs and AEs can be combined to produce a CAE, which, as mentioned in [
32], is one of the most preferred architectures in deep learning. This may explain why several approaches involving the combination of these methods have been explored previously. One problem with AEs and DAEs is that both do not account for the local 2D image structure and thus may not be translational-invariant. Furthermore, when using fully-connected AEs, realistic input sizes may introduce redundancy in the parameters to be learned and increase their number significantly. However, CNNs discover repetitive localized features all over the input, such as in successful models like [
33,
34]. As with CNNs, the CAE weights are shared among all locations in the input, preserving spatial locality and reducing the number of parameters. A common convention for combining CNNs with AEs (or DAEs), which maintains the input size, is to have for each encoder layer a corresponding decoder layer, i.e., each convolutional layer would have a
deconvolutional layer, and each max-pooling layer would have an
unpooling layer that restores the original values lost by the max-pooling subsampling.
Deconvolutional layers are essentially the same as convolutional layers, and, similarly to standard autoencoders, they can either be learned or be set equal to (the transpose of) the original convolutional layers, as with tied weights in autoencoders.
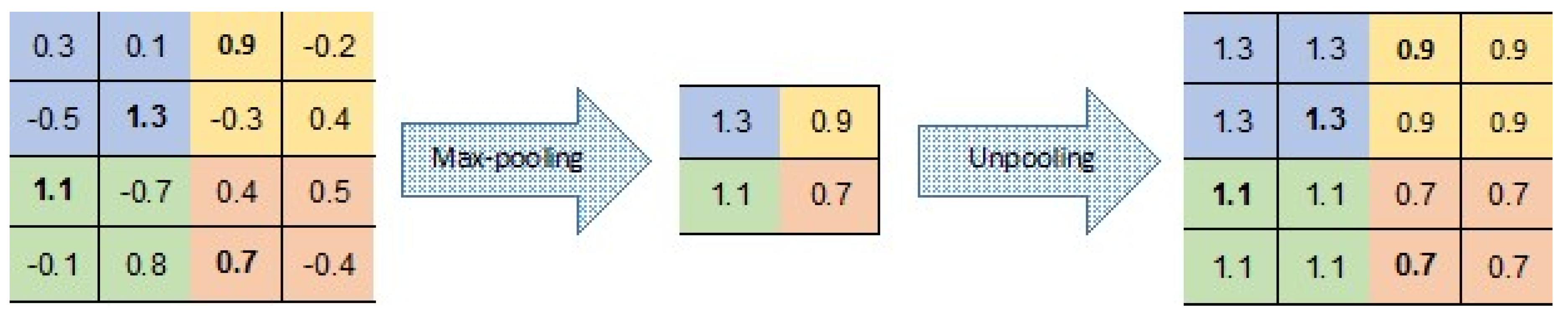
There are a number of variants to the
unpooling operation (see, e.g., [
35,
36,
37]). In our CAE, unpooling simply duplicates the same maximal value in the corresponding 2 × 2 window of the next layer (
Figure 7). This means that there is no need to record the locations of the maxima within each pooling region.
Similarly to an AE, after training a CAE, the unpooling and deconvolutional layers are removed. At this point, a neural network, composed from convolution and pooling layers, can be used to find a functional representation, as in our case, or initialize a supervised CNN. An example of a complete structure of a convolutional autoencoder is presented in
Figure 8.
Similarly to a DAE, a CAE with input corrupted by added noise is called a convolution denoising autoencoders (CDAE).
2.6. Challenges of Applying End-to-End Deep Learning for Annotating Gene Expression Patterns
In this section we discuss challenges present in applying end-to-end deep learning for functional representation and methods for overcoming them.
In the traditional approach to problems of this nature, raw data (e.g., pixels) are not fed directly into the training module, and, instead, a feature extraction phase is first performed, where raw data are converted into a list of features. When applying end-to-end deep learning, however, raw data are directly fed into the input layer of a deep neural network. The idea is that the neural network would perform implicit feature learning, and learn more complex and meaningful nonlinear features that would be superior to the handcrafted features by human experts.
While the results obtained due to deep learning represent major improvements over the traditional approach in nearly every domain, deep learning requires substantially larger amounts of training data. While in the traditional approach the model already receives useful features, and needs only to learn how to use those features for successful prediction, in deep learning, the features themselves need to be learned as well.
