1. Introduction
In this paper, the densest
k-subgraph (DkS) problem [
1,
2] is considered. For a given graph
G and a parameter
k, the DkS problem consists in finding a maximal average degree in the subgraph induced by the set of
k vertices. This problem was first introduced by Corneil and Perl as a natural generalization of the maximum clique problem [
3]. It is NP-hard on restricted graph classes such as chordal graphs [
3], bipartite graphs [
3] and planar graphs [
4]. The DkS problem is a classical problem of combinatorial optimization and arises in several applications, such as facility location [
5], community detection in social networks, identifying protein families and molecular complexes in protein–protein interaction networks [
6], etc. Since the DkS problem is in general NP-hard, there are a few approximation methods [
7,
8,
9] for solving it. It is well-known that semidefinite relaxation is a powerful and computationally efficient approximation technique for solving a host of very difficult optimization problems, for instance, the max-cut problem [
10] and the boolean quadratic programming problem [
11]. It also has been at the center of some of the very exciting developments in the area of signal processing [
12,
13].
Optimization problems over the doubly nonnegative cone arise, for example, as a strengthening of the Lovasz-
-number for approximating the largest clique in a graph [
14]. The recent work by Burer [
15] stimulated the interest in optimization problems over the completely positive cone. A tractable approximation to such problem being defined as an optimization problem over the doubly nonnegative cone. By using the technique of doubly nonnegative relaxation, Bai and Guo proposed an effective and promising method for solving multiple objective quadratic programming problems in [
16]. For more details and developments of this technique, one may refer to [
17,
18,
19] and the references therein. It is worth pointing out that the cone of doubly nonnegative matrices is a subset of a positive semidefinite matrices cone. Thus, the doubly nonnegative relaxation is more promising than the basic semidefinite relaxation. Moreover, such relaxation problems can be efficiently solved by some popular package software.
In this paper, motivated by the idea of doubly nonnegative relaxation and semidefinite relaxation, the two relaxation methods for solving the DkS problem are presented. One is doubly nonnegative relaxation, and the other is semidefinite relaxation with tighter relaxation. Furthermore, we prove that the two relaxation problems are equivalent under the suitable conditions. Some approximation accuracy results about these relaxation problems are also given. Finally, we report some numerical examples to show the comparison of the two relaxation problems. The numerical results show that the doubly nonnegative relaxation is more promising than the semidefinite relaxation for solving some DkS problems.
The paper is organized as follows: we present doubly nonnegative relaxation and a new semidefinite relaxation with tighter relaxation for the DkS problem in
Section 2.1 and
Section 2.2, respectively. In
Section 3, we prove that the two new relaxations proposed in
Section 2 are equivalent. In
Section 4, some approximation accuracy results for the proposed relaxation problems are given. Some comparative numerical results are reported in
Section 5 to show the efficiency of the proposed new relaxations. Moreover, some concluding remarks are given in
Section 6.
2. Two Relaxations for the Densest -Subgraph Problem
First of all, the definition of the densest k-subgraph (DkS) problem is given as follows.
Definition 1 (Densest
k-subgraph)
. For a given graph , where V is the vertex set and E is the edge set. The DkS problem on is the problem of finding a vertex subset of V of size k with the maximum induced average degree.
Given a symmetric
matrix
, the weighted graph with vertex set
associates with
A in such a way: the edge
with the weight
is introduced in the graph. Then,
A is interpreted as the weighted adjacency matrix of the graph with the vertex set
. Based on Definition 1, the DkS problem consists of determining a subset
consisting of
k vertices such that the total weight of edges in the subgraph spanned by
is maximized. To select subgraphs, assign a decision variable
for each node (
if the node is taken, and
if the node is not). The weight of the subgraph given by
y is
. Thus, the DkS problem can be phrased as the
quadratic problem
It is known that the (DkS) problem is NP-hard [
20], even though
A is assumed to be positive semidefinite, since the feasible space of the (DkS) problem is nonconvex. For solving this problem efficiently, we present the two new relaxations for the (DkS) problem in the following subsections, based on the idea of approximation methods.
2.1. Doubly Nonnegative Relaxation
Note that the quadratic term
in the (DkS) problem can also be expressed as
. By introducing a new variable
and taking lifting techniques, we could reformulate the (DkS) problem into the following completely positive programming problem:
where
is defined as follows:
and for some finite vectors
.
The following theorem shows the relationship between the (DkS) problem and the
problem. Its proof is similar to the one of Theorem 2.6 in [
15] and is omitted here.
Theorem 1. (i) The problem and the problem have the same optimal values of objective functions, i.e., ; (ii) if is an optimal solution for the problem; then, is in the convex hull of optimal solutions for the problem.
