Dissipation in Non-Steady State Regulatory Circuits

Abstract
1. Introduction
2. Model
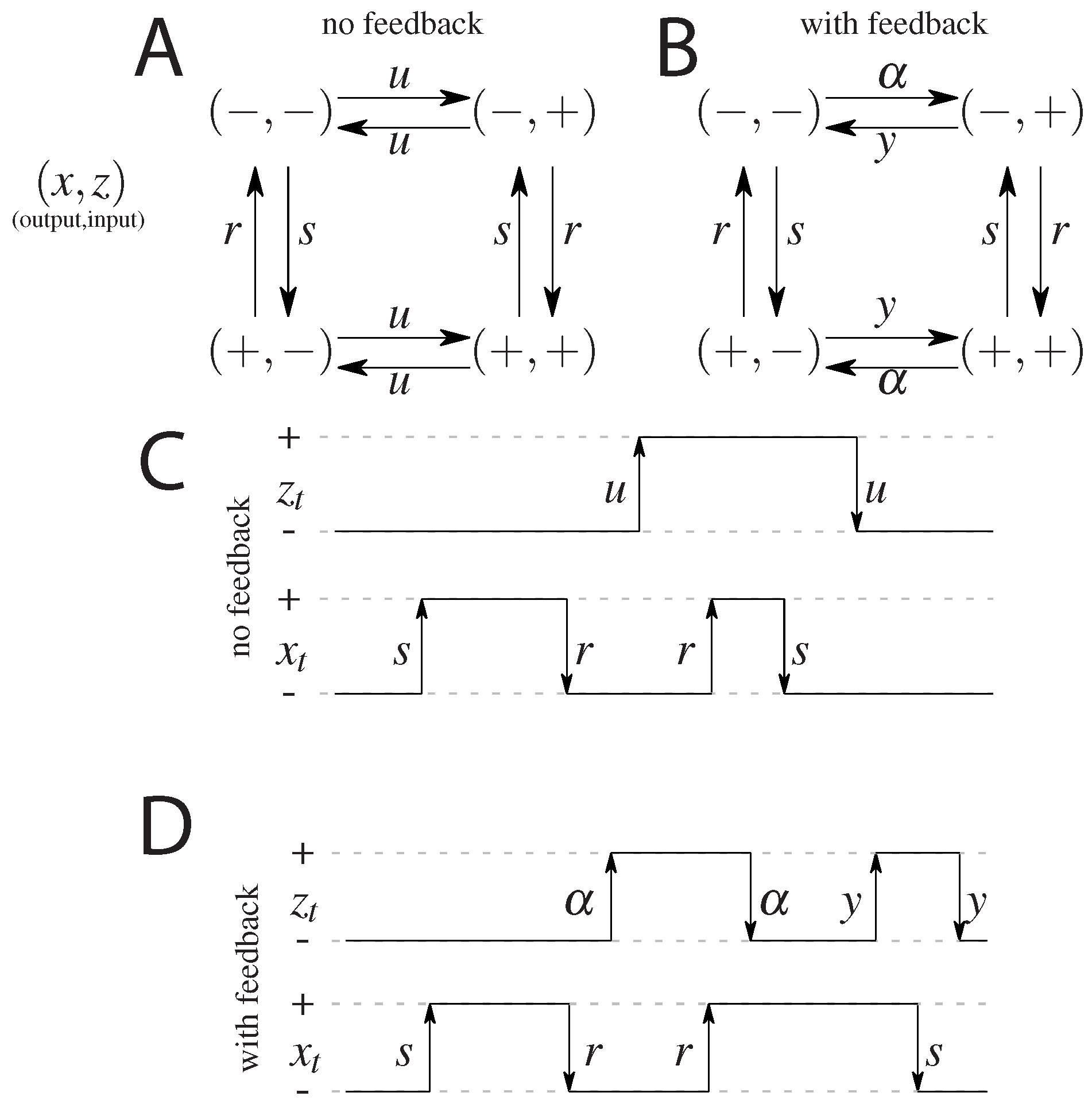
2.1. Model without Feedback: S and
2.2. Models with Feedback: F and
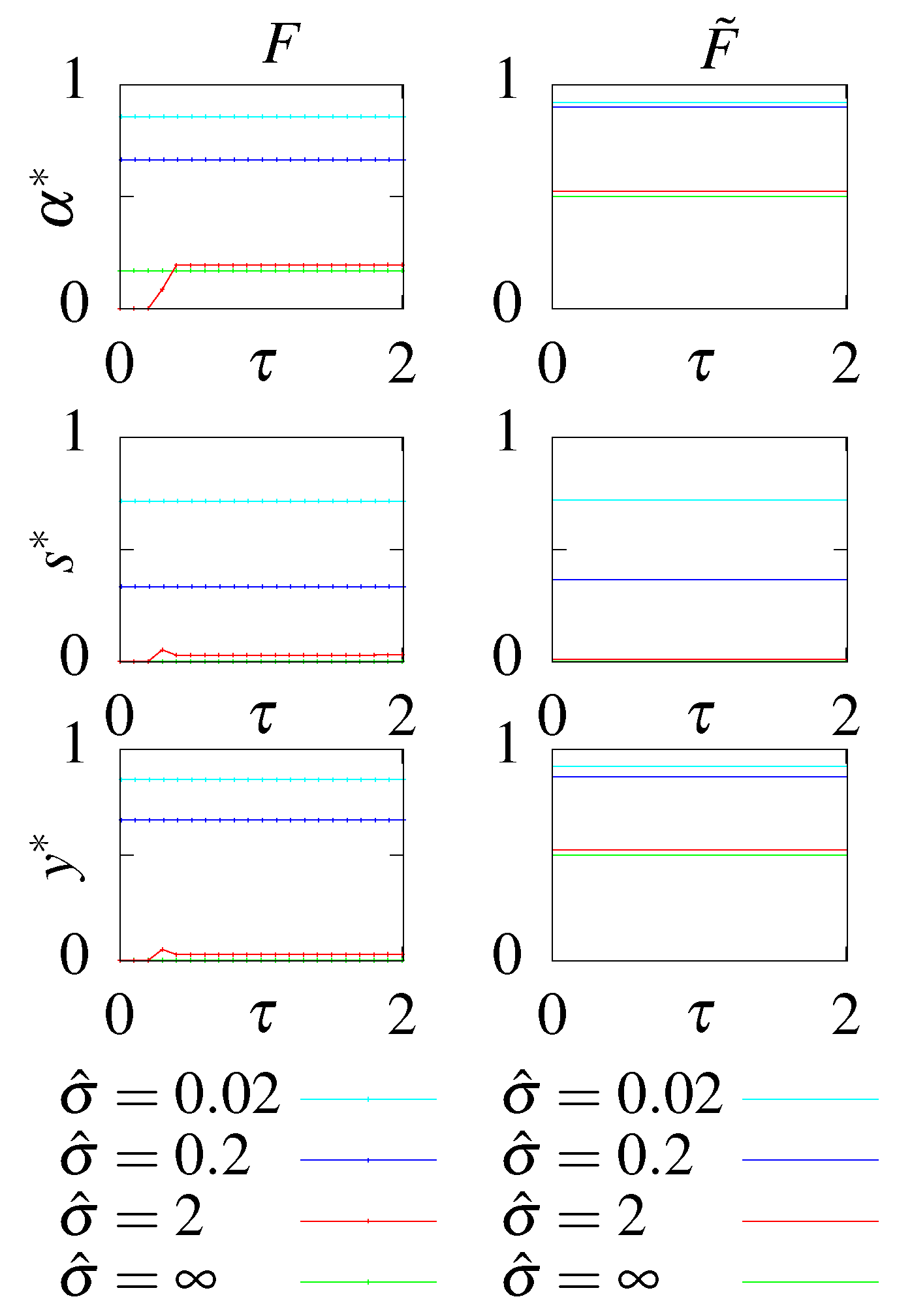
- S - no feedback, stationary initial condition;
- - no feedback, optimal initial condition;
- F - with feedback, stationary initial condition;
- - with feedback, optimal initial condition.
