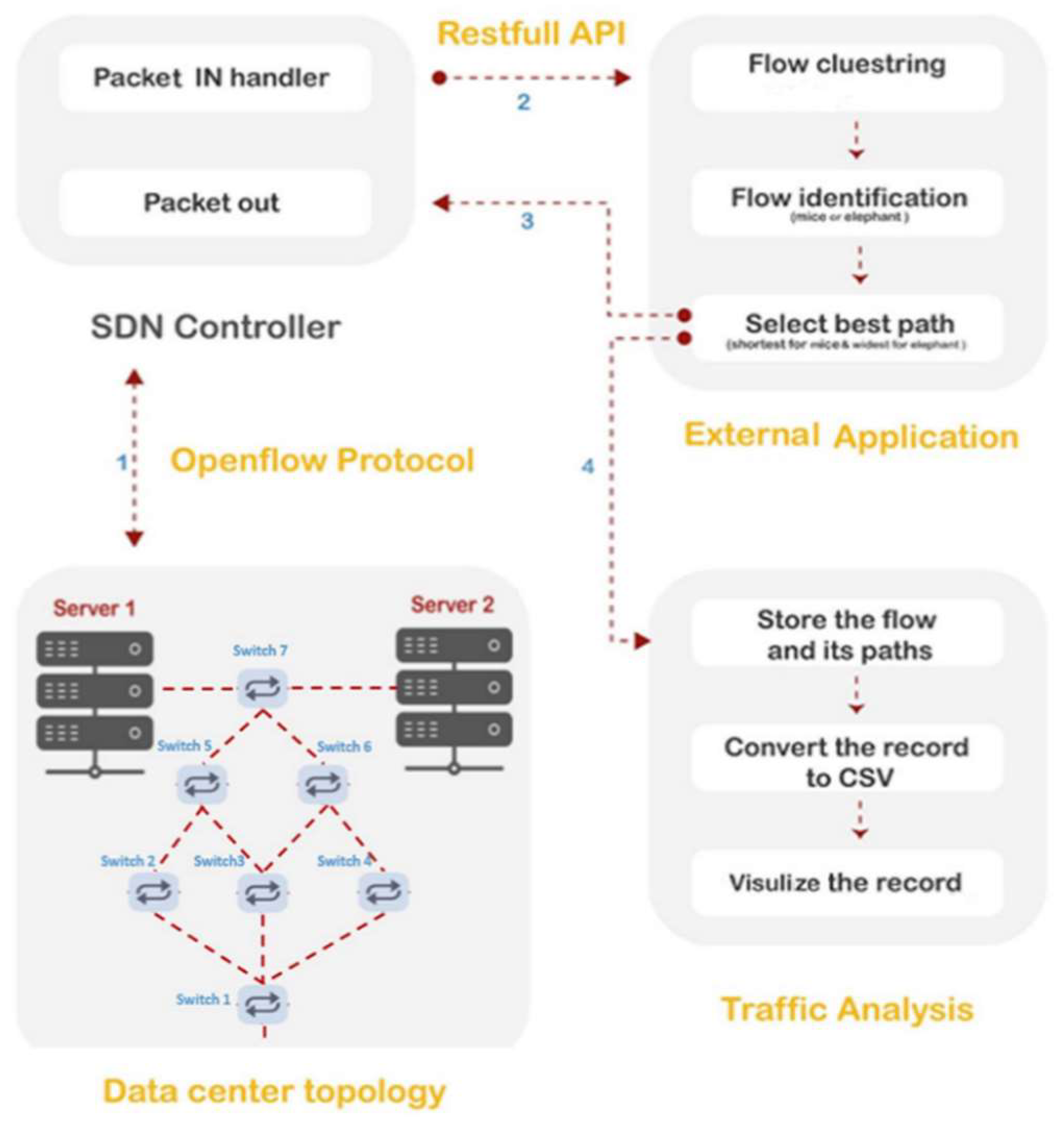
4.1. Experimental Design
Two DCN topologies were used to test the proposed framework.
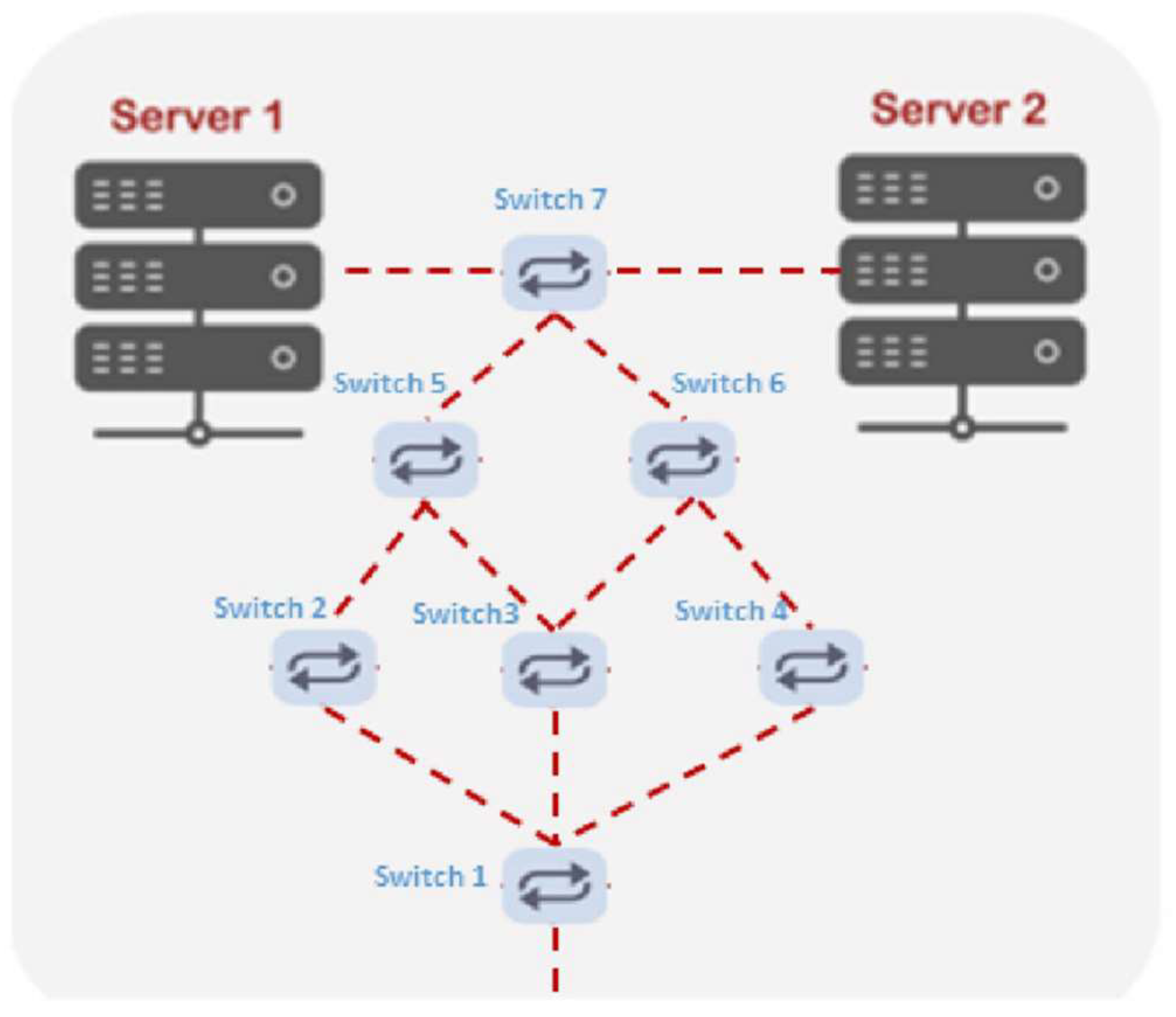
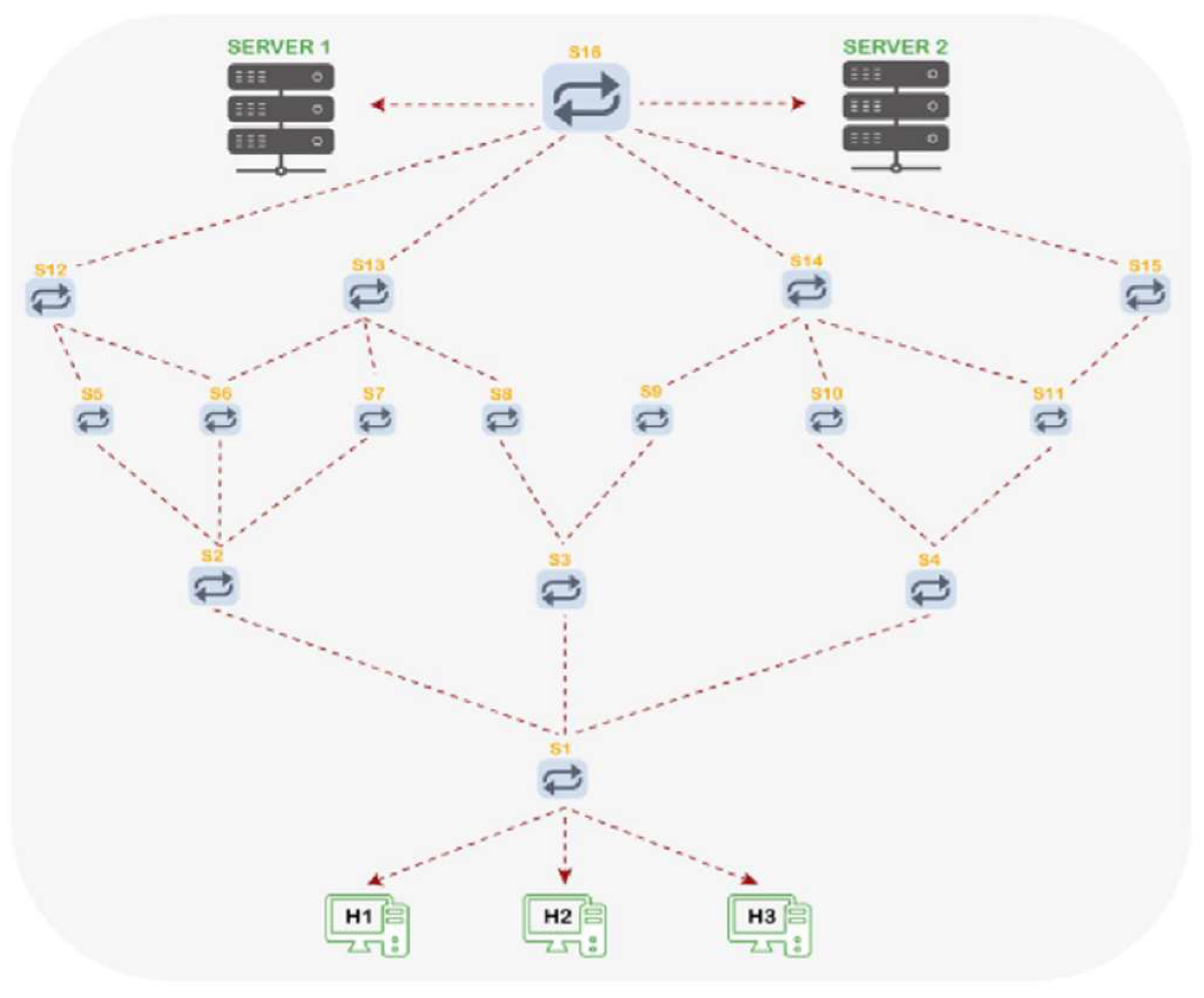
Figure 3 illustrates the first topology (No. 1), which consists of two servers, seven switches, and six hosts. The second topology (No. 2) includes two servers, sixteen switches, which are distributed on five layers, and three hosts, as shown in
Figure 4.
The experiment was carried out by a group of steps as described below.
4.1.1. Monitoring and Gathering Data
Traffic monitoring is vital for improving the comprehensive performance of a network and traffic flow optimization, which is the aim of this study. The SDN technology introduces an innovative concept by making the network infrastructure scalable, usable, programmable, and centralized controllable. Furthermore, the SDN presents a dynamic monitoring scheme for network traffic. The Mininet emulation paradigm was used for setting up and installing a SDN