
An Intelligent Method for Lead User Identification in Customer Collaborative Product Innovation




Abstract
1. Introduction
2. The Factor Sets for Lead User Identification
2.1. The Factors of User General Attributes
2.2. The Factors of User Activity Attributes
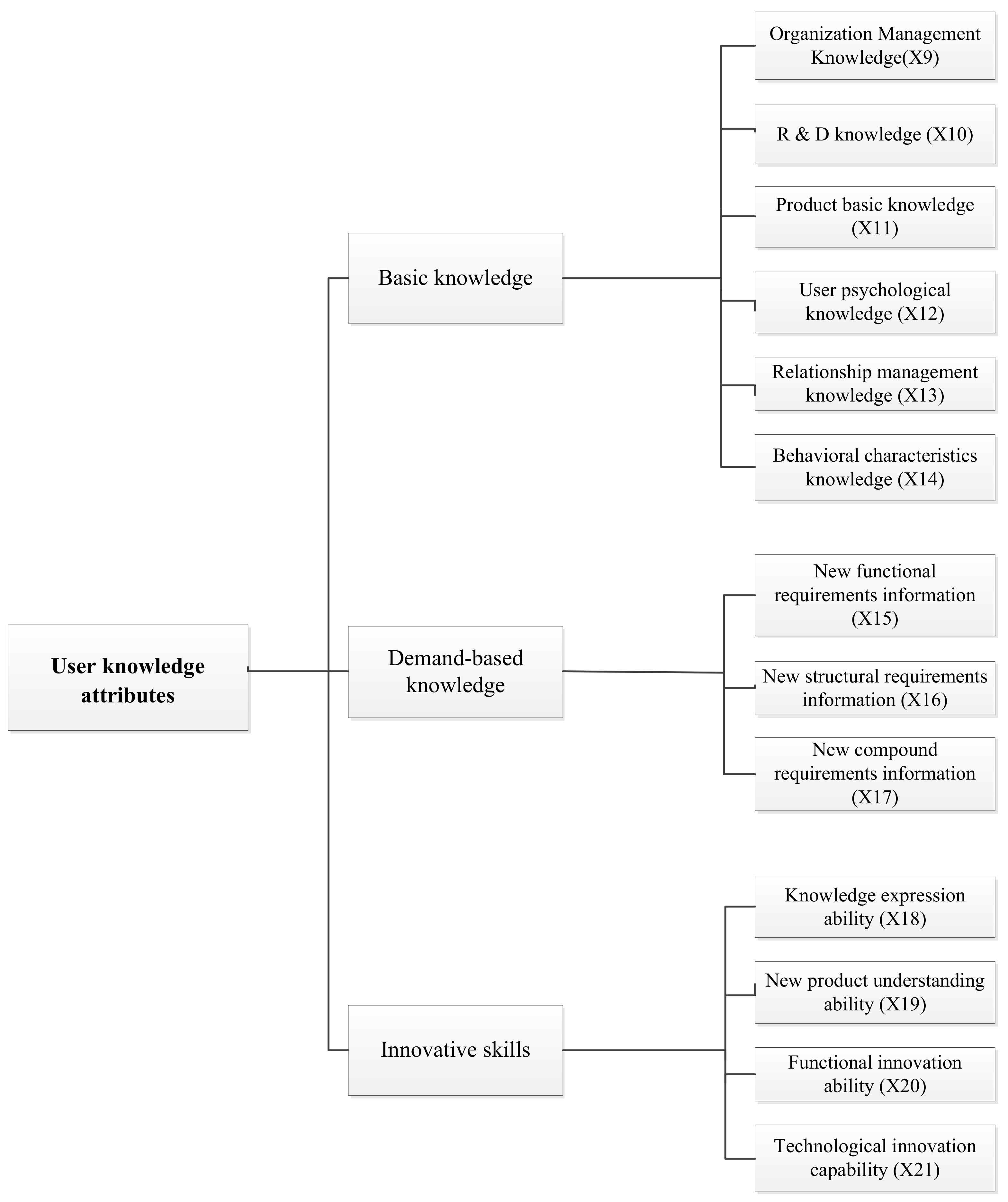
2.3. The Factors of User Knowledge Attributes
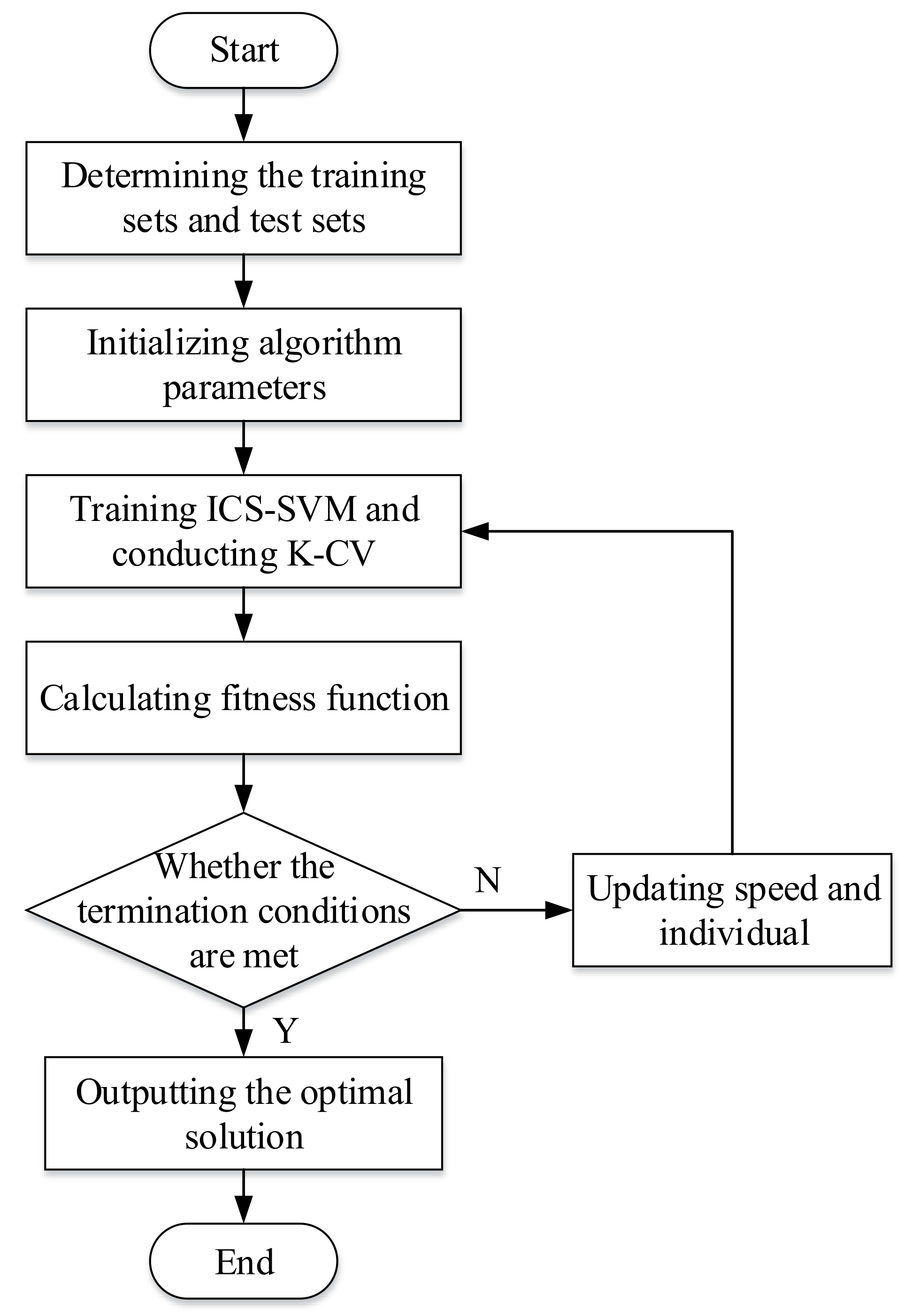
3. The ICS-SVM Method for Lead User Identification
3.1. Support Vector Machine
3.2. Lead User Identification Model
4. Case Study
4.1. Sample Data
4.2. Lead User Identification Using ICS-SVM Method
4.3. Comparison of Leading Customer Identification
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brem, A.; Bilgram, V. The search for innovative partners in co-creation: Identifying lead users in social media through netnography and crowdsourcing. J. Eng. Technol. Manag. 2015, 37, 40–51. [Google Scholar] [CrossRef]
- Chen, X.; Wang, X.; Xia, Y. Production coopetition strategies for competing manufacturers that produce partially substitutable products. Prod. Oper. Manag. 2019, 28, 1446–1464. [Google Scholar] [CrossRef]
- Brem, A.; Bilgram, V.; Gutstein, A. Involving Lead Users in Innovation: A Structured Summary of Research on the Lead User Method. Int. J. Innov. Technol. Manag. 2018, 15, 1850022. [Google Scholar] [CrossRef]
- Von Hippel, E. A customer-active paradigm for industrial product idea generation. Res. Policy 1978, 7, 240–266. [Google Scholar] [CrossRef]
- Von Hippel, E. Lead Users: A Source of Novel Product Concepts. Manag. Sci. 1986, 32, 791–805. [Google Scholar] [CrossRef]
- Awan, U.; Nauman, S.; Sroufe, R. Exploring the effect of buyer engagement on green product innovation: Empirical evidence from manufacturers. Bus. Strat. Environ. 2021, 30, 463–477. [Google Scholar] [CrossRef]
- Chen, X.; Wang, X.; Chan, H. Manufacturer and retailer coordination for environmental and economic competitiveness: A power perspective. Transp. Res. Part E Logist. Transp. Rev. 2017, 97, 268–281. [Google Scholar] [CrossRef]
