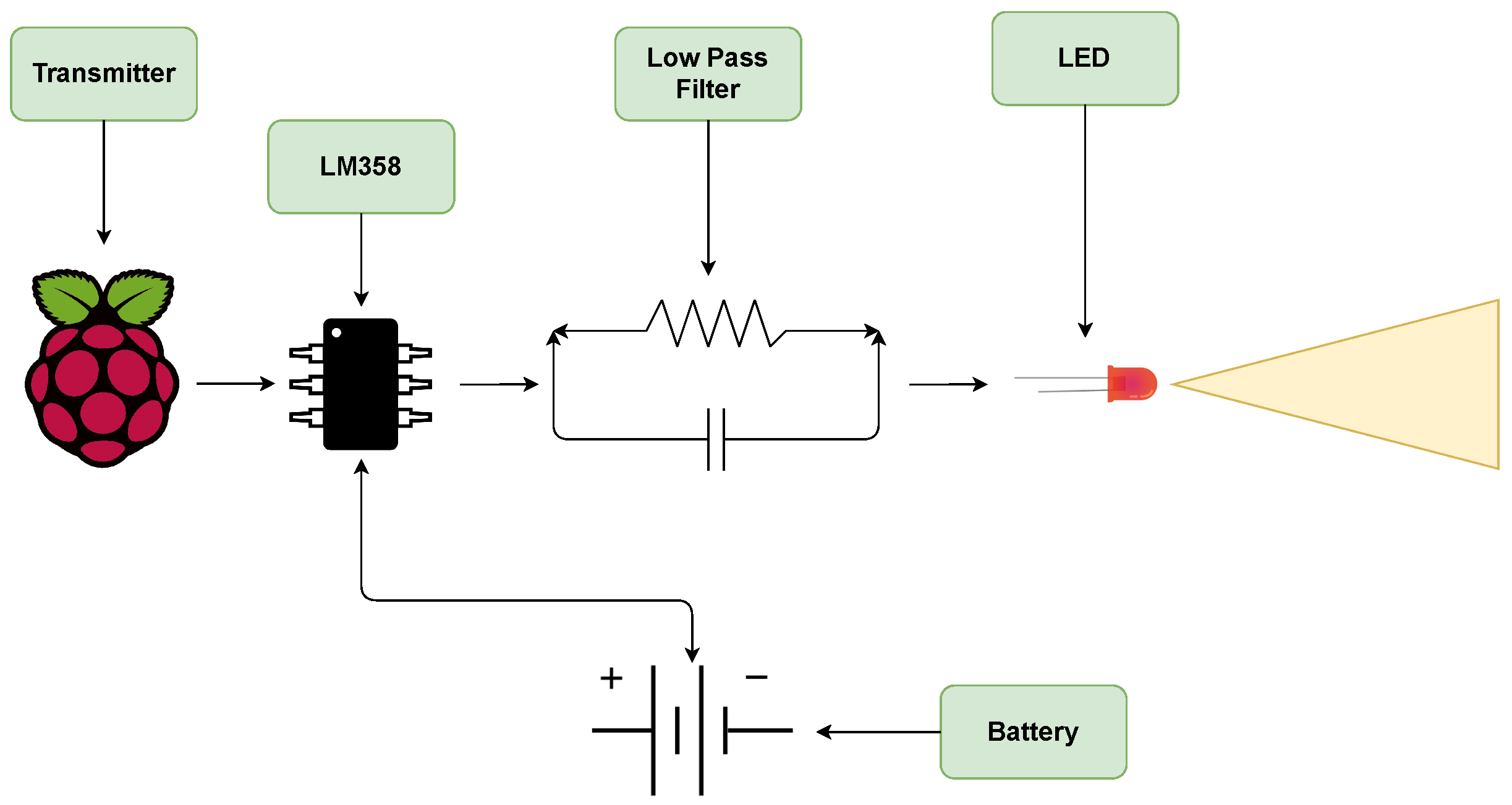
The next phase of this study is to empirically evaluate proof of concept of DNN-based OCC demodulation. In this regard, the first case study involves studying the performance of DNN demodulation of VGG16 for a 2 × 2 LED array under multiplexing configuration. We consider packetized communication to conform with traditional communication modalities.
