
Characterizing Agile Software Development: Insights from a Data-Driven Approach Using Large-Scale Public Repositories



Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Stage 1: Definition of Analysis Requirements
- (a)
- The repositories had to contain data from software product development projects;
- (b)
- The data had to originate from actual projects which have generated product;
- (c)
- There would preferably be no a priori limitation regarding whether the project owner was a commercial entity or an individual;
- (d)
- The data had to be public and sourced from a development community that operates under open-source principles [34];
- (e)
- The data would preferably include information reflecting characteristics typical of Agile development models (e.g., frequency of product delivery), which would allow for the identification of common patterns in projects with Agile development approaches.
- (f)
- The data had to be accessible, either through direct access (API—Application Programming Interface) or via a platform that hosts publicly accessible data repositories.
3.2. Stage 2: Source Identification, Data Capture and Variable Processing
- (a)
- The “GitHub Public Repository Metadata” dataset available in JSON format on the Kaggle collaborative platform (https://www.kaggle.com/datasets/pelmers/github-repository-metadata-with-5-stars/data (accessed on 24 September 2023)). It has general metadata information from more than 3 million projects with 5 or more ‘stars’. This first dataset was the basis for identifying study projects and the basis for which the first characterization and filtering analysis actions were carried out.
- (b)
- Mining repository metadata through GitHub’s Rest API obtained in JSON format. This data source was used to complete the overall dataset, adding the metadata corresponding to project releases (not included among Kaggle’s variables). These metadata were essential for understanding the nature of projects in terms of their development model.
- (c)
- The “github_repos” dataset available in the “Bigquery-public-data” public dataset in Google Big query (https://cloud.google.com/blog/topics/public-datasets/github-on-bigquery-analyze-all-the-open-source-code?hl=en (accessed on 24 September 2023)). Here, we found a table with the metadata of the commits of all the public repositories of GitHub. “commit”, according to the GitHub glossary, is a change in one of the files in the repository made by anyone who collaborates on the project. This information (not included among Kaggle’s variables) was considered important for reflecting the behavior of the developer community in projects, relevant to understanding the dynamics of development. Table 1 presents the number of items pulled from each of these data sources.
- (a)
- ‘isArchived’: This standard variable in GitHub repository metadata indicates projects that have concluded and have been marked as such by their developers. Those repositories that have a value of ‘True’ were selected to ensure that project data were used in a steady state that would not undergo modifications after the analysis process.
- (b)
- ‘diskUsageKb’: This standard variable in GitHub repository metadata indicates the size of the repository on disk (measured in KB). The values of this variable in the original dataset have an asymmetric distribution (lognormal), with great variability. It contains outliers with very large values compared to the rest of the values (µ = 26,748.72, σ = ±421,503; median: 552; min: 0; Max: 107 × 106; variance σ2 = 1.78 × 1011). Only repositories that have a value between 1000 and 100,000 KB in this variable were selected to ensure that atypical, immature or poorly developed projects (the typical “Hello World”) were excluded. The original data distribution is shown in Figure 3 with the Probability Density Function (PDF) of the fitted lognormal distribution. A logarithmic scale was used to better visualize the data and the fitted distribution.
- (c)
- ‘description’: This standard variable in GitHub repository metadata includes a description of the repository in text format. It is used to filter those projects related to software development, as there are repositories on GitHub that are not associated with software code and products. The filtering procedure involved searching this field for the presence of 24 predefined keywords commonly associated with code development. These keywords were identified through a review of the first 100 records in the dataset and included terms such as ‘source’, ‘program’, ‘app’, ‘display’, ‘API’, ‘library’, among others.
- (d)
- ‘tag_name’: This field stores the name of each published version of the project. These metadata were used to filter projects that follow a standardized versioning nomenclature, characterized by a three-digit numeric code separated by periods (e.g., ‘1.0.0’). This selection ensured that the analyzed projects follow established version control practices.
3.3. Stage 3: Analytical Procedure and Machine Learning for AgileScore Labeling
- (a)
- Data cleansing. Records with outliers in the statistical distribution of any variable were removed. Additionally, this process identified fields containing null values, which were considered during data processing in the machine learning model.
