A Fast Feature Selection Algorithm by Accelerating Computation of Fuzzy Rough Set-Based Information Entropy


Abstract
1. Introduction
2. Preliminaries
| Algorithm 1: Computing an -approximate reduct of a fuzzy decision system. |
 |
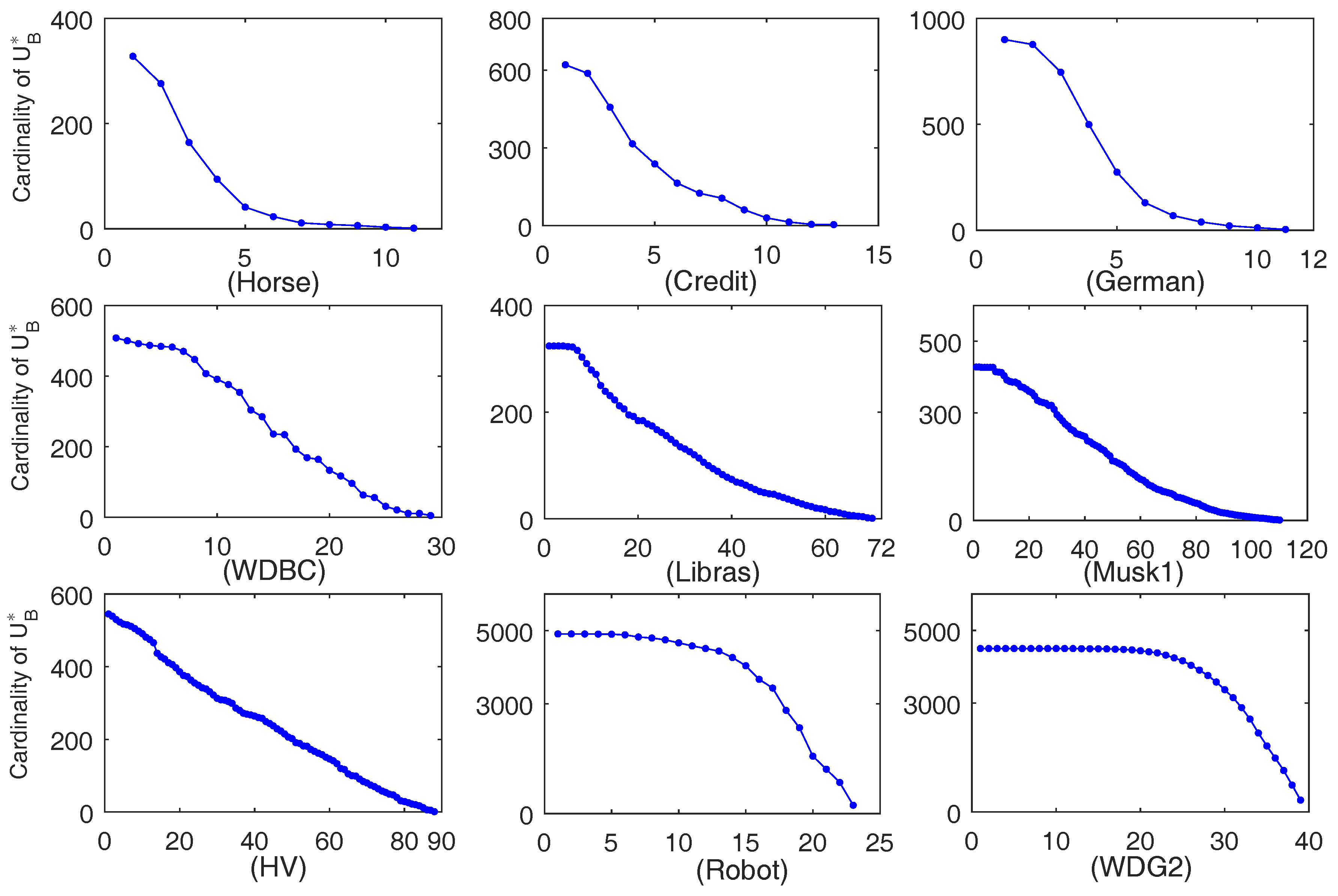
3. Accelerated Computation of -Conditional Entropy
| Algorithm 2: Accelerating computation of an -approximate reduct of a fuzzy decision system. |
 |
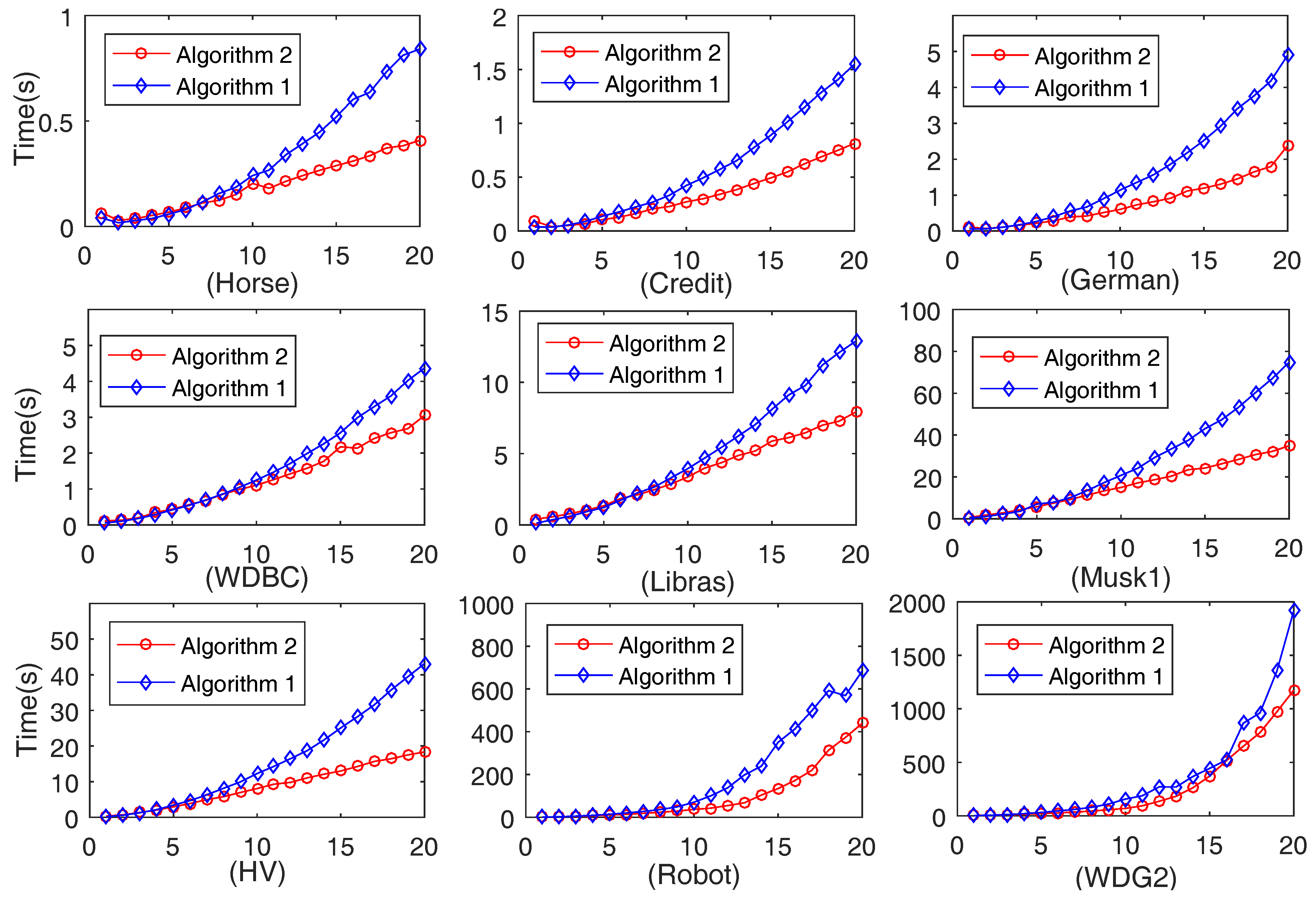
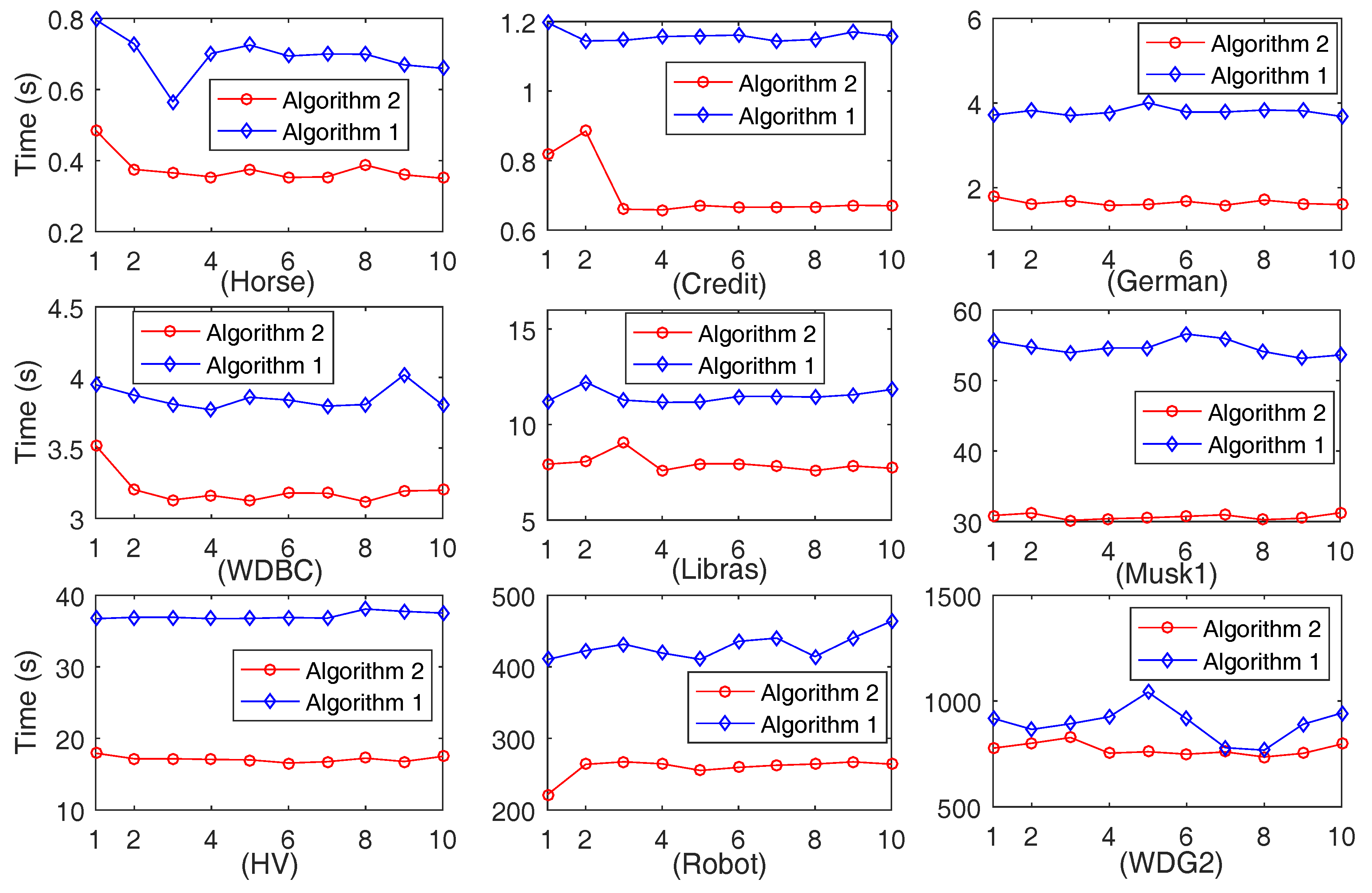
4. Numerical Experiment
4.1. Pretreatment of the Data Sets and Design of the Experiment
4.2. Comparison of Computation Time of Algorithms 1 and 2
4.2.1. Comparison of Computation Time on 20 Data Sets Generated by Each Data Set
4.2.2. Comparison of Computation Time on Ten-Folds Data Sets Produced by Each Data Set
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Pawlak, Z. Rough sets. Int. J. Comput. Inf. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Lin, T.Y.; Yao, Y.Y.; Zadeh, L.A. Data Mining, Rough Sets and Granular Computing; Physica-Verlag: Heidelberg, Germany, 2002. [Google Scholar]
- Qian, Y.H.; Zhang, H.; Sang, Y.L.; Liang, J.Y. Multigranulation decision-theoretic rough sets. Int. J. Approx. Reason. 2014, 55, 225–237. [Google Scholar] [CrossRef]
- Luo, C.; Li, T.R.; Yi, Z.; Fujita, H. Matrix approach to decision-theoretic rough sets for evolving data. Knowl.-Based Syst. 2016, 99, 123–134. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Tsang, E.; Chen, D.G. The model of fuzzy variable precision rough sets. IEEE Trans. Fuzzy Syst. 2009, 17, 451–467. [Google Scholar] [CrossRef]
- Qian, Y.H.; Liang, J.Y.; Pedrycz, W.; Dang, C.Y. Positive approximation: An accelerator for attribute reduction in rough set theory. Artif. Intell. 2010, 174, 597–618. [Google Scholar] [CrossRef]
