

Competitive Advantage and Personal Data Ecosystems: A Typology of Personal Data Control Constellations


Abstract
1. Introduction
- (RQ1) Which dimensions grounded in RBT determine data providers’ willingness to grant data access control to data subjects while preserving their competitive advantage in PDEs?
- (RQ2) What strategies can data providers use to grant access control without losing their competitive edge?
- (RQ3) How can the RBT be applied to the relationship between data providers and data subjects in the context of PDEs?
2. Literature Review
2.1. (Personal) Data Ecosystems and Data Sovereignty
2.2. (Personal) Data in the Resource-Based and Knowledge-Based Theories
2.3. Data Ecosystems: Existing Models in the Context of Data Sharing Between Companies
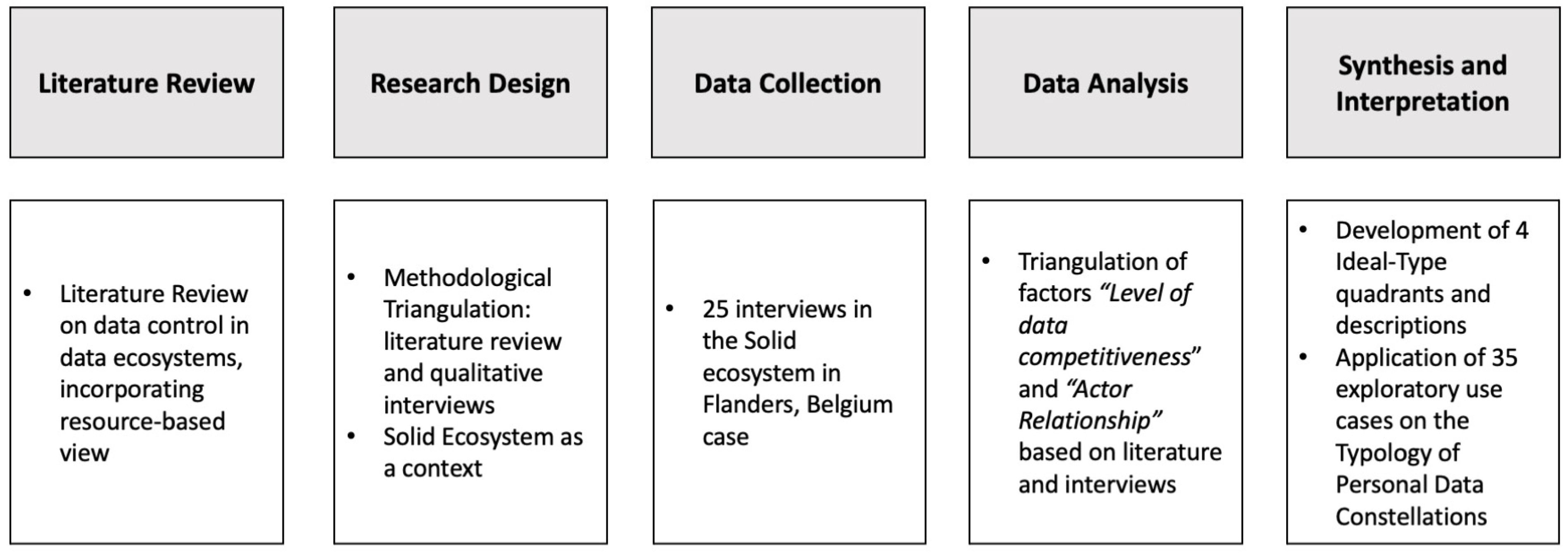
3. Methodology
- (i)
- Semi-structured interviews within the context of the Solid ecosystem in Flanders were performed (see data collection). To ensure practical relevance, interviews were performed to align with the current state of the art in business practices related to granting data access control within the Solid ecosystem. The semi-structured interview method allows researchers to balance guided questions with the flexibility to explore respondents’ perspectives in depth, blending structure with adaptability [52]. The Solid personal data ecosystem, which allows for data subject personal data control, is used as the context for the research. This has the advantage of generalizability as it offers standardization and interoperability through a W3C standards-based protocol [16,53]. The authors provided an explanation of general principles of data access control that extends beyond Solid, facilitating the generalizability of the findings to other technologies. The Solid ecosystem in Flanders is particularly interesting due to its active development, substantial policy stimulation, and private sector interest [54]. The Flemish government prioritizes Solid PDEs as a policy and innovation driver, and the establishment of a “data utility company” is evidence of this commitment [54]. This initiative is fostering an open ecosystem, promoting data exchange among data providers and data consumers while embedding personal data access control for data subjects [53]. Taking into account the inherent limited generalizability that springs from the case study approach, the selection of this ecosystem should offer insights that are generalizable beyond the case at hand by illustrating the emergence of data access control principles adoption.