- (b)
- Manual tagging of the ‘AgileScore’ variable. The identification of Agile projects was based on two key attributes: ‘stdDTRelease’ and ‘numReleases’. The ‘stdDTRelease’ was used as a proxy for regularity in delivery frequency, one of the core principles of Agile development, as established in references [1,11]. This variable was used to assign an AgileScore of 10 to projects with a ‘stdDTRelease’ value between 0 and 20 (lowest variability in cadence) and an AgileScore of 9 to projects with a ‘stdDTRelease’ value between 20 and 50. These thresholds were chosen to ensure a balanced distribution of positive and negative labels. For lower values of the AgileScore, the variable ‘numReleases’ was used. Since frequent deliveries imply the presence of multiple releases, projects with very few releases were identified as the least agile. Consequently, an AgileScore of 1 was assigned to projects with a single release and a score of 2 to projects with two releases. Moreover, ‘numReleases’ was used to prevent projects with few releases from being rated as highly agile, establishing that only those with more than 10 releases can be assigned a score of 9 or 10. ‘stdDTRelease’ was not used for assigning the lowest AgileScore values. Through these procedures, the dataset of 365 projects was labeled, which was used to train the predictive model (Table 3).
- (c)
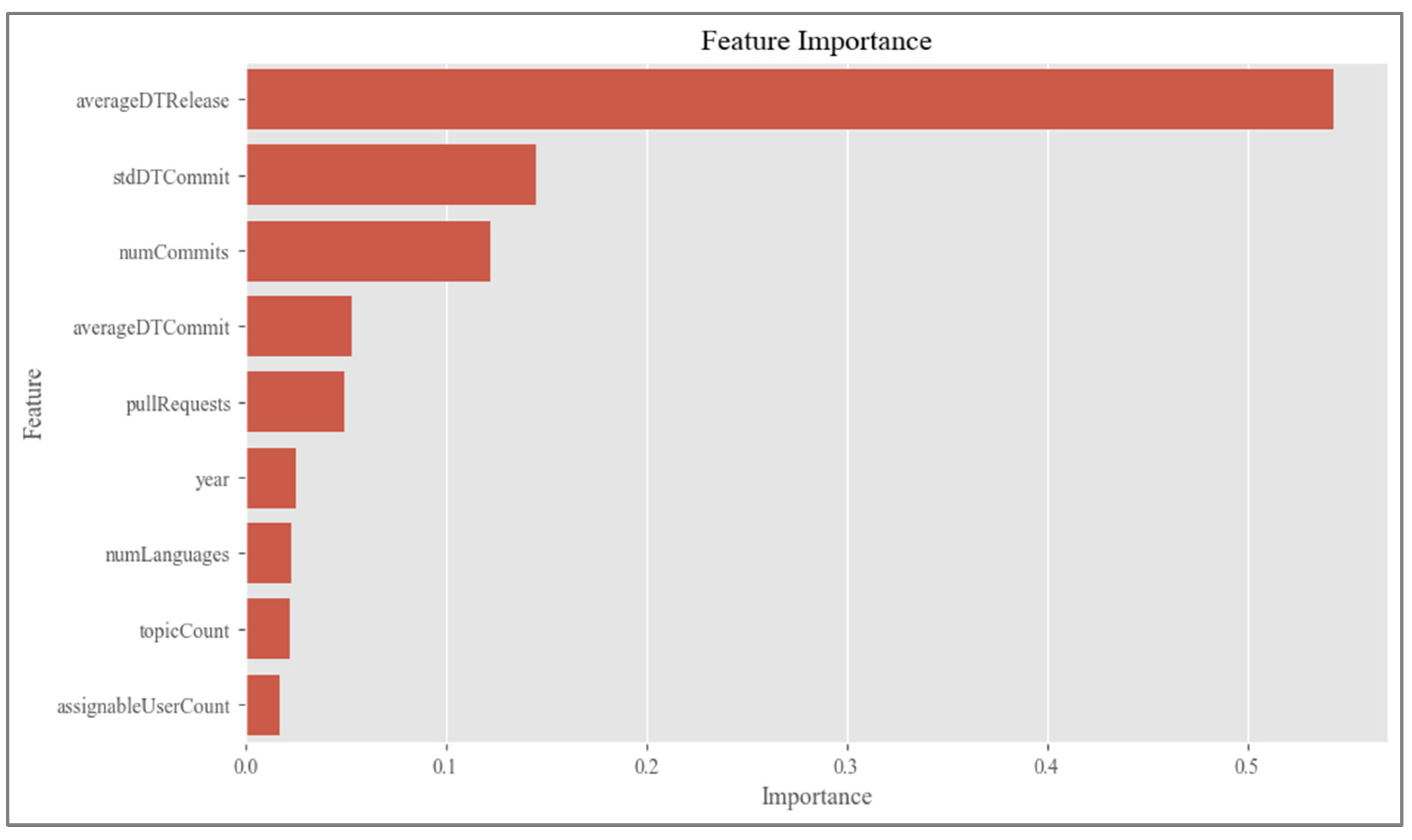
- Tagging intermediate Agile scores using machine learning. Since part of the sample was already labeled, supervised machine learning techniques could be applied to automatically infer intermediate values of the ‘AgileScore’ for the remaining samples. A Random Forest Regressor algorithm was