1. Introduction
The emergence of blockchain technology has initiated a significant transformation across various sectors, offering unmatched benefits such as transparency, immutability, and automation [
1]. Blockchain technology, which relies on a distributed ledger maintained by a network of nodes, ensures data integrity and security through cryptographic techniques. This decentralized approach eliminates the need for intermediaries, reducing costs and increasing efficiency.
Smart contracts, a key innovation of blockchain technology, are self-executing agreements with the terms of the contract directly written into code. These contracts automatically enforce and execute the agreed-upon terms when predetermined conditions are met, enabling trustless transactions without intermediaries. Platforms like Ethereum have popularized smart contracts, facilitating their adoption in diverse sectors including finance, supply chain management, healthcare, and governance [
2,
3,
4,
5].
In the finance sector, smart contracts enable the creation of decentralized financial (DeFi) applications, such as lending platforms, decentralized exchanges, and stablecoins. For instance, platforms like Uniswap and Compound leverage smart contracts to automate trading and lending, providing users with greater control over their assets [
6]. In supply chain management, companies like IBM and Maersk use blockchain-based smart contracts to enhance transparency and traceability, ensuring the authenticity of products and reducing fraud [
7]. In healthcare, smart contracts can be used to manage patient data securely, facilitate research collaboration, and streamline insurance claims processing [
8].
Despite their transformative potential, smart contracts are not without flaws. Significant security vulnerabilities have been exposed, leading to high-profile exploits such as the DAO attack, where an attacker exploited a re-entrancy vulnerability to drain 50 million USD worth of Ether from the decentralized autonomous organization (DAO) [
9,
10,
11]. Common vulnerabilities include re-entrancy, integer overflow, and underflow, unchecked return values, and access control issues [
12,
13]. Addressing these security issues is crucial for the widespread adoption and success of smart contracts.
Static analysis has become a cornerstone technique for identifying vulnerabilities within smart contracts, offering comprehensive code coverage and early detection of security flaws without the need for code execution [
14]. Data dependency analysis is a major static analysis technique applied to enhance the testing and security analysis of smart contracts. For instance, ILF [
15] and SmartTest [
16] include the reads and writes of state variables to train models for fuzzing and symbolic execution, respectively. Smartian [
17] employs read-and-write data to enhance the effectiveness of fuzzing for smart contracts. SmartExecutor [
18] requires dependency data for guided symbolic execution to increase code coverage. Sailfish [
19] needs the reads and writes of state variables to detect state inconsistency bugs.
Slither is one of the most widely used static analysis tools in both industry and academia [
20]. However, Slither is not without its limitations; it often misses critical state-variable dependencies, resulting in incomplete vulnerability detection [
21]. This limitation is particularly problematic, given the diverse and complex nature of smart contract code.
Recent advancements in large language models (LLMs), epitomized by GPT-4o, have demonstrated remarkable capabilities in code comprehension and analysis [
22,
23,
24]. These models excel in understanding and contextualizing source code, making them ideal for addressing the limitations of traditional static analysis tools.
We propose a novel methodology to harness the code-understanding capability of GPT-4o and the advantages of Slither to perform dependency analyses. The dependency analysis is converted into the process of refining the given dependency data. Slither is utilized to collect the dependency data, and GPT-4o is responsible for refining the data. The refining process is performed by the three roles made from GPT-4o: checker, evaluator, and verifier. The checker filters out the data that do not need to be refined. The evaluator and the verifier form the evaluation-verification loop; they are responsible for refining the to-be-refined data in loops until the verifier accepts the data or the maximum loop limit is reached.
Our approach is novel in two aspects: (a) the dependency analysis is designed as the process of refining the given dependency data. The given data can be easily obtained using a static analysis tool, allowing our approach to take advantage of existing static analysis tools. GPT-4o excels in the refining process as a reasoning tool, effectively leveraging the strengths of both an LLM and a traditional static analysis tool. (b) Our approach introduces three different roles based on GPT-4o to refine the given data. We empirically evaluate our approach using a curated dataset of Ethereum smart contracts, showcasing significant improvements in detection precision, recall, and overall analysis depth. Our findings underscore the potential of combining LLMs with static analysis tools, paving the way for more secure blockchain applications.
The contributions of this study can be encapsulated as follows:
Methodology Proposal: We introduce a comprehensive methodology named Sligpt, which integrates GPT-4o with the Slither static analysis framework to perform data dependency analyses.
Empirical Evaluation: Sligpt is rigorously evaluated using a meticulously curated dataset of Ethereum smart contracts. The results demonstrate enhanced performance in comparison to both Slither and GPT-4o.
Open Source Contribution: We have developed and released Sligpt (The repository can be accessed at
https://github.com/contractAnalysis/sligpt, accessed on 30 July 2024), making both the source code and experimental data publicly available for further research and validation.
The structure of this paper is organized as follows:
Section 3 delves into the foundational concepts of blockchain, smart contracts, static analysis, and large language models. It provides a comprehensive review of related work in the areas of smart contract security, static analysis, and the application of large language models in code comprehension.
