A Survey on Using Kolmogorov Complexity in Cybersecurity


Abstract
1. Introduction
- RQ1:
- What are the domains where it can impact?
- RQ2:
- Can it be an efficient solution to meet the Cybersecurity requirements?
- RQ3:
- Can its approximations be applied in new domains?
2. Kolmogorov Complexity
2.1. The Normalized Compression Distance
2.1.1. Optimizations of NCD
2.2. Compression-Based Dissimilarity Measure
2.3. Lempel–Ziv Jaccard Distance
2.4. Normalized Relative Compression
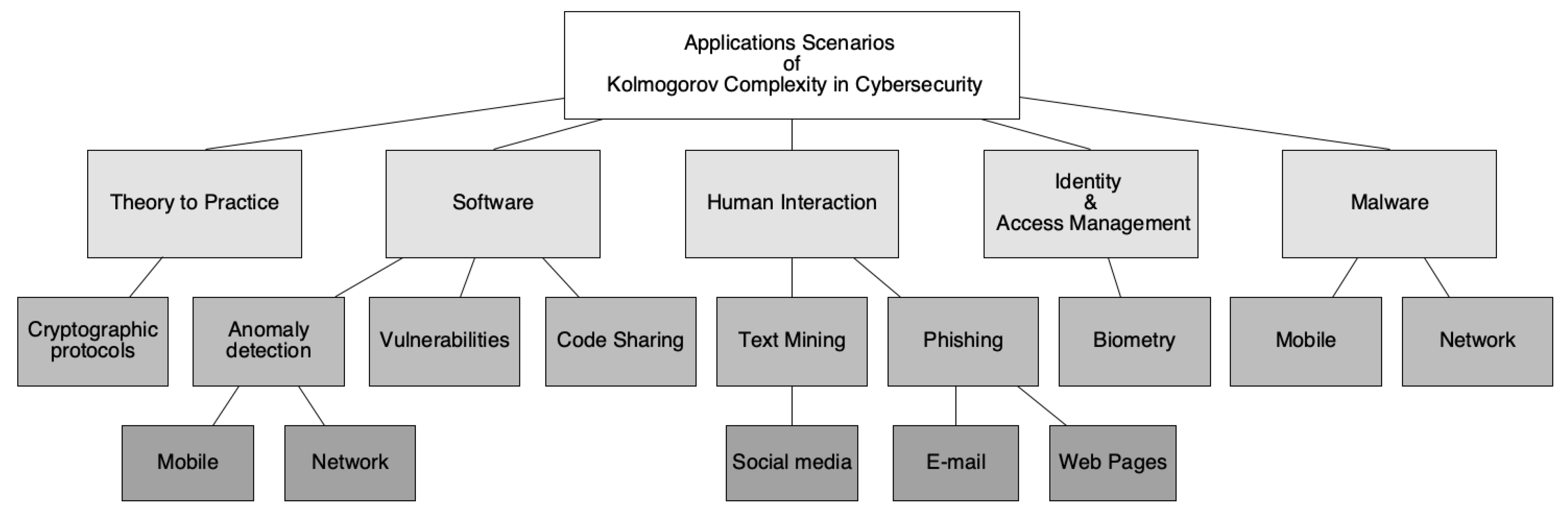
3. Kolmogorov Complexity Application Scenarios
- –
- –
- –
- Malware: In recent years, companies have been attacked with malware. The scalability to mount an attack on multiple institutions at once is not expensive compared to the reward. This leads to blackmail to companies/users, disclosure of files or credit card data in the web, or encryption of databases and files [9,12,33,34,35,36,37].
- –
- –
- Theory to practice: There are some protocols that enforce privacy and security in communications between users. With the emergence of new cyberattacks and with the recent developments in academia regarding privacy policies imposed by rules to protect user privacy, such as GDPR, it is of utmost important to validate existing implementations to ensure user privacy [43].
