B. Statistical Complexity is the Entropy of a Measurement
The statistical complexity
Cμ is the entropy of the probability distribution over causal states. Causal states themselves are groupings of pasts that are partitioned according to the predictive equivalence relation ~
ε [
4]:
Although causal states can be difficult to determine for complex processes, they are particularly easy for Markov processes (and finite-order Markov processes). Recall that a Markov process is defined by single-time step shielding:
It follows that:
Therefore, for a Markov process, groupings of pasts in which only the last measurement is recorded constitute at least a prescient partition. If:
then we can conclude that the causal states are simply groupings of pasts with the same last measurement:
ε(
x:0) =
x−1. In that case, the causal state space
![Entropy 16 04713f5]()
is isomorphic to the alphabet of the process
![Entropy 16 04713f4]()
and the statistical complexity is the entropy of a single measurement:
Cμ =
H[
X0].
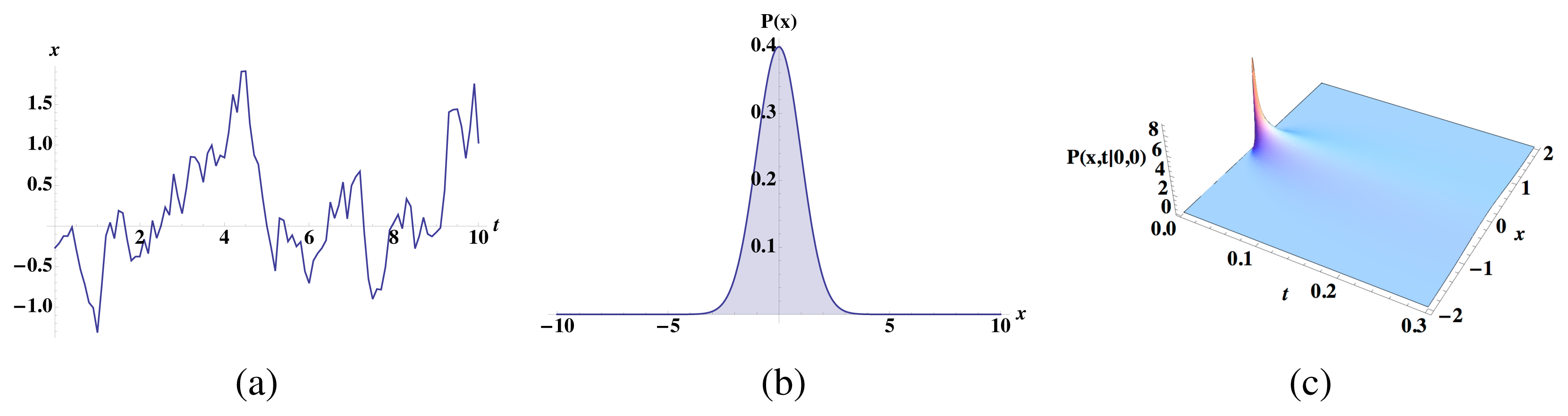
First-order Langevin equations generate Markov time series. Our claim, then, is that the stochastic differential equations considered here produce time series for which:
Therefore, the causal states are isomorphic to the present measurement
X0, and the statistical complexity is
Cμ =
H[
X0]. Implicit in these calculations is an assumption that the transition probabilities Pr(
X0|
X−τ) for a given stochastic differential equation exist and are unique, which is satisfied, since the drift term is analytic [
38].
For intuition, consider linear Langevin dynamics for an Ornstein–Uhlenbeck process:
As described in
Appendix D and many other places (e.g., [
21]), the transition probability density Pr(
Xt|
X0 =
x) is a Gaussian:
For Pr(Xt|X0 = x) = Pr(Xt|X0 = x′), the means and variances of the above probability distribution must match, meaning that eBtx = eBtx′ ⇒ x = x′. Therefore, for an Ornstein–Uhlenbeck process, the causal states are indeed isomorphic to the present measurement and the statistical complexity is H[X0]. The key here is that although Pr(Xt|X0 = x) may quickly forget its initial condition x, for any finite-time discretization, the transition probability Pr(Xt|X0 = x) still depends on x.
