1. Introduction
Model selection is the task of evaluating which of the statistical models under consideration best describes observed data. In the Bayesian formalism, this involves computing the marginal likelihood (also called the Bayesian model evidence), which gives a way to a quantitative comparison of the suitability of models for a given problem. Model selection is relevant in a range of fields such as astronomy, biostatistics, economics, medical research, and many more. However, in practice, Bayesian model selection is often difficult, as computing the marginal likelihood requires evaluating a high-dimensional integral, which can be a challenging task. A number of methods to compute the marginal likelihood have been proposed (for reviews see [
1,
2]), such as nested sampling [
3,
4].
The learned harmonic mean estimator was proposed recently by some of the authors of the current article as an effective technique with which to compute the marginal likelihood [
5]. The estimator requires only samples from the posterior and so is agnostic to the method used to generate samples, in contrast to nested sampling. Thus, the learned harmonic mean can be easily coupled with various MCMC sampling techniques or variational inference approaches. This property also allows the estimator to be adapted to address Bayesian model selection for simulation-based inference (SBI) [
6], where an explicit likelihood is unavailable or infeasible. The learned harmonic mean estimator is implemented in the harmonic Python code (
https://github.com/astro-informatics/harmonic, accessed on 30 June 2023).
In this work, we introduce the use of normalizing flows [
7] for the learned harmonic mean estimator, which addresses some limitations of the models used previously. The use of normalizing flows eliminates the need for bespoke training, resulting in a more robust and scalable approach, which is now implemented in the harmonic code. We first review the learned harmonic mean estimator, before describing how normalizing flows may be used for the estimator and their main advantages in this context. We then present a number of experiments that demonstrate the effectiveness of the use of flows in the learned harmonic mean estimator.
2. The Harmonic Mean Estimator
Bayesian model selection requires the computation of the marginal likelihood given by
where
y denotes observed data,
the parameters of interest, and
M the model under consideration. We adopt the shorthand notation for the likelihood of
and the prior of
.
The harmonic mean estimator was first proposed by [
8], who showed that the marginal likelihood
z can be estimated from the harmonic mean of the likelihood, given posterior samples. This follows by considering the expectation of the reciprocal of the likelihood with respect to the posterior distribution, leading to the following estimator of the reciprocal of the marginal likelihood
:
where
N specifies the number of samples
drawn from the posterior
. The marginal likelihood can then be estimated from its reciprocal straightforwardly [
5]. It was soon realized that the original harmonic mean estimator can fail catastrophically [
9], as it can suffer from an exploding variance.
The estimator can also be interpreted as importance sampling. Consider the reciprocal marginal likelihood, which may be expressed in terms of the prior and posterior as:
It is clear that the estimator has an importance sampling interpretation where the importance sampling target distribution is the prior
, while the sampling density is the posterior
, in contrast to typical importance sampling scenarios.
For importance sampling to be effective, one requires the sampling density to have fatter tails than the target distribution, i.e., to have greater probability mass in the tails of the distribution. Typically, the prior has fatter tails than the posterior since the posterior updates our initial understanding of the underlying parameters that are encoded in the prior, in the presence of new data y. For the harmonic mean estimator, the importance sampling density (the posterior) typically does not have fatter tails than the target (the prior) and so importance sampling is not effective. This explains why the original harmonic mean estimator can be problematic.
In [
10], an arbitrary density
is introduced to relate the reciprocal of the marginal likelihood to the likelihood through the following expectation:
The above expression motivates the estimator:
The normalized density
can be interpreted as an alternative importance sampling target distribution, hence we refer to this approach as the re-targeted harmonic mean estimator. Note that the original harmonic mean estimator is recovered for the target distribution
.
The learned harmonic mean estimator is introduced in [
5], where the target density
is learned by machine learning techniques. It is shown in [
5] that the optimal target distribution is the posterior. Since the target must be normalized, the normalized posterior is clearly not accessible since its normalizing constant is precisely the term of interest. The learned harmonic mean approximates the optimal target of the posterior with a learned model that is normalized. While the approximation need not be highly accurate, it is critical that the probability mass of the learned distribution is contained within the posterior in order to avoid the exploding variance problem. In [
5], a bespoke optimization problem is introduced when training models in order to ensure this property is satisfied. Specifically, the model is fitted by minimizing the variance of the resulting estimator, while ensuring it is also unbiased, and with possible regularization. Such an approach requires a careful selection of an appropriate model and its hyperparameters for a problem at hand, determined by cross-validation. Furthermore, only simple classical machine learning models were considered in [
5], which in many cases struggle to scale to high-dimensional settings.
3. Learning the Target Distribution Using Normalizing Flows
In this paper, we learn the target distribution of the learned harmonic mean estimator [
5] using normalizing flows. Using normalizing flows renders the previous bespoke approach to training no longer necessary since it provides an elegant way to ensure that the probability mass of the learned distribution is contained within the posterior, thereby resulting in a learned harmonic mean estimator that is more flexible and robust. Furthermore, normalizing flows also offer the potential to scale to higher dimensional settings. We first introduce normalizing flows, before describing how they may be used for the learned harmonic mean estimator and their main advantages in this context.
3.1. Normalizing Flows
Normalizing flows are a class of probabilistic models that allow one to evaluate the density of and sample from a learned probability distribution (for a review, see [
7]). They consist of a series of transformations that are applied to a simple base distribution. A vector
of an unknown distribution
can be expressed through a transformation
T of a vector
z sampled from a base distribution
:
Typically, the base distribution is chosen so that its density can be evaluated simply and so that it can be sampled from easily. Often a Gaussian is used for the base distribution. The unknown distribution can then be recovered by the change of variables formula:
where
is the Jacobian corresponding to transformation
T. In a flow-based model,
T consists of a series of learned transformations that are each invertible and differentiable, so that the full transformation is also invertible and differentiable. This allows us to compose multiple simple transformations with learned parameters, into what is called a flow, obtaining a normalized approximation of the unknown distribution that we can sample from and evaluate. Careful attention is given to construction of the transformations such that the determinant of the Jacobian can be computed easily.
