1. Introduction
The Maximum Entropy (ME) method is a powerful non-parametric technique for density approximation, first proposed by [
1] in an information theory setup. By maximizing the Shannon’s entropy contained in the data subject to moment constraints, it provides the best-fitting distribution given that the only information available are the first
k empirical moments, where “best-fitting” is defined in terms of maximum entropy. An appealing feature is that, besides working well in setups where a parametric approach would fail, the ME density nests most commonly used parametric distributions. Thus, when the true data generating process is a parametric model but the investigator is unable or unwilling to assume it a priori, the ME density identifies it a posteriori,
i.e., according to the empirical properties of the data. It also provides a rough measure of the distance between a specific parametric model and the true data-generating process, estimated by the ME distribution. In other words, the method gives a “data-driven” indication whether a parametric or a non-parametric approach should be employed. This is a distinctive feature that makes it more interesting than other non-parametric techniques.
Estimation of the ME distribution may be performed in a relatively straightforward manner by means of a sequential updating algorithm proposed by [
2]. On the other hand, exact simulation is not trivial. In general, the distribution function does not exist in closed form, so that the inverse transform method is computationally very expensive. An accept-reject scheme can be used for specific versions of the ME density (that is, for any given value of the parameters and of the number of constraints
k), but is difficult to set up in general, because the density can have very different tail behaviors, and therefore an instrumental density that works when the tail is heavy would be inefficient for light-tailed versions of the distribution. Thus, the method would require different implementations for each member of the ME family, making it quite impractical.
In this paper we resort to Adaptive Importance Sampling (AIS) for approximate simulation of the ME density. The version of AIS based on mixture distributions was first introduced by [
3]. [
4] extend it to general mixture classes; recently, it has been employed for estimation of cosmological parameters [
5] and for simulating copulas [
6]. The method is a generalization of standard Importance Sampling (IS) because, at each iteration, a sample is simulated from the instrumental density and used to improve the IS density itself. So, “adaptivity” means that the instrumental density sequentially provides a progressively better approximation of the target density. It also rigorously formalizes the well-known capacity of mixtures to approximate most distributions.
The implementation of AIS proposed by [
3] is based on mixtures of normal or Student-
t densities. In this paper we develop a modification using mixtures of lognormal distributions, which is necessary for the simulation of densities supported on
. The AIS-based simulation methodology fits perfectly the ME setup, because it only requires the knowledge of the density function. Moreover, it is easily implemented, being based on simulation of lognormal random variables, and extremely accurate, as will be shown by means of numerical experiments.