In the case of gene annotation of expression patterns, we only have thousands of images for training, which are not sufficient, by themselves, for obtaining optimal results. One successful approach in such a case is to use transfer learning, i.e., first train the neural network on a different dataset (for which ample data are available), and then use that pretrained neural network for training on the task at hand. The idea is that the neural network would learn to perform feature extraction by training it on the larger dataset, and then fine-tune the feature set for the desired task. This would work well assuming that the larger dataset and the target dataset have a similar sample distribution. (i.e., concepts learned from the larger dataset are transferable to the other).
Zeng et al. [
38] present such a transfer learning approach; in order to obtain a CNN for annotating, eventually, gene expression patterns, they first train a model from
OverFeat [
39] on natural images (during the pre-training phase), and then employ this pre-trained network for extracting features of ISH images. This rationale stems from recent studies of using
ImageNet data [
25] (an image dataset with thousands of categories and millions of labeled natural images) in training a CNN model, followed by feature extraction (by the model) from other datasets for obtaining overall promising performance.
Using the OverFeat model, Zeng et al. first resize all images to 231 × 231 pixels, as required by the model. Each ISH image is then processed by the CNN, extracting feature vectors only from the last layer in each stage. These vectors are flattened and concatenated into a single feature vector for each layer. Finally, to build the representation vector, features are extracted for each section separately and an element-wide maximum across feature vectors, from all sections of the same experiment of a gene expression, is computed. This global feature vector of size 10,521 represents the gene expression of a given ISH image. The representation is then used to perform gene expression pattern annotation, similarly to [
12], i.e., by training on
-regularized logistic regression classifiers. The overall average AUC obtained was
, compared with
, due to a similar bag-of-words approach presented in [
12].
Even though the results of Zeng et al. show some improvement obtained by transfer learning, these gains are limited, since the ImageNet dataset they have used for pretraining contains natural images, which are vastly different from images intended for gene annotation. In other words, pretraining a neural network on real-world natural images might not be entirely beneficial for its subsequent training for the gene attribution task in question.
In the next section, we present our novel method, which uses pretraining on the same sample distribution (as in [
12]), via our proposed unsupervised learning. This pretraining feature learning will prove more effective for the desired task, in terms of the eventual accuracy gained.
3. Proposed Approach
We now discuss our approach for generating a functional representation of ISH images. Deep learning methods have proven recently very successful in finding compact feature representations for many tasks. These networks are trained extensively, in an attempt to capture object representations that are invariant to changes in location, and to some extent also to scale, orientation, lighting, etc. CNNs and AEs, as described in the Background, achieve small errors when used in supervised and unsupervised learning modes, respectively. Challenging tasks tackled in a supervised learning mode are, e.g., ImageNet [
25] and large-scale image recognition [
40]; in an unsupervised mode, such tasks include, e.g., mimicking faithfully biological measurements of the visual areas [
41], building class-specific feature detectors from unlabeled images [
42], or creating short binary codes for images based on their content, using deep autoencoders according to Krizhevsky and Hinton [
20].
Our research follows [
12], but with a modified approach for learning the gene representation and training the GO classifiers. We use CNNs and CAEs to learn the representation, and then use the same classification method as in [
12] to measure the classification accuracy (that obviously depends on our different representation). The scheme representing the work flow of [
12] is presented in
Figure 9, while our work flow is presented in
Figure 10 (see
Section 3.1).
We applied our method to the genomic set of neural mouse ISH images available from the Allen Brain Atlas. This dataset contains whole-brain, expression-masked images of gene expression measured using ISH. For each gene, a different adult mouse brain was sliced into 25 slices, each 100 mm thick. We used the most medial slice for each series. In this way, the expression was measured for the entire mouse genome, for a total of 15,000 genes. That is, the dataset includes 16,351 images representing 15,612 genes. Each image reveals highly-complex patterns of gene expression varying on multiple scales.
