Online Reviews and Product Sales: The Role of Review Visibility




Abstract
1. Introduction
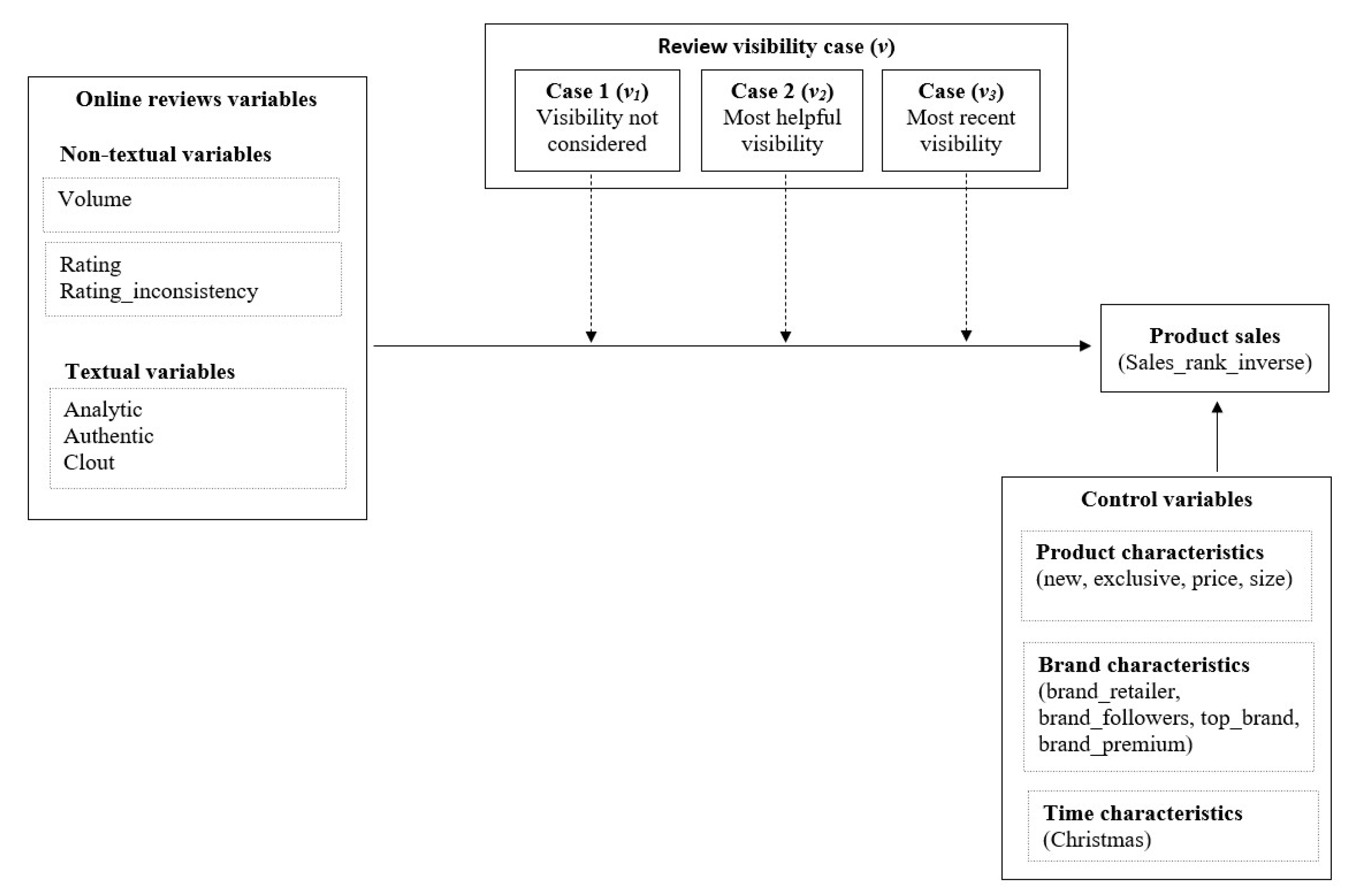
2. Theoretical Background and Conceptual Model
2.1. Influence of Online Reviews on Product Sales
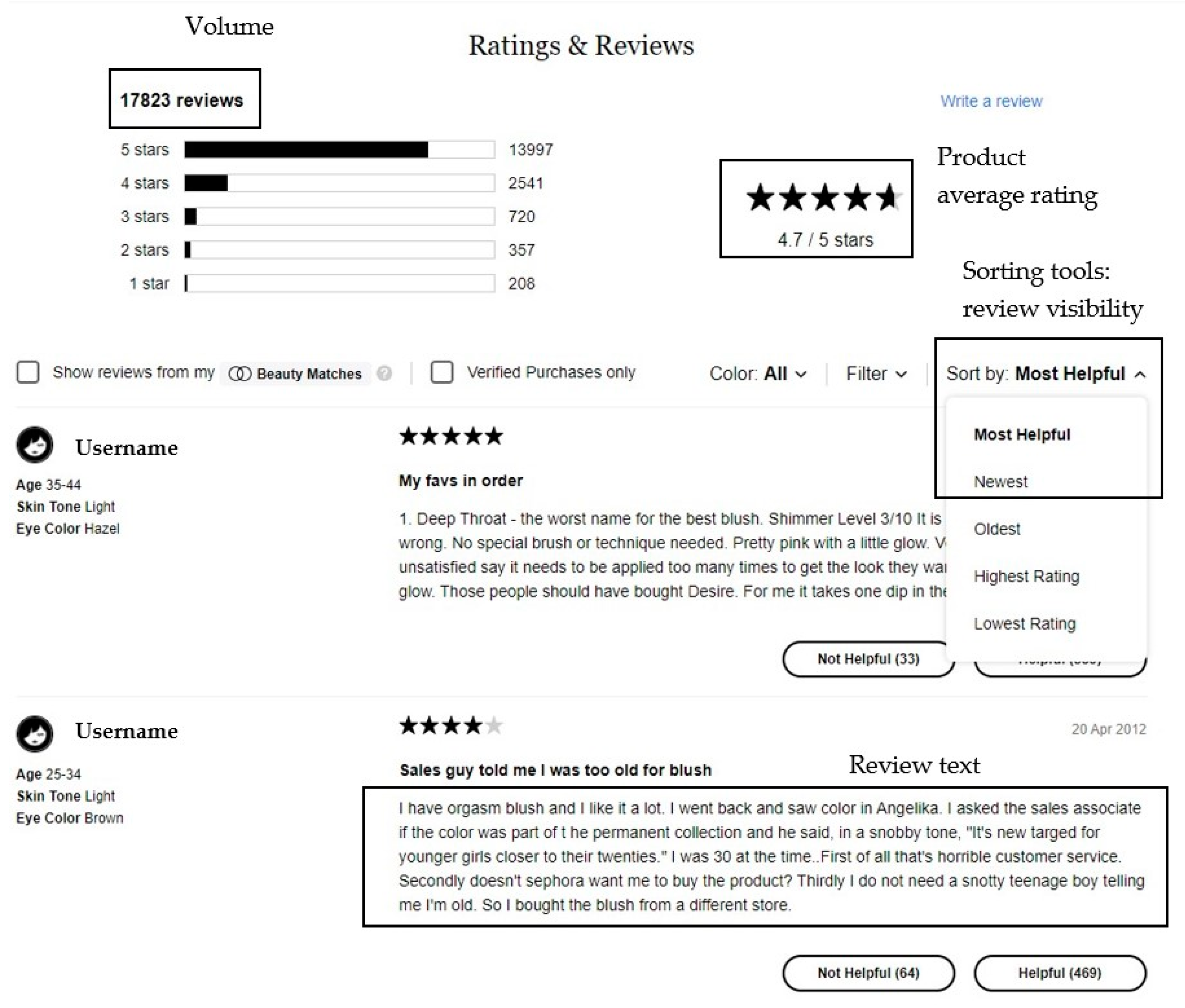
2.2. Decision-Making and Information Processing in the Online Environment: The Role of Review Visibility
2.3. Conceptual Model and Hypotheses Development
3. Methodology
3.1. Data
3.2. Research Variables
3.2.1. Dependent Variable
3.2.2. Independent Variables
3.2.3. Control Variables
3.3. Empirical Model and Estimation
4. Results
4.1. Descriptive Statistics
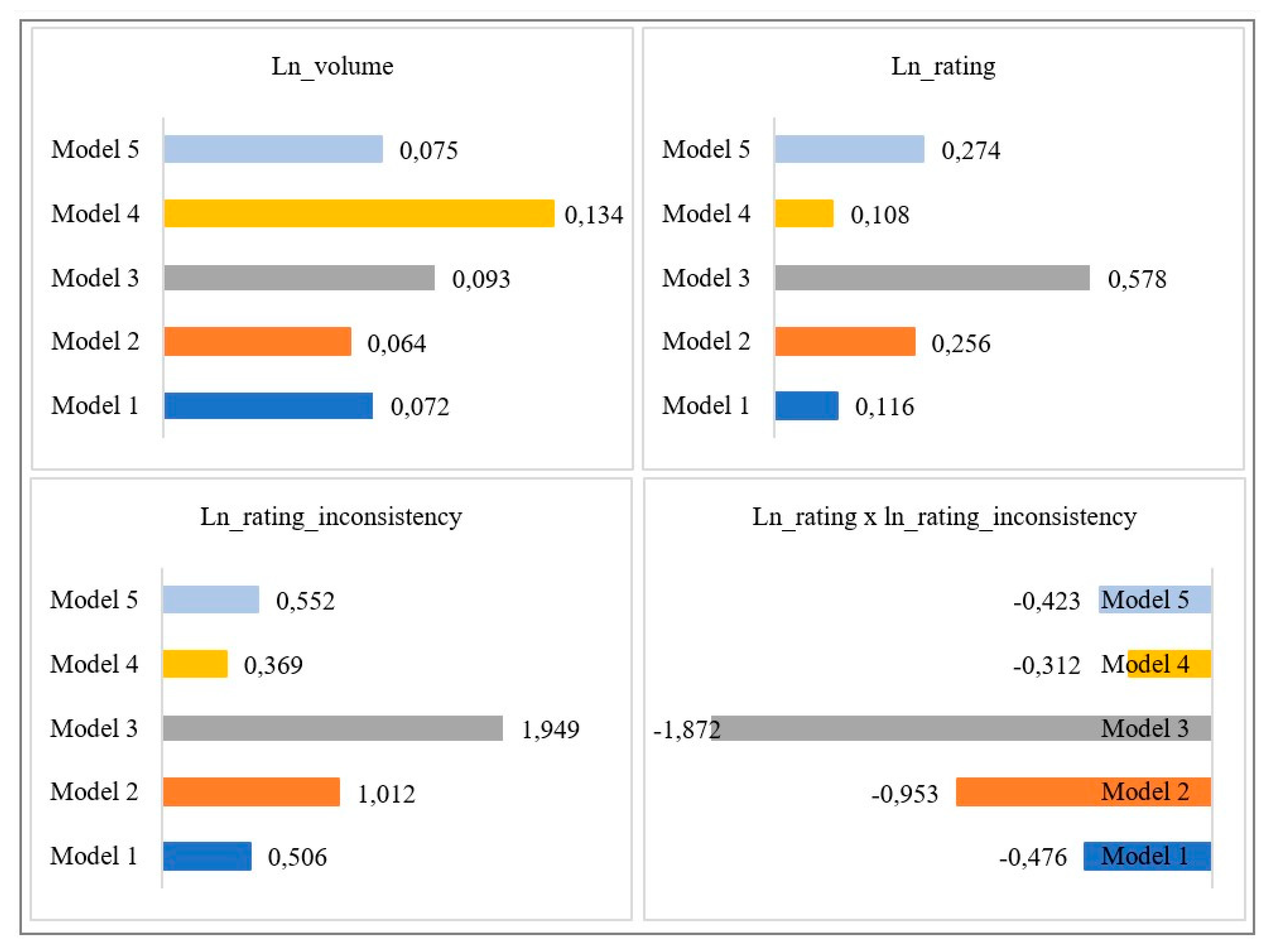
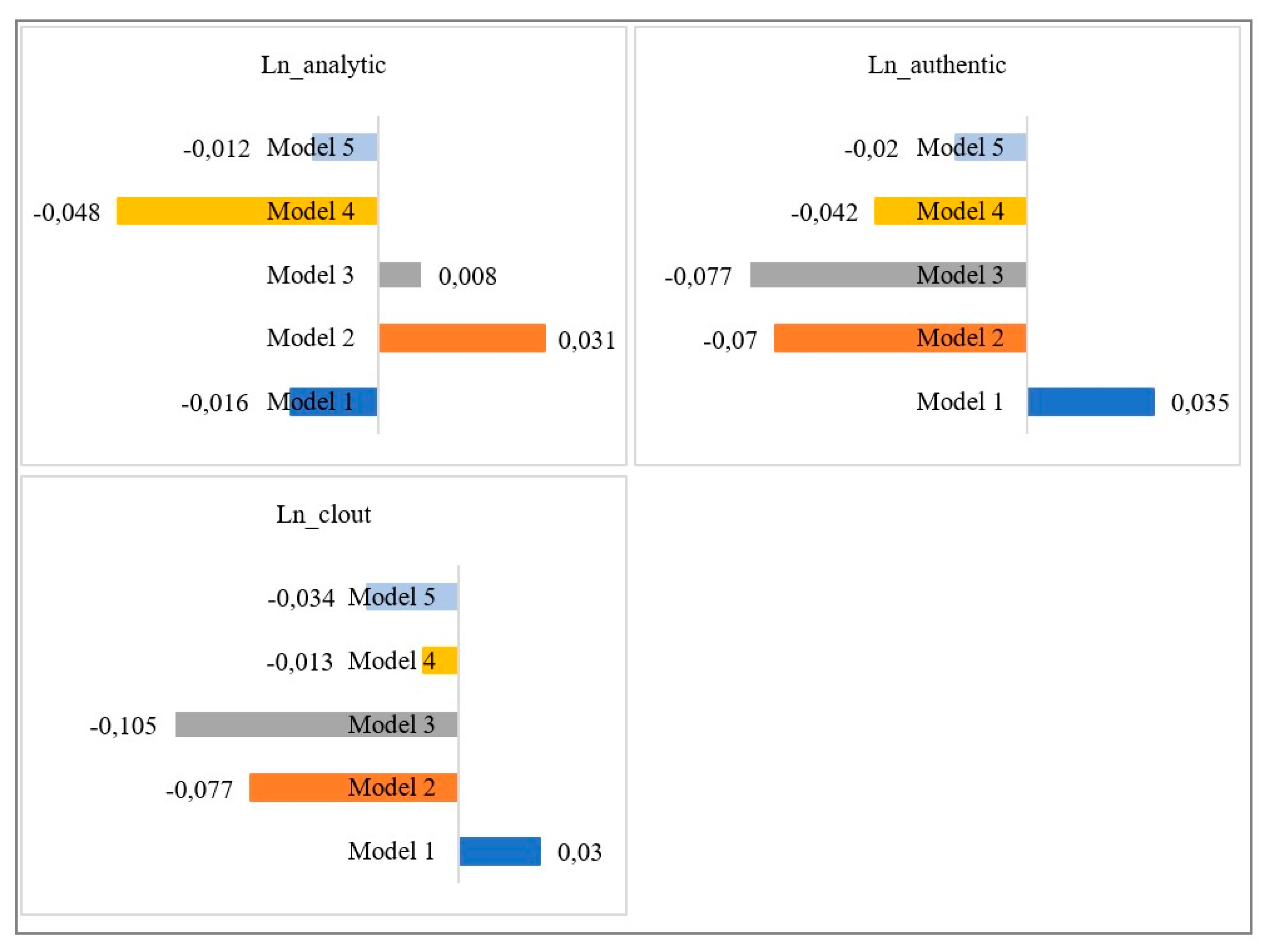
4.2. Model Findings
4.3. Misspecification Tests and Alternative Panel Data Models
5. Discussion
5.1. Theoretical Contribution
5.2. Managerial Implications
5.3. Limitations and Future Research
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| OLS | FE | RE | System GMM | |
| L1.ln_sales_rank_inverse | 0.918 *** | 0.644 *** | 0.918 *** | 0.919 *** |
| (0.01) | (0.03) | (0.01) | (0.00) | |
| Ln_volume | 0.058 *** | −0.889 ** | 0.058 *** | 0.072 *** |
| (0.01) | (0.28) | (0.01) | (0.01) | |
| Ln_rating | 0.035 | 0.013 | 0.035 | 0.116 *** |
| (0.02) | (0.08) | (0.02) | (0.00) | |
| Ln_rating_inconsistency | 0.081 | 0.614 * | 0.081 | 0.506 *** |
| (0.15) | (0.26) | (0.15) | (0.02) | |
| Ln_rating x ln_rating_inconsistency | −0.064 | −0.594 * | −0.064 | −0.476 *** |
| (0.15) | (0.26) | (0.15) | (0.02) | |
| Ln_analytic | 0.004 | −0.019 | 0.004 | −0.016 *** |
| (0.01) | (0.06) | (0.01) | (0.00) | |
| Ln_authentic | 0.001 | 0.018 | 0.001 | 0.035 *** |
| (0.01) | (0.05) | (0.01) | (0.00) | |
| Ln_clout | −0.001 | −0.041 | −0.001 | 0.030 *** |
| (0.01) | (0.08) | (0.01) | (0.01) | |
| Christmas | 0.011 | −0.005 | 0.011 | −0.003 |
| (0.04) | (0.04) | (0.04) | (0.00) | |
| New | 0.118 * | 0.217 ** | 0.118 ** | 0.100 *** |
| (0.05) | (0.08) | (0.05) | (0.01) | |
| Exclusive | 0.141 *** | 0.959 *** | 0.141 *** | 0.163 *** |
| (0.03) | (0.21) | (0.03) | (0.01) | |
| Ln_price | 0.039 | 0.000 | 0.039 | 0.321 *** |
| (0.03) | (.) | (0.03) | (0.01) | |
| Ln_size | 0.024 | −0.497 | 0.024 | 0.273 *** |
| (0.02) | (1.58) | (0.02) | (0.01) | |
| Brand_retailer | 0.001 | 0.000 | 0.001 | 0.309 *** |
| (0.05) | (.) | (0.05) | (0.02) | |
| Ln_brand_followers | −0.018 | 0.008 | −0.018 | −0.053 *** |
| (0.01) | (0.07) | (0.01) | (0.00) | |
| Brand_top | −0.004 | 0.000 | −0.004 | 0.057** |
| (0.04) | (.) | (0.04) | (0.02) | |
| Brand_premium | 0.038 | 0.000 | 0.038 | 0.013 |
| (0.03) | (.) | (0.03) | (0.01) | |
| Constant | −0.076 | −0.312 *** | −0.076 | −0.078 *** |
| (0.05) | (0.07) | (0.05) | (0.01) | |
| Observations | 944 | 944 | 944 | 944 |
| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| OLS | FE | RE | System GMM | |
| L1.ln_sales_rank_inverse | 0.913 *** | 0.581 *** | 0.913 *** | 0.767 *** |
