Recognition of Voltage Sag Sources Based on Phase Space Reconstruction and Improved VGG Transfer Learning

Abstract
1. Introduction
2. Voltage Sag Source Feature Extraction Based on Phase Space Reconstruction Theory
2.1. Classification of Voltage Sag Sources
- Short circuit fault is the main cause of voltage sag. Different short circuit faults can cause different sags. The voltage sag caused by three phase short circuit fault is equal in three-phase voltage magnitude. The three-phase magnitude of voltage sag caused by other short circuit types is different. Voltage swell may occur while sag occurs in an asymmetric short circuit. At the beginning and end of the voltage sag, the magnitude suddenly changes, and there is no change in the voltage magnitude during the sag.
- When a large induction motor is starting, it will draw much larger current from the power supply than normal operation. The typical starting current is 5-6 times the rated working current, thus resulting in voltage sag. When the sag occurs, the three-phase voltage drops at the same time, and the sag magnitude is basically the same. There is no sudden change in the recovery process, and it is gradually recovered.
- Because of the saturation characteristic of the core, the inrush current of transformer when switched on and off is several times the rated current, which will cause voltage sag. The initial phase angle of three-phase voltage always differs by 120 degrees, so the magnitude of three-phase sag is always unbalanced. Large transformers usually need dozens of cycles to recover because of their small resistance and large reactance. In addition, the voltage waveform of sag contains higher harmonics.
2.2. Phase Space Reconstruction Theory
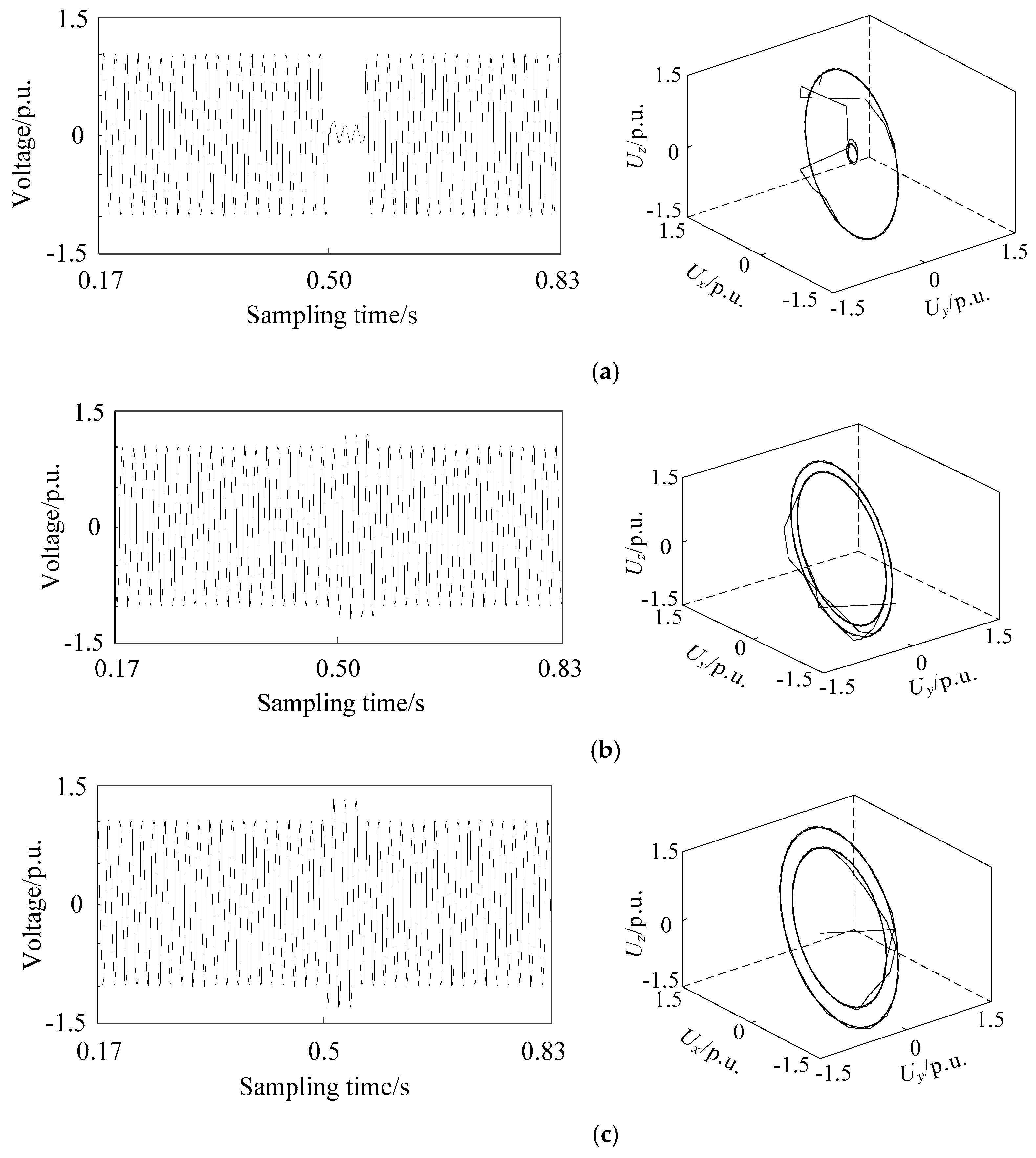
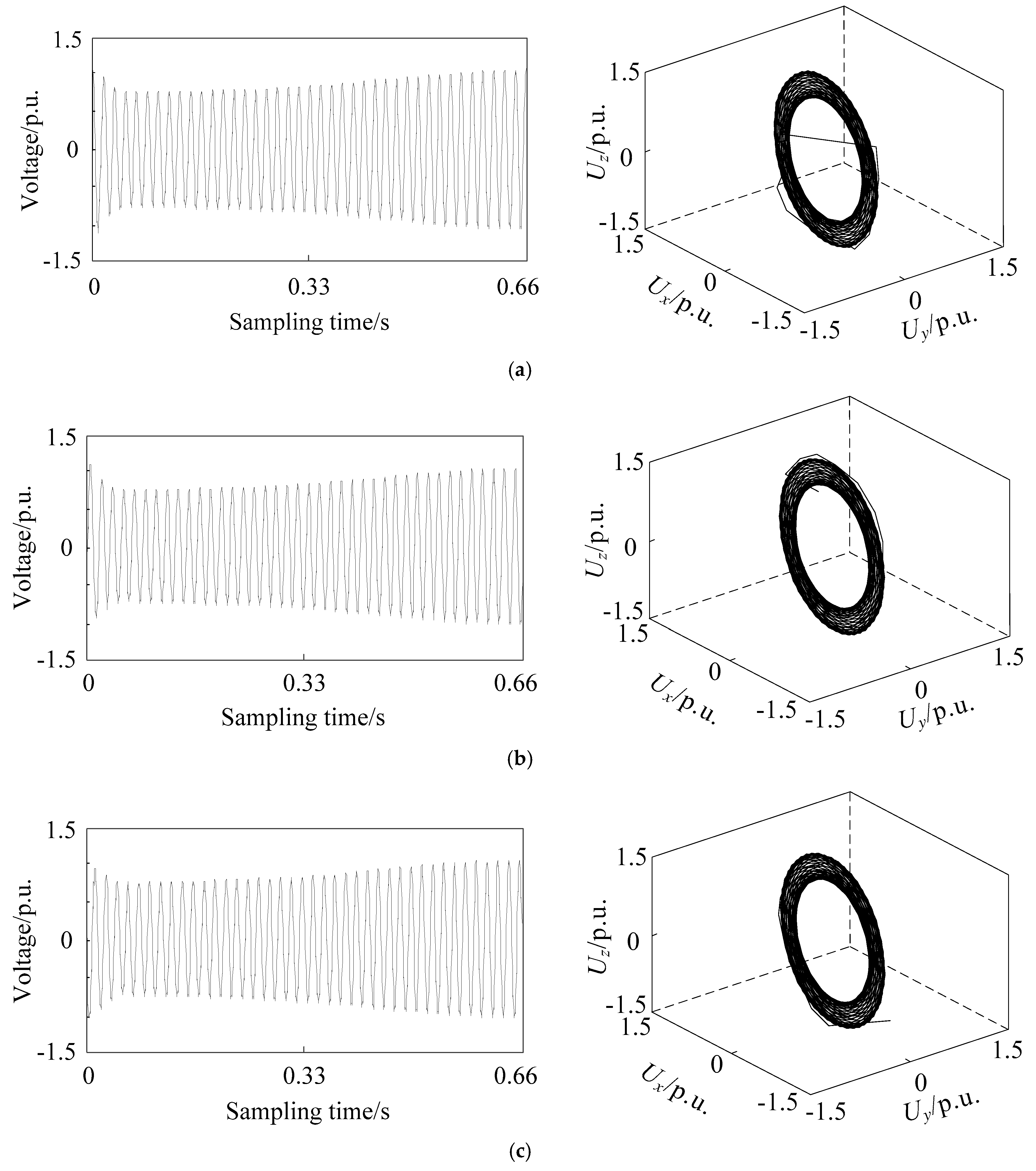
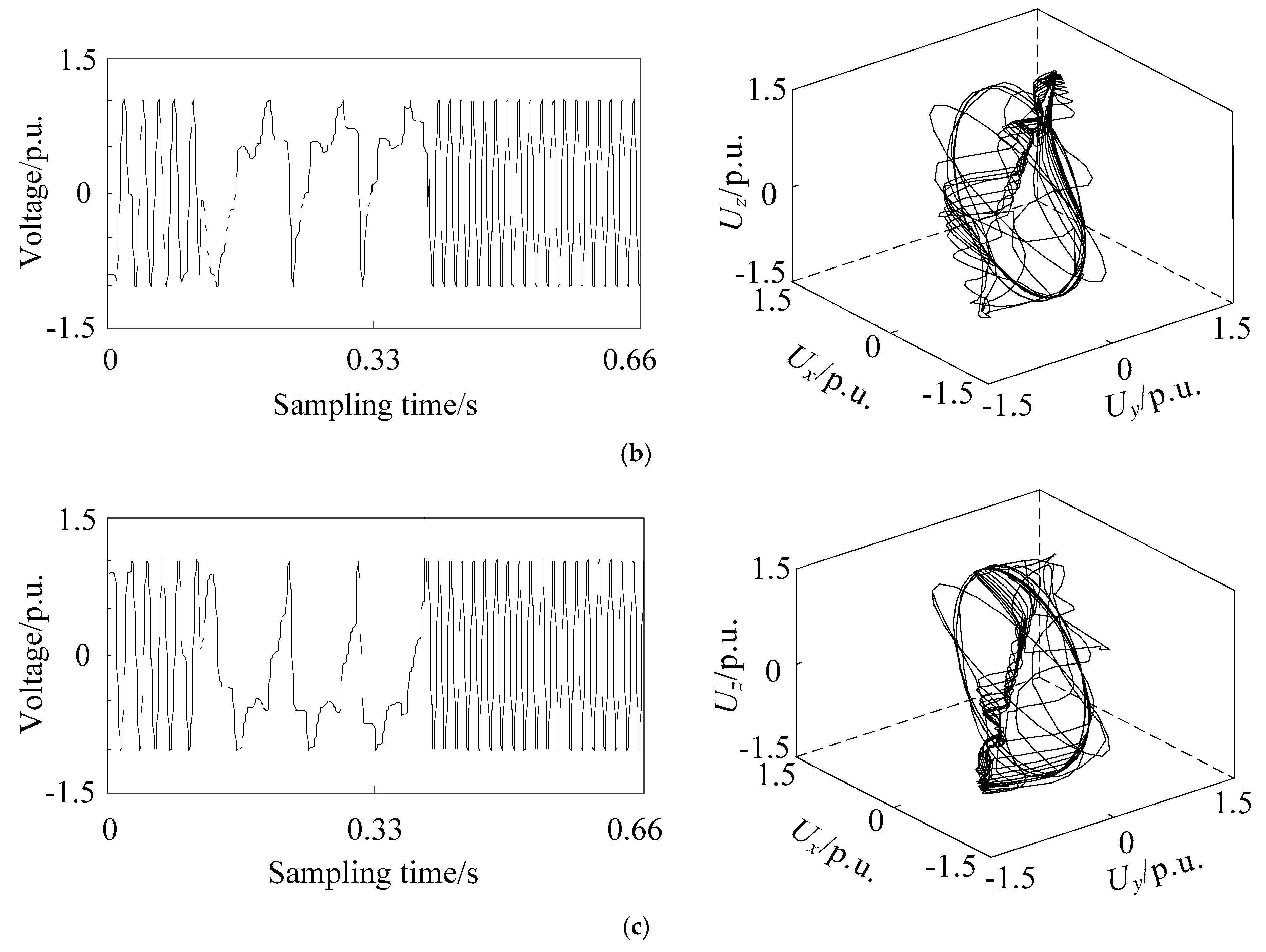
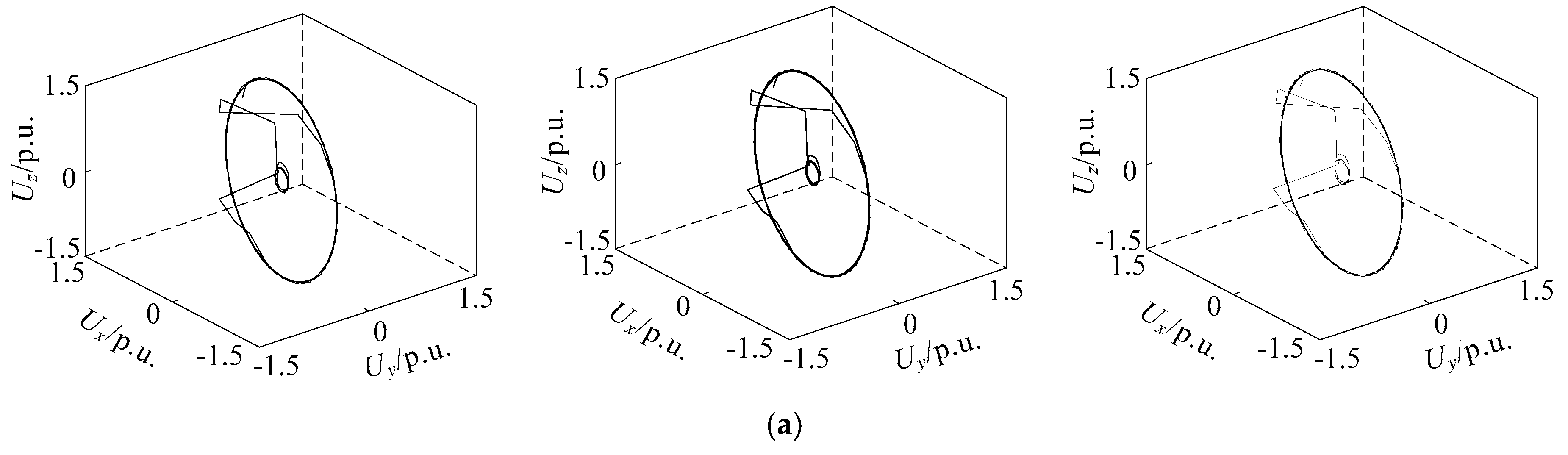
