

Machine Learning Techniques for Requirements Engineering: A Comprehensive Literature Review



Abstract
1. Introduction
1.1. Requirements Engineering Tasks and Issues
- Inception: This first activity involves, basically, the identification of a necessity, which will trigger a new project to develop a system capable of provisioning the necessity.
- Requirements Elicitation: This involves identifying the sources of requirements, and gathering requirements using various available techniques, such as interviews, observation of the environment and work processes that the system will support, etc.
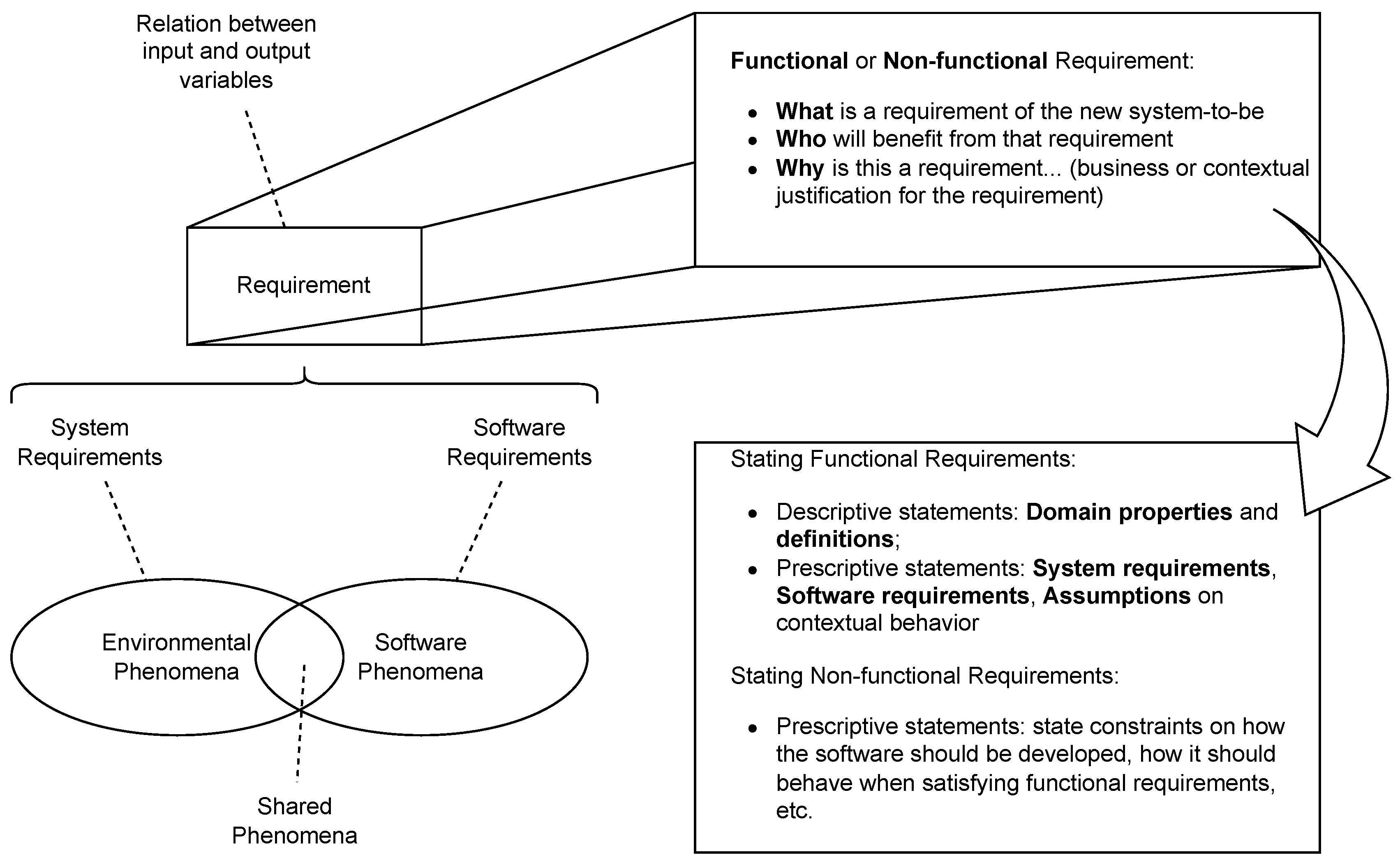
- Requirements Elaboration: This entails an analysis of the previously gathered requirements, their contextualization in the problem domain, and the identification of ambiguous, contradictory or meaningless requirements. It also involves the classification of requirements into functional and non-functional, as well as in the latter case their classification into an NFR category. In Figure 1, the types and dimensions of requirements are illustrated, leveraging FR and NFR.
- Requirements Negotiation: In this phase, candidate requirements, resulting from the previous activities, are negotiated, regulating divergences and adopting prioritization techniques [4].
- Requirements Documentation: Requirements documents, namely SRS documents, serve as the main reference for the subsequent software-engineering phases. These documents must display a set of requirements with a formalized structure, and the respective quality and verifiability criteria. At this stage, requirements are typically organized according to two perspectives: user requirements, which describe users’ needs; and, system requirements, which describe how the system should behave in different situations [4]. Both these perspectives may include FR and NFR.
- Requirements Validation: This activity includes examining the documented requirements and evaluating if they describe the system desired by the client. This may involve technical inspections and reviews and its main goal is to prevent defects in requirements from propagating to the following phases of the SDLC. Errors detected in this phase have much lower costs than errors detected in subsequent phases [4].
- Requirements Management: This activity runs throughout the whole system-development process. Its main goal is to manage requirements and their changes. Requirements traceability is a tool for keeping track of requirements aspects. For example, it may be used for tracing requirements change (each requirement is linked back to its previous version), requirements dependability (each requirement is linked to the requirements on which it depends), system features and requirements (each feature is linked to a set of logically related requirements).
1.2. Main Aim and Research Questions
- RQ1
- Which Requirements Engineering activities take advantage of the use of Artificial Intelligence techniques?
- RQ2
- Which Artificial Intelligence techniques are most used in each Requirements Engineering activity?
- RQ3
- Which Artificial Intelligence techniques have the best results in each Requirements Engineering activity?
1.3. Structure of the Article
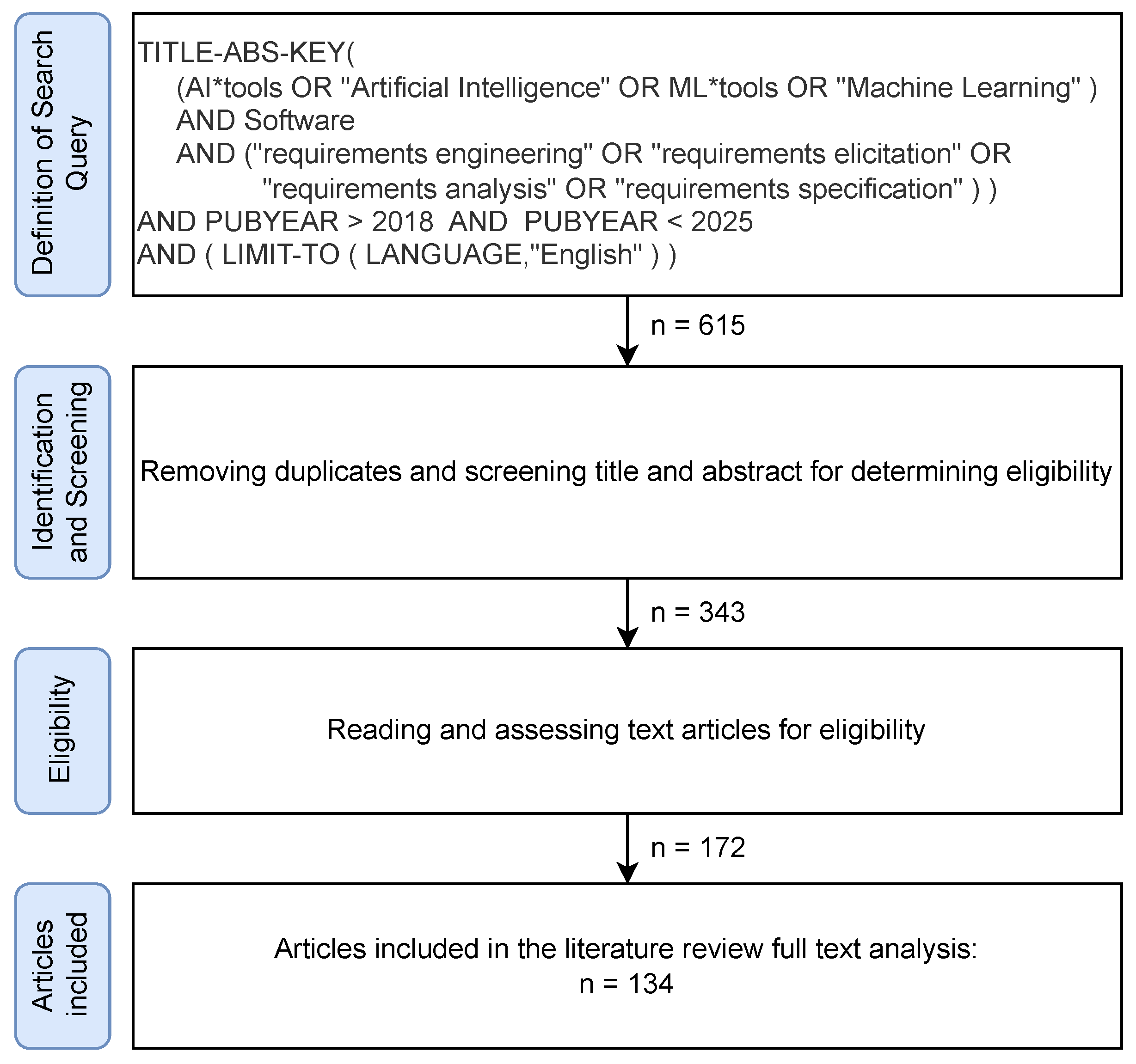
2. Materials and Methods
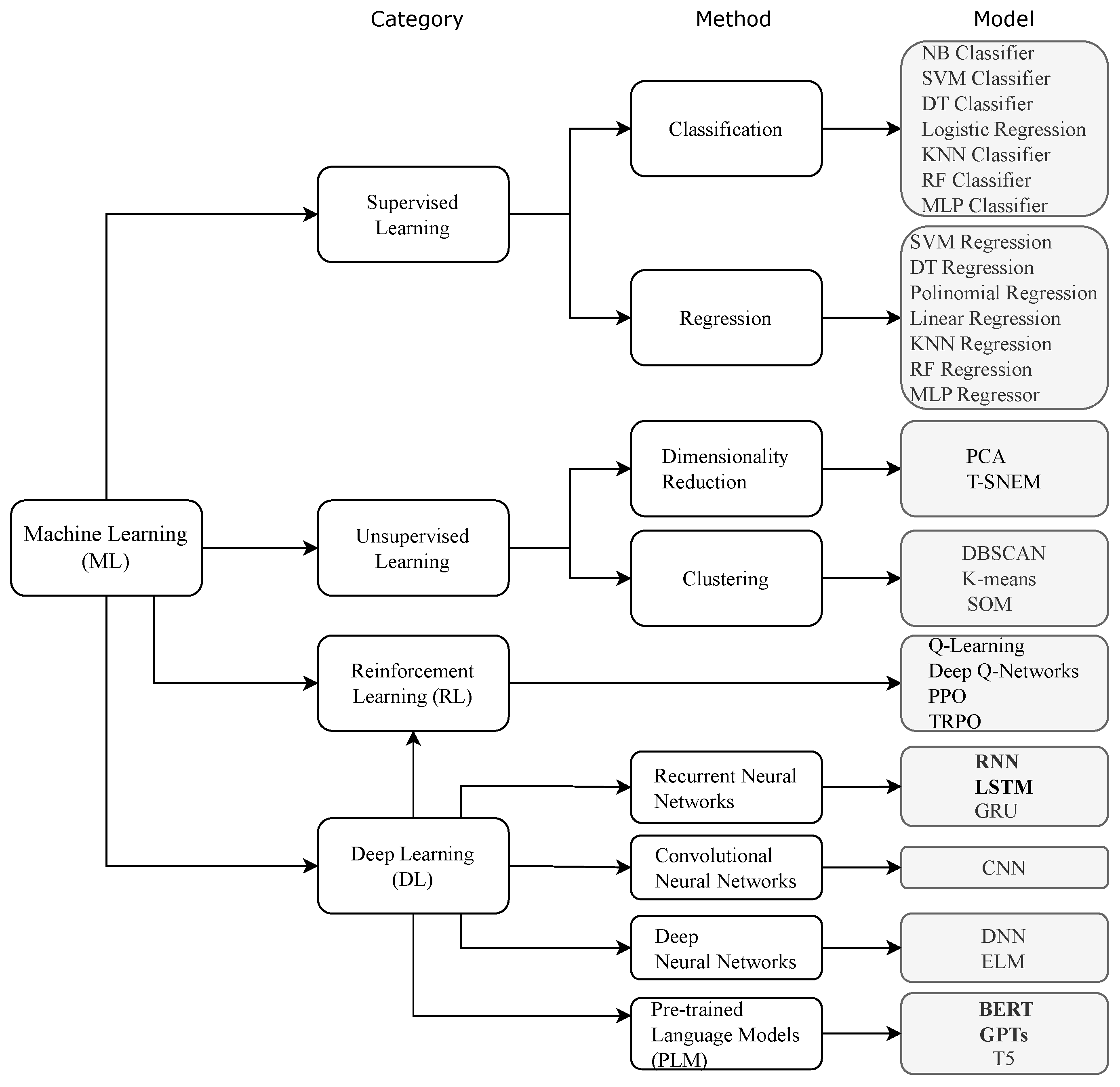
3. Machine Learning Techniques
- Supervised Learning—the model learns from labeled data, where input features are already associated with the correct outputs. These types of algorithms can be used in predictions such as price prediction, correct/incorrect classification and medical diagnosis. Within this group, we can further separate the algorithms between classification algorithms (used to classify yes/no) and regression algorithms (used to predict continuous values, such as prices or temperatures). In this group, we have algorithms such as Linear Regression, Logistic Regression, Decision Tree (DT), Random Forest (RF), Support Vector Machines (SVM), Multi-Layer Perceptron (MLP), Artificial Neural Networks (ANN)s, K-Nearest Neighbors (KNN), Gradient Boosting (XGBoost, LightGBM, CatBoost), etc.
