Building an Ensemble of Fine-Tuned Naive Bayesian Classifiers for Text Classification

Abstract
1. Introduction
2. Related Work
2.1. Building Ensembles of Classifiers
2.2. Fine-Tuning the NB Algorithm
| Algorithm 1 FTNB (training_instances) |
| phase 1 |
| Use training_instances to estimate the values of each probability term used by the NB algorithm |
| phase 2 |
| while training classification accuracy improves do |
| for each training instance, , do |
| let be the actual class of |
| let |
| if //misclassified instance |
| compute classification error |
| for each attribute value, , of inst do |
| endfor |
| endif |
| endfor |
| let |
| endwhile |
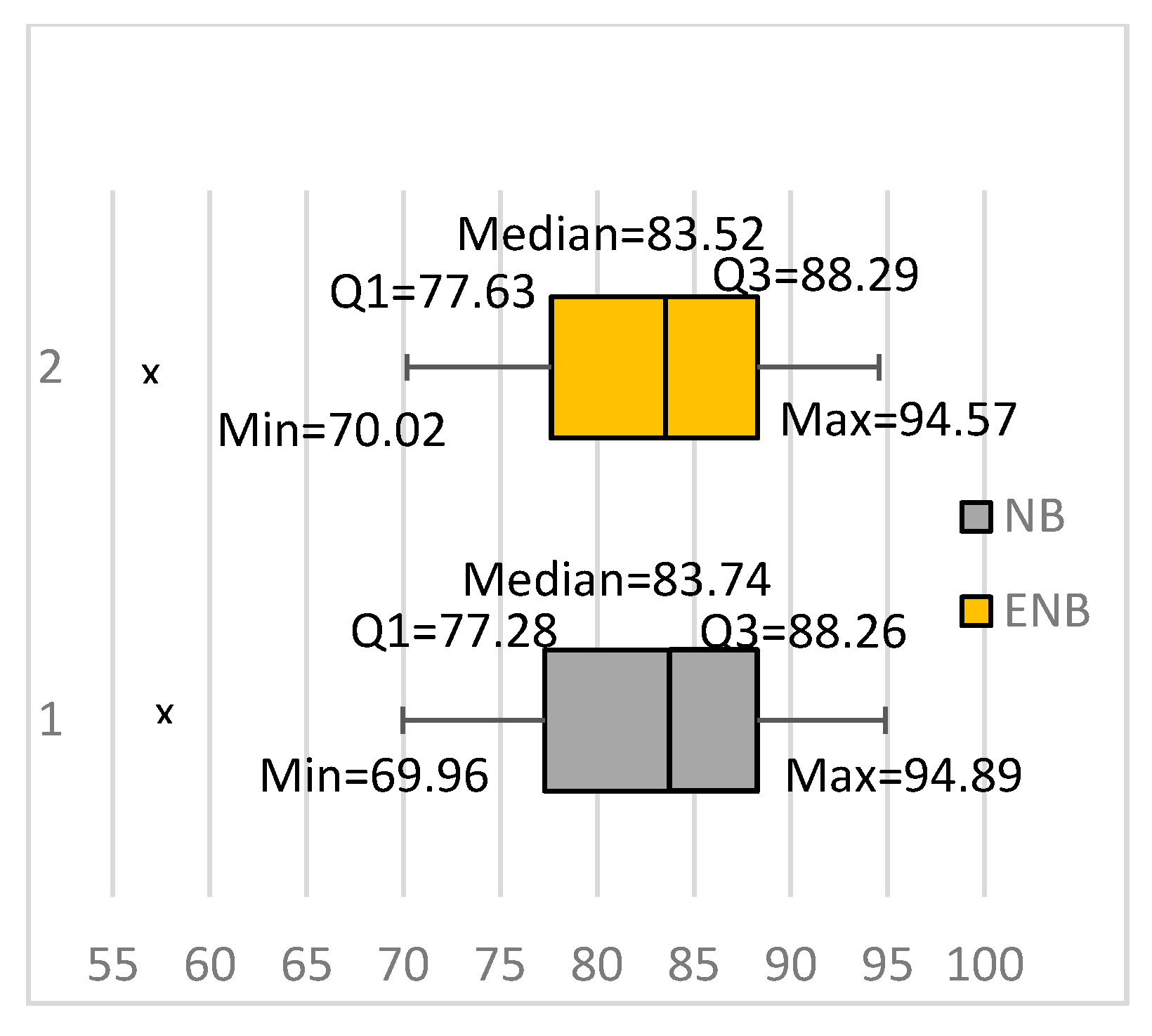
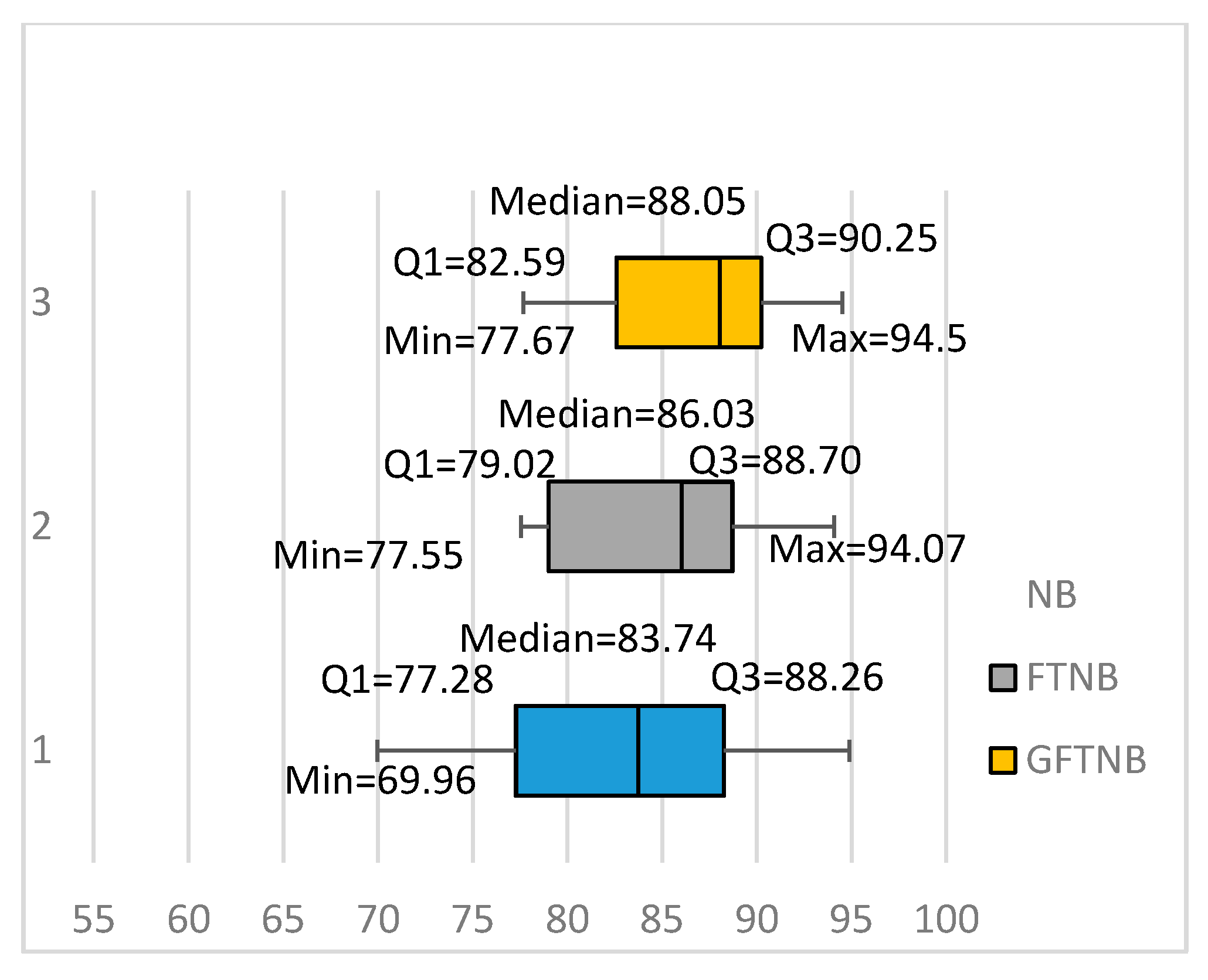
3. Bagging NB and the Fine-Tuning Algorithms
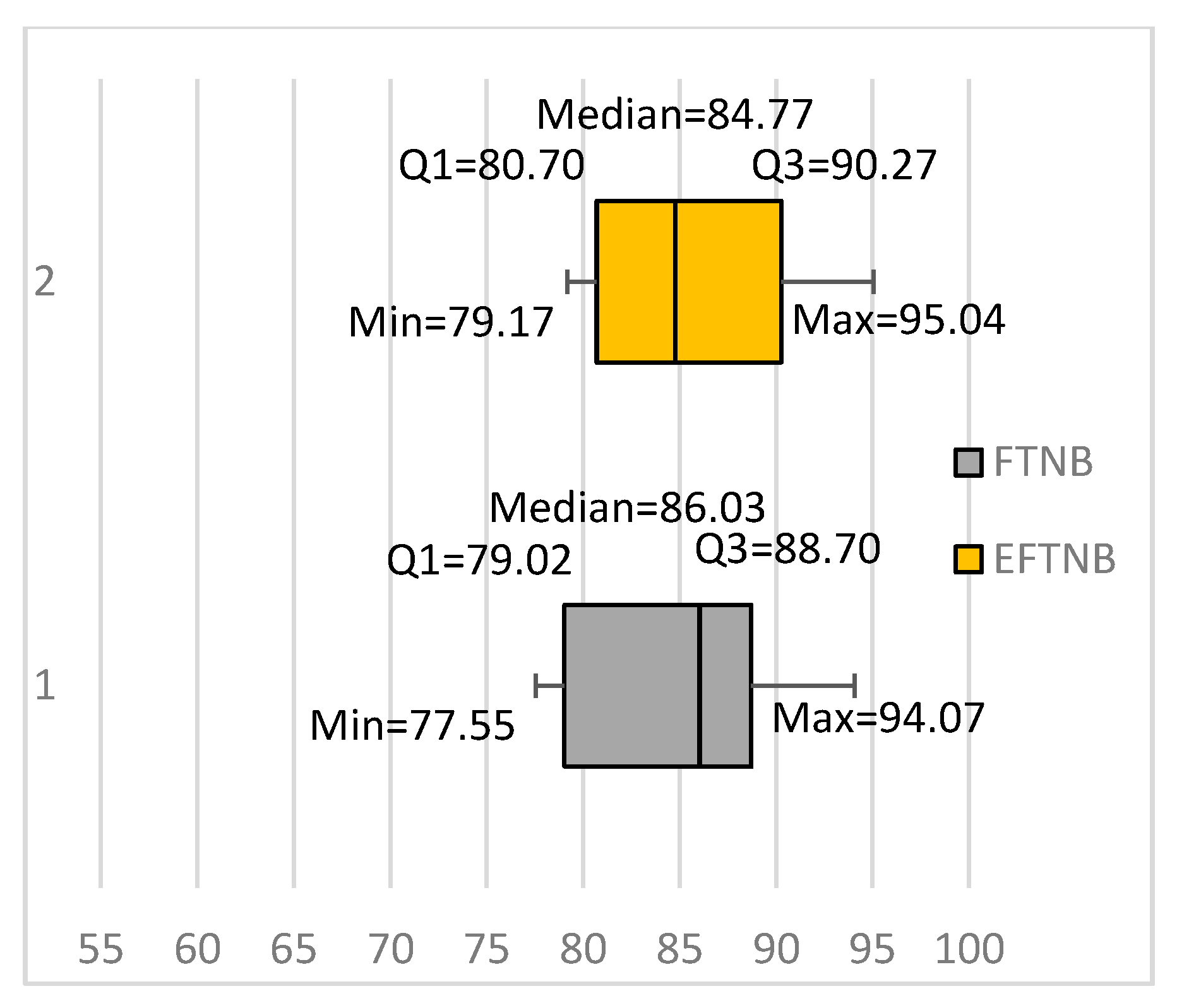
3.1. Bagging the NB and FTNB Algorithms for Text Classification
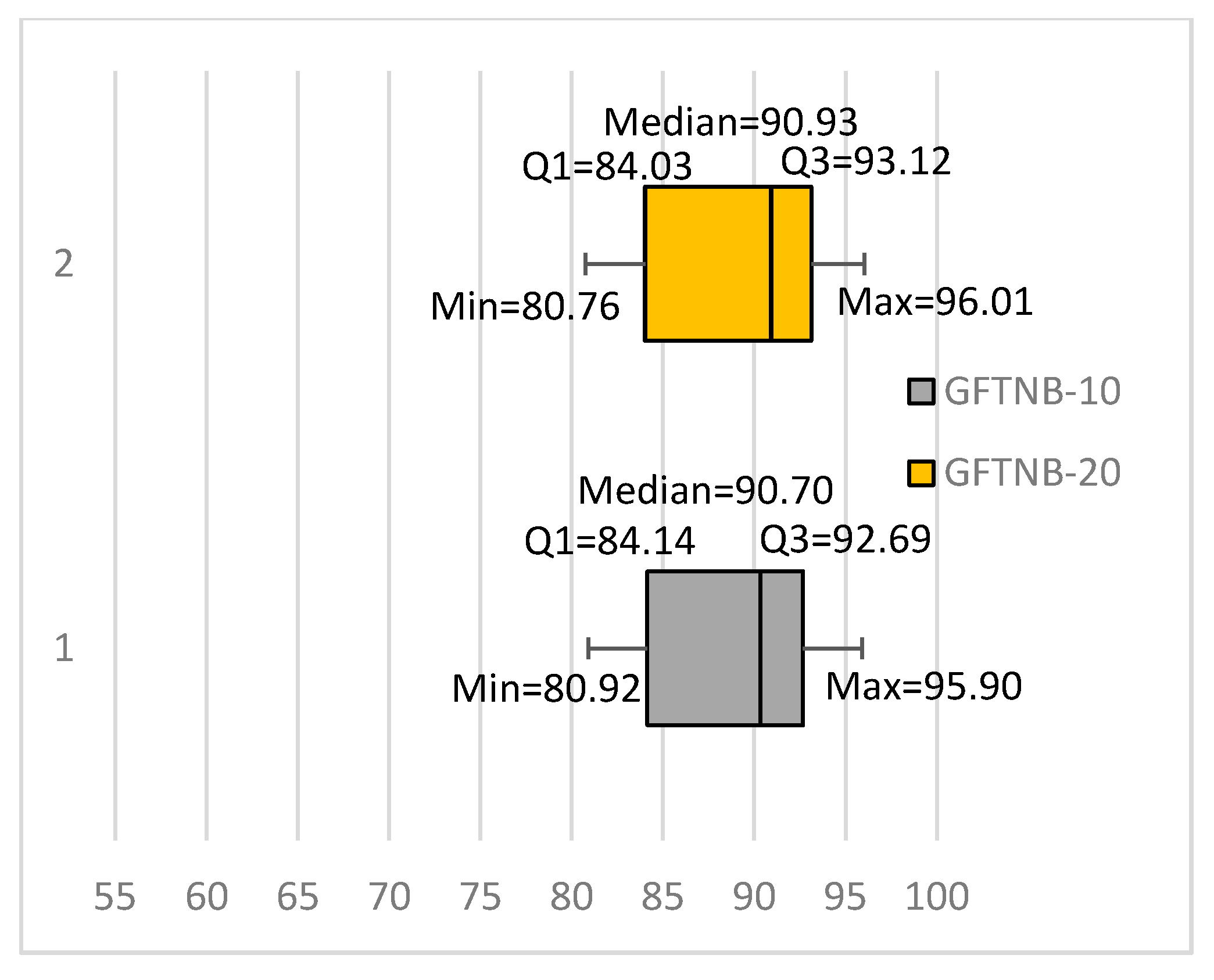
3.2. A More Gradual Fine-Tuning Algorithm (GFTNB)
3.2.1. Modifying the Update Equations
3.2.2. Modifying the Termination Condition
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Androutsopoulos, I.; Koutsias, J.; Chandrinos, K.V.; Spyropoulos, C.D. An Experimental Comparison of Naive Bayesian and Keyword-Based Anti-Spam Filtering with Personal E-mail Messages. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000. [Google Scholar]