A relatively simple example of a normalizing flow is the real-valued non-volume preserving (real NVP) flow introduced in [
11]. It consists of a series of bijective transformations given by affine coupling layers. Consider the
D dimensional input
z, split into elements up to and following
d, respectively,
and
, for
. Given input
z, the output
y of an affine couple layer is calculated by
where ⊙ denotes Hadamard (elementwise) multiplication. The scale
s and translation
t are typically represented by neural networks with learnable parameters that take as input
. This construction is easily invertible and ensures the Jacobian is a lower-triangular matrix, making its determinant efficient to calculate.
3.2. Concentrating the Probability Density for the Learned Harmonic Mean Estimator
Normalizing flows meet the core requirements of the learned target distribution of the learned harmonic mean estimator: namely, they provide a normalized probability distribution for which one can evaluate probability densities. In this work, we use them to introduce an elegant way to ensure the probability mass of the learned distribution is contained within the posterior. We thereby avoid the exploding variance issue of the original harmonic mean estimator and can evaluate the marginal likelihood accurately without the need for fine-tuning.
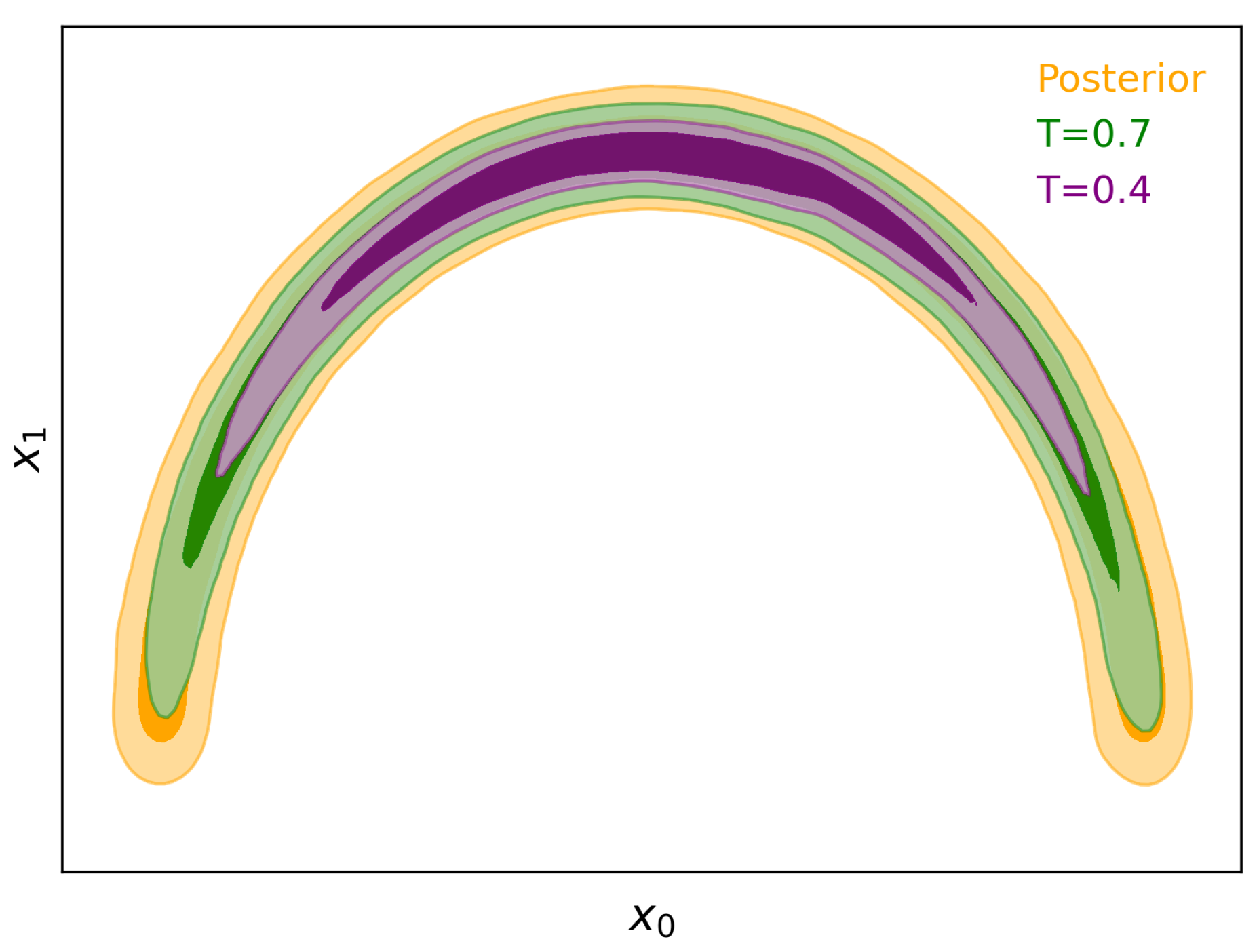
Reducing the variance of the base distribution, or equivalently lowering its “temperature” in a statistical mechanics perspective, clearly concentrates the probability density of the base distribution. This has the effect of also concentrating the probability density of the transformed distribution due to the continuity and differentiability of the flow. Consequently, once a flow is trained to approximate the posterior, by lowering the temperature of the base distribution (i.e., reducing its variance) we can concentrate the learned distribution to ensure its probability mass is contained within the posterior, as illustrated in
Figure 1.
The learned distributions considered previously for the learned harmonic mean estimator [
5] required the introduction of a bespoke optimization problem for training in order to ensure the learned target is contained within the posterior. This requires careful selection of an appropriate model and its hyperparameters, determined by cross-validation. The introduced normalizing flow approach renders bespoke training no longer necessary. Instead, we train a flow in the usual manner, based on maximum likelihood estimation, before concentrating its probability density. There is only one parameter to consider, the temperature
. Moreover, we expect a common value of
to be suitable for most problems. Once we have a flow with its probability density concentrated for
, the learned harmonic mean estimator can be computed in the usual manner [
5]. Using normalizing flows with the learned harmonic mean thus provides a much more robust method. Furthermore, an added benefit of using flows is that we can draw samples from the flow distribution efficiently, in order to easily visualize the concentrated target distribution and compare it to the posterior.
