Abstract
This paper focuses on test procedures under corrupted data. We assume that the observations are mismeasured, due to the presence of measurement errors. Thus, instead of for , we observe , with an unknown parameter and an unobservable random variable . It is assumed that the random variables are i.i.d., as are the and the . The test procedure aims at deciding between two simple hyptheses pertaining to the density of the variable , namely and . In this setting, the density of the is supposed to be known. The procedure which we propose aggregates likelihood ratios for a collection of values of . A new definition of least-favorable hypotheses for the aggregate family of tests is presented, and a relation with the Kullback-Leibler divergence between the sets and is presented. Finite-sample lower bounds for the power of these tests are presented, both through analytical inequalities and through simulation under the least-favorable hypotheses. Since no optimality holds for the aggregation of likelihood ratio tests, a similar procedure is proposed, replacing the individual likelihood ratio by some divergence based test statistics. It is shown and discussed that the resulting aggregated test may perform better than the aggregate likelihood ratio procedure.
1. Introduction
A situation which is commonly met in quality control is the following: Some characteristic Z of an item is supposed to be random, and a decision about its distribution has to be made based on a sample of such items, each with the same distribution (with density ) or (with density ). The measurement device adds a random noise to each measurement, mutually independent and independent of the item, with a common distribution function and density , where is an unknown scaling parameter. Therefore the density of the measurement is either or , where ∗ denotes the convolution operation. We denote (respectively ) to be the distribution function with density (respectively ).
The problem of interest, studied in [1], is how the measurement errors can affect the conclusion of the likelihood ratio test with statistics
For small , the result of [2] enables us to estimate the true log-likelihood ratio (true Kullback-Leibler divergence) even when we only dispose of locally perturbed data by additive measurement errors. The distribution function of the measurement errors is considered unknown, up to zero expectation and unit variance. When we use the likelihood ratio test, while ignoring the possible measurement errors, we can incur a loss in both errors of the first and second kind. However, it is shown, in [1], that for small the original likelihood ratio test (LRT) is still the most powerful, only on a slightly changed significance level. The test problem leads to a composite of null and alternative classes or of distributions of random variables with , where V has distribution If those families are bounded by alternating Choquet capacities of order 2, then the minimax test is based on the likelihood ratio of the pair of the least-favorable distributions of and , respectively (see Huber and Strassen [3]). Moreover, Eguchi and Copas [4] showed that the overall loss of power caused by a misspecified alternative equals the Kullback-Leibler divergence between the original and the corrupted alternatives. Surprisingly, the value of the overall loss is independent of the choice of null hypothesis. The arguments of [2] and of [5] enable us to approximate the loss of power locally, for a broad set of alternatives. The asymptotic behavior of the loss of power of the test based on sampled data is considered in [1], and is supplemented with numerical illustration.
Statement of the Test Problem
Our aim is to propose a class of statistics for testing the composite hypotheses and , extending the optimal Neyman-Pearson LRT between and . Unlike in [1], the scaling parameter is not supposed to be small, but merely to belong to some interval bounded away from 0.
We assume that the distribution H of the random variable (r.v.) V is known; indeed, in the tuning of the offset of a measurement device, it is customary to perform a large number of observations on the noise under a controlled environment.
Therefore, this first step produces a good basis for the modelling of the distribution of the density h. Although the distribution of V is known, under operational conditions the distribution of the noise is modified: For a given in with , denote by a r.v. whose distribution is obtained through some transformation from the distribution of V, which quantifies the level of the random noise. A classical example is when , but at times we have a weaker assumption, which amounts to some decomposability property with respect to : For instance, in the Gaussian case, we assume that for all , there exists some r.v. such that , where and are independent.
The test problem can be stated as follows: A batch of i.i.d. measurements is performed, where is unknown, and we consider the family of tests of () [X has density ] vs. () [X has density ], with Only the are observed. A class of combined tests of vs. is proposed, in the spirit of [6,7,8,9].
Under every fixed n, we assume that is allowed to run over a finite set of components of the vector . The present construction is essentially non-asymptotic, neither on n nor on , in contrast with [1], where was supposed to lie in a small neighborhood of 0. However, with increasing n, it would be useful to consider that the array is getting dense in and that
For the sake of notational brevity, we denote by the above grid , and all suprema or infima over are supposed to be over . For any event B and any in , (respectively ) designates the probability of B under the distribution (respectively ). Given a sequence of levels , we consider a sequence of test criteria of , and the pertaining critical regions
such that
leading to rejection of () for at least some
In an asymptotic context, it is natural to assume that converges to 0 as n increases, since an increase in the sample size allows for a smaller first kind risk. For example, in [8], takes the form for some sequence .
In the sequel, the Kullback-Leibler discrepancy between probability measures Q and P, with respective densities p and q (with respect to the Lebesgue measure on ), is denoted
whenever defined, and takes value otherwise.
The present paper handles some issues with respect to this context. In Section 2, we consider some test procedures based on the supremum of Likelihood Ratios (LR) for various values of , and define . The threshold for such a test is obtained for any level , and a lower bound for its power is provided. In Section 3, we develop an asymptotic approach to the Least Favorable Hypotheses (LFH) for these tests. We prove that asymptotically least-favorable hypotheses are obtained through minimization of the Kullback-Leibler divergence between the two composite classes and independently upon the level of the test.
We next consider, in Section 3.3, the performance of the test numerically; indeed, under the least-favorable pair of hypotheses we compare the power of the test (as obtained through simulation) with the theoretical lower bound, as obtained in Section 2. We show that the minimal power, as measured under the LFH, is indeed larger than the theoretical lower bound—this result shows that the simulation results overperform on theoretical bounds. These results are developed in a number of examples.
Since no argument plays in favor of any type of optimality for the test based on the supremum of likelihood ratios for composite testing, we consider substituting those ratios with other kinds of scores in the family of divergence-based concepts, extending the likelihood ratio in a natural way. Such an approach has a long history, stemming from the seminal book by Liese and Vajda [10]. Extensions of the Kullback-Leibler based criterions (such as the likelihood ratio) to power-type criterions have been proposed for many applications in Physics and in Statistics (see, e.g., [11]). We explore the properties of those new tests under the pair of hypotheses minimizing the Kullback-Leibler divergence between the two composite classes and . We show that, in some cases, we can build a test procedure whose properties overperform the above supremum of the LRTs, and we provide an explanation for this fact. This is the scope of Section 4.
2. An Extension of the Likelihood Ratio Test
For any in , let
and define
Consider, for fixed , the Likelihood Ratio Test with statistics which is uniformly most powerful (UMP) within all tests of vs. , where designates the distribution of the generic r.v. X. The test procedure to be discussed aims at solving the question: Does there exist some , for which () would be rejected vs. (), for some prescribed value of the first kind risk?
Whenever () is rejected in favor of (), for some , we reject in favor of . A critical region for this test with level is defined by
with
Since, for any sequence of events ,
it holds that
An upper bound for can be obtained, making use of the Chernoff inequality for the right side of (4), providing an upper bound for the risk of first kind for a given . The correspondence between and this risk allows us to define the threshold accordingly.
Turning to the power of this test, we define the risk of second kind by
a crude bound which, in turn, can be bounded from above through the Chernoff inequality, which yields a lower bound for the power of the test under any hypothesis in .
Let denote a sequence of levels, such that
We make use of the following hypothesis:
Remark 1.
Since
making use of the Chernoff-Stein Lemma (see Theorem A1 in the Appendix A), Hypothesis (6) means that any LRT with H0: vs. H1: is asymptotically more powerful than any LRT with H0: vs. H1:
Both hypotheses (7) and (8), which are defined below, are used to provide the critical region and the power of the test.
For all define
and let
With , the set of all t such that is finite, we assume
Define, further,
and let
For any , let
and let
Let be the set of all t such that is finite. Assume
Let
and
We also assume an accessory condition on the support of and , respectively under and under (see (A2) and (A5) in the proof of Theorem A1). Suppose the regularity assumptions (7) and (8) are fulfilled for all and . Assume, further, that fulfills (1).
The following result holds:
Proposition 2.
