1. Introduction
Consciousness is awash with relationships and associations which appear to be a fundamental aspect of conscious experience given that, for example, the colour red would lose much of its meaning if we couldn’t discern its relationship to the colour blue, a glass of water, the sound of a piano or anything else. Moreover, mathematics is also awash with relationships and this suggests a mathematical theory for how the brain defines the relational content of consciousness could well be possible. This is the objective of the article Quasi-Conscious Multivariate Systems (see reference [
1]) published in 2016 which greatly developed the theory first mentioned in reference [
2] and is based on expected float entropy minimisation, the definition of which is given below. The theory also has potential applications in areas such as artificial intelligence and mutual or effective interaction analysis in nerve fibres; see reference [
3].
In the present article we investigate the coincidence that whilst expected float entropy minimisation was developed as a way to uncover the relationships systems define, it is itself a learning process and this fact (at least in the context of the theory presented in [
1]) emphasises the relevance of association learning processes to the emergence of consciousness; for example see [
4]. Furthermore, for brain structures involved in generating consciousness that are configured by a biologically implemented association learning process, it is interesting to consider the extent to which the learning process and expected float entropy minimisation are analogous; [
5]. In the present article we focus on testing expected float entropy minimisation to see how effective an association learning process it actually is. We already know from [
1] that expected float entropy minimisation uncovers relationships that systems define but we wish to test the extent and significance of the relationships uncovered. To do this we apply expected float entropy minimisation to a set of data to obtain relationships and then apply the relationships learned to a data completion task that is analogous to the brain’s ability for filling in missing information. This is achieved by applying the theory in reverse by going from relationships to data instead of from data to relationships. The performance is then compared with a state of the art black box using the neural fitting tool in MATLAB which is applied to the same data completion task. We will now recall the basics of the theory presented in [
1].
Examples of relationships present in consciousness include: the relationships between the locations in the field of view with adjacent locations being strongly related, giving geometry; colours being strongly related such as red and burgundy or unrelated such as red and blue; similar examples involving sounds or smells or tastes or locations of touch; at a higher level of meaning involving several brain regions, objects being strongly related to particular colours, textures, places, nouns and other objects. It appears that every conscious experience involves relationships without which there would be little if any meaning.
The theory in [
1] provides a starting point for a mathematical theory of how the brain defines all of the relationships underlying consciousness. It proposes that a brain state in the context of all these relationships, defined by the brain, has meaning in the form of the relational content of the associated experience. If successful, such a theory would ultimately show how the brain defines the content of consciousness up to relationship isomorphism. See
Section 4.3 for a discussion on relationship isomorphism.
The issue of how a system such as the brain defines relationships is crucial. Importantly, various brain regions determine an inherent probability distribution (ergodic process) over their set of states which is not uniform due to learning processes that weaken or strengthen synapses. Hebb’s principle and its modern refinements are potentially examples of such learning processes and say that neurons increase the strength of their connections to neurons they are significantly influencing; see [
6,
7,
8]. Therefore, the brain is biased toward certain states as a result of a long history of sensory input and is not merely driven by the senses (also see [
9]). Because the system itself determines an inherent probability distribution over its states, the system can define expected quantities.
Expected float entropy can be thought of as a form of Shannon entropy parameterised by relationships where the float entropy of a state of the system is a measure of the amount of information required, in addition to the information given by the relationship parameters, in order to specify that state. Therefore, the relationship parameters that minimise the expected float entropy of the system are (according to the theory) the relationships that the system defines. According to the theory all of the relationships are defined across temporal moments and this applies, for example, to both relationships that give the underlying geometry of the field of view and the relationships between colours. The relationships provide a context relative to which the current state of the system has meaning. Whilst some aspects of consciousness are present at a given moment and some are not (which depends on the current state of the system) the context of underlying relationships defined by the system is always present, at least whilst the brain’s structure and functionality is stable. If the brain or some local region of the brain contributing to consciousness changes how it is functioning then this will change its inherent probability distribution over its states which will then change the relationships that minimise expected float entropy and consequently, according to the theory, the relational content of the experience. Such changes in functionality will occur due to the brain’s plasticity but also when activity patterns change as we transition from being awake to being in a deep sleep to being in REM sleep where activity patterns return to being similar to when awake. We recall the definition of float entropy in
Section 1.1 and the definition of multi-relational float entropy in
Section 4.
1.1. Definitions and Theory
In this subsection we provide the main definitions as previously given in [
1]. Systems such as the brain, and its various regions, are networks of interacting nodes. In the case of the brain we may take the nodes of the system to be the individual neurons or possibly larger structures such as cortical columns or tuples of neurons. The nodes of the system have a repertoire (range) of states that they can be in. For example, the states that neurons can be in could be associated with different firing frequencies where as the states of tuples of neurons could be given by the aggregate of the states of the neurons of the same tuple. In the present article we assume that the node repertoire is finite (as was assumed in [
1]), and the state of the system is the aggregate of the states of the nodes. In Definition 1 the elements of the set
S are to be taken as the nodes of the system. Also see the
Appendix A of notation.
