
Tether Force Estimation Airborne Kite Using Machine Learning Methods



Abstract
1. Introduction
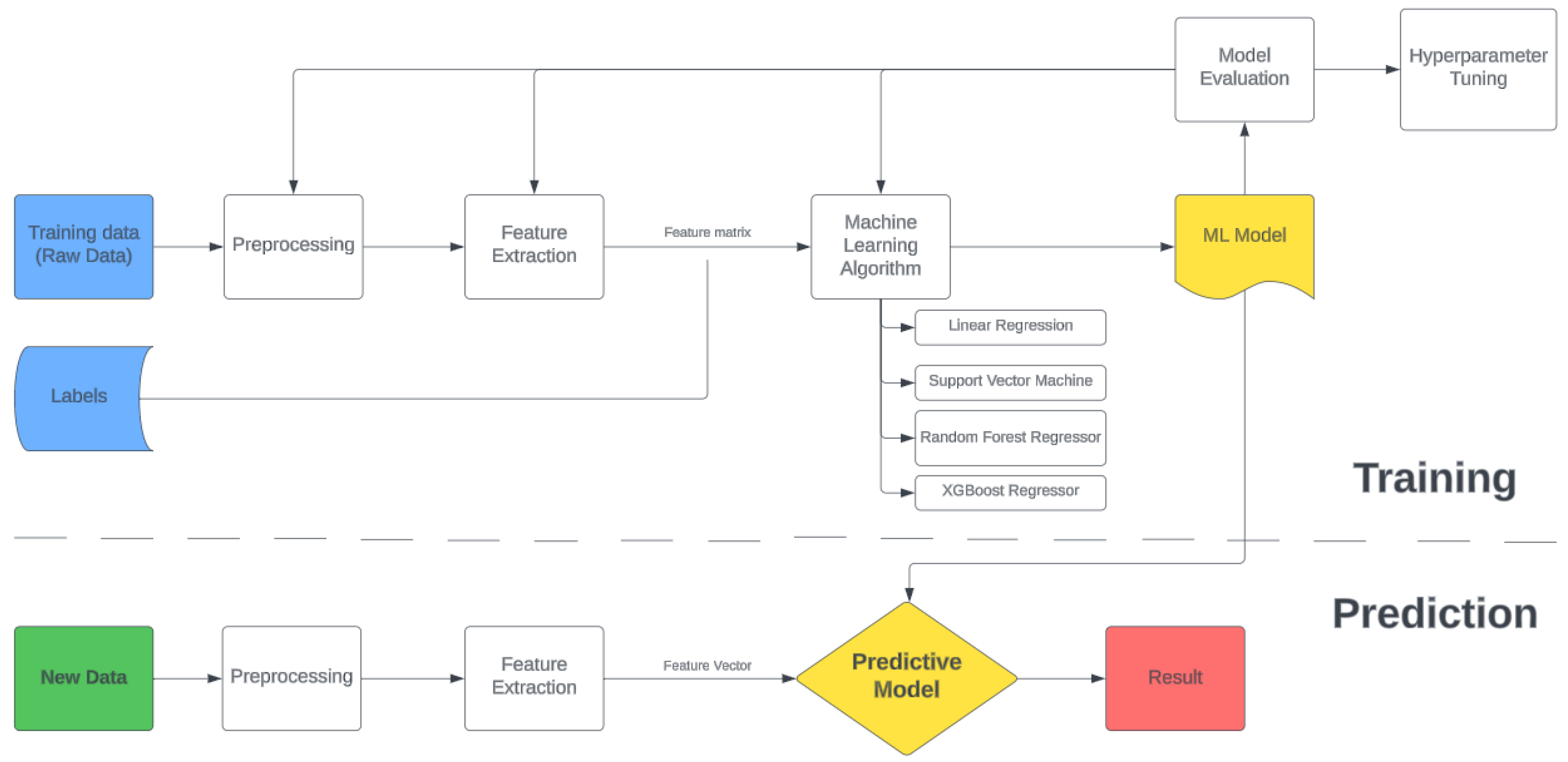
2. Tether Force Estimation Methods
2.1. Field Data Collection
- YawThe Yaw for a kite refers to its horizontal rotation around a vertical axis, similar to how an aircraft changes direction, but in this case, it is about the kite’s “nose”, which is usually the front tip, turning left or right in the air. The reason Yaw is important, is because when wind hits the kite unevenly or when the tension in the string shifts, the kite may yaw, causing it to swing or drift laterally. If not maintained, the kite can spiral out of control, which will not allow it to generate the most power at that moment.