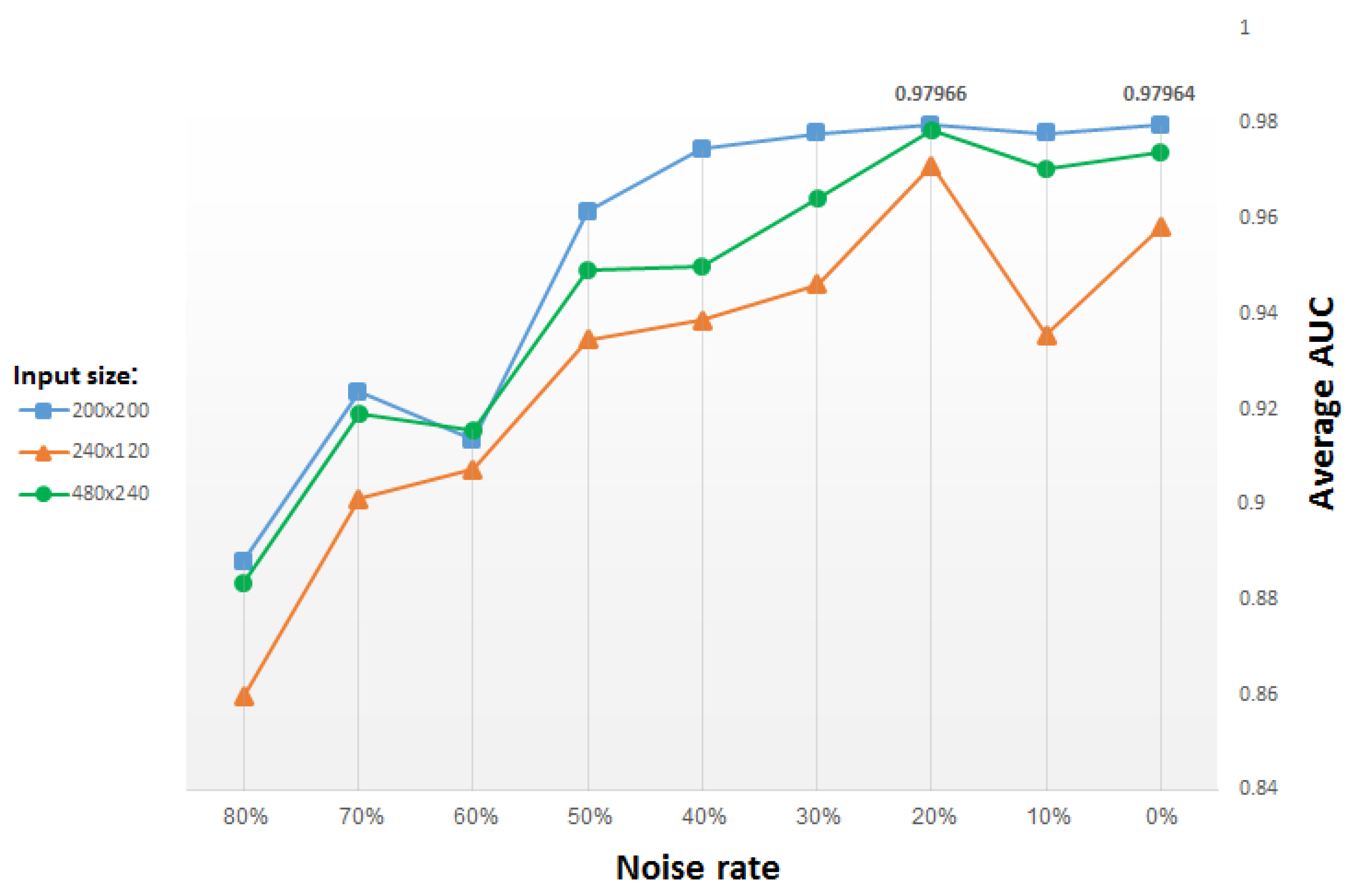
To learn detectors of functional GO categories, using the representation obtained for every gene, we introduce a novel CDAE architecture for the problem in question, to find the compact representation of each ISH image. The CDAE includes pooling and unpooling layers, as well as convolution and deconvolutional layers, as was explained in the Background. The input is corrupted for denoising purposes, and should be normalized, in principle, by subtracting its mean from each pixel value and dividing by its standard deviation. As for any AE, layers are trained in an unsupervised manner, using backpropagation for updating the network’s weights; this is a well-known procedure for feature extraction to gain a compact representation. After the CDAE is trained, the deconvolution and unpooling layers are removed, so that the middle (and smallest) hidden layer becomes the output layer. Feeding this network a single ISH image at a time, the resulting output serves as the compact representation of this image, i.e., the representation of the corresponding gene. These representations are vectors which can then be used to solve a variety of problems, including GO classification.
