
Investigating Reproducibility Challenges in LLM Bugfixing on the HumanEvalFix Benchmark


Abstract
1. Introduction
- We reproduce 16 of the 32 scores reported for the evaluated models. This implies that many of the discrepancies in the reported results can be attributed to using different or possibly incorrect evaluation settings.
- We quantify the impact of modifying the evaluation settings individually. For instance, the maximum generation length, sampling strategy, 4-bit quantization, and prompt template choice significantly influence the results, whereas precision and 8-bit quantization do not.
- We identify instances of possibly misreported results, likely due to confusion between base and instruction-tuned models.
2. Related Work
3. Method
3.1. Benchmarking with HumanEvalFix
3.2. Review of Reported Benchmark Results
3.3. Experimental Setup
- A differently tuned version of the model was used (e.g., the base model instead of its instruction-tuned variant), causing a large difference in benchmark result. (Two issues)
- The wrong variant of the same benchmark was used: MBPP instead of MBPP+ and HumanEval instead of its unstripped variant. (Two issues)
- The temperature was set incorrectly: while generating one sample for each prompt, the temperature turned out to be an improperly large value. (One issue)
- An incorrect prompt was used, causing more than of a decrease in pass@1 performance. (One issue)
- The reproduced results were different by only a few percentage points compared to the officially reported ones. Such a discrepancy was considered negligible, as this can be due to minor variations in evaluation settings, minor updates in model versions, or in hardware configurations. (Three issues)
- Prompt template: The evaluation framework defaults to the instruct prompt template, with only the context and instruction (the program and the instruction to fix it). The default prompt template lacks the model-specific formatting suggested by model authors. We evaluate models both with their suggested prompt template as well as the default instruct setting. All prompt settings used in our study are detailed in Appendix A.1.
- Sampling vs. greedy decoding: The default behavior in the framework is not to use greedy decoding, but to apply sampling with the temperature . Alongside greedy decoding, we conduct experiments using sampling with temperatures and .
- Limiting generation length: The default value of 512 tokens is insufficient, as it can lead to unfinished programs and reduced benchmark scores. We conducted our experiments using lengths of 512 and 2048. Since the max length generation parameter considers both the prompt and the generated output, it must be large enough to prevent cutting the output short. We found 2048 to be a good choice on this benchmark, as tokenizers typically fit the inputs within 1024 tokens, leaving enough space for the generated output.
- Precision and quantization: The majority of LLMs are released using bf16 precision, making it the preferred choice for precision. We evaluated the models using all three common precision formats: fp16, fp32, and bf16. While quantization is a useful technique to lower memory usage when running models, it is generally best to use models without it. In addition to our tests without quantization, we also ran experiments using 4-bit and 8-bit quantization (with fp16 precision).
- Other settings: Further settings (such as seed), were kept at their default values as defined by the framework for all evaluations. Specifically, the default value for seed is 0.
4. Experimental Results
4.1. The Effect of Individual Evaluation Settings
4.1.1. Temperature: Greedy Evaluation and Sampling
4.1.2. Maximum Generation Length
4.1.3. Using an Incorrect Prompt Template
4.1.4. Precision and Quantization
4.2. Reproducibility of Results in Existing Research
4.2.1. CodeLlama
4.2.2. DeepSeekCoder
4.2.3. CodeGemma
4.2.4. WizardCoder
5. Discussion
- 1.
- Use the same precision as specified in the original model release (bf16 for most models) or possibly fp32 to reduce the probability of rounding errors.
- 2.
- Avoid model quantization if possible.
- 3.
- Follow the prompt formatting recommended by model authors.
- 4.
- Unless stated otherwise by the model authors, use greedy decoding for generation stability or generate more samples (such as ) to provide a more refined pass@1 estimate.
- 5.
- Ensure that limits to generation length are sufficiently large to allow complete responses.
- 6.
- Report the exact model name, version, tuning, number of parameters.
- 7.
- Provide details about the used evaluation framework, evaluation settings, and benchmark dataset version.
6. Conclusions
- Broader Impact
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Prompt Template Formats
- 1.