- Wang, C.Z.; Qi, Y.L.; Shao, M.W.; Hu, Q.H.; Chen, D.G.; Qian, Y.H.; Lin, Y.J. A fitting model for feature selection with fuzzy rough sets. IEEE Trans. Fuzzy Syst. 2017, 25, 741–753. [Google Scholar] [CrossRef]
- Zhang, X.; Mei, C.L.; Chen, D.G.; Yang, Y.Y. A fuzzy rough set-based feature selection method using representative instances. Knowl.-Based Syst. 2018, 151, 216–229. [Google Scholar] [CrossRef]
- Ananthanarayana, V.; Murty, M.N.; Subramanian, D. Tree structure for efficient data mining using rough sets. Pattern Recognit. Lett. 2003, 24, 851–862. [Google Scholar] [CrossRef]
- Chen, H.M.; Li, T.R.; Luo, C.; Horng, S.J.; Wang, G.Y. A decision-theoretic rough set approach for dynamic data mining. IEEE Trans. Fuzzy Syst. 2015, 23, 1958–1970. [Google Scholar] [CrossRef]
- Yang, Y.Y.; Chen, D.G.; Wang, H. Active sample selection based incremental algorithm for attribute reduction with rough sets. IEEE Trans. Fuzzy Syst. 2017, 25, 825–838. [Google Scholar] [CrossRef]
- Hu, Q.H.; Zhang, L.J.; Zhou, Y.C.; Pedrycz, W. Large-scale multimodality attribute reduction with multi-kernel fuzzy rough sets. IEEE Trans. Fuzzy Syst. 2018, 26, 226–238. [Google Scholar] [CrossRef]
- Qian, J.; Xia, M.; Yue, X.D. Parallel knowledge acquisition algorithms for big data using MapReduce. Int. J. Mach. Learn. Cybern. 2018, 9, 1007–1021. [Google Scholar] [CrossRef]
- Ye, J.; Cui, W.H. Exponential entropy for simplified neutrosophic sets and its application in decision making. Entropy 2018, 20, 357. [Google Scholar] [CrossRef]
- Girault, J.M.; Humeau-Heurtier, A. Centered and averaged fuzzy entropy to improve fuzzy entropy precision. Entropy 2018, 20, 287. [Google Scholar] [CrossRef]
- Zhou, R.X.; Liu, X.; Yu, M.; Huang, K. Properties of risk measures of generalized entropy in portfolio selection. Entropy 2017, 19, 657. [Google Scholar] [CrossRef]