| (0.01) | (0.02) | (0.01) | (0.00) | |
| Ln_volume | 0.068 *** | −0.037 | 0.068 *** | 0.093 *** |
| (0.01) | (0.27) | (0.01) | (0.01) | |
| Ln_rating | 0.064 ** | 0.138 | 0.064 ** | 0.578 *** |
| (0.02) | (0.09) | (0.02) | (0.01) | |
| Ln_rating_inconsistency | 0.132 ** | 1.799 *** | 0.132 ** | 1.949 *** |
| (0.05) | (0.24) | (0.05) | (0.01) | |
| Ln_rating x ln_rating_inconsistency | −0.136 ** | −1.618 *** | −0.136 ** | −1.872 *** |
| (0.05) | (0.23) | (0.05) | (0.01) | |
| Ln_analytic | −0.009 | −0.126 * | −0.009 | 0.008 * |
| (0.01) | (0.06) | (0.01) | (0.00) | |
| Ln_authentic | 0.019 | −0.053 | 0.019 | −0.077 *** |
| (0.01) | (0.08) | (0.01) | (0.01) | |
| Ln_clout | 0.008 | 0.093 | 0.008 | −0.105 *** |
| (0.01) | (0.05) | (0.01) | (0.00) | |
| Christmas | 0.015 | 0.016 | 0.015 | 0.015 *** |
| (0.04) | (0.03) | (0.04) | (0.00) | |
| New | 0.128 ** | 0.315 *** | 0.128 ** | 0.352 *** |
| (0.05) | (0.08) | (0.05) | (0.01) | |
| Exclusive | 0.146 *** | 0.803 *** | 0.146 *** | 0.280 *** |
| (0.03) | (0.20) | (0.03) | (0.01) | |
| Ln_price | 0.059 * | 0.000 | 0.059 * | 0.060 *** |
| (0.03) | (.) | (0.03) | (0.01) | |
| Ln_size | 0.037 | −0.648 | 0.037 | 0.061 *** |
| (0.02) | (1.49) | (0.02) | (0.01) | |
| Brand_retailer | 0.024 | 0.000 | 0.024 | 0.255 *** |
| (0.05) | (.) | (0.05) | (0.04) | |
| Ln_brand_followers | −0.021 | 0.011 | −0.021 | −0.053 *** |
| (0.01) | (0.06) | (0.01) | (0.01) | |
| Brand_top | 0.001 | 0.000 | 0.001 | −0.011 |
| (0.04) | (.) | (0.04) | (0.03) | |
| Brand_premium | 0.038 | 0.000 | 0.038 | 0.147 *** |
| (0.03) | (.) | (0.03) | (0.02) | |
| Constant | −0.085 | −0.305 *** | −0.085 | −0.200 *** |
| (0.05) | (0.07) | (0.05) | (0.02) | |
| Observations | 944 | 944 | 944 | 944 |
| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| OLS | FE | RE | System GMM | |
| L1.ln_sales_rank_inverse | 0.920 *** | 0.654 *** | 0.920 *** | 0.937 *** |
| (0.01) | (0.02) | (0.01) | (0.00) | |
| Ln_volume | 0.064 *** | −0.827 ** | 0.064 *** | 0.134 *** |
| (0.01) | (0.25) | (0.01) | (0.01) | |
| Ln_rating | 0.046 * | 0.006 | 0.046 * | 0.108 *** |
| (0.02) | (0.04) | (0.02) | (0.01) | |
| Ln_rating_inconsistency | 0.102 | 0.076 | 0.102 | 0.369 *** |
| (0.10) | (0.17) | (0.10) | (0.03) | |
| Ln_rating x ln_rating_inconsistency | −0.083 | −0.057 | −0.083 | −0.312 *** |
| (0.10) | (0.16) | (0.10) | (0.03) | |
| Ln_analytic | 0.003 | −0.012 | 0.003 | −0.048 *** |
| (0.01) | (0.02) | (0.01) | (0.00) | |
| Ln_authentic | −0.022 | −0.025 | −0.022 | −0.042 *** |
| (0.01) | (0.02) | (0.01) | (0.01) | |
| Ln_clout | −0.021 | −0.019 | −0.021 | −0.013 ** |
| (0.01) | (0.02) | (0.01) | (0.00) | |
| Christmas | 0.014 | −0.000 | 0.014 | 0.008 |
| (0.04) | (0.04) | (0.04) | (0.00) | |
| New | 0.099 * | 0.203 * | 0.099 * | 0.017 * |
| (0.04) | (0.08) | (0.04) | (0.01) | |
| Exclusive | 0.142 *** | 0.983 *** | 0.142 *** | 0.145 *** |