Whenever (6) holds, for any sequence of levels bounded away from 1, defining
it holds, for large n, that
and
3. Minimax Tests under Noisy Data, Least-Favorable Hypotheses
3.1. An Asymptotic Definition for the Least-Favorable Hypotheses
We prove that the above procedure is asymptotically minimax for testing the composite hypothesis against the composite alternative . Indeed, we identify the least-favorable hypotheses, say and , which lead to minimal power and maximal first kind risk for these tests. This requires a discussion of the definition and existence of such a least-favourable pair of hypotheses in an asymptotic context; indeed, for a fixed sample size, the usual definition only leads to an explicit definition in very specific cases. Unlike in [1], the minimax tests will not be in the sense of Huber and Strassen. Indeed, on one hand, hypotheses and are not defined in topological neighbourhoods of and , but rather through a convolution under a parametric setting. On the other hand, the specific test of against does not require capacities dominating the corresponding probability measures.
Throughout the subsequent text, we shall assume that there exists such that
We shall call the pair of distributions least-favorable for the sequence of tests if they satisfy
for all The condition of unbiasedness of the test is captured by the central inequality in (11).
Because, for finite n, such a pair can be constructed only in few cases, we should take a recourse of (11) to the asymptotics We shall show that any pair of distributions achieving (10) are least-favorable. Indeed, it satisfies the inequality (11) asymptotically on the logarithmic scale.
Specifically, we say that is a least-favorable pair of distributions when, for any ,
Define the total variation distance
where the supremum is over all Borel sets B of . We will assume that, for all n,
We state our main result, whose proof is deferred to the Appendix B.
Theorem 3.
For any level satisfying (13), the pair is a least-favorable pair of hypotheses for the family of tests , in the sense of (12).
3.2. Identifying the Least-Favorable Hypotheses
We now concentrate on (10).
For given with , the distribution of the r.v. is obtained through some transformation from the known distribution of The classical example is , which is a scaling, and where is the signal to noise ratio. The following results state that the Kullback-Leibler discrepancy reaches its minimal value when the noise is “maximal”, under some additivity property with respect to This result is not surprising: Adding noise deteriorates the ability to discriminate between the two distributions and —this effect is captured in , which takes its minimal value for the maximal
Proposition 4.
Assume that, for all , there exists some r.v. such that where and are independent. Then
This result holds as a consequence of Lemma A5 in the Appendix C.
In the Gaussian case, when h is the standard normal density, Proposition 4 holds, since with In order to model symmetric noise, we may consider a symmetrized Gamma density as follows: Set , where designates the Gamma density with scale parameter 1 and shape parameter , and the Gamma density on with same parameter. Hence a r.v. with density is symmetrically distributed and has variance Clearly, , which shows that Proposition 4 also holds in this case. Note that, except for values of less than or equal to 1, the density is bimodal, which does not play in favour of such densities for modelling the uncertainty, due to the noise. In contrast with the Gaussian case, cannot be obtained from by any scaling. The centred Cauchy distribution may help as a description of heavy tailed symmetric noise, and keeps uni-modality through convolution; it satisfies the requirements of Proposition 4 since where . In this case, acts as a scaling, since is the density of where X has density
In practice, the interesting case is when is the variance of the noise and corresponds to a scaling of a generic density, as occurs for the Gaussian case or for the Cauchy case. In the examples, which will be used below, we also consider symmetric, exponentially distributed densities (Laplace densities) or symmetric Weibull densities with a given shape parameter. The Weibull distribution also fulfills the condition in Proposition 4, being infinitely divisible (see [12]).
3.3. Numerical Performances of the Minimax Test
As frequently observed, numerical results deduced from theoretical bounds are of poor interest due to the sub-optimality of the involved inequalities. They may be sharpened on specific cases. This motivates the need for simulation. We study two cases, which can be considered as benchmarks.
- In the first case, is a normal density with expectation 0 and variance 1, whereas is a normal density with expectation and variance .
- The second case handles a situation where and belong to different models: is a log-normal density with location parameter 1 and scale parameter , whereas is a Weibull density on with shape parameter 5 and scale parameter . Those two densities differ strongly, in terms of asymptotic decay. They are, however, very close to one another in terms of their symmetrized Kullback-Leibler divergence (the so-called Jeffrey distance). Indeed, centering on the log-normal distribution , the closest among all Weibull densities is at distance —the density is at distance from
Both cases are treated, considering four types of distribution for the noise:
- The noise is a centered normal density with variance ;
- the noise is a centered Laplace density with parameter ;
- the noise is a symmetrized Weibull density with shape parameter and variable scale parameter ; and
- the noise is Cauchy with density .
In order to compare the performances of the test under those four distributions, we have adopted the following rule: The parameter of the distribution of the noise is tuned such that, for each value , it holds that , where stands for the standard Gaussian cumulative function. Thus, distributions b to d are scaled with respect to the Gaussian noise with variance .
In both cases A and B, the range of is , and we have selected a number of possibilities for , ranging from to .
In case A, we selected , which has a signal-to-noise ratio equal to , a commonly chosen bound in quality control tests.
In case B, the variance of is roughly and the variance of is roughly The maximal value of is roughly This is thus a maximal upper bound for a practical modeling.
We present some power functions, making use of the theoretical bounds together with the corresponding ones based on simulation runs. As seen, the performances in the theoretical approach is weak. We have focused on simulation, after some comparison with the theoretical bounds.
3.3.1. Case A: The Shift Problem
In this subsection, we evaluate the quality of the theoretical power bound, defined in the previous sections. Thus, we compare the theoretical formula to the empirical lower performances obtained through simulations under the least-favorable hypotheses.
Theoretical Power Bound
While supposedly valid for finite n, the theoretical power bound given by (A8) still assumes some sort of asymptotics, since a good approximation of the bound implies a fine discretization of to compute . Thus, by condition (1), n has to be large. Therefore, in the following, we will compute this lower bound for n sufficiently large (that is, at least 100 observations), which is also consistent with industrial applications.
Numerical Power Bound
In order to obtain a minimal bound for the power of the composite test, we compute the power of the test against , where defines the LFH pair .
Following Proposition 4, the LFH for the test defined by when the noise follows a Gaussian, a Cauchy, or a symmetrized Weibull distribution is achieved for .
When the noise follows a Laplace distribution, the pair of LFH is the one that satisfies:
In both of the cases A and B, this condition is also satisfied for .