In the more general case, we have a nonlinear Langevin equation:
where the stationary distribution ρeq exists and is normalizable. Our goal is to show that if Pr(Xt|X0 = x) = Pr(Xt|X0 = x′), then x = x′. The transition probability Pr(Xt = x|X0 = x′) is a solution to the corresponding Fokker–Planck equation:
with initial condition
ρ(
x, 0) =
δ(
x −
x′). As in [
38], we can use an eigenfunction expansion to show that
ρ(
x,
t|
x′, 0) cannot equal
ρ(
x,
t|
x″, 0) unless
x′ =
x″ for finite time
t. Therefore, Pr(
Xt|
X0 =
x′) = Pr(
Xt|
X0 =
x″) ⇒
x′ =
x″. This implies that the causal states are again isomorphic to the present measurement and the statistical complexity is
Cμ =
H[
X0].
To summarize, this application of computational mechanics [
3,
4] to Langevin stochastic dynamics shows that the entropy of a single measurement is also the process’s statistical complexity
Cμ. Recall that the latter is the entropy of the probability distribution over the causal states which, in turn, are groupings of pasts that lead to equivalent predictions of future behavior. Therefore, for the stochastic differential equations considered here, causal states simply track the last measured position.
What the information anatomy analysis reveals, then, is that not all of the information required for optimal prediction is predictable information about the future. In other words, Langevin stochastic dynamics are inherently cryptic [
30,
31]. Unfortunately, as is so often the case, the necessary and the apparent come packaged together and cannot be teased apart without effort.
C. Approximating the Short-Time Propagator Entropy
The study of stochastic differential equations and short-time propagator approximations is mathematically rich and, as noted in the introduction, the application to nonlinear diffusion has a long history [
21]. What follows is a brief sketch, not a rigorous proof, that glosses over important pathological cases.
Consider the nonlinear Langevin equation:
with driving noise satisfying 〈
η(
t)〉 = 0 and 〈
η(
t)
η⊤ (
t′)〉 =
Dδ(
t −
t′), where det
D ≠ 0. Let
p(
x|
x′) be the transition probability Pr(
Xt =
x|
X0 =
x′) for the system in
Equation (A1). From arguments in [
38], it exists and is uniquely defined. Let
q(
x|
x′) be a Gaussian with the same mean and variance as
p(
x′|
x).
We show that H[p] = H[q] + o(τ) where H[p] = −∫ p(x|x′) log p(x|x′)dx and H[q] = −∫ q(x|x′) log q(x|x′)dx. Note that here, and in the following, we suppress notation for the dependence of these quantities on x′, using the shorthand H[p] ≡ H[X|X′ = x′] and the like. First, consider:
Since q(x|x′) is the maximum entropy distribution consistent with the mean and the variance of p(x|x′), averages of log q(x|x′) with respect to p are the same as those with respect to q. Specifically, if x̄ is the mean:
and if C(x′) is the variance:
then q is the normal distribution consistent with that mean and variance:
From this, we derive:
Since the mean and variance for p and q are consistent, we have:
and, thus:
We wish to show that DKL[p||q] is at least of o(τ). Then, we also want to show that H[q] can be determined to o(τ) from the linearized Langevin equation:
Then, we would be able to approximate H[p] to o(τ) by H[qlinearized], where qlinearized is the transition probability that results when we locally linearize the drift.
Our strategy is to construct a series expansion for the moments of
p in the timescale
τ, as in [
39]. Immediately, with that statement, we run into a problem. Moments do not uniquely specify a distribution unless an additional condition (e.g., Carleman’s condition) is satisfied. We will address this issue at the end of this Appendix. The second issue we find is that the sum of higher-order terms in the moment expansion is often divergent, but we have circumvented this limitation by working with infinitesimal time discretizations.
The Kullback–Leibler divergence is invariant to changes in the coordinate system and, for reasons that become apparent later, it is useful to move to the parametrization
. In a slight abuse of notation, p(z|x′) and q(z|x′) will be used to denote the re-parametrized distributions p(x|x′) and q(x|x′). Our moment expansion will show that all moments of p(z|x′) and q(z|x′) differ by a quantity that is at most of O(τ3/2), which implies that p(z|x′) = q(z|x′) + τ3/2δq, where δq is at most of O(1) in τ. From that, it would follow that DKL[q + τ3/2δq||q] = (τ3/2)2[q], where [q] is the Fisher information of a Gaussian (and hence bounded) and that H[p] = H[q] to O(τ3). That same moment expansion will show that the covariance and mean of p differ from the covariance and mean of qlinearized by a correction term of at most O(τ2). From this, it follows that H[q] is H[qlinearized] to o(τ). The bottleneck in this approximation scheme is not approximating the transition probability as a Gaussian, but rather approximating the covariance of that Gaussian by the covariance of the locally linearized stochastic differential equation.
