An Information-Theoretic Approach to Self-Organisation: Emergence of Complex Interdependencies in Coupled Dynamical Systems




Abstract
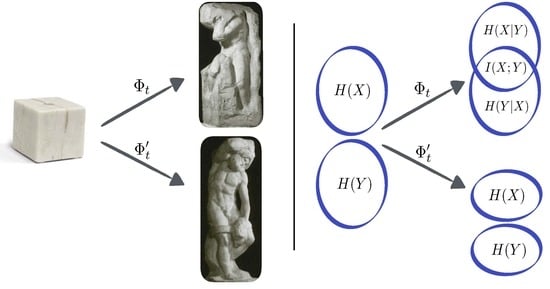
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. Context
1.2. Scope of this Work and Contribution
2. Key Intuitions
2.1. The Marble Sculpture Analogy
2.2. Self-Organisation Versus Dissipation
3. The Goal and Constraints of Self-Organisation
- (i)
- Global structure: the system evolves from less to more structured collective configurations.
- (ii)
- Autonomy: agents evolve in the absence of external guidance.
- (iii)
- Horizontality: no single agent can determine the evolution of a large number of other agents.
3.1. Multiple Agents as a Coupled Dynamical System
3.2. Formalising Self-Organisation
3.2.1. Autonomy
3.2.2. Horizontality and Locality
- (iii-b)
- Locality: agents can only interact with a small number of other agents.
3.2.3. Structure
4. Structure As Multi-Layered Statistical Interdependency
4.1. From Trajectories to Stochastic Processes
4.2. Information Dynamics
4.3. Binding and Residual Information
4.4. The Anatomy of the Interdependencies
4.4.1. Decomposition by Extension of Sharing
- (i)
- If , then and . Furthermore, because of the triple identity , and hence .
- (ii)
- If , then and . In this case, and hence .
- (iii)
- If , then and . Furthermore, due to the triple interdepedency , and hence .
4.4.2. Decomposition by Sharing Modes
- (i)
- If , then , as the information contained in any variable allows to predict the others, while .
- (ii)
- If , then similarly as above and . Both cases are redundancies (same i) of disimilar extension (different n).
- (iii)
- If , then measuring one agent does not allow any predictions over the others, while by measuring two agents one can predict the third one (for a discussion on the statistical properties of the xor, please see Reference [61], Section 4.2). This implies that , and hence .
5. A Quantitative Method to Study Time-Evolving Organisation
5.1. Bounds for the Information Decompositions
5.1.1. Upper Bounds for the Decomposition by Extension
- (i)
- If , then , and hence Equation (11) shows that . This bound is not tight, as (c.f. Example 1). Also, note that for one finds that , showing that the bounds don’t need to be monotonic on L.
- (ii)
- If , then . This bound is tight, as (c.f. Example 1).
- (iii)
- If (xor)V), then , and hence the bounds determine that .
5.1.2. Upper And Lower Bounds for the Decomposition by Sharing Modes
- (i)
- If , then . Therefore, the bounds in Equation (13) show that .
- (ii)
- If , then again , hence the bounds are the same as above.
- (iii)
- If (xor)V) then , which in turn guarantees that .
5.2. Protocol to Analyse Self-Organisation in Dynamical Systems
- (1)
- Check that the maps satisfy autonomy and locality (Section 3.2).
- (2)
- Consider a random initial condition given by a uniform distribution over the phase space, , and use it to drive the coupled dynamical system. This involves initialising the system in the least biased initial configuration, i.e., with maximally random and independent agents.
- (3)
- Compute the evolution of the probability distribution given by . This can be done directly using the map, a master equation [68], or in the case of a finite phase space by computing numerically all the trajectories.
- (4)
- Compute the joint Shannon entropy , the residual information , and the binding information as a function of t.
- (5)
- For values of at which , compute for .