On one hand, according to Definition 2, it is obviously that the
problem is equivalent to the
problem. On the other hand, in view of the definition of convex cone,
is a closed convex cone, and is called completely positive matrices cone. Thus, the
problem is convex. However, since checking whether or not a given matrix belongs to
is NP-hard, which has been shown by Dickinson and Gijen in [
21], the
problem is still NP-hard. Thus,
has to be replaced or approximated by some computable cones. For example,
and
are both computable cones; furthermore,
is also a computable cone.
It is worth mentioning that Diananda’s decomposition theorem [
22] can be reformulated as follows, and its proof can be found in it.
Theorem 2. holds for all n. If , then .
The matrices cone
is sometimes called “doubly nonnegative matrices cone”. Of course, in dimension
, there are matrices which are doubly nonnegative but not completely positive, the counterexample can be seen in [
23].
By using Theorem 2, the
problem can be relaxed to the problem
which is called the doubly nonnegative relaxation for the (DkS) problem. Some explanations are given below for this relaxation problem.
Remark 1. Obviously, the problem has a linear objective function and the linear constraints as well as a convex conic constraint, so it is a linear conic programming problem. Meanwhile, it is notable that and the types of variables in both the sets are the same, which further implies that the problem could be solved by some popular package softwares for solving semidefinite programs.
2.2. New Semidefinite Relaxation
It is well-known that semidefinite relaxation is a powerful approximation technique for solving a host of combinatorial optimization problems. In this subsection, we present a new semidefinite relaxation with tighter bound for the (DkS) problem.
The idea of the standard lifting is to introduce the symmetric matrix of rank one
. With the help of
Y, we could express the integer constraints
as
, and the quadratic objective function
as
. Thus, we can get the following equivalent formulation of the (DkS) problem
Notice then that the hard constraint in the above problem is the constraint
, which is moreover difficult to handle. Thus, we can relax the above problem to the following standard semidefinite relaxation problem by dropping the rank-one constraint
For the problem, some remarks are given below.
Remark 2. (i) Obviously, the problem is also a linear conic programming problem, it has the same objective function and the equality constraints with the problem. The only difference between the problem and the problem is that the problem has nonnegative constraints more than the problem.
(ii) Since , it holds that from Remark 2 (i). Thus, the bound of the problem is not larger than the one of the problem. In Section 5, we implement some numerical experiments to show the comparison between the problem and the problem from the computational point of view. Note that the (DkS) problem is inhomogeneous, but we can homogenize it as follows. First, let
in the (DkS) problem, it follows that
. Thus, the change of variable
gives the following equivalent formulation of the (DkS) problem:
Then, with the introduction of the extra variable
t, the (DkS) problem can be expressed as a homogeneous problem
where
is a zero matrix with appropriate dimension.
Remark 3. The problem is equivalent to the problem in the following sense: if is an optimal solution to the problem, then (resp. ) is an optimal solution to the problem with (resp. ).
By using the standard semidefinite relaxation technique, and letting let
, the
problem can be relaxed to the following problem:
Moreover, again by using the standard semidefinite relaxation technique directly to the
problem, we have from
,
The
problem and the
problem are both standard semidefinite relaxation problems for the (DkS) problem. The upshot of the formulations of these two relaxation problems is that they can be solved very conveniently and efficiently, to some arbitrary accuracy, by some readily available software packages, such as
CVX. Note that there is only one difference between these two relaxation problems, i.e., the
problem has one equality constraint more than the
problem. In
Section 5, some comparative numerical results are reported to show the effectiveness of these two relaxations problems for solving some random (DkS) problems, respectively.
It is worth noting that the constraint
in the
problem further implies
always holds. Thus, adding Formula (
1) to the (
) problem, we come up with the following new semidefinite relaxation problem
Obviously, the relationship holds since the feasible set of the problem is the subset of the feasible set of the problem and the two problems have the same objective function.
Up to now, three new semidefinite relaxation problems for the (DkS) problem are established, i.e., the problem, the () problem and the problem, in which the upper bound of the problem is more promising than the one of the () problem. In the following sections, we will further investigate the relationship between these three problems with the problem.
3. The Equivalence between the Relaxation Problems
The previous section establishes the doubly nonnegative relaxation (i.e., the problem) and the semidefinite relaxation with tighter bound (i.e., the problem) for the (DkS) problem. Note that the problem has n inequality constraints more than the problem. In this section, we will prove the equivalence between the two relaxations. First of all, the definition of the equivalence of two optimization problems is given as follows.