employed to predict this value for the 786 repositories that had not been manually labeled. To apply this technique, the sample was divided into two groups: one labeled group, used for training and testing the model in an 80/20 split, and one unlabeled group, to which the trained model was then applied. The parameters used in the model were the default settings, and a summary of some of them is provided below:
- ‘n_estimators’ = 100;
- ‘min_samples_split’ = 2;
- ‘max_features’ = auto.
- (d)
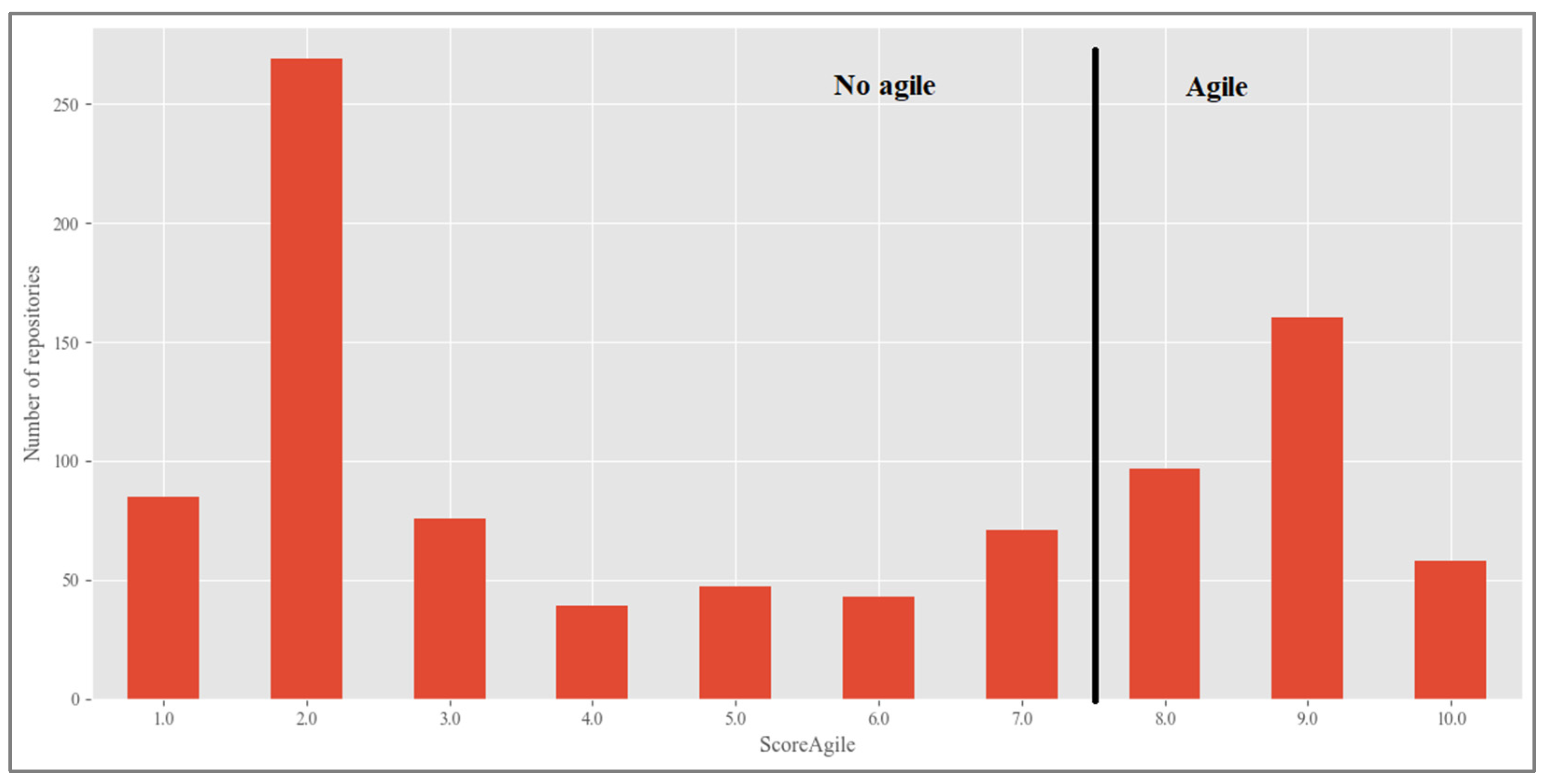
- Assignment of Agile/Non-Agile ‘Methodology’. Once the ‘AgileScore’ was assigned to all projects, the ‘methodology’ variable was used to clearly classify projects as either Agile or Non-Agile. Under an ideal, zero-error model, selecting projects with a score above the midpoint of the scale (i.e., >5 out of 10) would correctly identify those exhibiting a majority of Agile practices. However, our model’s validation on held-out repositories produced a root mean squared error (RMSE) of 2.2, which implies that a midpoint threshold lay well within the model’s uncertainty range and could lead to false positives. Consequently, we adopted a more conservative cutoff of ≥8 (i.e., midpoint + RMSE, rounded up) to reliably identify projects that predominantly follow Agile approaches. This conservative threshold helped to ensure that all repositories labeled as Agile truly adhered to Agile principles, even in light of the widespread hybridization of development methodologies observed in practice [36] (Figure 5).
3.4. Stage 4: Analytical Model Validation
4. Results
- (a)
