Patent Keyword Extraction Algorithm Based on Distributed Representation for Patent Classification


Abstract
:
1. Introduction
- (1)
- We propose a distributed representation based Patent Keyword Extraction Algorithm (PKEA), which could effectively extract keywords from patent text for patent classification.
- (2)
- We develop a method to extract representative keywords from patents, which are then used as the features of the patent text for high performance classification by Support Vector Machine (SVM) classifiers.
- (3)
- We design an evaluation method to measure the importance of each extracted keyword using information gain, which provides an indirect way to evaluate the effectiveness of extracting meaningful keywords when human-annotated keywords are not available.
- (4)
- We compared our PKEA algorithm with Frequency, Term Frequency-Inverse Document Frequency (TF-IDF), TextRank and Rapid Automatic Keyword Extraction (RAKE). The PKEA outperforms other peer algorithms in terms of achieving higher patent classification accuracies and higher performance in terms of matching extracted keywords with human-annotated ones.
2. Related Work
2.1. Keyword Extraction Methods
2.2. Keyword-Based Patent Analysis
3. Methods
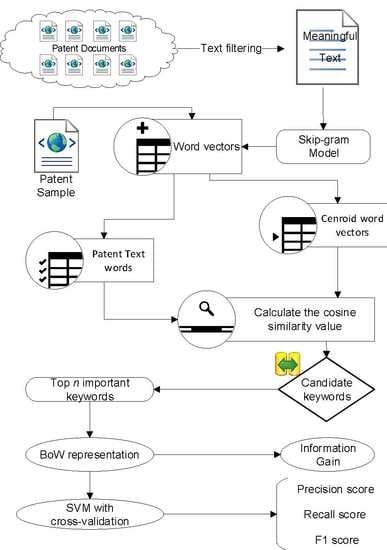
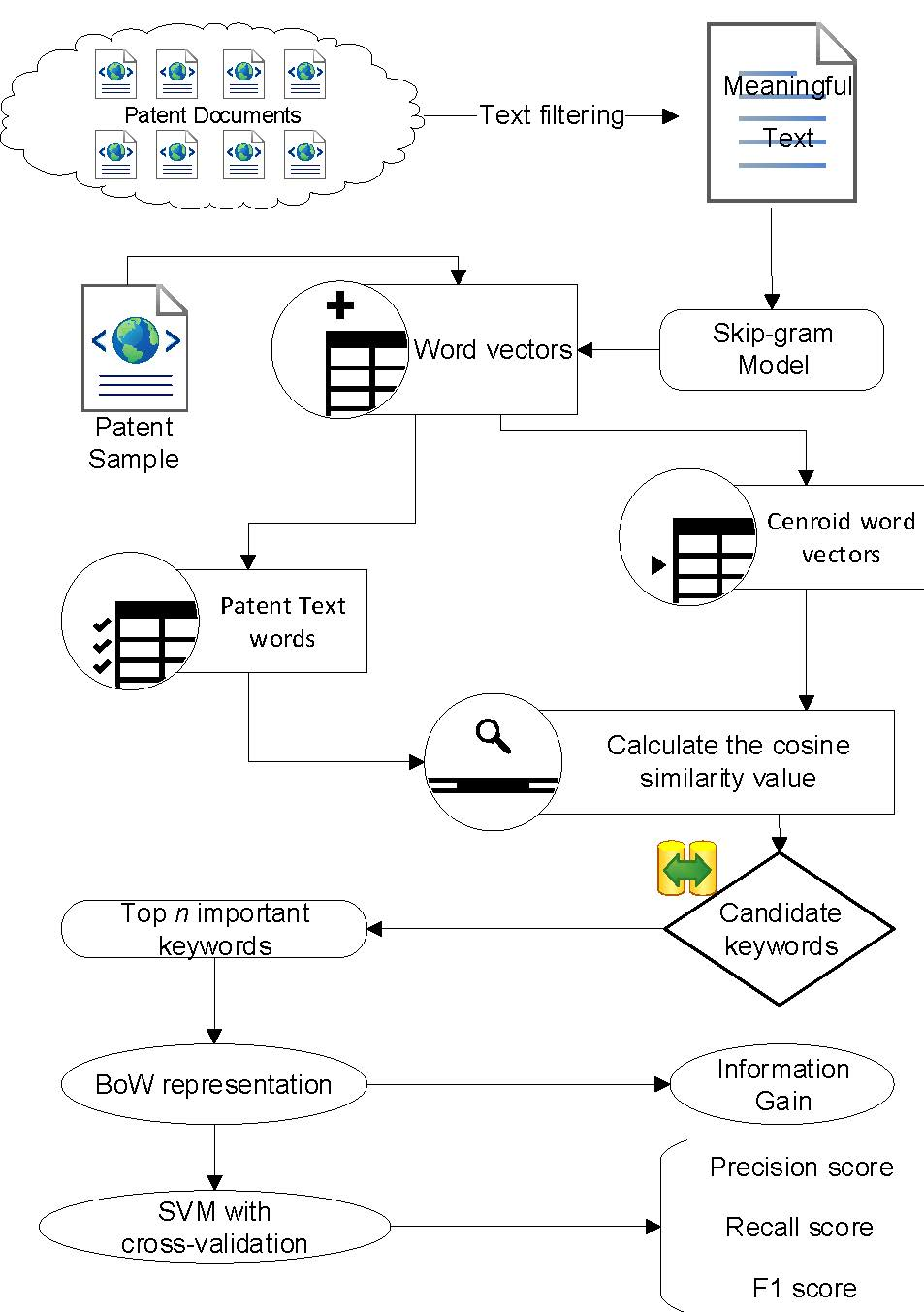
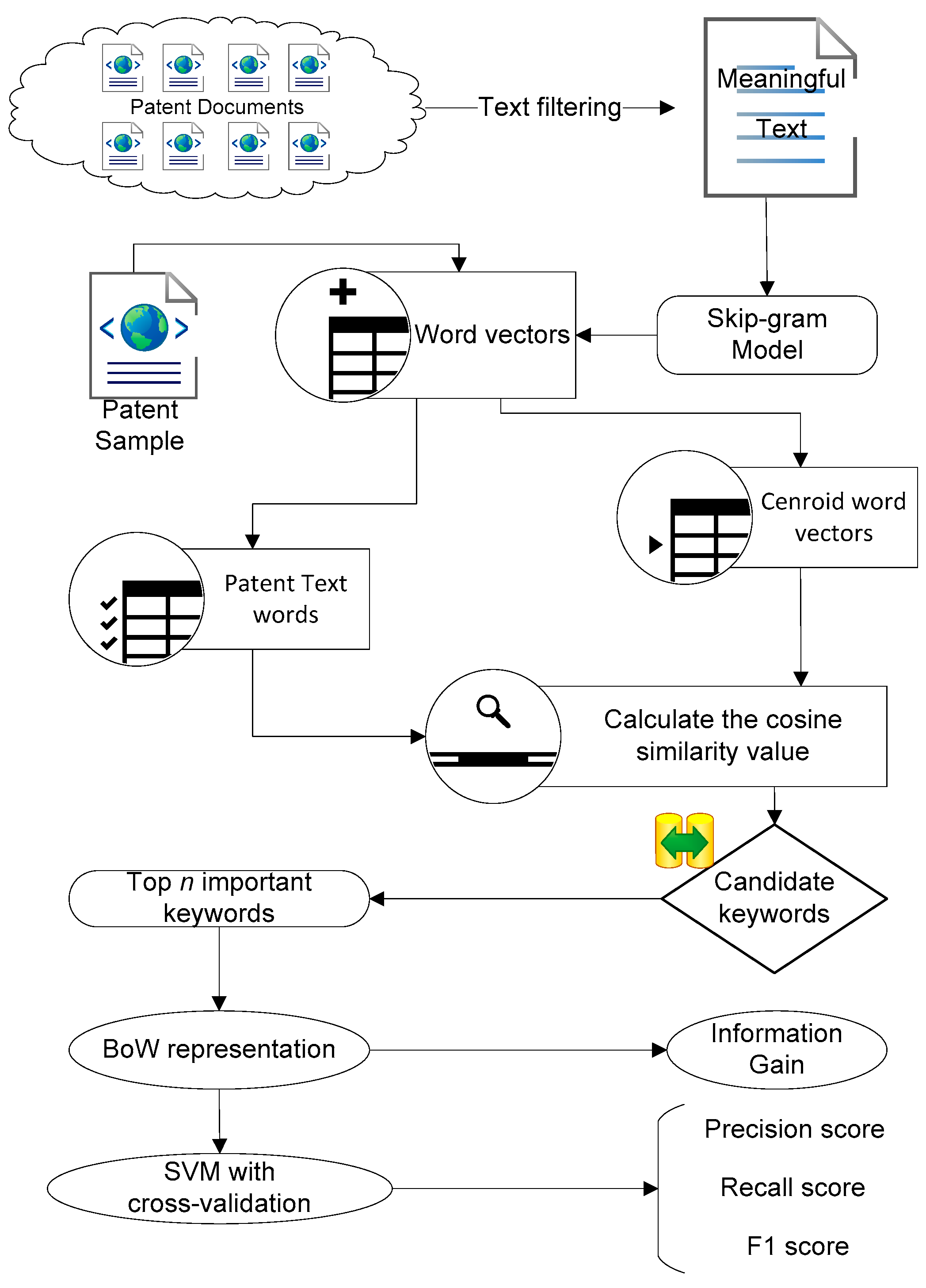
3.1. Overall Research Framework and Proposed Algorithm
| Algorithm 1 Patent Keyword Extraction Algorithm |
| 1: Input: Pre-defined category words list WordsList, Candidate keywords for each category list CanWordsList, Pre-trained word embedding Word2VevTable, Number of keywords n 2: Output: Ranked Keyword List KeywordsList 3: for i = 0 to length(WordsList) do 4: WordVectorsList = Word2VevTable[WordsList[i]] 5: CentroidVector = k-means(WordVectorsList) 6: for k = 0 to length(CanWordsList[i]) do 7: CurrentWordsList = CanWordsList[i, k] 8: CurrentWordVectorsList = Word2VevTable[CurrentWordsList] 9: SimilarityValuesList = CosineSimilarity(CentroidVector, CurrentWordVectors) 10: KeywordsDict = Zip(CurrentWordsList, SimilarityValuesList) 11: RankedKeywordsDict = SortByValue(KeywordsDict) 12: CurrentKeywordsList = RankedKeywordsDict[:n] 13: Append(CurrentCategoryKeywordsList, CurrentKeywordsList) 14: end for 15: Append(KeywordsList[i], CurrentCategoryKeywordsList) 16: end for 17: Output(KeywordsList) |
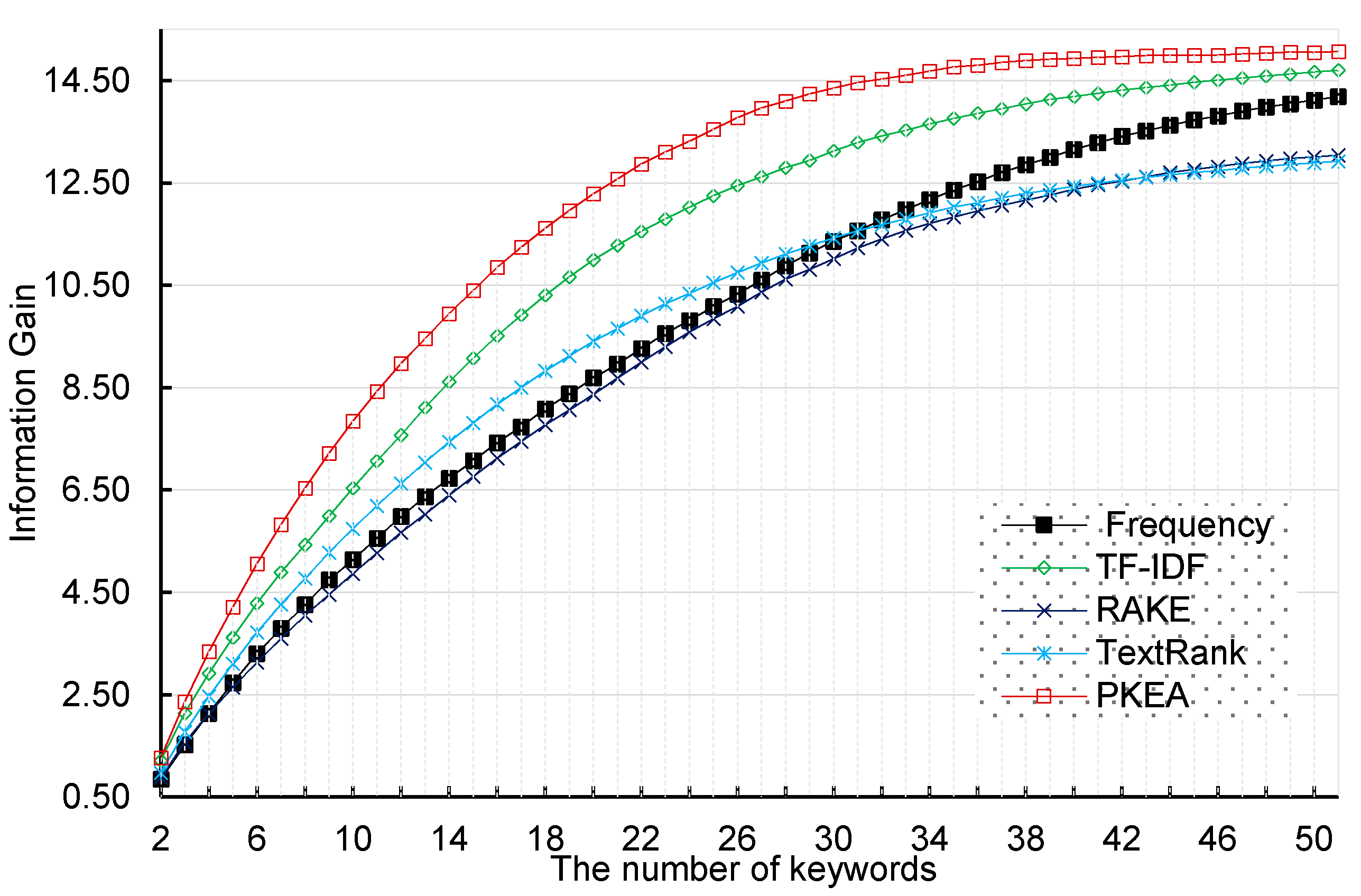
3.2. Information Gain Based Criterion
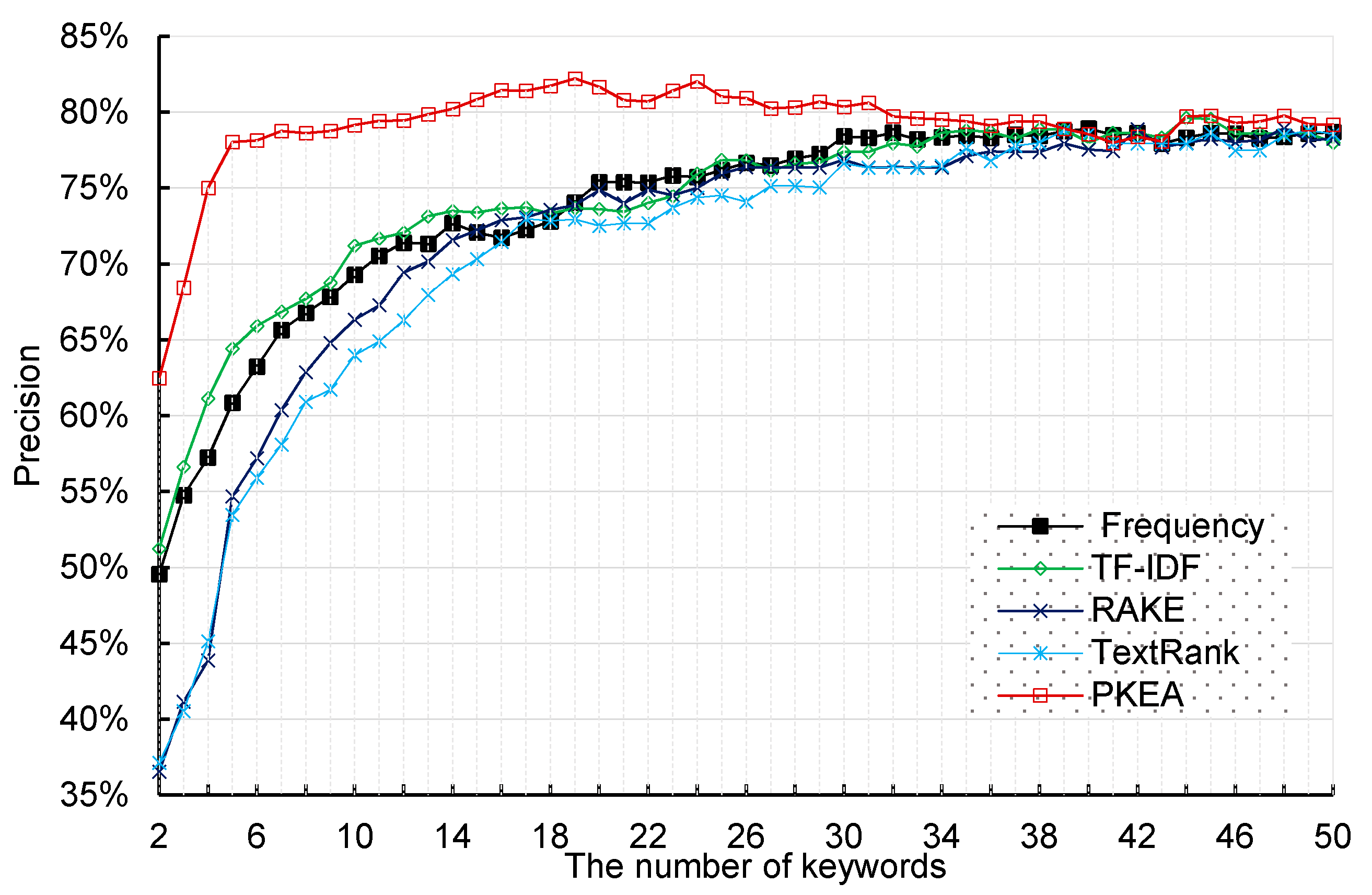
3.3. SVM Classification-Based Criterion
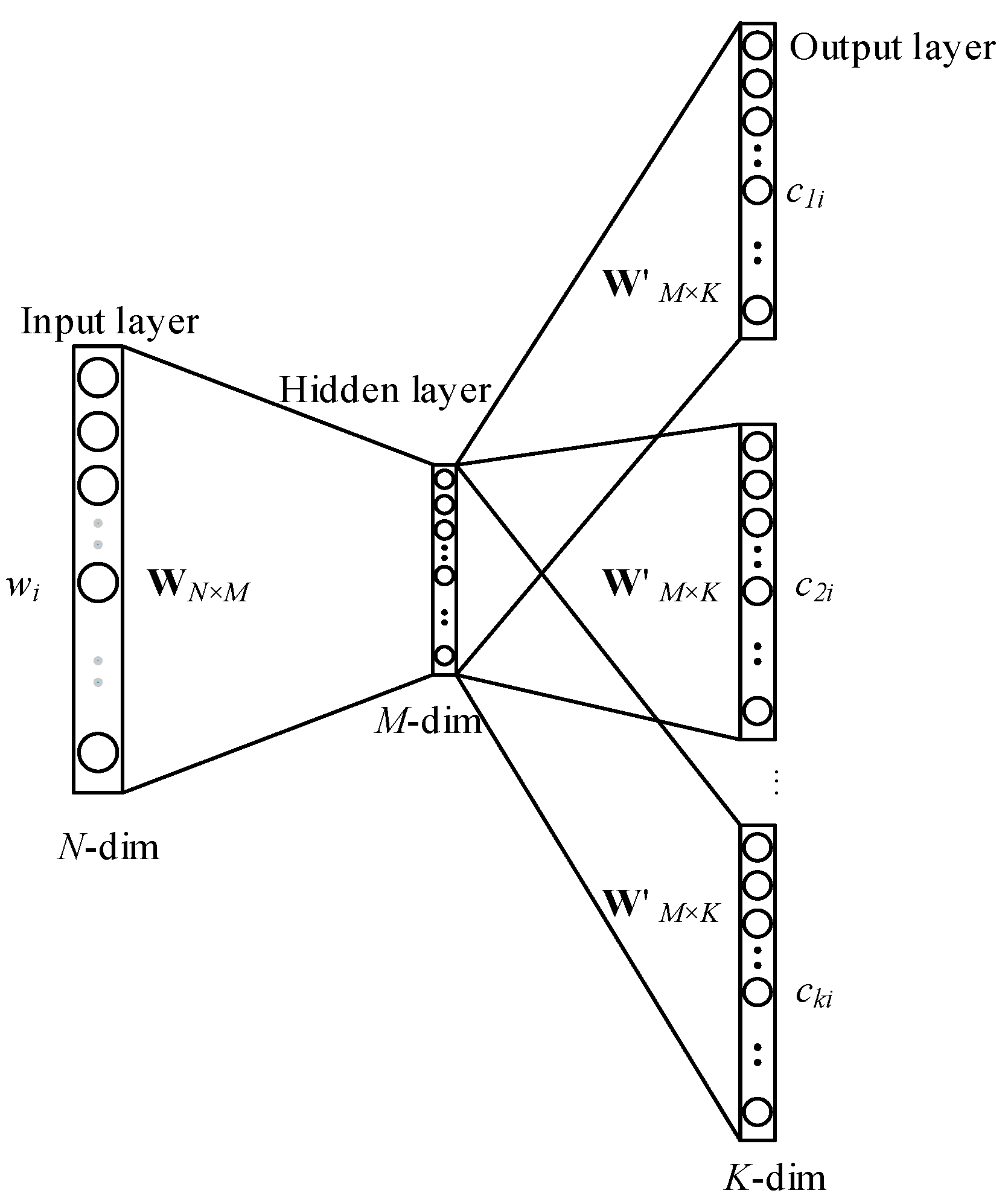
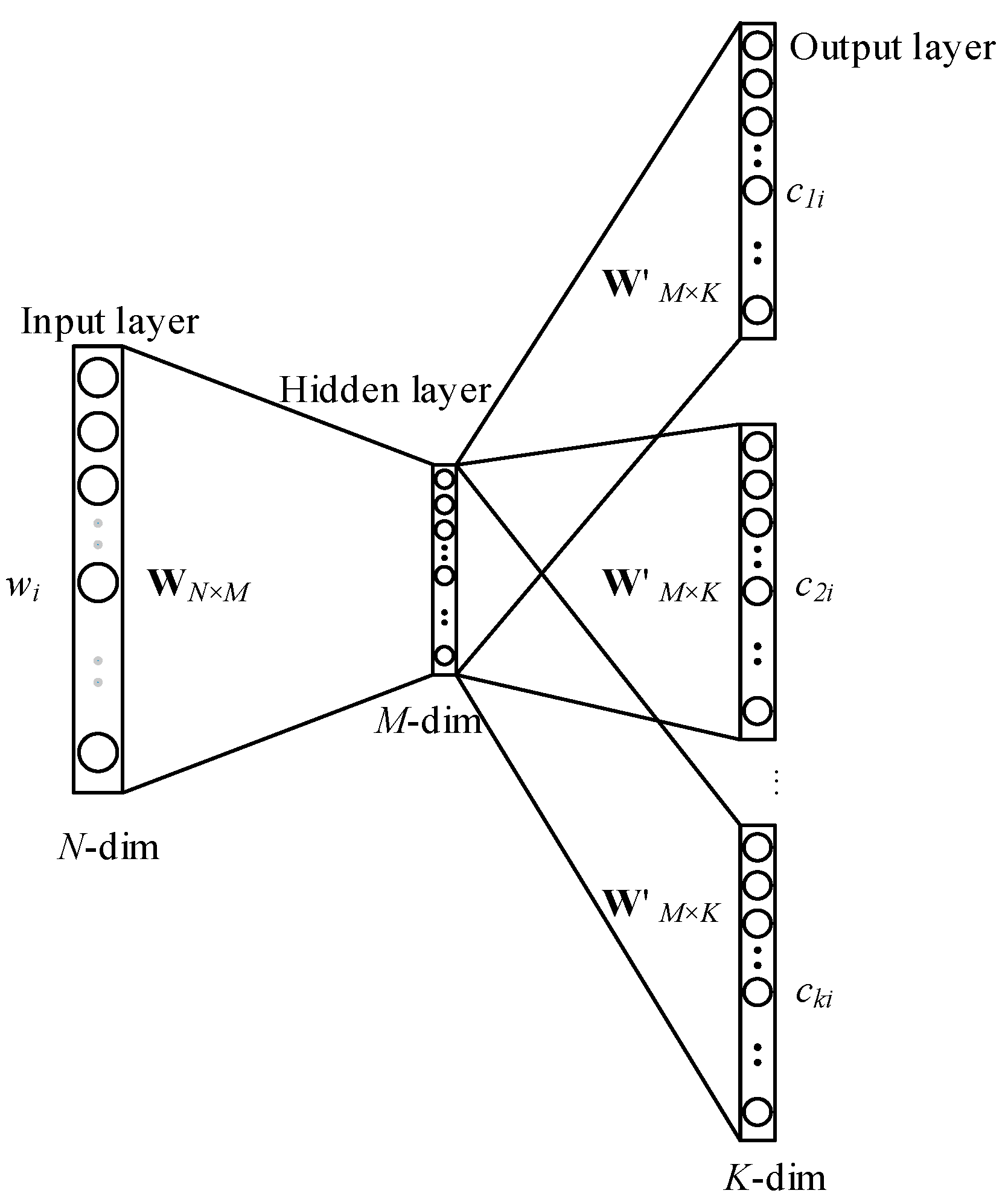
3.4. Skip-Gram Model for Patent Text Representation
3.5. Using k-Means to Find Centroid Words
3.6. Finding Keywords by Calculating the Similarity
4. Comparison Experiments Results and Analysis
4.1. Test Datasets
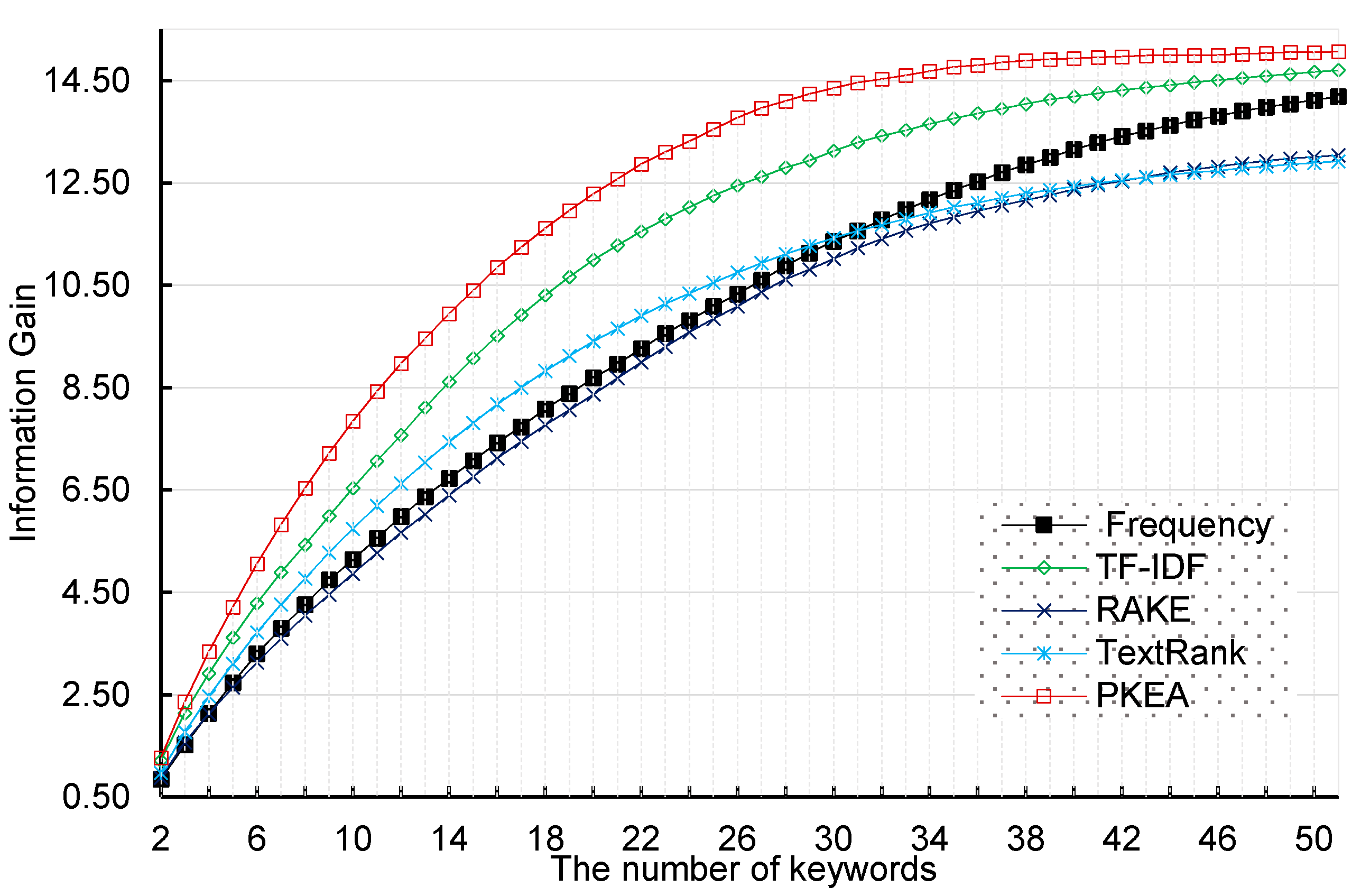
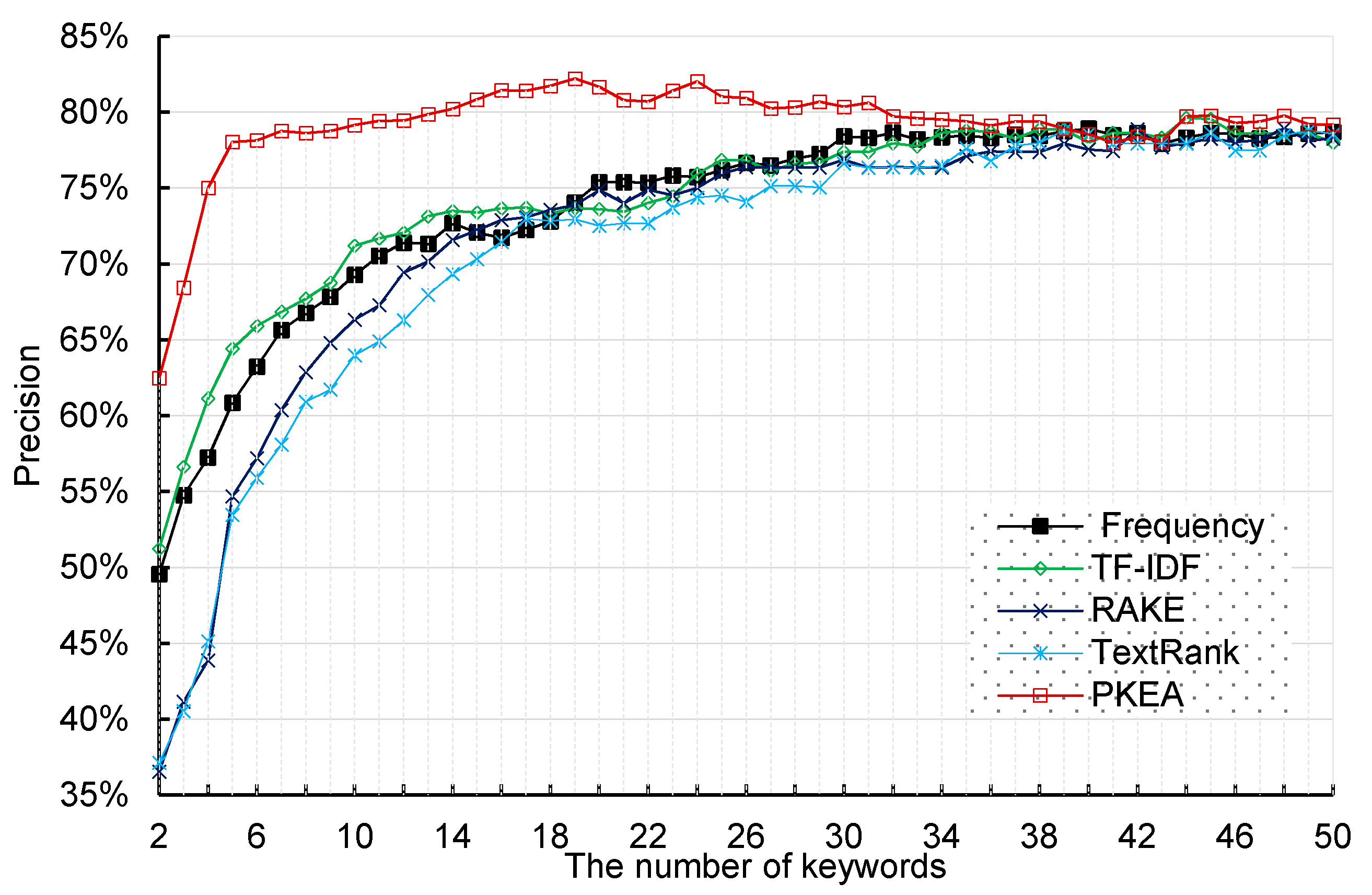
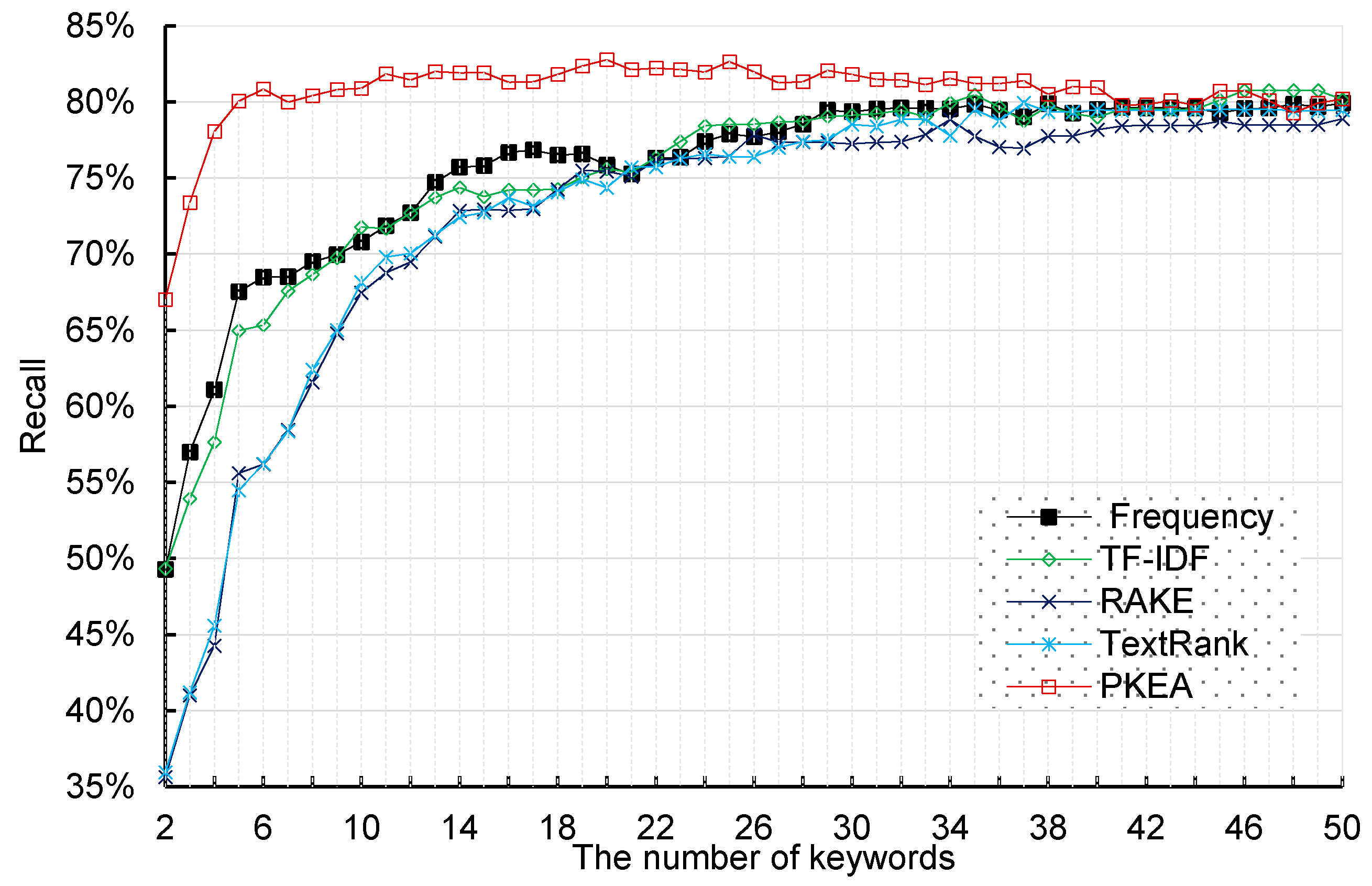
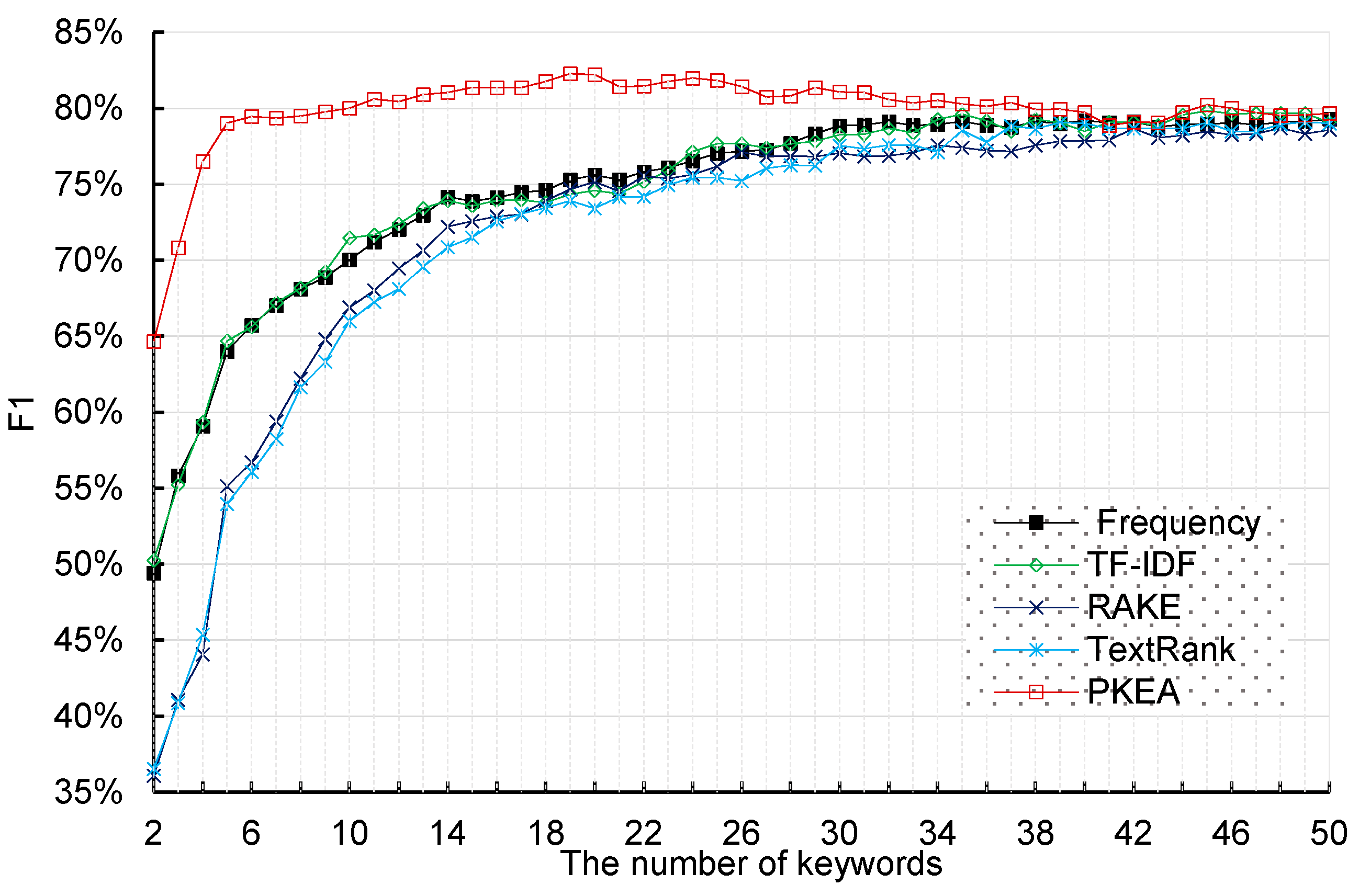
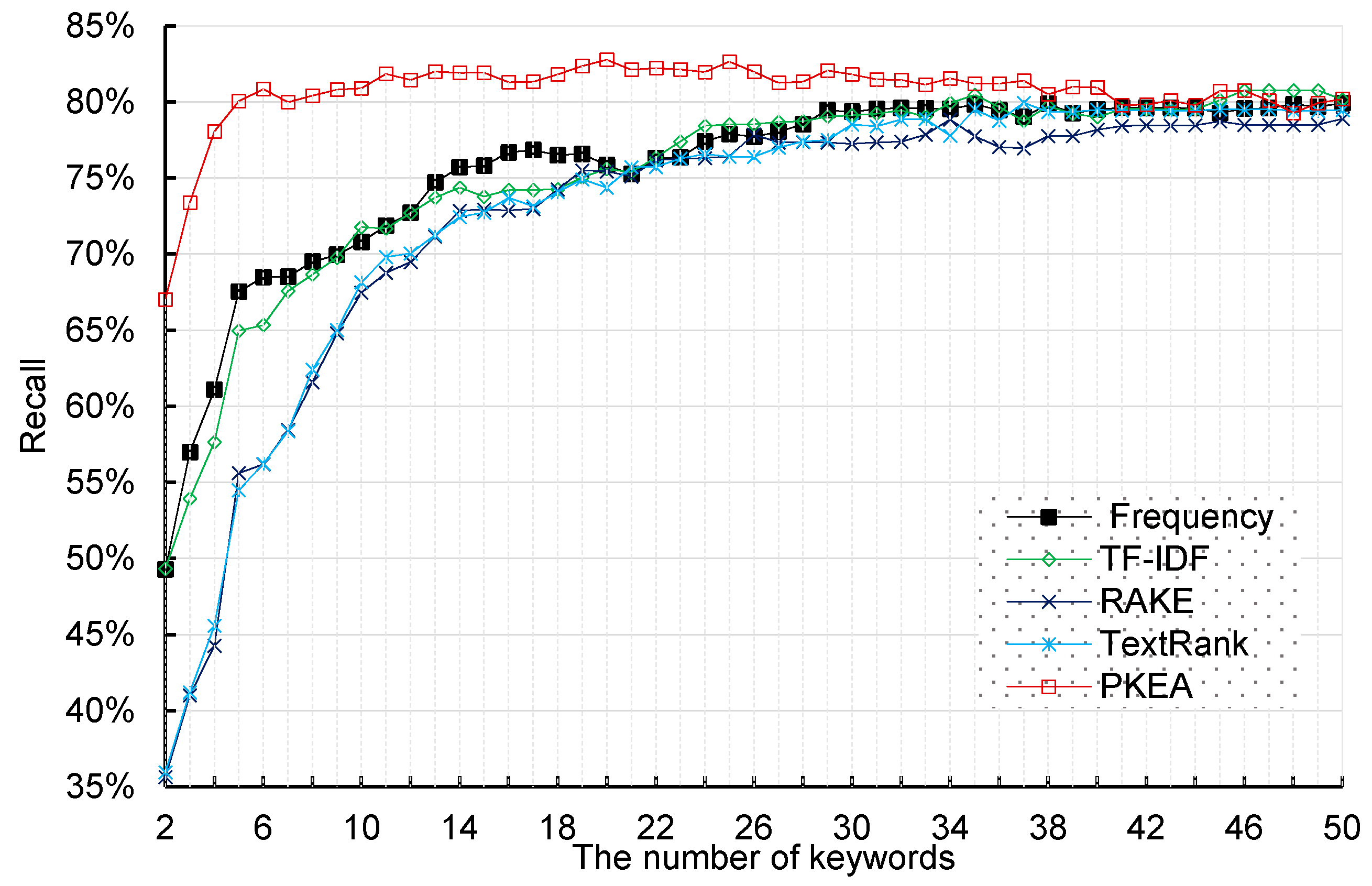
4.2. Comparison Results and Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gerken, J.M.; Moehrle, M.G. A New Instrument for Technology Monitoring: Novelty in Patents Measured by Semantic Patent Analysis; Springer-Verlag, Inc.: New York, NY, USA, 2012; pp. 645–670. [Google Scholar]
- Park, Y.; Yoon, J.; Phillips, F. Application technology opportunity discovery from technology portfolios: Use of patent classification and collaborative filtering. Technol. Forecast. Soc. Chang. 2017, 118, 170–183. [Google Scholar] [CrossRef]
- Joung, J.; Kim, K. Monitoring emerging technologies for technology planning using technical keyword based analysis from patent data. Technol. Forecast. Soc. Chang. 2017, 114, 281–292. [Google Scholar] [CrossRef]
- Altuntas, S.; Dereli, T.; Kusiak, A. Forecasting technology success based on patent data. Technol. Forecast. Soc. Chang. 2015, 96, 202–214. [Google Scholar] [CrossRef]
- Wu, C.C. Constructing a weighted keyword-based patent network approach to identify technological trends and evolution in a field of green energy: A case of biofuels. Qual. Quant. 2016, 50, 213–235. [Google Scholar] [CrossRef]