In this preliminary work, we consider real NVP flows only, as described above, which are implemented in the harmonic code. In the future, we will consider more expressive and scalable flows. The use of normalizing flows for the learned distribution therefore has the potential to extend the learned harmonic mean estimator to problems with complex, high-dimensional posteriors.
4. Experiments
To validate the effectiveness of the method described in
Section 3, we repeat a number of the numerical experiments carried out in [
5] but using normalizing flows as the target distribution of the learned harmonic mean estimator. In the experiments that follow, we consider a real NVP flow where the scale and translation networks of the affine coupling layers are given by two-layer dense neural networks with a leaky ReLU in between. The scaling layers additionally include a proceeding softplus activation. We typically consider a flow with six coupling layers, where typically only the first two include scaling, and permute elements of the vector between coupling layers to ensure the flow transforms all elements. We consider a Gaussian base distribution with unit variance. We use the emcee package [
12] to generate MCMC samples from the posterior. We then train the real NVP flow on half of the samples by maximum likelihood and calculate the marginal likelihood using the remaining samples by the learned harmonic mean estimator with the flow concentrated to temperature
T. In all experiments, we consider an identical temperature of
, which works well throughout, demonstrating that
T does not require fine-tuning. We consider a relatively simple flow in this preliminary work and a small number of simple experiments. In future work, we will consider more expressible and scalable flows, and further experiments to thoroughly evaluate the robustness and scalability of the method.
4.1. Rosenbrock
A common benchmark problem to test methods that compute the marginal likelihood is a likelihood specified by the Rosenbrock function, which exhibits a narrow curving degeneracy. We consider the Rosenbrock likelihood in
dimensions and a simple uniform prior with
and
. We sample the resulting posterior distribution, drawing 5000 samples for 200 chains, with burn-in of 2000 samples, yielding 3000 posterior samples per chain.
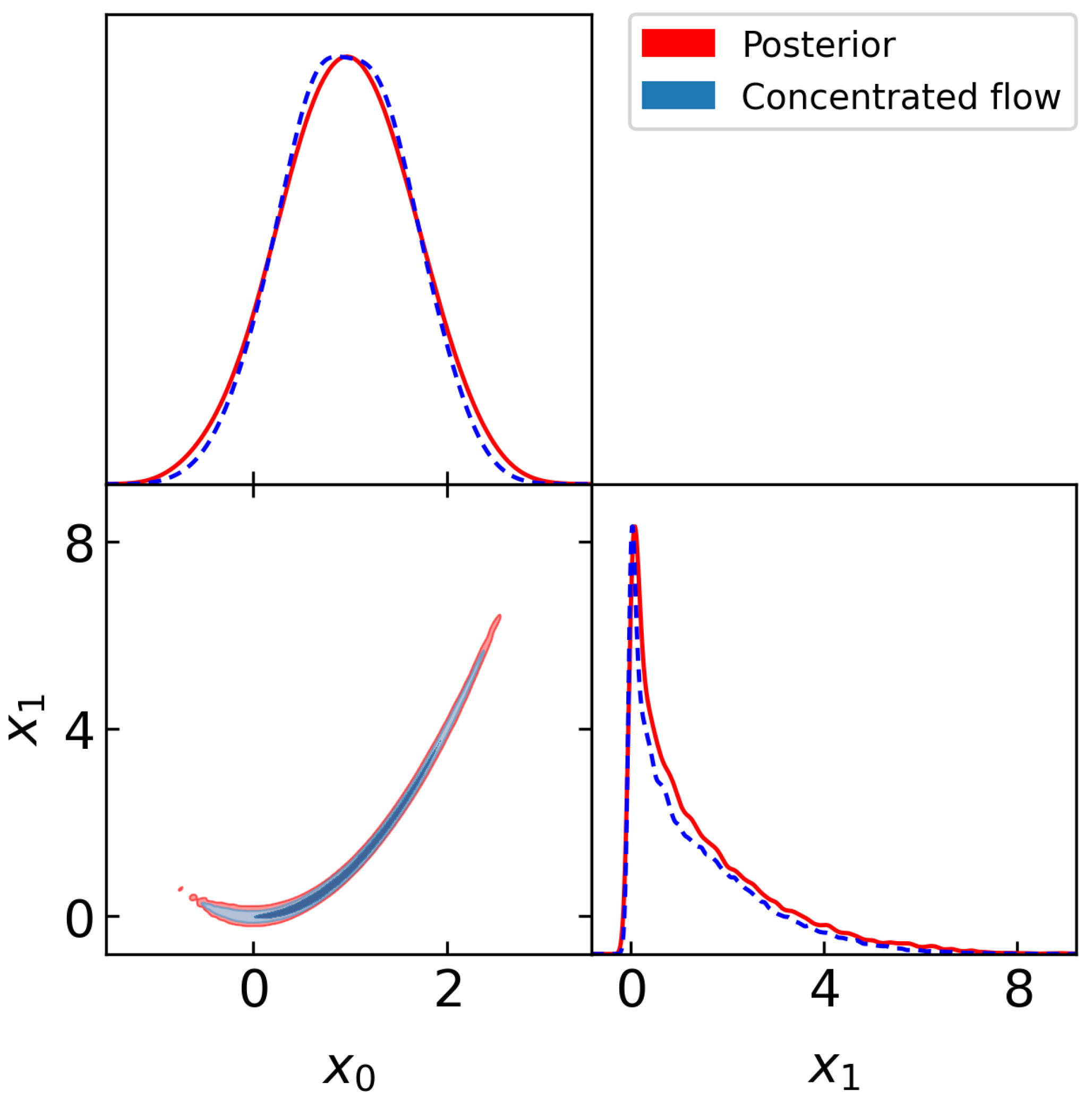
Figure 2 shows a corner plot of the training samples from the posterior (red) and from the normalizing flow (blue) at temperature
. It can be seen that the concentrated flow approximates the posterior well and has thinner tails, as required for the marginal likelihood estimate to be stable and accurate.
