
QoE Modeling on Split Features with Distributed Deep Learning



Abstract
:1. Introduction
1.1. QoE Machine Learning Challenges
- Model transfer might be inadequate: QoE data in the source domain (the domain that trains and sends out the pre-trained model), where the model is developed, and QoE data in the target domain (the domain that receives and uses the pre-trained model received from the source domain), where the model is to be deployed for real operations, need to have a similar data distribution as they need to represent the same underlying conditions and features. The authors of [6] show that when a model is trained with features that are only specific to the source domain, negative transfer (reducing the model performance) can occur, since the specific features at the source domain do not represent the target domain well enough. In addition, model transfer might leak information from the source domain to the target domain since there is no intermediate aggregation process before the target domain receives the model.
- Privacy-sensitive dataset: Specific local features in the source domain are potentially sensitive; detailed user profiles, among others, cannot be shared easily [7] without explicit consent. In addition, it may happen that one research group is interested in a QoE model particularly for video contents with high spatio-temporal complexity, e.g., within the scope of developing action games, while another research group is interested in assessing QoE for a different type of video content. At the same time, there might still be a common subset of non-sensitive indicative metrics, i.e., ML features, representing the underlying QoE factors in multiple domains or decentralized entities.
- Distributed user observations with different features: Model training can be inherently split into multiple partitions in cases when datasets are collected at multiple physically separated computation nodes. A typical example is when operators collect network datasets, while applications collect User Equipment (UE)-specific datasets on the application layers and user interfaces of applications. Another example is that some QoE research entity collects a user dataset with observations that are different from those obtained by other research entities. For example, operators that serve different customer segments, with different preferences and expectations might have different user profiles. These two datasets can be trained on separate models, which are trained only on local features, but collaboratively to improve local model accuracies further with minimally exchanged information in between.
1.2. Distributed Learning in QoE
- Low-level NumPy based framework for split-learning: Our vFL implementation is based on Split Neural Network (SplitNN) [12], but unlike PySyft [16], it does not operate on existing frameworks with high level abstraction such as TensorFlow or PyTorch. Hence, the most important difference in our framework is that we have full control including the communication protocol and the algorithms. This enables low level algorithmic development to optimize for computation, privacy, network footprint, training time, and energy-efficiency while sustaining good and robust model development in diverse scenarios especially in heterogeneous data settings. Our framework is not limited to a simulation on a single node and can easily be deployed on a Kubernetes cluster.
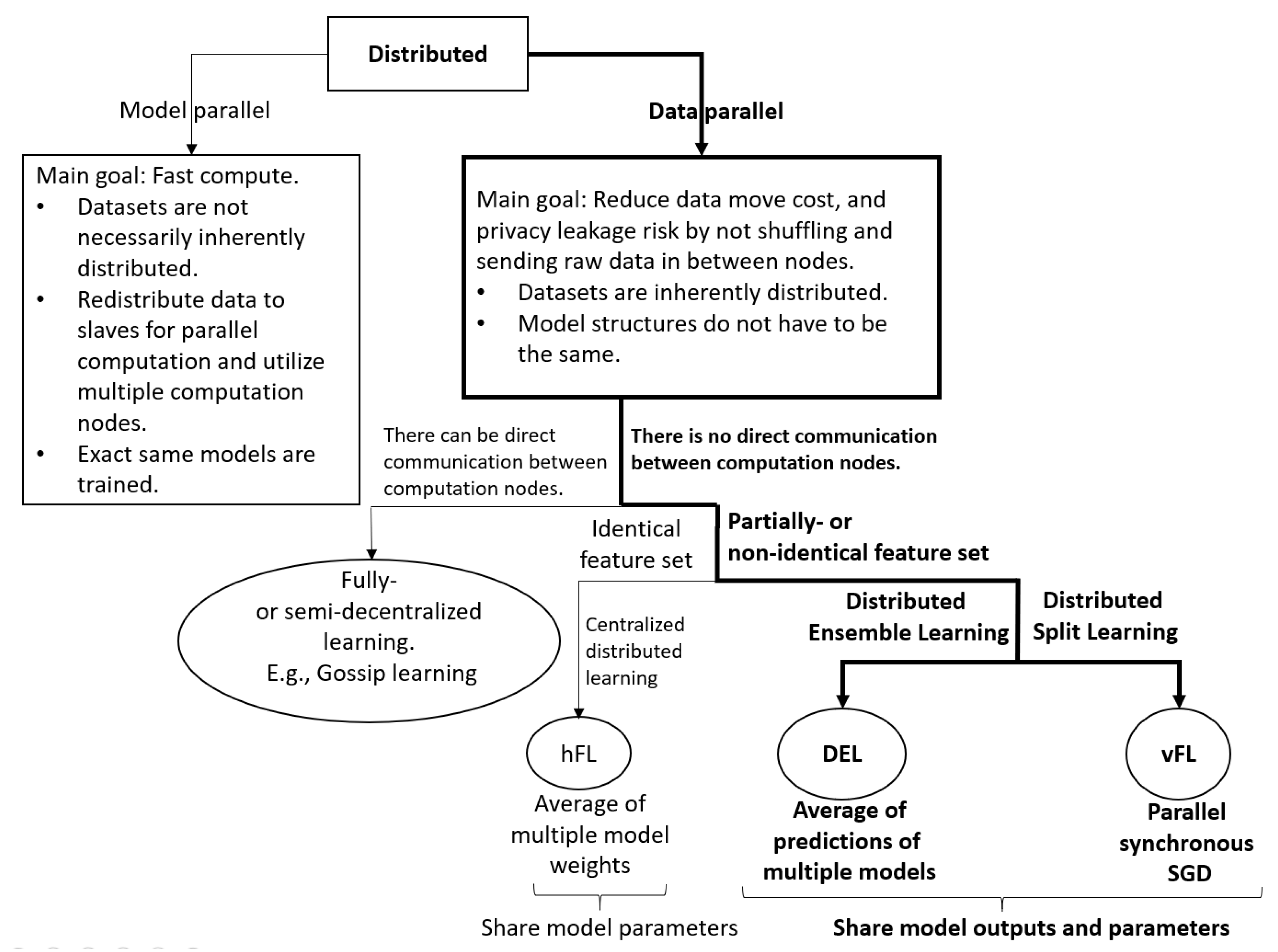
- A comparison of different techniques for training datasets with different feature spaces: In this article, we present Distributed Ensemble Learning (DEL), and Vertical Federated Learning (vFL) to address the aforementioned challenge. These techniques are appealing for different domains including the telecommunication segment where datasets are typically decentralized. The DEL approach is machine learning model-agnostic, while the vFL approach is based on neural networks. Furthermore, we recommend a few techniques to reduce network footprint, training time, and energy consumption of the model training process.
- Jointly trainable QoE modeling with split features: While we are demonstrating our vFL solution in this article, to the best of our knowledge, this work is the first of its kind, that demonstrates a QoE model training in a distributed deep learning setting with split features.
2. Related Work
- Horizontal Federated Learning (hFL): In horizontal federated learning [10], models are trained collaboratively by combining different models which have been trained locally on the same feature set, to a single model at a master node. When such a model is shared back to the individuals that contributed to the training process, immediate benefits can be detected for those that have similar data distribution representing similar underlying conditions and context. In [18], feature selection is studied within Neural Network-based Federated Learning, where model parameters are divided into private and federated parameters. Only the federated parameters are shared and aggregated during federated learning. It is shown that this model customization approach significantly improves the model performance while not sharing raw data in between.
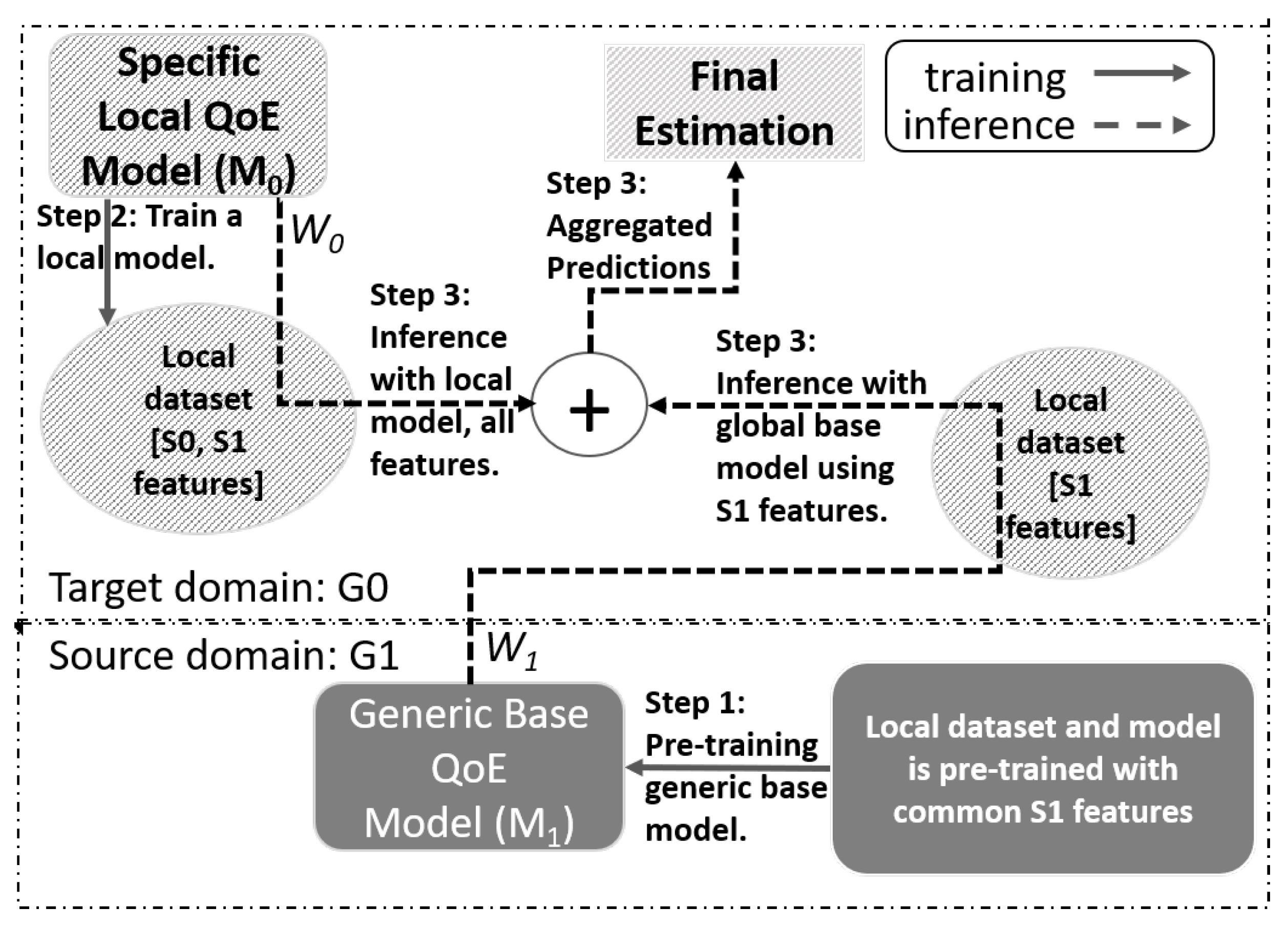
- Distributed Ensemble Learning (DEL): In [19], the authors used transfer learning to estimate the labels of an unlabeled dataset where the labels represent user emotions. In [11], a Round Robin-based learning technique (inspired by Baidu-AllReduce [20]) is presented within the scope of web QoE. This approach, similar to hFL, requires the distributed domains to have at least a subset of the features (if not all) to be the same.
- Vertical Federated Learning (vFL): Vertical federated learning enables collaborating nodes to jointly train a machine learning model with fully orthogonal feature sets. Most relevant vFL implementations in the literature are: PaddleFL [21], PySyft [16], FATE [22], and FedML [23]. Although all of the above solutions indicate great progress, PaddleFL, FATE, and PySyft implementations were inadequate for our needs due to their high level abstraction. The closest implementation among them all is FedML; however, we have not yet performed a complete comparison with that work and ours as it was very recently published.
- Privacy-preserving communication: It is shown in the literature [24] that sending model weights that emerged from training, instead of sending the actual raw dataset, may still leak sensitive information about the ground truth used to train the model. Therefore, there exist techniques to further protect privacy on the shared weights of the models. Techniques such as differential privacy [25] and secure aggregation [26] can be utilized for sharing private information for the purposes of training ML models without revealing the original dataset and also concealing the identity of the dataset’s origin. In DEL, only the generic model (architecture and internal representation) is shared, which is already known and as such does not need to be protected. In the scope of this study, we consider these techniques as complementary since they can be applied to hFL or vFL without affecting the inner workings of each approach.