The ME density is especially appropriate as a model for loss distributions in contexts where there are no theoretical reasons for choosing a specific parametric model. So, for example, even though the ME approach can give a satisfactory approximation of the P&L distribution of the log-returns obtained from equity prices, in this case the distribution is expected to be normal from standard financial theory, which is largely based on the hypothesis of Geometric Brownian Motion in continuous time. Thus, the use of the ME approach (similarly to the use of other ad hoc parametric distributions) is grounded on empirical reasons, but may be difficult to justify theoretically. On the other hand, the distribution of claims in non-life insurance or losses in operational risk is usually not expected to belong to any specific parametric family, and therefore, in absence of theoretical a priori information about the model, a non-parametric methodology such as ME can be very useful, as the choice has to be mostly motivated by the empirical features of the data. Finally, from the point of view of risk management, being able of sampling the ME distribution is crucial: although in simple cases risk measures can be computed by numerical integration, in a loss model obtained via compound distribution simulation is often the only way of measuring risk.
The main contribution of this paper is threefold. First, we extend the AIS methodology to the setup where the target distribution is supported on , instead of . Second, we use this technique for approximate simulation of the ME density. In this way, we overcome the difficulties encountered in exact simulation of the ME distribution. Finally, we show that the combination of ME and AIS provides an effective non-parametric approach for modelling different kinds of loss distributions and assessing the improvement with respect to classical parametric distributions.
The rest of this work is organized as follows.
Section 2 reviews the ME method.
Section 3 details the AIS approach to the simulation of the ME density.
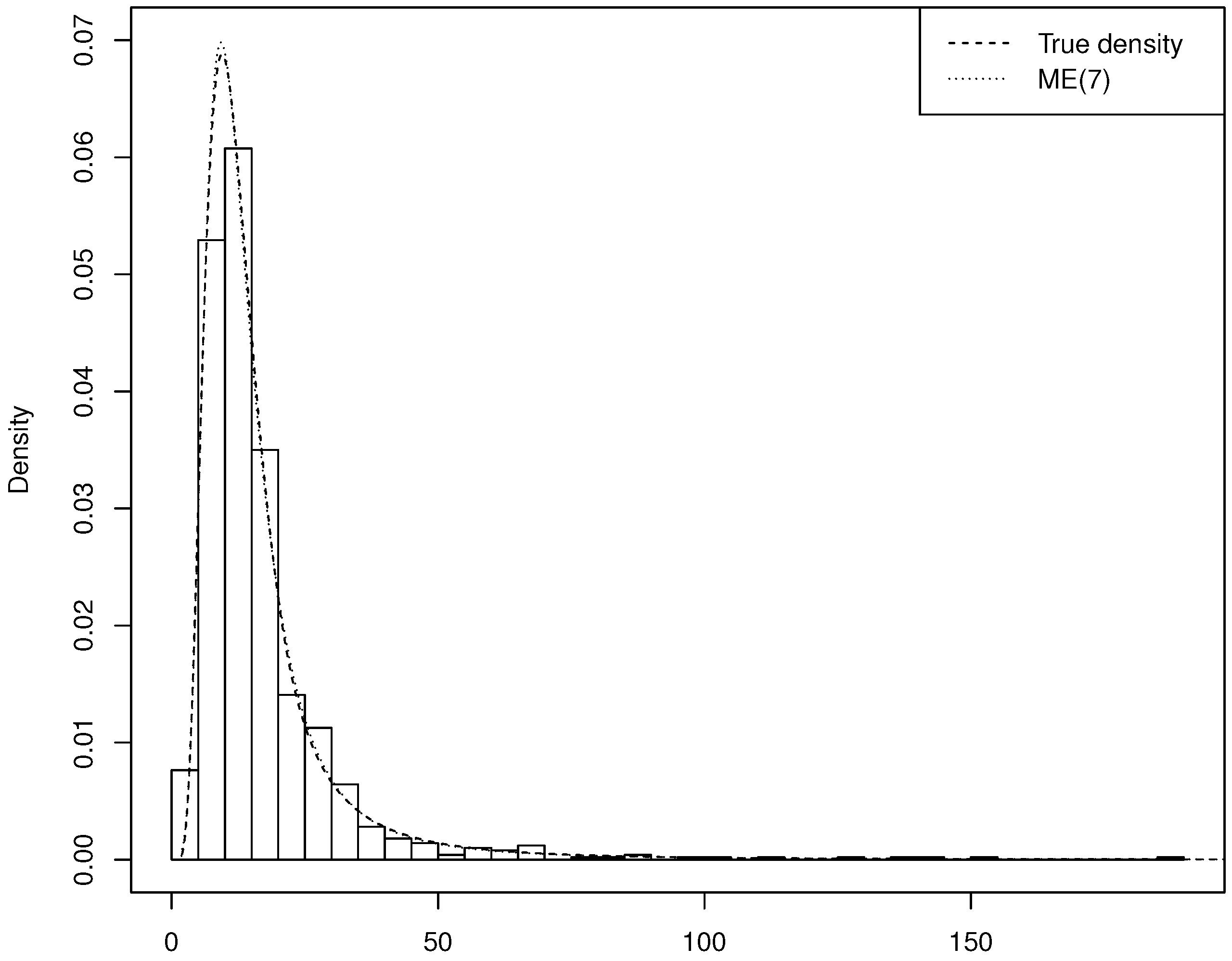
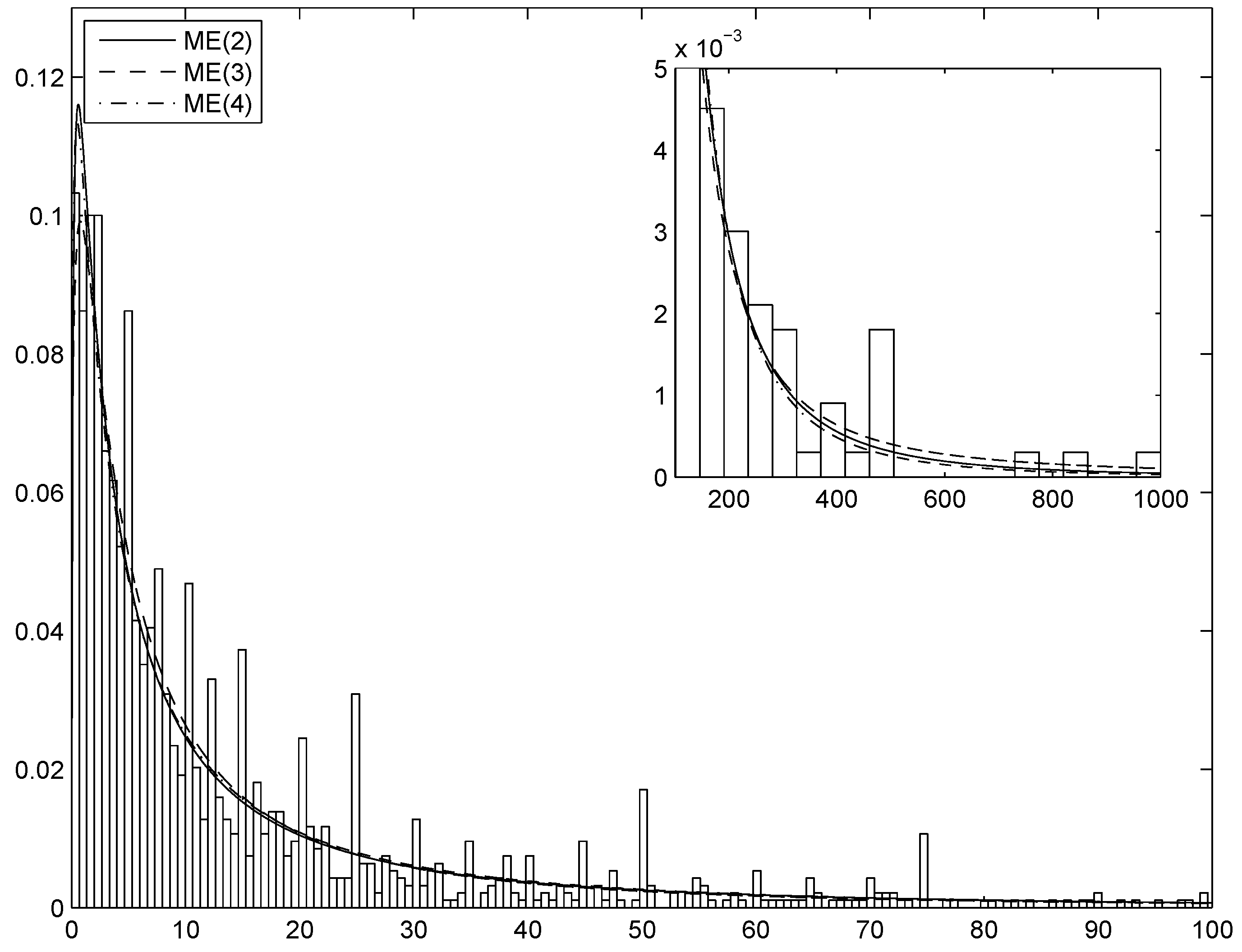
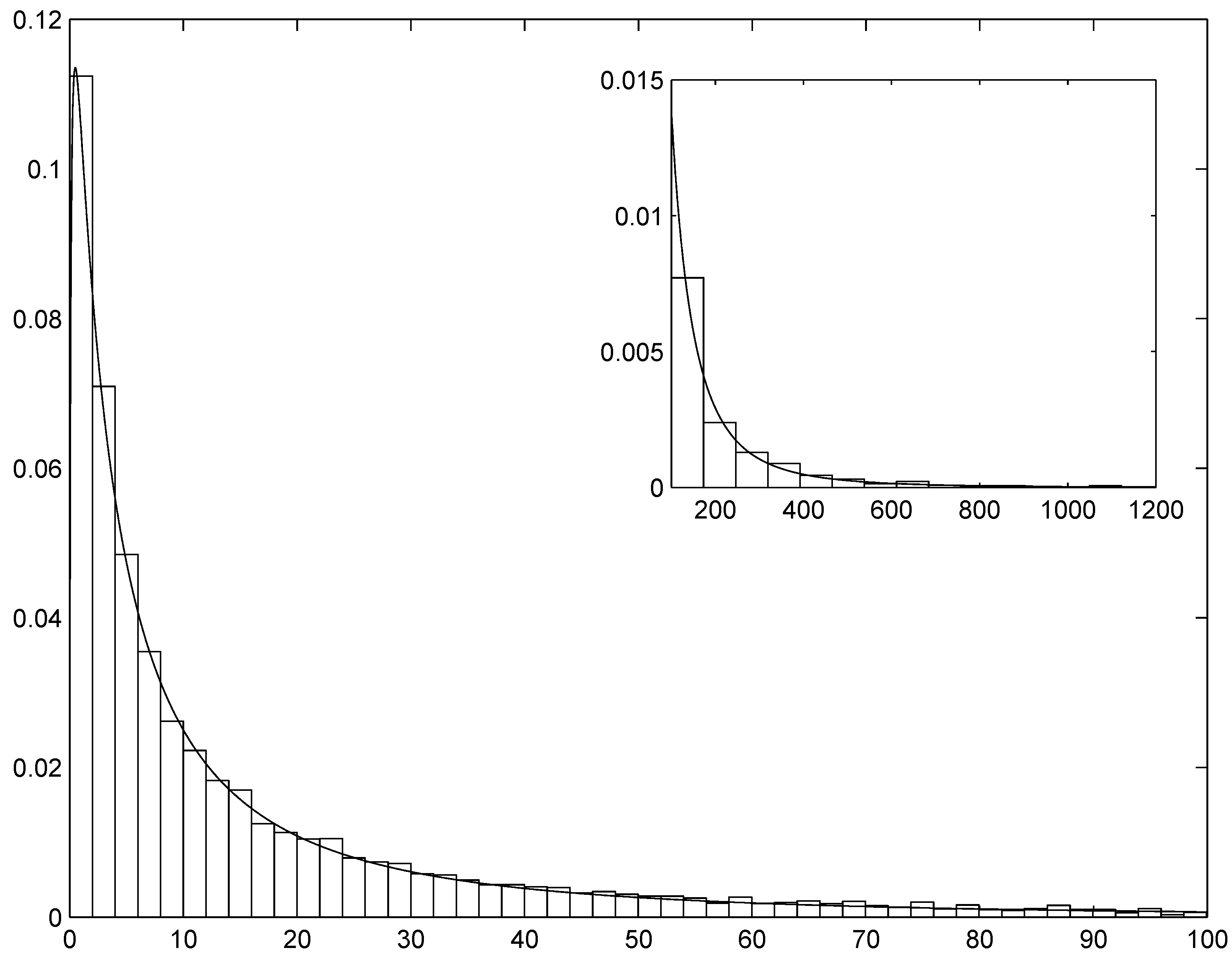
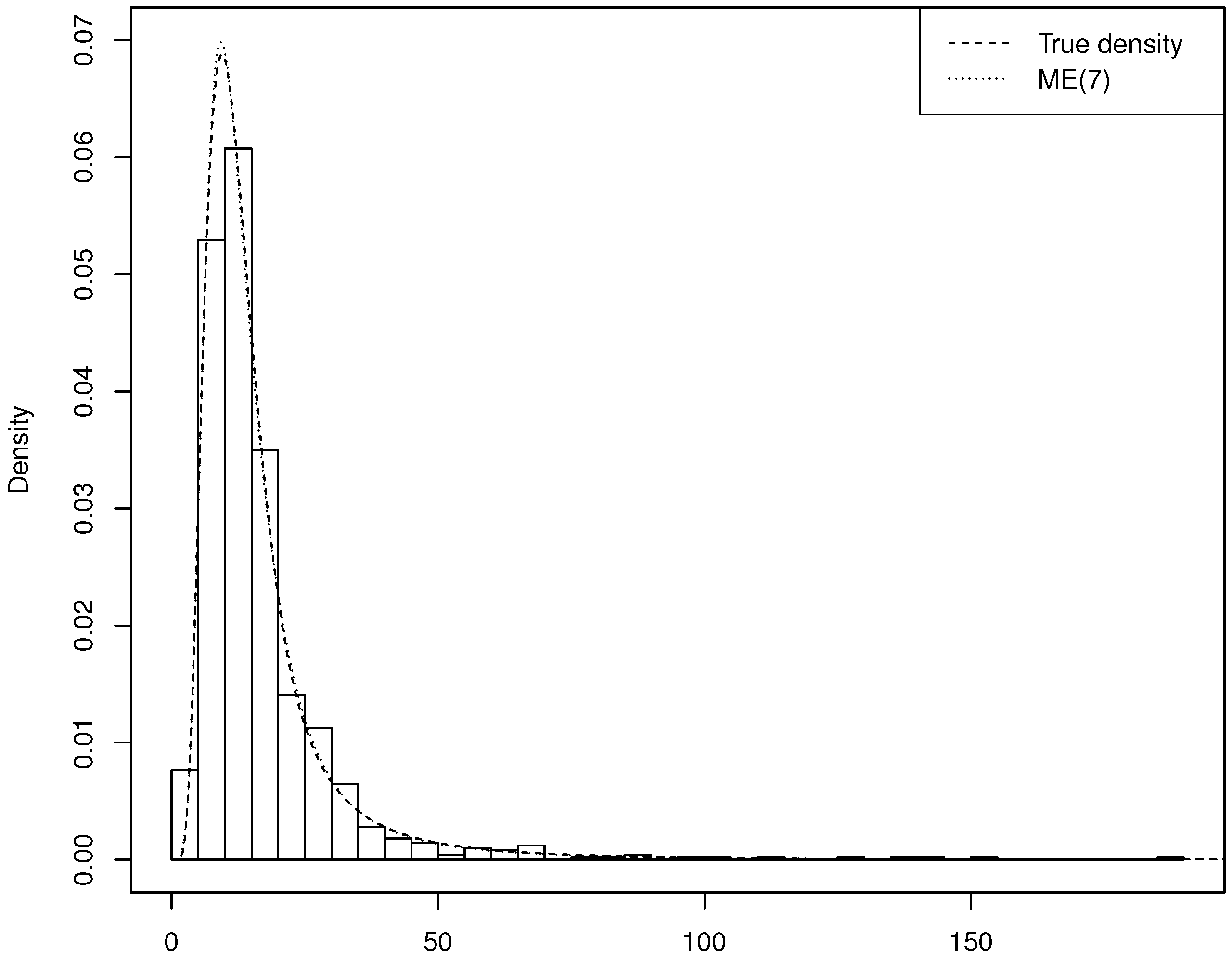
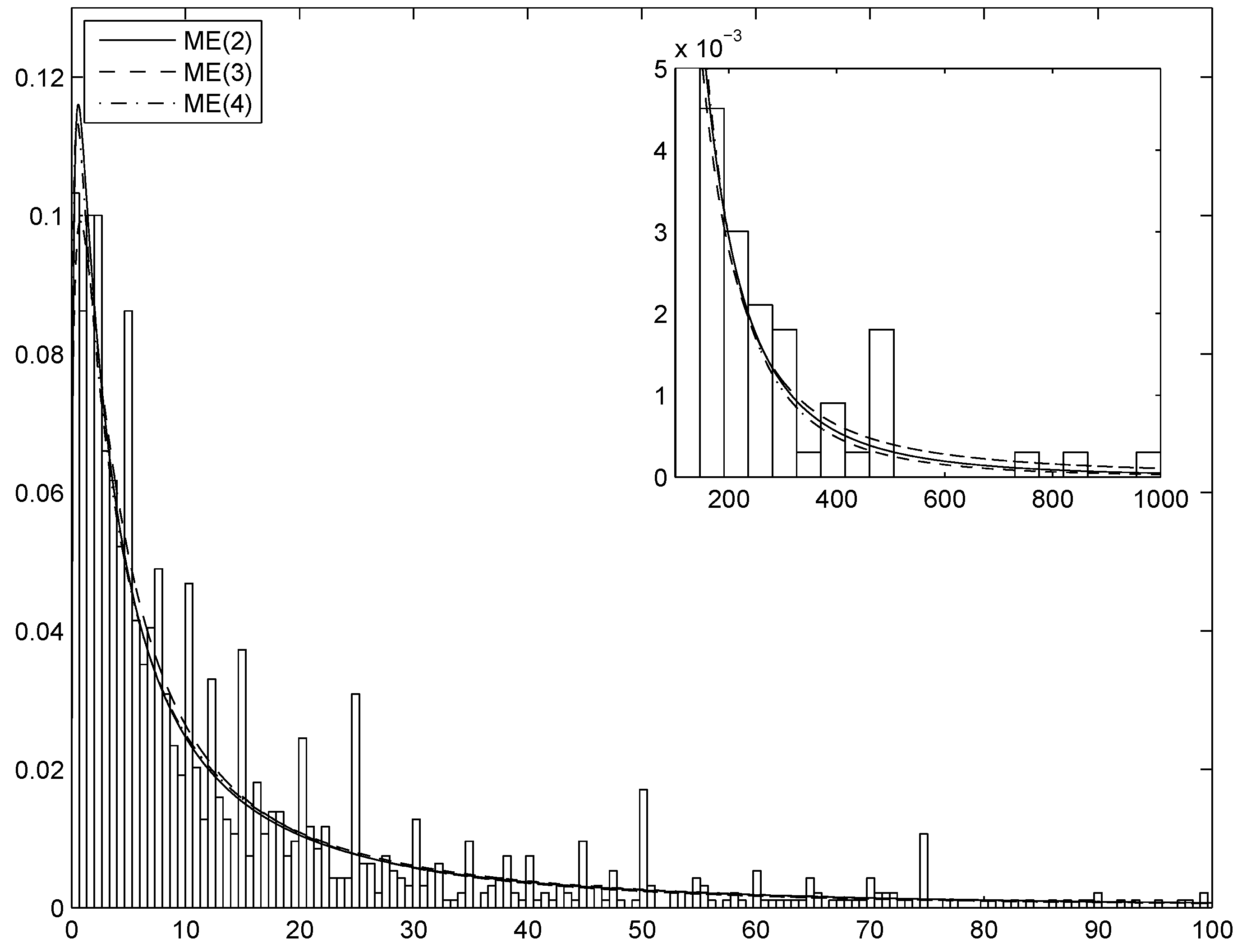
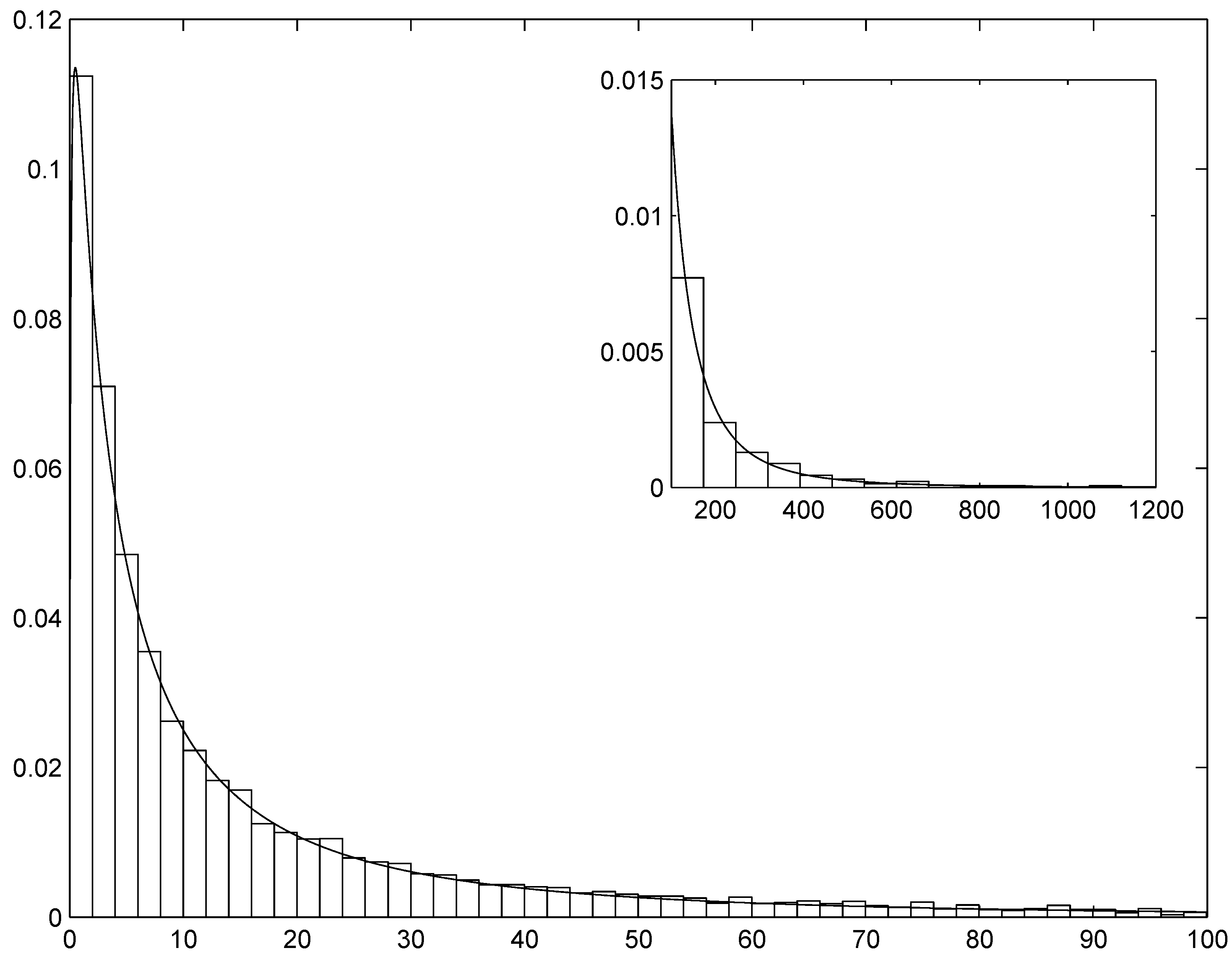
Section 4 shows selected results of the simulation experiments and applies the technique to the estimation and simulation of the distribution of indemnity payments. A thorough analysis of this example shall show the precision of the AIS simulation method and the merits of the ME approach in fitting the data and identifying the appropriateness or inappropriateness of standard parametric approaches. Finally,
Section 5 concludes.
2. Background about the Maximum Entropy Method
The Maximum Entropy method is best described by Jaynes’ (1957) words: the ME distribution is “uniquely determined as the one which is maximally noncommittal with respect to missing information, and it agrees with what is known, but expresses maximum uncertainty with respect to all other matters”. The ME density takes the form
where
k is the number of moment constraints and
s are the functional forms of the so-called “characterizing moments”. In most cases, they are the arithmetic or logarithmic moments, corresponding respectively to
and
, but other choices are possible [
7]. The
parameters are customarily defined using the Greek letter
λ because they are the Lagrange multipliers obtained by solving the maximization problem
under the constraints
where
f is a density,
W is the Shannon entropy associated to
f and
is the sample counterpart of the
i-th characterizing moment. It can be shown [
7] that the solution, called ME density, takes the form Equation (
1).
Despite its interesting properties, only very recently the method has been used more extensively in economics and finance ([
8,
9,
10,
11,
12,
13]). One reason is that Equation (
2) cannot be solved analytically for
, and the preferred algorithm for finding a solution, namely the Newton–Raphson algorithm, requires a very precise initialization to reach convergence, even for moderately large
k [
2]. However, [
2] has developed a generalization of the algorithm that makes it easier to find the optimal density. The idea is that there is no need to impose all the moment constraints simultaneously. Instead, one can impose the constraints one at a time, from the lowest to the highest moment, and update the ME density sequentially, every time a new constraint is taken into account. The advantage of such a procedure is twofold: first, the maximization subject to few moment constraints can be easily carried out with standard Newton–Raphson. Second, the moments are not independent, so that the estimates of the first
k parameters will typically be little changed when considering the ME density of order
, and can therefore be used as starting values for the (
)-order problem.
