Abstract
Background: Different treatments may be required for paroxysmal versus non-paroxysmal atrial fibrillation. However, they may be difficult to distinguish on an electrocardiogram (ECG). Machine learning methods may aid in differentiating these conditions, yet current approaches either do not preserve patient privacy or tend to make the unrealistic assumption of uniform data. Methods: We create a non-independently and identically distributed dataset for paroxysmal versus non-paroxysmal atrial fibrillation detection. Two baselines (a centralized classifier and a federated classifier) are trained, and the performances of classifiers pretrained on shared data before federated training are compared. Results: The centralized classifier outperforms all other models (), while the federated model is the worst-performing model (). Classifiers that are pretrained on 10%, 30%, and 50% of shared data (CNN-10, CNN-30, CNN-50, respectively) perform better than the purely federated model ( for all models). Furthermore, no performance difference is observed between any of the models trained on shared data (the null hypothesis of a one-way analysis of variance test between the shared data models is not rejected, ). Conclusions: The partial sharing of data in creating federated machine learning models may significantly improve performance. Furthermore, the volume of data required to be shared may be relatively small.
1. Introduction
Cardiovascular diseases continue to be a leading cause of death [1], yet many cardiovascular diseases can be detected via an analysis of the electrical rhythmicity of the heart as reflected on an electrocardiogram (ECG) [2]. An ECG can detect abnormal heart rhythms (arrhythmias), which are often reflective of specific cardiac pathologies. For instance, Wolff–Parkinson–White syndrome presents with delta waves on an ECG, which are pathognomic (that is, they provide a definitive diagnosis of the given condition) [3]. In addition to being generally useful for the diagnosis of a wide range of cardiac pathologies, ECGs are also beneficial in that they are noninvasive—no skin is breached, nor do any tools enter the body. An ECG can be recorded via the placement of electrodes on the skin, which can be easily removed after the recording. The advantages of the ECG are reflected in its ubiquity in the medical domain. In the United States alone, over 100 million ECGs are recorded every year, and they are a test included in about one fifth of annual health check-up or emergency department visits [4].
Despite the frequency with which they are recorded, there is significant variation in the ability of healthcare professionals to interpret ECGs, with cardiologists being the most adept, while other professionals, especially those for whom ECG interpretation falls outside the major scope of practice, are less adept [5]. Therefore, the availability of healthcare professionals skilled in ECG interpretation is insufficient with respect to the demand for ECG interpretation. Furthermore, cardiologists are highly-trained medical professionals who manage complex cases, so that ECG interpretation is not the main focus of the role. Thus, there is a need for skilled, accurate ECG interpretation to alleviate the burden from medical professionals. As ECGs measure the electrical activity of the heart over several cardiac cycles, and because the cardiac cycle varies in predictable patterns in pathology, machine learning models are a promising candidate for ECG diagnosis.
Before such a model can be trained, sufficient data must be available. A major limitation to the creation of models that generalize well is the availability of large amounts of data, as models generally tend to increase in performance with access to more data [6]. While some domains generate large amounts of data that are available to the public, healthcare data has special considerations. Of paramount importance is the right of a patient to privacy [7]—patient information cannot simply be shared amongst hospitals or other organizations, as this would be in gross violation of that right. Special attention must be given even in the sharing of anonymized data, since some data contains patterns that can identify an individual. For example, ECGs can be used to reliably identify individuals [8,9]. Therefore, although hospitals and other healthcare organizations may be repositories with significant amounts of ECGs, these cannot simply be released for model training.
Fortunately, methods for collaborative model training among many clients (in this case, hospitals or other healthcare organizations) exist. Federated learning [10,11] is a framework for training a central model using data from many clients, where data privacy is preserved, since the central model is updated using only the gradients computed locally from each client (the central model is not directly exposed to data from any client). Therefore, model training amongst different healthcare entities is possible in such a way that data privacy is maintained. Furthermore, federated learning allows for access to a larger overall dataset, which is important to ensure better model quality [12]. Other methods, such as transfer learning or ensemble learning, have an (implicit) assumption that some centralized data already exists: either to train an initial model whose weights can then be transferred, or to train an ensemble. Federated learning allows for institutions to work together to train a model on an overall larger dataset. While the case of independent and identically distributed data is well-researched [13,14,15], relatively few studies explore automated diagnosis in the context of non-independent and identically distributed data [16].
