
Machine Learning-Based Regression Models for Ironmaking Blast Furnace Automation



Abstract
:1. Introduction
2. Literature Review
2.1. Machine Learning for Large Scale Industrial Applications
2.2. Regression Modeling
2.2.1. Regression Trees
2.2.2. AdaBoost
2.2.3. Gradient Boost
2.2.4. XGBoost
2.3. Neural Networks for Regression
3. Methodology
3.1. Computational Fluid Dynamics Modeling of the Blast Furnace
CFD Model Validation and Case Matrix Scenarios
3.2. Regression with Neural Networks
3.3. Regression with Neural Networks and Probability Density Function Shaping
3.4. Regression with XGBoost
3.5. Data and Features
3.6. Performance Metrics
4. Results
4.1. Regression Models Comparison
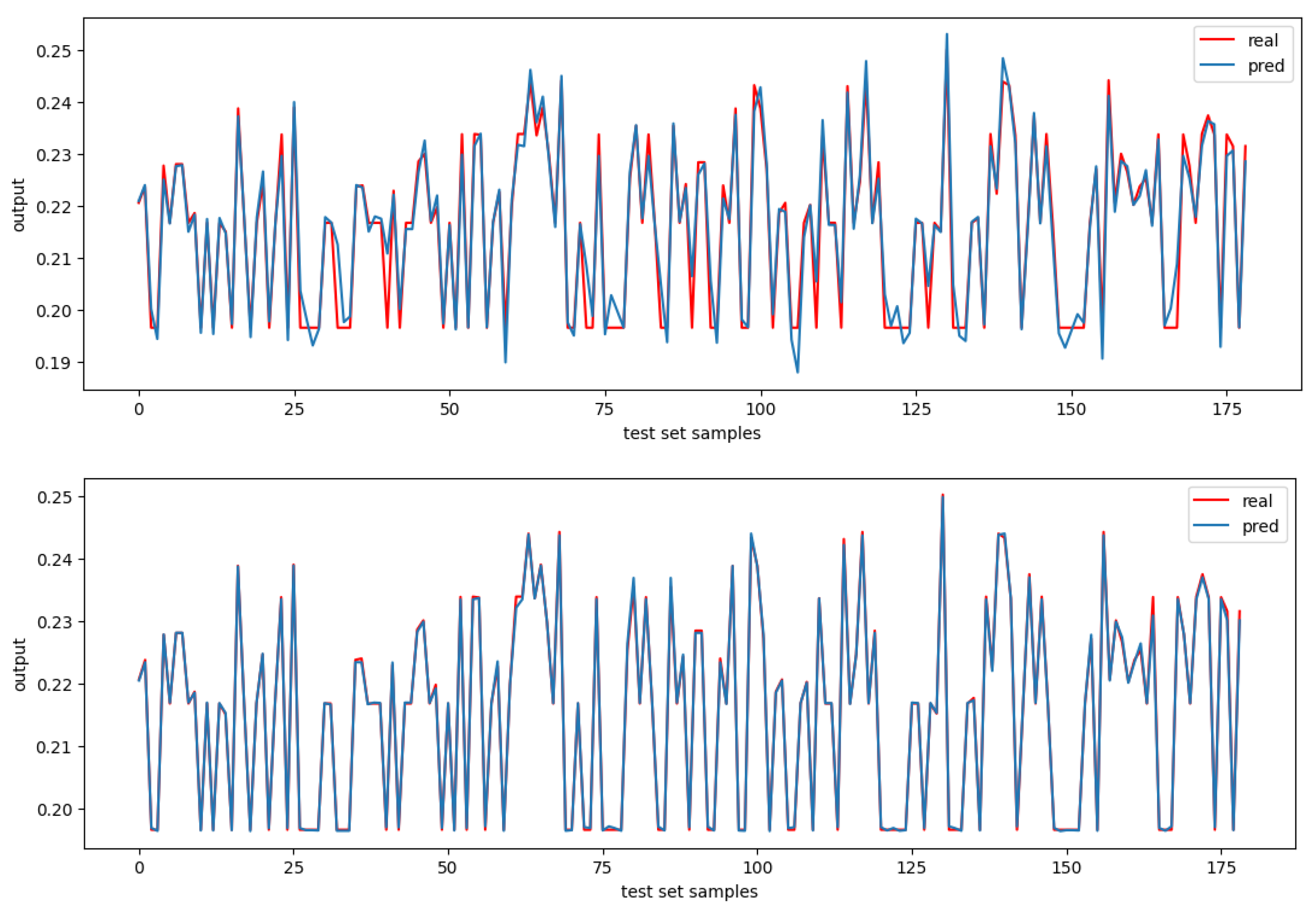
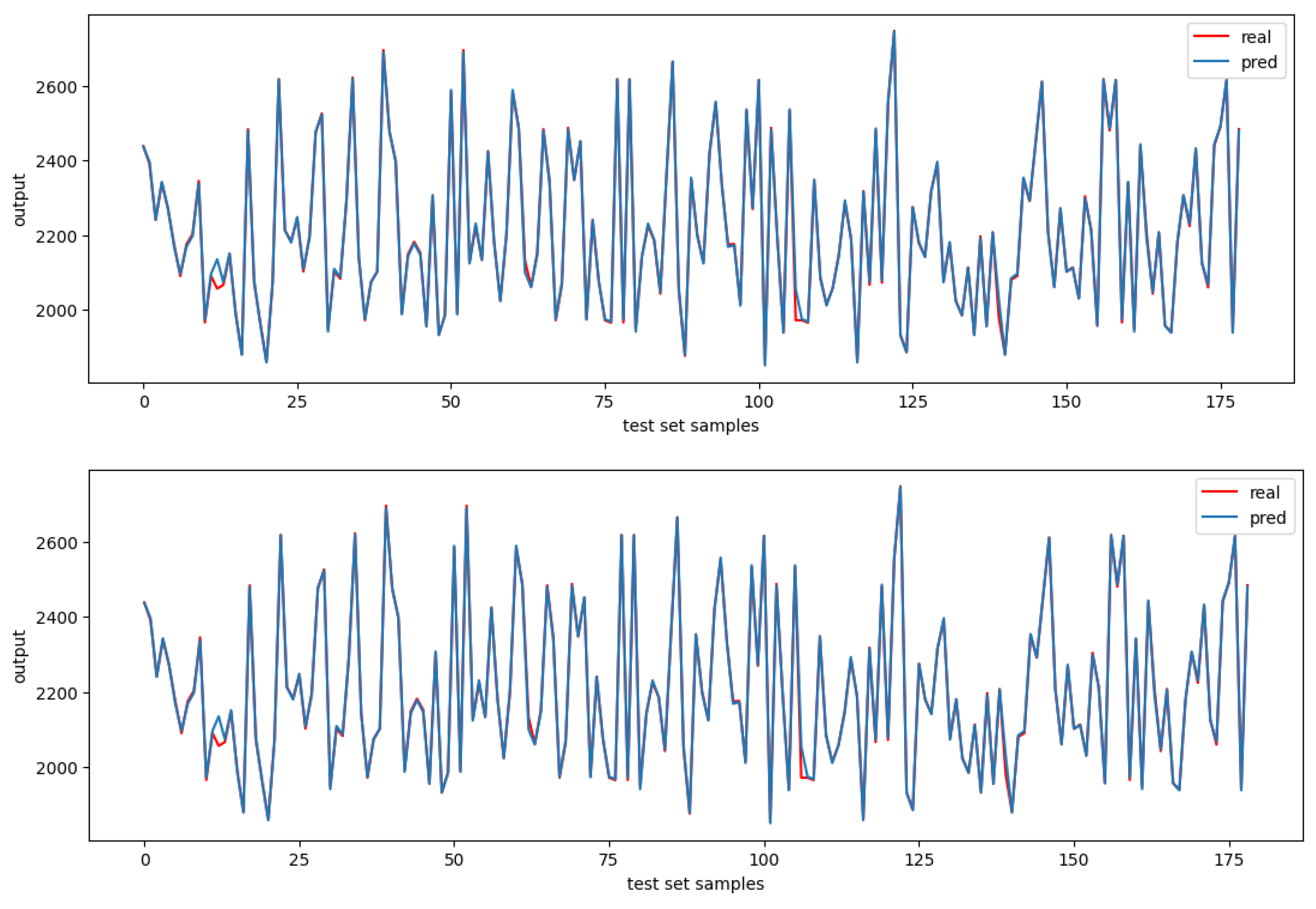
4.2. Regression Error Mappings of Predicted vs. Real Test Set
4.3. Regression Error Distribution Analysis for the Test Set
4.4. Correlations Matrix Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Steel Statistical Yearbook 2020, Concise Version. Available online: https://worldsteel.org/wp-content/uploads/Steel-Statistical-Yearbook-2020-concise-version.pdf (accessed on 11 August 2023).