Definition 1. Let S be a nonempty finite set of system nodes, . Then for S, a data element
representation of a system state is a set (having a unique arbitrary index label i)and is the state node is in when the system is in state . The set of all data elements for S given V is so that . For temporally well spaced observations, it is assumed that a given finite system defines a random variable with probability distribution for some finite set S and node repertoire V. If T is a finite set of numbered observations of the system then T is called the typical data
for S. The elements of T (called typical data elements
) are handled using a functionwhere is the data element representation of observation number k for . In particular, the function τ need not be injective since small systems may be in the same state for several observations. Remark 1. Note that P in Definition 1 extends to a probability measure on the power set of by defining Hence, we have a probability space with sample space , sigma-algebra , and probability measure P. For clarification, A is just a subset of .
We now need the definition of a weighted relation.
Definition 2 (Weighted relations)
. Let S be a nonempty set. A weighted relation
on S is a function of the formwhere is the unit interval. We say that R is: - 1.
reflexive if for all ;
- 2.
symmetric if for all .
The set of all reflexive, symmetric weighted-relations on S is denoted .
Remark 2. Except where stated, the weighted relations used in the present article are reflexive and symmetric. The formulation of the theory allows the symmetric condition to be dropped but when relationships (between nodes for example) are anticipated to be symmetric (such as in the case of relationships that give the geometry of Euclidean space), restricting to symmetric relations reduces the dimensionality which is computationally desirable when calculating values. Relative to a weighted relation, the value quantifies the strength of the relationship between a and b, interpreted in accordance with the usual order structure on so that is a maximum. For a small finite set, it is useful to display a weighted relation on that set as a weighted relation table (i.e., as a matrix). An example is given in Table 1. Before giving the definition of float entropy we require Definitions 3 and 4.
Definition 3. Let S be as in Definition 1 and let be a reflexive, symmetric weighted-relation on the node repertoire V; i.e., . Then, for each data element , we define a function of the form by settingwhere is the mapping associated with as in Definition 1. It is easy to see that . Definition 4. Let S be a nonempty finite set. Every weighted relation on S can be viewed as a -dimensional real vector. Hence, the metric is a metric on the set of all such weighted relations by settingwhere R and are any two weighted relations on S. Similarly we have the metric Definition 5 (Float entropy)
. Let S be as in Definition 1, let , and let . The float entropy
of a data element , relative to U and R, is defined aswhere, in the present article (unless otherwise stated), is the metric. Furthermore, let and T be as in Definition 1. The expected float entropy
, relative to U and R, is defined as The approximation of is defined aswhere τ need not be injective by Definition 1. By construction, is measured in bits per data element (bpe). It is proposed that a system (such as the brain and its subregions) will define
U and
R (up to a certain resolution) under the requirement that the
is minimised. Hence, for a given system (i.e., for a fixed
P), we attempt to find solutions in
U and
R to the equation
In practice we replace
in Equation (
1) with
.
Ultimately by minimising
in
R and
U we are finding relationships that have particular relevance to the more probable states of the system whilst avoiding relationships with relevance to large numbers of arbitrary improbable states of the system. Note that the ‘less than or equal to’ sign in the definition of float entropy avoids trivial solutions to Equation (
1) such as when
R and
U are the constant functions that everywhere take the value 1.
Shannon entropy is notably used in recent theories of consciousness and self-organization; see [
10,
11]. The definition of float entropy (see Definition 5) has some similarity to that of Boltzmann’s entropy where the entropy of a macrostate is proportional to the log of the number of microstates satisfying the macrostate. In the case of the float entropy of a system state, the macroscopic condition is the extent to which the system state adheres to the weighted relation parameters. Whilst not to be confused with Shannon entropy, expected float entropy,
, does have some similarities with Shannon entropy and conditional Shannon entropy in particular. Indeed,
is a measure (in bits per data element) of the expected amount of information needed, to specify the state of the system, beyond what is already known about the system from the weighted relations provided. Shannon entropy is a measure of information content in data. As data becomes more random, Shannon entropy increases because structure in data is actually a form of redundancy. By solving Equation (
1) for a given system we obtain a structure in the form of weighted relations defined by the system. Relative to these weighted relations, if the system was to become more random then the
value for the system would increase. In order to make the similarities between
and Shannon entropy (and in particular conditional Shannon entropy) clearer, consider the summation
where
. The summation in (
2) is similar in form to the definition of conditional Shannon entropy. Furthermore, (
2) can be written as
and, when the probabilities in the argument of the logarithm are comparable, this will give a value similar to
. Finally, we can write (
3) as
where
H is the Shannon entropy of the system and, with consideration of the log function, the second term has a negative value between
and 0; see [
12] where conditional Shannon entropy is similarly expressed by involving a mutual information term. For
U and
R the constant functions which everywhere take the value 1, (
4) simplifies to
H.
