1. Introduction
The rapid growth in the number of smart devices and the emergence of the Internet of Everything (IoE) applications, which require an ultra-reliable and low-latency communication, will result in a substantial burden on the current wireless networks [
1]. As such, the data rate that could be supplied by current wireless networks will be unlikely to sustain the enormous ongoing data traffic explosion. In addition, the latest statistics revealed that by 2023 nearly two-thirds of the global population will have Internet access with around 5.3 billion Internet users (66 percent of the global population), and by 2025 more than 80 billion devices will require communication connectivity [
2]. Therefore, this will create the requirements for massive communication systems and networks. These requirements and demands for data traffic have motivated research into continuing to advance the existing networks in addition to the innovation of new physical-layer techniques for the future generation of cellular systems. Massive MIMO (m-MIMO) is introduced as a key physical layer technique for the next generation wireless networks that is required to support the huge increasing demand for data traffic [
3,
4,
5], whilst improving the energy efficiency [
6]. In particular, the m-MIMO system is considered a potential solution for fifth generation (5G) wireless communications and beyond [
7]. However, from an information theoretic point of view, the performance of the m-MIMO system depends on the accuracy and availability of the channel state information (CSI) estimation. Obtaining the CSI at the BS depends on the duplexing operation mode, i.e., either frequency division duplex (FDD) or time division duplex (TDD) mode. Despite the promising results of TDD operation with m-MIMO when it comes to the CSI estimation, the vast majority of the currently deployed cellular networks operates in FDD mode. For example, over 85% of the current commercial long term evolution (LTE) wireless mobile networks operate in FDD mode [
8]. Therefore, this paper focuses on FDD systems, as the CSI can only be obtained by a dedicated training sequence in the downlink (DL). In particular, to obtain the CSI in FDD systems, the BS needs to optimize the DL training sequence and transmit it to the users [
9,
10]. However, the expansion of a number of antenna elements at the BS in the m-MIMO system makes the DL training sequence optimization for fast CSI estimation, i.e., with limited coherence time, in FDD systems very challenging.
To overcome the CSI estimation challenge in FDD m-MIMO systems, several studies have investigated the optimization of DL training sequences by considering the scenario where the users exhibit common spatial correlation at the BS under different system model assumptions; namely, refs. [
11,
12,
13,
14,
15,
16,
17,
18] exploit correlations in the spatial domain and correlations both in the time and spatial domains, respectively. However, in practice, users could exhibit distinct spatial correlation patterns, which arise due to independent propagation conditions and scattering geometries; hence, the optimization framework of the training sequences developed in [
11,
12,
13,
14,
15,
16,
17,
18] does not hold in general multiuser scenarios with
K distinct spatial correlations. Another line of research has focused on the channel estimation by using compressed sensing (CS) based techniques [
19,
20,
21,
22,
23,
24]. However, due to the unknown sparse nature of the channels, CS based approaches cannot be applied in practice to predict the DL achievable sum rate of an FDD m-MIMO system. Another development for CSI estimation is to use a hybrid two-stage precoding approaches, see e.g., [
25,
26,
27,
28]. However, the aforementioned research works do not address the single-stage precoding scenario with
K independent user covariance matrices.
To address the challenge of having distinct correlated channels and to find a more realistic solution with single-stage precoding scheme, several studies have investigated the design of training sequences by utilizing different iterative algorithms. For example, in [
29] the DL training sequences are optimized iteratively based on the average sum rate loss due to CSI estimation with zero forcing (ZF) precoding. In refs. [
30,
31] the DL training sequences are optimized iteratively as a solution to a sum conditional mutual information (SCMI) maximization problem and a sum mean square error (SMSE) minimization problem, respectively. While the investigations in refs. [
30,
31] have optimized the DL training sequences iteratively, the algorithms used in the optimization exhibit slow convergence speed, and thus, deliver high latency and computational complexity. However, in real-time systems, the CSI estimation must be obtained more frequently with an acceptable latency from channel estimation to precoding, especially when the channel exhibits a shorter coherence time. Therefore, there is an essential requirement for developing a new efficient iterative algorithm for the FDD m-MIMO systems that optimizes the DL training sequence, i.e., maximizes the sum rate, while at the same time exhibits the fast convergence rate so as to obtain the CSI estimation more quickly over a limited coherence time. Note that the design principles in refs. [
30,
31] are more general compared with [
29] since they do not enforce a specific precoding structure and do not consider a heuristic approximate upper bound of the sum rate loss for CSI estimation. This makes the approaches in refs. [
30,
31] more rigorous than the approach in [
29] for DL sequences optimization.