3.1. Human Interactions
3.1.1. Phishing
Web Pages
3.1.2. Text Analytic
Social Media
3.2. Software
3.2.1. Code Sharing and Vulnerabilities
3.2.2. Anomaly Detection
Network
Mobile
3.3. Malware Classification
3.4. Identity & Authentication
3.5. Theory to Practice
Cryptographic Protocols
- –
- Privacy: The inputs are never revealed to other parties;
- –
- Correctness: The output given at the end of the computation is correct.
4. Discussion and Future Research Directions
- –
- Identity and Access Management: This field focuses on ECG-based identity validations and authentication. This allows, for example, to collect this information with wearable and process the heartbeat to provide identity, for example, physical access to institutions, login at the computer/mobile phone, or identify patterns about the user feeling when reading an e-mail, among other approximations.
- –
- Theory to Practice: This domain is one of the most important when implementation arise from the theoretical/mathematical proofs to a real world implementations. The first version of the software must always be treated as unsafe and not immediately deployed at scale. The challenges aims for searching patterns in homomorphic encryption, searchable encryption and other similar protocols to measure the security and reliability of the system implementations. These type of protocols can have a high impact on society, but it is important to test and find ways to validate the security and privacy requirements.
Future Research Directions
- –
- Software: In the future, the Software domain needs to be tested in a real environment. In anomaly detection, the challenges is to test with known datasets, such as the summarized by Cinthya Grajeda et al. [94] to understand the usability in new sub-domains. Besides analyzing all the code, there should be a preprocessing of the data, following some rules depending on the implementation and application scenario, to remove external sources of entropy. Regarding Code Sharing and Vulnerabilities, the future directions should focus on the integration into open-source tools to detect events based on multiple sources.
- –
- Human Interactions: There is no evaluation in the real world environment of this approach. It is interesting to evaluate phishing detection over time, for example, to see if the solution is viable or not in a real context. Real-world deployments are needed to show the advantages of this approach in cooperation with other tools to test the ability of outperform the state-of-the-art deployments, especially in web pages and e-mail phishing. Further enhancements to Fakenews may benefit to address some open issues proposed in this domain, such as automation and specialized tools [63].
- –
- Malware: Regarding Malware, there is a clear need to compare all different articles against a common dataset to compare the performance of each approach. This is especially important when considering Table 1, where all articles are shown to use a different dataset. There are also more datasets available for performance testing [94]. Real application scenarios, in our opinion, should be based on an approach that uses NCD in the tool chain, but uses other external sources of information with known practical results validated by security experts, enhancing these tools.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hoepman, J.H.; Jacobs, B. Increased security through open source. arXiv 2019, arXiv:0801.3924. [Google Scholar] [CrossRef]
- Jang-Jaccard, J.; Nepal, S. A survey of emerging threats in cybersecurity. J. Comput. Syst. Sci. 2014, 80, 973–993. [Google Scholar] [CrossRef]
- Xin, Y.; Kong, L.; Liu, Z.; Chen, Y.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine learning and deep learning methods for cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. On tables of random numbers. Sankhyā Indian J. Stat. Ser. 2019, 25, 369–376. [Google Scholar] [CrossRef]