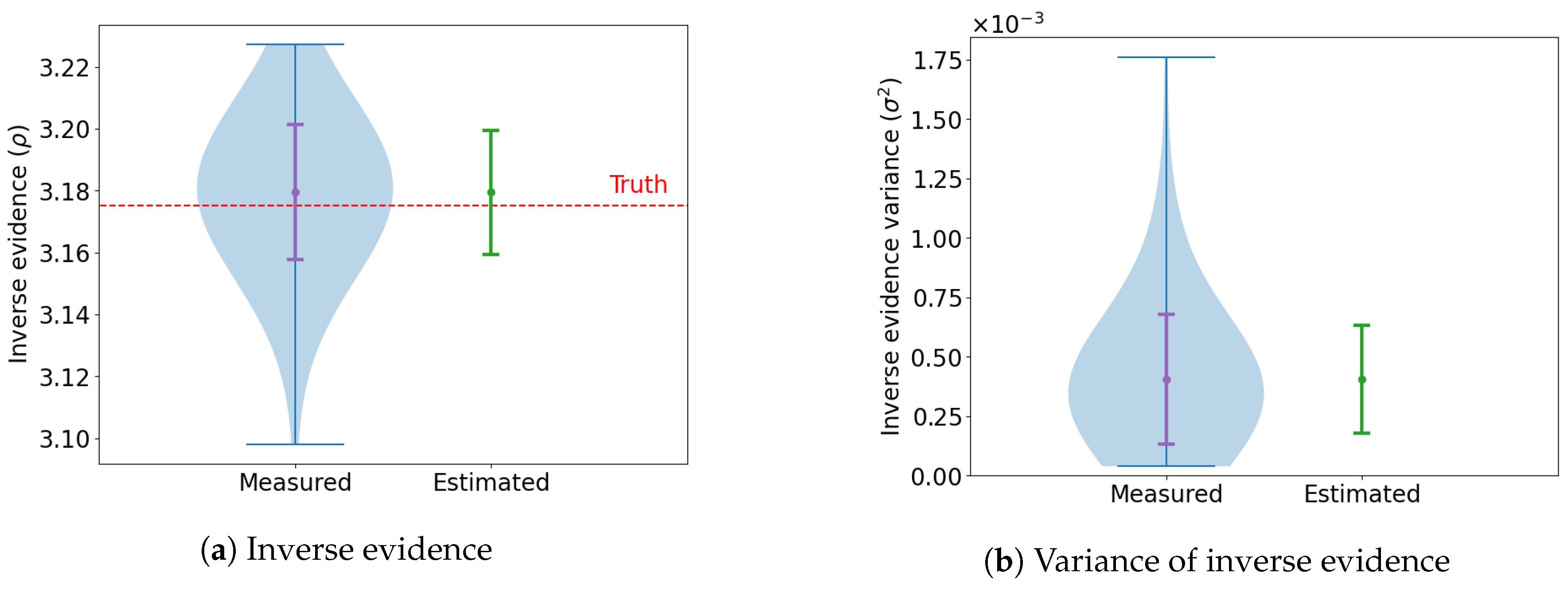
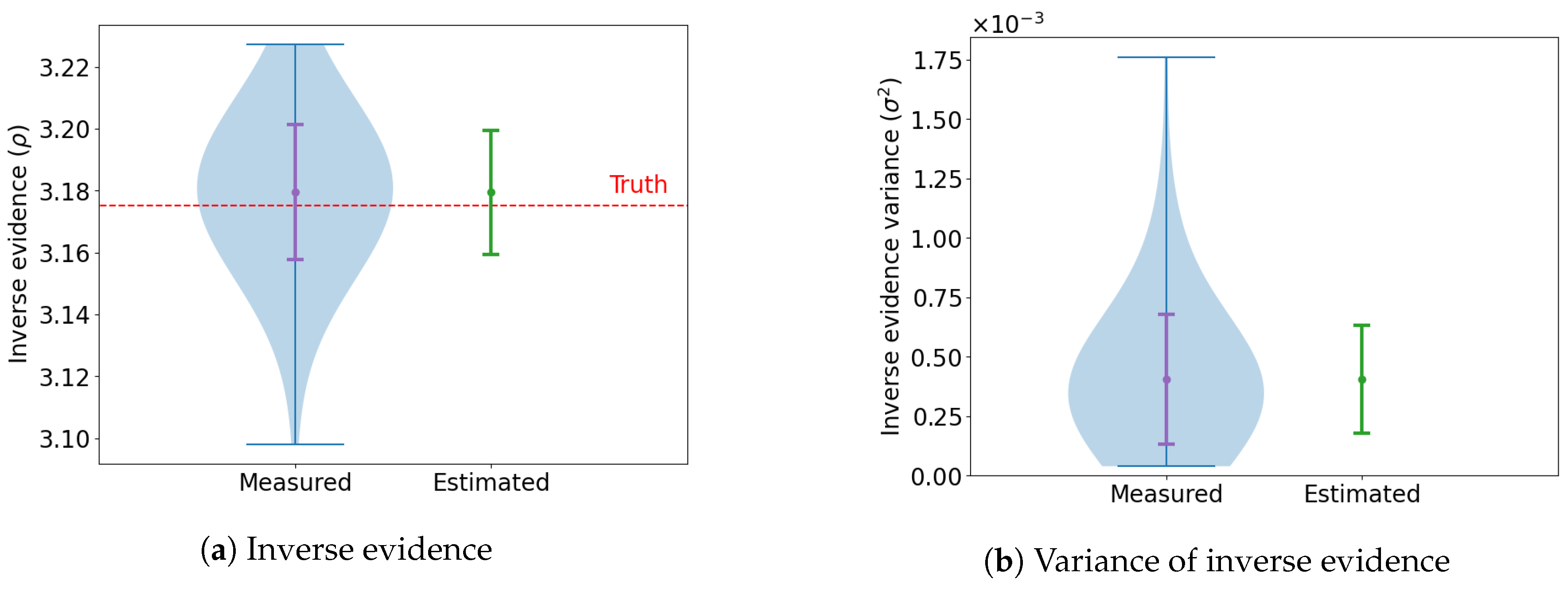
This process is repeated 100 times and the marginal likelihood is computed for each trial.