- (ii)
- The researchers employed methodological triangulation [55,56], combining semi-structured interviews with insights on the level of data competitiveness and actor relationships in data ecosystems from the extant academic literature. Methodological triangulation combines multiple research methods to strengthen the reliability and depth of findings, enhancing this study’s validity by reducing potential biases that could arise from a single method [55]. Triangulation enhances credibility, validity, and depth of findings [56]. The logic of triangulation is based on the premise that no single method ever adequately solves the problem of rival explanations. Because each method reveals different aspects of empirical reality, multiple methods of data collection and analysis provide credibility in the results. Convergent triangulation has been applied [57], as the aim of the research is to develop and test a typology.
- (iii)
- The theory was tested by validating the identified dimensions with the literature on data sharing grounded in the RBT. In the final step, the typology was validated using interview-based use cases. Case studies assessed whether the identified quadrants align with current business practices in granting data access control.
4. Results
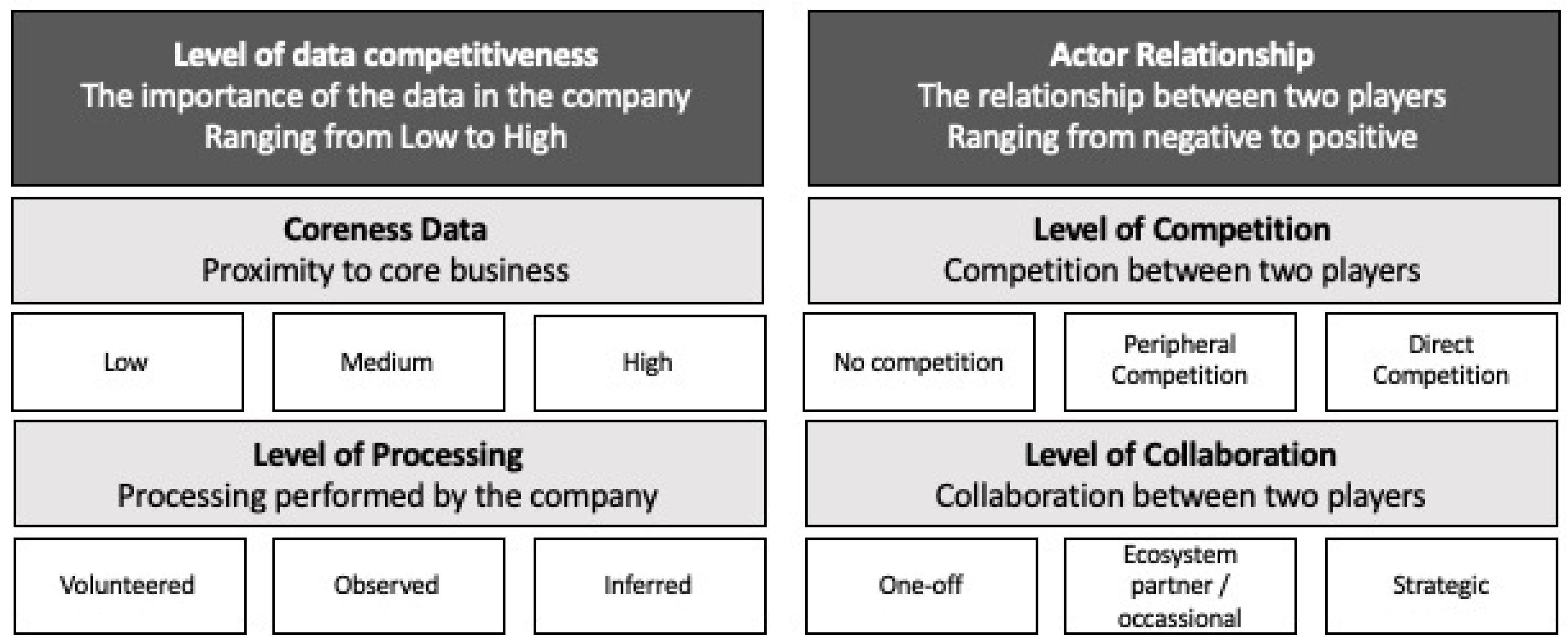
4.1. Level of Data Competitiveness of Personal Data
4.1.1. Coreness
4.1.2. Level of Processing
4.2. Actor Relationship
4.2.1. Level of Collaboration
4.2.2. Level of Competition
4.3. Typology of Personal Data Control Constellations
5. Discussion
5.1. Theoretical Implications
5.2. Practical Implications
6. Limitations and Further Research
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Company | Role in Ecosystem | Profile | Date Interview |
| 1 | Data consumer/provider | Content expert | 13 June 2022 |
| 2 | Data consumer/provider | C-level | 15 June 2022 |
| 3 | Data consumer/provider | Content expert | 16 June 2022 |
| 4 | Data consumer/provider | Content expert | 14 July 2022 |
| 5 | Data consumer/provider | Content expert | 28 June 2022 |
| 6 | Data consumer/provider | Content expert | 4 November 2021 |
| 7 | Technology service provider | C-level | 30 June 2021 |
| 8 | Data consumer/provider | Content expert | 14 October 2021 |
| 9 | Data consumer/provider | Content expert | 10 November 2021 |
| 10 | Data consumer provider | C-level | 6 July 2022 |
| 11 | Technology service provider | C-level | 7 July 2022 |
| 12 | Ecosystem level | Content expert | 12 July 2022 |
| 13 | Technology service provider | Content expert | 13 July 2022 |
| 14 | Ecosystem level | C-level | 28 October 2021 |
| 15 | Ecosystem Level | C-level | 15 October 2021 |
| 16 | Data consumer/provider | Content expert | 8 November 2021 |
| 17 | Data consumer/provider | Content expert | 27 July 2022 |
| 18 | Technology service provider | C-level | 28 July 2022 |
| 19 | Technology service provider | C-level | 2 August 2022 |
| 20 | Data consumer/provider | Content expert | 22 October 2022 |
| 21 | Technology service provider | C-level | 4 August 2022 |
| 22 | Data consumer/provider | C-level | 8 August 2022 |
| 23 | Data consumer/provider | Content expert | 10 August 2022 |
| 24 | Technology service provider | C-level | 11 August 2022 |
| 25 | Technology service provider | C-level | 7 September 2022 |
Appendix B
| Dimension (Mentions in Interviews) | Literature Dimension | Factor (Mentions) | Literature Factor |
| Level of data competitiveness (24/25) | [11,13,35,36,38,44,72,73,74,75] | Coreness (20/25) | [2,3,11,42,67] |
| Level of processing (23/25) | [1,33,40,47] | ||