environment in this study. The emulation environment includes a Ryu controller, OpenFlow switches, and hosts. Two scenarios for the DCN topologies were emulated, as presented in
Figure 3 and
Figure 4, for implementing the proposed method. The used topologies are configured for handling the TCP and UDP packets. These flows are generated using a virtual machine created by the VMware workstation in a Linux environment. The OpenFlow Wireshark and tcpdump tools are used with the Mininet emulator to understand the behavior of the proposed DCN topologies for analyzing the performance of the network.
In order to perform a flow background load on the network, the experiment started with generating UDP packets with different sizes and rates during 300 s of simulation, as shown in
Table 1.
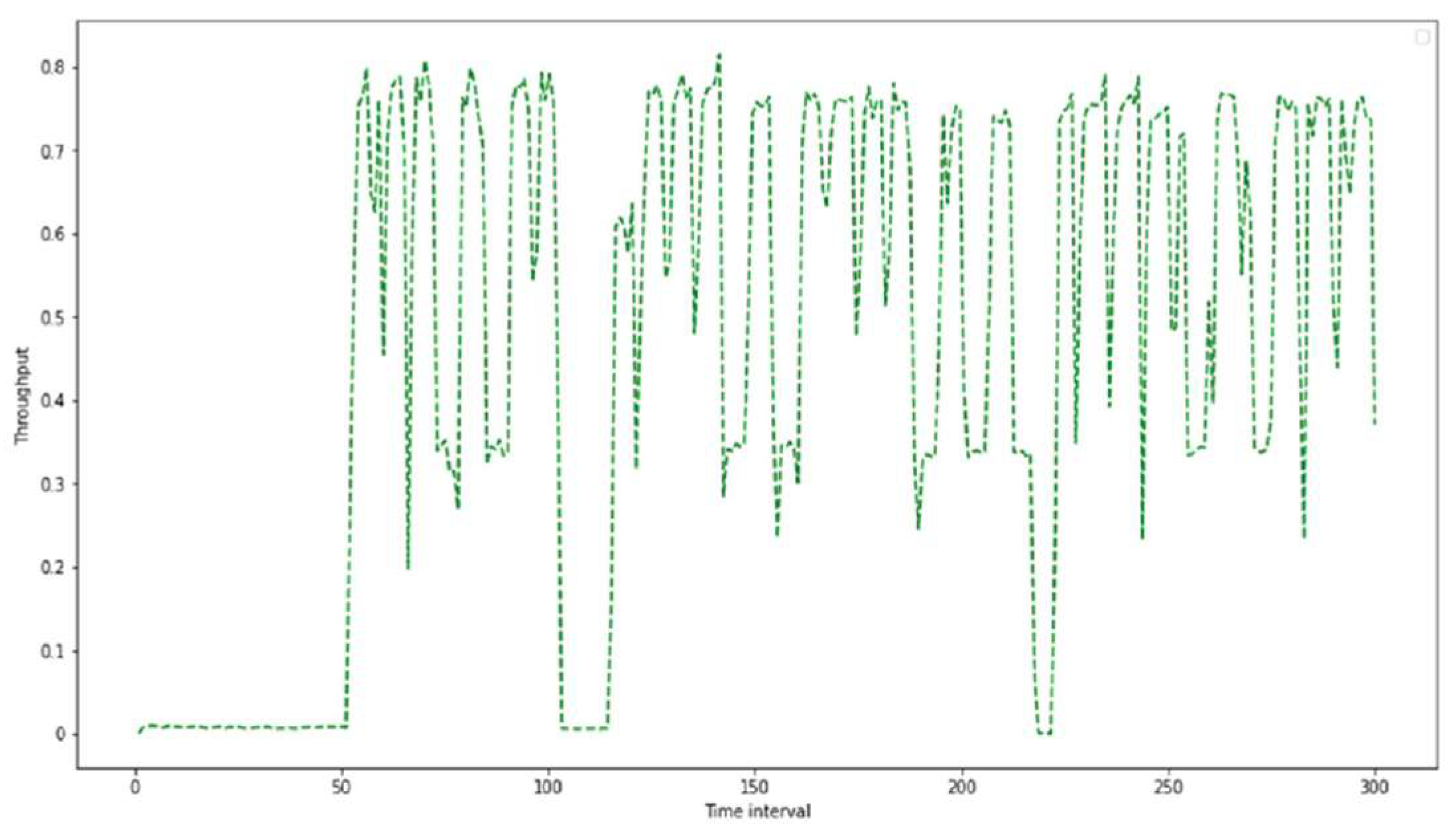
Following that, many TCP connections were initialized with different time flow between two hosts. The behavior of the first DCN topology using the throughput parameter is demonstrated in
Figure 5.