Because Shannon’s Information Theory is so well developed and useful it is interesting to consider whether expected float entropy can be recast to be fully compatible with Information Theory. The answer is yes although results of such a theory have yet to be obtained. To show this suppose we have a system with probability distribution
. For
and
we will define a partition
of
. Such a partition
can be treated as a set of states of a random variable with
and joint probability distribution
Note that this gives the correct marginal distributions,
and allows us to apply the standard definitions from Information Theory such as joint entropy, mutual information and conditional entropy; see [
12] for the Information Theory definitions mentioned. In particular, conditional entropy can be taken as a new definition of
provided that
(the set of states of the random variable used in the condition) depends on
R and
U in a suitable way to give a low conditional entropy value when
R and
U give a low
value. We introduce Algorithm 1 below to do this. To this end, suppose
R and
U minimise
, as defined in Definition 5, and
has a relatively large probability. Algorithm 1 below defines
such that in this case the unique set
with
contains few other elements besides
so that
, as a set of states of a random variable, is similar to the set of states
of the random variable defined by the system. This will result in a low conditional entropy value when
R and
U minimise
. Note that from the outset it is possible to use
in place of
without affecting conditional entropy.
| Algorithm 1: Partition algorithm for when using conditional entropy similarly to . |
Step 1: Let be such that: - (a)
has yet to be allocated to one of the subsets partitioning ; - (b)
of all the elements of satisfying (a), has the greatest probability; - (c)
for , if there is more than one element of satisfying (a) and (b) then is such that contains the fewest elements. If is still not unique then choose any such that satisfies (a), (b) and (c). It will turn out that is well defined because if then .
Step 2: Define the next subset of contributing to the partition of to be
Step 3: If all the elements of have been allocated then define the partition of as the set of the subsets defined during each occurrence of Step 2. Otherwise, if there are still elements of to be allocated then return to Step 1. |
Before moving on to
Section 2 it is worth noting that the examples in reference [
1] are intended to have relevance to the visual cortex and our experience of monocular vision. In the present article, in order to investigate the extent to which expected float entropy minimisation is an effective association learning process we will use typical data for digital photographs of natural scenes as training and testing data, although other data sources could have as easily been used such as auditory data. Expected float entropy minimisation will be used to determine relationships between pixel locations (recovering the spatial geometry of the photographs) and also relationships between the pixel states (recovering the similarity between similar shades of grey in the photographs). Subsequently, to test the effectiveness of expected float entropy minimisation as an association learning process, the learned relationships will be used to perform minimum float entropy completion. The test involves completing missing pixel states for a test set of photographs that each have 44% of their pixel state data involved removed. The performance of recovering missing pixel states by choosing those states that give the minimum float entropy value (relative to the relationships learned) is then compared with a state of the art black box using the neural fitting tool in MATLAB which is applied to the same data completion task.
For a discussion on how the theory under investigation solves the binding problem, see references [
1,
2]. In short, consciousness may largely be the state of the system in the context of the relationship parameters that minimise a version of expected float entropy that involves more than the two weighted relations used in Equation (
1); see the discussion in
Section 4 about multi-relational float entropy, the definition of which first appeared in reference [
1].
The rest of the article is organized as follows.
Section 2 looks at obtaining typical data from digital photographs, references the methods used for solving Equation (
1), and describes
-histograms.
Section 3 tests how well expected float entropy minimisation performs as an association learning process.
Section 4 discusses multi-relational float entropy, the inherent probability distribution of a system, experimental testing on the brain, and observable phenomenon and unobservable effects. The conclusion is given in
Section 5. The appendix provides a list of notation.
3. Results
In this test of how well expected float entropy minimisation performs as an association learning process, 600 digital photographs of the world around us are used such that 400 are for training and 200 are for testing. The typical data is obtained using the method shown in
Figure 1, where the photographs have a four shade gray scale. Hence,
and the system is comprised of nine nodes with a four state node repertoire giving
262,144. Similarly the data for the test set
W is also obtained using the method shown in
Figure 1 so that
. For
T a solution to Equation (
1) was found for a subset of five of the nine nodes by using the binary search algorithm given in [
1]. Using symmetry, the solution was then extended to all nine nodes as an approximate solution. The approximate solution is given in
Table 3.