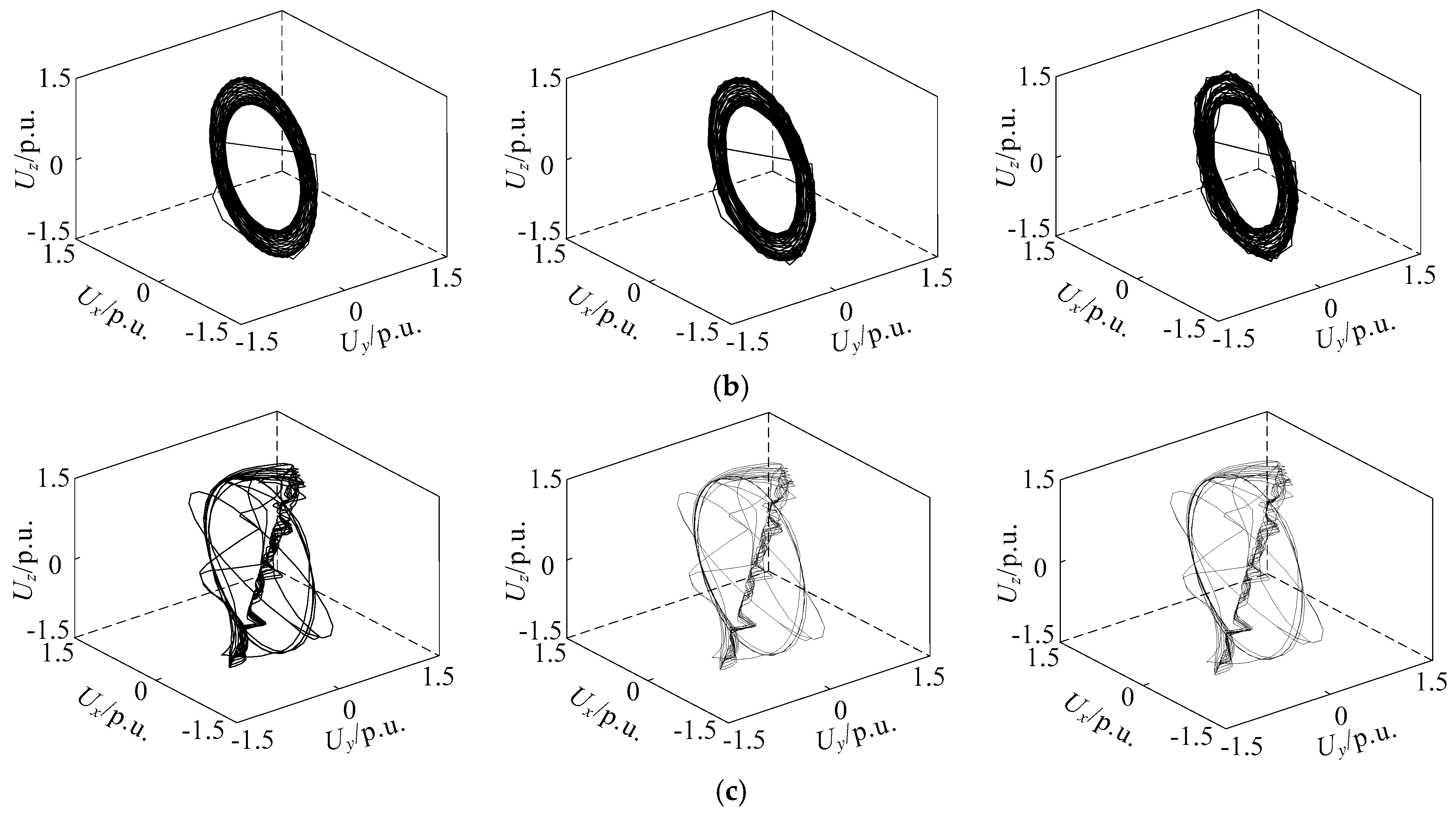
2.3. Phase Space Reconstruction of Different Voltage Sag Signals
- The number of limit cycles
- The size of limit cycles
- The existence of strange attractors
- The number of mutation trajectories
3. Recognition of Voltage Sag Source Based on VGG
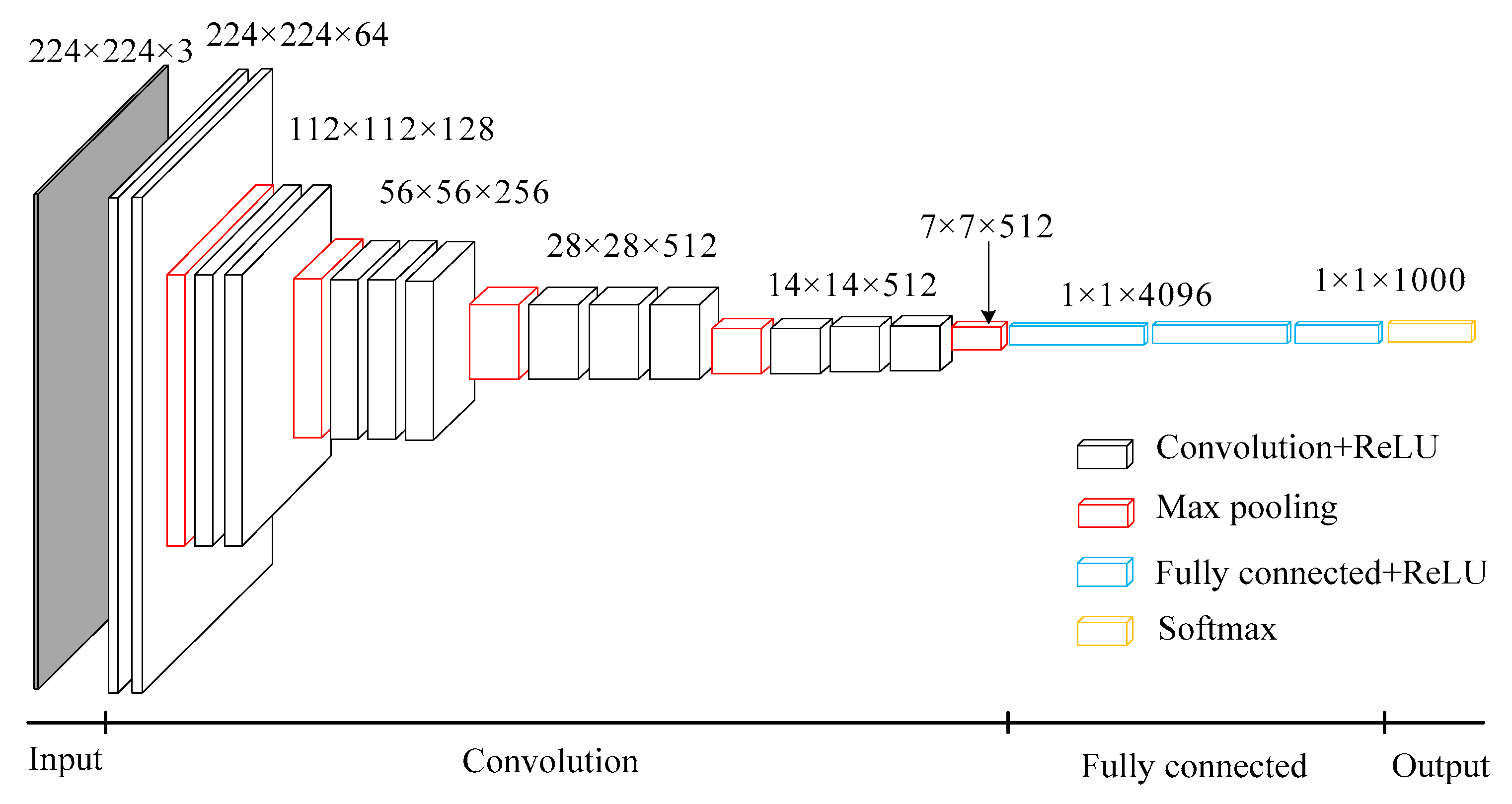
3.1. VGG Network Structure
3.2. Cross Entropy Loss Function
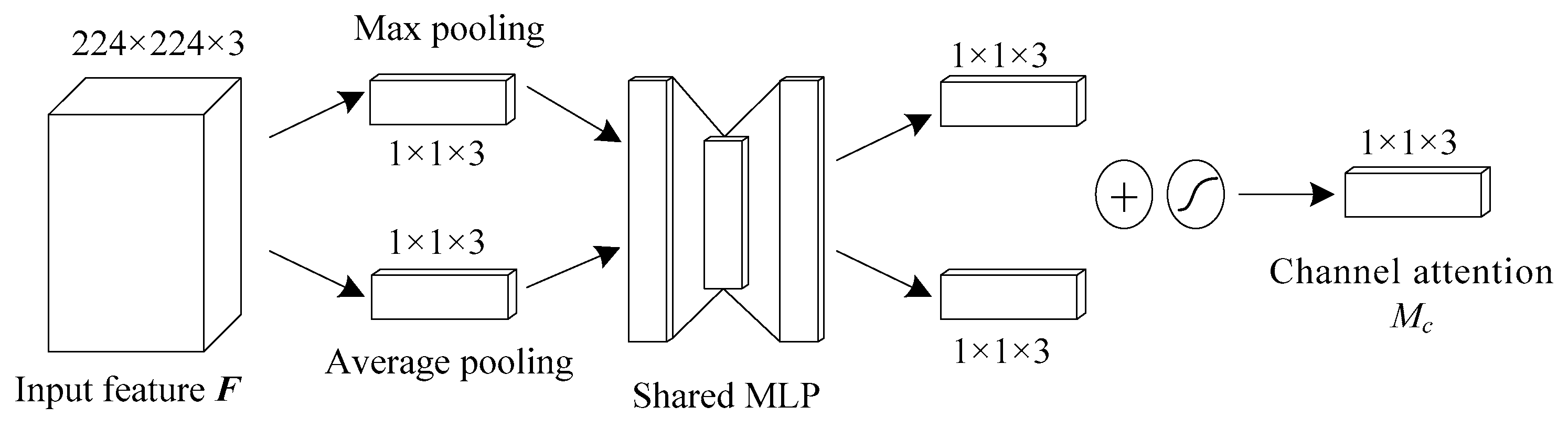
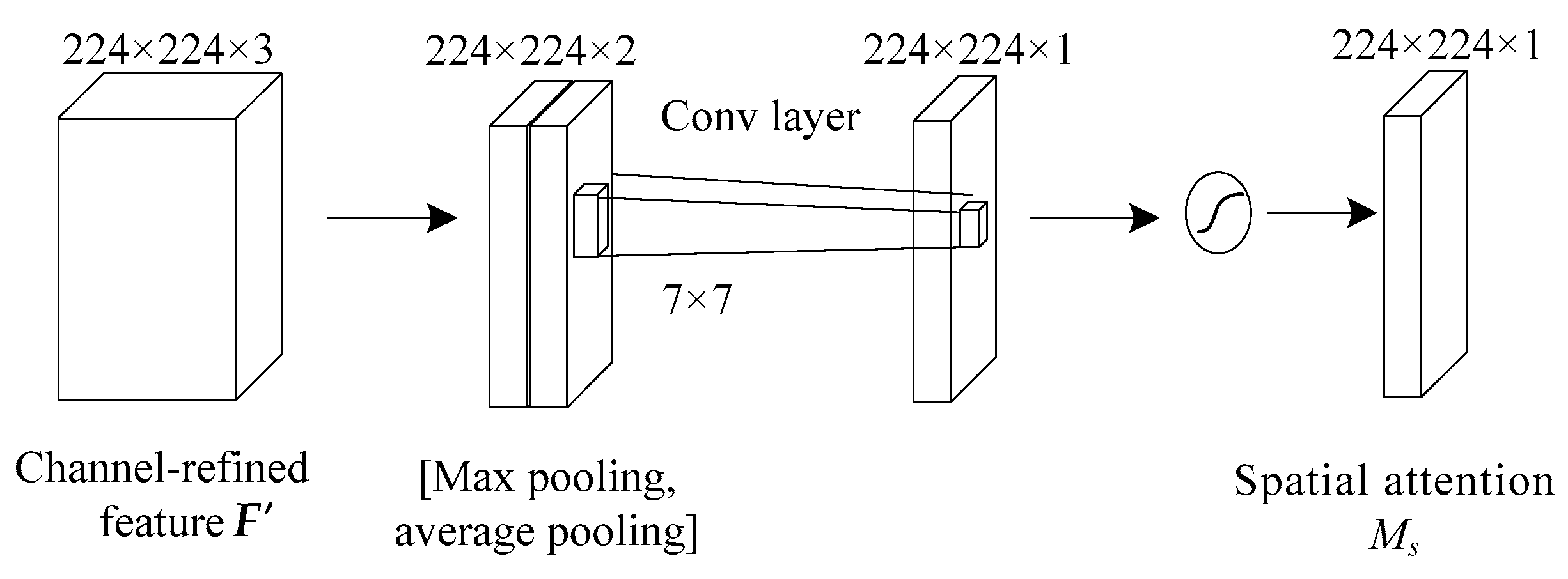
3.3. Attention Mechanism
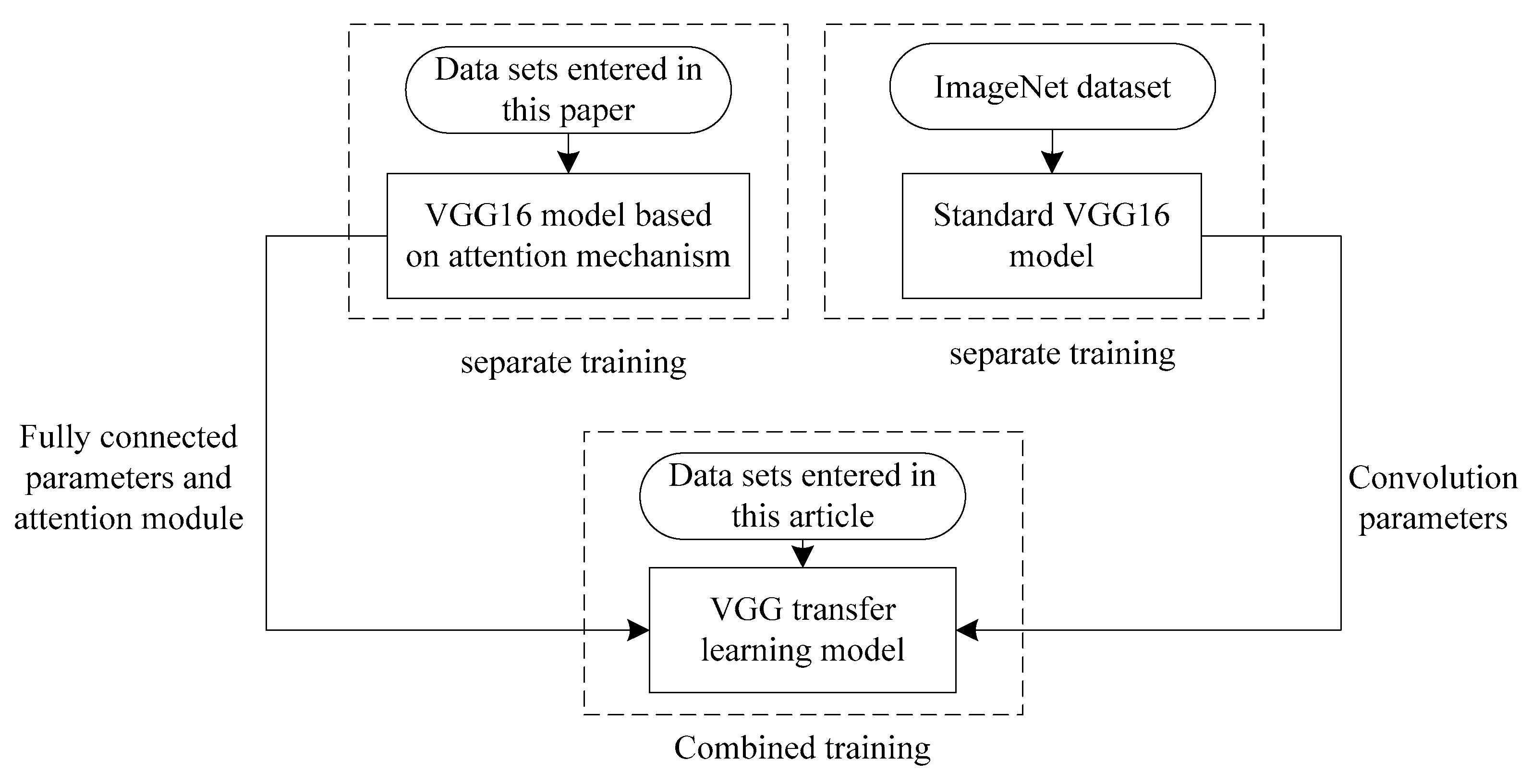
3.4. Voltage Sag Source Recognition Based on Improved VGG Transfer Learning
