
Combining International Survey Datasets to Identify Indicators of Stress during the COVID-19 Pandemic: A Machine Learning Approach to Improve Generalization




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
2.1. Study Populations
2.2. Dataset Selection
2.3. Data Harmonization
2.4. Statistical Approach
2.5. Interactions
2.6. Modeling Effort
2.7. Feature Selection
2.8. Model Selection
3. Results
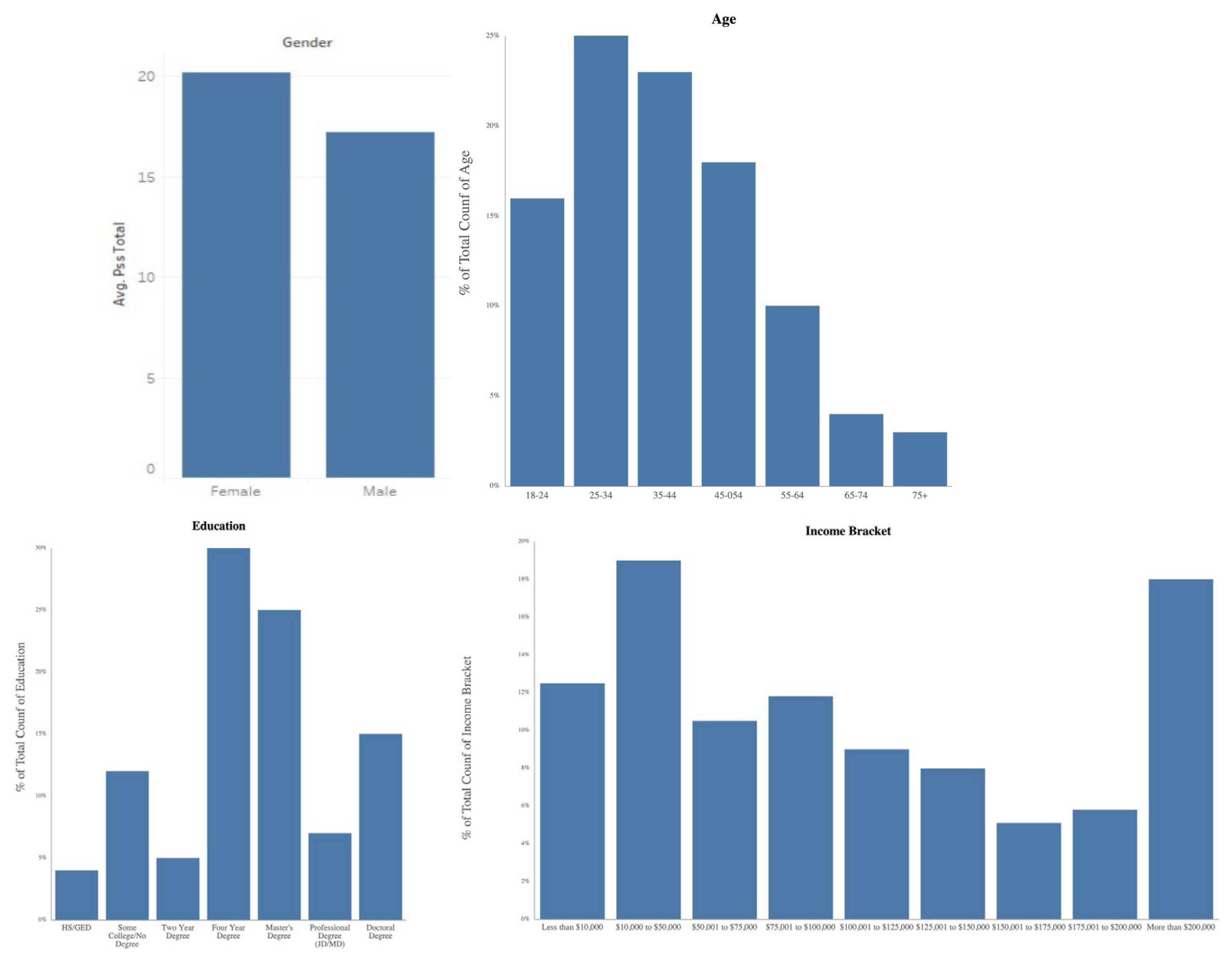
3.1. International Survey Demographics
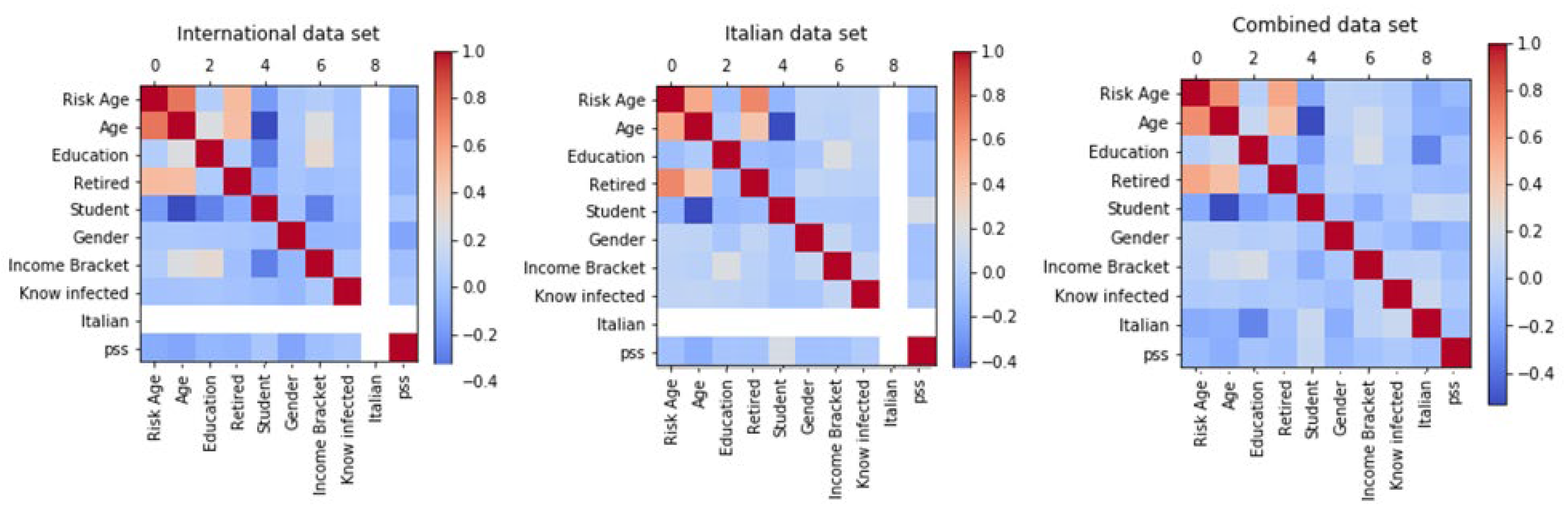
3.2. Correlation Analysis
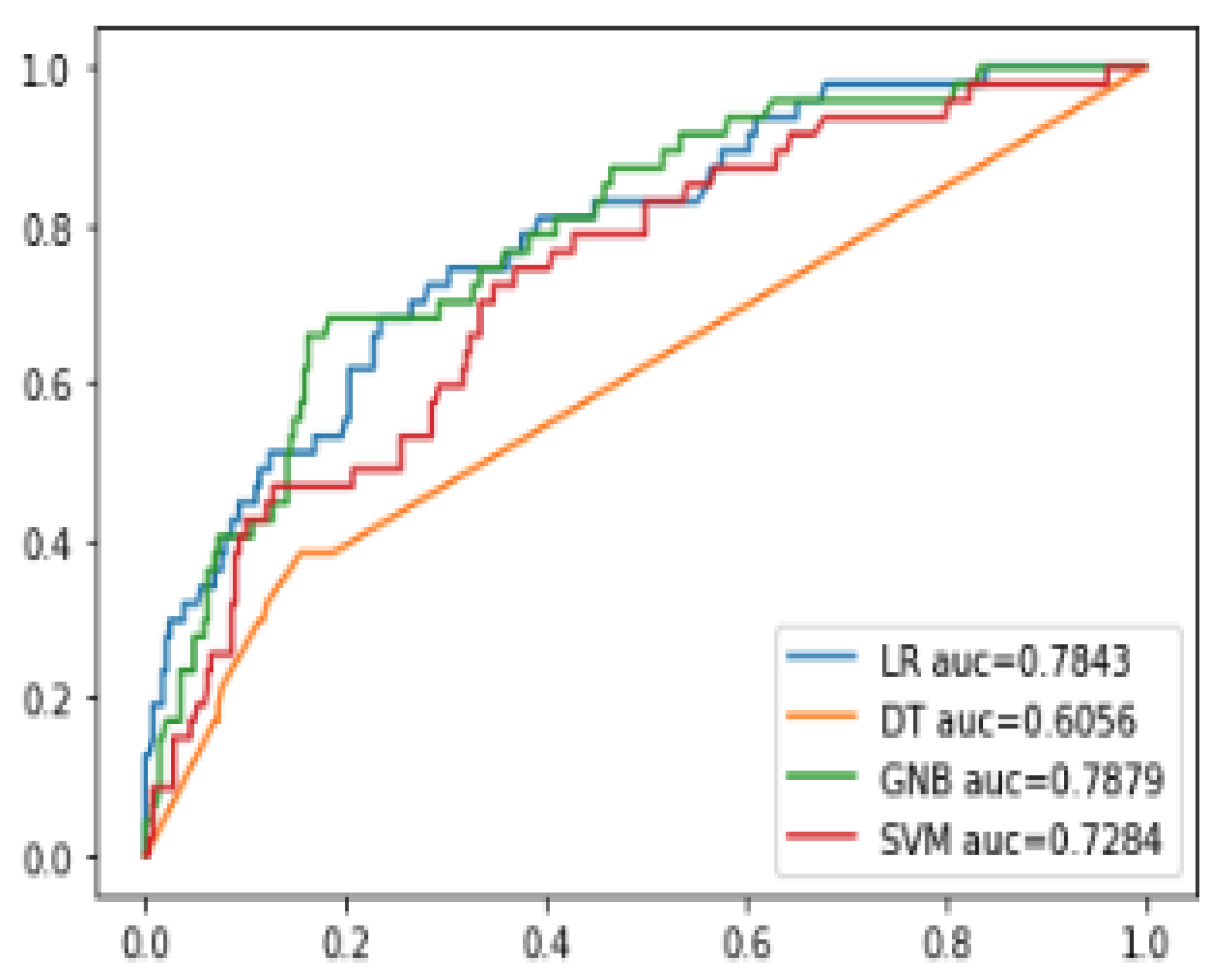
3.3. Primary ML Analysis: Gaussian naïve Bayes (GNB)
3.4. Gaussian Naïve Bayesian (GNB) MODEL
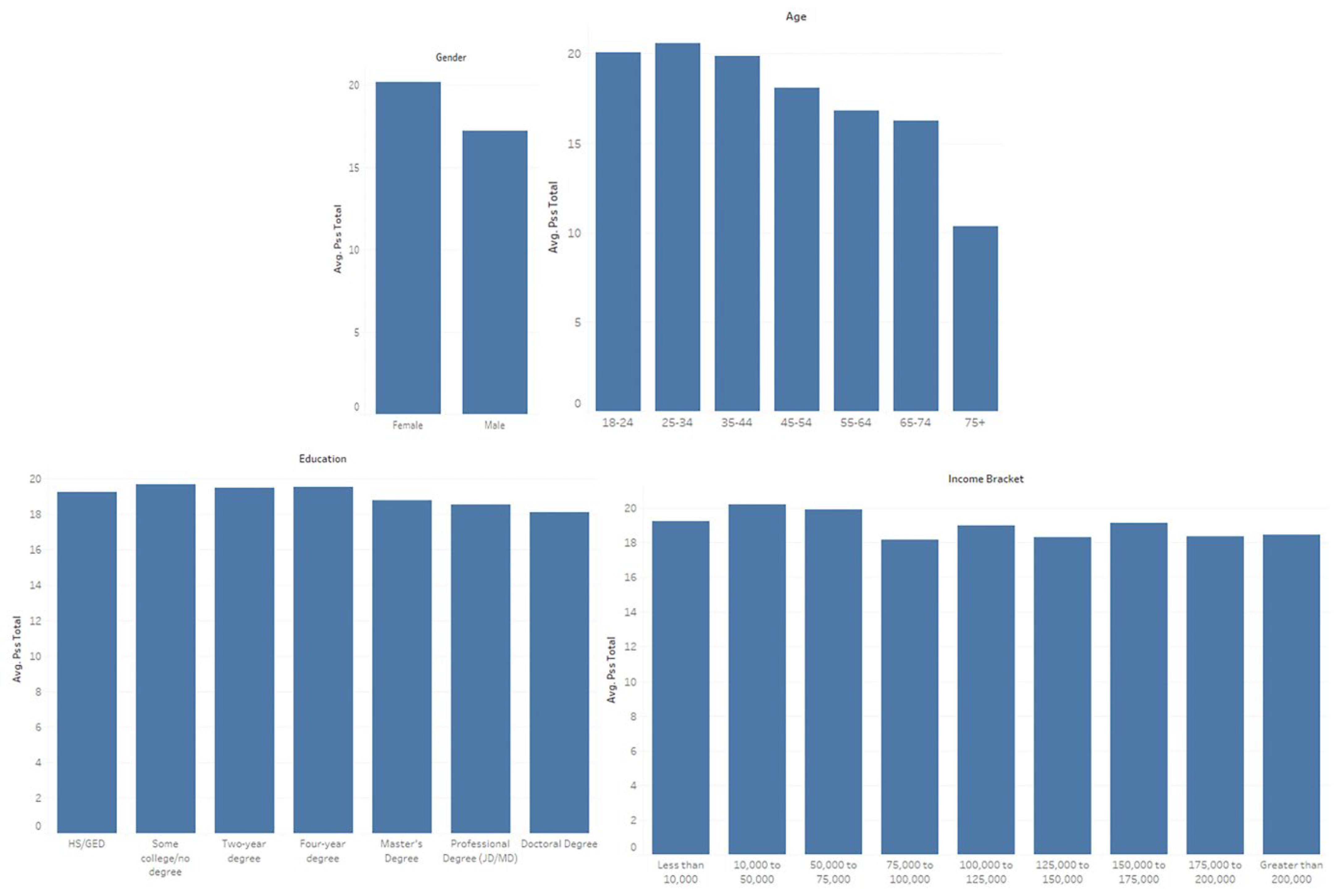
3.5. Sensitivity Analysis
3.6. Deep Learning Approach
3.7. Interaction Analysis
3.8. Integration with Italian Data
4. Discussion
4.1. Limitations
4.2. Future Directions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Galea, S.; Merchant, R.M.; Lurie, N. The mental health consequences of COVID-19 and physical distancing: The need for prevention and early intervention. JAMA Intern. Med. 2020, 180, 817–818. [Google Scholar] [CrossRef] [Green Version]
- Balkhair, A.A. COVID-19 Pandemic: A New Chapter in the History of Infectious Diseases. Oman Med. J. 2020, 35, e123. [Google Scholar] [CrossRef]
