
Mining Informative Hydrologic Data by Using Support Vector Machines and Elucidating Mined Data according to Information Entropy

Abstract
:1. Introduction
2. Methodology
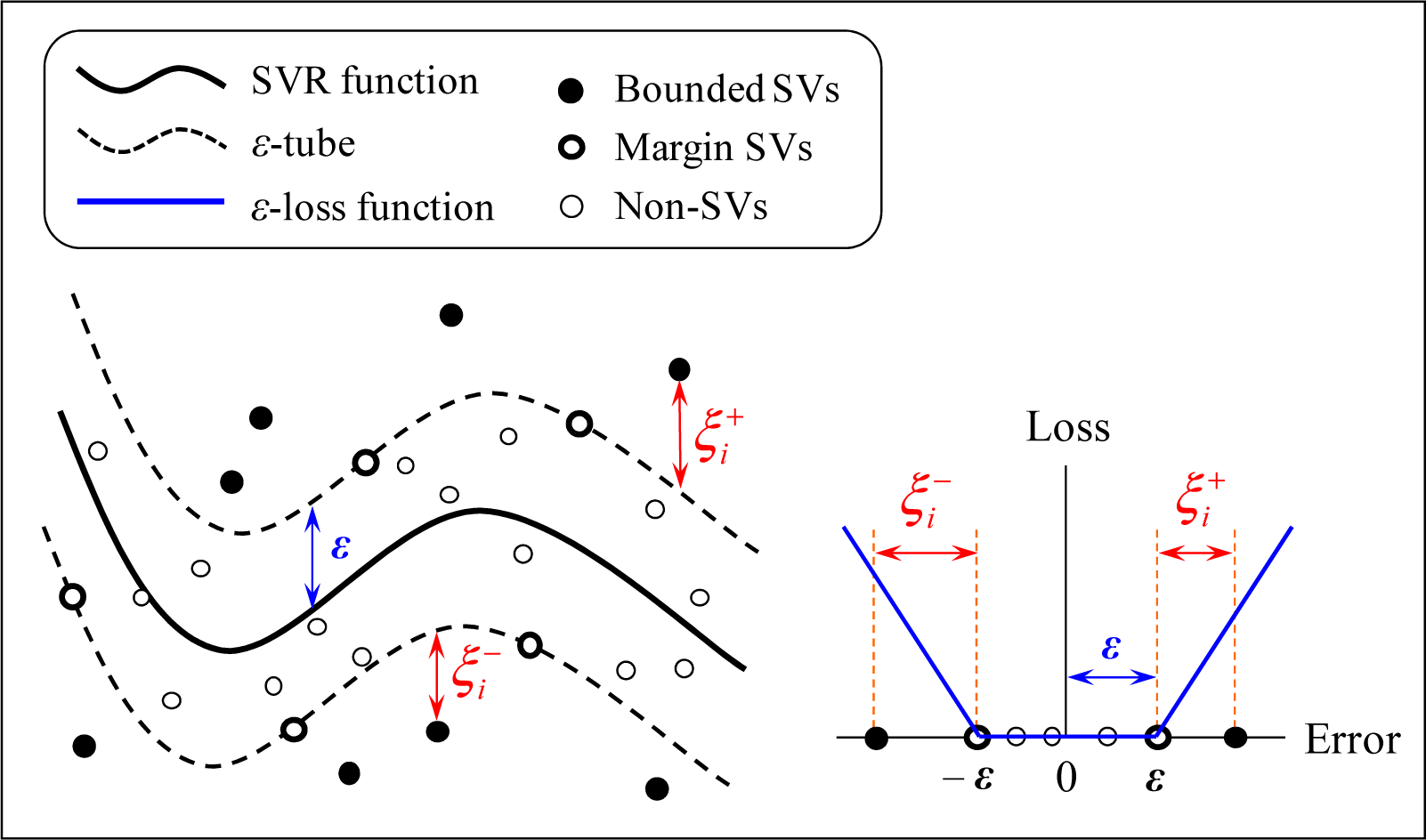
2.1. Support Vector Regression
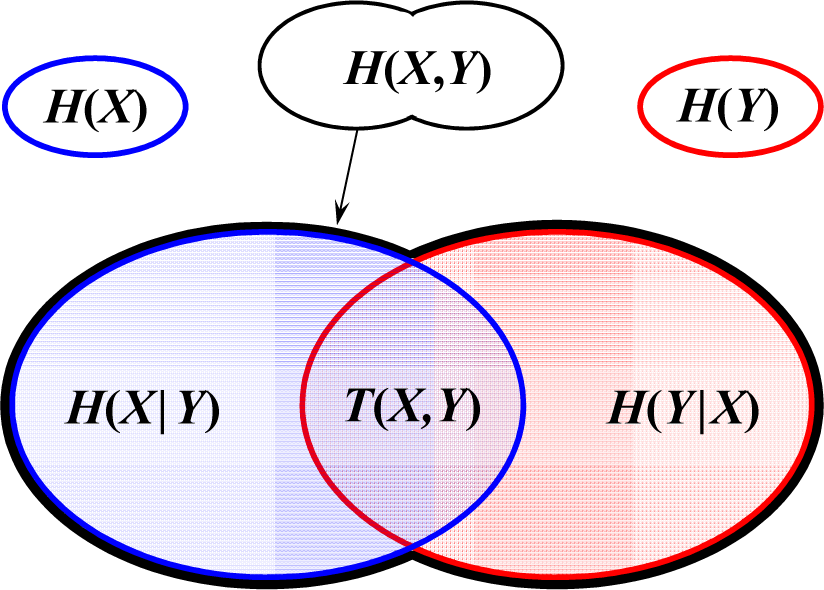
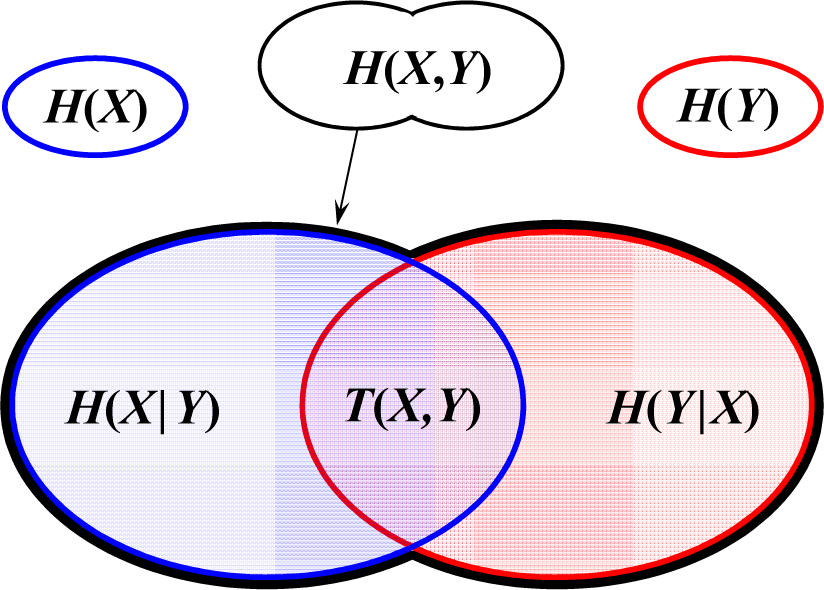
2.2. Information Entropy
3. Mining Informative Hydrologic Data
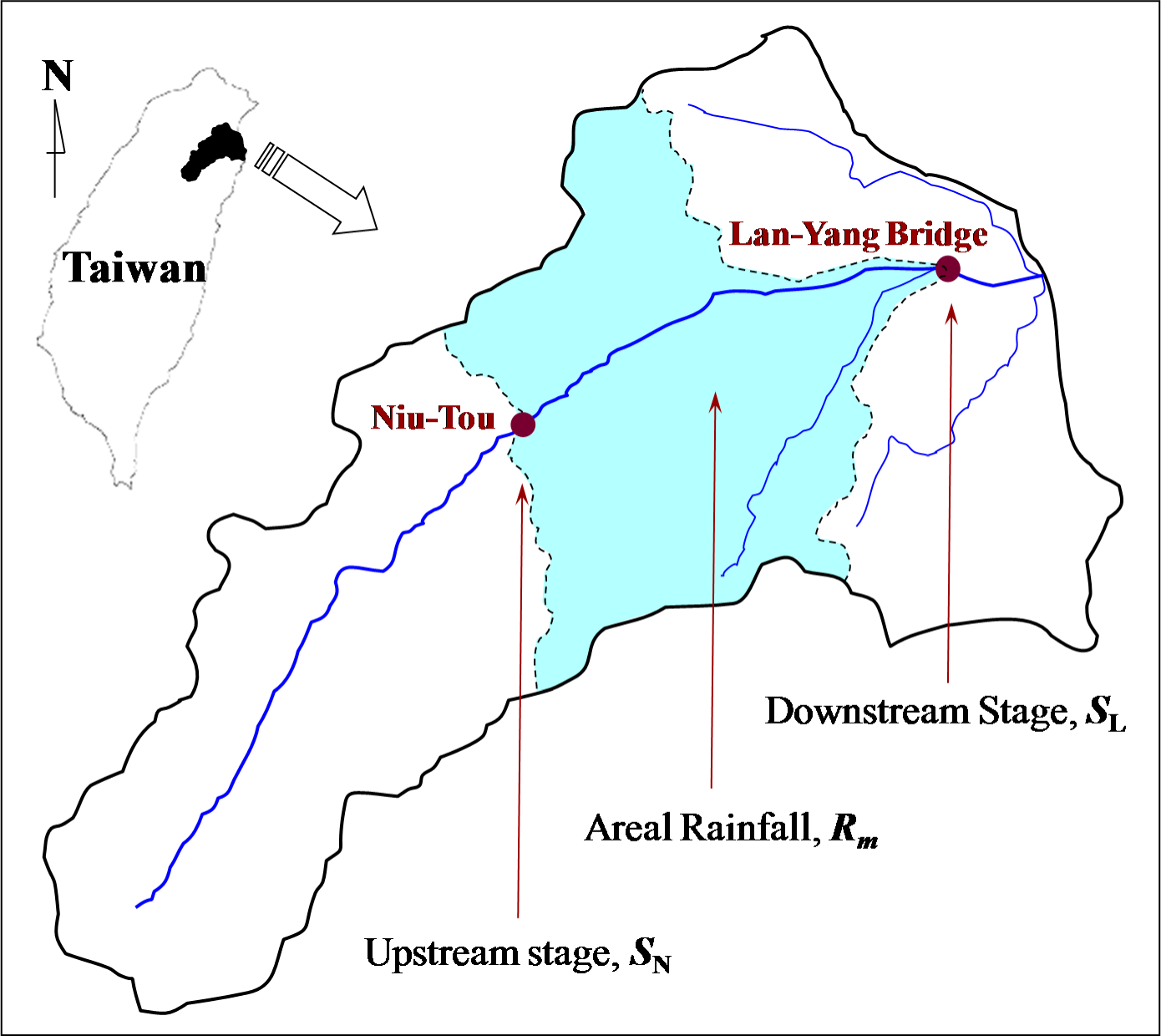
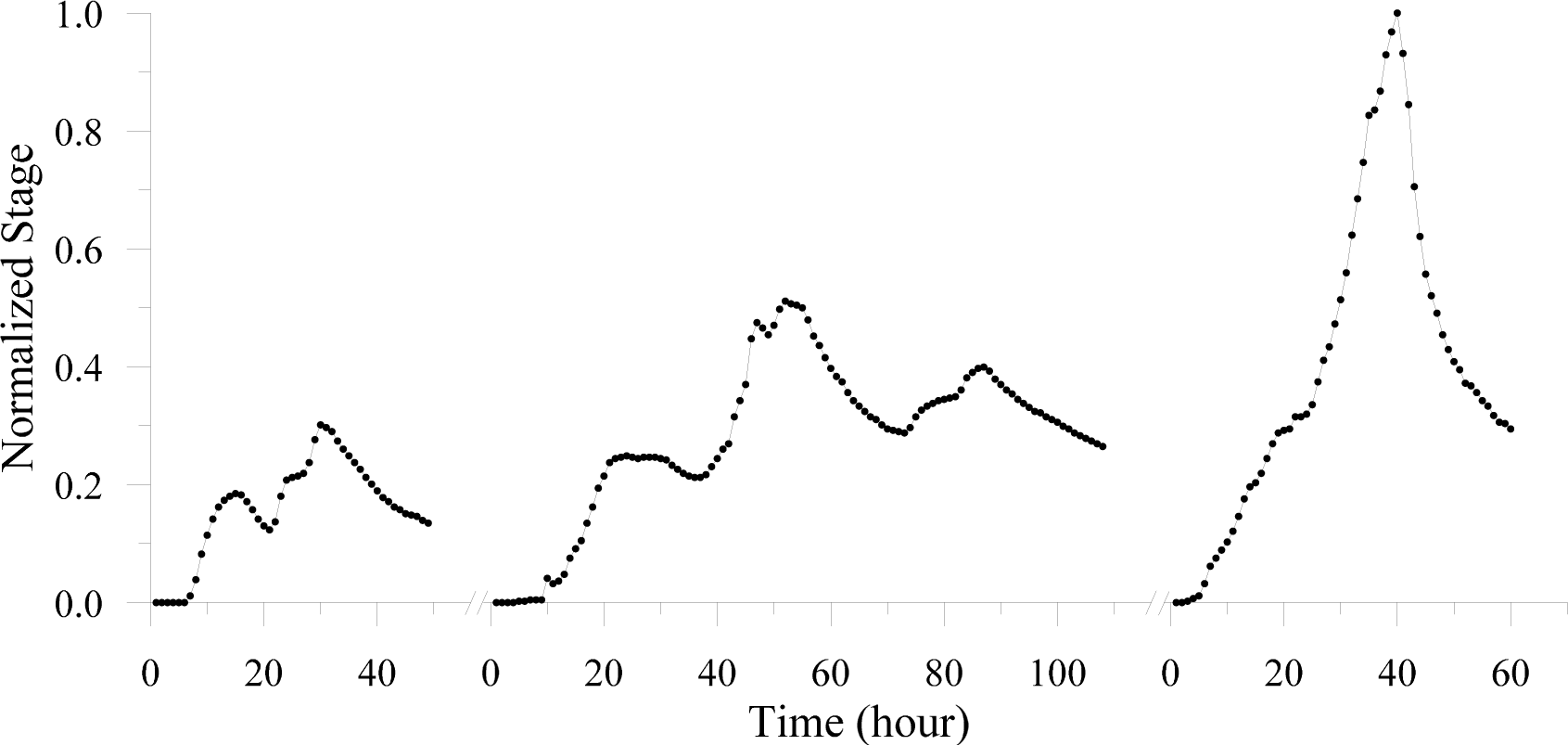
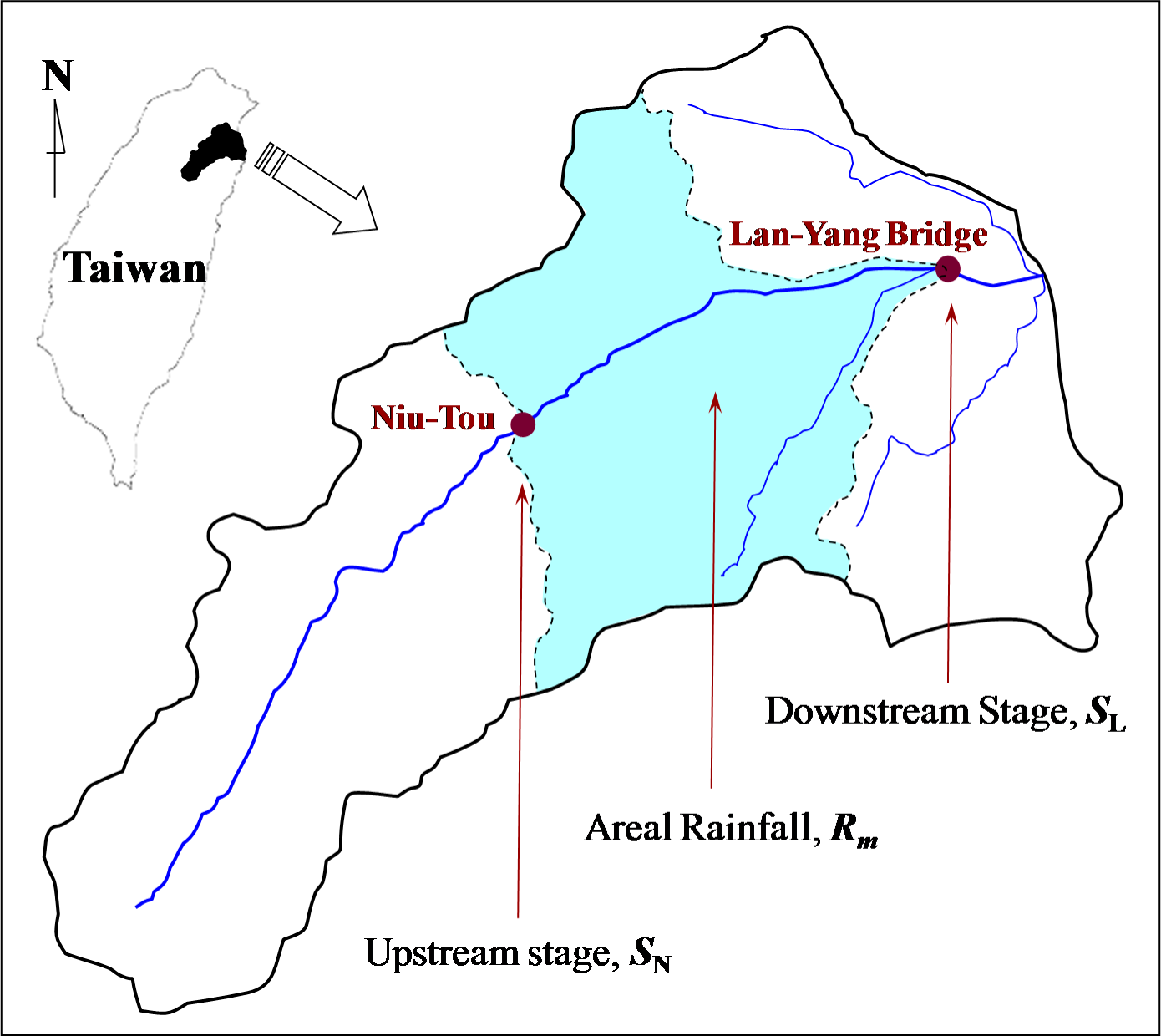
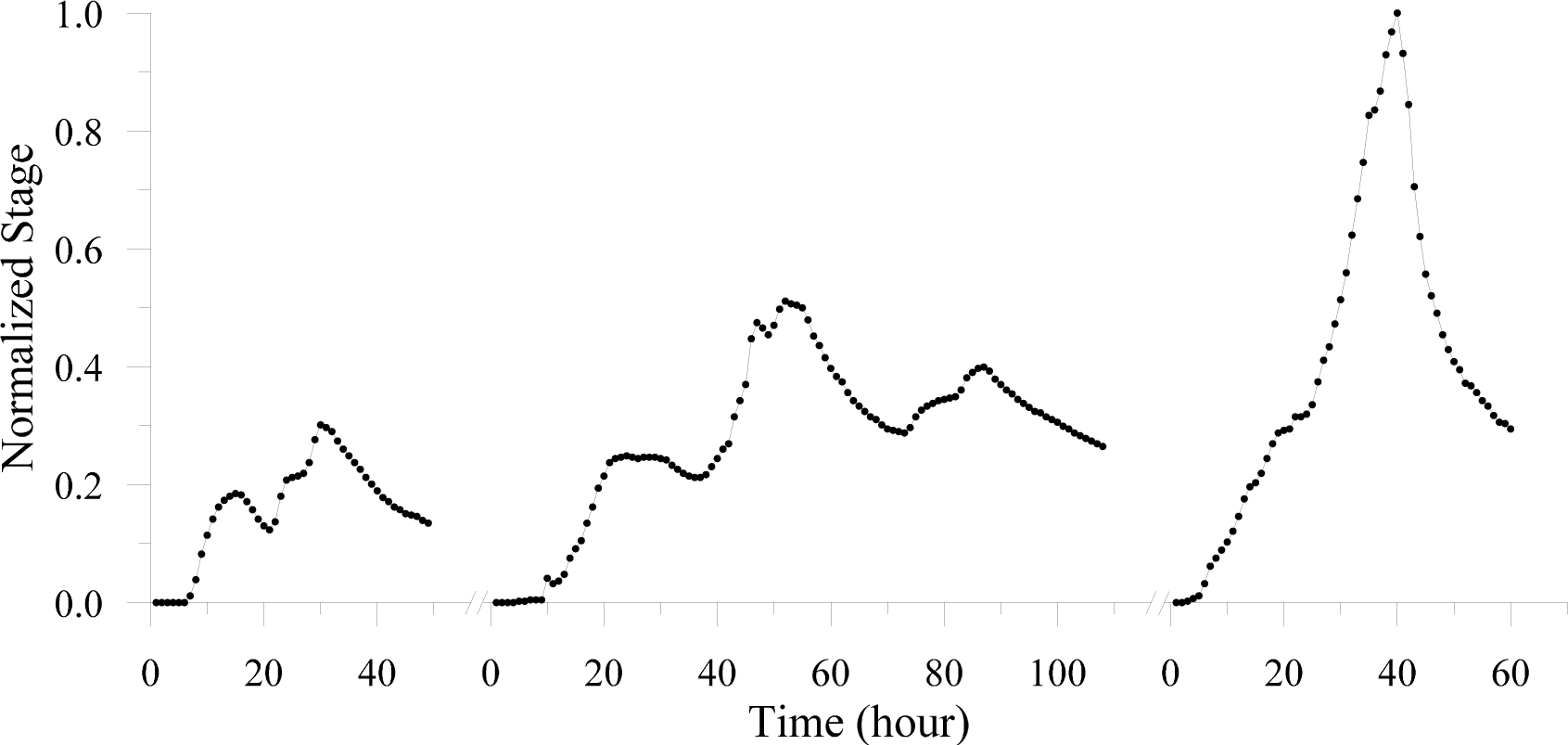
3.1. Hydrologic Data and Flood Forecasting Model
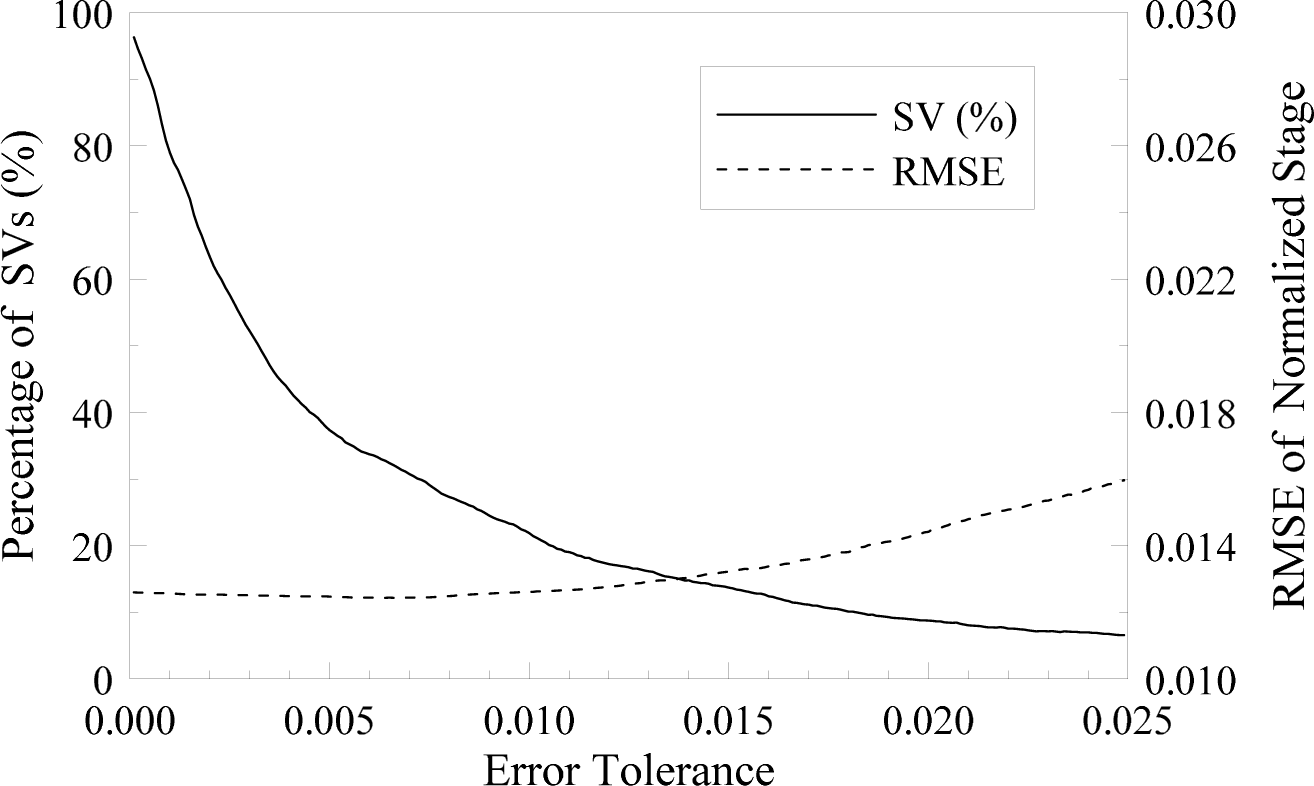
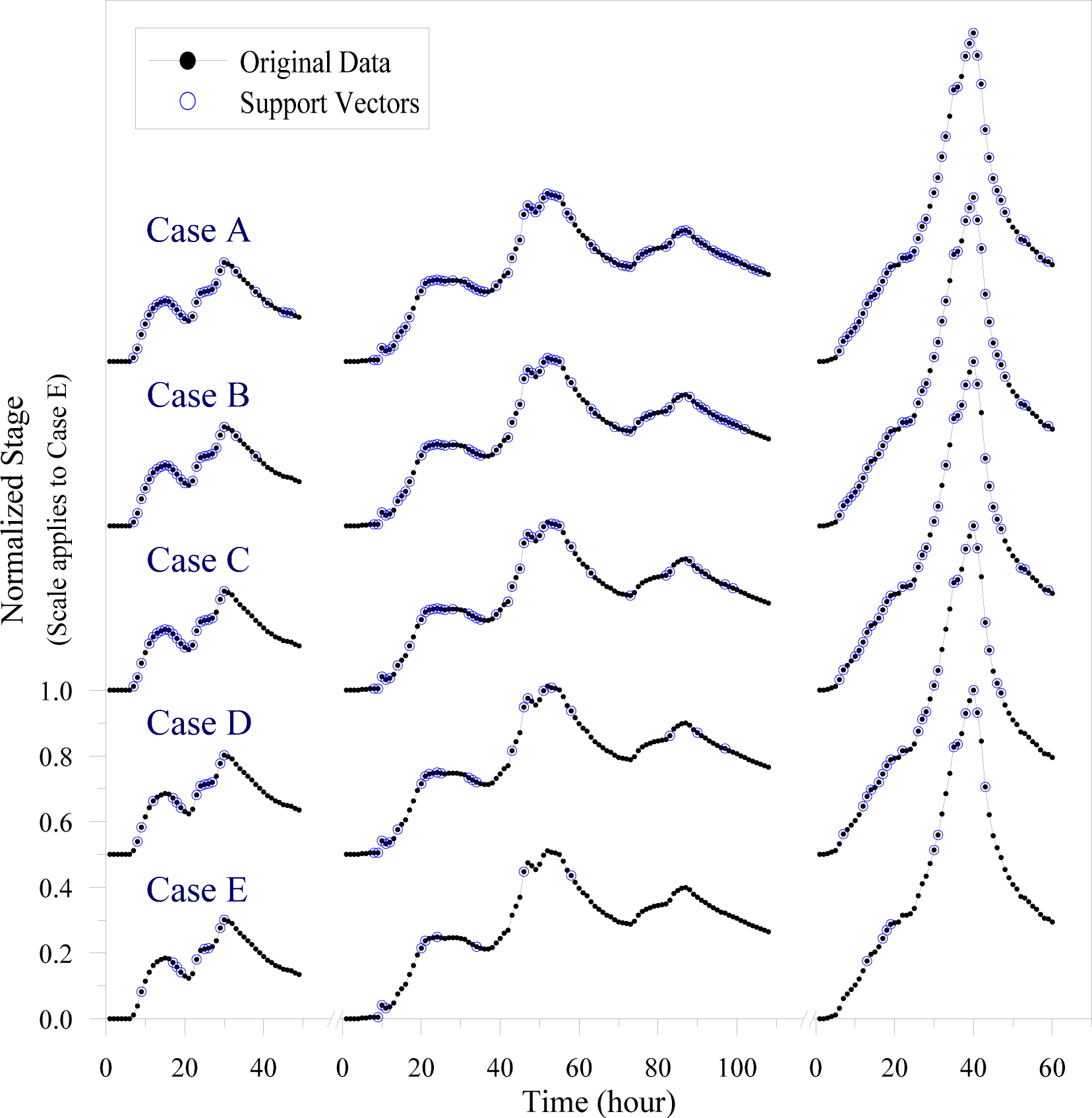
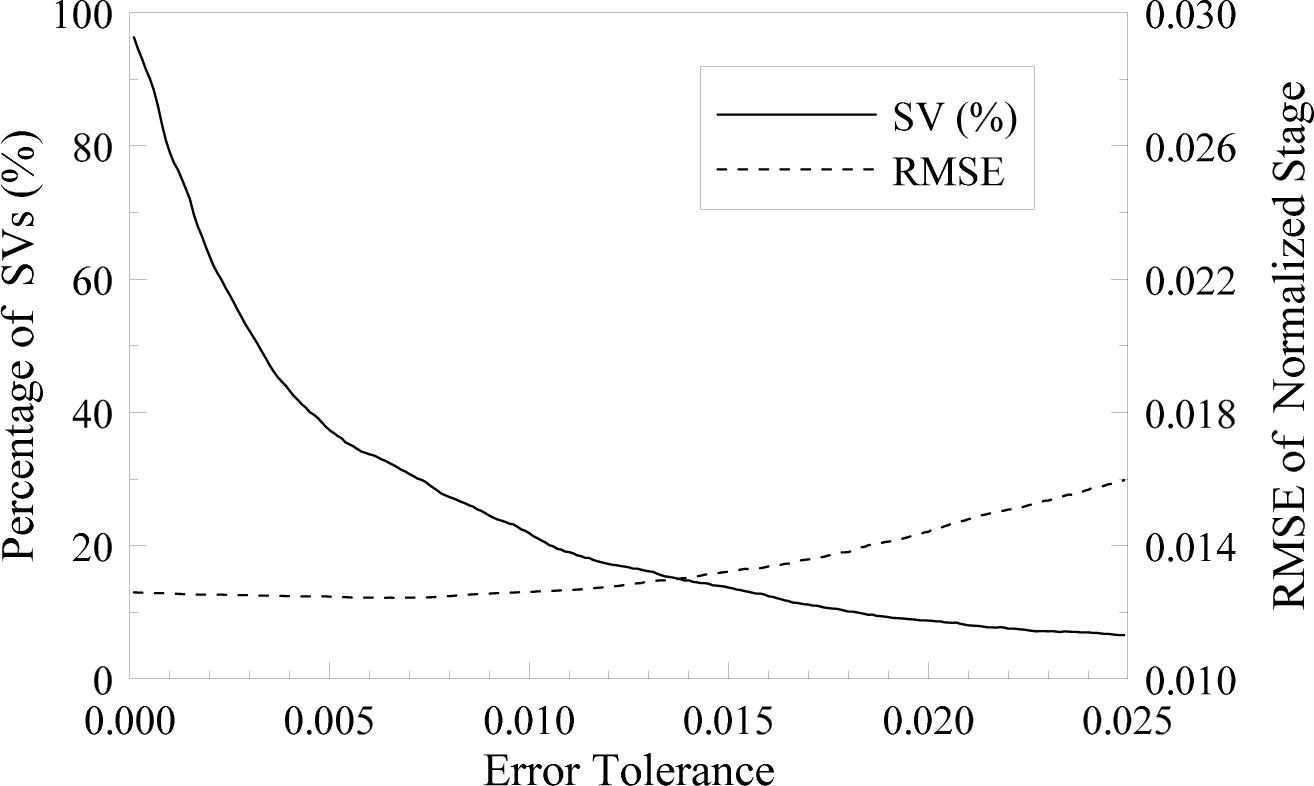
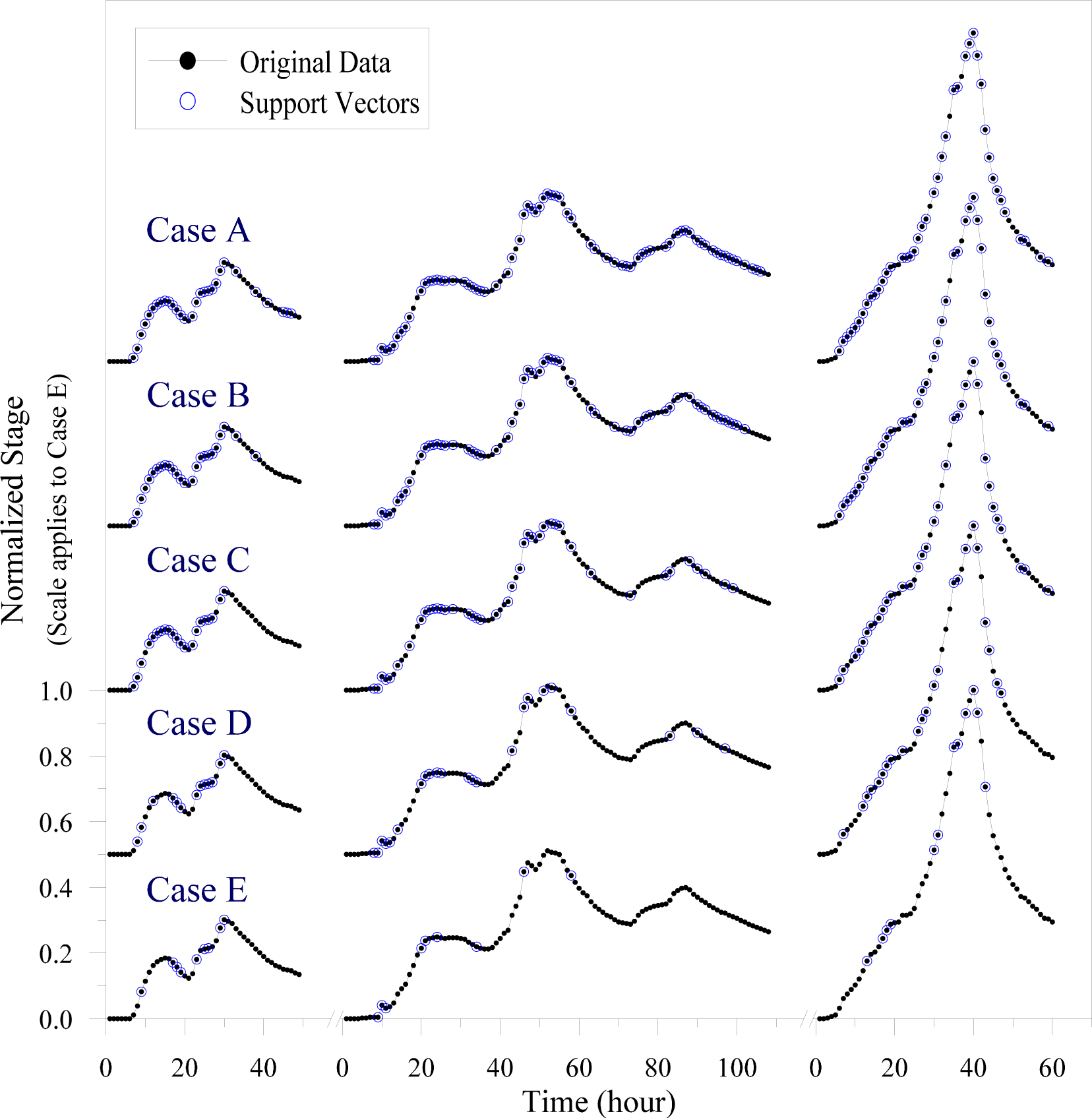
3.2. Support Vectors as Informative Data
4. Assessment of Information Entropy
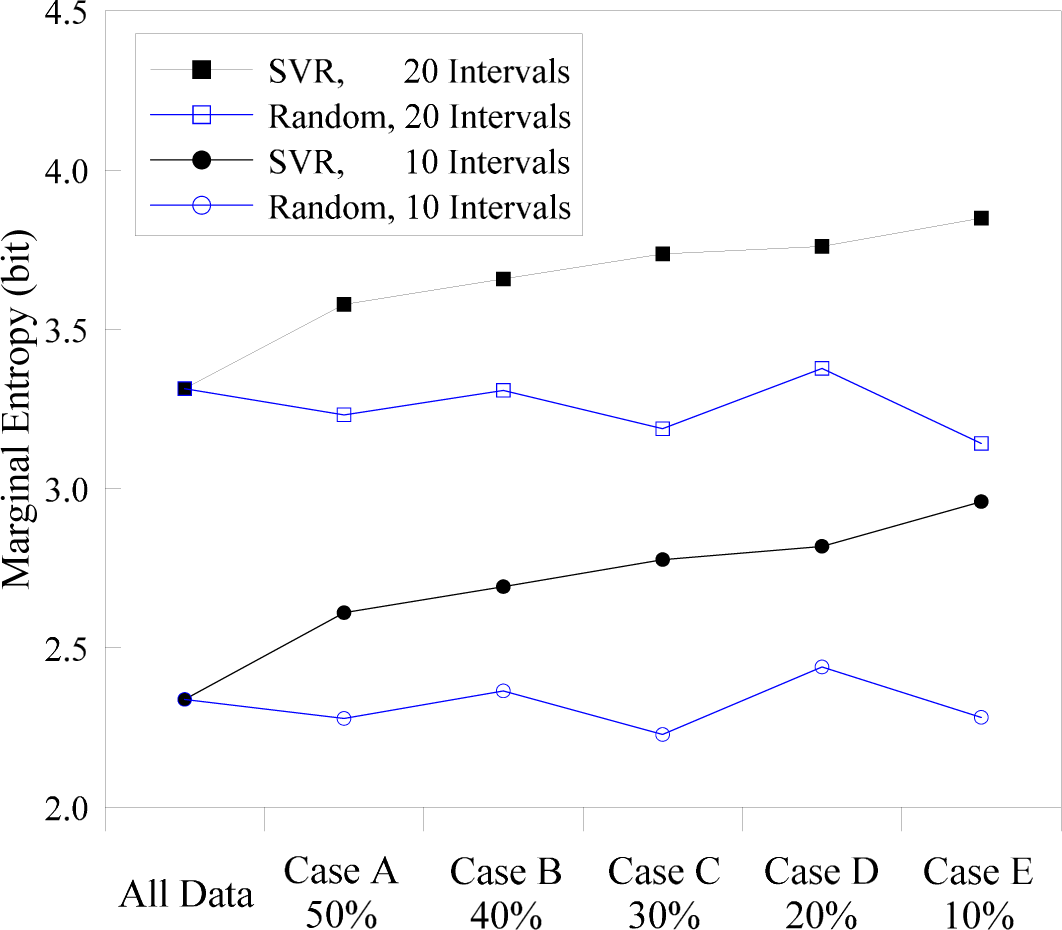
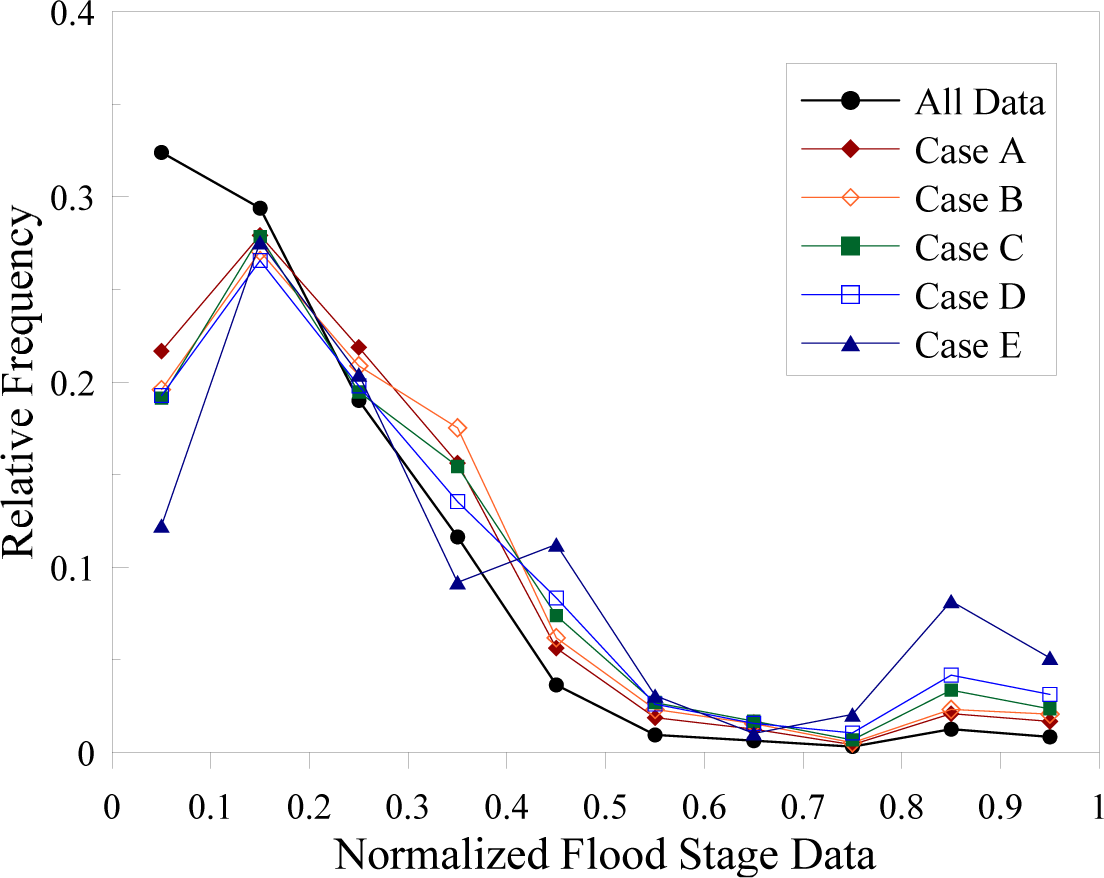
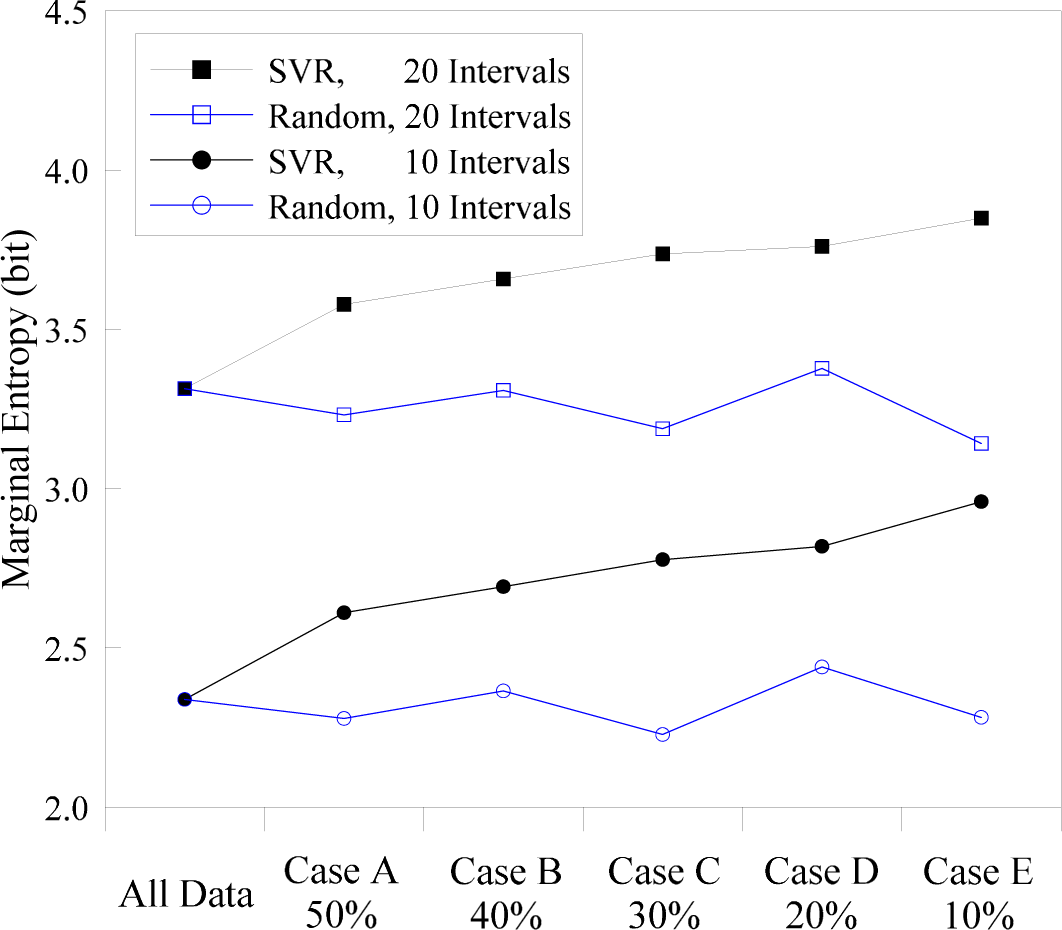
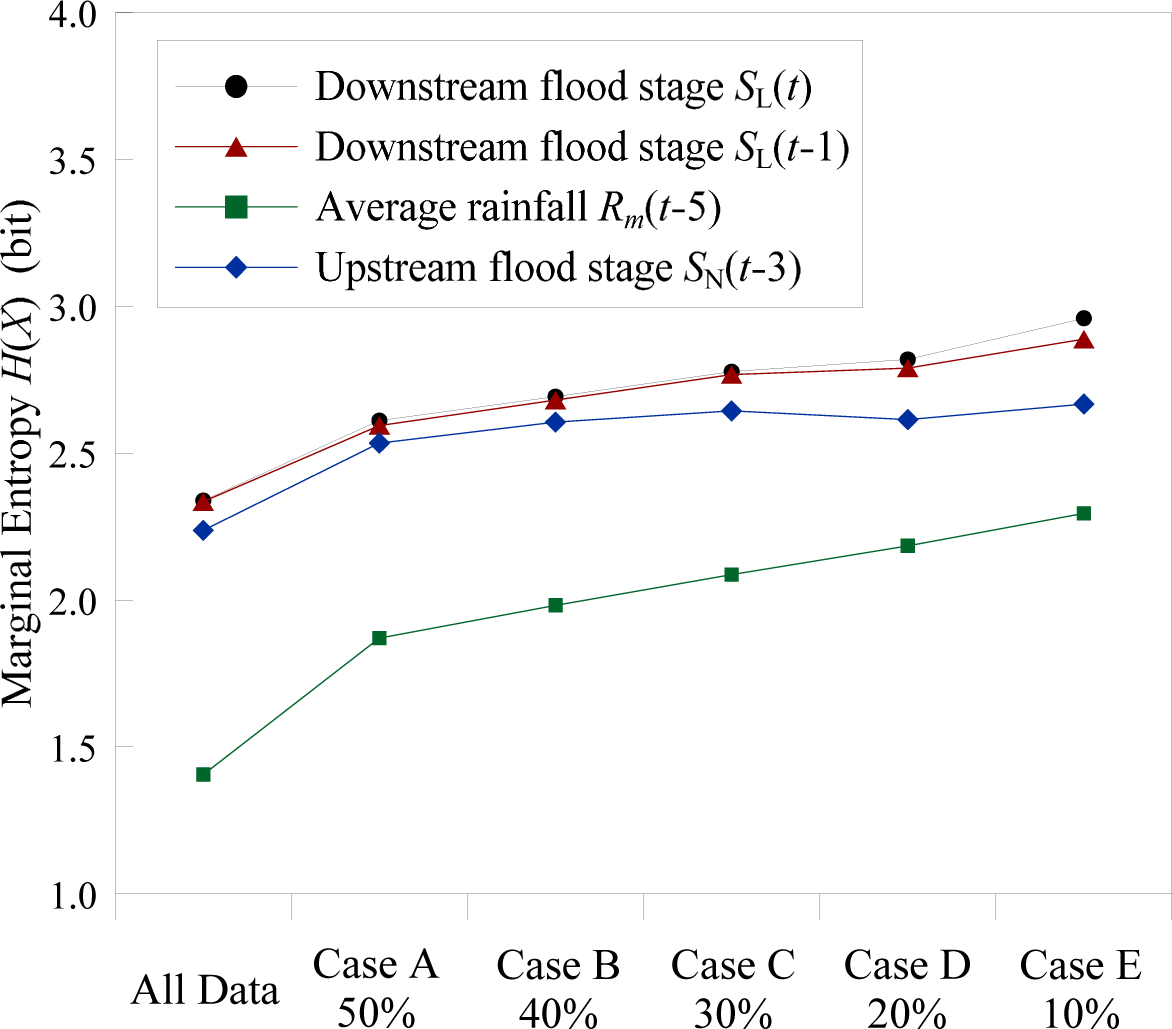
4.1. Marginal Entropies of the Flood Stages and Support Vectors
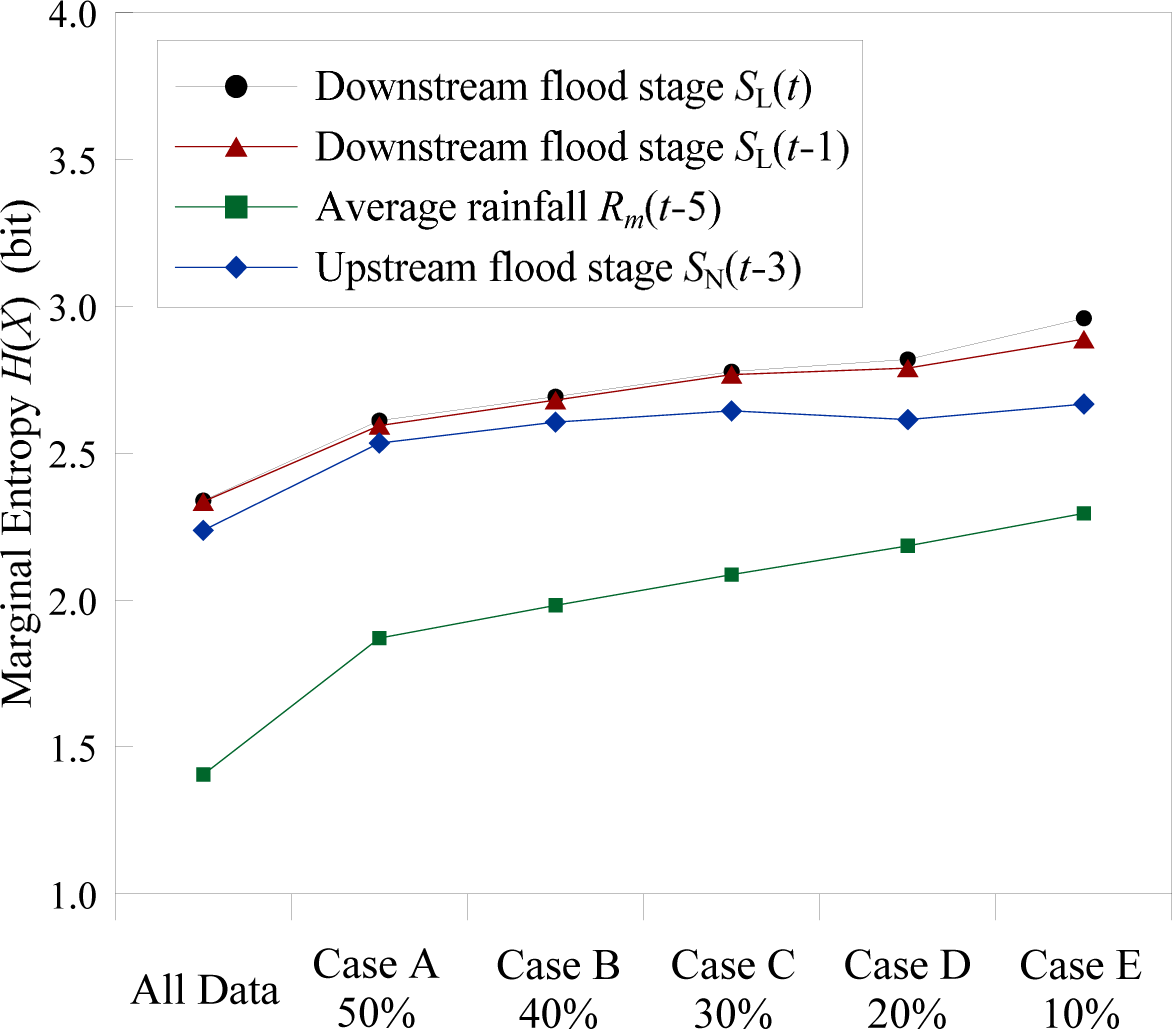
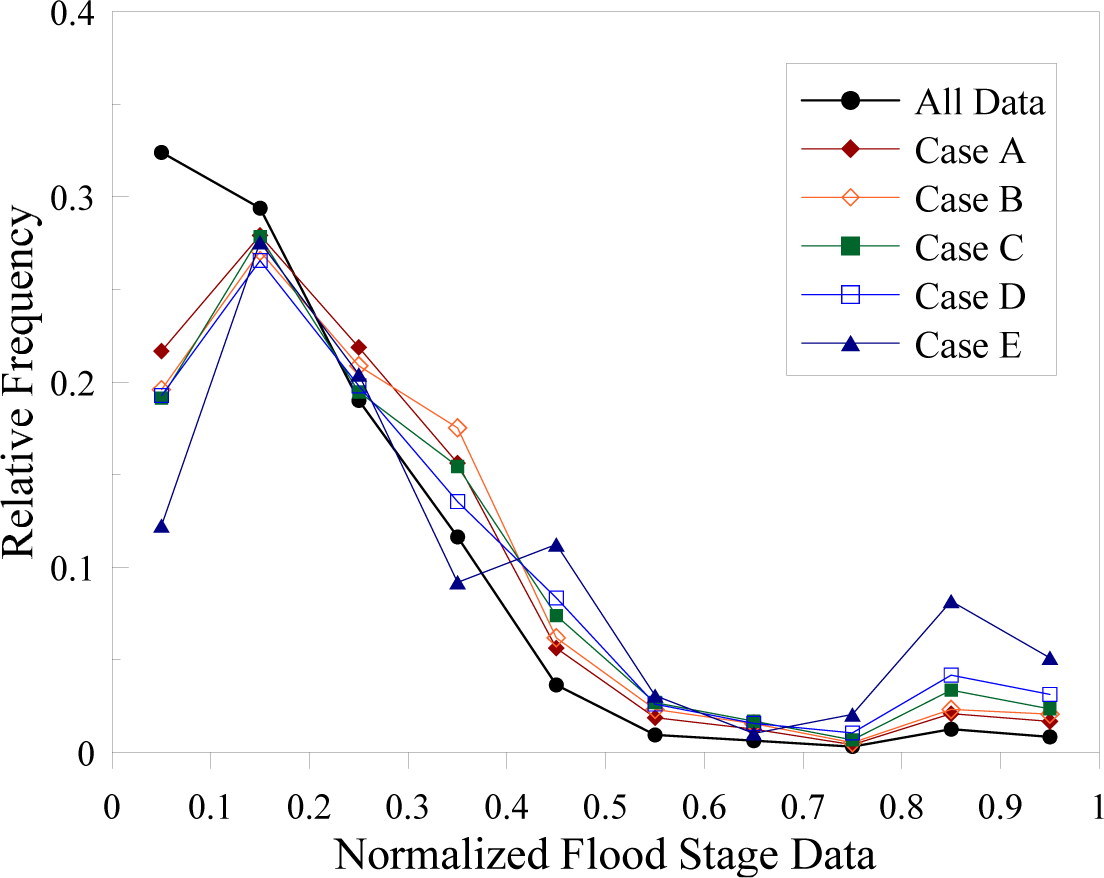
4.2. Entropies Related to Various Hydrologic Variables
5. Conclusions
Conflicts of Interest
References
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer-Verlag: New York, NY, USA, 1995. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Yu, X.; Liong, S.Y.; Babovic, V. EC-SVM approach for real-time hydrologic forecasting. J. Hydroinform. 2004, 6, 209–223. [Google Scholar]
- Bray, M.; Han, D. Identification of support vector machines for runoff modeling. J. Hydroinform. 2004, 6, 265–280. [Google Scholar]