Definition 2. Two problems P1 and P2 are called equivalent if they satisfy the following two conditions:
(i) .
(ii) If from a solution of P1, then a solution of P2 is readily found, and vice versa.
In order to establish the equivalence for the
problem and the
problem, a crucial theorem is given below and the details of its proof can be seen in [
24] (Appendix A.5.5).
Theorem 3 (Schur Complement)
. Let matrix is partitioned as If , the matrix is called the Schur complement of D in M. Then, the following relations hold:
(i) if and only if and .
(ii) If , then if and only if .
To the end, by using Definition 2 and Theorem 3, we have the following main equivalence theorem.
Theorem 4. Suppose that the feasible sets and are both nonempty. Then, the problem and the problem are equivalent.
Proof. First of all, we prove that .
Suppose that
is an optimal solution of the
problem, and let
Directly from
and Equation (
2), we have
By Equation (
2) and
, it holds that
Since
, Equation (
2) further implies that
From
for all
, it holds that
Combining with Equation (
5), it is true that from Formula (
6)
By Theorem 3 (ii) and Equation (
2), it follows that
i.e.,
From Equations (
3), (
4) and (
6)–(
8), we have
defined by Equation (
2) is a feasible solution of the
problem. Moreover, again from Equation (
2), we obtain
i.e.,
.
Conversely, given an optimal solution
to the
problem, and let
Since
, Equation (
9) further implies that
From Equation (
9) and
, it follows that
Again from Equation (
9) and
, it is true that
From Equation (
9) and Theorem 3 (ii), it holds that
By Equations (
11)–(
14), we can conclude that
defined by Equation (
9) is a feasible solution of the
problem. Furthermore, we have
i.e.,
.
Summarizing the analysis above, we obtain
. From Equations (
2) and (
9), we observe that
defined by Equation (
2) is an optimal solution for the
problem and
defined by Equation (
9) is also an optimal solution for the
problem, respectively. According to Definition 2, we conclude that the
problem and the
problem are equivalent. ☐
The above Theorem 4 shows that . Note that the problem has n inequality constraints more than the problem, thus the computational cost of solving problem may be greater than that of the problem.
4. The Approximation Accuracy
The above section shows that the problem is equivalent to the problem which has the tighter upper bound compared to the problem (see Theorem 4). In this section, we further investigate the approximation accuracy of the problem for solving the (DkS) problem, comparing with the standard semidefinite relaxation problems which was proposed in the above sections, under some conditions.
To simplify the expression, we denote
by
N. First of all, note that, if
, then the
problem is simplified to the following problem:
and the
problem can be simplified as follows:
Combining Theorem 3 in [
25] with the corresponding known approximation accuracy of semidefinite relaxation for some quadratic programming problems [
26], we immediately have that the following theorem holds.
Theorem 5. If , then we haveandfor . Moreover, if and , we further haveandhold. In the following analysis, we assume that
. We first observe that
since the
problem is the homogeneous problem for the
problem. In addition, note that the constraint
in the
problem can be relaxed to the quadratic form
. Thus, the
problem can be relaxed to
which can further be relaxed to the standard semidefinite programming problem
Obviously,
implies that
, i.e.,
, but we could not obtain
from
. These results further imply that
Similar to the Theorem 4.2 in [
27], we have that the following approximation accuracy theorem holds.
Theorem 6. .
Up to now, we not only establish the equivalence between the
problem and the
problem, but also some approximation accuracy results about the
problem and some standard semidefinite relaxation problems are given. In the following Section
5, we will implement some numerical experiments to give a flavour of the actual behaviour of the
problem and some semidefinite relaxation problems.
5. Numerical Experiments
In this section, some random (DkS) examples are tested to show the efficiency of the proposed relaxation problems. These relaxation problems are all solved by
CVX [
28], which is implemented by using MATLAB R2010a on the Windows XP platform, and on a PC with 2.53 GHz CPU. The corresponding comparative numerical results are reported in the following parts.
To give a flavour of the behaviour of the above relaxation problems, we consider results for the following test examples. The data of the test examples are given in
Table 1.
The first column of
Table 1 denotes the name of the test examples,
n and
k stand for the number of vertices of the given graph and the finding subgraph, respectively. The last column denotes the procedures for generating the coefficient matrices
A in the (DkS) problem. The more detailed explanations for the procedures are given as follows:
• P25. 50 random examples are generated from the ‘seed = 1,2,…,50’. The corresponding coefficient matrices A of order with integer weights are drawn from .
• P30. This example is generated by the MATLAB function randn from the ‘seed = 2012’. The elements of A satisfy the standard normal distribution.
