In this section, we first give a qualitative analysis by comparing the nearest neighbors of our embeddings with other embeddings. Next, we evaluate the performance of our word sense representations on three tasks, namely, word similarity task, analogical reasoning task, and word sense effect classification task respectively.
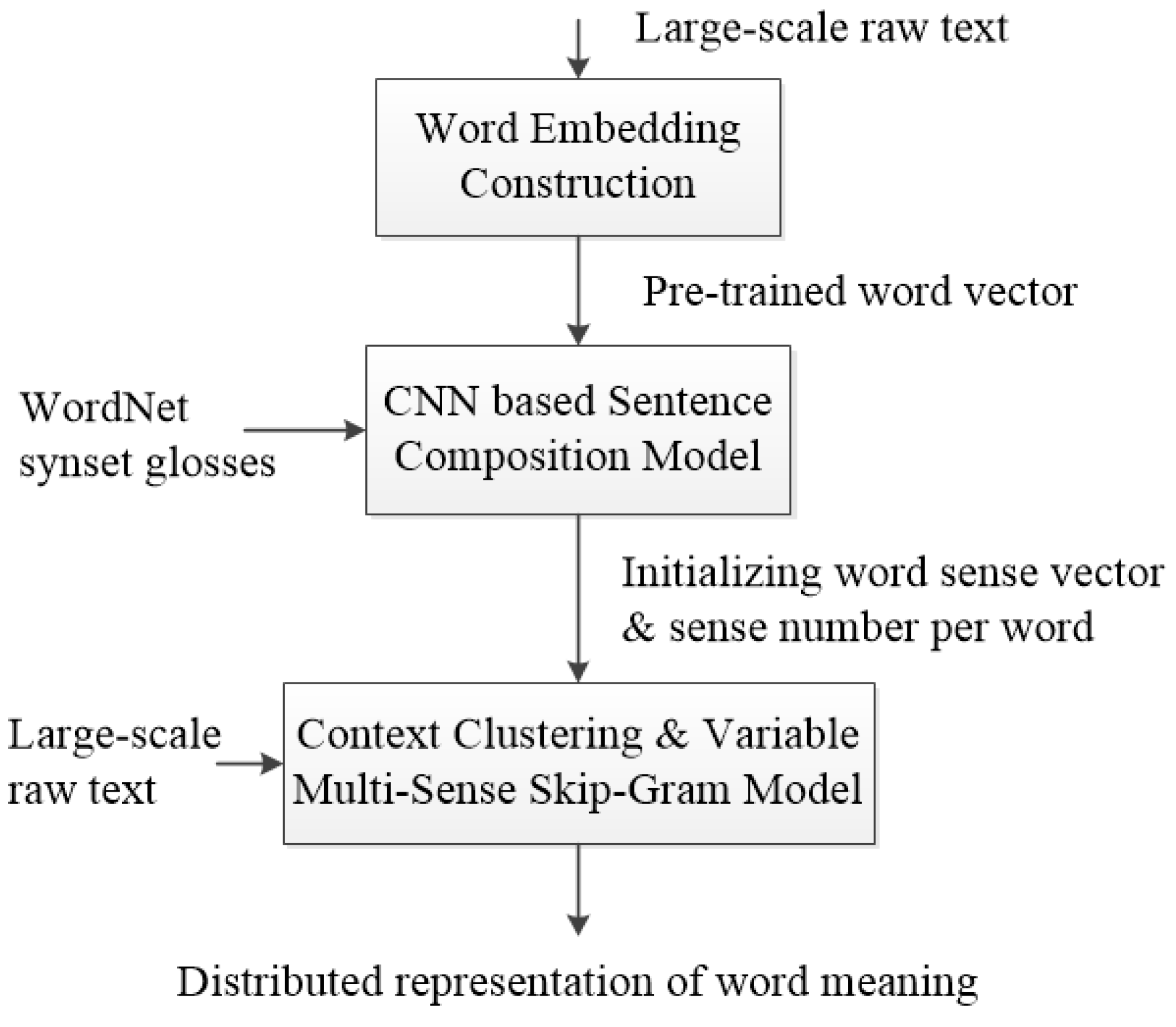
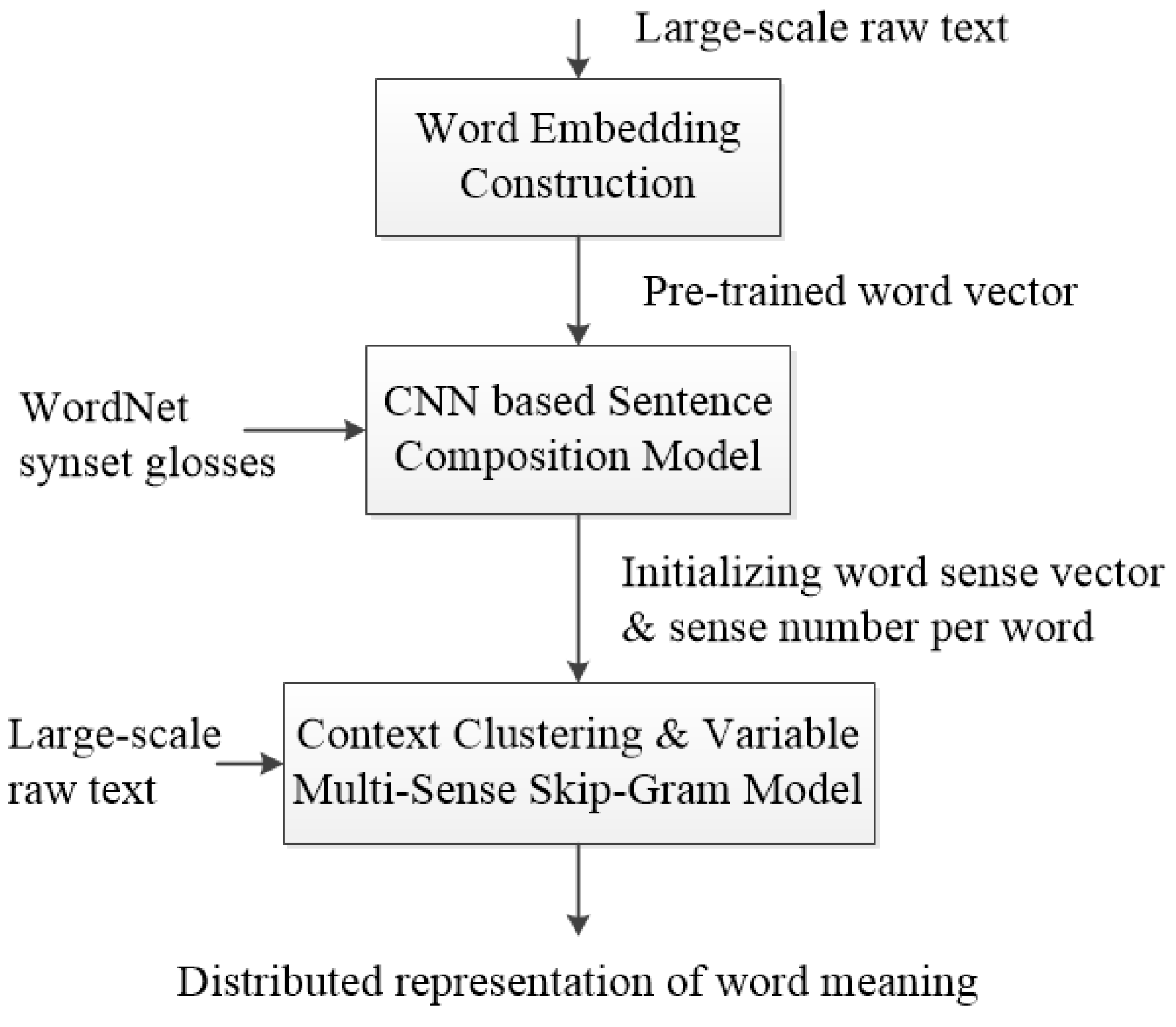
4.1. Experimental Setup
In all experiments, we use the publicly available word vectors trained on 100 billion words from Google News. The vectors have dimensionality of 300. They were trained using the CBOW model. For training sense vectors with VMSSG model, we use a snapshot of Wikipedia in April 2010 [
26] previously used in [
2,
4]. WordNet 3.1 is used for training the sentence composition model.