- Sivapragasam, C.; Liong, S.Y. Flow categorization model for improving forecasting. Nord. Hydrol. 2005, 36, 37–48. [Google Scholar]
- Han, D.; Chan, L.; Zhu, N. Flood forecasting using support vector machines. J. Hydroinform. 2007, 9, 267–276. [Google Scholar]
- Lin, G.F.; Chen, G.R.; Huang, P.Y.; Chou, Y.C. Support vector machine-based models for hourly reservoir inflow forecasting during typhoon-warning periods. J. Hydrol. 2009, 372, 17–29. [Google Scholar]
- Lin, G.F.; Chou, Y.C.; Wu, M.C. Typhoon flood forecasting using integrated two-stage support vector machine approach. J. Hydrol. 2013, 486, 334–342. [Google Scholar]
- Wu, M.C.; Lin, G.F.; Lin, H.Y. Improving the forecasts of extreme streamflow by support vector regression with the data extracted by self-organizing map. Hydrol. Process. 2014, 28, 386–397. [Google Scholar]
- Liong, S.Y.; Sivapragasam, C. Flood stage forecasting with support vector machines. J. Am. Water Resour. Assoc. 2002, 38, 173–196. [Google Scholar]
- Yu, P.S.; Chen, S.T.; Chang, I.F. Support vector regression for real-time flood stage forecasting. J. Hydrol. 2006, 328, 704–716. [Google Scholar]
- Chen, S.T.; Yu, P.S. Real-time probabilistic forecasting of flood stages. J. Hydrol. 2007, 340, 63–77. [Google Scholar]
- Chen, S.T.; Yu, P.S. Pruning of support vector networks on flood forecasting. J. Hydrol. 2007, 347, 67–78. [Google Scholar]
- Aggarwal, S.K.; Goel, A.; Singh, V.P. Stage and discharge forecasting by SVM and ANN Techniques. Water Resour. Manag. 2012, 26, 3705–3724. [Google Scholar]
- Wei, C.C. Wavelet kernel support vector machines forecasting techniques: Case study on water-level predictions during typhoons. Expert Syst. Appl. 2012, 39, 5189–5199. [Google Scholar]
