1. Introduction
Recent years have witnessed the rapid growth of smart technologies such as smartphones, smart glasses, and smartwatches. On the one hand, people rely heavily on smart devices to share information and gain services, which become primary elements of our daily lives [
1]. On the other hand, the security problem raised by smart devices has become more important than ever before [
2]. One of the most critical issues is user authentication, especially in cloud and edge computing.
To identify users, most of the existing systems use explicit approaches (explicit authentication), such as passwords, PINs, and draw patterns. However, explicit authentication requires user-system interaction, which could be frustrating, especially when the users possess many different passwords. A recent survey [
3] shows 3% percent of people forget a password at least once a week. Explicit authentication can also be circumvented and be broken [
4]. Therefore, researchers begin to study new authentication methods to enhance explicit authentication.
Utilizing sensors’ data sampled by the smart device, implicit authentication (IA) transparently identifies users by constantly comparing current users’ behavioral data with historical legitimate users’ behavioral data [
5]. The comparing or classification process is usually achieved using various machine learning models, e.g., SVM. At the same time, most of the calculations and storage are generally offloaded to the cloud due to the energy limitation of smart devices [
6]. Furthermore, since users do not need to interact with the system in the authentication, IA can be seamlessly applied to various authentication systems, which adds another layer of protection to the smart device. If suspicious behaviors were detected during the usage, IA will lock the device and ask users to perform a multi-factor authentication, e.g., inputting passwords [
7,
8]. From the users’ aspect, due to IA’s transparency, they will not notice IA until the device has been locked. In addition, implicit authentication does not require user–system interaction, which releases users from tedious password inputting and the burden of memorizing the passwords.
In implicit authentication (IA), the features used for the authentication are predefined by the system, which will not be able to change during the usage [
9,
10]. To achieve better coverage in user authentication, the existing approaches tend to use multiple features [
11,
12,
13], such as location, touch, and acceleration. However, only a small number of the features (personal features) in the entire feature set are needed for a specific user. Therefore, irrelevant features not only reduce the system’s efficiency, but decrease the authentication accuracy as well. Nevertheless, due to the high complexity of human behavior, it requires a massive calculation to derive personal features, which is infeasible in practice [
14]. Hence, finding a suitable scheme that dynamically derives personal features is critical for IA implementation.
This work introduces a human-centered implicit authentication (EchoIA), which utilizes user feedback to pinpoint personal features during the usage with a small amount of calculation. By comparing with current IA schemes, the experiment shows that our method can significantly improve the authentication accuracy of traditional IA. In addition, the proposed method is lightweight, which can be easily embedded into existing IA systems as an add-on to achieve efficient authentication. As far as we know, we are the first group that utilizes user feedback to improve authentication accuracy and energy efficiency in IA.
The major advantage of implicit authentication (IA) is its transparency, releasing users from the tedious authentication process. However, it is challenging to gather user feedback in a transparent environment since directly asking users’ input will break the transparency. Even though we could have various user feedback, pinpointing the best suitable features is also challenging. To this end, we propose a method that utilizes the correct rate of inputted passwords to implicitly collect user feedback and find personal features. In implicit authentication, the system will lock the device and deem current users illegitimate when their behavior mismatches legitimate users’ historical behavior. Legitimate users may be locked out due to the misidentification caused by using unsuitable features, but they can input a correct password to unlock the device. Illegitimate users may also input a valid password to unlock the device after several attempts, but their correct rate of inputted passwords will be lower than legitimate users’. EchoIA can utilize the correct rate of inputted passwords to deduce current users’ true identities and further adjust feature sets to better match users’ behavior. The detailed procedure is discussed in
Section 2.
This paper makes the following contributions:
We proposed EchoIA to find the best suitable features (personal features) for each user by utilizing user feedback. EchoIA maintains the transparency of implicit authentication, while can choose personal features for legitimate users based on their recent behavior.
We implemented EchoIA in a real environment using the Android system and multiple servers. To evaluate the proposed method, we also implemented four state-of-the-art implicit authentication schemes.
We collected users’ behavioral data in the past two years. In addition, we evaluated the proposed method in the aspect of authentication accuracy, computational efficiency, and energy efficiency. In the experiment, EchoIA has a better authentication accuracy and a lower energy cost.
2. Related Work
To improve explicit authentication mechanisms such as PIN and passlocks, various implicit authentication schemes have been proposed as secondary authentication mechanisms [
5,
6,
11,
13,
15,
16,
17,
18,
19,
20,
21]. Among them, leveraging different features, Shi scheme [
6], Multi-Sensor scheme [
11], Gait scheme [
19], and SilentSense scheme [
20] are four different schemes that represent four research directions of state-of-the-art implicit authentications [
22,
23]. In addition, current implicit authentication research tends to adopt all the available features to achieve better authentication accuracy [
11,
14,
24]. On one hand, due to the high complexity of users’ behavior, utilizing only a specific behavior metric is not sufficient to identify them in practice. On the other hand, to identify a specific user, only a small portion of the total behavior metrics is needed [
6,
11,
13,
22,
24]. Reducing the number of features can also exponentially decrease the system’s energy and time consumption [
25]. However, to find personal features requires additional calculation [
11,
14], which increases time and energy consumption. Leveraging user feedback, EchoIA can select the best suitable features for different users. During the usage, the legitimate users can also notify the system to update personal features if their behavior changed, e.g., injury.
Most of the existing research in implicit authentication utilizes the support vector machine (SVM) [
11,
20,
26,
27,
28] to identify users. Other classifiers, e.g., Gaussian mixture model (GMM [
25]), have also been used in implicit authentication [
6]. We mainly adopted SVM to achieve user authentication in this work.
3. The System Overview
Implicit authentication (IA) identifies users by constantly comparing current users’ behavioral data with legitimate users’ historical behavioral data. If current users’ behavioral data is different, IA will lock the device and ask the users to input passwords. Due to the noise and behavioral change, it is common that legitimate users are falsely blocked by the device [
14]. In implicit authentication, if users input correct passwords, they can continue to use the device, where the setting of the original IA system will not change. In EchoIA, however, if users input correct passwords and prove their identities, the system will unlock the device and adjust the features to align with legitimate users’ behavior.