Figure 2 provides a graph illustration of the weighted relations. For
U, values above 0.2 are indicated with a solid line, whilst values from 0.02 to 0.2 are indicated with a dash line. For
R, values above 0.9 are indicated with a solid line, whilst values from 0.75 to 0.9 are indicated with a dash line.
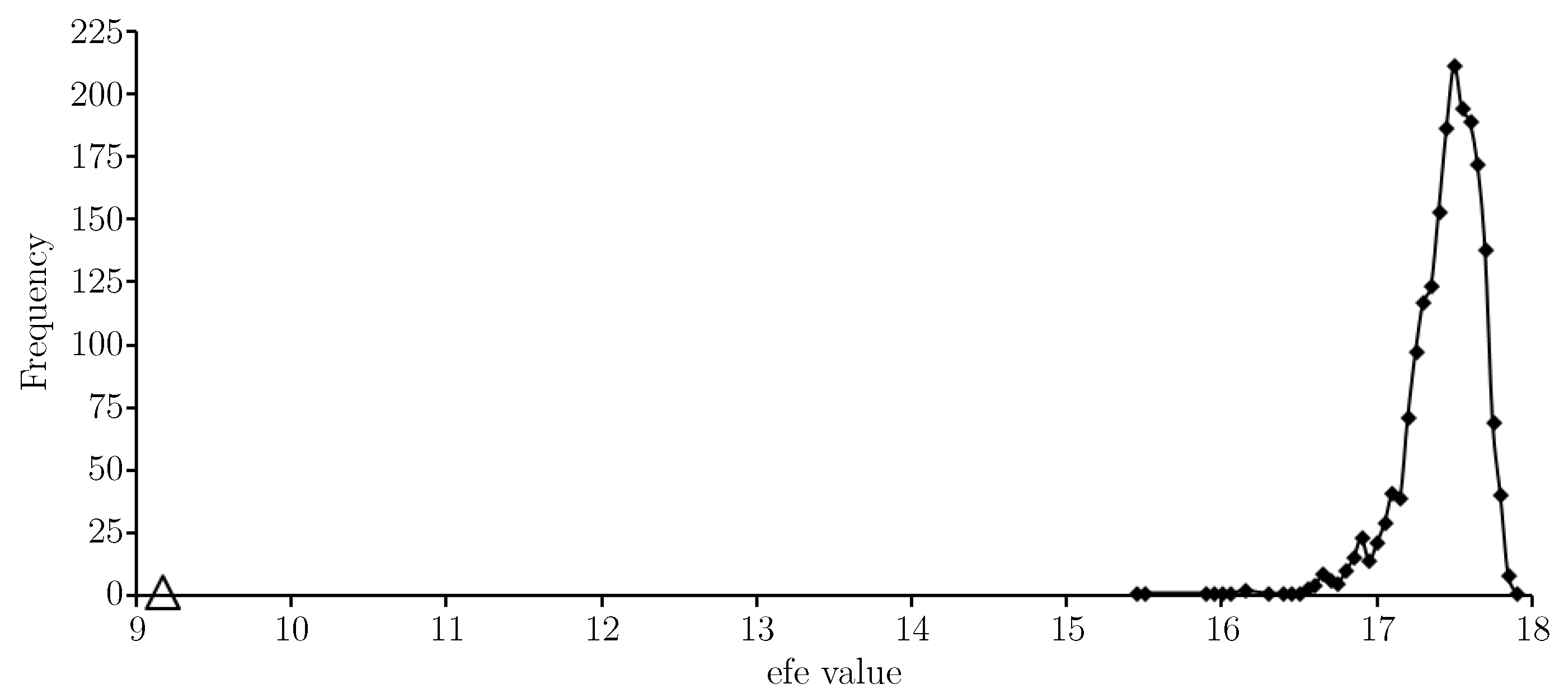
Figure 3 provides an
-histogram for
T. The
value for the approximate solution is indicated with a triangular marker and shows the approximate solution gives a very low expected float entropy value relative to other choices.
Having completed the training stage we now look at testing. As is the case for
T (see Definition 1), the test set
W is a set of numbered observations. The elements of
W are handled using a function
(analogous to
in Definition 1) where
is the data element representation of observation number
k for
. For each
k we obtain an obfuscated version of
by choosing four of the nine nodes uniformly at random and deleting their state information. There are
possibilities for how this obfuscated version of
can be completed and we denote these completions by
for
. Now using
U and
R obtained in the training stage (see
Table 3), we obtain the set of numbered minimum float entropy completions of the obfuscated observations,
The elements of
are numbered (that is they are made distinct by their
values) because the function
is not injective. Moreover,
not 200 because for each of two particular values of
k there were two values of
i for which
was the minimum float entropy value. The results of the test are given in
Figure 4 where the proportion of the obfuscated observations that have
n out of four nodes correctly completed are shown for
.
