
Predicting China’s SME Credit Risk in Supply Chain Finance Based on Machine Learning Methods



Abstract
:1. Introduction
2. Methodology and Data
2.1. Methodology Research
- (1)
- Input: the data set is , the base classifier algorithm is L , the number of random subspace rate is k , the number of learning rounds is T;
- (2)
- For ;
- (3)
- Random generate a subspace sample from ;
- (4)
- Train a base classifier from the subspace sample;
- (5)
- end;
- (6)
- Output: ;
- (1)
- The data set is , is the feature vector with m length; is the category label of ;
- (2)
- Initial distribution of training set sample: ;
- (3)
- The quantification of weak classifier is T, :a. The disjoint subspace is ,b. Obtain a class probability estimate ,c. Obtain the outputs of each weak classifier, ,,d. Re-normalize the sample distribution: ;
- (4)
- Output the classifier .
- (1)
- Input: the dataset is E, the attribute-valued is F;
- (2)
- , ;
- (3)
- if is “true” then , , return leaf;
- (4)
- else, , ;
- (5)
- Order as the best attribute according to above computed criteria, for each do;
- (6)
- , and ;
- (7)
- create as the decision node of ;
- (8)
- Attach to the corresponding branch of as v;
- (9)
- end for;
- (10)
- end if;
- (11)
- Return .
2.2. Data Preparation