- PitchThe Pitch of a kite is about the kite’s rotation around its lateral axis, essentially the side-to-side movement, reflecting whether the front of the kite tilts upward or downward. A positive pitch occurs when the nose of the kite tilts upward, causing the kite to climb higher in the air. A negative pitch, where the nose dips, often results in the kite descending or even nosediving. Proper pitch control is essential for achieving and maintaining a stable altitude. This often happens when the wind hits one side more strongly or when the kite string pulls unevenly. Excessive roll can cause instability, leading to the kite wobbling, spinning, or even crashing.
- RollThe Roll of the kite pertains to the tilting motion along its longitudinal axis, from the front to the tail, where one side of the kite tilts higher than the other. This often happens when the wind hits one side more strongly or when the kite string pulls unevenly. Excessive roll can cause instability, leading to the kite wobbling, spinning, or even crashing.
2.2. Tether Force Estimation for Kite Setup
2.2.1. Data Exploration
- and are the individual data points of variables X and Y respectively.
- and are the means of X and Y respectively.
- n is the size of our data pool.
2.2.2. Random Seeds
2.2.3. Linear Regression
2.2.4. Support Vector Machine Regressor
2.2.5. Random Forest Regressor
- T is the total number of trees.
- is the prediction of the i-th tree for the input x.
2.2.6. XGBoost Regressor
- T is the total number of trees.
- is the prediction of the i-th tree for the input x.
3. Results
3.1. Tether Force Validation
3.1.1. Linear Regression
3.1.2. Support Vector Machine Regressor (SVR)
3.1.3. Random Forest Regressor
3.1.4. XGBoost Regressor
3.1.5. Comparison and Validations of Models
RMSE Method
MAE Method
Method
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HAWT | Horizontal axis wind turbines |
| AWES | Airborne Wind Energy Systems |
| ANN | Artificial Neural Network |
| LSTM | Long Short Term Memory |
| SVR | Support Vector Regression |
| RFR | Random Forest Regression |
| RMSE | Root Mean Square Error |
| MAE | Mean Absolute Error |
References
- Salameh, M.G. Can renewable and unconventional energy sources bridge the global energy gap in the 21st century? Appl. Energy 2003, 75, 33–42. [Google Scholar] [CrossRef]
- Jurasz, J.; Canales, F.A.; Kies, A.; Guezgouz, M.; Beluco, A. A review on the complementarity of renewable energy sources: Concept, metrics, application and future research directions. Sol. Energy 2020, 195, 703–724. [Google Scholar] [CrossRef]
- Stančin, H.; Mikulčić, H.; Wang, X.; Duić, N. A review on alternative fuels in future energy system. Renew. Sustain. Energy Rev. 2020, 128, 109927. [Google Scholar] [CrossRef]
- Lund, H.; Østergaard, P.A.; Connolly, D.; Mathiesen, B.V. Smart energy and smart energy systems. Energy 2017, 137, 556–565. [Google Scholar] [CrossRef]
- Akbari, V.; Naghashzadegan, M.; Kouhikamali, R.; Afsharpanah, F.; Yaïci, W. Multi-Objective Optimization and Optimal Airfoil Blade Selection for a Small Horizontal-Axis Wind Turbine (HAWT) for Application in Regions with Various Wind Potential. Machines 2022, 10, 687. [Google Scholar] [CrossRef]
- Elkodama, A.; Ismaiel, A.; Abdellatif, A.; Shaaban, S.; Yoshida, S.; Rushdi, M.A. Control Methods for Horizontal Axis Wind Turbines (HAWT): State-of-the-Art Review. Energies 2023, 16, 6394. [Google Scholar] [CrossRef]
- Malz, E.C.; Verendel, V.; Gros, S. Computing the power profiles for an Airborne Wind Energy system based on large-scale wind data. Renew. Energy 2020, 162, 766–778. [Google Scholar] [CrossRef]
- Malz, E.C.; Walter, V.; Göransson, L.; Gros, S. The value of airborne wind energy to the electricity system. Wind Energy 2022, 25, 281–299. [Google Scholar] [CrossRef]