- QoE modeling with ML: ML techniques have been studied previously in QoE modeling [29]. Furthermore, a mix of conventional and a ML based QoE modeling has been implemented and demonstrated previously in [30]. All existing QoE models are trained via Fully Centralized manner. Our proposed vFL in this article, can be considered as a good candidate solution to ensemble local models at the workers without predefined model weight thresholds, and without necessitating the NN models to be of the same architecture and feature space.
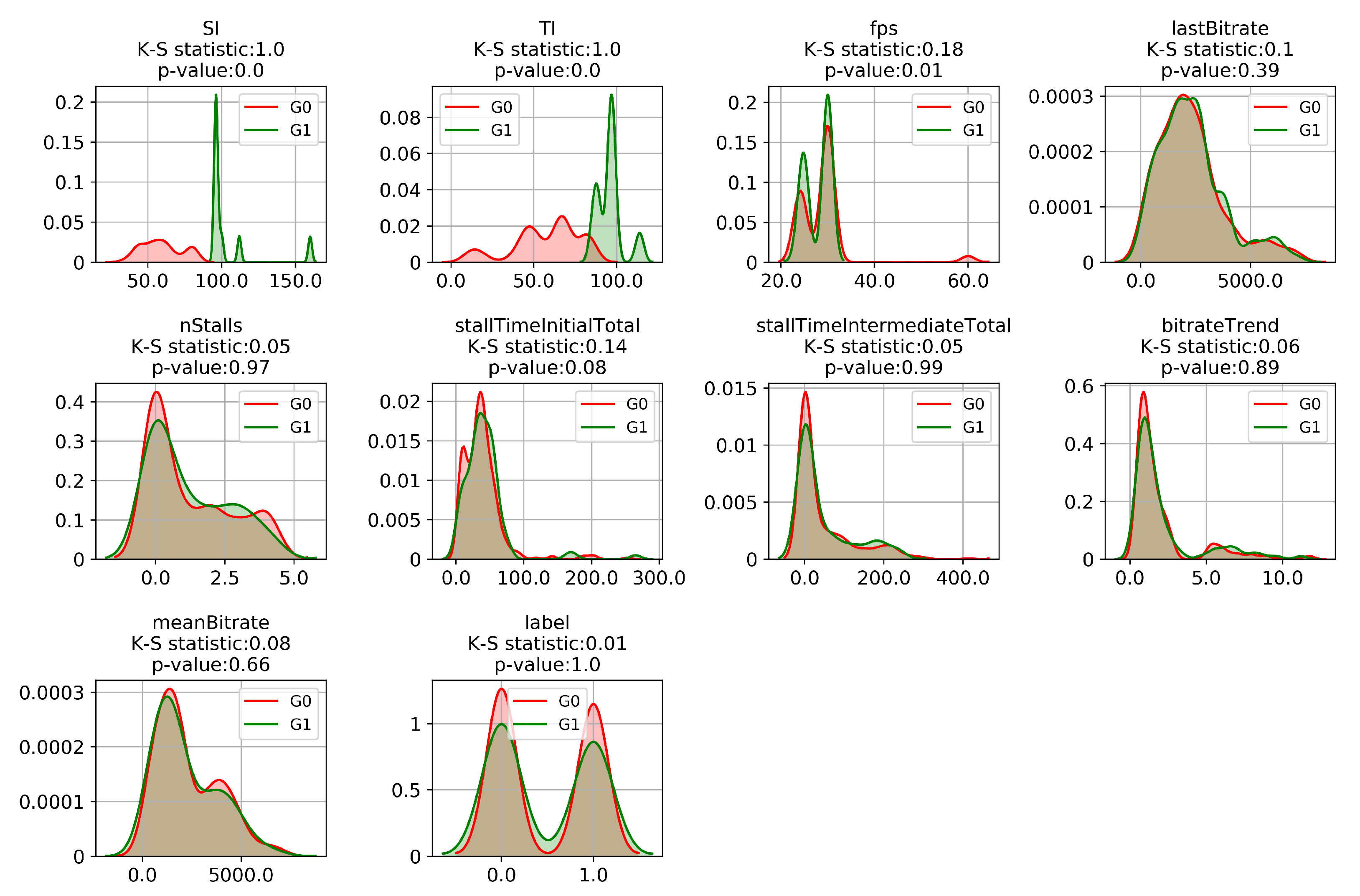
3. Dataset and Feature Extraction
4. Effect of Video Content on QoE
4.1. Training with or without Content Features
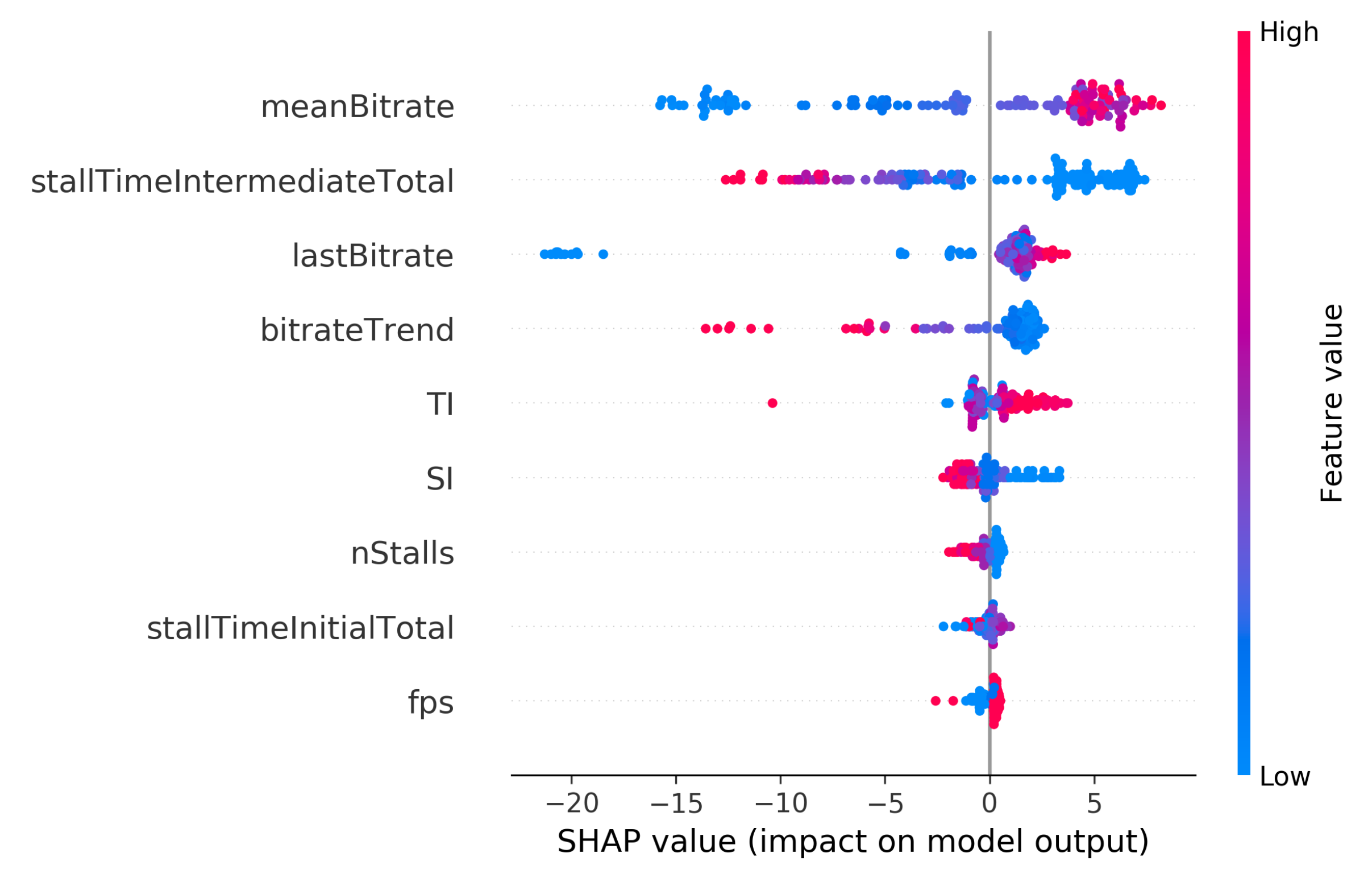
4.2. SHAP Sensitivity Analysis
5. Distributed Learning Approaches on Split Feature Scenarios
5.1. Neural Network
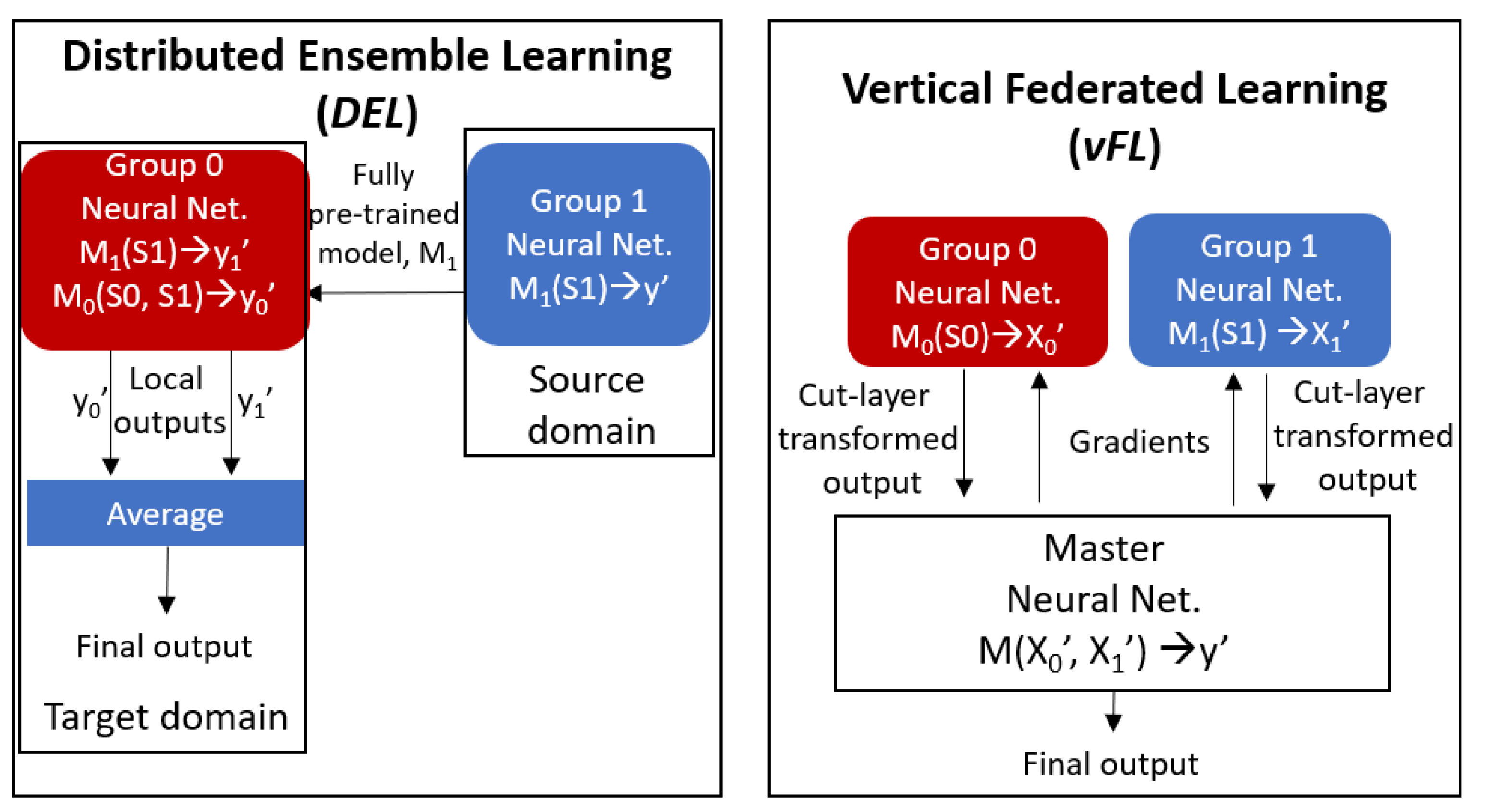
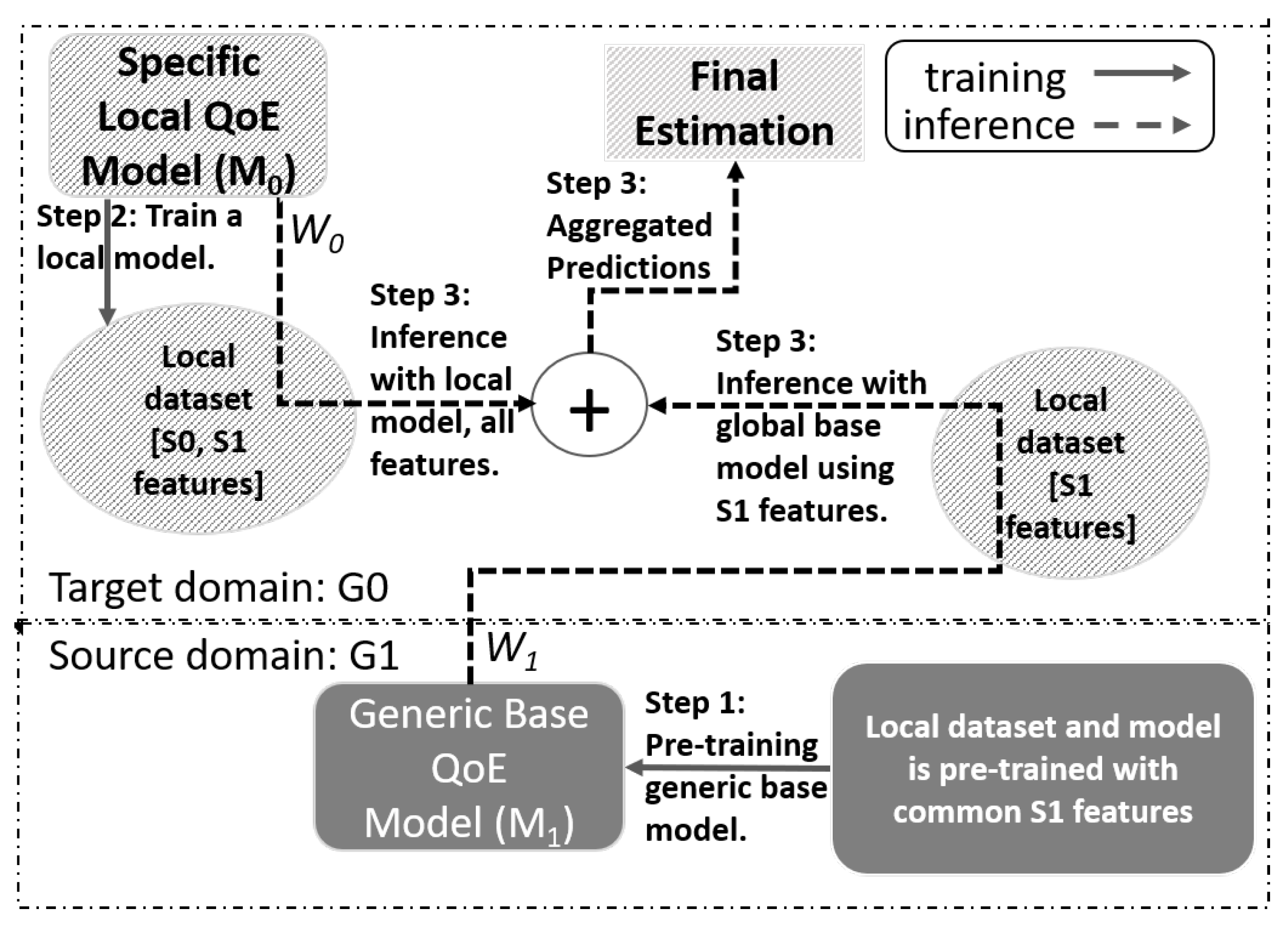