- Sivapragasam, C.; Liong, S.Y.; Pasha, M.F.K. Rainfall and runoff forecasting with SSA-SVM approach. J. Hydroinform. 2001, 3, 141–152. [Google Scholar]
- Sumi, S.M.; Zaman, M.F.; Hirose, H. A rainfall forecasting method using machine learning models and its application to the Fukuoka City case. Int. J. Appl. Math. Comput. Sci. 2012, 22, 841–854. [Google Scholar]
- Nikam, V.; Gupta, K. SVM-based model for short-term rainfall forecasts at a local scale in the Mumbai urban area, India. J. Hydrol. Eng. 2014, 19, 1048–1052. [Google Scholar]
- Chen, S.T. Multiclass support vector classification to estimate typhoon rainfall distribution. Disaster Adv. 2013, 6, 110–121. [Google Scholar]
- Lin, G.F.; Jhong, B.C.; Chang, C.C. Development of an effective data-driven model for hourly typhoon rainfall forecasting. J. Hydrol. 2013, 495, 52–63. [Google Scholar]
- Lin, G.F.; Jhong, B.C. A real-time forecasting model for the spatial distribution of typhoon rainfall. J. Hydrol. 2015, 521, 302–313. [Google Scholar]
- Chen, S.T.; Yu, P.S.; Liu, B.W. Comparison of neural network architectures and inputs for radar rainfall adjustment for typhoon events. J. Hydrol. 2011, 405, 150–160. [Google Scholar]
- Kusiak, A.; Wei, X.P.; Verma, A.P.; Roz, E. Modeling and prediction of rainfall using radar reflectivity data: A data-mining approach. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2337–2342. [Google Scholar]
- Tripathi, S.; Srinivas, V.V.; Nanjundiah, R.S. Downscaling of precipitation for climate change scenarios: A support vector machine approach. J. Hydrol. 2006, 330, 621–640. [Google Scholar]
