1. Introduction
Nonparametric two-sample testing (or homogeneity testing) deals with detecting differences between two d-dimensional distributions, given samples from both, without making any parametric distributional assumptions. The popular tests for are rather different from those for , and our interest is in tying together different tests used in both settings. There is massive literature on the two-sample problem, having been formally studied for nearly a century, and there is no way we can cover the breadth of this huge and historic body of work. Our aim is much more restricted—we wish to study this problem through the eyes of the versatile Wasserstein distance. We wish to form connections between several seemingly distinct families of such tests, both intuitively and formally, in the hope of informing both practitioners and theorists who may have familiarity with some sets of tests, but not others. We will also only introduce related work that has a direct relationship with this paper.
There are also a large number of tests for parametric two-sample testing (assuming a form for underlying distributions, like Gaussianity), and others for testing only differences in mean of distributions (like Hotelling’s t-test, Wilcoxon’s signed rank test, Mood’s median test). Our focus will be different from these—in this paper, we will restrict our attention only to nonparametric tests for testing differences in distributions, i.e., differences in any moment of distributions that may not have a known parametric form.
Our paper started as an attempt to understand testing with the Wasserstein distance (also called earth-mover’s distance or transportation distance). The main prior work in this area involved studying the “trimmed” comparison of distributions by [
1,
2] with applications to biostatistics, specifically population bioequivalence, and later by [
3,
4]. Apart from two-sample testing, the study of univariate
goodness-of-fit testing (or one-sample testing) was undertaken in [
5,
6,
7], and summarized exhaustively in [
8]. There are other semiparametric works specific to goodness-of-fit testing for location-scale families that we do not mention here, since they diverge from our interest in fully nonparametric two-sample testing for generic distributions.
1.1. Contributions
In this survey-style paper, we uncover an interesting relationship between the multivariate Wasserstein test and the (Euclidean) Energy distance test, also called the Cramer test, proposed independently by [
9,
10]. This proceeds through the construction of a
smoothed Wasserstein distance, by adding an entropic penalty/regularization—varying the weight of the regularization interpolates between the Wasserstein distance at one extreme and the Energy distance at the other extreme. Due to the relationship between distances and kernels, we will also establish connections to the kernel-based multivariate test by [
11] called the Maximum Mean Discrepancy (MMD).
We summarize connections between the univariate Wasserstein test and popular univariate data analysis tools like quantile–quantile (QQ) plots and the Kolmogorov–Smirnov test. Finally, the desire to design a univariate
distribution-free Wasserstein test will lead us to the formal study of Receiver Operating Characteristic (ROC) and Ordinal Dominance (ODC) curves, relating to work by [
12].
While we connect a wide variety of popular and seemingly disparate families of tests, there are still further classes of tests that we do not have space to discuss. Some examples of tests quite different from the ones studied here include rank based tests as covered by the excellent book [
13], and graphical tests that include spanning tree methods by [
14] (generalizing the runs test by [
15]), nearest-neighbor based tests by [
16,
17], and the cross-match tests by [
18]. The book by [
19] is also a useful reference.
1.2. Paper Outline
The rest of this paper proceeds as follows. In
Section 2, we formally present the notation and setup of nonparametric two-sample testing, as well as briefly introduce three different ways of comparing distributions—using cumulative distribution functions (CDFs), quantile functions (QFs) and characteristic functions (CFs). The main contribution of this paper is
Section 3, where we introduce the entropy-smoothed Wasserstein distance, and we form a novel connection between the multivariate Wasserstein distance to the multivariate Energy Distance, and to the kernel MMD. In
Section 4, we discuss the relation between the univariate Wasserstein two-sample test to PP and QQ plots/tests, including the popular Kolmogorov–Smirnov test. In
Section 6, we run some simulations to compare the different classes of tests discussed. Lastly, in
Section 5, we will design a univariate Wasserstein test statistic that is also “distribution-free” unlike its classical counterpart, providing a careful and rigorous analysis of its limiting distribution by connecting it to ROC/ODC curves. In summary,
Section 3,
Section 4 and
Section 5, respectively, discuss the following connections:
We view the similarities and differences between these above tests through two lenses. The first is the population viewpoint of how different tests work with different representations of distributions; most of these tests are based on differences between quantities that completely specify a distribution—(a) CDFs; (b) QFs; and (c) CFs. The second viewpoint is the finite sample behavior of these statistics under the null hypothesis; most of these tests have null distributions based on norms of Brownian bridges, alternatively viewed as infinite sums of weighted chi-squared distributions (due to the Karhunen–Loeve expansion). We will return to these points as the paper proceeds.
