3.1. Experimental Results
The software used in the conducted experiments was coded in ANSI C++ programming language, using the freely available Optimus programming tool, which can be downloaded from
https://github.com/itsoulos/GlobalOptimus/ (accessed on 17 February 2025). Each experiment was conducted 30 times, using a different seed for the random generator each time. For the validation of the experimental results, the ten-fold cross validation method was used. The average classification error as measured on the corresponding test set is reported for the classification datasets. This error is calculated using the following formula:
In this formula, the function class
is used for the class obtained by the application of the neural network to pattern
. The sum of the differences of the categories that the artificial neural network finds from the expected categories is divided by the number of patterns in the dataset. In addition, the average regression error is reported for the regression datasets, which can be calculated as follows:
In this formula, the squared sum of the differences from the values produced by the neural networks with the expected outputs is divided by the sum of patterns in the dataset. All experiments were performed on an AMD Ryzen 5950X with 128GB of RAM, and the operating system used was Debian Linux. The values used for the parameters of the proposed method are shown in
Table 1.
The following notation is used in the tables that contain the measurements from the conducted experiments:
The column DATASET contains the name of the used dataset.
The column ADAM represents the experimental results from the application of the ADAM optimization method [
11] to a neural network with
processing nodes. The Adam optimizer is a combination of Momentum [
83] and RMSprop [
84] techniques, and it has been used successfully for neural network training in many research papers.
The column BFGS denotes the incorporation of the BFGS optimization method [
85] to train an artificial neural network with
processing nodes. The Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm is a local optimization procedure that aims to discover the local minima of a multidimensional function.
The column GENETIC represents the usage of a Genetic Algorithm with the experimental settings in
Table 1, used to train a neural network with
processing nodes.
The column RBF denotes the incorporation of a Radial Basis Function (RBF) network [
86] with
processing nodes on the corresponding dataset.
The column PRUNE represents the usage of the OBS pruning method [
87], as implemented in the library Fast Compressed Neural Networks [
88].
The column PROPOSED denotes the proposed method.
The row AVERAGE is used to measure the average classification or regression error for all datasets.
The bold notation is used to indicate the method with the lowest classification or regression error.
Table 2 is used to provide the experimental results for the classification datasets, and
Table 3 provides the corresponding results for the regression datasets.
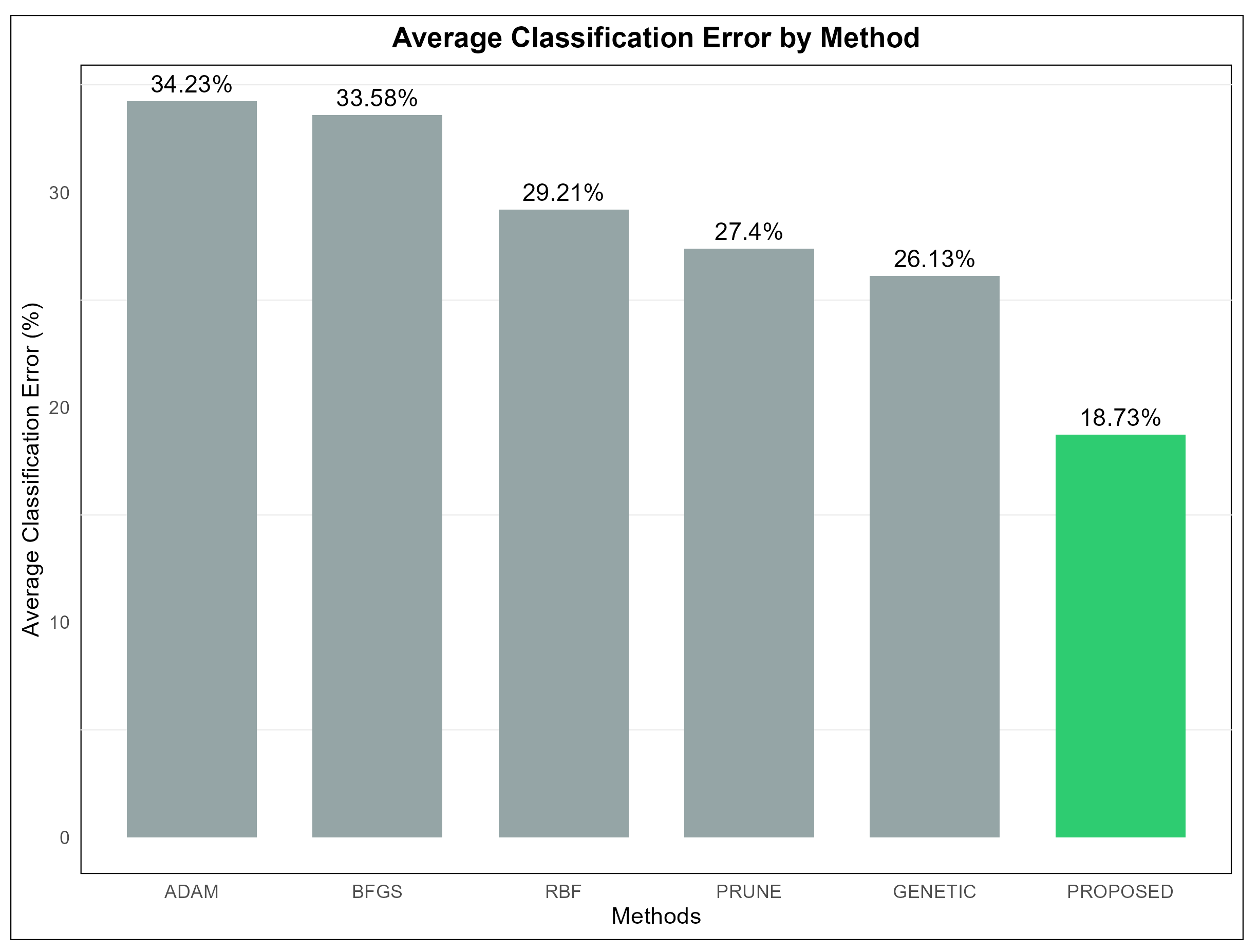
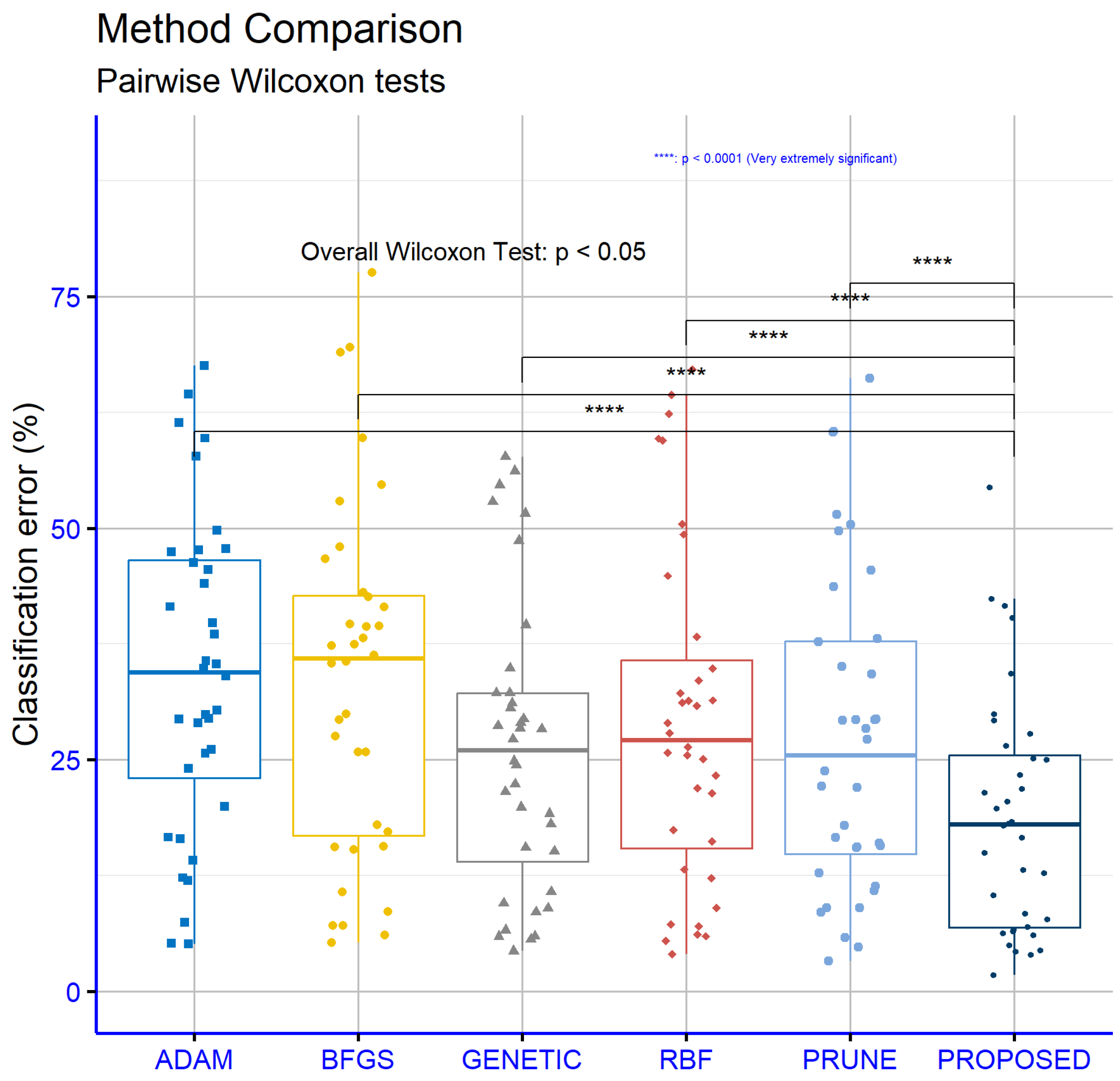
Table 2 presents a detailed comparison of the performance of six different machine learning models, namely ADAM, BFGS, GENETIC, RBF, PRUNE, and PROPOSED, evaluated across multiple classification datasets. The values in the table represent the error rates for each model on each dataset, expressed as percentages. Lower error rates indicate better performance for a given model on a specific dataset. The last row of the table provides the average error rate for each model, serving as a measure of their overall effectiveness across all datasets. From an analysis of this table, it becomes evident that the PROPOSED model achieved the best overall performance, with an average error rate of 18.73%. This was the lowest among all the models evaluated, demonstrating its superior effectiveness in solving classification problems across a diverse set of datasets. In particular, the PROPOSED model consistently outperformed the other models on datasets such as DERMATOLOGY, ZONF_S, and ZOO, where it recorded the smallest error rates, indicating its robustness in handling datasets of varying complexity and characteristics. The GENETIC model, on the other hand, had