3. Information
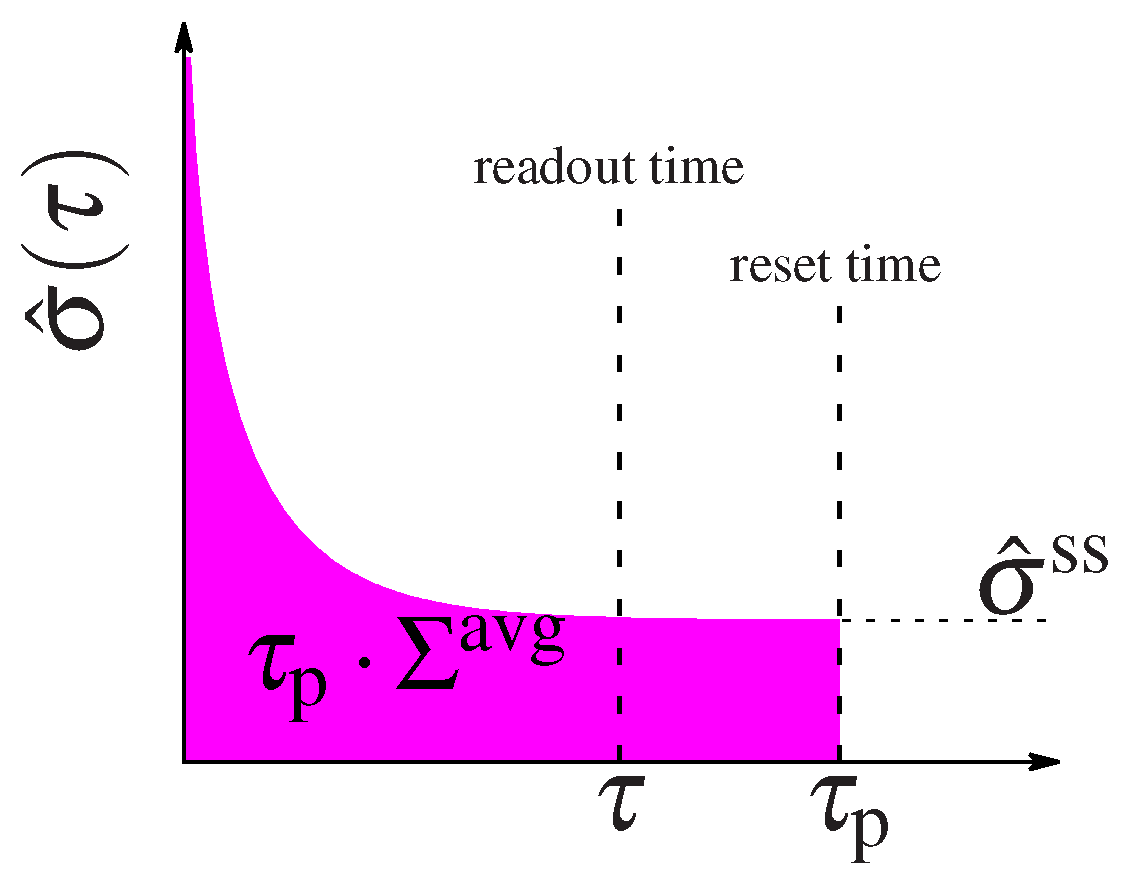
4. Non-Equilibrium Dissipation
5. Setup of the Optimization
6. Results
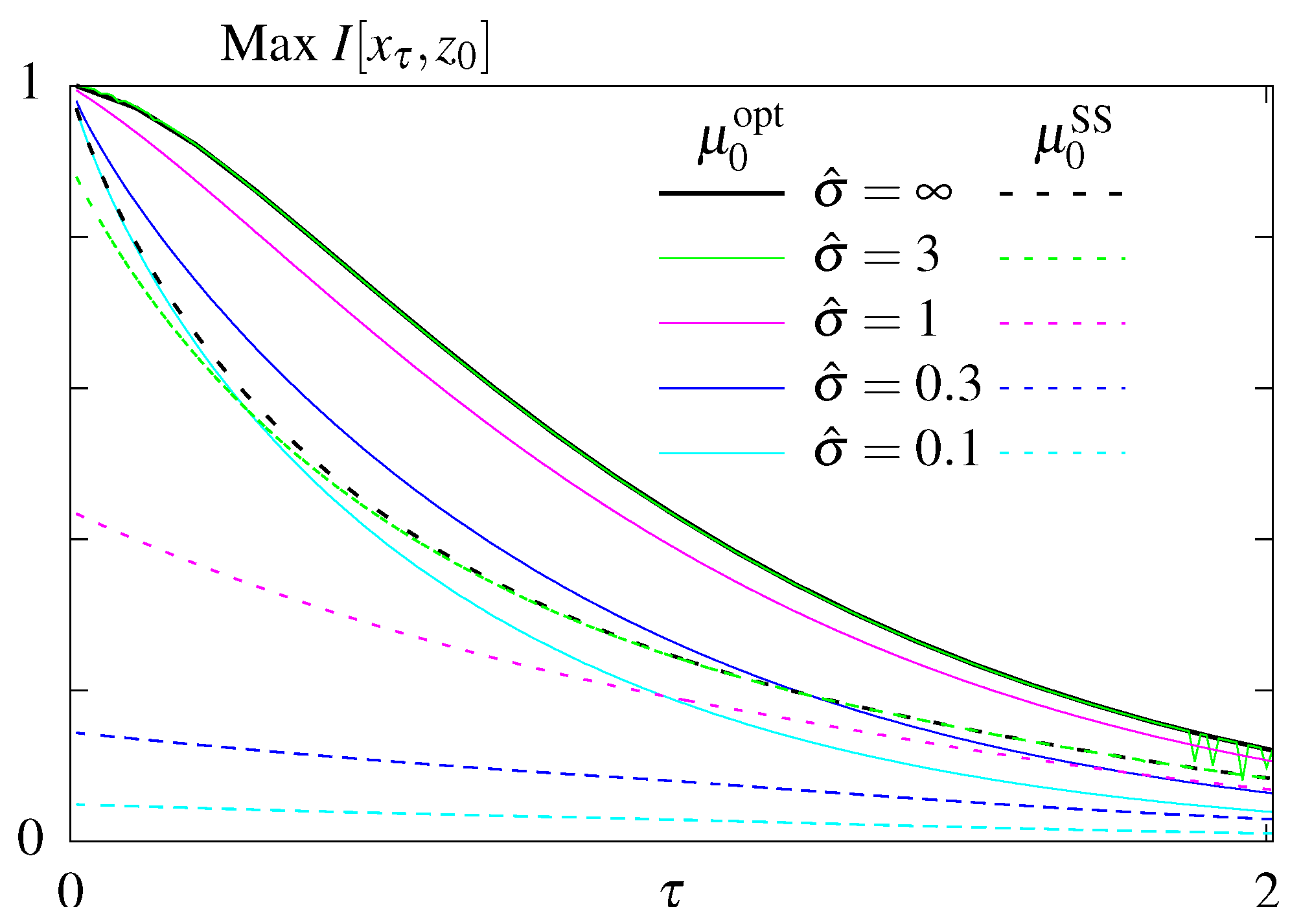
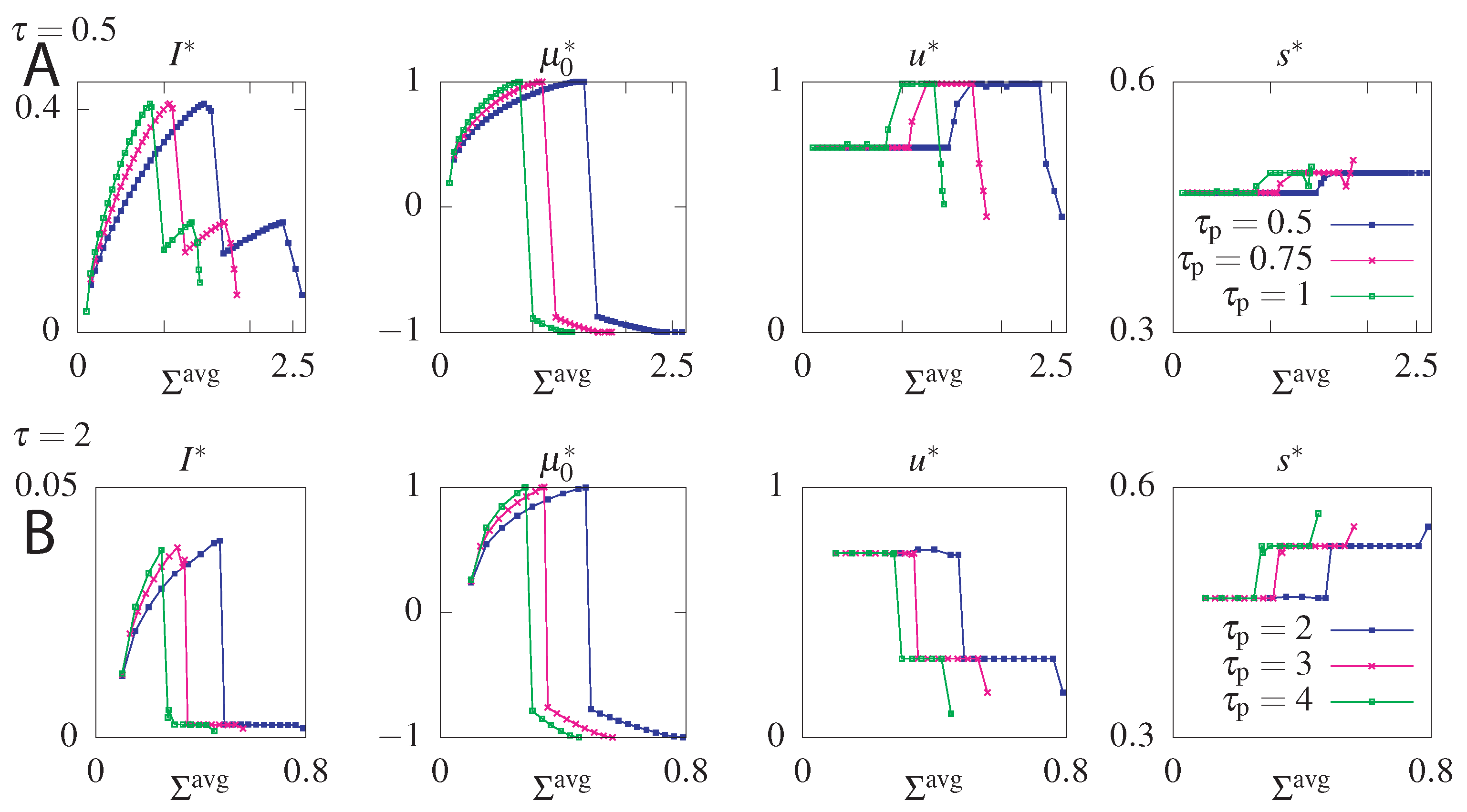
6.1. Unconstrained Optimization
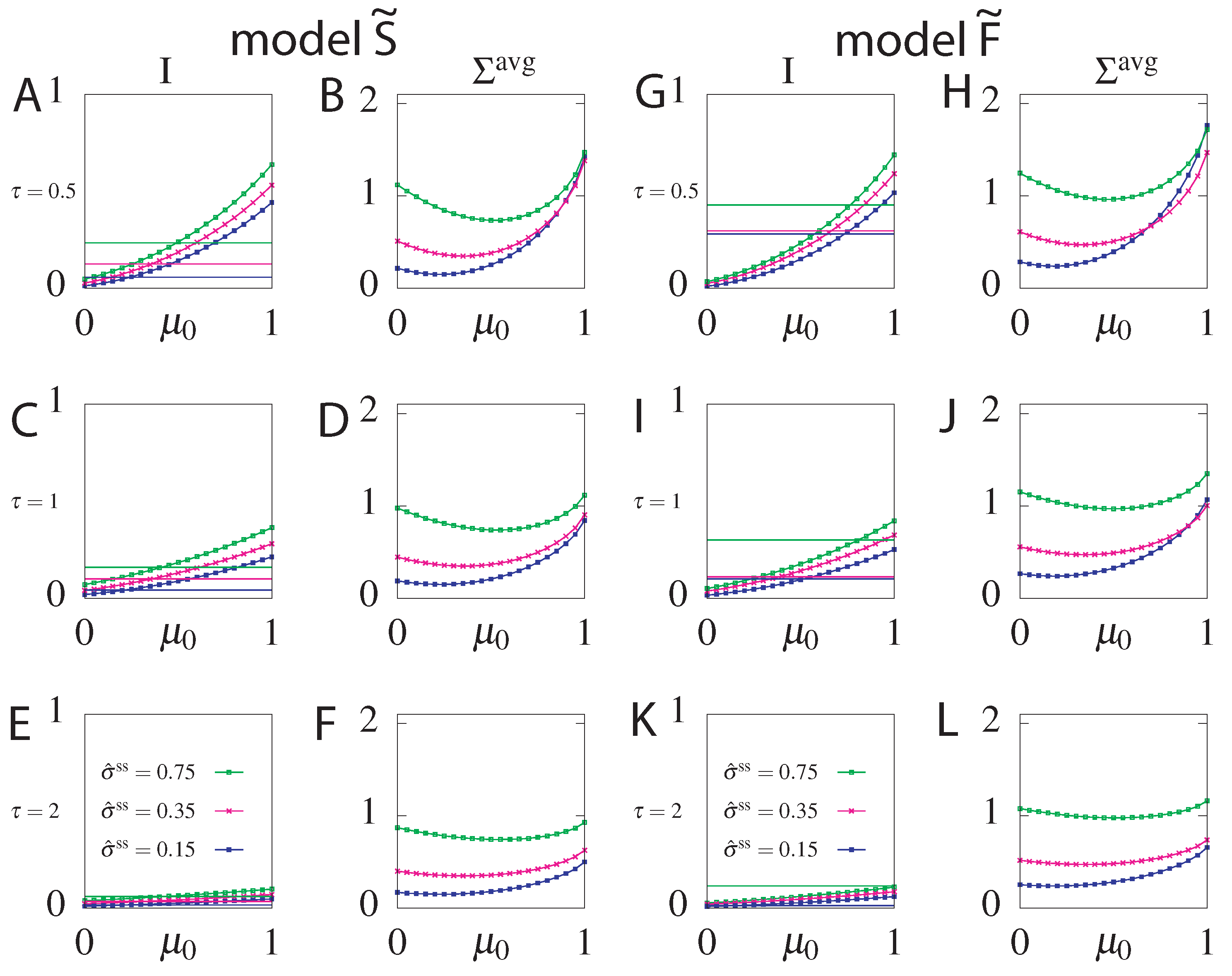
6.2. Constraining
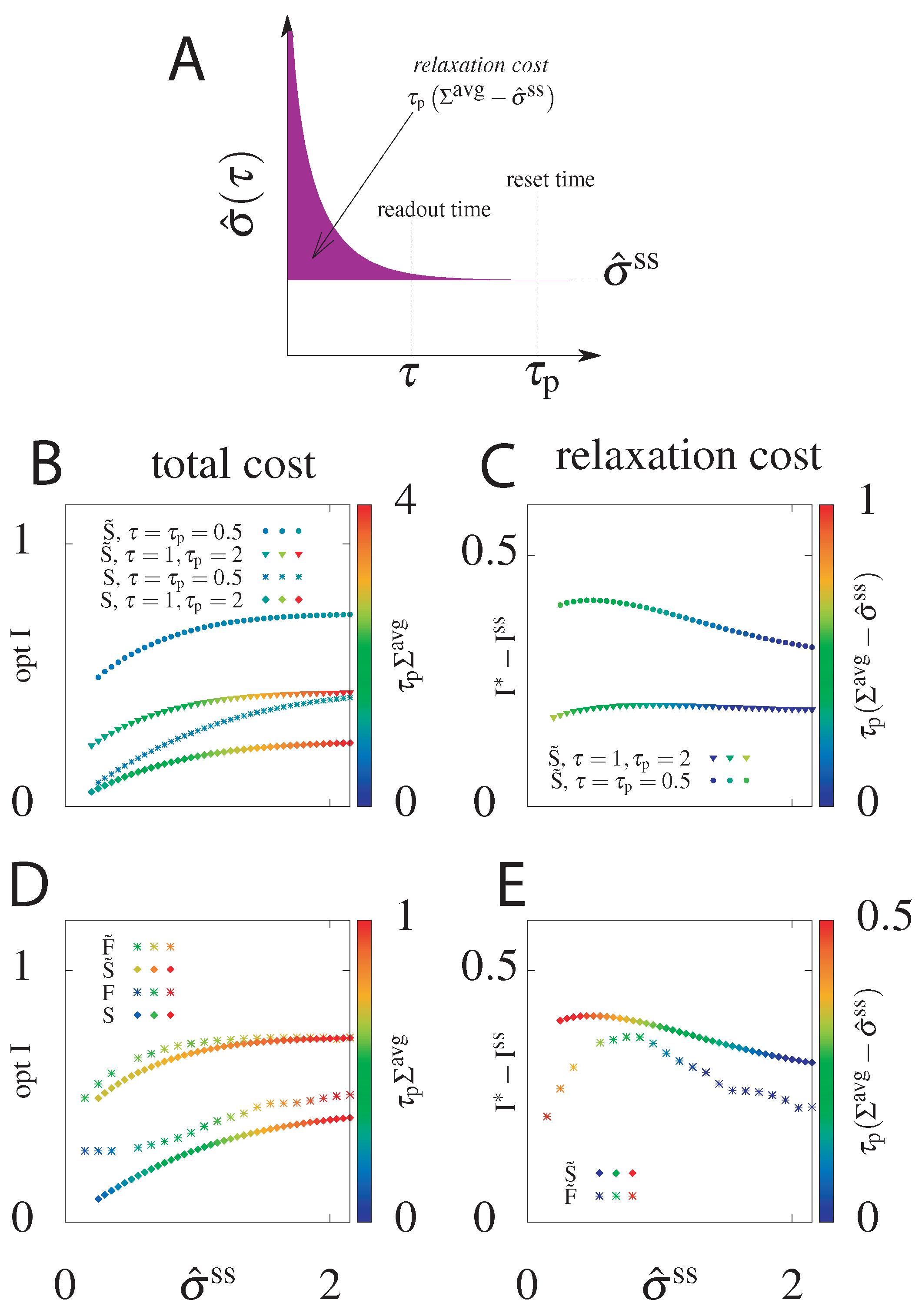
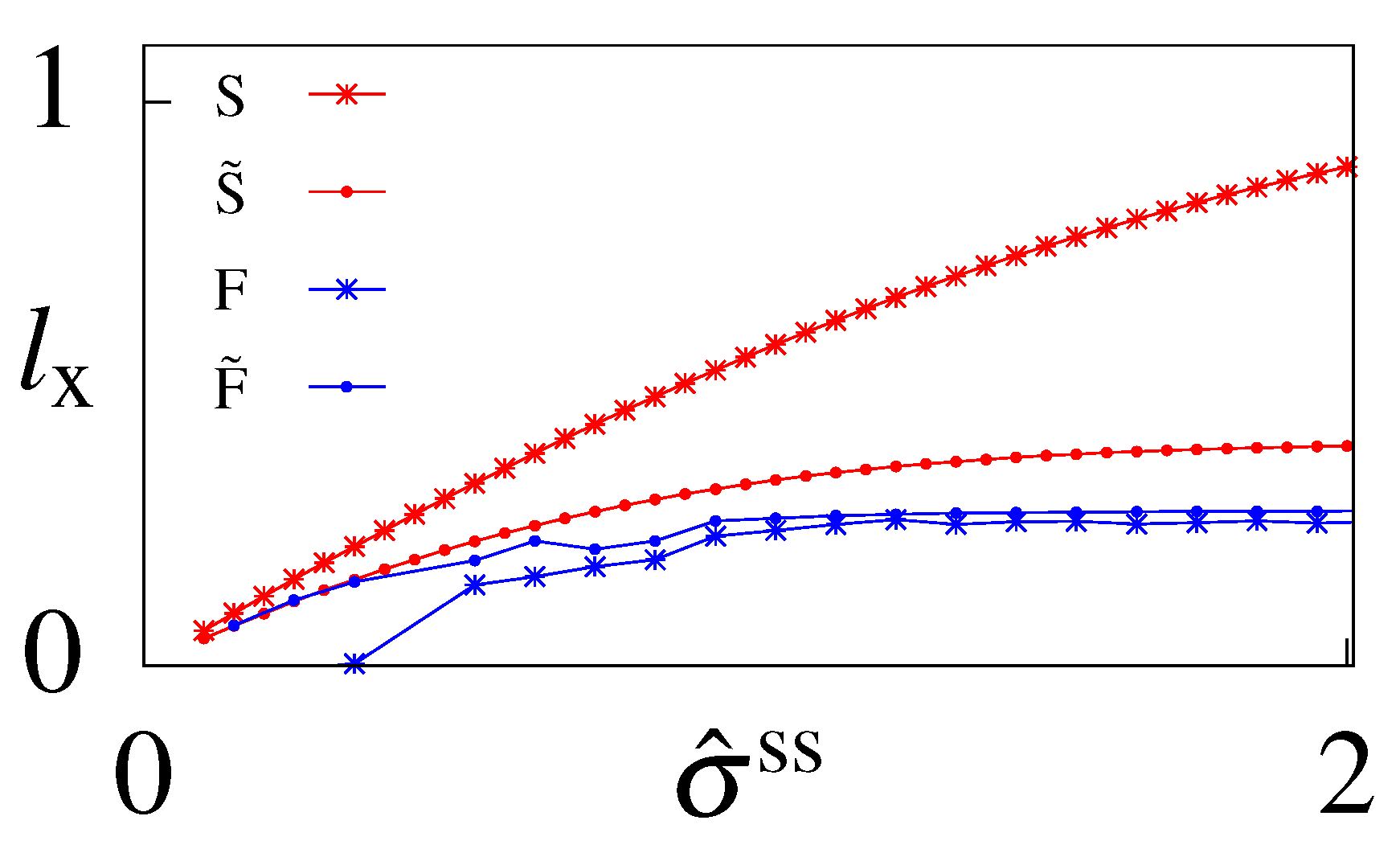
6.3. Cost of Optimal Information
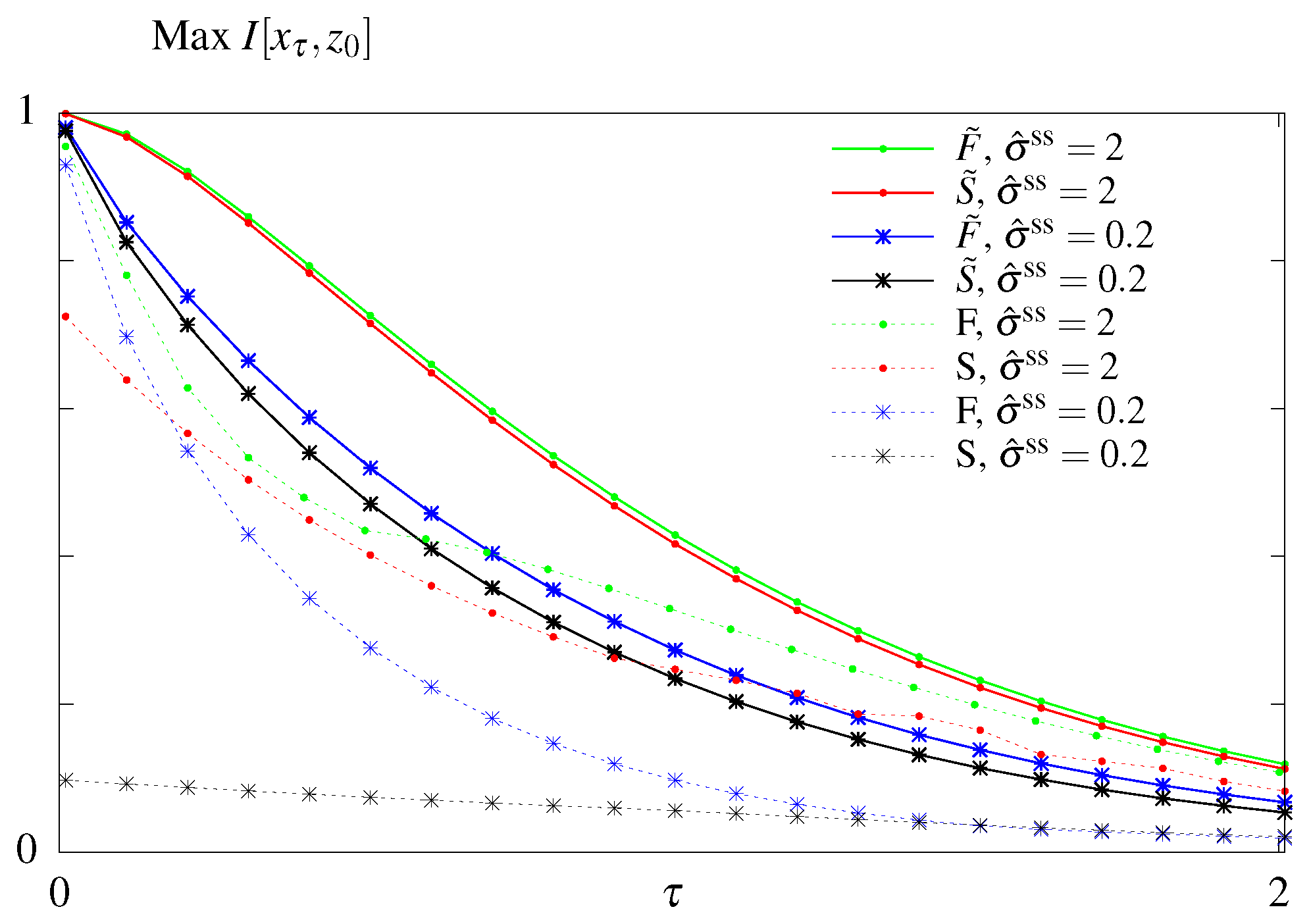
6.4. Suboptimal Circuits
7. Gene Regulatory Circuits
7.1. Bursty Gene Regulation
8. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Model without Feedback
Appendix B. Model with Feedback


Appendix C. Entropy Production Rate
Appendix D. Langevin Description of Bursty Gene Regulation
Entropy Production

Appendix E. Learning Rate
References
- Bialek, W. Biophysics; Princeton University Press: Princeton, NJ, USA, 2012. [Google Scholar]
- Alon, U. An Introduction to Systems Biology: Design Principles of Biological Circuits; Chapman & Hall: Boca Raton, FL, USA, 2006. [Google Scholar]
- Phillips, R.; Kondev, J.; Theriot, J.; Garcia, H. Physical Biology of the Cell; Garland Science: New York, NY, USA, 2012; p. 2012. [Google Scholar]
- Hopfield, J. Kinetic proofreading: A new mechanism for reducing errors in biosynthetic processes requiring high specificity. Proc. Natl. Acad. Sci. USA 1974, 71, 4135–4139. [Google Scholar] [CrossRef] [PubMed]
- Ninio, J. Kinetic amplification of enzyme discrimination. Biochimie 1975, 57, 587–595. [Google Scholar] [CrossRef]
- McKeithan, T.W. Kinetic proofreading in T-cell receptor signal transduction. Proc. Natl. Acad. Sci. USA 1995, 92, 5042–5046. [Google Scholar] [CrossRef]
- Tostevin, F.; Howard, M. A stochastic model of Min oscillations in Escherichia coli and Min protein segregation during cell division. Phys. Biol. 2006, 3, 1. [Google Scholar] [CrossRef] [PubMed]
- Tostevin, F.; Howard, M. Modeling the Establishment of {PAR} Protein Polarity in the One-Cell C. elegans Embryo. Biophys. J. 2008, 95, 4512–4522. [Google Scholar] [CrossRef] [PubMed]
- François, P.; Hakim, V. Design of genetic networks with specified functions by evolution in silico. Proc. Natl. Acad. Sci. USA 2004, 101, 580–584. [Google Scholar] [CrossRef]
- François, P.; Hakim, V.; Siggia, E.D. Deriving structure from evolution: Metazoan segmentation. Mol. Syst. Biol. 2007, 3, 154. [Google Scholar] [CrossRef]
- Saunders, T.E.; Howard, M. Morphogen profiles can be optimized to buffer against noise. Phys. Rev. E 2009, 80, 041902. [Google Scholar] [CrossRef] [PubMed]