- Unsupervised Learning—the model learns without labeled data, identifying hidden patterns in the data. These algorithms can be used for clustering, anomaly detection, etc. In this group, there are algorithms such as K-Means, which groups data into K clusters; Hierarchical Clustering, which creates a hierarchical structure of clusters; or DBSCAN, which identifies dense groups of points, useful for unstructured data.
- Reinforcement Learning—in this group, algorithms learn through trial and error, receiving rewards or punishments. This type of algorithm is used in games, robotics and optimization of financial strategies. This group includes algorithms such as Q-Learning, a table-based algorithm for finding the best action, Deep Q-Networks (DQN), which uses neural networks for Deep Learning; Proximal Policy Optimization (PPO), an advanced algorithm used by OpenAI, etc.
- Deep Learning—this involves algorithms that use artificial neural networks with multiple layers to learn complex representations of data. These algorithms are especially used in image recognition, natural language processing and speech and audio processing [24]. In this group, there are algoritms such as ANN, Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU). Pre-trained Language Models (PLM) algorithms, such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-trained Transformer (GPT), also belong to this group.
4. Previous Literature Reviews
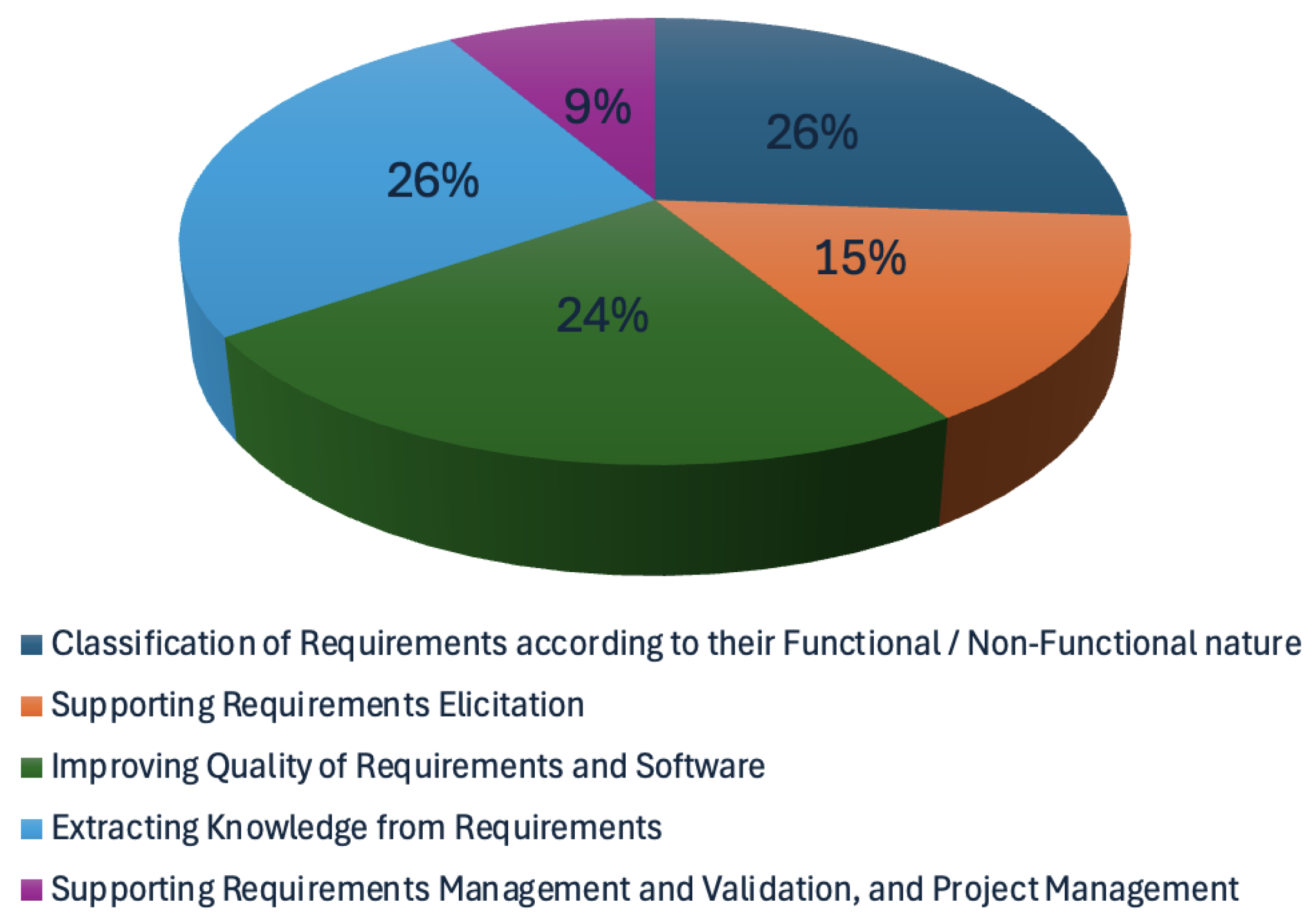
5. Results
- Classification of requirements according to their functional/non-functional nature;
- Supporting requirements elicitation;
- Improving the quality of requirements and software;
- Extracting knowledge from requirements;
- Supporting requirements management and validation, and project management.
5.1. RE Categories of Tasks
5.1.1. Classification of Requirements According to Their Functional/Non-Functional Nature
- Is clear, unambiguous and easy to interpret;
- Expresses objective intentions and not subjective opinions.
- Appearance, which is about the visual aspect of the system’s graphical user interface;
- Usability or User Experience (XP), which has to do with the system’s ease of use and the friendliness of the user experience;
- Performance, related to characteristics of speed, storage capacity, ability to scale to greater numbers of simultaneous users, among other aspects;
- Security, having to do with authentication and authorization access to the system and to the data, data protection and integrity, etc.;
- Legal, namely standards, laws and rules that apply to the system or to its domain of application.
5.1.2. Supporting Requirements Elicitation
5.1.3. Improving the Quality of Requirements and Software
- Contradictory requirements;
- Ambiguous requirements;
- Incoherent or senseless requirements;
- Complex requirements or requirements that need to be further divided into several requirements.
5.1.4. Extracting Knowledge from Requirements
- Rewriting requirements in a standard form;
- System features;
- Types of system users;
- System structural entities;
- Dependency between requirements;
- Related requirements, enabling requirements traceability.
5.1.5. Supporting Requirements Management and Validation, and Project Management
5.2. ML Techniques Used in RE Tasks
5.2.1. Classification of Requirements According to Their Functional/Non-Functional Nature
5.2.2. Supporting Requirements Elicitation
5.2.3. Improving Quality of Requirements and Software
5.2.4. Extracting Knowledge from Requirements
5.2.5. Supporting Requirements Management and Validation and Project Management
6. Analysis and Discussion
- RQ1
- Which Requirements Engineering activities take advantage of the use of Artificial Intelligence techniques?
- RQ2
- Which Artificial Intelligence techniques are most used in each Requirements Engineering activity?
- RQ3
- Which Artificial Intelligence techniques have the best results in each Requirements Engineering activity?
6.1. RQ1—Which Requirements Engineering Activities Take Advantage of the Use of Artificial Intelligence Techniques?
- Requirements Classification: Automatically distinguishing functional, non-functional and other requirement types;
- Requirements Prioritization: Ranking requirements by importance, risk or stakeholder value;
- Traceability (Link Generation and Refinement): Creating and refining links between requirements and other artifacts (design elements, test cases, code);
- Ambiguity Detection and Disambiguation: Identifying vague or conflicting language in natural language requirements;
- Model Generation: Translating requirements text into structured models (e.g., UML diagrams, domain ontologies);
- Validation and Verification: Checking requirements for correctness, completeness, consistency and other quality attributes;
- Change Impact Analysis: Predicting how modifications to one requirement affect other requirements or other RE artifacts (e.g., models, work time predictions);
6.2. RQ2—Which Artificial Intelligence Techniques Are Most Used in Each Requirements Engineering Activity?
6.3. RQ3—Which Artificial Intelligence Techniques Have the Best Results in Each Requirements Engineering Activity?
- Requirements Classification and Prioritization: Pipelines using TF-IDF feature vectors followed by ensemble classifiers (e.g., Bagged DT/RF, Gradient Boosting) consistently outperform Word2Vec based setups in accuracy and robustness [36]. Hybrid optimization methods, such as the ARPT technique improving Adam’s convergence [144] and GKA RE for stakeholder clustering [148], reduce error and speed up prioritization.
- Ambiguity Detection: Transformer-based models, such as BERT, GPT 3.5 and PRCBERT, offer superior contextual understanding, cutting ambiguity-detection errors by up to 20% over classic ML approaches [64].