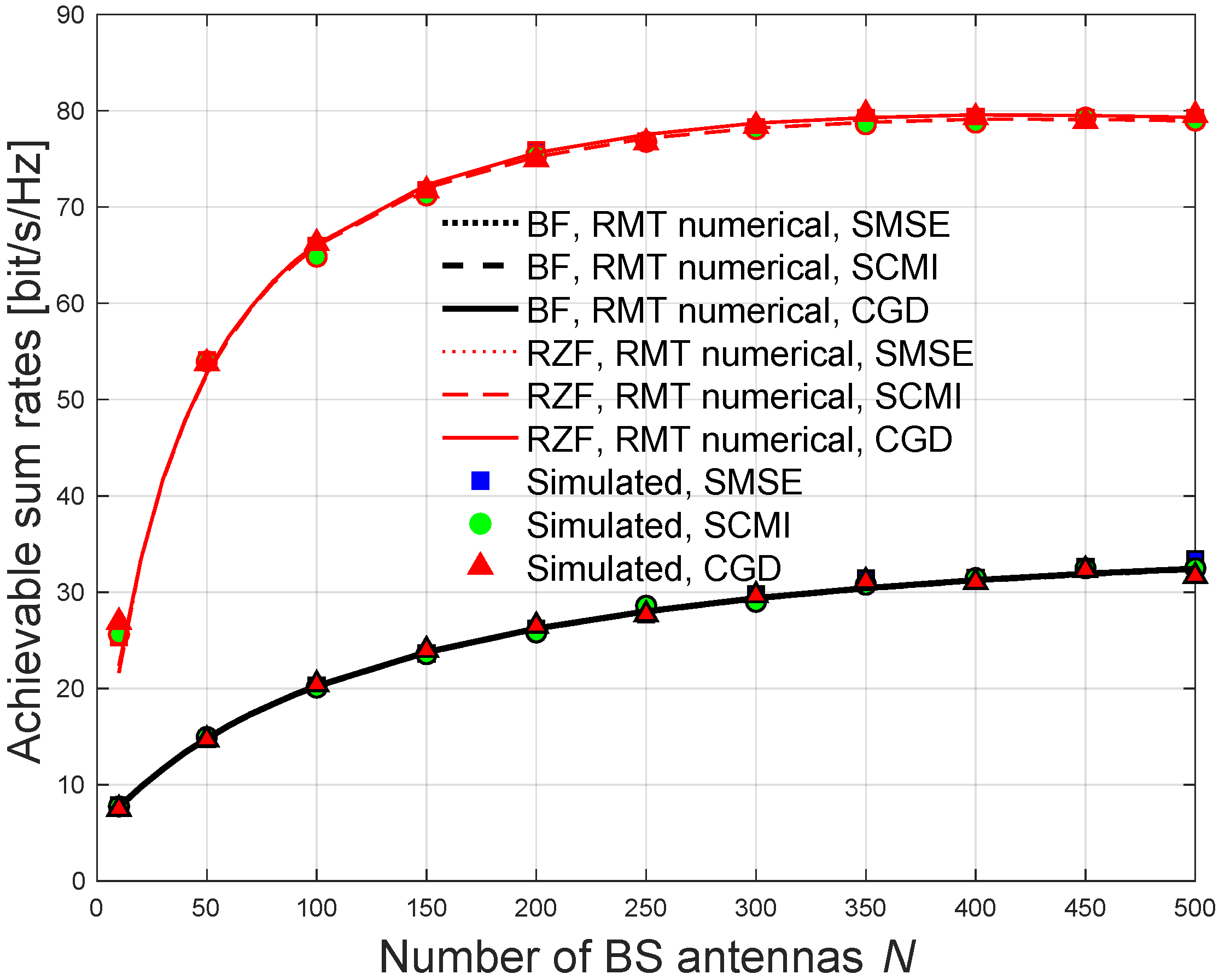
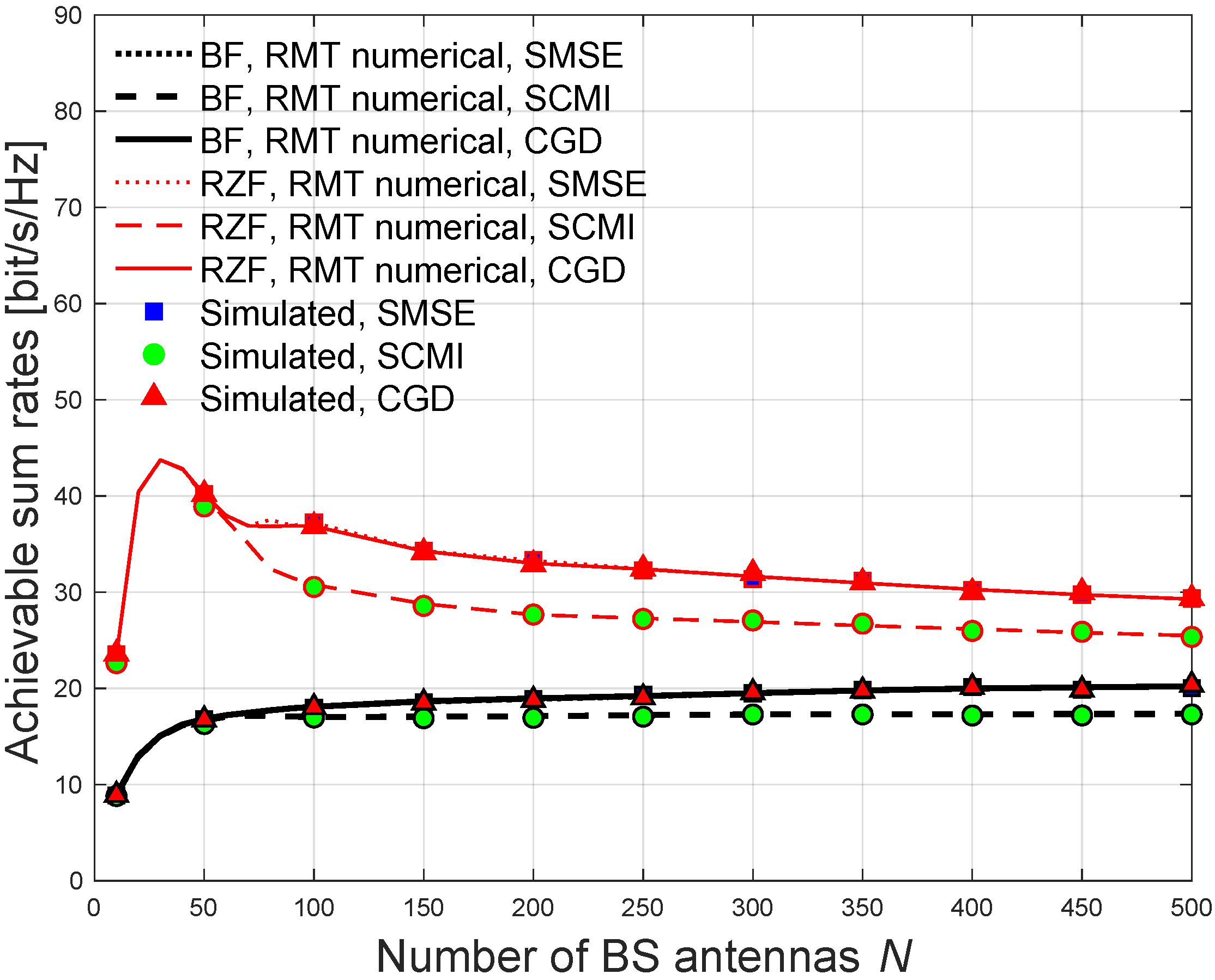
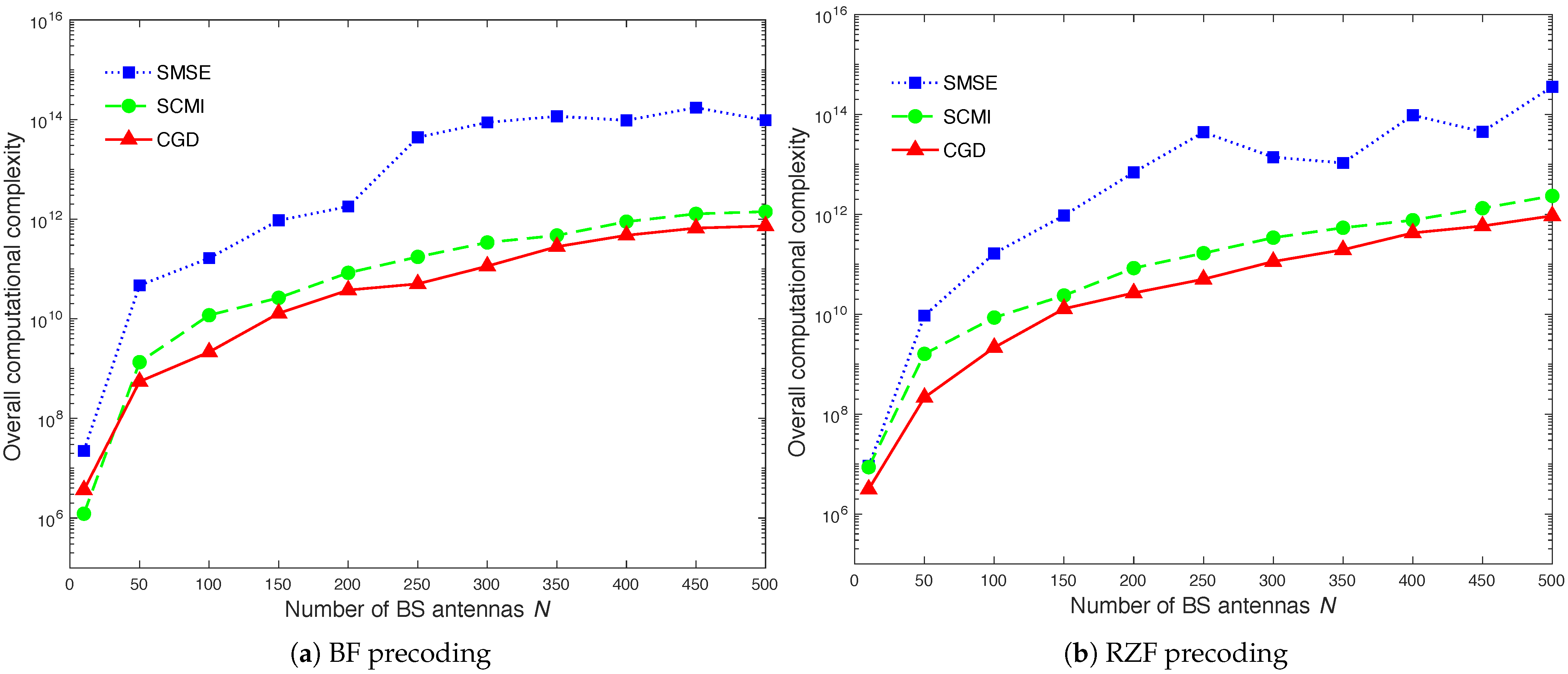
This paper addresses the challenge of CSI DL channel estimation in the FDD m-MIMO systems with limited coherence time considering the users have different correlations. We propose a conjugate gradient descent (CGD) optimization algorithm over the Riemannian manifold for optimizing the DL training sequences. The proposed algorithm is essentially required to speed up the convergence rate by lessening the required number of iterations for achieving fast CSI estimation and hence reduces the overall computational complexity. This proposed algorithm is also very useful for massive communication systems and networks. In this paper, a random matrix theory (RMT) method [
32,
33] is used to validate our Monte-Carlo simulations. This allows the achievement of a straightforward methodology without resorting to a computationally demanding exhaustive search. In addition, the computational complexity analyses of the proposed CGD algorithm and the state-of-the-art SCMI [
30] and SMSE [
31] iterative algorithms are provided. Comparisons are presented for the sum rate and overall complexity performances between the proposed CGD algorithm and existing SCMI [
30] and SMSE [