Wireshark was run in the background to capture the OpenFlow packets, which are a TCP packet type. Then, the tcpdump tool was utilized for the loopback interface. The collected data were stored as pcap files for the two proposed DCN topologies. To undertake a comprehensive analysis, the tcptrace tool was employed to produce all complete flows characterized based on the performance parameters and to store them in a CSV files.
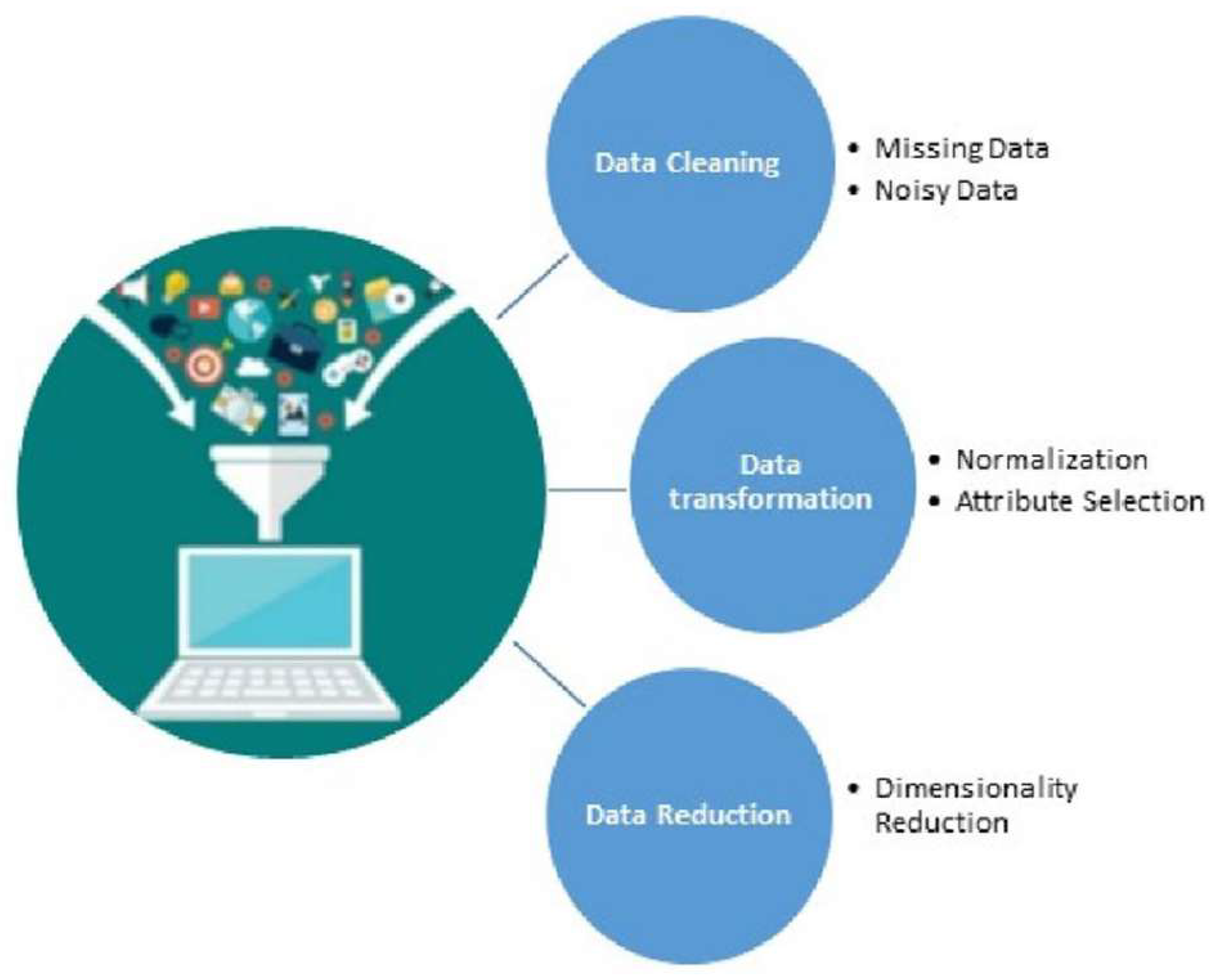
4.1.2. Pre-Processing
This step is essential to obtain consistent, integrated, and processable data using the machine learning techniques. The preprocessing starts with data cleaning and data transformation, and it ends with data reduction [
38], as illustrated in
Figure 6. The data cleaning process is used to clean the dataset by eliminating irrelevant and useless records and parameters. Afterward, data transformation is performed to convert all features. The step ends with data reduction, where PCA is utilized with 13 components. The results prove the validity of the findings of the preprocessing in [
38] by achieving a balance between completeness and simplicity and an accuracy of the clustering process.
4.1.3. Flow Characterization and Cluster Analysis
The first aim of this project is to develop a flow characterizing mechanism based on the metrics of network performance. Unsupervised machine learning techniques were proposed to achieve this goal. K-means as unsupervised clustering can create clusters of flow without the need for predefining the classes. This algorithm isutilized to understand the differentiation of flows with respect to their network performance features. It is applied to construct three clusters, where the minimum number of clusters was investigated in this experiment. The quality of clustering is measured by using the accuracy metric. This metric is determined by two factors: inter-cluster distance and intra-cluster distance [
38]. As a result, unique samples of flow are recognized for each cluster.
4.1.4. Identifying Flow
One of the serious problems that affects the quality of service for mice flows is a slow-down transfer caused by elephant flows through a network, which leads to a degradation of network performance. The identification mechanism was proposed to distinguish the flows as elephants and mice by leveraging some of the parameters clarified in
Section 4.1.3. Each elephant or mice flow is defined based on the threshold values marked on pre-decided features using the thresholding method [
32]. The final step in this phase includes representative flow extraction for the elephant and mice flows in each cluster that has resulted from the clustering process. It is interesting in this step that, in some clusters, one or two representative flows can be extracted for elephant or mice flows.