- Wang, C.; Pan, R.; Wan, X.; Tan, Y.; Xu, L.; Ho, C.S.; Ho, R.C. Immediate 1155 Psychological Responses and Associated Factors during the Initial Stage of the 2019 Coronavirus Disease (COVID-19) Epidemic among the General Population in China. Int. J. Environ. Res. Public Health 2020, 17, 1729. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mazza, C.; Ricci, E.; Biondi, S.; Colasanti, M.; Ferracuti, S.; Napoli, C.; Roma, P. A Nationwide Survey of Psychological Distress among Italian People during the COVID-19 Pandemic: Immediate Psychological Responses and Associated Factors. Int. J. Environ. Res. Public Health 2020, 17, 3165. [Google Scholar] [CrossRef]
- Adamson, M.M.; Phillips, A.; Seenivasan, S.; Martinez, J.; Grewal, H.; Kang, X.; Coetzee, J.; Luttenbacher, I.; Jester, A.; Harris, O.A.; et al. International prevalence and correlates of psychological stress during the global COVID-19 pandemic. Int. J. Environ. Res. Public Health 2020, 17, 9248. [Google Scholar] [CrossRef] [PubMed]
- Hopfenbeck, T. The Role and Value of International Datasets and Comparisons in Education Research. Res. Intell. 2012, 119, 7–8. [Google Scholar]
- Polit, D.F.; Beck, C.T. Generalization in quantitative and qualitative research: Myths and strategies. Int. J. Nurs. Stud. 2010, 47, 1451–1458. [Google Scholar] [CrossRef] [Green Version]
- Harlow, L.L.; Oswald, F.L. Big data in psychology: Introduction to the special issue. Psychol. Methods 2016, 21, 447. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stachl, C.; Pargent, F.; Hilbert, S.; Harari, G.M.; Schoedel, R.; Vaid, S.; Gosling, S.D.; Bühner, M. Personality research and assessment in the era of machine learning. Eur. J. Pers. 2019, 34, 613–631. [Google Scholar] [CrossRef]