- Wu, J.-L.; Chang, P.-C.; Tsao, C.-C.; Fan, C.-Y. A patent quality analysis and classification system using self-organizing maps with support vector machine. Appl. Soft Comput. 2016, 41, 305–316. [Google Scholar] [CrossRef]
- Trappey, A.J.; Trappey, C.V.; Wu, C.-Y.; Lin, C.-W. A patent quality analysis for innovative technology and product development. Adv. Eng. Inform. 2012, 26, 26–34. [Google Scholar] [CrossRef]
- Park, H.; Yoon, J.; Kim, K. Identification and evaluation of corporations for merger and acquisition strategies using patent information and text mining. Scientometrics 2013, 97, 883–909. [Google Scholar] [CrossRef]
- Madani, F.; Weber, C. The evolution of patent mining: Applying bibliometrics analysis and keyword network analysis. World Pat. Inf. 2016, 46, 32–48. [Google Scholar] [CrossRef]
- Li, Y.R.; Wang, L.H.; Hong, C.F. Extracting the significant-rare keywords for patent analysis. Expert Syst. Appl. 2009, 36, 5200–5204. [Google Scholar] [CrossRef]
- Kim, Y.G.; Suh, J.H.; Park, S.C. Visualization of patent analysis for emerging technology. Expert Syst. Appl. 2008, 34, 1804–1812. [Google Scholar] [CrossRef]
- Yoon, J.; Kim, K. Detecting signals of new technological opportunities using semantic patent analysis and outlier detection. Scientometrics 2012, 90, 445–461. [Google Scholar] [CrossRef]
- Xie, Z.; Miyazaki, K. Evaluating the effectiveness of keyword search strategy for patent identification. World Pat. Inf. 2013, 35, 20–30. [Google Scholar] [CrossRef]
- Zhang, C. Automatic Keyword Extraction from Documents Using Conditional Random Fields. J. Comput. Inf. Syst. 2008, 4, 1169–1180. [Google Scholar]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic Keyword Extraction from Individual Documents; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2010; pp. 1–20. [Google Scholar]
- Onan, A.; Korukoğlu, S.; Bulut, H. Ensemble of keyword extraction methods and classifiers in text classification. Expert Syst. Appl. 2016, 57, 232–247. [Google Scholar] [CrossRef]