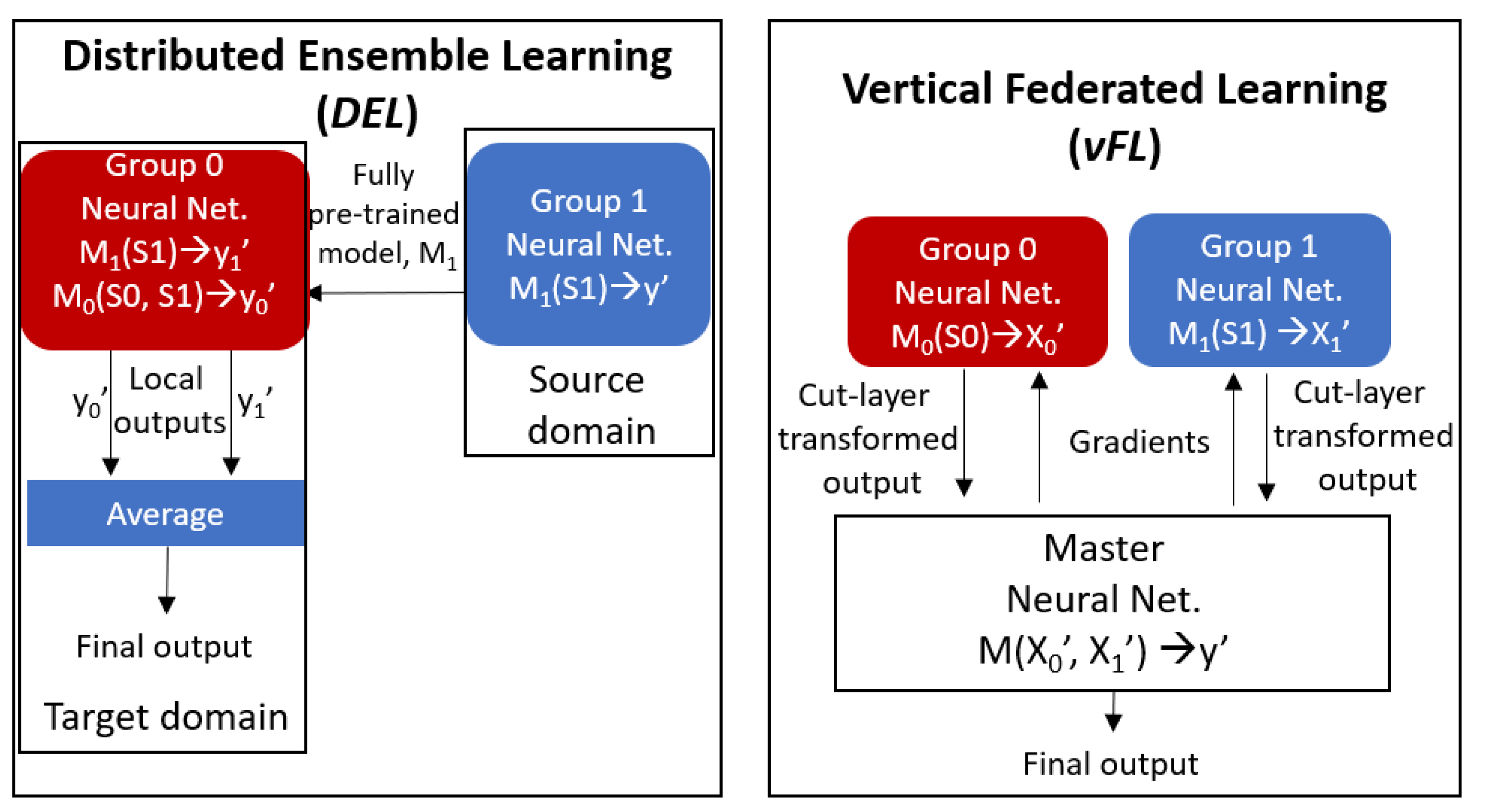
5.2. Distributed Ensemble Learning (DEL)
5.3. Vertical Federated Learning (vFL)
6. Results
6.1. Distributed Ensemble Learning (DEL)
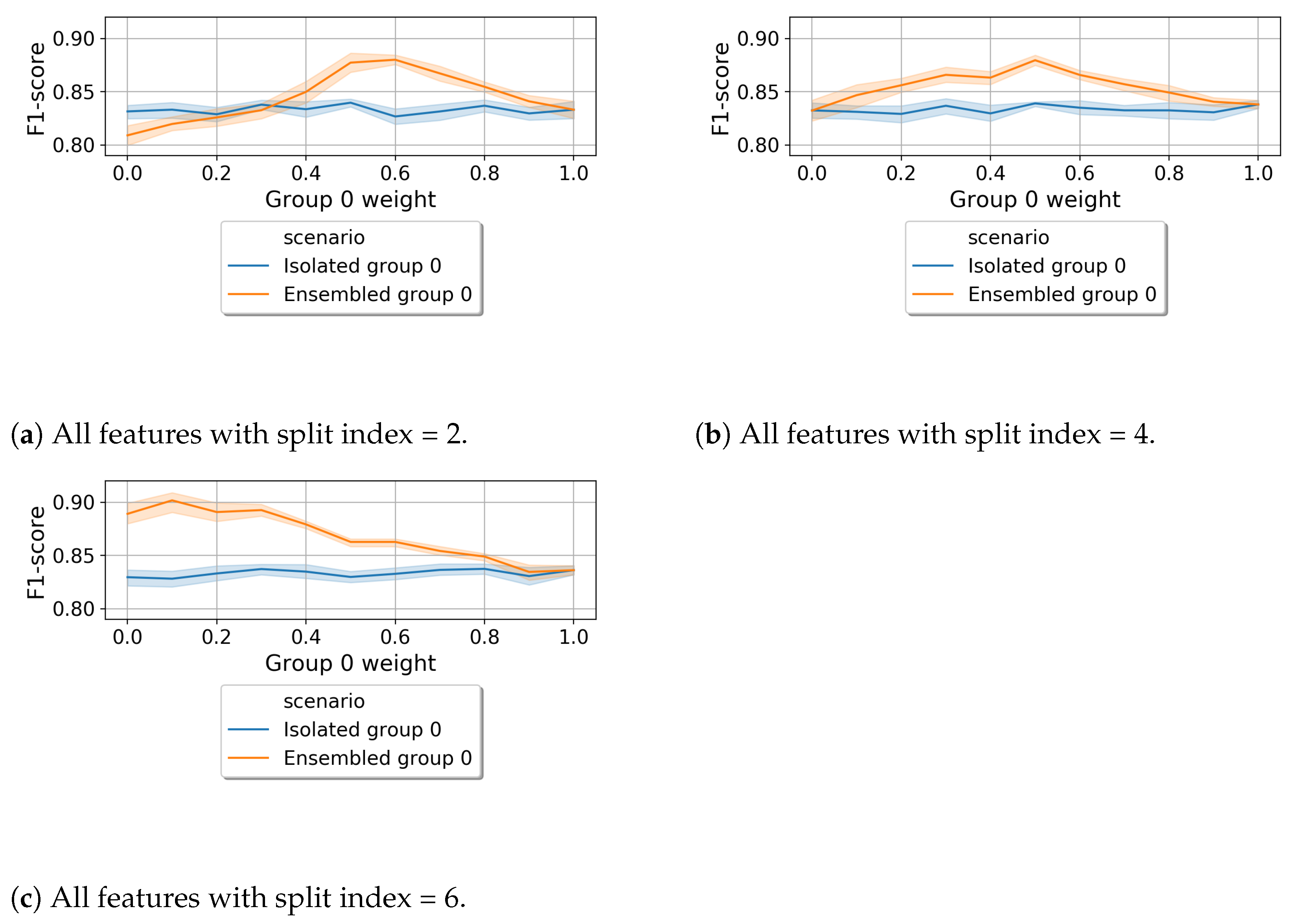
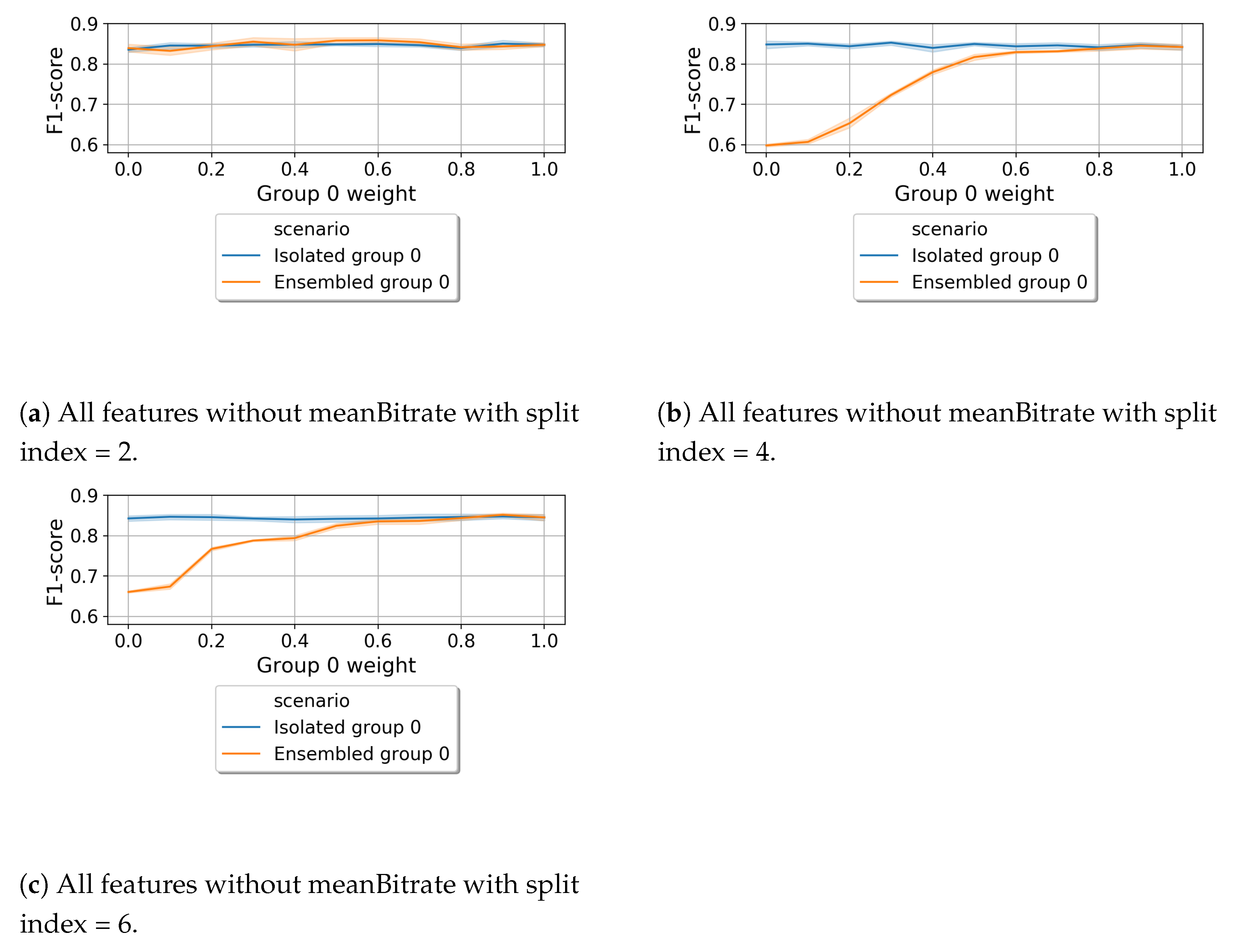
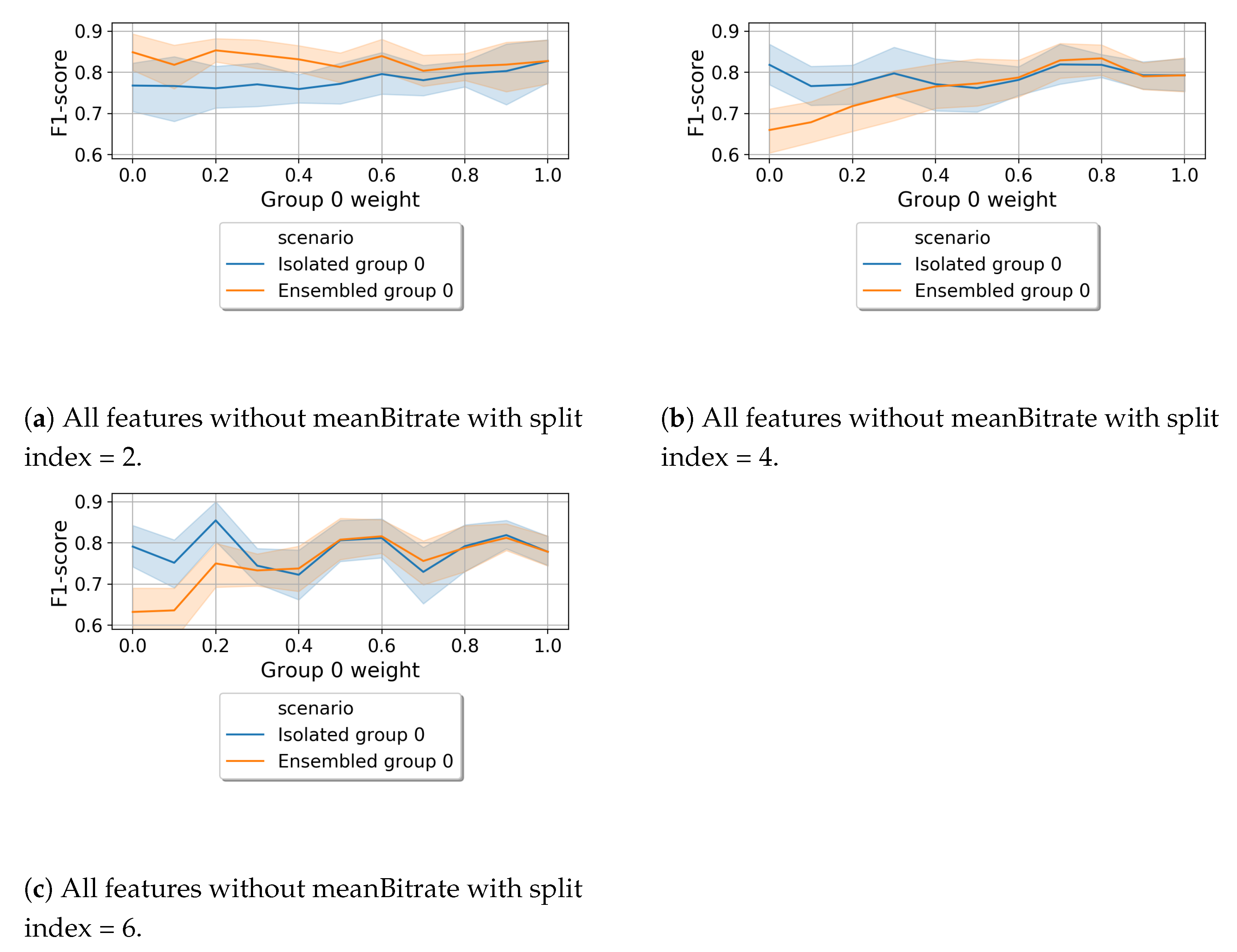
6.1.1. Content-Based Split
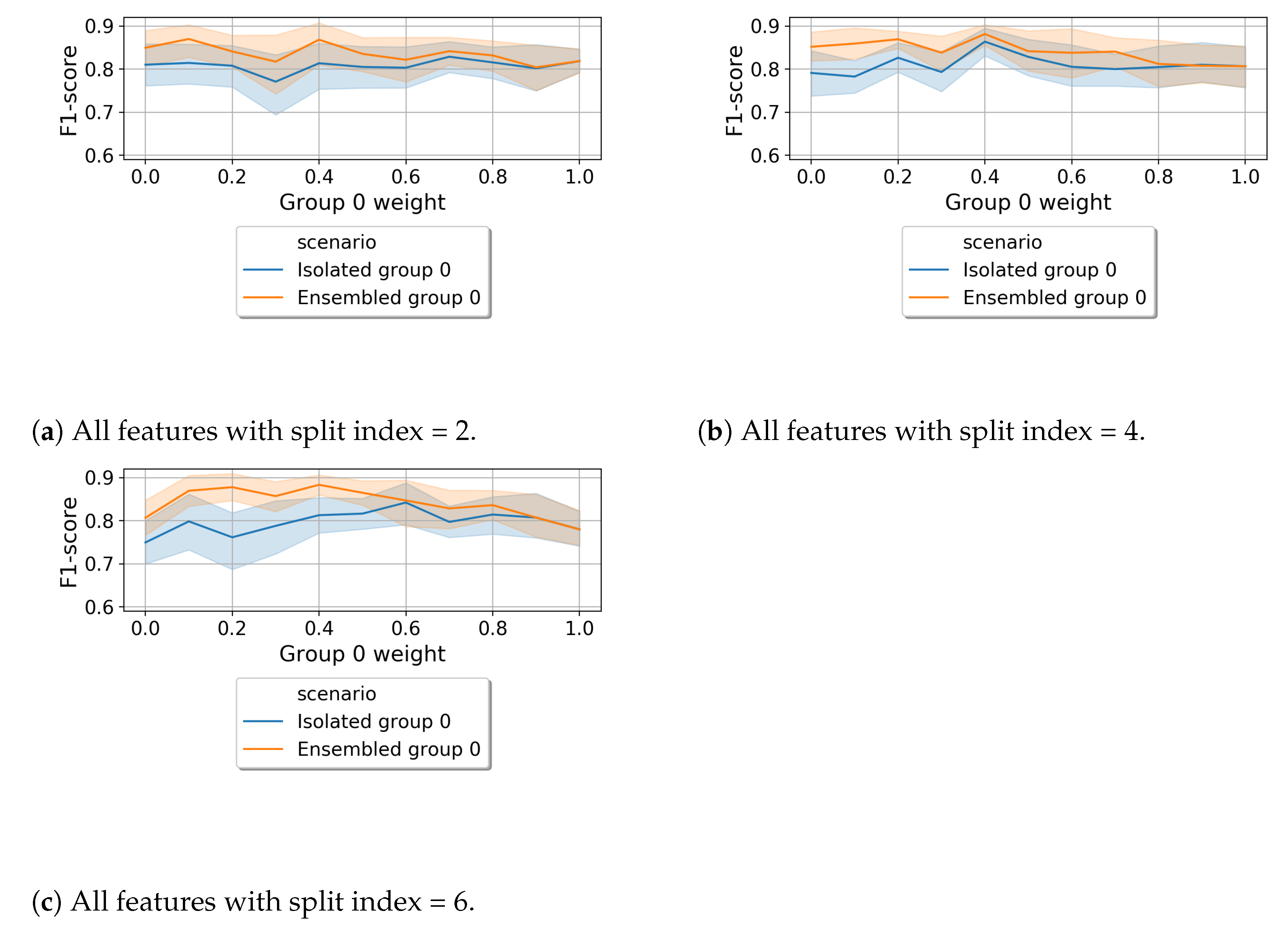
6.1.2. Random Split
6.1.3. Isolated G0 vs. DEL
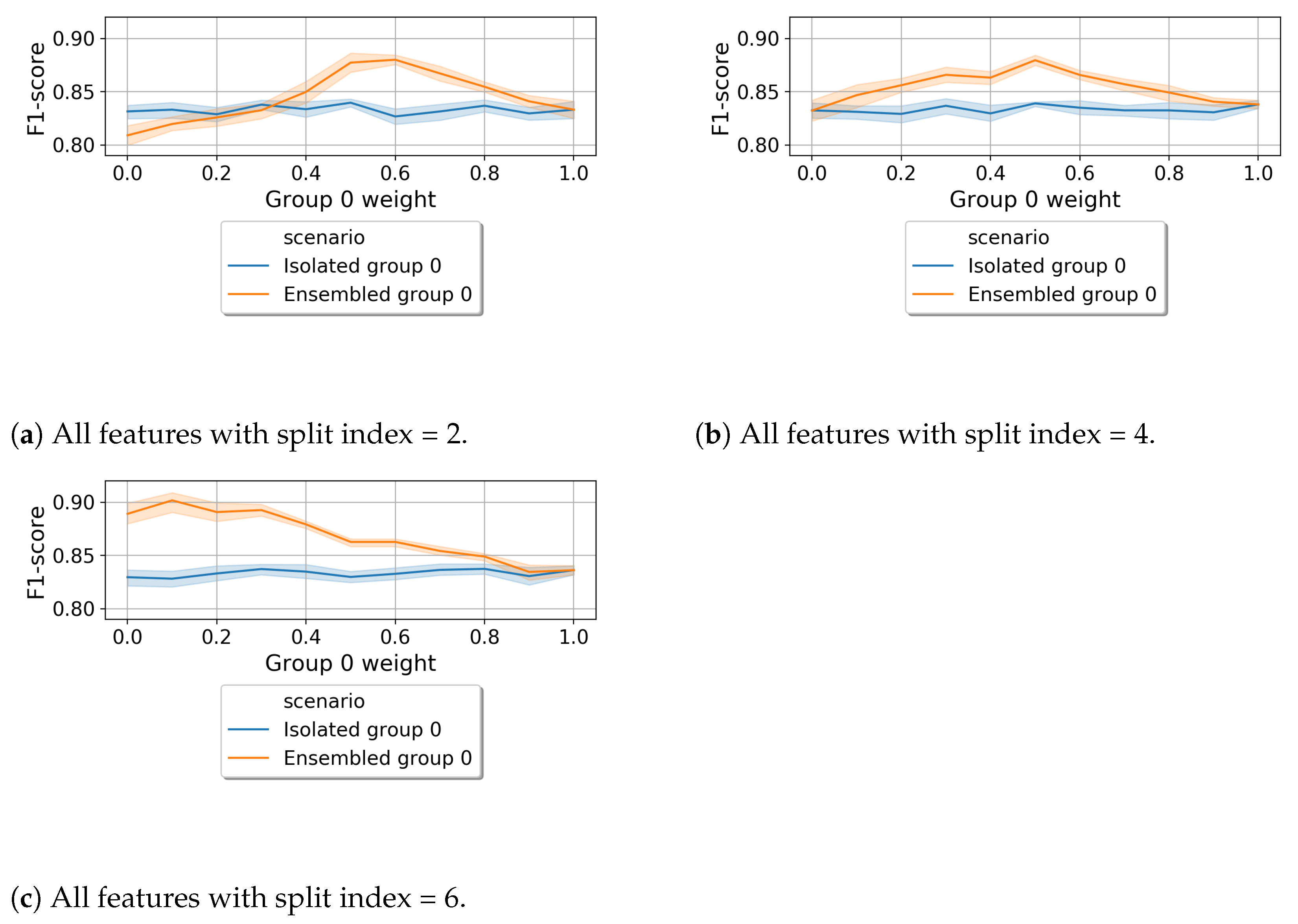
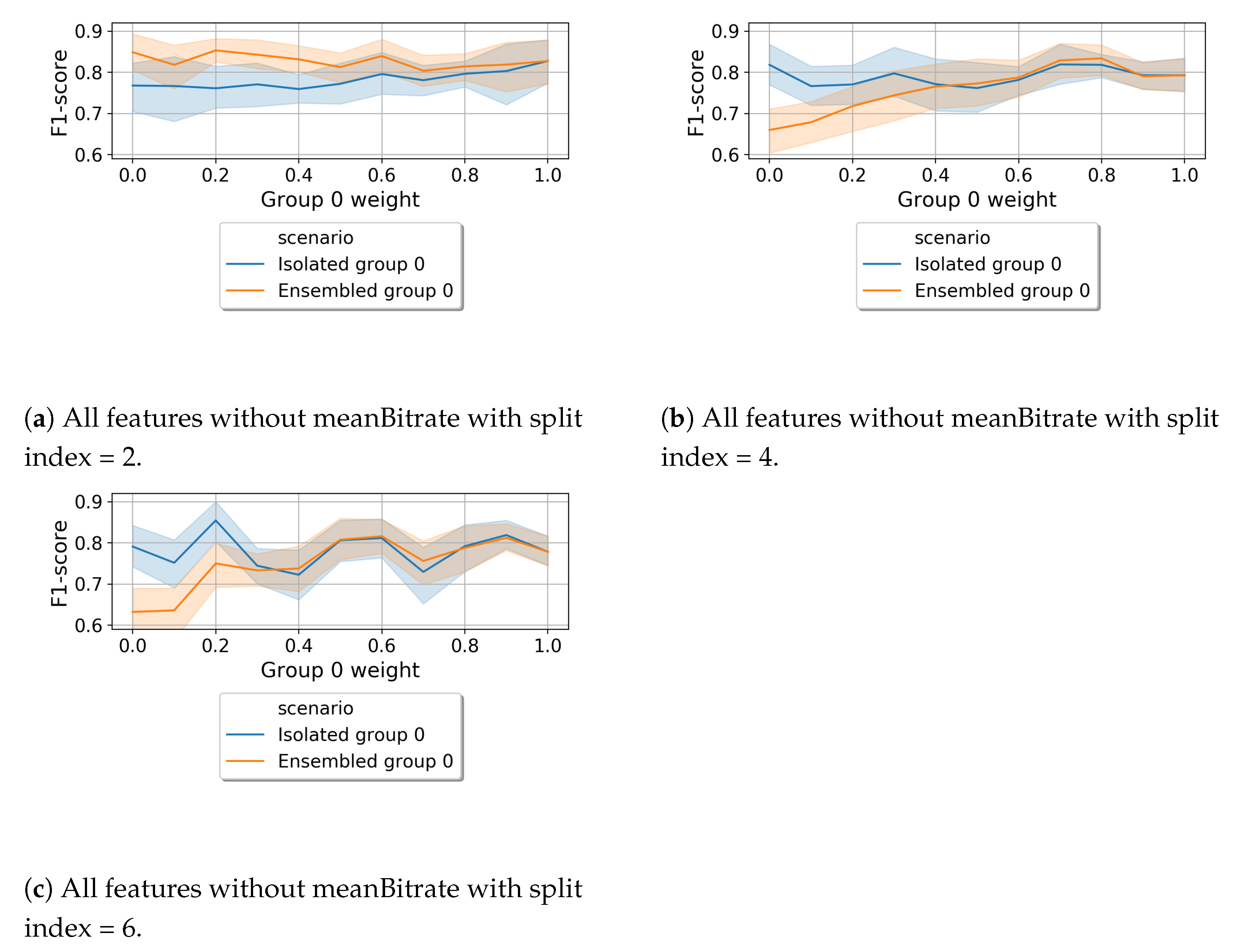
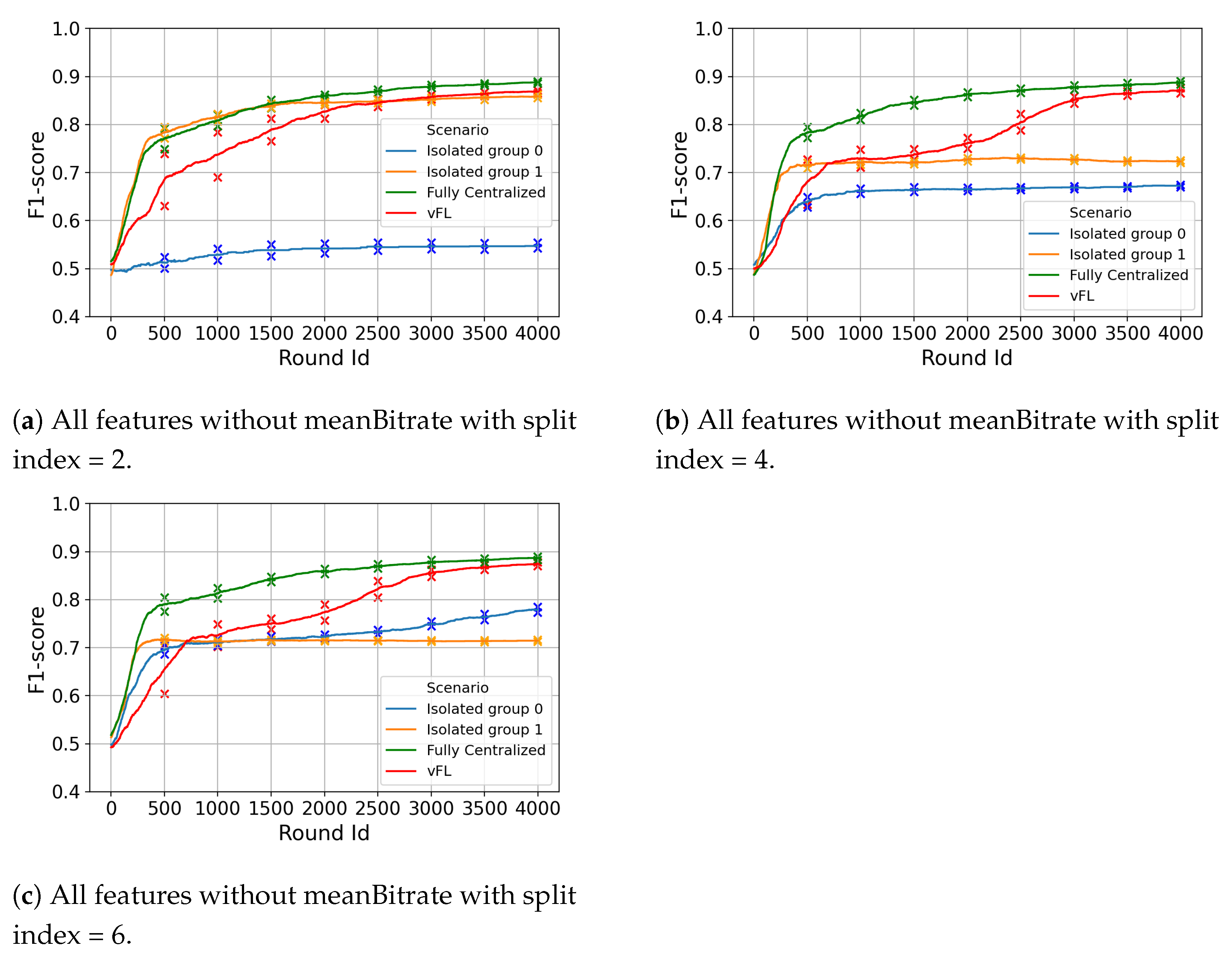
6.2. Vertical Federated Learning (VFL)
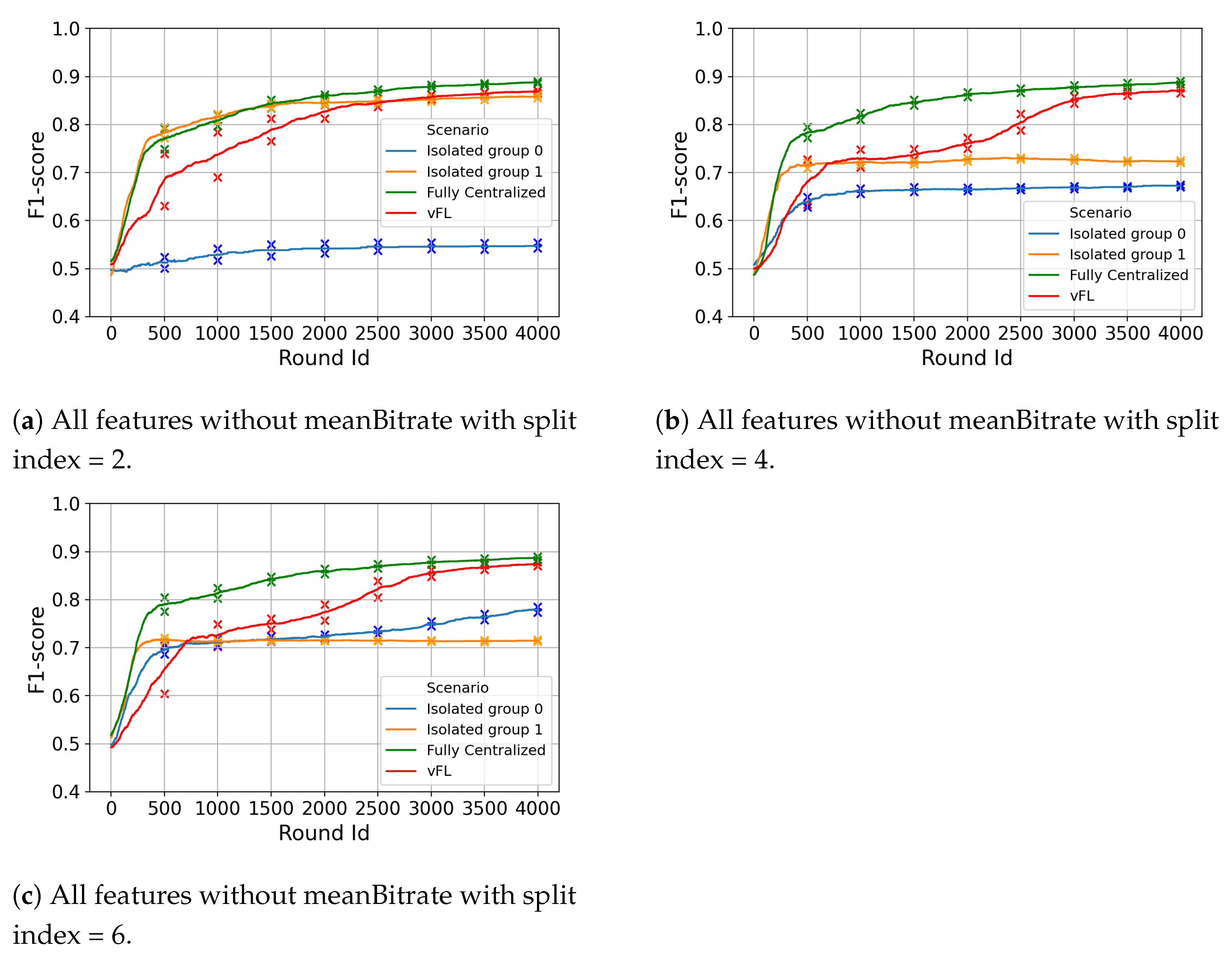
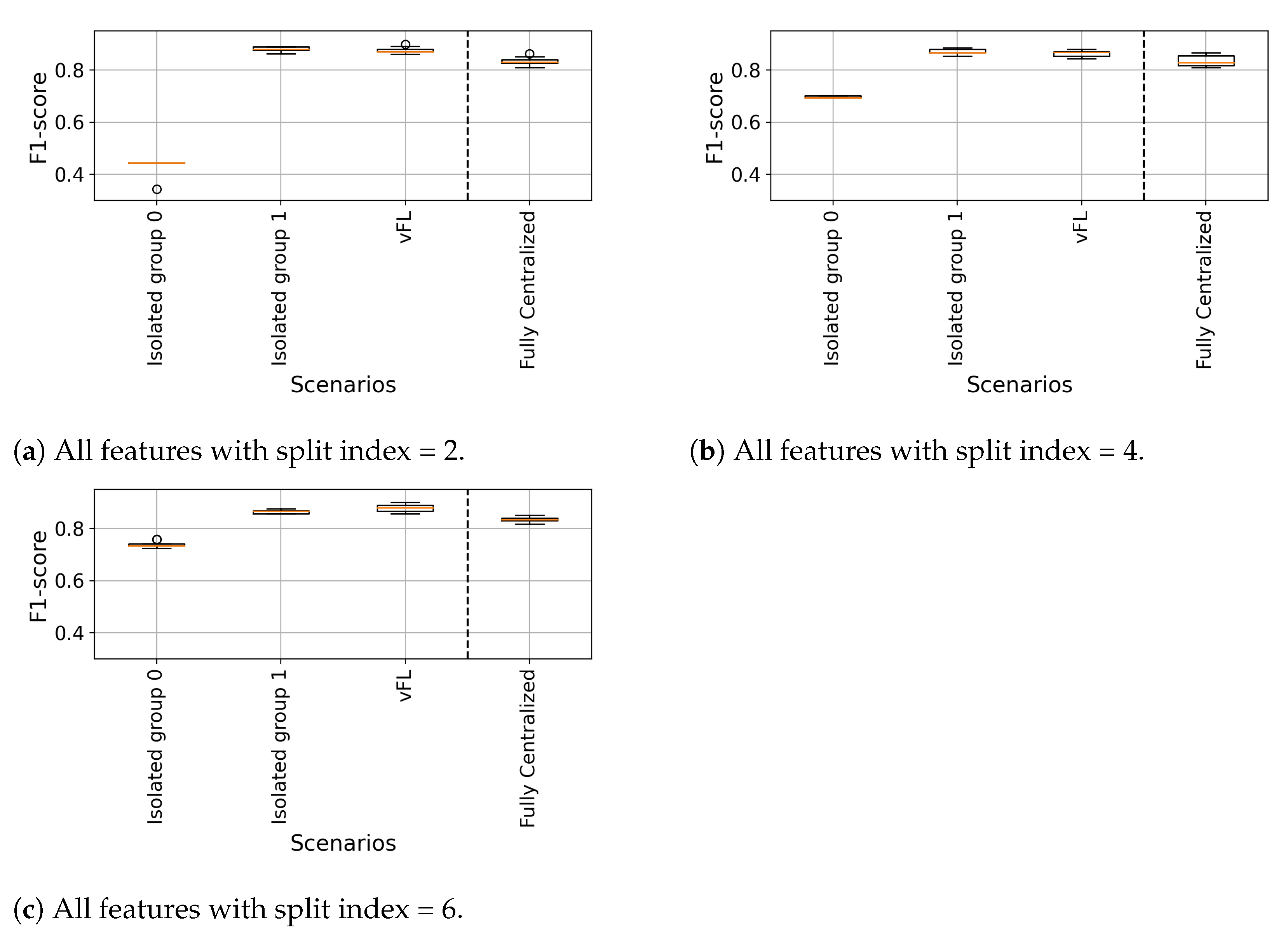
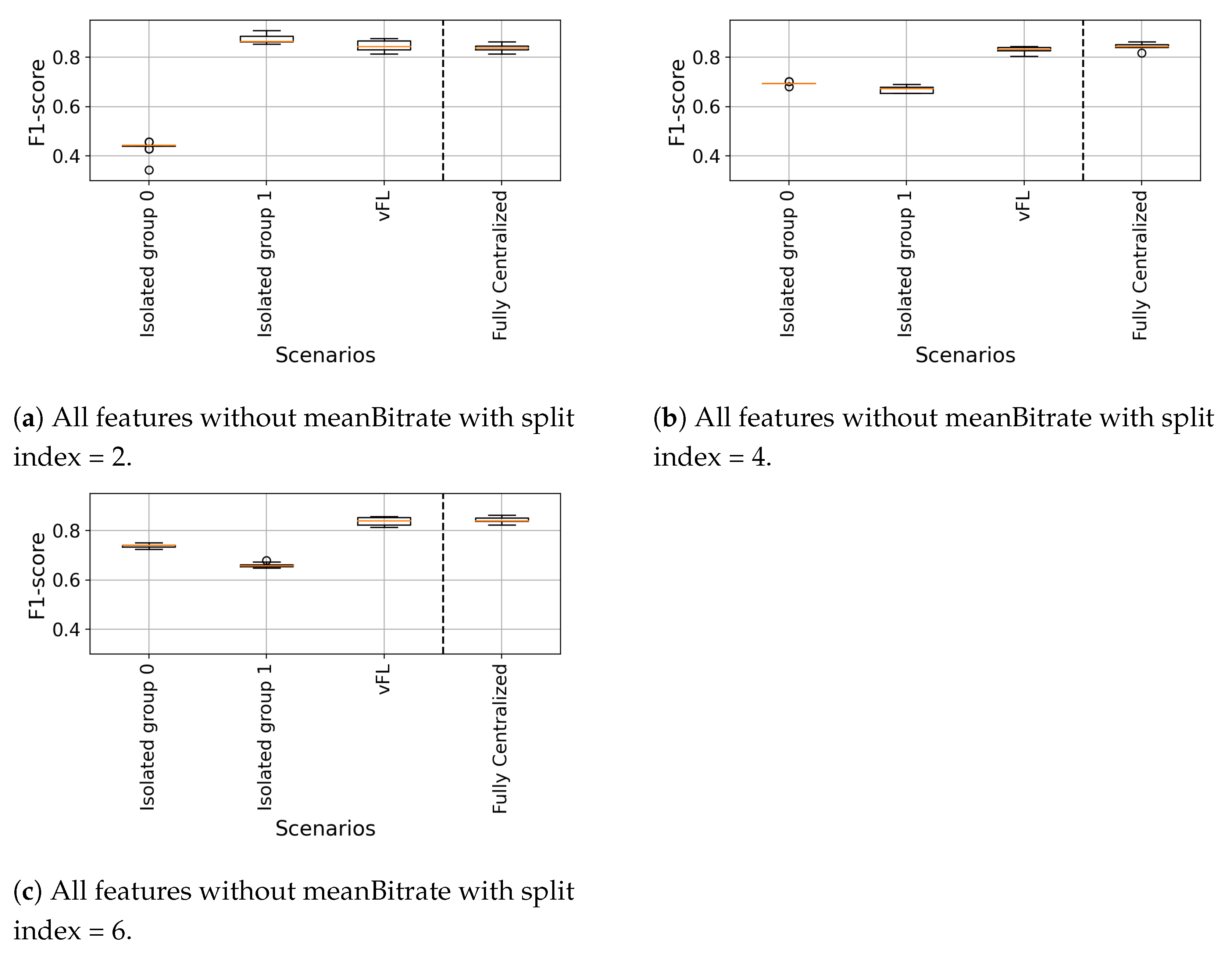
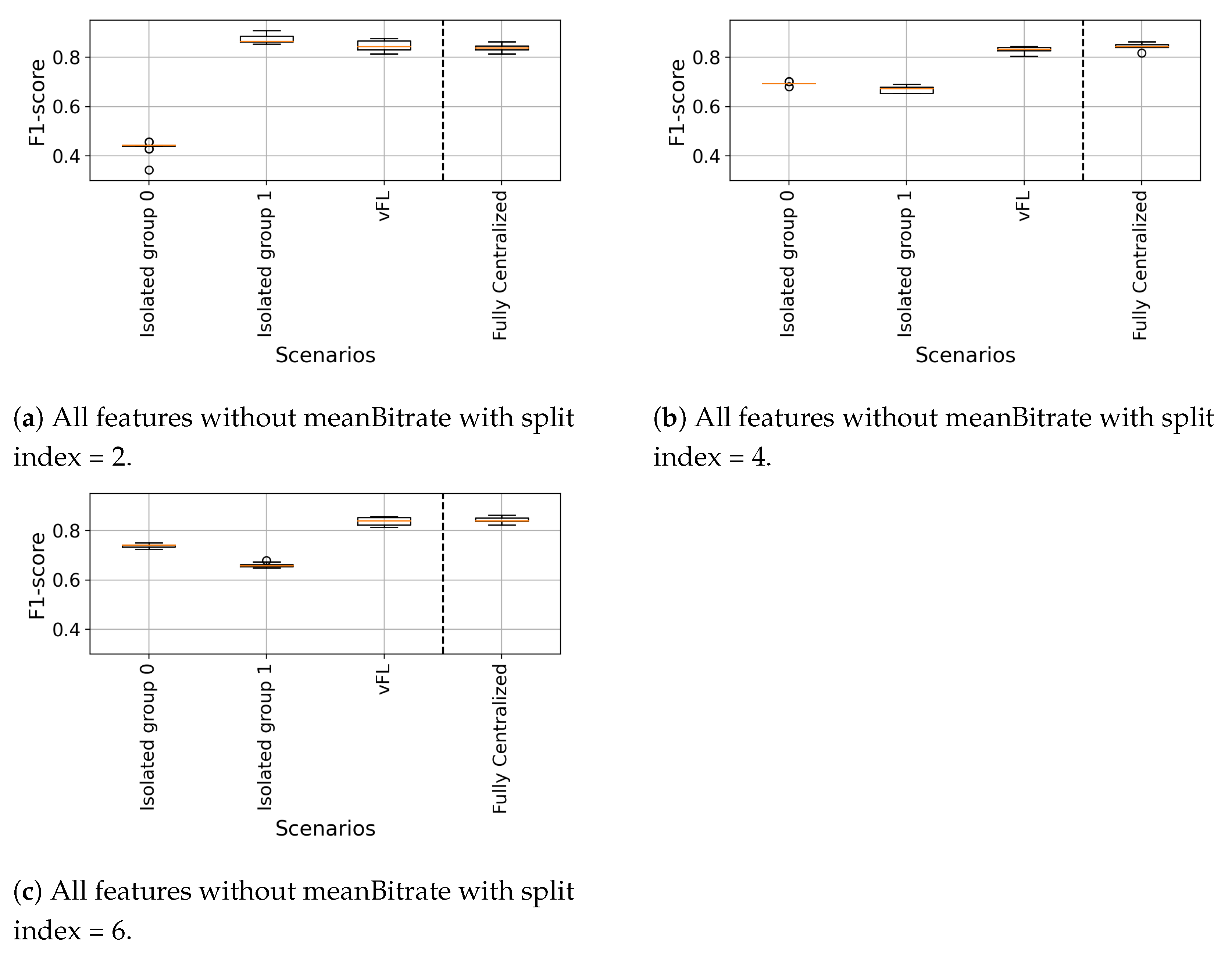
6.2.1. Isolated vs. vFL
6.2.2. Fully Centralized vs. vFL
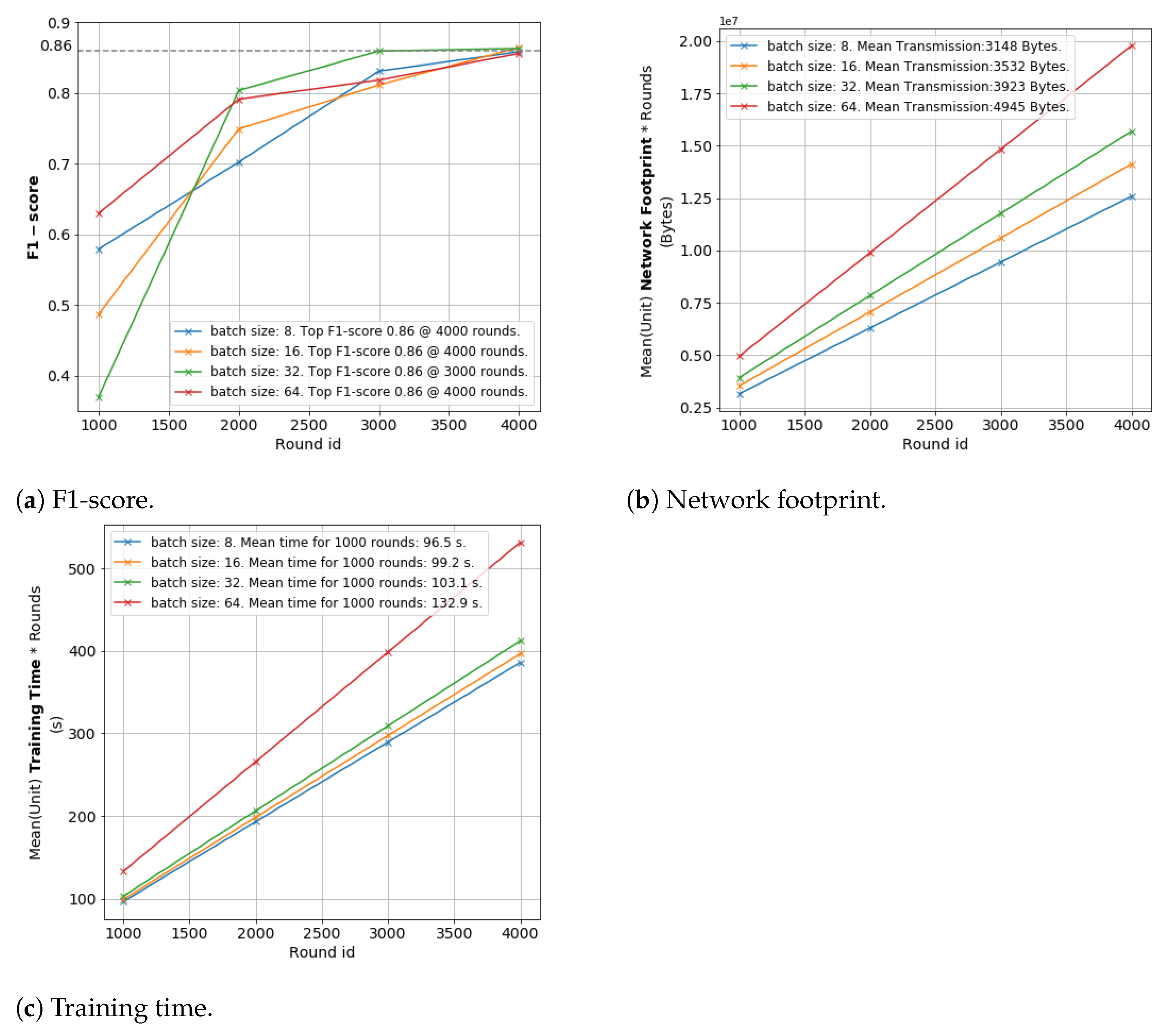
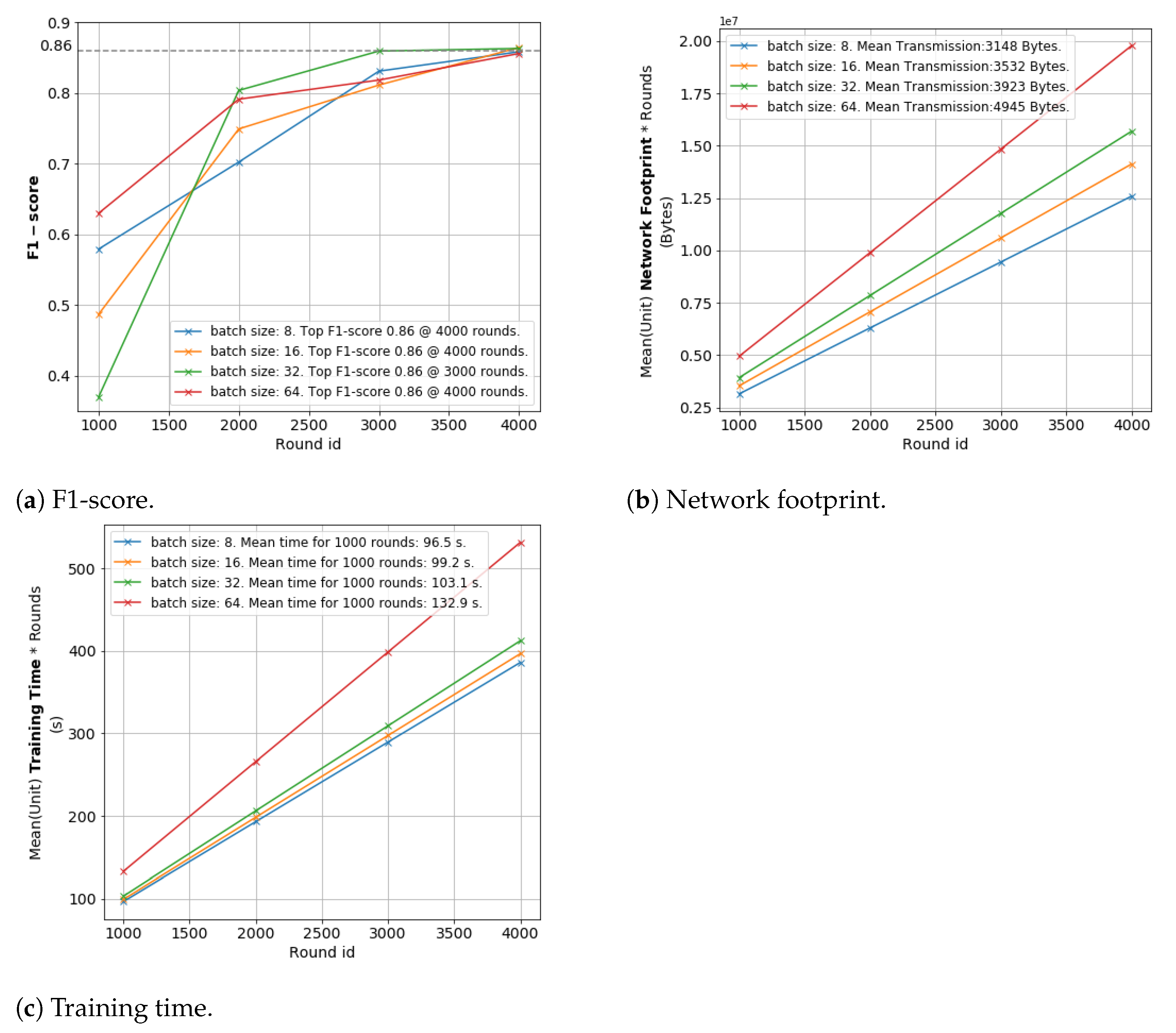
6.3. Optimizing vFL Training: Data Volume and Training Time Perspectives