Section 4 elaborates on the issues and existing solutions in four specific scenarios and outlines our motivation for this study.
Section 5 describes the proposed approach for Sligpt.
Section 6 presents the experimental setup and empirical findings of our study.
Section 7 and
Section 2 discuss the implications of our findings in the context of previous related work. Finally,
Section 8 concludes this paper.
4. Motivation
4.1. Function Dependency Analysis
Function dependency analysis is an analysis that explores the dependency relationships among functions. A smart contract is a stateful program that consists of state variables and functions. Some functions can use state variables in branching conditions to control the business logic. Some other functions can modify the state variable. Thus, one type of function dependency is based on the state variables read in branching conditions and written in functions. If function A reads a state variable in a branching condition and function B can write this state variable, then function A depends on function B.
Function dependency analysis is an important static analysis for both the testing and security analysis of smart contracts. When a contract is deployed, state variables can not be updated arbitrarily. In other words, state variables are modified by executing functions that can modify them. Therefore, to test a function, certain functions need to be executed first to change the values of the state variables used in the branching conditions of the function. As a result, when executing this function after them, the branching conditions of this function are more likely to be satisfied; thus, more code can be covered. When the code coverage increases, the chance of detecting vulnerabilities is improved as well. Therefore, function dependency analysis can be applied to the fuzzing and symbolic execution of smart contracts for testing and security analysis.
To perform the function dependency analysis, the first step is to identify the state variables read in branching conditions and the state variables written by each function. Slither [
20], a widely used static analysis tool in academia and industry, has the APIs to obtain the state variables read in conditions and the state variables written for a given function.
4.2. Limitations of Slither
However, studies show that Slither can fail to detect the state variables read in conditions (i.e., it has false negatives). Slither can also fail to distinguish branching conditions from other conditions. Below, we present four common cases where Slither fails to identify the state variables read in branching conditions.
4.2.1. False Negative 1
When a state variable is assigned to a local variable, and this local variable is used in a branching condition, the state variable is considered read in the branching condition. Slither fails to detect this.
In Contract FN1 shown in Listing 1, there is one function . The state variable a is assigned to a local variable in Line 9. Then, is used in the condition in Line 10. Therefore, a is considered read in the condition in Line 10. However, Slither can not detect that a is read in this condition in Line 10.
| Listing 1. Contract FN1. |
![Software 03 00018 i001]() |
4.2.2. False Negative 2
When a function that reads a state variable is called in a branching condition, this state variable should be considered read in this condition of the caller. Nevertheless, Slither fails to recognize that this state variable is read in the branching conditions of the caller function.
For example, in Contract FN2 shown in Listing 2, there are two functions, and . reads state variable a and is used in the condition of the function in Line 12. State variable a is used in this condition to compare with a constant 10. Slither can not identify that a is read in a branching condition in function .
| Listing 2. Contract FN2. |
![Software 03 00018 i002]() |
4.2.3. False Positive 1
When a function returns a state variable of the type , this state variable is read in a condition in this function according to Slither. However, this state variable is actually not read in a branching condition.
In Contract FP1 in Listing 3, Function returns , which is of the type . Slither considers the state variable read in a condition of Function . However, there is no branching condition in Function . Therefore, Slither treats a variable of type in the statement as a condition, which can result in a false positive.
| Listing 3. Contract FP1. |
![Software 03 00018 i003]() |
4.2.4. False Positive 2
When a function returns a conditional expression, the state variables used in the conditional expression are considered as the state variables read in conditions by Slither. In other words, Slither treats conditional expressions in the statement as conditions. However, these conditions are not the branching conditions in a function used to control the business logic of the function.
For instance, in contract FP2 in Listing 4, a and are two state variables. They appear in a conditional expression in the statement. Slither reports that a and are the state variables read in conditions of the function .
| Listing 4. Contract FP1. |
![Software 03 00018 i004]() |
4.3. Proposal to Perform a Function Dependency Analysis
We propose a method to perform a function dependency analysis based on GPT-4o and Slither. GPT-4o has shown remarkable capabilities in understanding and programming code. The advantage of GPT-4o is that it can analyze code like an expert and thus can be used to perform code analysis beyond the limits of traditional engineering tools. However, it sometimes behaves like a layman who has limited knowledge of the code being analyzed, which is known as a hallucination issue. Slither is a widely used static analysis tool that produces results deterministically and never generates anything that does not make any sense. This is the advantage of Slither. As shown in the subsection immediately above, however, Slither can fail in some cases. By combining GPT-4o and Slither, we can take advantage of both GPT-4o and Slither.
We formulate the function dependency analysis as the data-refining process. We first prepare for the initial dependency data. Then, we refine the initial dependency data. The key insights are as follows:
Slither can not only provide dependency data but also other information that can be used to provide additional information for further analysis.
GPT-4o fits the job of refining data, as it is good at analyzing code like a human. The hallucination issue can be alleviated by carefully designing the refining process and providing additional context information to limit the evaluation scope.