6. Proof of Concept: Cellular Automata
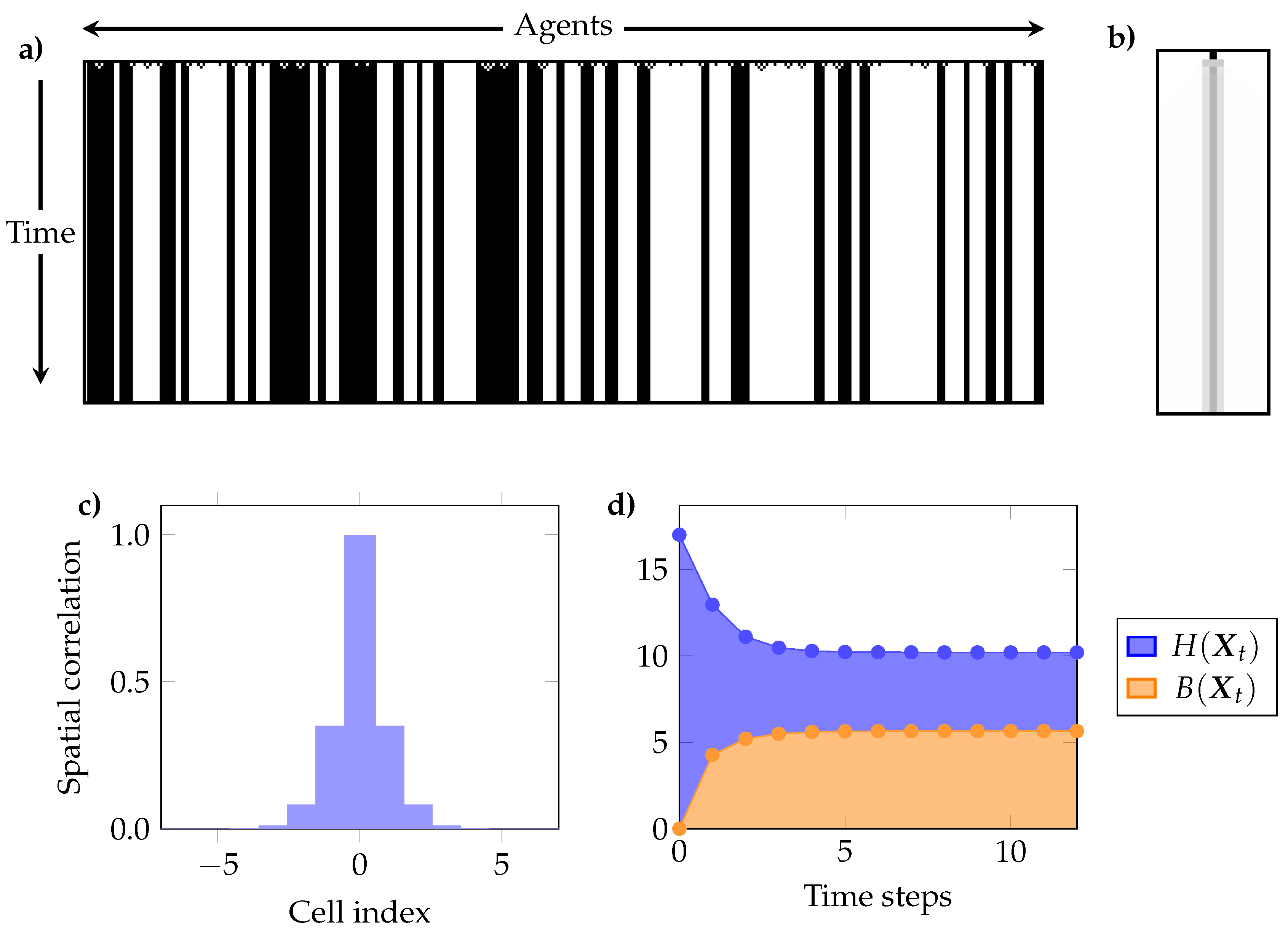
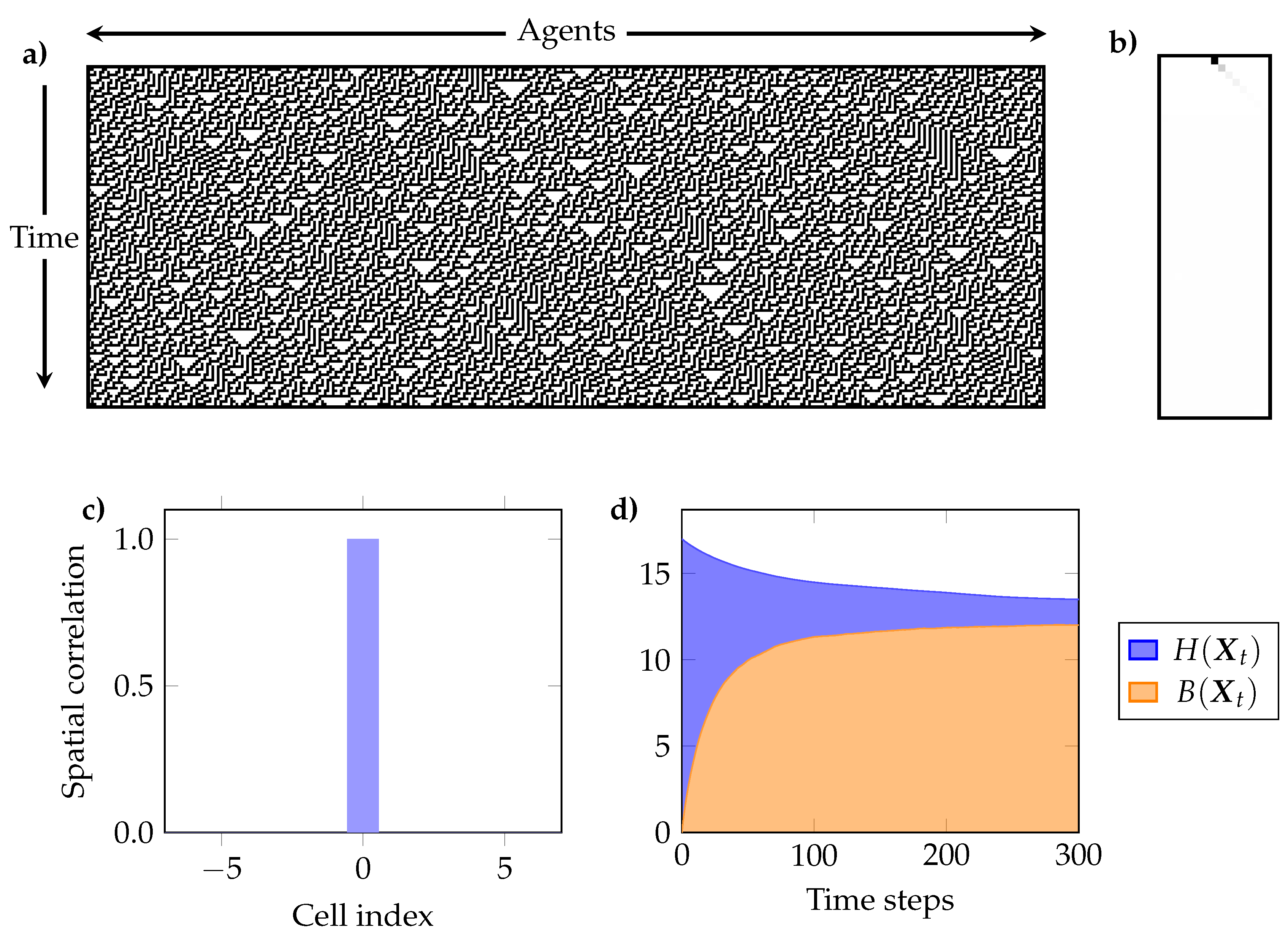
6.1. Method Description
- (a)
- The temporal evolution of , and . These plots show if the ECA shows signs of self-organisation according to Definition 1, and if the joint entropy decreases or remains constant (c.f. Section 4.2).
- (b)
- The interdependency between individual cells through time, as given by the mutual information between a single cell at time and all other cells in the same and successive times (i.e., for and ). This reflects the predictive power of the state of a cell in the initial condition over the future evolution of the system [77].
- (c)
- The mutual information between every pair of cells for the pseudo-stationary distribution. Because of the spatial translation symmetry of ECA, it suffices to take any cell and compute its mutual information with each other cell. We call this “spatial correlation,” as it measures interdependencies between cells at the same time t.