- In the sample of repositories to which the AgileScore index is applied (from 2011 to 2019), a growing trend in the adoption of Agile methodologies on GitHub is observed, with an average annual increase of 16% (±0.47). This trend is consistent with previous findings reported in [1]. However, while the situation identified by AgileScore across all analyzed projects reveals a clear upward trend, Agile projects do not yet constitute a prevailing majority. This is consistent with the observation made in [3], which identifies in its literature review the apparent belief that traditional processes have been entirely replaced by Agile. An anomaly in 2018 is evident but has been retained in the results to accurately reflect the actual state of the repositories. Figure 8 illustrates the evolution over time of the growth of projects marked with the AgileScore index.
- (b)
- When applying the AgileScore index from the perspective of organizational project dynamics, such as interest among the developer community in specific repositories or projects, a pattern emerges: a higher number of watchers is observed as the AgileScore index increases (Figure 9).
5. Discussion
6. Conclusions and Future Work
- (a)
- Feasibility of classifying projects in public repositories with an agility index (AgileScore): This research confirms that it is possible to classify projects in public repositories, particularly on GitHub, using an agility index based on empirical data. By applying data analysis and machine learning models, this study effectively identifies Agile projects and characterizes their adherence to specific Agile practices. The methodology allows for the classification and evaluation of projects in terms of their performance against specific metrics, demonstrating its practical applicability.