- Tkacik, G.; Callan, C.G.; Bialek, W. Information flow and optimization in transcriptional regulation. Proc. Natl. Acad. Sci. USA 2008, 105, 12265–12270. [Google Scholar] [CrossRef]
- Mehta, P.; Goyal, S.; Long, T.; Bassler, B.L.; Wingreen, N.S. Information processing and signal integration in bacterial quorum sensing. Mol. Syst. Biol. 2009, 5, 325. [Google Scholar] [CrossRef]
- Bintu, L.; Buchler, N.E.; Garcia, H.G.; Gerland, U.; Hwa, T.; Kondev, J.; Phillips, R. Transcriptional regulation by the numbers: Models. Curr. Opin. Genet. Dev. 2005, 15, 116–124. [Google Scholar] [CrossRef] [PubMed]
- Bintu, L.; Buchler, N.E.; Garcia, H.G.; Gerland, U.; Hwa, T.; Kondev, J.; Kuhlman, T.; Phillips, R. Transcriptional regulation by the numbers: Applications. Curr. Opin. Genet. Dev. 2005, 15, 125–135. [Google Scholar] [CrossRef] [PubMed]
- Garcia, H.G.; Phillips, R. Quantitative dissection of the simple repression input-output function. Proc. Natl. Acad. Sci. USA 2011, 108, 12173–12178. [Google Scholar] [CrossRef] [PubMed]
- Kuhlman, T.; Zhang, Z.; Saier, M.H.; Hwa, T. Combinatorial transcriptional control of the lactose operon of Escherichia coli. Proc. Natl. Acad. Sci. USA 2007, 104, 6043–6048. [Google Scholar] [CrossRef]
- Dubuis, J.O.; Tkacik, G.; Wieschaus, E.F.; Gregor, T.; Bialek, W. Positional information, in bits. Proc. Natl. Acad. Sci. USA 2013, 110, 16301–16308. [Google Scholar] [CrossRef]
- Tostevin, F.; ten Wolde, P.R. Mutual Information between Input and Output Trajectories of Biochemical Networks. Phys. Rev. Lett. 2009, 102, 218101. [Google Scholar] [CrossRef]
- Tostevin, F.; ten Wolde, P.R. Mutual information in time-varying biochemical systems. Phys. Rev. E 2010, 81, 061917. [Google Scholar] [CrossRef]
- de Ronde, W.H.; Tostevin, F.; ten Wolde, P.R. Effect of feedback on the fidelity of information transmission of time-varying signals. Phys. Rev. E 2010, 82, 031914. [Google Scholar] [CrossRef]
- Savageau, M. Design of molecular control mechanisms and the demand for gene expression. Proc. Natl. Acad. Sci. USA 1977, 74, 5647–5651. [Google Scholar] [CrossRef]
- Scott, M.; Gunderson, C.W.; Mateescu, E.M.; Zhang, Z.; Hwa, T. Interdependence of cell growth and gene expression: Origins and consequences. Science 2010, 330, 1099–1102. [Google Scholar] [CrossRef]
- Aquino, G.; Tweedy, L.; Heinrich, D.; Endres, R.G. Memory improves precision of cell sensing in fluctuating environments. Sci. Rep. 2014, 4, 5688. [Google Scholar] [CrossRef] [PubMed]
- Vergassola, M.; Villermaux, E.; Shraiman, B.I. ‘Infotaxis’ as a strategy for searching without gradients. Nature 2007, 445, 406–409. [Google Scholar] [CrossRef] [PubMed]