For intuition and simplicity, we start with the one-dimensional example. This is similar in flavor to the approach in [
39], but our point differs: we wish to understand how well we can approximate the full system with a linearized drift term. The stochastic differential equation for
x ∈ ℝ is:
with noise as above. The mean 〈x〉 evolves according to:
Using an Ito discretization scheme:
where
dη(
t) ~
![Entropy 16 04713f6]()
(0,
DΔ
t), we have:
From these, we derive evolution equations for the moments 〈(x − 〈x〉)n〉 for n ≥ 2:
Substituting
Equation (A2) into the above and simplifying leads to:
Now, we re-express:
where δ is at most O(1) in x − x′. Then:
When μ′(x′) = 0 and δ = 0 the Green’s function is a Gaussian with zero mean and variance Dt, so that 〈(x − 〈x〉)n〉 ∝ (Dt)n/2. Inspired by this base case, we consider the moments of the variable
:
We expand 〈zn〉 in terms of t, since we are interested in the small-t limit:
In terms of these coefficients, we have:
and
for O(1/t),
, and O(1), respectively. Note that none of Cn, αn, or βn have information about δ, which encapsulates higher-order drift nonlinearities. The
term finally has information about δ:
Interestingly, this implies that any dependencies of the moments on
δ are
O(
t3/2), at most.
Equations (A8)–
(A10) can be solved with the following initial conditions:
Then, Cn = αn = βn = 0 for n odd, and αn = 0 for n even, as well. Some algebra shows that:
A Gaussian with mean zero and variance
would also have Cn = αn = βn = 0 for n odd, αn = 0 for n even, and
. Thus, the moments zn of p(z|x′) are consistent with the moments of q(z|x′) to O(t3/2). Additionally, as described earlier, those moments are consistent with the moments of the linearized Langevin equation to o(t). From prior logic, H[p] can be approximated to o(t) by
.
The n-dimensional case follows the same principle, but the calculations are more arduous. We start with the stochastic differential equation for x ∈ ℝn:
with the noise as before. The initial condition is x(t = 0) = x′. Since we are interested not only in whether the distribution is effectively Gaussian, but also in how important the nonlinearities of μ(x) are, we re-express μ(x) as:
where Aij(x′) = ∂μj/∂xi:
and δijk is at most of O(1) in ||x − x′||. The evolution equation for the means is:
Using an Ito discretization scheme with time step Δt:
where
dη(
t) ~
![Entropy 16 04713f6]()
(0,
DΔ
t). From this, we find evolution equations for the moments of
x. As before, we subtract the mean:
For notational ease, let σ(1),..., σ(m) be a list of integers in the set {1,..., n} where n is the dimension of x; repeats are allowed. We want an evolution equation for Cov(xσ(1),..., xσ(m)):
Cov(
xσ(k):k≠i,j) denotes the covariance of the variables
xσ(k) for all
k in the integer list 1,...,
m with the restriction that we ignore
k =
i and
k =
j. We have a base case: when
f = 0,
A = 0 and
Dij =
Dδi,j, the Green’s function is a Gaussian with variance
. Therefore, again, we switch to variable
and calculate its covariance evolution, similarly to
Equation (A7), where we employ
Equation (A11) to find the appropriate
t scaling of the nonlinear
f term:
We expand the covariances as a series in
, assuming that they are indeed expressible for short times using such an expansion:
As before, we substitute the above series expansion into
Equation (A14) and match terms of
, and
O(1) to get:
and
The base case is that, by definition, 〈z〉 = 0 and 〈z0〉 = 1. This implies that βσ(1),...,σ(m) = 0 for all lists {σ(i): i = 1,..., m}. Since all moments are determined to at least O(t) by just the linearized version of the nonlinear Langevin equation and since linear Langevin equations have Gaussian Green’s functions, it follows that the Green’s function for the nonlinear Langevin equation is Gaussian to O(t). Some algebra shows that the variance of the linearized Langevin equation’s Green’s function is:
If D is invertible, the conditional entropy is then:
If the matrix
D is not invertible because det
D = 0, then we only have the leading order term in
t of the entropy
H[
p] and we cannot draw any conclusions about the
O(1) term in any of the information anatomy quantities. This becomes very clear by example in
Appendix D.