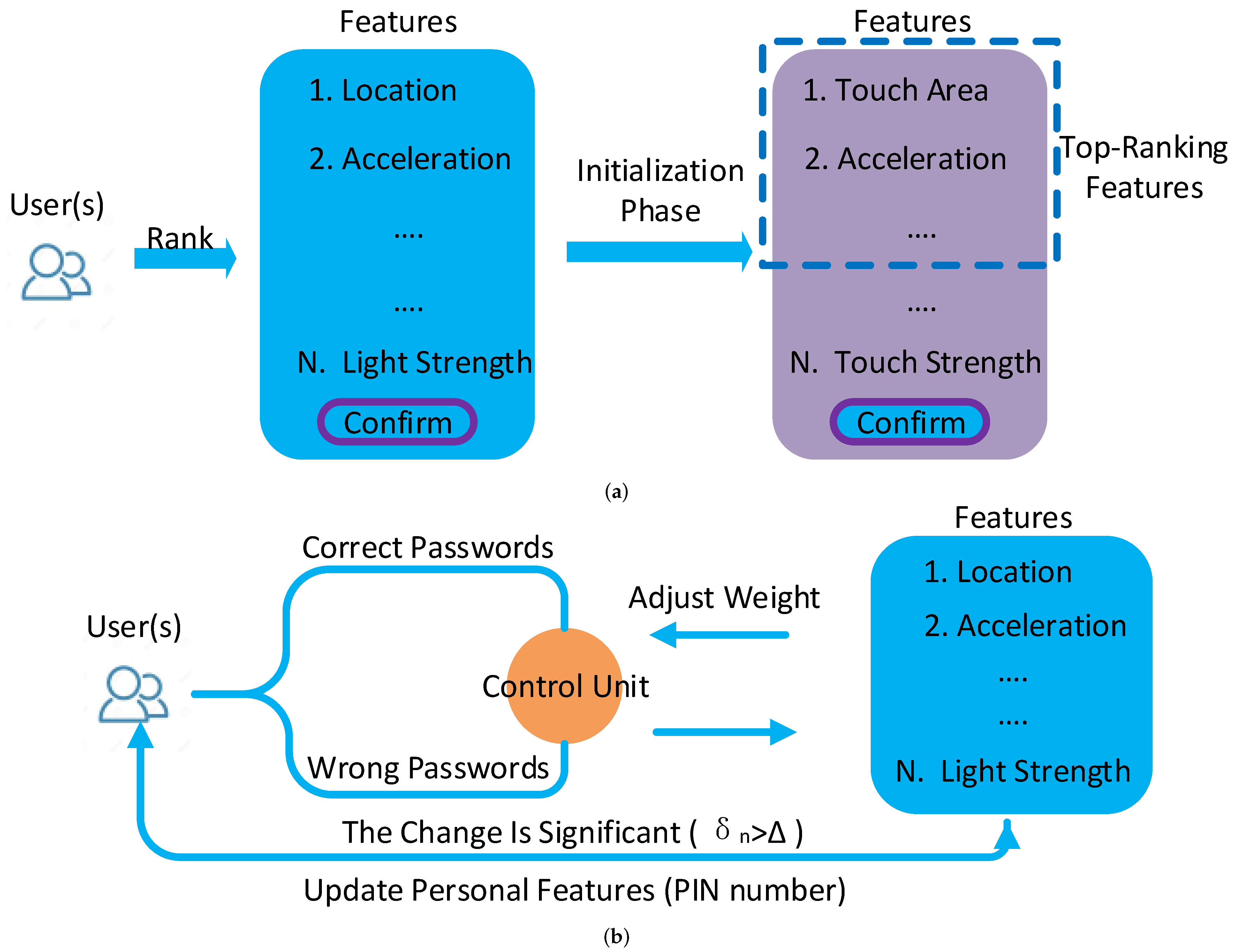
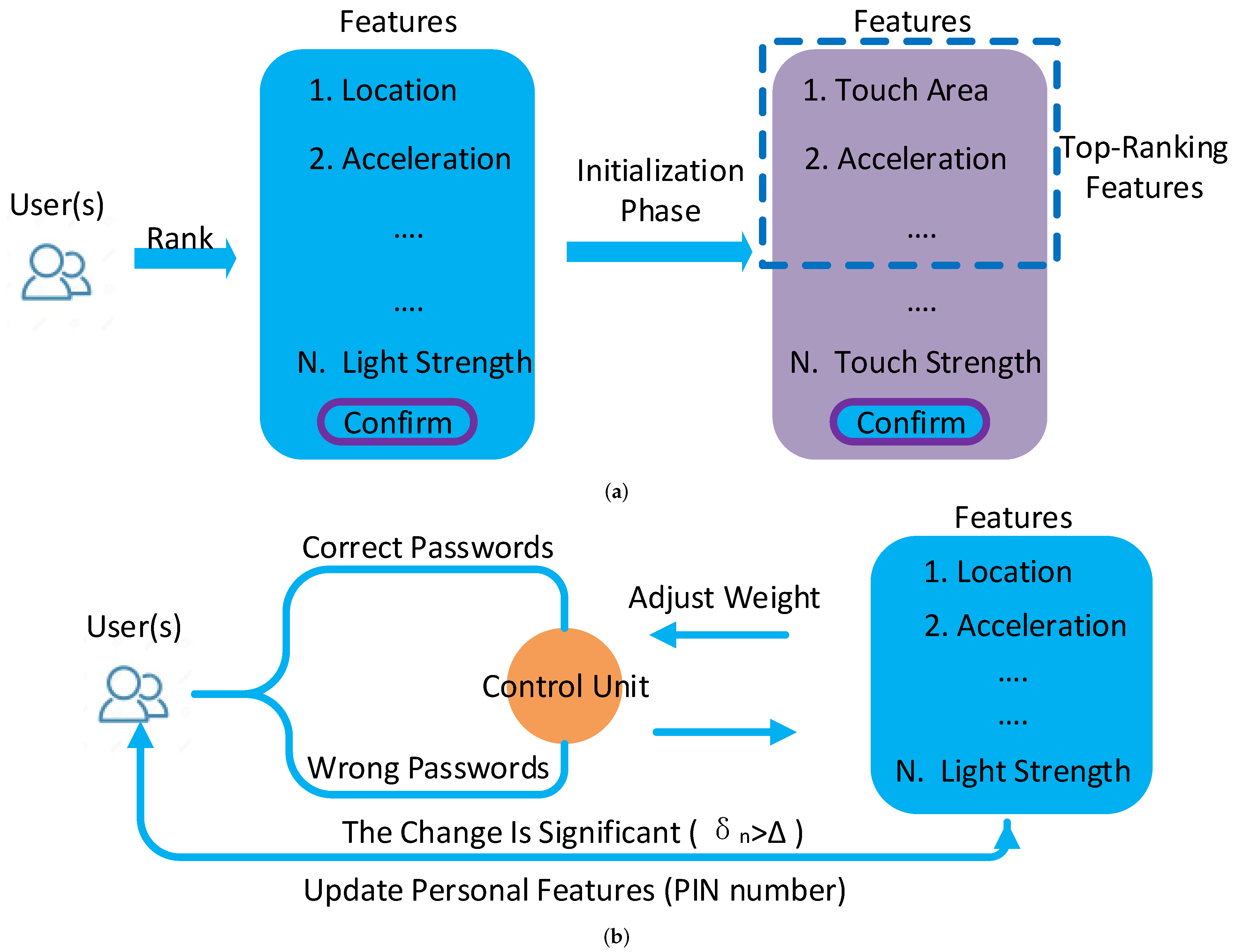
As shown in
Figure 1, EchoIA contains two phases,
Initialization and
Authentication. The
Initialization phase only takes place for the first time of the usage. Meanwhile, we assume the users at the
Initialization phase are legitimate. In the
Initialization phase, candidate features are sent to legitimate users, who may rank the features based on their behavior. The combination of top-ranking features and system-default features is used as personal features to identify users. Note that the personal features are dynamically adjusted according to different users and devices. In the
Authentication phase, EchoIA utilizes the correct rate of inputted passwords to adjust personal features. Specifically, user feedback is implicitly obtained through the process of inputting passwords (
Section 3.1), which keeps IA’s transparency. However, to prevent illegitimate users from taking advantage of the system, it only updates personal features after users entered a correct PIN number, which must be different from passwords used for unlocking the device. A secured channel is established to transmit data between client and server. We adopted a Wind Vane module [
14] to optimize the data transmission efficiency.
