
Know What You Don’t Know: Assessment of Overlooked Microplastic Particles in FTIR Images


Abstract
:1. Introduction
- (a)
- Assessment of single-spectrum class assignment: lack of a standard set of test spectra.
- (b)
- Assessment of particle recognition: lack of a standard IR image.
- (c)
- Lack of objective and concise performance metrics for evaluation on the level of particles.
- (d)
- Comparison of DARs: lack of standard test sets and IR images.
- (a)
- Providing a set of 9537 labeled transmission µFTIR spectra that can be used for a database, or as training/test sets for machine learning models.
- (b)
- Providing a manually evaluated transmission µFTIR image of 1289 MP and natural particles that can be used as a ground truth for evaluating and optimizing a DAR on a particle level: RefIMP.
- (c)
- Introducing performance metrics for particle-level evaluation.
- (d)
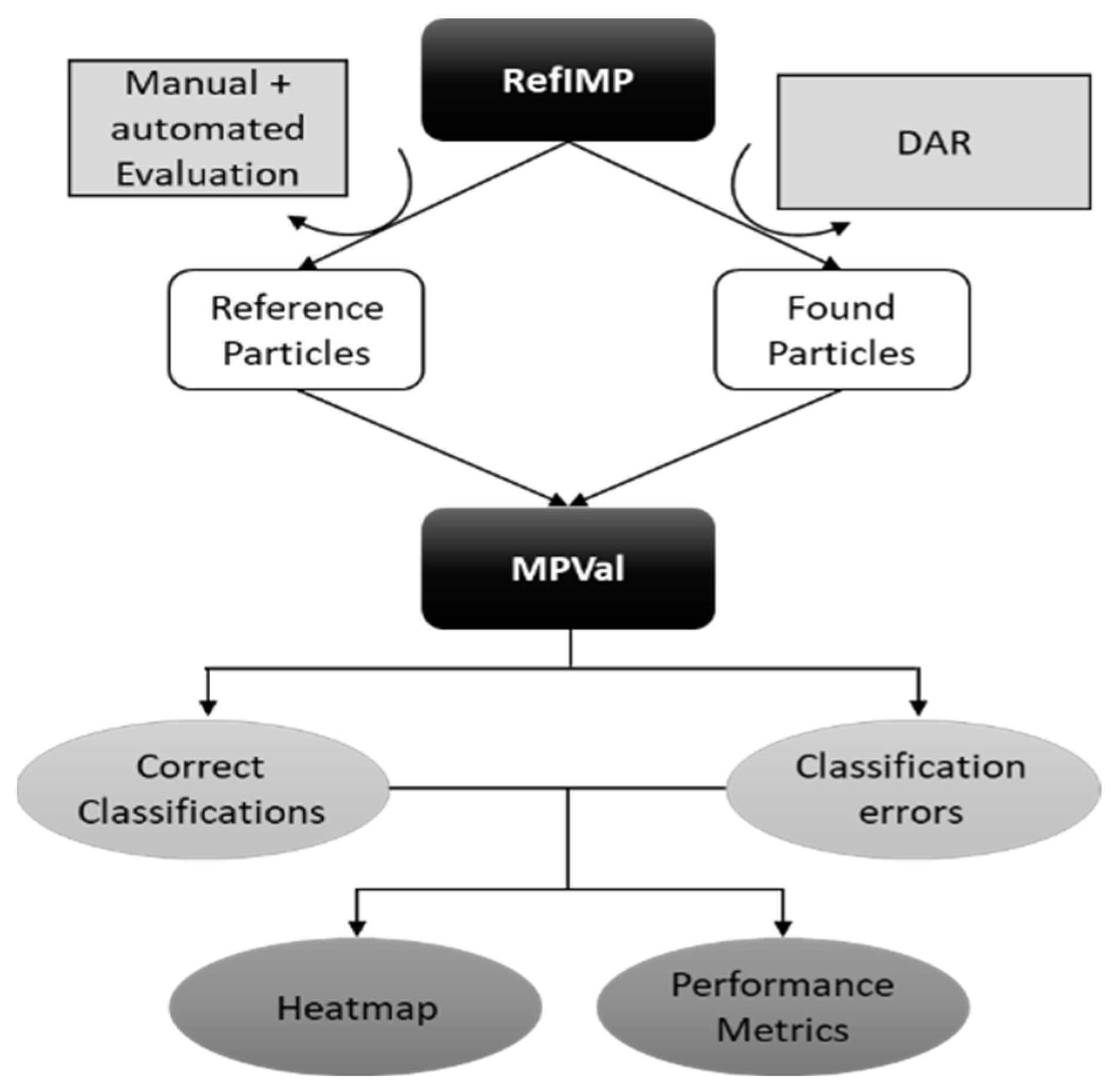
- Providing an easy-to-use object-oriented MatLab® script that automatically compares results gained using any DAR desired with RefIMP (see Figure 1).