31] iterative algorithms for DL sequence optimization in both eigenbeamforming (BF) and the regularized ZF (RZF) precoding. The aforementioned algorithms are considered the best known state-of-the-art iterative algorithms. The results demonstrate that the RZF precoder under correlated channels achieves a significant gain in the DL sum rate in comparison to the BF precoder. The results show that the proposed CGD algorithm achieves more or less the same rate performances as the state-of-the-art iterative algorithms for training designs, while reducing the computational complexity in both BF and RZF precoding. This computational complexity reduction is due to the use of matrix exponential search over the Riemannian manifold, which results in an optimized DL training sequence for fast CSI estimation in the FDD m-MIMO systems. These findings create a pathway for realizing FDD m-MIMO with massive communication systems. Finally, the results demonstrate that the analytical solution using the RMT method tightly agrees with the simulation, which underpins the contributions of this paper.
The present paper is organized as follows: in
Section 2, the system model is described. In
Section 3, the training sequence design in an FDD m-MIMO system is investigated. In
Section 4, the CGD iterative algorithm is developed. In
Section 5, the expressions that accurately approximate the SINR and the DL achievable sum rate are introduced. In
Section 6, the results are presented and discussed. Finally, in
Section 7, the conclusions are drawn.
Notation: In this paper, an upper boldface symbol denotes a matrix whereas a lower boldface symbol denotes a vector. The term refers to the expectation operator. The operators trace, transpose, Hermitian transpose, inverse and absolute value are denoted by , , , , and , respectively.
2. System Model Description
This paper considers a single-cell wireless communications system, where the BS is equipped with an
N transmit antenna that serves
K single antenna users. We consider a non-line-of-sight (NLOS) Rayleigh fading channels over a single-frequency band with an overall coherence time denoted by
and enumerated in symbols per transmission block.
Figure 1 demonstrates a BS with m-MIMO system and illustrates the DL and UL transmissions within each coherence block length. The received signal during the data transmission phase at the
k-th user is given as:
where
denotes the per-user signal-to-noise-ratio (SNR) during the data transmission phase and
refers to the normalization constant, which is defined as
, and
is the precoding matrix. The term
is independently and identically distributed (IID) with a zero mean circularly symmetric complex Gaussian (CSCG) vector of data symbols, which satisfies
, and
denotes the additive noise, which is modeled as a zero mean unit variance CSCG random variable. The DL instantaneous channel vector is given by
, where the elements of
are IID with zero mean and unit variance and
k-th user’s correlation matrix,
satisfies
. It is worth noting that