- Instruct Prompt (General Instruction Style)from typing import Listdef has_close_elements(numbers: List[float], threshold: float) -> bool:…def check(has_close_elements):…check(has_close_elements)Fix bugs in has_close_elements.…
- 2.
- DeepSeekCoder PromptYou are an AI programming assistant, utilizing the Deepseek Coder model,developed by Deepseek Company, and you only answer questions related tocomputer science. For politically sensitive questions, security and privacyissues, and other non-computer science questions, you will refuse to answer### Instruction:Fix bugs in has_close_elements.from typing import Listdef has_close_elements(numbers: List[float], threshold: float) -> bool:…def check(has_close_elements):…check(has_close_elements)### Response:…
- 3.
- CodeLlama Prompt[INST] Fix bugs in has_close_elements.from typing import Listdef has_close_elements(numbers: List[float], threshold: float) -> bool:…def check(has_close_elements):…check(has_close_elements) [/INST] …
- 4.
- CodeGemma Prompt<start_of_turn>userFix bugs in has_close_elements.from typing import Listdef has_close_elements(numbers: List[float], threshold: float) -> bool:…def check(has_close_elements):…check(has_close_elements)<end_of_turn><start_of_turn>model…
- 5.
- Wizardcoder PromptBelow is an instruction that describes a task. Write a response thatappropriately completes the request.### Instruction:Fix bugs in has_close_elements.from typing import Listdef has_close_elements(numbers: List[float], threshold: float) -> bool:…def check(has_close_elements):…check(has_close_elements)### Response:…
Appendix A.2. Links to GitHub Issues
- A differently tuned version of the model was used:
- −
- https://github.com/bigcode-project/bigcode-evaluation-harness/issues/82 (accessed on 5 November 2024)
- −
- https://github.com/bigcode-project/bigcode-evaluation-harness/issues/228 (accessed on 5 November 2024)
- The wrong benchmark variant was used:
- −
- https://github.com/bigcode-project/bigcode-evaluation-harness/issues/159 (accessed on 5 November 2024)
- −
- https://github.com/bigcode-project/bigcode-evaluation-harness/issues/246 (accessed on 5 November 2024)
- The temperature was set incorrectly:
- −
- https://github.com/bigcode-project/bigcode-evaluation-harness/issues/142 (accessed on 5 November 2024)
- An incorrect prompt was used:
- −
- https://github.com/bigcode-project/bigcode-evaluation-harness/issues/262 (accessed on 5 November 2024)
- The reproduced results were different by only a few percentage points compared to official reports:
- −
- https://github.com/bigcode-project/bigcode-evaluation-harness/issues/165 (accessed on 5 November 2024)
- −
- https://github.com/bigcode-project/bigcode-evaluation-harness/issues/220 (accessed on 5 November 2024)
- −
- https://github.com/bigcode-project/bigcode-evaluation-harness/issues/233 (accessed on 5 November 2024)
References
- Muennighoff, N.; Liu, Q.; Zebaze, A.; Zheng, Q.; Hui, B.; Zhuo, T.Y.; Singh, S.; Tang, X.; Werra, L.V.; Longpre, S. OctoPack: Instruction Tuning Code Large Language Models. In Proceedings of the NeurIPS 2023 Workshop on Instruction Tuning and Instruction, New Orleans, LA, USA, 15 December 2023. [Google Scholar]