2. Nonparametric Two-Sample Testing
More formally, given i.i.d. samples ∼P and ∼Q, where P and Q are probability measures on , we denote by and the corresponding empirical measures. A test η is a function from the data to (or to if it is a randomized test), where 0/1 indicates acceptance/rejection of the null hypothesis.
Most tests proceed by calculating a scalar test statistic
and deciding
or
depending on whether
, after suitable normalization, is smaller or larger than a threshold
.
is calculated based on a prespecified false positive rate
α, chosen so that
, at least asymptotically. Indeed, all tests considered in this paper are of the form
We follow the Neyman–Pearson paradigm, where a test is judged by its power
which is some function
. We say that a test
η is consistent, in the classical sense, when
All the tests we consider in this paper will be consistent in the classical sense mentioned above. Establishing general conditions under which these tests are consistent in the high-dimensional setting is largely open. All the test statistics considered here are of the form that they are typically small under and large under (usually with appropriate scaling, they converge to zero and to infinity, respectively, with infinite samples). The aforementioned threshold will be determined by the distribution of the test statistic being used under the null hypothesis (i.e., assuming the null was true, we would like to know the typical variation of the statistic, and we reject the null if our observation is far from what is typically expected under the null). This naturally leads us to study the null distribution of our test statistic, i.e., the distribution of our statistic under the null hypothesis. Since these are crucial to running and understanding the corresponding tests, we will pursue their description in detail in this paper.
2.1. Three Ways to Compare Distributions
The literature broadly has three dominant ways of comparing distributions, both in one and in multiple dimensions. These are based on three different ways of characterizing distributions—CDFs, CFs and QFs. Many of the tests we will consider involve calculating differences between (empirical estimates of) these quantities.
For example, it is well known that the Kolmogorov–Smirnov (KS) test by [
20,
21] involves differences in empirical CDFs. We shall later see that in one dimension, the Wasserstein distance calculates differences in QFs.
The KS test, the related Cramer von-Mises criterion by [
22,
23], and Anderson–Darling test by [
24] are very popular in one dimension, but their usage has been more restricted in higher dimensions. This is mostly due to the curse of dimensionality involved with estimating multivariate empirical CDFs. While there has been work on generalizing these popular one-dimensional to higher dimensions, like [
25], these are seemingly not the most common multivariate tests.
Kernel and distance based tests have recently gained in popularity. As we will recap in more detail in later sections, it is known that the Gaussian kernel MMD implicitly calculates a (weighted) difference in CFs and the Euclidean energy distance implicitly works with a difference in (projected) CDFs.
3. Entropy Smoothed Wasserstein Distances
The family of
p-Wasserstein distances is a by-product of optimal transport theory [
26]. Optimal transport can be used to compare probability measures in metric spaces; we consider here the classical case where that metric space is
endowed with the usual Euclidean metric.
3.1. Wasserstein Distance
Given an exponent , the definition of the p-Wasserstein distance reads:
Definition 1 (Wasserstein Distances)
. For and Borel probability measures on with finite p-moments, their p-Wasserstein distance ([26], Section 6) iswhere is the set of all joint probability measures on whose marginals are , i.e., for all subsets , we have and . A remarkable feature of Wasserstein distances is that Definition 1 applies to all measures regardless of their absolute continuity with respect to the Lebesgue measure: The same definition works for both empirical measures and for their densities if they exist.