| (0.03) | (0.21) | (0.03) | (0.01) | |
| Ln_price | 0.028 | 0.000 | 0.028 | 0.133 *** |
| (0.03) | (.) | (0.03) | (0.01) | |
| Ln_size | 0.014 | −0.154 | 0.014 | 0.108 *** |
| (0.02) | (1.59) | (0.02) | (0.01) | |
| Brand_retailer | −0.006 | 0.000 | −0.006 | 0.159 *** |
| (0.06) | (.) | (0.06) | (0.03) | |
| Ln_brand_followers | −0.014 | 0.015 | −0.014 | −0.068 *** |
| (0.01) | (0.07) | (0.01) | (0.01) | |
| Brand_top | −0.006 | 0.000 | −0.006 | 0.048 |
| (0.04) | (.) | (0.04) | (0.02) | |
| Brand_premium | 0.032 | 0.000 | 0.032 | 0.007 |
| (0.03) | (.) | (0.03) | (0.01) | |
| Constant | −0.076 | −0.324 *** | −0.076 | −0.070 *** |
| (0.05) | (0.07) | (0.05) | (0.01) | |
| Observations | 944 | 944 | 944 | 944 |
| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| OLS | FE | RE | System GMM | |
| L1.ln_sales_rank_inverse | 0.920 *** | 0.660 *** | 0.920*** | 0.942 *** |
| (0.01) | (0.03) | (0.01) | (0.00) | |
| Ln_volume | 0.059 *** | −0.823 *** | 0.059 *** | 0.075 *** |
| (0.01) | (0.24) | (0.01) | (0.01) | |
| Ln_rating | 0.087 *** | 0.069 | 0.087 *** | 0.274 *** |
| (0.02) | (0.04) | (0.02) | (0.01) | |
| Ln_rating_inconsistency | 0.179 ** | 0.144 | 0.179 ** | 0.552 *** |
| (0.07) | (0.11) | (0.07) | (0.04) | |
| Ln_rating x ln_rating_inconsistency | −0.152 ** | −0.116 | −0.152 ** | −0.423 *** |
| (0.06) | (0.09) | (0.06) | (0.03) | |
| Ln_analytic | 0.016 | 0.010 | 0.016 | −0.012 ** |
| (0.01) | (0.02) | (0.01) | (0.00) | |
| Ln_authentic | −0.003 | 0.007 | −0.003 | −0.020 ** |
| (0.01) | (0.02) | (0.01) | (0.01) | |
| Ln_clout | −0.016 | 0.004 | −0.016 | −0.034 *** |
| (0.01) | (0.02) | (0.01) | (0.01) | |
| Christmas | 0.014 | 0.000 | 0.014 | 0.005 |
| (0.04) | (0.04) | (0.04) | (0.00) | |
| New | 0.112 * | 0.200 * | 0.112 * | 0.092 *** |
| (0.04) | (0.08) | (0.04) | (0.01) | |
| Exclusive | 0.148 *** | 0.929 *** | 0.148 *** | 0.186 *** |
| (0.03) | (0.21) | (0.03) | (0.02) | |
| Ln_price | 0.033 | 0.000 | 0.033 | 0.033 * |
| (0.02) | (.) | (0.02) | (0.01) | |
| Ln_size | 0.020 | −0.424 | 0.020 | 0.045 *** |
| (0.02) | (1.59) | (0.02) | (0.01) | |
| Brand_retailer | 0.004 | 0.000 | 0.004 | 0.072 * |
| (0.05) | (.) | (0.05) | (0.03) | |
| Ln_brand_followers | −0.016 | 0.014 | −0.016 | −0.057 *** |
| (0.01) | (0.07) | (0.01) | (0.01) | |
| Brand_top | 0.005 | 0.000 | 0.005 | 0.046 * |
| (0.04) | (.) | (0.04) | (0.02) | |
| Brand_premium | 0.040 | 0.000 | 0.040 | 0.058 *** |
| (0.03) | (.) | (0.03) | (0.02) | |
| Constant | −0.080 | −0.307 *** | −0.080 | −0.107 *** |
| (0.05) | (0.07) | (0.05) | (0.01) | |
| Observations | 944 | 944 | 944 | 944 |
References
- Mudambi, S.; Schuff, D. What makes a Helpful online Review? MIS Quart. 2010, 28, 695–704. [Google Scholar]
- BrightLocal Local Consumer Review Survey. 2020. Available online: https://www.brightlocal.com/research/local-consumer-review-survey/ (accessed on 22 April 2020).