Table 1 compiles an overview of recent studies in ECG classification. In particular, these studies focus on cardiovascular abnormalities using federated learning or machine learning. In [17], convolutional neural networks (CNNs) were used to identify underlying paroxysmal atrial fibrillation (pAF) using ECGs in sinus rhythm from one single center with fair accuracy. In [18], pAF was predicted by integrating rhythm and P wave, which was quantified by Dynamic Time Warping (DTW) and an autoencoder network. In [19], random forests were used to identify pAF from sinus rhythm. In [20], residual neural networks (RNNs) were used to differentiate pAF from normal sinus rhythm. In [21], authors used a two-step method to detect pAF. This method starts with using support vector machines (SVMs) to identify pAF, followed by locating the pAF. A CNN was used to identify the start and end of pAF. In [22], authors used features related to heart rate variability to predict pAF using four machine learning models, with SVMs achieving the highest accuracy. In [23], a CNN was used to predict pAF in the context of heart rate and feature normalization. In [24], authors used an extreme learning machine to predict pAF with a feature extraction integrating ECG and its time domain. In [25], authors used random forests (RFs) to predict pAF using the heart rate variability (HRV) feature. In [26], a CNN was used to predict pAF using the HRV in the context of heart rate normalization. Privacy issues pose a concern when accessing sensitive patient data for model training to improve the accuracy of ECG classification [27]. Federated learning (FL) is a machine learning technique to address privacy issues [28]. In [29], FL–contrastive learning (CL) combining long short-term memory (LSTM) and CNNs is employed to predict atrial fibrillation with high accuracy. In [30], asynchronous FL was used to predict heart abnormalities with moderate accuracy. This learning technique asynchronously updates the parameters of a CNN with a weighted method to use existing locally trained models. In [31], authors used federated learning that combines bidirectional LSTM and classifier to predict cardiac abnormalities with an explainable artificial intelligence module to make sense of data. The LSTM was used for encoding and decoding the features, which were then processed by an SVM classifier. In [32], federated learning was used to train heterogenous ECG sets for arrhythmia classification using DNN and LSTM techniques. In [33], authors used federated semi-supervised learning (FSSL) to predict ECG abnormalities. The FSSL adopts pseudolabelling, data augmentation, and model aggregation algorithms to enhance the convergence in federated learning. In [34], authors used federated learning with a CNN technique to classify heterogeneous ECG data. In [35], ECG arrhythmia was detected by federated learning using ResNet technique. In [36], authors combined autoencoder and variational autoencoders with the Support Vector Data Description (SVDD) in a federated setting to predict ECG abnormalities to preserve privacy-sensitive data. In [37], federated learning demonstrated moderate accuracy in predicting the calcified coronary artery using the random forest technique. This result was similar to the results from the centralized machine learning. In [30], authors used an asynchronous federated deep learning approach with asynchronous weighted aggregation to predict cardiovascular disease. In general, although both federated and non-federated methods have been applied to the detection of atrial fibrillation, a paucity of studies have focused on how sharing data could be used to enhance diagnostic accuracy (to the best of the authors’ knowledge, this has been explored in the context of rice diseases [38]). Furthermore, some studies have failed to distinguish between pAF and npAF, which are treated differently.

Table 1.
Recent studies investigating automated diagnosis of atrial fibrillation. The table highlights whether or not patient privacy is respected, whether the data is uniformly distributed, and whether paroxysmal atrial fibrillation (pAF) is included in the data. We use ✓and ✗ to denote the presence or absence of an attribute in a study.
In this study, we focus on the development of a model capable of diagnosing non-paroxysmal atrial fibrillation (npAF) versus paroxysmal atrial fibrillation (or the absence of atrial fibrillation). Atrial fibrillation is an irregularly irregular heart rhythm that typically shows absent P waves on an ECG. It can further be classified as paroxysmal or non-paroxymsal. pAF is atrial fibrillation that spontaneously terminates within seven days [39], whereas npAF requires pharmacological or medical treatment to revert to a regular rhythm. Given that treatment objectives may vary between npAF and pAF [40] (for instance, due to greater susceptibility to interventions such as ablation therapy [41]), it is important to distinguish. Furthermore, studies have demonstrated that the risk profile between patients with pAF versus npAF is significantly different [42,43], with npAF patients having increased comorbidities and overall poorer prognosis [43]. All-cause mortality and bleeding events are higher in patients with npAF [42]. Finally, healthcare burden is also increased in those with npAF versus pAF [44]. However, distinguishing npAF versus pAF can be difficult on an ECG [45]; therefore, machine learning models could be a promising approach in this area. Indeed, machine learning models have shown to be highly successful in ECG diagnosis [46]. However, when methods of data collection may differ between hospitals or other healthcare entities, it is not guaranteed that such methods will have the same success. In this study, we demonstrate the following:
- How machine learning models perform in scenarios where data is not independently and identically distributed;
- That sharing a small amount of data makes a statistically significant impact on model performance;
- That federated models perform worse than their non-federated counterparts.
2. Materials and Methods
Suppose that there are hospitals with datasets respectively. Furthermore, suppose that each dataset is of the form , where and . In this case, each is an ECG, and the dimensions of are determined by the sampling rate and length over which the ECG is recorded (together, these determine p), as well as the number of leads used in the recording (which determines r). The label is provided by , where L is determined by the number of pathologies. Practically, is an ECG and is a label corresponding to , which the model will learn. The label is typically supplied by a cardiologist. Each hospital has a collection of ECGs, where each ECG has a corresponding label (an existing diagnosis).
In order to preserve privacy, federated learning is used to train a model , where is used to denote the parameters of the model. In federated learning, n hospitals (more generally, clients) train through interaction with a server. However, the server does not have access to any data. During round t, the server sends the current parameters to each hospital, which use their proper datasets to compute new parameters via
where F is an objective function (for diagnosis problems, cross-entropy loss is typically used) and is a constant that determines convergence. Each hospital then sends the proposed update to the server, which computes the update via
where , where denotes the size of . That is, represents the fraction of data owned by the ith hospital. Note in particular that this is known to converge, even in the case of non-independent and identically distributed data [47], and that the server never has access to any data owned by the individual hospitals, since each hospital computes proposed updated parameters locally before sending these to the server for aggregation.
In order to simulate a non-idealized environment for model training, we create five hospitals from three datasets (the Computers in Cardiology (CinC) 2001 and 2004 datasets [48,49], and the China Physiological Signal Challenge (CPSC) 2021 dataset [50]), with different sampling rates and dataset sizes. This is to simulate an n.i.i.d. dataset amongst clients—an assumption that accurately represents the healthcare environment (for instance, different recording standards, different distribution of diseases), yet which is often ignored by machine learning practitioners [16]. For each dataset, the conference organizers (groups that included physicians) labeled the data [48,49,50]. Given the standardized definition of pAF, it is assumed that this was used in determining the labels for each ECG. All ECGs from each dataset were used in the study and were separated into 30 s intervals because this is the standard for the diagnosis of atrial fibrillation [51]. ECGs whose label corresponded to the imminent onset of pAF were treated as identical to ECGs showing pAF (since the treatment would be identical, when pAF begins). Each signal was normalized using minimum–maximum normalization.