From the system’s point of view, inputting incorrect passwords will enhance its confidence in using existing personal features; inputting correct passwords will reduce its confidence in using existing personal features and encourage it to choose different features. Since most of the time, the system is running at the Authentication phase, the users will not be able to notice the existence of EchoIA during the usage. The following sections will discuss the detail of the Initialization phase and the Authentication phase.
3.1. The Initialization Phase
As its name suggests, the Initialization phase mainly focuses on initializing personal features and associated system settings. The users will spend a short time in this phase in order to help the system to prepare the authentication.
As shown in
Figure 1a, at the
Initialization phase, EchoIA will send a message contains all candidate features to the users. Based on their own behavior, the users will rank candidate features, where the result will be sent back to the remote servers for further processing. For each feature, there is an associated weight parameter, which will be initialized at this phase. The total available features in the smart device are
F. Note that the elements in
F are various for different devices, and can be updated during the usage once new features are introduced.
To ensure reliability, some of the features are system preserved, which is not shown in
F. For example, a touch trajectory feature is preserved since it has high accuracy when identifying most of the users. For each feature in
F, the corresponding weight is predefined in
W.
The users may rank the features based on their routine. To this end, EchoIA will renew the weight for each feature based on the users’ ranking.
where
is the weight of the
nth feature; and
is the associated ranking of the feature. The top-ranking features only contain a part of elements in
F and are dynamically changed during the usage. For example, at some moments, the top-ranking features,
, may only contain 5 different features
. Personal features in this example will have both
and system reserved features.
In real usage, users may change their behavior, which is common in practice. To better identify the users, the system also needs to adjust personal features according to the behavioral change. The details of adjusting personal features will be discussed in the next section.
3.2. The Authentication Phase
To dynamically adjust personal features, the system can directly send the message to users to request new features, but this approach will break IA’s transparency. In addition, it is difficult for the system to decide the “right time” to send the request, since the system will not know the behavioral change unless it analyzed the data. In EchoIA, instead of analyzing users’ behavioral data, the system leverages the correct rate of inputted passwords to dynamically adjust personal features.
At the
Authentication phase, as shown in
Figure 1b, the system will reduce the weights of each feature in
if users input correct passwords. Since users only need to input passwords when IA locks the device, correct passwords indicate current users have a large chance of being legitimate. Similarly, the system will increase the weight of each feature in
if users input incorrect passwords. The new weight is updated by
.
where
is the amount of weight increased for the feature
n in
;
