High Efficiency Video Coding Compliant Perceptual Video Coding Using Entropy Based Visual Saliency Model


Abstract
1. Introduction
- Performance comparison of different entropy based visual saliency algorithms is presented for videos using a newly developed pixel-labeled ground truth.
- Information maximization based visual saliency algorithm is incorporated in an HEVC framework.
- An efficient algorithm to allocate quantization parameters for salient and non-salient CTUs is presented that minimizes the data rate while preserving the perceived quality.
- The proposed entropy based PVC framework is evaluated objectively and subjectively and shows superior coding performance.
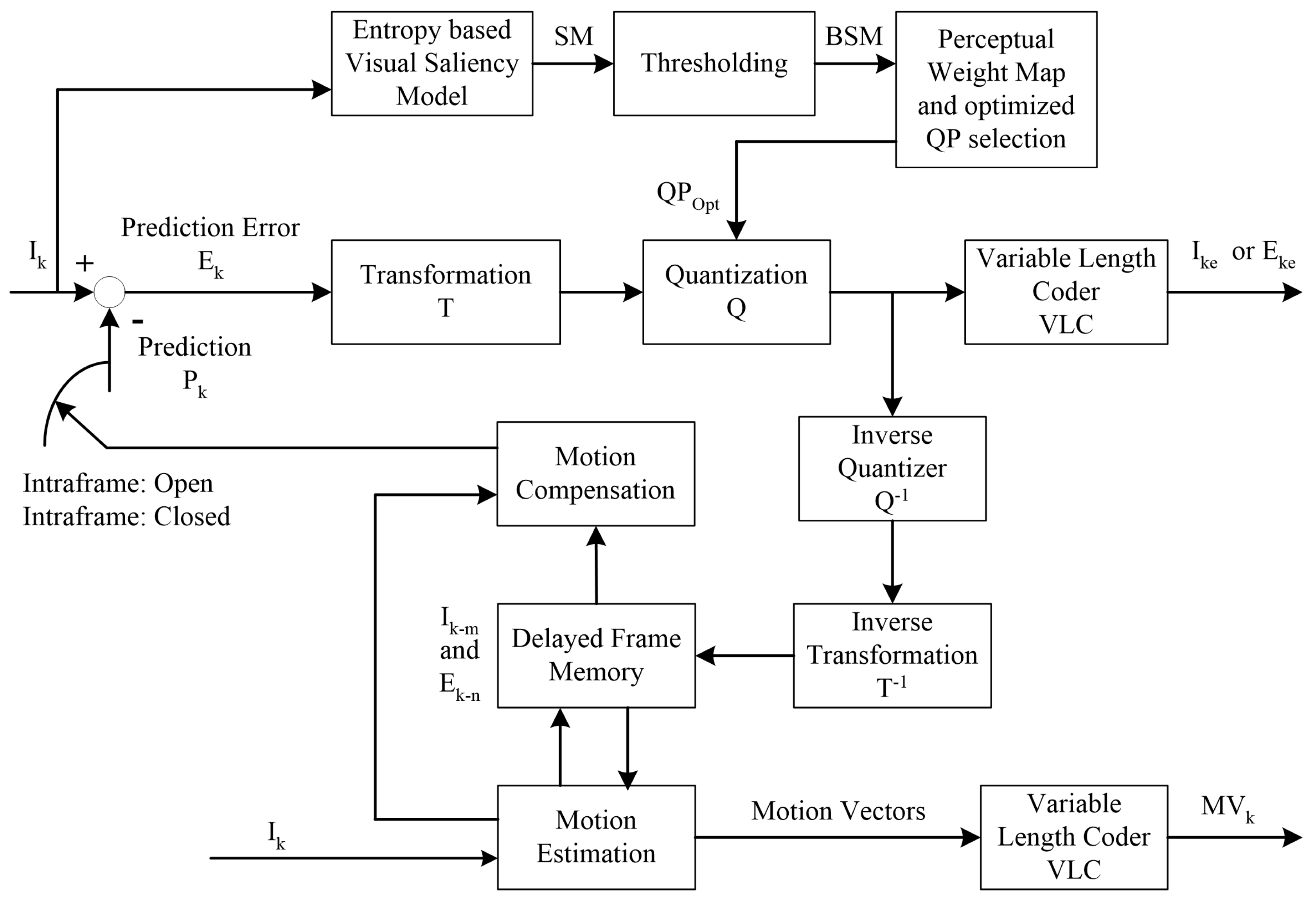
2. Proposed Methodology
2.1. Entropy Based Visual Saliency Model
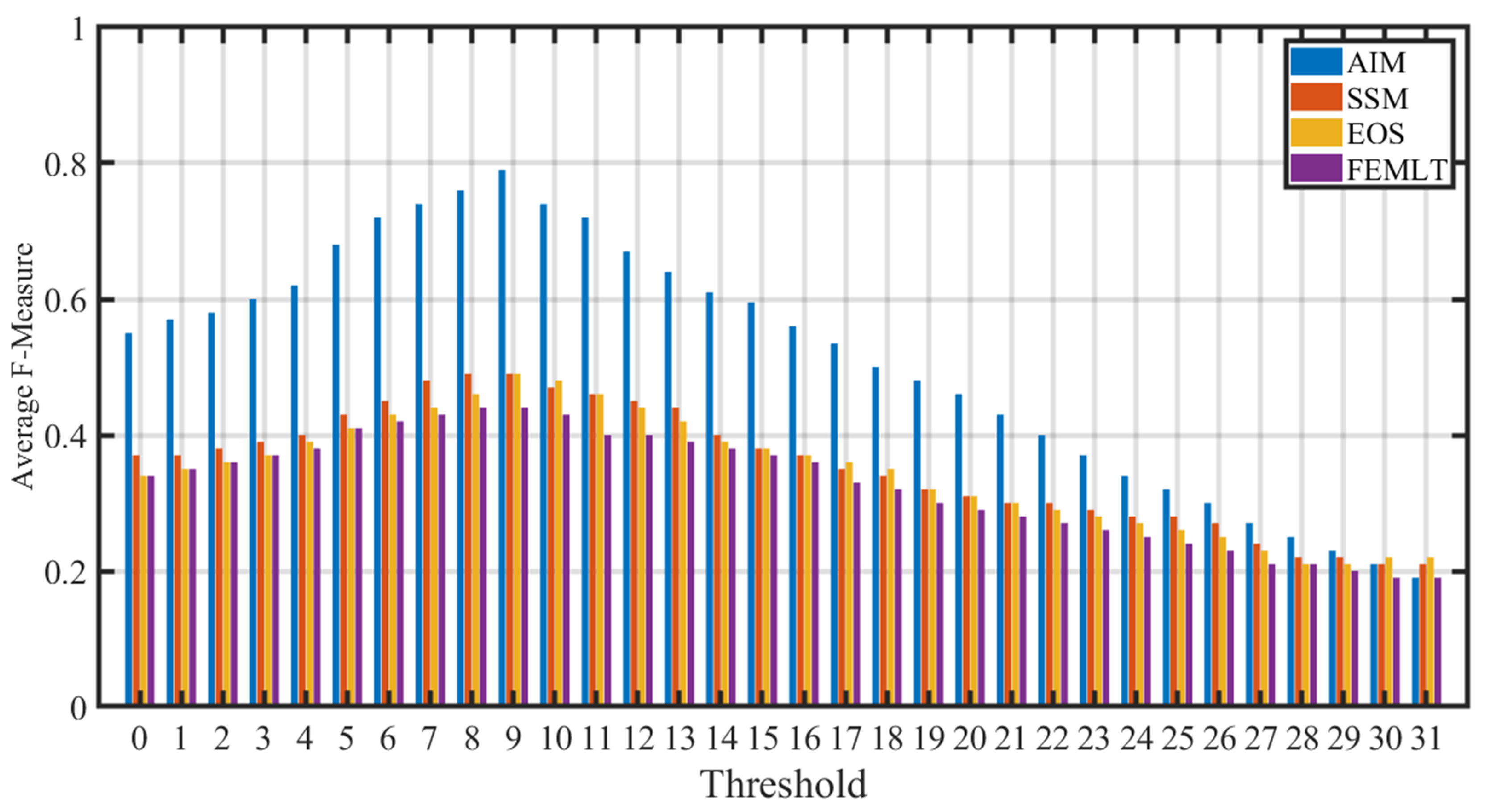
2.2. Thresholding
- Initialize the threshold vector with N values as,where and represents the minimum and maximum value of the saliency map generated by the visual saliency algorithm respectively. The number of threshold levels is represented by N and .
- Initialize a vector of size representing average F-measure values with all zeros.
- Calculate the thresholded saliency map of each video frame in the dataset at threshold value as
- Calculate the F-measure between the thresholded saliency mask and human labeled ground truth binary mask for all video frames in the dataset.
- Compute the average F-measure and store in the vector at position.
- Repeat steps 3 to 5 for all threshold values.
- Choose index from vector that gives maximum average threshold value as optimum threshold value.
2.3. Perceptual Weight Map and Optimized QP Selection

3. Experimental Results
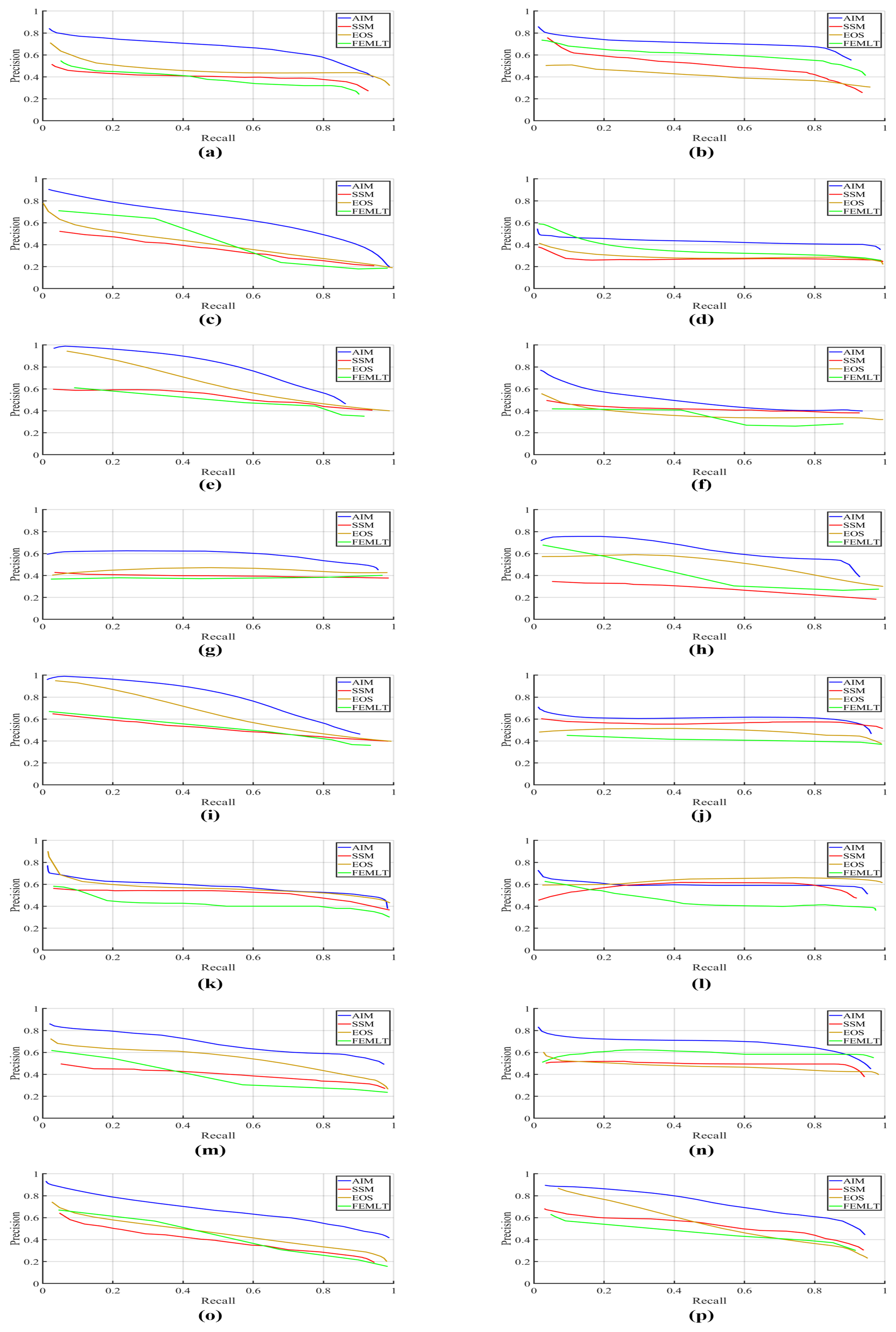
3.1. Performance Comparison of Entropy Based Visual Saliency Models
3.2. Perceptual Video Coding
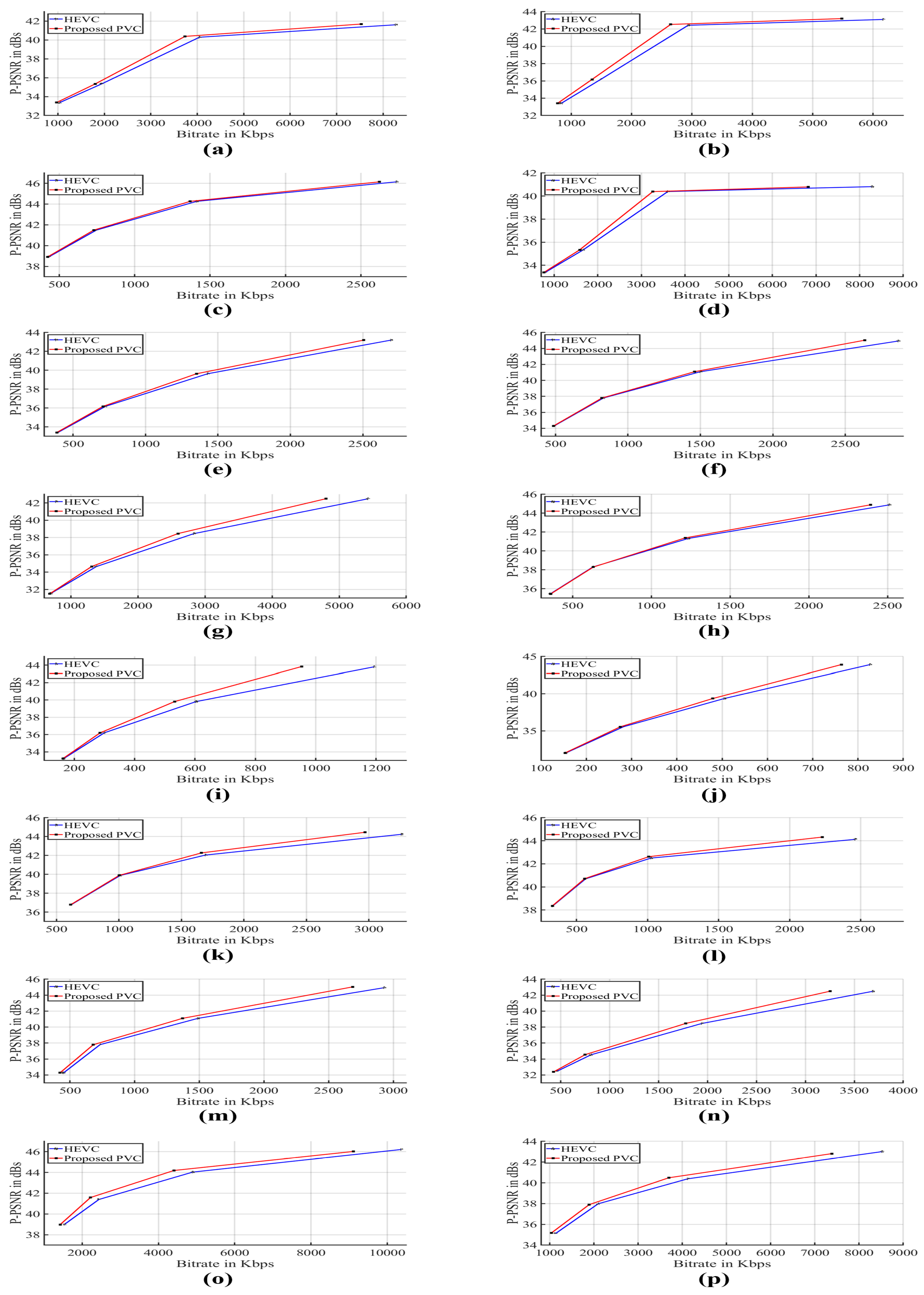
3.2.1. Bitrate Reduction and Computational Complexity
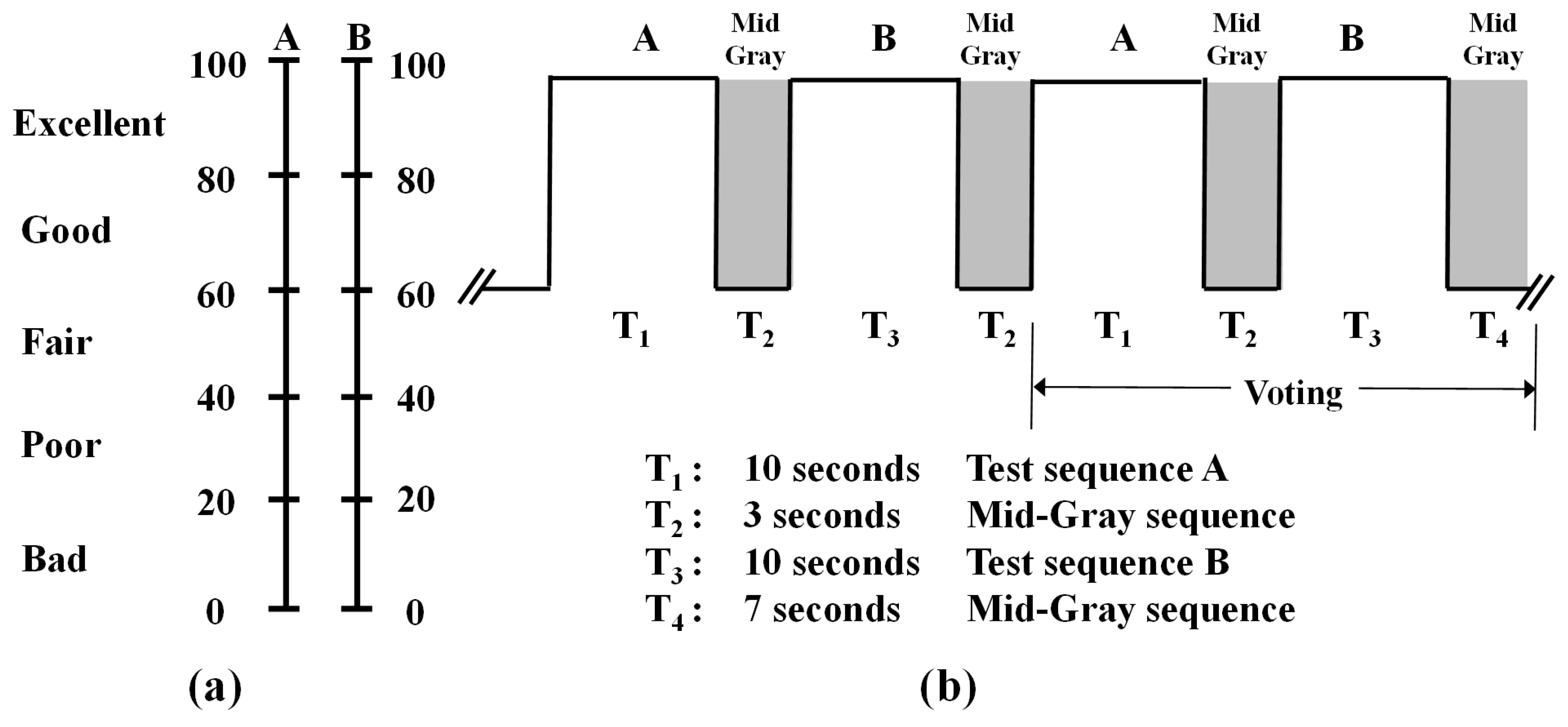
3.2.2. Objective and Subjective Quality Assessment
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sze, V.; Budagavi, M.; Sullivan, G.J. High efficiency video coding (HEVC). In Integrated Circuit and Systems, Algorithms and Architectures; Springer: Berlin/Heiderberg, Germany, 2014; Volume 39, p. 40. [Google Scholar]