In the case of the two obfuscated observations that have two completions in
, the average number of nodes correctly completed was used and rounded down when not an integer. We see from
Figure 4 that only
of minimum float entropy completions have no correctly completed nodes whilst
have all four nodes completed correctly. The average number of correctly completed nodes is 2.65. For comparison
Figure 4 shows results for when completing each node independently of the others by selecting for each node the most commonly observed state for that node in the training set. In this case, the average number of correctly completed nodes is 1.4.
Figure 4 also shows the binomial distribution B(4,1/4) which is the probability distribution for the number of correctly completed nodes if guessing the node states uniformly at random. In this case the expected number of correctly completed nodes is just 1.
Clearly minimum float entropy completion has performed far better than completing the nodes independently or just guessing node states uniformly at random. In fact the probability of this result happening by chance, under the assumption that minimum float entropy completion is no better than just guessing, is orders of magnitude smaller than . This was confirmed using the Normal approximation N(800(0.25),800(0.25)(1−0.25)) of the Binomial distribution B(800,0.25) for the total number of correctly guessed node states across all of the obfuscated elements of W. For there are 530 correctly completed nodes out of 800 and statistics tables show that the probability of there being more than 260 correct completed node states when just guessing is less than .
Although we have proven that minimum float entropy completion performs far better than completing the nodes independently or just guessing, it is also right to compare it with a current state of the art learning process. For this we used the Neural Fitting Tool (nftool) in MATLAB which is for input-output fitting problems. To use nftool, an input set and a target set is needed for training, validation and testing. The union was taken as the target set and an obfuscated version of constitutes the input set, where, for each element of , we obtain an obfuscated version by choosing four of the nine nodes uniformly at random and deleting their state information. Four hundred input and target pairs were allocated to training and the remaining were used for validation and testing. Using a validation sample prevents over fitting by halting training when performance on the validation sample stops improving.
On the input side of the neural network, each of the nine nodes connect to four neurones that are dedicated to just that node, that is they do not have an input connection from any of the other nodes. Therefore there are 36 neurons in the first layer. This allows each of the node states to be represented in binary vector form with the following representations: black (1,0,0,0); dark gray (0,1,0,0); light gray (0,0,1,0); white (0,0,0,1); obfuscated (0,0,0,0).
Next, nftool has a two-layer feed-forward network with sigmoid hidden neurons and linear output neurons. Such neural networks can fit multi-dimensional mapping problems arbitrarily well given consistent data and enough neurons in its hidden layer. In our case the data is not consistent since the target set can have different completions for two different instances of the same input. It was found that having 40 neurons in the hidden layer gave the best results. The network is trained with the Levenberg-Marquardt backpropagation algorithm.
As per the input side, there are four neurones for each of the nine nodes on the output side. However, a final max value layer is added so that a node output such as
is converted to (0,0,1,0), representing light gray in this case. The results are given in
Figure 5 where the proportion of the elements of the input set (which is the obfuscated version of
) that have
n out of nine nodes correctly completed are shown for
. For comparison, the histogram shown in
Figure 4 has also been included in
Figure 5, all be it shifted to the right by five because minimum float entropy completion preserves the states of the specified nodes noting there are five nodes per data element with given state.
When using nftool the average number of correctly completed nodes was 8.13. When using minimum float entropy completion the average number of correctly completed (and preserved) nodes was 7.65. This average drops to 6.4 in the case of completing the nodes independently, and when guessing the obfuscated node states uniformly at random the expected number of correctly completed (and preserved) nodes is 6. Clearly nftool has outperformed minimum float entropy completion, although, for these two learning processes, the average number of correctly completed nodes per data element only differs by 0.48; note the difference is 1.73 when comparing the nftool performance with completing the nodes independently, and 2.13 when guessing.
In
Section 4 we will discuss expected multi-relational float entropy minimisation which involves more than the two weighted relations used in Equation (
1) and was first introduced in [
1]. Although beyond the scope of the present article to demonstrate, additional relationship parameters should improve performance. In the case of the brain, multi-relational float entropy may reveal how the brain defines relationships between geometric structures in the field of view and, at a high level of meaning, between objects for example, noting that according to the theory, consciousness may largely be the states of the system in the context of the weighted relations that minimise expected multi-relational float entropy.
Before moving on to
Section 4 we now consider some
-histograms (see
Section 2.2) for the results presented in the present article.
Figure 6 provides an
-histogram for the test data
W as sampled.
The
value for the approximate solution (in
Table 3) to Equation (
1) is indicated with a triangular marker and shows the approximate solution gives a very low expected float entropy value (around 8.6) relative to other choices. In fact the value is slightly lower than that shown for the training set
T, see
Figure 3.