the highest average error rate at 26.13%, making it the least effective model overall. This result suggests that, while the GENETIC model may perform adequately in certain contexts, it lacks the adaptability and overall reliability exhibited by the PROPOSED model. Examining the ADAM model, we observed an average error rate of 34.23%, which was one of the highest among the models. Despite this, ADAM demonstrated good performance on specific datasets, such as CIRCULAR and SPIRAL, where its error rates were notably low. This indicates that the performance of ADAM is heavily dependent on the structure and features of the datasets, performing well in certain contexts but underperforming in others. Similarly, the BFGS model had an average error rate of 33.58%, slightly lower than ADAM, but it exhibited comparable variability in its performance across datasets. The RBF model, with an average error rate of 29.21%, performed better than both ADAM and BFGS. RBF appeared to be more stable in its performance, achieving lower error rates across a broader range of datasets, although it did not consistently outperform the PROPOSED model. The PRUNE model achieved an average error rate of 27.40%, which placed it between RBF and GENETIC in terms of overall effectiveness. While PRUNE did not outperform the PROPOSED model in most cases, it shows competitive performance on datasets such as GLASS, where it recorded one of the lowest error rates. This highlights that PRUNE can be effective on certain specialized datasets, though it lacks the overall adaptability of the PROPOSED model. A closer inspection of specific datasets further reinforces the dominance of the PROPOSED model. For instance, on the STATHEART and WINE datasets, which are characterized by increased complexity, the PROPOSED model achieved significantly lower error rates compared to the other models, indicating its ability to effectively handle challenging classification tasks. Additionally, on the HOUSEVOTES dataset, the PROPOSED model performed exceptionally well, suggesting its reliability on datasets with distinct structures. The GENETIC model, while generally less effective, demonstrated relatively strong performance on a few datasets, such as HAYES-ROTH and SPIRAL, where its error rates were comparable to or better than those of the other models. However, its overall high average error rate indicates that its performance was inconsistent and heavily dependent on the specific dataset. Similarly, PRUNE performed well on datasets like MAMMOGRAPHIC but fell behind on others, such as SEGMENT and BALANCE, where the PROPOSED model outperformed it by a considerable margin. The results for the BFGS model reveal a mixed performance profile. It achieved relatively low error rates on datasets such as BALANCE and HEART, but it struggled on datasets like CLEVELAND and LIVERDISORDER, where its error rates were higher than most of the other models. This inconsistency highlights the model’s limited generalizability across datasets. In conclusion, the PROPOSED model demonstrated the best overall performance across the majority of the datasets, achieving the lowest average error rate and consistently outperforming the other models in a wide range of contexts. This suggests that the PROPOSED model is highly adaptable and effective, making it suitable for diverse classification tasks. The analysis further underscores the importance of selecting an appropriate model based on the characteristics of the dataset, as models like ADAM, BFGS, and PRUNE showed strong performance in specific scenarios but fell short in others. The average error rate remains a critical indicator for evaluating the overall effectiveness of models, providing valuable insights into their strengths and weaknesses.
The dynamics of the proposed technique on the classification data are also presented graphically in
Figure 3, where the average classification error per method is presented.
Furthermore,
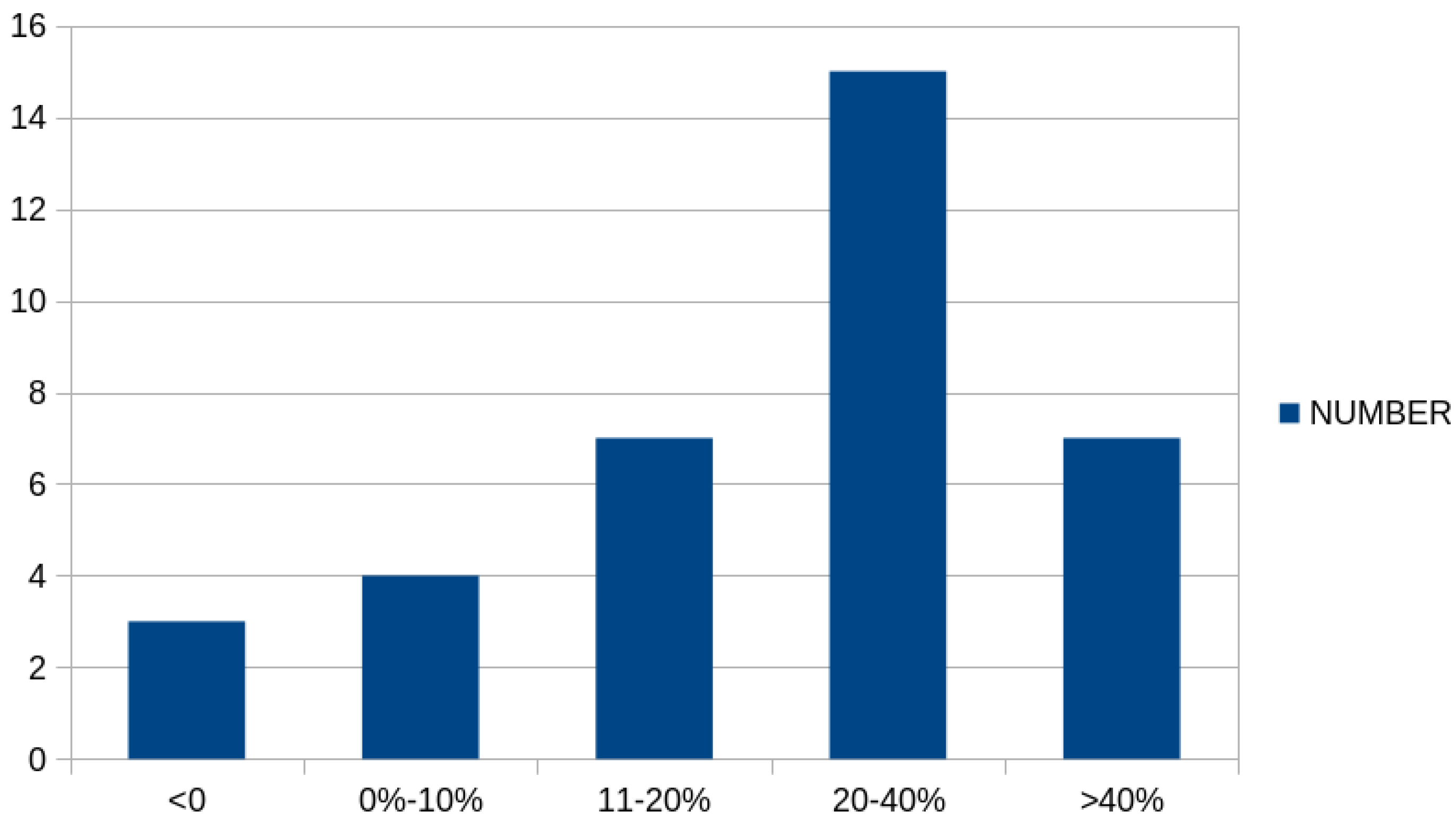
Figure 4 graphically presents the number of cases in which there was a significant reduction in classification error between the simple genetic algorithm and the proposed method. As is evident, in a significant number of cases, there was a drastic reduction in classification error, exceeding 20% or even 40%.