- Pastuszak, G.; Abramowski, A. Algorithm and architecture design of the H. 265/HEVC intra encoder. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 210–222. [Google Scholar] [CrossRef]
- Pastuszak, G. High-speed architecture of the CABAC probability modeling for H. 265/HEVC encoders. In Proceedings of the 2016 International Conference on Signals and Electronic Systems (ICSES), Krakow, Poland, 5–7 September 2016; pp. 143–146. [Google Scholar]
- Zhang, Y.; Lu, C. A Highly Parallel Hardware Architecture of Table-Based CABAC Bit Rate Estimator in an HEVC Intra Encoder. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1544–1558. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, C. High-Performance Algorithm Adaptations and Hardware Architecture for HEVC Intra Encoders. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef]
- Lee, J.S.; Ebrahimi, T. Perceptual video compression: A survey. IEEE J. Sel. Top. Signal Process. 2012, 6, 684–697. [Google Scholar] [CrossRef]
- Oh, H.; Kim, W. Video processing for human perceptual visual quality-oriented video coding. IEEE Trans. Image Process. 2013, 22, 1526–1535. [Google Scholar] [CrossRef] [PubMed]
- Boccignone, G.; Marcelli, A.; Napoletano, P.; Di Fiore, G.; Iacovoni, G.; Morsa, S. Bayesian integration of face and low-level cues for foveated video coding. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1727–1740. [Google Scholar] [CrossRef]
- Tsapatsoulis, N.; Rapantzikos, K.; Pattichis, C. An embedded saliency map estimator scheme: Application to video encoding. Int. J. Neural Syst. 2007, 17, 289–304. [Google Scholar] [CrossRef]
- Chen, Z.; Guillemot, C. Perceptually-friendly H.264/AVC video coding based on foveated just-noticeable-distortion model. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 806–819. [Google Scholar] [CrossRef]
- Rehman, A.; Wang, Z. SSIM-inspired perceptual video coding for HEVC. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo (ICME), Melbourne, VIC, Australia, 9–13 July 2012; pp. 497–502. [Google Scholar]
- Chun, K.; Lim, K.; Cho, H.; Ra, J. An adaptive perceptual quantization algorithm for video coding. IEEE Trans. Consum. Electron. 1993, 39, 555–558. [Google Scholar] [CrossRef]