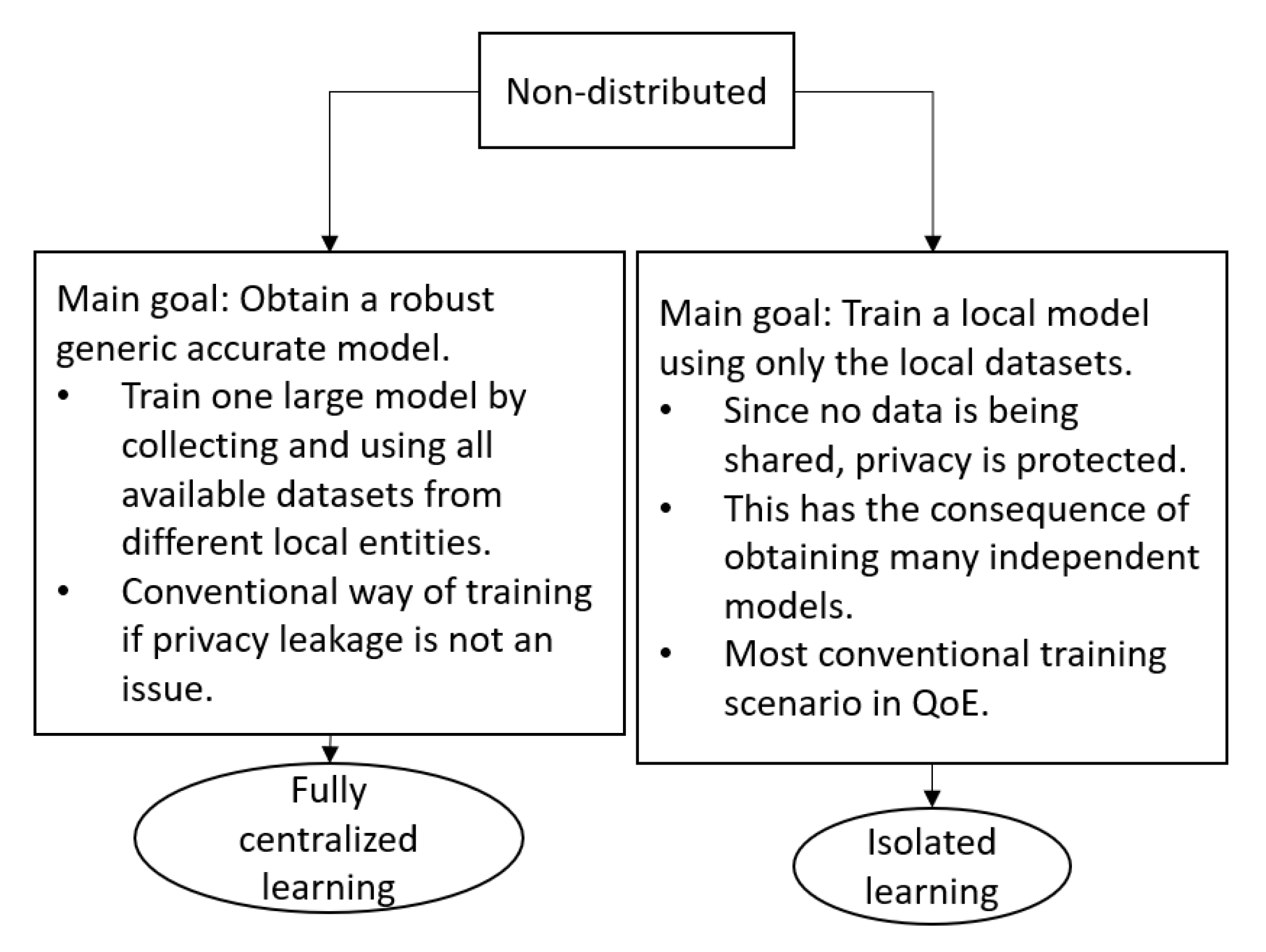
- Data share: Only in Fully Centralized training methodology, all the datasets that are collected in different other entities are being transferred to a centralized computation node to train a ML model.
- Model share: Since the data is not shared in DEL and vFL, the models have to be shared. In DEL, all layers of the NN model at the source domain are transferred to the target domain, while in vFL, only the computed output (so-called smashed wisdom) at the intermediate cut-layers are transferred to the master node. In return the worker nodes receive the subparts of gradients computed at the cut-layer of the master node.
- Sample dependency: An Isolated model can be trained with data instances of choice that are available to the local computation node, hence there is no sample dependency on data instances available at other nodes. In Fully Centralized scenario, the data instances