Figure 3 shows a summary of the estimates across all the runs. The dashed red line in
Figure 3a indicates the ground truth computed through numerical integration, which is tractable in two dimensions. It can be seen that the learned harmonic mean estimator using a real NVP flow provides an accurate and unbiased estimate of the marginal likelihood.
4.2. Normal-Gamma
We consider the Normal-Gamma example, for which the marginal likelihood can be computed analytically [
2,
5]. It was found that the marginal likelihood values computed by the original harmonic mean estimator do not vary with a varying prior [
2], highlighting this example as a pathological failure of the original harmonic mean estimator. We consider the same pathological example here and demonstrate that our learned harmonic mean estimator with normalizing flows is highly accurate (as is the learned harmonic mean with other models; [
5]). We consider the Normal-Gamma model [
5,
13] with data
, for
, with mean
and precision (inverse variance)
. A normal prior is assumed for
and a Gamma prior for
:
with mean
, shape
, and rate
. The precision scale factor
is varied to observe the impact of changing prior on the computed marginal likelihood.
We draw 1500 samples for 200 chains, with burn-in of 500 samples, yielding 1000 posterior samples per chain.
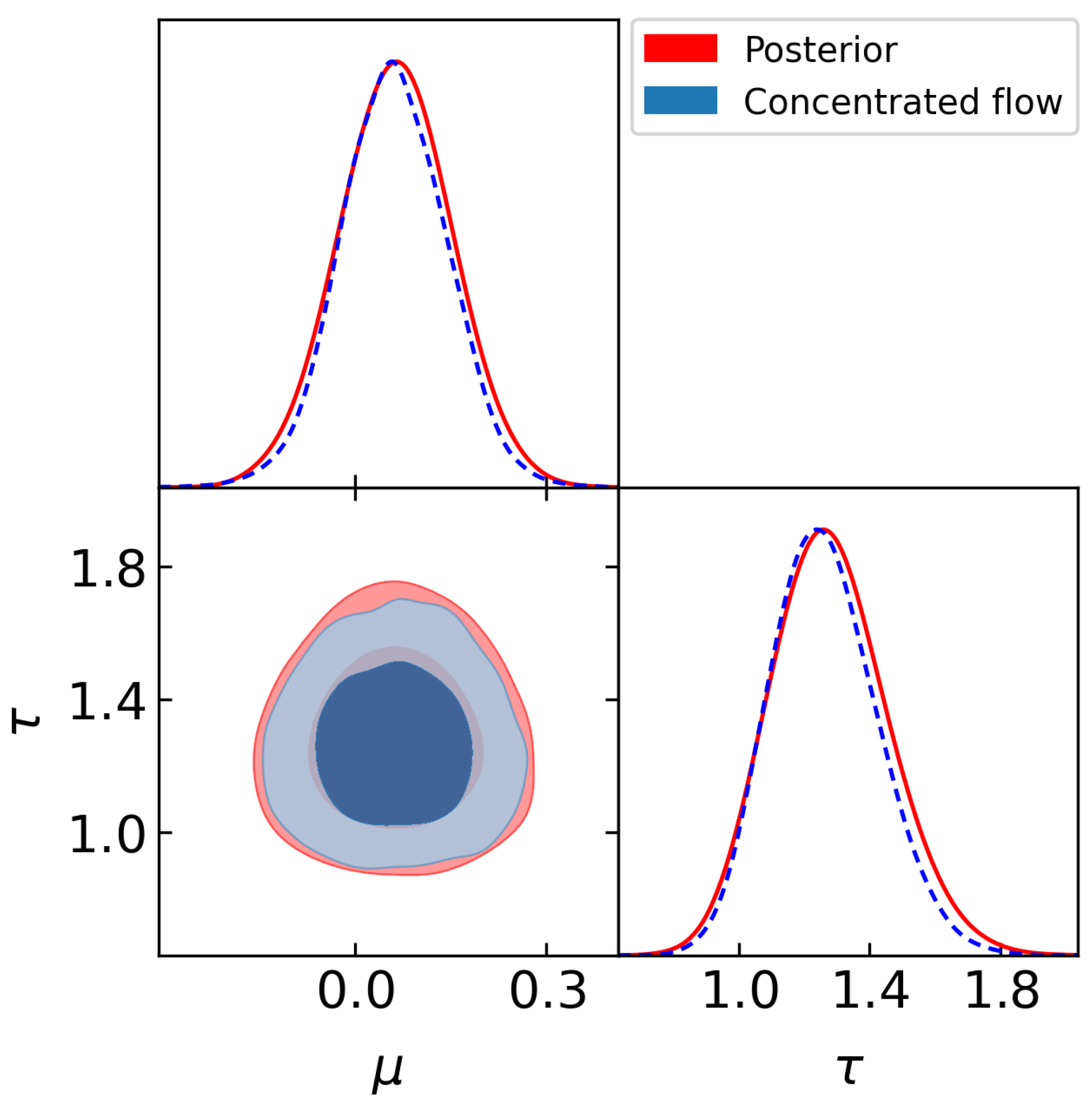
Figure 4 shows a corner plot of the training samples from the posterior for
(red) and from the normalizing flow (blue) at temperature
. Again, it can be seen the concentrated learned target is close to the posterior but with thinner tails, as expected. We consider priors with
.