Comparison of the Two Power Curves
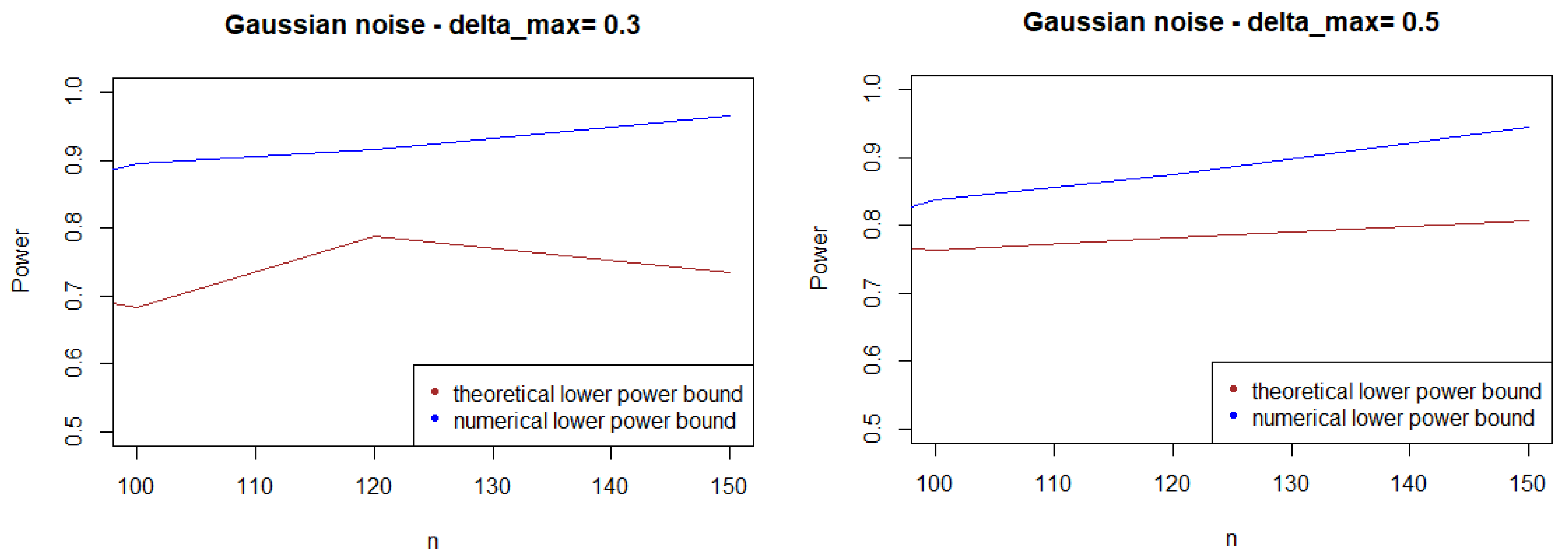
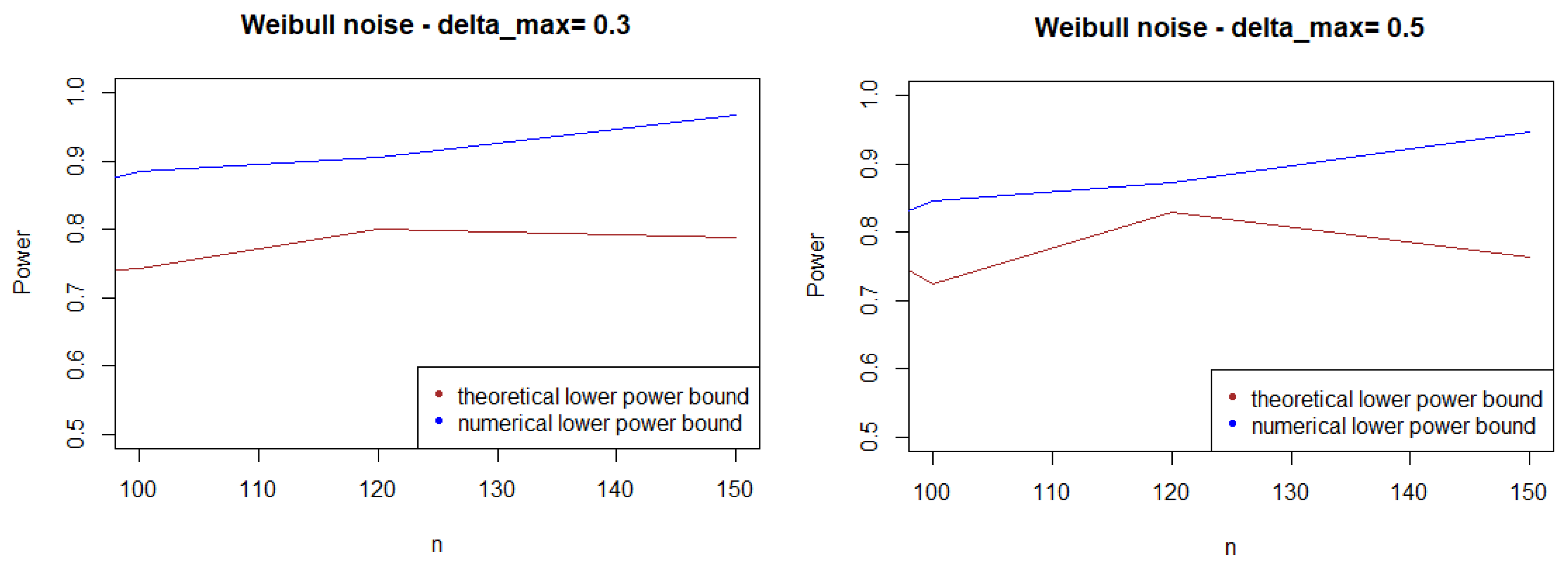
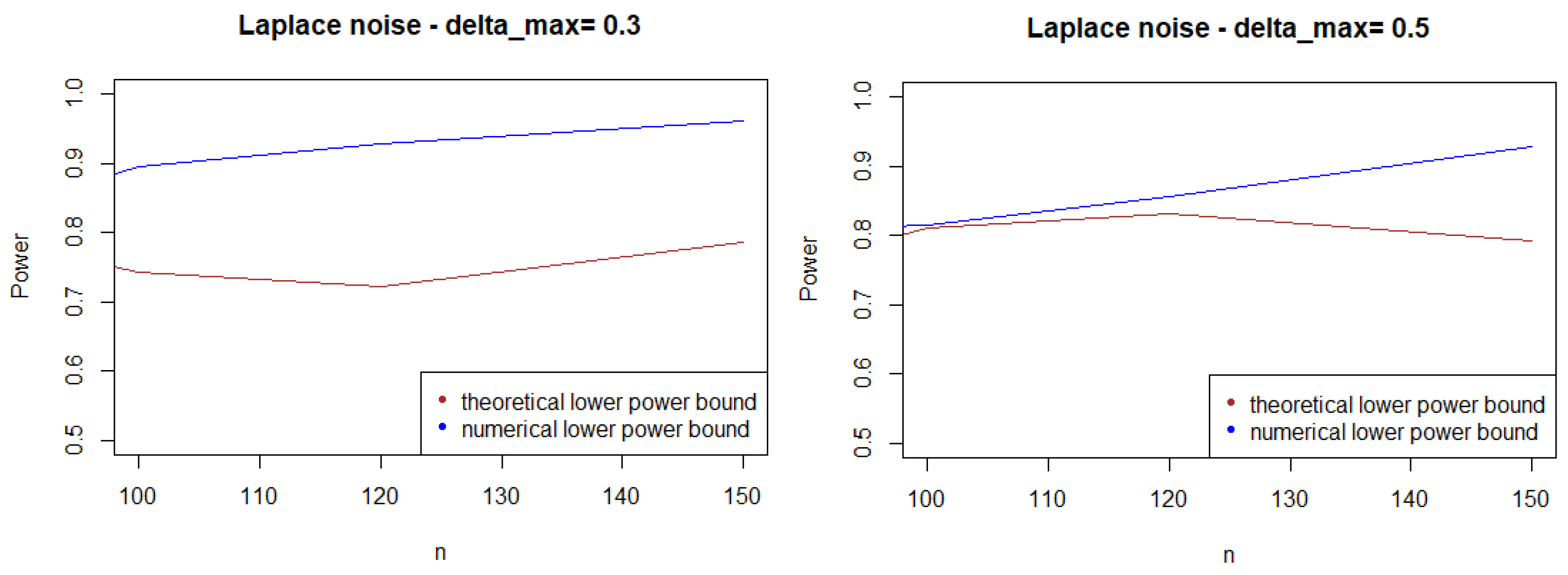
As expected, Figure 1, Figure 2 and Figure 3 show that the theoretical lower bound is always below the empirical lower bound, when n is high enough to provide a good approximation of . This is also true when the noise follows a Cauchy distribution, but for a bigger sample size than in the figures above ().
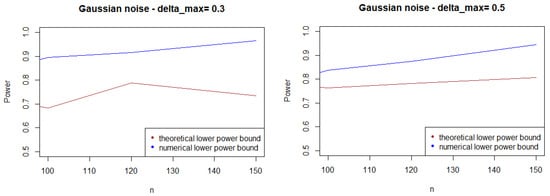
Figure 1.
Theoretical and numerical power bound of the test of case A under Gaussian noise (with respect to n), for the first kind risk .
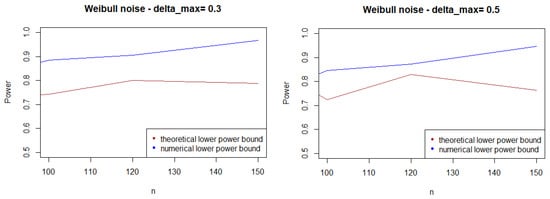
Figure 2.
Theoretical and numerical power bound of the test of case A under symmetrized Weibull noise (with respect to n), for the first kind risk .
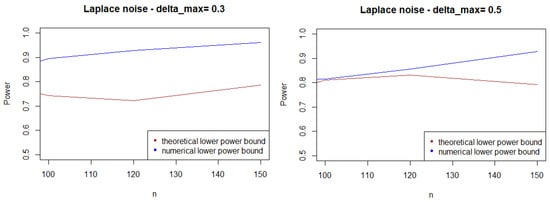
Figure 3.
Theoretical and numerical power bound of the test of case A under a symmetrized Laplacian noise (with respect to n), for the first kind risk .
In most cases, the theoretical bound tends to largely underestimate the power of the test, when compared to its minimal performance given by simulations under the least-favorable hypotheses. The gap between the two also tends to increase as n grows. This result may be explained by the large bound provided by (5), while the numerical performances are obtained with respect to the least-favorable hypotheses.
From a computational perspective, the computational cost of the theoretical bound is far higher than its numeric counterpart.
