1. Introduction
For high-income countries, international migration can represent an important contributor to population growth and a substantial share of the resident population. Changes in migration rates have accompanied changes in the economic and political environment in the destination country and migrants’ countries of origin, as well as changes in immigration policy [
1,
2,
3]. The United States represents the most common destination country for migrants globally, with the U.S. foreign-born population representing 18% of global migrant stocks, more than three times greater than that in any other single country [
4]. In 2023, 48 million foreign-born individuals resided in the United States, representing 14% of the U.S. population. Of this 48 million, 26 million are estimated to have entered the country since the turn of the century, while 16 million have entered since 2010, reflecting major migrant inflows over recent years [
5]. These individuals play important roles across multiple domains of economic and civic life in the United States [
6]. While immigration is an established feature of U.S. population dynamics, overall rates of immigration have changed substantially over time, and the mix of countries and world regions represented in successive immigration cohorts has also varied. In the early part of the 20th century, migrants to the United States were primarily from European countries. This pattern evolved with increasing migration from Asian and Latin American countries in more recent years, with individuals from these regions representing 42% and 39% of all new U.S. residents entering the country after 2010, respectively [
5,
7]. For some countries, migration to the United States has followed sharp changes driven by U.S. foreign policy, exemplified by the successive waves of immigration from Vietnam starting in the 1970s in the wake of the Vietnam War, which was preceded by low rates of immigration from this country [
8]. The question of how migrants impact U.S. society has been the subject of substantial academic and public discourse historically [
9,
10], as well as more recently [
11], and evidence on the changing composition of the U.S. foreign-born population is a critical input for these discussions.
For countries that receive substantial numbers of migrants, detailed estimates of the sizes and trends in the foreign-born resident population have many potential applications, including planning the provision of services for these individuals, gauging the impact of immigration policy, and generating evidence on other determinants of migration. For the United States, tabulations of foreign-born population stocks are routinely provided by the U.S. Census Bureau. However, these estimates may not stratify results according to all the dimensions that may be important for decision-making, or may be reported in categories that are overly broad for a particular use. Public-use microdata are also available for many of the large population surveys conducted in the United States, but while these datasets allow a high level of disaggregation, the sampling uncertainty associated with ‘raw’ estimates calculated directly from these data can be substantial [
12]. Moreover, evidence on foreign-born immigration flows is substantially weaker than evidence on current stocks, with direct estimates of individuals legally admitted to the United States [
13] excluding undocumented migrants, and indirect estimates back-calculated from the time series of population stocks affected by uncertainty around emigration volume.
The best current data on the foreign-born resident population come from the American Community Survey (ACS), which collects data on a large population-based sample of the U.S. resident population on an ongoing basis, with annual data releases [
14]. The ACS collects a range of socio-economic and demographic data on sampled individuals, including information on ancestry, family relationships, citizenship status, education, languages spoken, present and past locations of residence, selected disabilities, employment, income, and household characteristics. The content and wording of these surveys closely match variables previously collected on the ‘long form’ of the decennial U.S. census, which the ACS has largely replaced. For the ACS, the foreign-born population includes legal immigrants (‘green-card’ holders), legal non-immigrants (temporary migrants), asylees and refugees, and undocumented migrants as long as they meet survey criteria for current residence. Early variants of the ACS were introduced from 2000 to 2004, and the survey has been conducted in a standardized format since 2005. For the year 2000, the 5% sample of the decennial census provides similar information on country of origin and other basic demographic data.
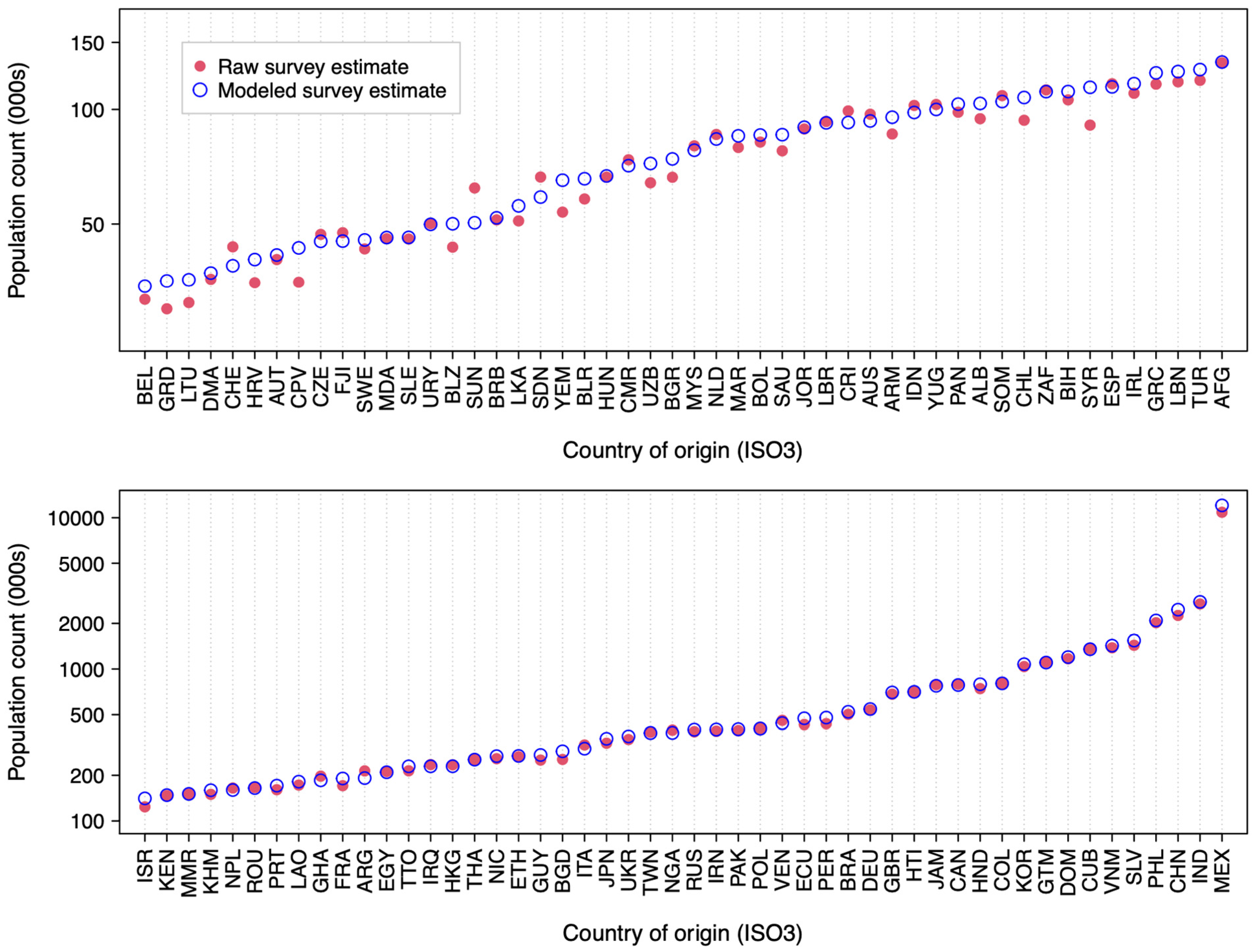