- (b)
- Characterizing the situation of software projects in public repositories concerning development process models, focusing on trend and community engagement: This study shows that public repositories, such as GitHub, host a wide range of development models, ranging from traditional approaches to Agile. This diversity reflects the flexibility of development teams in adapting processes to meet project-specific needs, underscoring the dynamic nature of software development practices, and advises following a hybrid approach in project development.
- (c)
- Replicability of the classification process in other types of repositories: This research proposes the AgileScore index methodology be adapted for use in other public repositories, as long as they provide sufficient and relevant metadata. The ability to replicate the process depends on data availability and the repository’s specific attributes, but the core approach is flexible enough to be applied to various platforms.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nicholls, D.; Dong, H.; Dacre, N.; Baxter, D.; Ceylan, S. Understanding Agile in Project Management. Assoc. Proj. Manag. 2022. Available online: https://www.apm.org.uk/resources/find-a-resource/agile-project-management/ (accessed on 5 June 2024).
- European Commission and Directorate-General for Informatics. The PM2-Agile Guide 3.0.1. 2021. Available online: https://data.europa.eu/doi/10.2799/162784 (accessed on 17 June 2024).
- Kuhrmann, M.; Tell, P.; Hebig, R.; Klünder, J.; Münch, J.; Linssen, O.; Pfahl, D.; Felderer, M.; Prause, C.R.; MacDonell, S.G.; et al. What Makes Agile Software Development Agile. IEEE Trans. Softw. Eng. 2022, 48, 3523–3539. [Google Scholar] [CrossRef]
- Highsmith, J.; Cockburn, A. Agile software development: The business of innovation. Computer 2001, 34, 120–122. [Google Scholar] [CrossRef]
- Henriques, V.; Tanner, M. A systematic literature review of agile and maturity model research. Interdiscip. J. Inf. Knowl. Manag. 2017, 12, 53–73. [Google Scholar] [CrossRef]
- Ghimire, D.; Charters, S. The Impact of Agile Development Practices on Project Outcomes. Software 2022, 1, 265–275. [Google Scholar] [CrossRef]
- Strode, D.; Dingsøyr, T.; Lindsjorn, Y. A teamwork effectiveness model for agile software development. Empir. Softw. Eng. 2022, 27, 56. [Google Scholar] [CrossRef]
- Alsaadi, B.; Saeedi, K. Data-Driven Effort Estimation Techniques of Agile User Stories: A Systematic Literature Review; Springer: Dordrecht, Netherlands, 2022; Volume 55. [Google Scholar] [CrossRef]
- Gemino, A.; Reich, B.H.; Agile, P.M.S. Traditional, and Hybrid Approaches to Project Success: Is Hybrid a Poor Second Choice? Proj. Manag. J. 2021, 52, 161–175. [Google Scholar] [CrossRef]
- Špundak, M. Mixed Agile/Traditional Project Management Methodology—Reality or Illusion? Procedia–Soc. Behav. Sci. 2014, 119, 939–948. [Google Scholar] [CrossRef]
- Kirpitsas, I.K.; Pachidis, T.P. Evolution towards Hybrid Software Development Methods and Information Systems Audit Challenges. Software 2022, 1, 316–363. [Google Scholar] [CrossRef]
- Glass, R.L. The State of the Practice of Software Engineering. IEEE Softw. 2003, 20, 20–21. [Google Scholar] [CrossRef]
- github.com. Octoverse: The State of Open Source and Rise of AI in 2023—The GitHub Blog. Available online: https://github.blog/2023-11-08-the-state-of-open-source-and-ai/ (accessed on 29 May 2024).