- Medelyan, O.; Medelyan, O.; Kan, M.Y.; Baldwin, T. SemEval-2010 task 5: Automatic keyphrase extraction from scientific articles. In Proceedings of the International Workshop on Semantic Evaluation, Los Angeles, CA, USA, 15–16 July 2010; pp. 21–26. [Google Scholar]
- Wang, R.; Liu, W.; Mcdonald, C. Using Word Embeddings to Enhance Keyword Identification for Scientific Publications. In Proceedings of the Australasian Database Conference, Melbourne, VIC, Australia, 4–7 June 2015; pp. 257–268. [Google Scholar]
- Chen, Y.; Yin, J.; Zhu, W.; Qiu, S. Novel Word Features for Keyword Extraction; Springer International Publishing: Cham, Switzerland, 2015; pp. 148–160. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781v3. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Chen, T.; Xu, R.; He, Y.; Wang, X. A Gloss Composition and Context Clustering Based Distributed Word Sense Representation Model. Entropy 2015, 17, 6007–6024. [Google Scholar] [CrossRef]
- Ardiansyah, S.; Majid, M.A.; Zain, J.M. Knowledge of extraction from trained neural network by using decision tree. In Proceedings of the International Conference on Science in Information Technology, Balikpapan, Indonesia, 26–27 October 2016; pp. 220–225. [Google Scholar]
- Witten, I.H.; Paynter, G.W.; Frank, E.; Gutwin, C.; Nevill-Manning, C.G. KEA: Practical automatic keyphrase extraction. In Proceedings of the ACM Conference on Digital Libraries, Berkeley, CA, USA, 11–14 August 1999; pp. 254–255. [Google Scholar]
- Kanis, J. Digging Language Model—Maximum Entropy Phrase Extraction. In Proceedings of the International Conference on Text, Speech, and Dialogue, Brno, Czech Republic, 12–16 September 2016; pp. 46–53. [Google Scholar]
- Zhou, C.; Li, S. Research of Information Extraction Algorithm based on Hidden Markov Model. In Proceedings of the International Conference on Information Science and Engineering, Hangzhou, China, 4–6 December 2010; pp. 1–4. [Google Scholar]