3.3.2. Case B: The Tail Thickness Problem
The calculation of the moment-generating function, appearing in the formula of in (9), is numerically unstable, which renders the computation of the theoretical bound impossible. Thus, in the following sections, the performances of the test will be evaluated numerically, through Monte Carlo replications.
4. Some Alternative Statistics for Testing
4.1. A Family of Composite Tests Based on Divergence Distances
This section provides a similar treatment as above, dealing now with some extensions of the LRT test to the same composite setting. The class of tests is related to the divergence-based approach to testing, and it includes the cases considered so far. For reasons developed in Section 3.3, we argue through simulation and do not develop the corresponding large deviation approach.
The statistics can be generalized in a natural way, by defining a family of tests depending on some parameter For , let
be a function defined on with values in , setting
and
For , this class of functions is instrumental in order to define the so-called power divergences between probability measures, a class of pseudo-distances widely used in statistical inference (see, for example, [13]).
Associated to this class, consider the function
We also consider
from which the statistics
and
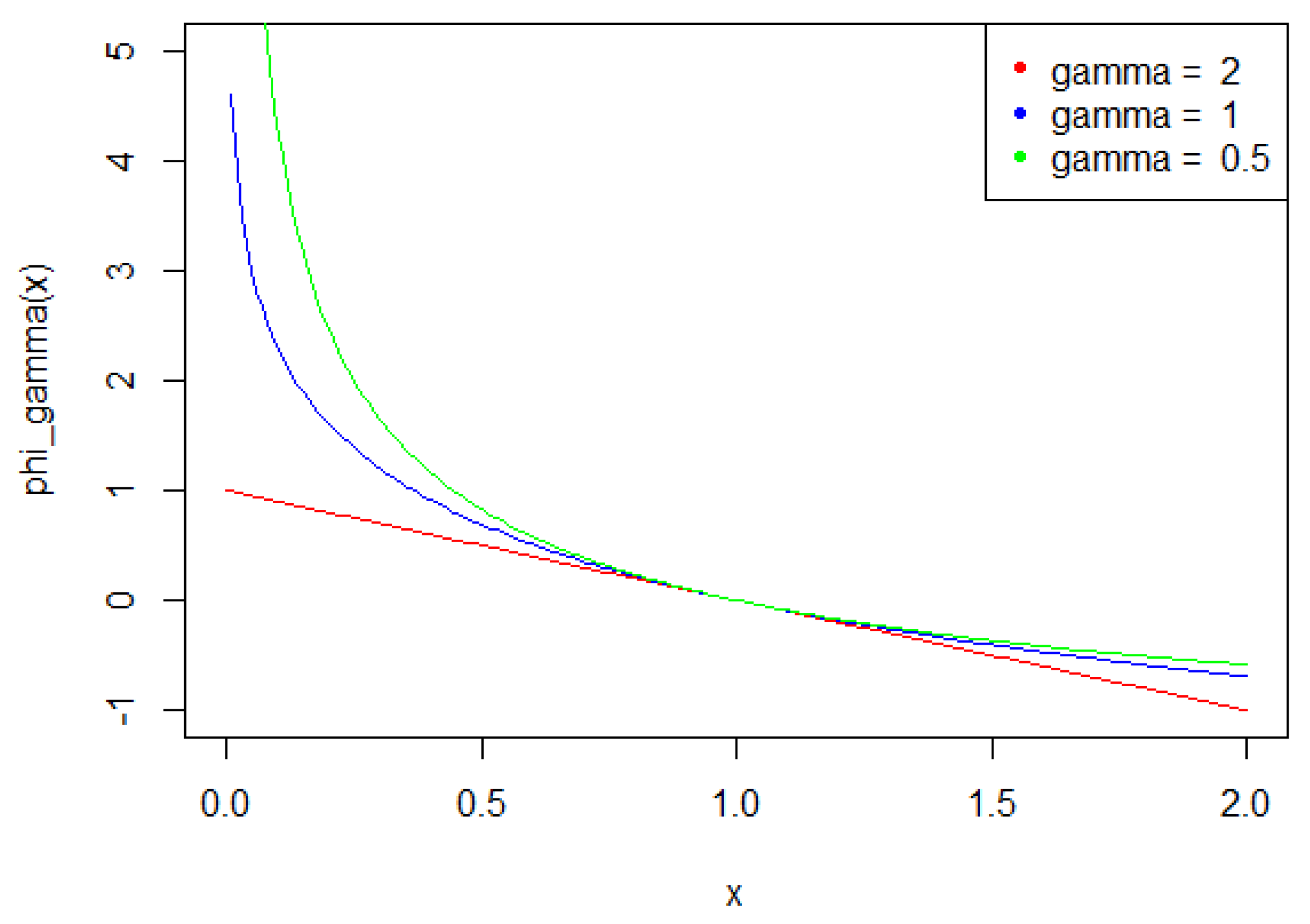
are well defined, for all . Figure 4 illustrates the functions , according to .
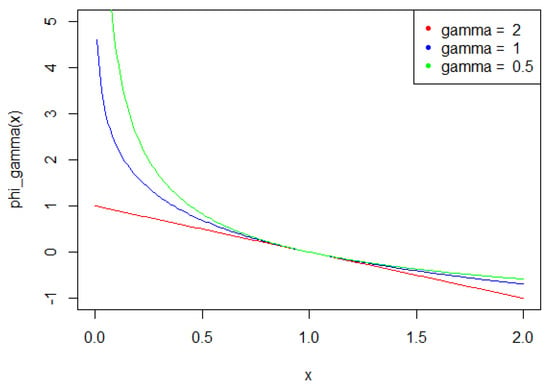
Figure 4.
for and 2.
Fix a risk of first kind , and the corresponding power of the LRT pertaining to vs. by
with
Define, accordingly, the power of the test, based on under the same hypotheses, by
and
First, defines the pair of hypotheses , such that the LRT with statistics has maximal power among all tests vs. Furthermore, by Theorem A1, it has minimal power on the logarithmic scale among all tests vs.
On the other hand, is the LF pair for the test with statistics among all pairs
These two facts allow for the definition of the loss of power, making use of instead of for testing vs. This amounts to considering the price of aggregating the local tests , a necessity since the true value of is unknown. A natural indicator for this loss consists in the difference
Consider, now, aggregated test statistics We do not have at hand a similar result, as in Proposition 2. We, thus, consider the behavior of the test vs. , although may not be a LFH for the test statistics The heuristics, which we propose, makes use of the corresponding loss of power with respect to the LRT, through
We will see that it may happen that improves over We define the optimal value of , say , such that
for all
In the various figures hereafter, NP corresponds to the LRT defined between the LFH’s KL to the test with statistics (hence, as presented Section 2), HELL corresponds to , which is associated to the Hellinger power divergence, and G = 2 corresponds to
4.2. A Practical Choice for Composite Tests Based on Simulation
We consider the same cases A and B, as described in Section 3.3.
As stated in the previous section, the performances of the different test statistics are compared, considering the test of against where is defined, as explained in Section 3.3 as the LFH for the test . In both cases A and B, this corresponds to .