Figure 7 provides an
-histogram for the minimum float entropy completed test data.
Not surprisingly, the
value given by the approximate solution in
Table 3 is lower (now around 6.5) on the minimum float entropy completed test data than on
W. Indeed, any discrepancy between the minimum float entropy completed test data and
W will result in the
value for the approximate solution being higher on
W. For
Figure 8 a set of completed test data was generated by choosing missing node values uniformly at random.
Completing the obfuscated test data in this way is a transformation of
W that makes it more random. As per the discussion comparing expected float entropy and Shannon entropy in
Section 1.1, the
value of the approximate solution is much higher on the uniform randomly completed test data than it is on
W. Finally we consider the nftool completed test data. In this case the
value for the approximate solution (in
Table 3) is very similar to what it is on
W; around 8.5. For the same reason as for
W, it is not surprising that this is higher than the result for the minimum float entropy completed test data.
4. Discussion
Section 3 shows expected float entropy minimisation is an effective association learning process and that minimum float entropy completion performed well at completing obfuscated observations. However, the results would likely be improved under expected multi-relational float entropy minimisation due to the additional relationship parameters involved. The following definition of multi-relational float entropy is slightly more general than the version given in [
1].
Definition 6 (Multi-relational float entropy)
. Let S be as in Definition 1, let , and let . Furthermore, let and be weighted relations analogous to U and R but involving structures such as tuples of the initial nodes, subsets of the initial nodes and, ultimately, even objects, locations and places. The multi-relational float entropy
of a data element , relative to and , is defined aswhere the first condition is , as in Definition 5. In Definition 6, all of the conditions need to be satisfied for a data element to contribute toward the multi-relational float entropy of a data element . The additional conditions should be those that increase the length of the left tail of the -histogram.
Let us consider an example that would likely improve the results obtained in
Section 3 by adding an additional condition
analogous to
but involving tuples of the initial nodes.
Figure 9 identifies eight tuples with each containing three of the initial nodes. Let
denote the set of new nodes.
The repertoire of the new nodes is large
but a much reduced repertoire
can be used instead of
to ease computation. For example a three state repertoire
can be used such that a tuple in state
is taken to be in state
if
, state
if
,
and
are not all the same but are strongly related according to
U (e.g., they involve two adjacent shades in
Figure 2), and state
otherwise. The condition
is
, where
and
. Note that
still depends on the elements of
because the states of the new nodes are a function of the states of the initial nodes. Minimising
will result in
giving relatively strong relationships between parallel structures within
S under the geometry determined by
R. This is just one example of adding an extra condition but many conditions can be added and the possibilities are quite abstract. In this setup, states of new nodes need only be functions of the states of the initial nodes and don’t have to be tuples. Node states can be objects determined by the states of nodes in a particular location etc. With such wide possibilities it is right to ask how the system defines the conditions to be included. As mentioned, the additional conditions should be those that increase the length of the left tail of the
-histogram. For a structure such as the brain, clues from the structure of the system itself should be sought. In particular the new nodes required may turn out to be within the system itself, in which case they can be included as initial nodes in
S and conditions such as
can be applied to different subsets of
S. Multi-relational float entropy greatly extends the scope of the theory and more research is needed in this area.
It may be useful to mention how the computation time (assuming serial processing) for calculating a single value depends on the size of the system involved. With reference to Definition 5, the time taken to compute an value equals the number of typical data elements sampled, , multiplied by the time it takes to compute one float entropy value, which largely scales with the size of . Therefore, a first approximation of the computation time is given by , where n is the number of nodes, m is the size of the node repertoire and C is a constant. It follows that the time increases linearly in , with polynomial time in m and with exponential time in n. If measuring time in seconds, C will typically be of order or depending on the contemporary processor used but will be larger for expected multi-relational float entropy where several conditions are involved. Note that calculating is an “embarrassingly parallel” task and lends itself to high performance computing methods.