- Filieri, R.; McLeay, F.; Tsui, B.; Lin, Z. Consumer perceptions of information helpfulness and determinants of purchase intention in online consumer reviews of services. Inf. Manag. 2018, 55, 956–970. [Google Scholar]
- Cyr, D.; Head, M.; Lim, E.; Stibe, A. Using the elaboration likelihood model to examine online persuasion through website design. Inf. Manag. 2018, 55, 807–821. [Google Scholar]
- Khwaja, M.G.; Zaman, U. Configuring the evolving role of ewom on the consumers information adoption. J. Open Innov. Technol. Mark. Complex. 2020, 6, 125. [Google Scholar]
- Park, D.H.; Lee, J. eWOM overload and its effect on consumer behavioral intention depending on consumer involvement. Electron. Commer. Res. Appl. 2008, 7, 386–398. [Google Scholar]
- Jiménez, F.R.; Mendoza, N.A. Too popular to ignore: The influence of online reviews on purchase intentions of search and experience products. J. Interact. Mark. 2013, 27, 226–235. [Google Scholar]
- Kostyk, A.; Niculescu, M.; Leonhardt, J.M. Less is more: Online consumer ratings’ format affects purchase intentions and processing. J. Consum. Behav. 2017, 16, 434–441. [Google Scholar]
- Chevalier, J.; Mayzlin, D. The Effect of Word of Mouth on Sales: Online Book Reviews. J. Mark. Res. 2006, 43, 345–354. [Google Scholar]
- Chintagunta, P.K.; Gopinath, S.; Venkataraman, S. The Effects of Online User Reviews on Movie Box Office Performance: Accounting for Sequential Rollout and Aggregation Across Local Markets. Mark. Sci. 2010, 29, 944–957. [Google Scholar]
- Li, X.; Wu, C.; Mai, F. The effect of online reviews on product sales: A joint sentiment-topic analysis. Inf. Manag. 2019, 56, 172–184. [Google Scholar]
- Hofmann, J.; Clement, M.; Völckner, F.; Hennig-Thurau, T. Empirical generalizations on the impact of stars on the economic success of movies. Int. J. Res. Mark. 2017, 34, 442–461. [Google Scholar]
- Marchand, A.; Hennig-Thurau, T.; Wiertz, C. Not all digital word of mouth is created equal: Understanding the respective impact of consumer reviews and microblogs on new product success. Int. J. Res. Mark. 2017, 34, 336–354. [Google Scholar]
- Lee, S.; Choeh, J.Y. Using the social influence of electronic word-of-mouth for predicting product sales: The moderating effect of review or reviewer helpfulness and product type. Sustainability 2020, 12, 7952. [Google Scholar]
- Rodríguez-Díaz, M.; Rodríguez-Díaz, R.; Espino-Rodríguez, T. Analysis of the Online Reputation Based on Customer Ratings of Lodgings in Tourism Destinations. Adm. Sci. 2018, 8, 51. [Google Scholar]
- Sun, Q.; Niu, J.; Yao, Z.; Yan, H. Exploring eWOM in online customer reviews: Sentiment analysis at a fine-grained level. Eng. Appl. Artif. Intell. 2019, 81, 68–78. [Google Scholar]
- Beach, L.R. Broadening the definition of decision making: The role of prechoice screening option. Psychol. Sci. 1993, 4, 215–220. [Google Scholar]
- Häubl, G.; Trifts, V. Consumer Decision Making in Online Shopping Environments: The Effects of Interactive Decision Aids Consumer Decision Making in Online Shopping Environments: The Effects of Interactive Decision Aids. Mark. Sci. 2000, 19, 4–21. [Google Scholar]
- Feldman, J.M.; Lynch, J.G. Self-Generated Validity and Other Effects of Measurement on Belief, Attitude, Intention, and Behavior. J. Appl. Psychol. 1988, 73, 421–435. [Google Scholar]
- Archak, N.; Ghose, A.; Ipeirotis, P.G. Deriving the Pricing Power of Product Features by Mining Consumer Reviews. Manag. Sci. 2011, 57, 1485–1509. [Google Scholar]
- Cui, G.; Lui, H.-K.; Guo, X. The Effect of Online Consumer Reviews on New Product Sales. Int. J. Electron. Commer. 2012, 17, 39–58. [Google Scholar]
- Sun, M. How Does the Variance of Product Ratings Matter? Manag. Sci. 2012, 58, 696–707. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Boyd, R.; Jordan, K.; Blackburn, K. The Development and Psychometric Properties of LIWC2015; University of Texas at Austin: Austin, TX, USA, 2015; pp. 1–22. [Google Scholar]
- Moe, W.W.; Trusov, M. The Value of Social Dynamics in Online Product Ratings Forums. J. Mark. Res. 2011, 48, 444–456. [Google Scholar] [CrossRef]
- Duan, W.; Gu, B.; Whinston, A.B. Do online reviews matter? An empirical investigation of panel data. Decis. Support Syst. 2008, 45, 1007–1016. [Google Scholar] [CrossRef]
- Godes, D.; Mayzlin, D. Using Online Conversations to Study Word-of-Mouth Communication. Mark. Sci. 2004, 23, 545–560. [Google Scholar] [CrossRef]
- Liu, Y. Word of Mouth for Movies: Its Dynamics and Impact on Box Office Revenue. J. Mark. 2006, 70, 74–89. [Google Scholar] [CrossRef]
- Floyd, K.; Freling, R.; Alhoqail, S.; Cho, H.Y.; Freling, T. How Online Product Reviews Affect Retail Sales: A Meta-analysis. J. Retail. 2014, 90, 217–232. [Google Scholar] [CrossRef]
- Dellarocas, C.; Zhang, X.; Awad, N.F. Exploring the value of online product reviews in forecasting sales: The case of motion pictures. J. Interact. Mark. 2007, 21, 23–45. [Google Scholar] [CrossRef]
- Wang, F.; Liu, X.; Fang, E.E. User Reviews Variance, Critic Reviews Variance, and Product Sales: An Exploration of Customer Breadth and Depth Effects. J. Retail. 2015, 91, 372–389. [Google Scholar] [CrossRef]
- Tausczik, Y.R.; Pennebaker, J.W. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Kim, M.; Lennon, S. The Effects of Visual and Verbal Information on Attitudes and Purchase Intentions in Internet Shopping. Psychol. Mark. 2007, 24, 763–785. [Google Scholar] [CrossRef]
- Ludwig, S.; de Ruyter, K.; Friedman, M.; Brüggen, E.C.; Wetzels, M.; Pfann, G. More Than Words: The Influence of Affective Content and Linguistic Style Matches in Online Reviews on Conversion Rates. J. Mark. 2013, 77, 87–103. [Google Scholar] [CrossRef]
- De Vries, L.; Gensler, S.; Leeflang, P.S.H. Popularity of Brand Posts on Brand Fan Pages: An Investigation of the Effects of Social Media Marketing. J. Interact. Mark. 2012, 26, 83–91. [Google Scholar] [CrossRef]
- Zhang, Y.; Moe, W.W.; Schweidel, D.A. Modeling the role of message content and influencers in social media rebroadcasting. Int. J. Res. Mark. 2017, 34, 100–119. [Google Scholar] [CrossRef]
- Chung, C.K.; Pennebaker, J.W. The psychological function of function words. Soc. Commun. Front. Soc. Psychol. 2007, 343–359. [Google Scholar]
- Liang, T.P.; Li, X.; Yang, C.T.; Wang, M. What in Consumer Reviews Affects the Sales of Mobile Apps: A Multifacet Sentiment Analysis Approach. Int. J. Electron. Commer. 2015, 20, 236–260. [Google Scholar] [CrossRef]
- Tang, T.Y.; Fang, E.E.; Wang, F. Is neutral really neutral? The effects of neutral user-generated content on product sales. J. Mark. 2014, 78, 41–58. [Google Scholar] [CrossRef]