Despite the large sample size of the ACS, there is substantial sampling uncertainty for detailed population estimates. The errors induced by this sampling uncertainty can be revealed by following a single immigration cohort over time. While population estimates for an immigration cohort should decline over time (as individuals exit the cohort due to death or emigration), the raw data show periods of apparently increasing populations. For example, the raw population estimate for the 2000 entry cohort from the Philippines (the country of origin with the fourth largest number of U.S. residents in the 2019 ACS) increased from 38,000 to 49,000 between 2001 and 2002 and from 46,000 to 59,000 between 2016 and 2017. Between 2001 and 2019, 10 of 18 years featured apparent population increases despite this being a closed cohort. These estimation errors are proportionally larger for countries with smaller resident populations and are also seen with other population attributes—for example, in the 2000 entry cohort from Moldova, the average age from the raw survey data declined from 50 years old in 2006 to 26 years old in 2007 before rising to 37 years old the next year.
In addition to random variation, there are also systematic artifacts apparent in ACS survey responses. For example, reported years of entry show periodic spikes, with foreign-born respondents being 34% more likely to report entering in the first year of the decade (1960, 1970, 1980, 1990, 2000, or 2010) than in the years immediately before or afterwards. Similar but smaller spikes are observed for ‘half-decade’ years (1955, 1965, etc.), with respondents being 14% more likely to report entering the United States in these years than in the years immediately before or afterwards. It is difficult to explain these periodic spikes as resulting from real immigration trends, and they are more likely caused by some bias in terms of how the year of entry is reported or recorded. The magnitude of these spikes makes it difficult to distinguish real changes in immigration volume from the reporting artifacts in the raw data.
The objective of this analysis was to propose a novel approach for generating estimates of the number of foreign-born individuals living in the United States, simultaneously stratified by several dimensions to provide high-precision estimates of the U.S. foreign-population for a large number of population strata, while minimizing sampling uncertainty and adjusting for reporting biases associated with available survey data. This analysis was additionally designed to produce estimates of migration into the United States by country, year, and age for the period covered by survey data, as well as past years. To achieve these objectives, this study combined 20 years of survey data with a mechanistic model of foreign-born population dynamics. In this model, each immigration cohort (by country, entry year, and age) was followed over time, with mortality rates based on published lifetables and emigration rates estimated from the survey data. As a result, the population of each immigration cohort was allowed to decline over time based on established components of population changes. By placing logical and probabilistic constraints on how individuals enter and exit the foreign-born population, the analytic approach was able to reduce the sampling uncertainty associated with the survey estimates and adjust for sources of bias in these data.
The results of this study represent precise estimates of the number of foreign-born individuals living in the United States for calendar years 2000–2019 stratified by multiple individual-level characteristics (country of origin, year of age, year of entry to the US, and calendar year). The analysis also provides annual estimates of foreign-born individuals newly entering the U.S. resident population, a measure of annual immigration volume that may have advantages compared to other approaches. This paper describes the statistical approach used to model population changes and generate results, reports tests of in- and out-of-sample predictive performance, provides the population estimates, and highlights applications for these estimates. While the focus of this study was the United States foreign-born population, the approaches developed through this study may be applicable to other countries that collect cross-sectional population data though large surveys or administrative records.
2. Materials and Methods
2.1. Data
The primary data source used for this analysis was the America Community Survey (ACS). We used ACS public-use microdata samples (PUMS) from surveys conducted from 2001 to 2019. We also used the 5% sample of the 2000 decennial census, which represents 5% of all eligible individuals. PUMS data are created from original survey responses, with edits made to impute missing, illegible, or illogical values and to prevent identification of survey respondents [
15]. ‘Foreign-born’ individuals were defined as survey respondents reporting a place of birth outside of the U.S. or U.S. territories, excluding individuals born to U.S. parents. To be a U.S. resident (and therefore be included in the ASC survey sample), an individual must have lived at their U.S. address for >2 months or anticipate living at that address for >2 months. Variables for place of birth, year of U.S. entry, and current age were extracted from survey data, in addition to analysis weights provided to inflate the individual samples to obtain national population estimates. The sum of these analysis weights was taken to represent the ‘raw’ population estimate for any given stratum.