- Stephan, S.; Sven, S.; Roman, G.A. Message classification in the call center. In Proceedings of the sixth Conference on Applied Natural Language Processing, Seattle, WA, USA, 29 April–4 May 2000. [Google Scholar]
- Eui-Hong, H.; George, K. Centroid-Based Document Classification: Analysis and Experimental Results. In Principles of Data Mining and Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Eui-Hong, H.; George, K.; Vipin, K. Text Categorization Using Weight Adjusted k-Nearest Neighbor Classification. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Leo, B. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y. Boosting a Weak Learning Algorithm by Majority. Inf. Comput. 1995, 121, 256–285. [Google Scholar] [CrossRef]
- Robert, E.S. A brief introduction to Boosting. In Proceedings of the 16th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 31 July–6 August 1999. [Google Scholar]
- Mitchell, T.M. Machine Learning; McGraw-Hill: Boston, MA, USA, 1997. [Google Scholar]
- Nigam, K.; McCallum, A.; Thrun, S.; Mitchell, T. Learning to classify text from labeled and unlabeled documents. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madisson, WI, USA, 24–26 July 1998. [Google Scholar]
- Jiang, L.X.; Cai, Z.H.; Harry, Z.; Wang, D.H. Naive Bayes text classifiers: A locally weighted learning approach. J. Exp. Theor. Artif. Intell. 2013, 25, 273–286. [Google Scholar] [CrossRef]
- Jiang, L.X.; Wang, D.H.; Cai, Z.H. Discriminatively weighted Naive Bayes and its application in text classification. Int. J. Artif. Intell. Tools 2012, 21, 1250007. [Google Scholar] [CrossRef]
- Kai, M.T.; Zheng, Z.J. A study of AdaBoost with Naive Bayesian classifiers: Weakness and improvement. Comput. Intell. 2003, 19, 186–200. [Google Scholar] [CrossRef]
- Nettleton, D.F.; Orriols-Puig, A.; Fornells, A. A study of the effect of different types of noise on the precision of supervised learning techniques. In Artificial Intelligence Review; Springer Netherlands: Berlin, Germany, 2010; Volume 33, pp. 275–306. [Google Scholar]
- Hindi, E.H. Fine tuning the Naïve Bayesian learning algorithm. AI Commun. 2014, 27, 133–141. [Google Scholar] [CrossRef]
- Hindi, E.H. A noise tolerant fine tuning algorithm for the Naïve Bayesian learning algorithm. J. King Saud Univ. Comput. Inf. Sci. 2014, 26, 237–246. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods Foundations and Algorithms; CRS Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Rokach, L. Pattern Classification Using Ensemble Methods; World Scientific: Dancers, MA, USA, 2010. [Google Scholar]