4.1.5. Best Path Selection
Normally, a large number of servers and switches are included in DCNs. In a wide DCN, each node has multiple flows. Therefore, accessing the data with reliability and in a simple way is extremely hard in this type of network. To solve this problem, different topologies are used to improve the utilization of bandwidth and reduce network congestion. In this part of the work, two types of DCNs based on the SDN are deployed, as explained in
Figure 3 and
Figure 4. In the DCN, the performance of the network is a critical aspect; hence, high throughput and sensitivity to packet loss are required. Elephant and mice flows are known as the main types of traffic in a DCN. Therefore, the need to manage the traffic of these types of flow still exists as discussed in the literature review section.
Many algorithms can provide routing for elephants and/or mice flows. For example, equal-cost multipath routing (ECMP) [
39] can be utilized for routing mice but not elephant flows [
40]. In this project, the primary aim is to select the best path for each elephant and mice flow. The best path for a flow is the path that achieves the requirements of the flow, such as low latency for mice flows and high bandwidth for elephant flows. A developed Dijkstra algorithm was proposed to find the route based on the type of flow (elephant or mice flows) by employing Algorithms 2, 3, and 5, as shown in
Section 3.2. Using a developed Dijkstra algorithm, the links that fulfill the conditions are determined, and the paths that contain the appropriate bandwidth and latency are selected.
The Dijkstra algorithm was applied to find the shortest path for mice flows, whereas for elephant flows, the Widest- Dijkstra algorithm was used to find multiple paths to route them and record all the available shortest paths. Because it has an appropriate complexity for real-time problems and it gives deterministic results, the Dijkstra algorithm was chosen in this part of the work.
4.1.6. Updating Cost of Link
Determining a route for a particular flow through a SDN efficiently is still challenging. The SDN controller must obtain a lot of information in order to accomplish this. The information includes getting a comprehensive vision of the network (i.e., network topology discovery and getting link state information), computing the optimum paths for the flows considering the information of the flows and the network, and reconfiguring the routing table based on the new forwarding rules in the infrastructure plane. Common routing algorithms depend on three concepts to compute the cost of a link. These concepts are static link cost (Hop-to-Hop count, distance, and link capacity), dynamic link cost (available link capacity, and link utilization), and dynamic link cost while minimizing the interference (available link capacity, link utilization, and flow count on a link) [
41]. The approach presented in this part explains the computing and updating of the cost of a link in the SDN framework. The cost of a link is calculated based on the inverse relationship between the bandwidth and the latency of the link, where latency is equal to the reciprocal value of bandwidth. The cost of the link is updated recursively. The cost of the link is calculated based on the updateCost algorithm in
Section 3.2. An example and figures are explained for this aspect below.
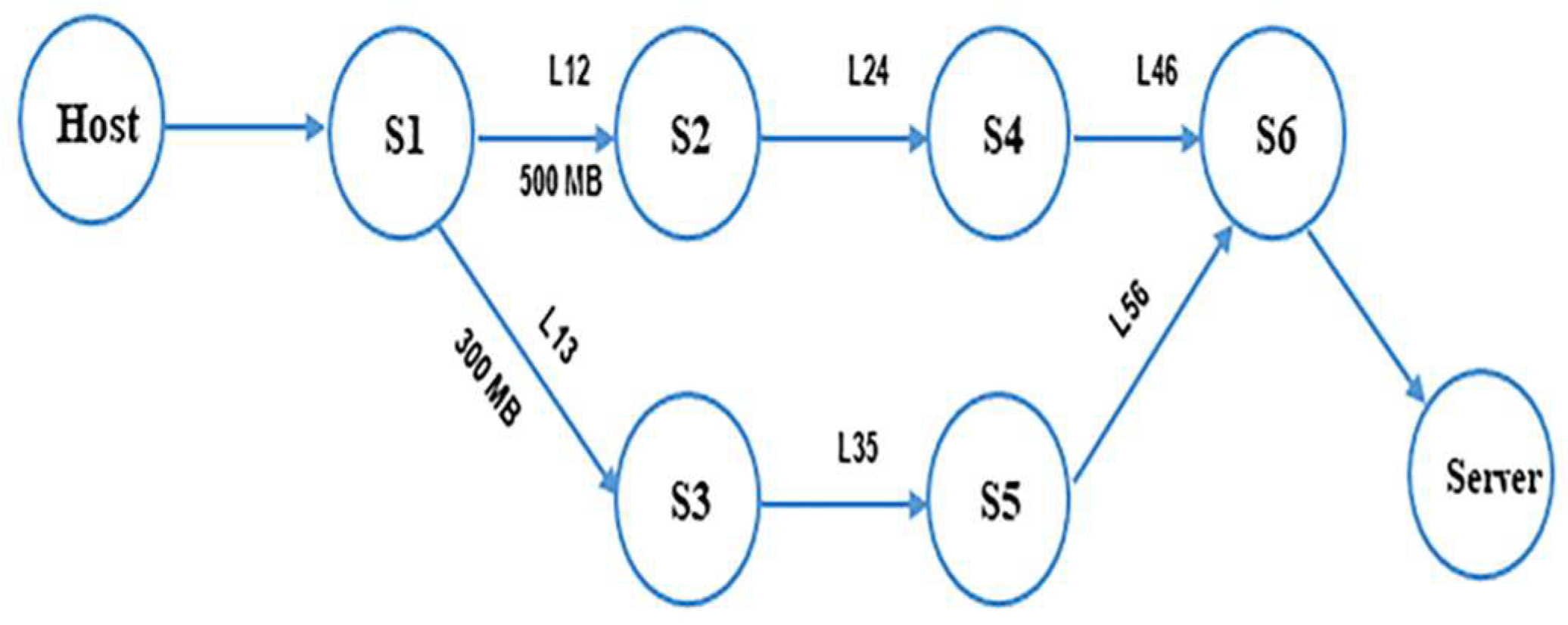
Suppose that a host (Host) wants to send a set of packets to a server (Server) and there are two different routes between the Host and the Server, as shown in
Figure 7, the steps below will be followed to calculate the link cost of both routes:
1st route R1 goes through switches S1- > S2- > S4- > S6- > Server
2nd route R2 goes through switches: S1- > S3- > -S5- > S6- > Server
The getAvailablePaths (Host, Server) algorithm will find these two paths (R1, R2) between Host and Server
For each link in R1,R2
B1 = Available bandwidth of P1 = availableBW(L12) + availableBW(L24) + availableBW(L46)
B2 = Available bandwidth of P2 = availableBW(L13) + availableBW(L35) + availableBW(L56)
Latency of P1 = D1 = 1/B1; Latency of P2 = D2 = 1/B2.
If D1–acceptableLatency > D2–acceptableLatency then bestCost = D2
else bestCost = D1
Then we get the nearest value to the acceptable Latency
If bestCost = D1 then best path is R1 else best path is R2.
4.2. Results and Evaluation
This experiment was implemented with a CSV file for each DCN topology. Each file contains 1 million flows and 129 features regarding network performance metrics. These features can be found in
Appendix A. The 129 features were chosen based on their efficiency in the clustering model [
42]. For each TCP flow, we have all the network performance parameters, such as packet loss, round trip time (RTT), and throughput. To reduce the dimensions of the dataset, the PCA technique was applied. A total of 13 PCA components were input into the clustering process. It is the best number of components to achieve a balance between completeness and simplicity [
38]. The outputs of the clustering and identification steps are three clusters. Each cluster consists of a group of elephants and mice flows, which have distinct characteristics. In each cluster, the representative flow are selected for each type of flow. To find the best path for each elephant and mice flow, a developed Dijkstra algorithm was utilized. The flow types and description for the experiments are provided in
Table 2.