- Model Generation: Heuristic rule-based frameworks for generating UML diagrams remain highly explainable [28]. When richer context is needed, semantic role labeling combined with SVM (e.g., SyAcUcNER) improves entity extraction and diagram accuracy [124]. RNNs with self attention (Bi LSTM + attention) also excel at mapping free text to structured model elements when ample training data are available [38,60].
- Validation and Verification: Knowledge-oriented ML methods, particularly Naïve Bayes and SVM, paired with formal modeling tools yield the most reliable defect-detection rates in requirements validation [30].
- Change Impact Analysis: Integrated NLP + ML frameworks, such as the combined model in [154], merge feature impact prediction with optimization algorithms to deliver the most accurate forecasts of requirement ripple effects.
7. Conclusions
7.1. Challenges and Open Problems
- Data Quality and Availability: Many requirement datasets lack full labels (e.g., FR vs. NFR) or use inconsistent labeling schemes, making supervised training difficult. Also, organizations often keep their requirements documents internal, which, while understandable, creates proprietary data silos that limit the public availability of corpora and make reproducibility and benchmarking difficult.
- Ambiguity and Natural Language Complexity: Human language can express the same intent in many ways, so simple keyword methods (BoW, TF-IDF) miss context that transformers can catch, but even these can misinterpret implied stakeholder intent. Requirements often refer to concepts introduced before in a document and capturing long-range concepts’ dependencies in long requirements documents is nontrivial.
- Feature Representation Trade-offs: BoW/TF-IDF give interpretable but high-dimensional sparse vectors, while embeddings (Word2Vec, BERT) are dense and semantically rich but opaque. Selecting or fusing these representations for optimal classifier performance in a given RE task remains undone. General purpose embeddings may not capture a specific domain concepts. Retraining or adapting embeddings for specific domains increases complexity.
- Model Explainability and Transparency: Ensemble Methods and deep networks can be highly accurate but offer little insight into why a requirement was classified a certain way or prioritized next. Stakeholders need clear/interpretable justification for predictions if they are to rely on automated suggestions.
- Generalization and Domain Adaptation: Models trained on one domain or corpus often underperform elsewhere. For instance, a model trained on finance domain requirements may perform poorly on healthcare or automotive texts. While fine tuning BERT helps, we still lack systematic methods to transfer small amounts of domain-specific data into robust RE models.
- Integration into Development Workflows: Seamless tool chain integration and automation of downstream SDLC steps is still a problem. AI models often run as separate services; tight integration with common RE tools (JIRA, IBM DOORS, GitHub Issues) is scarce. Also, in agile contexts, requirements change daily; models must process updates incrementally, ideally in real time, without full retraining.
- Traceability Link Quality: Precision vs. Recall Trade-off in automated link generation. High recall yields many false positives (spurious links), whereas high precision misses valid links. Striking the right balance for a particular project remains an open task. Automatic Link refinement (pruning or clustering similar links) to avoid over- or under-tracing artifacts is still underexplored.
- Scalability and Performance: Computational costs are high. Transformer models like BERT are resource intensive, making them slow on large backlogs. Few solutions exist for incremental learning, updating models on the fly, as new requirement data arrive.
- Evaluation and Benchmarking: Varying metrics and datasets make cross-study comparison difficult. Different studies use F1, accuracy, MCC or custom cost-based metrics, making comparison difficult. Also, there is a lack of standardized benchmarks for comparing RE-focused AI techniques.
7.2. Future Research Directions
- Unified Benchmark Suites: Curating and publishing RE corpora/datasets with consistent labels for classification, prioritization, traceability, etc., along with baseline results and shared evaluation scripts, is a future research direction. This would accelerate progress by enabling fair comparison of new algorithms.
- Hybrid Models for Explainability: Combining symbolic rule engines or small decision trees with dense embeddings, so that each prediction can be traced to a rule or feature weight, would give stakeholders a transparent explanation for the prediction, without sacrificing deep models’ accuracy.
- Domain Adaptive and Transfer Learning: To cut down expensive re-annotation efforts and improve domain performance, future research could work on developing systematic methods to adapt large pre-trained language models to new RE domains using minimal domain-specific data.
- Lightweight and Incremental Learning: Research online and continual learning algorithms that update models with each new requirement without retraining from scratch would keep models up to date with low computational overhead. This could be achieved by using techniques like parameter-efficient fine tuning, distillation or sparsity.
- Multimodal and Knowledge-Enhanced Approaches: Integrating text with UML sketches, prototypical screenshots and domain knowledge graphs (e.g., GDPR ontologies) in a unified model could leverage richer context, improving tasks like traceability and model generation.
- Human in the Loop and Active Learning: Building RE tools that identify the most uncertain or high impact requirements and query engineers for labels, refining the model with minimal human effort, could maximize label efficiency and continuously improve model accuracy.
- End to End RE Automation Pipelines: Seamlessly chain AI components (e.g., elicitation chatbots, classification, prioritization, traceability and impact analysis) so that the output of one directly feeds the next component. This could reduce manual component chaining and accelerate the entire requirements engineering lifecycle.
- Robustness and Fairness in RE Models: To ensure equitable prioritization and reduce systemic errors, requirements datasets and trained models could be audited for biases and develop mitigation strategies.
- Efficient Transformer Variants: Adapting lightweight transformer architectures (ALBERT, DistilBERT, MobileBERT) specifically tuned for RE tasks or exploring retrieval augmented generation to minimize fine tuning could delivers much of BERT’s power at a fraction of the computational cost.
- Empirical Studies and Industrial Adoption: Conducting large scale, real-world trials of AI-driven RE tools in diverse organizations and documenting ROI, usability and barriers to uptake would provide evidence for best practices, drive adoption and uncover new practical requirements for AI models.
- Ethical concerns: Carefully addressing ethical dimensions, through bias audits, explainable AI techniques, strict data governance, clear consent practices and human-in-the-loop oversight, will be crucial to responsibly deploying AI in requirements engineering.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ACM | Ambiguity Classification Model |
| AGER | Automated E-R Diagram Generation |
| AI | Artificial Intelligence |
| ALM | Application Lifecycle Management |
| ANN | Artificial Neural Networks |
| ASFR | Architecturally Significant Functional Requirement |
| ALBERT | A Lite BERT for Self-supervised Learning of Language Representations |
| BERT | Bidirectional Encoder Representations from Transformers |
| BERT-CNN | Bidirectional Encoder-Decoder Transformer Convolutional Neural Network |
| BiGRU | Bidirectional Gated Recurrent Neural Networks |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| BPMN | Business Process Model and Notation |
| CNN | Convolutional Neural Network |
| CrowdRE | Crowd-Based Requirements Engineering |
| DF4RT | Deep Forest for Requirements Traceability |
| DL | Deep Learning |
| DT | Decision Tree |
| FPDM | Fault-Prone Software Requirements Specification Detection Model |
| FR | Functional Requirement |
| GDPR | General Data Protection Regulation |
| GNB | Gaussian Naïve Bayes |
| GPT | Generative Pre-trained Transformer |
| GRU | Gated Recurrent Unit |
| IE | Information Extraction |
| KNN | K-Nearest Neighbors |
| LLM | Large Language Model |
| LR | Linear Regression |
| LogR | Logistic Regression |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| MNB | Multinomial Naïve Bayes |
| MTBE | Model Transformation by-Example |
| NB | Naïve Bayes |
| NER | Name Entity Recognition |
| NFR | Non-Functional Requirement |
| NL | Natural Language |
| NLP | Natural Language Processing |
| NLP4RE | Natural Language Processing for Requirements Engineering |
| NLP4ReF | Natural Language Processing for Requirements Forecasting |
| NN | Neural Networks |
| PLM | Pre-trained Language Models |
| PMBOK | Project Management Body of Knowledge |
| PoS | Part-of-speech (PoS tagging) |
| RE | Requirements Engineering |
| READ | Requirement Engineering Analysis Design |
| ReqVec | Semantic vector representation for requirements |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| ROF | Rule-Based Ontology Framework |
| SDLC | Software development life-cycle |
| SRS | Software Requirements Specification |
| SRXCRM | System Requirement eXtraction with Chunking and Rule Mining |
| SVM | Support Vector Machines |
| SyAcUcNER | System Actor Use-Case Named Entity Recognizer |
| TF-IDF | Term frequency-inverse document frequency |
| TLR-ELtoR | Evolutionary Learning to Rank for Traceability Link Recovery |
| T5 | Text-To-Text Transfer Transformer |
| UML | Unified Modeling Language |
References
- Liubchenko, V. The Machine Learning Techniques for Enhancing Software Requirement Specification: Literature Review. In Proceedings of the 2023 IEEE 12th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Dortmund, Germany, 7–9 September 2023; Volume 1, pp. 10–14. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, X.; Luo, H.; Yin, S.; Kaynak, O. Quo vadis artificial intelligence? Discov. Artif. Intell. 2022, 2, 4. [Google Scholar] [CrossRef]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent Advances in Natural Language Processing via Large Pre-trained Language Models: A Survey. ACM Comput. Surv. 2023, 56, 1–40. [Google Scholar] [CrossRef]
- Fernandes, J.M.; Machado, R.J. Requirements in Engineering Projects; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Pressman, R. Software Engineering: A Practitioner’s Approach; McGraw-Hill Higher Education, McGraw-Hill Education: New York, NY, USA, 2010. [Google Scholar]
- van Lamsweerde, A. Requirements Engineering: From System Goals to UML Models to Software Specifications; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- Zamani, K.; Zowghi, D.; Arora, C. Machine Learning in Requirements Engineering: A Mapping Study. In Proceedings of the 2021 IEEE 29th International Requirements Engineering Conference Workshops (REW), Notre Dame, IN, USA, 20–24 September 2021; pp. 116–125. [Google Scholar] [CrossRef]
- Liu, K.; Reddivari, S.; Reddivari, K. Artificial Intelligence in Software Requirements Engineering: State-of-the-Art. In Proceedings of the 2022 IEEE 23rd International Conference on Information Reuse and Integration for Data Science (IRI), San Diego, CA, USA, 9–11 August 2022; pp. 106–111. [Google Scholar] [CrossRef]