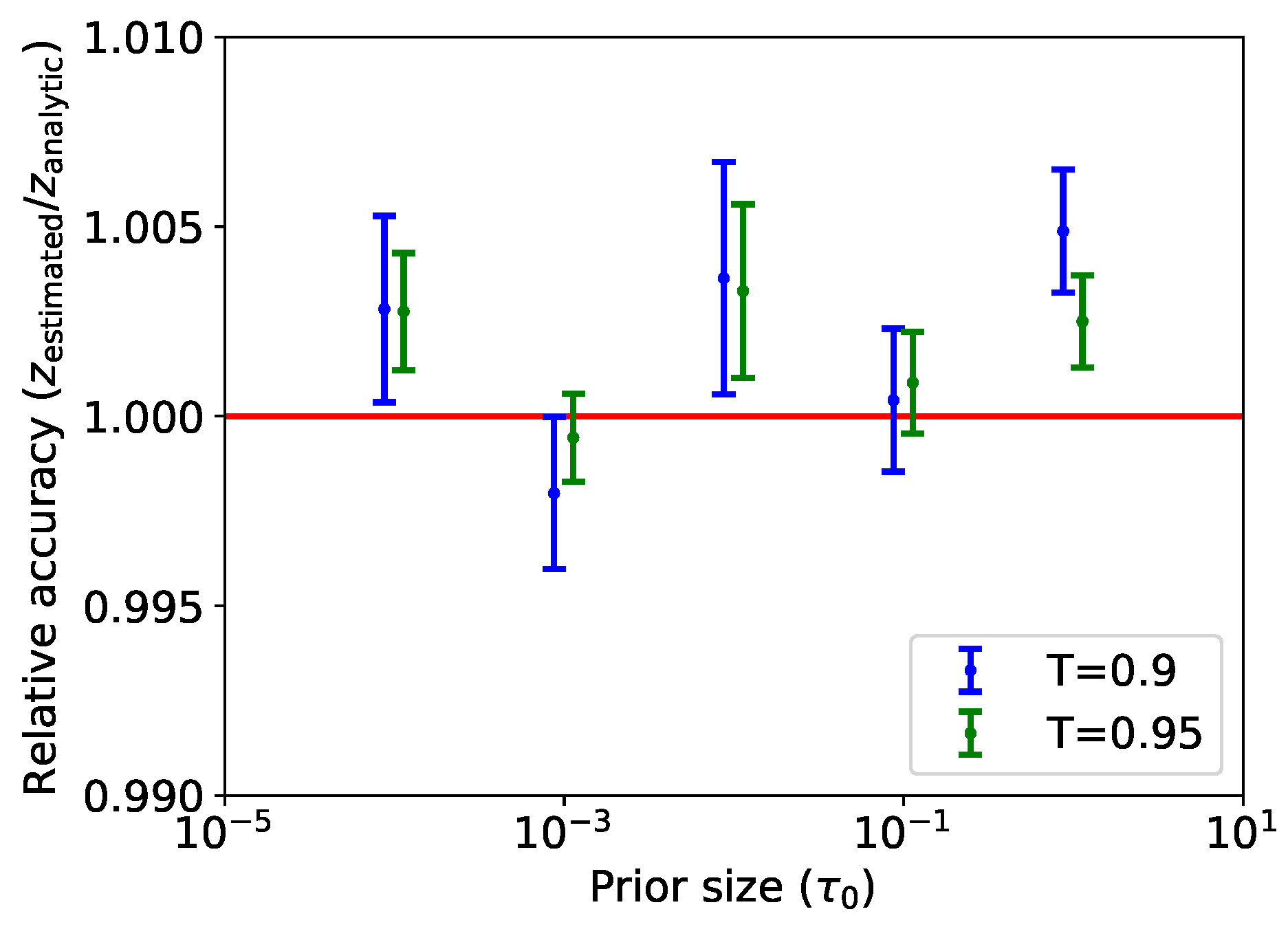
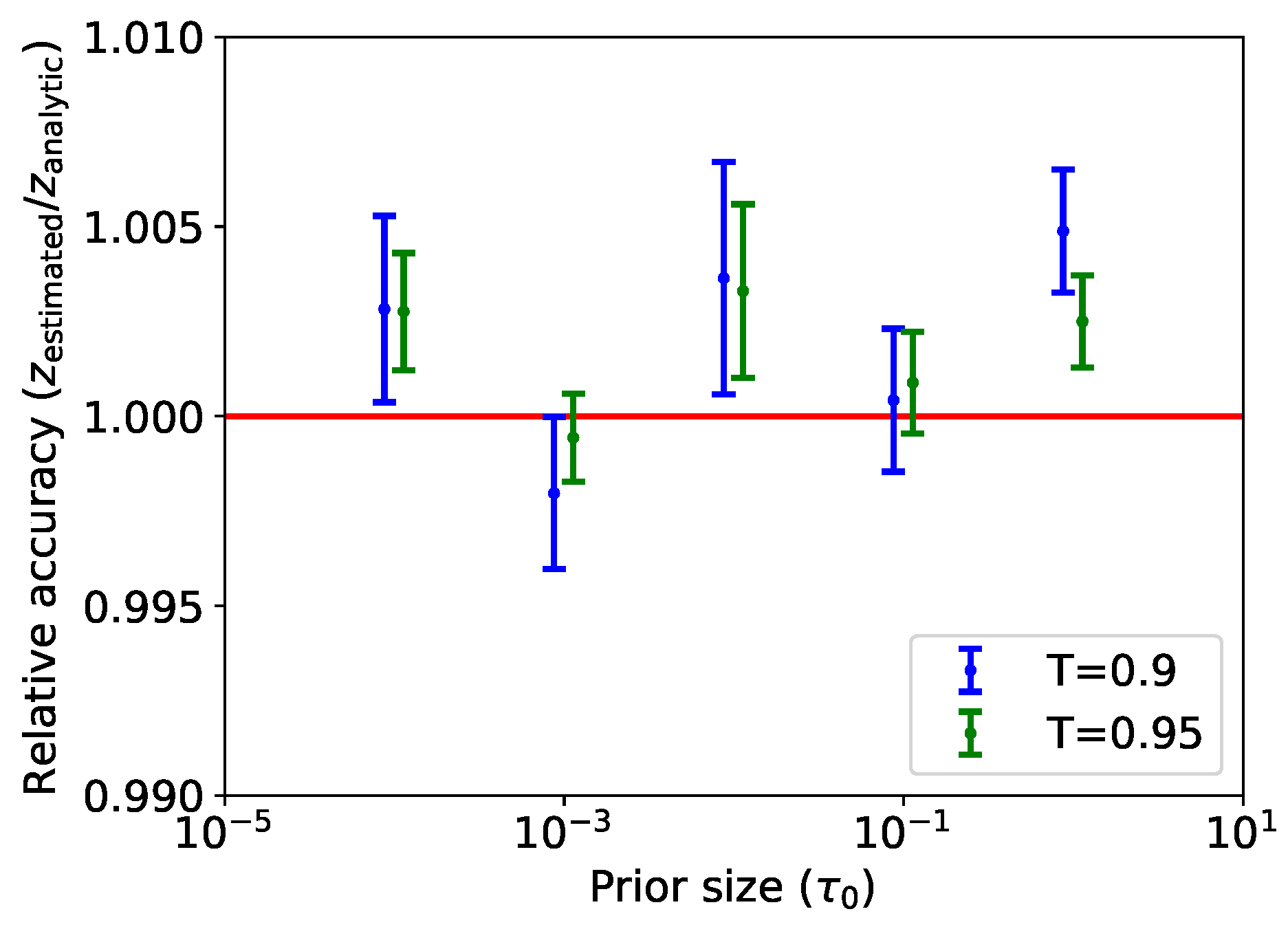
Figure 5 shows the relative accuracy of the marginal likelihood computed by the learned harmonic mean estimator using normalizing flows, that is, the ratio of the estimated marginal likelihood to the analytic ground truth. We additionally consider a concentrated flow with
to demonstrate that accuracy is not highly dependent on the temperature parameter. It can be seen that the estimate remains accurate and is indeed sensitive to the prior for both temperatures. The estimates for the flow with
T closer to one have a slightly lower variance, as one would expect, since the broader target
makes more efficient use of samples.