We first apply Slither to collect function dependency data and other information like state variables and modifiers. Next, we utilize GPT-4o to refine the function dependency data through three different roles: the checker, evaluator, and verifier. Given a piece of data of a function, some other data, and function code, the checker initially checks whether the function is required to be closely examined or not. If not, then the refining process stops. Otherwise, the evaluator further evaluates the function data through a conversation with the verifier. Receiving the function data to be evaluated, the evaluator first examines them. Next, the evaluator updates the function data if it finds them to be incorrect, or it accepts them if it agrees with the given data. Then, the function data are sent to the verifier to verify. If the verifier determines that the data should be allowed to pass, the function data are then accepted, and the refining process terminates. Otherwise, the verifier sends back the feedback to the evaluator, which then evaluates the function data again while being aware of the feedback. The updated function data then again go to the verifier. The conversation ends when the function data pass the verifier or the conversation length reaches a user-defined limit. Note that the conversation length refers to the number of evaluation–verification cycles.
The novelty of our proposal is that we define the dependency analysis as the data-refining process, and we create three different roles of GPT-4o to form a refining process to refine the data. Our proposal is named Sligpt, which is the concatenation of “sli” and “gpt”. “Sli” is the first three letters from “Slither”, and gpt is the first three letters from “GPT-4o”.
5. Approach
We present our approach, Sligpt, to perform a function dependency analysis. Sligpt employs GPT-4o to refine the function dependency data produced by Slither. The function dependency data are the state variables read in branching conditions and the state variables written in functions. Sligpt is designed to refine the state variables read in branching conditions while keeping the state variables written without evaluation. This design decision is based on the observation that Slither can detect the state variables written correctly and the general rule of selecting a tool for an engineering task. If the data can be correctly obtained using a traditional engineering tool, then it is better to use the traditional tool instead of a learning model that is not deterministic.
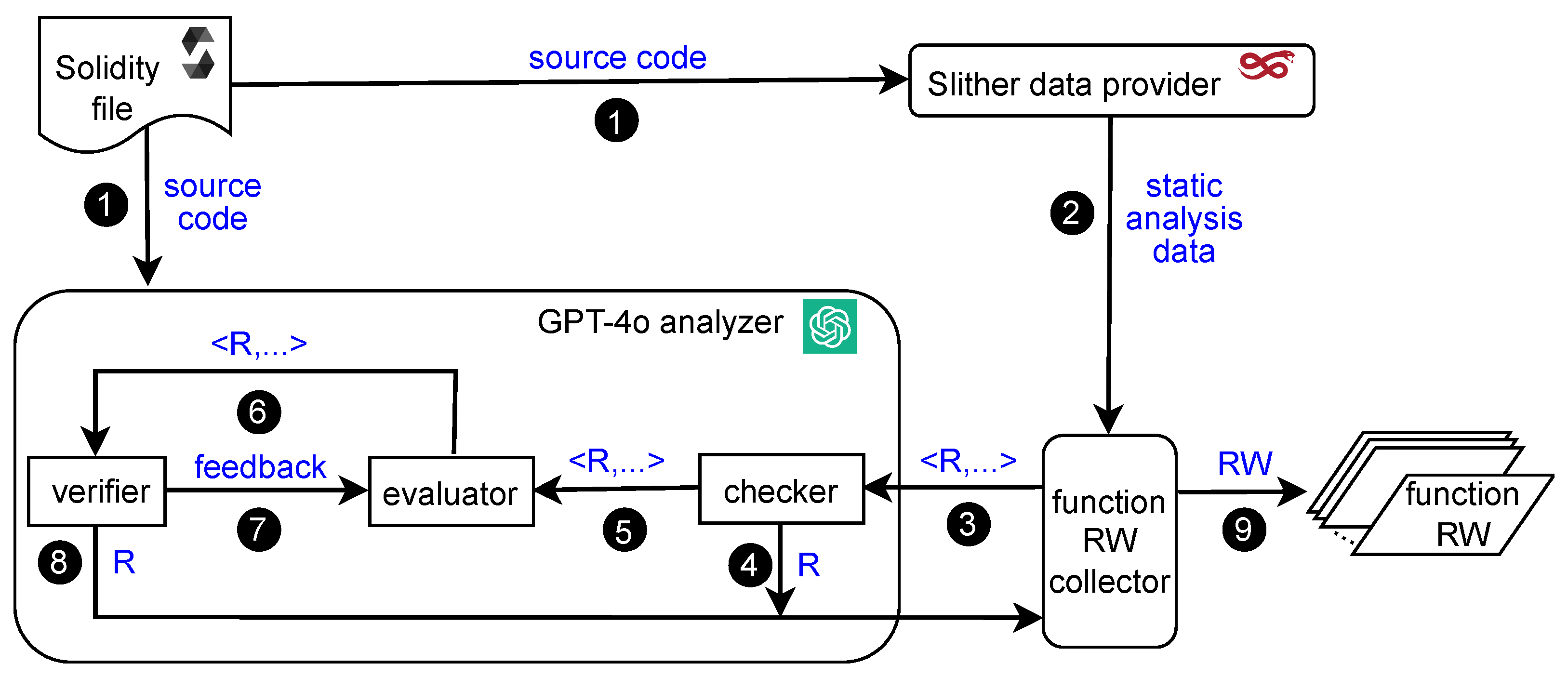
5.1. Architecture
Figure 1 presents the architecture of Sligpt. It has three main components: the Slither data provider, function RW collector, and GPT-4o analyzer. The components o the Solidity file and function RW denote the input and output entities, respectively. The labels of the arrows connecting the components show the data flowing between the components. The Slither data provider provides initial function dependency data for further refinement and other data that may serve as information to help the GPT-4o analyzer to reduce instances of hallucinations. the function RW collector deals with the state variables read in the branching conditions (
R) and the state variables written (
W) for each function. It relies on the GPT-4o analyzer to examine
R and outputs the RW data for each function. The GPT-4o analyzer investigates
R to refine it and returns to the function RW collector. The GPT-4o analyzer refines
R through three roles: the checker, evaluator, and verifier. The checker acts as a filter to filter out the functions that do not need to be refined. The evaluator and verifier form the evaluation–verification loop to refine
R.