3.4.1. Improved VGG Transfer Learning
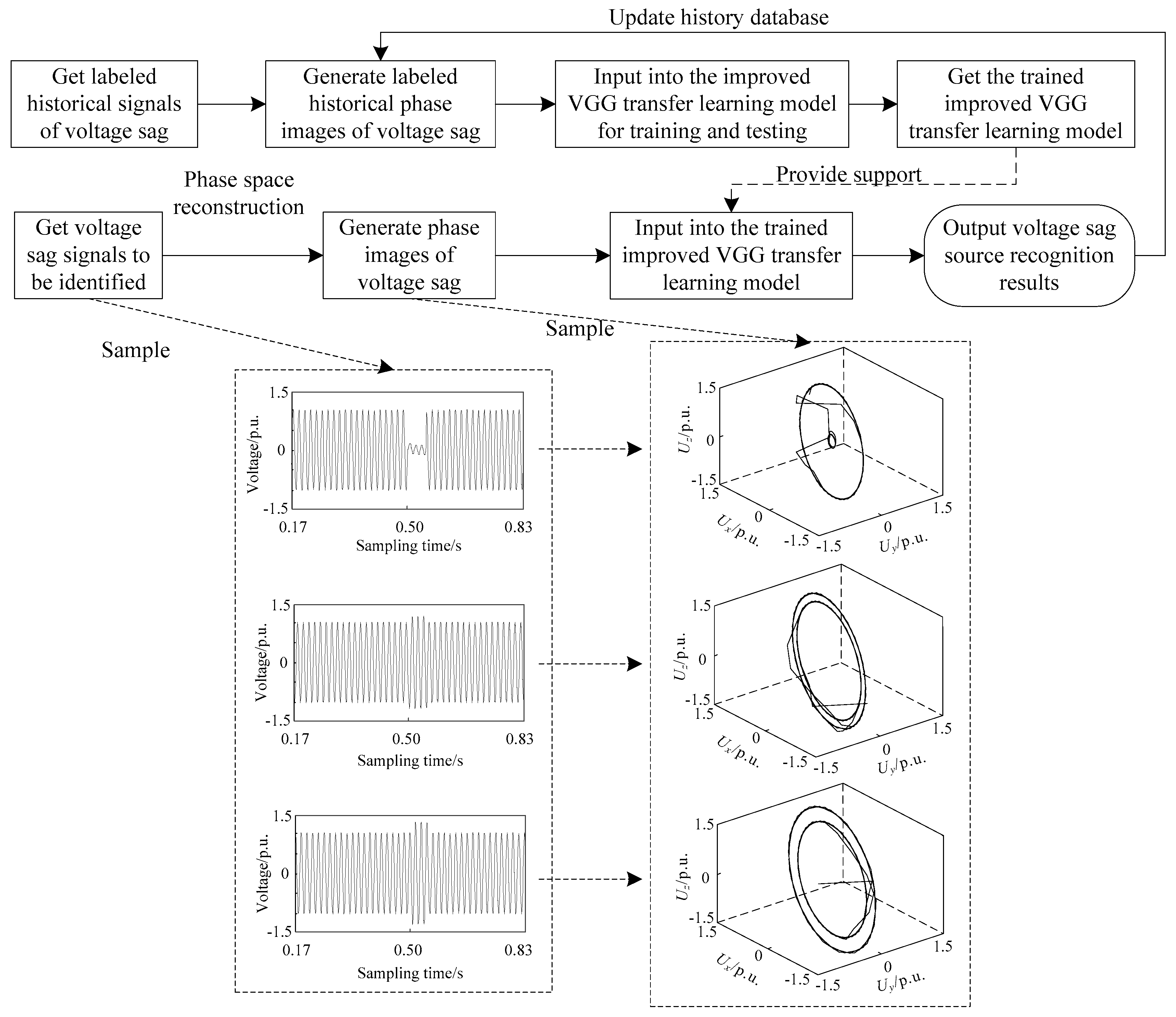
3.4.2. Voltage Sag Source Recognition Framework
- Step 1: The historical data of voltage sag are read from the database. With the technology of phase space reconstruction referred in Section 2, historical reconstruction images of labeled different voltage sag sources can be generated.
- Step 2: As training and testing data sets in this paper, the reconstruction image data in step 1 are input into the improved VGG transfer learning model in Section 3.4 for training and testing. Then, a trained improved VGG transfer learning model can be obtained.