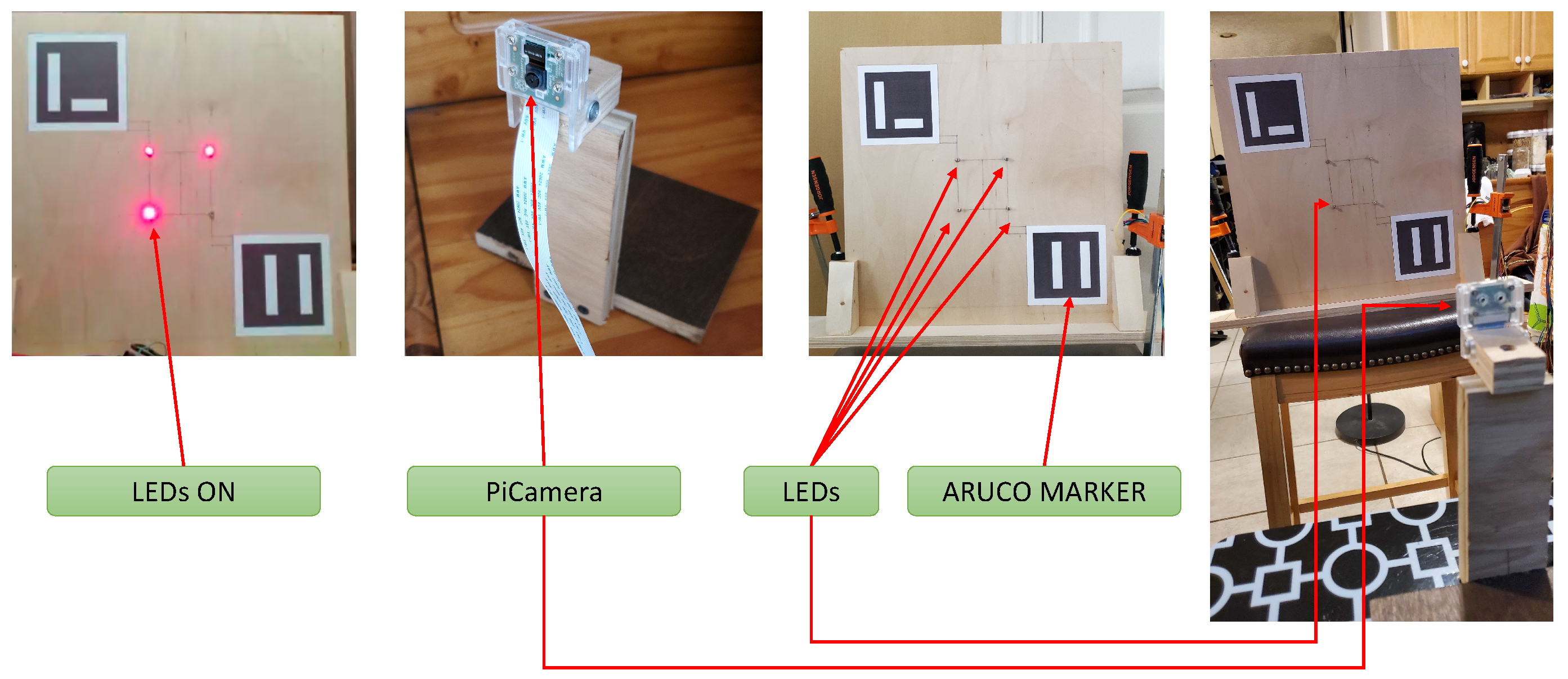
Figure 5 illustrates the experiment setup. As can be observed, a 2 × 2 LED grid was used with spacing of 3 inches in the vertical and horizontal direction and a Raspberry Pi 4 was used to operate the LEDs. The receiver was a Raspberry PiCamera V2 which was controlled by the same Raspberry Pi as the LEDs. The top left and bottom right markers are ARUCO markers, which are synthetic square marker similar to QR codes but for object detection and location [
33]. They were used to consistently locate the LEDs in each frame captured by the camera. The LEDs operated at 30 Hz and the camera recorded at 60 FPS, following the Nyquist criterion. However, the exact synchronization of the system was inaccurate and caused problems when transmitting a large volume of data in the order of 20 packets or more. This was primarily because the OS running on the Raspberry Pi was not a time-critical (Real-Time) OS, which meant that the accuracy of the operations could be variable to a degree and, therefore, causes synchronization issues between when the LED flashed and when the camera captured a frame.
4.2. Receiver
Stage 1. Preprocess received transmission: After detecting and localizing the ARUCO markers, each of the four LEDs is cropped into separate frames to be used as input to the DNN model for classifying the LED state. Each of the classifications are stored separately, and noise and outliers are removed. Then, we need to find the first occurrence of a bit equal to one in the predicted list for each LED, and all the previous bits in the predicted list are removed.