5.2. Workflow
In this subsection, we show the end-to-end workflow of Sligpt, starting with the given Solidity file of a contract and ending with the collected function dependency data of the contract. Initially, the Slither data provider and the GPT-4o analyzer receive the source code of the given Solidity file, as indicated by the arrow numbered ❶. Next, the Slither data provider invokes Slither to collect for each function the invoked modifiers, the state variables read in the branching conditions (i.e., R), the state variables written (i.e., W), and all the state variables defined in the contract. These collected data are the static analysis data that go to the function RW collector, as indicated by the arrow numbered ❷. Then, the function RW collector drives the GPT-4o analyzer to refine R for each function. Note that Sligpt is designed to refine R instead of W, as Slither can correctly identify W.
For each function, the function RW collector obtains the RW related to the function and other data (presented as
… in
Figure 1) from the static analysis data, including all state variables and the modifiers invoked in the function. Then, the collector calls the GPT-4o analyzer to refine
R by providing the
R and other data (see the arrow numbered as ❸. When the GPT-4o analyzer returns the refined
R, the function RW collector uses the returned
R and the original
W as the final RW of the function. When all the functions are considered, it outputs a collection of function RW, as indicated by the arrow numbered ❾.
The GPT-4o analyzer, to save on costs, avoids refining the functions that do not need to be examined (the reasons are given in
Section 5.3.1). Therefore, the checker is employed to filter out such functions. When a function is filtered out, the GPT-4o analyzer returns the received
R directly back to the function RW collector, shown by the arrow numbered ❹. Otherwise, the
R of the function and other data are sent to the evaluator (see the arrow numbered ❺) to refine.
The evaluator evaluates the R to determine whether to accept it or not. If the evaluator does not accept it, the evaluator then provides the updated R that it thinks is correct. Next, the evaluator passes the accepted or updated R along with other data to the verifier for verification, as shown by the arrow numbered as ❻. If the verifier agrees with the received R, the GPT-4o analyzer returns this R (see the arrow numbered as ❽). Otherwise, the verifier provides feedback to the evaluator (see the arrow numbered as ❼). When the evaluator receives the feedback, it re-evaluates R by considering the feedback. At this point, a loop is formed between the evaluator and the verifier. This evaluation–verification loop is repeated until the verifier agrees with the received R.
Figure 1.
Architecture of Sligpt. R: the state variables read in the branching conditions of a function. W: the state variables written in a function. ...: denotes the data providing additional information based on static analysis data (e.g., state variables, modifiers). Static analysis data: include all the defined state variables and the data of each public or external function: modifiers, the state variables read in branching conditions (R), and the state variables written (W). Note that Sligpt currently does not refine W, as Slither can correctly identify W.
Figure 1.
Architecture of Sligpt. R: the state variables read in the branching conditions of a function. W: the state variables written in a function. ...: denotes the data providing additional information based on static analysis data (e.g., state variables, modifiers). Static analysis data: include all the defined state variables and the data of each public or external function: modifiers, the state variables read in branching conditions (R), and the state variables written (W). Note that Sligpt currently does not refine W, as Slither can correctly identify W.
5.3. GPT-4o Analyzer
The GPT-4o analyzer is the core component of Sligpt to refine the given function dependency data. It is designed with consideration of the costs, the hallucination issue, and the indeterministic nature of LLMs. We design the analyzer based on chain-of-thought prompting, which is a type of few-shot learning with reasoning steps (thoughts) available.
5.3.1. Checker
The role of the checker is to initially examine the function to determine the necessity of further refining the process. This role is introduced while considering the cost. The GPT-4o analyzer is not free of charge. The unnecessary invoking of the GPT-4o analyzer should be recognized and reduced. Therefore, the checker is designed to reduce the unnecessary invoking of the GPT-4o analyzer.