The other relevant problem in practical applications is the choice of the “optimal” value of k. In general, a larger number of constraints results in a more precise approximation, but the estimation of more parameters introduces further noise and may lead to overfitting. There are two possible ways of proceeding.
Since the maximized log-likelihood is equal to , where the s are the parameters of the fitted ME(k) density and n is the sample size, a log-likelihood ratio (llr) test is easily computed. The test of the hypothesis () against is given by ; from standard limiting theory, its asymptotic distribution is . The model-selection procedure would thus be based on the following steps: (a) estimate sequentially the ME density with ; (b) perform the test for each value of s; (c) stop at the first value of s (, say) such that the hypothesis cannot be rejected and conclude that the optimal value of k (from now on denoted by ) is equal to .
The preceding solution does not take into account the cost of estimating a model with a larger number of parameters. A possible remedy consists in computing an information criterion, such as the Akaike (AIC) or Bayesian (BIC) Information Criterion. To avoid overfitting, one can stop at the value such that at least one of the following two conditions holds: (1) the llr test cannot reject the hypothesis ; (2) the numerical value of AIC [or BIC] is larger than the numerical value of AIC [or BIC]. In the following we will mostly employ this approach.
The ME method is practically very important when the distribution to be approximated is non-standard, with features such as high skewness and/or kurtosis and heavy tail: in this case the ME distribution is able to catch them, whereas a standard parametric model would fail. In the latter case, it may be necessary to consider many terms in the exponent of the ME density, with the consequence that application of standard Newton–Raphson is unfeasible and Wu’s (2003) sequential algorithm is the only way of estimating the parameters.
On the other hand, classical distributions, such as the normal, lognormal, exponential, Pareto and others are obtained (exactly) from Equation (
1) for small values of
k, so that if the empirical distribution is “similar” to one of them, usually one or two moments will suffice to find a very good approximation. In this case estimation results based on the ME distribution and on the correct parametric model are essentially the same.
For the purposes of risk analysis of loss models, the most important distributions encompassed by the ME distribution are the lognormal and the Pareto. The lognormal
is a logarithmic ME density with
; the values of the parameters are
The Pareto
is a logarithmic ME density with
and parameters
See [
7] for further details as well as for other examples.
This discussion suggests to use the ME approach as a procedure for verifying the appropriateness of a certain parametric model and/or assessing the distance of the data at hand from a given distribution: for example, when the investigator is uncertain between the Pareto and the lognormal distribution, a possible way of proceeding consists in fitting sequentially the ME(
k) distribution with
, stopping at the smallest value of
k such that the llr test cannot reject the null hypothesis. The data-generating process is Pareto if the test accepts
, lognormal if it accepts
, neither Pareto nor lognormal if it accepts
; moreover, a large value of
k implies a large difference between the lognormal and the fitted ME distribution. See [
14] for details.
3. Approximate Simulation of the ME Distribution
The ME distribution function does not exist in closed form, because the density (1) cannot be integrated analytically. Resorting to numerical integration may be reasonable for computing quantiles of X, but is rather cumbersome for the implementation of the inverse transform method. On the other hand, the flexibility of the ME distribution and, in particular, its widely varying tail-heaviness, make it difficult to find an envelope instrumental distribution general enough to set up an accept-reject scheme that works efficiently for any ME density.
Given these difficulties in simulating the ME distribution exactly, we propose a method based on Adaptive Importance Sampling (AIS; see [
15,
16,
17]). The implementation of AIS used here was developed by [
3,
4] in a Bayesian setup and can also be used for approximate simulation of any absolutely continuous random variable [
6]. Instead of a fixed IS density
g, AIS finds a sequence of importance densities
(
) aimed at approximating the target density
f. Thus, even starting from an initial instrumental density that is quite different from the optimal one, the algorithm eventually provides the most efficient (in a sense that shall be clarified below) IS density. A pseudo-code description of the algorithm is as follows:
Simulate a first sample by means of standard IS; compute the IS weights ().
Use this sample to approximate the moments of f and construct the updated importance function .
Measure the goodness of the approximation by means of the relative entropy (or Kullback–Leibler divergence; see ([
18][Section 3.3]) from the target:
“Adjust” the density so that . More formally, compute , where θ is the vector of parameters of .
Repeat the preceding steps until some convergence criterion is met.
The functional form of
g must satisfy the requirements of being positive for all values in the support of the target and making minimization of Equation (
5) as straightforward as possible. [
3,
4] show that a convenient instrumental density is a finite mixture of normal distributions, namely
where
,
and
are respectively the vector of weights, expected values and variances of the
D mixture components. If the target density is
p-variate with
, Equation (
6) is a
p-variate normal mixture and the dimensions of the normal parameters change accordingly.
All parameters of Equation (
6) are
adaptable, that is, they are supposed to be updated at each iteration of the algorithm. Furthermore, it is possible to use mixtures of different densities: [
3,
4] extend the algorithm to mixtures of Student-
t densities. The key issue is the minimization of the relative entropy at step 4. Clearly, this depends on the choice of the instrumental density
g: a detailed analysis when
g is a Gaussian mixture is presented below (see the description of Algorithm 2). We can now give a more precise formulation of the algorithm.
| Algorithm 1 (Adaptive Importance Sampling) |
For :- -
Choose an importance function ; - -
Simulate independently from ; - -
Compute the importance weights , where .