The variable for year of entry into the United States showed irregular patterns for entry years prior to 1950 resulting from census statistical disclosure controls, and this variable was therefore bottom-coded at 1949. Similarly, the variable for current age showed irregular patterns for advanced ages and was thus top-coded at 91. ISO 3166-1 alpha-3 codes (ISO3 codes) were used to identify countries. Individuals were assigned to a single ISO3 code according to their survey country-of-origin code. For survey country-of-origin codes describing a dependent territory without an ISO3 code, individuals were assigned to the governing state of the territory. All other individuals that could not be mapped to a unique ISO3 code were pooled into a residual category. In addition, countries becoming independent states after 2000 (Kosovo, Montenegro, Serbia, South Sudan, and Timor–Leste) were pooled with the state they were part of as of 2000 (Yugoslavia, Sudan, and Indonesia). Using the country-of-origin variable, an additional classification was created to group individuals into world region of origin using the World Bank regional classification (East Asia and Pacific, Europe and Central Asia, Latin America and the Caribbean, Middle East and North Africa, North America, South Asia, and Sub-Saharan Africa). Using these classifications, a combined dataset of raw survey estimates was created from the individual-level PUMS data for all possible combinations of country or region of origin, current age, year of entry, and survey year.
2.2. Analysis
Analyses were undertaken to obtain population estimates for the U.S. foreign-born population stratified by country or region of origin, current age, year of entry, and survey year. These included 76,830 unique values for each country or region of origin. Results were estimated for the overall foreign-born population, for each world region of origin, and for each of the top 100 countries of origin (ranked according to U.S. resident population size for each country of origin, averaged over the period 2000–2019).
2.2.1. Immigration Cohort Model
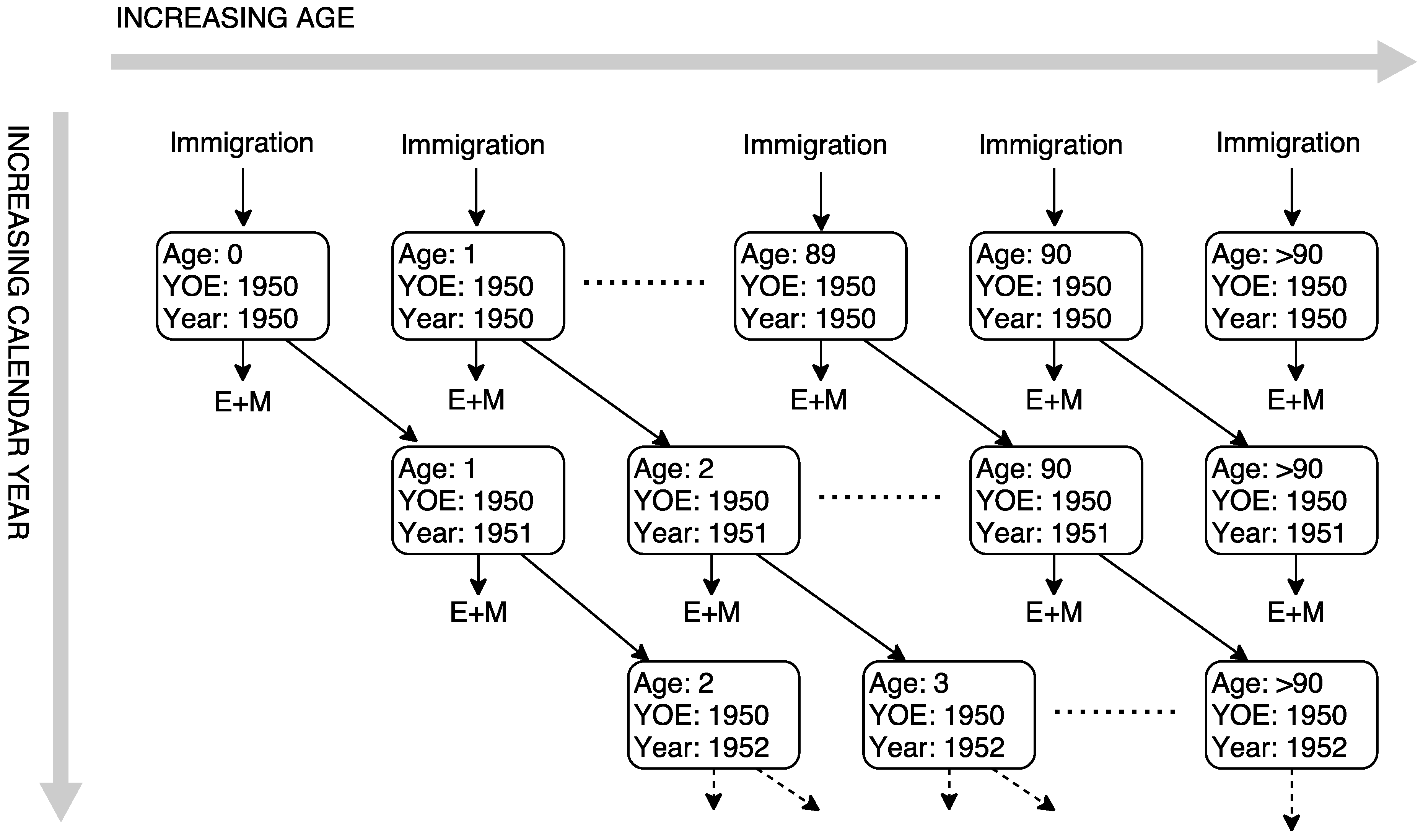
A compartmental stock–flow model was developed to represent the population dynamics of the foreign-born U.S. population from 1950 to 2019. This model allowed (i) an existing stock of foreign-born individuals in 1950, (ii) yearly additions to the foreign-born population in each year from 1950 to 2019 due to immigration, and (iii) yearly exits from the foreign-born population due to emigration or death. In this model, individuals residing in the United States in a given calendar year were stratified by year of age and entry year. The number of individuals in a particular immigration cohort (defined by year and age of entry) present in the United States in a given year was assumed to be equal to the number of individuals in the same immigration cohort in the previous year minus exits to emigration or death.