Moreover, a comparison of the factors of precision and recall between the original genetic algorithm and the proposed method is outlined in
Table 4 for the classification datasets.
Similarly,
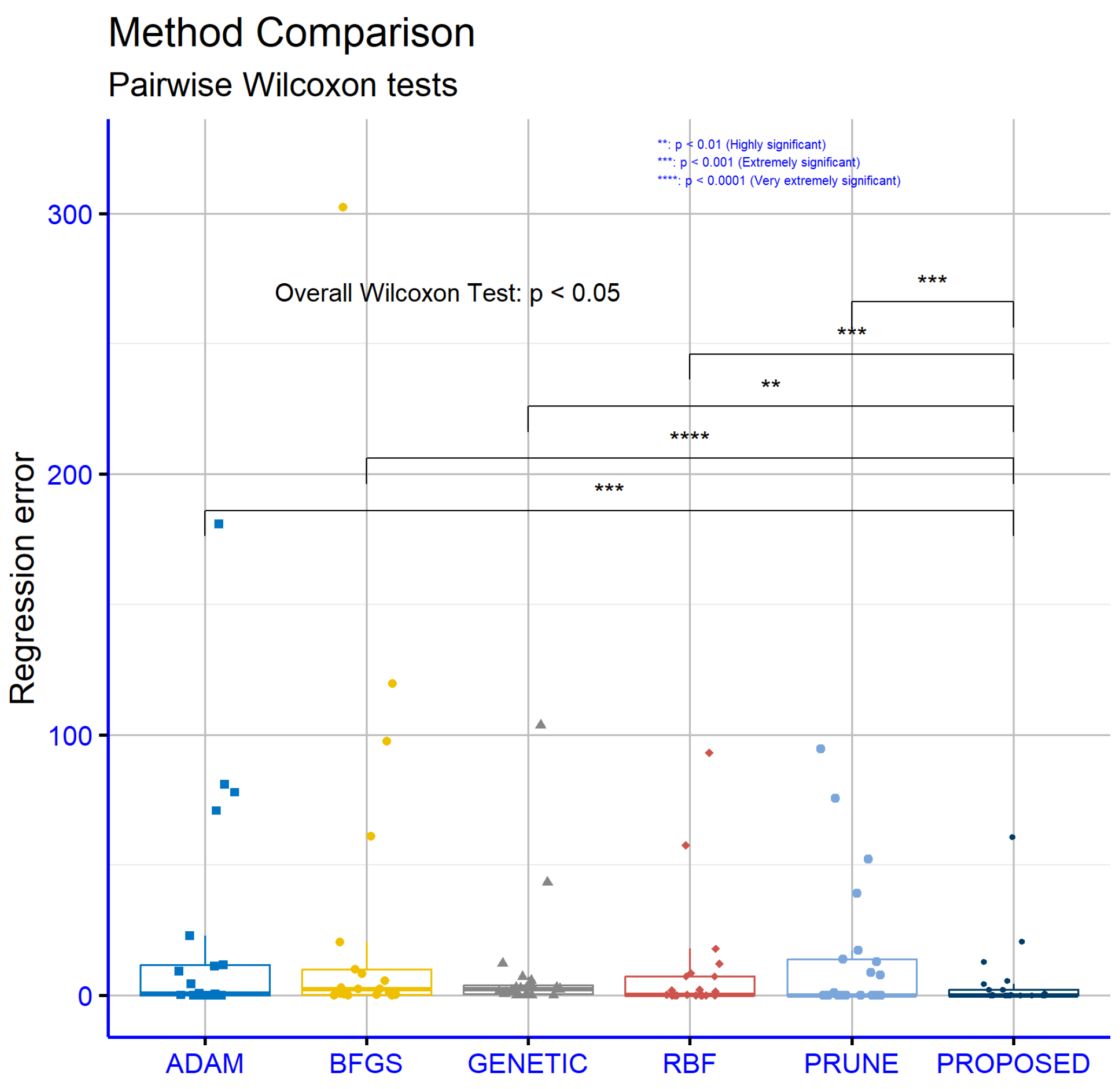
Table 3 presents a comparison of the performance of the same machine learning models, across a series of regression datasets. The values in the table are absolute and represent the error of each model for each dataset. From the analysis, it is evident that the proposed model (PROPOSED) demonstrated the best overall performance, with an average error of 5.23. This value is significantly lower than the average errors of the other models, highlighting that PROPOSED was the most effective model for regression problems. The GENETIC model exhibited the second-lowest average error, 9.31, indicating that it is also a reliable choice, though noticeably less effective than PROPOSED. The RBF model achieved an average error of 10.02, ranking third in performance, while showing consistent results across many datasets. The PRUNE model had an average error of 15.4, which is higher than GENETIC and RBF, but it still showed remarkable performance on specific datasets, such as CONCRETE and LASER. The ADAM and BFGS models had the highest average errors, 22.46 and 30.29, respectively, making them the least effective overall. At the individual dataset level, the PROPOSED model demonstrated superior performance in many instances. For example, on the AIRFOIL, CONCRETE, LASER, and MORTGAGE datasets, PROPOSED recorded the smallest error values, underscoring its high effectiveness in addressing problems with varying characteristics. On the BL dataset, the PROPOSED model achieved an exceptionally low error of 0.006, the smallest among all models. On more complex datasets, such as BASEBALL and HOUSING, PROPOSED significantly outperformed the other models, with error values of 60.74 and 20.74, respectively. These results emphasize its adaptability to problems with different levels of complexity. The GENETIC model, while performing well overall, showed significant variability. For instance, it recorded relatively low errors on the AUTO and PLASTIC datasets, with values of 12.18 and 2.791, respectively, but exhibited considerably higher errors on others, such as STOCK and BASEBALL. This inconsistency suggests limited stability. Similarly, the RBF model demonstrated good overall performance, with notable results on datasets like MORTGAGE and PL, where its errors were among the lowest. However, on datasets like AUTO and STOCK, its errors were significantly higher than those of the PROPOSED model. The PRUNE model delivered noteworthy results on specific datasets. For example, on CONCRETE, it achieved one of the smallest errors, only 0.0077, while on datasets such as PLASTIC and TREASURY, its error was larger, indicating less consistency under varying conditions. On the other hand, ADAM, despite being generally less effective, performed well on a few datasets like BK and QUAKE, where it recorded lower errors compared to the other models. The BFGS model, with the highest average error, consistently underperformed across most datasets, with standout poor results on BASEBALL and STOCK, where it records particularly high error values. In summary, an analysis of the table reveals that the proposed model, PROPOSED, achieved the best overall performance compared to the other models, while being particularly effective on datasets with varying levels of complexity. The average error serves as a useful indicator of the effectiveness of each model, reaffirming the superiority of the PROPOSED model across a wide range of regression problems.