The key insight to creating the checker is that the Slither data provider can provide correct dependency data except for the failure cases mentioned in the Motivation section. Therefore, our idea for designing the checker is to examine the function code to determine whether it has the code patterns resulting in the failure cases. Recall that there are four code patterns causing the failure cases:
Having a local variable in a branching condition that has the value expressed in terms of a state variable.
Having a function call in a branching condition such that the invoked function reads a state variable.
Having a return statement that returns a state variable of type bool.
Having a return statement that returns a boolean expression involving state variables.
We design the checker as the prompt design. The design is based on the four code patterns.
Figure 2 visualizes the prompt design of the checker. The checker prompt first defines the constraints that are used to capture the code patterns mentioned above. As long as one of the constraints is satisfied, the function should be further checked.
The next part of the checker prompt content depends on the provided inputs at runtime: the Solidity source code of a contract, a function defined in this contract, and others. Others include the defined state variables and modifiers. They are optional and can be added to the prompt after the constraint description as an extra scope limit (not presented in the prompt design). The contract code is provided instead of the function code. The reason is that the function code may involve other functions and modifiers. Identifying function code needs to correctly collect all the function calls and modifiers and then their corresponding code. This process requires careful engineering. In addition, the token limit of GPT-4o is 128,000 tokens. Directly giving the contract code does not cause the input tokens to reach the limit.
At the end of this prompt, a few examples are provided to show the steps to conclude whether a constraint is satisfied or not. Since the task is about reasoning whether a piece of code satisfies the unseen constraints, we thus provide examples to demonstrate how to perform such a task. For each constraint, we provide at least one example. Take the example shown in
Figure 2, the question is, "does the function updateValue(uint256) need to be checked?" The steps necessary before reaching a conclusion are as follows:
- (a)
A local variable temp is defined in function updateValue(uint256).
- (b)
State variable a is assigned to temp.
- (c)
temp is used in a condition from an if statement.
- (d)
Constraint 1 is thus satisfied.
- (e)
The answer is yes.
By defining the constraints to detect the code patterns and giving examples to demonstrate how to evaluate if the given piece of code satisfies one of the constraints, the prompt can be prompted to GPT-4o to answer questions related to the given function defined in the given contract code.
5.3.2. Evaluator
The role of the evaluator is to evaluate the function code to determine whether the given data of the function are acceptable or not. The evaluation process is designed as the iteration of the evaluation–verification cycles due to the issue of hallucination of LLMs. In this section, we first show the design of the prompt of determining the acceptance of the given data. Then, we present the prompt during the iteration process.
To evaluate the given data, we identify a list of rules to detect the state variables read in branching conditions (
R). A few examples are provided to demonstrate how to identify the state variables based on the given rules. The rules and examples are the main elements of the initial evaluator prompt. The design of the initial evaluator prompt is shown in
Figure 3. Note that the prompt of the evaluator grows along with the evaluation–verification loops. Therefore, we have the initial prompt.
As shown in
Figure 3, there are five rules defined to detect
R. These five rules encompass the general or common patterns of how
R appears in the code. We admit that we may miss some patterns that we have not observed so far. However, the evaluator can be easily adapted by adding more rules.
To further assist the evaluation task, we provide at least one example for each rule so that the GPT-4o can learn and know how to evaluate. Each example has the contract code, the question based on a function of the code, and the answer to the question. Take the example shown in
Figure 3. The contract
FN1 has a function named
updateValue with a parameter of type
uint256. The question is whether the given data about the function are correct. The answer formats are also provided for the question. As for the answer, it shows the steps of how to reach the final answer.
The initial evaluator prompt also includes the contract code that contains the function to be analyzed and the question about the function. The question is not directly to ask the evaluator to identify R for the given function. Instead, the question is to evaluate the function code based on the rules first and then check if the given data are acceptable based on the evaluation.
To reduce the hallucination issue, the evaluator is designed to enable multiple iterations, such that in each iteration the feedback of the evaluation is provided. The feedback (from the verifier, which is presented in
Section 5.3.3) can provide some insight, helping the evaluator to reason. In terms of the evaluator, in each iteration, it has a question about
R, obtains the accepted
R from the answer to the question, and receives the feedback about
R.