- (e)
- Example hypothesis tests presented here will show how the influence of selected factors on DAR performance can be quantified using RefIMP and MPVal.
2. An FTIR MP Reference Image: Design, Objectives and Limitations
3. Evaluating Data Evaluation Routines: Error Types and Metrics
4. Random Decision Forest Classifier for MP Detection
5. Thorough DAR Evaluation Using RefIMP and MPVal
- (1)
- Masking of background pixels increases the risk of overlooking particles.
- (2)
- RDF models benefit from high training data diversity.
- (3)
- Model hyperparameters have substantial influence on the classification results.
5.1. First Hypothesis: Masking of Background Pixels Increases the Risk of Overlooking Particles
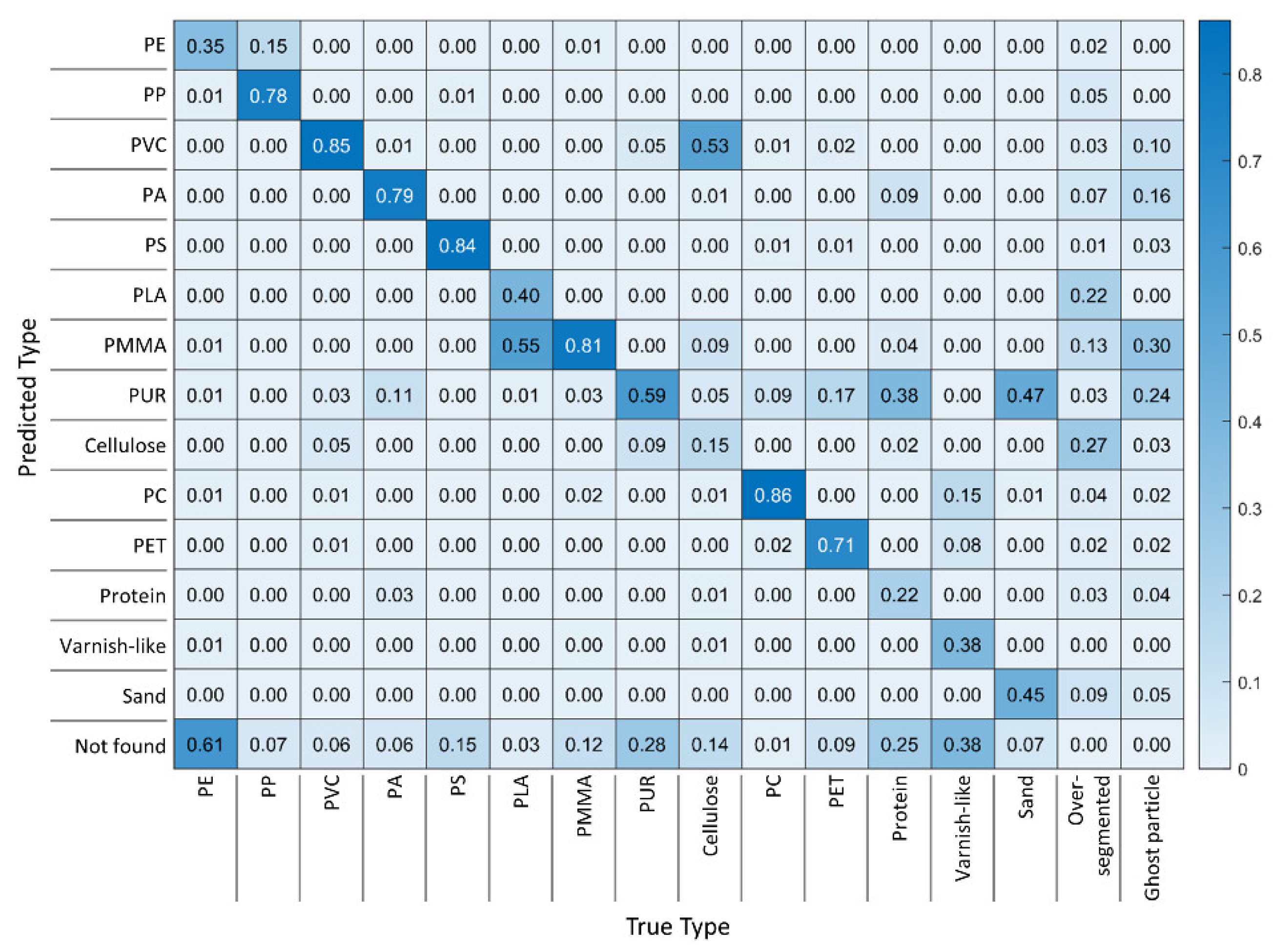
5.2. Second Hypothesis: RDF Models Benefit from High Training Data Diversity
5.3. Third Hypothesis: Model Hyperparameters Have Substantial Influence on the Classification Results
6. Conclusions
- (1)
- background masks can strongly reduce ghost particles but, according to our results, they should not cover too much of the image to avoid overlooking of particles;
- (2)
- RDF models benefit from highly diverse training spectra. In particular, the share of overlooked particles was drastically reduced;
- (3)
- among the model hyperparameters, the classification threshold was shown to be the most important one, influencing NER, accuracy and especially Pr strongly.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
References
- Löder, M.G.J.; Kuczera, M.; Mintening, S.; Lorenz, C.; Gerdts, G. Focal plane array detector-based micro-Fourier-transform infrared imaging for the analysis of microplastics in environmental samples. Environ. Chem. 2015, 12, 563–581. [Google Scholar] [CrossRef]
- Morgado, V.; Palma, C.; Bettencourt da Silva, R.J.N. Microplastics identification by infrared spectroscopy—Evaluation of identification criteria and uncertainty by the Bootstrap method. Talanta 2020, 224, 121814. [Google Scholar] [CrossRef] [PubMed]
- Primpke, S.; Wirth, M.; Lorenz, C.; Gerdts, G. Reference database design for the automated analysis of microplastic samples based on Fourier transform infrared (FTIR) spectroscopy. Anal. Bioanal. Chem. 2018, 410, 5131–5141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Primpke, S.; Cross, R.K.; Mintenig, S.M.; Simon, M.; Vianello, A.; Gerdts, G.; Vollertsen, J. Toward the Systematic Identification of Microplastics in the Environment: Evaluation of a New Independent Software Tool (siMPle) for Spectroscopic Analysis. Appl. Spectrosc. 2020, 74, 1127–1138. [Google Scholar] [CrossRef]
- Renner, G.; Schmidt, T.C.; Schram, J. Automated rapid & intelligent microplastics mapping by FTIR microscopy: A Python–based workflow. MethodsX 2020, 7, 100742. [Google Scholar]