- Rozière, B.; Gehring, J.; Gloeckle, F.; Sootla, S.; Gat, I.; Tan, X.E.; Adi, Y.; Liu, J.; Sauvestre, R.; Remez, T.; et al. Code Llama: Open Foundation Models for Code. arXiv 2024, arXiv:2308.12950. [Google Scholar]
- Guo, D.; Zhu, Q.; Yang, D.; Xie, Z.; Dong, K.; Zhang, W.; Chen, G.; Bi, X.; Wu, Y.; Li, Y.K.; et al. DeepSeek-Coder: When the Large Language Model Meets Programming—The Rise of Code Intelligence. arXiv 2024, arXiv:2401.14196. [Google Scholar]
- Lin, D.; Koppel, J.; Chen, A.; Solar-Lezama, A. QuixBugs: A multi-lingual program repair benchmark set based on the quixey challenge. In Proceedings of the Companion of the 2017 ACM SIGPLAN International Conference on Systems, Programming, Languages, and Applications: Software for Humanity, New York, NY, USA, 22–27 October 2017; pp. 55–56. [Google Scholar] [CrossRef]
- Widyasari, R.; Sim, S.Q.; Lok, C.; Qi, H.; Phan, J.; Tay, Q.; Tan, C.; Wee, F.; Tan, J.E.; Yieh, Y.; et al. BugsInPy: A database of existing bugs in Python programs to enable controlled testing and debugging studies. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, New York, NY, USA, 8–13 November 2020; pp. 1556–1560. [Google Scholar] [CrossRef]
- Liu, S.; Chai, L.; Yang, J.; Shi, J.; Zhu, H.; Wang, L.; Jin, K.; Zhang, W.; Zhu, H.; Guo, S.; et al. MdEval: Massively Multilingual Code Debugging. arXiv 2024, arXiv:2411.02310. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; de Oliveira Pinto, H.P.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Wang, S.; Asilis, J.; Ömer, F.A.; Bilgin, E.B.; Liu, O.; Neiswanger, W. Tina: Tiny Reasoning Models via LoRA. arXiv 2025, arXiv:2504.15777. [Google Scholar]
- Biderman, S.; Schoelkopf, H.; Sutawika, L.; Gao, L.; Tow, J.; Abbasi, B.; Aji, A.F.; Ammanamanchi, P.S.; Black, S.; Clive, J.; et al. Lessons from the Trenches on Reproducible Evaluation of Language Models. arXiv 2024, arXiv:2405.14782. [Google Scholar]
- Laskar, M.T.R.; Alqahtani, S.; Bari, M.S.; Rahman, M.; Khan, M.A.M.; Khan, H.; Jahan, I.; Bhuiyan, A.; Tan, C.W.; Parvez, M.R.; et al. A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Recommendations. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 13785–13816. [Google Scholar] [CrossRef]
- Hochlehnert, A.; Bhatnagar, H.; Udandarao, V.; Albanie, S.; Prabhu, A.; Bethge, M. A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility. arXiv 2025, arXiv:2504.07086. [Google Scholar]
- Yuan, J.; Li, H.; Ding, X.; Xie, W.; Li, Y.J.; Zhao, W.; Wan, K.; Shi, J.; Hu, X.; Liu, Z. Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning. arXiv 2025, arXiv:2506.09501. [Google Scholar]
- Team, C.; Zhao, H.; Hui, J.; Howland, J.; Nguyen, N.; Zuo, S.; Hu, A.; Choquette-Choo, C.A.; Shen, J.; Kelley, J.; et al. CodeGemma: Open Code Models Based on Gemma. arXiv 2024, arXiv:2406.11409. [Google Scholar]
- Luo, Z.; Xu, C.; Zhao, P.; Sun, Q.; Geng, X.; Hu, W.; Tao, C.; Ma, J.; Lin, Q.; Jiang, D. WizardCoder: Empowering Code Large Language Models with Evol-Instruct. arXiv 2023, arXiv:2306.08568. [Google Scholar]
- Ben Allal, L.; Muennighoff, N.; Kumar Umapathi, L.; Lipkin, B.; von Werra, L. A Framework for the Evaluation of Code Generation Models. 2022. Available online: https://github.com/bigcode-project/bigcode-evaluation-harness (accessed on 5 November 2024).