- Hu, N.; Koh, N.S.; Reddy, S.K. Ratings lead you to the product, reviews help you clinch it? the mediating role of online review sentiments on product sales. Decis. Support. Syst. 2014, 57, 42–53. [Google Scholar] [CrossRef]
- Yazdani, E.; Gopinath, S.; Carson, S. Preaching to the Choir: The Chasm Between Top-Ranked Reviewers, Mainstream Customers, and Product Sales. Mark. Sci. 2018, 37, 838–851. [Google Scholar] [CrossRef]
- Chevalier, J.A.; Goolsbee, A. Measuring Prices and Price Competition Online: Amazon.com and BarnesandNoble.com. Quant. Mark. Econ. 2003, 1, 203–222. [Google Scholar] [CrossRef]
- Petty, R.E.; Cacioppo, J.T. The elaboration likelihood model of persuasion. Adv. Exp. Soc. Psychol. 1986, 19, 123–205. [Google Scholar]
- Chaiken, S. Heuristic Versus Systematic Information Processing and the Use of Source Versus Message Cues in Persuasion. J. Pers. Soc. Psychol. 1980, 39, 752–766. [Google Scholar] [CrossRef]
- Lin, C.-L.; Lee, S.-H.; Horng, D.-J. The effects of online reviews on purchasing intention: The moderating role of need for cognition. Soc. Behav. Personal. Int. J. 2011, 39, 71–81. [Google Scholar] [CrossRef]
- Park, D.H.; Kim, S. The effects of consumer knowledge on message processing of electronic word-of-mouth via online consumer reviews. Electron. Commer. Res. Appl. 2008, 7, 399–410. [Google Scholar] [CrossRef]
- Filieri, R.; McLeay, F. E-WOM and Accommodation: An Analysis of the Factors That Influence Travelers’ Adoption of Information from Online Reviews. J. Travel Res. 2014, 53, 44–57. [Google Scholar] [CrossRef]
- Park, D.-H.; Lee, J.; Han, I. The Effect of On-Line Consumer Reviews on Consumer Purchasing Intention: The Moderating Role of Involvement. Int. J. Electron. Commer. 2007, 11, 125–148. [Google Scholar] [CrossRef]
- Lee, J.; Park, D.H.; Han, I. The effect of negative online consumer reviews on product attitude: An information processing view. Electron. Commer. Res. Appl. 2008, 7, 341–352. [Google Scholar] [CrossRef]
- Agnihotri, A.; Bhattacharya, S. Online Review Helpfulness: Role of Qualitative Factors. Psychol. Mark. 2016, 33, 1006–1017. [Google Scholar] [CrossRef]
- Ruiz-Mafe, C.; Chatzipanagiotou, K.; Curras-Perez, R. The role of emotions and conflicting online reviews on consumers’ purchase intentions. J. Bus. Res. 2018, 89, 336–344. [Google Scholar] [CrossRef]
- Zhang, K.Z.K.; Zhao, S.J.; Cheung, C.M.K.; Lee, M.K.O. Examining the influence of online reviews on consumers’ decision-making: A heuristic-systematic model. Decis. Support Syst. 2014, 67, 78–89. [Google Scholar] [CrossRef]
- SanJosé-Cabezudo, R.; Gutiérrez-Arranz, A.M.; Gutiérrez-Cillán, J. The Combined Influence of Central and Peripheral Routes in the Online Persuasion Process. CyberPsychol. Behav. 2009, 12, 299–308. [Google Scholar] [CrossRef]
- Aljukhadar, M.; Senecal, S.; Daoust, C.-E. Using Recommendation Agents to Cope with Information Overload. Int. J. Electron. Commer. 2012, 17, 41–70. [Google Scholar] [CrossRef]
- Miller, G.A. The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychol. Rev. 1956, 63, 81–97. [Google Scholar] [CrossRef] [PubMed]
- Gobet, F.; Lane, P.; Croker, S.; Cheng, P.; Jones, G.; Oliver, I.; Pine, J. Chunking mechanisms in human learning. Trends Cogn. Sci. 2001, 5, 236–243. [Google Scholar] [CrossRef]
- Liu, Q.; Karahanna, E. An agent-based modeling analysis of helpful vote on online product reviews. In Proceedings of the 2015 48th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2015; pp. 1585–1595. [Google Scholar]
- Herr, P.M.; Kardes, F.R.; Kim, J. Effects of Word-of-Mouth and Product-Attribute Information on Persuasion: An Accessibility-Diagnosticity Perspective. J. Consum. Res. 1991, 17, 454. [Google Scholar] [CrossRef]
- Van Hoye, G.; Lievens, F. Social influences on organizational attractiveness: Investigating if and when word of mouth matters. J. Appl. Soc. Psychol. 2007, 37, 2024–2047. [Google Scholar] [CrossRef]
- Lynch, J.G., Jr.; Marmorstein, H.; Weigold, M.F. Choices from Sets Including Remembered Brands: Use of Recalled Attributes and Prior Overall Evaluations. J. Consum. Res. 1988, 15, 169. [Google Scholar] [CrossRef]
- Slovic, P. From Shakespeare to Simon: Speculations and some evidence. Or. Res. Inst. Bull. 1972, 12, 1–19. [Google Scholar]
- Bettman, J.R.; Luce, M.F.; Payne, J.W. Constructive Consumer Choice Processes. J. Consum. Res. 1998, 25, 187–217. [Google Scholar] [CrossRef]
- Payne, J.W. Contingent Decision Behavior. Psychol. Bull. 1982, 92, 382. [Google Scholar] [CrossRef]
- Shugan, S.M. The Cost of Thinking. J. Consum. Res. 1980, 7, 99–111. [Google Scholar] [CrossRef]
- Pang, J.; Qiu, L. Effect of online review chunking on product attitude: The moderating role of motivation to think. Int. J. Electron. Commer. 2016, 20, 355–383. [Google Scholar] [CrossRef]
- Racherla, P.; Friske, W. Perceived “usefulness” of online consumer reviews: An exploratory investigation across three services categories. Electron. Commer. Res. Appl. 2012, 11, 548–559. [Google Scholar] [CrossRef]
- Zhou, S.; Guo, B. The order effect on online review helpfulness: A social influence perspective. Decis. Support Syst. 2017, 93, 77–87. [Google Scholar] [CrossRef]
- Singh, J.P.; Irani, S.; Rana, N.P.; Dwivedi, Y.K.; Saumya, S.; Kumar Roy, P. Predicting the “helpfulness” of online consumer reviews. J. Bus. Res. 2017, 70, 346–355. [Google Scholar] [CrossRef]
- Lee, P.J.; Hu, Y.H.; Lu, K.T. Assessing the helpfulness of online hotel reviews: A classification-based approach. Telemat. Inform. 2018, 35, 436–445. [Google Scholar] [CrossRef]
- Saumya, S.; Singh, J.P.; Baabdullah, A.M.; Rana, N.P.; Dwivedi, Y.K. Ranking online consumer reviews. Electron. Commer. Res. Appl. 2018, 29, 78–89. [Google Scholar] [CrossRef]
- Westerman, D.; Spence, P.R.; Van Der Heide, B. Social Media as Information Source: Recency of Updates and Credibility of Information. J. Comput. Commun. 2014, 19, 171–183. [Google Scholar] [CrossRef]
- Fogg, B.J.; Marshall, J.; Laraki, O.; Osipovich, A.; Varma, C.; Fang, N.; Paul, J.; Rangnekar, A.; Shon, J.; Swani, P.; et al. What makes web sites credible? A report on a large quantitative study. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems; ACM SIGCHI: New York, NY, USA, 2001; pp. 61–68. [Google Scholar]
- Levinson, P. New New Media; Allyn & Bacon: Boston, MA, USA, 2013; p. 223. [Google Scholar]
- Brown, C.L.; Krishna, A. The skeptical shopper: A metacognitive account for the effects of default options on choice. J. Consum. Res. 2004, 31, 529–539. [Google Scholar] [CrossRef]