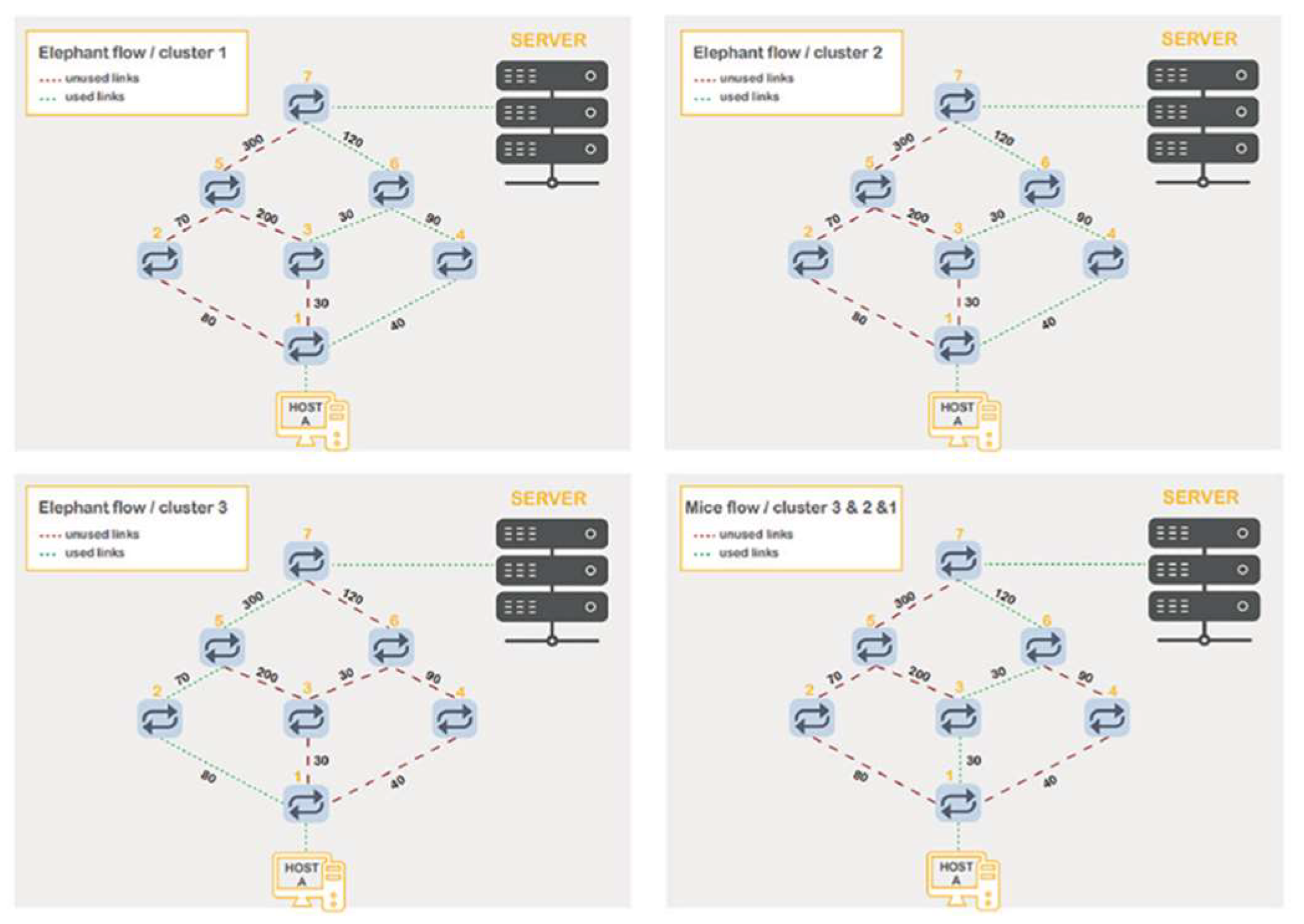
Figure 8 depicts the routing process of each type of flow (elephant or mice) for all three clusters. To accomplish a high efficiency and obtain a higher throughput, a flow of the elephant type is sent by more than one path. At the same time, some available paths are kept to serve higher-priority flows, such as real-time traffic. The top left corner of the figure presents the best path that has been selected by the proposed algorithm (Widest- Dijkstra algorithm) for all elephant flows in cluster 1. Using the same technique, the best path for the elephant flows in clusters 2 and 3 are chosen. On the other hand, the bottom right corner of the figure shows the best path for the mice flows in the three clusters. This path has been selected based on Algorithm 5 and the Dijkstra algorithm. The figures clarify the used links with a green dotted line, whereas an unused link is represented by a red dashed line.
The evaluation results show the effectiveness of the proposed flow routing optimization method against the SDN-Ryu controller. Employing a developed Dijkstra algorithm to optimize flow routing results in improved network performance in relation to data center network resources. Furthermore, the evaluation aims to present the benefit of routing-based traffic management over network performance, regardless of the routing of a particular type of flow that is being optimized by the developed routing algorithm, using the SDN framework.
The evaluation of the proposed system conducted for both topologies is provided in
Figure 3 and
Figure 4. The first test includes a comparison between the SDN-Ryu controller and the proposed system based on their performance using the DCN topology in