Writing
for the
n-dimensional vector of ones, when comparing two empirical measures with uniform (the Wasserstein machinery works also for non-uniform weights. We do not mention this in this paper because all of the measures we consider in the context of two-sample testing are uniform) weight vectors
and
, the Wasserstein distance
exponentiated to the power
p is the optimum of a network flow problem known as the transportation problem ([
27], Section 7.2). This problem has a linear objective and a polyhedral feasible set, defined, respectively, through the matrix
of pairwise distances between elements of
X and
Y raised to the power
p:
and the polytope
defined as the set of
nonnegative matrices such that their row and column sums are equal to
and
, respectively:
Let
be the usual Frobenius dot-product of matrices. Combining Equations (
2) and (
3), we have that
is the optimum of a linear program
S of
variables,
of feasible set
and cost matrix
.
We finish this section by pointing out that the rate of convergence as
of
towards
gets slower as the dimension
d grows under mild assumptions. For simplicity of exposition, consider
. For any
, it follows from [
28] that for
, the difference between
and
scales as
. We also point out that when
, the rate actually scales as
(see [
29]). Finally, we note that when considering
, the rates of convergence are different to those when
. The work of [
30,
31,
32] shows that the rate of convergence of
towards
is of the order
when
and
when
. Hence, the original Wasserstein distance by itself may not be a favorable choice for a multivariate two-sample test.
3.2. Entropic Smoothing
Aside from the slow convergence rate of the Wasserstein distance between samples from two different measures to their distance in population, computing the optimum of Equation (
4) is expensive. This can be easily seen by noticing that the transportation problem boils down to an optimal assignment problem when
. Since the resolution of the latter has a cubic cost in
n, all known algorithms that can solve the optimal transport problem scale at least super-cubicly in
n. Using an idea that can be traced back as far as Schrodinger [
33], Cuturi [
34] recently proposed to use an entropic regularization of the optimal transport problem, in order to define the Sinkhorn divergence between
parameterized by
as
where
is the entropy of
T seen as a discrete joint probability distribution, namely
: = −
This approach has two benefits: (i) because
is 1-strongly convex with respect to the
norm, the regularized problem is itself strongly convex and admits a unique optimal solution, written
, as opposed to the initial OT problem, for which the minimizer may not be unique; (ii) this optimal solution
is a diagonal scaling of
, the element-wise exponential matrix of
. One can easily show using the Lagrange method of multipliers that there must exist two non-negative vectors
such that
: =
, where
are diagonal matrices with
u and
v on their diagonal. The solution to this diagonal scaling problem can be found efficiently through Sinkhorn’s algorithm [
35], which has a linear convergence rate [
36]. Sinkhorn’s algorithm can be implemented in a few lines of code that only require matrix vector products and elementary operations, hence they are easily parallelized on modern hardware.
3.3. Two Extremes of Smoothing: Wasserstein and Energy Distance
An interesting class of tests are distance-based “energy statistics” as introduced originally by [
9], and later by [
10]. The statistic, called the
Cramer statistic by the latter paper and
Energy Distance by the former, corresponds to the population quantity
where
and
(all i.i.d.). The associated test statistic is
It was proved by the authors that
iff
. Hence, rejecting when
is larger than an appropriate threshold leads to a test which is consistent against all fixed alternatives where
under mild conditions (like finiteness of
); see aforementioned references for details. Then, the Sinkhorn divergence defined in Equation (
5) can be linked to the the energy distance when the parameter
λ is set to
— namely when only entropy is considered in the resolution of Equation (
5), through the following formula:
Indeed, notice first that the solution to Equation (
5) at
is the maximum entropy table in
, namely the outer product
of the marginals
and
. Hence, Equation (
6) follows from the observations that
It is also known that the population energy distance is related to the integrated difference in CDFs, i.e.,
where
(similarly
) is the population CDF of
X when projected along direction
a and
is the surface of the
d-dimensional unit sphere; see [
9] for a proof.
3.4. From Energy Distance to Kernel Maximum Mean Discrepancy
Another popular class of tests that has emerged over the last decade are kernel-based tests introduced independently by [
37,
38], and expanded on in [
11]. Without getting into technicalities that are irrelevant for this paper, the
Maximum Mean Discrepancy between
is defined as
where
is a Reproducing Kernel Hilbert Space associated with Mercer kernel
, and
is its unit norm ball.