Table 2 gives an overview of each client and their data. Note in particular that sampling rates differ between some of the clients, and that the number of samples is not evenly distributed between clients. Furthermore, Table 3 shows the distribution of labels across clients. The datasets are n.i.i.d., to represent different labeling conventions or different (but related) desired tasks at different institutions, which may be more representative of the healthcare environment [16]. We note that the uneven distribution of samples, as well as the n.i.i.d. data amongst the clients, creates a more challenging learning environment. Nevertheless, the federated averaging algorithm theoretically converges to an optimum on n.i.i.d. data, though the speed at which this occurs may be reduced [47]. Typically, in situations with unevenly distributed data, clients with larger datasets can dominate distributions, and q-fair federated learning can be used to mitigate this, although overall model results may be less optimal [52].
Table 2.
Each client derived from the datasets described above.
Table 3.
Label distribution across the five hospitals used in the study.
In this study, ECGs are interpreted using a convolutional neural network (CNN). Convolutional layers are feature detectors [53], and thus are natural choices for ECG interpretation, since they can represent relevant features such as P waves (or the lack thereof). Stacked convolutions are able to learn higher-order features [54], so we make use of a five-layer CNN with two densely connected layers for classification. In addition to being commonly used in ECG analysis (for instance, [55,56,57]), CNNs are relatively lightweight models that can be deployed in resource-constrained settings. Therefore, the CNN is a model that could be feasibly deployed in many hospitals. The first convolutional layer uses 32 filters with a kernel size of seven and a single stride. The second, third, and fourth convolutional layers all use 64 filters with a kernel size of seven and a single stride. The final convolutional layer uses 32 filters with a kernel size of seven and a single stride. Each convolutional layer uses a ReLU activation function and maximum pooling with a stride and window of two. The signal is then flattened and passed to a linear layer that compresses the 11,552 dimensional signal into 64 dimensions, with a ReLU activation function. The final layer compresses these 64 dimensions into three dimensions (corresponding to the possible classes), which then uses a softmax activation to obtain probabilities. Figure 1 also depicts this information visually.
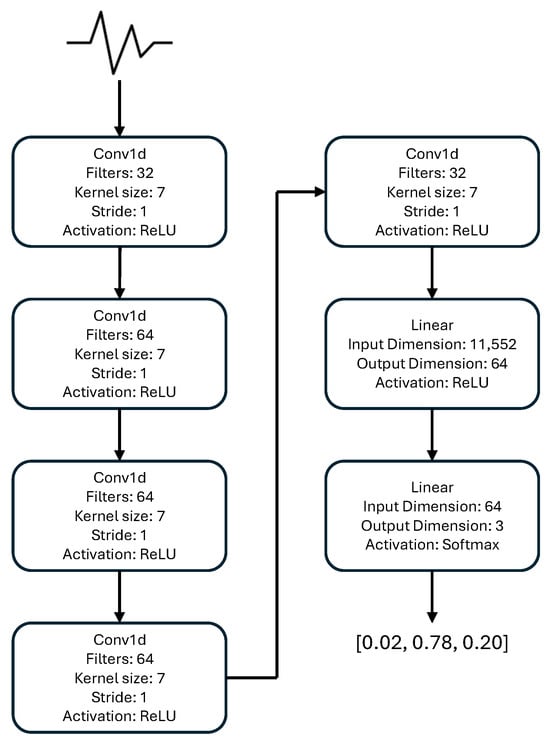
Figure 1.
The CNN model architecture used in the study.
To train the model, federated averaging with 100 communication rounds is used. At each communication round, the centralized weights are broadcast, and each client performs one epoch of training on their local dataset. The optimizer used by clients is the Adam optimizer with Nesterov momentum with a learning rate of , , , , and a momentum decay of . When the proposed client updates are returned to the server, they are aggregated via Equation (2). When data sharing is used, the centralized model is first pretrained on the pooled data for 30 epochs, using the Adam optimizer with Nesterov momentum with identical hyperparameters to the above. Five-fold cross-validation is used to generate better estimates of resutls.
Statistical Analysis
Models are evaluated with respect to accuracy, precision, recall, and F1 score (the harmonic mean of precision and recall). Continuous variables are generated from five-fold cross-validation and reported as means with standard deviations. Whenever comparisons between two models are made, Welch’s t-test is used, while comparisons between multiple models were made using a one-way analysis of variance (ANOVA), and was considered statistically significant in all cases. We note that Welch’s test does not assume a homogeneity of variance, although ANOVA does. Additionally, the assumption of normality is made in performing these comparisons. All statistical analyses were performed with Python 3.10.3.
3. Results
The overall results are described in Table 4. Additionally, Table 5 displays the confidence intervals for each metric, as well as the p-values when each model is compared to CNN-0 and CNN-100. Models are named for how much data they are able to access in a centralized fashion: CNN-10, CNN-30, and CNN-50 refer to the CNN model that is pretrained on 10%, 30%, and 50% of the data from each institution before being trained in a federated manner, respectively. Each institution randomly samples the data to be used for pretraining. For instance, for CNN-10, hospital i would sample samples (10% of the training set) to be used for pretraining. The model CNN-100 is trained on all of the data in a centralized fashion, as is typical for machine learning models. Both CNN-0 and CNN-100 serve as baselines for two different extremes (no data sharing possible, and an idealized setting where all data can be shared, respectively).
Table 4.
Results of the experiments, reported as mean ± standard deviation. Five-fold cross-validation is used to obtain means and standard deviations.
Table 5.
The confidence intervals for each tested metric, with associated p-values with respect to accuracy calculated compared to CNN-0 and CNN-100.
Three observations are merited. First, the model that does not have access to any pretraining data performs significantly worse than all other models ( when compared to the next least performant model). The models that have access to a subset of the data, even a small amount, perform significantly better than the model that does not have access to any common data. Furthermore, these models do not have a statistically significant difference in performance compared to each other, that is, there is no apparent gain in contributing (large amounts of) additional data to the federated model ( in a one-way ANOVA between all models trained on a subset of shared data). Finally, the model trained in a centralized fashion performs significantly better than all other models ( when compared to the next most performant model). Figure 2 displays boxplots of the results for each tested metric.