Figure 5 focuses on regression datasets and reveals similar results favoring the proposed model, although the “
p” values are slightly higher compared to those in the classification datasets. The comparison between PROPOSED and ADAM produced a “
p” value of 0.0001, indicating a statistically significant difference in favor of the PROPOSED model. Comparisons with the other models, specifically PROPOSED vs. BFGS (
p = 4.1 × 10
−5), PROPOSED vs. GENETIC (
p = 0.0022), PROPOSED vs. RBF (
p = 0.00073), and PROPOSED vs. PRUNE (
p = 0.00042), also demonstrated statistically significant differences. All “
p” values remained below the 0.05 threshold, affirming that the observed performance differences are not attributable to randomness. Notably, the very low “
p” values on the regression datasets underscore the overall effectiveness of the PROPOSED model in addressing regression problems. The PROPOSED model demonstrated a high level of adaptability across various datasets with diverse characteristics, consistently maintaining its superiority over the other models.
Consequently, the results from
Figure 6 further strengthen the position of the PROPOSED model as the most effective solution for regression problems, providing a reliable and statistically significant performance.
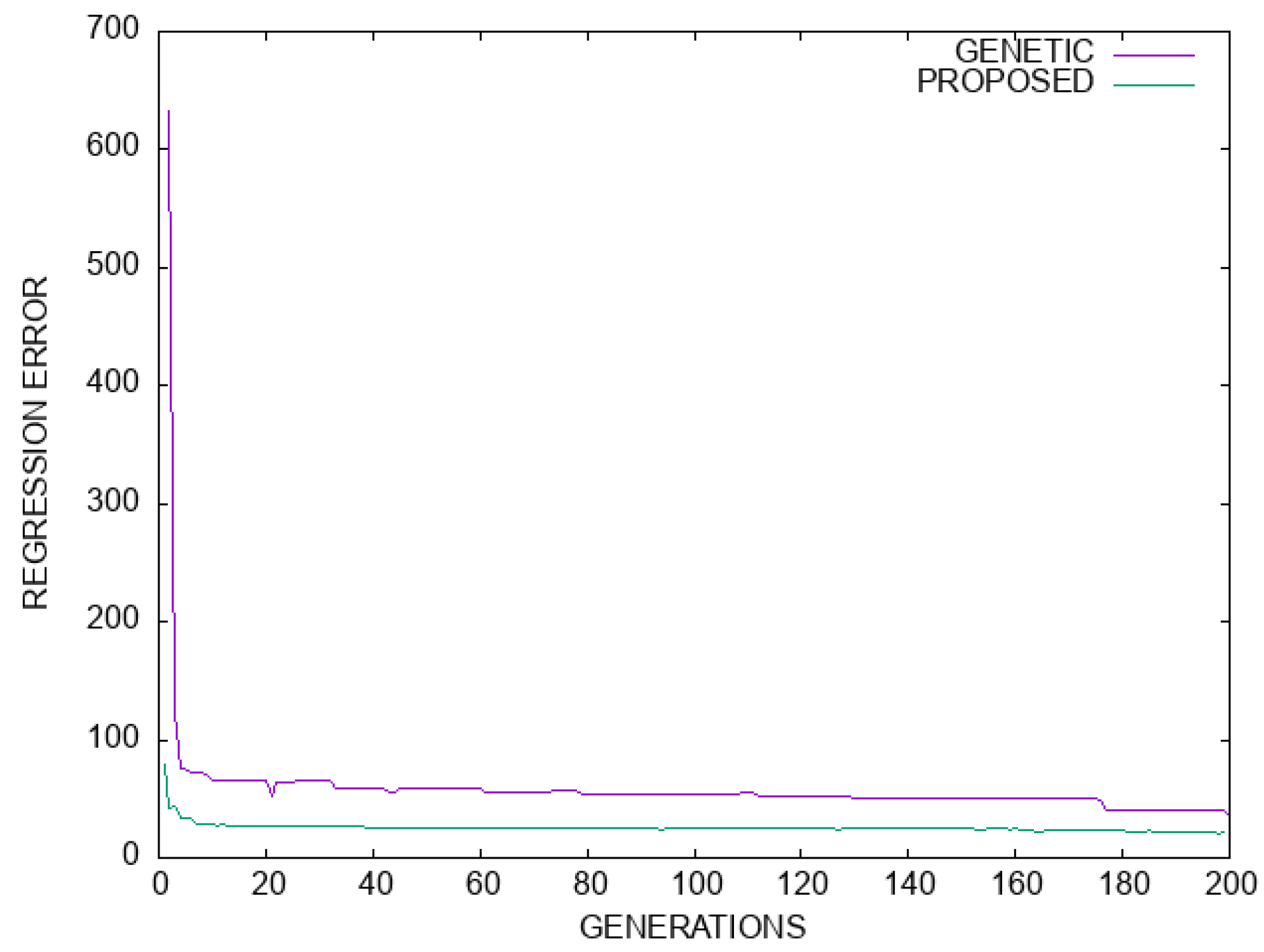
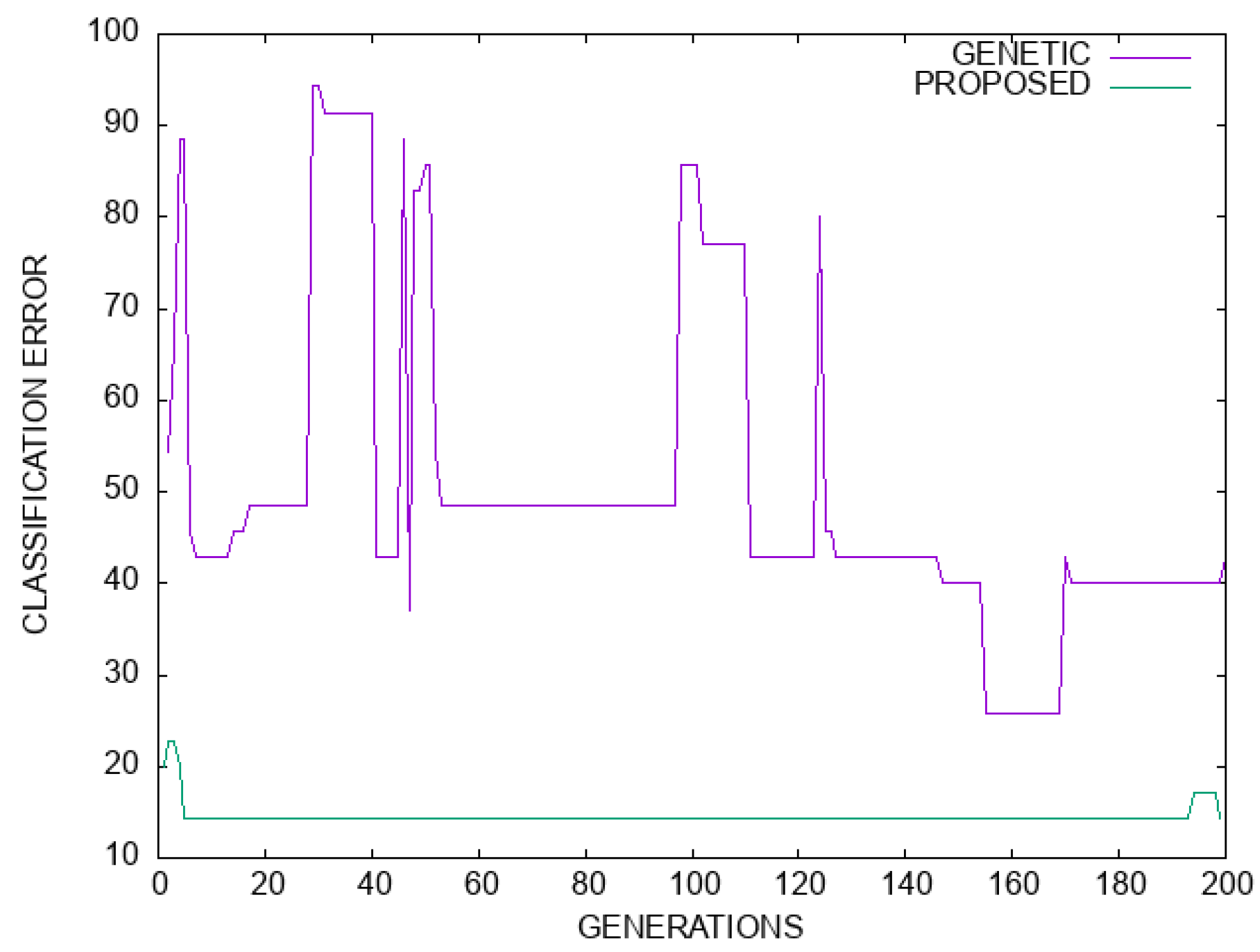
Moreover, in the plot of
Figure 7 a comparison in terms of classification error is made between the simple genetic algorithm and the proposed model for the Dermatology dataset. Likewise, in
Figure 8 a plot of the regression error is outlined for the genetic algorithm and the proposed method. For both cases, there is a significant improvement in terms of error values.