4.2.1. Case A: The Shift Problem
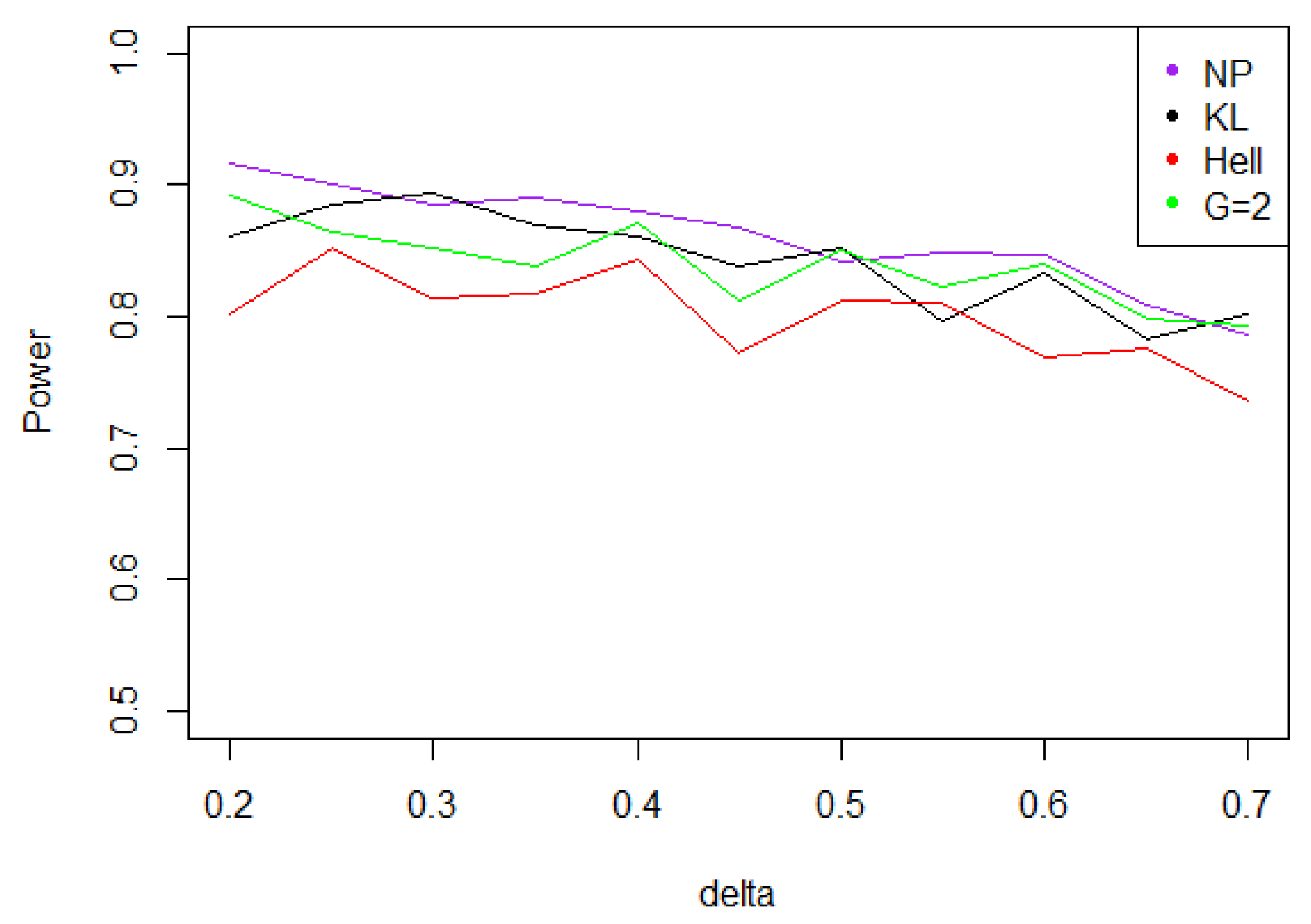
Overall, the aggregated tests perform well, when the problem consists in identifying a shift in a distribution. Indeed, for the three values of (0.5, 1, and 2), the power remains above 0.7 for any kind of noise and any value of . Moreover, the power curves associated to mainly overlap with the optimal test .
- Under Gaussian noise, the power remains mostly stable over the values of , as shown by Figure 5. The tests with statistics and are equivalently powerful for large values of , while the first one achieves higher power when is small.
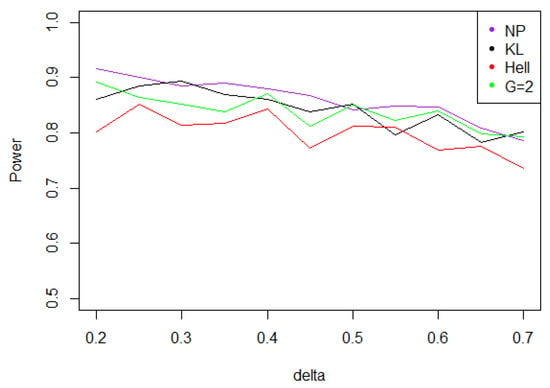 Figure 5. Power of the test of case A under Gaussian noise (with respect to ), for the first kind risk and sample size .
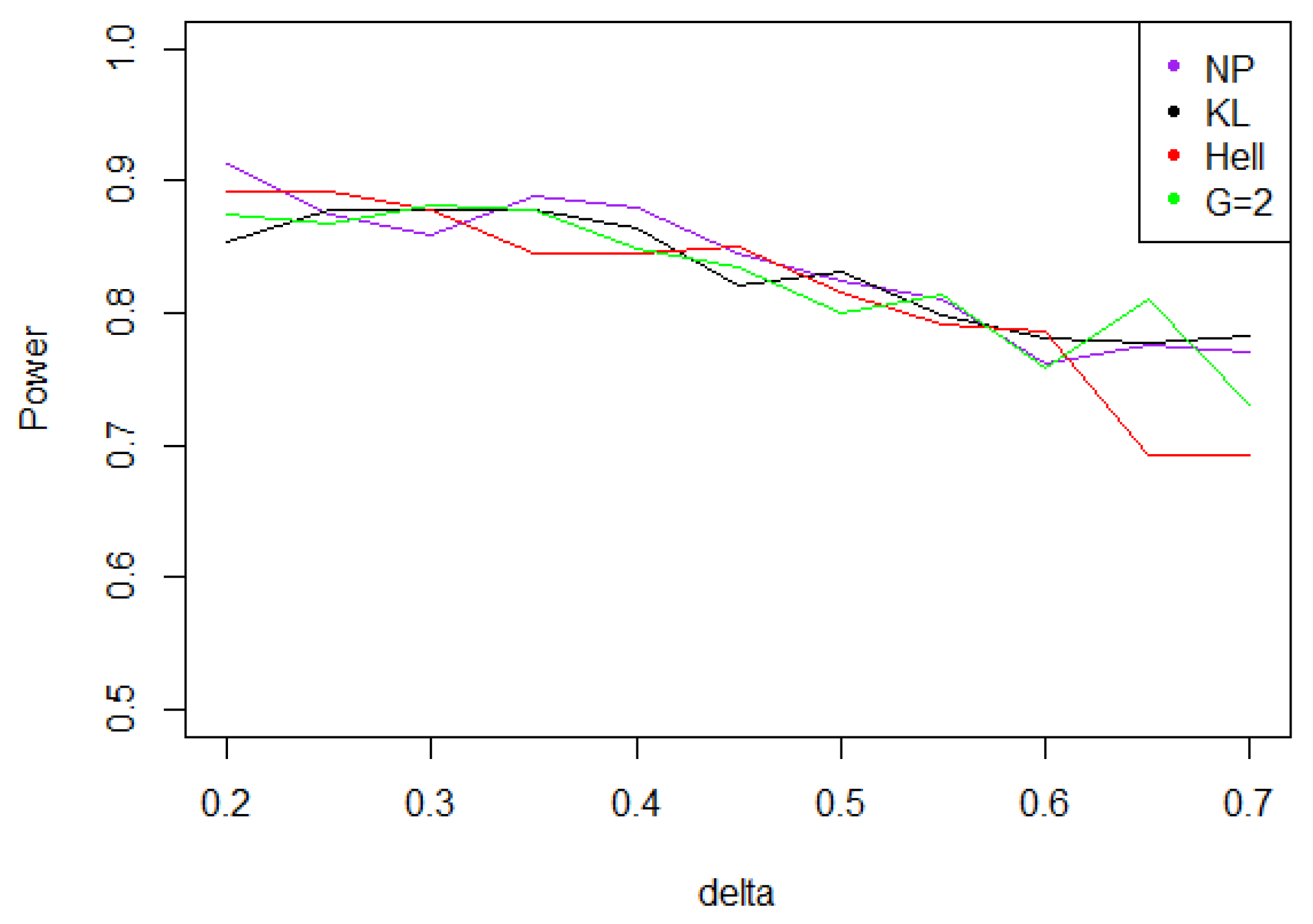
Figure 5. Power of the test of case A under Gaussian noise (with respect to ), for the first kind risk and sample size . - When the noise follows a Laplace distribution, the three power curves overlap the NP power curve, and the different test statistics can be indifferently used. Under such a noise, the alternative hypotheses are extremely well distinguished by the class of tests considered, and this remains true as increases (cf. Figure 6).
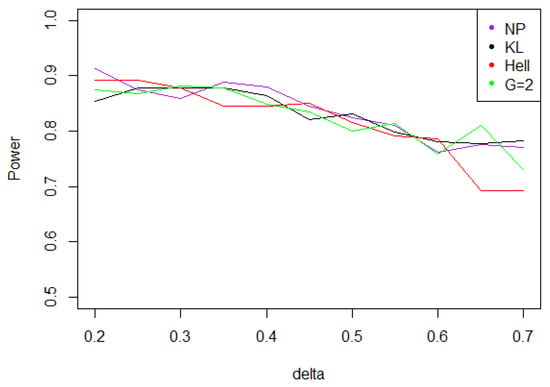 Figure 6. Power of the test of case A under Laplacian noise (with respect to ), for the first kind risk and sample size .