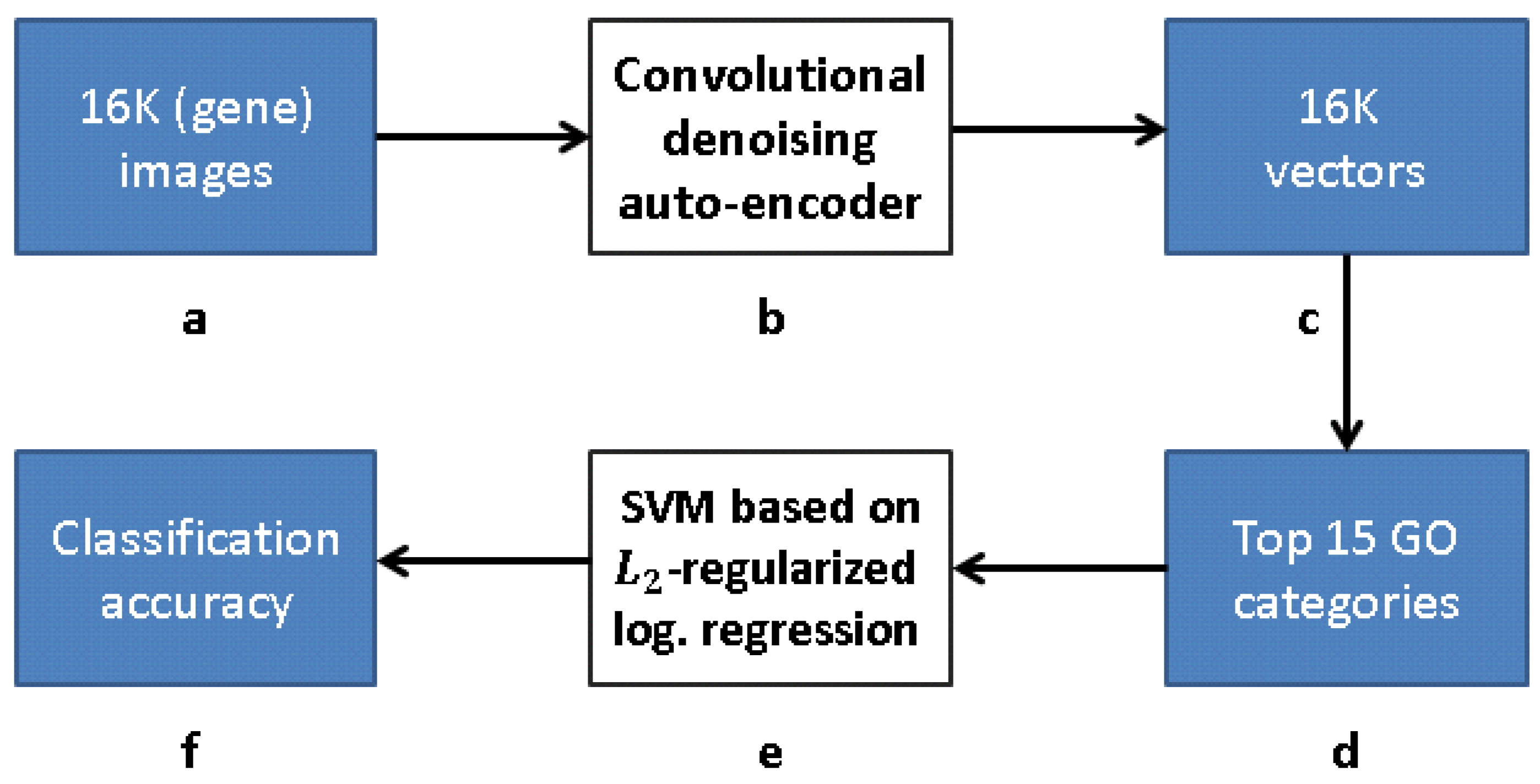
3.1. CDAE for GO Classification
Figure 10 depicts a framework for capturing the representation similar to FuncISH. Recall that a SIFT-based module was used in [
12] for feature extraction. Our scheme learns, alternatively, a CDAE-based representation, before carrying out the GO classification.