- Düntsch, I.; Gediga, G. Uncertainty measures of rough set prediction. Artif. Intell. 1998, 106, 109–137. [Google Scholar] [CrossRef]
- Liang, J.Y.; Shi, Z.Z. The information entropy, rough entropy and knowledge granulation in rough set theory. Int. J. Uncertain. Fuzz. Knowl.-Based Syst. 2004, 12, 37–46. [Google Scholar] [CrossRef]
- Liang, J.Y.; Shi, Z.Z.; Li, D.Y.; Wierman, M.J. Information entropy, rough entropy and knowledge granulation in incomplete information systems. Int. J. Gen. Syst. 2006, 35, 641–654. [Google Scholar] [CrossRef]
- Hu, Q.H.; Yu, D.R.; Xie, Z.X.; Liu, J.F. Fuzzy probabilistic approximation spaces and their information measures. IEEE Trans. Fuzzy Syst. 2006, 14, 191–201. [Google Scholar] [CrossRef]
- Xu, W.H.; Zhang, X.Y.; Zhang, W.X. Knowledge granulation, knowledge entropy and knowledge uncertainty measure in ordered information systems. Appl. Soft Comput. 2009, 9, 1244–1251. [Google Scholar] [CrossRef]
- Mi, J.S.; Leung, Y.; Zhao, H.Y.; Feng, T. Generalized fuzzy rough sets determined by a triangular norm. Inf. Sci. 2008, 178, 3203–3213. [Google Scholar] [CrossRef]
- Qian, Y.H.; Liang, J.Y. Combination entropy and combination granulation in rough set theory. Int. J. Uncertain. Fuzz. Knowl.-Based Syst. 2008, 16, 179–193. [Google Scholar] [CrossRef]
- Ma, W.M.; Sun, B.Z. Probabilistic rough set over two universes and rough entropy. Int. J. Approx. Reason. 2012, 53, 608–619. [Google Scholar] [CrossRef]
- Dai, J.H.; Tian, H.W. Entropy measures and granularity measures for set-valued information systems. Inf. Sci. 2013, 240, 72–82. [Google Scholar] [CrossRef]
- Dai, J.H.; Wang, W.T.; Xu, Q.; Tian, H.W. Uncertainty measurement for interval-valued decision systems based on extended conditional entropy. Knowl.-Based Syst. 2012, 27, 443–450. [Google Scholar] [CrossRef]