For training CNN, we use: rectified linear units, filter windows of 3, 4, 5 with 100 feature maps each, AdaDelta decay parameter of 0.95, the dropout rate of 0.5. For training VMSSG, we use MSSG-KMeans as the clustering algorithm, and CBOW for learning sense vectors. We set the size of word vectors to 300, using boot vectors and sense vectors. For other parameter, we use default parameter settings for MSSG.
4.2. Qualitative Evaluations
In
Table 1,
Table 2 and
Table 3, we list the nearest neighbors of each sense of three example words generated from two single-prototype word vector models (C & W and Skip-gram) and five multi-prototype word representation models. C & W refers to the word embedding published in [
9]. Skip-gram refers to the language model proposed in [
12]. Huang
et al. refers to the multi-prototype word embedding proposed in [
2]. Unified-WSR refers to the word sense embedding proposed in [
3]. Both MSSG and NP-MSSG were previously proposed in [
4] where MSSG assumes each word has the same number of senses and NP-MSSG extends from MSSG by automatically inferring the number of senses from data. CNN-VMSSG is our model. The column heading
N of the tables shows the number of sense vectors generated by different models, and it is 1 for single-prototype word vector models. The nearest neighbor is selected by comparing the cosine similarity between each sense vector and all the sense vectors of other words in the vocabulary.
It is observed that single-prototype word vector models such as C & W and Skip-gram are not able to learn different sense representations for each word while Huang et al. and MSSG always generate a fixed number of sense vectors. NP-MSSG finds fewer number of sense vectors than the actual number of word senses. Our model can find a diverse range of word senses, for example, “edge” and “IMF” for bank, “MVP” and “circle” for star, “seed” and “Spedding” for plant. It shows that our model learns more different sense representations.
Table 1.
Nearest neighbors of each sense of word bank.
Table 1.
Nearest neighbors of each sense of word bank.
| Model | N | Nearest Neighbors |
|---|
| C & W | 1 | district |
| Skip-gram | 1 | banks |
| Huang et al. | 10 | memorabilia harbour cash corporation illegal branch distributed central corporation perth |
| Unified-WSR | 18 | banking_concern incline blood_bank bank_buildingn panoply piggy_bank ridge pecuniary_resource camber vertical_bank tip border transact agent turn_a_trick deposit steel trust |
| MSSG | 3 | banks savings river |
| NP-MSSG | 2 | banks banking |
| CNN-VMSSG | 18 | HDFC mouth credit Barclays almshouses banking bancshares subsidiary check joint edge Bancshares IMF strip reserve right frank depositors |
Table 2.
Nearest neighbors of each sense of word star.
Table 2.
Nearest neighbors of each sense of word star.
| Model | N | Nearest Neighbors |
|---|
| C & W | 1 | fist |
| Skip-gram | 1 | stars |
| Huang et al. | 10 | princess silver energy version workshop guard appearance fictional die galaxy |
| Unified-WSR | 12 | supergiant ace starlet hexagram headliner asterisk star_topology co-star lead premiere dot leading |
| MSSG | 3 | stars trek superstar |
| NP-MSSG | 2 | wars stars supergiant |
| CNN-VMSSG | 12 | cast galaxies Carradine MVP newspaper Ursae sign beat trek purple circle sun |
Table 3.
Nearest neighbors of each sense of word plant.
Table 3.