- Li, J.; Fan, Q.; Zhang, K. Keyword Extraction Based on tf/idf for Chinese News Document. Wuhan Univ. J. Nat. Sci. 2007, 12, 917–921. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Texts. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Nielsen, A. Identifying predators of Halyomorpha halys using molecular gut content analysis. J. Inf. 2015, 40, 38–49. [Google Scholar]
- Rose, S.J.; Cowley, W.E.; Crow, V.L.; Cramer, N.O. Rapid Automatic Keyword Extraction for Information Retrieval and Analysis. U.S. Patent 8131735 B2, 6 March 2012. [Google Scholar]
- Wartena, C.; Brussee, R.; Slakhorst, W. Keyword Extraction Using Word Co-occurrence. In Proceedings of the Workshops on Database and Expert Systems Applications, Bilbao, Spain, 30 August–3 September 2010; pp. 54–58. [Google Scholar]
- Wartena, C.; Brussee, R. Topic Detection by Clustering Keywords. In Proceedings of the International Workshop on Database and Expert Systems Application, Turin, Italy, 1–5 September 2008; pp. 54–58. [Google Scholar]
- Yoon, B.; Phaal, R.; Probert, D. Morphology analysis for technology roadmapping: Application of text mining. R&D Manag. 2008, 38, 51–68. [Google Scholar]
- Lee, S.; Lee, H.-J.; Yoon, B. Modeling and analyzing technology innovation in the energy sector: Patent-based HMM approach. Comput. Ind. Eng. 2012, 63, 564–577. [Google Scholar] [CrossRef]
- Tseng, Y.H.; Lin, C.J.; Lin, Y.I. Text mining techniques for patent analysis. Inf. Process. Manag. 2007, 43, 1216–1247. [Google Scholar] [CrossRef]
- Wang, M.Y.; Chang, D.S.; Kao, C.H. Identifying technology trends for R&D planning using TRIZ and text mining. R&D Manag. 2010, 40, 491–509. [Google Scholar]
- Noh, H.; Jo, Y.; Lee, S. Keyword selection and processing strategy for applying text mining to patent analysis. Expert Syst. Appl. 2015, 42, 4348–4360. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processin (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Methods | Advantages | Drawbacks | Application Scenarios |
|---|---|---|---|---|