While it is easy to see that
always, and also that
implies
, Reference [
37] shows that if
k is “characteristic”, the equality holds iff
. The Gaussian kernel
is a popular example of a characteristic kernel, and in this case,
can be interpreted as the integrated difference between characteristic functions. Indeed, by Bochner’s theorem (see [
39]), the population quantity
with the Gaussian kernel is precisely (up to constants)
where
is the characteristic function of
X at frequency
t (similarly
). Using the Riesz representation theorem and the reproducing property of
, one can argue that
and conclude that
This gives rise to a natural associated test statistic, a plugin estimator of
:
At first sight, the Energy Distance and the MMD look like fairly different tests. However, there is a natural connection that proceeds in two steps. Firstly, there is no reason to stick to only the Euclidean norm
to measure distances for ED—the test can be extended to other norms, and in fact also other metrics; Reference [
40] explains the details for the closely related independence testing problem. Following that, Reference [
41] discusses the relationship between distances and kernels (again for independence testing, but the same arguments also hold in the two-sample testing setting). Loosely speaking, for every kernel
k, there exists a metric
d (and also vice versa), given by
, such that MMD with kernel
k equals ED with metric
d. This is a very strong connection between these two families of tests—the energy distance is a special case of the kernel MMD, corresponding to a particular choice of kernel, and the kernel MMD itself corresponds to an extremely smoothed Wasserstein distance, for a particular choice of distance.
4. Univariate Wasserstein Distance and PP/QQ Tests
For univariate random variables, a PP plot is a graphical way to view differences in empirical CDFs, while QQ plots are analogous to comparing QFs. Instead of relying on graphs, we can also make such tests more formal and rigorous as follows. We first present some results on the asymptotic distribution of the difference between and when using the distance between the CDFs and and then later when using the distance between the QFs and . For simplicity, we assume that both distributions P and Q are supported on the interval ; we remark that under mild assumptions on P and Q, the results we present in this section still hold without such a boundedness assumption. We assume for simplicity that the CDFs F and G have positive densities on .
4.1. Comparing CDFs (PP)
We start by noting
may be interpreted as a random element taking values in the space
of right continuous functions with left limits. It is well known that
where
is a standard Brownian bridge in
and where the weak convergence
is understood as convergence of probability measures in the space
; see Chapter 3 in [
42] for details. From this fact and the independence of the samples, it follows that under the null hypothesis
, as
The previous fact and continuity of the function
imply that as
, we have under the null,
Observe that the above asymptotic null distribution depends on
F, which is unknown in practice. This is an obstacle when considering any
-distance, with
, between the empirical cdfs
and
. Luckily, a different situation occurs when one considers the
-distance between
and
. Under the null, using Equation (
7) again, we deduce that
where the equality in the previous expression follows from the fact that the continuity of
F implies that the interval
is mapped onto the interval
. This is known as the Kolmogorov–Smirnov test, and is hence appropriate for two-sample problems. A related statistic, called the Anderson-Darling test, will also be considered in the experiments.
4.2. Comparing QFs (QQ)
We now turn our attention to QQ (quantile–quantile) plots and specifically the
-distance between
and
. It can be shown that if
F has a differentiable density
f which (for the sake of simplicity) we assume is bounded away from zero, then
For a proof of the above statement, see Chapter 18 in [
43]; for an alternative proof where the weak convergence is considered in the space of probability measures on
(as opposed to the space
we have been considering thus far), see [
8]. We note that from the previous result and independence, it follows that under the null hypothesis
,
In particular, by continuity of the function
, we deduce that
Hence, as was the case when we considered the difference of the cdfs
and
, the asymptotic distribution of the
-difference (or analogously any
-difference for finite
p) of the empirical quantile functions is also distribution dependent. Note, however, that there is an important difference between QQ and PP plots when using the
norm. We saw that the asymptotic distribution of the
norm of the difference of
and
is (under the null hypothesis) distribution free. Unfortunately, in the quantile case, we obtain
which, of course, is distribution dependent. Since one would have to resort to computer-intensive Monte-Carlo techniques (like bootstrap or permutation testing) to control type-1 error, these tests are sometimes overlooked (though with modern computing speeds, they merit further study).
4.3. Wasserstein Is a QQ Test
Recall that, for
, the
p-Wasserstein distance between two probability measures
on
with finite
p-moments is given by Equation (
1).