- Wander, L.; Vianello, A.; Vollertsen, J.; Westad, F.; Braun, U.; Paul, A. Exploratory analysis of hyperspectral FTIR data obtained from environmental microplastics samples. Anal. Methods 2020, 12, 781–791. [Google Scholar] [CrossRef]
- Xu, J.-L.; Hassellöv, M.; Yu, K.; Gowen, A.A. Microplastic Characterization by Infrared Spectroscopy. In Handbook of Microplastics in the Environment; Rocha-Santos, T., Costa, M., Mouneyrac, C., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 1–33. [Google Scholar]
- Shan, J.; Zhao, J.; Zhang, Y.; Liu, L.; Wu, F.; Wang, X. Simple and rapid detection of microplastics in seawater using hyperspectral imaging technology. Anal. Chim. Acta 2019, 1050, 161–168. [Google Scholar] [CrossRef]
- Hufnagl, B.; Steiner, D.; Renner, E.; Löder, M.G.J.; Laforsch, C.; Lohninger, H. A methodology for the fast identification and monitoring of microplastics in environmental samples using random decision forest classifiers. J. Anal. Methods 2019, 11, 2277–2285. [Google Scholar] [CrossRef] [Green Version]
- Back, H.d.M.; Vargas Junior, E.C.; Alarcon, O.E.; Pottmaier, D. Training and evaluating machine learning algorithms for ocean microplastics classification through vibrational spectroscopy. Chemosphere 2022, 287, 131903. [Google Scholar] [CrossRef]
- Weisser, J.; Pohl, T.; Heinzinger, M.; Ivleva, N.P.; Hofmann, T.; Glas, K. The identification of microplastics based on vibrational spectroscopy data—A critical review of data analysis routines. TrAC Trends Anal. Chem. 2022, 148, 116535. [Google Scholar] [CrossRef]
- Renner, G.; Nellessen, A.; Schwiers, A.; Wenzel, M.; Schmidt, T.C.; Schram, J. Data preprocessing & evaluation used in the microplastics identification process: A critical review & practical guide. TrAC Trends Anal. Chem. 2019, 111, 229–238. [Google Scholar]
- Primpke, S.; Lorenz, C.; Rascher-Friesenhausen, R.; Gerdts, G. An automated approach for microplastics analysis using focal plane array (FPA) FTIR microscopy and image analysis. Anal. Methods 2017, 9, 1499–1511. [Google Scholar] [CrossRef] [Green Version]
- Primpke, S.; Christiansen, S.H.; Cowger, C.W.; De Frond, H.; Deshpande, A.; Fischer, M.; Holland, E.B.; Meyns, M.; O’Donnell, B.A.; Ossmann, B.E.; et al. Critical Assessment of Analytical Methods for the Harmonized and Cost-Efficient Analysis of Microplastics. Appl. Spectrosc. 2020, 74, 1012–1047. [Google Scholar] [CrossRef]
- Patro, R. Cross-Validation: K Fold vs Monte Carlo… Choosing the Right Validation Technique. 2021. Available online: https://towardsdatascience.com/cross-validation-k-fold-vs-monte-carlo-e54df2fc179b (accessed on 20 April 2022).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Ivleva, N.P. Chemical Analysis of Microplastics and Nanoplastics: Challenges, Advanced Methods, and Perspectives. Chem. Rev. 2021, 121, 11886–11936. [Google Scholar] [CrossRef]