3. Empirical Study
3.1. Empirical Procedure
3.2. Experimental Performance Measure
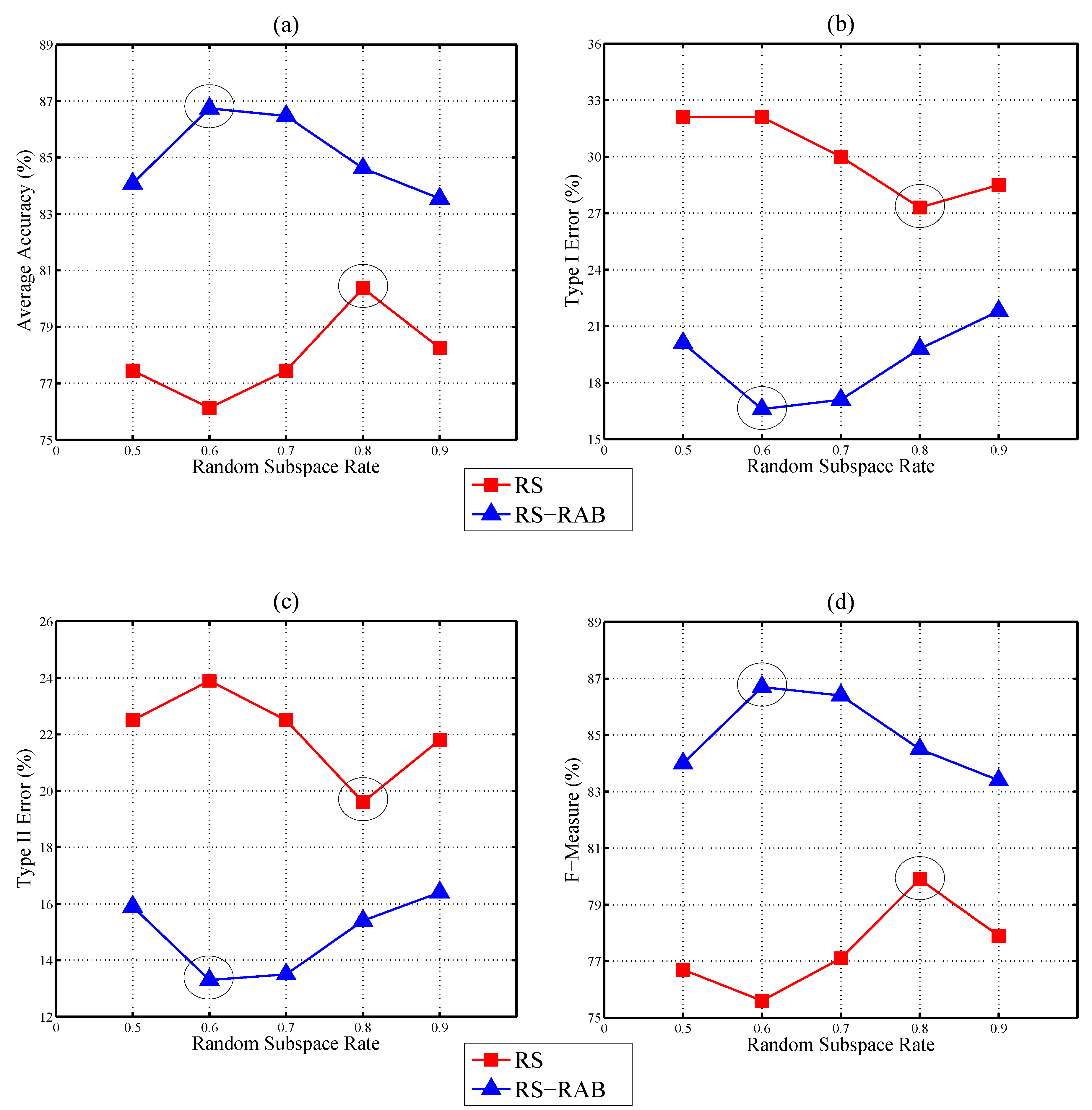
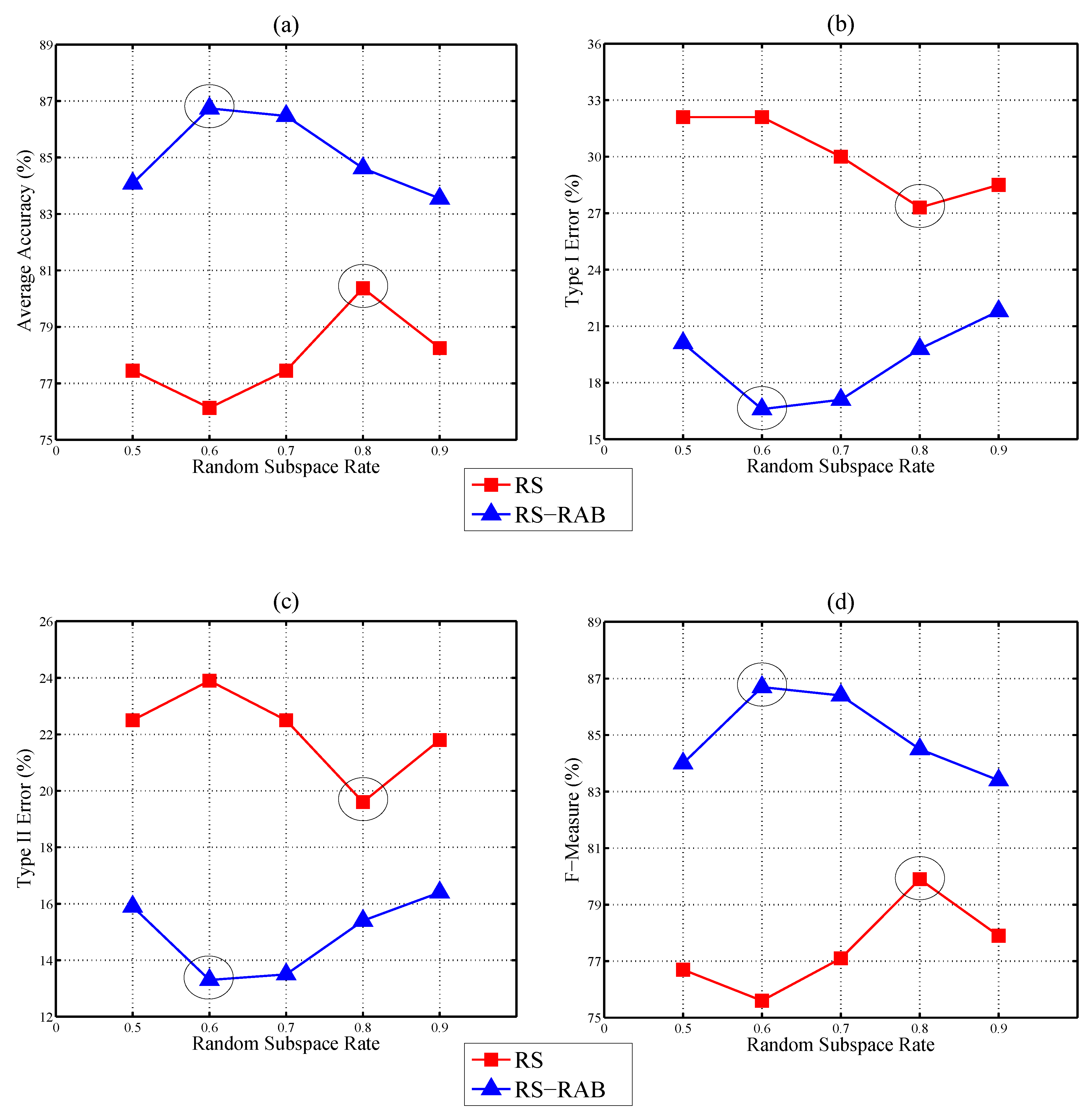
3.3. Experimental Results and Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- More, D.; Basu, P. Challenges of supply chain finance: A detailed study and a hierarchical model based on the experiences of an Indian firm. Bus. Process Manag. J. 2013, 19, 624–647. [Google Scholar] [CrossRef]
- Seifert, R.W.; Seifert, D. Financing the chain. Int. Commer. Rev. 2011, 10, 32–44. [Google Scholar] [CrossRef]
- Sopranzetti, B.J. Selling accounts receivable and the underinvestment problem. Q. Rev. Econ. Financ. 1999, 39, 291–301. [Google Scholar] [CrossRef]
- Wuttke, D.A.; Blome, C.; Henke, M. Focusing the financial flow of supply chains: An empirical investigation of financial supply chain management. Int. J. Prod. Econ. 2013, 145, 773–789. [Google Scholar] [CrossRef]
- Thomas, L.C. A survey of credit and behavioral scoring: Forecasting financial risks of lending to customers. Int. J. Forecast. 2000, 16, 149–172. [Google Scholar] [CrossRef]
- Jiang, Y. Credit scoring model based on the decision tree and the simulated annealing algorithm. In Proceedings of the 2009 World Congress on Computer Science and Information Engineering, Los Angeles, CA, USA, 31 March–2 April 2009.