is the amount of weight decreased for the feature
n in
. The new weight of the feature
n is calculated by
(
indicates the system has less confidence in the current data samples).
In EchoIA, a predefined threshold
is used to measure the significance of the weight change. In practice, we choose
by using k-fold cross-validation. If the change is significant,
, the system will challenge the users to input a PIN number, which is the number different from passwords used to unlock the device. The users can choose the PIN number at the
Initialization phase. If the users type a correct PIN and agree with personal features’ change, EchoIA will update
and personal features according to the new weights in
F. In this process, decayed features will be replaced by new features. The system will use the updated personal features to identify the users until
again. We adopted the support vector machine (SVM) to achieve the user classification and to identify legitimate users. The parameters in the model are optimized by using k-fold cross-validation. We have summarized the
Authentication phase in Algorithm 1.
| Algorithm 1: EchoIA (Simplified). |
![Network 02 00013 i001]() |
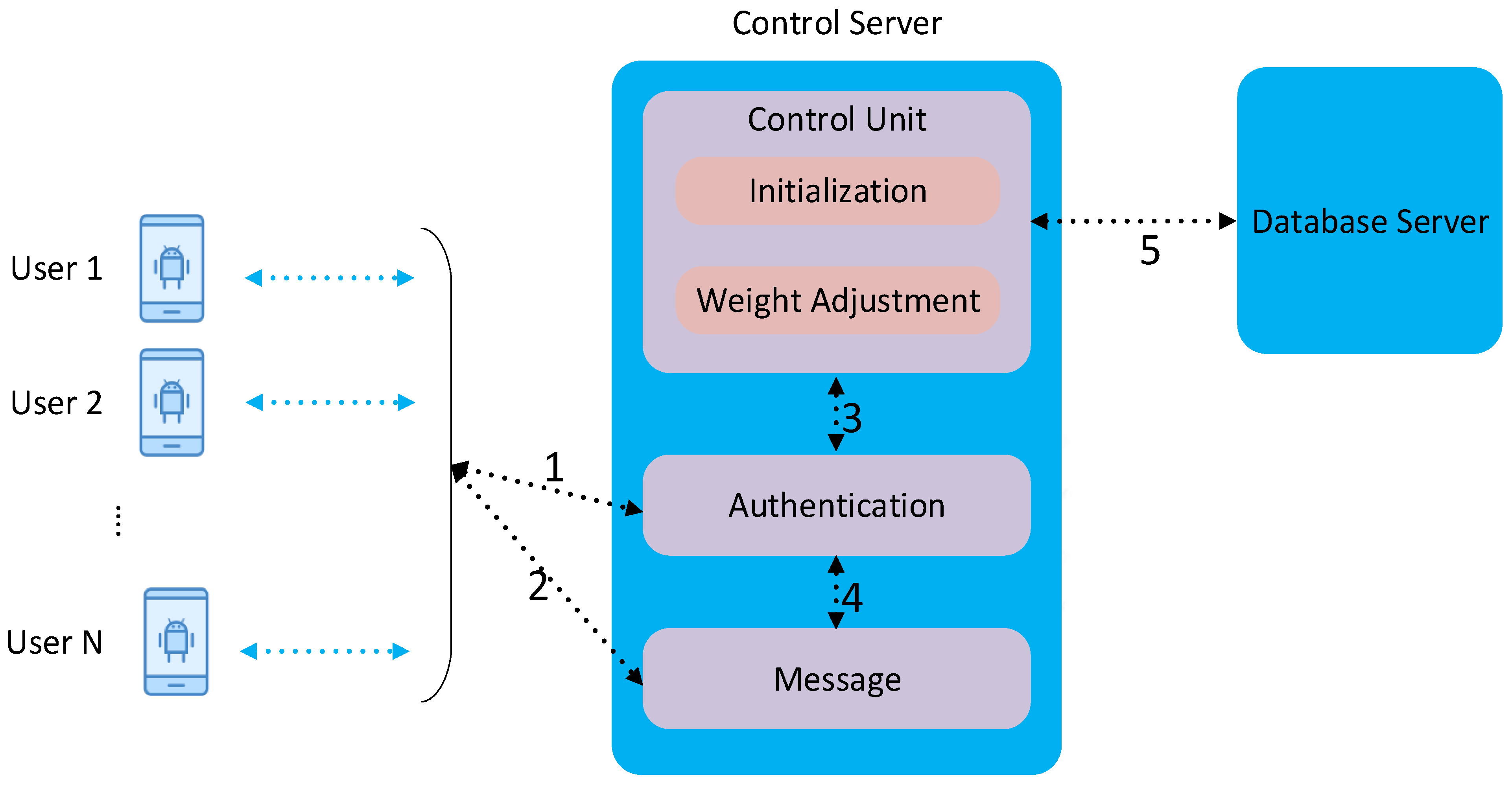
4. Implementation
We implemented EchoIA by using the Android system and multiple servers. The system architecture is shown in
Figure 2. The data collection is achieved at the user-end, in which an application is created to collect users’ behavioral data. The user-end application constantly samples users’ behavioral data from various sensors and sends it to the Control Server by using a secured channel. As shown in
Figure 2, multiple users can connect with the Control Server at the same time. The Control Server contains three main components, Control Unit, Authentication Unit, and Message Unit. As mentioned in
Section 3, the Control Unit is responsible for updating the weight parameter associated with each feature. The Authentication Unit leverages implicit authentication to constantly monitor users’ behavior and compare it with legitimate users’ historical behavior. In order to compare EchoIA with other IA schemes, we also implemented four state-of-the-art IA schemes in the Authentication Unit, called Shi-IA [
6], Multi-Sensor-IA [
11], Gait-IA [
19], and SilentSense-IA [
20]. Finally, the Message Unit is used to communicate with users during the
Initialization phase and the
Authentication phase. All users’ data is formatted and stored in the Database Server.
5. Evaluation
In the real experiment, we tracked the usage of 17 participants during the past two years. Each user was in turn selected as the legitimate user, while another user was deemed as illegitimate users. Illegitimate users were required to use the device at least 10% of the total usage time. Utilizing our system, we gathered rich information from all users under different environments. In the experiment, we mainly use the following 12 features to achieve user authentication: accelerometer, orientation, magnetometer, gyroscope, touch, light, pressure, temperature, GPS, microphone, battery usage, and WiFi status.
To compare EchoIA with other state-of-the-art IA schemes [
22], we implemented Shi-IA [
6], Multi-Sensor-IA [
11], Gait-IA [
19], and SilentSense-IA [
20]. We used the recommended settings of the original papers [
6,
11,
19,