Because the Wasserstein distance measures the cost of transporting mass from the original distribution
P into the target distribution
Q, one can say that it measures “horizontal” discrepancies between
P and
Q. Intuitively, two probability distributions
P and
Q that are different over “long” (horizontal) regions will be far away from each other in the Wasserstein distance sense because, in that case, mass has to travel long distances to go from the original distribution to the target distribution. In the one-dimensional case (in contrast with what happens in dimension
), the
p-Wasserstein distance has a simple interpretation in terms of the quantile functions
and
of
P and
Q, respectively. The reason for this is that the optimal way to transport mass from
P to
Q has to satisfy a certain monotonicity property that we describe in the proof of the following proposition. This is a well known fact that can be found, for example, in [
19].
Proposition 1. The p-Wasserstein distance between two probability measures P and Q on with p-finite moments can be written aswhere and are the quantile functions of P and Q, respectively. Having considered the
p-Wasserstein distance
for
in Proposition 1, we conclude this section by considering the case
. Let
be two probability measures on
with bounded support. That is, assume that there exists a number
such that
and
. We define the ∞-Wasserstein distance between
P and
Q by
Proceeding as in the case
, it is possible to show that the ∞-Wasserstein distance between
P and
Q with bounded supports can be written in terms of the difference of the corresponding quantile functions as
The Wasserstein distance is called the Mallow’s distance in the statistical literature, where it has been studied due to its ability to capture weak convergence precisely—
converges to 0 if and only if
converges in distribution to
F and also the
p-th moment of
X under
converges to the corresponding moment under
F; see [
44,
45,
46]. It is also related to the Kantorovich–Rubinstein metric from optimal transport theory.
5. Distribution-Free Wasserstein Tests and ROC/ODC Curves
As we earlier saw, under , the statistic has an asymptotic distribution that is not distribution free, i.e., it depends on F. We also saw that as opposed to what happens with the asymptotic distribution of the distance between and , the asymptotic distribution of does depend on the cdf F. In this section, we show how we can construct a distribution-free Wasserstein test by connecting it to the theory of ROC and ODC curves.
5.1. Relating Wasserstein Distance to ROC and ODC Curves
Let
P and
Q be two distributions on
with cdfs
F and
G and quantile functions
and
, respectively. We define the
ROC curve between
F and
G as the function.
In addition, we define their
ODC curve by
The following are properties of the ROC curve (see [
12]):
The curve is increasing and , .
If for all t, then for all t.
If have densities with monotone likelihood ratio, then the ROC curve is concave.
The area under the ROC curve is equal to , where Y∼Q and X∼P.
Intuitively speaking, the faster the ROC curve increases towards the value 1, the easier it is to distinguish the distributions P and Q. Observe from their definitions that the ROC curve can be obtained from the ODC curve after reversing the axes. Given this, we focus from this point on only one of them, the ODC curve being more convenient.
The first observation about the ODC curve is that it can be regarded as the quantile function of the distribution
(the push forward of
P by
G) on
, which is defined by
Similarly, we can consider the measure
, that is, the push forward of
by
. We crucially note that the empirical ODC curve
is the quantile function of
. From
Section 4, we deduce that
for every
and also
That is, the p-Wasserstein distance between the measures and can be computed by considering the distance of the ODC curve and its empirical version.
First, we argue that under the null hypothesis
, the distribution of the empirical ODC curve is actually independent of
P. In particular,
and
are distribution free under the null! This is the content of the next lemma, proved in the
Appendix.
Lemma 1 (Reduction to uniform distribution)
. Let be two continuous and strictly increasing CDFs and let and be the empirical CDFs. Consider the (unknown) random variables, which are distributed uniformly on , Let be the empirical CDF associated with the (uniform) s and let be the empirical CDF associated with the (uniform) s. Then, under the null , we have In particular, we have
Proof. We denote by
the order statistic associated to the
Ys. For
and
, we have
if and only if
, which holds if and only if
, which, in turn, is equivalent to
. Thus,
if and only if
. From the previous observations, we conclude that
. Finally, since
, we conclude that
This concludes the proof. ☐
Note that since are obviously instantiations of uniformly distributed random variables, the right hand side of the last equation only involves uniform random variables, and hence the distribution of is independent of under the null. Now, we are almost done, and this above lemma will imply that the Wasserstein distance between and the uniform distribution (since for when ) also does not depend on .