- Step 3: For the voltage sag signals to be identified, the corresponding reconstruction images are generated which are input into the trained model in step 2. Finally, the results of voltage sag source recognition are achieved.
4. Example Analysis
4.1. Data Acquisition
4.2. Analysis of Noise Immunity for Voltage Sag Phase Space Reconstruction
4.3. Analysis of Attention Mechanism
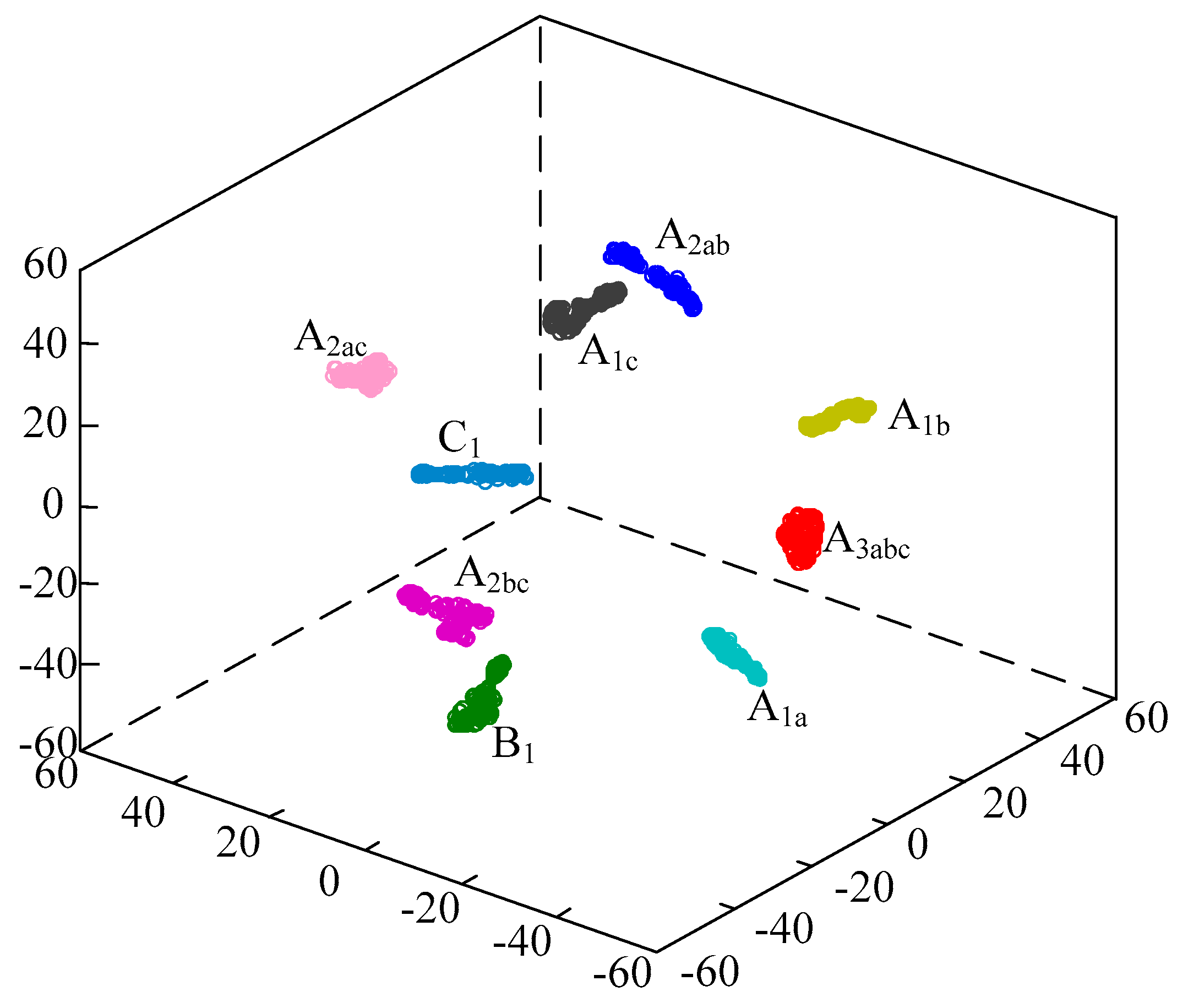
4.4. Analysis of Classification Effect of Feature Vector
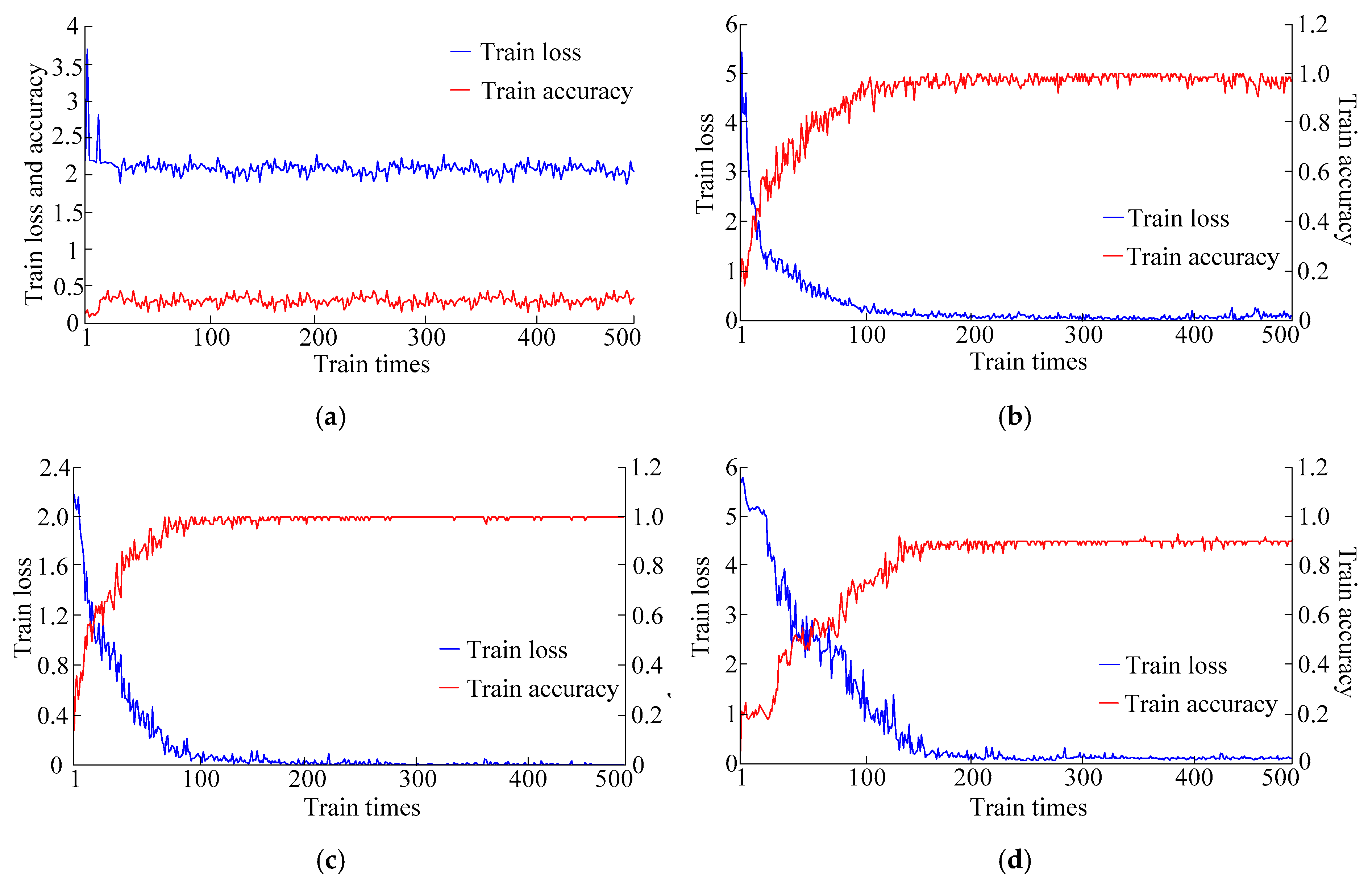
4.5. Network Training Process and Contrastive Analysis
4.6. Result Analysis
5. Conclusions
- Voltage sag signal image is reconstructed into phase space image, which not only retains the complete characteristics of sag, but also has more intuitive and concise image features.