| Supervised | Machine learning approaches (Decision Tree [23], Naïve Bayes [24], SVM [19], Maximum Entropy [25], HMM [26], CRF [14]) | High readability, great flexibility to include a wide variety of arbitrary, non-independent features of the input. Can find several new terms which have not appeared in the training | Need labeled corpus | News, scientific articles, etc. Wildly applied. |
| Unsupervised | TF-IDF [27] | Without the need for a labeled corpus. Easy to implement, widely applied | Cannot extract semantically meaningful words. The keywords are not comprehensive. Not accurate enough. | News, scientific articles, etc. Wildly applied. |
| TextRank [28] | Without the need for a labeled corpus. Has a strong ability to apply to other topic texts. | Ignored semantic relevance of keywords. The effect of low frequency keyword extraction is poor. High computational complexity. | Used in small-scale text keyword extraction task. | |
| LDA [29] | Without the need for a labeled corpus. Can obtain semantic keywords and solve the problem of polysemous. Easy to apply to various languages. | Prefer to extract general keywords which cannot represent the topic of corresponding text well. | Various languages. | |
| RAKE [30] | Without the need for a corpus. Very fast and the complexity is low. Easy to implement. | Cannot extract semantically meaningful words. Not accurate enough. | Extracting key-phrases from texts. | |
| PKEA (Our approach) | Can both extract semantic and discriminative keywords. Without the need for a corpus. Low computational complexity. High performance on extracting discriminative keywords. Easy to implement and apply to other type texts. | Need pre-defined category corpus. | Specially designed for extracting keyword from patent texts. Easy to extend to other scientific articles. |
| Dataset | Number of Documents | Number of Categories | Number of Key Phrases | ||
|---|---|---|---|---|---|
| Author | Reader | Combined | |||
| Training | 144 | 4 | 559 | 1824 | 2223 |
| Test | 100 | 4 | 387 | 1217 | 1482 |
| Patent Categories | GPS System | Object Recognition | Vehicle Control System | Radar System | Lidar System |