- Rist, A.; Meysson, N. A Dual Graphic Representation of the Blast-Furnace Mass and Heat Balances. JOM 1967, 19, 50. [Google Scholar] [CrossRef]
- Shi, Q.; Tang, J.; Chu, M. Key issues and progress of industrial big data-based intelligent blast furnace ironmaking technology. Int. J. Miner. Metall. Mater. 2023, 30, 1651–1666. [Google Scholar] [CrossRef]
- Abhale, P.; Viswanathan, N.; Saxén, H. Numerical modelling of blast furnace—Evolution and recent trends. Miner. Process. Extr. Metall. 2020, 129, 166–183. [Google Scholar] [CrossRef]
- Rahnama, A.; Li, Z.; Sridhar, S. Machine Learning-Based Prediction of a BOS Reactor Performance from Operating Parameters. Processes 2020, 8, 371. [Google Scholar] [CrossRef]
- Li, M.; Wang, X.; Yao, H.; Saxén, H.; Yu, Y. Analysis of Particle Size Distribution of Coke on Blast Furnace Belt Using Object Detection. Processes 2022, 10, 1902. [Google Scholar] [CrossRef]
- Jiang, D.; Wang, Z.; Li, K.; Zhang, J.; Ju, L.; Hao, L. Predictive Modeling of Blast Furnace Gas Utilization Rate Using Different Data Pre-Processing Methods. Metals 2022, 12, 535. [Google Scholar] [CrossRef]
- Zhai, X.; Chen, M. Comparison of data-driven prediction methods for comprehensive coke ratio of blast furnace. High Temp. Mater. Process. 2023, 42, 20220261. [Google Scholar] [CrossRef]
- Saxén, H.; Gao, C.; Gao, Z. Data-Driven Time Discrete Models for Dynamic Prediction of the Hot Metal Silicon Content in the Blast Furnace—A Review. IEEE Trans. Ind. Inform. 2013, 9, 2213–2225. [Google Scholar] [CrossRef]
- Sekar, V.; Jiang, Q.; Shu, C.; Khoo, B. Fast flow field prediction over airfoils using deep learning approach. Phys. Fluids 2019, 31, 057103. [Google Scholar] [CrossRef]
- Kochkov, D.; Smith, J.; Alieva, A.; Wang, Q.; Brenner, M.; Hoyer, S. Machine learning–accelerated computational fluid dynamics. Proc. Natl. Acad. Sci. USA 2021, 118, e2101784118. [Google Scholar] [CrossRef]
- Usman, A.; Rafiq, M.; Saeed, M.; Nauman, A.; Almqvist, A.; Liwicki, M. Machine Learning Computational Fluid Dynamics. In Proceedings of the 2021 Swedish Artificial Intelligence Society Workshop (SAIS), Luleå, Sweden, 14–15 June 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Geman, S.; Bienenstock, E.; Doursat, R. Neural networks and the bias/variance dilemma. Neural Comput. 1992, 4, 1–58. [Google Scholar]
- Torgo, L. Regression Trees. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2017. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Desicion-Theoretic [Sic] Generalization of On-Line Learning and an Application to Boosting; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1995; pp. 23–37. ISBN 978-3-540-59119-1. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar]