20] in the experiment. In addition, the feature selection strictly follows the descriptions of the original works, while the parameters were optimized by using k-fold cross-validation. Finally, we tested the performance of different schemes by using the same data.
In the experiment, we evaluated the authentication accuracy, CPU utilization, memory utilization, and energy consumption for each IA schemes, including EchoIA. The experiment details are described in the following sections.
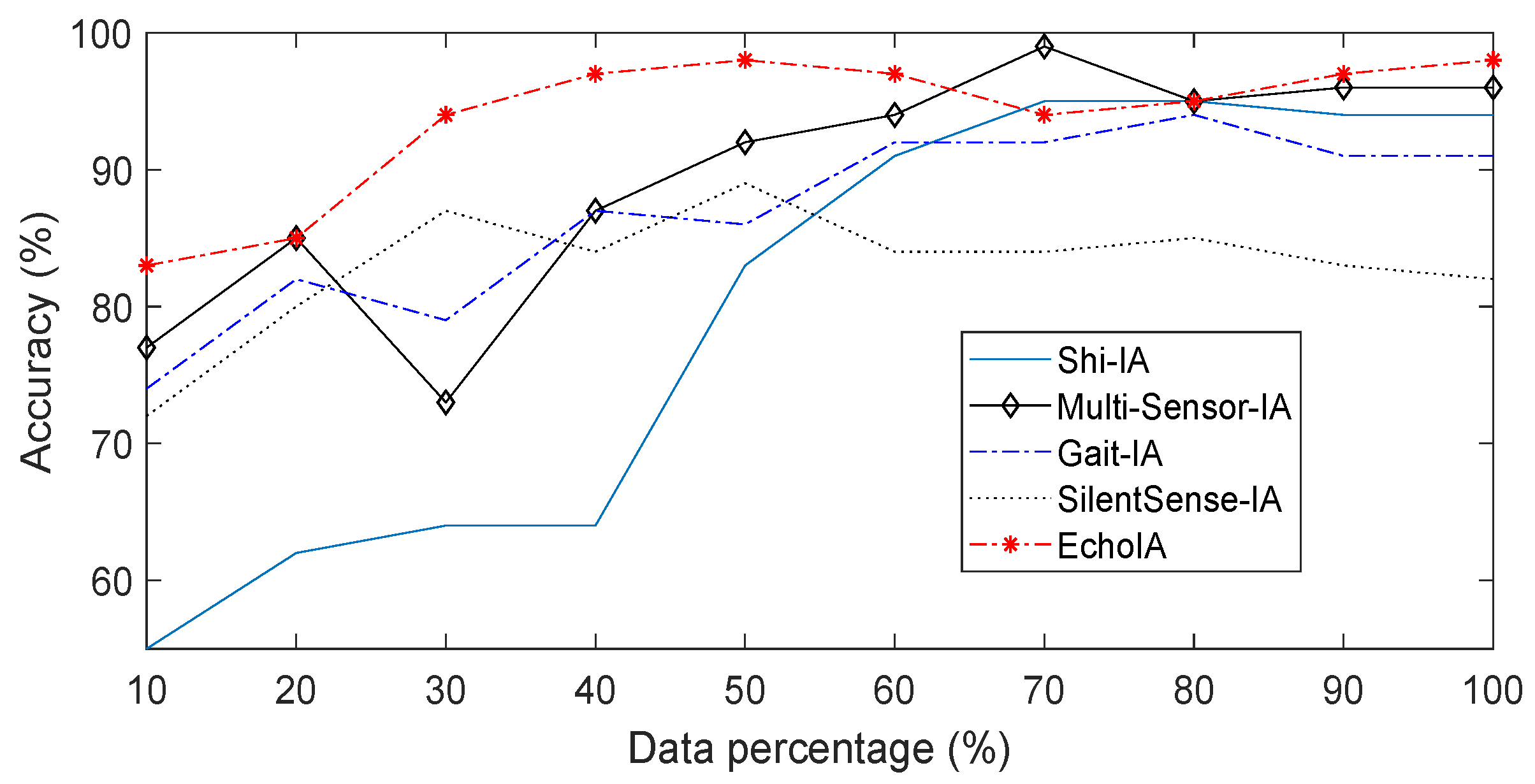
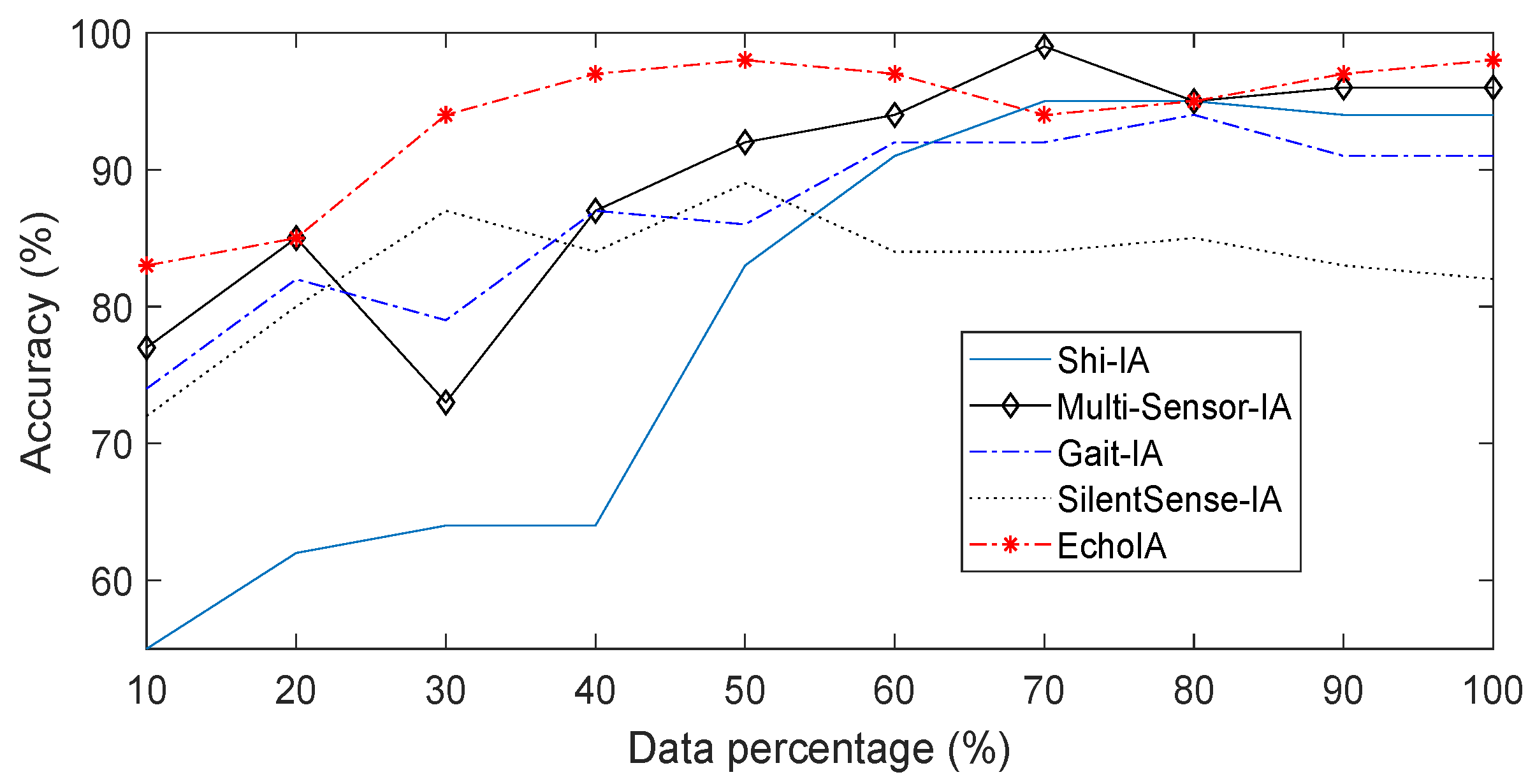
We first compared the authentication accuracy of different IA schemes, where results are shown in
Figure 3. In the figure, users’ data was divided into ten parts based on the timeline. The first part of the data was used to train the models (The first parts contain 15% of the total data since the training data of this size optimizes the authentication accuracy across all five IA schemes). We then calculated the authentication accuracies for different schemes by using the other parts of the data. The authentication accuracy was calculated by
, where true accept (
TA) indicates the legitimate user has been correctly identified; the false reject (
FR) indicates the legitimate user has been incorrectly identified to be the illegitimate user; the true reject (
TR) indicates the illegitimate user has been correctly identified; the false accept (
FA) indicates the illegitimate user has been incorrectly identified to be the legitimate user. The ultimate goal of the authentication is to reduce both
FR and
FA to 0, where the system will achieve 100% accuracy. We also adopted the retraining techniques discussed in our previous work [
7] to improve the authentication accuracy for all five schemes.
5.1. Authentication Accuracy
EchoIA has the highest authentication accuracy in most of the tests, as shown in
Figure 3. Multi-Sensor-IA also has a high authentication accuracy compared to other IA schemes. In the experiment, most of the schemes reach to more than 90% accuracy after using 80% of the data except SilentSense-IA. Note that there are some fluctuations in different IA schemes due to behavior changes, where both Multi-Sensor-IA and Gait-IA have an accuracy drop at the point of 30%. We analyzed the data of Multi-Sensor IA at that point, which shows that most users traveled to different places that did not appear in the training phase. The machine learning model cannot separate users based on the given training data. Since, for some users, the traveling and staying time is non-negligible, it becomes harder for Multi-Sensor IA to make a decision based on the previous training data. After the behavioral data in this new location is collected and stored in training data, the accuracy of Multi-Sensor IA eventually increases and becomes similar to other IA schemes. However, this behavior change does not affect the proposed EchoIA since the system automatically updates users’ personal features during usage. In such a case, the accuracy curve for EchoIA is much smoother than the other schemes. As literature usually does in template updating related research [
22,
29,
30], we measured the EERs and ROCs for EchoIA, Multi-Sensor-IA, Gait-IA, SilentSenseIA, and Shi-IA, which provide more reliable results. The EERs for EchoIA, Shi-IA, Muti-Sensor-IA, Gait-IA, and SilentSense-IA are 0.1428, 0.2200, 0.1635, 0.2700, and 0.2720, respectively; and corresponding AUCs are 0.8991, 0.8588, 0.9244, 0.8103, and 0.8013, respectively.