- Celani, A.; Vergassola, M. Bacterial strategies for chemotaxis response. Proc. Natl. Acad. Sci. USA 2010, 107, 1391–1396. [Google Scholar] [CrossRef] [PubMed]
- Siggia, E.D.; Vergassola, M. Decisions on the fly in cellular sensory systems. Proc. Natl. Acad. Sci. USA 2013, 110, E3704–E3712. [Google Scholar] [CrossRef]
- Cheong, R.; Rhee, A.; Wang, C.J.; Nemenman, I.; Levchenko, A. Information Transduction Capacity of Noisy Biochemical Signaling. Science 2011, 334, 354–358. [Google Scholar] [CrossRef]
- Lan, G.; Sartori, P.; Neumann, S.; Sourjik, V.; Tu, Y. The energy-speed-accuracy trade-off in sensory adaptation. Nat. Phys. 2012, 8, 422–428. [Google Scholar] [CrossRef]
- Mehta, P.; Schwab, D.J. Energetic costs of cellular computation. Proc. Natl. Acad. Sci. USA 2012, 109, 17978–17982. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, H.; Ouyang, Q.; Tu, Y. Biochemical oscillations. Nature Physics 2015, 1–8. [Google Scholar] [CrossRef]
- Milo, R.; Phillips, R. Cell Biology by the Numbers; Garland Science: New York, NY, USA, 2015; p. 2015. [Google Scholar]
- Moran, U.; Phillips, R.; Milo, R. SnapShot: Key numbers in biology. Cell 2010, 141, 1262. [Google Scholar] [CrossRef]
- Seifert, U. Stochastic thermodynamics, fluctuation theorems and molecular machines. Rep. Prog. Phys. 2012, 75, 126001. [Google Scholar] [CrossRef]
- Still, S.; Sivak, D.A.; Bell, A.J.; Crooks, G.E. Thermodynamics of Prediction. Phys. Rev. Lett. 2012, 109, 120604. [Google Scholar] [CrossRef] [PubMed]
- Ouldridge, T.E.; Govern, C.C.; Rein, P. Thermodynamics of Computational Copying in Biochemical Systems. Phys. Rev. X 2017, 021004. [Google Scholar] [CrossRef]
- Rein, P.; Becker, N.B.; Ouldridge, T.E.; Mugler, A. Fundamental Limits to Cellular Sensing. J. Stat. Phys. 2016, 162, 1395–1424. [Google Scholar] [CrossRef]
- Sagawa, T.; Ito, S. Maxwell’s demon in biochemical signal transduction transduction with feedback loop. Nat. Commun. 2015, 6, 7498. [Google Scholar] [CrossRef]
- Barato, A.C.; Hartich, D.; Seifert, U. Information-theoretic versus thermodynamic entropy production in autonomous sensory networks. Phys. Rev. E 2013, 87, 042104. [Google Scholar] [CrossRef]
- Barato, A.C.; Hartich, D.; Seifert, U. Efficiency of cellular information processing. New J. Phys. 2014, 16, 103024. [Google Scholar] [CrossRef]
- Bo, S.; Giudice, M.D.; Celani, A. Thermodynamic limits to information harvesting by sensory systems. J. Stat. Mech. Theory Exp. 2015, 2015, P01014. [Google Scholar] [CrossRef][Green Version]
- Govern, C.C.; ten Wolde, P.R. Energy Dissipation and Noise Correlations in Biochemical Sensing. Phys. Rev. Lett. 2014, 113, 258102. [Google Scholar] [CrossRef]