- Zhang, C.; Ma, Y.Q. Ensemble Machine Learning: Methods and Applications; Springer: Berlin, Germany, 2012. [Google Scholar]
- Seni, G.; Elder, J.F. Ensemble Methods in Data Mining: Improving Accuracy Through Combining Predictions. Synth. Lect. Data Min. Knowl. Discov. 2010, 2, 1–126. [Google Scholar] [CrossRef]
- Dietterich, T.G. Machine learning research: Four current directions. Artif. Intell. Mag. 1997, 18, 97–135. [Google Scholar]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar] [CrossRef]
- Bazell, D.; Aha, D.W. Ensembles of Classifiers for Morphological Galaxy Classification. Astrophys. J. 2001, 548, 219–223. [Google Scholar] [CrossRef]
- Prinzie, A.; Poel, D. Random Multiclass Classification: Generalizing Random Forests to Random MNL and Random NB. Database Expert Syst. Appl. 2007, 4653, 349–358. [Google Scholar] [CrossRef]
- Breiman, L. Random Forrest. Mach. Learn. 2001, 45, 1–33. [Google Scholar] [CrossRef]
- Alhussan, A.; Hindi, K.E. An Ensemble of Fine-Tuned Heterogeneous Bayesian Classifiers. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 439–448. [Google Scholar] [CrossRef]