Figure 1 shows a schematic of this stock–flow model for the 1950 immigration cohort.
2.2.2. Initial Population
The initial population for the model was composed of all foreign-born individuals present in the United States at the start of 1950 stratified by age. Data for cohorts immigrating to the United States before 1950 were combined into a single cohort, as this group represents a small fraction of the current foreign-born population (approximately 1%).
2.2.3. Immigration
The total immigration volume each year from 1950 to 2019 was modeled as a geometric random walk, and the age distribution of immigrating cohorts was represented using penalized B-splines [
16,
17]. This age distribution consisted of the following two components: a one-dimensional spline representing the average age distribution across all entry years and a two-dimensional spline surface representing temporal deviations from this average pattern.
2.2.4. Emigration and Mortality
Individuals exited the resident foreign-born population through mortality and emigration. Evidence on mortality rates by single year of age was drawn from recent U.S. life tables [
18]. Variation in these age-based mortality rates was modeled via a penalized B-spline to allow for deviations in mortality rates between the general population and individual immigrant groups. In addition, age-specific mortality rates were assumed to decline log-linearly over time based on trends reported in decennial life tables for 1950–2010 [
18].
Exits due to emigration were assumed to decline with increasing time since entry [
19,
20], with the emigration rate allowed to decline smoothly up to 15 years after entry to the US, after which it was held fixed.
2.2.5. Misclassification of Reported Age and Entry Year
Population estimates calculated directly from the survey data showed periodic spikes in the population distribution as a function of reported age and entry year (
Supplementary Materials, Figure S4). For both of these variables, large spikes were apparent, coinciding with the end of each decade, and smaller spikes were apparent at mid-decades. In other studies, implausible patterns in ACS results have revealed systematic biases due to misreporting by survey respondents [
21,
22], and it was hypothesized that the periodic effects observed in the raw estimates resulted from misreporting by survey respondents, with the true value for age and/or entry year being rounded to the nearest decade or mid-decade. A measurement–error model was used to correct for this misclassification.
2.2.6. Undercounting of Foreign-Born Populations
Previous research suggests that raw estimates derived from the ACS underestimate true population sizes for foreign-born populations [
23]. While analysis weights provided for the ACS are adjusted to account for under- or over-reporting, the ACS is only controlled by age, sex, race, and Hispanic origin, not nativity. The extent of undercounting is thought to be greater for recent immigrants, undocumented migrants, immigrants of Hispanic origin, younger age groups, and older ACS survey years [
23,
24,
25]. The magnitude of this bias cannot be estimated from the survey data alone, and evidence of undercounting is generally derived from comparison with other data sources. Using estimates of the size of the ACS undercount reported by the U.S. Census Bureau [
23], the analysis allowed for underreporting in the PUMS data so that final analytic estimates would provide an estimate of the true population size. These adjustments were specified as inflation factors that varied with time since entry (higher for more recent immigrants), country of origin (higher for countries in Latin America and the Caribbean), and survey year (higher for earlier survey years with smaller sample sizes). For countries in Latin America and the Caribbean, an average undercount rate of 5.0% was assumed for survey years 2005–2019, and an average undercount of 2.0% was assumed for other countries over the same period, consistent with recent Census Bureau estimates [
23].
2.3. Estimation
A Bayesian approach was used to implement the analysis. First, formulae describing the relationship between model parameters and population totals were defined, and a likelihood function was constructed for the survey data. In these likelihoods, the raw population estimates were calculated as the sum of analytic weights for each stratum in the analysis. Second, probability distributions were defined for each model parameter. In general, weakly informative priors [
26] were specified, except where substantial prior information was available, such as with age-specific population mortality rates. Final parameter values were estimated as the product of the prior distribution and the likelihood function, following conventional Bayesian approaches. These fitted parameter values were used to calculate the population estimates. The analysis was conducted separately for each country and region of origin.
Model estimates for the surveyed population (reflecting any misreporting and underreporting) were compared to the raw survey values to validate the estimation results (next section). For each country or region of origin, ‘true’ values were also produced, which were adjusted to remove the effects of misreporting and underreporting. In addition to these population estimates, the analysis produced estimates of annual entries to the population covered by the ACS and census as a measure of immigration volume.
Data processing was conducted in R v4.0.2 [
27], and the model was fitted using adaptive Hamiltonian Monte Carlo sampling, as implemented by the Stan probabilistic programming software v2.21.2 [
28,
29]. The sampler was run with 3 chains of 2000 iterations each. Each country was fit separately, and the first 1000 draws were discarded as warm-up values. The remaining samples were thinned to retain every 5th draw, producing a posterior sample of 600 parameter sets for each country. The mean of these posterior samples was used to create point estimates for each population group of interest, and equal-tailed 95% uncertainty intervals were calculated to quantify uncertainty in estimates. Full details of the technical specification of this analysis, including model equations, prior distributions, and likelihood function, are provided in the
Supplementary Materials.