depends on large-scale statistics, i.e., angles of arrival and departure or spatial/temporal correlation, which are considered to be frequency-invariant, and thus, can be efficiently obtained in the FDD or TDD systems [
34]. To this end, the received signal-to-interference-plus-noise ratio (
), denoted
, is given as:
Accordingly, the DL achievable sum rate,
, for an FDD m-MIMO system under consideration can be expressed as:
where parameter
represents the training sequence length used during the training-phase. This paper uses
that maximizes the achievable sum rate. The received SINR term in (
2) depends on the channel statistics, the channel estimates, and the linear precoding technique used at the BS. We consider two commonly prevailing types of linear precoders, named the BF and the RZF, as defined in [
33]. The expectation (i.e., the averaging process) in (
2) is taken with respect to different channel realizations, which are obtained separately by means of Monte Carlo simulation. As the purpose of the present paper is to concentrate on the DL training sequence design, the UL feedback time and associated error rate are assumed to be zero. Efficient feedback schemes can be considered in the future, see, e.g., [
35,
36,
37,
38]. Besides, advanced signal processing techniques can also be considered for feedback, see e.g., [
39,
40]. A large system limit based on random matrix theory methods is used to provide asymptotic expressions that accurately approximate the SINR and achievable sum rate for the BF and RZF precoders.