- Hung, C.; Chen, J. A selective ensemble based on expected probabilities for bankruptcy prediction. Expert Syst. Appl. 2009, 36, 5297–5303. [Google Scholar] [CrossRef]
- Nanni, L.; Lumini, A. An experimental comparison of ensemble of classifiers for bankruptcy prediction and credit scoring. Expert Syst. Appl. 2009, 36, 3028–3033. [Google Scholar] [CrossRef]
- Tsai, C.; Wu, J. Using neural network ensembles for bankruptcy prediction and credit scoring. Expert Syst. Appl. 2008, 34, 2639–2649. [Google Scholar] [CrossRef]
- Yu, L.; Wang, S.; Lai, K.K. Credit risk assessment with a multistage neural network ensemble learning approach. Expert Syst. Appl. 2008, 34, 1434–1444. [Google Scholar] [CrossRef]
- West, D.; Dellana, S.; Qian, J. Neural network ensemble strategies for financial decision applications. Comput. Oper. Res. 2005, 32, 2543–2559. [Google Scholar] [CrossRef]
- Wang, G.; Ma, J. Study of corporate credit risk prediction based on integrating boosting and random subspace. Expert Syst. Appl. 2011, 38, 13871–13878. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the 13th International Conference on Machine Learning, Bari, Italy, 3–6 July 1996.