2.4. Cross-Validation
To validate the estimation approach, how well the model could predict data not used for model fitting (“out-of-sample predictive performance”) was assessed [
30,
31]. To do so, the model was re-estimated for a sample of seven countries with selected survey years removed, testing the ability of the estimation procedure to reproduce the population estimates for the held-out survey years. This block cross-validation approach was adopted to provide a more rigorous test of predictive performance (as compared to assessing predictive performance in randomly chosen hold-out samples), giving the potential for non-independence of population data within each survey year [
32,
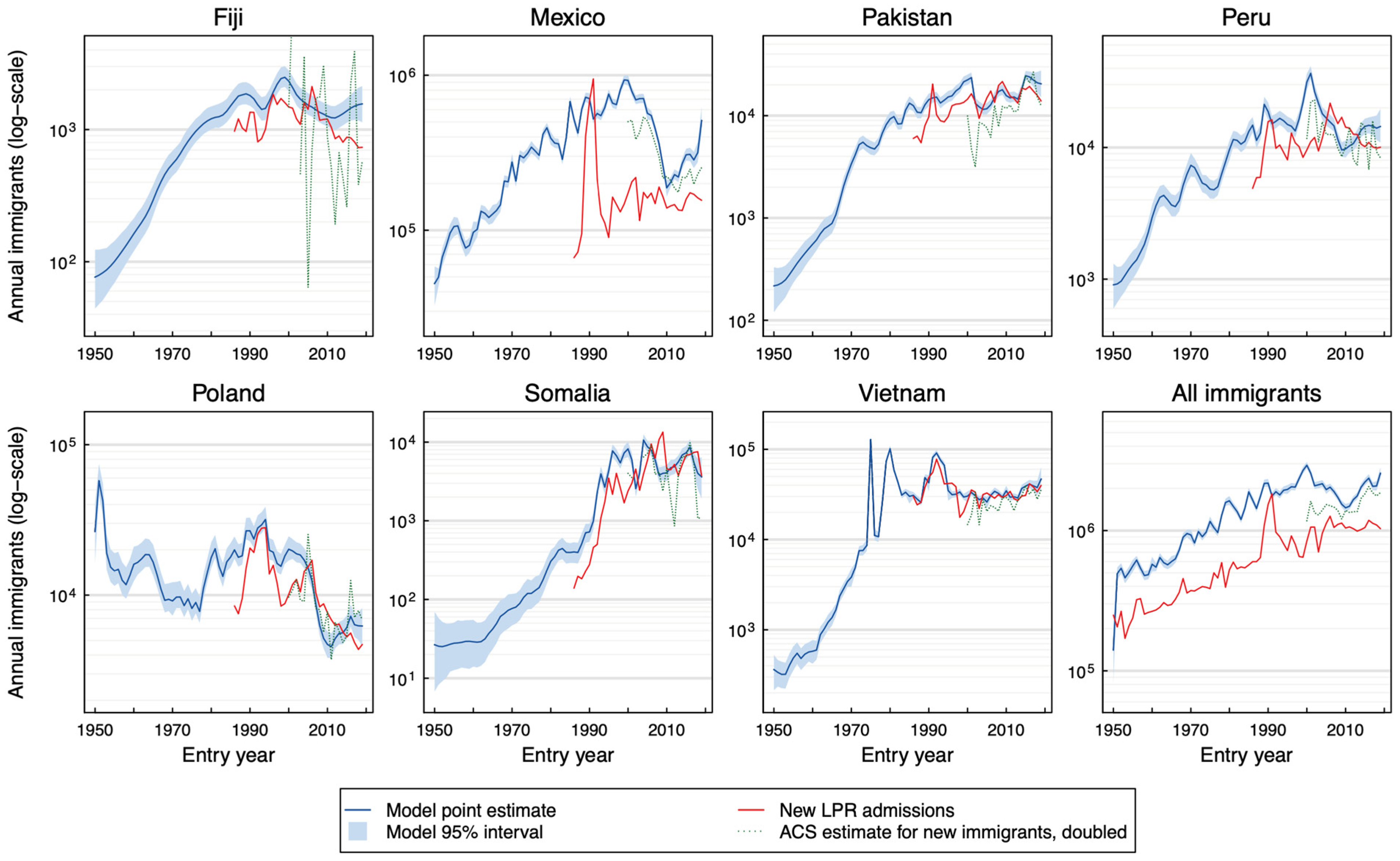
33]. The countries used for this validation exercise—Fiji, Mexico, Pakistan, Peru, Poland, Somalia, and Vietnam—were chosen to represent a range of world regions and resident population sizes, which may present different estimation challenges. For each of these countries, the model was re-estimated three times, holding out data for the years 2005, 2010, and 2015, and fitting the model to the remaining data. These models were refit a fourth time, holding out data for the last two survey years (2018–2019) to assess the ability of the estimation approach to predict future population values.