- Johnson, E.J.; Bellman, S.; Lohse, G.L. Defaults, Framing and Privacy: Why Opting In-Opting Out. Mark Lett. 2002, 13, 5–15. [Google Scholar] [CrossRef]
- Nazlan, N.H.; Tanford, S.; Montgomery, R. The effect of availability heuristics in online consumer reviews. J. Consum. Behav. 2018, 17, 449–460. [Google Scholar] [CrossRef]
- Herrmann, A.; Goldstein, D.G.; Stadler, R.; Landwehr, J.R.; Heitmann, M.; Hofstetter, R.; Huber, F. The effect of default options on choice-Evidence from online product configurators. J. Retail. Consum. Serv. 2011, 18, 483–491. [Google Scholar] [CrossRef]
- Gu, B.; Park, J.; Konana, P. The Impact of External Word-of-Mouth Sources on Retailer Sales of High-Involvement Products. Inf. Syst. 2012, 23, 182–196. [Google Scholar] [CrossRef]
- Lee, S.; Choeh, J.Y. The interactive impact of online word-of-mouth and review helpfulness on box office revenue. Manag. Decis. 2018, 56, 849–866. [Google Scholar] [CrossRef]
- Ho-Dac, N.N.; Carson, S.J.; Moore, W.L. The Effects of Positive and Negative Online Customer Reviews: Do Brand Strength and Category Maturity Matter? J. Mark. 2013, 77, 37–53. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Chung, C.K.; Ireland, M.; Gonzales, A.; Booth, R.J. The Development and Psychometric Properties of LIWC2007; LIWC.net: Austin, TX, USA, 2007. [Google Scholar]
- Motyka, S.; Grewal, D.; Aguirre, E.; Mahr, D.; de Ruyter, K.; Wetzels, M. The emotional review–reward effect: How do reviews increase impulsivity? J. Acad. Mark. Sci. 2018, 46, 1032–1051. [Google Scholar] [CrossRef]
- Selkirk, E. The prosodic structure of function words. In Signal to Syntax Bootstrapping from speech to Gramm (early Acquis.); Lawrence Erlbaum Associates Inc.: Hillsdale, MI, USA, 1996; pp. 187–214. [Google Scholar]
- Smith, C.A.; Ellsworth, P.C. Patterns of cognitive appraisal in emotion. J. Personal. Soc. Psychol. 1985, 48, 813–838. [Google Scholar] [CrossRef]
- Areni, C.S. The Effects of Structural and Grammatical Variables on Persuasion: An Elaboration Likelihood Model Perspective. Psychol. Mark. 2003, 20, 349–375. [Google Scholar] [CrossRef]
- Munch, J.M.; Swasy, J.L. Rhetorical question, summarization frequency, and argument strength effects on recall. J. Consum. Res. 1988, 15, 69–76. [Google Scholar] [CrossRef]
- Payan, J.M.; McFarland, R.G. Decomposing Influence Strategies: Argument Structure and Dependence as Determinants of the Effectiveness of Influence Strategies in Gaining Channel Member Compliance. J. Mark. 2005, 69, 66–79. [Google Scholar] [CrossRef]
- Darley, W.K.; Smith, R.E. Advertising Claim Objectivity: Antecedents and Effects. J. Mark. 1993, 57, 100. [Google Scholar] [CrossRef]
- Holbrook, M.B. Beyond Attitude Structure: Toward the Informational Determinants of Attitude. J. Mark. Res. 1978, 15, 545. [Google Scholar] [CrossRef]
- Chen, C.C.; Tseng, Y. De Quality evaluation of product reviews using an information quality framework. Decis. Support Syst. 2011, 50, 755–768. [Google Scholar] [CrossRef]
- Ghose, A.; Ipeirotis, P.G.; Li, B. Designing Ranking Systems for Hotels on Travel Search Engines by Mining User-Generated and Crowdsourced Content. Mark. Sci. 2012, 31, 493–520. [Google Scholar] [CrossRef]
- Liu, J.; Cao, Y.; Lin, C.; Huang, Y.; Zhou, M. Low-quality product review detection in opinion summarization. In Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 334–342. [Google Scholar]
- Sniezek, J.A.; Van Swol, L.M. Trust, confidence, and expertise in a judge-advisor system. Organ Behav. Hum. Decis. Process. 2001, 84, 288–307. [Google Scholar] [CrossRef]
- Price, P.C.; Stone, E.R. Intuitive Evaluation of Likelihood Judgment Producers: Evidence for a Confidence Heuristic. J. Behav. Decis. Mak. 2004, 17, 39–57. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Chung, C.K.; Frazee, J.; Lavergne, G.M.; Beaver, D.I. When small words foretell academic success: The case of college admissions essays. PLoS ONE 2014, 9, 1–10. [Google Scholar] [CrossRef]
- Kacewicz, E.; Pennebaker, J.W.; Davis, M.; Jeon, M.; Graesser, A.C. Pronoun Use Reflects Standings in Social Hierarchies. J. Lang. Soc. Psychol. 2014, 33, 125–143. [Google Scholar] [CrossRef]
- Newman, M.L.; Pennebaker, J.W.; Berry, D.S.; Richards, J.M. Personality and Social Psychology Bulletin Lying Words: Predicting Deception From Linguistic Styles. Personal. Soc. Psychol. Bull. 2003, 29, 665–675. [Google Scholar] [CrossRef]
- Social Blade. 2017. Available online: https://socialblade.com/ (accessed on 22 April 2020).
- Euromonitor International. Colour Cosmetics in the US; Euromonitor International: Chicago, IL, USA, 2017. [Google Scholar]
- Nielsen. The Sweet Smell of Seasonal Success; Nielsen: New York, NY, USA, 2016. [Google Scholar]
- Elberse, A.; Eliashberg, J. Demand and Supply Dynamics for Sequentially Released Products in International Markets: The Case of Motion Pictures. Mark. Sci. 2003, 22, 329–354. [Google Scholar] [CrossRef]
- Godes, D.; Silva, J.C. Sequential and Temporal Dynamics of Online Opinion. Mark. Sci. 2012, 31, 448–473. [Google Scholar] [CrossRef]
- Duan, W.; Gu, B.; Whinston, A.B. The dynamics of online word-of-mouth and product sales-An empirical investigation of the movie industry. J. Retail. 2008, 84, 233–242. [Google Scholar] [CrossRef]
- Zhu, F. Impact of Online Consumer Reviews on Sales: The Moderating Role of Product and Consumer Characteristics. J. Mark. 2010, 74, 133–148. [Google Scholar] [CrossRef]
- Decker, R.; Trusov, M. Estimating aggregate consumer preferences from online product reviews. Int. J. Res. Mark. 2010, 27, 293–307. [Google Scholar] [CrossRef]
- Park, E.J.; Kim, E.Y.; Funches, V.M.; Foxx, W. Apparel product attributes, web browsing, and e-impulse buying on shopping websites. J. Bus. Res. 2012, 65, 1583–1589. [Google Scholar] [CrossRef]
- Xu, P.; Liu, D. Product engagement and identity signaling: The role of likes in social commerce for fashion products. Inf. Manag. 2019, 56, 143–154. [Google Scholar] [CrossRef]
- Cheng, Y.H.; Ho, H.Y. Social influence’s impact on reader perceptions of online reviews. J. Bus. Res. 2015, 68, 883–887. [Google Scholar] [CrossRef]
- Arellano, M.; Bover, O. Another look at the instrumental variable estimation of error-components models. J. Econom. 1995, 68, 29–51. [Google Scholar] [CrossRef]
- Blundell, R.; Bond, S. Initial conditions and moment restrictions in dynamic panel data models. J. Econom. 1998, 87, 115–143. [Google Scholar] [CrossRef]
- Lozano, M.B.; Martínez, B.; Pindado, J. Corporate governance, ownership and firm value: Drivers of ownership as a good corporate governance mechanism. Int. Bus. Rev. 2016, 25, 1333–1343. [Google Scholar] [CrossRef]