- Navaei, M.; Tabrizi, N. Machine Learning in Software Development Life Cycle: A Comprehensive Review. ENASE 2022, 1, 344–354. [Google Scholar]
- Abdelnabi, E.A.; Maatuk, A.M.; Hagal, M. Generating UML Class Diagram from Natural Language Requirements: A Survey of Approaches and Techniques. In Proceedings of the 2021 IEEE 1st International Maghreb Meeting of the Conference on Sciences and Techniques of Automatic Control and Computer Engineering MI-STA, Tripoli, Libya, 25–27 May 2021; pp. 288–293. [Google Scholar] [CrossRef]
- Kulkarni, V.; Kolhe, A.; Kulkarni, J. Intelligent Software Engineering: The Significance of Artificial Intelligence Techniques in Enhancing Software Development Lifecycle Processes. In Proceedings of the Intelligent Systems Design and Applications; Abraham, A., Gandhi, N., Hanne, T., Hong, T.P., Nogueira Rios, T., Ding, W., Eds.; Springer: Cham, Switzerland, 2022; pp. 67–82. [Google Scholar]
- Sofian, H.; Yunus, N.A.M.; Ahmad, R. Systematic Mapping: Artificial Intelligence Techniques in Software Engineering. IEEE Access 2022, 10, 51021–51040. [Google Scholar] [CrossRef]
- Sufian, M.; Khan, Z.; Rehman, S.; Haider Butt, W. A Systematic Literature Review: Software Requirements Prioritization Techniques. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; pp. 35–40. [Google Scholar] [CrossRef]
- Talele, P.; Phalnikar, R. Classification and Prioritisation of Software Requirements using Machine Learning—A Systematic Review. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 912–918. [Google Scholar] [CrossRef]
- Kaur, K.; Kaur, P. The application of AI techniques in requirements classification: A systematic mapping. Artif. Intell. Rev. 2024, 57, 57. [Google Scholar] [CrossRef]
- López-Hernández, D.A.; Octavio Ocharán-Hernández, J.; Mezura-Montes, E.; Sánchez-García, A. Automatic Classification of Software Requirements using Artificial Neural Networks: A Systematic Literature Review. In Proceedings of the 2021 9th International Conference in Software Engineering Research and Innovation (CONISOFT), San Diego, CA, USA, 25–29 October 2021; pp. 152–160. [Google Scholar] [CrossRef]
- Pérez-Verdejo, J.M.; Sánchez-García, A.J.; Ocharán-Hernández, J.O. A Systematic Literature Review on Machine Learning for Automated Requirements Classification. In Proceedings of the 2020 8th International Conference in Software Engineering Research and Innovation (CONISOFT), Chetumal, Mexico, 4–6 November 2020; pp. 21–28. [Google Scholar] [CrossRef]
- Li, X.; Wang, B.; Wan, H.; Deng, Y.; Wang, Z. Applications of Machine Learning in Requirements Traceability: A Systematic Mapping Study. In Proceedings of the 35th International Conference on Software Engineering and Knowledge Engineering, Virtual, 5–10 July 2023; pp. 566–571. [Google Scholar] [CrossRef]
- Yadav, A.; Patel, A.; Shah, M. A comprehensive review on resolving ambiguities in natural language processing. AI Open 2021, 2, 85–92. [Google Scholar] [CrossRef]
- Aberkane, A.J.; Poels, G.; Broucke, S.V. Exploring Automated GDPR-Compliance in Requirements Engineering: A Systematic Mapping Study. IEEE Access 2021, 9, 66542–66559. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. Available online: https://www.bmj.com/content/372/bmj.n71.full.pdf (accessed on 9 May 2024). [CrossRef]
- Nagarhalli, T.P.; Vaze, V.; Rana, N.K. Impact of Machine Learning in Natural Language Processing: A Review. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1529–1534. [Google Scholar] [CrossRef]
- Badillo, S.; Banfai, B.; Birzele, F.; Davydov, I.I.; Hutchinson, L.; Kam-Thong, T.; Siebourg-Polster, J.; Steiert, B.; Zhang, J.D. An Introduction to Machine Learning. Clin. Pharmacol. Ther. 2020, 107, 871–885. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S.S. A Survey on Deep Learning: Algorithms, Techniques, and Applications. ACM Comput. Surv. 2018, 51, 92. [Google Scholar] [CrossRef]
- Zhao, L.; Alhoshan, W.; Ferrari, A.; Letsholo, K.J. Classification of natural language processing techniques for requirements engineering. arXiv 2022, arXiv:2204.04282. [Google Scholar]
- Zhang, H.; Shafiq, M.O. Survey of transformers and towards ensemble learning using transformers for natural language processing. J. Big Data 2024, 11, 25. [Google Scholar] [CrossRef]
- da Cruz Mello, O.; Fontoura, L.M. Challenges in Requirements Engineering and Its Solutions: A Systematic Review. In Proceedings of the 24th International Conference on Enterprise Information Systems—Volume 2: ICEIS; INSTICC, SciTePress: Setúbal, Portugal, 2022; pp. 70–77. [Google Scholar] [CrossRef]
- Ahmed, S.; Ahmed, A.; Eisty, N.U. Automatic Transformation of Natural to Unified Modeling Language: A Systematic Review. In Proceedings of the 2022 IEEE/ACIS 20th International Conference on Software Engineering Research, Management and Applications (SERA), Las Vegas, NV, USA, 25–27 May 2022; pp. 112–119. [Google Scholar] [CrossRef]
- Sonbol, R.; Rebdawi, G.; Ghneim, N. The Use of NLP-Based Text Representation Techniques to Support Requirement Engineering Tasks: A Systematic Mapping Review. IEEE Access 2022, 10, 62811–62830. [Google Scholar] [CrossRef]
- Atoum, I.; Baklizi, M.K.; Alsmadi, I.; Otoom, A.A.; Alhersh, T.; Ababneh, J.; Almalki, J.; Alshahrani, S.M. Challenges of Software Requirements Quality Assurance and Validation: A Systematic Literature Review. IEEE Access 2021, 9, 137613–137634. [Google Scholar] [CrossRef]
- Santos, R.; Groen, E.C.; Villela, K. An Overview of User Feedback Classification Approaches. In Proceedings of the REFSQ Workshops, Essen, Germany, 18–21 March 2019; Volume 3, pp. 357–369. [Google Scholar]
- Ahmad, A.; Feng, C.; Tahir, A.; Khan, A.; Waqas, M.; Ahmad, S.; Ullah, A. An Empirical Evaluation of Machine Learning Algorithms for Identifying Software Requirements on Stack Overflow: Initial Results. In Proceedings of the 2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 18–20 October 2019; pp. 689–693. [Google Scholar] [CrossRef]
- Budake, R.; Bhoite, S.; Kharade, K. Identification and Classification of Functional and Nonfunctional Software Requirements Using Machine Learning. AIP Conf. Proc. 2023, 2946, 050009. [Google Scholar] [CrossRef]
- Talele, P.; Phalnikar, R. Multiple correlation based decision tree model for classification of software requirements. Int. J. Comput. Sci. Eng. 2023, 26, 131502. [Google Scholar] [CrossRef]
- Alhoshan, W.; Ferrari, A.; Zhao, L. Zero-shot learning for requirements classification: An exploratory study. Inf. Softw. Technol. 2023, 159, 107202. [Google Scholar] [CrossRef]
- Talele, P.; Phalnikar, R.; Apte, S.; Talele, H. Semi-automated Software Requirements Categorisation using Machine Learning Algorithms. Int. J. Electr. Comput. Eng. Syst. 2023, 14, 1107–1114. [Google Scholar] [CrossRef]
- Tasnim, A.; Akhter, N.; Ali, K. A Fine Tuned Ensemble Approach to Classify Requirement from User Story. In Proceedings of the 2023 26th International Conference on Computer and Information Technology, ICCIT 2023, Cox’s Bazar, Bangladesh, 13–15 December 2023. [Google Scholar] [CrossRef]
- Kaur, K.; Kaur, P. SABDM: A self-attention based bidirectional-RNN deep model for requirements classification. J. Softw. Evol. Process 2024, 36. [Google Scholar] [CrossRef]
- Peer, J.; Mordecai, Y.; Reich, Y. NLP4ReF: Requirements Classification and Forecasting: From Model-Based Design to Large Language Models. In Proceedings of the IEEE Aerospace Conference Proceedings, Big Sky, MT, USA, 2–9 March 2024. [Google Scholar] [CrossRef]
- Budake, R.; Bhoite, S.; Kharade, K. Machine Learning-Based Identification as Well as Classification of Functional and Non-functional Requirements. In High Performance Computing, Smart Devices and Networks; Lecture Notes in Electrical Engineering; Springer: Singapore, 2024; Volume 1087. [Google Scholar] [CrossRef]
- AlDhafer, O.; Ahmad, I.; Mahmood, S. An end-to-end Deep Learning system for requirements classification using recurrent neural networks. Inf. Softw. Technol. 2022, 147, 106877. [Google Scholar] [CrossRef]
- Patel, V.; Mehta, P.; Lavingia, K. Software Requirement Classification Using Machine Learning Algorithms. In Proceedings of the 2023 International Conference on Artificial Intelligence and Applications, ICAIA 2023 and Alliance Technology Conference, ATCON-1 2023—Proceeding, Bangalore, India, 21–22 April 2023. [Google Scholar] [CrossRef]
- Jp, S.; Menon, V.; Soman, K.; Ojha, A. A Non-Exclusive Multi-Class Convolutional Neural Network for the Classification of Functional Requirements in AUTOSAR Software Requirement Specification Text. IEEE Access 2022, 10, 117707–117714. [Google Scholar] [CrossRef]
- Nayak, U.A.; Swarnalatha, K.; Balachandra, A. Feasibility Study of Machine Learning & AI Algorithms for Classifying Software Requirements. In Proceedings of the MysuruCon 2022—2022 IEEE 2nd Mysore Sub Section International Conference, Mysuru, India, 16–17 October 2022. [Google Scholar] [CrossRef]
- Kaur, K.; Kaur, P. BERT-CNN: Improving BERT for Requirements Classification using CNN. Procedia Comput. Sci. 2022, 218, 2604–2611. [Google Scholar] [CrossRef]
- Vijayvargiya, S.; Kumar, L.; Murthy, L.; Misra, S. Software Requirements Classification using Deep Learning Approach with Various Hidden Layers. In Proceedings of the 17th Conference on Computer Science and Intelligence Systems, FedCSIS 2022, Sofia, Bulgaria, 4–7 September 2022. [Google Scholar] [CrossRef]
- Luo, X.; Xue, Y.; Xing, Z.; Sun, J. PRCBERT: Prompt Learning for Requirement Classification using BERT-based Pretrained Language Models. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, Rochester, MI, USA, 10–14 October 2022. [Google Scholar] [CrossRef]
- Magalhães, C.; Araujo, J.; Sardinha, A. MARE: An Active Learning Approach for Requirements Classification. In Proceedings of the IEEE 29th International Requirements Engineering Conference (RE), Notre Dame, IN, USA, 20–24 September 2021. [Google Scholar] [CrossRef]
- Pérez-Verdejo, J.; Sánchez-García, Á.; Ocharán-Hernández, J.; Mezura-Montes, E.; Cortés-Verdín, K. Requirements and GitHub Issues: An Automated Approach for Quality Requirements Classification. Program. Comput. Softw. 2021, 47, 704–721. [Google Scholar] [CrossRef]
- Quba, G.; Qaisi, H.A.; Althunibat, A.; Alzu’Bi, S. Software Requirements Classification using Machine Learning algorithm’s. In Proceedings of the 2021 International Conference on Information Technology, ICIT 2021—Proceedings, Amman, Jordan, 14–15 July 2021. [Google Scholar] [CrossRef]
- Dave, D.; Anu, V. Identifying Functional and Non-functional Software Requirements from User App Reviews. In Proceedings of the 2022 IEEE International IOT, Electronics and Mechatronics Conference, IEMTRONICS 2022, Toronto, ON, Canada, 1–4 June 2022. [Google Scholar] [CrossRef]
- Dave, D.; Anu, V.; Varde, A. Automating the Classification of Requirements Data. In Proceedings of the IEEE International Conference on Big Data, Big Data 2021, Orlando, FL, USA, 15–18 December 2021. [Google Scholar] [CrossRef]
- Vijayvargiya, S.; Kumar, L.; Malapati, A.; Murthy, L.; Misra, S. Software Functional Requirements Classification Using Ensemble Learning. In Proceedings of the International Conference on Computational Science and Its Applications, Malaga, Spain, 4–7 July 2022; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), LNCS. Springer: Cham, Switzerland, 2022; Volume 13381. [Google Scholar] [CrossRef]
- Rahimi, N.; Eassa, F.; Elrefaei, L. An ensemble Machine Learning technique for functional requirement classification. Symmetry 2020, 12, 1601. [Google Scholar] [CrossRef]