are collected from different nodes hence the overall model is dependent on the data instances obtained from the workers. Although in DEL, data instances at the source domain are used in training, as the pre-trained source model is transferred to the master target domain, there is no dependency on the data instances at the source node during inference phase. In contrast in vFL, since the data instances need to be synchronized in time or in space, the output of the final model highly depends on the input data instance from all workers.
- Feature dependency: As the local computation nodes can train on any available features at the local nodes, there is no feature dependency in Isolated learning. In a Fully Centralized setting, all local nodes need to provide exactly the same feature space to a central computation node, hence we consider that there is a feature dependency. In DEL, there is a requirement that at least some subset of the features need to be common both on other source and target domain so that a knowledge transfer from source domain to target domain on generic features can be transferred. In vFL, all features located at the distributed nodes can be different, hence there is no feature dependency.
- Jointly trainable: Fully Centralized setting allows collaborative training with samples received from different worker nodes. In DEL, joint training is not possible as the knowledge transfer is unidirectional and also it is performed after pre-training phase. The most outstanding advantage of vFL is its ability to allow joint training and inference, hence all workers can potentially benefit and perform continuous training.
- Aggregation: In DEL, the aggregation of outputs are performed by means of weighted averaging, while in vFL the intermediate output of the workers and the computed gradients are aggregated via concatenation and splitting procedure. It is again important to emphasize that in DEL, aggregation occurs only in inference phase, while in vFL, it is performed both in training and inference phases and in every round of training.
- Model agnostic: As long as the full dataset is available at a computation node such as in the cases of Isolated, Fully Centralized, and DEL, there is no model dependency, hence any suitable ML model can be selected and trained. For instance, in DEL, the model that is transferred from the source domain can be of any algorithm, since it is not the model that is being aggregated but instead the output of the models. The vFL is based on Neural Network algorithm where the training occurs with a Stochastic Gradient Descent (SGD), and it is an important requirement for workers to train on the same algorithm (although not necessarily the exactly the same NN model structure) and update the local neural weights.