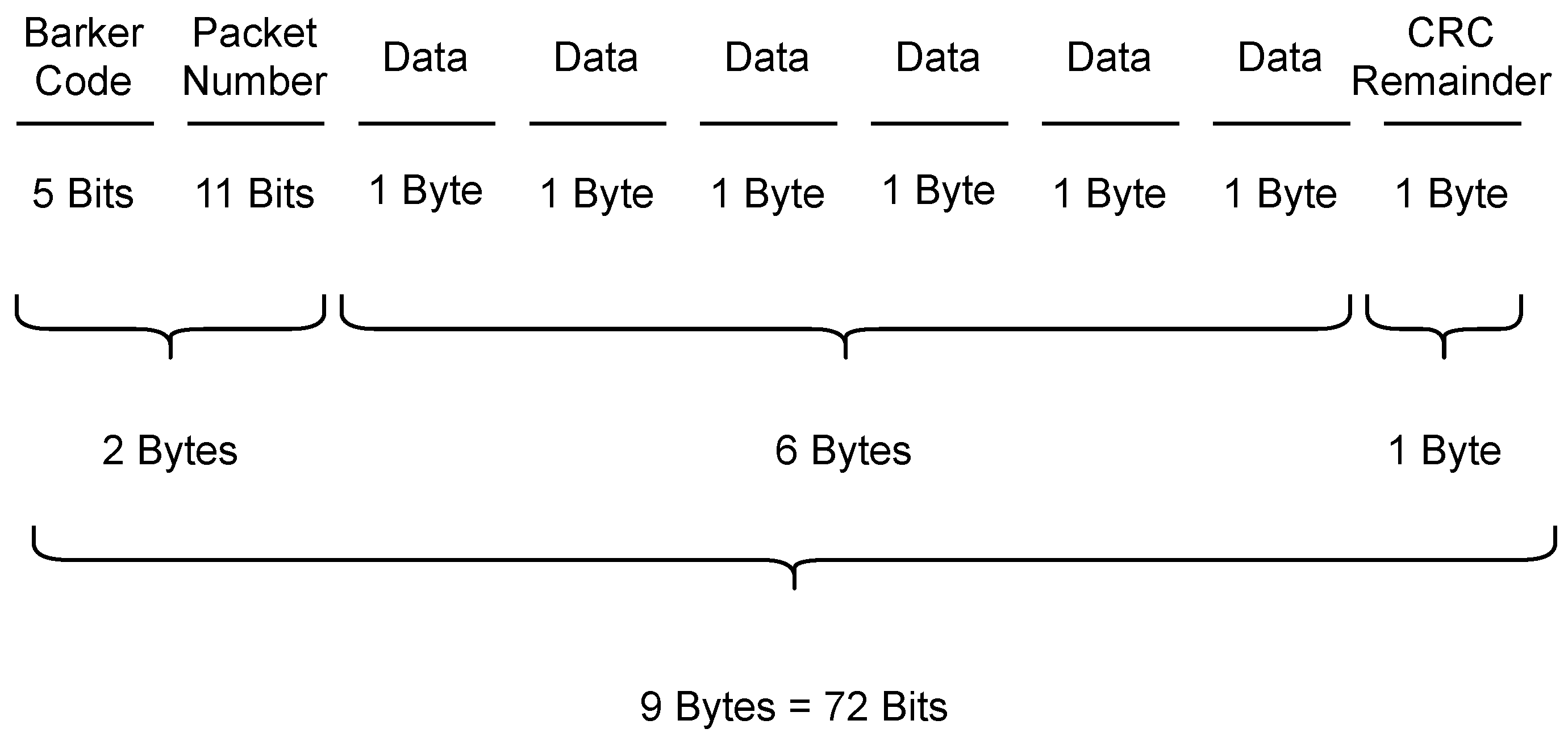
Stage 2. Process packet metadata for each LED: From the pre-processed data, the Barker index needs discovered and parsed with classified packets in each LED List. Then, Packet Number bits are checked along with CRC remainder calculation to verify transmission correctness. The parsed data bytes from the packet are stored in memory.
Stage 3: Data demodulation: In this final demodulation step, data bytes are combined from each LED list in order and compared with every 6 bytes of ground truth. Every byte error in every packet is counted and reported as packets with the Barker code Error, Packet Number Error, Data Error and CRC Errors. Finally, the starting and ending markers are removed to convert every 6 bytes of data to ASCII representation.
4.3. Experimentation
Due to the underlying hardware issues, a new methodology had to be taken to show that the system, specifically the model, is capable of working even with the hardware issues. To showcase this, the following steps were taken:
Step 1: Find the number of characters, which will be called the chunk size for the remainder of the study, that can be successfully transmitted without any type of error (Camera or LED). As mentioned earlier, for shorter transmission the hardware inconsistencies are not prevalent;
Step 2: Transmit a 1000 word file in a single transmission. This was the original/ideal target for the empirical study to transmit with as few errors as possible;
Step 3: Evaluate the 1000 word file transmission by dividing it into chunks established from Step 1 and evaluate each chunk;
Step 4: Transmit the 1000 word file in several videos in which each video sends one chunk of data where the chunk size is defined by the the steps used in Step 1;
Step 5: Analyze the results.