For :- -
Update the importance function to according to the minimum Cross-Entropy criterion, using of the previous weighted sample , ⋯, . - -
Simulate independently from ; - -
Compute the importance weights .
|
An approximate sample from the target density is obtained by sampling with replacement from
and weighting the observations by means of the vector
. This algorithm cannot be, however, directly applied to the simulation of the ME density based on logarithmic moments. The reason is that the support of a normal (or Student-
t) mixture is the real line, whereas the support of the logarithmic ME density is
. It follows that the approximation is necessarily bad because, when simulating from the mixture, there is a non-zero probability of obtaining negative values. To overcome this difficulty, we need an instrumental distribution with support
, with
and
. Fortunately, there is a convenient solution, whose great advantage consists in leaving unchanged the updating equations obtained for a normal mixture. Assume the instrumental density is a finite mixture of lognormal distributions:
, where
is the lognormal density with parameters
and
; it is immediate to verify that, if
X has density
g, the density of
is Equation (
6), namely a normal mixture where both the mixing weights and the parameters of the component densities are the same of
g. For the setup at hand, Algorithm 1 can thus be rewritten as follows.
| Algorithm 2 (Lognormal mixture Adaptive Importance Sampling) |
For :Let , where ; Simulate independently from ; Compute the importance weights , where .
For :Update the importance function to according to the minimum Cross-Entropy criterion, using the logarithm of previous weighted sample , ⋯, . Simulate independently from ; Compute the importance weights .
|
It is worth stressing that at step 2(a) we take the logarithm of the current sample, which has a normal distribution, so that we can update π, and using the updating equations of the normal distribution. Then, at step 2(b), we use the updated values of the parameters for simulating the lognormal distribution.
The main technical issue is the update of the importance function
g at each iteration. When it is a
p-variate normal mixture, the algorithm works as follows. At iteration
t, the importance weights associated with the sample
are given by
and the normalized weights are
. Let now
. Similarly to [
3], the update is performed by iterating, for any
, the equations:
where
Convergence of the algorithm has been established by [
4]. In practice, to determine a stopping criterion, the goodness of the approximation must be evaluated at each iteration. An approximate diagnostic directly related to the relative entropy Equation (
5) is the normalized perplexity
, where
is the Shannon entropy of the normalized weights
. ([