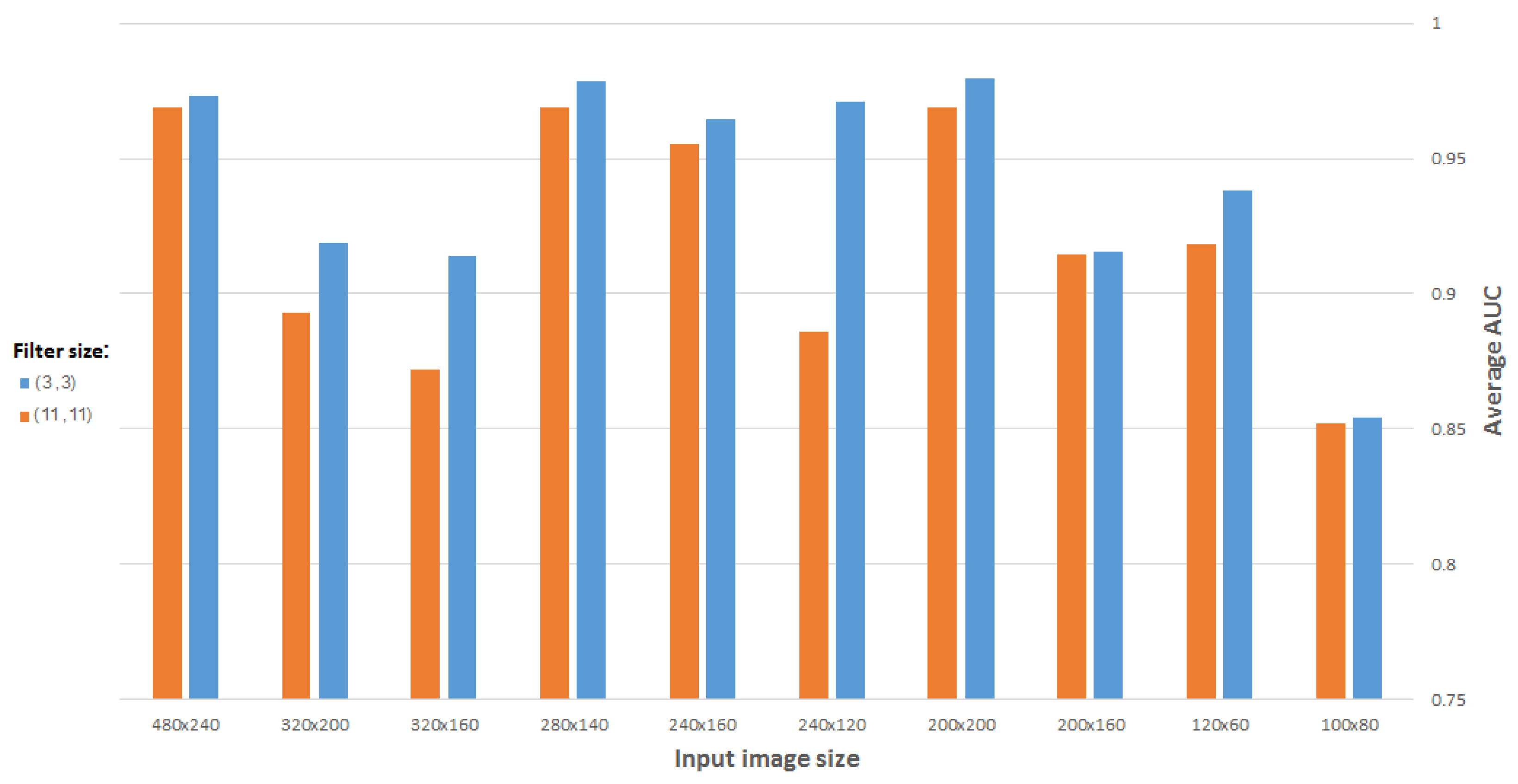
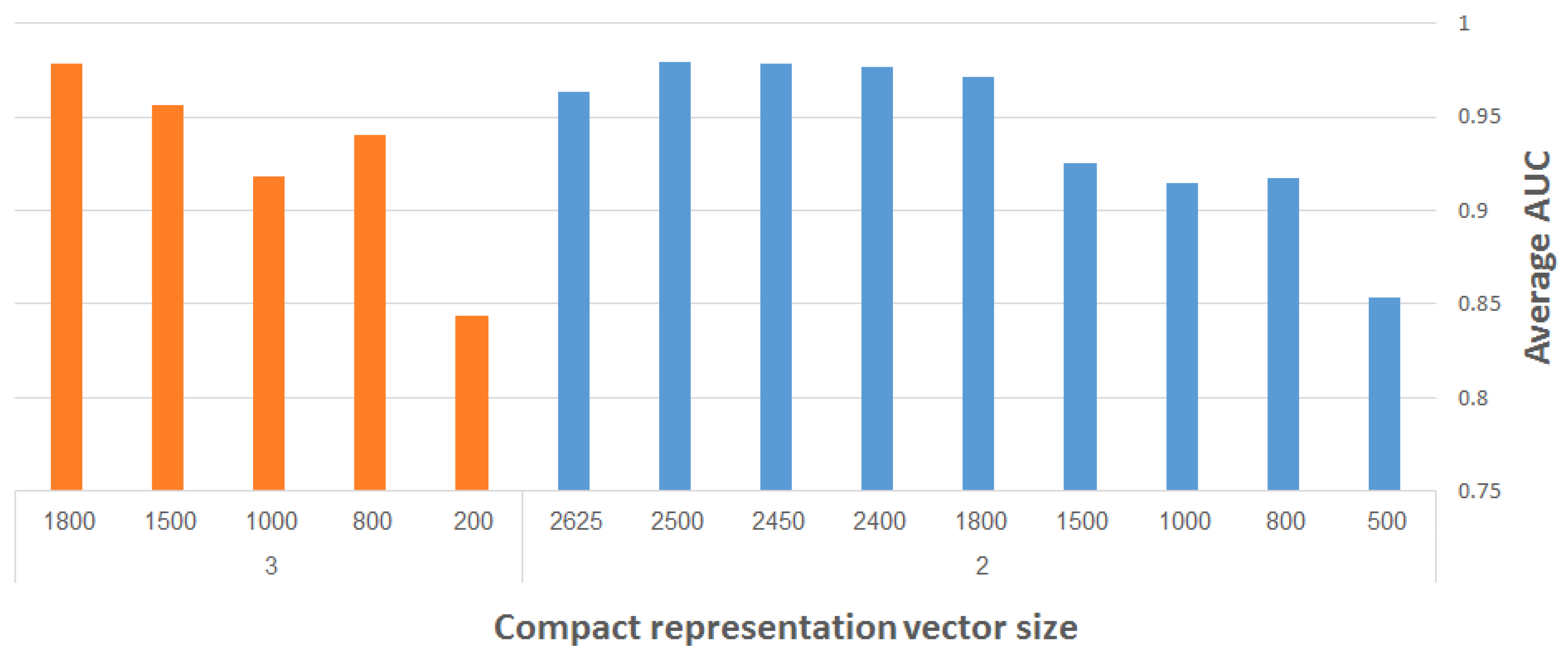
For the unsupervised training of our CDAE we use the genomic set of neural mouse ISH images available from the Allen Brain Atlas, which includes 16,351 images representing 15,612 genes. These JPEG images have an average resolution of 16,000 × 8000 pixels. To obtain a representation vector of size ∼2000, the images were resampled initially to 960 × 480 pixels, and were eventually downsampled (via successive max unpooling operations) to 60 × 30 pixels. Despite this heavy down-sampling, we believe that local and global patterns of expression are still preserved to a sufficient extent, in the sense that significant differences between ISH images of different genes can still be captured, thus rendering their representation at the above spatial resolution as meaningful. This working assumption is supported by the down-sampling done also in [
12], which succeeded in generating adequate representation, as well as by our own results, as detailed below.
Regarding the supervised GO classification, we used the
-regularized logistic regression classifier as described in [
12]; specifically, a two-phase
5-fold cross validation was invoked, per each category, for training the classifier and tuning the logistic regression regularization hyper-parameter. Training requires careful consideration, in this case, due to the highly-imbalanced nature of the training sets. While in [