- Cilibrasi, R.; Vitányi, P.M. Clustering by compression. IEEE Trans. Inf. Theory 2019, 51, 1523–1545. [Google Scholar] [CrossRef]
- Cilibrasi, R.; Vitányi, P.; Wolf, R.D. Algorithmic clustering of music based on string compression. Comput. Music J. 2019, 28, 49–67. [Google Scholar] [CrossRef]
- Santos, C.C.; Bernardes, J.; Vitányi, P.M.; Antunes, L. Clustering fetal heart rate tracings by compression. In Proceedings of the 19th IEEE Symposium on Computer-Based Medical Systems (CBMS’06), Salt Lake, UT, USA, 22–23 June 2006; pp. 685–690. [Google Scholar]
- Li, M.; Chen, X.; Li, X.; Ma, B.; Vitányi, P.M. The similarity metric. IEEE Trans. Inf. Theory 2019, 50, 3250–3264. [Google Scholar] [CrossRef]
- Borbely, R.S. On normalized compression distance and large malware. J. Comput. Virol. Hacking Tech. 2016, 12, 235–242. [Google Scholar] [CrossRef]
- Keogh, E.; Lonardi, S.; Ratanamahatana, C.A.; Wei, L.; Lee, S.H.; Handley, J. Compression-based data mining of sequential data. Data Min. Knowl. Discov. 2019, 14, 99–129. [Google Scholar] [CrossRef]
- Christen, P.; Goiser, K. Towards automated data linkage and deduplication. Computer 2019, 16, 22–24. [Google Scholar]
- Raff, E.; Nicholas, C. An alternative to ncd for large sequences, lempel-ziv jaccard distance. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1007–1015. [Google Scholar]
- Pinho, A.; Pratas, D.; Ferreira, P. Authorship attribution using compression distances. In Proceedings of the 2016 Data Compression Conference, Snowbird, UT, USA, 30 March–1 April 2016. [Google Scholar]
- Prilepok, M.; Jezowicz, T.; Platos, J.; Snasel, V. Spam detection using compression and PSO. In Proceedings of the 2012 Fourth International Conference on Computational Aspects of Social Networks (CASoN), Sao Carlos, Brazil, 21–23 November 2012; pp. 263–270. [Google Scholar]
- Prilepok, M.; Berek, P.; Platos, J.; Snasel, V. Spam detection using data compression and signatures. Cybern. Syst. 2013, 44, 533–549. [Google Scholar] [CrossRef]
- Delany, S.J.; Bridge, D. Catching the drift: Using feature-free case-based reasoning for spam filtering. In Proceedings of the International Conference on Case-Based Reasoning, Berlin/Heidelberg, Germany, 13 August 2019; pp. 314–328. [Google Scholar]
- Chen, T.C.; Dick, S.; Miller, J. Detecting visually similar web pages: Application to phishing detection. Acm Trans. Internet Technol. Toit 2010, 10, 5. [Google Scholar] [CrossRef]
- Chen, T.C.; Stepan, T.; Dick, S.; Miller, J. An anti-phishing system employing diffused information. Acm Trans. Inf. Syst. Secur. Tissec 2014, 16, 16. [Google Scholar] [CrossRef]
- Bartoli, A.; De Lorenzo, A.; Medvet, E.; Tarlao, F. How Phishing Pages Look Like? Cybern. Inf. Technol. 2018, 18, 43–60. [Google Scholar] [CrossRef]
- Alami, S.; Beqqali, O.E. Detecting suspicious profiles using text analysis within social media. J. Theor. Appl. Inf. Technol. 2015, 73, 405–410. [Google Scholar]
- Alami, S.; Elbeqqali, O. Cybercrime profiling: Text mining techniques to detect and predict criminal activities in microblog posts. In Proceedings of the 10th International Conference on Intelligent Systems: Theories and Applications (SITA), Rabat, Morocco, 20–21 October 2015; pp. 1–5. [Google Scholar]
- Rasheed, H.R.; Khan, F.H.; Bashir, S.; Fatima, I. Detecting Suspicious Discussion on Online Forums Using Data Mining. In Proceedings of the International Conference on Intelligent Technologies and Applications, Singapore, 23 October 2018; pp. 262–273. [Google Scholar]
- Brounstein, T.R.; Killian, A.L.; Skryzalin, J.; Garcia, D. Stylometric and Temporal Techniques for Social Media Account Resolution; Technical Report for Sandia National Lab. (SNL-NM): Albuquerque, NM, USA, 1 March 2017. [Google Scholar]
- Brounstein, T.R. Social Media Account Resolution and Verification; Technical Report for Sandia National Lab. (SNL-NM): Albuquerque, NM, USA, 1 September 2019. [Google Scholar]