- Kaheil, Y.H.; Rosero, E.; Gill, M.K.; Mckee, M.; Bastidas, L.A. Downscaling and forecasting of evapotranspiration using a synthetic model of wavelets and support vector machines. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2692–2707. [Google Scholar]
- Chen, S.T.; Yu, P.S.; Tang, Y.H. Statistical downscaling of daily precipitation using support vector machines and multivariate analysis. J. Hydrol. 2010, 385, 13–22. [Google Scholar]
- Yang, T.C.; Yu, P.S.; Wei, C.M.; Chen, S.T. Projection of climate change for daily precipitation: A case study in Shih-Men Reservoir catchment in Taiwan. Hydrol. Process. 2011, 25, 1342–1354. [Google Scholar]
- Mao, K.Z. Feature subset selection for support vector machines through discriminative function pruning analysis. IEEE Trans. Syst. Man Cybern. B 2004, 34, 60–67. [Google Scholar]
- Hao, P.Y.; Chiang, J.H. Pruning and model-selecting algorithms in the RBF frameworks constructed by support vector learning. Int. J. Neural Syst. 2006, 16, 283–293. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27. [Google Scholar]
- Sonuga, J.O. Principle of maximum entropy in hydrologic frequency analysis. J. Hydrol. 1972, 17, 177–191. [Google Scholar]
- Jowitt, P.W. The extreme-value type-1 distribution and the principle of maximum entropy. J. Hydrol. 1979, 42, 23–38. [Google Scholar]
- Padmanabhan, G.; Rao, A.R. Maximum entropy spectral analysis of hydrologic data. Water Resour. Res. 1988, 24, 1519–1533. [Google Scholar]
- Yu, H.L.; Chen, J.C.; Christakos, G. BME Estimation of Residential Exposure to Ambient PM10 and Ozone at Multiple Time-Scales. Environ. Health Perspect. 2009, 117, 537–544. [Google Scholar]