- Su, J.; Zhang, F.; Chen, S.; Zhang, N.; Wang, H.; Jian, J. Member Selection for the Collaborative New Product Innovation Teams Integrating Individual and Collaborative Attributions. Complexity 2021, 2021, 8897784. [Google Scholar] [CrossRef]
- Awan, U. Effects of buyer-supplier relationship on social performance improvement and innovation performance improvement. Int. J. Appl. Manag. Sci. 2019, 11, 21–35. [Google Scholar] [CrossRef]
- Omidvar, A.; Garakani, M.; Safarpour, H.R. Context based user ranking in forums for expert finding using WordNet dictionary and social network analysis. Inf. Technol. Manag. 2014, 15, 51–63. [Google Scholar] [CrossRef]
- Schweisfurth, T.G. Comparing internal and external lead users as sources of innovation. Res. Policy 2017, 46, 238–248. [Google Scholar] [CrossRef]
- Hienerth, C.; Lettl, C.; Keinz, P. Synergies among Producer Firms, Lead Users, and User Communities: The Case of the LEGO Producer–User Ecosystem. J. Prod. Innov. Manag. 2014, 31, 848–866. [Google Scholar] [CrossRef]
- Kratzer, J.; Lettl, C. A Social Network Perspective of Lead Users and Creativity: An Empirical Study among Children. Creat. Innov. Manag. 2008, 17, 26–36. [Google Scholar] [CrossRef]
- Anser, M.K.; Khan, M.A.; Awan, U.; Batool, R.; Zaman, K.; Imran, M.; Bakar, Z.A. The role of technological innovation in a dynamic model of the environmental supply chain curve: Evidence from a panel of 102 countries. Processes 2020, 8, 1033. [Google Scholar] [CrossRef]
- Wang, L.; Li, Q.; Ma, Y. Identifying lead users in open innovation community based on extended netnography. Sci. Res. Manag. 2019, 40, 259–267. [Google Scholar]
- Belz, F.-M.; Baumbach, W. Netnography as a Method of Lead User Identification. Creat. Innov. Manag. 2010, 19, 304–313. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, C.; Song, L.; Yang, J.; Su, J. A multidimensional information fusion-based matching decision method for manufacturing service resource. IEEE Access 2021, 9, 39839–39851. [Google Scholar] [CrossRef]
- Schreier, M.; Prügl, R. Extending Lead-User Theory: Antecedents and Consequences of Consumers’ Lead Userness. J. Prod. Innov. Manag. 2008, 25, 331–346. [Google Scholar] [CrossRef]