- Cassano, F.; Li, L.; Sethi, A.; Shinn, N.; Brennan-Jones, A.; Lozhkov, A.; Anderson, C.J.; Guha, A. Can It Edit? Evaluating the Ability of Large Language Models to Follow Code Editing Instructions. In Proceedings of the Conference on Language Modelling (COLM), Philadelphia, PA, USA, 7–9 October 2024. [Google Scholar]
- Chae, H.; Kwon, T.; Moon, S.; Song, Y.; Kang, D.; Ong, K.T.i.; Kwak, B.w.; Bae, S.; Hwang, S.w.; Yeo, J. Coffee-Gym: An Environment for Evaluating and Improving Natural Language Feedback on Erroneous Code. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; Association for Computational Linguistics: Miami, FL, USA, 2024; pp. 22503–22524. [Google Scholar]
- Dehghan, M.; Wu, J.J.; Fard, F.H.; Ouni, A. MergeRepair: An Exploratory Study on Merging Task-Specific Adapters in Code LLMs for Automated Program Repair. arXiv 2024, arXiv:2408.09568. [Google Scholar]
- Campos, V. Bug Detection and Localization using Pre-trained Code Language Models. In INFORMATIK 2024; Gesellschaft für Informatik e.V.: Bonn, Germany, 2024; pp. 1419–1429. [Google Scholar] [CrossRef]
- Jiang, Y.; He, Q.; Zhuang, X.; Wu, Z. Code Comparison Tuning for Code Large Language Models. arXiv 2024, arXiv:2403.19121. [Google Scholar]
- Jiang, H.; Liu, Q.; Li, R.; Ye, S.; Wang, S. CursorCore: Assist Programming through Aligning Anything. arXiv 2024, arXiv:2410.07002. [Google Scholar]
- Lozhkov, A.; Li, R.; Allal, L.B.; Cassano, F.; Lamy-Poirier, J.; Tazi, N.; Tang, A.; Pykhtar, D.; Liu, J.; Wei, Y.; et al. StarCoder 2 and The Stack v2: The Next Generation. arXiv 2024, arXiv:2402.19173. [Google Scholar]
- Mishra, M.; Stallone, M.; Zhang, G.; Shen, Y.; Prasad, A.; Soria, A.M.; Merler, M.; Selvam, P.; Surendran, S.; Singh, S.; et al. Granite Code Models: A Family of Open Foundation Models for Code Intelligence. arXiv 2024, arXiv:2405.04324. [Google Scholar]
- Moon, S.; Chae, H.; Song, Y.; Kwon, T.; Kang, D.; iunn Ong, K.T.; won Hwang, S.; Yeo, J. Coffee: Boost Your Code LLMs by Fixing Bugs with Feedback. arXiv 2024, arXiv:2311.07215. [Google Scholar]
- Nakamura, T.; Mishra, M.; Tedeschi, S.; Chai, Y.; Stillerman, J.T.; Friedrich, F.; Yadav, P.; Laud, T.; Chien, V.M.; Zhuo, T.Y.; et al. Aurora-M: Open Source Continual Pre-training for Multilingual Language and Code. In Proceedings of the 31st International Conference on Computational Linguistics: Industry Track, Abu Dhabi, United Arab Emirates, 19–24 January 2025; Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S., Darwish, K., Agarwal, A., Eds.; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2025; pp. 656–678. [Google Scholar]