- Yu, H.L.; Chu, H.J. Understanding Space-time Patterns of Groundwater Systems by Empirical Orthogonal Functions: A case study in the Choshui River Alluvial Fan, Taiwan. J. Hydrol. 2010, 381, 239–247. [Google Scholar]
- Yu, H.L.; Wang, C.H.; Liu, M.C.; Kuo, Y.M. Estimation of fine particulate matter in Taipei using landuse regression and Bayesian maximum entropy methods. Int. J. Environ. Res. Public Health. 2011, 8, 2153–2169. [Google Scholar]
- Yu, H.L.; Wang, C.H. Quantile-based Bayesian maximum entropy approach for spatiotemporal modeling of ambient air quality levels. Environ. Sci. Technol. 2013, 47, 1416–1424. [Google Scholar]
- Amorocho, J.; Espildora, B. Entropy in the assessment of uncertainty in hydrologic systems and models. Water Resour. Res. 1973, 9, 1511–1522. [Google Scholar]
- Chapman, T.G. Entropy as a measure of hydrologic data uncertainty and model performance. J. Hydrol. 1986, 85, 111–126. [Google Scholar]
- Husain, T. Hydrologic uncertainty measure and network design. Water Resour. Bull. 1989, 25, 527–534. [Google Scholar]
- Harmancioglu, N.B.; Alpaslan, N. Water quality monitoring network design: A problem of multi-objective decision making. AWRA Water Resour. Bull. 1992, 28, 179–192. [Google Scholar]
- Yang, Y.; Burn, D.H. An entropy approach to data collection network design. J. Hydrol. 1994, 157, 307–324. [Google Scholar]
- Markus, M.; Knapp, H.V.; Tasker, G.D. Entropy and generalized least square methods in assessment of the regional value of streamgages. J. Hydrol. 2003, 283, 107–121. [Google Scholar]
- Mishra, A.K.; Coulibaly, P. Hydrometric network evaluation for Canadian watersheds. J. Hydrol. 2010, 380, 420–437. [Google Scholar]