- Attention mechanism is added to VGG model to further automatically extract image features to prevent over-fitting. It has an excellent classification effect and improves the accuracy of model recognition.
- The idea of transfer learning is introduced to train the network on the basis of other image classification results, which improves the efficiency of network training.
Author Contributions
Funding
Conflicts of Interest
References
- Saini, M.K.; Kapoor, R.; Beniwal, R.K.; Aggarwal, A. Recognition of voltage sag causes using fractionally delayed biorthogonal wavelet. Trans. Inst. Meas. Control 2019, 41, 2851–2863. [Google Scholar] [CrossRef]
- Ding, N.; Cai, W.; Suo, J.; Wang, J.W. Research on voltage sag sources recognition method. Power Syst. Technol. 2008, 32, 55–59. [Google Scholar]
- De Santis, M.; Noce, C.; Varilone, P.; Verde, P. Analysis of the origin of measured voltage sags in interconnected networks. Electric Pow. Syst. Res. 2018, 154, 391–400. [Google Scholar] [CrossRef]
- Zheng, Z.C.; Wang, H.; Qi, L.H. Recognition method of voltage sag sources based on deep learning models’ fusion. Proc. CSEE 2019, 39, 97–104+324. [Google Scholar]
- Mei, F.; Ren, Y.; Wu, Q.L.; Zhang, C.Y.; Pan, Y.; Sha, H.Y.; Zheng, J.Y. Online recognition method for voltage sags based on a deep belief network. Energies 2019, 12, 1. [Google Scholar] [CrossRef]
- Li, D.Q.; Mei, F.; Zhang, C.Y.; Sha, H.Y.; Zheng, J.Y. Self-supervised voltage sag source identification method based on CNN. Energies 2019, 12, 1059. [Google Scholar] [CrossRef]
- Bagheri, A.; Gu, I.Y.H.; Bollen, M.H.J.; Balouji, E. A robust transform-domain deep convolutional network for voltage dip classification. IEEE Trans. Power Del. 2018, 33, 2794–2802. [Google Scholar] [CrossRef]
- Wang, K.X.; Song, Z.X.; Chen, D.G.; Wang, J.H.; Geng, Y.S. Interference source identification of voltage sag in distribution system based on wavelet transform. Proc. CSEE 2003, 23, 29–34+54. [Google Scholar]
- Saini, M.; Aggarwal, A. Fractionally delayed Legendre wavelet transform based detection and optimal features based classification of voltage sag causes. J. Renew. Sustain. Energy 2019, 11, 1. [Google Scholar] [CrossRef]
- Zhao, F.Z.; Yang, R.G. Voltage sag disturbance detection based on short time fourier transform. Proc. CSEE 2007, 27, 28–34. [Google Scholar]
- Xu, Y.H.; Zhao, Y. Identification of power quality disturbance based on short-term fourier transform and disturbance time orientation by singular value decomposition. Power Syst. Technol. 2011, 35, 174–180. [Google Scholar]
- Li, P.; Zhang, Q.S.; Zhang, G.L.; Liu, W.; Chen, F.R. Adaptive S transform for feature extraction in voltage sags. Appl. Soft Comput. 2019, 80, 438–449. [Google Scholar] [CrossRef]
- Foroughi, A.; Mohammadi, E.; Esmaeili, S. Application of Hilbert-Huang transform and support vector machine for detection and classification of voltage sag sources. Turk. J. Electr. Eng. Comput. Sci. 2014, 22, 1116–1129. [Google Scholar] [CrossRef]
- Manjula, M.; Mishra, S.; Sarma, A.V.R.S. Empirical mode decomposition with Hilbert transform for classification of voltage sag causes using probabilistic neural network. Int. J. Electr. Power Ener. Syst. 2013, 44, 597–603. [Google Scholar] [CrossRef]
- Jia, Y.; He, Z.Y.; Zhao, J. A method to identify voltage sag sources in distribution network based on wavelet entropy and probability neural network. Power Syst. Technol. 2009, 33, 63–69. [Google Scholar]
- Jadhav, V.R.; Patil, A.S. Classification of Voltage sags at Induction Motor by Artificial Neural Network. In Proceedings of the 2015 International Conference on Energy Systems and Applications, Pune, India, 30 October–1 November 2015. [Google Scholar]
- Sha, H.Y.; Mei, F.; Zhang, C.Y.; Pan, Y.; Zheng, J.Y. Identification method for voltage sags based on k-means-singular value decomposition and least squares support vector machine. Energies 2019, 12, 1137. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, C.; Ye, H.; Yu, F. Method to reduce identification feature of different voltage sag disturbance source based on principal component analysis. Power Syst. Protect. Control 2015, 43, 105–110. [Google Scholar]
- Li, C.Y.; Yang, J.L.; Xu, Y.H.; Wu, Y.P.; Wei, P.F. Application of Comprehensive Fuzzy Evaluation Method on Recognition of Voltage Sag Disturbance Sources. Power Syst. Technol. 2017, 41, 1022–1028. [Google Scholar]
- Rabinovitch, A.; Thieberger, R. Time series analysis of chaotic signals. Physica D 1987, 28, 409–415. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Gabriel, G.; Adrian, C.; Valery, N. First-stage prostate cancer identification on histopathological images: Hand-driven versus automatic learning. Entropy 2019, 21, 356. [Google Scholar]
- Ha, I.; Kim, H.; Park, S.; Kim, H. Image retrieval using BIM and features from pretrained VGG network for indoor localization. Build. Environ. 2018, 140, 23–31. [Google Scholar] [CrossRef]
- Matlani, P.; Shrivastava, M. Hybrid Deep VGG-NET Convolutional Classifier for Video Smoke Detection. Comput. Model. Eng. Sci. 2019, 119, 427–458. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Choi, H.; Cho, K.; Bengio, Y. Fine-grained attention mechanism for neural machine translation. Neurocomputing 2018, 284, 171–176. [Google Scholar] [CrossRef]