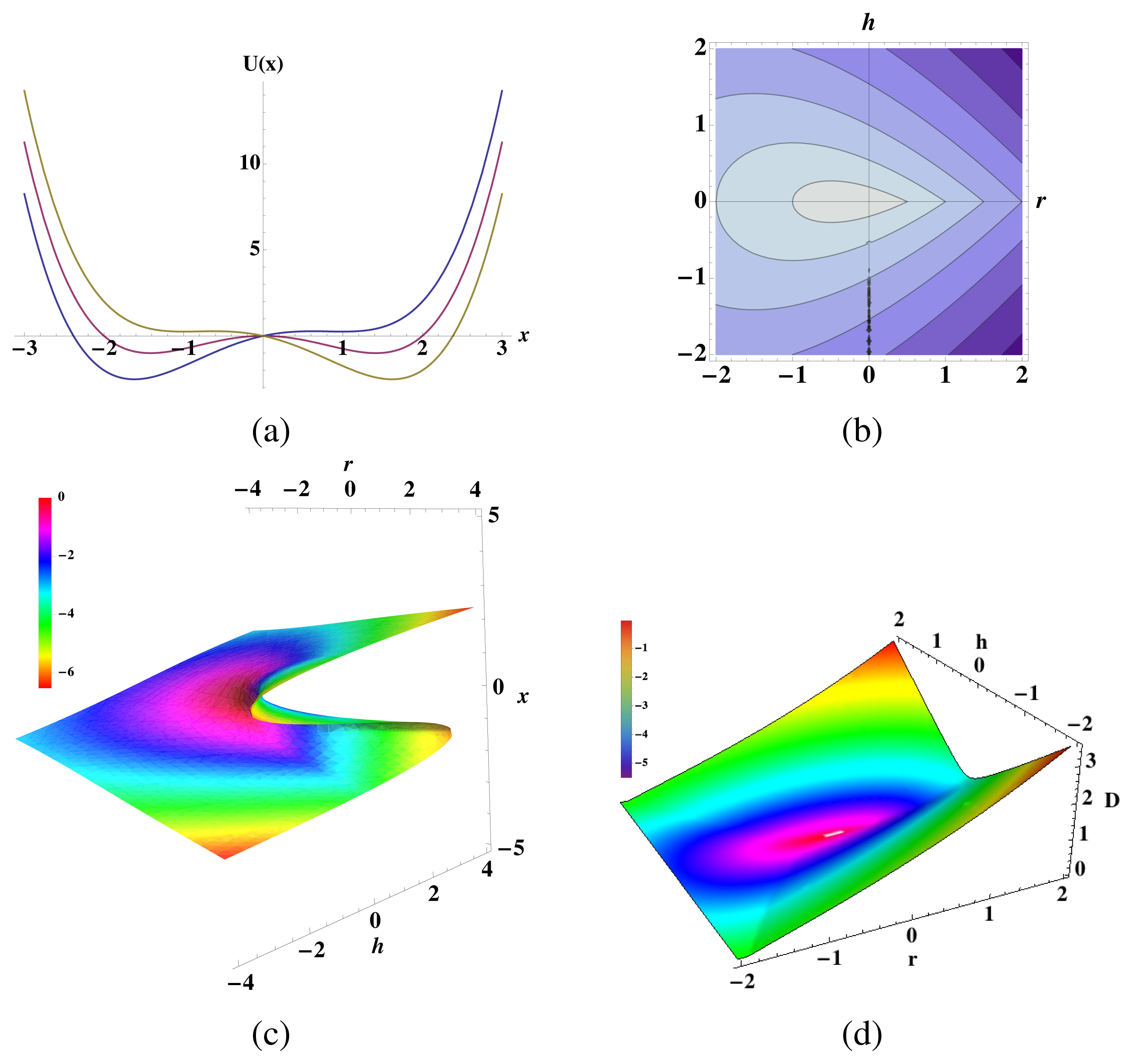
Now, we return to the question of whether or not we can circumvent the issue of using a moment expansion to approximate entropies of a probability distribution function whose support is not bounded. The key idea is that we are only interested in potential functions U(x) that grow quickly enough with ||x||, such that the partition function Z = ∫ e−U(x)dx is normalizable. This suggests that we can approximate the potential function arbitrarily well by a potential function whose support is bounded such that transition probabilities are uniquely determined by moments. Consider, for instance, the sequence of potentials UL(x) defined by:
By construction, the transition probabilities have support over the bounded region ||x|| ≤ L. For any of these potentials, the moment expansion above uniquely determines the transition probability distribution. Therefore, the manipulations above give a corresponding sequence of conditional entropies:
where:
If limL→∞ H(L)[Xt+τ|Xt] = H[Xt+τ|Xt] to o(τ), then we can claim that the formulae in the main text applies, even when the support of the transition probability distribution function is unbounded. To o(τ), we see that:
Thus, we want to know the conditions under which the latter limit converges. In the main text, we limited ourselves to certain types of potential functions, stipulating that Z = ∫ℝn e−U(x)dx < ∞, so that there is a normalizable equilibrium probability distribution. We also stipulate that
, so that the bound information rate would be finite. Hence, both limL→∞ ∫||x||≤L e−U(x)dx = Z < ∞and limL→∞ ∫||x||≤L e−U(x)tr(A(x))dx = ∫ℝn e−U(x)tr(A(x))dx < ∞. Since both of these converge to finite, nonzero values, the ratio of the limit is the limit of the ratios, and we have:
Therefore, this sketch suggests that we can circumvent concerns about using moment expansions. Again, we require that the stationary probability distribution and bound information rate exist and are finite.