- Alrashedy, K.; Binjahlan, A. How do Software Engineering Researchers Use GitHub? An Empirical Study of Artifacts & Impact. In Proceedings of the 2024 IEEE International Conference on Source Code Analysis and Manipulation (SCAM), Flagstaff, AZ, USA, 7–8 October 2024; pp. 118–130. [Google Scholar] [CrossRef]
- Khan, A.A.; Khan, J.A.; Akbar, M.A.; Zhou, P.; Fahmideh, M. Insights into software development approaches: Mining Q &A repositories. Empir. Softw. Eng. 2024, 29, 1–38. [Google Scholar] [CrossRef]
- Sheoran, J.; Blincoe, K.; Kalliamvakou, E.; Damian, D.; Ell, J. Understanding ‘watchers’ on GitHub. In Proceedings of the 11th Working Conference on Mining Software Repositories, Hyderabad, India, 31 May–1 June 2014; pp. 336–339. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, Y.; Zhou, Y.; Wu, J.; Jiang, H.; Huang, G. Exploring GitHub Topics: Unveiling Their Content and Potential. In Proceedings of the 2024 IEEE International Conference on Software Services Engineering, SSE, Shenzhen, China, 7–13 July 2024; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2024; pp. 25–35. [Google Scholar] [CrossRef]
- Xiong, Y.; Meng, Z.; Shen, B.; Yin, W. Mining developer behavior across git hub and stack overflow. In SEKE; Ksi Research Inc.: Pittsburgh, PA, USA, 2017; pp. 578–583. [Google Scholar] [CrossRef]
- Dabbish, L.; Stuart, C.; Tsay, J.; Herbsleb, J. Social coding in GitHub: Transparency and collaboration in an open software repository. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, Seattle, WA, USA, 15 February 2012; pp. 1277–1286. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, J.; Jeon, H.; Kim, Y.-H.; Song, H.; Kim, B.; Seo, J. Githru: Visual analytics for understanding software development history through git metadata analysis. IEEE Trans. Vis. Comput. Graph. 2021, 27, 656–666. [Google Scholar] [CrossRef] [PubMed]
- Mrvar, G. Leveraging Open-Source Data for Software Cost Estimation: A Predictive Modeling Approach. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2023. [Google Scholar]
- Tawosi, V.; Moussa, R.; Sarro, F. Agile Effort Estimation: Have We Solved the Problem Yet? Insights From a Replication Study. IEEE Trans. Softw. Eng. 2023, 49, 2677–2697. [Google Scholar] [CrossRef]
- Robles, G.; Capiluppi, A.; Gonzalez-Barahona, J.M.; Lundell, B.; Gamalielsson, J. Gamalielsson. Development effort estimation in free/open source software from activity in version control systems. Empir. Softw. Eng. 2022, 27, 135. [Google Scholar] [CrossRef]
- Siddiq, M.L.; Santos, J.C.S. BERT-Based GitHub Issue Report Classification. In Proceedings of the 1st International Workshop on Natural Language-Based Software Engineering, NLBSE, Lisbon, Portugal, 20 April 2022; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2022; pp. 33–36. [Google Scholar] [CrossRef]
- Tawosi, V.; Al-Subaihin, A.; Moussa, R.; Sarro, F. A Versatile Dataset of Agile Open Source Software Projects. In Proceedings of the 19th International Conference on Mining Software Repositories, Pittsburgh, PA, USA, 23–24 May 2022; Association for Computing Machinery: New York, NY, USA, 2022; Volume 1. [Google Scholar] [CrossRef]
- Pickerill, P.; Jungen, H.J.; Ochodek, M.; Maćkowiak, M.; Staron, M. PHANTOM: Curating GitHub for engineered software projects using time-series clustering. Empir. Softw. Eng. 2020, 25, 2897–2929. [Google Scholar] [CrossRef]
- Mckay, J.; Marshall, P. The dual imperatives of action research. Inf. Technol. People 2001, 14, 46–59. [Google Scholar] [CrossRef]
- Hevner, A.; March, S.T.; Ram, S.; Jinsoo, P. Design Science in Information Systems Research. MIS Q. 2004, 28, 75–105. [Google Scholar] [CrossRef]
- Creswell, J.W.; Creswell, J.D. Research Design: Qualitative; Quantitative, and Mixed Methods Approaches, 6th ed.; Sage Publications: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Mariscal, G.; Marbán, Ó.; Fernández, C. A survey of data mining and knowledge discovery process models and methodologies. Knowl. Eng. Rev. 2010, 25, 137–166. [Google Scholar] [CrossRef]
- Chapman, P. CRISP-DM 1.0 Step-by-step data mining guide. SPSS Inc 2000, 78, 1–78. Available online: http://www.crisp-dm.org/CRISPWP-0800.pdf (accessed on 8 July 2024).