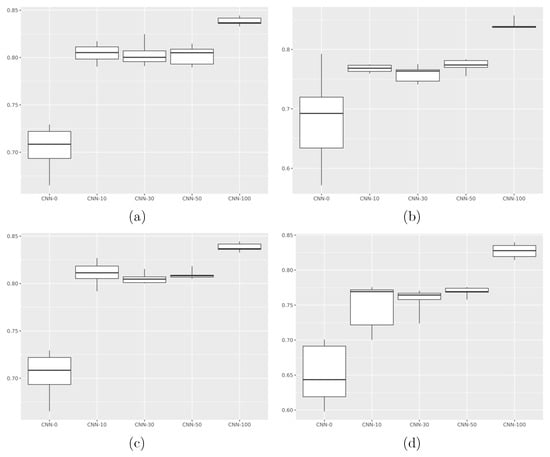
Figure 2.
Performance of each model, with respect to (a) accuracy, (b) precision, (c) recall, (d) F1 score. CNN-0 performs significantly worse than other models with respect to accuracy, recall, and F1 score (, , , respectively, for all other models), while CNN-100 performs significantly better than all other models with respect to accuracy, precision, recall, and F1 score (, , , , respectively, for all other models). ANOVA comparing the three models with different amounts of shared data revealed no significant difference across all metrics ().
Given that CNN-100 is trained in a centralized fashion, the higher performance is not surprising; however, the disparity between the models that pretrain on some centralized data before training in a federated fashion indicates the potential promise in sharing even a modicum of data in order to create a stronger model.
Explainability
While the proposed model may have utility as a diagnostic aide, it is important to note how it might be combined with methods that increase model interpretability or explainability. Given that a better understanding of how or why a model predicts a certain class or diagnosis increases clinician confidence in artificial intelligence models [58] and may lead to increased use, explainability is a concept of central importance. Various methods of increasing model explainability may be used, such as Shapley values [59] or gradient-weighted class activation mapping (GradCAM) [60].
Because methods such as GradCAM rely predominately on model weights, they can be used to allow for model explainability after training a federated classifier per the proposed approach. After initial data pooling and federated averaging have been used to obtain a classifier, the server broadcasts the final model weights to each client, after which clients may use GradCAM with the trained classifier on their data. Figure 3 shows an example of the GradCAM algorithm applied to the trained CNN-30 model on the CPSC 2021 dataset. In particular, we note that the model tends to focus on the regular RR interval in the non-pathological ECG, while, for ECGs showing pAF and npAF, the focus seems to be on the irregular RR interval.
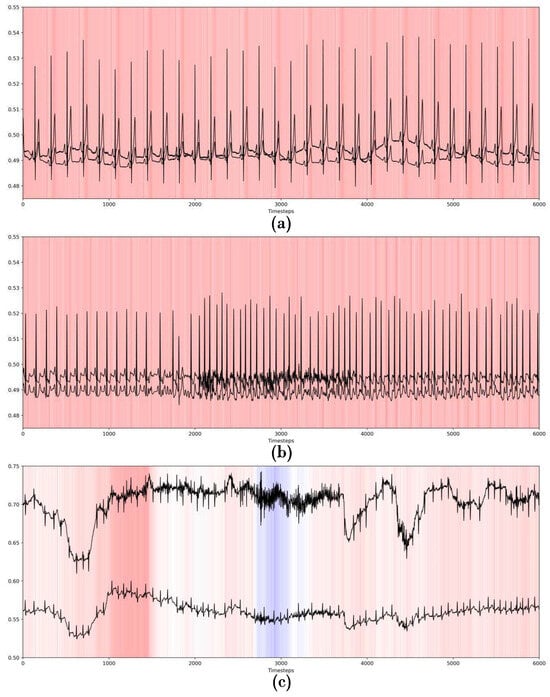
Figure 3.
Examples of GradCAM with the trained CNN-30 model on the CPSC 2021 dataset, for a (a) non-pathological ECG, (b) ECG showing pAF, and (c) ECG showing npAF.
4. Discussion
In this study, we demonstrated that data sharing can have a powerful effect on a classifier trained between various hospitals, and that even a small amount of data sharing can have a powerful effect in improving classifier quality. Creating scalable classifiers requires large volumes of data [6], yet the assumption of availability of large, centralized datasets is not representative of machine learning in healthcare. Therefore, methods such as federated learning must be used, so that classifiers can access more data and increase how well they generalize, while respecting that data may be in different locations and inaccessible centrally. However, models trained through federated learning underperform when compared to centralized classifiers, especially when the data is n.i.i.d. [61] (which would be the case in practical healthcare settings). Methods that begin to bridge the gap between federated and centralized classifiers could thus significantly advance practical machine learning in healthcare. In particular, we demonstrated that, in the setting of distinguishing atrial fibrillation from paroxysmal atrial fibrillation across a small cluster of hospitals, pretraining on a small amount of centralized data donated from each hospital before training a federated classifier drastically improves the classifier quality. Furthermore, the amount of data shared can be relatively small with respect to the overall volume of data owned by each institution.
We hypothesize that the utility of data sharing stems from the mechanism behind federated learning. In the federated setting, model weights are updated based on weighted averages, where weights are determined by dataset size [10,11]. While this method guarantees optimal convergence [62], it also means that clients with larger datasets tend to dominate the process, leading to unequal performance amongst clients [63]. This affects how well the model learns to classify samples from clients with small datasets. However, this is not the case in centralized learning, where models weight each individual sample evenly, and thus are able to learn classifications of samples in a less biased manner. Sharing data before training a federated model takes advantage of this fact, allowing for better performance across all clients, before further model training with federated learning.
Consulting Table 1, we note that the accuracy of the proposed model is competitive, particularly amongst those models that include pAF in their data. However, some models attain significantly better performance [18,19,26], most likely due to the assumption that centralized, uniform data is available. As this assumption does not mirror the healthcare setting [16], it is unlikely that these results would be observed in clinical practice. Contrarily, the proposed model attains a lower accuracy due to significant heterogeneity in the data distribution, which is more similar to the healthcare environment, and thus would likely generalize better.