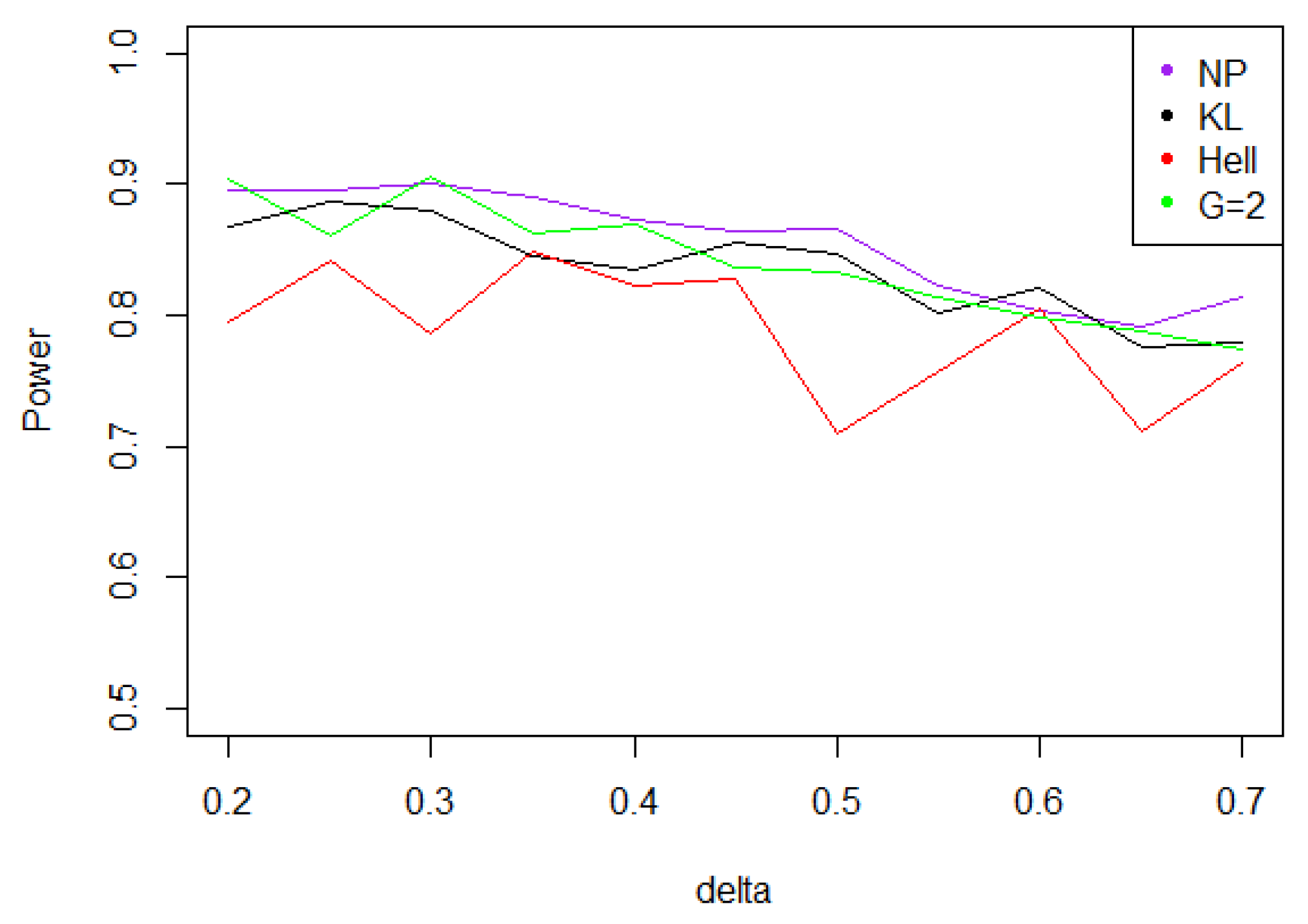
Figure 6. Power of the test of case A under Laplacian noise (with respect to ), for the first kind risk and sample size . - Under the Weibull hypothesis, and perform similarly well, and almost always as well as , while the power curve associated to remains below. Figure 7 illustrates that, as increases, the power does not decrease much.
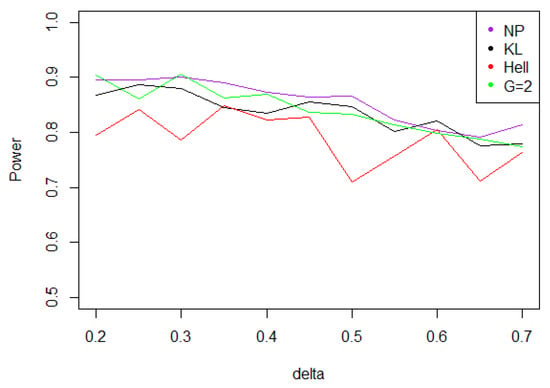 Figure 7. Power of the test of case A under symmetrized Weibull noise (with respect to ), for the first kind risk and sample size .
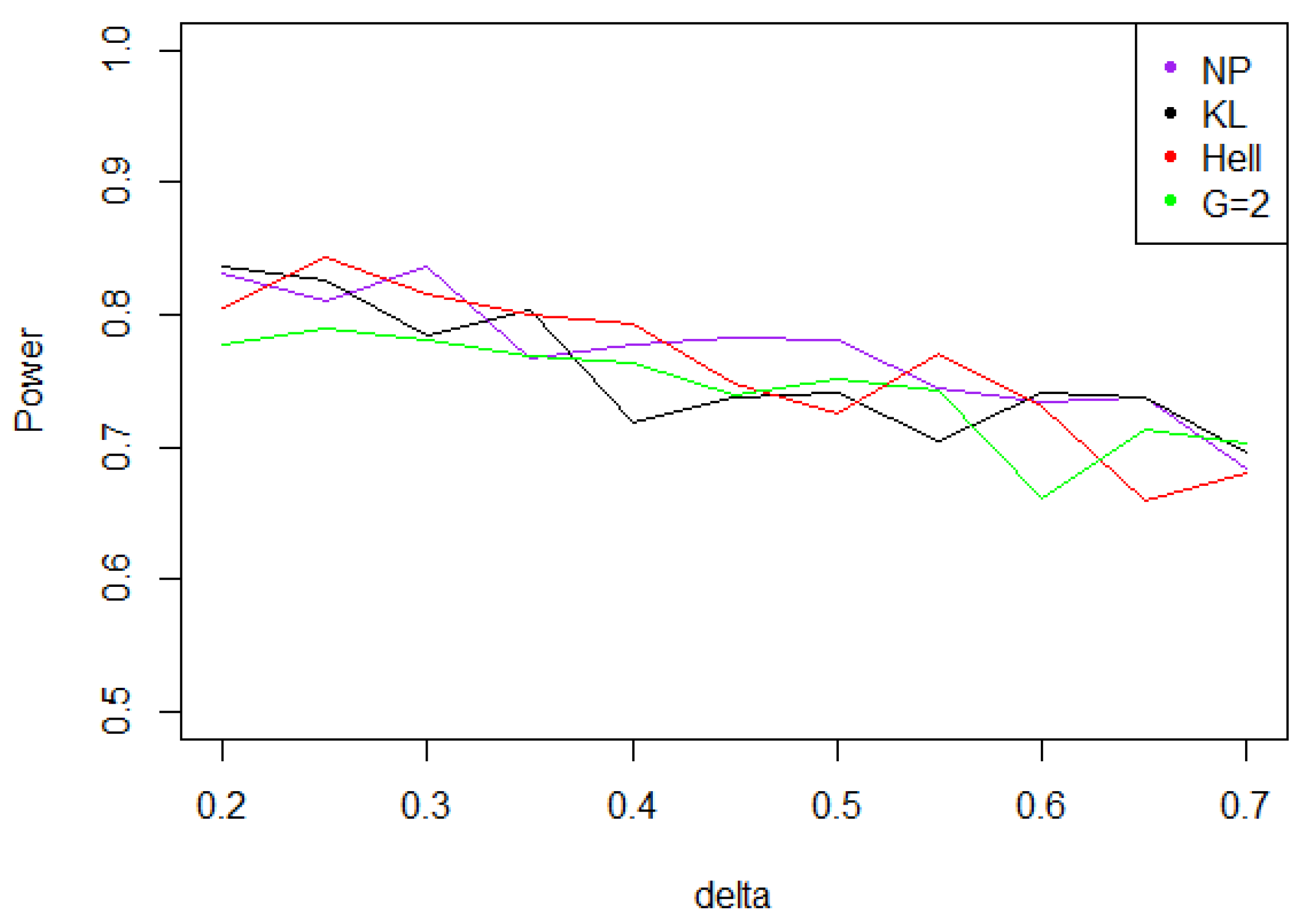
Figure 7. Power of the test of case A under symmetrized Weibull noise (with respect to ), for the first kind risk and sample size . - Under a Cauchy assumption, the alternate hypotheses are less distinguishable than under any other parametric hypothesis on the noise, since the maximal power is about 0.84, while it exceeds 0.9 in cases a, b, and c (cf. Figure 5, Figure 6, Figure 7 and Figure 8). The capacity of the tests to discriminate between and is almost independent of the value of , and the power curves are mainly flat.