| Actor relationship (24/25) | [3,34,35,43,45,46,47,48] | Level of competition (22/25) | [45,46,47,48,71] |
| Level of collaboration (21/25) |
References
- Oliveira, M.I.S.; Barros Lima, G.d.F.; Farias Lóscio, B. Investigations into Data Ecosystems: A Systematic Mapping Study. Knowl. Inf. Syst. 2019, 61, 589–630. [Google Scholar] [CrossRef]
- Alexy, O.; George, G.; Salter, A.J. Cui Bono? The Selective Revealing of Knowledge and Its Implications for Innovative Activity. Acad. Manag. Rev. 2013, 38, 270–291. [Google Scholar] [CrossRef]
- Kembro, J.; Naslund, D.; Olhager, J. Information Sharing across Multiple Supply Chain Tiers: A Delphi Study on Antecedents. Int. J. Prod. Econ. 2017, 193, 77–86. [Google Scholar] [CrossRef]
- Hummel, P.; Braun, M.; Dabrock, P. Own Data? Ethical Reflections on Data Ownership. Philos. Technol. 2021, 34, 545–572. [Google Scholar] [CrossRef]
- Knaapi-Junnila, S.; Rantanen, M.M.; Koskinen, J. Are You Talking to Me?—Calling Laypersons in the Sphere of Data Economy Ecosystems. Inf. Technol. People 2022, 35, 292–310. [Google Scholar] [CrossRef]
- Koskinen, J.; Knaapi-Junnila, S.; Helin, A.; Rantanen, M.M.; Hyrynsalmi, S. Ethical Governance Model for the Data Economy Ecosystems. Digit. Policy Regul. Gov. 2023, 25, 221–235. [Google Scholar] [CrossRef]
- Scheider, S.; Lauf, F.; Möller, F.; Otto, B. A Reference System Architecture with Data Sovereignty for Human-Centric Data Ecosystems. Bus. Inf. Syst. Eng. 2023, 65, 577–595. [Google Scholar] [CrossRef]
- Zrenner, J.; Möller, F.O.; Jung, C.; Eitel, A.; Otto, B. Usage Control Architecture Options for Data Sovereignty in Business Ecosystems. J. Enterp. Inf. Manag. 2019, 32, 477–495. [Google Scholar] [CrossRef]
- Gupta, M.; George, J.F. Toward the Development of a Big Data Analytics Capability. Inf. Manag. 2016, 53, 1049–1064. [Google Scholar] [CrossRef]
- Barney, J. Firm Resources and Sustained Competitive Advantage. J. Manag. 1991, 17, 99–120. [Google Scholar] [CrossRef]
- Enders, T.; Wolff, C.; Satzger, G. Knowing What to Share: Selective Revealing in Open Data. In Proceedings of the European Conference on Information Systems, Marrakech, Morocco, 15–17 June 2020. [Google Scholar]
- Kugler, P.; Plank, T.J. Coping with the Double-Edged Sword of Data-Sharing in Ecosystems. Technol. Innov. Manag. Rev. 2022, 11, 5–16. [Google Scholar] [CrossRef]
- Loebbecke, C.; van Fenema, P.C.; Powell, P. Managing Inter-Organizational Knowledge Sharing. J. Strateg. Inf. Syst. 2016, 25, 4–14. [Google Scholar] [CrossRef]
- Mamonov, S.; Triantoro, T.M. The Strategic Value of Data Resources in Emergent Industries. Int. J. Inf. Manag. 2018, 39, 146–155. [Google Scholar] [CrossRef]
- Abbas, A.E.; van Velzen, T.; Ofe, H.; van de Kaa, G.; Zuiderwijk, A.; de Reuver, M. Beyond Control over Data: Conceptualizing Data Sovereignty from a Social Contract Perspective. Electron. Mark. 2024, 34, 20. [Google Scholar] [CrossRef]
- Debackere, L.; Colpaert, P.; Taelman, R.; Verborgh, R. A Policy-Oriented Architecture for Enforcing Consent in Solid. In Proceedings of the WWW’22: The ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 516–524. [Google Scholar]
- Verbrugge, S.; Vannieuwenborg, F.; Van der Wee, M.; Colle, D.; Taelman, R.; Verborgh, R. Towards a Personal Data Vault Society: An Interplay between Technological and Business Perspectives. In Proceedings of the 2021 60th FITCE Communication Days Congress for ICT Professionals: Industrial Data—Cloud, Low Latency and Privacy (FITCE), Vienna, Austria, 29 September 2021; IEEE: New York, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Couldry, N.; Mejias, U.A. Data Colonialism: Rethinking Big Data’s Relation to the Contemporary Subject. Telev. New Media 2019, 20, 336–349. [Google Scholar] [CrossRef]