- Von Hippel, E.A.; Franke, N.; Prügl, R. Pyramiding: Efficient search for rare subjects. Res. Policy 2009, 38, 1397–1406. [Google Scholar] [CrossRef]
- Bettencourt, L.A.; Ostrom, A.L.; Brown, S.W.; Roundtree, R.I. Client co-production in knowledge-intensive business services. Calif. Manag. Rev. 2002, 44, 100–128. [Google Scholar] [CrossRef]
- Füller, J.; Mühlbacher, H.; Matzler, K.; Jawecki, G. Consumer Empowerment through Internet-Based Co-creation. J. Manag. Inf. Syst. 2009, 26, 71–102. [Google Scholar] [CrossRef]
- Ye, S. Identification Research of Lead Users Based on Online Brand Communities. Sci-Tech. Dev. Enterp. 2013, 4, 11–14. [Google Scholar]
- Tang, H.; Yang, Y.; Song, L.; Yang, J. Identification and Fuzzy Evaluation of Innovative User in Collaborative Product Innovation. J. Chongqing Univ. 2008, 31, 130–135. [Google Scholar]
- Lettl, C.; Hienerth, C.; Gemuenden, H.G. Exploring How Lead Users Develop Radical Innovation: Opportunity Recognition and Exploitation in the Field of Medical Equipment Technology. IEEE Trans. Eng. Manag. 2008, 55, 219–233. [Google Scholar] [CrossRef]
- Stockstrom, C.S.; Goduscheit, R.C.; Lüthje, C.; Jørgensen, J.H. Identifying valuable users as informants for innovation processes: Comparing the search efficiency of pyramiding and screening. Res. Policy 2016, 45, 507–516. [Google Scholar] [CrossRef]
- Su, J.; Yang, Y.; Zhang, X. Knowledge transfer efficiency measurement with application for open innovation networks. Int. J. Technol. Manag. 2019, 81, 118–142. [Google Scholar]
- Amanatiadis, A.; Mitsinis, N.; Maditinos, D. A neural network-based approach for user experience assessment. Behav. Inf. Technol. 2014, 34, 304–315. [Google Scholar] [CrossRef]
- Xia, G.-E.; Jin, W.-D. Model of Customer Churn Prediction on Support Vector Machine. Syst. Eng. Theory Pract. 2008, 28, 71–77. [Google Scholar] [CrossRef]
- Kratzer, J.; Lettl, C.; Franke, N.; Gloor, P.A. The Social Network Position of Lead Users. J. Prod. Innov. Manag. 2015, 33, 201–216. [Google Scholar] [CrossRef]