Nearest neighbors of each sense of word plant.
| Model | N | Nearest Neighbors |
|---|
| C & W | 1 | yeast |
| Skip-gram | 1 | plants |
| Huang et al. | 10 | insect robust food seafood facility treatment facility natural matter vine |
| Unified-WSR | 10 | industrial_plant plant_life dodge tableau set engraft found restock bucket implant |
| MSSG | 3 | plants factory flowering |
| NP-MSSG | 4 | stars Fabaceae manufacturing power |
| CNN-VMSSG | 10 | mill power GWh production seed factory microbial Asteraceae tree Spedding |
4.3. Word Similarity Task
In this task, we evaluate our learned word sense embedding on two datasets: the WordSim-353 (WS353) dataset [
27] and the Contextual Word Similarities (SCWS) dataset [
2], respectively.
WS353 dataset consists of 353 pairs of nouns. Each pair is associated with 13 to 16 human judgments on similarity and relatedness on a scale from 0 to 10. For example, (car, flight) received an average score of 4.94, while (car, automobile) received an average score of 8.94.
SCWS dataset contains 2003 pairs of words and their sentential contexts. It consists of 1328 noun-noun pairs, 399 verb-verb, 140 verb-noun, 97 adjective-adjective, 30 noun-adjective, and 9 verb-adjective. 241 pairs are same-word pairs. Each pair is associated with 10 human judgments of similarity on a scale from 0 to 10.
We use the same metrics in [
4] to measure the similarity between two words
w and
w′ given their respective context
c and
c′. The
avgSim metric computes the average similarity of all pairs of prototype vectors for each word, ignoring information from the context:
where
d(·, ·) is a standard distributional similarity measure. Here, cosine similarity is adopted.
is the sense vector of
w.
K1,
K2 are the numbers of word senses of
w and
w′, respectively. The
avgSimC metric weights each similarity term in avgSim by the likelihood of the word context appearing in its respective cluster:
where
is the likelihood of context
c belonging to cluster
. The
globalSim metric computes each word vector ignoring the many senses:
The
localSim metric chooses the most similar sense in context to estimate the similarity of word pairs:
where
and
.
We report the Spearman’s correlation ρ × 100 between a model’s similarity scores and the human judgements in the datasets.
Table 4 shows the performance achieved on the WordSim-353 dataset. In this table, the avgSimC and localSim metrics are not given since no context is provided in this dataset. Random-VMSSG refers to MSSG trained with the sense number of each word taken from WordNet. Average-VMSSG refers to MSSG trained with the average vector of the candidate word vectors of WordNet glosses which has previously proposed by Chen
et al. [
3]. In
Average-VMSSG, for each sense
sensei of word
w, a candidate set from golss(
sensei) is defined as follows:
where POS(
u) is the part-of-speech tagging of the word
u and
CW is the set of possible part-of speech tags in WordNet: noun, verb, adjective and adverb.
vw and
vu are word vectors of
w and
u, respectively. Following Chen
et al. [
3], we set the similarity threshold
σ = 0 in this experiment. The average of the word vectors in cand(
sensei) is used to initialize sense vectors in the VMSSG model.
Table 4.
Experimental results in the WordSim-353 (WS353) task. We compute the avgSim value using the published word vectors for Unified-WSR 200 d. Other results of the compared models, e.g., Huang
et al.,
Non-Parametric Multi-Sense Skip-Gram (NP-MSSG) and
MSSG, were reported in [
4].
50 d,
200 d and
300 d refer to the dimension of the vector. The best results are highlighted in bold face.
Table 4.
Experimental results in the WordSim-353 (WS353) task. We compute the avgSim value using the published word vectors for Unified-WSR 200 d. Other results of the compared models, e.g., Huang et al., Non-Parametric Multi-Sense Skip-Gram (NP-MSSG) and MSSG, were reported in [4]. 50 d, 200 d and 300 d refer to the dimension of the vector. The best results are highlighted in bold face.
| Model | avgSim | globalSim |
|---|
| Huang et al. 50 d | 64.2 | 22.8 |
| Unified-WSR 200 d | 41.4 | - |
| NP-MSSG 300 d | 68.6 | 69.1 |
| MSSG 300 d | 70.9 | 69.2 |
| Random-VMSSG 300 d | 63.3 | 69.1 |
| Average-VMSSG 300 d | 61.5 | 69.2 |
| CNN-VMSSG 300 d | 64.4 | 69.8 |
| Pruned TF-IDF | 73.4 | - |
| ESA | - | 75.0 |
| Tiered TF-IDF | 76.9 | - |
We also present the results obtained using the word distributional representations including Pruned TF-IDF [
23], Tiered TF-IDF [
28] and Explicit Semantic Analysis (ESA) [
29]. Pruned TF-IDF and Tiered TF-IDF combine the vector-space model and context clustering. TF-IDF represents words in a word-word matrix capturing co-occurrence counts in all context windows.