- Barato, A.C.; Seifert, U. Thermodynamic Uncertainty Relation for Biomolecular Processes. Phys. Rev. Lett. 2015, 114, 158101. [Google Scholar] [CrossRef]
- Brittain, R.A.; Jones, N.S.; Ouldridge, T.E. What we learn from the learning rate. J. Stat. Mech. Theory Exp. 2017, 6, 063502. [Google Scholar] [CrossRef]
- Goldt, S.; Seifert, U. Stochastic Thermodynamics of Learning. Phys. Rev. Lett. 2017, 118, 010601. [Google Scholar] [CrossRef] [PubMed]
- Parrondo, J.M.R.; Horowitz, J.M.; Sagawa, T. Thermodynamics of information. Nat. Phys. 2015, 11, 131–139. [Google Scholar] [CrossRef]
- Becker, N.B.; Mugler, A.; ten Wolde, P.R. Prediction and Dissipation in Biochemical Sensing. arXiv 2013, arXiv:1312.5625. Available online: http://arxiv.org/abs/1312.5625 (accessed on 9 December 2019).
- Horowitz, J.M.; Esposito, M. Thermodynamics with Continuous Information Flow. Phys. Rev. X 2014, 4, 031015. [Google Scholar] [CrossRef]
- Allahverdyan, A.E.; Janzing, D.; Mahler, G. Thermodynamic efficiency of information and heat flow. J. Stat. Mech. Theory Exp. 2009, 2009, P09011. [Google Scholar] [CrossRef]
- Sartori, P.; Granger, L.; Lee, C.F.; Horowitz, J.M. Thermodynamic costs of information processing in sensory adaptation. PLoS Comput. Biol. 2014, 10, e1003974. [Google Scholar] [CrossRef]
- Hartich, D.; Barato, A.C.; Seifert, U. Sensory capacity: An information theoretical measure of the performance of a sensor and sensory capacity. Phys. Rev. E 2016, 93, 022116. [Google Scholar] [CrossRef]
- Falasco, G.; Rao, R.; Esposito, M. Information Thermodynamics of Turing Patterns. Phys. Rev. Lett. 2018, 121, 108301. [Google Scholar] [CrossRef]
- Tkačik, G.; Walczak, A.M. Information transmission in genetic regulatory networks: A review. J. Phys. Condens. Matter Inst. Phys. J. 2011, 23, 153102. [Google Scholar] [CrossRef]
- Tkačik, G.; Walczak, A.M.; Bialek, W. Optimizing information flow in small genetic networks. Phys. Rev. E 2009, 80, 031920. [Google Scholar] [CrossRef]
- Walczak, A.M.; Tkačik, G.; Bialek, W. Optimizing information flow in small genetic networks. II. Feed-forward interactions. Phys. Rev. E 2010, 81, 041905. [Google Scholar] [CrossRef] [PubMed]
- Tkačik, G.; Walczak, A.M.; Bialek, W. Optimizing information flow in small genetic networks. III. A self-interacting gene. Phys. Rev. E 2012, 85, 041903. [Google Scholar] [CrossRef] [PubMed]
- Mugler, A.; Walczak, A.; Wiggins, C. Spectral solutions to stochastic models of gene expression with bursts and regulation. Phys. Rev. E 2009, 80, 041921. [Google Scholar] [CrossRef] [PubMed]