- Zuboff, S. Big Other: Surveillance Capitalism and the Prospects of an Information Civilization. J. Inf. Technol. 2015, 30, 75–89. [Google Scholar] [CrossRef]
- Ojasalo, J.; Miskeljin, P. Proposing a Preliminary Concept for a Personal Data Ecosystem. In Proceedings of the INTED2020 Proceedings, 14th International Technology, Education and Development Conference, Valencia, Spain, 1 March 2020; pp. 7451–7459. [Google Scholar]
- Spiekermann, S.; Acquisti, A.; Böhme, R.; Hui, K.-L. The Challenges of Personal Data Markets and Privacy. Electron. Mark. 2015, 25, 161–167. [Google Scholar] [CrossRef]
- Lehtiniemi, T. Personal Data Spaces: An Intervention in Surveillance Capitalism? Surveill. Soc. 2017, 15, 626–639. [Google Scholar] [CrossRef]
- Otto, B.; Teuscher, S. International Data Spaces Association—Reference Architecture Model; International Data Spaces Association: Dortmund, Germany, 2019; p. 118. [Google Scholar]
- Hummel, P.; Braun, M.; Tretter, M.; Dabrock, P. Data Sovereignty: A Review. Big Data Soc. 2021, 8, 2053951720982012. [Google Scholar] [CrossRef]
- von Scherenberg, F.; Hellmeier, M.; Otto, B. Data Sovereignty in Information Systems. Electron. Mark. 2024, 34, 15. [Google Scholar] [CrossRef]
- Rubinfeld, D. Data Portability and Interoperability: An E.U.-U.S. Comparison. Eur. J. Law Econ. 2024, 57, 163–179. [Google Scholar] [CrossRef]
- Lam, W.M.W.; Liu, X. Does Data Portability Facilitate Entry? Int. J. Ind. Organ. 2020, 69, 102564. [Google Scholar] [CrossRef]
- Lauf, F.; Scheider, S.; Bartsch, J.; Herrmann, P.; Radic, M.; Rebbert, M.; Nemat, A.; Langdon, C.S.; Konrad, R.; Sunyaev, A.; et al. Linking Data Sovereignty and Data Economy: Arising Areas of Tension. In Proceedings of the Wirtschaftsinformatik 2022, Online, 21–23 February 2022. [Google Scholar]
- Grant, R.M. Toward a Knowledge-Based Theory of the Firm. Strateg. Manag. J. 1996, 17, 109–122. [Google Scholar] [CrossRef]
- Amit, R.; Schoemaker, P.J.H. Strategic Assets and Organizational Rent. Strateg. Manag. J. 1993, 14, 33–46. [Google Scholar] [CrossRef]
- Spender, J.-C. Making Knowledge the Basis of a Dynamic Theory of the Firm. Strateg. Manag. J. 1996, 17, 45–62. [Google Scholar] [CrossRef]
- Nonaka, I.; Toyama, R.; Konno, N. SECI, Ba and Leadership: A Unified Model of Dynamic Knowledge Creation. Long Range Plann. 2000, 33, 5–34. [Google Scholar] [CrossRef]
- Dyer, J.H.; Singh, H. The Relational View: Cooperative Strategy and Sources of Interorganizational Competitive Advantage. Acad. Manag. Rev. 1998, 23, 660–679. [Google Scholar] [CrossRef]
- Li, S.; Lin, B. Accessing Information Sharing and Information Quality in Supply Chain Management. Decis. Support Syst. 2006, 42, 1641–1656. [Google Scholar] [CrossRef]
- Dahlberg, T.; Nokkala, T. Willigness to Share Supply Chain Data in an Ecosystem Governed Platform—An Interview Study. In Proceedings of the 32nd Bled eConference Humanizing Technology for a Sustainable Society, Bled, Slovenia, 16–19 June 2019; AIS Electronic Library (AISeL): Atlanta, GA, USA, 2019; Volume 32, pp. 619–638. [Google Scholar]
- Jarman, H.; Luna-Reyes, L.; Pardo, T. Private Data and Public Value: Governance, Green Consumption, and Sustainable Supply Chains; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Klein, T.; Verhulst, S. Access to New Data Sources for Statistics Business Models and Incentives for the Corporate Sector; OECD Statistics Working Papers; OECD Publishing: Paris, France, 2017. [Google Scholar] [CrossRef]