3. CSI Estimation Using DL Training Sequences
To gain further insight into the problem of DL CSI estimation, this section investigates the training sequence design in an FDD m-MIMO system. To estimate the DL channel, the BS transmits a predetermined training sequence of length
during the training-phase. The DL pilot sequences, collected by each user and returned to the BS, provide instantaneous channel realizations at the BS, which in turn implement regular BF or RZF precoding based on channel estimates. As such, the training sequences for channel estimation [
41] are updated according to the dynamics of each
, which in turn is updated at every coherence time interval. To this end, the received signal during training-phase,
, at the
k-th user is given by:
where
is the training matrix. The receiver noise
exhibits a CSCG distribution
.
Extensive research has been carried out to address the challenge of CSI estimation, see e.g., [
11,
12,
13,
14,
15,
16,
17,
18]. In these investigations, a special scenario when the users exhibit common spatial correlation at the BS is considered. However, a more general scenario when the users exhibit distinct spatial correlation at the BS is needed. Besides, compressed sensing based approaches for CSI estimation have been used in [
19,
20,
21,
22,
23,
24]. In these works, the sparsity structure on the virtual angular domain is used to reduce the training length required for the CSI estimation. However, the compressed sensing based approaches cannot be applied in practice due to the unknown sparsity nature of the channels that cannot be predicted in these approaches. Another area of research on CSI estimation is to exploit the hybrid two-stage precoding based approaches, see e.g., [
25,
26,
27,
28]. In particular, the hybrid based approaches exploit correlation in the spatial domain, where the users within each group exhibit the same spatial correlation, and a linear superposition of each group correlation matrix is utilized to perform the first of two stages of precoding, thus forming a beam for each group. However, sophisticated scheduling and clustering algorithms of the user groups, and of the users inside each group, are required in these hybrid approaches. Hence, these works cannot be applied to predict the achievable sum rate performance in a more general single-stage scenario with
K independent user covariance matrices. To address the challenge of CSI estimation in the more general single-stage precoding scenario when the users exhibit distinct correlated channels, several studies have been carried out, see, e.g., [
30,
31,
42,
43]. Specifically, the training sequences in [
30,
31,
42,
43] are designed by exploiting different iterative algorithms as a solution to an SCMI maximization criterion and an SMSE minimization criterion, respectively. However, the limited coherence time interval in practice implies that the CSI estimation should be determined more frequently, and thus, iterative-based solutions for the DL training sequence design may be infeasible. In addition, the algorithms used in the aforementioned optimizations exhibit slow convergence speed, and thus, deliver high latency and computational complexity. Hence, there is a crucial need to develop a lower complexity iterative algorithm solution for the FDD m-MIMO systems, which has the ability to optimize the DL training sequence, i.e., maximizes the achievable sum rate, while at the same time exhibits a fast convergence rate so that obtaining a fast CSI estimation when a limited coherence time is considered.
This paper proposes a computationally efficient CGD iterative algorithm, described in detail in
Section 4, to optimize
for pre-selected training length
, and training power
. The proposed algorithm aims to achieve a robust sum rate performance when the users exhibit different correlations while at the same time reducing the computational complexity. Let
denote the sum MSE of the channel estimate cost function, which needs to be minimized with respect to the DL training matrix
, as
where
, which denotes the
k-th user’s covariance matrix with minimum mean square error (MMSE) channel estimation. To this end, the formulation of the CSI estimation optimization problem is provided. Minimizing the sum MSE over the training sequence
for a given training-phase duration
in the FDD m-MIMO system equates to the optimization problem defined in (
6).
The sum MSE cost function, which corresponds to a function of the subspace that is spanned by the pilot matrix , is invariant to the unitary rotation, i.e., .