12] the full set of 16K gene images was split into five non-overlapping equal sets (without controlling the number of “positives” in each split), we split the “positives” into five non-overlapping equal subsets and the “negatives” into five non-overlapping equal subsets, and combined a different positive subset with each negative subset to obtain five non-overlapping equal-sized subsets, per each category. We then trained the classifiers on four of these subsets, and tested the performance on the fifth. This procedure was repeated five times, each time with a different test subset.
5. Conclusions
Many machine learning algorithms have been designed recently to predict GO annotations. For the task of learning meaningful functional representations of mammalian neural images, we employed in this paper deep learning techniques, and found convolutional denoising autoencoders to be very effective. Specifically, the presented scheme for feature learning of functional GO categories improved the previous state-of-the-art classification accuracy from an average AUC of 0.92 to 0.997, i.e., a 96% reduction in error rate. In fact, we managed to classify 86% of the categories with an exemplary AUC of 1.
Furthermore, we demonstrated how to reduce the vector dimensionality by 10% compared to the SIFT vectors used in [
12], with very little degradation in accuracy.
Our results attest to the advantages of deep convolutional autoencoders, and especially the novel architecture as was applied here, for extracting meaningful information from very high resolution images and highly complex anatomical structures. Until gene product functions of all species are discovered, the use of CDAEs may well continue to serve in the ongoing design of novel biological experiments.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