- Ensign, P.C.; Hébert, L. Competing Explanations for Knowledge Exchange: Technology Sharing within the Globally Dispersed R&D of the Multinational Enterprise. J. High Technol. Manag. Res. 2009, 20, 75. [Google Scholar]
- Frey, R.M. The Effect of a Blockchain-Supported, Privacy-Preserving System on Disclosure of Personal Data. In Proceedings of the 2017 IEEE 16th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 30 October–1 November 2017; pp. 1–5. [Google Scholar]
- Weydert, V.; Desmet, P.; Lancelot-Miltgen, C. Convincing Consumers to Share Personal Data: Double-Edged Effect of Offering Money. J. Consum. Mark. 2019, 37, 1–9. [Google Scholar] [CrossRef]
- Zhao, J.; Zhu, C.; Peng, Z.; Xu, X.; Liu, Y. User Willingness toward Knowledge Sharing in Social Networks. Sustainability 2018, 10, 4680. [Google Scholar] [CrossRef]
- Zanetti, D.; Capkun, S. Protecting Sensitive Business Information While Sharing Serial-Level Data. In Proceedings of the 2008 12th Enterprise Distributed Object Computing Conference Workshops, Munich, Germany, 16 September 2008; pp. 183–191. [Google Scholar]
- Fawcett, S.; Osterhaus; Magnan, G.; Brau, J.; Mccarter, M. Information Sharing and Supply Chain Performance: The Role of Connectivity and Willingness. Supply Chain Manag. Int. J. 2007, 12, 358–368. [Google Scholar] [CrossRef]
- Trkman, P.; Desouza, K.C. Knowledge Risks in Organizational Networks: An Exploratory Framework. J. Strateg. Inf. Syst. 2012, 21, 1–17. [Google Scholar] [CrossRef]
- Gnyawali, D.R.; Park, B.-J. (Robert) Co-Opetition between Giants: Collaboration with Competitors for Technological Innovation. Res. Policy 2011, 40, 650–663. [Google Scholar] [CrossRef]
- Wiener, M.; Saunders, C. Forced Coopetition in IT Multi-Sourcing. J. Strateg. Inf. Syst. 2014, 23, 210–225. [Google Scholar] [CrossRef]
- Young, M.-L.; Kuo, F.-Y.; Myers, M.D. To Share or Not to Share: A Critical Research Perspective on Knowledge Management Systems. Eur. J. Inf. Syst. 2012, 21, 496–511. [Google Scholar] [CrossRef]
- Seepana, C.; Paulraj, A.; Huq, F.A. The Architecture of Coopetition: Strategic Intent, Ambidextrous Managers, and Knowledge Sharing. Ind. Mark. Manag. 2020, 91, 100–113. [Google Scholar] [CrossRef]
- Kaššaj, M.; Peráček, T. Synergies and Potential of Industry 4.0 and Automated Vehicles in Smart City Infrastructure. Appl. Sci. 2024, 14, 3575. [Google Scholar] [CrossRef]
- Chigbu, U.E.; Atiku, S.O.; Du Plessis, C.C. The Science of Literature Reviews: Searching, Identifying, Selecting, and Synthesising. Publications 2023, 11, 2. [Google Scholar] [CrossRef]
- Goertel, R.A. Literature Review. In The Cambridge Handbook of Research Methods and Statistics for the Social and Behavioral Sciences: Volume 1: Building a Program of Research; Nichols, A.L., Edlund, J., Eds.; Cambridge Handbooks in Psychology; Cambridge University Press: Cambridge, UK, 2023; pp. 65–84. ISBN 978-1-316-51852-6. [Google Scholar]
- Fontana, A.; Frey, J.H. The Interview: From Structured Questions to Negotiated Text. In Handbook in Qualitative Research, 2nd ed.; Sage Publications: Thousand Oaks, CA, USA, 2000; pp. 645–672. [Google Scholar]
- Buyle, R.; Taelman, R.; Mostaert, K.; Joris, G.; Mannens, E.; Verborgh, R.; Berners-Lee, T. Streamlining Governmental Processes by Putting Citizens in Control of Their Personal Data. In Proceedings of the Electronic Governance and Open Society: Challenges in Eurasia, St. Petersburg, Russia, 18–19 November 2020; Chugunov, A., Khodachek, I., Misnikov, Y., Trutnev, D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 346–359. [Google Scholar]