- Chen, J.; Zheng, J.; He, Y. Macroblock-level adaptive frequency weighting for perceptual video coding. IEEE Trans. Consum. Electron. 2007, 53, 775–781. [Google Scholar] [CrossRef]
- Gupta, R.; Khanna, M.T.; Chaudhury, S. Visual saliency guided video compression algorithm. Signal Process. Image Commun. 2013, 28, 1006–1022. [Google Scholar] [CrossRef]
- Li, S.; Xu, M.; Deng, X.; Wang, Z. Weight-based R-λ rate control for perceptual HEVC coding on conversational videos. Signal Process. Image Commun. 2015, 38, 127–140. [Google Scholar] [CrossRef]
- Xu, M.; Deng, X.; Li, S.; Wang, Z. Region-of-interest based conversational HEVC coding with hierarchical perception model of face. IEEE J. Sel. Top. Signal Process. 2014, 8, 475–489. [Google Scholar] [CrossRef]
- Bae, S.H.; Kim, J.; Kim, M. HEVC-Based Perceptually Adaptive Video Coding Using a DCT-Based Local Distortion Detection Probability Model. IEEE Trans. Image Process. 2016, 25, 3343–3357. [Google Scholar] [CrossRef] [PubMed]
- Yang, T.; Yu, M.; Peng, Z.; Jiang, G.; Jiang, H.; Zeng, X.; Zhang, Q. New rate distortion optimization method for video coding. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 468–472. [Google Scholar]
- Li, B.; Li, H.; Li, L.; Zhang, J. lambda Domain Rate Control Algorithm for High Efficiency Video Coding. IEEE Trans. Image Process. 2014, 23, 3841–3854. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Song, T.; Zhu, D.; Katayama, T.; Wang, L. Quality-Oriented Perceptual HEVC Based on the Spatiotemporal Saliency Detection Model. Entropy 2019, 21, 165. [Google Scholar] [CrossRef]
- Yi, Q.; Fan, W.; Shi, M. A Perceptual Video Coding Based on JND Model. J. Comput. Commun. 2018, 6, 53. [Google Scholar] [CrossRef][Green Version]
- Wang, G.; Zhang, Y.; Li, B.; Fan, R.; Zhou, M. A fast and HEVC-compatible perceptual video coding scheme using a transform-domain Multi-Channel JND model. Multimed. Tools Appl. 2018, 77, 12777–12803. [Google Scholar] [CrossRef]
- Frintrop, S.; Rome, E.; Christensen, H.I. Computational visual attention systems and their cognitive foundations: A survey. ACM Trans. Appl. Percept. 2010, 7, 6. [Google Scholar] [CrossRef]