4][Section 2.1]) show that
is an estimator of
and that
. On average, the normalized perplexity increases at each iteration, so that it is reasonable to stop the algorithm when it cannot be further increased (hence the entropy cannot be further decreased). Thus, the algorithm can be stopped when the normalized perplexity does not change significantly over some (five, say) successive iterations or a predefined “large” number of iterations is reached. Alternatively, it is possible to fix in advance a perplexity value
such that the algorithm stops the first time that the normalized perplexity reaches
: this guarantees the desired accuracy level.
In a simulation setup such as the present one, we are interested in assessing whether the simulated data can actually be treated as generated by the ME density. To this aim, we shall also test the discrepancy between the simulated data and the cdf of the ME density, computed numerically, by means of the Kolmogorov–Smirnov test.
5. Conclusions
In this paper we have developed a non-parametric approach to loss distribution analysis based on the concept of Maximum Entropy. The main technical contribution is a flexible procedure for approximate simulation of the ME distribution, based on an extension of the Adaptive Importance Sampling algorithm introduced by [
3,
4]. More generally, the paper details the merits of the ME approach in the typical risk analysis process of loss distributions, from model building to estimation, simulation and risk measurement.
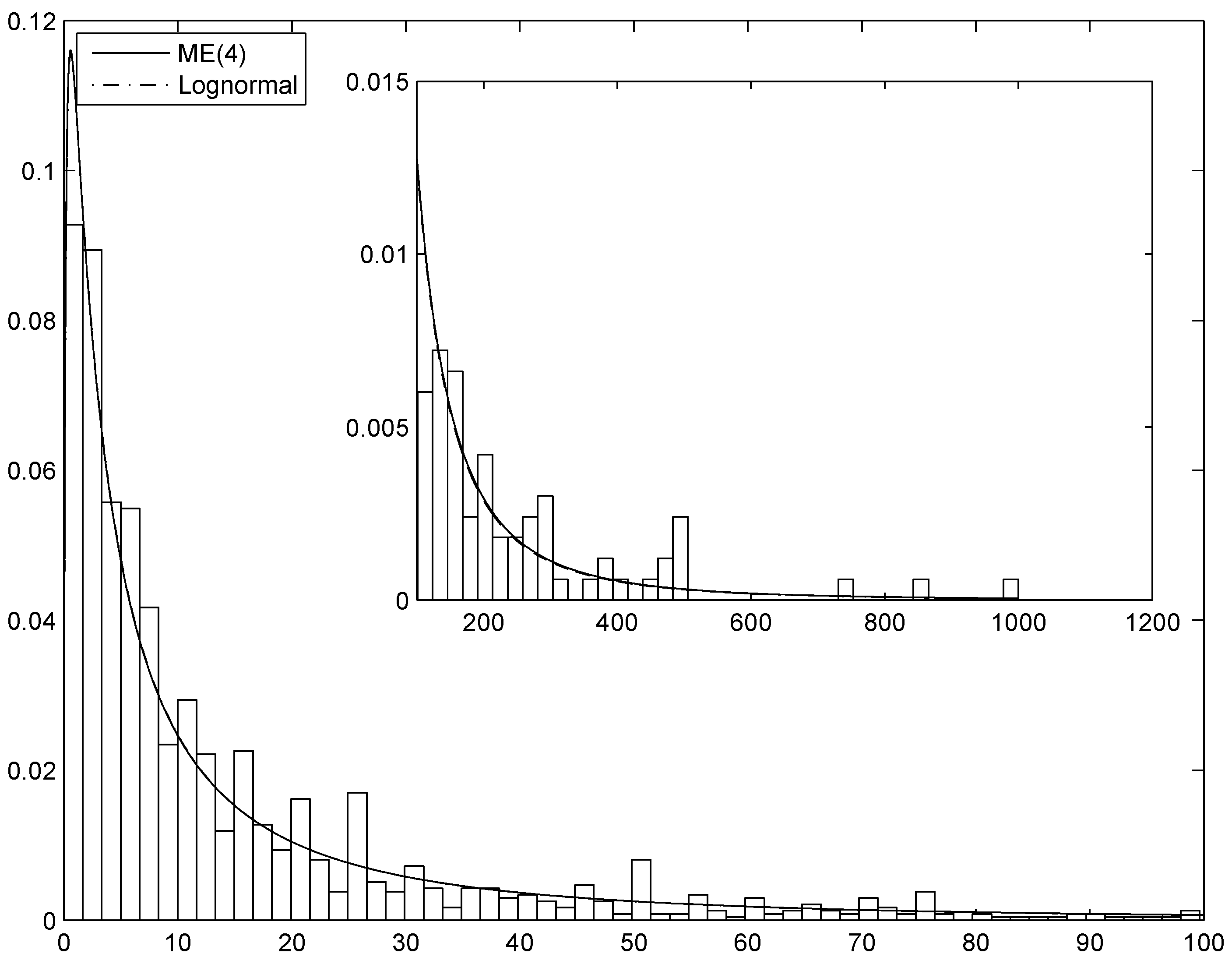
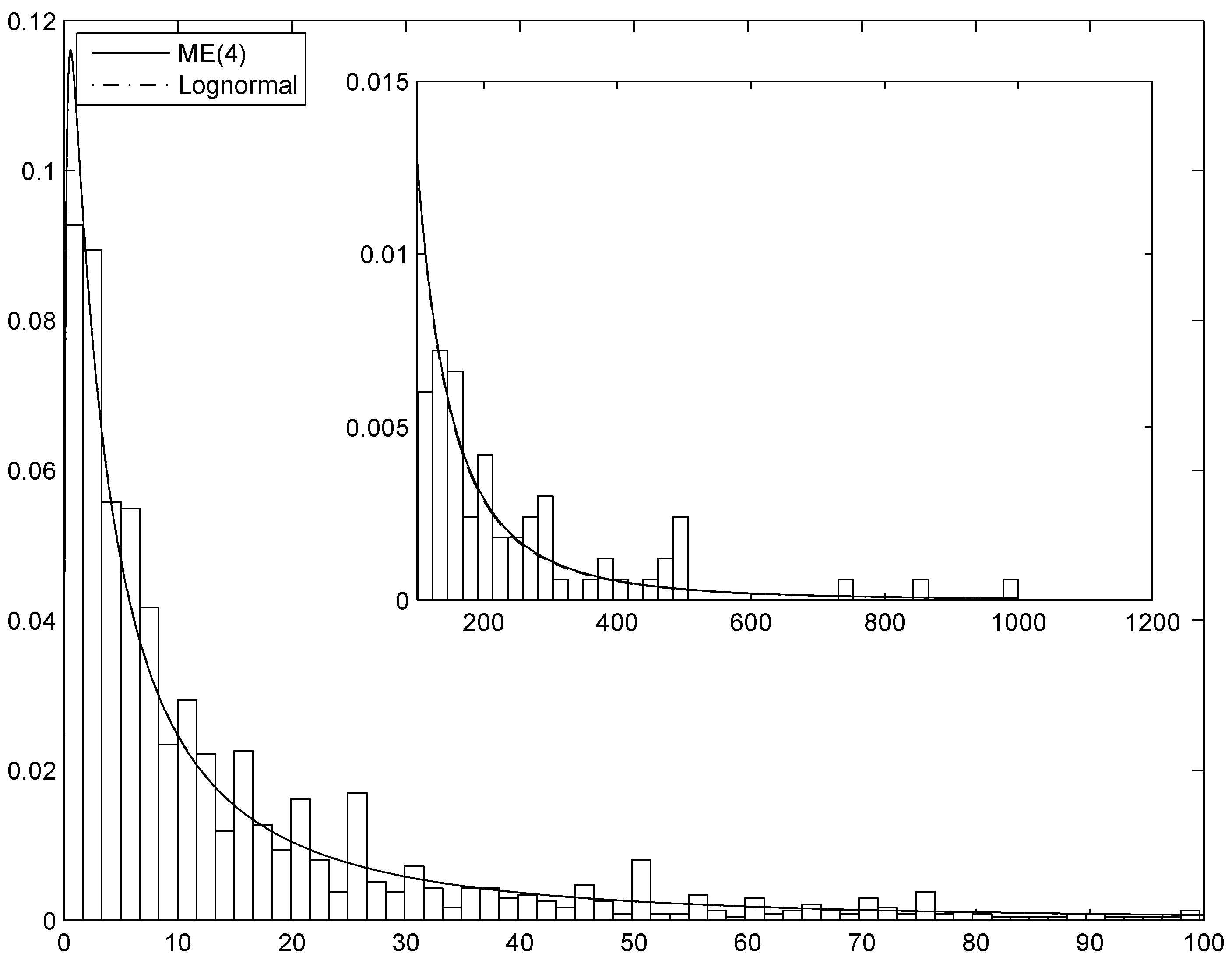
Figure 4.
The estimated ME(4) and lognormal densities superimposed on the histogram of the General Liability Claims observations.
Figure 4.
The estimated ME(4) and lognormal densities superimposed on the histogram of the General Liability Claims observations.
The method is appealing for various reasons. First, it allows to fit the best distribution (“best” being defined according to the Maximum Entropy principle) for the data at hand, which is particularly useful when there are no theoretical reasons for adopting a parametric distribution. Second, it may serve as a test of the choice between two (or more) parametric models. Finally, both estimation and simulation are computationally feasible.
The simulation method proposed in this paper has proved to be very precise and may be of crucial importance in models such as the compound Poisson distribution commonly used for modelling non-life insurance claims and operational losses.
A relevant topic that requires further research is the extension of the AIS instrumental density to mixtures that can approximate target distributions with support for some , such as the Pareto or the truncated lognormal distribution.


{kind=link}
{kind=link}
{kind=link}
{kind=link}