- Ishio, T.; Maeda, N.; Shibuya, K.; Inoue, K. Cloned Buggy Code Detection in Practice Using Normalized Compression Distance. In Proceedings of the 2018 IEEE International Conference on Software Maintenance and Evolution (ICSME), Madrid, Spain, 23–29 September 2018; pp. 591–594. [Google Scholar]
- Alrabaee, S.; Shirani, P.; Wang, L.; Debbabi, M.; Hanna, A. On leveraging coding habits for effective binary authorship attribution. In Proceedings of the European Symposium on Research in Computer Security, Barcelona, Spain, 3–7 September 2018; Springer: Cham, Switzerland, 2018; pp. 26–47. [Google Scholar]
- de la Torre-Abaitua, G.; Lago-Fernández, L.F.; Arroyo, D. A compression based framework for the detection of anomalies in heterogeneous data sources. arXiv 2019, arXiv:1908.00417. [Google Scholar]
- de la Torre-Abaitua, G.; Lago-Fernández, L.F.; Arroyo, D.; Abaitua, G.; Lago-Fernández, L.F.; Arroyo, D. A Parameter-Free Method for the Detection of Web Attacks. In International Joint Conference SOCO’17-CISIS’17-ICEUTE’17 León; Springer: Cham, Switzerland, 2017; pp. 661–671. [Google Scholar]
- Ting, C.; Field, R.; Fisher, A.; Bauer, T. Compression Analytics for Classification and Anomaly Detection within Network Communication. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1366–1376. [Google Scholar] [CrossRef]
- Desnos, A. Android: Static analysis using similarity distance. In Proceedings of the 2012 45th Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2012; pp. 5394–5403. [Google Scholar]
- Kishore, S.; Kumar, R.; Rajan, S. Towards Accuracy in Similarity Analysis of Android Applications. In Proceedings of the International Conference on Information Systems Security, Funchal, Portugal, 22–24 January 2018; Springer: Cham, Switzerland, 2018; pp. 146–167. [Google Scholar]
- Tamada, H.; Nakamura, M.; Monden, A.; Matsumoto, K.I. Java Birthmarks–Detecting the Software Theft–. Ieice Trans. Inf. Syst. 2019, 88, 2148–2158. [Google Scholar] [CrossRef]
- Raff, E.; Nicholas, C. Malware classification and class imbalance via stochastic hashed lzjd. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, New York, NY, USA, 3 November 2017; pp. 111–120. [Google Scholar]
- Bailey, M.; Oberheide, J.; Andersen, J.; Mao, Z.M.; Jahanian, F.; Nazario, J. Automated classification and analysis of internet malware. In Proceedings of the International Workshop on Recent Advances in Intrusion Detection, Gold Goast, Australia, 5–7 September 2017; Springer: Berlin/Heidelberg, Germany, 2007; pp. 178–197. [Google Scholar]
- Alshahwan, N.; Barr, E.T.; Clark, D.; Danezis, G. Detecting malware with information complexity. arXiv 2015, arXiv:1502.07661. [Google Scholar]
- Raff, E. Malware Detection and Cyber Security via Compression; University of Maryland: Baltimore County, MD, USA, 2018. [Google Scholar]
- Faridi, H.; Srinivasagopalan, S.; Verma, R. Performance Evaluation of Features and Clustering Algorithms for Malware. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 13–22. [Google Scholar]
- Carvalho, J.M.; Brãs, S.; Ferreira, J.; Soares, S.C.; Pinho, A.J. Impact of the acquisition time on ECG compression-based biometric identification systems. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Faro, Portugal, 20–23 June 2017; Springer: Cham, Switzerland, 2017; pp. 169–176. [Google Scholar]
- Israel, S.A.; Irvine, J.M.; Cheng, A.; Wiederhold, M.D.; Wiederhold, B.K. ECG to identify individuals. Pattern Recognit. 2019, 38, 133–142. [Google Scholar] [CrossRef]
- Arteaga-Falconi, J.S.; Al Osman, H.; El Saddik, A. ECG authentication for mobile devices. IEEE Trans. Instrum. Meas. 2015, 65, 591–600. [Google Scholar] [CrossRef]
- Carvalho, J.M.; Brás, S.; Pinho, A.J. Compression-Based ECG Biometric Identification Using a Non-fiducial Approach. arXiv 2018, arXiv:1804.00959. [Google Scholar]
- Brás, S.; Ferreira, J.H.; Soares, S.C.; Pinho, A.J. Biometric and emotion identification: An ECG compression based method. Front. Psychol. 2018, 9, 467. [Google Scholar] [CrossRef] [PubMed]