- Shi, Y.; Wang, S.; Wan, C.; Gu, X. From Code to Correctness: Closing the Last Mile of Code Generation with Hierarchical Debugging. arXiv 2024, arXiv:2410.01215. [Google Scholar]
- Singhal, M.; Aggarwal, T.; Awasthi, A.; Natarajan, N.; Kanade, A. NoFunEval: Funny How Code LMs Falter on Requirements Beyond Functional Correctness. arXiv 2024, arXiv:2401.15963. [Google Scholar]
- Wang, X.; Li, B.; Song, Y.; Xu, F.F.; Tang, X.; Zhuge, M.; Pan, J.; Song, Y.; Li, B.; Singh, J.; et al. OpenHands: An Open Platform for AI Software Developers as Generalist Agents. arXiv 2024, arXiv:2407.16741. [Google Scholar]
- Yang, J.; Jimenez, C.E.; Wettig, A.; Lieret, K.; Yao, S.; Narasimhan, K.; Press, O. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. In Proceedings of the Advances in Neural Information Processing Systems; Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2024; Volume 37, pp. 50528–50652. [Google Scholar]
- Yu, Z.; Zhang, X.; Shang, N.; Huang, Y.; Xu, C.; Zhao, Y.; Hu, W.; Yin, Q. WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 5140–5153. [Google Scholar] [CrossRef]
- Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al. The Llama 3 Herd of Models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- BigScience Workshop; Scao, T.L.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, G.; et al. BLOOM: A 176B-Parameter Open-Access Multilingual Language Model. arXiv 2023, arXiv:2211.05100. [Google Scholar]
- Li, R.; Allal, L.B.; Zi, Y.; Muennighoff, N.; Kocetkov, D.; Mou, C.; Marone, M.; Akiki, C.; Li, J.; Chim, J.; et al. StarCoder: May the source be with you! arXiv 2023, arXiv:2305.06161. [Google Scholar]
- Zheng, Q.; Xia, X.; Zou, X.; Dong, Y.; Wang, S.; Xue, Y.; Shen, L.; Wang, Z.; Wang, A.; Li, Y.; et al. CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Benchmarking on HumanEval-X. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 6–10 August 2023; KDD ’23; pp. 5673–5684. [Google Scholar] [CrossRef]
- Wang, Y.; Le, H.; Gotmare, A.; Bui, N.; Li, J.; Hoi, S. CodeT5+: Open Code Large Language Models for Code Understanding and Generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Singapore, 2023; pp. 1069–1088. [Google Scholar] [CrossRef]