• P40. This example is generated by MATLAB function rand from the ‘seed = 2017’. The elements of A satisfy the standard uniform distribution on the interval .
• P50. We generate 50 examples of order from the ‘seed = 2001,2002,…,2050’. For each coefficient matrix of these examples, half of the entries are randomly set to zero, and the remaining ones are chosen from .
• P60. This example is generated by MATLAB function rand from the ‘seed = 2020’. The elements of A are drawn from .
• P80. This example is generated by MATLAB function rand from the ‘seed = 2023’. The coefficient matrix A of order with integer weights drawn from .
First of all, the performances of the
problem and the
problem as well as the
problem, for solving P25 and P50, are compared. We use the performance profiles described in Dolan and Moré’s paper [
29]. Our profiles are based on optimal values (i.e., average degree) and the number of iterations of these relaxation problems. The
Cumulative Probability denotes the cumulative distribution function for the performance ratio within a factor
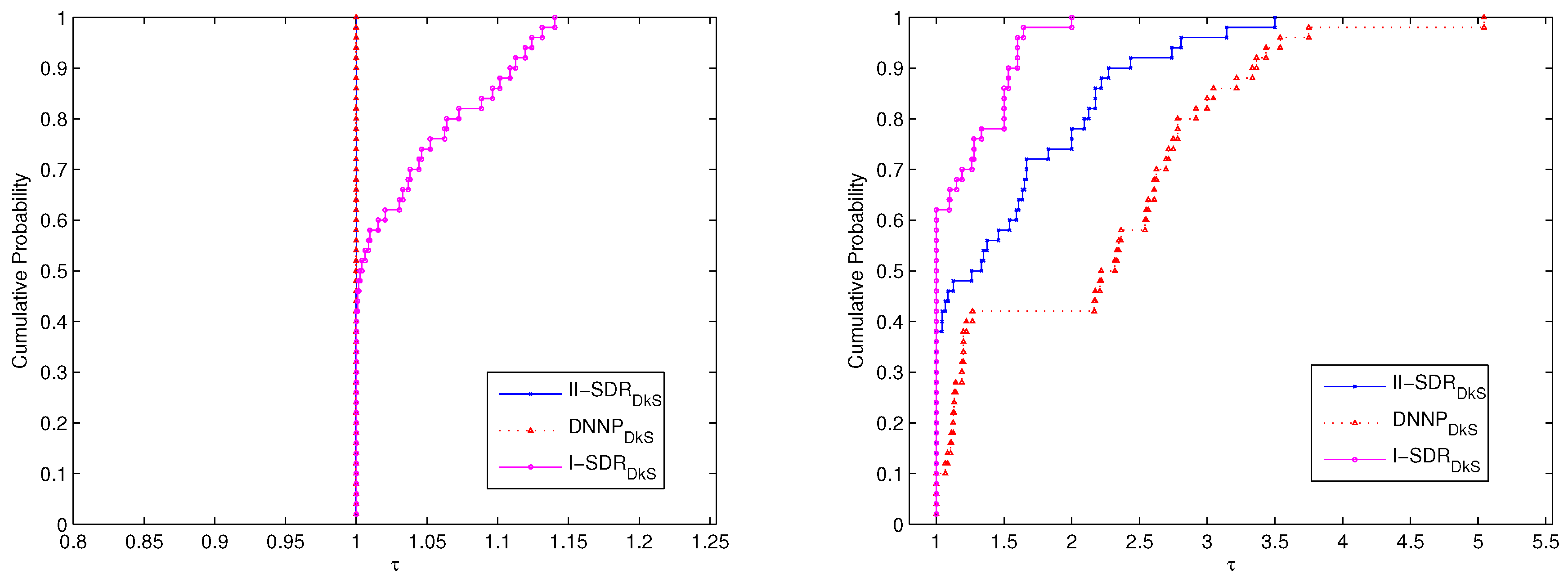
, i.e., is the probability that the solver will win over the rest of the solvers. The corresponding comparative results of performance are shown in
Figure 1 and
Figure 2.
The comparative results for P25 are shown in
Figure 1. It is obvious that the
problem and the
problem have the same performance, which is a bit better than that of the
problem from the viewpoint of optimal values. In view of the number of iterations, the performance of the
problem is the best, and the performance of the
problem is better than that of the
problem.