- Kim, H.G.; Lee, H.; Kim, G.; Oh, S.H.; Lee, S.Y. Rescoring of N-best hypotheses using top-down selective attention for automatic speech recognition. IEEE Signal Proc. Lett. 2018, 25, 199–203. [Google Scholar] [CrossRef]
- Kim, B.; Shin, S.; Jung, H. Variational autoencoder-based multiple image captioning using a caption attention map. Appl. Sci. 2019, 9, 13. [Google Scholar] [CrossRef]
- Khanna, R.; Oh, D.; Kim, Y. Through-wall remote human voice recognition using doppler radar with transfer learning. IEEE Sens. J. 2019, 19, 4571–4576. [Google Scholar] [CrossRef]
- Takens, F. Detecting Strange Atractors in Turbulence; Springer: Berlin, Germany, 1981; pp. 366–381. [Google Scholar]
- Kim, H.S.; Eykholt, R.; Salas, J.D. Nonlinear dynamics, delay times and embedding windows. Physica D 1999, 127, 48–60. [Google Scholar] [CrossRef]
- Meijia, J.; Ochoa, A.; Mederos, B. Reconstruction of PET images using cross-entropy and field of experts. Entropy 2019, 21, 83. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.H.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Laurens, V.D.M. Accelerating t-SNE using Tree-Based Algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar]
- Alohaly, M.; Takabi, H.; Blanco, E. Automated extraction of attributes from natural language attribute-based access control (ABAC) policies. Cybersecurity 2019, 2, 2. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | … |
|---|---|---|---|---|---|---|---|---|---|
| A 1a | 4.574108 | 0.630084 | 0 | 0 | 5.079928 | 0 | 4.930518 | 0 | … |
| 4.555246 | 0.635833 | 0 | 0 | 5.045293 | 0 | 4.893074 | 0 | … | |
| 4.459694 | 0.652800 | 0 | 0 | 4.856162 | 0 | 4.799524 | 0 | … | |
| A1b | 3.613004 | 5.856254 | 0 | 0 | 0.665880 | 0 | 0 | 0 | … |
| 3.523590 | 5.643432 | 0 | 0 | 0.597539 | 0 | 0 | 0 | … | |
| 3.550356 | 5.732181 | 0 | 0 | 0.459643 | 0 | 0 | 0 | … | |
| A1c | 2.309263 | 0.511907 | 0 | 0 | 5.853089 | 3.568975 | 2.278446 | 0 | … |
| 2.218758 | 0.484885 | 0 | 0 | 5.708840 | 3.486815 | 2.193294 | 0 | … | |
| 2.673487 | 0.980059 | 0 | 0 | 6.963194 | 4.116153 | 2.532054 | 0 | … | |
| A2ab | 4.865230 | 1.006909 | 0 | 0 | 0 | 0 | 2.188855 | 0 | … |
| 4.929275 | 1.037814 | 0 | 0 | 0 | 0 | 2.162757 | 0 | … | |
| 4.954888 | 1.041241 | 0 | 0 | 0 | 0 | 2.105883 | 0 | … | |
| A2ac | 3.729304 | 1.305431 | 0 | 0 | 3.439787 | 0.934509 | 1.063446 | 0 | … |
| 3.763325 | 1.190667 | 0 | 0 | 3.463085 | 1.109307 | 1.093839 | 0 | … | |
| 3.919007 | 1.267426 | 0 | 0 | 3.706130 | 1.129699 | 1.240683 | 0 | … | |
| A2bc | 1.402077 | 0.637477 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 1.228110 | 0.477076 | 0 | 0 | 0 | 0 | 0 | 0 | … | |
| 1.315113 | 0.497585 | 0 | 0 | 0 | 0 | 0 | 0 | … | |
| A3abc | 3.255797 | 0 | 0 | 0 | 0.732882 | 2.763226 | 0 | 0 | … |
| 3.085777 | 0 | 0 | 0 | 0.683569 | 2.616498 | 0 | 0 | … | |
| 3.267628 | 0 | 0 | 0 | 0.797595 | 2.761694 | 0 | 0 | … | |
| B1 | 0 | 3.584848 | 0 | 0.130128 | 1.752869 | 0 | 0 | 0 | … |
| 0 | 3.790805 | 0 | 0.230235 | 1.670009 | 0 | 0 | 0 | … | |
| 0 | 3.980163 | 0 | 0.123113 | 1.961738 | 0 | 0 | 0 | … | |
| C1 | 0 | 2.755503 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 0 | 2.504199 | 0 | 0 | 0 | 0 | 0 | 0 | … | |
| 0 | 2.720874 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| Sag Source Type | Accuracy/% | F1/% | ||||
|---|---|---|---|---|---|---|
| Noise-Free | 20 dB | 10 dB | Noise-Free | 20 dB | 10 dB | |
| A1a | 100 | 100 | 98.4 | 100 | 98.7 | 95.8 |
| A1b | 100 | 99.6 | 98.0 | 100 | 98.8 | 95.8 |
| A1c | 100 | 100 | 98.4 | 100 | 98.6 | 95.1 |
| A2ab | 100 | 99.8 | 99.6 | 100 | 96.8 | 93.9 |
| A2ac | 100 | 100 | 98.4 | 100 | 95.8 | 93.7 |
| A2bc | 100 | 99.2 | 98.4 | 100 | 96.9 | 95.9 |
| A3abc | 100 | 100 | 97.2 | 100 | 99.3 | 93.8 |
| B1 | 100 | 100 | 98.8 | 100 | 99.6 | 96.8 |
| C1 | 100 | 100 | 99.2 | 100 | 99.9 | 96.8 |
| Sag Source Type | Accuracy/% | ||||
|---|---|---|---|---|---|
| Method 1 | Method 2 | Method 3 | Method 4 | Proposed Method | |
| A1a | 99.4 | 97.8 | 96.5 | 93.4 | 99.5 |
| A1b | 99.6 | 98.2 | 96.3 | 93.6 | 99.2 |
| A1c | 98.5 | 97.1 | 95.2 | 94.1 | 99.5 |
| A2ab | 98.9 | 97.8 | 96.4 | 94.2 | 99.8 |
| A2ac | 98.1 | 97.6 | 96.9 | 93.6 | 99.6 |
| A2bc | 99.3 | 97.9 | 97.1 | 93.8 | 99.2 |
| A3abc | 99.2 | 98.2 | 96.3 | 94.5 | 99.1 |
| B1 | 99.2 | 98.3 | 97.2 | 94.2 | 99.6 |
| C1 | 99.6 | 98.6 | 96.8 | 93.6 | 99.7 |
| Method 1 | Method 2 | Method 3 | Method 4 | Proposed Method | |
|---|---|---|---|---|---|
| Train times | 416 | 465 | 614 | 750 | 305 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, Y.; Yang, H.; Ma, X.; Sun, X. Recognition of Voltage Sag Sources Based on Phase Space Reconstruction and Improved VGG Transfer Learning. Entropy 2019, 21, 999. https://doi.org/10.3390/e21100999
Pu Y, Yang H, Ma X, Sun X. Recognition of Voltage Sag Sources Based on Phase Space Reconstruction and Improved VGG Transfer Learning. Entropy. 2019; 21(10):999. https://doi.org/10.3390/e21100999
Chicago/Turabian StylePu, Yuting, Honggeng Yang, Xiaoyang Ma, and Xiangxun Sun. 2019. "Recognition of Voltage Sag Sources Based on Phase Space Reconstruction and Improved VGG Transfer Learning" Entropy 21, no. 10: 999. https://doi.org/10.3390/e21100999
APA StylePu, Y., Yang, H., Ma, X., & Sun, X. (2019). Recognition of Voltage Sag Sources Based on Phase Space Reconstruction and Improved VGG Transfer Learning. Entropy, 21(10), 999. https://doi.org/10.3390/e21100999