- Chen, T.Q.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Tanzil, W.B.U.; Mellor, D.G.; Burgess, J.M. Application of a two dimensional flow, heat transfer and chemical reaction model for process guidance and gas distribution control on Port Kembla no. 5 blast furnace. In Proceedings of the 6th International Iron and Steel Congress, Nagoya, Japan, 21–26 October 1990. [Google Scholar]
- Austin, P.R.; Nogami, H.; Yagi, J. Mathematical Model for Blast Furnace Reaction Analysis Based on the Four Fluid Model. ISIJ Int. 1996, 37, 748–755. [Google Scholar]
- Austin, P.R.; Nogami, H.; Yagi, J.T. A Mathematical Model of Four Phase Motion and Heat Transfer in the Blast Furnace. ISIJ Int. 1997, 37, 458–467. [Google Scholar]
- Yeh, C.P.; Du, S.W.; Tsai, C.H.; Yang, R.J. Numerical Analysis of Flow and Combustion Behavior in Tuyere and Raceway of Blast Furnace Fueled with Pulverized Coal and Recycled Top Gas. Energy 2012, 42, 233–240. [Google Scholar]
- Babich, A.; Senk, D.; Gudenau, H.W. An Outline of the Process. Ironmaking 2016, 180–185. [Google Scholar]
- Zhuo, Y.; Shen, Y. Transient 3D CFD Study of Pulverized Coal Combustion and Coke Combustion in a Blast Furance: Effect of Blast Conditions. Fuel 2023, 340, 127468. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, E.; An, Q.; Chionoso, O.P. CFD Study of Bio-syngas and Coal Co-Injection in a Blast Furnace with Double Lance. Energy 2023, 263, 125906. [Google Scholar]
- Okosun, T.; Silaen, A.K.; Zhou, C.Q. Review on Computational Modeling and Visualization of the Ironmaking Blast Furnace at Purdue University Northwest. Steel Res. Int. 2019, 90, 1900046. [Google Scholar]
- Fu, D. Numerical Simulation of Ironmaking Blast Furnace Shaft. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, May 2014. [Google Scholar]
- Okosun, T. Numerical Simulation of Combustion in the Ironmaking Blast Furnace Raceway. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, May 2018. [Google Scholar]
- Wang, A.; Wang, H. Survey on stochastic distribution systems: A full probability density function control theory with potential applications. Optim. Control 2021, 42, 1812–1839. [Google Scholar]
- Wang, H.; Chakraborty, I.; Hong, W.; Tao, G. Co-Optimization Scheme for the Powertrain and Exhaust Emission Control System of Hybrid Electric Vehicles Using Future Speed Prediction. IEEE Trans. Intell. Veh. 2021, 6, 533–545. [Google Scholar] [CrossRef]
- Data Set. 2023. Available online: https://github.com/rcalix1/ProbabilityDensityFunctionsFromNeuralNets (accessed on 11 August 2023).