- (e)
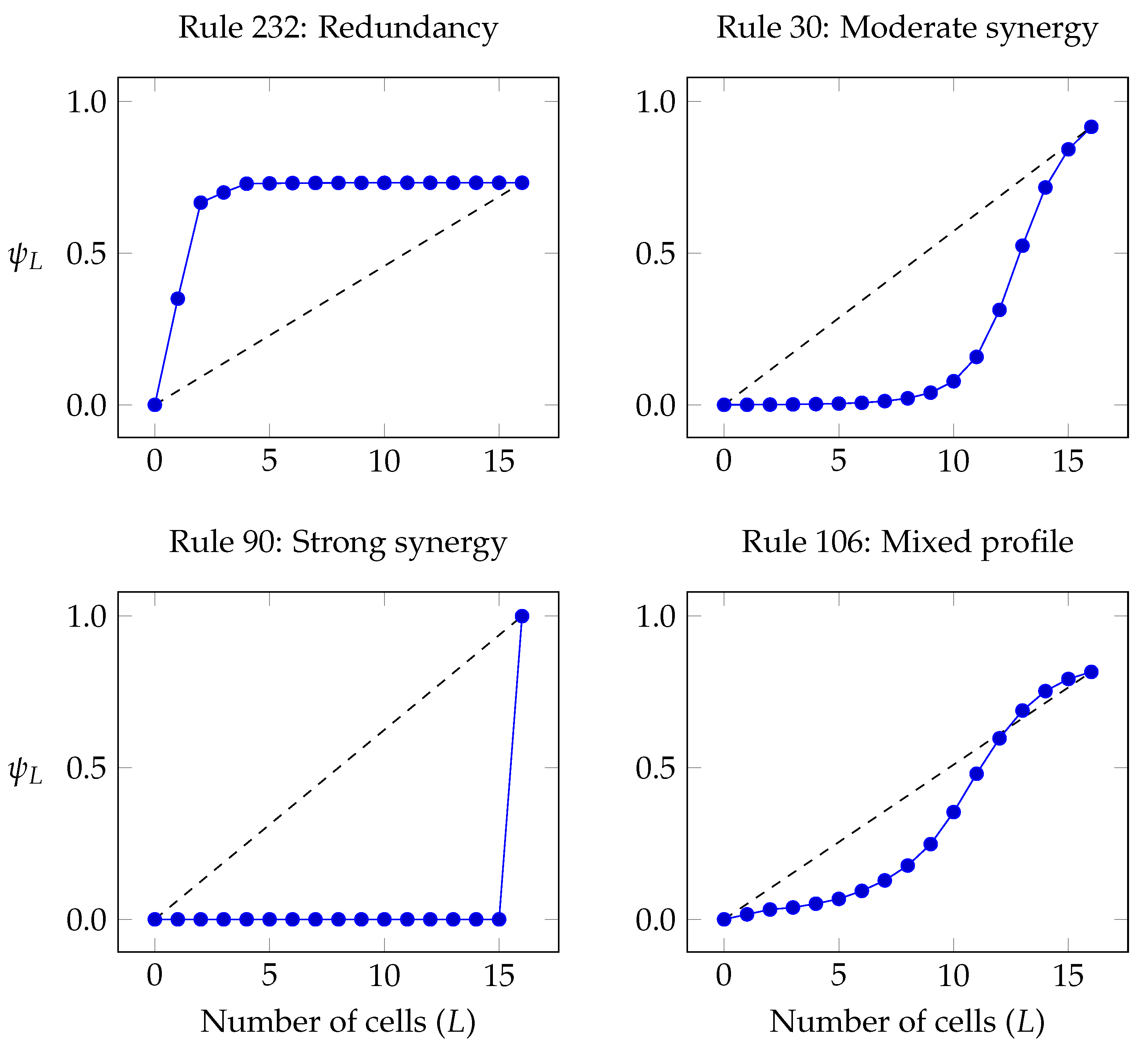
- The curve (c.f. Section 5) for the pseudo-stationary distribution, which is used to characterise a self-organising system as either redundancy- or synergy-dominated as per Definition 2. This curve can also be interpreted as how much of a cell can be predicted by the most informative group of L other cells.
6.2. Results
6.2.1. Strong Redundancy: Rule 232
6.2.2. Synergistic Profile: Rule 30
6.2.3. Pure Synergy: Rules 60 and 90
6.2.4. Coexistence of Convex and Concave Segments in
7. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Alternative Approaches to Formalising Global Structure
Appendix Structure as Geometrical Properties of Attractors
Appendix Structure as Pattern Complexity
Appendix B. From a Dynamical System to a Stochastic Process
Appendix C. Information and Entropy
Appendix D. Simulation Details
- Initialize the components of with zeros.
- For each : compute and then add to (i.e., add to ).