- Yan, L.; Zhu, R.; Liu, Y.; Mo, N. Color-Boosted Saliency-Guided Rotation Invariant Bag of Visual Words Representation with Parameter Transfer for Cross-Domain Scene-Level Classification. Remote Sens. 2018, 10, 610. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, T.; Wan, W.; Han, X.; Xu, M. A Novel STDM Watermarking Using Visual Saliency-Based JND Model. Information 2017, 8, 103. [Google Scholar] [CrossRef]
- Li, X.; Li, D.; Yang, Z.; Chen, W. A Patch-Based Saliency Detection Method for Assessing the Visual Privacy Levels of Objects in Photos. IEEE Access 2017, 5, 24332–24343. [Google Scholar] [CrossRef]
- Gao, R.; Uchida, S.; Shahab, A.; Shafait, F.; Frinken, V. Visual saliency models for text detection in real world. PLoS ONE 2014, 9, e114539. [Google Scholar] [CrossRef]
- Gu, G.; Zhu, J.; Liu, Z.; Zhao, Y. Visual saliency detection based object recognition. J. Inf. Hiding Multimed. Signal Process. 2015, 6, 1250–1263. [Google Scholar]
- Chen, M.; Tang, Y.; Zou, X.; Huang, K.; Li, L.; He, Y. High-accuracy multi-camera reconstruction enhanced by adaptive point cloud correction algorithm. Opt. Lasers Eng. 2019, 122, 170–183. [Google Scholar] [CrossRef]
- Tang, Y.C.; Li, L.J.; Feng, W.X.; Liu, F.; Zou, X.J.; Chen, M.Y. Binocular vision measurement and its application in full-field convex deformation of concrete-filled steel tubular columns. Measurement 2018, 130, 372–383. [Google Scholar] [CrossRef]
- Ogasawara, K.; Miyazaki, T.; Sugaya, Y.; Omachi, S. Object-Based Video Coding by Visual Saliency and Temporal Correlation. IEEE Trans. Emerg. Top. Comput. 2017. [Google Scholar] [CrossRef]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2106–2113. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Horowitz, T.S. What attributes guide the deployment of visual attention and how do they do it? Nat. Rev. Neurosci. 2004, 5, 495–501. [Google Scholar] [CrossRef]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. In Matters of Intelligence; Springer: Berlin/Heidelberg, Germany, 1987; pp. 115–141. [Google Scholar]
- Bruce, N.D.; Tsotsos, J.K. Saliency, attention, and visual search: An information theoretic approach. J. Vis. 2009, 9, 5.1–5.24. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Li, Q.; Liu, P. Hierarchical geometry verification via maximum entropy saliency in image retrieval. Entropy 2014, 16, 3848–3865. [Google Scholar] [CrossRef]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 545–552. [Google Scholar]