- Orrù, G.; Monaro, M.; Conversano, C.; Gemignani, A.; Sartori, G. Machine Learning in Psychometrics and Psychological Research. Front. Psychol. 2020, 10, 2970. [Google Scholar] [CrossRef]
- Cawley, G.C.; Talbot, N.L.C. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B Methodol. 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Flesia, L.; Monaro, M.; Mazza, C.; Fietta, V.; Colicino, E.; Segatto, B.; Roma, P. Predicting Perceived Stress Related to the Covid-19 Outbreak through Stable Psychological Traits and Machine Learning Models. J. Clin. Med. 2020, 9, 3350. [Google Scholar] [CrossRef] [PubMed]
- Cohen, S.; Williamson, G. Perceived stress in a probability sample of the United States. Soc. Psychol. Health 1988, 13, 31–67. [Google Scholar] [CrossRef]
- Cohen, S.; Kamarck, T.; Mermelstein, R. A Global Measure of Perceived Stress. J. Health Soc. Behav. 1983, 24, 385–396. [Google Scholar] [CrossRef] [PubMed]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Dong, E.; Du, H.; Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Inf. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, F.; Wei, C.; Jia, Y.; Shang, Z.; Sun, L.; Wu, L.; Sun, Z.; Zhou, Y.; Wang, Y.; et al. Prevalence and predictors of PTSS during COVID-19 outbreak in China hardest-hit areas: Gender differences matter. Psychiatry Res. 2020, 287, 112921. [Google Scholar] [CrossRef]