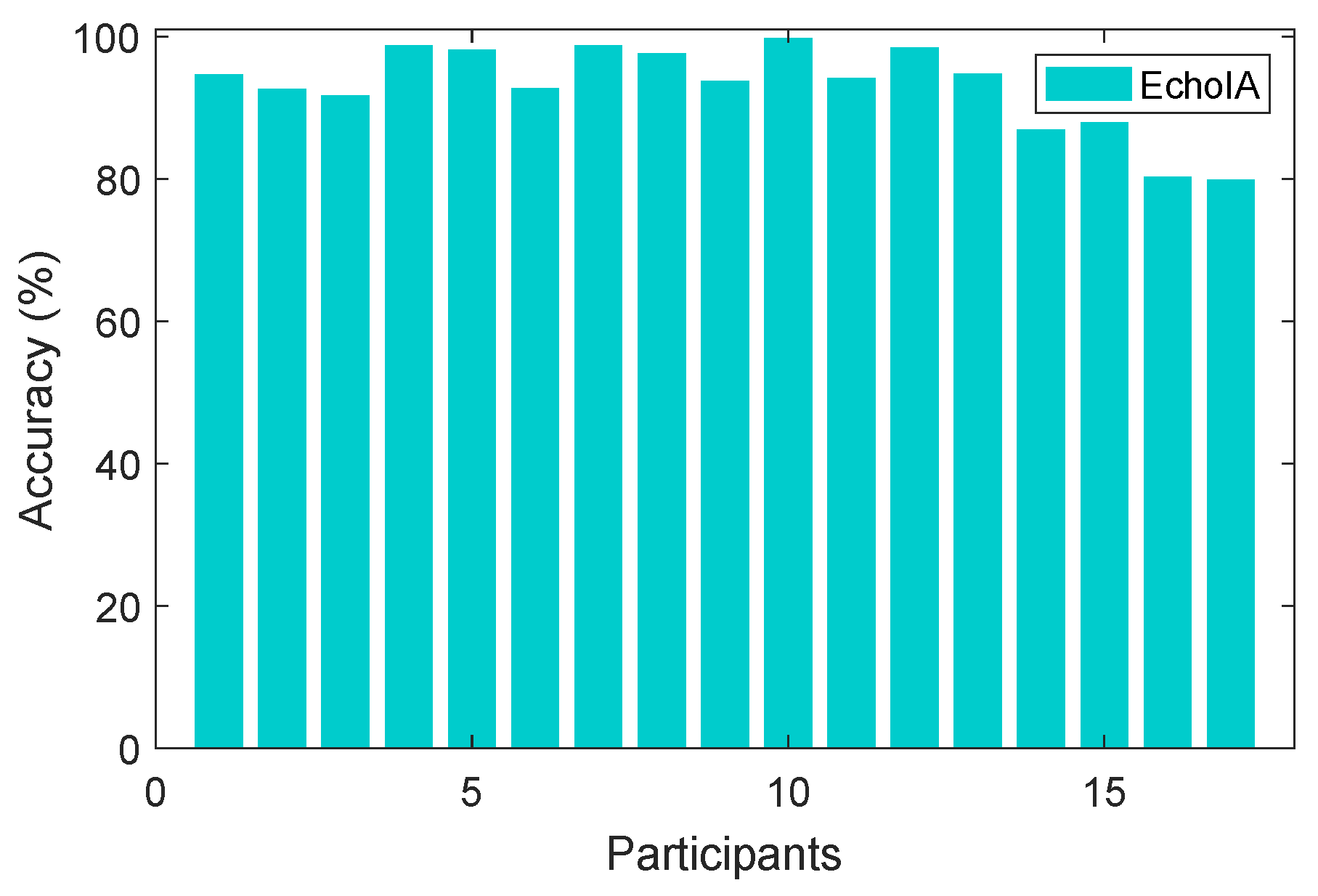
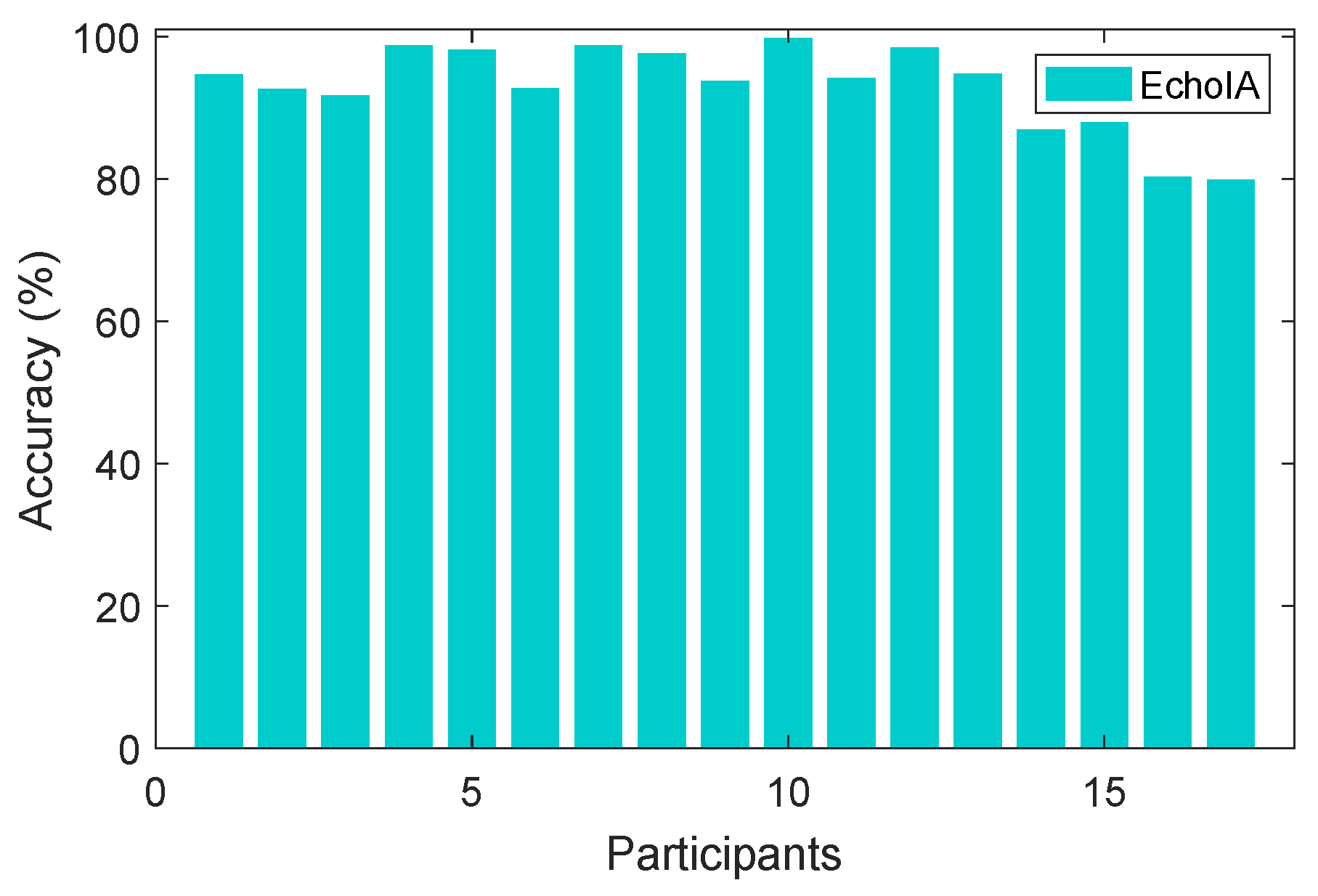
In EchoIA, we calculated an average authentication accuracy for 17 users by utilizing all the data spanned two years. The result is shown in
Figure 4, where the average accuracy across all users is 93.23%.