4.1. The Inherent Probability Distribution a System Defines
According to the theory, the relationships a system defines are those that minimise expected (multi-relational) float entropy and this depends on the inherent probability distribution a system has. The theory, initially presented in [
1], suggests that, to contribute to consciousness, a system will at least need an inherent probability distribution on its set of states that gives an efe-histogram with a long left tail because when the tail is very long the solutions to Equation (
1) are isolated from other weighted relations and are therefore strongly determined by the system. Further, systems with an inherent probability distribution that is close to being uniform give a very short left tail and it is not expected that such uniformly random systems would give rise to consciousness. If a brain region processes information in a very compressed form then its inherent probability distribution will be more uniform than other regions and, according to the theory, regions contributing to consciousness should be found among those that are pre and post high compression. Further, as mentioned in the introduction, if the brain or some local region of the brain contributing to consciousness changes how it is functioning then this will change its inherent probability distribution over its states which will then change the relationships that minimise expected float entropy and consequently, according to the theory, the relational content of the experience. Such changes in functionality will occur due to the brain’s plasticity but also when activity patterns change as we transition from being awake to being in a deep sleep to being in REM sleep where activity patterns return to being similar to when awake. An important question to ask is when does a system actually define an inherent probability distribution, where the emphasis here is on the probability distribution being inherent as opposed to being applied by an external observer. For example, an external observer might associate audio compact discs (CDs) if they are in the same stack but this is a circumstantial association only and isn’t internal to any system. Similarly a television is rather like an electronic version of a flicker book of images and a flicker book is rather like a stack of images. On the other hand, the brain is a highly interconnected dynamical network which will snap to a state in response to a stimulus due to bias and learning. Understanding when an inherent probability distribution can be assumed for a system or subsystem is important for the presented theory and this issue might indicate a connection to other theories of consciousness such as Integrated Information Theory (IIT, see [
16]) if a high
value were to correspond with the probability distribution being inherent. However, it is not necessary to answer this question in order to apply the theory, extract relationships and more generally accept expected (multi-relational) float entropy minimisation as a theory for the content of consciousness up to relationship isomorphism when consciousness is present. Also areas of the theory can be further explored and developed such as multi-relational float entropy without answering the question of when the probability distribution involved is inherent.
4.2. Experimental Testing on the Brain
In accordance with the scientific method, float entropy minimisation as a theory for uncovering the relationships a system defines needs to be tested on the brain noting it is propose that a brain state in the context of these relationships has meaning in the form of the relational content of the associated experience. The main obstacle to undertaking such testing is the lack of access to brain state data. In the future synthetic brains such as those sought by the Human brain project, if possible, would be able to provide the data needed but in the meantime less ideal tests are possible using FMRI data for the brain. One such possibility is to apply the theory to voxel data for layers within the visual cortex and possibly the Dorsal and Ventral streams. For example, the geometry of V1 cannot account for the perceived geometry of monocular vision because the retino-cortical mapping is approximately logarithmic and is far from being an isometry (see [
17,
18]) and signals from the right side of each retina are mapped to the right side of the brain, whereas signals from the left side of each retina are mapped to the left side of the brain. Despite the signals from the retina being split across two different brain regions in this way, the perceived geometry is a seamless isometric version of the image on the retina further enhanced by the brain’s abilities such as filling in. Applying expected float entropy minimisation to samples of voxel data for various parts of the visual system may recover the relationships that give the perceived geometry of the field of view. Note, the geometry could be very different from that of the actual physical locations of the voxel positions within the brain. However, difficulties may arise from the limited resolution of voxel data and also because the voxel states are not the neuron states but are instead a measure of blood flow. Therefore both the nodes and node repertoire involved are different to what we would be using if actual brain state data was available. However, the theory would identify relationships form voxel data and a thorough approach to the research could well produce valuable insights.
4.3. Observable Phenomenon and Unobservable Effects of Relationship Isomorphism
There are several different types of ambiguities that arise from the presented theory. Some of these ambiguities arguably result in observable phenomenon. In
Section 3 a solution to Equation (
1) was obtained and then minimum float entropy completion was used to complete missing node states for an obfuscated version of the observations. Two out of 200 of the obfuscated observations were able to be completed in two different ways under minimum float entropy completion. It is likely that the ambiguity in this case would disappear when using multi-relational float entropy but, more generally, ambiguities in the state a system should adopt under a given stimulation do occur in the form of bistable and multistable optical illusions. Another type of potentially observable ambiguity is due to the fact that expected float entropy minimisation only defines relationship parameters up to a certain resolution. Our experience of peripheral vision may be connected to this. We will now consider another type of ambiguity that we are unable to observe. According to the presented theory, expected (multi-relational) float entropy minimisation reveals relationships defined by the brain, and a brain state in the context of all these relationships acquires meaning in the form of the relational content of the associated experience. If the theory is correct then it explains how the brain defines the content of consciousness up to relationship isomorphism. It is important to note that this leads to an ambiguity because there can be several versions of consciousness that are relationally isomorphic to each other. An isomorphism is a form of symmetry. To formally clarify what is meant by relationship isomorphism, let
and
be two structures where
X and
Y are sets,
and
are weighted relations on
X and
Y respectively and the dots represent any other attributes that the structures may have. If a bijective mapping
is such that
for all
then
is a relationship isomorphism. In the case where the structures are not distinct,
is also a relationship automorphism. One potential example of relevance is the Inverted Spectrum hypothesis (which goes back to John Locke) which involves two people. Alice and Bob share the same colour vocabulary but one sees the inverse of the colours the other sees. Assuming that colour inversion is a relationship isomorphism, Alice and Bob will always agree on colours that are similar to each other and colours that are different even though they experience differently the colours they refer to. An alternative version of the Inverted Spectrum hypothesis (and a solution to the ambiguity of there being several relationally isomorphic versions of consciousness) is the hypothesis that Alice’s brain gives rise to several different versions of her consciousness with some versions seeing the inverse of the colours the others see. Each version of Alice will be unaware of the others and unable to access them because to do so would also affect colours when recollecting memories so that present experience always remains consistent with past experience. Another example of this involves the mirror image of the world around us. Mapping our experience of the geometry of the world around us to its mirror image is an isometry and therefore a relationship isomorphism. According to the hypothesis, some versions of Alice’s consciousness will see the mirror image of the world as perceived by the other versions. This is a very mathematical approach to resolving the problem of the ambiguity left behind by relationship isomorphism. When such ambiguities arise in mathematics usually the mathematical structure involved is enlarged to include the different possibilities and the isomorphisms involved form a group under composition. Issues involving mirror image mapping and relations have in the past been thought about by Kant and also arise in what is known as the Ozma problem. If the hypothesis that the brain defines several relationally isomorphic versions of consciousness is correct then a theory for how the brain defines the content of consciousness up to relationship isomorphism may be the best science can do. If the hypothesis is wrong then further theory may be possible.