- Chen, Y.M.; Wu, K.S.; Chen, X.H.; Tang, C.H.; Zhu, Q.X. An entropy-based uncertainty measurement approach in neighborhood systems. Inf. Sci. 2014, 279, 239–250. [Google Scholar] [CrossRef]
- Wang, C.Z.; He, Q.; Shao, M.W.; Xu, Y.Y.; Hu, Q.H. A unified information measure for general binary relations. Knowl.-Based Syst. 2017, 135, 18–28. [Google Scholar] [CrossRef]
- Beaubouef, T.; Petry, F.E.; Arora, G. Information-theoretic measures of uncertainty for rough sets and rough relational databases. Inf. Sci. 1998, 109, 185–195. [Google Scholar] [CrossRef]
- Jiang, F.; Sui, Y.F.; Cao, C.G. An information entropy-based approach to outlier detection in rough sets. Expert Syst. Appl. 2010, 37, 6338–6344. [Google Scholar] [CrossRef]
- Pal, S.K.; Shankar, B.U.; Mitra, P. Granular computing, rough entropy and object extraction. Pattern Recognit. Lett. 2005, 26, 2509–2517. [Google Scholar] [CrossRef]
- Tsai, Y.C.; Cheng, C.H.; Chang, J.R. Entropy-based fuzzy rough classification approach for extracting classification rules. Expert Syst. Appl. 2006, 31, 436–443. [Google Scholar] [CrossRef]
- Chen, C.B.; Wang, L.Y. Rough set-based clustering with refinement using Shannon’s entropy theory. Comput. Math. Appl. 2006, 52, 1563–1576. [Google Scholar] [CrossRef]
- Sen, D.; Pal, S.K. Generalized rough sets, entropy, and image ambiguity measures. IEEE Trans. Syst. Man Cybern. B 2009, 39, 117–128. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Zhang, Z.; Zheng, J.; Ma, Y.; Xue, Y. Gene selection for tumor classification using neighborhood rough sets and entropy measures. J. Biomed. Inform. 2017, 67, 59–68. [Google Scholar] [CrossRef] [PubMed]
- Miao, D.Q.; Hu, G.R. A heuristic algorithm for reduction of knowledge. J. Comput. Res. Dev. 1999, 36, 681–684. [Google Scholar]
- Wang, G.Y.; Yu, H.; Yang, D.C. Decision table reduction based on conditional information entropy. Chin. J. Comput. 2002, 25, 759–766. [Google Scholar]