- Wang, Z.Z.; Asai, A.; Yu, X.V.; Xu, F.F.; Xie, Y.; Neubig, G.; Fried, D. CodeRAG-Bench: Can Retrieval Augment Code Generation? In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2025; Chiruzzo, L., Ritter, A., Wang, L., Eds.; Association for Computational Linguistics: Albuquerque, New Mexico, 2025; pp. 3199–3214. [Google Scholar] [CrossRef]
- Matton, A.; Sherborne, T.; Aumiller, D.; Tommasone, E.; Alizadeh, M.; He, J.; Ma, R.; Voisin, M.; Gilsenan-McMahon, E.; Gallé, M. On Leakage of Code Generation Evaluation Datasets. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; Association for Computational Linguistics: Miami, FL, USA, 2024; pp. 13215–13223. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Liu, J.; Ding, Y.; Zhang, L. Magicoder: Empowering code generation with OSS-INSTRUCT. In Proceedings of the 41st International Conference on Machine Learning, JMLR.org, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Zheng, T.; Zhang, G.; Shen, T.; Liu, X.; Lin, B.Y.; Fu, J.; Chen, W.; Yue, X. OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 12834–12859. [Google Scholar] [CrossRef]
- Lei, B.; Li, Y.; Chen, Q. AutoCoder: Enhancing Code Large Language Model with AIEV-INSTRUCT. arXiv 2024, arXiv:2405.14906. [Google Scholar]
- Hui, B.; Yang, J.; Cui, Z.; Yang, J.; Liu, D.; Zhang, L.; Liu, T.; Zhang, J.; Yu, B.; Lu, K.; et al. Qwen2.5-Coder Technical Report. arXiv 2024, arXiv:2409.12186. [Google Scholar]
- Yu, Z.; Zhao, Y.; Cohan, A.; Zhang, X.P. HumanEval Pro and MBPP Pro: Evaluating Large Language Models on Self-invoking Code Generation. arXiv 2024, arXiv:2412.21199. [Google Scholar]
- Miao, Y.; Gao, B.; Quan, S.; Lin, J.; Zan, D.; Liu, J.; Yang, J.; Liu, T.; Deng, Z. Aligning CodeLLMs with Direct Preference Optimization. arXiv 2024, arXiv:2410.18585. [Google Scholar]
- Dou, S.; Jia, H.; Wu, S.; Zheng, H.; Zhou, W.; Wu, M.; Chai, M.; Fan, J.; Huang, C.; Tao, Y.; et al. What’s Wrong with Your Code Generated by Large Language Models? An Extensive Study. arXiv 2024, arXiv:2407.06153. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
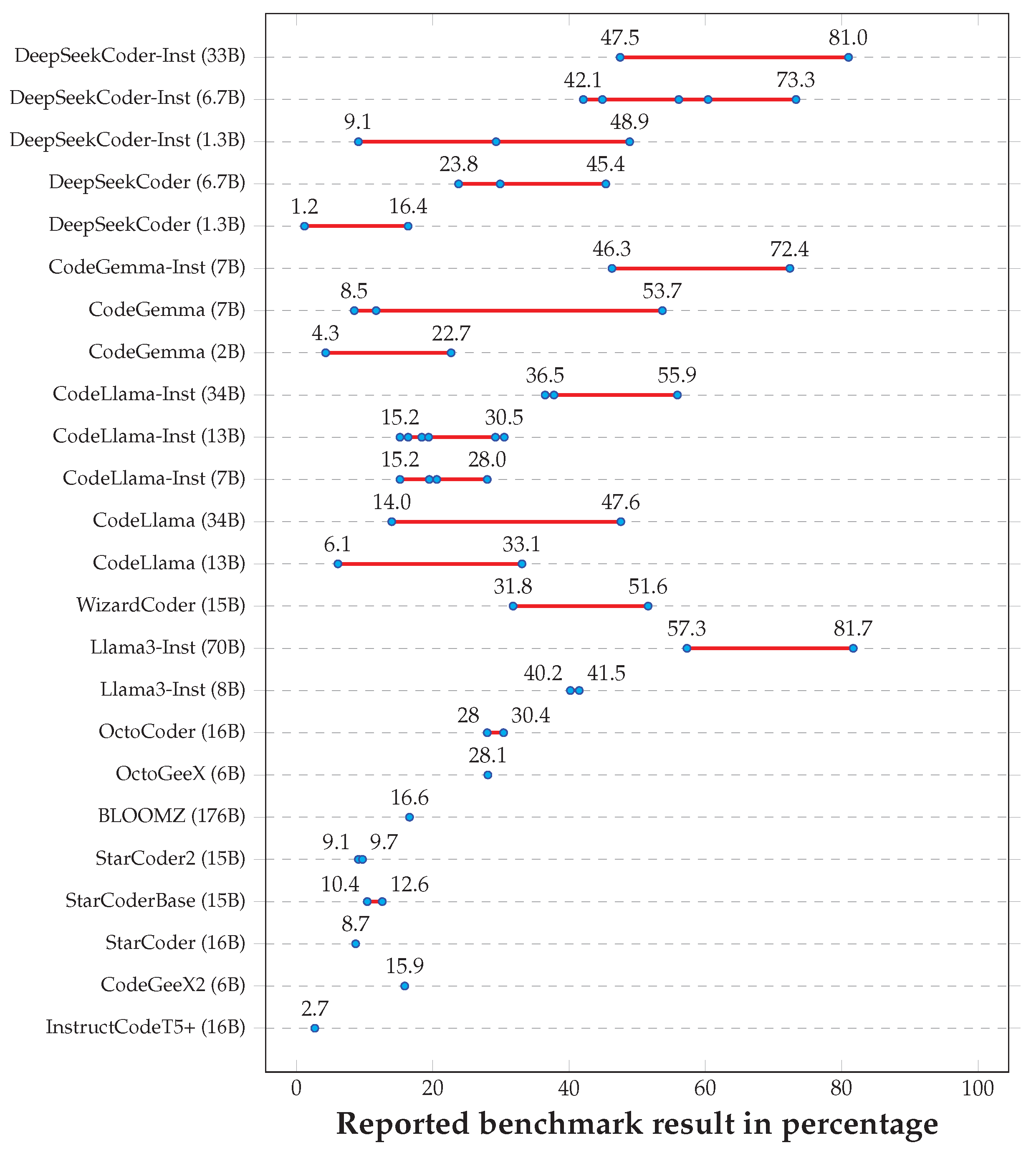
| Model | Reported Results |
|---|---|
| DeepSeekCoder-Inst (33B) [3] | 47.5 [16,22], 81.0 [27] |
| DeepSeekCoder-Inst (6.7B) [3] | 42.1 [21], 44.9 [16,22], 56.1 [30], 60.4 [17], 73.3 [27] |
| DeepSeekCoder-Inst (1.3B) [3] | 9.1 [16], 29.3 [21], 48.9 [27] |
| DeepSeekCoder (6.7B) [3] | 23.8 [21], 29.9 [30], 45.4 [27] |
| DeepSeekCoder (1.3B) [3] | 1.2 [21], 16.4 [27] |
| CodeGemma-Inst (7B) [13] | 46.3 [23], 72.4 [27] |
| CodeGemma (7B) [13] | 8.5 [23], 11.7 [27], 53.7 [17] |