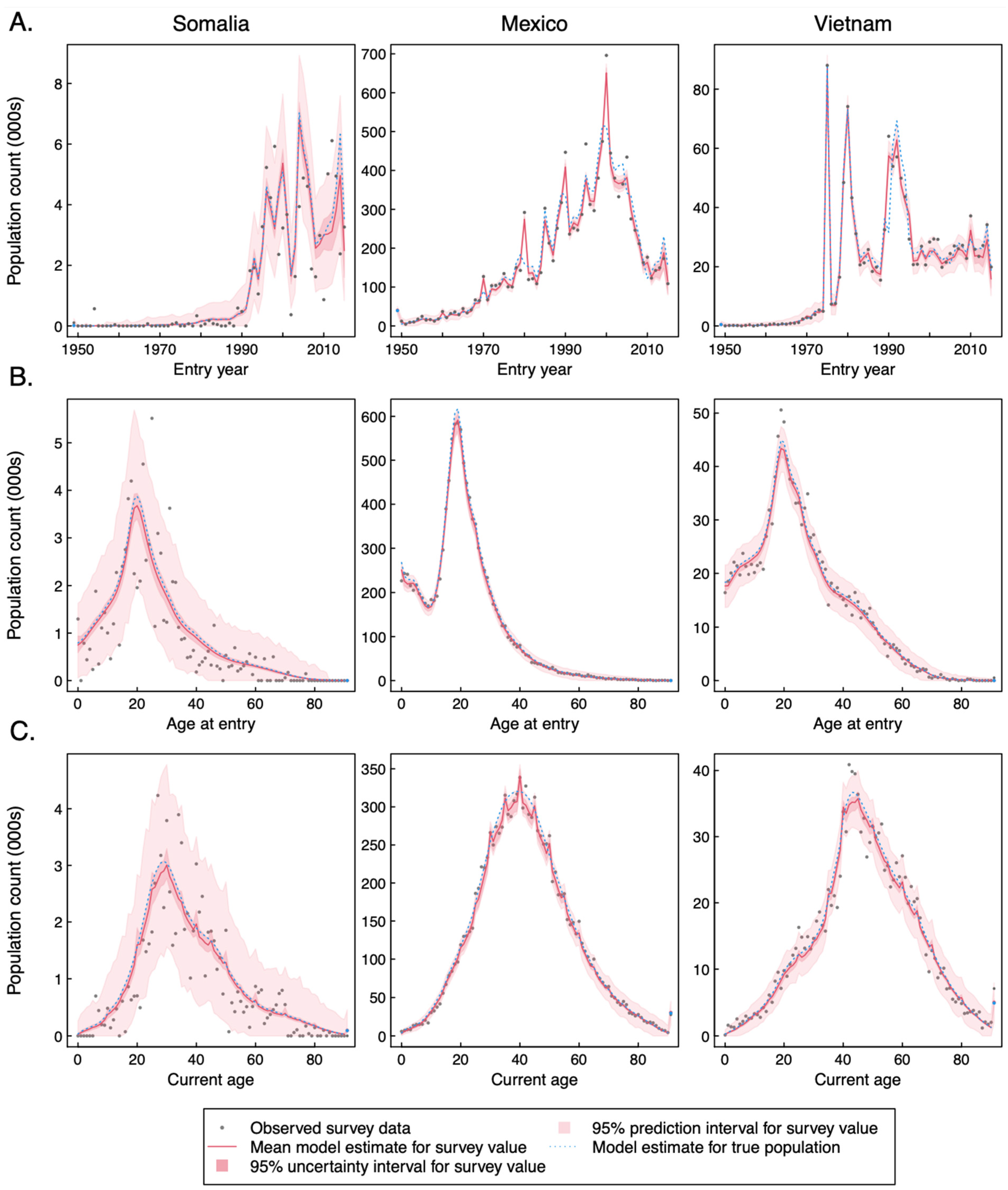
Results from these analyses were compared to the data from survey years not used for model fitting to assess out-of-sample predictive performance. Estimated values and held-out survey data were compared visually, plotting the estimated population as a function of each dimension of interest (year of entry, age at entry, and current age) in order to identify systematic deviations that might suggest a problem with the estimation approach. In addition, standardized residuals were calculated by dividing the estimation residuals (raw survey estimate for a unique combination of place of birth, year of entry, and current age minus the modeled estimate for the same value) by the standard error estimates provided by the survey methodology [
34]. Theoretically, these standardized residuals would have a standard deviation of 1.0 for a model that perfectly predicted the mean of each observation. The fraction of instances in which the survey estimate was predicted to be zero (i.e., no individuals with a given set of characteristics included in the sample) was also calculated and then compared to the empirical distribution from the survey. With a well-performing model, the modeled probabilities should reproduce the observed frequencies. Finally, logged values for modeled vs. raw population estimates were plotted to assess any estimation errors associated with the magnitude of population estimates. With a well-performing model, the points on these scatterplots should cluster on the diagonal. The out-of-sample predictions were also compared to the estimates obtained in the main analysis using rank correlation and the mean absolute difference (calculated as a percentage of the main analysis value) to characterize the differences between the two sets of estimates.
Two additional tests of validity were performed. Firstly, the model was re-estimated having excluded all data for survey years 2001 to 2005 for each of the seven test countries described above (Fiji, Mexico, Pakistan, Peru, Poland, Somalia, and Vietnam). Before 2006, the ACS samples were substantially smaller than the final size (approximately 1% of the U.S. population) and excluded individuals in group quarters. Including the data from these earlier ACS rounds provided additional information for the analysis, although doing so could potentially bias the results due to the different populations covered by the pre-2006 ACS rounds compared to later rounds. The results for 2001–2005 from this analysis were compared to those obtained in the main analysis, quantifying the agreement between these estimates using rank correlation and the mean absolute difference. Secondly, the model was re-estimated using a dataset that excluded individuals with imputed values for at least one of the variables used in the analysis. This imputation is performed by the U.S. Census Bureau when an individual’s response on a given survey question is missing or illegible or has inconsistent values. While this imputation facilitates data analysis, systematic errors in the imputation approach could lead to biased inference. To implement this sensitivity analysis, a new dataset was created that excluded individuals with imputed variables, and then the analytic weights were inflated by a constant proportion to match the original population estimate for each survey year. Using these adjusted datasets, population estimates were calculated for each of the seven test countries (Fiji, Mexico, Pakistan, Peru, Poland, Somalia, and Vietnam). These estimates were compared to those obtained in the main analysis, with differences quantified using rank correlation and the mean absolute difference.