- Pindado, J.; Requejo, I.; de la Torre, C. Family control and investment-cash flow sensitivity: Empirical evidence from the Euro zone. J. Corp. Financ. 2011, 17, 1389–1409. [Google Scholar] [CrossRef]
- Forman, C.; Ghose, A.; Wiesenfeld, B. Examining the relationship between reviews and sales: The role of reviewer identity disclosure in electronic markets. Inf. Syst. Res. 2008, 19, 291–313. [Google Scholar] [CrossRef]
- Arellano, M.; Bond, S. Some Tests of Specification for Panel Data: Monte Carlo Evidence and an Application to Employment Equations. Rev. Econ. Stud. 1991, 58, 277. [Google Scholar] [CrossRef]
- Roodman, D. How to do xtabond2: An introduction to difference and system GMM in Stata. Stata J. 2009, 9, 86–136. [Google Scholar] [CrossRef]
- Aiken, L.S.; West, S.G. Multiple Regression: Testing and Interpreting Interactions; Sage: Newcastle Upon Tyne, UK, 1991. [Google Scholar]
- Roodman, D. Practitioners’ corner: A note on the theme of too many instruments. Oxf Bull Econ Stat. 2009, 71, 135–158. [Google Scholar] [CrossRef]
- Ngo-Ye, T.L.; Sinha, A.P. The influence of reviewer engagement characteristics on online review helpfulness: A text regression model. Decis. Support Syst. 2014, 61, 47–58. [Google Scholar] [CrossRef]
- Vermeer, S.A.M.; Araujo, T.; Bernritter, S.F.; van Noort, G. Seeing the wood for the trees: How machine learning can help firms in identifying relevant electronic word-of-mouth in social media. Int. J. Res. Mark. 2019, 36, 492–508. [Google Scholar] [CrossRef]




| Definition | |
|---|---|
| Dependent variable | |
| Ln_sales_rank_inverseit | The natural Log of the multiplicative inverse of the sales rank of product i at time t (1/sales_rankit) |
| Independent variables | |
| Review non-textual variables | |
| Ln_volumeit | The natural Log of the cumulative number of online consumer reviews for product i at time t |
| Ln_ratingivt | The natural Log of the average of ratings for product i at time t considering review visibility case v |
| Ln_rating_inconsistencyivt | The natural Log of the average difference in absolute value between review rating and product average rating for product i at time t considering review visibility case v |
| Review textual variables | |
| Ln_analyticivt | The natural Log of the average of analytical thinking shown in online reviews for product i at time t considering review visibility case v The variable captures the degree to which consumers use words that suggest formal, logical and hierarchical thinking patterns [94]. It is extracted using the text mining tool LIWC [23]. |
| Ln_authenticivt | The natural Log of the average of authenticity shown in online reviews for product i at time t considering review visibility case v The variable captures the degree to which consumers reveal themselves in an authentic or honest way, so their discourse is more personal and humble [96]. It is extracted using the text mining tool LIWC [23]. |
| Ln_cloutivt | The natural Log of the average of clout shown in online reviews for product i at time t considering review visibility case v The variable captures the relative social status, confidence or leadership displayed by consumers through their writing style [95]. It is extracted using the text mining tool LIWC [23]. |
| Control variables | |
| Christmast | Binary variable: 1 if it is between 21 December 2016 and 5 January 2017; 0 otherwise. |
| Newit | Binary variable: 1 if product i at time t had the label of “new”; 0 otherwise |
| Exclusiveit | Binary variable: 1 if product i had the exclusive label at time t; 0 otherwise |
| Ln_priceit | The natural Log of the of the price per gram of product i at time t |
| Ln_sizeit | The natural Log of the of the size in gr of product i at time t |
| Brand_retaileri | Binary variable: 1 if product i´s brand belongs to the retailer private brand; 0 otherwise |
| Ln_brand_followersit | The natural Log of the cumulative number of brand Instagram followers for product i at time t. Data collected from Socialblade.com [97] |
| Brand_topi | Binary variable: 1 if product i´s brand was in the top 10 bestselling brands in the US in 2016; 0 otherwise. Data from Euromonitor International [98] |
| Band_premiumi | Binary variable: 1 if the product i´s brand is was categorized as premium brand in 2016; 0 otherwise. Data from Euromonitor International [98] |
| Product (i) | Review Rating | Case 1 | Case 2 | ||
|---|---|---|---|---|---|
| Approach 1 (v1) | Review Visibility When Sorting by Most Helpful (Review Rank Order) | Approach 1 (v2.1) | Approach 2 (v2.2) | ||
| All Reviews the Same Probability of Being Viewed | Review Visibility Weight (w) All Reviews Have a Decreasing Probability of Being Viewed When Sorting by Most Helpful (1/Review Rank Order) | Review Visibility Weight (w) Only Reviews in the First Page (top 5) are Viewed When Sorting by Most Helpful | |||
| 1 | 5 | 1 | 1 | 1 | 1 |
| 4 | 1 | 2 | 0.5 | 1 | |
| 3 | 1 | 3 | 0.33 | 1 | |
| 5 | 1 | 4 | 0.25 | 1 | |
| 4 | 1 | 5 | 0.2 | 1 | |
| 3 | 1 | 6 | 0.16 | 0 | |
| 4 | 1 | 7 | 0.14 | 0 | |
| 5 | 1 | 8 | 0.12 | 0 | |
| 1 | 1 | 9 | 0.11 | 0 | |
| 2 | 1 | 10 | 0.1 | 0 | |
| Sum of probabilities | 10 | 2.93 | 5 | ||
| Rating | Rating v1 = 3.6 | Ratingv2.1 = 4.12 | Ratingv2.2 = 4.2 | ||
| ln_rating | Ln 3.6 = 1.28 | Ln 4.12 = 1.42 | Ln 4.2 = 1.44 | ||
| Variable | N | Mean | SD | Min | Max |
|---|---|---|---|---|---|
| Sales_rank_inverse | 1062 | 68.13 | 39.01 | 1 | 146 |
| Volume | 1062 | 523.18 | 1604.49 | 1 | 16,404 |
| Ratingv1 | 1062 | 4.29 | 0.38 | 2.9 | 5 |
| Ratingv2.1 | 1062 | 4.29 | 0.49 | 1.91 | 5 |
| Ratingv2.2 | 1062 | 4.39 | 0.66 | 1.6 | 5 |
| Ratingv3.1 | 1062 | 4.17 | 0.49 | 2.4 | 5 |
| Ratingv3.2 | 1062 | 4.18 | 0.66 | 2 | 5 |
| Rating_inconsistencyv1 | 1062 | 0.02 | 0.02 | 0 | 0.34 |
| Rating_inconsistencyv2.1 | 1062 | 0.23 | 0.21 | 0 | 1.06 |
| Rating_inconsistencyv2.2 | 1062 | 0.41 | 0.37 | 0 | 2.5 |
| Rating_inconsistencyv3.1 | 1062 | 0.22 | 0.2 | 0 | 1.06 |
| Rating_inconsistencyv3.2 | 1062 | 0.41 | 0.36 | 0 | 2 |
| Analyticv1 | 1062 | 46.16 | 6.02 | 11 | 70.86 |
| Analyticv2.1 | 1062 | 47.06 | 8.43 | 11 | 70.54 |
| Analyticv2.2 | 1062 | 49.52 | 10.94 | 11 | 72.72 |
| Analyticv3.1 | 1062 | 44.44 | 8.86 | 11 | 75.47 |
| Analyticv3.2 | 1062 | 44.02 | 12.10 | 10.02 | 75.33 |
| Authenticv1 | 1062 | 49.96 | 7.71 | 27.39 | 73.34 |
| Authenticv2.1 | 1062 | 49.54 | 10.48 | 19.22 | 76.78 |
| Authenticv2.2 | 1062 | 49.18 | 15.38 | 2.24 | 80.39 |
| Authenticv3.1 | 1062 | 48.69 | 11.43 | 11.94 | 79.90 |
| Authenticv3.2 | 1062 | 49.52 | 15.15 | 7.40 | 92.01 |
| Cloutv1 | 1062 | 27.14 | 5.66 | 8.65 | 64.45 |