- Wang, W.; Wang, Y.; Huang, Q.; Gao, W. Measuring visual saliency by site entropy rate. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2368–2375. [Google Scholar]
- Kadir, T.; Brady, M. Saliency, scale and image description. Int. J. Comput. Vis. 2001, 45, 83–105. [Google Scholar] [CrossRef]
- Lin, Y.; Fang, B.; Tang, Y. A Computational Model for Saliency Maps by Using Local Entropy. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Sarkar, S.; Paul, S.; Burman, R.; Das, S.; Chaudhuri, S.S. A fuzzy entropy based multi-level image thresholding using differential evolution. In Proceedings of the International Conference on Swarm, Evolutionary, and Memetic Computing, Bhubaneswar, India, 18–20 December 2014; pp. 386–395. [Google Scholar]
- Suzuki, T.; Baroncini, V.; François, E.; Topiwala, P.; Wenger, S.; Yu, H. JCT-VC AHG Report: Test Sequence Material (AHG5). Technical Report, Joint Collaborative Team on Video Coding (JCT-VC). 2017. Available online: https://www.itu.int/en/ITU-T/studygroups/2017-2020/16/Pages/video/jctvc.aspx (accessed on 20 September 2019).
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [PubMed]
- HM. HM Reference Software 16.11. Available online: https://hevc.hhi.fraunhofer.de/svn/svn_HEVCSoftware/ (accessed on 25 January 2018).
- Bossen, F. JCTVC-L1100: Common HM Test Conditions and Software Reference Configurations. JCT-VC Document Management System (April 2013). 2013. Available online: https://www.itu.int/wftp3/av-arch/jctvc-site/2013_01_L_Geneva/ (accessed on 23 September 2019).
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thirty-Seventh Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Majid, M.; Owais, M.; Anwar, S.M. Visual saliency based redundancy allocation in HEVC compatible multiple description video coding. Multimed. Tools Appl. 2018, 77, 20955–20977. [Google Scholar] [CrossRef]
- Series, B. Methodology for the Subjective Assessment of the Quality of Television Pictures. Recommendation ITU-R BT. Available online: http://www.itu.int/dms_pubrec/itu-r/rec/bt/R-REC-BT.500-12-200909-S!!PDF-E.pdf (accessed on 20 September 2019).