- da Silva, V.H.; Murphy, F.; Amigo, J.M.; Stedmon, C.; Strand, J. Classification and Quantification of Microplastics (<100 μm) Using a Focal Plane Array – Fourier Transform Infrared Imaging System and Machine Learning. Anal. Chem. 2020, 92, 13724–13733. [Google Scholar] [CrossRef]
- Renner, G.; Sauerbier, P.; Schmidt, T.C.; Schram, J. Robust Automatic Identification of Microplastics in Environmental Samples Using FTIR Microscopy. J. Anal. Chem. 2019, 91, 9656–9664. [Google Scholar] [CrossRef]
- Renner, G.; Schmidt, T.C.; Schram, J. A New Chemometric Approach for Automatic Identification of Microplastics from Environmental Compartments Based on FT-IR Spectroscopy. J. Anal. Chem. 2017, 89, 12045–12053. [Google Scholar] [CrossRef]
- Tin Kam, H. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar] [CrossRef] [Green Version]
- Vinay Kumar, B.N.; Löschel, L.A.; Imhof, H.K.; Löder, M.G.J.; Laforsch, C. Analysis of microplastics of a broad size range in commercially important mussels by combining FTIR and Raman spectroscopy approaches. Environ. Pollut. 2021, 269, 116147. [Google Scholar] [CrossRef]
- Hufnagl, B.; Stibi, M.; Martirosyan, H.; Wilczek, U.; Möller, J.N.; Löder, M.G.J.; Laforsch, C.; Lohninger, H. Computer-Assisted Analysis of Microplastics in Environmental Samples Based on μFTIR Imaging in Combination with Machine Learning. Environ. Sci. Technol. Lett. 2022, 9, 90–95. [Google Scholar] [CrossRef]
- Weisser, J.; Beer, I.; Hufnagl, B.; Hofmann, T.; Lohninger, H.; Ivleva, N.; Glas, K. From the Well to the Bottle: Identifying Sources of Microplastics in Mineral Water. Water 2021, 13, 841. [Google Scholar] [CrossRef]
- Schymanski, D.; Oßmann, B.E.; Benismail, N.; Boukerma, K.; Dallmann, G.; von der Esch, E.; Fischer, D.; Fischer, F.; Gilliland, D.; Glas, K.; et al. Analysis of microplastics in drinking water and other clean water samples with micro-Raman and micro-infrared spectroscopy: Minimum requirements and best practice guidelines. Anal. Bioanal. Chem. 2021, 413, 5969–5994. [Google Scholar] [CrossRef]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Primpke, S.; Dias, P.A.; Gerdts, G. Automated identification and quantification of microfibres and microplastics. Anal. Methods 2019, 11, 2138–2147. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Reference Image Provided in This Work |
|---|---|
| Plastic types | 10 most frequent types, including 1 bioplastic |
| Matrix residues | Cellulose, proteinaceous material and sand |
| MP sizes | 11–666 µm |
| MP shapes | Fragments for all types, plus cellulose fibers |