Pruned TF-IDF prunes the low-value TF-IDF features while
Tiered TF-IDF uses tiered clustering that leverages feature exchangeability to allocate data features between a clustering model and shared components. ESA explicitly represents the meaning of texts in a high-dimensional space of concepts derived from Wikipedia.
It is observed that our model achieves the best performance on the globalSim metric. It indicates that the use of pre-trained word vector and initializing word sense vector is helpful to improve the quality of global word vector generated by CNN-VMSSG. Unified-WSR has the same number of senses as in our model but gives a much worse result on avgSim, being 23.0% lower. Random-VMSSG also takes the same number of senses for each word from WordNet as in our model but still performs worse on both avgSim and globalSim. CNN-VMSSG is 2.9% higher than Average-VMSSG on the avgSim metric (64.4 vs. 61.5), and 0.6% higher than Average-VMSSG on the globalSim metric (69.8 vs. 69.2), respectively. It indicates that the WordNet glosses composition approach proposed in our model performs better than using the average of the candidate word vectors of WordNet glosses.
Our model gives lower avgSim results compared to MSSG and NP-MSSG. One possible reason is that we set the number of context clusters for each word to be the same as the number of its corresponding senses in WordNet. However, not all senses appear in the our experimented corpus which could lead to fragmented context clustering results. One possible way to alleviate this problem is to perform post-processing to merge clusters which have smaller inter-cluster differences or to remove sense clusters which are under-represented in our data. We will leave it as our future work.
We report the Spearman’s correlation
ρ × 100 between a model’s similarity scores and the human judgements of SCWS dataset in
Table 5. It is observed that our model achieves the best performance on the
globalSim and
localSim metrics, being 0.8% higher on
globalSim and 1.3% higher on
localSim compared to the second best performing model
NP-MSSG. Comparing with
Average-VMSSG, our model achieves better performance on all the four metrics. It indicates that the CNN composition approach proposed in our model is beneficial for this task. Our approach however performs worse on
avgSim and
avgSimC possibly due to the same reason explained for the WS353 task.
Table 5.
Experimental results in the Contextual Word Similarities (SCWS) task. We compute the evaluation results using the published word vectors for Unified-WSR 200 d. Other results of the compared models, e.g., Huang
et al.,
NP-MSSG and
MSSG, were reported in [
4].
Table 5.
Experimental results in the Contextual Word Similarities (SCWS) task. We compute the evaluation results using the published word vectors for Unified-WSR 200 d. Other results of the compared models, e.g., Huang et al., NP-MSSG and MSSG, were reported in [4].
| Model | globalSim | avgSim | avgSimC | localSim |
|---|
| Huang et al. 50 d | 58.6 | 62.8 | 65.7 | 26.1 |
| Unified-WSR 200 d | 64.2 | 66.2 | 68.9 | - |
| NP-MSSG 300 d | 65.5 | 67.3 | 69.1 | 59.8 |
| MSSG 300 d | 65.3 | 67.2 | 69.3 | 57.3 |
| Random-VMSSG 300 d | 65.4 | 65.3 | 65.7 | 58.1 |
| Average-VMSSG 300 d | 65.5 | 64.9 | 65.9 | 59.2 |
| CNN-VMSSG 300 d | 66.3 | 65.7 | 66.4 | 61.1 |
4.4. Analogical Reasoning Task
The analogical reasoning task introduced by [
12] consists of questions of the form “
a is to
b as
c is to _”, where (
a,
b) and (
c, _) are two word pairs. The goal is to find a word
d* in vocabulary
V whose representation vector is the closest to
,
i.e.,
The question is judged as correctly-answered only if
d* is exactly the answer word in the evaluation set [
22].