- Alhussan, A.; Hindi, K.E. Selectively Fine-Tuning Bayesian Network Learning Algorithm. Int. J. Pattern Recognit. Artif. Intell. 2016, 30, 1651005. [Google Scholar] [CrossRef]
- Diab, D.M.; Hindi, K.E. Using differential evolution for fine tuning naïve Bayesian classifiers and its application for text classification. Appl. Soft Comput. J. 2017, 54, 183–199. [Google Scholar] [CrossRef]
- Diab, D.M.; Hindi, K.E. Using differential evolution for improving distance measures of nominal values. Appl. Soft Comput. J. 2018, 64, 14–34. [Google Scholar] [CrossRef]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef]
- Stanfill, C.; Waltz, D. Toward memory-based reasoning. Commun. ACM 1986, 29, 1213–1228. [Google Scholar] [CrossRef]
- Hindi, K.E. Specific-class distance measures for nominal attributes. AI Commun. 2013, 26, 261–279. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Elsevier: Cambridge, MA, USA, 2011. [Google Scholar]
- Fayyad, U.M.; Irani, K.B. Multi-interval discretization of continuous-valued attribute for classification learning. Proc. Int. Jt. Conf. Uncertain. AI. 1993, 1022–1027. Available online: https://trs.jpl.nasa.gov/handle/2014/35171 (accessed on 31 October 2018).
- McCallum, A.; Nigam, K. A Comparison of Event Models for Naive Bayes Text Classification. In Proceedings of the AAAI-98 Workshop on Learning Text Category, Madison, WI, USA, 26–27 July 1998; pp. 41–48. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