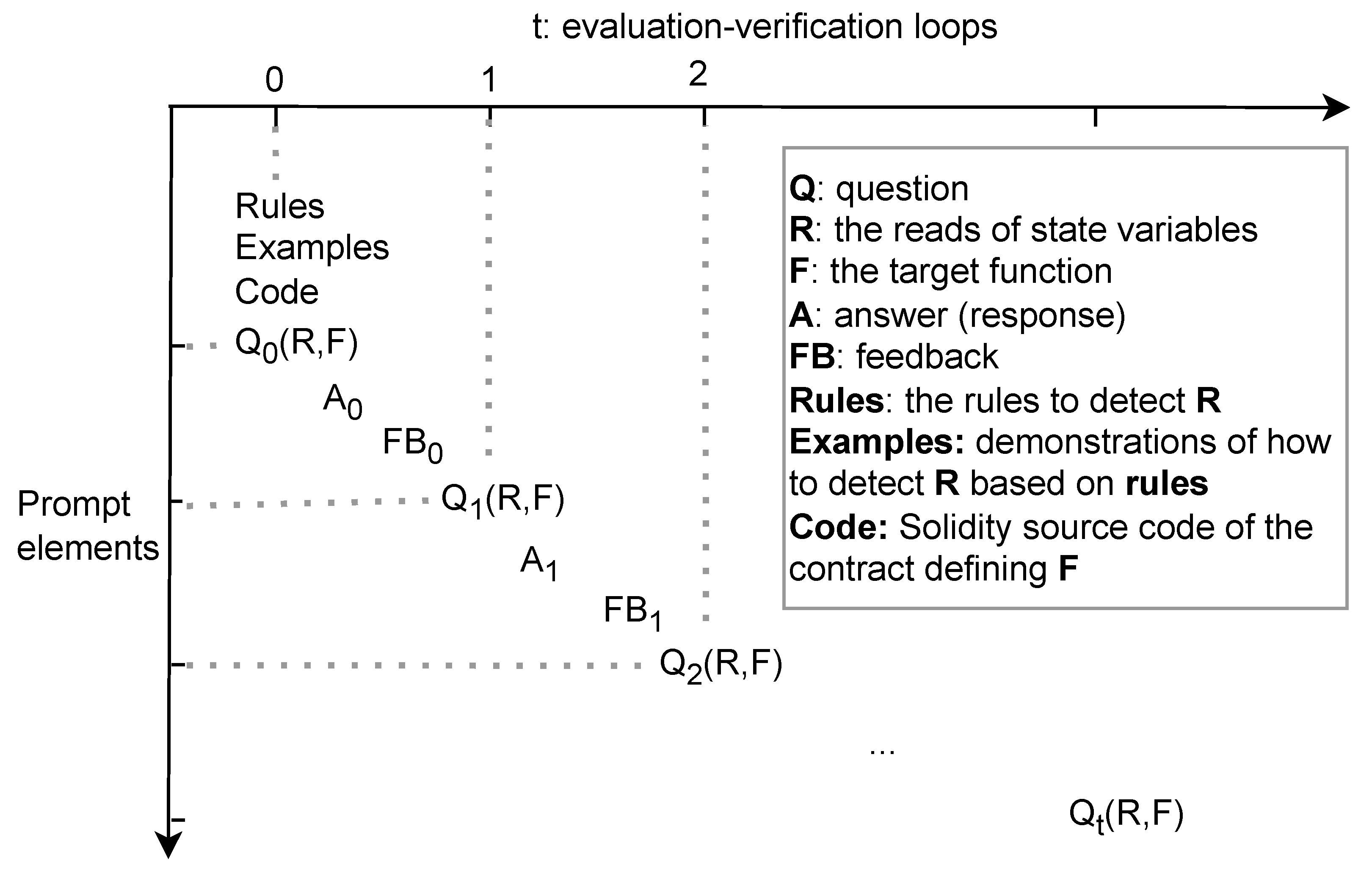
As the past iterations are important for the evaluation in the current iteration, at the beginning of each iteration, the prompt is designed to be accumulated such that it can have a comprehensive record of this history. The prompt elements of the evaluator are visualized in
Figure 4. When t (iteration loop) = 0, the prompt is the initial prompt, which is presented in
Figure 3. It consists of rules (
Rules), rule demonstration examples (
Examples), contract code (
Code), and the question (
) about a function (
F) and
R of the function. In this iteration, the answer (
) to the question is obtained, and the feedback (
) is received from the verifier. When t = 1, the question
is based on the
R that is accepted when t = 0. The prompt in this iteration is thus the concatenation of
Rules,
Examples,
Code,
,
,
, and
. This process is continued until the maximum iteration limit is reached.
5.3.3. Verifier
The verifier is included as a mechanism to reduce the impact of hallucinations. It further examines the given R accepted by the evaluator. If the reasoning process of the evaluator has inconsistency, the verifier then investigates the R from a different perspective, which is supposed to reveal the inconsistency. If the verifier finds no issues, then it allows the given R to pass so that the GPT-4o analyzer stops the refining process and returns the R. Otherwise, the verifier delivers the investigation results to the evaluator as feedback, such that the evaluator will re-evaluate R.
The verifier is designed to verify the given R accepted by the evaluator. In this case, the verifier acts as an expert in function data dependency analysis. Generally, an expert is expected to know the parts that are more likely to go wrong. Therefore, our idea to verify the given R is to analyze the points where R is likely wrongly identified. Hence, we design the verification as the process used to answer a list of questions regarding those points.