| Substrate | Aluminum oxide filter, 25 mm diameter, pore size 0.2 µm with PP support ring (Whatman Anodisc) placed on a BaF2 window in a customized filter holder to enhance filter flatness; for fiber samples, a second BaF2 window was placed onto the filter |
| Measurement mode | Transmission |
| Spectral range | 3700–1250 cm−1 |
| Spectral resolution | 8 cm−1 |
| Objective and projected pixel size | 15×, 5.5 µm |
| Background scans | 120 (on a blank spot of the filter) |
| Sample scans | 30 |
| Ground truth establishment | Pre-filtering using spectral descriptors and manual evaluation of ROIs by an expert; correction for particles found by a random decision forest model |
| Image size | 1280 × 896 pixels, 2.72 GB (.dmd and .spe formats) |
| Class | Quantity in RefIMP | Size Range [µm] |
|---|---|---|
| PE | 97 | 11–170 |
| PP | 71 | 21–382 |
| PVC | 92 | 13–445 |
| PA | 94 | 18–320 |
| PS | 98 | 11–204 |
| PLA | 83 | 17–388 |
| PMMA | 124 | 13–320 |
| PUR | 103 | 17–227 |
| PC | 89 | 17–666 |
| Varnish-like | 10 | 41–100 |
| Total MP | 948 | 11–666 |
| Cellulose | 133 | 17–1890 |
| Protein | 166 | 11–330 |
| Sand | 42 | 17–292 |
| Total non-MP | 341 | 11–1890 |
| Total | 1289 | 11–1890 |
| Diversity Level | 0 | 25 | 50 | 75 | 100 |
|---|---|---|---|---|---|
| % copies | 100 | 75 | 50 | 25 | 0 |
| Metric | Threshold ↑ | Min. Distance ↑ | Min. Purity ↑ | Min. Neighboring Correlation ↑ |
|---|---|---|---|---|
| Accuracy | ↓ | ↓ | ↓ | → |
| NER | ↓ | ↓ | ↓ | → |
| Pr | ↑ | ↑ | ↑ | → |
| Over-segmentation with true and false type splits | ↓ | ↑ | ↓ | → |
| Ghost particles | ↓ | ↓ | ↓ | → |
| Overlooked particles | ↑ | ↑ | ↑ | → |
| Total TPs incl. over-segmentation | ↓ | ↓ | ↓ | ↑ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weisser, J.; Pohl, T.; Ivleva, N.P.; Hofmann, T.F.; Glas, K. Know What You Don’t Know: Assessment of Overlooked Microplastic Particles in FTIR Images. Microplastics 2022, 1, 359-376. https://doi.org/10.3390/microplastics1030027
Weisser J, Pohl T, Ivleva NP, Hofmann TF, Glas K. Know What You Don’t Know: Assessment of Overlooked Microplastic Particles in FTIR Images. Microplastics. 2022; 1(3):359-376. https://doi.org/10.3390/microplastics1030027
Chicago/Turabian StyleWeisser, Jana, Teresa Pohl, Natalia P. Ivleva, Thomas F. Hofmann, and Karl Glas. 2022. "Know What You Don’t Know: Assessment of Overlooked Microplastic Particles in FTIR Images" Microplastics 1, no. 3: 359-376. https://doi.org/10.3390/microplastics1030027
APA StyleWeisser, J., Pohl, T., Ivleva, N. P., Hofmann, T. F., & Glas, K. (2022). Know What You Don’t Know: Assessment of Overlooked Microplastic Particles in FTIR Images. Microplastics, 1(3), 359-376. https://doi.org/10.3390/microplastics1030027