Practically, the issue of data privacy still exists when training a classifier with some shared data. However, the current study implies that, in certain contexts, only a small amount of data must be shared to create an effective classifier. For instance, in the creation of an ECG classifier, it may be necessary for only 10% of patients to agree to release their ECG recordings to the hospital. While training a centralized classifier cooperatively between multiple hospitals would require a broad-scale release of data by patients, which is not feasible in practice, securing a much smaller amount of data that can be shared is far more realistic. Furthermore, in similar contexts, this is expected to increase model performance significantly versus a purely federated classifier. Therefore, while healthcare institutions may collaborate purely via federated learning in order to train a classifier, the current study suggests that it may be worthwhile to seek permission to share a small portion of data.
While these results are encouraging, there are some limitations that merit discussion. First, while data sharing was shown to improve results significantly, care must be taken not to overgeneralize. The current study investigated data sharing with respect to n.i.i.d. npAF and pAF ECG data. Therefore, it is uncertain to what extent data sharing might improve model performance in other contexts (such as with other cardiovascular diseases or other healthcare data entirely). Second, the method of data sharing likely matters. The current study assumes randomly sampled data, which guarantees that the shared data from each institution mirrors the underlying distribution of data at the respective institution. In practice, this cannot be guaranteed, since willingness to release data may not be randomly distributed across all patients. Moreover, while the proposed method yields significantly improved results over a purely federated classifier, the resultant model produces probabilistic results that would need to be verified by a cardiologist. The federated classifier could serve as a diagnostic aide or confirmatory test, but it is not a substitute for skilled ECG interpretation by a trained cardiologist. Furthermore, while the results are encouraging for this specific configuration of data, it is unclear to what extent similar performance gains would be achieved in other environments. Ideally, further analyses could investigate which aspects of the distribution of data allow for significant performance gains when sharing a subset of data, or could analyze how shared data leads to performance gains based on client sample sizes or the distribution of different types of pathology. Finally, while federated learning does preserve patient privacy, specific attacks against federated learning (such as privacy leakage [64] and model inversion [65]) can be leveraged to gain access to information used to train the algorithm [66], which have serious consequences in a clinical setting. Therefore, implementation in a clinical setting would require a thorough security analysis. Additionally, various mitigation strategies exist to offset security risk. For example, differential privacy relies on adding noise to the locally updated model weights to prevent an adversary exposing private data [67], while secure aggregation restricts the server to using the sum of client updates, rather than individual updates themselves, which could expose client data [68]. Additionally, while the proposed approach showed promising results when evaluated on test data from CinC and CPSC datasets, the external validity of the proposed approach would best be measured through testing on an unseen, institutional dataset. Future work could evaluate the proposed approach on institutional data to better determine generalizability.
Given the nature of unevenly distributed data with significant differences in sample sizes, future studies could explore methods to improve model robustness. For example, data augmentation techniques such as time warping or noise addition could be used, or other methods of oversampling, such as generative models, could be used. By increasing the dataset size of smaller hospitals, the federation would be less dominated by larger institutions with accompanying larger datasets. Although this is mitigated, at least in part, by data sharing, augmentation techniques could improve model robustness, or serve as an alternative method for creating a more robust model.
Overall, the proposed approach achieves competitive results with respect to ECG analysis for atrial fibrillation. While early studies focused on the distinction of atrial fibrillation versus a non-pathological state, more recent studies have focused on the more difficult task of differentiating paroxysmal versus non-paroxysmal atrial fibrillation. Additionally, a subset of studies have investigated methods that protect patient privacy, though, to the best of our knowledge, no current study has achieved both of these goals. The proposed approach is a privacy-preserving model that can distinguish between pAF and npAF. It is simple, yet the effects are significant (though further studies are required to verify how well these generalize). Contrary to a number of recent approaches, the proposed approach allows for the preservation of privacy and does not require the assumption of centralized data. However, it may be challenging for institutions to implement such a method, since it requires some data sharing, which would require patients to release data. Additionally, future work could address some limitations in the work—such as data augmentation methods or the use of more complex or bespoke models. The proposed approach fills a literature gap with respect to privacy-preserving, automated ECG diagnosis that distinguishes between pAF and npAF.
5. Conclusions
The assumption of centralized data is often made by machine learning practitioners, but does not reflect the reality of healthcare. While federated learning methods allow for the training of a classifier that preserves patient privacy, they also suffer from poorer performance compared to their centralized counterparts. In the context of an automated classification model for npAF versus pAF, we demonstrated that sharing a small amount of data for presharing can lead to significant performance gains. In particular, we showed the non-inferiority of a model trained on 10% of shared data versus one trained on 50% of shared data. Therefore, institutions interested in collaborating to create a more robust model should consider collecting patient authorizations to release data. A relatively small amount of data available for centralized training could significantly impact federated model performance, though additional studies are required to confirm this point. Overall, this study demonstrates the promise of data sharing in federated learning in healthcare environments.
Author Contributions
Conceptualization, W.C. and S.H.L.; methodology, W.C.; software, W.C.; validation, W.C.; formal analysis, W.C.; investigation, W.C. and S.H.L.; resources, W.C.; data curation, W.C.; writing—original draft preparation, W.C. and S.H.L.; writing—review and editing, W.C. and S.H.L.; visualization, W.C.; supervision, W.C.; project administration, W.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Datasets used in this study are freely available via PhysioNet [48].