- Chen, Y.C.; Kuo, J.J.; Yu, S.R.; Liao, Y.J.; Yang, H.C. Discharge estimation in a lined canal using information entropy. Entropy 2014, 16, 1728–1742. [Google Scholar]
- Wei, C.; Yeh, H.C.; Chen, Y.C. Spatiotemporal scaling effect on rainfall network design using entropy. Entropy 2014, 16, 4626–4647. [Google Scholar]
- Singh, V.P. The use of entropy in hydrology and water resources. Hydrol. Process. 1997, 11, 587–626. [Google Scholar]
- Mishra, A.K.; Coulibaly, P. Development in hydrometric networks design: A review. Rev. Geophys. 2009, 47. [Google Scholar] [CrossRef]
- Sang, Y.F.; Wang, D.; Wu, J.C.; Zhu, Q.P.; Wang, L. Wavelet-based analysis on the complexity of hydrologic series data under multi-temporal scales. Entropy 2011, 13, 195–210. [Google Scholar]
- Zhang, L.; Singh, V.P. Bivariate rainfall and runoff analysis using entropy and copula theories. Entropy 2012, 14, 1784–1812. [Google Scholar]
- Ahmadi, A.; Han, D.; Karamouz, M.; Remesan, R. Input data selection for solar radiation estimation. Hydrol. Process. 2009, 23, 2754–2764. [Google Scholar]
- Remesan, R.; Azadeh, A.; Muhammad Ali, S.; Han, D. Effect of data time interval on real-time flood forecasting. J. Hydroinform. 2010, 12, 396–407. [Google Scholar]
- Ahmadi, A.; Han, D.; Lafdani, E.K.; Moridi, A. Input selection for long-lead precipitation prediction using large-scale climate variables: A case study. J. Hydroinform. 2015, 17, 114–129. [Google Scholar]
- Singh, V.P. Hydrologic synthesis using entropy theory: Review. J. Hydrol. Eng. 2011, 16, 421–433. [Google Scholar]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. Available online: http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf accessed on 16 December 2014.