- Ki, S.; Bae, S.H.; Kim, M.; Ko, H. Learning-based just-noticeable-quantization-distortion modeling for perceptual video coding. IEEE Trans. Image Process. 2018, 27, 3178–3193. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Video Sequence | Spatial Resolution | Frame Count | Frame Rate |
|---|---|---|---|---|
| A | Nebuta | 2560 × 1600 | 300 | 60 |
| A | SteamLocomotive | 2560 × 1600 | 300 | 60 |
| B | BasketballDrive | 1920 × 1080 | 500 | 50 |
| B | ParkScene | 1920 × 1080 | 240 | 24 |
| C | RaceHorses | 832 × 480 | 300 | 30 |
| C | BQMall | 832 × 480 | 600 | 60 |
| C | PartyScene | 832 × 480 | 500 | 50 |
| C | BasketballDrill | 832 × 480 | 500 | 50 |
| D | RaceHorses | 416 × 240 | 300 | 30 |
| D | BlowingBubbles | 416 × 240 | 500 | 50 |
| E | FourPeople | 1280 × 720 | 600 | 60 |
| E | Johnny | 1280 × 720 | 600 | 60 |
| F | BasketballDrillText | 832 × 480 | 500 | 50 |
| F | SlideShow | 1280 × 720 | 500 | 20 |
| 4K | Bosphorus | 3840 × 2160 | 600 | 120 |
| 4K | Jockey | 3840 × 2160 | 600 | 120 |
| Visual Saliency Model | Precision | Recall | F-Measure |
|---|---|---|---|
| AIM [37] | 0.851 | 0.738 | 0.790 |
| SSM [41] | 0.349 | 0.828 | 0.491 |
| EOS [42] | 0.357 | 0.785 | 0.490 |
| FEMLT [43] | 0.326 | 0.693 | 0.443 |
| Video | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Datarate in Kbps | Execution Time in Seconds | Datarate in Kbps | Execution Time in Seconds | |||||||||
| Nebuta Class A, (2560 × 1600) | 8273.54 | 7530.27 | −8.98 | 615.43 | 624.36 | 1.45 | 4045.32 | 3735.82 | −7.65 | 579.97 | 587.88 | 1.36 |
| SteamLocomotive Class A, (2560 × 1600) | 6167.96 | 5483.52 | −11.10 | 604.76 | 611.89 | 1.18 | 2937.66 | 2648.242 | −9.85 | 584.66 | 591.23 | 1.12 |
| BasketballDrive Class B, (1920 × 1080) | 2735.02 | 2621.11 | −4.16 | 436.98 | 442.22 | 1.20 | 1411.63 | 1368.20 | −3.08 | 389.59 | 401.38 | 3.03 |
| ParkScene Class B, (1920 × 1080) | 8284.99 | 6819.50 | −17.69 | 469.80 | 481.23 | 2.43 | 3606.23 | 3260.44 | −9.59 | 376.31 | 391.10 | 3.93 |
| RaceHorses Class C, (832 × 480) | 2694.51 | 2505.65 | −7.01 | 129.27 | 131.65 | 1.84 | 1429.59 | 1352.99 | −5.36 | 105.54 | 108.04 | 2.37 |
| BQMall Class C, (832 × 480) | 2866.08 | 2634.54 | −8.08 | 83.48 | 91.01 | 9.03 | 1499.76 | 1446.73 | −3.54 | 71.22 | 74.25 | 4.25 |
| PartyScene Class C, (832 × 480) | 5429.73 | 4804.70 | −11.51 | 114.32 | 115.99 | 1.46 | 2833.48 | 2595.78 | −8.39 | 95.90 | 97.09 | 1.24 |
| BasketballDrill Class C, (832 × 480) | 2511.80 | 2371.85 | −5.57 | 95.85 | 101.12 | 5.50 | 1235.53 | 1205.83 | −2.40 | 78.98 | 81.75 | 3.51 |
| RaceHorses Class D, (416 × 240) | 1193.70 | 954.00 | −20.08 | 33.61 | 34.36 | 2.24 | 603.53 | 533.07 | −11.67 | 27.09 | 29.01 | 7.09 |
| BlowingBubbles Class D, (416 × 240) | 826.60 | 763.50 | −7.63 | 16.25 | 16.99 | 4.53 | 504.90 | 479.40 | −5.05 | 14.63 | 15.13 | 3.39 |
| FourPeople Class E, (1280 × 720) | 3262.20 | 2970.21 | −8.95 | 144.35 | 149.52 | 3.58 | 1692.81 | 1660.50 | −1.91 | 129.69 | 132.87 | 2.45 |
| Johnny Class E, (1280 × 720) | 2461.98 | 2228.79 | −9.47 | 149.62 | 151.18 | 1.04 | 1024.89 | 1009.11 | −1.54 | 127.18 | 129.60 | 1.90 |
| BasketballDrillText Class F, (832 × 480) | 2929.41 | 2685.74 | −8.32 | 114.52 | 118.39 | 3.38 | 1488.25 | 1369.92 | −7.95 | 98.34 | 101.46 | 3.17 |
| SlideShow Class F, (1280 × 720) | 3688.73 | 3251.62 | −11.85 | 152.73 | 156.75 | 2.63 | 1942.56 | 1778.11 | −8.47 | 121.89 | 125.78 | 3.19 |
| Bosphorus 4K, (3840 × 2160) | 10,367.34 | 9108.77 | −12.14 | 986.33 | 998.54 | 1.24 | 4898.65 | 4406.66 | −10.04 | 902.42 | 912.70 | 1.14 |
| Jockey 4K, (3840 × 2160) | 8522.09 | 7382.45 | −13.37 | 979.25 | 992.38 | 1.34 | 4122.54 | 3691.52 | −10.46 | 899.77 | 909.61 | 1.09 |
| Average | −10.37 | 2.96 | −6.68 | 2.97 | ||||||||
| Video | ||||||||||||
| Datarate in Kbps | Execution Time in Seconds | Datarate in Kbps | Execution Time in Seconds | |||||||||
| Nebuta Class A, (2560 × 1600) | 1936.38 | 1798.56 | −7.12 | 556.82 | 563.96 | 1.28 | 1038.88 | 972.49 | −6.39 | 529.44 | 535.84 | 1.21 |
| SteamLocomotive Class A, (2560 × 1600) | 1488.45 | 1345.26 | −9.62 | 541.75 | 547.56 | 1.07 | 834.64 | 773.84 | −7.28 | 519.63 | 524.62 | 0.96 |
| BasketballDrive Class B, (1920 × 1080) | 746.62 | 729.32 | −2.32 | 348.82 | 356.21 | 2.12 | 432.17 | 421.54 | −2.46 | 319.04 | 337.32 | 5.73 |