|---|---|---|---|---|---|
| Keywords | GPS | Camera | Automobile | Radar | Lidar |
| Satellite | Environment | Controller | Trajectory | Laser | |
| Altitude | Image | Communication | Operation | Detection | |
| Position | ORC | Assistance | Present-azimuth | Three-axis | |
| Synchronization | GUI | Speed | Prior-azimuth | Microwave | |
| Wavelength | Visibility | Guidance | Radiation | Receiver | |
| Telecommunication | Autonomous | Acceleration | Path | Luminescence | |
| Geo-mobile | Surrounding | Acquisition | Plurality | Reflection | |
| GPS-enabled | Video | Remote | Reference-location | Speedometer | |
| MS (communication device) | Multi-target | Roadway | Radar-sensor | Collision |
| Patent Documents | Keywords | Categories | |||
|---|---|---|---|---|---|
| GPS | Image | Camera | Vehicle | ||
| Patent 1 | 1 | 0 | 0 | 1 | A |
| Patent 2 | 0 | 1 | 1 | 0 | B |
| Patent 3 | 0 | 0 | 1 | 1 | B |
| Patent 4 | 0 | 0 | 1 | 1 | A |
| Patent 5 | 1 | 1 | 0 | 1 | A |
| Paired F1-Score Statistics | |||||
|---|---|---|---|---|---|
| Mean | N | Std. Deviation | Std. Error Mean | ||
| Pair 1 | PKEA | 0.8199 | 10 | 0.03040 | 0.00961 |
| Frequency | 0.7897 | 10 | 0.02141 | 0.00677 | |
| Pair 2 | PKEA | 0.8199 | 10 | 0.03040 | 0.00961 |
| TFIDF | 0.7972 | 10 | 0.03500 | 0.01107 | |
| Pair 3 | PKEA | 0.8199 | 10 | 0.03040 | 0.00961 |
| RAKE | 0.7851 | 10 | 0.03826 | 0.01210 | |
| Pair 4 | PKEA | 0.8199 | 10 | 0.03040 | 0.00961 |
| TextRank | 0.7905 | 10 | 0.04965 | 0.01570 | |
| Paired F1-Score Test | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Paired Differences | t | df | Sig. (2-Tailed) | ||||||
| Mean | Std. Deviation | Std. Error Mean | 95% Confidence Interval of the Difference | ||||||
| Lower | Upper | ||||||||
| Pair 1 | PKEA-Frequency | 0.03015 | 0.01052 | 0.00333 | 0.02263 | 0.03768 | 9.065 | 9 | 0.000 |
| Pair 2 | PKEA-TFIDF | 0.02271 | 0.00878 | 0.00278 | 0.01642 | 0.02899 | 8.175 | 9 | 0.000 |
| Pair 3 | PKEA-RAKE | 0.03482 | 0.01177 | 0.00372 | 0.02640 | 0.04325 | 9.354 | 9 | 0.000 |