- Resende, J.S.; Sousa, P.R.; Martins, R.; Antunes, L. Breaking MPC implementations through compression. Int. J. Inf. Secur. 2019. [Google Scholar] [CrossRef]
- Sasse, M.A.; Brostoff, S.; Weirich, D. Transforming the ‘weakest link’—A human/computer interaction approach to usable and effective security. Technol. J. 2019, 19, 122–131. [Google Scholar]
- Khonji, M.; Iraqi, Y.; Jones, A. Phishing detection: A literature survey. IEEE Commun. Surv. Tutor. 2013, 15, 2091–2121. [Google Scholar] [CrossRef]
- Parsons, K.; McCormac, A.; Pattinson, M.; Butavicius, M.; Jerram, C. Phishing for the truth: A scenario-based experiment of users’ behavioural response to emails. In Proceedings of the IFIP International Information Security Conference, Auckland, New Zealand, 8–10 July 2013; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Zheng, L.; Narayan, S.; Risher, M.E.; Wei, S.K.; Ramarao, V.T.; Kundu, A. Spam Filtering Based on Statistics and Token Frequency Modeling. US Patent 8,364,766, 29 January 2013. [Google Scholar]
- Spam Track. Available online: https://trec.nist.gov/data/spam.html (accessed on 3 December 2019).
- Dorner, D. The Logic of Failure: Recognizing and Avoiding Error in Complex Situations; Basic Books: New York, NY, USA, 1997. [Google Scholar]
- Wertheimer, M. Gestalt Theory; American Psychological Association: Washington, DC, USA, 1938. [Google Scholar]
- PhishTank. Available online: https://www.phishtank.com/index.php (accessed on 3 December 2019).
- Ivanov, I.; Hantova, C.; Nisheva, M.; Stanchev, P.L.; Ein-Dor, P. Software Library for Authorship Identification. Digit. Present. Preserv. Cult. Sci. Herit. 2015, V, 91–97. [Google Scholar]
- Axelsson, S. The Normalised Compression Distance as a file fragment classifier. Digit. Investig. 2010, 7, S24–S31. [Google Scholar] [CrossRef]
- Axelsson, S. Using normalized compression distance for classifying file fragments. In Proceedings of the 2010 International Conference on Availability, Reliability and Security, Krakow, Poland, 15–18 February 2010; pp. 641–646. [Google Scholar]
- Cerra, D.; Datcu, M.; Reinartz, P. Authorship analysis based on data compression. Pattern Recognit. Lett. 2014, 42, 79–84. [Google Scholar] [CrossRef]
- Kulekci, M.O.; Kamasak, M.E. A Method of Privacy Preserving Document Similarity Detection. US Patent App. 16/082,272, 21 March 2019. [Google Scholar]
- Kulekci, M.O.; Habib, I.; Aghabaiglou, A. Privacy–Preserving Text Similarity via Non-Prefix-Free Codes. In Proceedings of the International Conference on Similarity Search and Applications, Newark, NJ, USA, 2–4 October 2019; Springer: Cham, Switzerland, 2019; pp. 94–102. [Google Scholar]
- Lambers, M.; Veenman, C.J. Forensic authorship attribution using compression distances to prototypes. In Proceedings of the International Workshop on Computational Forensics, The Hague, The Netherlands, 13–14 August 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 13–24. [Google Scholar]
- Lazer, D.M.; Baum, M.A.; Benkler, Y.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Metzger, M.J.; Nyhan, B.; Pennycook, G.; Rothschild, D.; et al. The science of fake news. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef]
- Ahmad, S.; Asghar, M.Z.; Alotaibi, F.M.; Awan, I. Detection and classification of social media-based extremist affiliations using sentiment analysis techniques. Hum.-Centric Comput. Inf. Sci. 2019, 9, 24. [Google Scholar] [CrossRef]
- Hon, L.; Varathan, K. Cyberbullying detection system on twitter. IJABM 2015, 1, 1–11. [Google Scholar]
- Pinto, A.; Oliveira, H.G.; Figueira, Á.; Alves, A.O. Predicting the Relevance of Social Media Posts Based on Linguistic Features and Journalistic Criteria. New Gener. Comput. 2017, 35, 451–472. [Google Scholar] [CrossRef]