- Fu, S.; Jiao, Y.; Gao, X. Identifying Lead Users in Innovation Communities: The Signaling Role of Linguistic Style. Stud. Sci. Sci. 2019, 5, 919–929. [Google Scholar]
- Yu, C.; Zuo, Y.; Feng, B.; An, L.; Chen, B. An individual-group-merchant relation model for identifying fake online reviews: An empirical study on a Chinese e-commerce platform. Inf. Technol. Manag. 2018, 20, 123–138. [Google Scholar] [CrossRef]
- Sun, J.; Fujita, H.; Chen, P.; Li, H. Dynamic financial distress prediction with concept drift based on time weighting combined with Adaboost support vector machine ensemble. Knowl.-Based Syst. 2017, 120, 4–14. [Google Scholar] [CrossRef]
- Wu, J.L.; Chang, P.C.; Tsao, C.C.; Fan, C.Y. A patent quality analysis and classification system using self-organizing maps with support vector machine. Appl. Soft Comput. 2016, 41, 305–316. [Google Scholar] [CrossRef]
- Lee, W.; Jun, C.-H.; Lee, J.-S. Instance categorization by support vector machines to adjust weights in AdaBoost for imbalanced data classification. Inf. Sci. 2017, 381, 92–103. [Google Scholar] [CrossRef]
- Cao, J.; Lu, H.; Wang, W.; Wang, J. A loan default discrimination model using cost-sensitive support vector machine improved by PSO. Inf. Technol. Manag. 2013, 14, 193–204. [Google Scholar] [CrossRef]
- Chen, Q.; Zhang, M.; Zhao, X. Analysing customer behaviour in mobile app usage. Ind. Manag. Data Syst. 2017, 117, 425–438. [Google Scholar] [CrossRef]
- Olson, D.L. Recency Frequency and Monetary Model, in Descriptive Data Mining; Springer: Berlin/Heidelberg, Germany, 2017; pp. 43–59. [Google Scholar]
- Su, J.; Yang, Y.; Yang, T. Measuring knowledge diffusion efficiency in R&D networks. Knowl. Manag. Res. Pract. 2018, 16, 208–219. [Google Scholar]
- Brandes, U.; Borgatti, S.P.; Freeman, L.C. Maintaining the duality of closeness and betweenness centrality. Soc. Netw. 2016, 44, 153–159. [Google Scholar] [CrossRef]
- Zhang, X.; Su, J. A combined fuzzy DEMATEL and TOPSIS approach for estimating participants in knowledge-intensive crowdsourcing. Comput. Ind. Eng. 2019, 137, 106085. [Google Scholar] [CrossRef]