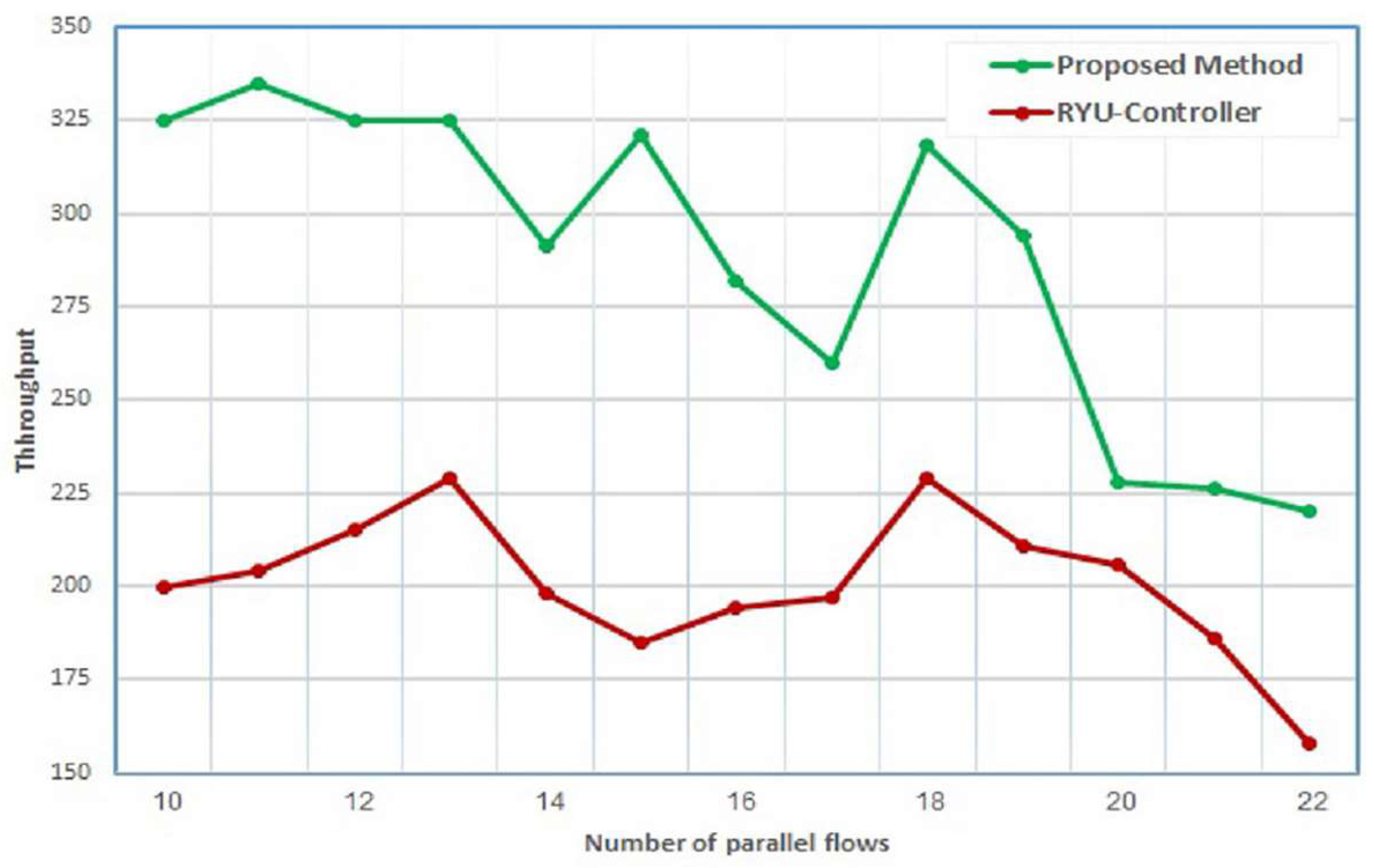
Figure 3. The comparison is accomplished based on the throughput and bandwidth parameters. As shown below in
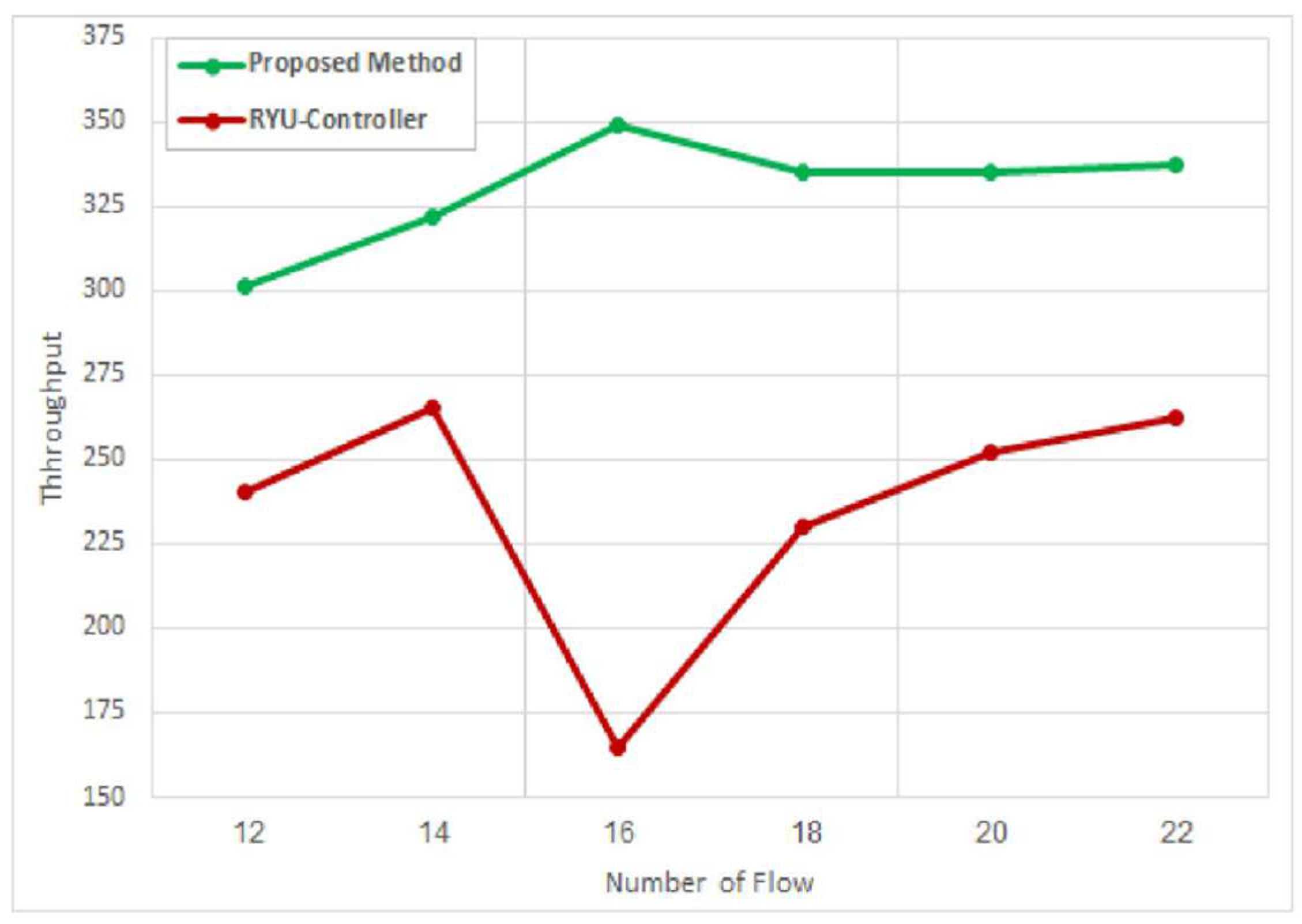
Figure 9, the proposed application provides a higher throughput than the Ryu controller. This is achieved for all flows. For example, at flow number 10, the throughput of the proposed application improves by a ratio of 61.5% compared to the throughput of the Ryu controller.
In addition, it is observed that a higher number of parallel flows leads to a decline in the throughput for both the proposed application and the Ryu controller. However, the performance of the proposed method is still better than the Ryu controller. The comparison of throughput was performed for the two types of flows.
Figure 10 presents the throughput for elephant flows for the proposed approach and the Ryu controller. The findings show that the throughput provided by the proposed application outperforms that of the Ryu controller. For instance, for flow number 16, the result changes because the routing process is based on the type of flow and the ID of the cluster. Therefore, the type of representative flow for each cluster is determined precisely, which is not applied in the Ryu controller. Consequently, the route for the representative flow is selected in a particular cluster and then applied to all the elephant flows in that cluster. For flow number 22, the throughput of our application is about 88.2% superior to that of the Ryu controller for elephant flows, when the throughput measurement is executed for intervals of 0–40 s and has a bandwidth of 100 MB.