This property allows the CGD algorithm over the Riemannian manifold to be effectively used to solve the optimization problem in (
6). To apply the CGD optimization algorithm on a Riemannian manifold, the partial derivative of the sum MSE cost function in (
5) needs to be determined with respect to
. To this end, the partial derivative
is given by [
31]:
where the right hand side in (
7) is obtained by differentiating the cost function in (
6) with respect to pilot matrix, (i.e.,
).
4. Training Sequence Optimization Based on CGD Algorithm over the Riemannian Manifold
Optimization on manifolds means finding an optimum solution of a desired function using a smooth finite-dimensional Riemannian manifold. The Riemannian gradient is simply the orthogonal projection of the classical gradient. Conceptually, the key point is to perform as unconstrained nonlinear optimization. Exploiting the Riemannian makes it easy to deal with various types of constraints, which arise in low rank matrices. In particular, optimization on manifolds is a powerful scheme to address the nonlinear optimization problems such as the problem of finding the training sequence matrix that maximizes the achievable sum rate of the FDD massive MIMO systems, which is considered in this present paper. In wireless communication systems and array signal processing, several studies have considered various optimization problems under a unitary matrix constraint [
44,
45,
46,
47]. Consequently, advanced gradient-based iterative algorithms have been developed to find efficient solutions with fast convergence rate to such optimization problems [
48,
49,
50,
51]. Some of those efficient solutions have been obtained using a geometrical approach based on the smooth parameter space known as the Riemannian manifold. The potential of the Riemannian manifold has motivated the author of this paper to explore the application of such a geometrical approach for optimising the training sequence in an FDD massive MIMO system when the users exhibit distinct spatial correlations. In this section, the CGD iterative algorithm based on the Riemannian manifold is explored to optimize the DL pilot matrix
iteratively across multiple users with independent channel covariance matrices. In optimizing (
6) for
, the CGD method uses the almost periodic property of the matrix exponential search [
52,
53] over the Riemannian manifold to increase the algorithm convergence speed by lessening the required number of iterations. In particular, the introduction of matrix exponential on the Riemannian manifold aids the proposed CGD algorithm to operate over a smaller dimensional search space and thus provide a fast convergence behaviour. In addition, the existence of matrix exponential parametrization in the proposed CGD method is a sufficient condition to satisfy the semi-unitary matrices
. Further details on the matrix exponential property on the Riemannian manifold can be found in [
52,
53,
54]. This algorithm can also be used to increase the capacity with interference channel [
55]. Algorithm 1 summarizes the proposed CGD iterative algorithm. The following steps explain Algorithm 1 in further detail.
| Algorithm 1 Iterative CGD optimization algorithm. |
- 1:
- 2:
Determine the gradient using ( 8), and set - 3:
- 4:
- 5:
- 6:
- 7:
. - 8:
.
|
Step 1—Initial step: The proposed iterative gradient algorithm starts by selecting an initial training sequence matrix . For the sake of notational simplicity, in the algorithm, the training sequence matrix notation is used instead, where the subscript t corresponds to the number of iterations.
Step 2—Gradient evaluation and projection on the Riemannian parameter space: In this step, the gradient of the sum MSE cost function defined in (
5) is determined, and the projection on the Riemannian manifold is computed to find the descent direction and set
.
where
is the descent direction for iteration
t and
corresponds to the Euclidean gradient with respect to the training sequence matrix as given in (
7).
Step 3—Stopping criteria: Check the gradient on the Riemannian parameter space (i.e.,
) whether it reaches convergence or not according to:
where Re stands for the real value and
in step 3 of Algorithm 1 denotes the error tolerance. If the steepest direction is sufficiently small, which implies a close to local minimum value of the cost function the algorithm stops.
Step 4—Matrix exponential computation: Determine the local parametrisation based on the matrix exponential on the Riemannian manifold, i.e.,
, where
corresponds to the step size that controls the steepest direction. The complex matrix exponential is determined by the convergent power series [
52,
53], where a Matlab function
expm is used for this purpose.