- Rieckh, G.; Tkačik, G. Noise and Information Transmission in Promoters with Multiple Internal States. Biophys. J. 2014, 106, 1194–1204. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Sokolowski, T.R.; Tkačik, G. Optimizing information flow in small genetic networks. IV. Spatial coupling. Phys. Rev. E 2015, 91, 062710. [Google Scholar] [CrossRef] [PubMed]
- de Ronde, W.H.; Tostevin, F.; ten Wolde, P.R. Feed-forward loops and diamond motifs lead to tunable transmission of information in the frequency domain. Phys. Rev. E 2012, 86, 021913. [Google Scholar] [CrossRef] [PubMed]
- Gregor, T.; Wieschaus, E.F.; McGregor, A.P.; Bialek, W.; Tank, D.W. Stability and nuclear dynamics of the Bicoid morphogen gradient. Cell 2007, 130, 141–152. [Google Scholar] [CrossRef]
- Gregor, T.; Tank, D.W.; Wieschaus, E.F.; Bialek, W. Probing the limits to positional information. Cell 2007, 130, 153–164. [Google Scholar] [CrossRef]
- Pahle, J.; Green, A.K.; Dixon, C.J.; Kummer, U. Information transfer in signaling pathways: A study using coupled simulated and experimental data. BMC Bioinform. 2008, 9, 139. [Google Scholar] [CrossRef]
- Selimkhanov, J.; Taylor, B.; Yao, J.; Pilko, A.; Albeck, J.; Hoffmann, A.; Tsimring, L.; Wollman, R. Accurate information transmission through dynamic biochemical signaling networks. Science 2014, 346, 1370–1373. [Google Scholar] [CrossRef]
- Mancini, F.; Wiggins, C.H.; Marsili, M.; Walczak, A.M. Time-dependent information transmission in a model regulatory circuit. Phys. Rev. E 2013, 88, 022708. [Google Scholar] [CrossRef] [PubMed]
- Mancini, F.; Marsili, M.; Walczak, A.M. Trade-offs in delayed information transmission in biochemical networks. J. Stat. Phys. 2015, 1504, 03637. [Google Scholar] [CrossRef][Green Version]
- Kepler, T.B.; Elston, T.C. Stochasticity in Transcriptional Regulation: Origins, Consequences, and Mathematical Representations. Biophys. J. 2001, 81, 3116–3136. [Google Scholar] [CrossRef]
- Raj, A.; Peskin, C.S.; Tranchina, D.; Vargas, D.Y.; Tyagi, S. Stochastic mRNA Synthesis in Mammalian Cells. PLoS Biol. 2006, 4, e309. [Google Scholar] [CrossRef] [PubMed]
- Friedman, N.; Cai, L.; Xie, X. Linking Stochastic Dynamics to Population Distribution: An Analytical Framework of Gene Expression. Phys. Rev. Lett. 2006, 97, 168302. [Google Scholar] [CrossRef] [PubMed]
- Walczak, A.M.; Sasai, M.; Wolynes, P.G. Self-consistent proteomic field theory of stochastic gene switches. Biophys. J. 2005, 88, 828–850. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.; Friedman, N.; Xie, X.S. Stochastic protein expression in individual cells at the single molecule level. Nature 2006, 440, 358–362. [Google Scholar] [CrossRef]