- Panichella, S.; Ruiz, M. Requirements-Collector: Automating requirements specification from elicitation sessions and user feedback. In Proceedings of the IEEE International Conference on Requirements Engineering, Zurich, Switzerland, 31 August–4 September 2020. [Google Scholar] [CrossRef]
- Surana, C.S.R.K.; Gupta, D.B.; Shankar, S.P. Intelligent Chatbot for Requirements Elicitation and Classification. In Proceedings of the 2019 4th IEEE International Conference on Recent Trends on Electronics, Information, Communication and Technology, RTEICT 2019—Proceedings, Bangalore, India, 17–18 May 2019. [Google Scholar] [CrossRef]
- Li, L.; Jin-An, N.; Kasirun, Z.; Piaw, C. An empirical comparison of Machine Learning algorithms for classification of software requirements. Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef]
- Kim, D.K.; Chen, J.; Ming, H.; Lu, L. Assessment of ChatGPT’s Proficiency in Software Development. In Proceedings of the Congress in Computer Science, Computer Engineering, and Applied Computing, Las Vegas, NV, USA, 24–27 July 2023. [Google Scholar] [CrossRef]
- Apte, S.; Honrao, Y.; Shinde, R.; Talele, P.; Phalnikar, R. Automatic Extraction of Software Requirements Using Machine Learning. In International Conference on Information and Communication Technology for Intelligent Systems; LNNS; Springer: Singapore, 2023; Volume 719. [Google Scholar] [CrossRef]
- Chatterjee, R.; Ahmed, A.; Anish, P. Identification and Classification of Architecturally Significant Functional Requirements. In Proceedings of the 7th International Workshop on Artificial Intelligence and Requirements Engineering, AIRE 2020, Zurich, Switzerland, 1 September 2020. [Google Scholar] [CrossRef]
- Baker, C.; Deng, L.; Chakraborty, S.; Dehlinger, J. Automatic multi-class non-functional software requirements classification using neural networks. In Proceedings of the International Computer Software and Applications Conference, Milwaukee, WI, USA, 15–19 July 2019; Volume 2. [Google Scholar] [CrossRef]
- Lafi, M.; Abdelqader, A. Automated Business Rules Classification Using Machine Learning to Enhance Software Requirements Elicitation. In Proceedings of the 2023 International Conference on Information Technology: Cybersecurity Challenges for Sustainable Cities, ICIT 2023-Proceeding, Amman, Jordan, 9–10 August 2023. [Google Scholar] [CrossRef]
- Gobov, D.; Huchenko, I. Software requirements elicitation techniques selection method for the project scope management. In Proceedings of the CEUR Workshop Proceedings, Online, 13–15 December 2021; Volume 2851. [Google Scholar]
- Yeow, J.; Rana, M.; Majid, N.A. An Automated Model of Software Requirement Engineering Using GPT-3.5. In Proceedings of the 2024 ASU International Conference in Emerging Technologies for Sustainability and Intelligent Systems, ICETSIS 2024, Manama, Bahrain, 28–29 January 2024. [Google Scholar] [CrossRef]
- Tizard, J.; Devine, P.; Wang, H.; Blincoe, K. A Software Requirements Ecosystem: Linking Forum, Issue Tracker, and FAQs for Requirements Management. IEEE Trans. Softw. Eng. 2023, 49, 2381–2393. [Google Scholar] [CrossRef]
- Shen, Y.; Breaux, T. Stakeholder Preference Extraction from Scenarios. IEEE Trans. Softw. Eng. 2024, 50, 69–84. [Google Scholar] [CrossRef]
- Devine, P.; Koh, Y.; Blincoe, K. Evaluating software user feedback classifier performance on unseen apps, datasets, and metadata. Empir. Softw. Eng. 2023, 28, 26. [Google Scholar] [CrossRef]
- Gudaparthi, H.; Niu, N.; Wang, B.; Bhowmik, T.; Liu, H.; Zhang, J.; Savolainen, J.; Horton, G.; Crowe, S.; Scherz, T.; et al. Prompting Creative Requirements via Traceable and Adversarial Examples in Deep Learning. In Proceedings of the IEEE 31st International Requirements Engineering Conference (RE), Hannover, Germany, 4–8 September 2023. [Google Scholar] [CrossRef]
- Gôlo, M.; Araújo, A.; Rossi, R.; Marcacini, R. Detecting relevant app reviews for software evolution and maintenance through multimodal one-class learning. Inf. Softw. Technol. 2022, 151, 106998. [Google Scholar] [CrossRef]
- Kauschinger, M.; Vieth, N.; Schreieck, M.; Krcmar, H. Detecting Feature Requests of Third-Party Developers through Machine Learning: A Case Study of the SAP Community. In Proceedings of the 56th Annual Hawaii International Conference on System Sciences, Kaanapali Beach, Maui, Hawaii, USA, 3–6 January 2023. [Google Scholar]
- Mehder, S.; Aydemir, F.B. Classification of Issue Discussions in Open Source Projects Using Deep Language Models. In Proceedings of the IEEE International Conference on Requirements Engineering, Melbourne, Australia, 15–19 August 2022. [Google Scholar] [CrossRef]
- Devine, P. Finding Appropriate User Feedback Analysis Techniques for Multiple Data Domains. In Proceedings of the International Conference on Software Engineering, Pittsburgh, PA, USA, 21–29 May 2022. [Google Scholar] [CrossRef]
- Araujo, A.; Marcacini, R. Hierarchical Cluster Labeling of Software Requirements using Contextual Word Embeddings. In Proceedings of the ACM International Conference Proceeding Series, Joinville, Brazil, 27 September–1 October 2021. [Google Scholar] [CrossRef]
- Bhatia, K.; Sharma, A. Sector classification for crowd-based software requirements. In Proceedings of the ACM Symposium on Applied Computing, Virtual Event, Republic of Korea, 22–26 March 2021. [Google Scholar] [CrossRef]
- Do, Q.; Bhowmik, T.; Bradshaw, G. Capturing creative requirements via requirements reuse: A machine learning-based approach. J. Syst. Softw. 2020, 170, 110730. [Google Scholar] [CrossRef]
- Iqbal, T.; Seyff, N.; Mendez, D. Generating requirements out of thin air: Towards automated feature identification for new apps. In Proceedings of the IEEE 27th International Requirements Engineering Conference Workshops, REW 2019, Jeju, Republic of Korea, 23–27 September 2019. [Google Scholar] [CrossRef]
- Morales-Ramirez, I.; Kifetew, F.; Perini, A. Speech-acts based analysis for requirements discovery from online discussions. Inf. Syst. 2019, 86, 94–112. [Google Scholar] [CrossRef]
- Do, Q.; Chekuri, S.; Bhowmik, T. Automated Support to Capture Creative Requirements via Requirements Reuse. In Reuse in the Big Data Era, Proceedings of the 18th International Conference on Software and Systems Reuse, ICSR 2019, Cincinnati, OH, USA, 26–28 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11602, LNCS. [Google Scholar] [CrossRef]
- Tizard, J.; Wang, H.; Yohannes, L.; Blincoe, K. Can a conversation paint a picture? Mining requirements in software forums. In Proceedings of the IEEE International Conference on Requirements Engineering, Jeju, Republic of Korea, 23–27 September 2019. [Google Scholar] [CrossRef]
- Peng, S.; Xu, L.; Jiang, W. Itemization Framework of Requirements using Machine Reading Comprehension. In Proceedings of the SPIE—The International Society for Optical Engineering, Chongqing, China, 29–31 July 2022; Volume 12451. [Google Scholar] [CrossRef]
- Ehresmann, M.; Beyer, J.; Fasoulas, S.; Schorfmann, M.; Brudna, T.; Schoolmann, I.; Brüggmann, J.; Hönle, A.; Gerlich, R.; Gerlich, R. ExANT: Exploring NLP AI Systems for Requirements Development. In Proceedings of the International Astronautical Congress, IAC, Baku, Azerbaijan, 2–6 October 2023. [Google Scholar]
- Muhamad, F.; Hamid, S.A.; Subramaniam, H.; Rashid, R.A.; Fahmi, F. Fault-Prone Software Requirements Specification Detection Using Ensemble Learning for Edge/Cloud Applications. Appl. Sci. 2023, 13, 8368. [Google Scholar] [CrossRef]
- Nguyen, T.; Sayar, I.; Ebersold, S.; Bruel, J.M. Identifying and fixing ambiguities in, and semantically accurate formalisation of, behavioural requirements. Softw. Syst. Model. 2024, 23, 1513–1545. [Google Scholar] [CrossRef]
- Berhanu, F.; Alemneh, E. Classification and Prioritization of Requirements Smells Using Machine Learning Techniques. In Proceedings of the 2023 International Conference on Information and Communication Technology for Development for Africa, ICT4DA 2023, Bahir Dar, Ethiopia, 26–28 October 2023., ICT4DA 2023. [Google Scholar] [CrossRef]
- Luitel, D.; Hassani, S.; Sabetzadeh, M. Improving requirements completeness: Automated assistance through large language models. Requir. Eng. 2024, 29, 73–95. [Google Scholar] [CrossRef]
- Habib, M.; Wagner, S.; Graziotin, D. Detecting Requirements Smells with Deep Learning: Experiences, Challenges and Future Work. In Proceedings of the IEEE International Conference on Requirements Engineering, Notre Dame, IN, USA, 20–24 September 2021. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, Z.; Zhang, L.; Li, Z. Automated conditional statements checking for complete natural language requirements specification. Appl. Sci. 2021, 11, 7892. [Google Scholar] [CrossRef]
- Singh, S.; Saikia, L.P.; Baruah, S. A study on Quality Assessment of Requirement Engineering Document using Text Classification Technique. In Proceedings of the 2nd International Conference on Electronics and Sustainable Communication Systems, ICESC 2021, Coimbatore, India, 4–6 August 2021. [Google Scholar] [CrossRef]
- Moharil, A.; Sharma, A. Identification of Intra-Domain Ambiguity using Transformer-based Machine Learning. In Proceedings of the 1st International Workshop on Natural Language-Based Software Engineering, NLBSE 2022, Pittsburgh, PA, USA, 21 May 2022. [Google Scholar] [CrossRef]
- Subedi, I.; Singh, M.; Ramasamy, V.; Walia, G. Application of back-translation: A transfer learning approach to identify ambiguous software requirements. In Proceedings of the ACMSE Conference—ACMSE 2021: The Annual ACM Southeast Conference, Virtual Event, USA, 15–17 April 2021. [Google Scholar] [CrossRef]
- Onyeka, E.; Varde, A.; Anu, V.; Tandon, N.; Daramola, O. Using Commonsense Knowledge and Text Mining for Implicit Requirements Localization. In Proceedings of the International Conference on Tools with Artificial Intelligence, ICTAI, Baltimore, MD, USA, 9–11 November 2020. [Google Scholar] [CrossRef]
- Femmer, H.; Müller, A.; Eder, S. Semantic Similarities in Natural Language Requirements. In Software Quality: Quality Intelligence in Software and Systems Engineering, Proceedings of the 12th International Conference, SWQD 2020, Vienna, Austria, 14–17 January 2020; LNBIP; Springer International Publishing: Cham, Switzerland; Volume 371. [CrossRef]
- Memon, K.; Xia, X. Deciphering and analyzing software requirements employing the techniques of Natural Language processing. In Proceedings of the ACM International Conference on Mathematics and Artificial Intelligence, Chegndu, China, 12–15 April 2019. [Google Scholar] [CrossRef]
- Atoum, I. Measurement of key performance indicators of user experience based on software requirements. Sci. Comput. Program. 2023, 226, 102929. [Google Scholar] [CrossRef]
- Althar, R.; Samanta, D. BERT-Based Secure and Smart Management System for Processing Software Development Requirements from Security Perspective. In Machine Intelligence and Data Science Applications; Lecture Notes on Data Engineering and Communications Technologies; Springer: Singapore, 2022; Volume 132. [Google Scholar] [CrossRef]
- Imtiaz, S.; Amin, M.; Do, A.; Iannucci, S.; Bhowmik, T. Predicting Vulnerability for Requirements. In Proceedings of the IEEE 22nd International Conference on Information Reuse and Integration for Data Science, IRI 2021, Las Vegas, NV, USA, 10–12 August 2021. [Google Scholar] [CrossRef]
- Aberkane, A.-J. Automated GDPR-compliance in requirements engineering. In Proceedings of the Doctoral Consortium Papers Presented at the 33rd International Conference on Advanced Information Systems Engineering (CAiSE 2021), Virtual Event, Australia, Victoria, 28 June–2 July 2021; Volume 2906. Available online: https://ceur-ws.org/Vol-2906/paper3.pdf (accessed on 22 June 2024).