| ParkScene Class B, (1920 × 1080) | 1669.40 | 1587.44 | −4.91 | 326.31 | 341.22 | 4.57 | 792.64 | 768.59 | −3.03 | 296.06 | 306.06 | 3.38 |
| RaceHorses Class C, (832 × 480) | 723.77 | 707.04 | −2.31 | 87.60 | 89.33 | 1.97 | 395.37 | 388.12 | −1.83 | 75.24 | 79.12 | 5.15 |
| BQMall Class C, (832 × 480) | 830.85 | 812.59 | −2.20 | 65.15 | 70.91 | 8.84 | 488.82 | 475.40 | −2.75 | 58.91 | 61.24 | 3.96 |
| PartyScene Class C, (832 × 480) | 1379.75 | 1310.73 | −5.00 | 76.29 | 78.82 | 3.32 | 703.90 | 684.93 | −2.70 | 62.64 | 64.71 | 3.31 |
| BasketballDrill Class C, (832 × 480) | 630.00 | 614.10 | −2.52 | 67.80 | 70.34 | 3.74 | 360.58 | 352.75 | −2.17 | 62.21 | 66.44 | 6.79 |
| RaceHorses Class D, (416 × 240) | 299.90 | 285.74 | −4.72 | 22.01 | 23.68 | 7.59 | 165.11 | 161.60 | −2.12 | 18.65 | 19.78 | 6.09 |
| BlowingBubbles Class D, (416 × 240) | 282.38 | 271.83 | −3.74 | 13.78 | 14.09 | 2.24 | 154.78 | 151.01 | −2.43 | 12.92 | 13.64 | 5.53 |
| FourPeople Class E, (1280 × 720) | 1010.52 | 989.04 | −2.13 | 123.37 | 127.43 | 3.29 | 619.92 | 607.62 | −1.98 | 120.30 | 124.96 | 3.87 |
| Johnny Class E, (1280 × 720) | 563.64 | 551.97 | −2.07 | 118.48 | 122.58 | 3.46 | 332.31 | 325.61 | −2.02 | 115.17 | 120.55 | 4.67 |
| BasketballDrillText Class F, (832 × 480) | 732.76 | 680.68 | −7.11 | 86.12 | 88.46 | 2.72 | 451.89 | 424.03 | −6.17 | 72.78 | 74.56 | 2.45 |
| SlideShow Class F, (1280 × 720) | 811.33 | 750.45 | −7.50 | 110.34 | 112.85 | 2.27 | 460.81 | 429.31 | −6.84 | 97.54 | 100.28 | 2.81 |
| Bosphorus 4K, (3840 × 2160) | 2438.52 | 2217.94 | −9.05 | 881.15 | 890.45 | 1.06 | 1542.44 | 1424.17 | −7.67 | 854.34 | 862.65 | 0.97 |
| Jockey 4K, (3840 × 2160) | 2093.55 | 1890.78 | −9.69 | 861.02 | 869.93 | 1.03 | 1127.29 | 1039.41 | −7.80 | 837.88 | 846.12 | 0.98 |
| Average | −5.12 | 3.46 | −4.10 | 3.99 | ||||||||
| Video | ||||||||
|---|---|---|---|---|---|---|---|---|
| Nebuta Class A (2560 × 1600) | 22 | 0.992 | 0.994 | 0.192 | 41.614 | 41.691 | 0.077 | 0.07 |
| 27 | 0.992 | 0.991 | −0.040 | 40.289 | 40.384 | 0.095 | 0.20 | |
| 32 | 0.987 | 0.986 | −0.091 | 36.472 | 36.384 | −0.087 | 0.13 | |
| 37 | 0.981 | 0.979 | −0.133 | 33.371 | 33.380 | 0.009 | −0.13 | |
| SteamLocomotive Class A (2560 × 1600) | 22 | 0.997 | 0.994 | −0.248 | 43.102 | 43.203 | 0.101 | 0.20 |
| 27 | 0.993 | 0.989 | −0.357 | 42.430 | 42.529 | 0.099 | −0.13 | |
| 32 | 0.989 | 0.996 | 0.749 | 36.171 | 36.170 | −0.001 | −0.53 | |
| 37 | 0.983 | 0.974 | −0.851 | 33.405 | 33.403 | −0.002 | −0.60 | |
| BasketballDrive Class B (1920 × 1080) | 22 | 0.996 | 0.994 | −0.171 | 46.145 | 46.143 | −0.002 | 0.13 |
| 27 | 0.992 | 0.990 | −0.232 | 44.267 | 44.266 | −0.001 | −0.13 | |
| 32 | 0.985 | 0.982 | −0.304 | 41.496 | 41.494 | −0.002 | −0.20 | |
| 37 | 0.974 | 0.969 | −0.472 | 38.918 | 38.917 | −0.001 | −0.07 | |
| ParkScene Class B (1920 × 1080) | 22 | 0.990 | 0.990 | −0.077 | 40.814 | 40.791 | −0.023 | 0.20 |
| 27 | 0.983 | 0.982 | −0.065 | 40.391 | 40.384 | −0.007 | 0.07 | |
| 32 | 0.969 | 0.968 | −0.047 | 35.339 | 35.337 | −0.002 | 0.07 | |
| 37 | 0.944 | 0.944 | −0.034 | 33.371 | 33.380 | 0.009 | −0.13 | |
| RaceHorses Class C (832 × 480) | 22 | 0.995 | 0.989 | −0.583 | 43.192 | 43.192 | 0.000 | 0.27 |
| 27 | 0.989 | 0.982 | −0.728 | 39.630 | 39.629 | −0.001 | −0.20 | |
| 32 | 0.976 | 0.947 | −3.022 | 36.171 | 36.170 | −0.001 | 0.07 | |
| 37 | 0.954 | 0.947 | −0.786 | 33.405 | 33.403 | −0.002 | −0.33 | |
| BQMall Class C (832 × 480) | 22 | 0.997 | 0.996 | −0.167 | 44.933 | 45.034 | 0.101 | 0.13 |
| 27 | 0.994 | 0.992 | −0.182 | 41.087 | 41.092 | 0.005 | −0.07 | |
| 32 | 0.988 | 0.986 | −0.223 | 37.799 | 37.791 | −0.008 | −0.33 | |
| 37 | 0.976 | 0.974 | −0.258 | 34.281 | 34.278 | −0.003 | −0.47 | |
| PartyScene Class C (832 × 480) | 22 | 0.996 | 0.986 | −1.074 | 42.480 | 42.492 | 0.012 | 0.33 |
| 27 | 0.991 | 0.978 | −1.241 | 38.452 | 38.458 | 0.006 | 0.13 | |
| 32 | 0.976 | 0.963 | −1.375 | 34.644 | 34.653 | 0.009 | 0.07 | |
| 37 | 0.950 | 0.938 | −1.302 | 31.552 | 31.493 | −0.059 | −0.07 | |
| BasketballDrill Class C (832 × 480) | 22 | 0.995 | 0.994 | −0.097 | 44.879 | 44.884 | 0.005 | 0.13 |
| 27 | 0.990 | 0.989 | −0.105 | 41.321 | 41.379 | 0.058 | 0.00 | |
| 32 | 0.981 | 0.979 | −0.158 | 38.299 | 38.290 | −0.009 | −0.60 | |
| 37 | 0.964 | 0.962 | −0.255 | 35.459 | 35.444 | −0.015 | −0.53 | |
| RaceHorses Class D (416 × 240) | 22 | 0.995 | 0.989 | −0.614 | 43.809 | 43.844 | 0.035 | 0.07 |