We raised six questions based on the given R of the target function based on the points that the Slither data provider and the evaluator are likely to make mistakes. The verifier verifies the given R by answering these questions one by one. When all the answers to these questions are “no”, the verifier accepts the R and allows it to pass. Otherwise, the verifier provides the reasons for the questions, the answers to which are not “no”. These reasons are the feedback sent to the evaluator.
Figure 5 shows an example of how to verify the given data for the function
updateValue(uint256) in contract FN1. Questions (a) and (b) examine the case that the state variables are used in a function, while this function is then invoked in
updateValue(uint256). Question (c) checks the state variables used in the modifiers. Question (d) is to check if a state variable is considered because it is used in the return statement. Question (e) is to evaluate if all the state variables in the
R are correctly identified. If each state variable in the
R has the related conditions, then all the state variables in the
R are correctly identified. Note that the related conditions of a state variable
svar are the branching conditions that
svar is identified as read in them. For example, if
v is a state variable and there is a function
F that has a local variable
temp having the value expressed by
v and a branching condition
temp > 10, then
v is identified as read in a branching condition of the function
F, and
temp > 10 is a related condition of
v. Question (f) examines whether a state variable is missed when it is used to express the value of a local variable that is then used in a branching condition.
As shown in
Figure 5, for each question, the steps to reach the answer are provided. The answers to the first five questions are “no”. However, the answer to the last question is “yes”. Therefore, the given data fail to pass the verification. The final answer is “not pass”.
The prompt design of the verifier is shown in
Figure 6. It includes the rules used to identify
R, examples of how to verify, and the questions related to
R, the target function, and a series of verification questions. Note that the verifier does not depend on the evaluator. It only sees the given data and verifies them. Therefore, the identification rules should also be provided to help answer the questions.
In addition, the number of questions can be reduced based on other data. For example, if the function has no modifier, then question (c) can be removed. If all the state variables defined in a contract are in the given data, then questions (a), (b), (c), and (f) can be ignored, as it is impossible to miss any state variables.
5.4. Discussion of How to Handle Hallucinations
Large language models (LLMs) suffer from hallucinations [
47,
48,
49], a phenomenon where AI generates convincing but nonsensical answers. OpenAI acknowledges that the responses generated by ChatGPT may sound plausible but be nonsensical or incorrect.
Our approach is designed with an awareness of the hallucination issue. While we cannot entirely overcome the hallucination problem, we have implemented several strategies to minimize its occurrence:
Refinement of dependency data: We refine the dependency data obtained through a static analysis tool rather than rely on an LLM to directly generate this data.
Multiple evaluation–verification loops: We employ multiple evaluation–verification loops in the refining process instead of one loop.
Minimizing LLM dependency: We reduce the parts of the process that require an LLM for refinement or evaluation. For example, we only refine the reads of the state variables and evaluate the reads for functions that are likely to present failure patterns identified by Slither.
Providing context information: We supply additional context information, referred to as “other data” in this paper. This includes providing a list of state variables that the LLM can consider and the modifiers of a function. All this information can be obtained along with the dependency data.
By implementing these strategies, we aim to reduce the impact of hallucinations and enhance the reliability of our method.
6. Evaluation
In this section, we evaluate Sligpt based on its performance when identifying the dependency data.
Dataset. To better evaluate Sligpt, we collected 10 Solidity smart contracts, each containing functions where the state variables read in branching conditions are hard to identify. These 10 contracts include all the cases mentioned in
Section 4. (Please note that we can consider many more contracts; however, they either do not present the failure patterns mentioned in the Motivation section, or they repeat the same patterns in the selected 10 contracts). There are a total of 73 public or external functions (i.e., user-callable functions) without considering the constructor and the public functions of the state variables (note that public state variables are treated as public functions). On average, each contract has seven functions, indicating that the contracts selected are not simple.
Tools for comparison. We compare Sligpt with Slither (version 0.9.6), a state-of-the-art static analysis tool, using Solidity smart contracts. Slither converts Solidity source code to an intermediate presentation and then performs different analyses on the intermediate presentation. It provides APIs to collect the state variables read and written in functions. We also compare Sligpt with GPT-4o(version gpt-4o-2024-05-13), one of the most popular and powerful LLMs. It is trained on code and can understand code syntax and semantics like a human. We prompted GPT-4o with the proper requests. We admit that the content of the prompts may impact the performance of GPT-4o. However, we attempted to prepare the prompts based on content that was similar to the prompts used in Sligpt to reduce the impact of the prompts.
Metrics. We used the common metrics [
50] to measure the performance based on the precision, recall, accuracy, and F1 score. In this paper, precision reflects how many state variables read in branching conditions are correctly identified out of the reported state variables, recall describes the actual state variables read in the branching conditions (i.e., the ground truth), and accuracy reflects the combination of the reported state variables and the ground truth. The F1 score reflects a balance between precision and recall.
Experiments. We run Slither to obtain the state variables read in the branching conditions and the state variables written for each function of 10 contracts. As Slither is a deterministic tool that always produces the same results with the same input, we only run it once. Due to the non-deterministic and unpredictable nature of LLMs, we prompt GPT-4o and run Sligpt five times. To avoid overloading GPT-4o, we send requests every 20 s.