- Ghorani, M.M.; Karimi, B.; Mirghavami, S.M.; Saboohi, Z. A numerical study on the feasibility of electricity production using an optimized wind delivery system (Invelox) integrated with a Horizontal axis wind turbine (HAWT). Energy 2023, 268, 126643. [Google Scholar] [CrossRef]
- Johansen, K. Blowing in the wind: A brief history of wind energy and wind power technologies in Denmark. Energy Policy 2021, 152, 112139. [Google Scholar] [CrossRef]
- Caduff, M.; Huijbregts, M.A.; Althaus, H.J.; Koehler, A.; Hellweg, S. Wind power electricity: The bigger the turbine, the greener the electricity? Environ. Sci. Technol. 2012, 46, 4725–4733. [Google Scholar] [CrossRef] [PubMed]
- Schmehl, R. Airborne Wind Energy—An innovative renewable energy technology. In Proceedings of the Aerospace Engineering Seminar, Toronto, ON, Canada, 30 July–1 August 2019. [Google Scholar] [CrossRef]
- Cayon, O.; Watson, S.; Schmehl, R. Kite as a Sensor: Wind and State Estimation in Tethered Flying Systems. Wind Energy Sci. Discuss. 2025, 2015, 1–41. [Google Scholar] [CrossRef]
- Candade, A.; Ranneberg, M.; Schmehl, R. Structural analysis and optimization of a tethered swept wing for airborne wind energy generation. Wind Energy 2020, 23, 1006–1025. [Google Scholar] [CrossRef]
- Schelbergen, M.; Kalverla, P.; Schmehl, R.; Watson, S. Clustering wind profile shapes to estimate airborne wind energy production. Wind Energy Sci. Discuss. 2020, 2020, 1–34. [Google Scholar] [CrossRef]
- Aza-Gnandji, M.; Fifatin, F.X.; Hounnou, A.H.J.; Dubas, F.; Chamagne, D.; Espanet, C.; Vianou, A. Complementarity between Solar and Wind Energy Potentials in Benin Republic. Adv. Eng. Forum 2018, 28, 128–138. [Google Scholar] [CrossRef]
- Zolfaghari, M.; Co, S.; Azarsina, F.; Kani, A. Feasibility Analysis of Airborne Wind Energy System (AWES) Pumping Kite (PK). J. Adv. Res. Fluid Mech. Therm. Sci. J. Homepage 2020, 74, 133–143. [Google Scholar] [CrossRef]
- Cherubini, A.; Papini, A.; Vertechy, R.; Fontana, M. Airborne Wind Energy Systems: A review of the technologies. Renew. Sustain. Energy Rev. 2015, 51, 1461–1476. [Google Scholar] [CrossRef]
- Castelino, R.V.; Kashyap, Y.; Kosmopoulos, P. Airborne Kite Tether Force Estimation and Experimental Validation Using Analytical and Machine Learning Models for Coastal Regions. Remote Sens. 2022, 14, 6111. [Google Scholar] [CrossRef]
- De Amorim, L.B.V.; Cavalcanti, G.D.C.; Cruz, R.M.O. The choice of scaling technique matters for classification performance. Appl. Soft Comput. 2022, 133, 109924. [Google Scholar] [CrossRef]
- Maulud, D.; Abdulazeez, A.M. A Review on Linear Regression Comprehensive in Machine Learning. J. Appl. Sci. Technol. Trends 2020, 1, 140–147. [Google Scholar] [CrossRef]
- Filzmoser, P.; Nordhausen, K. Robust linear regression for high-dimensional data: An overview. Wiley Interdiscip. Rev. Comput. Stat. 2021, 13, e1524. [Google Scholar] [CrossRef]
- Zheng, Y.; Ge, Y.; Muhsen, S.; Wang, S.; Elkamchouchi, D.H.; Ali, E.; Ali, H.E. New ridge regression, artificial neural networks and support vector machine for wind speed prediction. Adv. Eng. Softw. 2023, 179, 103426. [Google Scholar] [CrossRef]
- Tariq, A.; Jiango, Y.; Li, Q.; Gao, J.; Lu, L.; Soufan, W.; Almutairi, K.F.; ur Rahman, M.H. Modelling, mapping and monitoring of forest cover changes, using support vector machine, kernel logistic regression and naive bayes tree models with optical remote sensing data. Heliyon 2023, 9, e13212. [Google Scholar] [CrossRef] [PubMed]
- Ita, K.; Prinze, J. Machine learning for skin permeability prediction: Random forest and XG boost regression. J. Drug Target. 2024, 32, 57–65. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Lyu, Z.; Li, X. An Optimized Random Forest Regression Model for Li-Ion Battery Prognostics and Health Management. Batteries 2023, 9, 332. [Google Scholar] [CrossRef]
- Gatera, A.; Kuradusenge, M.; Bajpai, G.; Mikeka, C.; Shrivastava, S. Comparison of random forest and support vector machine regression models for forecasting road accidents. Sci. Afr. 2023, 21, e01739. [Google Scholar] [CrossRef]