| 27 | 0.988 | 0.980 | −0.863 | 39.811 | 39.822 | 0.011 | 0.20 | |
| 32 | 0.974 | 0.965 | −0.921 | 36.209 | 36.201 | −0.008 | 0.13 | |
| 37 | 0.948 | 0.938 | −1.130 | 33.227 | 33.224 | −0.003 | −0.13 | |
| BlowingBubbles Class D (416 × 240) | 22 | 0.998 | 0.995 | −0.255 | 43.908 | 43.911 | 0.003 | 0.13 |
| 27 | 0.994 | 0.991 | −0.225 | 39.366 | 39.364 | −0.002 | −0.40 | |
| 32 | 0.985 | 0.983 | −0.148 | 35.562 | 35.540 | −0.022 | −0.53 | |
| 37 | 0.967 | 0.965 | −0.207 | 32.022 | 32.021 | −0.001 | −0.60 | |
| FourPeople Class E (1280 × 720) | 22 | 0.995 | 0.995 | −0.026 | 44.239 | 44.455 | 0.216 | 0.13 |
| 27 | 0.993 | 0.993 | −0.022 | 42.042 | 42.270 | 0.229 | −0.27 | |
| 32 | 0.989 | 0.989 | 0.000 | 39.883 | 39.884 | 0.001 | −0.13 | |
| 37 | 0.982 | 0.982 | 0.013 | 36.802 | 36.781 | −0.021 | −0.40 | |
| Johnny Class E (1280 × 720) | 22 | 0.993 | 0.993 | −0.028 | 44.122 | 44.318 | 0.196 | 0.07 |
| 27 | 0.991 | 0.991 | −0.009 | 42.502 | 42.622 | 0.120 | −0.27 | |
| 32 | 0.987 | 0.987 | 0.003 | 40.700 | 40.715 | 0.016 | −0.13 | |
| 37 | 0.981 | 0.981 | 0.012 | 38.351 | 38.347 | −0.003 | −0.60 | |
| BasketballDrillText Class F (832 × 480) | 22 | 0.992 | 0.991 | −0.082 | 44.933 | 45.034 | 0.101 | 0.13 |
| 27 | 0.990 | 0.989 | −0.094 | 41.087 | 41.092 | 0.005 | 0.07 | |
| 32 | 0.986 | 0.985 | −0.139 | 37.799 | 37.791 | −0.008 | −0.07 | |
| 37 | 0.972 | 0.970 | −0.187 | 34.281 | 34.278 | −0.003 | −0.53 | |
| SlideShow Class F (1280 × 720) | 22 | 0.996 | 0.994 | −0.203 | 42.533 | 42.572 | 0.039 | 0.20 |
| 27 | 0.994 | 0.992 | −0.231 | 39.165 | 39.169 | 0.004 | −0.07 | |
| 32 | 0.986 | 0.982 | −0.411 | 35.626 | 35.644 | 0.018 | −0.33 | |
| 37 | 0.982 | 0.977 | −0.442 | 32.452 | 32.393 | −0.059 | −0.47 | |
| Bosphorus 4K (3840 × 2160) | 22 | 0.993 | 0.992 | −0.058 | 46.214 | 46.021 | −0.193 | 0.20 |
| 27 | 0.991 | 0.990 | −0.120 | 44.035 | 44.191 | 0.156 | 0.13 | |
| 32 | 0.987 | 0.985 | −0.220 | 41.398 | 41.586 | 0.188 | -0.07 | |
| 37 | 0.978 | 0.976 | −0.274 | 39.017 | 38.981 | −0.036 | −0.53 | |
| Jockey 4K (3840 × 2160) | 22 | 0.995 | 0.991 | −0.354 | 43.011 | 42.813 | −0.198 | 0.13 |
| 27 | 0.991 | 0.985 | −0.687 | 40.389 | 40.488 | 0.099 | 0.00 | |
| 32 | 0.988 | 0.979 | −0.869 | 37.982 | 37.901 | −0.081 | −0.13 | |
| 37 | 0.979 | 0.969 | −0.971 | 35.110 | 35.183 | 0.073 | −0.53 | |
| Average | 0.985 | 0.981 | −0.367 | 39.262 | 39.281 | 0.019 | −0.107 | |
| Video | QP | Sehwan [51] | Bae [17] | ||||
|---|---|---|---|---|---|---|---|
| ParkScene Class B (1920 × 1080) | 22 | −12.39 | −1.00 | −21.10 | 2.00 | −17.69 | 0.2 |
| 27 | −13.52 | −0.90 | −6.00 | −1.20 | −9.59 | 0.07 | |
| 32 | −6.23 | −0.10 | −0.80 | 0.00 | −4.91 | 0.07 | |
| 37 | −0.43 | 0.40 | 0.00 | −0.10 | −3.03 | −0.13 | |
| BQMall Class C (832 × 480) | 22 | −2.75 | −0.60 | −17.5 | 1.70 | −8.08 | 0.13 |
| 27 | −10.43 | −0.20 | −5.60 | −1.10 | −3.54 | −0.07 | |
| 32 | −8.43 | −1.00 | −0.30 | −0.20 | −2.2 | −0.33 | |
| 37 | −1.78 | 0.10 | −0.30 | 0.10 | −2.75 | −0.47 | |
| RaceHorses Class C (832 × 480) | 22 | −15.53 | −0.20 | −27.40 | 1.20 | −7.01 | 0.27 |
| 27 | −14.78 | −0.80 | −10.40 | −0.80 | −5.36 | −0.2 | |
| 32 | −9.42 | 0.40 | −1.10 | 0.50 | −2.31 | 0.07 | |
| 37 | −1.86 | 0.00 | −0.10 | 1.10 | −1.83 | −0.33 | |
| PartyScene Class C (832 × 480) | 22 | −6.23 | −0.20 | −26.70 | 0.30 | −11.51 | 0.33 |
| 27 | −14.93 | −0.60 | −9.70 | 1.10 | −8.39 | 0.13 | |
| 32 | −13.69 | −0.10 | −1.50 | 0.10 | −4.91 | 0.07 | |
| 37 | −2.95 | −0.60 | −0.40 | −0.10 | −3.03 | −0.07 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeeshan, M.; Majid, M. High Efficiency Video Coding Compliant Perceptual Video Coding Using Entropy Based Visual Saliency Model. Entropy 2019, 21, 964. https://doi.org/10.3390/e21100964
Zeeshan M, Majid M. High Efficiency Video Coding Compliant Perceptual Video Coding Using Entropy Based Visual Saliency Model. Entropy. 2019; 21(10):964. https://doi.org/10.3390/e21100964
Chicago/Turabian StyleZeeshan, Muhammad, and Muhammad Majid. 2019. "High Efficiency Video Coding Compliant Perceptual Video Coding Using Entropy Based Visual Saliency Model" Entropy 21, no. 10: 964. https://doi.org/10.3390/e21100964
APA StyleZeeshan, M., & Majid, M. (2019). High Efficiency Video Coding Compliant Perceptual Video Coding Using Entropy Based Visual Saliency Model. Entropy, 21(10), 964. https://doi.org/10.3390/e21100964