D. Linear Langevin Dynamics with Noninvertible Diffusion Matrix
If the stochastic differential equation is linear:
where η(t) is white noise 〈η(t)〉 = 0 and 〈η(t)η(t′)⊤ 〉 = Dδ(t−t′), then we can solve it in terms of η(t) as follows:
yielding:
Since η(t) is white, x(t) is a Gaussian random variable with mean:
and variance:
Since the Green’s function is Gaussian for all time (not approximately in the short time limit) and since the variance of this Gaussian does not depend on the initial state, we can calculate the conditional entropies H[Xt|X0] via:
The goal here is to calculate this quantity for small t when the matrix D is not invertible. We assume that it has the block matrix form:
where
. Let B have the corresponding block matrix form:
(Recall subscript
d stands for deterministic and subscript
n for noisy.) We can rewrite the variance in
Equation (A21) as a power series in
t:
Since we are concerned about the small-t limit, we consider only the first few terms of this power series and, for reasons that will become clear, we write all steps in block-matrix form. The first term, which is of O(t), is the usual:
The second term, of O(t2), has the form:
The third term, of O(t3), has the form:
We place a dash in the lower right block matrix entry, since, as it turns out, it does not matter for this calculation. The fourth term, of O(t4), has the form:
Similar to the
Q3 calculation, we care only about the upper left hand entry, and so, every other matrix entry can be ignored. Substituting
Equations (A24)–
(A27) into
Equation (A23), we find that:
where:
Since det Dnn ≠ 0, Dnn is invertible:
Again, we have used the fact that:
Additionally, since Dnn is invertible and symmetric, we can also write:
Then:
With some algebra, this becomes:
We assume that
is invertible; i.e.,
. Therefore:
where:
and:
so that:
Liberal application of several identities—tr(XY ) = tr(Y X), tr(X) = tr(X⊤ ) and tr(X +Y ) = tr(X)+ tr(Y )—reveals:
E. Time-Local Predictive Information
Information anatomy measures should have a broad application to monitoring and guiding the behavior of adaptive autonomous agents. Practically, information anatomy gives a suite of semantically distinct kinds of information [
6,
40] that is substantially richer and structurally more incisive than simple uses of Shannon mutual information that implicitly assume there is only a single kind of (correlational) information. For example, it is reasonable to hypothesize that biological sensory systems are optimized to transmit with high fidelity information that is predictively useful about stimuli or environmental organization. In such a setting, the bound information quantifies how much predictability is lost if one has extracted the full predictable information
E from the past, but chooses to ignore the present
H[
X0]. Along these lines, the time-local predictive information (TiPi) was recently proposed as a quantity that agents maximize in order to access different behavioral modes when adapting to their environment [
12].
(For clarity, we must address a persistently misleading terminology at use here, since it is critical to correctly interpreting the benefits of information-theoretic analyses. The proposed measure is a special case of bound information
bμ. Recall that both
bμ and the excess entropy
E capture the amount of information in the future that is predictable [
5,
6] and not that which is predictive. The latter is the amount of information that must be stored to optimally predict, and this is given by the statistical complexity
Cμ. Therefore, when we use the abbreviation, TiPi, we mean the time-local
predictable information: information the agent immediately sees as advantageous.)