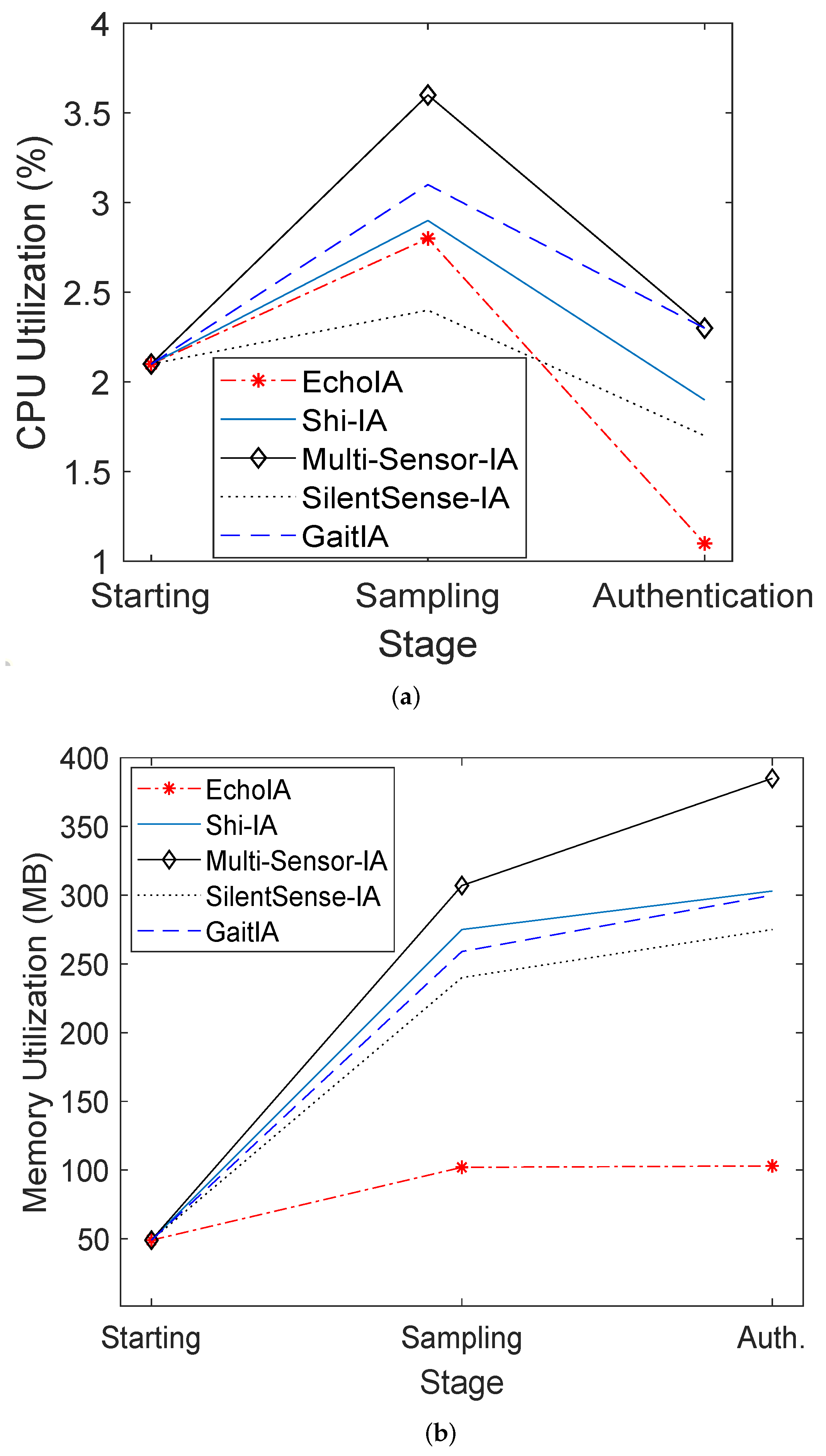
5.2. CPU Utilization and Memory Utilization
In addition, we evaluated the CPU usage and memory usage for different schemes. In the experiment, we recorded the CPU utilization of different IA schemes at three stages, Start, Sampling, and Authentication. The experiment results are shown in
Figure 5a. At the Sampling stage, the CPU utilization of EchoIA is the second-lowest for all five schemes. At the Authentication stage, the CPU utilization of EchoIA is the lowest among all the schemes. Since most of the time the users are at the Authentication stage, the total amount of CPU utilization of EchoIA is the smallest for all the schemes. In the experiment, Multi-Sensor-IA has the highest CPU utilization, but it also has a high authentication accuracy similar to EchoIA.
We recorded the memory utilization of various schemes at different stages. The result is shown in
Figure 5b, in which the EchoIA has the lowest memory utilization among all the five schemes. Since EchoIA only uses a small portion of features to train the model and to authenticate users, the total amount of memory used to store the data is smaller than other schemes. As shown in
Figure 5b, the memory utilization of Multi-Sensor-IA is the highest since it uses all the features and associated sensors’ data on the device.