- Van Damme, S.; Mechant, P.; Vlassenroot, E.; Van Compernolle, M.; Buyle, R.; Bauwens, D. Towards a Research Agenda for Personal Data Spaces: Synthesis of a Community Driven Process. In Electronic Government; Janssen, M., Csáki, C., Lindgren, I., Loukis, E., Melin, U., Viale Pereira, G., Rodríguez Bolívar, M.P., Tambouris, E., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2022; Volume 13391, pp. 563–577. ISBN 978-3-031-15085-2. [Google Scholar]
- Denzin, N. Sociological Methods: A Sourcebook; McGraw-Hill: New York, NY, USA, 1978. [Google Scholar]
- Patton, M. Enhancing the Quality and Credibility of Qualitative Analysis. Health Serv. Res. 1999, 34, 1208. [Google Scholar]
- Turner, S.F.; Cardinal, L.B.; Burton, R.M. Research Design for Mixed Methods: A Triangulation-Based Framework and Roadmap. Organ. Res. Methods 2017, 20, 243–267. [Google Scholar] [CrossRef]
- Roloff, J. Learning from Multi-Stakeholder Networks: Issue-Focussed Stakeholder Management. J. Bus. Ethics 2008, 82, 233–250. [Google Scholar] [CrossRef]
- Berg, S. Snowball Sampling—I. In Encyclopedia of Statistical Sciences; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2006. [Google Scholar]
- Adams, W.C. Conducting Semi-Structured Interviews. In Handbook of Practical Program Evaluation; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2015; pp. 492–505. ISBN 978-1-119-17138-6. [Google Scholar]
- Myers, M.D.; Newman, M. The Qualitative Interview in IS Research: Examining the Craft. Inf. Organ. 2007, 17, 2–26. [Google Scholar] [CrossRef]
- Corbin, J.M.; Strauss, A. Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory, 3rd ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2008. [Google Scholar]
- Mandara, J. The Typological Approach in Child and Family Psychology: A Review of Theory, Methods, and Research. Clin. Child Fam. Psychol. Rev. 2003, 6, 129–146. [Google Scholar] [CrossRef]
- Gerhardt, U. The Use of Weberian Ideal-Type Methodology in Qualitative Data Interpretation: An Outline for Ideal-Type Analysis. Bull. Sociol. Methodol. Méthodol. Sociol. 1994, 45, 74–126. [Google Scholar] [CrossRef]
- Stapley, E.; O’Keeffe, S.; Midgley, N. Developing Typologies in Qualitative Research: The Use of Ideal-Type Analysis. Int. J. Qual. Methods 2022, 21, 160940692211006. [Google Scholar] [CrossRef]
- Nickerson, R.C.; Varshney, U.; Muntermann, J. A Method for Taxonomy Development and Its Application in Information Systems. Eur. J. Inf. Syst. 2013, 22, 336–359. [Google Scholar] [CrossRef]
- Henkel, J. Selective Revealing in Open Innovation Processes: The Case of Embedded Linux. Res. Policy 2006, 35, 953–969. [Google Scholar] [CrossRef]
- Fosso Wamba, S.; Gunasekaran, A.; Akter, S.; Ren, S.; Dubey, R.; Childe, S. Big Data Analytics and Firm Performance: Effect of Dynamic Capabilities. J. Bus. Res. 2016, 70, 356–365. [Google Scholar] [CrossRef]
- Abrams, M. The Origins of Personal Data and Its Implications for Governance. SSRN Electron. J. 2014. [Google Scholar] [CrossRef]
- OECD. Enhancing Access to and Sharing of Data; OECD: Paris, France, 2019. [Google Scholar]
- Wieninger, S.; Götzen, R.; Gudergan, G.; Wenning, K.M. The Strategic Analysis of Business Ecosystems: New Conception and Practical Application of a Research Approach. In Proceedings of the 2019 IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Valbonne Sophia-Antipolis, France, 17 June 2019; pp. 1–8. [Google Scholar]
- Martens, B.; Duch-Brown, N. The Economics of Business-to-Government Data Sharing 2020; JRC Digital Economy Working Paper: Brussels, Belgium, 2020; Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3540122 (accessed on 4 December 2024).