3.2. Using Different Weight Methods
An additional experiment was executed, where the parameter F of the differential evolution was altered using some well-known approaches from the relevant literature. In the following tables, the following methods, as denoted in the experimental tables, were used for the calculation of the parameter F:
The experimental results using the current method and the previously mentioned method for differential weight are listed in
Table 5 and
Table 6 for the classification datasets and the regression datasets, respectively.
Figure 8.
Comparison between the genetic algorithm and the proposed method for the Housing regression dataset. The horizontal axis denotes the number of generations, and the vertical axis gives the regression error as measured on the test set.
Figure 8.
Comparison between the genetic algorithm and the proposed method for the Housing regression dataset. The horizontal axis denotes the number of generations, and the vertical axis gives the regression error as measured on the test set.
The statistical analysis in
Table 5 examines the percentage error rates across various classification datasets using four different computations of the critical weight differential parameter for the proposed machine learning model: RANDOM, FIXED, ADAPT, and MIGRANT. The RANDOM computation exhibited the lowest overall average error rate (18.73%), indicating superior performance compared to the other computations: FIXED (19.12%), ADAPT (19.52%), and MIGRANT (20.62%). This suggests that the RANDOM computation was the most reliable overall. Analyzing individual datasets, the RANDOM computation achieved the best error rates in several cases. For instance, it recorded the lowest error rates for datasets such as “ALCOHOL” (18.33%), “BALANCE” (7.79%), “CIRCULAR” (6.50%), “HOUSEVOTES” (6.09%), “PARKINSONS” (12.79%), “POPFAILURES” (4.45%), and “WDBC” (6.73%). These results highlight its effectiveness across a wide range of datasets. Specifically, the 4.45% error rate for “POPFAILURES” stands out as one of the lowest overall. In certain datasets, the FIXED computation outperformed the others, such as on “Z_F_S” (7.00%) and “ZOO” (4.90%). However, the difference from RANDOM is minimal. The MIGRANT computation demonstrated the lowest error rates in only a few cases, such as “CIRCULAR” (4.74%) and “WDBC” (4.18%), suggesting it may be particularly effective for specific datasets. Meanwhile, the ADAPT computation achieved lower error rates on a few scenarios but generally remained less competitive. On other datasets, such as “GLASS”, “SPIRAL”, and “SEGMENT”, all computations showed high error rates, indicating that these datasets are challenging to classify, regardless of the computation. Nevertheless, the RANDOM computation remained consistently competitive, even with these difficult datasets, as observed on “STATHEART” and “ZONF_S”. In conclusion, the analysis revealed that the RANDOM computation was the most effective overall, achieving the lowest average error rate and demonstrating superior performance across a broad range of datasets. However, there were instances where other computations, such as FIXED and MIGRANT, showed specialized advantages.
The statistical analysis in
Table 6 pertains to regression datasets, using four different calculations of the critical parameter of differential weighting for the proposed machine learning model: RANDOM, FIXED, ADAPT, and MIGRANT. The RANDOM calculation exhibited the lowest average error (5.23), making it the most efficient overall compared to FIXED (5.74), ADAPT (5.82), and MIGRANT (5.27). The small difference between RANDOM and MIGRANT suggests a comparable performance between these two approaches, with RANDOM maintaining a slight edge. For individual datasets, the RANDOM calculation achieved the lowest error values in several cases, such as the “AUTO” (12.78), “FRIEDMAN” (2.21), “HO” (0.015), “MORTGAGE” (0.32), and “SN” (0.023) datasets. These results demonstrate the effectiveness of the RANDOM calculation across a wide range of datasets. On the “FRIEDMAN” dataset, the error value of 2.21 was significantly lower than the corresponding values of FIXED (2.79) and ADAPT (3.18), underscoring its performance on this specific dataset. The MIGRANT calculation demonstrated the best performance on certain datasets, such as “AUTO” (11.46) and “STOCK” (4.41), where it outperformed RANDOM. However, on other datasets, such as “PLASTIC” and “SN”, it showed slightly higher error rates, indicating limitations with specific data. The FIXED calculation tended to have consistent but not top-performing results, while ADAPT generally showed higher error values, making it less effective overall. In summary, the analysis highlighted that the RANDOM calculation was the most reliable and efficient, with the lowest average error and strong performance across various datasets. However, the MIGRANT calculation exhibited competitive performance in specific cases, while FIXED and ADAPT appear to require improvements to rival the other calculations.
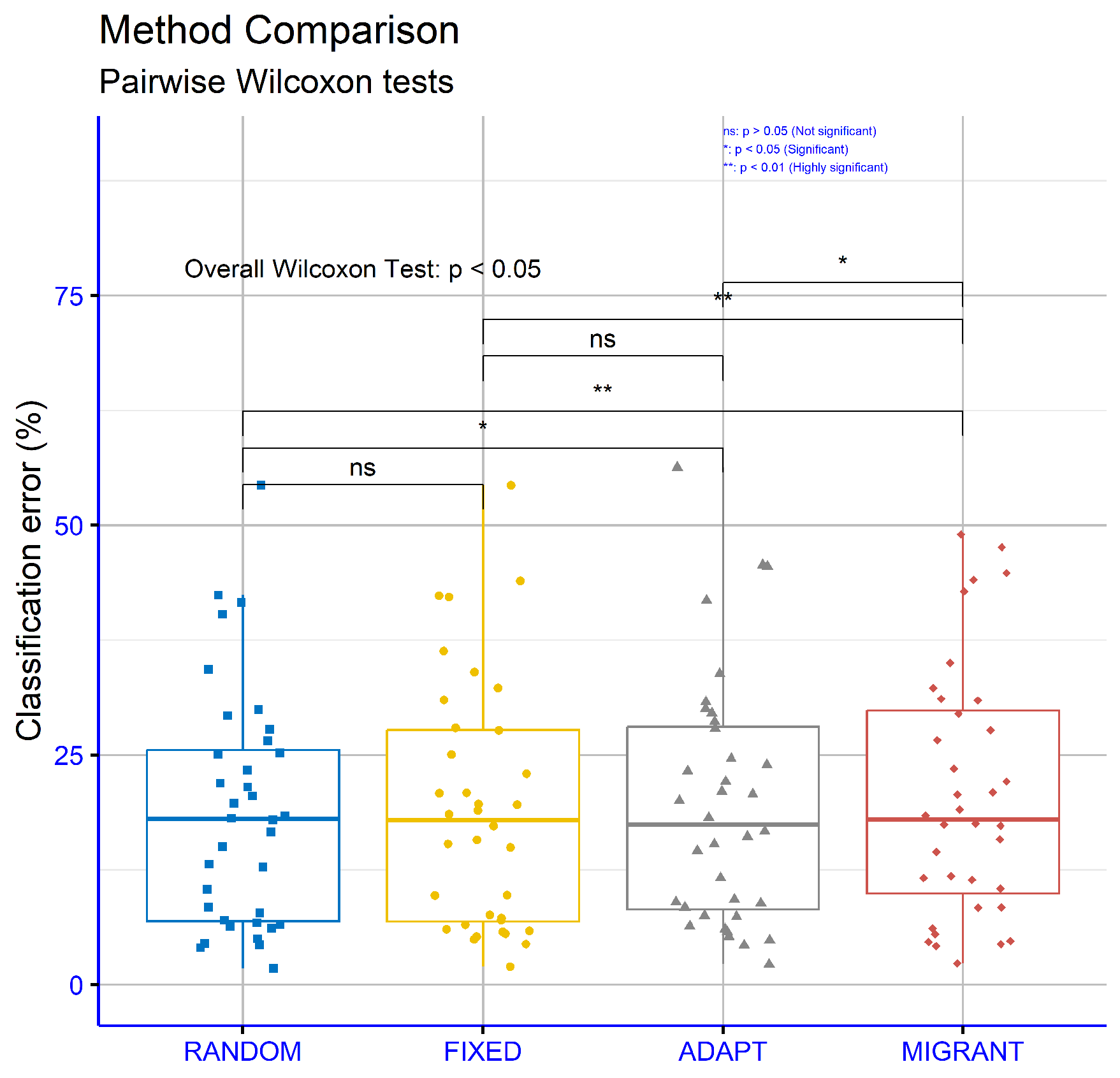
Figure 9 evaluates the classification datasets for different differential weight computations within the proposed machine learning model. The
p-values are as follows: RANDOM vs. FIXED:
p = 0.43, RANDOM vs. ADAPT:
p = 0.024, RANDOM vs. MIGRANT:
p = 0.0021, FIXED vs. ADAPT
p = 0.12, FIXED vs. MIGRANT:
p = 0.0033, and ADAPT vs. MIGRANT:
p = 0.043. These results suggest that some comparisons, such as RANDOM vs. MIGRANT and FIXED vs MIGRANT, showed strong statistical significance, while others, such as RANDOM vs FIXED, did not demonstrate significant differences.