Result collection. We first manually identify the state variables read in branching conditions and written in each function in the dataset as the ground truth. Then for each function, we collect the state variables read in the branching conditions and the state variables that can be written in it for the three tools. Finally, we compute the values of the metrics we use to measure the performance on the state variables read in the branching conditions, as identifying them is challenging. For a function, given a list of reported state variables read in the branching conditions and a set of the actual state variables read in the branching conditions of this function, we count the number of successfully identified state variables, the number of state variables that fail to be detected, and the number of state variables that are reported but are not expected (i.e., not the state variables read in the branching conditions). These three numbers denote the numbers of true positives (TPs), false-negatives (FNs), and false positives (FPs), respectively. For each function, we collect these three numbers. Then, we sum the corresponding numbers across all the functions. Finally, we compute the F1 score.
Table 1 presents the values.
In
Table 1, the numerators represent the counts of the correctly identified reads of state variables. For the Precision column, the denominators are the total counts of the reads of state variables in the branching conditions reported by the tools. For the Recall column, the denominators are the total counts of the reads of the state variables actually occurring in the branching conditions (i.e., the ground truth). In the Accuracy column, the denominators are the union of the reads reported by the tools and the ground truth.
Result analysis.
Figure 7 visualizes the metric data for the three tools after averaging the five data points for GTP-4o and Sligpt.
Figure 7 indicates that Sligpt has an accuracy of about 0.88; the highest. Slither has an accuracy of 0.76, while the accuracy of GPT-4o is about 0.67. When it comes to the F1 score, Sligpt achieves an accuracy of about 0.93; the highest as well. Slither and GPT-4o have accuracies of 0.86 and 0.8, respectively.
Generally, GPT-4o has the lowest performance. Although GPT-4o can identify more state variables read in branching conditions than Slither, as shown in
Table 1 (GPT-4o correctly identifies 80 state variables read in branching conditions, while Slither only identifies 75 state variables), GPT-4o can report many more state variables that are not read in the branching conditions compared to Slither (see the denominators in the Precision column in
Table 1). Sligpt, by taking advantage of Slither and GPT-4o, manages to identify even more state variables correctly than GPT-4o, but it also reduces the number of false positives.
Discussion. We notice that Sligpt is quite unstable. This instability is demonstrated by the data in the tables and is due to the unpredictable nature of GPT-4o.
Manually, we can make Sligpt correctly identify all state variables read in branching conditions without false positives for each contract at least once. But if we run it multiple times, Sligpt can have false positives and false negatives as well.
GPT-4o may also produce nonsensical responses that can impact Sligpt. Mostly, GPT-4o can learn from the given examples about how to analyze and then apply the analysis patterns like an expert. However, it can still fabricate data. For example, for a function with the declaration
function join(address urn, uint wad) public note, which has the modifier “note”, one response from GPT-4o can be as follows:
Function
join(address,uint) uses the modifier ‘auth’, which contains a require
statement with the branching condition wards[msg.sender] == 1. This condition
reads the state variable wards. |
In this response, it shows that GPT-4o considers auth as the modifier of the function join(address,uint). However, only note is the modifier of the function join(address,uint).
Another response is shown in the box below:
Function
join(address,uint) has the modifier auth invoked in it because
‘auth’ appears in the function declaration ‘function join (address urn, uint wad)
public note auth’. The modifier reads a state variable ‘wards’. |
This response goes even further. GPT-4o provides the wrong function declaration function join(address urn, uint wad) public note auth as evidence to support its statement that auth is the modifier of the function join(address,uint).
8. Conclusions
This research presents an innovative approach called Sligpt to perform data dependency analyses by integrating GPT-4o with Slither, a static analysis tool. Sligpt performs the dependency analysis through the process of refining the given dependency data. The given dependency data are collected using Slither, while the refining process is completed by the multiple roles of GPT-4o. The empirical evaluation reveals that Sligpt achieves significant improvements in dependency analyses.
Sligpt can be utilized for various downstream tasks, including taint analyses, fuzzing, guided symbolic execution, and the construction of machine-learning models. For instance, Sligpt can be directly applied to SmartExecutor for graph construction used to guide the symbolic execution process. This demonstrates Sligpt’s potential to significantly enhance the effectiveness of these tasks by improving the data dependency analysis.
Our research makes several significant contributions to the field of program analysis for smart contracts. Firstly, we developed a detailed methodology for integrating GPT-4o with the Slither static analysis framework to perform data dependency analysis. Secondly, through rigorous empirical evaluation using a curated dataset of Ethereum smart contracts, our approach demonstrated substantial improvements in precision, recall, and overall analysis depth when compared to Slither alone. These findings underscore the promise of combining LLMs with static analysis tools to fortify the testing and security analysis of smart contracts, paving the way for more secure and reliable blockchain applications.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}