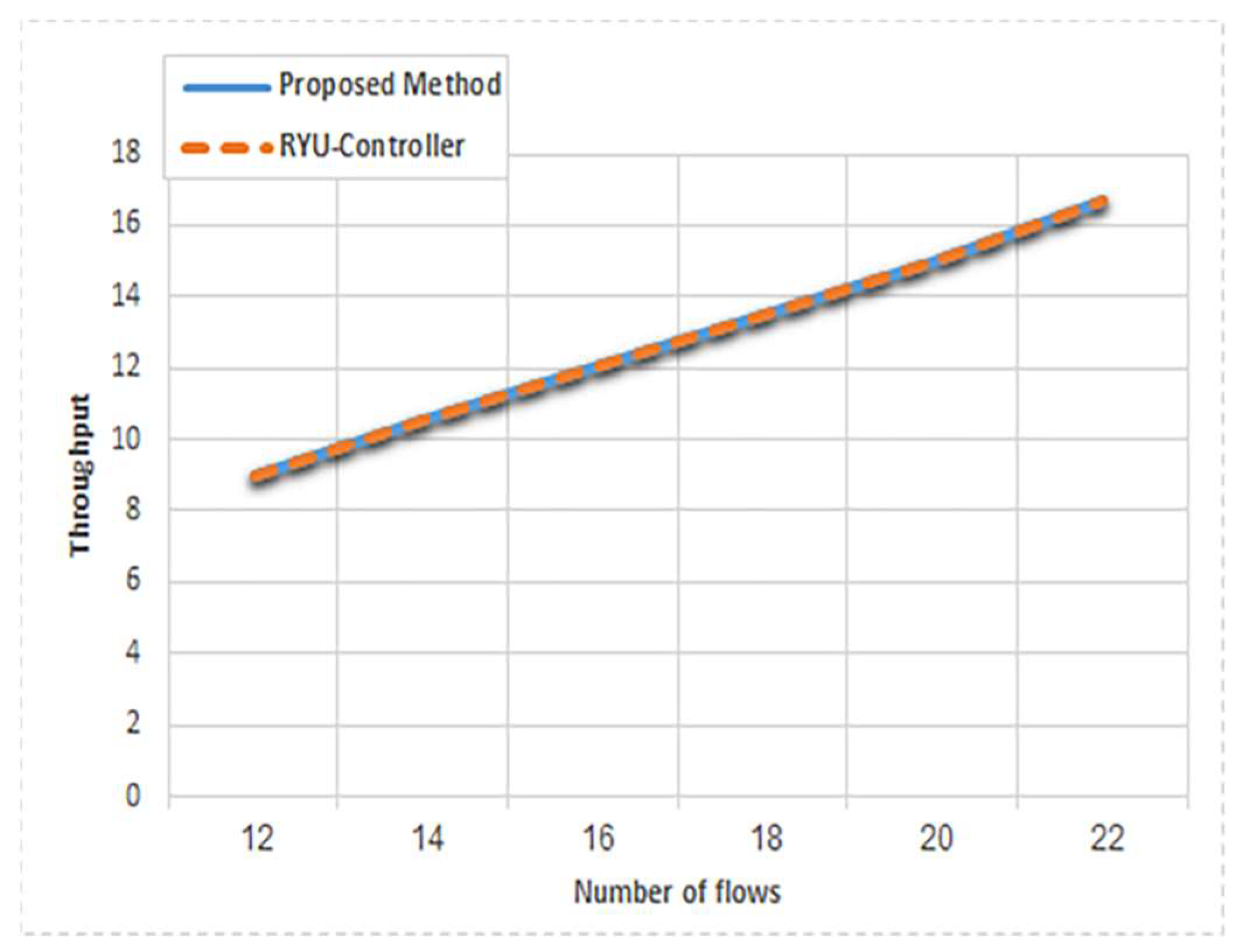
On the other side, the throughput of mice flows is presented in
Figure 11. It shows that both the proposed application and the Ryu controller provide the same throughput. It is interpreted by the fact that both of these methods use the shortest path for routing the mice flows. The measurement of mice throughput is run for interval 0–60 s with a bandwidth 100 KB.
For the second parameter, which is bandwidth usage,
Figure 12 shows that the performance of the proposed application is higher in most of the flows compared to the Ryu controller. The reasons behind that are (i) the use of a clustering process and (ii) the use of a developed Dijkstra algorithm. The low performance of the proposed method in flows 14 and 22 is because of the need to serve higher-priority flows.
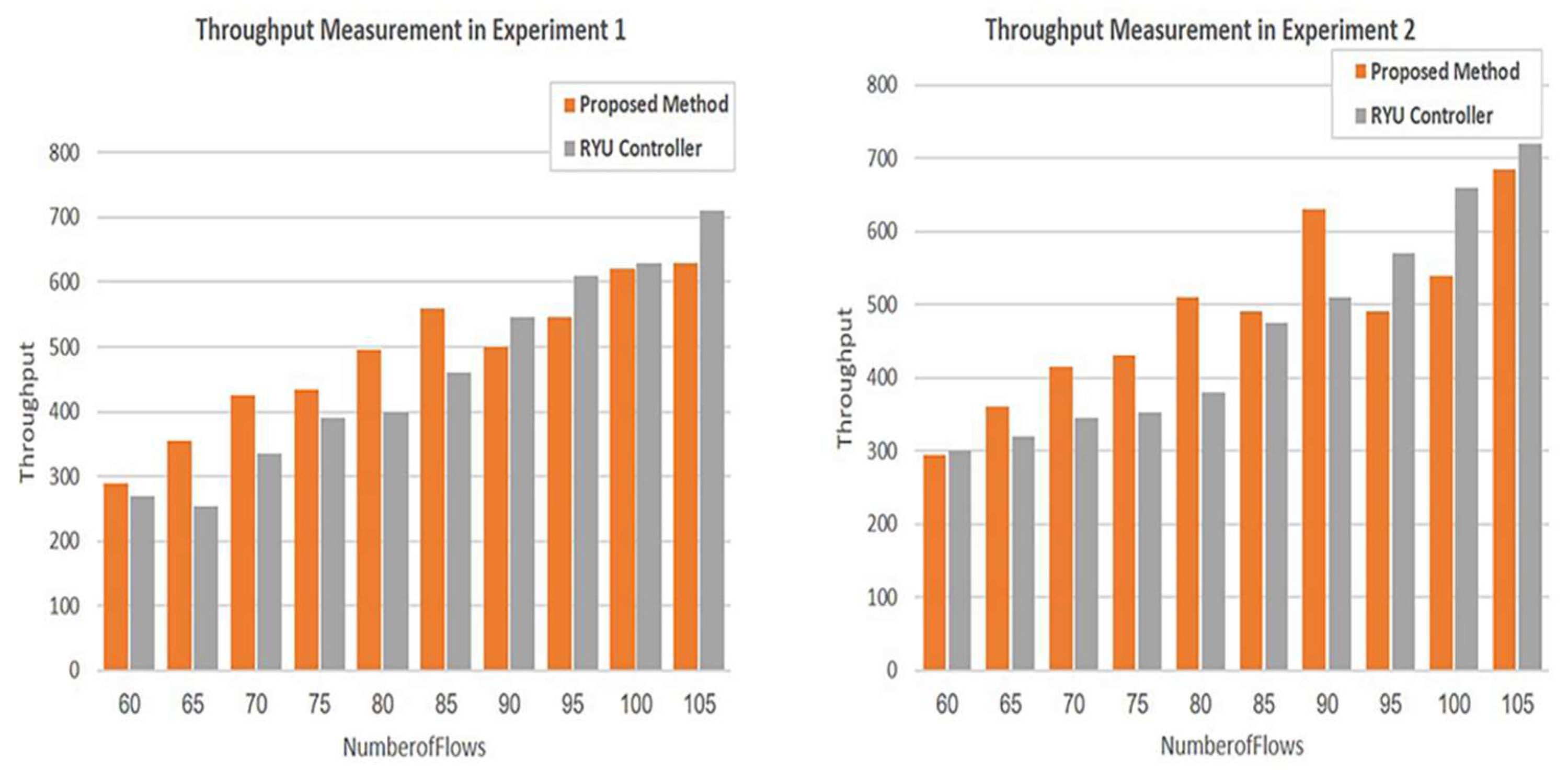
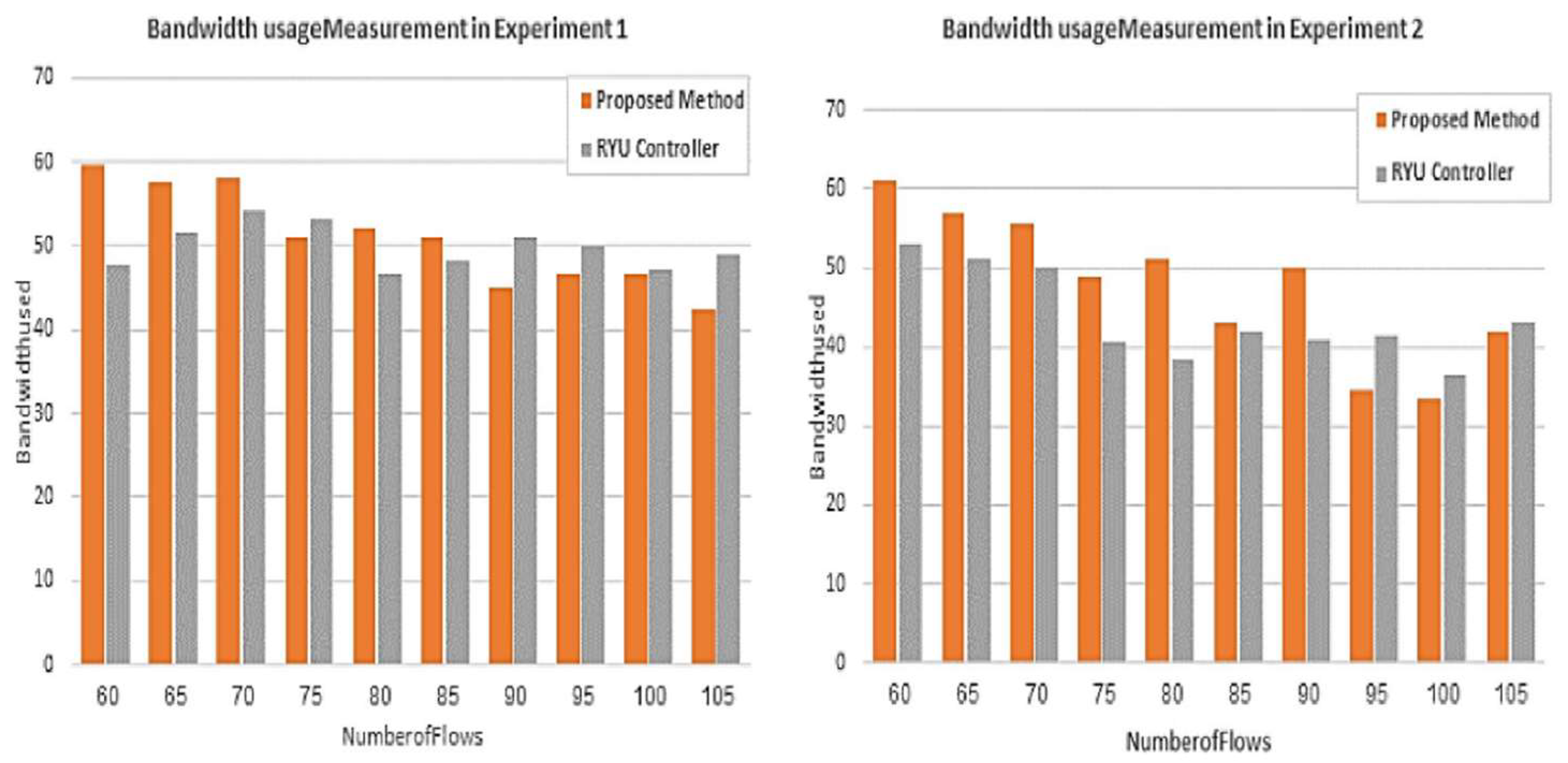
The evaluation of the proposed mechanism for the second topology was accomplished by running two experiments to compare the performance of the Ryu controller and our proposed method. The comparison was based on the same parameters for the first topology.
Figure 13 and
Figure 14 depict the throughput and bandwidth usage measurement provided by the proposed mechanism and the Ryu controller in the two experiments. It is clear from the charts of experiment 1 that the performance of the proposed method is better than that of the Ryu controller for the majority of flows for both parameters. However, as the number of flows increases, the performance of the proposed method is equal to or slightly less than that of the