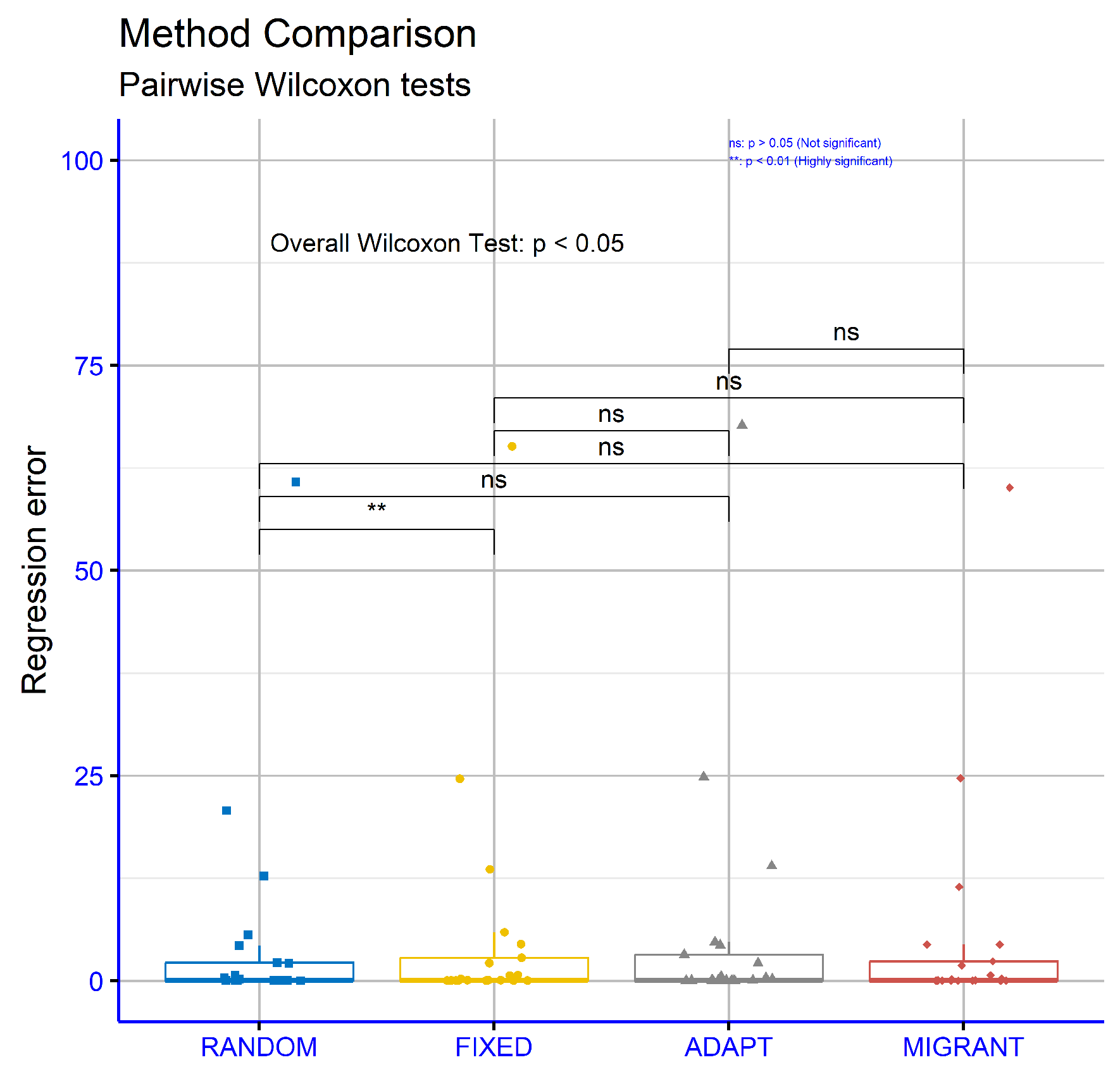
Figure 10 presents the results for regression datasets using different differential weight computations within the proposed model. The observed p-values were RANDOM vs. FIXED:
p = 0.0066, RANDOM vs ADAPT:
p = 0.15, RANDOM vs. MIGRANT:
p = 0.66, FIXED vs. ADAPT:
p = 0.64, FIXED vs. MIGRANT:
p = 0.84, and ADAPT vs. MIGRANT:
p = 0.47. These findings indicate that most comparisons did not show significant differences, except for RANDOM vs. FIXED, which demonstrated a notable level of significance.
3.3. Experiment with the Number of Agents
An additional experiment was conducted using different values for the parameter NP, which represents the number of agents. In this experiment, the parameter NP took the values 50, 100, and 200. The experimental results for the classification datasets are shown in
Table 7 and for the regression datasets in
Table 8.
The statistical analysis in
Table 7 pertains to classification datasets, utilizing three different values for the critical parameter “NP” in the proposed machine learning model: NP = 50, NP = 100, and NP = 200. The computation with NP = 200 demonstrated the lowest average error rate (18.73%), indicating the highest efficiency compared to NP = 100 (19.94%) and NP = 50 (20.36%). This suggests that a higher value of the NP parameter was generally associated with better performance. On individual datasets, the computation with NP = 200 achieved the lowest error rate in many cases, such as in “ALCOHOL” (18.33%), “AUSTRALIAN” (21.49%), “BALANCE” (7.79%), “DERMATOLOGY” (4.97%), “ECOLI” (40.30%), and “HEART” (13.11%). On some of these datasets, the difference between NP = 200 and the other two values was notable. For instance, on the “DERMATOLOGY” dataset, the error rate with NP = 200 (4.97%) was significantly lower than the corresponding values for NP = 50 (9.89%) and NP = 100 (11.34%), highlighting the clear superiority of NP = 200 for this dataset. However, there were also datasets where the differences were less pronounced. For example, on “PHONEME”, the error rates were relatively close across all parameter values, with NP = 200 showing the smallest error (18.10%). On some other datasets, such as “HOUSEVOTES”, NP = 50 had a lower error rate (3.91%) than the other two parameter values. This indicates that, on certain datasets, increasing the NP parameter did not necessarily lead to improved performance. Similarly, on the “Z_F_S” dataset, NP = 100 achieved the lowest error rate (6.73%), while NP = 200 exhibited a higher rate (8.38%), suggesting that performance may also depend on the characteristics of the data. Despite these exceptions, NP = 200 generally exhibited the best overall performance, achieving the lowest average error rate and delivering strong results across a wide range of datasets.