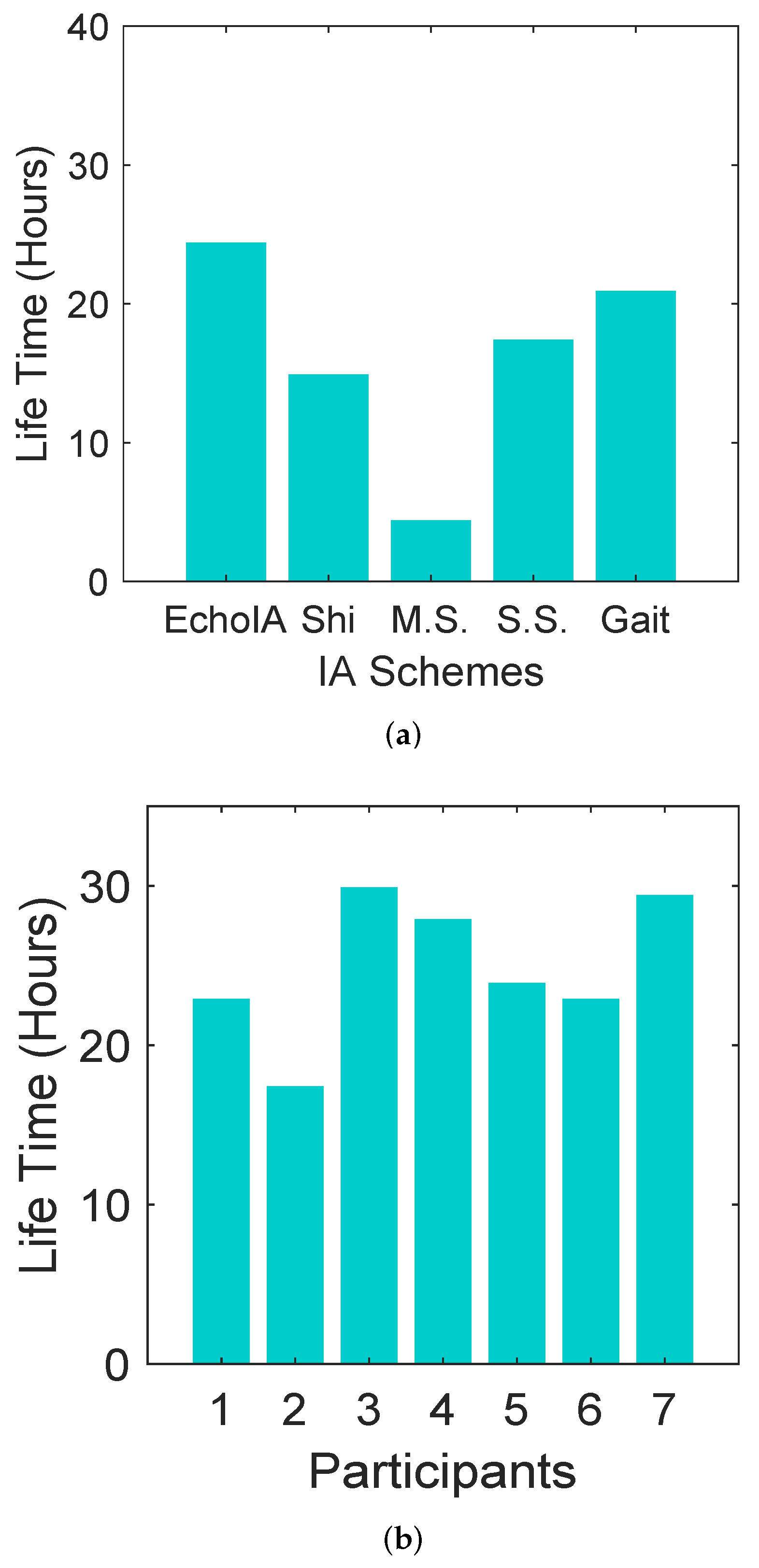
In the experiment, we evaluated the battery consumption for different schemes. The result is shown in
Figure 6. We measure the battery usage of different schemes by calculating the average working hours of battery after fully charged. As shown in
Figure 6a, EchoIA has the longest battery lifetime, 23 h on average. The Multi-Sensor-IA has the shortest battery lifetime, four hours on average.
We also calculated the average battery lifetime of each participant by using EchoIA.
Figure 6b shows the battery lifetime derived from the data of seven different participants. They are randomly selected. We calculated an average battery lifetime across all participants’ data for comparison purposes, which is 23 h. There are large differences in the battery utilization between users. As shown in the figure, participant 2 has the shortest battery lifetime, which is 16 h. Participant 7, however, has the longest battery lifetime, which is 30 h.
5.3. Energy Consumption of the User-End Application
We also tracked the performance of the user-end application. In the experiment, we compared EchoIA with popular applications, such as Instagram, Facebook, Twitter, eBay, and LinkedIn. We continuously tracked CPU utilization and memory utilization for different applications during the usage. The result is shown in
Table 1. Please note that in
Figure 5, we calculated the CPU and battery utilization only based on the data at the sampling and authentication stages. In
Table 1, we also gathered data from other stages, e.g., switching to a different application.
Table 1 shows the average and maximum CPU consumption for each application. EchoIA has the lowest average CPU consumption compared to other applications, which is 1.3%. Similarly, EchoIA also has the lowest maximum CPU consumption, which is 3.9%. EchoIA also consumes a small amount of memory in real usage, which only occupies a maximum of 103 MB memory.
6. Conclusions
We proposed EchoIA to find the best suitable features (personal features) for different users by utilizing user feedback. To achieve better coverage, the existing works in implicit authentication tend to use many different features to identify users, which is less efficient and may decrease the authentication accuracy. Without using additional calculations, it is difficult to dynamically choose personal features due to the transparency of IA. Leveraging the correct rate of inputted passwords, EchoIA implicitly gathers user feedback to choose personal features, while maintaining the transparency of IA. To evaluate the proposed method, we implemented EchoIA and four state-of-the-art IA schemes by using the Android system and multiple servers. The results show that EchoIA has better authentication accuracy (93%) and less energy consumption (23-h battery lifetimes) than other IA schemes. EchoIA can automatically update the personal feature for each user when their behavior changes, which significantly boosts IA’s accuracy and usability. In addition, the low energy consumption makes EchoIA suitable for most smart devices, such as smartphones, smartwatches, and smart glasses. In the future, to benefit associated research, we will share the system’s source code, parameter settings, and dataset on our lab website.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}