More formally, one may establish a result on the asymptotic distribution of the statistic
and
. We do this by first considering the asymptotic distribution of the difference between the empirical ODC curve and the population ODC curve regarding both of them as elements in the space
. This is the content of the following Theorem which follows directly from the work of [
47] (see [
12]).
Theorem 1. Suppose that F and G are two CDFs with densities satisfyingfor all . In addition, assume that as . Then,where and are two independent Brownian bridges and where the weak convergence must be interpreted as weak convergence in the space of probability measures on the space . As a corollary, under the null hypothesis
:
, we obtain the following. Suppose that the CDF
F of
P is continuous and strictly increasing. Then,
To see this, note that by Lemma 1 that it suffices to consider
in
. In that case, the assumptions of Theorem 1 are satisfied and the result follows directly. The latter test based on the infinity norm is extremely similar to the Kolmogorov–Smirnov test in theory and practice—one may also note the similarity of the above expressions with Equations (
9) and (
10).
The takeaway message of this section is that instead of considering the Wasserstein distance between and , whose null distribution depends on unknown F, one can instead consider the Wasserstein distance between and the uniform distribution , since its null distribution is independent of F.
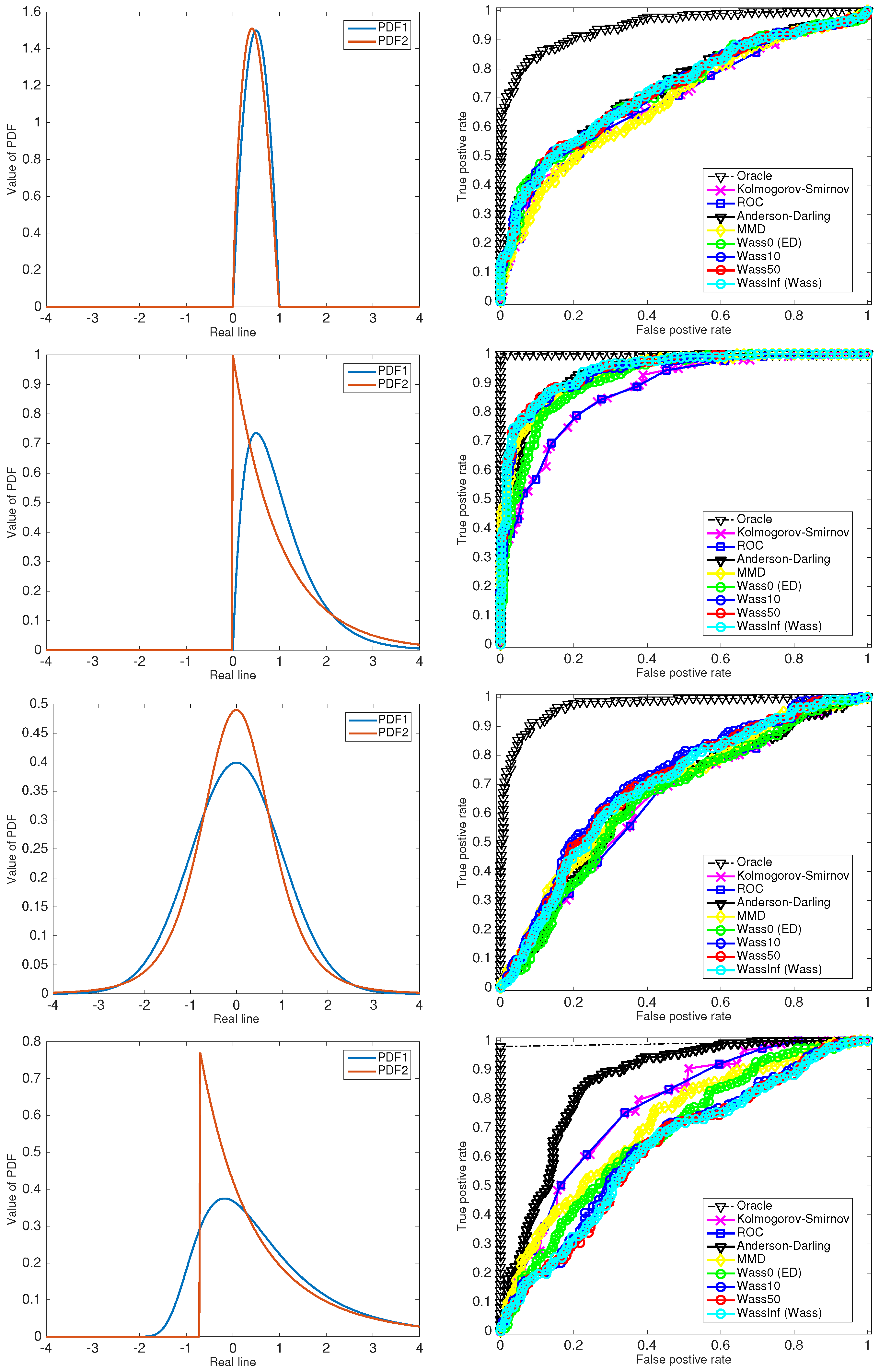
6. Experiments
One cannot, in general, have results comparing the powers of different nonparametric tests. Which test achieves a higher power depends on the class of alternatives being considered—some tests are more sensitive to deviations near the median, others are more sensitive to differences in the tails, and yet others are more sensitive to deviations that are not represented in the original space but instead in an underlying Hilbert space embedding of distributions (MMD and ED are examples of this). Hence, the statistical literature has very sparse results on theoretical comparisons between distributions, and one must often resort to experiments to get a sense of their relative performance on examples of interest.
In this section, we report results for two-sample tests run with the following example distributions (the parameters for the
k-th pair of distributions (for
) so that the distributions have their first
k-1 central moments as identical, but differ in their
k-th central moments):
Beta(2,2) versus Beta(1.8,2.16);
Exponential(1), equivalently Gamma(1,1), versus Gamma(2,0.5);
Standard Normal versus Student’s t;