- Vapnik, V.; Guyon, I.; Hastie, T. Support vector machines. Mach. Learn 1995, 20, 273–297. [Google Scholar]
- Li, H.; Huang, L.-J. Generalized predictive control based on LS-SVM inverse system method. In Proceedings of the 2010 8th World Congress on Intelligent Control and Automation, Jinan, China, 7–9 July 2010; pp. 2604–2609. [Google Scholar]
- Li, Y.; Chai, Y.; Hu, Y.; Yin, H. Review of imbalanced data classification methods. Control Decis. 2019, 34, 673–688. [Google Scholar] [CrossRef]
- Trelea, I.C. The particle swarm optimization algorithm: Convergence analysis and parameter selection. Inf. Process. Lett. 2003, 85, 317–325. [Google Scholar] [CrossRef]
- Wang, W.; Yang, Y.; Wang, M.; Song, L. RS and SVM-based partner selection research for customer collaborative innovation. Comput. Eng. Appl. 2007, 43, 245–248. [Google Scholar]



{kind=link}
{kind=link}
| Factor Attributes | Factors | Variable Definition |
|---|---|---|
| User general attributes | Gender | X1 |
| Age | X2 | |
| Monthly income | X3 | |
| Number of owned products of a brand | X4 | |
| Investment in purchasing products of a brand | X5 | |
| User activity attributes | Recency | X6 |
| Frequency | X7 | |
| Monetary value | X8 | |
| User knowledge attributes | Organization management knowledge | X9 |
| R&D knowledge | X10 | |
| Product basic knowledge | X11 | |
| User psychological knowledge | X12 | |
| Relationship management knowledge | X13 | |
| Behavioral characteristics knowledge | X14 | |
| New functional requirements information | X15 | |
| New structural requirements information | X16 | |
| New compound requirements information | X17 | |
| Knowledge expression ability | X18 | |
| New product understanding ability | X19 | |
| Functional innovation ability | X20 | |
| Technological innovation capability | X21 |
| X1 | X2 | X3 | X4 | X5 | X6 | X17 | X18 | X19 | X20 | X21 | Y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.143 | 0.05 | 0.286 | 0.357 | 0.6 | 0.5 | 0.5 | 0.1 | 0.7 | 0.5 | −1 |
| 2 | 1 | 1 | 0.55 | 0.143 | 0.589 | 0.167 | 0.2 | 0.7 | 0.1 | 0.2 | 0.1 | −1 |
| 3 | 1 | 0.857 | 0.35 | 0 | 0 | 0.133 | 0.3 | 0.6 | 0.4 | 0 | 0.5 | −1 |