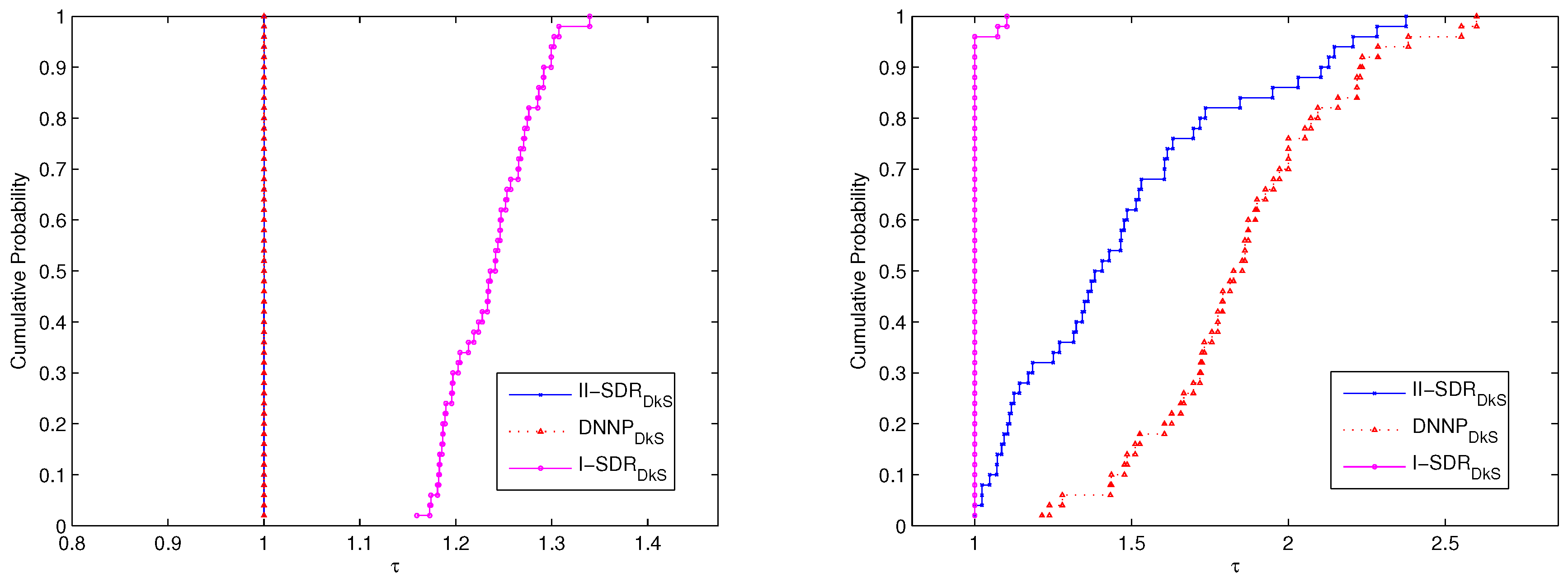
The performance of the three relaxation problems for solving P50 is shown in
Figure 2. The results show that the performance of the
problem is the same as that of the
problem; they are both much better than that of the
problem in view of optimal values—although the performance of the
problem is better than the one of the
problem and the
problem from the viewpoint of the number of iterations.
All of results show in
Figure 1 and
Figure 2 further imply that the
problem and the
problem can generate more promising bounds for solving P25 and P50, compared with the
problem, while the number of iterations is a bit more. Moreover, the
problem and the
problem have the same performance based on optimal values, although the performance of the
problem is better than that of the
problem from the viewpoint of the number of iterations, for solving P25 and P50.
In order to further show the computational efficiency of the
problem, which is compared with the
problem and some other types of semidefinite relaxation problems proposed in [
30], for solving some (DkS) problems. The test examples A50 and A100 are chosen from [
30]. (R-20), (R-24) and (R-MET) denote the three semidefinite relaxation problems proposed in [
30], respectively. The corresponding numerical results are shown in
Table 2, where “−” means that the corresponding information about the number of iterations is not given in [
30]. The results show that the computational efficiency of the
problem is better than the one of the
problem from the viewpoints of optimal values and number of iterations, respectively. Note that the performance of the
problem and the
problem are both much better than that of
and
. Moreover, the performance of the
problem is more competitive with
for solving these two problems.
Finally, we further compare the efficiency of the
,
,
and
problems, for solving examples P30, P40, P60 and P80. The comparative results are shown in
Table 3. The results signify that the efficiency of the
problem is always better than that of the
problem from the viewpoint of optimal values and the number of iterations as well as CPU time, respectively, for solving these examples. The performance of the
problem and the
problem are almost the same for solving these examples. Moreover, note that the optimal value of the
problem for solving P80 is larger than that of the
problem. Thus, we can conclude that it may be more promising to use the
problem than to use the
problem for solving some specific (DkS) problems in practice.





{kind=link}
{kind=link}