- Wirth, R.; Hipp, J. CRISP-DM: Towards a standard process model for data mining. In Proceedings of the Fourth International Conference on the Practical Application of Knowledge Discovery and Data Mining, Manchester, UK, 11–13 April 2000; pp. 29–39. Available online: https://www.researchgate.net/publication/239585378_CRISP-DM_Towards_a_standard_process_model_for_data_mining (accessed on 8 July 2024).
- Schröer, C.; Kruse, F.; Gómez, J.M. A systematic literature review on applying CRISP-DM process model. Procedia Comput. Sci. 2021, 181, 526–534. [Google Scholar] [CrossRef]
- Bruce, P. The Open Source Definition. Open Source Softw. 2004, 1, 321–322. [Google Scholar] [CrossRef]
- Kalliamvakou, E.; Singer, L.; Gousios, G.; German, D.M.; Blincoe, K.; Damian, D. The promises and perils of mining GitHub. In Proceedings of the 11th Working Conference on Mining Software Repositories, MSR 2014, New York, NY, USA, 14 April 2014; Association for Computing Machinery, Inc.: New York, NY, USA, 2014; pp. 92–101. [Google Scholar] [CrossRef]
- Kuhrmann, M.; Diebold, P.; Münch, J.; Tell, P.; Garousi, V.; Felderer, M.; Trektere, K.; McCaffery, F.; Linssen, O.; Hanser, E.; et al. Hybrid software and system development in practice: Waterfall, scrum, and beyond. In Proceedings of the 2017 International Conference on Software and System Process, Paris, France, 5–7 July 2017; pp. 30–39. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Peng, S.; Kalliamvakou, E.; Cihon, P.; Demirer, M. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot. arXiv 2023, arXiv:2302.06590. Available online: http://arxiv.org/abs/2302.06590 (accessed on 24 May 2024).
- Appio, F.P.; Frattini, F.; Petruzzelli, A.M.; Neirotti, P. Digital Transformation and Innovation Management: A Synthesis of Existing Research and an Agenda for Future Studies. J. Prod. Innov. Manag. 2021, 38, 4–20. [Google Scholar] [CrossRef]
- Srisathan, W.A.; Ketkaew, C.; Jitjak, W.; Ngiwphrom, S.; Naruetharadhol, P. Open innovation as a strategy for collaboration-based business model innovation: The moderating effect among multigenerational entrepreneurs. PLoS ONE 2022, 17, e0265025. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kaggle | API Mined Dataset | BigQuery | |
|---|---|---|---|
| Num. of documents | 3,274,587 | 84,970 | 1,180,160 |
| Num. of repositories | 3,274,587 | 6195 | 6195 |
| Num. of attributes | 25 | 35 | 8 |
| Main contribution | Repositories metadata | Project releases data | Commit data |
| Attribute Name | Description | Selection Criteria | Origin | Type |
|---|---|---|---|---|
| owner | Name of the repository creator | F | Kaggle | String |
| Forks | Number of copies made of the repository | G | Kaggle | Integer |
| Watchers | Number of project followers | G | Kaggle | Integer |
| topicCount | Number of categorization labels assigned | S—The use of labels and categories could indicate an organized and modular approach, which is characteristic of Agile methodologies, where requirements and tasks are managed iteratively. | Kaggle | Integer |
| diskUsageKb | Disk size of repository data | G | Kaggle | Integer |
| pullRequests | Number of change approval requests | S—The number of pull requests is a direct indicator of collaboration and continuous code review, key elements of Agile. A high number of pull requests suggests an iterative development approach. | Kaggle | Integer |
| primaryLanguage | The most widely used programming language in the repository | G | Kaggle | String |
| defaultBranchCommitCount | Number of commits made in the repository | G | Kaggle | Integer |
| license | Name of the development license used | G | Kaggle | String |
| assignableUserCount | Number of users responsible for changes | S—A lower or moderate number of assignable users could be characteristic of a small, self-organizing Agile team, while larger teams might be more typical of traditional methodologies. | Kaggle | Integer |