- So, L.h.; Ghosh, A.; Zong, C.; Sepúlveda, L.A.; Segev, R.; Golding, I. General properties of the transcriptional time-series in E. Coli. Nat. Genet. 2011, 43, 554–560. [Google Scholar] [CrossRef]
- Desponds, J.; Tran, H.; Ferraro, T.; Lucas, T.; Dostatni, N.; Walczak, A.M. Precision of Readout at the hunchback Gene: Analyzing Short Transcription Time Traces in Living Fly Embryos. PLoS Comput. Biol. 2016, 12, e1005256. [Google Scholar] [CrossRef]
- Cover, T.; Thomas, J. Elements of Information Theory; John Wiley: New York, NY, USA, 1991. [Google Scholar]
- Levine, M.V.; Weinstein, H. AIM for Allostery: Using the Ising Model to Understand Information Processing and Transmission in Allosteric Biomolecular Systems. Entropy 2015, 17, 2895–2918. [Google Scholar] [CrossRef]
- Cuendet, M.A.; Weinstein, H.; Levine, M.V. The Allostery Landscape: Quantifying Thermodynamic Couplings in Biomolecular Systems. J. Chem. Theory Comput. 2016. [Google Scholar] [CrossRef] [PubMed]
- Crooks, G.E. Nonequilibrium Measurements of Free Energy Differences for Microscopically Reversible Markovian Systems. J. Stat. Phys. 1998, 90, 1481–1487. [Google Scholar] [CrossRef]
- Tome, T.; de Oliveira, M.J. Entropy Production in Nonequilibrium Systems at Stationary States. Phys. Rev. Lett. 2012, 108, 020601. [Google Scholar] [CrossRef]
- Hornos, J.E.M.; Schultz, D.; Innocentini, G.C.P.; Wang, J.; Walczak, A.M.W.; Onuchic, J.N.; Wolynes, P.G. Self-regulating gene: An exact solution. Phys. Rev. E 2005, 1–5. [Google Scholar] [CrossRef]
- Miekisz, J.; Szymanska, P. Gene Expression in Self-repressing System with Multiple Gene Copies. Bull. Math. Biol. 2013, 317–330. [Google Scholar] [CrossRef]
- Crisanti, A.; Puglisi, A.; Villamaina, D. Nonequilibrium and information: The role of cross correlations. Phys. Rev. E 2012, 061127. [Google Scholar] [CrossRef]
- Puglisi, A.; Pigolotti, S.; Rondoni, L.; Vulpiani, A. Entropy production and coarse graining in Markov processes. J. Stat. Mech. Theory Exp. 2010, 05015. [Google Scholar] [CrossRef]
- Busiello, D.M.; Hidalgo, J.; Maritan, A. Entropy production for coarse-grained dynamics. arXiv 2019, arXiv:1810.01833v2. [Google Scholar] [CrossRef]
- Xiong, W.; Ferrell, J.E., Jr. A positive feedback based bistable memory module that governs a cell fate decision. Nature 2003, 426, 460–465. [Google Scholar] [CrossRef]
- Tanaka, K.; Augustine, G.J. A Positive Feedback Signal Transduction Loop Determines Timing of Cerebellar Long-Term Depression. Neuron 2008, 59, 608–620. [Google Scholar] [CrossRef]