4.3. Logistic Regression Models: Pima Indian Example
We consider the comparison of two logistic regression models using the Pima Indians data, which is another common benchmark problem for comparing estimators of the marginal likelihood. The original harmonic mean estimator has been shown to fail catastrophically for this example [
2]. The Pima Indians data [
14], originally from the National Institute of Diabetes and Digestive and Kidney Diseases, were compiled from a study of indicators of diabetes in
Pima Indian women aged 21 or over. Seven primary predictors of diabetes were recorded, including: number of prior pregnancies (NP); plasma glucose concentration (PGC); diastolic blood pressure (BP); triceps skin fold thickness (TST); body mass index (BMI); diabetes pedigree function (DP); and age (AGE). The probability of diabetes
for person
can be modelled by the logistic function. An independent multivariate Gaussian prior with precision
is assumed for parameters
. Two different logistic regression models are compared, with different subsets of covariates:
A reversible jump algorithm [
15] is used by [
2] to compute a benchmark Bayes factor
of
(
), which is treated as ground truth.
We draw 5000 samples from for 200 chains, with burn-in of 1000 samples, yielding 4000 posterior samples per chain. We train a flow consisting of six scaled layers followed by two unscaled ones.
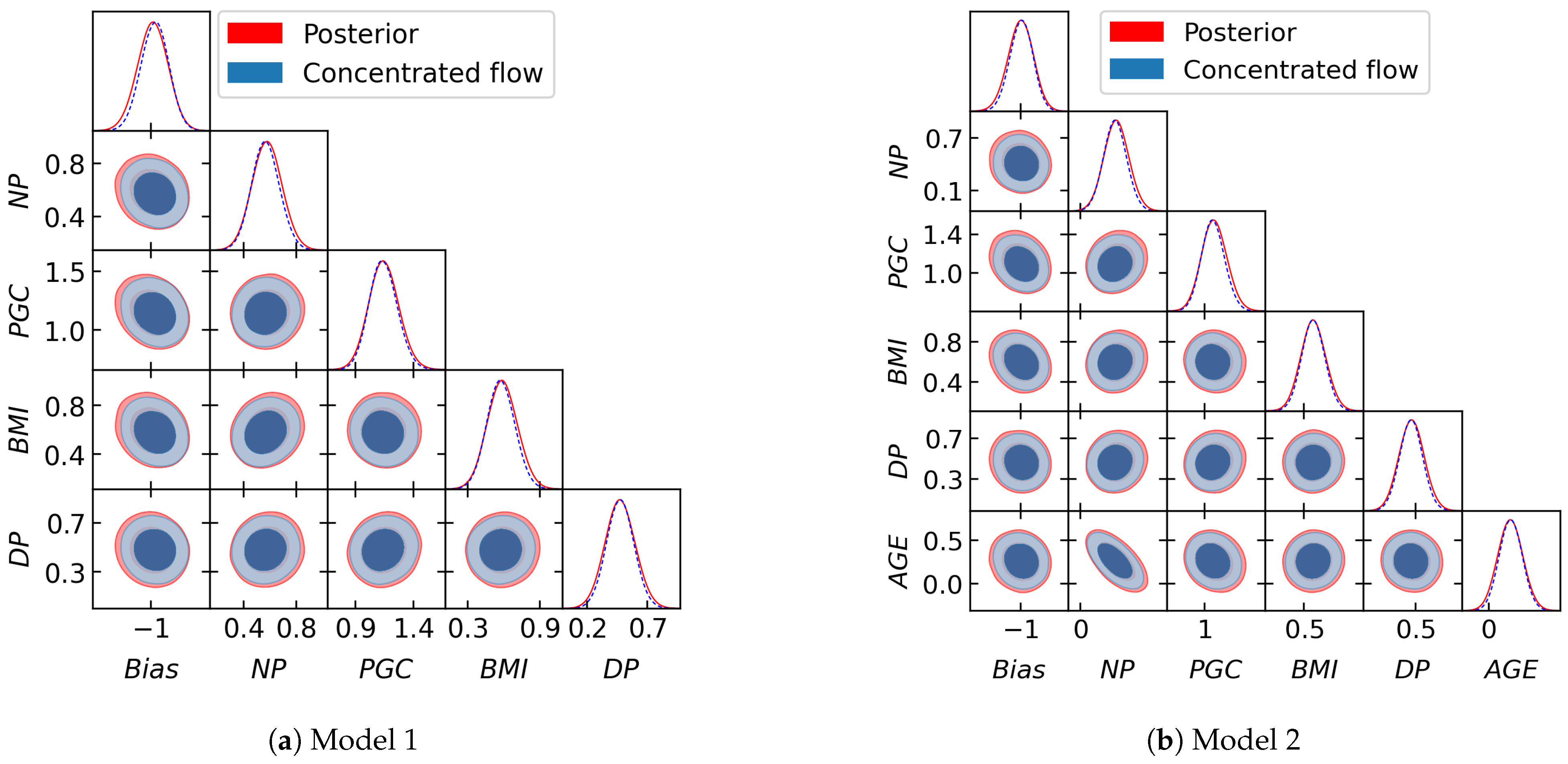
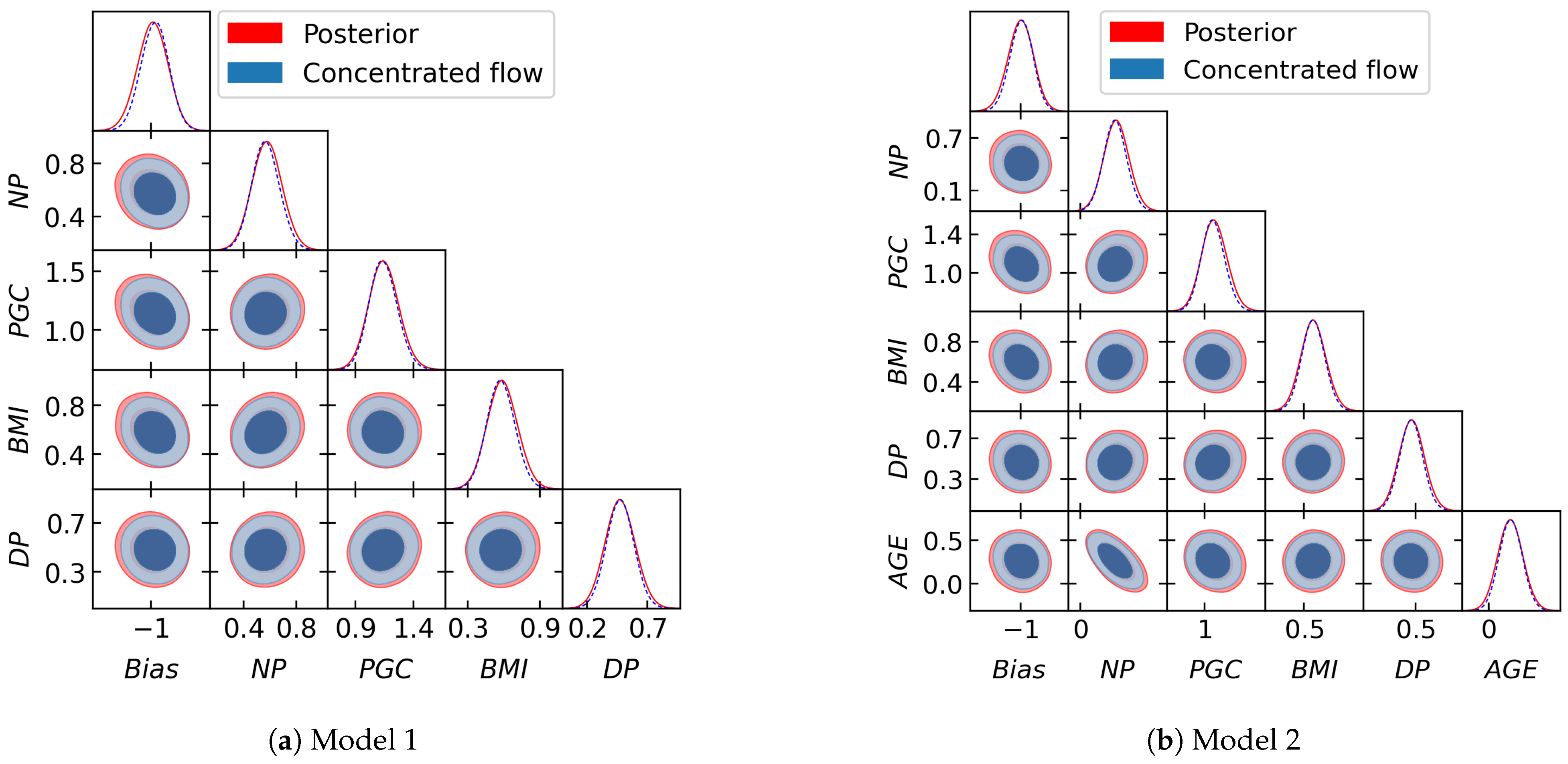
Figure 6 shows a corner plot of the training samples from the posterior (red) and from the normalizing flow (blue) at temperature