4. Discussion
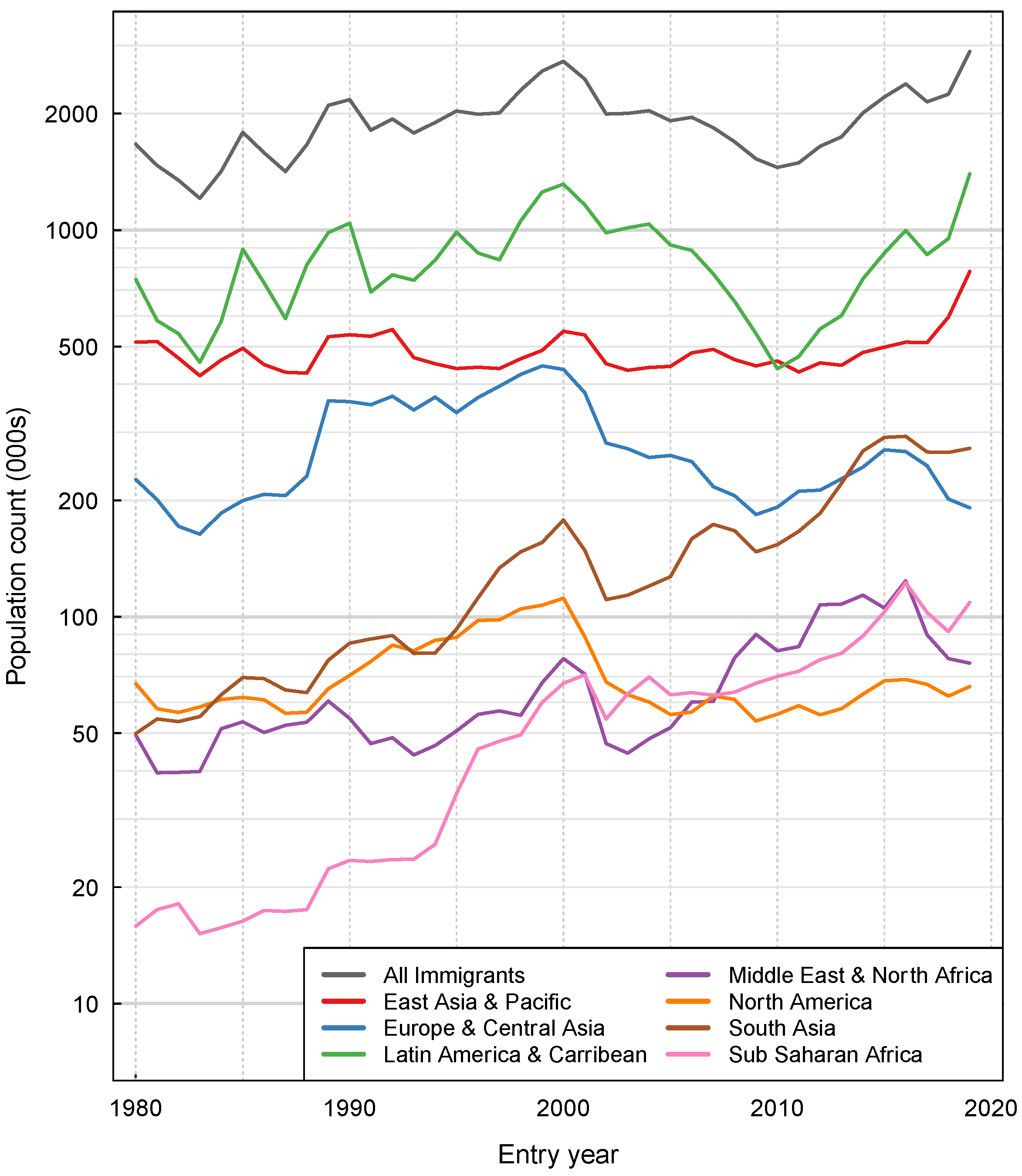
This paper reports highly disaggregated estimates of the foreign-born population residing in the United States for the period 2000–2019 stratified by country and region of origin, current age, and year of entry to the US. By pooling estimates across several survey years, these estimates are substantially more precise than estimates calculated directly from the raw survey data. The approach used to obtain more precise estimates—following individual immigration cohorts through the time series of survey data and assuming smooth distributions for various demographic characteristics—differs from variance reduction approaches commonly applied to these data, which involve aggregating data within larger categories [
36] or across multiple survey years via the ACS 3-year and 5-year estimates. While these approaches can successfully reduce variance, they can also obscure important features of the data in those circumstances where outcomes of interest vary across the categories being aggregated. As well as providing improved precision, the modeled population estimates adjust for biases in the ACS data, including the tendency for some survey respondents to round their demographic data to the nearest decade and under-coverage of the foreign-born population, particularly in the early years of the ACS. In addition to these population estimates, estimates of new entries to the resident foreign-born population are also reported as a measure of annual immigration volume. These estimates are inclusive of undocumented and temporary migrants, populations for whom immigration and residency estimates are of substantive interest but are difficult to obtain [
37,
38,
39,
40].