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Schapire, R.E.; Freund, Y.; Bartlett, P.; Lee, W.S. Boosting the margin: A new explanation for the effectiveness of voting methods. Ann. Stat. 1998, 26, 1651–1686. [Google Scholar] [CrossRef]
- Schapire, R.E. Improved boosting algorithms using confidence-rated predictions. Mach. Learn. 1999, 37, 297–336. [Google Scholar] [CrossRef]
- Maclin, R.; Opitz, D. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar]
- Fu, Z.W.; Golden, B.L.; Lele, S.; Raghavan, S.; Wasil, E. Diversification for better classification trees. Comput. Oper. Res. 2006, 33, 3185–3202. [Google Scholar] [CrossRef]
- Zhu, Y.; Xie, C.; Wang, G.J.; Yan, X.G. Comparison of individual, ensemble and integrated ensemble machine learning methods to predict China’s SME credit risk in supply chain finance. Neural Comput. Appl. 2016. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers: San Francisco, CA, USA, 1993. [Google Scholar]
- China Stock Market and Accounting Research (CSMAR). Stock Market Data-Base in China (2012–2013). Available online: http://www.gtarsc.com (accessed on 18 May 2016).
- Xiong, X.; Ma, J.; Zhao, W. Credit risk analysis of supply chain finance. Nankai Bus. Rev. 2009, 12, 92–98. [Google Scholar]
- Zhu, Y.; Xie, C.; Sun, B.; Wang, G.J.; Yan, X.G. Predicting China’s SME credit risk in supply chain financing by logistic regression, artificial neural network and hybrid models. Sustainability 2016, 8, 433. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From Precision, Recall and F-measure to ROC, informedness, markedness & correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]


{kind=link}
{kind=link}
| Factors | Code | Variables | Categories |
|---|---|---|---|
| Applicant factors | R1 | Current ratio | Liquidity |
| R2 | Quick ratio | Liquidity | |
| R3 | Cash ratio | Liquidity | |
| R4 | Working capital turnover | Liquidity | |
| R5 | Return on equity | Leverage | |
| R6 | Profit margin on sales | Profitability | |
| R7 | Rate of Return on Total Assets | Leverage | |
| R8 | Total Assets Growth Rate | Activity | |
| Counter party factors | R9 | Credit rating of CE | Non-finance |
| R10 | Quick ratio | Liquidity | |
| R11 | Turnover of total capital | Liquidity | |
| R12 | Profit margin on sales | Profitability | |
| Items’ characteristics factors | R13 | Price rigidity, liquidation and vulnerable degree of trade goods | Non-finance |
| R14 | Account receivable collection period | Leverage | |
| R15 | Accounts receivable turnover ratio | Leverage | |
| Operation condition factors | R16 | Industry trends | Non-finance |
| R17 | Transaction time and transaction frequency | Non-finance | |
| R18 | Credit rating of SME | Non-finance |
| DT | RS a | RAB | RS-RAB b | |
|---|---|---|---|---|
| Average accuracy | 79.58% | 80.37% | 73.47% | 86.74% |
| Type I error | 23.60% | 27.30% | 33.90% | 16.60% |
| Type II error | 20.40% | 19.60% | 26.50% | 13.30% |
| F-Measure | 79.70% | 79.90% | 73.20% | 86.70% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Xie, C.; Wang, G.-J.; Yan, X.-G. Predicting China’s SME Credit Risk in Supply Chain Finance Based on Machine Learning Methods. Entropy 2016, 18, 195. https://doi.org/10.3390/e18050195
Zhu Y, Xie C, Wang G-J, Yan X-G. Predicting China’s SME Credit Risk in Supply Chain Finance Based on Machine Learning Methods. Entropy. 2016; 18(5):195. https://doi.org/10.3390/e18050195
Chicago/Turabian StyleZhu, You, Chi Xie, Gang-Jin Wang, and Xin-Guo Yan. 2016. "Predicting China’s SME Credit Risk in Supply Chain Finance Based on Machine Learning Methods" Entropy 18, no. 5: 195. https://doi.org/10.3390/e18050195
APA StyleZhu, Y., Xie, C., Wang, G.-J., & Yan, X.-G. (2016). Predicting China’s SME Credit Risk in Supply Chain Finance Based on Machine Learning Methods. Entropy, 18(5), 195. https://doi.org/10.3390/e18050195