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Tsao, C.W.; Aday, A.W.; Almarzooq, Z.I.; Anderson, C.A.; Arora, P.; Avery, C.L.; Baker-Smith, C.M.; Beaton, A.Z.; Boehme, A.K.; Buxton, A.E.; et al. Heart disease and stroke statistics—2023 update: A report from the American Heart Association. Circulation 2023, 147, e93–e621. [Google Scholar] [CrossRef]
- De Bacquer, D.; De Backer, G.; Kornitzer, M.; Blackburn, H. Prognostic value of ECG findings for total, cardiovascular disease, and coronary heart disease death in men and women. Heart 1998, 80, 570–577. [Google Scholar] [CrossRef]
- Haider, S.S.; Bath, A. A bundle in the heart: Wolff-parkinson-white syndrome presenting as cardiac arrest. Chest 2019, 156, A748. [Google Scholar] [CrossRef]
- Tison, G.H.; Zhang, J.; Delling, F.N.; Deo, R.C. Automated and interpretable patient ECG profiles for disease detection, tracking, and discovery. Circ. Cardiovasc. Qual. Outcomes 2019, 12, e005289. [Google Scholar] [CrossRef]
- Kashou, A.H.; Noseworthy, P.A.; Beckman, T.J.; Anavekar, N.S.; Cullen, M.W.; Angstman, K.B.; Sandefur, B.J.; Shapiro, B.P.; Wiley, B.W.; Kates, A.M.; et al. ECG interpretation proficiency of healthcare professionals. Curr. Probl. Cardiol. 2023, 48, 101924. [Google Scholar] [CrossRef]
- Jones, N. How machine learning could help to improve climate forecasts. Nature 2017, 548. [Google Scholar] [CrossRef] [PubMed]
- Abouelmehdi, K.; Beni-Hessane, A.; Khaloufi, H. Big healthcare data: Preserving security and privacy. J. Big Data 2018, 5, 1. [Google Scholar] [CrossRef]
- Kyoso, M.; Uchiyama, A. Development of an ECG identification system. In Proceedings of the 23rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Istanbul, Turkey, 25–28 October 2001; Volumer 4, pp. 3721–3723. [Google Scholar]
- Singh, Y.N.; Gupta, P. ECG to individual identification. In Proceedings of the 2008 IEEE Second International Conference on Biometrics: Theory, Applications and Systems, Washington, DC, USA, 29 September–1 October 2008; pp. 1–8. [Google Scholar]
- Konečnỳ, J. Federated Learning: Strategies for Improving Communication Efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics; PMLR: Cambridge, MA, USA, 2017; pp. 1273–1282. [Google Scholar]
- Covert, I.; Ji, W.; Hashimoto, T.; Zou, J. Scaling laws for the value of individual data points in machine learning. arXiv 2024, arXiv:2405.20456. [Google Scholar] [CrossRef]
- Sakib, S.; Fouda, M.M.; Fadlullah, Z.M.; Abualsaud, K.; Yaacoub, E.; Guizani, M. Asynchronous federated learning-based ECG analysis for arrhythmia detection. In Proceedings of the 2021 IEEE International Mediterranean Conference on Communications and Networking (MeditCom), Athens, Greece, 7–10 September 2021; pp. 277–282. [Google Scholar]
- Raza, A.; Tran, K.P.; Koehl, L.; Li, S. Designing ecg monitoring healthcare system with federated transfer learning and explainable ai. Knowl.-Based Syst. 2022, 236, 107763. [Google Scholar] [CrossRef]
- Goto, S.; Solanki, D.; John, J.E.; Yagi, R.; Homilius, M.; Ichihara, G.; Katsumata, Y.; Gaggin, H.K.; Itabashi, Y.; MacRae, C.A.; et al. Multinational federated learning approach to train ECG and echocardiogram models for hypertrophic cardiomyopathy detection. Circulation 2022, 146, 755–769. [Google Scholar] [CrossRef] [PubMed]
- Chorney, W.; Wang, H. Towards federated transfer learning in electrocardiogram signal analysis. Comput. Biol. Med. 2024, 170, 107984. [Google Scholar] [CrossRef]
- Gruwez, H.; Barthels, M.; Haemers, P.; Verbrugge, F.H.; Dhont, S.; Meekers, E.; Wouters, F.; Nuyens, D.; Pison, L.; Vandervoort, P.; et al. Detecting paroxysmal atrial fibrillation from an electrocardiogram in sinus rhythm: External validation of the AI approach. Clin. Electrophysiol. 2023, 9, 1771–1782. [Google Scholar] [CrossRef]
- Ma, C.; Liu, C.; Wang, X.; Li, Y.; Wei, S.; Lin, B.S.; Li, J. A multistep paroxysmal atrial fibrillation scanning strategy in long-term ECGs. IEEE Trans. Instrum. Meas. 2022, 71, 4004010. [Google Scholar] [CrossRef]
- Myrovali, E.; Hristu-Varsakelis, D.; Tachmatzidis, D.; Antoniadis, A.; Vassilikos, V. Identifying patients with paroxysmal atrial fibrillation from sinus rhythm ECG using random forests. Expert Syst. Appl. 2023, 213, 118948. [Google Scholar] [CrossRef]
- Baek, Y.S.; Lee, S.C.; Choi, W.; Kim, D.H. A new deep learning algorithm of 12-lead electrocardiogram for identifying atrial fibrillation during sinus rhythm. Sci. Rep. 2021, 11, 12818. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Liu, S.; Jia, H.; Deng, X.; Li, C.; Wang, A.; Yang, C. A two-step method for paroxysmal atrial fibrillation event detection based on machine learning. Math. Biosci. Eng. 2022, 19, 9877–9894. [Google Scholar] [CrossRef] [PubMed]
- Parsi, A.; Glavin, M.; Jones, E.; Byrne, D. Prediction of paroxysmal atrial fibrillation using new heart rate variability features. Comput. Biol. Med. 2021, 133, 104367. [Google Scholar] [CrossRef]
- Surucu, M.; Isler, Y.; Perc, M.; Kara, R. Convolutional neural networks predict the onset of paroxysmal atrial fibrillation: Theory and applications. Chaos Interdiscip. J. Nonlinear Sci. 2021, 31, 113119. [Google Scholar] [CrossRef]