References and Notes
- Haken, H. Synergetics: an introduction. Non-equilibrium phase transition and self-organisation in physics, chemistry and biology. Phys. Bull. 1983, 28. [Google Scholar] [CrossRef]
- Camazine, S. Self-Organization in Biological Systems; Princeton University Press: Princeton, NJ, USA, 2003. [Google Scholar]
- Tognoli, E.; Kelso, J.S. The metastable brain. Neuron 2014, 81, 35–48. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Jin, Y.; Ren, L.; Hao, K. An Intelligent Self-Organization Scheme for the Internet of Things. IEEE Comput. Intell. Mag. 2013, 8, 41–53. [Google Scholar] [CrossRef]
- Athreya, A.P.; Tague, P. Network self-organization in the Internet of Things. In Proceedings of the International Conference on Sensing, Communications and Networking (SECON), New Orleans, LA, USA, 24–24 June 2013. [Google Scholar] [CrossRef]
- MacDonald, T.J.; Allen, D.W.; Potts, J. Blockchains and the boundaries of self-organized economies: Predictions for the future of banking. In Banking Beyond Banks and Money; Springer: Cham, Switzerland, 2016; pp. 279–296. [Google Scholar]
- Prokopenko, M. (Ed.) Guided Self-Organization: Inception; Springer Science & Business Media: Berlin, Germany, 2013; Volume 9. [Google Scholar]
- Kuze, N.; Kominami, D.; Kashima, K.; Hashimoto, T.; Murata, M. Controlling large-scale self-organized networks with lightweight cost for fast adaptation to changing environments. ACM Trans. Auto Adapt. Syst. 2016, 11, 9. [Google Scholar] [CrossRef]
- Rosas, F.; Hsiao, J.H.; Chen, K.C. A technological perspective on information cascades via social learning. IEEE Access 2017, 5, 22605–22633. [Google Scholar] [CrossRef]
- Ashby, W.R. Principles of the self-organizing dynamic system. J. Gen. Psychol. 1947, 37, 125–128. [Google Scholar] [CrossRef] [PubMed]
- Foerster, H.V. On self-organizing systems and their environments. In Understanding Understanding; Springer: New York, NY, USA, 1960. [Google Scholar]
- Haken, H.; Jumarie, G. A Macroscopic Approach to Complex System; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Crommelinck, M.; Feltz, B.; Goujon, P. Self-Organization and Emergence in Life Sciences; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Heylighen, F.; Gershenson, C. The meaning of self-organization in computing. IEEE Intell. Syst. 2003, 18, 72–75. [Google Scholar] [CrossRef]
- Mamei, M.; Menezes, R.; Tolksdorf, R.; Zambonelli, F. Case studies for self-organization in computer science. J. Syst. Archit. 2006, 52, 443–460. [Google Scholar] [CrossRef]
- De Boer, B. Self-organization in vowel systems. J. Phon. 2000, 28, 441–465. [Google Scholar] [CrossRef]
- Steels, L. Synthesising the origins of language and meaning using co-evolution, self-organisation and level formation. In Approaches to the Evolution of Language: Social and Cognitive Bases; Cambridge University Press: Cambridge, UK, 1998; pp. 384–404. [Google Scholar]
- Prehofer, C.; Bettstetter, C. Self-organization in communication networks: principles and design paradigms. IEEE Commun. Mag. 2005, 43, 78–85. [Google Scholar] [CrossRef]
- Dressler, F. A study of self-organization mechanisms in ad hoc and sensor networks. Comput. Commun. 2008, 31, 3018–3029. [Google Scholar] [CrossRef]
- Kugler, P.N.; Kelso, J.S.; Turvey, M. On the concept of coordinative structures as dissipative structures: I. Theoretical lines of convergence. Tutor. Motor Behav. 1980, 3, 3–47. [Google Scholar]
- Kelso, J.S.; Schöner, G. Self-organization of coordinative movement patterns. Hum. Mov. Sci. 1988, 7, 27–46. [Google Scholar] [CrossRef]
- Kelso, J.S. Dynamic Patterns: The Self-Organization of Brain and Behavior; MIT Press: London, UK, 1997. [Google Scholar]
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. Neur. 2010, 11, 127. [Google Scholar] [CrossRef] [PubMed]
- Shalizi, C.R.; Shalizi, K.L.; Haslinger, R. Quantifying self-organization with optimal predictors. Phys. Rev. L 2004, 93, 118701. [Google Scholar] [CrossRef] [PubMed]
- Gershenson, C. Guiding the self-organization of random Boolean networks. Theory Biol. 2012, 131, 181–191. [Google Scholar] [CrossRef] [PubMed]
- Gershenson, C.; Heylighen, F. When can we call a system self-organizing? In Advances in Artificial Life; Springer: Berlin/Heidelberg, Gerany, 2003; pp. 606–614. [Google Scholar]
- Krakauer, D.; Bertschinger, N.; Olbrich, E.; Ay, N.; Flack, J.C. The information theory of individuality. arXiv, 2014; arXiv:1412.2447. [Google Scholar]
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: London, UK, 2003. [Google Scholar]