- Wikipedia: Joint entropy. Available online: http://en.wikipedia.org/wiki/Joint_entropy accessed on 16 December 2014.
- Solomatine, D.P.; Dulal, K.N. Model trees as an alternative to neural networks in rainfall-runoff modelling. Hydrol. Sci. J. 2003, 48, 399–411. [Google Scholar]
- Chen, C.S.; Jhong, Y.D.; Wu, T.Y.; Chen, S.T. Typhoon event-based evolutionary fuzzy inference model for flood stage forecasting. J. Hydrol. 2013, 490, 134–143. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Parameters
| Number of SVs | Percentage of SVs (%) | RMSE | ||
|---|---|---|---|---|---|---|
| C | ε | γ | ||||
| Case A | 40.8 | 0.0032 | 0.131 | 480 | 49.8 | 0.0127 |
| Case B | 47.3 | 0.0045 | 0.134 | 388 | 40.3 | 0.0126 |
| Case C | 54.3 | 0.0072 | 0.164 | 298 | 30.9 | 0.0124 |
| Case D | 50.3 | 0.0105 | 0.173 | 192 | 19.9 | 0.0126 |
| Case E | 49.0 | 0.0182 | 0.183 | 98 | 10.2 | 0.0139 |
| Entropy | All Data | Case A | Case B | Case C | Case D | Case E |
|---|---|---|---|---|---|---|
| H(X) | 2.34 | 2.61 | 2.69 | 2.78 | 2.82 | 2.96 |
| H(X|Y) | 0.49 | 0.68 | 0.76 | 0.82 | 0.91 | 1.06 |
| T(X,Y) | 1.85 | 1.93 | 1.93 | 1.96 | 1.91 | 1.90 |
| H(Y|X) | 0.49 | 0.66 | 0.75 | 0.81 | 0.88 | 0.98 |
| H(Y) | 2.34 | 2.59 | 2.68 | 2.77 | 2.79 | 2.89 |
| H(X,Y) | 2.83 | 3.27 | 3.44 | 3.59 | 3.70 | 3.94 |
| R(X,Y) | 0.79 | 0.74 | 0.72 | 0.70 | 0.68 | 0.64 |
| Entropy | All Data | Case A | Case B | Case C | Case D | Case E |
|---|---|---|---|---|---|---|
| H(X) | 2.34 | 2.61 | 2.69 | 2.78 | 2.82 | 2.96 |
| H(X|Y) | 2.12 | 2.35 | 2.41 | 2.42 | 2.37 | 2.28 |