5. Conclusions
The theory further investigated in this article brings together the facts that consciousness is full of relationships and that various brain regions determine an inherent probability distribution over their set of states which is not uniform due to learning processes that weaken or strengthen synapses. Hebb’s principle and its modern refinements are potentially examples of such learning processes and say that neurons increase the strength of their connections to neurons they are significantly influencing; see [
6,
7,
8]. According to our theory, the link between these facts is made by expected (multi-relational) float entropy minimisation which takes the probability distribution of the system as an input along with relationship parameters of which a restricted choice is determined by the minimisation requirement. It is proposed that a brain state in the context of these relationship parameters has meaning in the form of the relational content of the associated experience. The theory, initially presented in [
1], suggests that, to contribute to consciousness, a system will at least need an inherent probability distribution on its set of states that gives an
-histogram with a long left tail. The length of the left tail may turn out to be of great importance because when the tail is very long the solutions to Equation (
1) are isolated from other weighted relations and are therefore strongly determined by the system. Further, systems with an inherent probability distribution that is close to being uniform give a very short left tail and it is not expected that such uniformly random systems would give rise to consciousness.
In the present article we have established that expected float entropy minimisation is an effective association learning process. In particular, having used expected float entropy minimisation for training, minimum float entropy completion was compared with the Neural Fitting Tool (nftool) in MATLAB and also with completing the nodes independently as well as with completing missing node states uniformly at random. The nftool did outperform minimum float entropy completion but, for these two learning processes, the average number of correctly completed nodes per data element only differed by 0.48 where as the difference is 1.73 when comparing the nftool performance with completing the nodes independently, and the difference is 2.13 when guessing. Expected multi-relational float entropy minimisation will almost certainly give further improvements in performance and provides wide scope for further development of the theory involving many more relationships.
We have also shown that expected (multi-relational) float entropy minimisation can be recast to be fully compatible with Shannon’s Information Theory (see Algorithm 1) allowing us to apply the definitions of joint entropy, mutual information and conditional entropy. This also makes available a well developed body of theory that can be exploited in future work. In particular, conditional entropy minimisation can be implemented such that it should reveal similar relationships as those revealed using expected (multi-relational) float entropy minimisation. However, unlike expected (multi-relational) float entropy and (
3), Algorithm 1 may place too much emphasis on the most probable states of the system and refinements may be needed. In
Section 4.1 we noted the theory suggests consciousness is less likely to be found in brain regions that process highly compressed information. We noted functional changes affecting the inherent probability distribution a system defines will also affect the relational content of experience according to the theory. The issue of when a probability distribution is inherent to a system was also discussed. In
Section 4.2 we put forward suggestions for how the theory could be tested on the brain using FMRI voxel data. In
Section 4.3 we considered the possibility of there being a connection between bistable optical illusions and the occasional occurrence of there being more than one state satisfying minimum float entropy completion. We also considered the potential of there being unobservable effects of relationship isomorphism if the brain defines several relationally isomorphic versions of consciousness.
The overall conclusion is that expected float entropy minimisation is an effective association learning process but more research is desirable in to expected multi-relational float entropy minimisation. The theory and test results presented in this article are clearly consistent with the proposition of there being a close connection between association learning processes and consciousness. Whilst rather different in content, readers may also find [
19,
20,
21,
22,
23] to be of interest.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