In fact, [
12] does a calculation very similar to the ones above, considering discrete-time stochastic dynamics of the form:
and calculating the TiPi:
with fixed T > 1. The motivation being that, whatever the history prior to t − T, the agent knows the environment state xt−T then. However, from that time forward, the agent, making no further observations, is ignorant. The stochastic dynamics then models the evolution of that ignorance from the given state to a distribution of states at t − 1 and then at t, taking into account only the model φ the agent has learned or is given. They report that TiPi is the difference between state information and noise entropy:
where:
and:
with L(0) = I.
Since ∑ depends on the states between times
t −
T and
t − 1, the TiPi expression in
Equation (A33) also depends on the states between times
t −
T and
t − 1. The TiPi definition in
Equation (A32) does not. Thus, even though the numerical results of [
12] are quite interesting, the quantity that the behavioral agents there were maximizing was not the stated conditional mutual information.
To address this concern and explore informational adaptation hypotheses, let us consider alternatives. If desired, for example, one could define an averaged TiPi as:
or one could define TiPi to be:
so that it depends on both xt−T and xt−1.
Even with these modifications,
Equation (A33) still cannot be a general expression for TiPi, since it depends on measurements at intermediate times that must be marginalized out of the conditional probability distribution with which we are calculating the mutual information.
Moving to discrete time with a small discretization time, let us find expressions for all three:
Suppose that the underlying dynamical system is a nonlinear Langevin equation with invertible diffusion matrix and an analytic potential function Uθ parametrized by θ:
with white noise: 〈η(t)〉 = 0 and 〈η(t)η(t′)⊤ 〉 = Dδ(t − t′). Following the argument used in Section 3:
and
These formulae lead to the following expressions for the TiPi alternatives:
and
Maximizing these with respect to θ has a different effect on the action policy. Maximizing the original TiPi IN[Xt;Xt−τ] leads the agent to alter the landscape, so that it is driven into unstable regions. Maximizing the averaged TiPi
leads to a flattening of the potential landscape. Additionally, the effect of maximizing
is not yet clear.
Not surprisingly, when
N is small, we recover the result that maximizing
IN[
Xt;
Xt−τ] has the same effect on the potential landscape as maximizing the TiPi in [
12] when
T = 2. Though the model there is set up for a discrete-time analysis, it is natural to suppose that adaptive agents in an environment move according to a continuous-time dynamic, but receive sensory signals in a discrete-time manner. Equating notation used here and there:
gives:
where
Aij =
∂(
D∇
U(
x))
i/
∂xj. When
N = 2, substituting this into
Equation (A34) yields:
The above expression is identical to that in
Equation (A35) for all practical purposes, as derivatives of the two with respect to
θ are identical up to an unimportant multiplicative constant to subleading order in
τ. Therefore, for
T = 2, many of the qualitative conclusions from numerical simulations are likely to carry over when
Equation (A35) is used as the objective function.
Finally, the difference in how these quantities were calculated is interesting to us. For instance, was the series expansion for the coefficients of the moments of the Green’s function in
Appendix C actually necessary? Could we have used an Ito discretization scheme to write
xt+Δt in terms of
xt−Δt and noise terms and use that expression to evaluate
bμ? This is related to the approach taken in [
12]. However, the answer obtained using the moment series expansions is a factor of two different than what would have been obtained with such a discretization scheme. Additionally, by keeping track of the order of the approximation errors in
Appendix C, we found that these formulae for both bound information and TiPi would only hold for invertible diffusion matrices. As suggested by
Appendix D, our estimates for such conditional mutual information change qualitatively when the diffusion matrix is not invertible. That, in turn, may be relevant to environments that are hidden Markov, settings for which the agent’s sensorium does not directly report the environmental states.



 . In this setting, the present X0 is the random variable measured at t = 0, the past is the chain X:0 = …X−2X−1 leading up the present and the future is the chain following the present X1: = X1X2 · · ·. (We suppress the infinite index in these.)
. In this setting, the present X0 is the random variable measured at t = 0, the past is the chain X:0 = …X−2X−1 leading up the present and the future is the chain following the present X1: = X1X2 · · ·. (We suppress the infinite index in these.)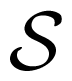 is isomorphic to the alphabet of the process
is isomorphic to the alphabet of the process
 (0, DΔt), we have:
(0, DΔt), we have:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}