- Guisbert, E.; Herman, C.; Lu, C.Z.; Gross, C.A. A chaperone network controls the heat shock response in E. coli. Genes Dev. 2004, 2812–2821. [Google Scholar] [CrossRef] [PubMed]
- Lahav, G.; Rosenfeld, N.; Sigal, A.; Geva-zatorsky, N.; Levine, A.J.; Elowitz, M.B.; Alon, U. Dynamics of the p53-Mdm2 feedback loop in individual cells. Nat. Genet. 2004, 36, 147–150. [Google Scholar] [CrossRef] [PubMed]
- Tyson, J.J.; Novák, B. Models in biology: Lessons from modeling regulation of the eukaryotic cell cycle. BMC Biol. 2015, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Lucas, T.; Tran, H.; Perez Romero, C.A.; Guillou, A.; Fradin, C.; Coppey, M.; Walczak, A.M.; Dostatni, N. 3 minutes to precisely measure morphogen concentration. PLoS Genet. 2018, 14, e1007676. [Google Scholar] [CrossRef]
- Sagawa, T.; Ueda, M. Fluctuation theorem with information exchange: Role of correlations in stochastic thermodynamics. Phys. Rev. Lett. 2012, 109, 1–5. [Google Scholar] [CrossRef]
- Sagawa, T.; Ueda, M. Nonequilibrium thermodynamics of feedback control. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2012, 85, 1–16. [Google Scholar] [CrossRef]
- Raser, J.; O’Shea, E. Control of stochasticity in eukaryotic gene expression. Science 2004, 304, 1811–1814. [Google Scholar] [CrossRef]
- Walczak, A.M.; Onuchic, J.N.; Wolynes, P.G. Absolute rate theories of epigenetic stability. Proc. Natl. Acad. Sci. USA 2005, 102, 18926–18931. [Google Scholar] [CrossRef]
- Puglisi, A.; Villamaina, D. Irreversible effects of memory. EPL (Europhys. Lett.) 2009, 88, 30004. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
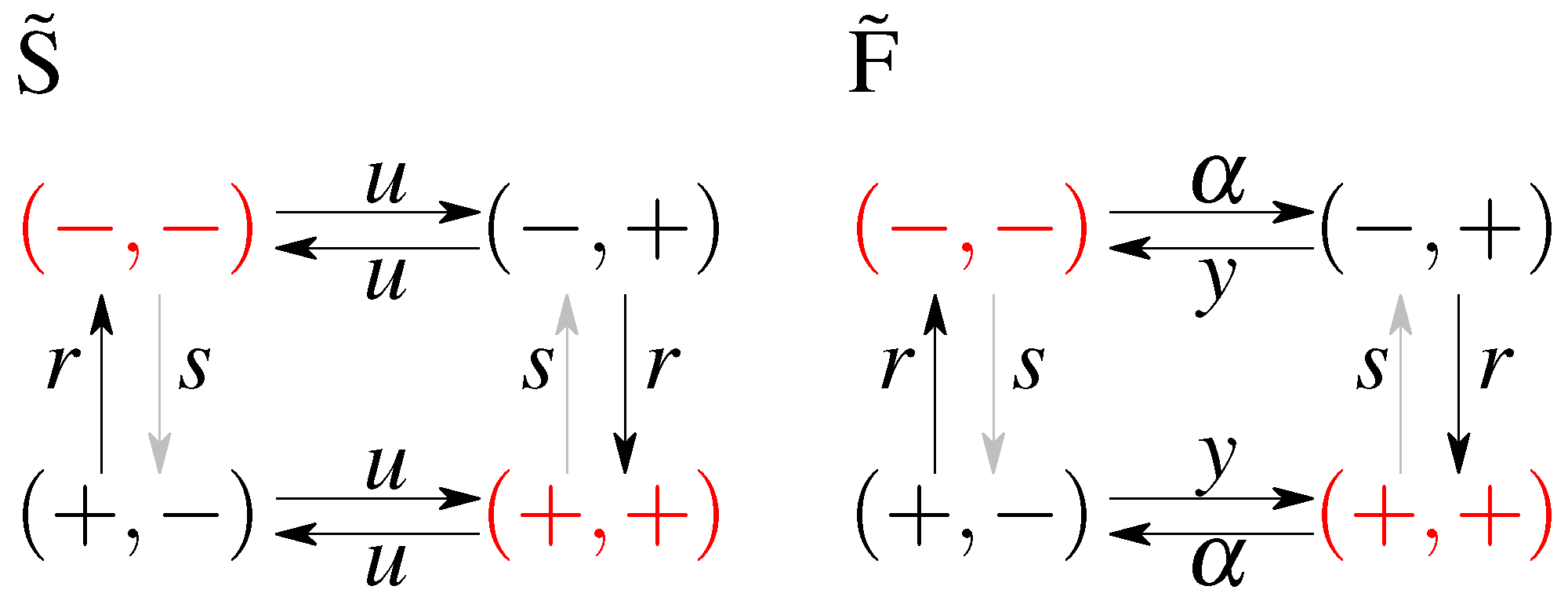{kind=link}
{kind=link}
{kind=link}
{kind=link}
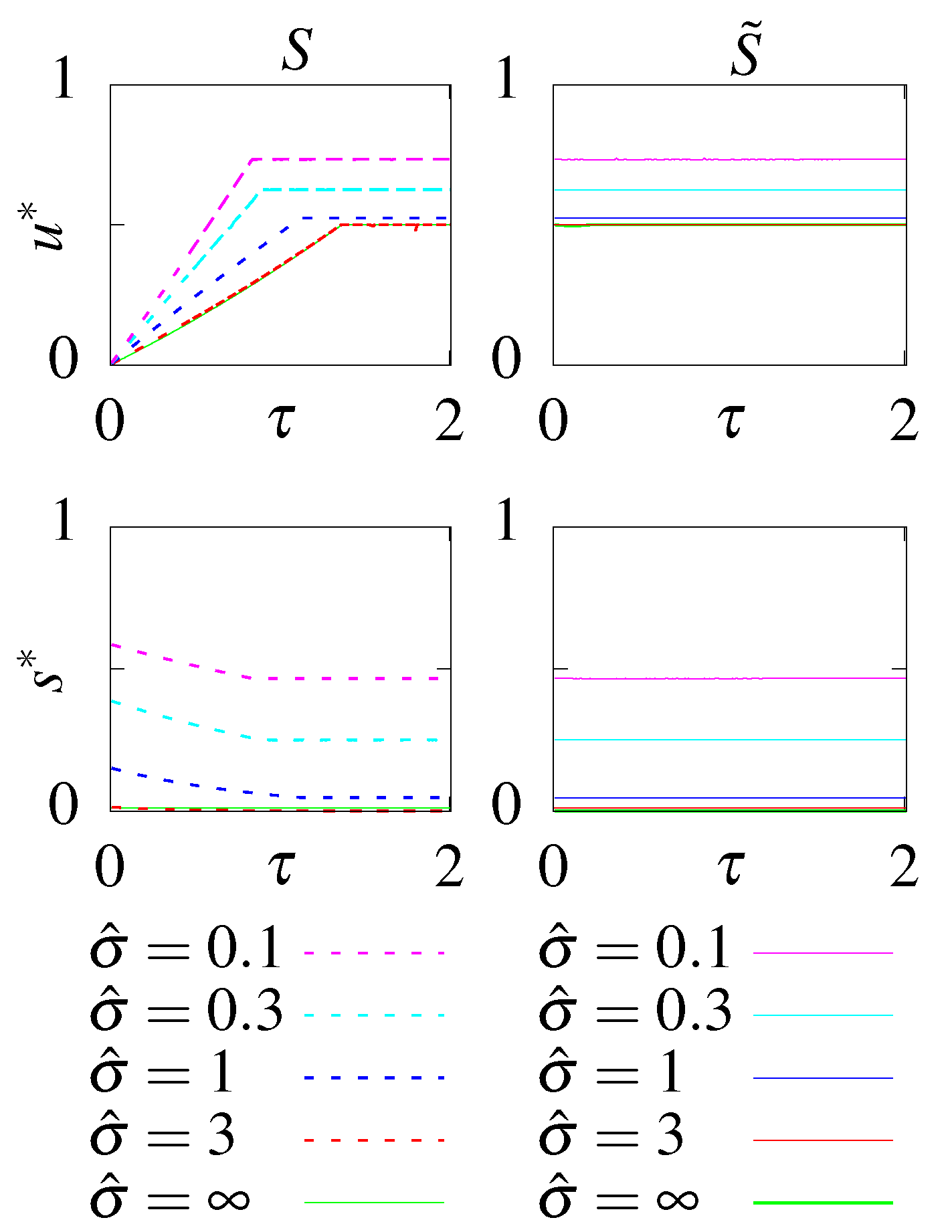{kind=link}
{kind=link}
{kind=link}
| Cost | ||
|---|---|---|
| S, F | ||
| , |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szymańska-Rożek, P.; Villamaina, D.; Miȩkisz, J.; Walczak, A.M. Dissipation in Non-Steady State Regulatory Circuits. Entropy 2019, 21, 1212. https://doi.org/10.3390/e21121212
Szymańska-Rożek P, Villamaina D, Miȩkisz J, Walczak AM. Dissipation in Non-Steady State Regulatory Circuits. Entropy. 2019; 21(12):1212. https://doi.org/10.3390/e21121212
Chicago/Turabian StyleSzymańska-Rożek, Paulina, Dario Villamaina, Jacek Miȩkisz, and Aleksandra M. Walczak. 2019. "Dissipation in Non-Steady State Regulatory Circuits" Entropy 21, no. 12: 1212. https://doi.org/10.3390/e21121212
APA StyleSzymańska-Rożek, P., Villamaina, D., Miȩkisz, J., & Walczak, A. M. (2019). Dissipation in Non-Steady State Regulatory Circuits. Entropy, 21(12), 1212. https://doi.org/10.3390/e21121212