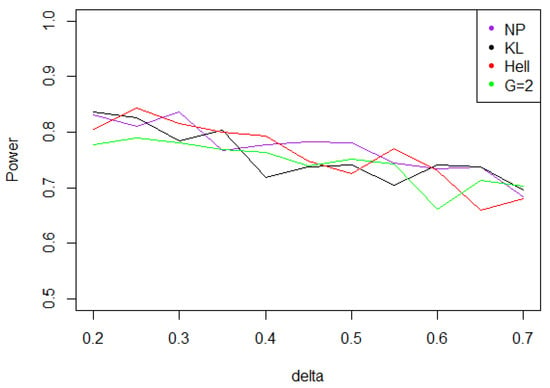 Figure 8. Power of the test of case A under noise following a Cauchy distribution (with respect to ), for the first kind risk and sample size .
Figure 8. Power of the test of case A under noise following a Cauchy distribution (with respect to ), for the first kind risk and sample size .
4.2.2. Case B: The Tail Thickness Problem
- With the noise defined by case A (Gaussian noise), for KL (), due to Proposition 4 and statistics provides the best power uniformly upon Figure 9 shows a net decrease of the power as increases (recall that the power is evaluated under the least favorable alternative ).
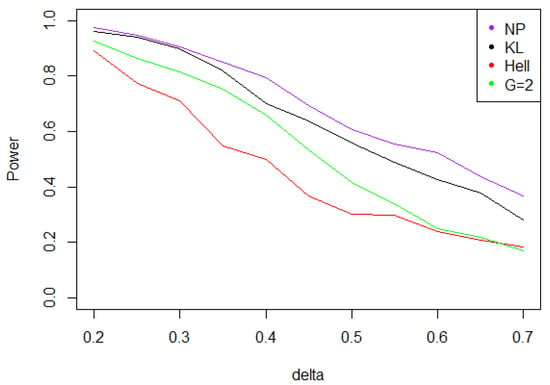 Figure 9. Power of the test of case B under Gaussian noise (with respect to ), for the first kind risk and sample size . The NP curve corresponds to the optimal Neyman Pearson test under . The KL, Hellinger, and curves stand respectively for , and cases.
Figure 9. Power of the test of case B under Gaussian noise (with respect to ), for the first kind risk and sample size . The NP curve corresponds to the optimal Neyman Pearson test under . The KL, Hellinger, and curves stand respectively for , and cases. - When the noise follows a Laplace distribution, the situation is quite peculiar. For any value of in , the modes and of the distributions of under and under are quite separated; both larger than Also, for all the values of are quite large for large values of We may infer that the distributions of under and under are quite distinct for all , which in turn implies that the same fact holds for the distributions of for large Indeed, simulations presented in Figure 10 show that the maximal power of the test tends to be achieved when
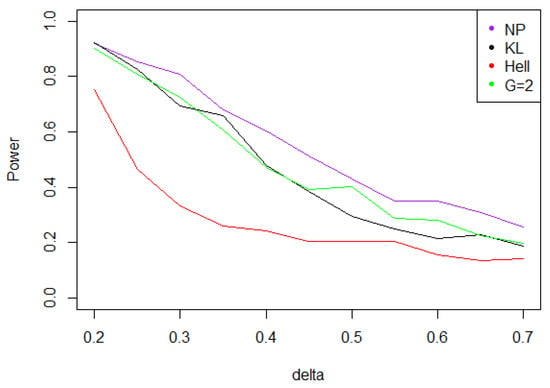 Figure 10. Power of the test of case B under Laplacian noise (with respect to ), for the first kind risk and sample size .
Figure 10. Power of the test of case B under Laplacian noise (with respect to ), for the first kind risk and sample size . - When the noise follows a symmetric Weibull distribution, the power function when is very close to the power of the LRT between and (cf. Figure 11). Indeed, uniformly on , and on x, the ratio is close to 1. Therefore, the distribution of is close to that of , which plays in favor of the KL composite test.
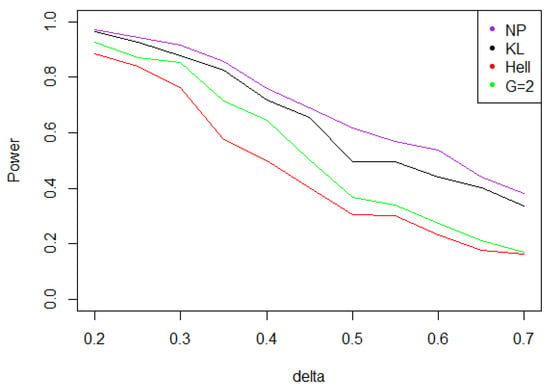 Figure 11. Power of the test of case B under symmetrized Weibull noise (with respect to ), for the first kind risk and sample size .
Figure 11. Power of the test of case B under symmetrized Weibull noise (with respect to ), for the first kind risk and sample size . - Under a Cauchy distribution, similarly to case A, Figure 12 shows that achieves the maximal power for and 2, closely followed by .
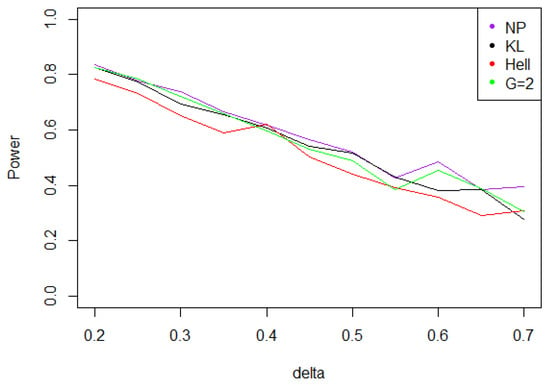 Figure 12. Power of the test of case B under a noise following a Cauchy distribution (with respect to ), for the first kind risk and sample size .
Figure 12. Power of the test of case B under a noise following a Cauchy distribution (with respect to ), for the first kind risk and sample size .
5. Conclusions
We have considered a composite testing problem, where simple hypotheses in either and were paired, due to corruption in the data. The test statistics were defined through aggregation of simple likelihood ratio tests. The critical region for this test and a lower bound of its power was produced. We have shown that this test is minimax, evidencing the least-favorable hypotheses. We have considered the minimal power of the test under such a least favorable hypothesis, both theoretically and by simulation, and for a number of cases (including corruption by Gaussian, Laplacian, symmetrized Weibull, and Cauchy noise). Whatever this noise, the actual minimal power, as measured through simulation, was quite higher than obtained through analytic developments. Least-favorable hypotheses were defined in an asymptotic sense, and were proved to be the pair of simple hypotheses in and which are closest, in terms of the Kullback-Leibler divergence; this holds as a consequence of the Chernoff-Stein Lemma. We, next, considered aggregation of tests where the likelihood ratio was substituted by a divergence-based statistics. This choice extended the former one, and may produce aggregate tests with higher power than obtained through aggregation of the LRTs, as examplified and analysed. Open questions are related to possible extensions of the Chernoff-Stein Lemma for divergence-based statistics.