Generalized extreme value versus Generalized Pareto.
We use some common test statistics that have already been mentioned in this paper—Kolmogorov–Smirnov, Anderson–Darling, Maximum Mean Discrepancy (MMD), ROC (infinity norm) and the smoothed Wasserstein distance with four regularizations: 0 (corresponding to Energy Distance), 10, 50 and infinity (corresponding to Wasserstein distance).
All of these statistics are nonparametric, in the sense that they do not assume a particular form or have access to the true underlying PDFs. Nevertheless, all of the examples that we construct are parametric, so we also include the “oracle” likelihood ratio test (we term it as an oracle since it uses extra knowledge, namely the exact form of the PDFs, to which the other tests do not have access).
One may note from
Figure 1 that the precision-recall curve of nonparametric tests are often much worse than the oracle likelihood ratio test, and this is indeed to be expected—the true utility of the nonparametric tests would be observed in a real-world example where one wishes to abstain from making any (possibly wrong, biased or misleading) parametric assumptions. As might be expected from the discussion at the start of the section, the tests are rather difficult to compare. Among the tests considered, the ordering of the curves changes over different experiments, and even within the class of Wasserstein tests. While general comparisons are difficult, there is a need for theoretical analysis comparing classes of tests in special cases of practical interest (for example, mean-separated Gaussians).
The role of entropic smoothing parameter λ is also currently unclear, and whether there is a data dependent way to pick it so as to maximize power. This could be an interesting direction of future research.
7. Conclusions
In this paper, we connect a wide variety of univariate and multivariate test statistics, with the central piece being the Wasserstein distance. The Wasserstein statistic is closely related to univariate tests like the Kolmogorov–Smirnov test, graphical QQ plots, and a distribution-free variant of the test is proposed by connecting it to ROC/ODC curves. Through entropic smoothing, the Wasserstein test is also related to the multivariate tests of Energy Distance and hence transitively to the Kernel Maximum Mean Discrepancy. We hope that this is a useful resource to connect the different families of two-sample tests, many of which can be analyzed under the two umbrellas of our paper—whether they differentiate between CDFs, QFs or CFs, and what their null distributions look like. Many questions remain open—for example, the role of smoothing parameter λ.


{kind=link}