| 4 | 1 | 1 | 0.4 | 0.571 | 0.714 | 0.3 | 0.6 | 0.8 | 0.1 | 0 | 0.1 | −1 |
| 5 | 1 | 0.857 | 0.45 | 0.857 | 0.929 | 0 | 0.8 | 0.7 | 0.8 | 0.4 | 0.8 | 1 |
| 92 | 1 | 0.857 | 0.75 | 0.857 | 0.857 | 0.2 | 0.7 | 0.2 | 0.4 | 0.8 | 0.5 | 1 |
| 93 | 1 | 1 | 0.95 | 0.429 | 0.214 | 0.467 | 0.3 | 0.2 | 0.5 | 0.3 | 0.4 | −1 |
| 94 | 1 | 0 | 0.05 | 0.571 | 0.571 | 0.3 | 0.1 | 0.3 | 0.5 | 0.4 | 0.2 | −1 |
| 95 | 0 | 0.286 | 0.9 | 0 | 0.054 | 1 | 0.1 | 0.1 | 0.3 | 0.6 | 0.5 | −1 |
| 96 | 1 | 0.286 | 0.5 | 0.857 | 0.036 | 0.533 | 0.4 | 0.3 | 0.2 | 0.5 | 0.5 | −1 |
| Sample Group | Lead User | Ordinary User | |
|---|---|---|---|
| Classification Group Cost | |||
| Lead user | TN | FP | |
| Ordinary user | FN | TP | |
| Z | WZ | FZ1 | FZ2 | EC | |
|---|---|---|---|---|---|
| BP neural network | 87.5% | 82.93% | 20% | 9.09% | 43.75% |
| RS-SVM | 93.75% | 85.37% | 20% | 0 | 37.5% |
| ICS-SVM | 93.75% | 97.56% | 0 | 9.09% | 6.25% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, J.; Chen, X.; Zhang, F.; Zhang, N.; Li, F. An Intelligent Method for Lead User Identification in Customer Collaborative Product Innovation. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 1571-1583. https://doi.org/10.3390/jtaer16050088
Su J, Chen X, Zhang F, Zhang N, Li F. An Intelligent Method for Lead User Identification in Customer Collaborative Product Innovation. Journal of Theoretical and Applied Electronic Commerce Research. 2021; 16(5):1571-1583. https://doi.org/10.3390/jtaer16050088
Chicago/Turabian StyleSu, Jiafu, Xu Chen, Fengting Zhang, Na Zhang, and Fei Li. 2021. "An Intelligent Method for Lead User Identification in Customer Collaborative Product Innovation" Journal of Theoretical and Applied Electronic Commerce Research 16, no. 5: 1571-1583. https://doi.org/10.3390/jtaer16050088
APA StyleSu, J., Chen, X., Zhang, F., Zhang, N., & Li, F. (2021). An Intelligent Method for Lead User Identification in Customer Collaborative Product Innovation. Journal of Theoretical and Applied Electronic Commerce Research, 16(5), 1571-1583. https://doi.org/10.3390/jtaer16050088