WordRep is a benchmark collection for research on learning distributed word representations, which expands the Mikolov et al.’s analogical reasoning questions. It includes two kinds of evaluation sets: an enlarged evaluation set where the word pairs are collected from Wikipedia, and WordNet evaluation set where the word pairs are collected from WordNet. Considering the size of evaluation set, in our experiments, we use one evaluation set in WordRep, the WordNet collection which consists of 13 sub tasks. Let the sense numbers of a, b, c be , , , and the size of vocabulary be , the number of candidate vectors for a word sense model is , while it is only for single-prototype word vector models. This shows that the evaluation task is computationally more complicated for the word sense based models than for the single prototype models.
Table 6 shows the precision results on the 13 sub tasks. The
Word Pair column is the number of word pairs of each sub task (
). The results of C&W were obtained using the 50-dimensional word embeddings that were made publicly available by Turian
et al. [
30]. The CBOW results were previously reported in [
22]. Weighted Average is computed as follows:
It can be observed that our learned representations outperform all the other 4 embeddings on weighted average. Among 13 sub tasks, our model outperforms the others by a good margin in six sub tasks, Attribute, Causes, Entails, IsA, MadeOf and RelatedTo. Overall, our model gives superior performance compared to all the other models.
Table 6.
Experimental results in the analogical reasoning task. The numbers are the precision p × 100.
Table 6.
Experimental results in the analogical reasoning task. The numbers are the precision p × 100.
| Subtask | Word Pairs | C & W | CBOW | MSSG | NP-MSSG | CNN-VMSSG |
|---|
| Antonym | 973 | 0.28 | 4.57 | 0.25 | 0.10 | 1.01 |
| Attribute | 184 | 0.22 | 1.18 | 0.03 | 0.15 | 1.63 |
| Causes | 26 | 0.00 | 1.08 | 0.31 | 0.31 | 1.23 |
| DerivedFrom | 6,119 | 0.05 | 0.63 | 0.09 | 0.05 | 0.17 |
| Entails | 114 | 0.05 | 0.38 | 0.49 | 0.34 | 1.29 |
| HasContext | 1,149 | 0.12 | 0.35 | 1.73 | 1.56 | 1.41 |
| InstanceOf | 1,314 | 0.08 | 0.58 | 2.52 | 2.34 | 2.46 |
| IsA | 10,615 | 0.07 | 0.67 | 0.15 | 0.08 | 0.86 |
| MadeOf | 63 | 0.03 | 0.72 | 0.80 | 0.48 | 1.28 |
| MemberOf | 406 | 0.08 | 1.06 | 0.14 | 0.86 | 0.90 |
| PartOf | 1,029 | 0.31 | 1.27 | 1.50 | 0.73 | 0.48 |
| RelatedTo | 102 | 0.00 | 0.05 | 0.12 | 0.11 | 1.28 |
| SimilarTo | 3,489 | 0.02 | 0.29 | 0.03 | 0.01 | 0.12 |
| WeightedAvg | | 0.06 | 0.66 | 0.17 | 0.11 | 0.67 |
4.5. Word Sense Effect Classification
In this section, we evaluate our approach on word sense effect classification proposed by Choi and Wiebe [
31]. In this task, each sense is annotated with three classes: + effect, − effect and Null. In total, 258 + effect senses, 487 − effect senses, and 440 Null senses are manually annotated as a word sense lexicon with the help of FrameNet [
32]. Half of each set is used as training data, and the other half is used for evaluation.
Choi and Wiebe [
31] propose three word sense effect classification methods, namely, supervised learning (onlySL) method, graph-based learning (onlyGraph) method and hybrid method. In the onlySL method, the gloss classifier (SVM) is trained with word features and sentiment features for WordNet Gloss. The method also uses WordNet relations and WordNet similarity information as training features. In the onlyGraph method, a graph is constructed by using WordNet relations, such as
hypernymy,
troponymy and
grouping, and a graph-based semi-supervised learning method is used to perform label propagation. In the hybrid method, the results generated from onlySL and onlyGraph are combined by some rules, e.g.,
If the labels assigned by both models are + effect (or − effect), it is + effect (or − effect).