- Arshad, H.; Jantan, A.; Omolara, E. Evidence collection and forensics on social networks: Research challenges and directions. Digit. Investig. 2019, 28, 126–138. [Google Scholar] [CrossRef]
- Li, R.; Wang, S.; Deng, H.; Wang, R.; Chang, K.C.C. Towards social user profiling: Unified and discriminative influence model for inferring home locations. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12 August 2012; pp. 1023–1031. [Google Scholar]
- Acar, Y.; Backes, M.; Fahl, S.; Kim, D.; Mazurek, M.L.; Stransky, C. You get where you’re looking for: The impact of information sources on code security. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 289–305. [Google Scholar]
- Abdalkareem, R.; Shihab, E.; Rilling, J. On code reuse from StackOverflow: An exploratory study on Android apps. Inf. Softw. Technol. 2017, 88, 148–158. [Google Scholar] [CrossRef]
- Thomas, T.W.; Tabassum, M.; Chu, B.; Lipford, H. Security during application development: An application security expert perspective. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21 April 2018; p. 262. [Google Scholar]
- Acar, Y.; Stransky, C.; Wermke, D.; Weir, C.; Mazurek, M.L.; Fahl, S. Developers need support, too: A survey of security advice for software developers. In Proceedings of the 2017 IEEE Cybersecurity Development (SecDev), Cambridge, MA, USA, 23 October 2017; pp. 22–26. [Google Scholar]
- He, W.; Tian, X.; Shen, J. Examining Security Risks of Mobile Banking Applications through Blog Mining. MAICS 2015, 103–108. [Google Scholar]
- Vaarandi, R.; Blumbergs, B.; Kont, M. An unsupervised framework for detecting anomalous messages from syslog log files. In Proceedings of the NOMS 2018-2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–6. [Google Scholar]
- HTTP DATASET CSIC 2010. Available online: http://www.isi.csic.es/dataset/l (accessed on 3 December 2019).
- Intrusion Detection Evaluation Dataset (ISCXIDS2012). Available online: https://www.unb.ca/cic/datasets/ids.html (accessed on 3 December 2019).
- Zhang, Y.; Ren, W.; Zhu, T.; Ren, Y. SaaS: A situational awareness and analysis system for massive android malware detection. Future Gener. Comput. Syst. 2019, 95, 548–559. [Google Scholar] [CrossRef]
- You, I.; Yim, K. Malware obfuscation techniques: A brief survey. In Proceedings of the 2010 International conference on broadband, wireless computing, communication and applications, Fukuoka, Japan, 4–6 November 2010; pp. 297–300. [Google Scholar]
- Menéndez, H.D.; Llorente, J.L. Mimicking Anti-Viruses with Machine Learning and Entropy Profiles. Entropy 2019, 21, 513. [Google Scholar] [CrossRef]
- Ronen, R.; Radu, M.; Feuerstein, C.; Yom-Tov, E.; Ahmadi, M. Microsoft malware classification challenge. arXiv 2018, arXiv:1802.10135. [Google Scholar]
- Wehner, S. Analyzing worms and network traffic using compression. J. Comput. Secur. 2007, 15, 303–320. [Google Scholar] [CrossRef]
- Menéndez, H.D.; Bhattacharya, S.; Clark, D.; Barr, E.T. The arms race: Adversarial search defeats entropy used to detect malware. Expert Syst. Appl. 2019, 118, 246–260. [Google Scholar] [CrossRef]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. Drebin: Effective and explainable detection of android malware in your pocket. Ndss 2014, 14, 23–26. [Google Scholar]
- Ekhtoom, D.; Al-Ayyoub, M.; Al-Saleh, M.; Alsmirat, M.; Hmeidi, I. A compression-based technique to classify metamorphic malware. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–6. [Google Scholar]
- Lee, J. Compression-Based Analysis of Metamorphic Malware. Master’s Thesis, San Jose State University, Washington, CA, USA, 2013. [Google Scholar]
- De Luca, A.; Lindqvist, J. Is secure and usable smartphone authentication asking too much? Computer 2015, 48, 64–68. [Google Scholar] [CrossRef]
- Davidson, S.; Smith, D.; Yang, C.; Cheah, S. Smartwatch User Identification as a Means of Authentication. Available online: https://pdfs.semanticscholar.org/989c/b3f52f9c3d31c305eeb251afd1a7b6e0aeb0.pdf (accessed on 3 December 2019).