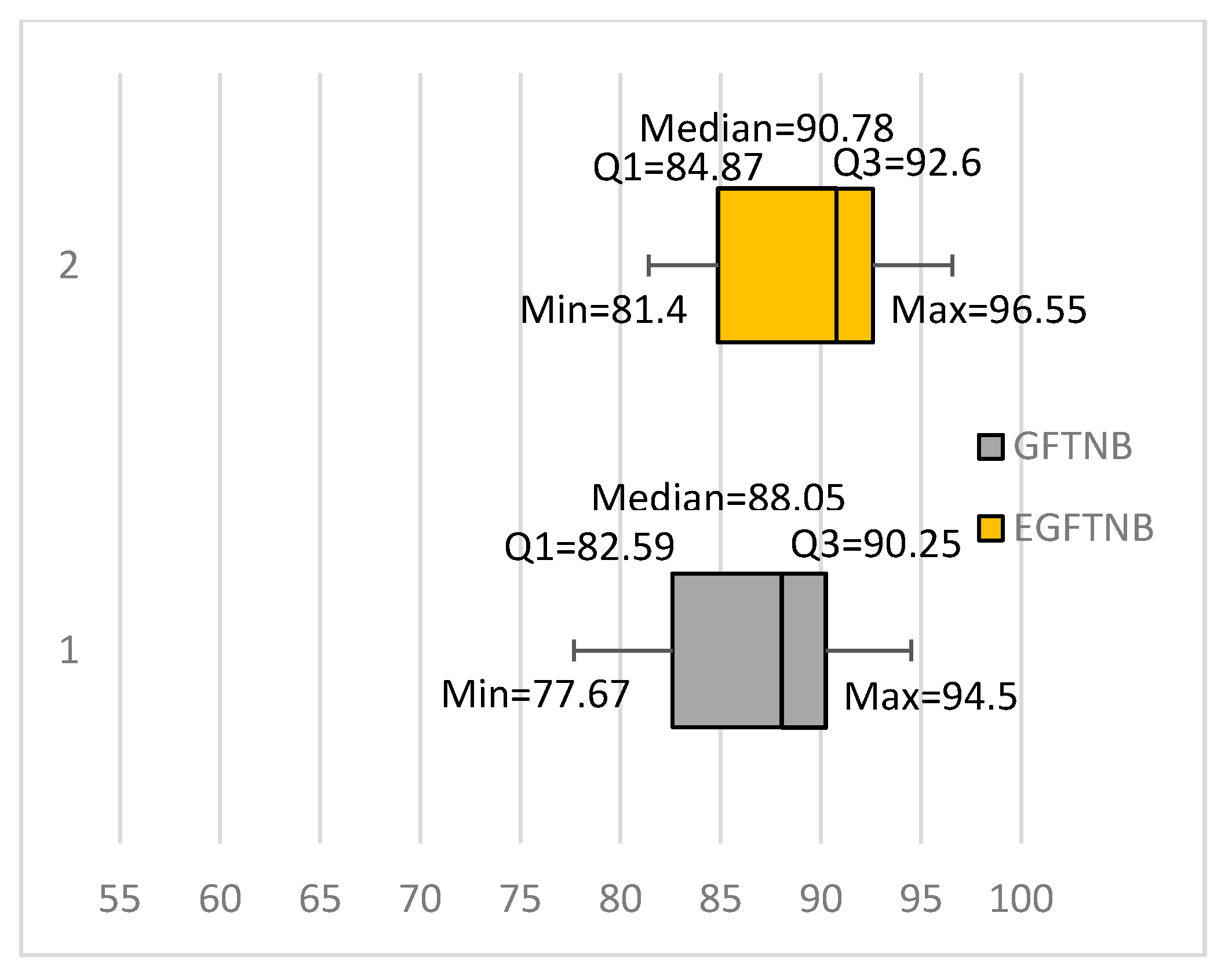{kind=link}
{kind=link}
| Dataset | #Documents | #Words | #Classes |
|---|---|---|---|
| Fbis | 2463 | 2000 | 17 |
| La1s | 3204 | 13,196 | 6 |
| La2s | 3075 | 12,433 | 6 |
| Oh0 | 1003 | 3182 | 10 |
| Oh10 | 1050 | 3238 | 10 |
| Oh15 | 913 | 3100 | 10 |
| Oh5 | 918 | 3012 | 10 |
| Re0 | 1657 | 3758 | 25 |
| Re1 | 1504 | 2886 | 13 |
| Tr11 | 414 | 6429 | 9 |
| Tr12 | 313 | 5804 | 8 |
| Tr21 | 336 | 7902 | 6 |
| Tr31 | 927 | 10,128 | 7 |
| Tr41 | 878 | 7454 | 10 |
| Tr45 | 690 | 8261 | 10 |
| Wap | 1560 | 8460 | 20 |
| Data Set | FTNB vs. GFTNB | #Iterations | NB vs. GFTNB | GFTNB vs. EGFTNB | #Iterations | NB vs. EGFTNB | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FTNB% | GFTNB% | FTNB | GFTNB | NB% | GFTNB% | GFTNB% | EGFTNB% | EGFTNB | NB% | EGFTNB% | |
| Fbis.wc | 77.55 | 77.67 | 10.3 | 13.1 | 69.96 | 77.67 | 77.67 | 81.20 | 68.1 | 69.96 | 81.20 |
| La1s.wc | 86.33 | 89.79 | 2.8 | 5 | 86.55 | 89.79 | 89.79 | 91.26 | 57.1 | 86.55 | 91.26 |
| La2s.wc | 84.26 | 89.63 | 3.1 | 6.1 | 87.48 | 89.63 | 89.63 | 91.71 | 53.7 | 87.48 | 91.71 |
| Oh0.wc | 89.63 | 91.63 | 3.3 | 4.1 | 91.43 | 91.63 | 91.63 | 93.12 | 46.3 | 91.43 | 93.12 |