- Coyle, D.; Diepeveen, S.; Wdowin, J.; Tennison, J.; Lawrence, K. The Value of Data Summary Report; Benett Institute for Public Policy: Cambridge, UK, 2020; p. 17. [Google Scholar]
- Hallberg, N.L.; Brattström, A. Concealing or Revealing? Alternative Paths to Profiting from Innovation. Eur. Manag. J. 2019, 37, 165–174. [Google Scholar] [CrossRef]
- Soper, D.S.; Demirkan, H.; Goul, M. An Interorganizational Knowledge-Sharing Security Model with Breach Propagation Detection. Inf. Syst. Front. 2007, 9, 469–479. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Interview Quote | Dimension | Factor |
|---|---|---|
| Competitive data, like an assessment, we made, we will not share with anyone, especially not with our competitors. [Interview 3, personal communication, 16 June 2022.] | Level of data competitiveness | Level of processing |
| Competitive data, like an assessment, we will not share with anyone, especially not with our competitors. [Interview 3, personal communication, 16 June 2022.] | Actor relationship | Level of competition |
| When companies engage in a collaboration, it’s an agreement to do something together which leads to a joint benefit. Thus, not only buying and selling data. In a data collaboration, there is an engagement of a data provider and data [consumer] with a benefit for both. [Interview 25, personal communication, 7 September 2022.] | Actor relationship | Level of collaboration |
| Some data, like address, name… would be possible to share as it would be useful. For other data sources, we invest a lot of money to process the data. Those data we will not share. [Interview 4, personal communication, 28 October 2021.] | Level of data competitiveness | Level of processing |
| Exclusive Provider Data Control | Involuntary Shared Data Control | Strategically Shared Data Control | Fully Shared Data Control | |
|---|---|---|---|---|
| Definition | Data providers do not grant data access control to data subjects as they aim to protect critical data from competitors. | Data providers are obliged to grant data access control to data subjects due to legal obligations. | Data providers grant data access control to data subjects in strategic collaborations with partners. | Data providers fully grant data access control to data subjects. |
| Characteristics | High data competitiveness. Negative actor relationship. | Low data competitiveness. Negative actor relationship. | High data competitiveness. Positive actor relationship. | Low data competitiveness. Positive actor relationship. |
| Data access control | Data provider. | Data subject (enforced). | Data subject and data provider. | Data subject (enabled). |
| Core strategic and business model considerations | Sensitive data protection. Protect competitive advantage of the data provider. Limited potential for value-capturing. Focus on data security and confidentiality. | Legal compliance. Customer-centric considerations. Value-capturing by trust creation, customer relationship, and legal compliance. | Data monetization. Strategic collaboration and joint go-to-market. Value-capturing through joint partnerships and data monetization. | Consumer trust and customer centricity. Improve user experience. Value-capturing through new revenue streams and customer centricity. |
| Tactics | Avoid legal obligations. Develop technical barriers. | Grant data access control to non-competitive data. Develop technical barriers. | Grant data access control in strategic partnerships. | Fully grant data access control. Optimize user experience. |