- Mezard, M.; Montanari, A. Information, Physics, and Computation; Oxford University Press: New York, NY, USA, 2009. [Google Scholar]
- Nicolis, G.; Prigogine, I. Self-Organization in Non-Equilibrium Systems: From Dissipative Structures to Order Through Fluctuations; Wiley: Hoboken, NJ, USA, 1977. [Google Scholar]
- Heylighen, F. The science of self-organization and adaptivity. Encyclopedia Life Support Syst. 2001, 5, 253–280. [Google Scholar]
- Pulselli, R.; Simoncini, E.; Tiezzi, E. Self-organization in dissipative structures: A thermodynamic theory for the emergence of prebiotic cells and their epigenetic evolution. Biosystem 2009, 96, 237–241. [Google Scholar] [CrossRef] [PubMed]
- Klimontovich, Y.L. Turbulent Motion. The Structure of Chaos. In Turbulent Motion and the Structure of Chaos; Springer: Berlin, Germany, 1991; pp. 329–371. [Google Scholar]
- Gershenson, C.; Fernández, N. Complexity and information: Measuring emergence, self-organization, and homeostasis at multiple scales. Complexity 2012, 18, 29–44. [Google Scholar] [CrossRef]
- Vijayaraghavan, V.S.; James, R.G.; Crutchfield, J.P. Anatomy of a spin: the information-theoretic structure of classical spin systems. Entropy 2017, 19, 214. [Google Scholar] [CrossRef]
- Lloyd, S. Measures of complexity: A nonexhaustive list. IEEE Control Syst. Mag. 2001, 21, 7–8. [Google Scholar]
- Tononi, G.; Sporns, O.; Edelman, G.M. A measure for brain complexity: relating functional segregation and integration in the nervous system. Proc. Nat. Acad. Sci. USA 1994, 91, 5033–5037. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J.; Tononi, G.; Sporns, O.; Edelman, G. Characterising the complexity of neuronal interactions. Hum. Brain Map. 1995, 3, 302–314. [Google Scholar] [CrossRef]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv, 2010; arXiv:1004.2515. [Google Scholar]
- Bar-Yam, Y. Multiscale complexity/entropy. Adv. Complex Syst. 2004, 7, 47–63. [Google Scholar] [CrossRef]
- Allen, B.; Stacey, B.C.; Bar-Yam, Y. Multiscale information theory and the marginal utility of information. Entropy 2017, 19, 273. [Google Scholar] [CrossRef]
- Beck, C.; Schögl, F. Thermodynamics of Chaotic Systems: An Introduction; Cambridge University Press: London, UK, 1995. [Google Scholar]
- Vasari, G. The Lives of the Artists; Oxford University Press: New York, NY, USA, 1991; Volume 293, pp. 58–59. [Google Scholar]
- Robinson, R.C. An Introduction to Dynamical Systems: Continuous and Discrete; American Mathemathical Society: Providence, RI, USA, 2012. [Google Scholar]
- Nurzaman, S.; Yu, X.; Kim, Y.; Iida, F. Goal-directed multimodal locomotion through coupling between mechanical and attractor selection dynamics. Bioinspir. Biomim. 2015, 10, 025004. [Google Scholar] [CrossRef] [PubMed]
- Additionally, autonomous systems allow simple descriptions. Thanks to the property ϕt1(ϕt2(x)) = ϕt1+t2(x), autonomous evolutions in discrete time are characterised by the single maping ϕ := ϕ1 by noting that ϕn = (ϕ)n, while autonomous evolutions in continuous time can be characterised by a vector field or a set of time-invariant differential equations.
- Schuster, H.G.; Just, W. Deterministic Chaos: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Technically speaking, a sequence of symbols in isolation has no Shannon entropy or mutual information because it involves no uncertainty. The literature usually associates a value of entropy by considering a stochastic model which most likely generated the sequence. However, this practice relies on strong assumptions (e.g., ergodicity, or independence of sucessive symbols), which might not hold in practice. A more principled approach is provided stochastic thermodynamics, as presented in References [49,50].
- Ao, P. Deterministic Chaos: An Introduction. In Turbulent Motion and the Structure of Chaos. Fundamental Theories of Physics; Springer: Heidelberg/Berlin, Germany, 2006. [Google Scholar]
- Seifert, U. Stochastic thermodynamics, fluctuation theorems and molecular machines. Rep. Prog. Phys. 2012, 75, 126001. [Google Scholar] [CrossRef] [PubMed]
- Ott, E. Chaos in Dynamical Systems; Cambridge University Press: London, UK, 2002. [Google Scholar]
- Interestingly, there exists a subset of (Ω) that is isomorphic to Ω, namely the set of distributions of the form {μx = x|x ∈ Ω}. Therefore, it is consistent to call (Ω) a generalised state space, which corresponds to the notion of “state” that is used by quantum mechanics [53].