Author Contributions
Conceptualization, M.B. and J.J.; Methodology, M.B., J.J., A.K.M. and E.M.; Software, E.M.; Validation, M.B., A.K.M. and E.M.; Formal Analysis, M.B. and J.J.; Writing Original Draft Preparation, M.B., J.J., E.M. and A.K.M.; Supervision, M.B.
Funding
The research of Jana Jurečková was supported by the Grant 18-01137S of the Czech Science Foundation. Michel Broniatowski and M. Ashok Kumar would like to thank the Science and Engineering Research Board of the government of India for the financial support for their collaboration through the VAJRA scheme.
Acknowledgments
The authors are thankful to Jan Kalina for discussion; they also thank two anonymous referees for comments which helped to improve on a former version of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Proposition 2
Appendix A.1. The Critical Region of the Test
Define
which satisfies
Note that, for all ,
is negative for close to , assuming that
is a continuous mapping. Assume, therefore, that (6) holds, which means that the classes of distributions and are somehow well separated. This implies that , for all and
In order to obtain an upper bound for , for all in , through the Chernoff Inequality, consider
Let
The function is continuous on its domain, and since is a strictly convex function which tends to infinity as t tends to , it holds that
for all in
We now consider an upper bound for the risk of first kind on a logarithmic scale.
We consider
for all . Then, by the Chernoff inequality
Since should satisfy
with bounded away from 1, surely satisfies (A1) for large
The mapping is a homeomorphism from onto the closure of the convex hull of the support of the distribution of under (see, e.g., [14]). Denote
We assume that
which is convenient for our task, and quite common in practical industrial modelling. This assumption may be weakened, at notational cost mostly. It follows that
It holds that
and, as seen previously
On the other hand,
Let
By (A2), the interval is not void.
We now define such that (4) holds, namely
holds for any in Note that
for all n large enough, since is bounded away from
The function
is continuous and increasing, as it is the infimum of a finite collection of continuous increasing functions defined on .
Since
given , define
This is well defined for , as and
Appendix A.2. The Power Function
We now evaluate a lower bound for the power of this test, making use of the Chernoff inequality to get an upper bound for the second risk.
Starting from (5),
and define
It holds that
and
which is an increasing homeomorphism from onto the closure of the convex hull of the support of under For any , the mapping
is a strictly increasing function of onto , where the same notation as above holds for (here under ), and where we assumed
for all
Assume that satisfies
namely
Making use of the Chernoff inequality, we get
Each function is increasing on Therefore the function
is continuous and increasing, as it is the infimum of a finite number of continuous increasing functions on the same interval , which is not void due to (A5).
We have proven that, whenever (A7) holds, a lower bound tor the test of vs. is given by
We now collect the above discussion, in order to complete the proof.
Appendix A.3. A Synthetic Result
The function J is one-to-one from I onto Since = 0, it follows that Since , whenever in there exists a unique which defines the critical region with level
For the lower bound on the power of the test, we have assumed .
In order to collect our results in a unified setting, it is useful to state some connection between and See (A3) and (A7).
Since is positive, it follows from (6) that
which implies the following fact:
Let be bounded away from Then (A3) is fulfilled for large n, and therefore there exists such that
Furthermore, by (A9), Condition (A7) holds, which yields the lower bound for the power of this test, as stated in (A8).
Appendix B. Proof of Theorem 3
We will repeatedly make use of the following result (Theorem 3 in [15]), which is an extension of the Chernoff-Stein Lemma (see [16]).
Theorem A1.
[Krafft and Plachky] Let , such that
with Then
Remark A2.
The above result indicates that the power of the Neyman-Pearson test only depends on its level on the second order on the logarithmic scale.
Define such that
This exists and is uniquely defined, due to the regularity of the distribution of under Since is the likelihood ratio test of against of the size it follows, by unbiasedness of the LRT, that
We shall later verify the validity of the conditions of Theorem A1; namely, that
Assuming (A10) we get, by Theorem A1,
We shall now prove that
Let , such that
By regularity of the distribution of under , such a is defined in a unique way. We will prove that the condition in Theorem A1 holds, namely
Incidentally, we have obtained that exists. Therefore we have proven that
which is a form of unbiasedness. For , let be defined by
As above, is well-defined. Assuming
it follows, from Theorem A1, that
Since we have proven
It remains to verify the conditions (A10)–(A12). We will only verify (A12), as the two other conditions differ only by notation. We have
by hypothesis (13). By the law of large numbers, under
Therefore, for large n,
Since, under ,
this implies that
Appendix C. Proof of Proposition 4
We now prove the three lemmas that we used.
Lemma A3.
Let P, Q, and R denote three distributions with respective continuous and bounded densities p, q, and Then
Proof.
Let be a partition of and denote the probabilities of under P. Set the same definition for and for Recall that the log-sum inequality writes
for positive vectors , and By the above inequality, for any , denoting to be the convolution of p and r,
Summing over yields
which is equivalent to
where designates the Kullback-Leibler divergence defined on Refine the partition and go to the limit (Riemann Integrals), to obtain (A13). □
We now set a classical general result which states that, when denotes a family of distributions with some decomposability property, then the Kullback-Leibler divergence between and is a decreasing function of
Lemma A4.
Let P and Q satisfy the hypotheses of Lemma A3 and let denote a family of p.m.’s on , and denote accordingly to be a r.v. with distribution Assume that, for all δ and η, there exists a r.v. , independent upon , such that
Then the function is non-increasing.
Proof.
Using Lemma A3, it holds that, for positive η,
which proves the claim. □
Lemma A5.
Let P, Q, and R be three probability distributions with respective continuous and bounded densities and r.Assume that
where all involved quantities are assumed to be finite. Then
Proof.
We proceed as in Lemma A3, using partitions and denoting by the induced probability of P on . Then,
where we used the log-sum inequality and the fact that implies , by the data-processing inequality. □
References
- Broniatowski, M.; Jurečková, J.; Kalina, J. Likelihood ratio testing under measurement errors. Entropy 2018, 20, 966. [Google Scholar] [CrossRef]
- Guo, D. Relative entropy and score function: New information-estimation relationships through arbitrary additive perturbation. In Proceedings of the IEEE International Symposium on Information Theory (ISIT 2009), Seoul, Korea, 28 June–3 July 2009; pp. 814–818. [Google Scholar]
- Huber, P.; Strassen, V. Minimax tests and the Neyman-Pearson lemma for capacities. Ann. Stat. 1973, 2, 251–273. [Google Scholar] [CrossRef]
- Eguchi, S.; Copas, J. Interpreting Kullback-Leibler divergence with the Neyman-Pearson lemma. J. Multivar. Anal. 2006, 97, 2034–2040. [Google Scholar] [CrossRef]
- Narayanan, K.R.; Srinivasa, A.R. On the thermodynamic temperature of a general distribution. arXiv, 2007; arXiv:0711.1460. [Google Scholar]
- Bahadur, R.R. Stochastic comparison of tests. Ann. Math. Stat. 1960, 31, 276–295. [Google Scholar] [CrossRef]
- Bahadur, R.R. Some Limit Theorems in Statistics; Society for Industrial and Applied Mathematics: Philadelpha, PA, USA, 1971. [Google Scholar]
- Birgé, L. Vitesses maximales de décroissance des erreurs et tests optimaux associés. Z. Wahrsch. Verw. Gebiete 1981, 55, 261–273. [Google Scholar] [CrossRef]
- Tusnády, G. On asymptotically optimal tests. Ann. Stat. 1987, 5, 385–393. [Google Scholar] [CrossRef]
- Liese, F.; Vajda, I. Convex Statistical Distances; Teubner: Leipzig, Germany, 1987. [Google Scholar]
- Tsallis, C. Possible generalization of BG statistics. J. Stat. Phys. 1987, 52, 479–485. [Google Scholar] [CrossRef]
- Goldie, C. A class of infinitely divisible random variables. Proc. Camb. Philos. Soc. 1967, 63, 1141–1143. [Google Scholar] [CrossRef]
- Basu, A.; Shioya, H.; Park, C. Statistical Inference: The Minimum Distance Approach; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Barndorff-Nielsen, O. Information and Exponential Families in Statistical Theory; John Wiley & Sons: New York, NY, USA, 1978. [Google Scholar]
- Krafft, O.; Plachky, D. Bounds for the power of likelihood ratio tests and their asymptotic properties. Ann. Math. Stat. 1970, 41, 1646–1654. [Google Scholar] [CrossRef]
- Chernoff, H. Large-sample theory: Parametric case. Ann. Math. Stat. 1956, 27, 1–22. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).