- Maghawry, E.; Ismail, R.; Gharib, T.F. An efficient approach for paroxysmal atrial fibrillation events prediction using extreme learning machine. J. Intell. Fuzzy Syst. 2021, 40, 5087–5099. [Google Scholar] [CrossRef]
- Castro, H.; Garcia-Racines, J.D.; Bernal-Norena, A. Methodology for the prediction of paroxysmal atrial fibrillation based on heart rate variability feature analysis. Heliyon 2021, 7, e08244. [Google Scholar] [CrossRef]
- SÜRÜCÜ, M.; İŞLER, Y.; Kara, R. Diagnosis of paroxysmal atrial fibrillation from thirty-minute heart ratevariability data using convolutional neural networks. Turk. J. Electr. Eng. Comput. Sci. 2021, 29, 2886–2900. [Google Scholar] [CrossRef]
- Liu, B.; Ding, M.; Shaham, S.; Rahayu, W.; Farokhi, F.; Lin, Z. When machine learning meets privacy: A survey and outlook. ACM Comput. Surv. (CSUR) 2021, 54, 31. [Google Scholar] [CrossRef]
- He, J.; Cao, T.; Duffy, V.G. Machine learning techniques and privacy concerns in human-computer interactions: A systematic review. In International Conference on Human-Computer Interaction; Springer: Cham, Switzerland, 2023; pp. 373–389. [Google Scholar]
- Alreshidi, F.S.; Alsaffar, M.; Chengoden, R.; Alshammari, N.K. Fed-CL-an atrial fibrillation prediction system using ECG signals employing federated learning mechanism. Sci. Rep. 2024, 14, 21038. [Google Scholar]
- Khan, M.A.; Alsulami, M.; Yaqoob, M.M.; Alsadie, D.; Saudagar, A.K.J.; AlKhathami, M.; Farooq Khattak, U. Asynchronous federated learning for improved cardiovascular disease prediction using artificial intelligence. Diagnostics 2023, 13, 2340. [Google Scholar] [CrossRef]
- Manocha, A.; Sood, S.K.; Bhatia, M. Federated learning-inspired smart ECG classification: An explainable artificial intelligence approach. Multimed. Tools Appl. 2024, 84, 21673–21696. [Google Scholar] [CrossRef]
- Jimenez Gutierrez, D.M.; Hassan, H.M.; Landi, L.; Vitaletti, A.; Chatzigiannakis, I. Application of federated learning techniques for arrhythmia classification using 12-lead ecg signals. In International Symposium on Algorithmic Aspects of Cloud Computing; Springer: Cham, Switzerland, 2023; pp. 38–65. [Google Scholar]
- Ying, Z.; Zhang, G.; Pan, Z.; Chu, C.; Liu, X. FedECG: A federated semi-supervised learning framework for electrocardiogram abnormalities prediction. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 101568. [Google Scholar] [CrossRef]
- Mehta, S.; Rathour, A. ECG Data Security and Privacy: Leveraging Federated Learning for Better Classification. In Proceedings of the 2023 4th International Conference on Intelligent Technologies (CONIT), Hubli, India, 23–25 June 2023; pp. 1–6. [Google Scholar]
- Mane, D.; Jain, J.; Jaju, U.; Agarwal, K.; Kalamkar, A. A Federated Approach Towards Detecting ECG Arrhythmia. In Proceedings of the 2024 2nd International Conference on Sustainable Computing and Smart Systems (ICSCSS), Coimbatore, India, 10–12 July 2024; pp. 106–111. [Google Scholar]
- Raza, A.; Tran, K.P.; Koehl, L.; Li, S. AnoFed: Adaptive anomaly detection for digital health using transformer-based federated learning and support vector data description. Eng. Appl. Artif. Intell. 2023, 121, 106051. [Google Scholar] [CrossRef]
- Wolff, J.; Matschinske, J.; Baumgart, D.; Pytlik, A.; Keck, A.; Natarajan, A.; von Schacky, C.E.; Pauling, J.K.; Baumbach, J. Federated machine learning for a facilitated implementation of Artificial Intelligence in healthcare–a proof of concept study for the prediction of coronary artery calcification scores. J. Integr. Bioinform. 2022, 19, 20220032. [Google Scholar] [CrossRef]
- Chorney, W.; Rahman, A.; Wang, Y.; Wang, H.; Peng, Z. Federated Learning for Heterogeneous Multi-Site Crop Disease Diagnosis. Mathematics 2025, 13, 1401. [Google Scholar] [CrossRef]
- Nesheiwat, Z.; Goyal, A.; Jagtap, M. Atrial Fibrillation; StatPearls: Treasure Island, FL, USA, 2023. [Google Scholar]
- Lip, G.Y.; Hee, F.L.S. Paroxysmal atrial fibrillation. QJM 2001, 94, 665–678. [Google Scholar] [CrossRef] [PubMed]
- Nattel, S.; Dobrev, D. Electrophysiological and molecular mechanisms of paroxysmal atrial fibrillation. Nat. Rev. Cardiol. 2016, 13, 575–590. [Google Scholar] [CrossRef]
- Boriani, G.; Laroche, C.; Diemberger, I.; Fantecchi, E.; Popescu, M.I.; Rasmussen, L.H.; Dan, G.A.; Kalarus, Z.; Tavazzi, L.; Maggioni, A.P.; et al. ‘Real-world’ management and outcomes of patients with paroxysmal vs. non-paroxysmal atrial fibrillation in Europe: The EURObservational Research Programme–Atrial Fibrillation (EORP-AF) General Pilot Registry. EP Eur. 2016, 18, 648–657. [Google Scholar] [CrossRef] [PubMed]
- Al-Makhamreh, H.; Alrabadi, N.; Haikal, L.; Krishan, M.; Al-Badaineh, N.; Odeh, O.; Barqawi, T.; Nawaiseh, M.; Shaban, A.; Abdin, B.; et al. Paroxysmal and non-paroxysmal atrial fibrillation in middle eastern patients: Clinical features and the use of medications. analysis of the Jordan atrial fibrillation (JoFib) study. Int. J. Environ. Res. Public Health 2022, 19, 6173. [Google Scholar] [CrossRef]