- Geerdes, M.; Chaigneau, R.; Kurunov, I.; Lingiardi, O.; Ricketts, J. Modern Blast Furnace Ironmaking An Introduction, 3rd ed.; IOS Press: Amsterdam, The Netherlands, 2015; p. 195. [Google Scholar]
- Association for Iron & Steel Technology. 2022 AIST North American Blast Furnace Roundup. Iron Steel Technol. 2022. [Google Scholar]
- Lewis-Beck, C.; Lewis-Beck, M. Applied Regression: An Introduction; Sage Publications: Thousand Oaks, CA, USA, 2015; Volume 22. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cons. of mass: | |
| Cons. of momentum: | |
| Cons. of energy: | |
| Species transport | |
| Turbulent kinetic energy | |
| Turbulence dissipation rate | |
| Where: | |
| , and |
| (kPa) | Top Gas Temp. (K) | Coke Rate (lb/ton of HM) | CO Utilization | |
|---|---|---|---|---|
| CFD | 109 | 391 | 925 | 47.2 |
| Industrial data | ∼115 | ∼370 | ∼926 | 46.8 |
| Difference (%) | 5.6 | 5.9 | 0.06 | 0.85 |
| Category | Variable | Definition |
|---|---|---|
| Input | i_h2_inj_kg_thm | H2 injection rate in kg per ton of hot metal |
| Input | i_pul_coal_inj_kg_thm | Pulverized coal injection rate in kg per ton of hot metal |
| Input | i_nat_gas_inj_kg_thm | Natural gas injection rate in kg per ton of hot metal |
| Input | i_nat_gas_t_k | Natural gas injection temperature in Kelvin |
| Input | i_o2_vol_perce | Blast oxygen enrichment in % |
| Input | i_hot_blast_temp_k | Hot blast temperature in Kelvin |
| Input | i_ore_moisture_weight_perce | Ore moisture content by weight in % |
| Input | i_ore_weight_kg | Weight of iron ore charged per layer in kg |
| Output | o_tuyere_exit_velo_m_s | Tuyere exit velocity in meters per second |
| Output | o_raceway_flame_temp_k | Raceway flame temperature in Kelvin |
| Output | o_raceway_coal_burn_perce | Pulverized coal burnout in % |
| Output | o_raceway_volume_m | Raceway volume in cubic meters |
| Output | o_shaft_co_utiliz | CO use in % |
| Output | o_shaft_H2_utiliz | H2 use in % |
| Output | o_shaft_top_gas_temp_c | Blast furnace top gas temperature in Celcius |
| Output | o_shaft_press_drop_pa | Shaft region pressure drop in Pascals |
| Output | o_shaft_coke_rate_kg_thm | Change in BF coke consumption in kg per ton of hot metal |
| Output | o_shaft_gasspecies_v_perc | Top gas CO, CO2, H2, N2 volume % |
| Output | Multi- Output NN | Multi- Output NN-PDF | Single- Output NN | Single- Output NN-PDF | Single- Output XGBoost |
|---|---|---|---|---|---|
| Tuyere exit velocity | 0.97 | 0.96 | 0.98 | 0.96 | 0.99 |
| Tuyere exit temp. | 0.95 | 0.96 | 0.95 | 0.93 | 0.99 |
| Raceway flame temp. | 0.98 | 0.98 | 0.99 | 0.96 | 0.99 |
| Raceway coal burn | 0.83 | 0.68 | 0.89 | 0.86 | 0.99 |
| Raceway volume | 0.77 | 0.73 | 0.94 | 0.91 | 0.99 |
| H2 use | 0.83 | 0.82 | 0.80 | 0.78 | 0.85 |
| Top gas temp. | 0.95 | 0.95 | 0.98 | 0.98 | 0.98 |
| Shaft pressure drop | 0.88 | 0.88 | 0.86 | 0.68 | 0.92 |
| Shaft coke rate | 0.98 | 0.98 | 0.98 | 0.96 | 0.99 |
| Top gas CO vol % | 0.90 | 0.87 | 0.92 | 0.81 | 0.92 |
| Top gas CO2 vol % | 0.93 | 0.93 | 0.95 | 0.91 | 0.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calix, R.A.; Ugarte, O.; Okosun, T.; Wang, H. Machine Learning-Based Regression Models for Ironmaking Blast Furnace Automation. Dynamics 2023, 3, 636-655. https://doi.org/10.3390/dynamics3040034
Calix RA, Ugarte O, Okosun T, Wang H. Machine Learning-Based Regression Models for Ironmaking Blast Furnace Automation. Dynamics. 2023; 3(4):636-655. https://doi.org/10.3390/dynamics3040034
Chicago/Turabian StyleCalix, Ricardo A., Orlando Ugarte, Tyamo Okosun, and Hong Wang. 2023. "Machine Learning-Based Regression Models for Ironmaking Blast Furnace Automation" Dynamics 3, no. 4: 636-655. https://doi.org/10.3390/dynamics3040034
APA StyleCalix, R. A., Ugarte, O., Okosun, T., & Wang, H. (2023). Machine Learning-Based Regression Models for Ironmaking Blast Furnace Automation. Dynamics, 3(4), 636-655. https://doi.org/10.3390/dynamics3040034