- dos Santos, R.; Villela, K.; Avila, D.; Thom, L. A practical user feedback classifier for software quality characteristics. In Proceedings of the International Conference on Software Engineering and Knowledge Engineering, SEKE, Virtual conference at the KSIR Virtual Conference Center, Pittsburgh, USA, 1–10 July 2021. [Google Scholar] [CrossRef]
- Atoum, I.; Almalki, J.; Alshahrani, S.; Shehri, W. Towards Measuring User Experience based on Software Requirements. Int. J. Adv. Comput. Sci. Appl. 2021, 12. [Google Scholar] [CrossRef]
- Hovorushchenko, T.; Pavlova, O. Method of activity of ontology-based intelligent agent for evaluating initial stages of the software lifecycle. In Proceedings of the Advances in Intelligent Systems and Computing, Kyiv, Ukraine, 4–7 June 2018; Springer: Cham, Switzerland, 2019; Volume 836. [Google Scholar] [CrossRef]
- Groher, I.; Seyff, N.; Iqbal, T. Towards automatically identifying potential sustainability effects of requirements. In Proceedings of the CEUR Workshop Proceedings, Castiglione della Pescaia (Grosseto), Italy, 16–19 June 2019; Volume 2541. [Google Scholar]
- Chazette, L. Mitigating challenges in the elicitation and analysis of transparency requirements. In Proceedings of the IEEE International Conference on Requirements Engineering, Jeju, Korea, 23–27 September 2019. [Google Scholar] [CrossRef]
- Adithya, V.; Deepak, G. OntoReq: An Ontology Focused Collective Knowledge Approach for Requirement Traceability Modelling. In AI Systems and the Internet of Things in the Digital Era, Proceedings of EAMMIS 2021, Istanbul, Turkey, 19–20 March 2021; Musleh Al-Sartawi, A.M., Razzaque, A., Kamal, M.M., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 358–370. [Google Scholar] [CrossRef]
- Fadhlurrohman, D.; Sabariah, M.; Alibasa, M.; Husen, J. Naïve Bayes Classification Model for Precondition-Postcondition in Software Requirements. In Proceedings of the 2023 International Conference on Data Science and Its Applications, ICoDSA 2023, Bandung, Indonesia, 9–10 August 2023. [Google Scholar] [CrossRef]
- Sawada, K.; Pomerantz, M.; Razo, G.; Clark, M. Intelligent requirement-to-test case traceability system via Natural Language Processing and Machine Learning. In Proceedings of the IEEE 9th International Conference on Space Mission Challenges for Information Technology, SMC-IT 2023, Pasadena, CA, USA, 18–27 July 2023. [Google Scholar] [CrossRef]
- Subedi, I.; Singh, M.; Ramasamy, V.; Walia, G. Classification of Testable and Valuable User Stories by using Supervised Machine Learning Classifiers. In Proceedings of the IEEE International Symposium on Software Reliability Engineering Workshops, ISSREW 2021, Wuhan, China, 25–28 October 2021. [Google Scholar] [CrossRef]
- Merugu, R.; Chinnam, S. Automated cloud service based quality requirement classification for software requirement specification. Evol. Intell. 2021, 14, 389–394. [Google Scholar] [CrossRef]
- Ueda, K.; Tsukada, H. Accuracy Improvement by Training Data Selection in Automatic Test Cases Generation Method. In Proceedings of the 2021 9th International Conference on Information and Education Technology, ICIET 2021, Okayama, Japan, 27–29 March 2021. [Google Scholar] [CrossRef]
- Kikuma, K.; Yamada, T.; Sato, K.; Ueda, K. Preparation method in automated test case generation using machine learning. In Proceedings of the ACM International Conference Proceeding Series, Hanoi Ha Long Bay, Vietnam, 4–6 December 2019. [Google Scholar] [CrossRef]
- Kaya, A.; Keceli, A.; Catal, C.; Tekinerdogan, B. Model analytics for defect prediction based on design-level metrics and sampling techniques. In Model Management and Analytics for Large Scale Systems; Academic Press: Cambridge, MA, USA, 2019. [Google Scholar] [CrossRef]
- Petcuşin, F.; Stănescu, L.; Bădică, C. An Experiment on Automated Requirements Mapping Using Deep Learning Methods. In Proceedings of the Studies in Computational Intelligence; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 868. [Google Scholar] [CrossRef]
- Zhang, J.; Yuan, M.; Huang, Z. Software Requirements Elicitation Based on Ontology Learning. In Proceedings of the Communications in Computer and Information Science; Springer: Singapore, 2019; Volume 861. [Google Scholar] [CrossRef]
- Lano, K.; Kolahdouz-Rahimi, S.; Fang, S. Model Transformation Development Using Automated Requirements Analysis, Metamodel Matching, and Transformation by Example. ACM Trans. Softw. Eng. Methodol. 2022, 31, 3471907. [Google Scholar] [CrossRef]
- Koscinski, V.; Gambardella, C.; Gerstner, E.; Zappavigna, M.; Cassetti, J.; Mirakhorli, M. A Natural Language Processing Technique for Formalization of Systems Requirement Specifications. In Proceedings of the IEEE International Conference on Requirements Engineering, Notre Dame, IN, USA, 20–24 September 2021. [Google Scholar] [CrossRef]
- Yanuarifiani, A.; Chua, F.F.; Chan, G.Y. Feasibility Analysis of a Rule-Based Ontology Framework (ROF) for Auto-Generation of Requirements Specification. In Proceedings of the IEEE International Conference on Artificial Intelligence in Engineering and Technology, IICAIET 2020, Kota Kinabalu, Malaysia, 26–27 September 2020. [Google Scholar] [CrossRef]
- Arulmohan, S.; Meurs, M.J.; Mosser, S. Extracting Domain Models from Textual Requirements in the Era of Large Language Models. In Proceedings of the ACM/IEEE International Conference on Model Driven Engineering Languages and Systems Companion, MODELS-C 2023, Västerås, Sweden, 1–6 October 2023. [Google Scholar] [CrossRef]
- Saini, R.; Mussbacher, G.; Guo, J.; Kienzle, J. Automated, interactive, and traceable domain modelling empowered by artificial intelligence. Softw. Syst. Model. 2022, 21, 1015–1045. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, S.; Hua, J.; Niu, N.; Liu, C. Automatic Terminology Extraction and Ranking for Feature Modeling. In Proceedings of the IEEE International Requirements Engineering Conference (RE), Melbourne, Australia, 15–19 August 2022. [Google Scholar] [CrossRef]
- Sree-Kumar, A.; Planas, E.; Clarisó, R. Validating Feature Models with Respect to Textual Product Line Specifications. In Proceedings of the ACM International Conference Proceeding Series, Krems, Austria, 9–11 February 2021. [Google Scholar] [CrossRef]
- Bonner, M.; Zeller, M.; Schulz, G.; Beyer, D.; Olteanu, M. Automated Traceability between Requirements and Model-Based Design. In Proceedings of the REFSQ Posters and Tools (CEUR Workshop Proceedings), Barcelona, Spain, 17–20 April 2023; Volume 3378. [Google Scholar]
- Bashir, N.; Bilal, M.; Liaqat, M.; Marjani, M.; Malik, N.; Ali, M. Modeling Class Diagram using NLP in Object-Oriented Designing. In Proceedings of the IEEE 4th National Computing Colleges Conference, NCCC 2021, Taif, Saudi Arabia, 27–28 March 2021. [Google Scholar] [CrossRef]
- Vineetha, V.; Samuel, P. A Multinomial Naïve Bayes Classifier for identifying Actors and Use Cases from Software Requirement Specification documents. In Proceedings of the 2nd International Conference on Intelligent Technologies, CONIT 2022, Hubli, India, 24–26 June 2022. [Google Scholar] [CrossRef]
- Schouten, M.; Ramackers, G.; Verberne, S. Preprocessing Requirements Documents for Automatic UML Modelling. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2022; Volume 13286. [Google Scholar] [CrossRef]
- Imam, A.; Alhroob, A.; Alzyadat, W. SVM Machine Learning Classifier to Automate the Extraction of SRS Elements. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 0120322. [Google Scholar] [CrossRef]
- Leitão, V.; Medeiros, I. SRXCRM: Discovering Association Rules between System Requirements and Product Specifications. In Proceedings of the REFSQ Workshops, Essen, Germany, 12–15 April 2021; Volume 2857. Available online: https://ceur-ws.org/Vol-2857/nlp4re9.pdf (accessed on 22 June 2024).
- Sonbol, R.; Rebdawi, G.; Ghneim, N. Towards a Semantic Representation for Functional Software Requirements. In Proceedings of the 7th International Workshop on Artificial Intelligence and Requirements Engineering, AIRE 2020, Zurich, Switzerland, 1 September 2020. [Google Scholar] [CrossRef]
- Saini, R.; Mussbacher, G.; Guo, J.; Kienzle, J. Towards Queryable and Traceable Domain Models. In Proceedings of the IEEE International Conference on Requirements Engineering, Zurich, Switzerland, 31 August–4 September 2020. [Google Scholar] [CrossRef]
- Tiwari, S.; Rathore, S.; Sagar, S.; Mirani, Y. Identifying Use Case Elements from Textual Specification: A Preliminary Study. In Proceedings of the IEEE International Conference on Requirements Engineering, Zurich, Switzerland, 31 August–4 September 2020. [Google Scholar] [CrossRef]
- Saini, R.; Mussbacher, G.; Guo, J.; Kienzle, J. A Neural Network Based Approach to Domain Modelling Relationships and Patterns Recognition. In Proceedings of the 10th International Model-Driven Requirements Engineering Workshop, MoDRE 2020, Zurich, Switzerland, 31 August 2020. [Google Scholar] [CrossRef]
- Saini, R.; Mussbacher, G.; Guo, J.; Kienzle, J. DoMoBOT: A bot for automated and interactive domain modelling. In Proceedings of the 23rd ACM/IEEE International Conference on Model Driven Engineering Languages and Systems, MODELS-C 2020—Companion Proceedings, Virtual Event, Canada, 16–23 October 2020. [Google Scholar] [CrossRef]
- Ghosh, S.; Bashar, R.; Mukherjee, P.; Chakraborty, B. Automated generation of e-r diagram from a given text in natural language. In Proceedings of the International Conference on Machine Learning and Data Engineering, iCMLDE 2018, Sydney, NSW, Australia, 3–7 December 2019. [Google Scholar] [CrossRef]
- Khan, J. Mining requirements arguments from user forums. In Proceedings of the IEEE International Conference on Requirements Engineering, Jeju, Republic of Korea, 23–27 September 2019. [Google Scholar] [CrossRef]
- Osman, M.; Alabwaini, N.; Jaber, T.; Alrawashdeh, T. Generate use case from the requirements written in a natural language using Machine Learning. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology, JEEIT 2019-Proceedings, Amman, Jordan, 9–11 April 2019. [Google Scholar] [CrossRef]
- Wever, M.; Rooijen, L.V.; Hamann, H. Multioracle coevolutionary learning of requirements specifications from examples in on-the-fly markets. Evol. Comput. 2019, 28, 165–193. [Google Scholar] [CrossRef] [PubMed]
- Motger, Q.; Borrull, R.; Palomares, C.; Marco, J. OpenReq-DD: A requirements dependency detection tool. In Proceedings of the NLP4RE Workshop, Essen, Germany, 18–21 March 2019; Volume 2376. Available online: https://ceur-ws.org/Vol-2376/NLP4RE19_paper01.pdf (accessed on 22 June 2025).