- Peigh, G.; Zhou, J.; Rosemas, S.C.; Roberts, A.I.; Longacre, C.; Nayak, T.; Schwab, G.; Soderlund, D.; Passman, R.S. Impact of atrial fibrillation burden on health care costs and utilization. Clin. Electrophysiol. 2024, 10, 718–730. [Google Scholar] [CrossRef]
- Stahrenberg, R.; Weber-Krüger, M.; Seegers, J.; Edelmann, F.; Lahno, R.; Haase, B.; Mende, M.; Wohlfahrt, J.; Kermer, P.; Vollmann, D.; et al. Enhanced detection of paroxysmal atrial fibrillation by early and prolonged continuous holter monitoring in patients with cerebral ischemia presenting in sinus rhythm. Stroke 2010, 41, 2884–2888. [Google Scholar] [CrossRef]
- Zhu, H.; Cheng, C.; Yin, H.; Li, X.; Zuo, P.; Ding, J.; Lin, F.; Wang, J.; Zhou, B.; Li, Y.; et al. Automatic multilabel electrocardiogram diagnosis of heart rhythm or conduction abnormalities with deep learning: A cohort study. Lancet Digit. Health 2020, 2, e348–e357. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef]
- Moody, G.E. Spontaneous termination of atrial fibrillation: A challenge from physionet and computers in cardiology 2004. In Proceedings of the Computers in Cardiology, Chicago, IL, USA, 19–22 September 2004; pp. 101–104. [Google Scholar]
- Wang, X.; Ma, C.; Zhang, X.; Gao, H.; Clifford, G.D.; Liu, C. Paroxysmal atrial fibrillation events detection from dynamic ecg recordings: The 4th china physiological signal challenge 2021. Proc. PhysioNet 2021, 1–83. [Google Scholar] [CrossRef]
- Tran, R.; Rankin, A.; Abdul-Rahim, A.; Lip, G.; Rankin, A.; Lees, K. Short runs of atrial arrhythmia and stroke risk: A European-wide online survey among stroke physicians and cardiologists. J. R. Coll. Physicians Edinb. 2016, 46, 87–92. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Sanjabi, M.; Beirami, A.; Smith, V. Fair resource allocation in federated learning. arXiv 2019, arXiv:1905.10497. [Google Scholar]
- Joshi, K.; Patel, M.I. Recent advances in local feature detector and descriptor: A literature survey. Int. J. Multimed. Inf. Retr. 2020, 9, 231–247. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, L.; Zhang, Y.; Han, X.; Deveci, M.; Parmar, M. A review of convolutional neural networks in computer vision. Artif. Intell. Rev. 2024, 57, 99. [Google Scholar] [CrossRef]
- Nogimori, Y.; Sato, K.; Takamizawa, K.; Ogawa, Y.; Tanaka, Y.; Shiraga, K.; Masuda, H.; Matsui, H.; Kato, M.; Daimon, M.; et al. Prediction of adverse cardiovascular events in children using artificial intelligence-based electrocardiogram. Int. J. Cardiol. 2024, 406, 132019. [Google Scholar] [CrossRef]
- Gibson, C.M.; Mehta, S.; Ceschim, M.R.; Frauenfelder, A.; Vieira, D.; Botelho, R.; Fernandez, F.; Villagran, C.; Niklitschek, S.; Matheus, C.I.; et al. Evolution of single-lead ECG for STEMI detection using a deep learning approach. Int. J. Cardiol. 2022, 346, 47–52. [Google Scholar] [CrossRef]
- Chorney, W.; Wang, H.; Fan, L.W. AttentionCovidNet: Efficient ECG-based diagnosis of COVID-19. Comput. Biol. Med. 2024, 168, 107743. [Google Scholar] [CrossRef]
- Chaddad, A.; Peng, J.; Xu, J.; Bouridane, A. Survey of explainable AI techniques in healthcare. Sensors 2023, 23, 634. [Google Scholar] [CrossRef]
- Rozemberczki, B.; Watson, L.; Bayer, P.; Yang, H.T.; Kiss, O.; Nilsson, S.; Sarkar, R. The shapley value in machine learning. In The 31st International Joint Conference on Artificial Intelligence and the 25th European Conference on Artificial Intelligence; International Joint Conferences on Artificial Intelligence Organization: Los Angeles, CA, USA, 2022; pp. 5572–5579. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A performance evaluation of federated learning algorithms. In Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning, Rennes, France, 10 December 2018; pp. 1–8. [Google Scholar]
- Haddadpour, F.; Mahdavi, M. On the convergence of local descent methods in federated learning. arXiv 2019, arXiv:1910.14425. [Google Scholar] [CrossRef]
- Cui, S.; Pan, W.; Liang, J.; Zhang, C.; Wang, F. Addressing algorithmic disparity and performance inconsistency in federated learning. Adv. Neural Inf. Process. Syst. 2021, 34, 26091–26102. [Google Scholar]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond inferring class representatives: User-level privacy leakage from federated learning. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2512–2520. [Google Scholar]
- Hatamizadeh, A.; Yin, H.; Molchanov, P.; Myronenko, A.; Li, W.; Dogra, P.; Feng, A.; Flores, M.G.; Kautz, J.; Xu, D.; et al. Do gradient inversion attacks make federated learning unsafe? IEEE Trans. Med. Imaging 2023, 42, 2044–2056. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Wan, W.; Hu, S.; Lu, J.; Zhang, L.Y. Challenges and approaches for mitigating byzantine attacks in federated learning. In Proceedings of the 2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Wuhan, China, 9–11 December 2022; pp. 139–146. [Google Scholar]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for federated learning on user-held data. arXiv 2016, arXiv:1611.04482. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).