| Oh5.wc | 85.73 | 88.13 | 3.2 | 5.9 | 84.42 | 88.13 | 88.13 | 89.98 | 50.6 | 84.42 | 89.98 |
| Oh10.wc | 77.62 | 82.10 | 2.8 | 5.7 | 83.05 | 82.10 | 82.10 | 83.62 | 50.1 | 83.05 | 83.62 |
| Oh15.wc | 83.24 | 85.21 | 2.6 | 4.9 | 85.43 | 85.21 | 85.21 | 86.09 | 52.3 | 85.43 | 86.09 |
| Re0.wc | 79.06 | 80.19 | 6.7 | 5 | 74.47 | 80.19 | 80.19 | 82.71 | 54.3 | 74.47 | 82.71 |
| Re1.wc | 78.76 | 79.72 | 3 | 3.5 | 77.37 | 79.72 | 79.72 | 83.40 | 47 | 77.37 | 83.40 |
| Tr11.wc | 86.96 | 87.92 | 4 | 4.4 | 77.29 | 87.92 | 87.92 | 87.68 | 45.3 | 77.29 | 87.68 |
| Tr12.wc | 92.33 | 92.97 | 2.9 | 3 | 94.89 | 92.97 | 92.97 | 92.65 | 39.5 | 94.89 | 92.65 |
| Tr21.wc | 88.39 | 88.39 | 4.1 | 2.6 | 58.04 | 88.39 | 88.39 | 91.67 | 41.5 | 58.04 | 91.67 |
| Tr31.wc | 94.07 | 94.50 | 5.3 | 5.6 | 90.61 | 94.50 | 94.50 | 95.90 | 40 | 90.61 | 95.90 |
| Tr41.wc | 91.23 | 92.14 | 2.6 | 4.2 | 92.14 | 92.14 | 92.14 | 92.94 | 43.6 | 92.14 | 92.94 |
| Tr45.wc | 88.12 | 87.97 | 3.1 | 5.1 | 77.25 | 87.97 | 87.97 | 93.04 | 44.3 | 77.25 | 93.04 |
| Wap.wc | 78.91 | 82.76 | 3.1 | 5.4 | 81.35 | 82.76 | 82.76 | 81.67 | 54.9 | 81.35 | 81.67 |
| average | 85.14 | 86.92 | 3.93 | 5.23 | 81.98 | 86.92 | 86.92 | 88.67 | 49.29 | 81.98 | 88.67 |