- Deshpande, G.; Arora, C.; Ruhe, G. Data-driven elicitation and optimization of dependencies between requirements. In Proceedings of the IEEE International Conference on Requirements Engineering, Jeju, Republic of Korea, 23–27 September 2019. [Google Scholar] [CrossRef]
- Atas, M.; Samer, R.; Felfernig, A. Automated Identification of Type-Specific Dependencies between Requirements. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, WI 2018, Santiago, Chile, 3–6 December 2019. [Google Scholar] [CrossRef]
- Deshpande, G. SReYantra: Automated software requirement inter-dependencies elicitation, analysis and learning. In Proceedings of the IEEE/ACM 41st International Conference on Software Engineering: Companion, ICSE-Companion 2019, Montreal, QC, Canada, 25–31 May 2019. [Google Scholar] [CrossRef]
- Wang, B.; Deng, Y.; Wan, H.; Li, X. DF4RT: Deep Forest for Requirements Traceability Recovery Between Use Cases and Source Code. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Oahu, HI, USA, 1–14 October 2023. [Google Scholar] [CrossRef]
- Al-walidi, N.; Azab, S.; Khamis, A.; Darwish, N. Clustering-based Automated Requirement Trace Retrieval. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 0131292. [Google Scholar] [CrossRef]
- Marcén, A.C.; Lapeña, R.; Pastor, O.; Cetina, C. Traceability Link Recovery between Requirements and Models using an Evolutionary Algorithm Guided by a Learning to Rank Algorithm: Train control and management case. J. Syst. Softw. 2020, 163, 110519. [Google Scholar] [CrossRef]
- Wang, S.; Li, T.; Yang, Z. Exploring Semantics of Software Artifacts to Improve Requirements Traceability Recovery: A Hybrid Approach. In Proceedings of the Asia-Pacific Software Engineering Conference, APSEC, Putrajaya, Malaysia, 2–5 December 2019. [Google Scholar] [CrossRef]
- Chen, L.; Wang, D.; Wang, J.; Wang, Q. Enhancing Unsupervised Requirements Traceability with Sequential Semantics. In Proceedings of the Asia-Pacific Software Engineering Conference, APSEC, Putrajaya, Malaysia, 2–5 December 2019. [Google Scholar] [CrossRef]
- Talele, P.; Phalnikar, R. Automated Requirement Prioritisation Technique Using an Updated Adam Optimisation Algorithm. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 1211–1221. [Google Scholar]
- Fatima, A.; Fernandes, A.; Egan, D.; Luca, C. Software Requirements Prioritisation Using Machine Learning. In Proceedings of the 15th International Conference on Agents and Artificial Intelligence, ICAART, Lisbon, Portugal, 22–24 February 2023; Volume 3. [Google Scholar] [CrossRef]
- Lunarejo, M. Requirements prioritization based on multiple criteria using Artificial Intelligence techniques. In Proceedings of the IEEE International Conference on Requirements Engineering, Notre Dame, IN, USA, 20–24 September 2021. [Google Scholar] [CrossRef]
- Limaylla, M.; Condori-Fernandez, N.; Luaces, M. Towards a Semi-Automated Data-Driven Requirements Prioritization Approach for Reducing Stakeholder Participation in SPL Development. Eng. Proc. 2021, 7, 27. [Google Scholar] [CrossRef]
- Reyad, O.; Dukhan, W.; Marghny, M.; Zanaty, E. Genetic K-Means Adaption Algorithm for Clustering Stakeholders in System Requirements. In Proceedings of the Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2021; Volume 1339. [Google Scholar] [CrossRef]
- Talele, P.; Phalnikar, R. Software Requirements Classification and Prioritisation Using Machine Learning. In Proceedings of the Lecture Notes in Networks and Systems; Springer: Singapore, 2021; Volume 141. [Google Scholar] [CrossRef]
- Pereira, F.; Neto, G.; Lima, L.D.; Silva, F.; Peres, L. A Tool For Software Requirement Allocation Using Artificial Intelligence Planning. In Proceedings of the IEEE International Conference on Requirements Engineering, Melbourne, Australia, 15–19 August 2022. [Google Scholar] [CrossRef]
- Blincoe, K.; Dehghan, A.; Salaou, A.D.; Neal, A.; Linaker, J.; Damian, D. High-level software requirements and iteration changes: A predictive model. Empir. Softw. Eng. 2019, 24, 1610–1648. [Google Scholar] [CrossRef]
- Liu, Y.; Lin, J.; Cleland-Huang, J.; Vierhauser, M.; Guo, J.; Lohar, S. SENET: A Semantic Web for Supporting Automation of Software Engineering Tasks. In Proceedings of the 7th International Workshop on Artificial Intelligence and Requirements Engineering, AIRE 2020, Zurich, Switzerland, 1 September 2020. [Google Scholar] [CrossRef]
- Khan, B.; Naseem, R.; Alam, I.; Khan, I.; Alasmary, H.; Rahman, T. Analysis of Tree-Family Machine Learning Techniques for Risk Prediction in Software Requirements. IEEE Access 2022, 10, 98220–98231. [Google Scholar] [CrossRef]
- Zamani, K. A Prediction Model for Software Requirements Change Impact. In Proceedings of the 36th IEEE/ACM International Conference on Automated Software Engineering, ASE 2021, Melbourne, Australia, 15–19 November 2021. [Google Scholar] [CrossRef]
- Cherdsakulwong, N.; Suwannasart, T. Impact Analysis of Test Cases for Changing Inputs or Outputs of Functional Requirements. In Proceedings of the 20th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, SNPD 2019, Toyama, Japan, 8–11 July 2019. [Google Scholar] [CrossRef]
- Olson, R.; Bartley, N.; Urbanowicz, R.; Moore, J. Evaluation of a tree-based pipeline optimization tool for automating data science. In Proceedings of the Genetic and Evolutionary Computation GECCO’16, Denver, CO, USA, 20–24 July 2016; pp. 485–492. [Google Scholar]
- Aberkane, A.J. Exploring Ethics in Requirements Engineering. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2018. Available online: https://studenttheses.uu.nl/handle/20.500.12932/30674 (accessed on 21 June 2024).
- Peterson, B. Ethical Considerations of AI in Software Engineering: Bias, Reliability, and Human Oversight. Unpublished. 2025. Available online: https://www.researchgate.net/publication/390280753 (accessed on 21 June 2024).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RE Category | RE Activity | References |
|---|---|---|
| Classification of Requirements according to their Functional/ Non-Functional nature | Binary FR/NFR Classification, and ternary Classif. FR/NFR/Non-Req | [33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58] |
| Classifying NFR in further subcategories, and Classifying ASFR | [35,38,40,41,43,45,47,48,49,52,57,59,60,61] | |
| Supporting Requirements Elicitation | Categorize and Classify Business Rules (as a source for RE) | [62] |
| Predicting/recommending Techniques for Req. elicitation | [63] | |
| Generating questions for Requirements elicitation | [56,64] | |
| Identifying/Generating new Requirements from existing Requirements or from User Feedback; Identifying ASFR; Classifying User Feedback | [39,51,55,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79] | |
| Improving Quality of Requirements and Software | Requirements itemization, simplification, disambiguation; Detecting incompleteness, ambiguity, inaccuracy, implicit requirements, semantic similarity, and other risks (smells) in Requirements Specification; Coping with ambiguity through the use of controlled vocabulary and Ontologies | [39,58,80,81,82,83,84,85,86,87,88,89,90,91,92,93] |
| Verification of Quality Characteristics in NFR (e.g., usability, UX, security, explainability) and user feedback; Ensuring security of Requirements; GDPR; Assessing the SRS quality by ISO 25010; Test case generation/Automate the quality checking/analysis of a Req./user story | [94,95,96,97,98,99,100] | |
| Identify potential effects on Sustainability; Assess Transparency and Sustainability as NFR | [101,102,103] | |
| Verification of pre-/post-conditions of Requirements; Requirements to Test Cases Traceability; Predicting probability of defects using design-level attributes | [96,104,105,106,107,108,109,110] | |
| Classification of requirements in two classes: “Integration Test” and “Software Test” using ML approaches | [111] | |
| Extracting Knowledge from Requirements | Requirements Formalization; Extracting/Associating Features (Feature Extraction) or Model Elements from/to Requirements; Extract domain vocabulary from requirements for Feature Modeling or ontology construction | [43,58,81,83,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134] |
| Detecting or Extracting Requirements Dependencies/Requirements Traceability (forward and backward) | [105,120,121,135,136,137,138,139,140,141,142,143] | |
| Supporting Requirements Management and Validation, and Project Management | Requirements Prioritization | [77,144,145,146,147,148,149] |
| Allocating requirements to software versions based on development time, priority, and dependencies; Predicting whether a software feature will be completed within its planned iteration | [150,151,152] | |
| Project Management Risks Assessment/Req. Change Impact analysis on other requirements and on planned test cases | [153,154,155] |
| RE Category | RE Activity | Main Approaches Used for NLP and Feature Extraction from NL Text, and for Dataset Preparation, and Main ML Approaches Used for Achieving the RE Activity |
|---|---|---|
|
Classification of Requirements according to their Functional/ Non-Functional nature | Binary FR/NFR Classification, and ternary classification FR/NFR/Non-Req |
TF; BoW; TF-IDF; Word2Vec; FastText; Doc2Vec; SMOTE; PCA; RST; DT; SVM; KNN; NB; MNB; NN; RF; K-means; Hierarchical Clustering; SVC; Bagged KNN; Bagged DT; Bagged NB; ExtraTree; GNB; SGD; GB; XGBoost; AdaBoost; ANN; RNN; LSTM; Bi-LSTM; MLP; CNN; BERT; PRCBERT; NoRBERT; MLM-BERT; GPT; BoW + MNB; TF-IDF + SVM; Doc2Vec + MLP + CNN; BoW + SVM; BoW + KNN; TF-IDF + SGD; Multiple correlation coefficient-based DT; Bi-LSTM-Att (Bi-LSTM + Attention Model); Ensemble Grid Search classifier using 5 models (RF, MNB, GB, XGBoost, AdaBoost); Trans_PRCBERT (PRCBERT fine-tuned on PROMISE); TPOT; Ensemble classif. combining 5 models (NB, SVM, DT, LR, SVC); Self-attention Bidirectional-RNN Deep Model (SABDM); Bidirectional Gated Recurrent Neural Networks (BiGRU); BERT-CNN. |
Classifying NFR in further subcategories, and Classifying ASFR |
| RE Category | RE Activity | Main Approaches Used for NLP and Feature Extraction from NL Text, and for Dataset Preparation, and Main ML Approaches Used for Achieving the RE Activity |
|---|---|---|
| Supporting Requirements Elicitation | Categorize and Classify Business Rules (as a source for RE) | TF; BoW; TF-IDF; Word2Vec; FastText; Doc2Vec; Rasa-NLU; Rasa-Core; MNB; SVM; Multi-dataset training; zero-shot approaches; Having a perturbator and a classifier positively influencing each other; Multimodal Autoencoder and Multimodal Variational Autoencoder methods; Supervised ML models; BERT; GPT; DL; NN; Transformer-based DL models; Neural Language Models; Hierarchical cluster labeling; Speech-acts based analysis technique; Part-of-Speech (POS) Tagging; NLP + ML techniques leveraging the concept of requirement boilerplate; NLP4ReF; NLP4ReF-NLTK; NLP4ReF-GPT; Trained LSTM RNN model (based on Rasa) + MNB or SVM; BERT-based transformer + static preference linker. |
| Predicting/recommending Techniques for Req. Elicitation | ||
| Generating questions for Requirements elicitation | ||