The analysis in
Table 8 focuses on regression datasets, considering three distinct values for the critical parameter “NP” in the proposed machine learning model: NP = 50, NP = 100, and NP = 200. The parameter NP = 200 achieved the lowest average error (5.23), making it more effective than NP = 100 (5.48) and NP = 50 (5.92). This suggests that higher NP values are generally associated with improved performance. On specific datasets, NP = 200 stood out for its superior performance. For instance, on “AIRFOIL” (0.002), “AUTO” (12.78), “BL” (0.006), “CONCRETE” (0.006), “FRIEDMAN” (2.21), and “TREASURY” (0.68), the error values for NP = 200 were the lowest. On the “FRIEDMAN” dataset, NP = 200 (2.21) significantly outperformed NP = 50 (3.43) and NP = 100 (2.83), demonstrating its effectiveness. However, there were cases where other NP values showed stronger performance. For example, on the “BK” dataset, NP = 100 achieved the lowest error (0.018), while NP = 200 (0.02) was slightly worse. Similarly, on the “FY” dataset, NP = 100 exhibited the best performance (0.041), with NP = 200 showing a higher error (0.067). Additionally, on the “BASEBALL” dataset, NP = 100 outperformed NP =2 00, recording an error of 57.75 compared to 60.74. These variations indicate that the effectiveness of the NP parameter can depend on the characteristics of the dataset. Overall, NP = 200 demonstrated the best average performance, highlighting its value in most cases. While the other NP values achieved lower error rates on some datasets, NP = 200 stood out for its general reliability and efficiency.
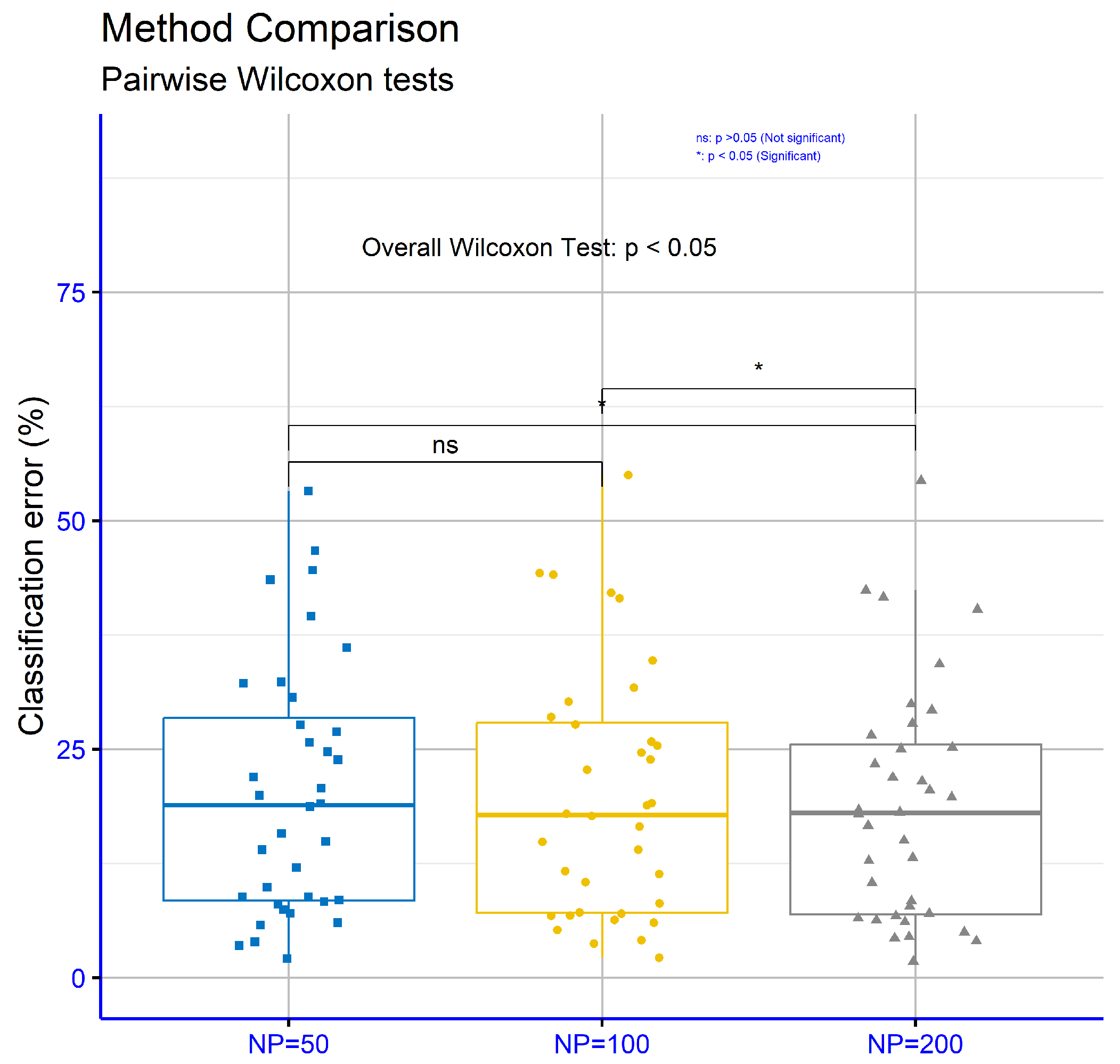
In
Figure 11, focusing on classification datasets for different values of the critical parameter “NP” within the proposed model, the
p-values are NP = 50 vs. NP = 100:
p = 0.17, NP = 50 vs. NP = 200:
p = 0.117, and NP = 100 vs. NP = 200:
p = 0.032. These results indicate that only the comparison between NP = 100 and NP = 200 demonstrated statistical significance.
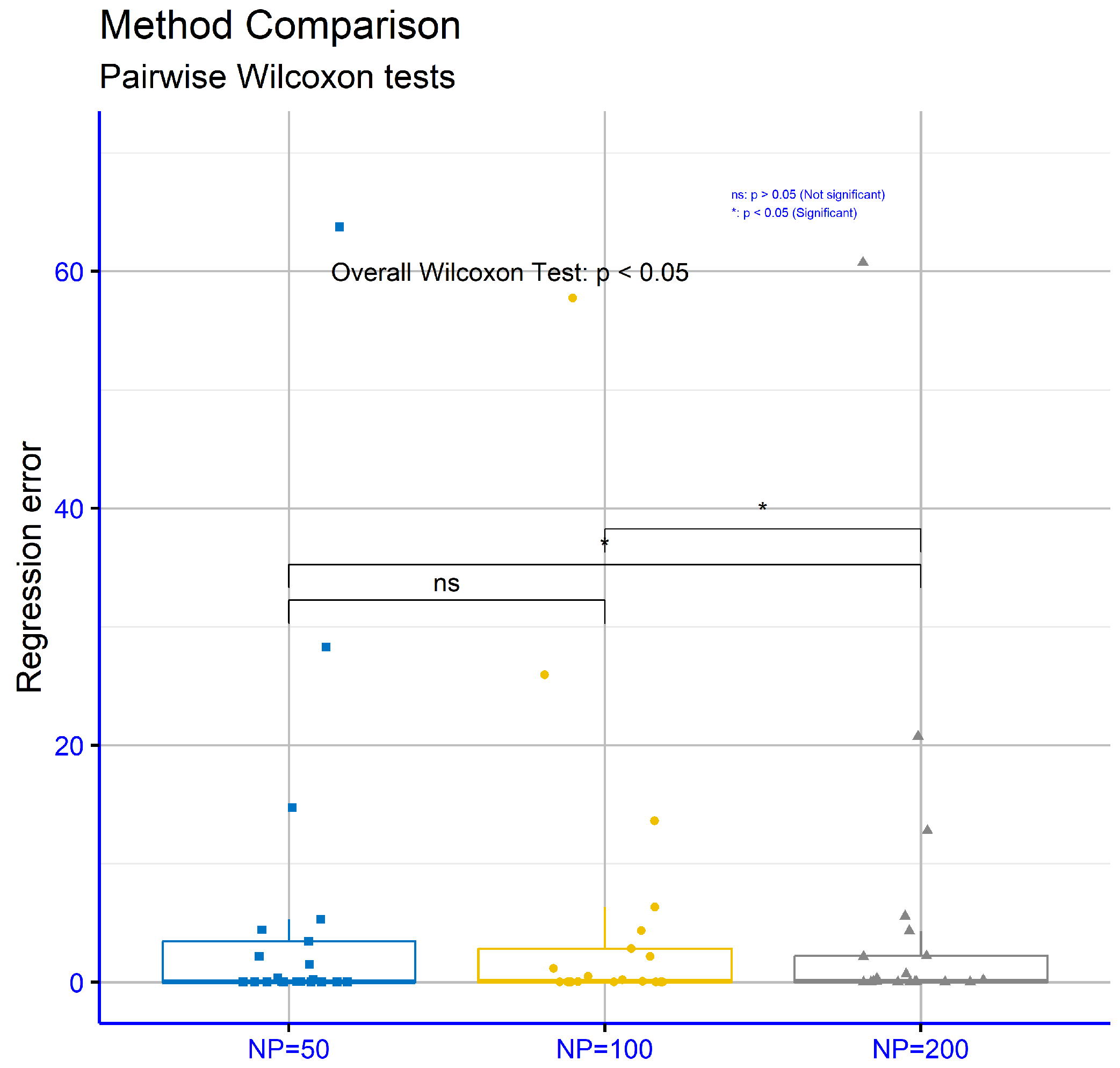
Finally,
Figure 12 evaluates regression datasets for different values of the critical parameter “NP” within the proposed model. The respective
p-values are NP = 50 vs. NP = 100:
p = 0.08, NP = 50 vs. NP = 200:
p = 0.012, and NP = 100 vs NP = 200:
p = 0.025. These results show that the comparisons NP = 50 vs. NP = 200 and NP = 100 vs. NP = 200 exhibited statistically significant differences, while the comparison NP = 50 vs. NP = 100 did not.