For evaluation metrics, we use precision (
P × 100), recall (
R × 100) and F1 score (
F1 × 100) for each class, and an overall accuracy. For classifiers, we use support vector machines (LibSVM [
33]) with default parameters in the Weka software tool [
34].
Table 7 shows the overall accuracy results and
Table 8 gives a more detailed analysis of the results obtained using different models on each word sense effect class. In both two tables, the first three models were proposed by Choi and Wiebe [
31]. For distributed sense representation models, we only compare our approach with
Unified-WSR, because other word sense models, such as Huang
et al.,
MSSG and
NP-MSSG, do not provide a one-to-one correspondence between a word sense and a WordNet synset. As such, they cannot be used for this task.
Table 7.
Experimental results on word sense effect classification task.
Table 7.
Experimental results on word sense effect classification task.
| Model | Accuracy |
|---|
| OnlySL | 61.0 |
| OnlyGraph | 59.6 |
| Hybrid | 63.4 |
| Unified-WSR | 65.0 |
| Random-VMSSG | 62.7 |
| Average-VMSSG | 63.4 |
| CNN-VMSSG | 66.1 |
Table 8.
Performance for each word sense effect class. The best and the second best results for each matric category are denoted with bold font and underlined, respectively.
Table 8.
Performance for each word sense effect class. The best and the second best results for each matric category are denoted with bold font and underlined, respectively.
| Model | + Effect | − Effect | Null |
|---|
| P | R | F1 | P | R | F1 | P | R | F1 |
|---|
| OnlySL | 58.4 | 40.0 | 47.5 | 77.8 | 31.6 | 44.9 | 44.0 | 81.3 | 57.1 |
| OnlyGraph | 70.1 | 36.4 | 48.0 | 65.1 | 56.2 | 60.3 | 47.3 | 67.9 | 55.7 |
| Hybrid | 61.0 | 73.5 | 66.7 | 71.7 | 66.9 | 69.2 | 55.6 | 52.0 | 53.8 |
| Unified-WSR | 60.0 | 40.2 | 48.1 | 70.8 | 79.7 | 75.0 | 61.6 | 65.0 | 63.3 |
| Random-VMSSG | 61.1 | 61.3 | 61.2 | 65.7 | 76.1 | 70.5 | 60.3 | 64.3 | 62.2 |
| Average-VMSSG | 61.9 | 61.6 | 61.8 | 66.3 | 76.3 | 70.9 | 61.1 | 64.7 | 62.8 |
| CNN-VMSSG | 65.1 | 63.4 | 64.2 | 68.0 | 76.6 | 72.0 | 64.5 | 67.1 | 65.8 |
It is observed that CNN-VMSSG achieves the best overall accuracy of 66.1%, outperforming Unified-WSR and Hybrid by 1.7% and 4.3%, respectively. For each effect class, the Hybrid model achieves the best F1 performance of 66.7% on the + effect class, but the worst F1 performance of 53.8% on the Null class. The Unified-WSR model gives the best F1 performance of 75.0% on the − effect class, but much worse F1 performance of 48.1% on the + effect class. Our Model achieves the best F1 result of 65.8% on the Null class and comes at the second place on both the + effect and − effect classes. Overall, Our Model gives the superior performance in F1, outperforming Unified-WSR and Hybrid by 5.2% and 4.1%, respectively. It indicates the robustness and effectiveness of our proposed model in improving the quality of sense-level word vectors. Random-VMSSG also gives with a one-to-one correspondence mapping between a word sense and a WordNet synset, so that it can be used in this task. Comparing with Average-VMSSG which uses the average of the candidate word vectors of WordNet glosses, CNN-VMSSG achieves 2.7% higher on overall accuracy (66.1 vs. 63.4), that is 4.3% relative improvement. It further verifies the superiority of our proposed WordNet glosses composition approach.




{kind=link}
{kind=link}