- Breuer, H.P.; Petruccione, F. The Theory of Open Quantum Systems; Oxford University Press: New York, NY, USA, 2002. [Google Scholar]
- Schreiber, T.; Kantz, H. Noise in chaotic data: Diagnosis and treatment. Chaos 1995, 5, 133–142. [Google Scholar] [CrossRef] [PubMed]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Schulman, L.S. Time’s Arrows and Quantum Measurement; Cambridge University Press: London, UK, 1997. [Google Scholar]
- Martynov, G. Liouville’s theorem and the problem of the increase of the entropy. Soviet J. Exp. Theory Phys. 1995, 80, 1056–1062. [Google Scholar]
- Slepian, D.; Wolf, J. Noiseless coding of correlated information sources. IEEE Trans. Inf. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- El Gamal, A.; Kim, Y.H. Network Information Theory; Cambridge University Press: London, UK, 2011. [Google Scholar]
- Te Sun, H. Nonnegative entropy measures of multivariate symmetric correlations. Inf. Control 1978, 36, 133–156. [Google Scholar]
- Rosas, F.; Ntranos, V.; Ellison, C.J.; Pollin, S.; Verhelst, M. Understanding interdependency through complex information sharing. Entropy 2016, 18, 38. [Google Scholar] [CrossRef]
- Feldman, D.P.; Crutchfield, J.P. Measures of statistical complexity: Why? Phys. Lett. A 1998, 238, 244–252. [Google Scholar] [CrossRef]
- Olbrich, E.; Bertschinger, N.; Rauh, J. Information decomposition and synergy. Entropy 2015, 17, 3501–3517. [Google Scholar] [CrossRef]
- Barrett, A.B. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Phys. Rev. E 2015, 91, 052802. [Google Scholar] [CrossRef] [PubMed]
- Lizier, J.T.; Bertschinger, N.; Jost, J.; Wibral, M. Information Decomposition of Target Effects from Multi-Source Interactions: Perspectives on Previous, Current and Future Work. Entropy 2018, 20. [Google Scholar] [CrossRef]
- Rosas, F.; Ntranos, V.; Ellison, C.J.; Verhelst, M.; Pollin, S. Understanding high-order correlations using a synergy-based decomposition of the total entropy. In Proceedings of the 5th joint WIC/IEEE Symposium on Information Theory and Signal Processing in the Benelux, Brussels, Belgium, 5 June 2015; pp. 146–153. [Google Scholar]
- Ince, R.A. The Partial Entropy Decomposition: Decomposing multivariate entropy and mutual information via pointwise common surprisal. arXiv, 2017; arXiv:1702.01591. [Google Scholar]
- Van Kampen, N.G. Stochastic Processes in Physics and Chemistry; Elsevier: Oxford, UK, 1992. [Google Scholar]
- Mitchell, M. Computation in cellular automata: A selected review. In Nonstandard Computation; Schuster, H.G., Gramss, T., Eds.; Wiley-VCH Verlag: Hoboken, NJ, USA, 1998; pp. 95–140. [Google Scholar]
- For a survey about asynchronous CA, please see Reference [71].
- Fates, N. A guided tour of asynchronous cellular automata. In International Workshop on Cellular Automata and Discrete Complex Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 15–30. [Google Scholar]
- Wolfram, S. A New Kind of Science; Wolfram Media: Champaign, IL, USA, 2002. [Google Scholar]
- Wolfram, S. Universality and complexity in cellular automata. Phys. D Nonlinear Phenom. 1984, 10, 1–35. [Google Scholar] [CrossRef]
- Lizier, J. The Local Information Dynamics of Distributed Computation in Complex Systems. Ph.D. Thesis, University of Sydney, Sydney, Australia, 2010. [Google Scholar]
- Esposito, M.; Van den Broeck, C. Three faces of the second law. I. Master equation formulation. Phys. Rev. E 2010, 82, 011143. [Google Scholar] [CrossRef] [PubMed]
- Tomé, T.; de Oliveira, M.J. Entropy production in nonequilibrium systems at stationary states. Phys. Rev. L 2012, 108, 020601. [Google Scholar] [CrossRef] [PubMed]
- To use an analogy, one can think of the information content of a cell as a drop of ink that is thrown into the river of the temporal evolution of the system.