| CodeGemma (2B) [13] | 4.3 [23], 22.7 [27] |
| CodeLlama-Inst (34B) [2] | 36.5 [16,22], 37.8 [23], 55.9 [27] |
| CodeLlama-Inst (13B) [2] | 15.2 [20], 16.4 [24], 18.9 [23], 19.4 [22], 29.2 [30], 30.5 [27] |
| CodeLlama-Inst (7B) [2] | 15.2 [24], 19.5 [23], 20.6 [27], 28.0 [30] |
| CodeLlama (34B) [2] | 14.0 [23], 47.6 [27] |
| CodeLlama (13B) [2] | 6.1 [23], 33.1 [27] |
| WizardCoder (15B) [14] | 31.8 [1,20,24,30], 51.6 [27] |
| Llama3-Inst (70B) [31] | 57.3 [23], 81.7 [27] |
| Llama3-Inst (8B) [31] | 40.2 [23], 41.5 [27] |
| OctoCoder (16B) [1] | 28 [23], 30.4 [1,20,22,24,25,30] |
| OctoGeeX (6B) [1] | 28.1 [1,24] |
| BLOOMZ (176B) [32] | 16.6 [1,20,25] |
| StarCoder2 (15B) [22] | 9.1 [23], 9.7 [22,25] |
| StarCoderBase (15B) [33] | 10.4 [23], 12.6 [22,25] |
| StarCoder (16B) [33] | 8.7 [1,20,24,30] |
| CodeGeeX2 (6B) [34] | 15.9 [1,20,24] |
| InstructCodeT5+ (16B) [35] | 2.7 [1,20,24] |
| Model | MBPP | MBPP+ |
|---|---|---|
| DeepSeekCoder-Inst (33B) [3] | 61 [36], 66 [37], 73.2 [22], 78.7 [38,39], 80.4 [40,41,42] | 59.1 [22], 66.7 [38,39], 70.1 [40,41,42] |
| DeepSeekCoder-Inst (6.7B) [3] | 60.8 [36], 70.2 [22], 72.7 [38], 73.2 [39], 74.3 [43], 74.9 [40,41,42] | 56.6 [22], 63.4 [38,39], 65.1 [43], 65.6 [40,41,42] |
| DeepSeekCoder-Inst (1.3B) [3] | 55.4 [22], 63.7 [38], 65.3 [41] | 46.9 [22], 53.1 [38], 54.8 [41] |
| DeepSeekCoder (33B) [3] | 74.2 [41,42] | 60.7 [41,42] |
| DeepSeekCoder (6.7B) [3] | 70.2 [38,39,41,42] | 51.6 [42], 56.6 [38,39,41], 66.4 [44] |
| DeepSeekCoder (1.3B) [3] | 55.4 [38], 55.6 [41] | 46.9 [38,41] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szalontai, B.; Márton, B.; Pintér, B.; Gregorics, T. Investigating Reproducibility Challenges in LLM Bugfixing on the HumanEvalFix Benchmark. Software 2025, 4, 17. https://doi.org/10.3390/software4030017
Szalontai B, Márton B, Pintér B, Gregorics T. Investigating Reproducibility Challenges in LLM Bugfixing on the HumanEvalFix Benchmark. Software. 2025; 4(3):17. https://doi.org/10.3390/software4030017
Chicago/Turabian StyleSzalontai, Balázs, Balázs Márton, Balázs Pintér, and Tibor Gregorics. 2025. "Investigating Reproducibility Challenges in LLM Bugfixing on the HumanEvalFix Benchmark" Software 4, no. 3: 17. https://doi.org/10.3390/software4030017
APA StyleSzalontai, B., Márton, B., Pintér, B., & Gregorics, T. (2025). Investigating Reproducibility Challenges in LLM Bugfixing on the HumanEvalFix Benchmark. Software, 4(3), 17. https://doi.org/10.3390/software4030017