| #better | 1 | 14 | 3 | 12 | 3 | 13 | 1 | 15 | |||
| #Sig Better | 0 | 7 | 1 | 10 | 0 | 11 | 1 | 12 | |||
| Algorithm | Average Higher by | Wins | Ties | Losses |
|---|---|---|---|---|
| ENB | −0.02% | 1 | 12 | 3 |
| FTNB | 3.16% | 7 | 4 | 5 |
| EFTNB | 3.28% | 5 | 9 | 2 |
| GFTNB | 4.92% | 10 | 5 | 1 |
| EGFTNB | 6.69% | 12 | 3 | 1 |
| GFTNB-10 | 6.85% | 12 | 4 | 0 |
| GFTNB-20 | 7.19% | 13 | 3 | 0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Hindi, K.; AlSalman, H.; Qasem, S.; Al Ahmadi, S. Building an Ensemble of Fine-Tuned Naive Bayesian Classifiers for Text Classification. Entropy 2018, 20, 857. https://doi.org/10.3390/e20110857
El Hindi K, AlSalman H, Qasem S, Al Ahmadi S. Building an Ensemble of Fine-Tuned Naive Bayesian Classifiers for Text Classification. Entropy. 2018; 20(11):857. https://doi.org/10.3390/e20110857
Chicago/Turabian StyleEl Hindi, Khalil, Hussien AlSalman, Safwan Qasem, and Saad Al Ahmadi. 2018. "Building an Ensemble of Fine-Tuned Naive Bayesian Classifiers for Text Classification" Entropy 20, no. 11: 857. https://doi.org/10.3390/e20110857
APA StyleEl Hindi, K., AlSalman, H., Qasem, S., & Al Ahmadi, S. (2018). Building an Ensemble of Fine-Tuned Naive Bayesian Classifiers for Text Classification. Entropy, 20(11), 857. https://doi.org/10.3390/e20110857