| Pair 4 | PKEA-TextRank | 0.02937 | 0.02150 | 0.00680 | 0.01399 | 0.04475 | 4.319 | 9 | 0.002 |
| Methods | Assigned by | Top 5 Candidates | Top 10 Candidates | Top 15 Candidates | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precsion | Recall | F1 | Precise | Recall | F1 | ||
| TF × IDF [17] | R | 17.8% | 7.4% | 10.4% | 13.9% | 11.5% | 12.6% | 11.6% | 14.5% | 12.9% |
| C | 22.0% | 7.5% | 11.2% | 17.7% | 12.1% | 14.4% | 14.9% | 15.3% | 15.1% | |
| NB [17] | R | 16.8% | 7.0% | 9.9% | 13.3% | 11.1% | 12.1% | 11.4% | 14.2% | 12.7% |
| C | 21.4% | 7.3% | 10.9% | 17.3% | 11.8% | 14.0% | 14.5% | 14.9% | 14.7% | |
| ME [17] | R | 16.8% | 7.0% | 9.9% | 13.3% | 11.1% | 12.1% | 11.4% | 14.2% | 12.7% |
| C | 21.4% | 7.3% | 10.9% | 17.3% | 11.8% | 14.0% | 14.5% | 14.9% | 14.7% | |
| PKEA | R | 20.0% | 8.5% | 11.9% | 15.8% | 12.7% | 14.1% | 13.2% | 15.8% | 14.4% |
| C | 24.6% | 8.6% | 12.8% | 19.4% | 12.9% | 15.5% | 16.1% | 15.6% | 15.9% | |
| HUMB [17] | R | 30.4% | 12.6% | 17.8% | 24.8% | 20.6% | 22.5% | 21.2% | 26.4% | 23.5% |
| C | 39.0% | 13.3% | 19.8% | 32.0% | 21.8% | 26.0% | 27.2% | 27.8% | 27.5% | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, J.; Li, S.; Yao, Y.; Yu, L.; Yang, G.; Hu, J. Patent Keyword Extraction Algorithm Based on Distributed Representation for Patent Classification. Entropy 2018, 20, 104. https://doi.org/10.3390/e20020104
Hu J, Li S, Yao Y, Yu L, Yang G, Hu J. Patent Keyword Extraction Algorithm Based on Distributed Representation for Patent Classification. Entropy. 2018; 20(2):104. https://doi.org/10.3390/e20020104
Chicago/Turabian StyleHu, Jie, Shaobo Li, Yong Yao, Liya Yu, Guanci Yang, and Jianjun Hu. 2018. "Patent Keyword Extraction Algorithm Based on Distributed Representation for Patent Classification" Entropy 20, no. 2: 104. https://doi.org/10.3390/e20020104
APA StyleHu, J., Li, S., Yao, Y., Yu, L., Yang, G., & Hu, J. (2018). Patent Keyword Extraction Algorithm Based on Distributed Representation for Patent Classification. Entropy, 20(2), 104. https://doi.org/10.3390/e20020104