| Cloutv2.1 | 1062 | 26.50 | 6.56 | 5.90 | 52.76 |
| Cloutv2.2 | 1062 | 27.29 | 9.77 | 6.64 | 64.45 |
| Cloutv3.1 | 1062 | 26.64 | 7.56 | 7.13 | 72.27 |
| Cloutv3.2 | 1062 | 26.59 | 10.92 | 2.33 | 64.45 |
| Christmas | 1062 | 0.33 | 0.47 | 0 | 1 |
| New | 1062 | 0.08 | 0.27 | 0 | 1 |
| Exclusive | 1062 | 0.27 | 0.44 | 0 | 1 |
| Price | 1062 | 5.63 | 3.87 | 0.35 | 26.25 |
| Size | 1062 | 8.8 | 8.22 | 0.8 | 57 |
| Brand_retailer | 1062 | 0.07 | 0.25 | 0 | 1 |
| Brand_followers | 1062 | 3,512,608 | 3,649,264 | 2837 | 14,000,000 |
| Brand_top | 1062 | 0.09 | 0.29 | 0 | 1 |
| Brand_premium | 1062 | 0.32 | 0.47 | 0 | 1 |
| Case 1 (v1) No Visibility Considered | Case 2 (v2) Most Helpful Visibility | Case 3 (v3) Most Recent Visibility | |||
|---|---|---|---|---|---|
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | |
| Case v1 | Case v2.1 | Case v2.2 | Case v3.1 | Case v3.2 | |
| All Reviews Same Probability of Being Viewed | All Reviews Decreasing Probability | Five Most Helpful Reviews | All Reviews Decreasing Probability | Five Most Recent Reviews | |
| L1_ln_sales_rank_inverse | 0.919 *** | 0.889 *** | 0.767 *** | 0.937 *** | 0.942 *** |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| Ln_volume | 0.072 *** | 0.064 *** | 0.093 *** | 0.134 *** | 0.075 *** |
| (0.01) | (0.01) | (0.01) | (0.01) | (0.01) | |
| Ln_rating | 0.116 *** | 0.256 *** | 0.578 *** | 0.108 *** | 0.274 *** |
| (0.00) | (0.01) | (0.01) | (0.01) | (0.01) | |
| Ln_rating_inconsistency | 0.506 *** | 1.012 *** | 1.949 *** | 0.369 *** | 0.552 *** |
| (0.02) | (0.03) | (0.01) | (0.03) | (0.04) | |
| Ln_rating x ln_rating_inconsistency | −0.476 *** | −0.953 *** | −1.872 *** | −0.312 *** | −0.423 *** |
| (0.02) | (0.03) | (0.01) | (0.03) | (0.03) | |
| Ln_analytic | −0.016 *** | 0.031 *** | 0.008 * | −0.048 *** | −0.012 ** |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| Ln_authentic | 0.035 *** | −0.070 *** | −0.077 *** | −0.042 *** | −0.020 ** |
| (0.00) | (0.01) | (0.01) | (0.01) | (0.01) | |
| Ln_clout | 0.030 *** | −0.077 *** | −0.105 *** | −0.013 ** | −0.034 *** |
| (0.01) | (0.00) | (0.00) | (0.00) | (0.01) | |
| Christmas | −0.003 | 0.003 | 0.015*** | 0.008 | 0.005 |
| (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | |
| New | 0.100 *** | 0.105 *** | 0.352 *** | 0.017 * | 0.092 *** |
| (0.01) | (0.01) | (0.01) | (0.01) | (0.01) | |
| Exclusive | 0.163 *** | 0.218 *** | 0.280 *** | 0.145 *** | 0.186 *** |
| (0.01) | (0.01) | (0.01) | (0.01) | (0.02) | |
| Ln_price | 0.321 *** | 0.294 *** | 0.060 *** | 0.133 *** | 0.033 * |
| (0.01) | (0.01) | (0.01) | (0.01) | (0.01) | |
| Ln_size | 0.273 *** | 0.256 *** | 0.061 *** | 0.108 *** | 0.045 *** |
| (0.01) | (0.02) | (0.01) | (0.01) | (0.01) | |
| Brand_retailer | 0.309 *** | 0.293 *** | 0.255 *** | 0.159 *** | 0.072 * |
| (0.02) | (0.03) | (0.04) | (0.03) | (0.03) | |
| Brand_followers | −0.053 *** | −0.027 *** | −0.053 *** | −0.068 *** | −0.057 *** |
| (0.00) | (0.00) | (0.01) | (0.01) | (0.01) | |
| Top_brand | 0.057 ** | 0.059 | −0.011 | 0.048 | 0.046 * |
| (0.02) | (0.04) | (0.03) | (0.02) | (0.02) | |
| Brand_premium | 0.013 | 0.036 ** | 0.147 *** | 0.007 | 0.058 *** |
| (0.01) | (0.01) | (0.02) | (0.01) | (0.02) | |
| Constant | −0.078 *** | −0.353 *** | −0.200 *** | −0.070 *** | −0.107 *** |
| (0.01) | (0.02) | (0.02) | (0.01) | (0.01) | |
| Observations | 944 | 944 | 944 | 944 | 944 |
| z1 | 4.1 × 106 (17) | 4.1 × 106 (17) | 5.6 × 107 (17) | 1.7 × 106 (17) | 7.6 × 105 (17) |
| z2 | 63.30 (6) | 47.90 (6) | 109.89 (6) | 133.99 (6) | 47.25 (6) |
| Hansen | 70.19, p = 0.666 | 79.70, p = 0.364 | 82.28, p = 0.291 | 86.86, p = 0.185 | 84.60, p = 0.234 |
| AR (2) | 0.66, p = 0.512 | 0.65, p = 0.518 | 0.40, p = 0.687 | 0.64, p = 0.522 | 0.60, p = 0.548 |
| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| OLS | FE | RE | System GMM | |
| L1.ln_sales_rank_inverse | 0.915 *** | 0.643 *** | 0.915 *** | 0.889 *** |
| (0.01) | (0.02) | (0.01) | (0.00) | |
| Ln_volume | 0.063 *** | −0.730 ** | 0.063 *** | 0.064 *** |
| (0.01) | (0.26) | (0.01) | (0.01) | |
| Ln_rating | 0.054 ** | 0.030 | 0.054 ** | 0.256 *** |
| (0.02) | (0.08) | (0.02) | (0.01) | |
| Ln_rating_inconsistency | 0.182 | 0.397 * | 0.182 | 1.012 *** |
| (0.09) | (0.18) | (0.09) | (0.03) | |
| Ln_rating x ln_rating_inconsistency | −0.173 * | −0.322 | −0.173* | −0.953 *** |
| (0.09) | (0.18) | (0.09) | (0.03) | |
| Ln_analytic | −0.004 | −0.071 | −0.004 | 0.031 *** |
| (0.01) | (0.06) | (0.01) | (0.00) | |
| Ln_authentic | −0.003 | −0.066 | −0.003 | −0.070 *** |
| (0.01) | (0.05) | (0.01) | (0.01) | |
| Ln_clout | −0.002 | −0.049 | −0.002 | −0.077 *** |
| (0.01) | (0.06) | (0.01) | (0.00) | |
| Christmas | 0.014 | −0.001 | 0.014 | 0.003 |
| (0.04) | (0.04) | (0.04) | (0.00) | |
| New | 0.112 * | 0.205 * | 0.112 * | 0.105 *** |
| (0.05) | (0.08) | (0.05) | (0.01) | |
| Exclusive | 0.144 *** | 0.945 *** | 0.144 *** | 0.218 *** |
| (0.03) | (0.21) | (0.03) | (0.01) | |
| Ln_price | 0.043 | 0.000 | 0.043 | 0.294 *** |
| (0.03) | (.) | (0.03) | (0.01) | |
| Ln_size | 0.027 | −0.302 | 0.027 | 0.256 *** |
| (0.02) | (1.58) | (0.02) | (0.02) | |
| Brand_retailer | 0.004 | 0.000 | 0.004 | 0.293 *** |
| (0.06) | (.) | (0.06) | (0.03) | |
| Ln_brand_followers | −0.020 | 0.014 | −0.020 | −0.027 *** |
| (0.01) | (0.07) | (0.01) | (0.00) | |
| Brand_top | −0.008 | 0.000 | −0.008 | 0.059 |
| (0.04) | (.) | (0.04) | (0.04) | |
| Brand_premium | 0.038 | 0.000 | 0.038 | 0.036** |
| (0.03) | (.) | (0.03) | (0.01) | |
| Constant | −0.087 | −0.462 * | −0.087 | −0.353 *** |
| (0.06) | (0.19) | (0.06) | (0.02) | |
| Observations | 944 | 944 | 944 | 944 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzate, M.; Arce-Urriza, M.; Cebollada, J. Online Reviews and Product Sales: The Role of Review Visibility. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 638-669. https://doi.org/10.3390/jtaer16040038
Alzate M, Arce-Urriza M, Cebollada J. Online Reviews and Product Sales: The Role of Review Visibility. Journal of Theoretical and Applied Electronic Commerce Research. 2021; 16(4):638-669. https://doi.org/10.3390/jtaer16040038
Chicago/Turabian StyleAlzate, Miriam, Marta Arce-Urriza, and Javier Cebollada. 2021. "Online Reviews and Product Sales: The Role of Review Visibility" Journal of Theoretical and Applied Electronic Commerce Research 16, no. 4: 638-669. https://doi.org/10.3390/jtaer16040038
APA StyleAlzate, M., Arce-Urriza, M., & Cebollada, J. (2021). Online Reviews and Product Sales: The Role of Review Visibility. Journal of Theoretical and Applied Electronic Commerce Research, 16(4), 638-669. https://doi.org/10.3390/jtaer16040038