- Hu, Q.H.; Yu, D.R.; Xie, Z.X. Information-preserving hybrid data reduction based on fuzzy-rough techniques. Pattern Recognit. Lett. 2006, 27, 414–423. [Google Scholar] [CrossRef]
- Hu, Q.H.; Zhang, L.; Chen, D.G.; Pedrycz, W.; Yu, D.R. Gaussian kernel based fuzzy rough sets: Model, uncertainty measures and applications. Int. J. Approx. Reason. 2010, 51, 453–471. [Google Scholar] [CrossRef]
- Sun, L.; Xu, J.C.; Tian, Y. Feature selection using rough entropy-based uncertainty measures in incomplete decision systems. Knowl.-Based Syst. 2012, 36, 206–216. [Google Scholar] [CrossRef]
- Liang, J.Y.; Wang, F.; Dang, C.Y.; Qian, Y.H. A group incremental approach to feature selection applying rough set technique. IEEE Trans. Knowl. Data Eng. 2014, 26, 294–308. [Google Scholar] [CrossRef]
- Foithong, S.; Pinngern, O.; Attachoo, B. Feature subset selection wrapper based on mutual information and rough sets. Expert Syst. Appl. 2012, 39, 574–584. [Google Scholar] [CrossRef]
- Chen, Y.M.; Xue, Y.; Ma, Y.; Xu, F.F. Measures of uncertainty for neighborhood rough sets. Knowl.-Based Syst. 2017, 120, 226–235. [Google Scholar] [CrossRef]
- Zhang, X.; Mei, C.L.; Chen, D.G.; Li, J.H. Feature selection in mixed data: A method using a novel fuzzy rough set-based information entropy. Pattern Recognit. 2016, 56, 1–15. [Google Scholar] [CrossRef]
- Chen, D.G. Theory and Methods of Fuzzy Rough Sets; Science Press: Beijing, China, 2013. [Google Scholar]
- Dubois, D.; Prade, H. Rough fuzzy sets and fuzzy rough sets. Int. J. Gen. Syst. 1990, 17, 191–209. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Data Set | Abbreviation of Data Set | Number of Objects | Number of Conditional Attributes | Number of Classes | ||
|---|---|---|---|---|---|---|
| All | Nominal | Real-Valued | ||||
| Horse Colic | Horse | 368 | 22 | 15 | 7 | 2 |