| codeOfConduct | Rules of conduct to be followed by participants | G | Kaggle | String |
| nameWithOwner | Unique repository identifier (creator/project) | F | Kaggle | String |
| numLanguages | Number of programming languages used | S—Agile projects often use multiple technologies and programming languages, as the adaptability and integration of new tools are Agile principles. A higher number of languages might suggest a flexible and adaptive approach. | Kaggle | Integer |
| year | Year of creation of the repository | G | Kaggle | Integer |
| topReleaserName | Name of the user who has published the most releases | G | Rest API | String |
| numReleases | Number of releases released | S—The number of releases reflects the ability to deliver software frequently, a fundamental principle of Agile methodologies, which emphasize small, continuous releases. | Rest API | Integer |
| firstReleaseDay | Number of days until the first release | S—Agile projects tend to have quicker initial releases as part of their iterative cycle. | Rest API | float |
| averageDTRelease | Average number of days between one release and another | S—A short release cycle suggests an Agile approach, with frequent deliveries and constant feedback, which is a hallmark of Agile methodologies. | Rest API | float |
| stdDTRelease | Standard deviation of days between one release and another | S—A low standard deviation indicates a consistent release rhythm, which is common in Agile teams that maintain a predictable cadence of development. | Rest API | float |
| topCommitterName | Repo member who has posted the most commits | G | Big Query | String |
| numCommits | Number of commits made in the repository | S—A high number of commits reflects frequent and continuous development, a central principle of Agile methodologies, which promote incremental, ongoing work. | Big Query | Integer |
| averageDTCommit | Average number of days between one commit and another | S—A short time interval between commits indicates a consistent development rhythm, which is a key feature of Agile methodologies, promoting continuous, incremental work. | Big Query | float |
| stdDTCommit | Standard deviation of days between commit and commit | S—A low standard deviation between commits reflects a predictable work rhythm, which is common in Agile teams that maintain a consistent development pace. | Big Query | float |
| ‘AgileScore’ | ‘numReleases’ | ‘stdDTRelease’ | Label Distribution (%) in Manual Tagging (n = 365) |
|---|---|---|---|
| 1 | n = 1 | Not applicable | 23% |
| 2 | n = 2 | Not applicable | 32% |
| 9 | n >= 10 | n <= 20 | 30% |
| 10 | n >= 10 | 20 < n <= 50 | 15% |
| AgileScore | Average Num. of Watchers (±std) |
|---|---|
| High, meaning Agile projects (8 to 10) | 48.75 ± 2.54 |
| Low, meaning non-Agile projects (1 to 3) | 37.33 ± 5.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moreno Martínez, C.; Gallego Carracedo, J.; Sánchez Gallego, J. Characterizing Agile Software Development: Insights from a Data-Driven Approach Using Large-Scale Public Repositories. Software 2025, 4, 13. https://doi.org/10.3390/software4020013
Moreno Martínez C, Gallego Carracedo J, Sánchez Gallego J. Characterizing Agile Software Development: Insights from a Data-Driven Approach Using Large-Scale Public Repositories. Software. 2025; 4(2):13. https://doi.org/10.3390/software4020013
Chicago/Turabian StyleMoreno Martínez, Carlos, Jesús Gallego Carracedo, and Jaime Sánchez Gallego. 2025. "Characterizing Agile Software Development: Insights from a Data-Driven Approach Using Large-Scale Public Repositories" Software 4, no. 2: 13. https://doi.org/10.3390/software4020013
APA StyleMoreno Martínez, C., Gallego Carracedo, J., & Sánchez Gallego, J. (2025). Characterizing Agile Software Development: Insights from a Data-Driven Approach Using Large-Scale Public Repositories. Software, 4(2), 13. https://doi.org/10.3390/software4020013