| T(X,Y) | 0.22 | 0.27 | 0.29 | 0.36 | 0.45 | 0.68 |
| H(Y|X) | 1.19 | 1.60 | 1.70 | 1.73 | 1.74 | 1.62 |
| H(Y) | 1.41 | 1.87 | 1.98 | 2.09 | 2.18 | 2.30 |
| H(X,Y) | 3.53 | 4.22 | 4.39 | 4.51 | 4.56 | 4.57 |
| R(X,Y) | 0.09 | 0.10 | 0.11 | 0.13 | 0.16 | 0.23 |
| Entropy | All Data | Case A | Case B | Case C | Case D | Case E |
|---|---|---|---|---|---|---|
| H(X) | 2.34 | 2.61 | 2.69 | 2.78 | 2.82 | 2.96 |
| H(X|Y) | 1.65 | 1.92 | 1.98 | 2.03 | 2.00 | 1.96 |
| T(X,Y) | 0.69 | 0.69 | 0.71 | 0.75 | 0.82 | 1.00 |
| H(Y|X) | 1.55 | 1.84 | 1.89 | 1.90 | 1.80 | 1.66 |
| H(Y) | 2.24 | 2.53 | 2.61 | 2.64 | 2.61 | 2.67 |
| H(X,Y) | 3.88 | 4.46 | 4.59 | 4.68 | 4.62 | 4.62 |
| R(X,Y) | 0.30 | 0.26 | 0.26 | 0.27 | 0.29 | 0.34 |
© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.-T. Mining Informative Hydrologic Data by Using Support Vector Machines and Elucidating Mined Data according to Information Entropy. Entropy 2015, 17, 1023-1041. https://doi.org/10.3390/e17031023
Chen S-T. Mining Informative Hydrologic Data by Using Support Vector Machines and Elucidating Mined Data according to Information Entropy. Entropy. 2015; 17(3):1023-1041. https://doi.org/10.3390/e17031023
Chicago/Turabian StyleChen, Shien-Tsung. 2015. "Mining Informative Hydrologic Data by Using Support Vector Machines and Elucidating Mined Data according to Information Entropy" Entropy 17, no. 3: 1023-1041. https://doi.org/10.3390/e17031023
APA StyleChen, S.-T. (2015). Mining Informative Hydrologic Data by Using Support Vector Machines and Elucidating Mined Data according to Information Entropy. Entropy, 17(3), 1023-1041. https://doi.org/10.3390/e17031023