| Amount of cases in quadrant | 3 cases. | 4 cases. | 18 cases. | 8 cases. |
| Case example | A health startup with an algorithm for measuring patient movement imbalances risks losing its competitive edge if it shares patient outcomes with a competitor, as these data could allow the competitor to replicate the algorithm [Interview 22, personal communication, 8 August 2022]. | A bank is legally required by the Payment Services Directive 2 to share family information with a competing insurance company if requested by the data subject [Interview 2, personal communication, 15 June 2022]. | A recruiter sharing personal assessments with a partnering hiring company, all resulting in mutual benefits [Interview 3, personal communication 16 June 2022]. | An employer shares an employee’s employment history data with a partner HR firm responsible for managing the employee’s payments [Interview 8, personal communication, 14 October 2021]. |
| Resource-Based View on Data in Data Analysis | Resource-Based Theory on Data Sharing Between Businesses | Resource-Based Theory in Personal Data Ecosystems |
|---|---|---|
| Big data analysis is a core resource within the company [9] | Data are shareable and aid in developing the firm’s performance [14]. Firms need to manage whether to share data or protect data, and they control with whom they share which data [12,13]. | Data control is shared between the data provider and the data subject depending on data competitiveness and the relationship between data provider and data consumer, leading to four scenarios: Exclusive Data Provider Control, Involuntary Shared Data Control, Fully Shared Data Control, and Strategically Shared Data Control. |
| Quadrant | Access Control Strategy | Data Provider Strategy | Prioritization for Ecosystem Design |
|---|---|---|---|
| Exclusive Provider Data Control | Restricted control | Data protection | Lowest potential, avoid |
| Involuntary Shared Data Control | Limited access control (only certain types of data) | Customer trust creation and legal compliance | Medium potential, requires (legal) enforcement |
| Strategically Shared Data Control | Limited access control (only partners) | Trusted alliances and joint go-to-market strategies, data monetization | Potential, requires trustworthy data-sharing mechanisms |
| Fully Shared Data Control | Open access | Customer services and optimal customer experience | Highest potential, requires use case identification with highest value |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Hauwers, R.; Vandercruysse, L. Competitive Advantage and Personal Data Ecosystems: A Typology of Personal Data Control Constellations. J. Theor. Appl. Electron. Commer. Res. 2025, 20, 8. https://doi.org/10.3390/jtaer20010008
D’Hauwers R, Vandercruysse L. Competitive Advantage and Personal Data Ecosystems: A Typology of Personal Data Control Constellations. Journal of Theoretical and Applied Electronic Commerce Research. 2025; 20(1):8. https://doi.org/10.3390/jtaer20010008
Chicago/Turabian StyleD’Hauwers, Ruben, and Laurens Vandercruysse. 2025. "Competitive Advantage and Personal Data Ecosystems: A Typology of Personal Data Control Constellations" Journal of Theoretical and Applied Electronic Commerce Research 20, no. 1: 8. https://doi.org/10.3390/jtaer20010008
APA StyleD’Hauwers, R., & Vandercruysse, L. (2025). Competitive Advantage and Personal Data Ecosystems: A Typology of Personal Data Control Constellations. Journal of Theoretical and Applied Electronic Commerce Research, 20(1), 8. https://doi.org/10.3390/jtaer20010008