- Betel, H.; de Oliveira, P.P.; Flocchini, P. Solving the parity problem in one-dimensional cellular automata. Nat. Comput. 2013, 12, 323–337. [Google Scholar] [CrossRef]
- Cattaneo, G.; Finelli, M.; Margara, L. Investigating topological chaos by elementary cellular automata dynamics. Theory Comput. Sci. 2000, 244, 219–241. [Google Scholar] [CrossRef]
- Wolfram, S. Cryptography with cellular automata. In Proceedings of the Conference on the Theory and Application of Cryptographic Techniques; Springer: New York, NY, USA, 1985; pp. 429–432. [Google Scholar]
- Wolfram, S. Random sequence generation by cellular automata. Adv. Appl. Math. 1986, 7, 123–169. [Google Scholar] [CrossRef]
- Martinez, G.J.; Seck-Tuoh-Mora, J.C.; Zenil, H. Computation and universality: Class IV versus class III cellular automata. arXiv, 2013; arXiv:1304.1242. [Google Scholar]
- Ince, R.A. Measuring multivariate redundant information with pointwise common change in surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- James, R.G.; Ellison, C.J.; Crutchfield, J.P. dit: A Python package for discrete information theory. J. Open Source Softw. 2018. [Google Scholar] [CrossRef]
- Makkeh, A.; Theis, D.O.; Vicente, R. BROJA-2PID: A robust estimator for bivariate partial information decomposition. Entropy 2018, 20, 271. [Google Scholar] [CrossRef]
- Finn, C.; Lizier, J.T. Pointwise partial information decomposition using the specificity and ambiguity lattices. Entropy 2018, 20, 297. [Google Scholar] [CrossRef]
- Gelman, A.; Stern, H.S.; Carlin, J.B.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: New York, NY, USA, 2013. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Young, L.S. What are SRB measures, and which dynamical systems have them? J. Stat. Phys. 2002, 108, 733–754. [Google Scholar] [CrossRef]
- Sándor, B.; Jahn, T.; Martin, L.; Gros, C. The sensorimotor loop as a dynamical system: how regular motion primitives may emerge from self-organized limit cycles. Front. Robot. AI 2015, 2, 31. [Google Scholar] [CrossRef]
- Pikovsky, A.; Rosenblum, M.; Kurths, J.; Kurths, J. Synchronization: A Universal Concept in Nonlinear Sciences; Cambridge University Press: London, UK, 2003. [Google Scholar]
- Kuramoto, Y. Chemical Oscillations, Waves, and Turbulence; Springer Science & Business Media: Heidelberg/Berlin, Germany, 2012. [Google Scholar]
- Haken, H. Synergetics. Phys. Bull. 1977, 28, 412. [Google Scholar] [CrossRef]
- Chalmers, D.J. Strong and weak emergence. In Clayton and Davies; Oxford University Press: Oxford, UK, 2006; pp. 244–256. [Google Scholar]
- Jensen, H.J.; Pazuki, R.; Pruessner, G.; Tempesta, P. Statistical mechanics of exploding phase spaces: Ontic open systems. J. Phys. A Math. Theory 2018, 51. [Google Scholar] [CrossRef]
- Strogatz, S.H. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Ashby, W.R. Principles of the self-organizing system. In Principles of Self-Organization: Transactions of the University of Illinois Symposium; Foerster, H.V., Zopf, J., Eds.; Springer: New York, NY, USA, 1962; pp. 255–278. [Google Scholar]
- Kolmogorov, A.N. Three approaches to the quantitative definition ofinformation. Prob. Inf. Trans. 1965, 1, 1–7. [Google Scholar]
- Li, M.; Vitanyi, P. An Introduction to Kolmogorov Complexity and Its Applications, 3rd ed.; Springer: New York, NY, USA, 2008. [Google Scholar]
- Chaitin, G.J. Information, Randomness & Incompleteness: Papers on Algorithmic Information Theory; World Scientific: Singapore, 1990. [Google Scholar]
- Loeve, M. Probability Theory; Springer: New York, NY, USA, 1978. [Google Scholar]




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosas, F.; Mediano, P.A.M.; Ugarte, M.; Jensen, H.J. An Information-Theoretic Approach to Self-Organisation: Emergence of Complex Interdependencies in Coupled Dynamical Systems. Entropy 2018, 20, 793. https://doi.org/10.3390/e20100793
Rosas F, Mediano PAM, Ugarte M, Jensen HJ. An Information-Theoretic Approach to Self-Organisation: Emergence of Complex Interdependencies in Coupled Dynamical Systems. Entropy. 2018; 20(10):793. https://doi.org/10.3390/e20100793
Chicago/Turabian StyleRosas, Fernando, Pedro A.M. Mediano, Martín Ugarte, and Henrik J. Jensen. 2018. "An Information-Theoretic Approach to Self-Organisation: Emergence of Complex Interdependencies in Coupled Dynamical Systems" Entropy 20, no. 10: 793. https://doi.org/10.3390/e20100793
APA StyleRosas, F., Mediano, P. A. M., Ugarte, M., & Jensen, H. J. (2018). An Information-Theoretic Approach to Self-Organisation: Emergence of Complex Interdependencies in Coupled Dynamical Systems. Entropy, 20(10), 793. https://doi.org/10.3390/e20100793