- Thomson, K.C.; Jenkins, E.; Gill, R.; Richardson, C.G.; Gagné Petteni, M.; McAuliffe, C.; Gadermann, A.M. Impacts of the COVID-19 Pandemic on Family Mental Health in Canada: Findings from a Multi-Round Cross-Sectional Study. Int. J. Environ. Res. Public Health 2021, 18, 12080. [Google Scholar] [CrossRef]
- Angwenyi, V.; Kabue, M.; Chongwo, E.; Mabrouk, A.; Too, E.K.; Odhiambo, R.; Nasambu, C.; Marangu, J.; Ssewanyana, D.; Njoroge, E.; et al. Mental Health during COVID-19 Pandemic among Caregivers of Young Children in Kenya’s Urban Informal Settlements. A Cross-Sectional Telephone Survey. Int. J. Environ. Res. Public Health 2021, 18, 10092. [Google Scholar] [CrossRef]
- Hung, M.S.; Lam, S.K.; Chan, L.C.; Liu, S.P.; Chow, M.C. The Psychological and Quality of Life Impacts on Women in Hong Kong during the COVID-19 Pandemic. Int. J. Environ. Res. Public Health 2021, 18, 6734. [Google Scholar] [CrossRef]
- Suárez-Rico, B.V.; Estrada-Gutierrez, G.; Sánchez-Martínez, M.; Perichart-Perera, O.; Rodríguez-Hernández, C.; González-Leyva, C.; Osorio-Valencia, E.; Cardona-Pérez, A.; Helguera-Repetto, A.C.; Espino y Sosa, S.; et al. Prevalence of depression, anxiety, and perceived stress in postpartum Mexican women during the COVID-19 lockdown. Int. J. Environ. Res. Public Health 2021, 18, 4627. [Google Scholar] [CrossRef] [PubMed]