- Worker contribution adjustment: In Isolated setting there is only one worker, which is the local individual node. In Fully Centralized setting, the data instances from all workers are fed into the ML model in batches, hence the ML model adjusts its weights depending on all data instances. Therefore the contributions from every worker get mixed. In DEL, there is a manual weight adjustment process during the inference on the validation set depending on the magnitude of contribution of source domain model on the final output at the target domain. vFL adjusts the weights during the training process over the rounds, hence the adjustment of contribution of workers is seamless and automatic.
- Network Footprint at the master and worker: The network footprint is given in the form of mathematical formulation for both worker (source in DEL and master (target in DEL) nodes. The expected network footprint is presented for all scenarios. W is the worker; r is the round; s is the data instance; f is the feature; l is the NN layer; and n are the neurons at layer, l; c is the neuron at the NN cut-layer of worker, w. As there is no data or model shared in between training entities in Isolated learning, the network footprint is 0. In Fully Centralized scenario, all data instances and features from all workers have to be transferred to the central computation node. In DEL, the data is not shared; however, the pre-trained model, which consists of multiple NN layers with potentially many neurons at every layer, at the source domain are transferred to the master node for only once. In vFL, only the output of the cut-layer for all data instances and rounds is shared. In return, the worker nodes receive the gradients calculated for the data instances, hence the traffic is bidirectional so that the total sum is multiplied by 2.
- Accuracy: In Isolated setting, the dataset size is small, and the model training is limited to local observations which might prevent the model to achieve accuracy values that a Fully Centralized model (trained on with richer and large size dataset) can achieve. We consider Fully Centralized as a model that can reach upper bound accuracy levels, and moreover it is possible to reach on-par accuracy values without sharing datasets using both DEL and vFL.
7. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DEL | Distributed Ensemble Learning |
| ML | Machine Learning |
| MOS | Mean Opinion Score |
| QoE | Quality of Experience |
| vFL | Vertical Federated Learning |
References
- Le Callet, P.; Möller, S.; Perkis, A. Qualinet White Paper on Definitions of Quality of Experience. European Network on Quality of Experience in Multimedia Systems and Services (COST Action IC 1003) 2012; Volume 3. Available online: http://www.qualinet.eu/index.php?option=com_content&view=article&id=45&Itemid=52 (accessed on 18 May 2021).
- Akhtar, Z.; Siddique, K.; Rattani, A.; Lutfi, S.L.; Falk, T.H. Why is multimedia Quality of Experience assessment a challenging problem? IEEE Access 2019, 7, 117897–117915. [Google Scholar] [CrossRef]
- Matinmikko-Blue, M.; Aalto, S.; Asghar, M.I.; Berndt, H.; Chen, Y.; Dixit, S.; Jurva, R.; Karppinen, P.; Kekkonen, M.; Kinnula, M.; et al. White Paper on 6G drivers and the UN SDGs. White Paper. 2020. Available online: https://arxiv.org/abs/2004.14695 (accessed on 21 June 2021).
- Alharbi, H.A.; El-Gorashi, T.E.H.; Elmirghani, J.M.H. Energy efficient virtual machine services placement in cloud-fog architecture. In Proceedings of the 2019 21st International Conference on Transparent Optical Networks (ICTON), Angers, France, 9–13 July 2019. [Google Scholar]
- Sogaard, J.; Forchhammer, S.; Brunnström, K. Quality assessment of adaptive bitrate videos using image metrics and machine learning. In Proceedings of the 2015 7th International Workshop on Quality of Multimedia Experience (QoMEX), Messinia, Greece, 26–29 May 2015. [Google Scholar]
- Wang, Z.; Dai, Z.; Póczos, B.; Carbonell, J. Characterizing and Avoiding Negative Transfer. 2018. Available online: https://arxiv.org/abs/1811.09751 (accessed on 28 June 2021).
- He, D.; Chan, S.; Guizani, M. User privacy and data trustworthiness in mobile crowd sensing. IEEE Wirel. Comm. 2015, 22, 28–34. [Google Scholar] [CrossRef]
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A survey on distributed machine learning. ACM Comput. Surv. 2020, 53, 30–33. [Google Scholar] [CrossRef] [Green Version]
- Savazzi, S.; Nicoli, M.; Rampa, V. Federated learning with cooperating devices: A consensus approach for massive IoT networks. IEEE Internet Things J. 2020, 7, 4641–4654. [Google Scholar] [CrossRef] [Green Version]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Ickin, S.; Vandikas, K.; Fiedler, M. Privacy preserving QoE modeling using collaborative learning. In Proceedings of the 4th QoE-Based Analysis and Management of Data Communication Networks, Los Cabos, Mexico, 21 October 2019. [Google Scholar]
- Vepakomma, P.; Gupta, O.; Swedish, T.; Raskar, R. Split learning for health: Distributed deep learning without sharing raw patient data. arXiv 2018, arXiv:1812.00564. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 12. [Google Scholar] [CrossRef]
- Wolpert, D. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Statist. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Ryffel, T.; Trask, A.; Dahl, M.; Wagner, B.; Mancuso, J.; Rueckert, D.; Passerat-Palmbach, J. A generic framework for privacy preserving deep learning. arXiv 2018, arXiv:1811.04017. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Bui, D.; Malik, K.; Goetz, J.; Liu, H.; Moon, S.; Kumar, A.; Shin, K.G. Federated User Representation Learning. 2019. Available online: https://arxiv.org/abs/1909.12535 (accessed on 28 June 2021).
- Hao, Y.; Yang, J.; Chen, M.; Hossain, M.S.; Alhamid, M.F. Emotion-aware video QoE assessment via transfer learning. IEEE Multimed. 2019, 26, 31–40. [Google Scholar] [CrossRef]
- Baidu All Reduce. Available online: https://github.com/baidu-research/baidu-allreduce (accessed on 28 June 2021).
- Ma, Y.; Yu, D.; Wu, T.; Wang, H. Paddlepaddle: An open-source deep learning platform from industrial practice. Front. Data Comput. 2019, 1, 105–115. [Google Scholar]
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated learning. Synth. Lect. Artif. Intell. Mach. Learn. 2019, 13, 1–207. [Google Scholar] [CrossRef]
- He, C.; Li, S.; So, J.; Zeng, X.; Zhang, M.; Wang, H.; Wang, X.; Vepakomma, P.; Singh, A.; Qiu, H.; et al. FedML: A research library and benchmark for federated machine learning. arXiv 2020, arXiv:2007.13518. [Google Scholar]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. arXiv 2019, arXiv:1906.08935. [Google Scholar]
- Dwork, C. Differential privacy. In Automata, Languages and Programming; Springer: Boston, MA, USA, 2011; pp. 338–340. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS’17), New York, NY, USA, 30 October –3 November 2017. [Google Scholar]
- Elias, P. Universal codeword sets and representations of the integers. IEEE Trans. Inf. Theory 1975, 21, 194–203. [Google Scholar] [CrossRef]
- PyArrow LZ4 Codec. Available online: https://arrow.apache.org/docs/python/generated/pyarrow.compress.html (accessed on 28 June 2021).
- Casas, P.; D’Alconzo, A.; Wamser, F.; Seufert, M.; Gardlo, B.; Schwind, A.; Tran-Gia, P.; Schatz, R. Predicting QoE in cellular networks using machine learning and in-smartphone measurements. In Proceedings of the 2017 Ninth International Conference on Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 29 May–2 June 2017; pp. 1–6. [Google Scholar]
- Robitza, W.; Göring, S.; Raake, A.; Lindegren, D.; Heikkilä, G.; Gustafsson, J.; List, P.; Feiten, B.; Wüstenhagen, U.; Garcia, M.-N.; et al. HTTP adaptive streaming QoE estimation with ITU-T rec. P. 1203: Open databases and software. In Proceedings of the 9th ACM Multimedia Systems Conference, Amsterdam, The Netherlands, 12–15 June 2018; pp. 466–471. [Google Scholar]
- Duanmu, Z.; Rehman, A.; Wang, Z. A Quality-of-Experience database for adaptive video streaming. IEEE Trans. Broadcast. 2018, 64, 474–487. [Google Scholar] [CrossRef]
- Robitza, W.; Garcia, M.-N.; Raake, A. A modular HTTP adaptive streaming QoE model—Candidate for ITU-T P.1203 (‘P. NATS’). In Proceedings of the IEEE International Conference Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 31 May–2 June 2017. [Google Scholar]
- ITU-T P.910, Subjective Video Quality Assessment Methods for Multimedia Applications. 1999. Available online: https://www.itu.int/rec/T-REC-P.910-200804-I (accessed on 28 June 2021).
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar]
- Hoßfeld, T.; Heegaard, P.E.; Varela, M.; Möller, S. QoE beyond the MOS: An in-depth look at QoE via better metrics and their relation to MOS. Qual. User Exp. 2016, 1, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Post Hoc Pairwise Test. Available online: https://scikit-posthocs.readthedocs.io/en/latest/generated/scikit_posthocs.posthoc_dunn/ (accessed on 28 June 2021).
- Plaut, D.C.; Hinton, G.E. Learning sets of filters using back-propagation. Comput. Speech Lang. 1987, 2, 35–61. [Google Scholar] [CrossRef] [Green Version]
- RabbitMQ. Available online: https://www.rabbitmq.com/ (accessed on 28 June 2021).
- EarlyStopping. Available online: https://keras.io/api/callbacks/early_stopping/ (accessed on 28 June 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Split Index | Feature | Description |
|---|---|---|
| 0 | TI | Video temporal complexity |
| 1 | SI | Video spatial complexity |
| 2 | FPS | Played frames per second |
| 3 | lastbitrate | Last playout bitrate |
| 4 | nstalls | Number of stalls |
| 5 | stallTimeInitialTotal | Initial stalling/buffering duration |
| 6 | stallTimeIntermediateTotal | Total stalling duration |
| 7 | bitrateTrend | Slope of the video playout bitrate |
| 8 | meanBitrate | Average playout bitrate |
| MOS (target variable) | Mean Opinion Score |
| Technique | Features | What Is Shared? Traffic Direction? | Training Data Location |
|---|---|---|---|
| hFL | All features are same. | Full model. Bidirectional and iteratively. | Input and Output at the same worker. |
| DEL | Target has some source features. | Full model. From Source to Target once. | Input and Output at the same worker. |
| vFL | All features are different. | Cut-layer outputs and gradients. Bidirectional and iteratively. | Input at the workers. Output at the master. |
| Neuron Count at the Cut-Layer | F1-Score | Network Footprint [Bytes] | Training Time [s] | ||
|---|---|---|---|---|---|
| Elias ON | Elias OFF | Elias ON | Elias OFF | ||
| 2 | 0.75 ± 0.05 | 5413 ± 3 | 6348 ± 8 | 1472 ± 372 | 1378 ± 150 |
| 4 | 0.85 ± 0.03 | 8102 ± 7 | 10,725 ± 17 | 1161 ± 98 | 1281 ± 122 |
| 8 | 0.86 ± 0.01 | 13,522 ± 11 | 19,087 ± 30 | 1313 ± 24 | 1106 ± 119 |
| 16 | 0.87 ± 0.01 | 23,899 ± 22 | 34,165 ± 48 | 1806 ± 158 | 1624 ± 32 |
| 32 | 0.87 ± 0.01 | 44,602 ± 45 | 66,322 ± 118 | 2885 ± 166 | 1545 ± 114 |
| Isolated | Fully Centralized | DEL | vFL | |
|---|---|---|---|---|
| Data share | × | ✓ | × | × |
| Model share | × | × | ✓ All-layers | ✓ Cut-layer |
| Sample dep. | × | ✓ | × | ✓ Synch. required |
| Feature dep. | × | ✓ | ✓ Subset | × |
| Jointly train. | × | ✓ | × | ✓ |
| Aggr. | × | × | Average | Concatenate & Split |
| Model agnos. | ✓ | ✓ | ✓ | × Neural Net. |
| Worker contrib. adjustment | N/A | N/A | Manual | Automatic |
| Worker Netw. Footpr. | 0 | |||
| Master Netw. Footpr. | 0 | |||
| Accuracy | Poor | Good | Good | Good |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ickin, S.; Fiedler, M.; Vandikas, K. QoE Modeling on Split Features with Distributed Deep Learning. Network 2021, 1, 165-190. https://doi.org/10.3390/network1020011
Ickin S, Fiedler M, Vandikas K. QoE Modeling on Split Features with Distributed Deep Learning. Network. 2021; 1(2):165-190. https://doi.org/10.3390/network1020011
Chicago/Turabian StyleIckin, Selim, Markus Fiedler, and Konstantinos Vandikas. 2021. "QoE Modeling on Split Features with Distributed Deep Learning" Network 1, no. 2: 165-190. https://doi.org/10.3390/network1020011
APA StyleIckin, S., Fiedler, M., & Vandikas, K. (2021). QoE Modeling on Split Features with Distributed Deep Learning. Network, 1(2), 165-190. https://doi.org/10.3390/network1020011