The Bayesian statistical approach taken by this analysis is becoming more commonly used to produce migration estimates, allowing the synthesis of multiple evidence sources, representation of various artifacts in source data, and quantification of uncertainty in resulting estimates [
41,
42]. Prior applications of this approach have focused on individuals countries and regions [
43,
44,
45] or have generated global estimates for all county–country dyads [
41,
42,
46]. Most Bayesian applications have used regression models to pool data, with migration estimates calculated from a linear function of chosen predictors. For example, Cohen et al.’s approach to producing international migration projections for any country–country dyad fit a generalized linear model to migration data reported by 11 countries, with final estimates calculated as the product of the population of origin and destination countries, the area of the origin country, and the distance between the two counties, each raised to a power term estimated from the data [
46]. In contrast, this analysis specified a mechanistic model relating migration estimates to study data. This difference stems from the data available for estimation—while these other studies used data on migration flows directly, the present study inferred migration indirectly based on cross-sectional population estimates, an approach previously used by Aparicio Castro et al. to infer migration flows between South American countries using census data [
45]. As compared to other studies, the present analysis did not use data on known determinants of migration (economic and social factors, immigration policy) [
1,
2,
3] as part of the estimation approach. While incorporating this evidence may have produced more precise estimates, it would have undermined the utility of the resulting estimates for investigating these migration determinants.
There are multiple potential uses for the detailed population estimates produced by this analysis—by improving the precision of stratified population estimates, patterns and temporal trends in these populations can be more easily observed, which may suggest directions for further investigation. Changes in the resident population for individual countries of origin are difficult to discern from the raw ACS data, particularly for countries with small resident populations, yet these trends can be reported directly from the new estimates. Similarly, changes in age distribution can also be reported with greater precision using the new estimates. These outcomes are useful for describing the changing composition of the foreign-born population residing in the United States. Similarly, the results for immigration volume have multiple applications for understanding who is entering the United States to live and how this has changed over time. In particular, by comparing the immigration flows estimated by this analysis to reported data on rates of legal migration [
13], it is possible to estimate migration rates for undocumented individuals, extending approaches developed in other analyses to estimate current population volumes for undocumented individuals [
37,
47,
48].
In addition to describing patterns and trends, the disaggregated population estimates can also be used as inputs into other analyses. The initial motivation for this study was to obtain population denominators for an epidemiological assessment of infectious disease burden in the foreign-born U.S. population [
49], where it was expected that disease burden would likely differ according to several of the demographic characteristics considered in this study. It is likely that other analyses would also benefit from fine-grained data on population distributions for this group, providing population denominators with which measures of the incidence or prevalence of a condition of interest can be calculated [
50,
51,
52]. Similarly, estimates of immigration rates can provide inputs into analyses that seek to identify the underlying causes of changing migration rates [
53,
54,
55], or that investigate how immigration has influenced other outcomes within the United States [
56,
57]. Finally, by investigating situations when model fit to data is poorer than predicted by sampling uncertainty, it could be possible to identify reporting artifacts or biases affecting how current data are being interpreted, which could allow progressive improvements to survey approaches. Apart from the estimates themselves, the estimation approach developed in this study can be implemented in other county settings and will be applicable in situations where time-series cross-sectional data are available on the foreign-born population [
58] and where sampling uncertainty is sufficiently large that reduced-variance population estimates are needed.
This study has several limitations. Some issues may be inherited from the data source, as the validity of the modeled estimates is contingent on the validity of the ACS data themselves. While several sources of bias were considered in the analysis, there could potentially be other systematic biases in the data used to estimate the model. However, given the extensive assessment and validation undertaken around the ACS, any remaining biases [
59] are likely to be small. One potential point of concern is the edits made to the microdata before public release to prevent respondent identification. These statistical disclosure controls affected the variables for age and year of entry. These variables were top- and bottom-coded (respectively) for the analysis, removing rounded responses that might have otherwise produced incorrect results. While existing disclosure controls are unlikely to have biased the present analysis, changes in the approach used by the Census Bureau to prevent respondent identification (‘differential privacy’ [
60]) could have a major impact on the feasibility and accuracy of the analyses undertaken in this study [
61,
62]. The mortality rate inputs represent another potential source of bias. As these are not reported for specific countries of origin, it is possible that mortality rates for a given country of origin could have been higher or lower than the values assumed in the analysis. Similarly, there is limited external information on how emigration rates differ by country of origin, and these rates may not have been estimated precisely by the analytic model.
It is possible that biases may have been introduced by the approaches used to smooth survey estimates. For example, while a flexible function was used to describe secular trends in the age distribution of new immigrants, this function still assumed that this distribution would be smooth. If the distribution changed discontinuously over time or age, this sharp change would be captured imprecisely in the model. Similarly, the assumption that emigration rates asymptote to a constant rate after 15 years since entry could also introduce distortions if this assumption does not hold. These are two examples of simplifying assumptions that were necessary to make the model feasible but that could introduce bias to the modeled estimates if they conflict with survey data. Moreover, poor fit in one part of a model can have downstream effects for other parts of the model, introducing biases that are difficult to diagnose and resolve. The various cross-validation checks demonstrated good out-of-sample predictive performance on a range of test countries and scenarios, reducing the likelihood that major biases exist, but it is still possible that biases could exist for countries or years not included in the validation. One alternative specification in which results differed meaningfully from the main analysis was the sensitivity analysis, which excluded census-imputed values. This highlights the importance of the Census Bureau’s approach for resolving missing or inconsistent entries. While this imputation may have little impact for analyses that pool results across large population groups, they are shown to be consequential for this particular application. In addition, the cross-validation results were worse when predicting future immigration flows. This is consistent with the high year-to-year variability estimated for immigration volume, where historical values provide less information on what can be expected in future years.
In contrast to the population estimates, the estimates of immigration volume describe a quantity that is not directly observed in the survey data but is instead computed indirectly as the number of new immigrants needed to populate an observed immigration cohort. As a consequence, these estimates depend more heavily on the validity of modeling assumptions. The comparison data available to validate these estimates are also weaker and have their own biases. If this estimation approach proves useful as a supplement to more direct measures of foreign-born population dynamics, additional testing and validation of the resulting estimates will be valuable.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}