- Storer, T. Bridging the chasm: A survey of software engineering practice in scientific programming. Acm Comput. Surv. Csur 2017, 50, 47. [Google Scholar] [CrossRef]
- Naylor, T.H.; Finger, J.M. Verification of computer simulation models. Manag. Sci. 2019, 14. [Google Scholar] [CrossRef]
- Yao, A.C. Protocols for secure computations. In Proceedings of the 23rd annual symposium on foundations of computer science (sfcs 1982), Chicago, IL, USA, 3–5 November 1982; pp. 160–164. [Google Scholar]
- Yao, A.C. How to generate and exchange secrets. In Proceedings of the 27th Annual Symposium on Foundations of Computer Science (sfcs 1986), Toronto, ON, Canada, 27–29 October 1986; pp. 162–167. [Google Scholar]
- Yao, A.C. Theory and application of trapdoor functions. In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science (sfcs 1982), Chicago, IL, USA, 3–5 November 1982; pp. 80–91. [Google Scholar]
- Araki, T.; Furukawa, J.; Lindell, Y.; Nof, A.; Ohara, K. High-throughput semi-honest secure three-party computation with an honest majority. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 24–28 October; pp. 805–817.
- Demmler, D.; Schneider, T.; Zohner, M. ABY-A Framework for Efficient Mixed-Protocol Secure Two-Party Computation. NDSS 2015. [Google Scholar] [CrossRef]
- Damgård, I.; Keller, M.; Larraia, E.; Pastro, V.; Scholl, P.; Smart, N.P. Practical covertly secure MPC for dishonest majority—Or: Breaking the SPDZ limits. In Proceedings of the European Symposium on Research in Computer Security, Egham, UK, 9–13 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–18. [Google Scholar]
- Frederiksen, T.K.; Jakobsen, T.P.; Nielsen, J.B.; Trifiletti, R. TinyLEGO: An Interactive Garbling Scheme for Maliciously Secure Two-party Computation. Iacr Cryptol. Eprint Arch. 2015, 2015, 309. [Google Scholar]
- Kolesnikov, V.; Nielsen, J.B.; Rosulek, M.; Trieu, N.; Trifiletti, R. DUPLO: Unifying cut-and-choose for garbled circuits. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, NJ, USA, 30 October–3 November 2017; pp. 3–20. [Google Scholar]
- Grajeda, C.; Breitinger, F.; Baggili, I. Availability of datasets for digital forensics–and what is missing. Digit. Investig. 2017, 22, S94–S105. [Google Scholar] [CrossRef]


{kind=link}
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
S. Resende, J.; Martins, R.; Antunes, L. A Survey on Using Kolmogorov Complexity in Cybersecurity. Entropy 2019, 21, 1196. https://doi.org/10.3390/e21121196
S. Resende J, Martins R, Antunes L. A Survey on Using Kolmogorov Complexity in Cybersecurity. Entropy. 2019; 21(12):1196. https://doi.org/10.3390/e21121196
Chicago/Turabian StyleS. Resende, João, Rolando Martins, and Luís Antunes. 2019. "A Survey on Using Kolmogorov Complexity in Cybersecurity" Entropy 21, no. 12: 1196. https://doi.org/10.3390/e21121196
APA StyleS. Resende, J., Martins, R., & Antunes, L. (2019). A Survey on Using Kolmogorov Complexity in Cybersecurity. Entropy, 21(12), 1196. https://doi.org/10.3390/e21121196