controller. In experiment 2, as shown in the charts of the aforementioned figures, the throughput and bandwidth provided by the proposed mechanism are improved compared to those by the Ryu controller. Consequently, the performance of the proposed mechanism is enhanced for 70% of the flows. Nevertheless, compared to the performance of the Ryu controller, the performance of the proposed application declines for the remaining 30% of the flows. The reason behind this reduction in performance is the need to serve higher-priority flows.
In general, it is observed that the performance of the two methods improves as the number of flows increases in both experiments.
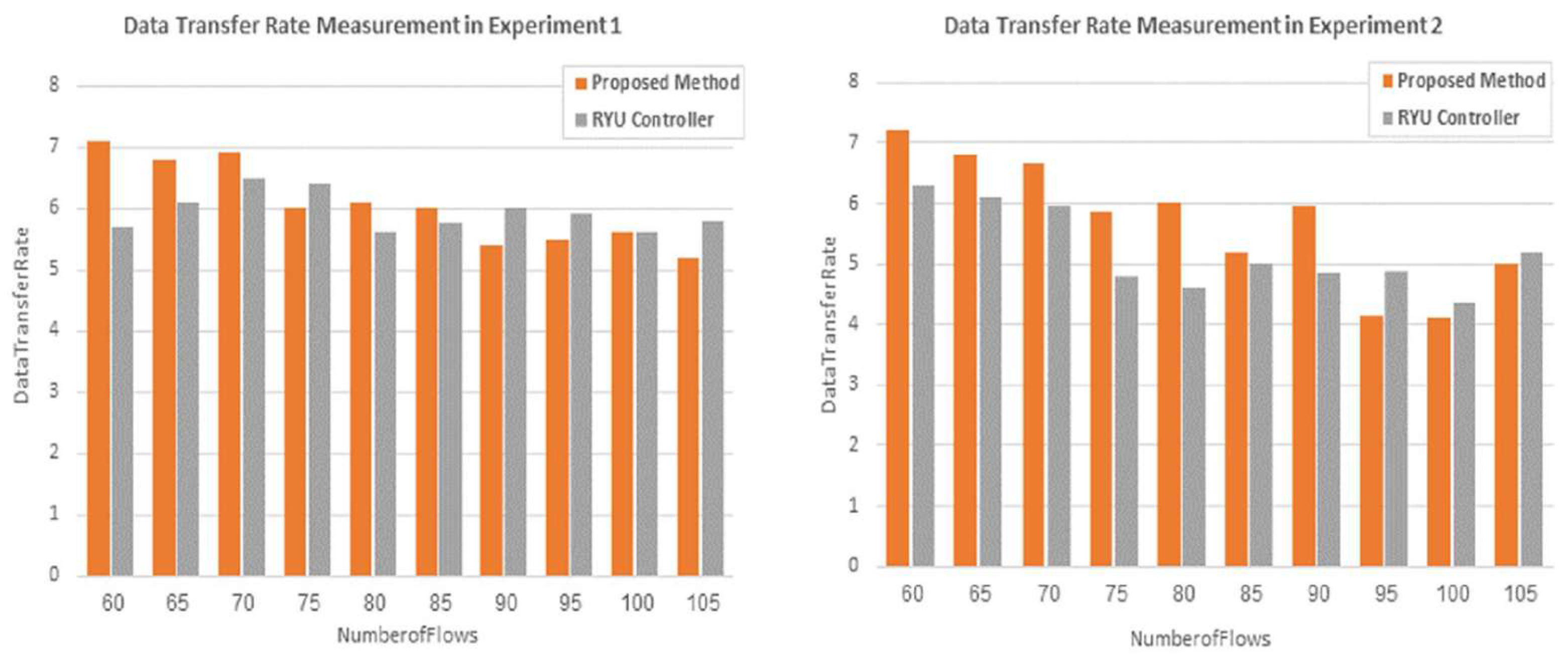
The third parameter that was used to compare the performance of the proposed approach and the RYU controller is the data transfer rate. This parameter was added to support the evaluation of the proposed method.
Figure 15 shows that the proposed method is more effective in transferring data than the Ryu controller for most of the flows in both experiments. Based on the measurement of the rate of data transfer, the proposed method in the second experiment has the same behavior as the previous parameters for the majority of flows, where the performance becomes better than it is in the first experiment, although it may be slightly less than the performance of the controller sometimes.
As a result, the proposed approach is more efficient than the Ryu controller and proves its ability to find the best route according to the flow type.



 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