| Identifying/Generating new Requirements from existing Requirements or from User Feedback; Identifying ASFR; Classifying User Feedback |
| RE Category | RE Activity | Main Approaches Used for NLP and Feature Extraction from NL Text, and for Dataset Preparation, and Main ML Approaches Used for Achieving the RE Activity |
|---|---|---|
|
Improving Quality of Requirements and Software |
Requirements itemization, simplification, disambiguation; Detecting incompleteness, ambiguity, inaccuracy, implicit requirements, semantic similarity, and other risks (smells) in Req. Spec.; Coping with ambiguity through the use of controlled vocabulary and Ontologies |
Tokenization; POS Tagging; Dependency Parsing; Data balancing techniques such as SMOTE, RUS, ROS, and Back translation (BT); LLM; GPT; ACM; SVM; LogR; MNB; FPDM using Adaptive Boosting, Gradient Boosting, and Extreme Gradient Boosting; BASAALT / FORM-L; NLP4ReF-NLTK and NLP4ReF-GPT; NLP techniques with features extracted using TF-IDF and BoW + Various classifiers (LR, NB, SVM, DT, KNN); BERT’s masked language model to generate contextualized predictions + ML-based filter to post-process BERT’s predictions; Text classification technique; Sentence embedding and antonym-based approach for finding incomplete Reqs.; BERT-based and clustering approach for detecting intra- or cross-domain ambiguities; ULMFiT (Transfer learning approach where the model is pre-trained to a general-domain corpus and then fine-tuned to classify ambiguous vs unambiguous reqs); COTIR (integrates Commonsense knowledge, Ontology and Text mining for early detecting Implicit Reqs.); ML approach to extract UX characteristics from FR; BERT + knowledge graphs integrating information from various sources on security and vulnerabilities + Transfer learning is applied to reduce the training demands of ML and DL models; Adaboost ensemble method; ML algorithms to predict vulnerabilities for new reqs; ML-based defect prediction models using design-level metrics and data sampling techniques; Knowledge engineering-based architecture to create a traceability matrix using NLP and ML techniques, using an ontology and optimization algorithm, including real world knowledge and not requiring a lot of data; Test case generation using text classification with NB algorithm, Scikit-learn and NLTK to identify preconditions and postconditions within requirements; Combining NLP and ML to automate software requirement-to-test mapping; Supervised ML classifiers to classify user stories according to valuable and testable metrics; TF-IDF + LR achieved highest performance for req. smells classif.; TF-IDF + SVM outperformed other algorithms; ULMFiT achieved higher accuracy than SVM; LogR; MNB classifiers; COTIR outperforms other IMR tools. |
|
Verification of Quality Characteristics in NFR (e.g., usability, UX, security, explainability) and user feedback; Ensuring security of Requirements; GDPR; Assessing the SRS quality by ISO 25010; Test case generation / Automate the quality checking/analysis of a Req./user story | ||
| Identify potential effects on Sustainability; Assess Transparency and Sustainability as NFR | ||
| Verification of pre-/post-conditions of Requirements; Requirements to Test Cases Traceability; Predicting probability of defects using design-level attributes | ||
| Classification of requirements in two classes: “Integration Test” and “Software Test” using Machine Learning approaches |
| RE Category | RE Activity | Main Approaches Used for NLP and Feature Extraction from NL Text, and for Dataset Preparation, and Main ML Approaches Used for Achieving the RE Activity |
|---|---|---|
|
Extracting Knowledge from Requirements | Requirements Formalization; Extracting/Associating Features (Feature Extraction) or Model Elements from/to Requirements; Extract domain vocabulary from requirements for Feature Modeling or ontology construction |
NLP techniques and ML algorithms; IE; GPT; BASAALT/FORM-L;
TextRank (NLP techniques and ML algorithms); Ontology learning method (the ontology is semi-automatically constructed) + Information Entropy and CCM method; NB; Linear SVM; KNN; RF; MTBE techniques; LLM; READ; MNB; GNB; SVM; NER; NLP + WSL+ (RF or SVM or NB); Combining matching with automated reqs analysis and ROF; AGER System; Extension of the Siemens toolchain for ALM that creates trace links between requirements and models; DL-based, non-exclusive classification approach for FRs, using Word2Vec and FastText, and a CNN; SyAcUcNER; SRXCRM; ReqVec; BiLSTM NN to find relationships and patterns among sentences around domain concepts; DoMoBOT; DF4RT; TLR-ELtoR; OpenReq-DD dependency detection tool (NLP + ML); Cascade DF model integrating infor. retrieval (IR), query quality (QQ) and distance metrics; ML + Logical reasoning; Combination of evolutionary computation and ML techniques to recover traceability links between requirements and models; S2Trace (Unsupervised reqs traceability approach). |
|
Detecting or Extracting Requirements Dependencies / Requirements Traceability (forward and backward) |
| RE Category | RE Activity | Main Approaches Used for NLP and Feature Extraction from NL Text, and for Dataset Preparation, and Main ML Approaches Used for Achieving the RE Activity |
|---|---|---|
| Supporting Requirements Management and Validation, and Project Management | Requirements Prioritization | Adam algorithm; ARPT (Automated Requirement Prioritization Technique); Decision Tree, Random Forest, and K-Nearest Neighbors; NLP + ML; Combination of NLP techniques and Machine Learning algorithms; Adapted genetic K-means algorithm for software requirements engineering (GKA-RE), which automatically identifies the optimal number of clusters by dynamically readjusting initial seeds for improved quality; AI Task Allocation tool (ATA’); Tree-Family Machine Learning (TF-ML); Credal Decision Tree (CDT). |
| Allocating requirements to software versions based on development time, priority, and dependencies; Predicting whether a software feature will be completed within its planned iteration | ||
| Project Management Risks Assessment / Req. Change Impact analysis on other requirements and on planned test cases |
| RE Activity | Common AI/ML Techniques | Feature Extraction & Preprocessing |
|---|---|---|
| Requirements Classification | Naïve Bayes (NB), Decision Trees (DT), Support Vector Machines (SVM), Random Forest (RF), K-Nearest Neighbors (KNN), Logistic Regression (LR) | Bag-of-Words (BoW), TF-IDF, Word2Vec, FastText, GloVe, Doc2Vec |
| Requirements Prioritization | SVM, DT, KNN, NB, LR, Multinomial NB (MNB), Ensemble Methods (Bagged KNN/DT/NB), Genetic K-means (GKA-RE), ARPT optimization | TF-IDF, Feature selection via optimization |
| Traceability | RF, DT, NB, Ensemble classifiers (e.g., cascade deep forest DF4RT), Sequential-semantics models (S2Trace), Hybrid approaches | TF-IDF, Embeddings, Knowledge-graph features |
| Ambiguity Detection & Disambiguation | Transformer models (BERT, PRCBERT, GPT-3.5), Semi-automated NLP tools | Contextual embeddings (BERT), Lexical analyses |
| Model Generation | Heuristic Rule-based methods, Ontology-based frameworks (ROF), RNNs (Bi-LSTM, Bi-GRU), CNN, BERT-CNN hybrids | Dependency parses, Semantic Role Labeling |
| Validation & Verification | ML classifiers (NB, SVM, RF), Knowledge-oriented methods, Formal models, Prototyping tools | TF-IDF, Syntactic Features |
| Change Impact Analysis | Combined NLP+ML (e.g., ARPT-Adam, cascade models), Optimization algorithms, Feature-impact prediction models | TF-IDF, Domain-specific information extraction |
| Key Ethical Concerns | Explanation |
|---|---|
| Bias and Fairness | Training datasets reflect historical biases (e.g., under-serving certain user groups) and AI may prioritize or classify requirements in ways that perpetuate inequity. Automated prioritization risks amplifying the needs of louder or more active stakeholders (whose feedback dominates the data), marginalizing quieter or less technical voices. |
| Transparency and Accountability | Deep Learning or ensemble models often lack clear explanations, making it hard to justify why a requirement was flagged, deprioritized or linked. Another issue has to do with decision ownership. When AI makes suggestions, who bears responsibility for errors? |
| Privacy and Confidentiality | Requirements documents can contain proprietary, personal or security-critical information. Feeding them into third-party AI services or cloud-based models risks leaks or unauthorized data exposure. In CrowdRE, scraping and analyzing user comments may inadvertently harvest personal data or violate users’ expectations of privacy. |
| Over-Reliance and De-Skilling | Excessive dependence on AI suggestions can weaken engineers’ requirement-analysis skills over time, reducing their ability to spot subtle domain issues or think critically. Teams may uncritically accept AI outputs, even when they are flawed, simply because “the tool suggested it.” |
| Consent and Ethical Data Use | Using stakeholder inputs, such as chat logs or survey responses, to train or fine-tune models requires clear consent, especially if data is repurposed for unrelated RE tasks. Also, data collected for one purpose (e.g., feature requests) might be redeployed elsewhere without stakeholders’ knowledge or approval. |
| Job Displacement and Workforce Impact | Automating routine tasks (e.g., classification, traceability) may shift or eliminate parts of requirements-engineer roles, demanding reskilling or raising concerns about job security. Organizations should plan for fair upskilling pathways rather than abrupt layoffs. |
| Security and Adversarial Manipulation | Malicious stakeholders could inject misleading or adversarial requirement descriptions to skew AI outputs (e.g., burying safety-critical requirements in noise). Model robustness requires that AI remains reliable under intentionally crafted or noisy inputs. This is essential for safety-critical domains. |
| Legal and Regulatory Compliance | If AI-driven requirement decisions lead to non-compliance (e.g., with GDPR), determining legal liability between tool vendors, integrators and engineering teams can be complex. Regulations may mandate clear records of how requirements were derived and prioritized, enabling audit trails. Opaque AI processes complicate compliance. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosado da Cruz, A.M.; Cruz, E.F. Machine Learning Techniques for Requirements Engineering: A Comprehensive Literature Review. Software 2025, 4, 14. https://doi.org/10.3390/software4030014
Rosado da Cruz AM, Cruz EF. Machine Learning Techniques for Requirements Engineering: A Comprehensive Literature Review. Software. 2025; 4(3):14. https://doi.org/10.3390/software4030014
Chicago/Turabian StyleRosado da Cruz, António Miguel, and Estrela Ferreira Cruz. 2025. "Machine Learning Techniques for Requirements Engineering: A Comprehensive Literature Review" Software 4, no. 3: 14. https://doi.org/10.3390/software4030014
APA StyleRosado da Cruz, A. M., & Cruz, E. F. (2025). Machine Learning Techniques for Requirements Engineering: A Comprehensive Literature Review. Software, 4(3), 14. https://doi.org/10.3390/software4030014