3.4. Discussion
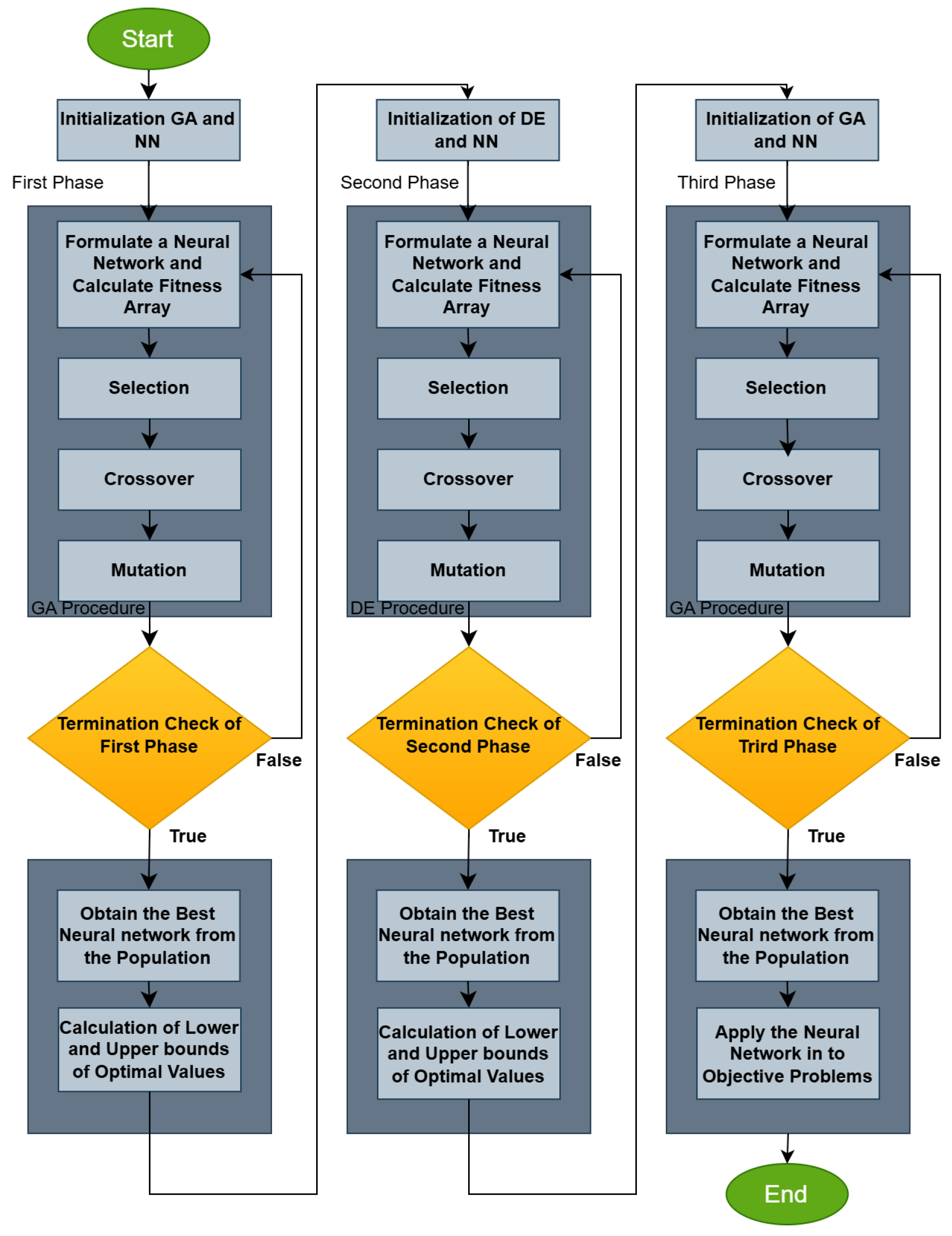
This study introduced an innovative three-stage evolutionary method for training artificial neural networks (ANNs), with the primary goal of reducing both training error and overfitting. The results show that the proposed approach achieved a mean classification error of 18.73% and a mean regression error of 5.23, significantly outperforming conventional methods such as ADAM, BFGS, PRUNE, genetic algorithms, and radial basis function (RBF) networks. This improvement demonstrates that combining genetic algorithms with differential evolution to define optimal parameter bounds is an effective strategy for enhancing model generalization. Specifically, the use of a modified fitness function, which penalizes large deviations in weight values, appeared to limit the networks’ tendency to overfit training data. For example, on datasets like “DERMATOLOGY”, where the classification error dropped to 4.97%, the method maintained high accuracy, even in cases of high variability.
Compared to previous studies that focused on standalone techniques like genetic-algorithm-based training or Adam optimizers, the current method introduces two critical innovations. First, the differential evolution in the second stage enables systematic exploration of the parameter space to identify optimal value intervals for weights. Second, the multi-stage nature of the process initial boundary estimation, interval optimization, and final training provides a structured framework for managing problem complexity. These enhancements explain the significant reduction in mean error compared to prior methods, such as the decrease from 26.13% to 18.73% in classification and from 10.02 to 5.23 in regression.
However, the method is not without limitations. A primary constraint is its high computational cost, stemming from the three-stage process and the large number of agents (NP = 200) required to explore the parameter space. Additionally, the method’s performance heavily depends on hyperparameter tuning, such as crossover probability (CR). For instance, on datasets like “SEGMENT” (27.80% error) or “STOCK” (5.57 error), the method showed relative weakness, likely due to data complexity or noise. Furthermore, the use of a single hidden layer (H = 10) may be insufficient for high-dimensional problems, highlighting the need for more complex architectures.
Error sources can be attributed to multiple factors. On medical datasets like “CLEVELAND” (42.38% error), noise or class imbalance may have affected accuracy. Additionally, the random weight initialization in the first stage can lead to suboptimal solutions, while the network’s static architecture limits its ability to handle non-linear relationships. However, a clear trend emerged: increasing the number of agents (NP) improves performance, as seen in the reduction in mean classification error from 20.36% (NP = 50) to 18.73% (NP = 200). This suggests that a broader parameter space exploration enhances generalization.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}