| Credit Approval | Credit | 690 | 15 | 9 | 6 | 2 |
| German Credit Data | German | 1000 | 20 | 13 | 7 | 2 |
| Wisconsin Diagnostic Breast Cancer | WDBC | 569 | 30 | 0 | 30 | 2 |
| Libras Movement | Libras | 360 | 90 | 0 | 90 | 15 |
| Musk (Version 1) | Musk1 | 476 | 166 | 0 | 166 | 2 |
| Hill-Valley | HV | 606 | 100 | 0 | 100 | 2 |
| Wall-Following Robot Navigation Data | Robot | 5456 | 24 | 0 | 24 | 4 |
| Waveform Database Generator (Version 2) | WDG2 | 5000 | 40 | 0 | 40 | 3 |
| Data Set | Algorithm 2 | Algorithm 1 [44] | |||
|---|---|---|---|---|---|
| Average Running Time (s) | |·| | Average Running Time (s) | |·| | ||
| Horse | 0.38 | 12.7 | 0.69 | 12.7 | |
| Credit | 0.70 | 13.9 | 1.16 | 13.9 | |
| German | 1.65 | 12.9 | 3.79 | 12.9 | |
| WDBC | 3.20 | 30.0 | 3.85 | 30.0 | |
| Libras | 7.94 | 71.4 | 11.48 | 71.4 | |
| Musk1 | 30.69 | 112.4 | 54.69 | 112.4 | |
| HV | 17.12 | 90.0 | 37.11 | 90.0 | |
| Robot | 259.00 | 24.0 | 428.85 | 24.0 | |
| WDG2 | 771.46 | 40.0 | 894.15 | 40.0 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Liu, X.; Yang, Y. A Fast Feature Selection Algorithm by Accelerating Computation of Fuzzy Rough Set-Based Information Entropy. Entropy 2018, 20, 788. https://doi.org/10.3390/e20100788
Zhang X, Liu X, Yang Y. A Fast Feature Selection Algorithm by Accelerating Computation of Fuzzy Rough Set-Based Information Entropy. Entropy. 2018; 20(10):788. https://doi.org/10.3390/e20100788
Chicago/Turabian StyleZhang, Xiao, Xia Liu, and Yanyan Yang. 2018. "A Fast Feature Selection Algorithm by Accelerating Computation of Fuzzy Rough Set-Based Information Entropy" Entropy 20, no. 10: 788. https://doi.org/10.3390/e20100788
APA StyleZhang, X., Liu, X., & Yang, Y. (2018). A Fast Feature Selection Algorithm by Accelerating Computation of Fuzzy Rough Set-Based Information Entropy. Entropy, 20(10), 788. https://doi.org/10.3390/e20100788