- Mrabet, Z.E.; Sugunaraj, N.; Ranganathan, P.; Abhyankar, S. Random Forest Regressor-Based Approach for Detecting Fault Location and Duration in Power Systems. Sensors 2022, 22, 458. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Yan, C.; Gao, C.; Malin, B.A.; Chen, Y. Predicting Missing Values in Medical Data Via XGBoost Regression. J. Healthc. Inform. Res. 2020, 4, 383–394. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Chen, Y.; Yao, B.; Zhang, X.; Zeng, N. A neural network boosting regression model based on XGBoost. Appl. Soft Comput. 2022, 125, 109067. [Google Scholar] [CrossRef]
- Nguyen, H.; Cao, M.T.; Tran, X.L.; Tran, T.H.; Hoang, N.D. A novel whale optimization algorithm optimized XGBoost regression for estimating bearing capacity of concrete piles. Neural Comput. Appl. 2023, 35, 3825–3852. [Google Scholar] [CrossRef]
- Wang, R.; Wang, L.; Zhang, J.; He, M.; Xu, J. XGBoost Machine Learning Algorism Performed Better Than Regression Models in Predicting Mortality of Moderate-to-Severe Traumatic Brain Injury. World Neurosurg. 2022, 163, e617–e622. [Google Scholar] [CrossRef]
- Sardar, I.; Karakaya, K.; Makarovskikh, T.; Abotaleb, M.; Aflake, S.; Mishra, P.; Gardazi, H. Machine Learning-Based COVID-19 Forecasting: Impact on Pakistan Stock Exchange. Int. J. Agricult. Stat. Sci 2021, 17, 53–61. [Google Scholar]
- Pan, B. Application of XGBoost algorithm in hourly PM2.5 concentration prediction. IOP Conf. Ser. Earth Environ. Sci. 2018, 113, 012127. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Count | Mean | Std. Dev. | Min | 25% | 50% | Max |
|---|---|---|---|---|---|---|---|
| Yaw | 8473 | −58.3763 | 107.9977 | −270.0000 | −122.7673 | −32.2179 | 89.9804 |
| Pitch | 8473 | 79.8286 | 115.6201 | −180.0000 | 40.7037 | 131.6634 | 179.9786 |
| Roll | 8473 | 5.7942 | 36.8290 | −90.0000 | −22.2469 | 7.1577 | 90.0000 |
| Altitude (m) | 8473 | 12.7562 | 7.3817 | −5.7500 | 9.7500 | 14.6900 | 24.0100 |
| Latitude | 8473 | 13.0092 | 0.0001 | 13.0089 | 13.0091 | 13.0092 | 13.0095 |
| Longitude | 8473 | 74.7884 | 0.0001 | 74.7882 | 74.7884 | 74.7885 | 74.7889 |
| Accel_Cal | 8473 | 3.0 | 0.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| Gyro_Cal | 8473 | 3.0 | 0.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| Mag_Cal | 8473 | 2.9687 | 0.1934 | 1.0 | 3.0 | 3.0 | 3.0 |
| System_Cal | 8473 | 3.0 | 0.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| Wind speed (m/s) | 8473 | 3.03 | 0.565 | 0.68 | 2.7 | 3.0 | 4.65 |
| Model | MAE (in N) | RMSE (in N) | |
|---|---|---|---|
| Artificial Neural Network (Steady) [19] | 115 | 150 | 0.36 |
| LSTM (Steady) [19] | 100 | 126 | 0.43 |
| Physical Model (Steady) [19] | 94 | 127 | 0.52 |
| Artificial Neural Network (Turbulent) [19] | 131 | 187 | 0.28 |
| LSTM (Turbulent) [19] | 130 | 168 | 0.43 |
| Physical Model (Turbulent) [19] | 128 | 179 | 0.29 |
| XGBoost Regressor | 32.1 | 52.3 | 0.93 |
| Model | MAE (in %) | RMSE (in %) |
|---|---|---|
| Linear Regression | 97.26 | 145.21 |
| RFR | 30.76 | 50.33 |
| SVR | 46.31 | 78.53 |
| XGBoost Regressor | 13.68 | 22.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gupta, A.; Kashyap, Y.; Kosmopoulos, P. Tether Force Estimation Airborne Kite Using Machine Learning Methods. Wind 2025, 5, 5. https://doi.org/10.3390/wind5010005
Gupta A, Kashyap Y, Kosmopoulos P. Tether Force Estimation Airborne Kite Using Machine Learning Methods. Wind. 2025; 5(1):5. https://doi.org/10.3390/wind5010005
Chicago/Turabian StyleGupta, Akarsh, Yashwant Kashyap, and Panagiotis Kosmopoulos. 2025. "Tether Force Estimation Airborne Kite Using Machine Learning Methods" Wind 5, no. 1: 5. https://doi.org/10.3390/wind5010005
APA StyleGupta, A., Kashyap, Y., & Kosmopoulos, P. (2025). Tether Force Estimation Airborne Kite Using Machine Learning Methods. Wind, 5(1), 5. https://doi.org/10.3390/wind5010005