Steps 5 and 6—Step size evaluation: The step size is required to be tuned in order to ensure an appropriate steepest direction movement towards the training solution. In particular, in steps 5 and 6, the sum MSE cost function of different sequences are evaluated based on different possibilities of . If is too small and the condition of the cost function is not met, then is doubled, as given in step 5. If is too large and the condition of the cost function is not met, then is halved, as provided in step 6.
Step 7—Updating the training sequence and the gradient direction: In this step, the pilot matrix and the gradient direction are updated according to the obtained matrix exponential . Due to the unitary invariant rotation of the cost function, the obtained training sequence has unitary columns.
Step 8—The new conjugate gradient direction is obtained by updating
, where
is determined by substituting the obtained sequence matrix into (
8), and the parameter
is given as [
53]:
where
denotes the Polak–Ribièrre formula, as defined in [
53]. If the stopping criteria is met, the algorithm is executed and the sequence is optimized. In contrast, if the stopping criteria is not met, a new iteration
is started.
We provide the flops calculation (obtained by counting the number of multiplications and additions per iteration) for the proposed CSD algorithm and the existing SCMI and SMSE algorithms.
Table 1 summarises the complexity analysis in flops [
56] per iteration for the three training designs considered. Parameters (
,
) and (
,
) represent the number of iterations required for doubling and halving the step size in the proposed CGD method and the SMSE iterative algorithm, respectively. In this paper, the gradient descent based approach is applied, which can be defined as a first-order iterative optimization solution. This approach is useful for finding a local minimum of the MSE differentiable function with respect to the pilot matrix. In particular, the proposed solution exploits the doubling or halving of the gradient direction to direct steps proportional to the negative of the gradient in order to find the local minimum of the MSE function using a gradient descent based approach. The subscript
denotes doubling the step size in the proposed CGD method, whereas subscript
refers to halving the step size in the proposed CGD, where the letter
g stands for the gradient. The variable
X is given as
for SMSE and the variable
B is given as
for CGD. The flops calculations show that all three gradient algorithms grow with the number of training sequences as
, with the number of antennas as
, and with the number of users as
.
The complexity of calculating the gradient in step 2 of Algorithm 1, so that the term requires flops.
Calculating the matrix exponential requires
flops [
52,
53].
Checking the gradient convergence in step 3 using the squared Frobenius norm of an
matrix requires
flops [
56].
Calculating the term step size adaptation in step 5 and step 6 of Algorithm 1 requires
flops [
52].
Multiplying an matrix with an matrix, entails flops.
Multiplying a matrix with an matrix, entails flops.
Multiplying a matrix with an matrix, entails flops.
Multiplying a matrix with a matrix requires flops.
Multiplying an matrix with an matrix, entails flops.
Multiplying an matrix with a matrix, entails flops.
Multiplying an matrix with a matrix, entails flops.
The scalar matrix multiplication with an matrix needs flops.
Adding an matrix to an matrix requires flops.
Inverting of a matrix requires flops.
5. Achievable Sum Rate Analysis Using RMT Method
This section provides the expressions that accurately approximate the SINR and DL achievable sum rate based on the asymptotic RMT approach in [
32,
33]. In particular, asymptotically tight approximations of
for the BF and RZF precoders are obtained when
N and
K grow without bounds while the ratio
is kept constant. To this end, the asymptotic expression for BF precoding is given as:
where
. The SINR approximation for the RZF precoder is given as:
where the term
is determined later in (
20). Defining a recursion on integer
t, where
with an initial value
for all
k with
, the variable
is found numerically by the standard fixed-point algorithm as
After the solution of the fixed-point equations in (
13) and (
14) is numerically obtained, it is substituted into:
to obtain random matrix
. Auxiliary matrix
is given by
and
is given as:
where
and
are obtained from the expressions given in (
18) and (
19).
Parameter
in (
12) is obtained by substituting the matrices
and
into:
The auxiliary variable
in (
12) is obtained from the expressions given in (
21)–(
23),
where
denotes
The aforementioned analyses of BF and RZF precoding with the RMT method can be very useful for validating our work.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}