- Wade, M.; Prime, H.; Johnson, D.; May, S.S.; Jenkins, J.M.; Browne, D.T. The disparate impact of COVID-19 on the mental health of female and male caregivers. Soc. Sci. Med. 2021, 275, 113801. [Google Scholar] [CrossRef] [PubMed]
- Varma, P.; Junge, M.; Meaklim, H.; Jackson, M.L. Younger people are more vulnerable to stress, anxiety and depression during COVID-19 pandemic: A global cross-sectional survey. Prog. Neuro-Psychopharmacol. Biol. Psychiatry 2021, 109, 110236. [Google Scholar] [CrossRef] [PubMed]
- Racine, N.; McArthur, B.A.; Cooke, J.E.; Eirich, R.; Zhu, J.; Madigan, S. Global prevalence of depressive and anxiety symptoms in children and adolescents during COVID-19: A meta-analysis. JAMA Pediatrics 2021, 175, 1142–1150. [Google Scholar] [CrossRef]
- Al Omari, O.; Al Sabei, S.; Al Rawajfah, O.; Abu Sharour, L.; Aljohani, K.; Alomari, K.; Shkman, L.; Al Dameery, K.; Saifan, A.; Al Zubidi, B.; et al. Prevalence and predictors of depression, anxiety, and stress among youth at the time of COVID-19: An online cross-sectional multicountry study. Depress. Res. Treat. 2020. [Google Scholar] [CrossRef] [PubMed]
- Sher, L. The impact of the COVID-19 pandemic on suicide rates. QJM Int. J. Med. 2020, 113, 707–712. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; McGoogan, J.M. Characteristics of and Important Lessons From the 1175 Coronavirus Disease 2019 (COVID-19) Outbreak in China. JAMA 2020, 323, 1239–1242. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, E.Y.; Xia, D.; Greenhalgh, M.; Colicino, E.; Monaro, M.; Hitching, R.; Harris, O.A.; Adamson, M.M. Combining International Survey Datasets to Identify Indicators of Stress during the COVID-19 Pandemic: A Machine Learning Approach to Improve Generalization. COVID 2021, 1, 728-738. https://doi.org/10.3390/covid1040058
Zhao EY, Xia D, Greenhalgh M, Colicino E, Monaro M, Hitching R, Harris OA, Adamson MM. Combining International Survey Datasets to Identify Indicators of Stress during the COVID-19 Pandemic: A Machine Learning Approach to Improve Generalization. COVID. 2021; 1(4):728-738. https://doi.org/10.3390/covid1040058
Chicago/Turabian StyleZhao, Eric Yunan, Daniel Xia, Mark Greenhalgh, Elena Colicino, Merylin Monaro, Rita Hitching, Odette A. Harris, and Maheen M. Adamson. 2021. "Combining International Survey Datasets to Identify Indicators of Stress during the COVID-19 Pandemic: A Machine Learning Approach to Improve Generalization" COVID 1, no. 4: 728-738. https://doi.org/10.3390/covid1040058
APA StyleZhao, E. Y., Xia, D., Greenhalgh, M., Colicino, E., Monaro, M., Hitching, R., Harris, O. A., & Adamson, M. M. (2021). Combining International Survey Datasets to Identify Indicators of Stress during the COVID-19 Pandemic: A Machine Learning Approach to Improve Generalization. COVID, 1(4), 728-738. https://doi.org/10.3390/covid1040058