The reason why the chunk size is established is to showcase the effectiveness of the model as independently as possible, rather than with the entire system. Similarly the reason why a single transmission of a 1000 word file is compared versus a fragmented transmission of a 1000 word file is, again, to showcase the models performance but, more importantly, to illustrate how the hardware issues can cause serious problem for this communication system.
To achieve Step 1, several videos of varying character length were transmitted at each distance. After computing the results, 100 character transmissions were found to be the best chunk size. One hundred character transmissions were roughly 17 packets; 18 packets if the starting and ending markers are included. The results showed that across five trials at each distance from 1 m to 7 m, there are no hardware issues nor model misclassifications except for when the distance is at 7 m. This is when a few model misclassifications start to appear. Out of the nearly 6200 frames collected across the five trials at a distance of 7 m, there were only 16 model misclassifications. this illustrates another point which is that as the LED moves farther and farther away, the model is susceptible to more misclassifications for multiple reasons, some of which include the resolution of the image becoming too degraded.
Steps 2 and 3 was performed by transmitting the 1000 word file at each distance twice. Then, every 17 packets, which is roughly equal to 100 characters which equals 1 chunk, were analyzed for byte errors only for the data and not for the packet metadata. In the 1000 word file, there were about 50 chunks or about 850 packets worth of data. After demodulating the transmission, the 50 chunks were checked for the total number of packets with any number of errors, and the Cumulative Average Packet Error Rate was also calculated. The reason why the cumulative average was used was because, as will be discussed later, the hardware issues would pop up randomly during the transmission and distort the transmission. Thus, to obtain an intuitive idea of the success of the entire transmission, the cumulative average was utilized. The formula for the Cumulative Average Packet Error Rate is given in Equation (
1). Then, the average of both the number of packet errors and Cumulative Average Packet Error Rate between the two trials was calculated.
For Step 4, instead of transmitting a single 1000 word file in 1 video, the 1000 word file was sliced such that approximately 100 characters were transmitted in each video. This resulted in having to transmit 50 videos to obtain the entire 1000 word file. This was performed twice at each distance and then the same procedure was used to calculate the total number of packet errors per chunk (in this case, 1 video), and the Cumulative Average Packet Error Rate was calculated with the average between the two trials that were also included.
Overall, we observed that the PER for the 1000 word file transmission was close to 15% at its maximum and about 10% on average. To understand if this is a model error or a hardware error, analysis has to be performed packet by packet. In doing so, to check for hardware error, the transmission was checked for the time difference between consecutive captured frames. This is where the problem actually lay. For example, in one particular transmission, there were actually eight frames where the difference between it and the previous frame was well above 16.666 milliseconds, i.e., below 30 Hz. These eight locations had the following time difference between themselves and the previous frame: 697.68, 1079.739, 33.224, 249.171, 33.223, 1046.517, 531.565 and 647.844 in milliseconds. As it can be observed, some of these values correspond to whole seconds between frame captures, which has the effect of distorting the received data by shifting the data bits and losing whole chunks of data. This is why the received text is actually less than the actual text. The way to correlate these time difference errors back to the location in the message is by correlating the frame number of where the time difference error occurred relative to the chunk that it occurred in. Basically, the following procedure is performed: find the first time difference error-index and then multiply the index of the error by four for the number of LEDs, then divide by 72 for the number bits in each packet and then multiple by 6, which represents the number of bytes in each packet. The returning value should be equal, or close, to the number of characters that are transmitted correctly before the sequence of garbage text begins. In the current case, the previous calculation yields 520 characters correctly transmitted considering the index of the first error is 1559th frame. This is about the same as in the demodulated text. Once the frame capture error occurs, the rest of the transmission is out of sync, which is why the demodulation returns garbage characters. What this proves is that the major issue with this system is the hardware issue, specifically the camera not capturing at a regular interval.
To confirm that the issue is truly a hardware issue and not a model issue, the transmission of the 1000 word file was broken into chunks of 100 characters, and then one video at a time was transmitted at about 100 characters each. This produced 50 videos each transmitting about 100 characters. Presented here is just the result of the videos captured at a distance of 1 m. When the data to transfer is small, the average PER reduced to 1% and lower. However, there were a few cases where the PER was higher (5% at maximum) in comparison to the rest of the transmission. To understand if these are a model issue or a hardware issue, the consecutive frame time difference should be checked. In doing, it is discovered that there are camera issues present for some of the chunks and not all. For instance, in the case of Trial 1, chunks 1 and 12 had camera issues near the end, which is why both had one packet error each. However, the other chunks did not have camera issues, which means that these were probably caused by model misclassifying.
The same trend in both the 1000 word single transmission and 1000 word multi-transmission can be observed in the rest of the distances from 2 m to 7 m. However, as distance increases, the model misclassifications increase. However, by comparing the one large transmission versus the 50 multi transmissions, it is clear that the model error is secondary to the hardware issue.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}