. Again, it can be seen that the concentrated learned target is close to the posterior but with thinner tails, as expected. We compute the marginal likelihood for Model 1 and Model 2 using our learned harmonic mean estimator. The log evidence found for Model 1 and 2 is
and
, respectively, resulting in the estimate
, which is in close agreement with the benchmark.
5. Conclusions
In this work, we propose using normalizing flows for the learned harmonic mean estimator of the marginal likelihood. The flow may be fitted to posterior samples by the usual maximum likelihood estimation. Its probability density may then be concentrated by lowering the temperature of the base distribution, ensuring that the probability mass of the transformed distribution is contained within the posterior to avoid the exploding variance issue of the original harmonic mean estimator. The use of flows therefore results in a more robust learned harmonic mean estimator. We perform a number of experiments to compute the marginal likelihood with the proposed approach, using a real NVP flow, finding excellent agreement with ground truth values. In this preliminary work, we consider only simple real NVP flows and a simple set of experiments. In a follow-up article, we will consider more expressive and scalable flows to address problems with complex, high-dimensional posteriors. We will also perform a more extensive set of numerical experiments to thoroughly assess performance. This preliminary work nevertheless suggests that the learned harmonic mean estimator with normalizing flows provides an effective technique with which to compute the marginal likelihood for Bayesian model selection. Furthermore, it is applicable for any MCMC sampling technique or variational inference approach.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}